data-intensive computing: from multi-cores and gpgpus to cloud computing and deep web gagan agrawal...
TRANSCRIPT

Data-Intensive Computing: From Multi-Cores and GPGPUs to Cloud
Computing and Deep Web
Gagan Agrawal
u

Data-Intensive Computing
• Simply put: scalable analysis of large datasets • How is it different from: related to
– Databases: • Emphasis on processing of static datasets
– Data Mining • Community focused more on algorithms, and not scalable
implementations
– High Performance / Parallel Computing • More focus on compute-intensive tasks, not I/O or large datasets
– Datacenters • Use of large resources for hosting data, less on their use for
processing

Why Now ?
• Amount of data is increasing rapidly • Cheap Storage • Better connectivity, easy to move large
datasets on web/grids • Science shifting from compute-X to X-
informatics • Business intelligence and analysis • Google’s Map-Reduce has created excitement

Architectural Context
• Processor architecture has gone through a major change – No more scaling with clock speeds – Parallelism – multi-core / many-core is the trend
• Accelerators like GPGPUs have become effective
• More challenges for scaling any class of applications

Grid/Cloud/Utility Computing
• Cloud computing is a major new trend in industry – Data and computation in a Cloud of resources – Pay for use model (like a utility)
• Has roots in many developments over the last decade – Service-oriented computing, Software as a Service
(SaaS) – Grid computing – use of wide-area resources

My Research Group
• Data-intensive computing on emerging architectures
• Data-intensive computing in Cloud Model • Data-integration and query processing – deep
web data • Querying low-level datasets through
automatic workflow composition • Adaptive computation – time as a constraint

Personnel
• Current students – 6 PhD students – 2 MS thesis students – Talking to several first year students
• Past students – 7 PhDs completed between 2005 and 2008

Outline
• FREERIDE: Data-intensive Computing on Cluster of Multi-cores
• A system for exploiting GPGPUs for data-intensive computing
• FREERIDE-G: Data-intensive computing on Cloud Environments
• Quick overview of three other projects

FREERIDE - Motivation
• Availability of very large datasets and it’s analysis (Data-intensive applications)
• Adaptation of Multi-core and inevitability of parallel programming
• Need for abstraction of difficulties of parallel programming.

FREERIDE
• A middle-ware for parallelizing Data-intensive applications
• Motivated by difficulties in implementing and performance tuning of Datamining applications
• Based on observation of similar generalized reduction among datamining, OLAP and other scientific applications

Generalized Reduction structure

SMP Techniques
• Full-replication(f-r) (obvious technique)• Locking based techniques– Full-locking (f-l)– Optimized Full-locking(o-f-l)– Fixed Locking(fi-l)– Cache-sensitive locking( Hybrid of o-f-l & fi-l)

Memory Layout of SMP techs

Experimental setup
• Intel Xeon E5345 CPU• 2 Quad-core machine• Each core 2.33GHz• 6GB Main memory• Nodes in cluster connected by Infiniband

Experimental Results – K-means (CMP)

K-means (cluster)

Apriori (CMP)

Apriori (cluster)

E-M (CMP)

E-M (cluster)

Summary of Results
• Both Full-replication and Cache-sensitive locking can outperform each other based on the nature of application
• Cache-sensitive locking seems to have high overhead when there is little computation between updates in ReductionObject
• MPI processes competes well with best of other two when run on smaller cores, but experiences communication overheads when run on larger number of cores

Background: GPU Computing
• Multi-core architectures are becoming more popular in high performance computing
• GPU is inexpensive and fast• CUDA is a high level language that supports
programming on GPU

Architecture of GeForce 8800 GPU (1 multiprocessor)

Challenges of Data-intensive Computing on GPU
• SIMD shared memory programming• 3 steps involved in the main loop– Data read– Computing update–Writing update

Complication of CUDA Programming
• User has to have thorough knowledge of the architecture of GPU and the programming model of CUDA
• Must specify the grid configuration• Has to deal with the memory allocation and copy• Need to know what data to be copied onto shared
memory and how much shared memory to use• ……

Architecture of the Middleware
• User input• Code analyzer– Analysis of variables (variable type and size)– Analysis of reduction functions (sequential code
from the user)• Code Generator ( generating CUDA code and
C++ code invoking the kernel function)

Architecture of the middleware
Variable information
Reduction functions
Optional functions Code
Analyzer( In LLVM)
Variable Analyzer
Code Generator
Variable Access Pattern and Combination Operations
Host Program
Grid configuration and kernel invocation
Kernel functions
Executable

User Input
A sequential reduction function
Optional functions (initialization function, combination function…)
Values of each variable (typically specified as length of arrays)
Variables to be used in the reduction function

Analysis of Sequential Code
• Get the information of access features of each variable
• Figure out the data to be replicated• Get the operator for global combination• Calculate the size of shared memory to use
and which data to be copied to shared memory

Experiment Results
Speedup of k-means

Speedup of EM

Emergence of Cloud and Utility Computing
• Group generating data– use remote resources for storing data – Already popular with SDSC/SRB
• Scientist interested in deriving results from data– use distinct but remote resources for processing
• Remote Data Analysis Paradigm • Data, Computation, and User at Different Locations• Unaware of location of other

Remote Data Analysis
• Advantages – Flexible use of resources – Do not overload data repository– No unnecessary data movement – Avoid caching process once data
• Challenge: Tedious details: – Data retrieval and caching – Use of parallel configurations – Use of heterogeneous resources – Performance Issues
• Can a Grid Middleware Ease Application Development for Remote Data Analysis and Yet Provide High Performance ?

Computer Science and Engineering
Our WorkFREERIDE-G (Framework for Rapid Implementation of Datamining
Engines in Grid) Enable Development of Flexible and Scalable Remote Data Processing Applications
Repository cluster
Compute cluster
Middleware user

Challenges
• Support use of parallel configurations – For hosting data and processing data
• Transparent data movement • Integration with Grid/Web Standards • Resource selection – Computing resources – Data replica
• Scheduling and Load Balancing • Data Wrapping Issues

Computer Science and Engineering
FREERIDE (G) Processing Structure
KEY observation: most data mining algorithms follow canonical loop
Middleware API: • Subset of data to be processed• Reduction object • Local and global reduction
operations • IteratorDerived from precursor system
FREERIDE
While( ) {
forall( data instances d) {
(I , d’) = process(d)
R(I) = R(I) op d’
}
…….
}

FREERIDE-G Evolution
FREERIDEdata stored locally
FREERIDE-G• ADR responsible for remote data retrieval• SRB responsible for remote data retrievalFREERIDE-G grid serviceGrid service featuring• Load balancing• Data integration

Computer Science and Engineering
EvolutionFREERIDE FREERIDE-G-ADR
FREERIDE-G-SRB FREERIDE-G-GT
ApplicationDataADRSRBGlobus

FREERIDE-G System Architecture

Compute Node
More compute nodes than data hosts
Each node:1. Registers IO (from index)2. Connects to data hostWhile (chunks to process)3. Dispatch IO request(s)4. Poll pending IO5. Process retrieved chunks

FREERIDE-G in Action
SRB Agent
SRB Agent
SRB MasterMCAT
Data Host I/O Registration
Connection establishment
While (more chunks to process)
I/O request dispatchedPending I/O polled
Retrieved data chunksanalyzed
Compute Node
Compute Node

Implementation Challenges
• Interaction with Code Repository– Simplified Wrapper and Interface Generator– XML descriptors of API functions– Each API function wrapped in own class
• Integration with MPICH-G2– Supports MPI– Deployed through Globus components (GRAM)– Hides potential heterogeneity in service startup
and management

Experimental setup
Organizational Grid:• Data hosted on Opteron 250 cluster• Processed on Opteron 254 cluster• Connected using 2 10 GB optical fibersGoals:• Demonstrate parallel scalability of applications• Evaluate overhead of using MPICH-G2 and
Globus Toolkit deployment mechanisms

Computer Science and Engineering
Deployment Overhead Evaluation
Clearly a small overhead associated with using Globus and MPICH-G2 for middleware deployment.
Kmeans Clustering with 6.4 GB dataset: 18-20%.
Vortex Detection with 14.8 GB dataset: 17-20%.
02
00
40
06
00
Ex
ec
uti
on
Tim
e (
se
c)
4 8
Data Repository Nodes (#)
compute - GT 4comute - no GT 4compute - GT 8compute - no GT 8

Deep Web Data Integration
• The emerge of deep web– Deep web is huge– Different from surface web– Challenges for integration
• Not accessible through search engines
• Inter-dependences among deep web sources
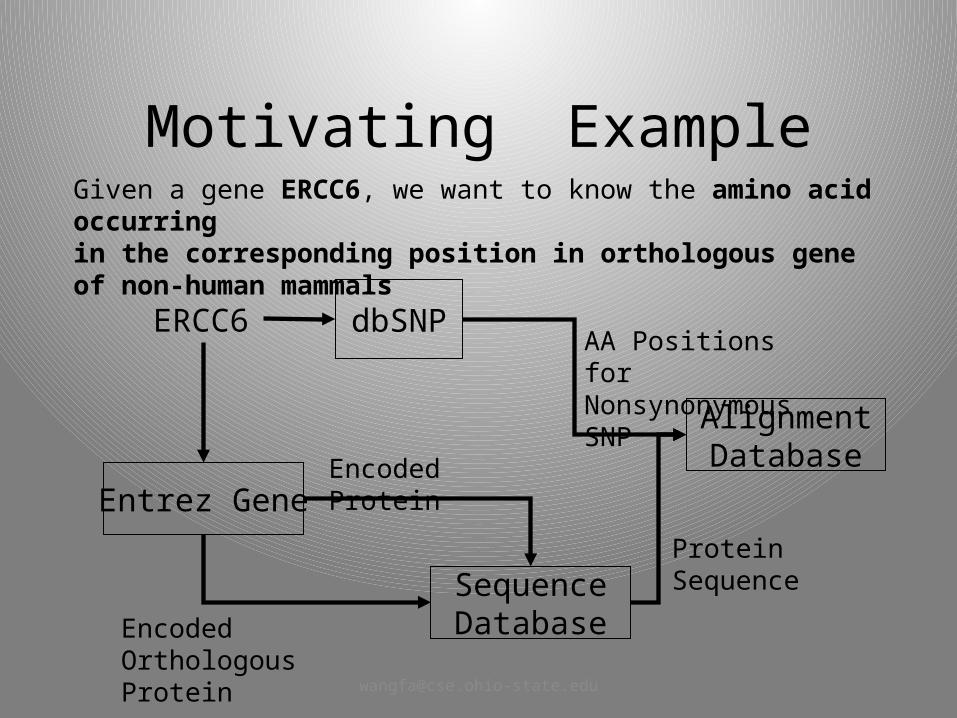
Motivating Example
ERCC6
dbSNP
Entrez Gene
SequenceDatabase
AlignmentDatabase
AA Positions for Nonsynonymous SNP
Encoded Protein
Encoded Orthologous Protein
Protein Sequence
Given a gene ERCC6, we want to know the amino acid occurring in the corresponding position in orthologous gene of non-human mammals

Observations
• Inter-dependences between sources• Time consuming if done manually• Intelligent order of querying• Implicit sub-goals in user query

Contributions
• Formulate the query planning problem for deep web databases with dependences
• Propose a dynamic query planner• Develop cost models and an approximate
planning algorithm• Integrate the algorithm with a deep web
mining tool

49
HASTE Middleware Design Goals
• To Enable the Time-critical Event Handling to Achieve the Maximum Benefit, While Satisfying the Time Constraint
• To be Compatible with Grid and Web Services• To Enable Easy Deployment and Management
with Minimum Human Intervention• To be Used in a Heterogeneous Distributed
Environment
ICAC 2008

50
HASTE Middleware Design
ICAC 2008
Application Layer
Service Layer
OGSA Infrastructure (Globus Toolkit 4.0)
Application Deployment Service
AUTONOMIC SERVICECOMPONENTS
App.Service 1
Agent/Controller
...
...App.
Service 3
Agent/Controller
App.Service 4
Agent/Controller
App.Service 5
Agent/ControllerApp.
Service 2
Agent/Controller
Application
CodeConfiguration
FileBenefit
Function
Time-CriticalEvent
Resource Allocation Service
Resource Monitoring Service
CPU Memory Bandwidth
SchedulingEfficiency
ValueEstimation
Autonomic Adaptation Service
SystemModel
Estimator

Summary
• Several projects cross cutting Parallel Computing, Distributed Computing and Database/ Data mining
• Number of opportunities for MS thesis, MS project, and PhD students
• Relevant Courses – CSE 621/721 – CSE 762 – CSE 671 / 674