data science workshop
TRANSCRIPT

Page 1 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Data Science with Hadoop
Fall, 2014
Ajay Singh Director, Technical Alliance

Page 2 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Agenda
• Data Science
• Machine Learning – quick overview
• Data Science with Hadoop
• Demo

Page 3 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Data Science

Page 4 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
What is Data Science?
Data facts and statistics collected together for reference or analysis
Science The intellectual and practical activity encompassing the systematic study of the structure and behavior of the physical and natural world through observation and experiment.
Data Science The scien&fic explora+on of data to extract meaning or insight, and the construction of software systems to utilize such insight in a business context.
Someone who does this … Data Scientist

Page 5 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Where Can We Use Data Science?
Healthcare • Predict diagnosis • Prioritize screenings • Reduce re-admittance rates
Financial services • Fraud Detection/prevention • Predict underwriting risk • New account risk screens
Public Sector • Analyze public sentiment • Optimize resource allocation • Law enforcement & security
Retail • Product recommendation • Inventory management • Price optimization
Telco/mobile • Predict customer churn • Predict equipment failure • Customer behavior analysis
Oil & Gas • Predictive maintenance • Seismic data management • Predict well production levels

Page 6 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Data Science is an Iterative Activity
Visualize, Explore
Hypothesize; Model
Measure/Evaluate Acquire Data
Clean Data
Formulate the question Deploy

Page 7 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Data Science combines proficiencies…
Data Exploration
Feature Engineering
Raw Transforms
The data science process is comprised of three main tasks, requiring different skill types, including technical, analytical and programming.
Signal Processing
OCR
Geo-spatial
Normalize
Transform/aggregate
Sample
Dimensionality reduction
Feature Selection
NLP
Mutual Information
Data Modeling
Frequent Itemset
Anomaly Detection
Clustering
Collaborative Filter
Regression
Classification
Supervised Learning
Unsupervised Learning
Reporting Visualization Data Quality
technical analytical
A data scientist needs to be proficient in all these tasks.
Pre-processing

Page 8 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Data Science with Big Data…
Very large raw datasets are now available:
- Log files
- Sensor data
- Sentiment information
With more raw data, we can build better models with improved predictive performance.
To handle the larger datasets we need a scalable processing platform like Hadoop and YARN

Page 9 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Data scientists master many skills Applied Science
• Statistics, applied math • Machine Learning • Tools: Python, R, SAS, SPSS
Big data engineering • Big data pipeline engineering
• Statistics and machine learning over large datasets
• Tools: Hadoop, PIG, HIVE, Cascading, SOLR, etc
Business Analysis • Data Analysis, BI
• Business/domain expertise
• Tools: SQL, Excel, EDW
Data engineering • Database technologies
• Computer science
• Tools: Java, Scala, Python, C++

Page 10 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Which makes them hard to find… Applied Science
• Statistics, applied math • Machine Learning • Tools: Python, R, SAS, SPSS
Business Analysis • Data Analysis, BI
• Business/domain expertise
• Tools: SQL, Excel, EDW
Data engineering • Database technologies
• Computer science
• Tools: Java, Scala, Python, C++
Big data engineering • Big data pipeline engineering
• Statistics and machine learning over large datasets
• Tools: Hadoop, PIG, HIVE, Cascading, SOLR, etc

Page 11 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
The Data Science Team
Business Analyst
Data engineer Applied
Scientist

Page 12 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Machine Learning Overview

Page 13 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
What is Machine Learning?
WALL-E was a machine that learned how to feel emotions after 700 years of experiences on Earth collecting human artifacts.
Machine learning is the science of getting computers to learn from data and act without being explicitly programmed. • Machine learning is about the construction and
study of systems that can learn from data.
• The core of machine learning deals with representation and generalization so that the system will perform well on unseen data instances and predict unknown events.
• There is a wide variety of machine learning tasks and successful applications.

Page 14 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Supervised vs. Unsupervised learning
Data Modeling
Frequent Itemset
Anomaly Detection
Clustering
Collaborative Filter
Regression
Classification
Supervised Learning
Unsupervised Learning
Supervised learning: Applications in which the training data is a set of “labeled” examples of the input vectors along with their corresponding target variable (labels) Unsupervised learning: Applications in which the training data comprises examples of input vectors WITHOUT any corresponding target variables. The goal is to unearth “naturally occurring patterns” in the data, such as in clustering Collaborative filtering: (recommendations engine) uses techniques from both supervised and unsupervised world.

Page 15 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Supervised Learning: learn from examples
Labeled dataset
Test data
Patient Age
Tumor Size
Clump Thickness
… Malignant?
55 5 3 TRUE
70 4 7 TRUE
85 4 6 FALSE
35 2 1 FALSE
… … … … FALSE
TRUE
Patient age Tumor size Clump … 72 3 3 66 4 4
Cancer model F(k1, k2, k3, k4)
Malignant
? ?
f(V1, V2, V3, …) = ?
Feature Matrix
Target function
Feature Vector

Page 16 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Classification: predicting a category
Some techniques: - Naïve Bayes - Decision Tree - Logistic Regression - SGD - Support Vector Machines - Neural Network - Ensembles

Page 17 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Regression: predict a continuous value
Some techniques: - Linear Regression / GLM - Decision Trees - Support vector regression - SGD - Ensembles

Page 18 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Example: Ad Click-Through Rates in Ad Search
Rank = bid * CTR Predict CTR for each ad to determine placement, based on: - Historical CTR - Keyword match - Etc…

Page 19 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Unsupervised Learning: detect natural patterns
Age State Annual Income Marital status
25 CA $80,000 M 45 NY $150,000 D 55 WA $100,500 M 18 TX $85,000 S … … … …
No labels
Model Naturally occurring (hidden) structure

Page 20 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Clustering: detect similar instance groupings
Some techniques: - k-means - Spectral clustering - DB-scan - Hierarchical
clustering

Page 21 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Example: market segmentation

Page 22 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Outlier Detection: identify abnormal patterns
Example: identify engine anomalies Features: - Heat generated - Vibration of engine

Page 23 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Outlier Detection Target Function: outlier factor
Outlier factor (0…1)
ID Total$ Age City OF 101 $200 25 SF 0.1 102 $350 35 LA 0.05 103 $25 15 LA 0.2 … … … … 0.1
0.9 0.2 0.15 0.1
Some techniques: - Statistical techniques - Local outlier factor - One-class SVM

Page 24 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Example: Credit Card Fraud Detection

Page 25 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Affinity Analysis: identifying frequent item sets
Y N N Y N Y N N Y N Y Y N Y N N N Y Y Y
Tx 1 Tx 2
Tx 3
Tx 4 Tx 5
…
Item
1
Item
2
Item
3
Item
4
Item
5
…
Y N N Y N Y N N Y N Y Y N Y N N N Y Y Y
Tx 1 Tx 2
Tx 3
Tx 4 Tx 5
…
Item
1
Item
2
Item
3
Item
4
Item
5
…
Goal: identify frequent item set Techniques: FP Growth, a priori

Page 26 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Example: Affinity Analysis
Use affinity analysis for - store layout design - Coupons

Page 27 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Product recommendation: predicting “preference”
Collaborative Filtering Identify users with similar “taste”

Page 28 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Collaborative filtering -> matrix completion
5 2 4 ? ? ? ? 5 2 ? 1 2 ? ? 3
Har
ry p
otte
r
X-M
en
Hob
bit
Arg
o
Pira
tes
5 2 4 1 3 4 1 5 2 3 1 2 4 1 3
101 102 103 104 105 …
101 102 103 104 105 …
Har
ry p
otte
r
X-M
en
Hob
bit
Arg
o
Pira
tes

Page 29 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Example: Netflix

Page 30 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Hadoop and Data Science

Page 31 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
• Data Lake: all the data in one place – Ability to store ALL the data in raw format – Data silo convergence
• Data/compute capabilities available as shared asset – Data scientists can quickly prototype a new idea without an up-front request for funding – YARN enables multiple processing applications
Hadoop Improves Data Scientist Productivity

Page 32 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
I need new data
Finally, we start
collec+ng
Let me see… is it any good?
Start 6 months 9 months
“Schema change” project
Let’s just put it in a folder on HDFS
Let me see… is it any good?
3 months
My model is awesome!
“Schema on read” Accelerates Data Innovation

Page 33 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Hadoop is ideal for pre-processing
Feature Engineering
Raw Transforms
Signal Processing
OCR
Geo-spatial
Normalize
Transform/aggregate
Sample
Dimensionality reduction
Feature Selection
NLP
Mutual Information
Data Modeling
Frequent Itemset
Anomaly Detection
Clustering
Collaborative Filter
Regression
Classification
Supervised Learning
Unsupervised Learning
Pre-processing
Build a better feature matrix - More/new features - More instances - Faster and at more scale

Page 34 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Training a Supervised Learning model with Hadoop
• Typically “training set” is not that large – In this case, it’s very common to train on a high-memory node – Using existing tools: R, Python Scikit-learn or SAS
• For really large training sets that don’t fit in memory – SAS – Spark ML-Lib is a promising (albeit new) solution – Mahout is workable in some cases (but future is unclear)
• Hadoop is also useful in parameter tuning: – Grid-search: optimizing the model’s parameters

Page 35 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Scoring a Supervised Learning Model with Hadoop
• Scoring of a single instance is usually fast • Some use-cases require frequent batch re-scoring of a
large population (e.g, 20M customers): - Use PMML scoring engine (e.g., Zementis, Pattern) - Custom implementation with Python, R, Java, etc

Page 36 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Unsupervised learning with Hadoop
• Clustering: – Many clustering algorithms are parallelizable – Distributed K-means is popular and available in Spark ML-Lib &
Mahout
• Collaborative Filtering: – Alternating Least Squares (ALS) – very parallelizable – ALS implemented in Mahout, Spark ML-Lib, others – Item-based or user-based collaborative filtering available in Mahout

Page 37 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Deployment Considerations: Hadoop and Spark
Page 37
• User runs Spark (or ML-Lib) job directly from Edge Node • Scala API or Java API • Python API also good
• Spark runs directly as a YARN job
• No need to install anything else
Spark ML-Lib Edge node
Spark . .
. . .
. . Spark
YARN

Page 38 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Deployment Considerations: Hadoop and R
Page 38
• R and relevant packages installed on each node
• User runs R on high-memory node • Rstudio or Rstudio server • RCloud
• Interfaces to Hadoop
• RMR: run map-reduce with R • RHDFS: access HDFS files from R • RHIVE: run hive queries from R • RHBase: Hbase from R • RODBC
Rstudio, Rcloud Rhadoop RHive
R . .
. . .
. . R
YARN
R high-memory node

Page 39 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Deployment Considerations: Hadoop and Python
Page 39
• Python and relevant packages installed on each node and high-memory nodes
• User runs Python on high-memory node • IPython notebook is a great UI
• Interfaces to Hadoop
• PyDoop: access HDFS from Python • Map-reduce jobs with Hadoop streaming • Python UDFs with PIG
IPython Pandas, Scikit-learn Numpy, Scipy Matplotlib PyDoop
PythonScikit-learn
Pandas. .
. . .
. .Python
Scikit-learnPandas
YARN
Python high-memory node

Page 40 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Supervised Learning with Hadoop More details + demo
Page 41 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Model
Predict
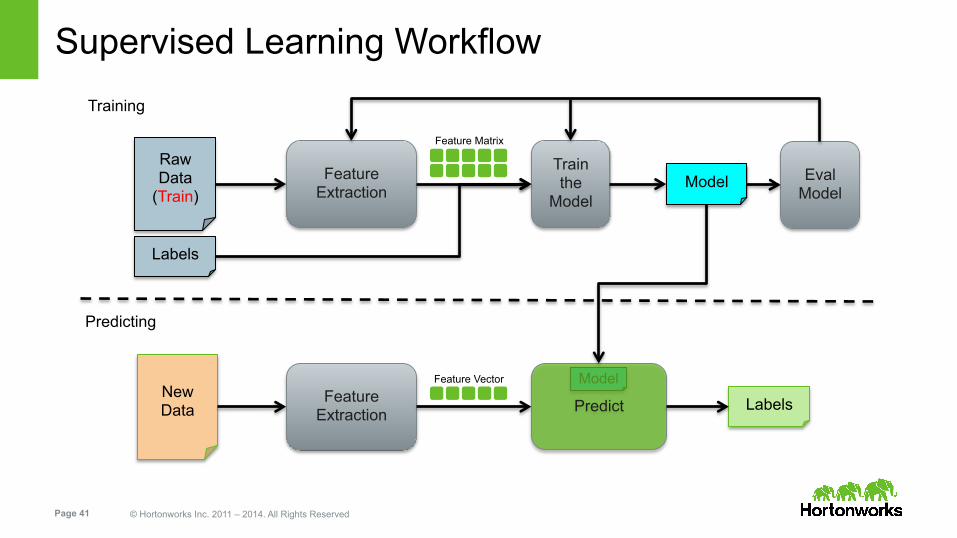
Supervised Learning Workflow
Feature Extraction
Train the
Model Model
Raw Data
(Train)
Labels
New Data
Feature Extraction Labels
Training
Predicting
Eval Model
Feature Matrix
Feature Vector
Page 42 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
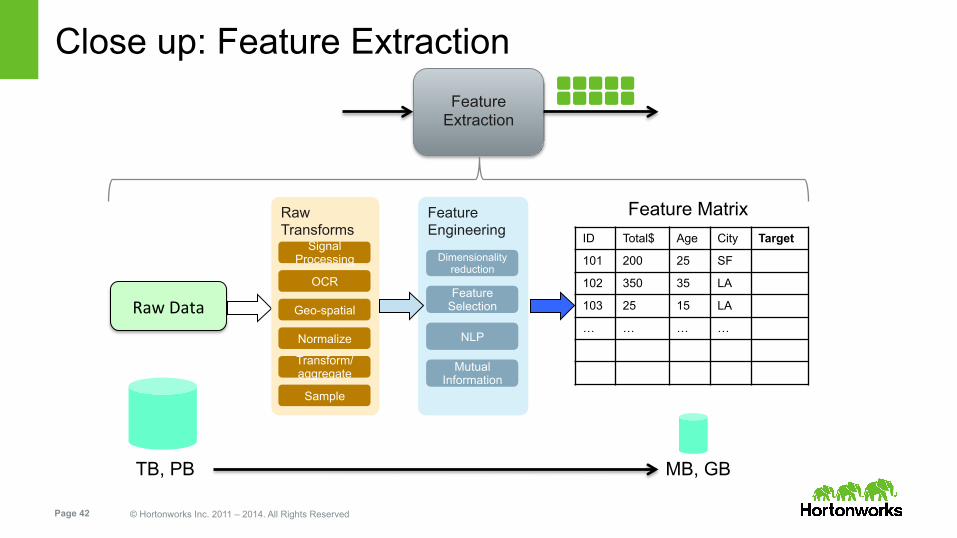
Close up: Feature Extraction
Raw Data
ID Total$ Age City Target
101 200 25 SF
102 350 35 LA
103 25 15 LA
… … … …
Feature Matrix Feature Engineering
Raw Transforms
Signal Processing
OCR
Geo-spatial
Normalize
Transform/aggregate
Sample
Dimensionality reduction
Feature Selection
NLP
Mutual Information
TB, PB
Feature Extraction
MB, GB

Page 43 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
How Big is your Feature Matrix?
Example: • 10M rows, 100 features • Each feature = 8 bytes (double) • Total memory = ~7.5GB

Page 44 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Close-Up: Training the Model
Train the
Model Training
Set Model Eval
Model Metric
- Feature matrix randomly split into “training” (70%) and “validation” set (30%) - Model is built using training set and error measure is computed over validation set - Iterative process or grid-search to determine the best algorithm and choice of
parameters so that: - We get optimal model accuracy - We prevent over-fitting
Validation Set

Page 45 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Evaluating Performance of a Classifier
• Determine “confusion matrix” • Compute metrics: precision, recall, accuracy and specificity
Actual
Yes No
Pred
icte
d Yes True positives
False positives
No False negatives
True negatives
Confusion Matrix
From confusion matrix, we can compute these metrics: Precision = % of positive predicts that are correct Recall = % of positive instances that were predicts as positive F1 score = a measure of test’s accuracy, combining precision and recall Accuracy = % of correct classifications

Page 46 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Demo overview • Datasets:
– Airline delay data (we’re using only 2007, 2008 years) – http://stat-computing.org/dataexpo/2009/the-data.html
– Weather data from http://ncdc.noaa.gov/ • Goal:
– Predict delay (delayTime >= 15 mins) in flights – For simplicity, limited to flights originating from ORD
• Tools: – Pre-process: PIG or Spark on Hadoop – Modeling: Scikit-learn or Spark/ML-Lib or R

Page 47 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Demo Flow
Feature Extraction
Train the
Model
Predict / Score
Model Raw Data
(Train)
Labels
Raw Data (Test)
Feature Extraction Labels
Training Prediction
Airline, Weather (2007) ORD_2007
ORD_2008
Airline, Weather (2008)

Page 48 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
DEMO now!

Page 49 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
© Hortonworks Inc. 2014
Q&A, Open discussion
Architecting the Future of Big Data Page 49