deploying bigdata from zero to million of records in amazon web services
TRANSCRIPT

Implementar su Bigdata de Cero a Millones de Registros en AMAZON WEB SERVICES
Alex Coqueiro Arquitecto de Soluciones Amazon Web Services LATAM

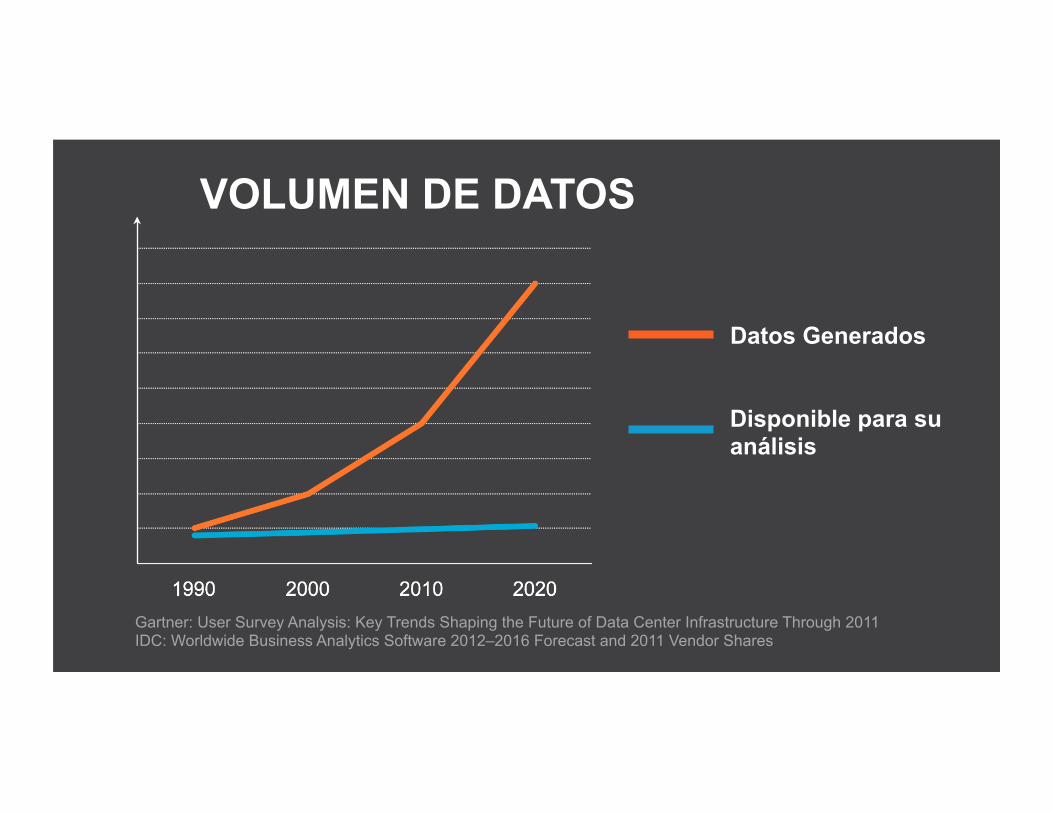
Datos Generados
Disponible para su análisis
VOLUMEN DE DATOS
Gartner: User Survey Analysis: Key Trends Shaping the Future of Data Center Infrastructure Through 2011 IDC: Worldwide Business Analytics Software 2012–2016 Forecast and 2011 Vendor Shares

gran complejidad


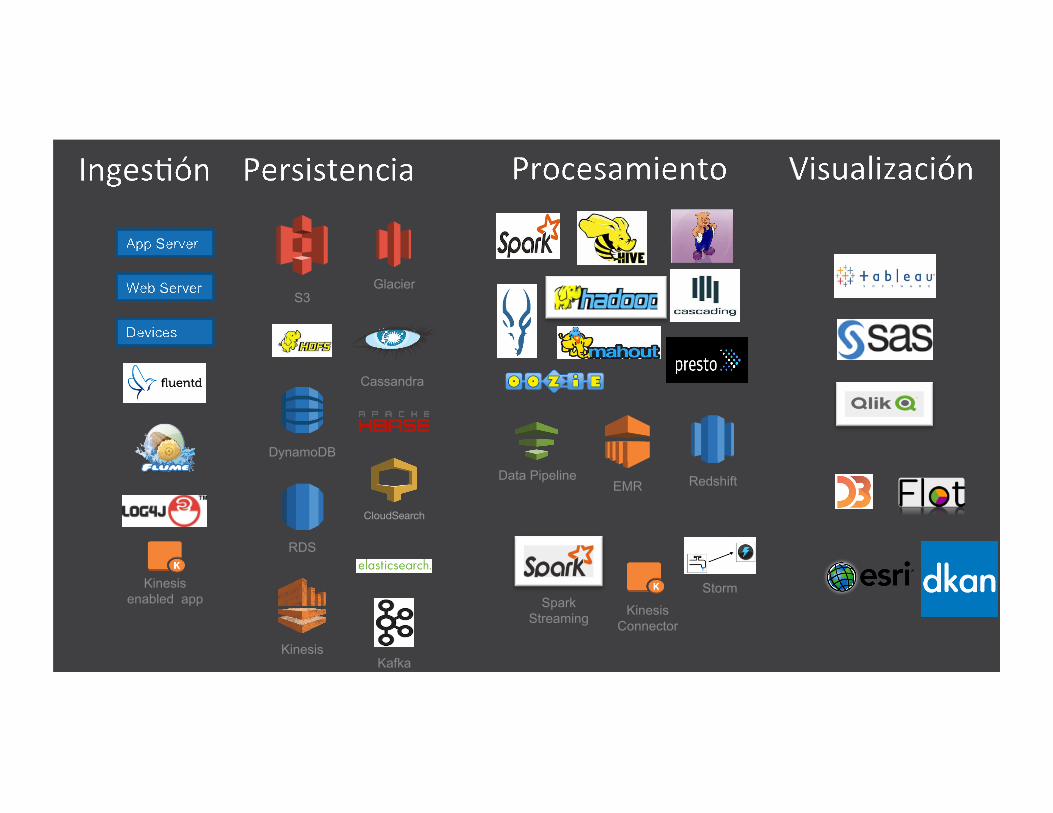
Una gran variedad de soluciones y componentes
Glacier
S3 DynamoDB
RDS
EMR
Redshift
Data Pipeline Kinesis
Cassandra CloudSearch
AML

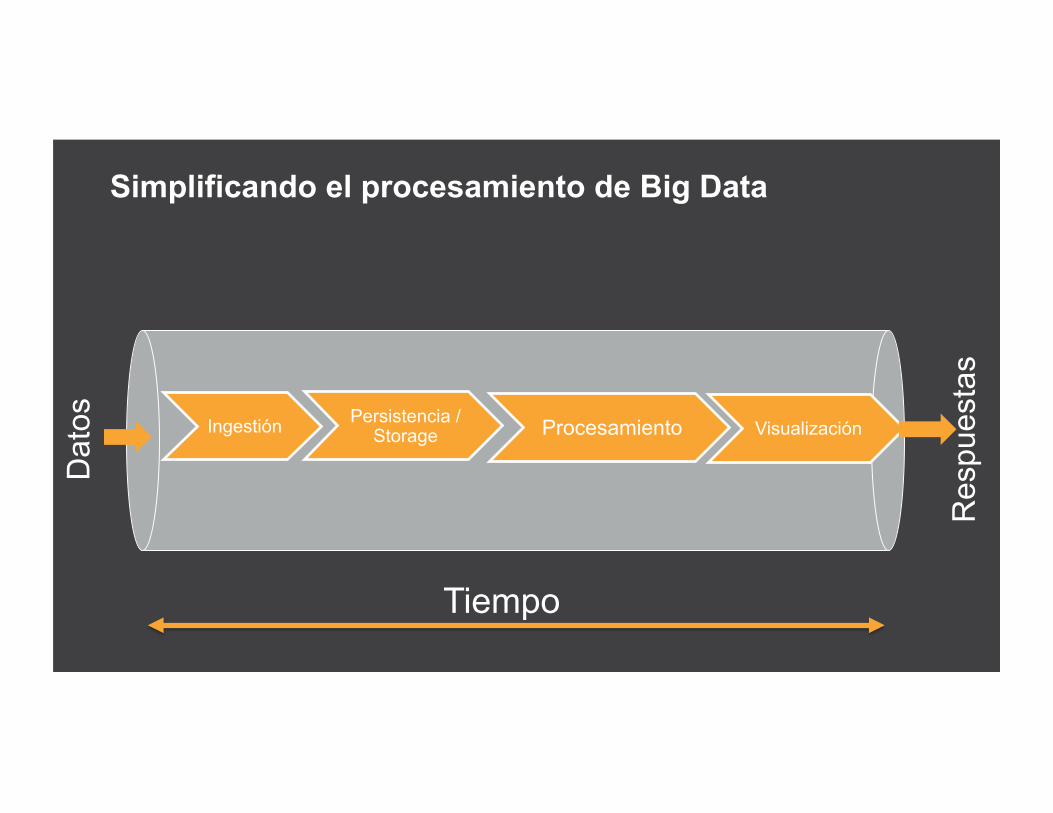
Simplificando el procesamiento de Big Data
Ingestión Persistencia / Storage Procesamiento Visualización
Dat
os
Res
pues
tas
Tiempo
Glacier S3
DynamoDB
RDS
Kinesis
Spark Streaming
EMR Data Pipeline
Storm
Kafka
Redshift
Cassandra
CloudSearch
Kinesis Connector
Kinesis enabled app

Amazon Kinesis Lo
gs d
e Se
rvid
ores
Amazon EMR
Amazon S3 Amazon Redshift
Visualização e Análise
Caso de Uso – Análisis de logs de vuelos
Map Reduce
Parallel Copy
SQL Query

INGESTIÓNè PERSISTENCIA è PROCESARè VISUALIZACIÓN

INGESTIÓNè PERSISTENCIA è PROCESARè VISUALIZACIÓN
Policy

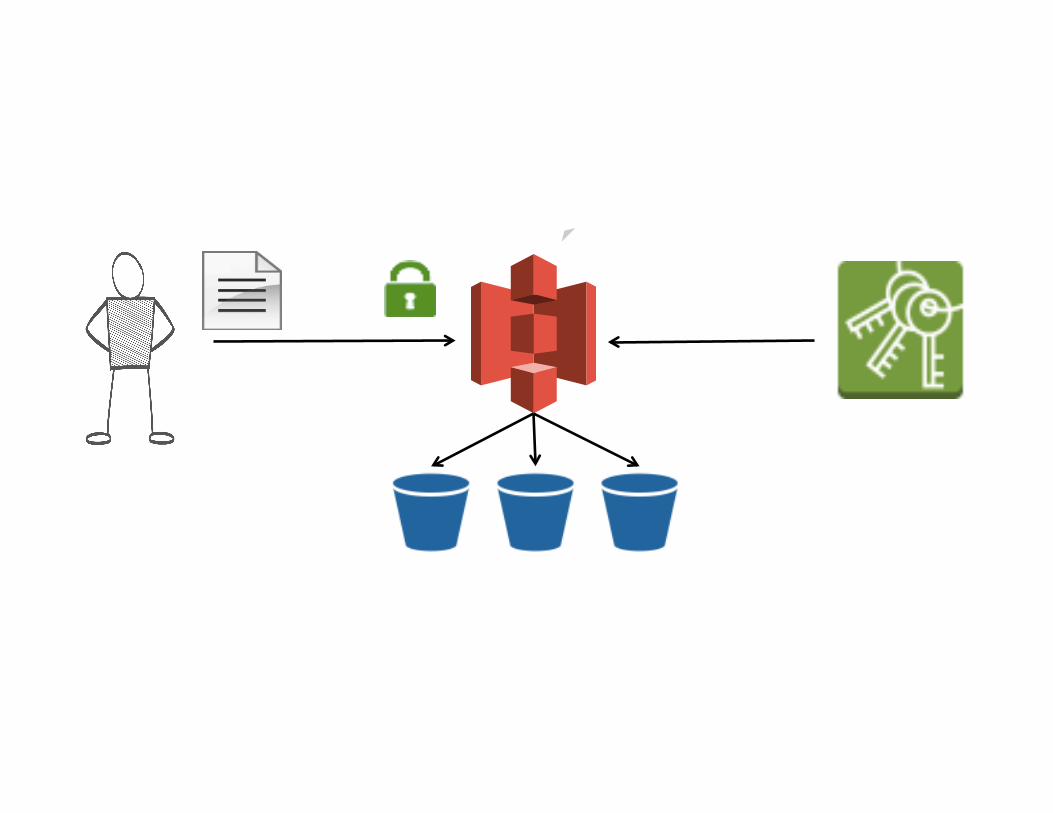
AMAZON S3 SIMPLE STORAGE SERVICE

Nuevo Bucket

99.999999999% 2.000.000.000.000.000+ 1.1+ Millones

INGESTIÓNè PERSISTENCIA è PROCESARè VISUALIZACIÓN

Tipos de datos para ingestión
Transaccionales – RDBMS lectura/
escritura Archivos
– Click-stream logs – Texto libre
Stream – IoT devices – Tweets
Database
Cloud Storage
Stream Storage

AMAZON KINESIS REAL TIME STREAMING

Ejemplo de archivo de log

Ejemplo de kinesis firehose

INGESTIÓNè PERSISTENCIA è PROCESARè VISUALIZACIÓN

AMAZON REDSHIFT
PETA-BYTE SCALE DATAWAREHOUSE

Ejemplo de cluster en redshift

Massively parallel online Analytic Processing Resizible sin Downtime Compatible con PostgreSQL


AMAZON ELASTIC MAPREDUCE HADOOP AS A SERVICE

Ejemplo de cluster en EMR – Hive y Spark

INGESTIÓNè PERSISTENCIA è PROCESARè VISUALIZACIÓN


Marketplace para software en Nube
Mas de 1,900 opciones en 23 categorias
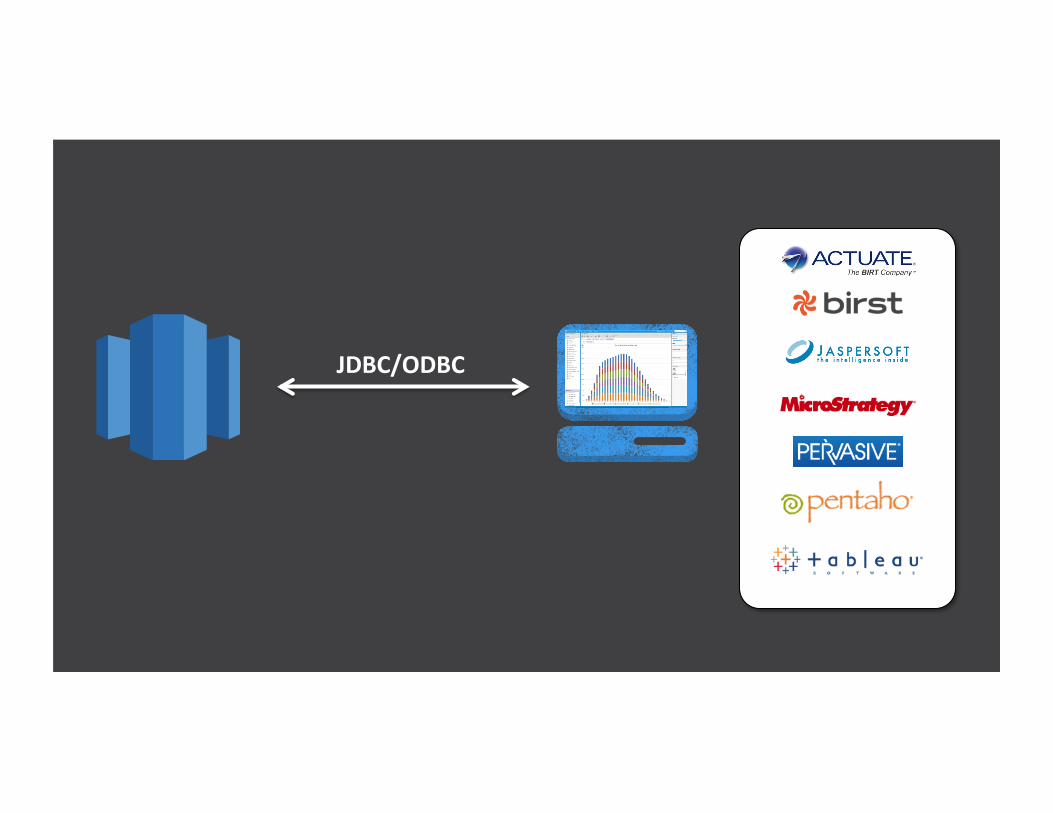
JDBC/ODBC


Muchas Gracias