developing scalable parallel applications in...
TRANSCRIPT

© 2012 IBM Corporation
Developing Scalable Parallel Applications in X10
David Grove, Vijay Saraswat, Olivier TardieuIBM TJ Watson Research Center
Based on material from previous X10 Tutorials by Bard Bloom, David Cunningham, Evelyn Duesterwald Steve Fink, Nate Nystrom,
Igor Peshansky, Christoph von Praun, and Vivek SarkarAdditional contributions from Anju Kambadur, Josh Milthorpe and Juemin Zhang
This material is based upon work supported in part by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002.
Please see http://x10-lang.org/tutorials/sc2012 for the most up-to-date version of this tutorial.

© 2012 IBM Corporation
Tutorial Objectives
Learn to develop scalable parallel applications using X10– X10 language and class library fundamentals– Effective patterns of concurrency and distribution– Case studies: draw material from real working code
Exposure to Asynchronous Partitioned Global Address Space (APGAS) Programming Model– Concepts broader than any single language– Move beyond Single Program/Multiple Data (SPMD) to more flexible paradigms
Updates on the X10 project and user/research community– Highlight what is new in X10 since SC’11
Gather feedback from you– About your application domains– About X10

© 2012 IBM Corporation
Tutorial Outline
X10 Overview (70 minutes)– Programming model concepts– Key language features– Implementation highlights
Scaling SPMD-style computations in X10 (40 minutes)– Scaling finish/async – Scaling communication– Collective operations
Unbalanced computations (20 minutes)– Global Load Balancing & UTS
Application frameworks (20 minutes)– Global Matrix Library– SAT X10
Summary and Discussion (20 minutes)
© 2012 IBM Corporation
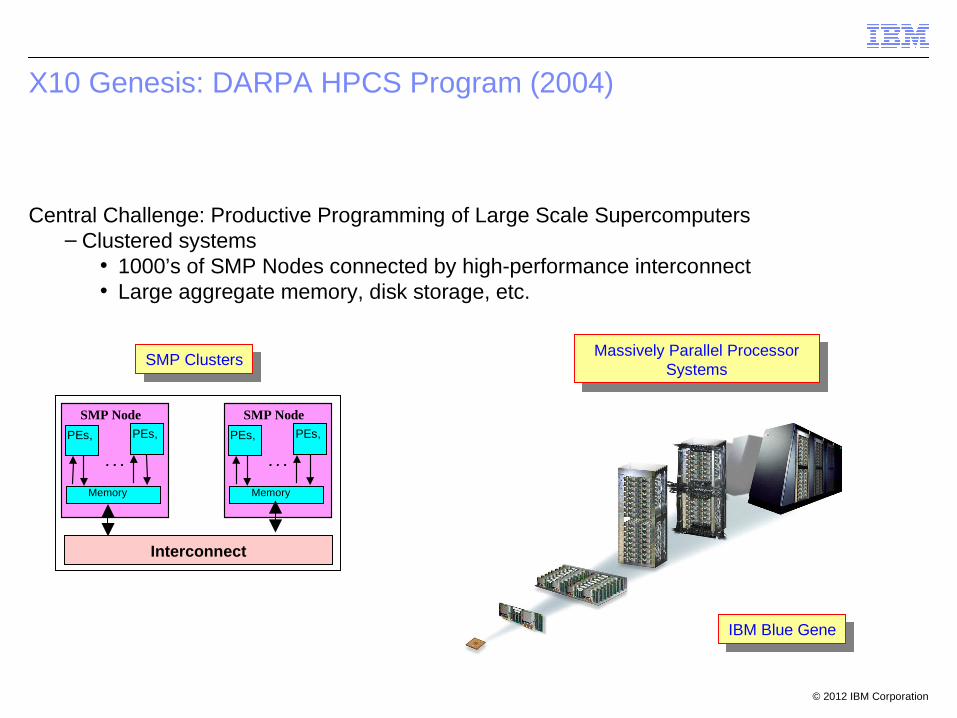
X10 Genesis: DARPA HPCS Program (2004)
Central Challenge: Productive Programming of Large Scale Supercomputers– Clustered systems
• 1000’s of SMP Nodes connected by high-performance interconnect• Large aggregate memory, disk storage, etc.
SMP ClustersSMP Clusters
. . .
Memory
PEs,
SMP Node
PEs,
. . . . . .
Memory
PEs,
SMP Node
PEs,
Interconnect
Massively Parallel Processor Systems
Massively Parallel Processor Systems
IBM Blue GeneIBM Blue Gene

© 2012 IBM Corporation
Flash forward a few years… Big Data and Commercial HPC
Central Challenge: Productive programming of large commodity clusters– Clustered systems
• 100’s to 1000’s of SMP Nodes connected by high-performance network• Large aggregate memory, disk storage, etc.
SMP ClustersSMP Clusters
. . .
Memory
PEs,
SMP Node
PEs,
. . . . . .
Memory
PEs,
SMP Node
PEs,
Network
Commodity cluster != MPP systembut the programming model problem is highly similar

© 2012 IBM Corporation
X10 Performance and Productivity at Scale
An evolution of Java for concurrency, scale out, and heterogeneity– Language focuses on high productivity and high performance– Bring productivity gains from commercial world to HPC developers
The X10 language provides:– Java-like language (statically typed, object oriented, garbage-collected)– Ability to specify scale-out computations (multiple places, exploit modern networks)– Ability to specify fine-grained concurrency (exploit multi-core)– Single programming model for computation offload and heterogeneity (exploit GPUs)– Migration path
• X10 concurrency/distribution idioms can be realized in other languages via library APIs that wrap the X10 runtime
• X10 interoperability with Java and C/C++ enables reuse of existing libraries
© 2012 IBM Corporation
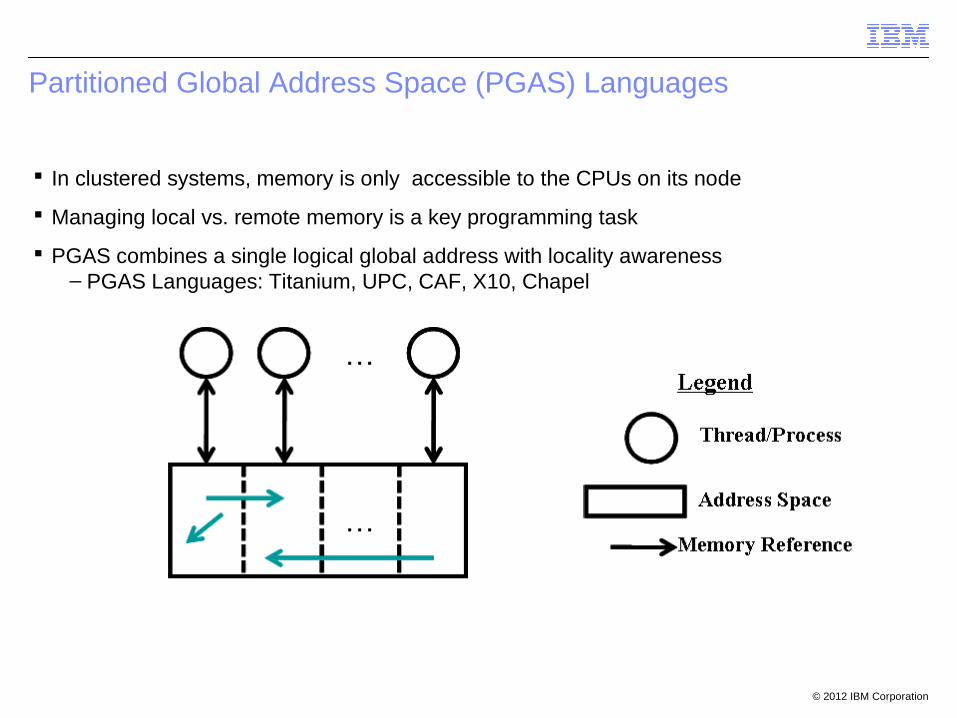
Partitioned Global Address Space (PGAS) Languages
In clustered systems, memory is only accessible to the CPUs on its node
Managing local vs. remote memory is a key programming task
PGAS combines a single logical global address with locality awareness– PGAS Languages: Titanium, UPC, CAF, X10, Chapel
© 2012 IBM Corporation
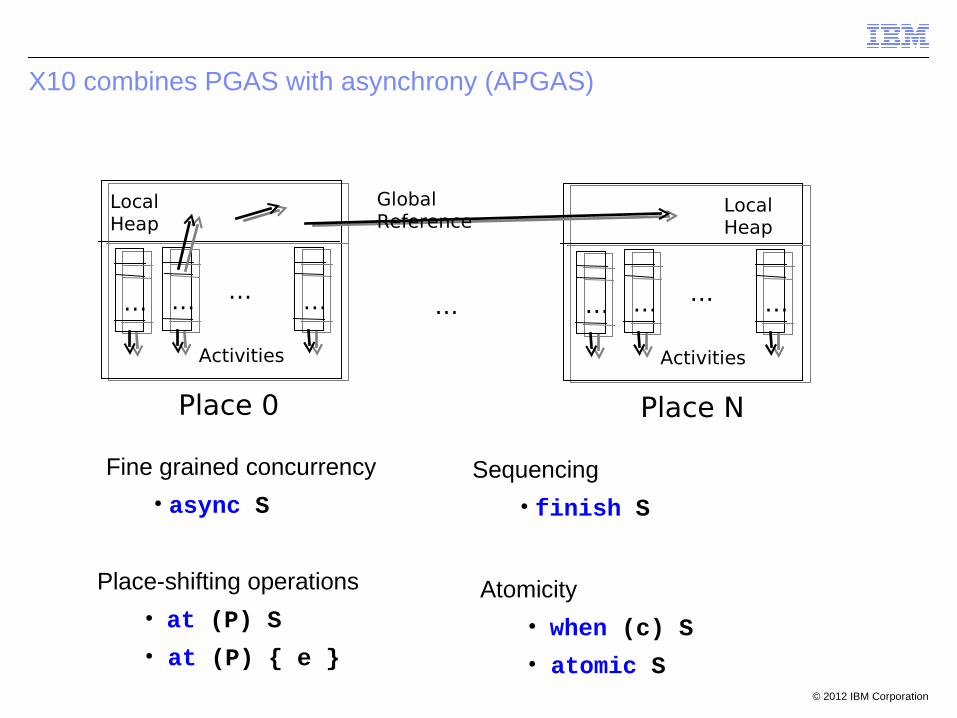
Fine grained concurrency
• async S
Place-shifting operations
• at (P) S
• at (P) { e }
Sequencing
• finish S
… …… …
Activities
Local Heap
Place 0
… …… …
Activities
Local Heap
Place N
…
Global Reference
X10 combines PGAS with asynchrony (APGAS)
Atomicity
• when (c) S
• atomic S

© 2012 IBM Corporation
Hello Whole World
1/class HelloWholeWorld {2/ public static def main(args:Rail[String]) {3/ finish 4/ for (p in Place.places()) 5/ at (p) 6/ async 7/ Console.OUT.println(p+" says " +args(0)); 8/ }9/}
("
% x10c++ HelloWholeWorld.x10
% X10_NPLACES=4; ./a.out hello
Place 0 says hello
Place 2 says hello
Place 3 says hello
Place 1 says hello
© 2012 IBM Corporation
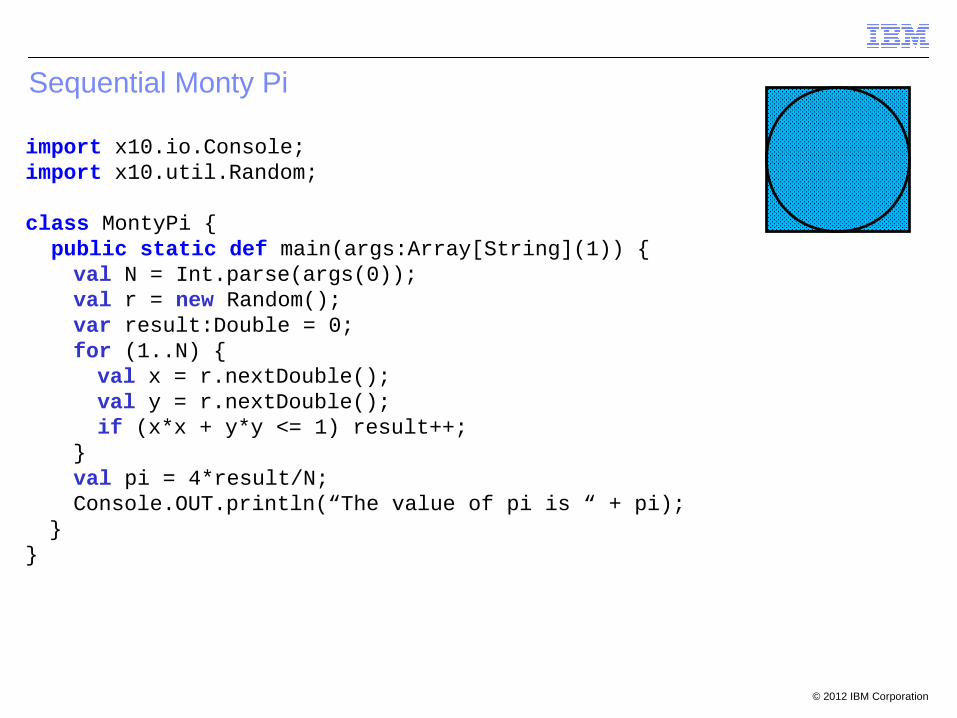
Sequential Monty Pi
import x10.io.Console;import x10.util.Random;
class MontyPi { public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));val r = new Random();var result:Double = 0;for (1..N) {val x = r.nextDouble();val y = r.nextDouble();if (x*x + y*y <= 1) result++;
}val pi = 4*result/N;Console.OUT.println(“The value of pi is “ + pi);
}}
© 2012 IBM Corporation
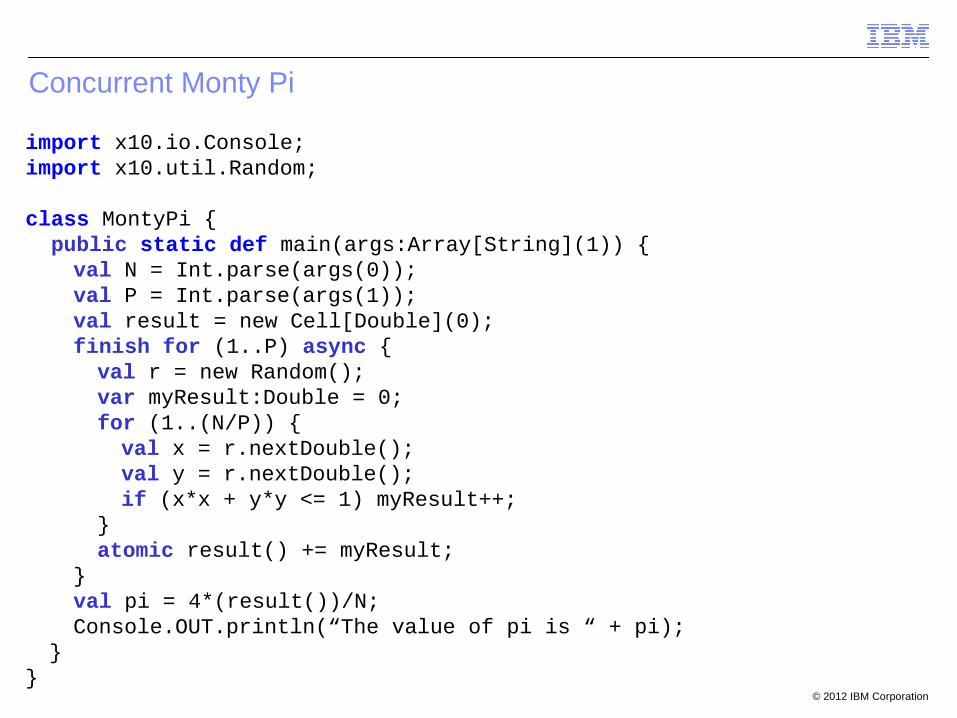
Concurrent Monty Pi
import x10.io.Console;import x10.util.Random;
class MontyPi { public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));val P = Int.parse(args(1));val result = new Cell[Double](0);finish for (1..P) async {val r = new Random();var myResult:Double = 0;for (1..(N/P)) {val x = r.nextDouble();val y = r.nextDouble();if (x*x + y*y <= 1) myResult++;
}atomic result() += myResult;
}val pi = 4*(result())/N;Console.OUT.println(“The value of pi is “ + pi);
}}
© 2012 IBM Corporation
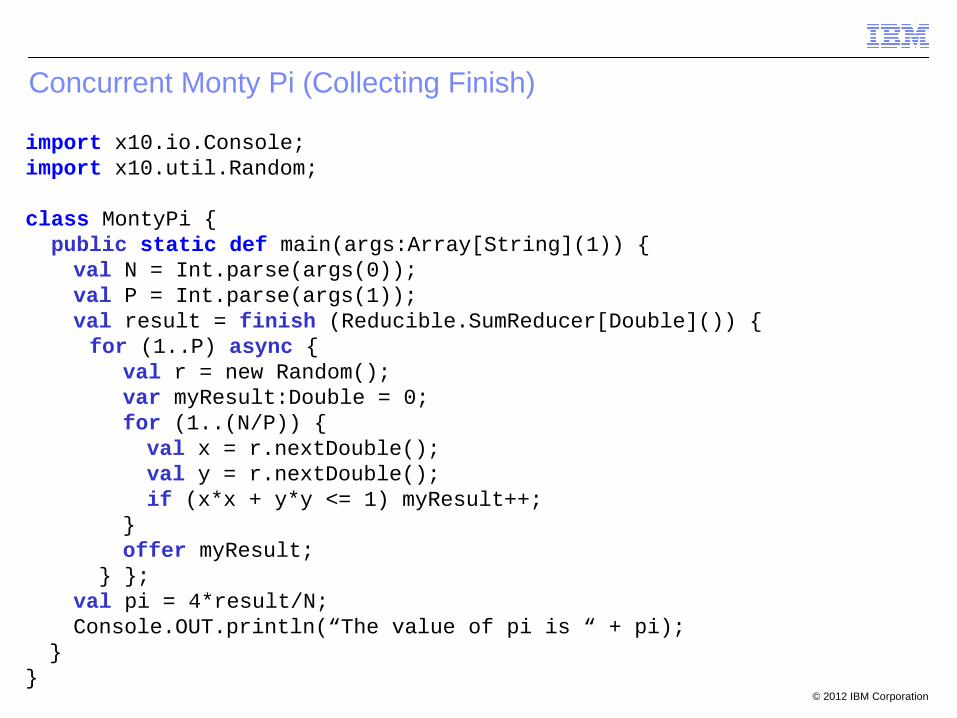
Concurrent Monty Pi (Collecting Finish)
import x10.io.Console;import x10.util.Random;
class MontyPi { public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));val P = Int.parse(args(1));val result = finish (Reducible.SumReducer[Double]()) {
for (1..P) async { val r = new Random(); var myResult:Double = 0; for (1..(N/P)) { val x = r.nextDouble(); val y = r.nextDouble(); if (x*x + y*y <= 1) myResult++;
} offer myResult;
} };val pi = 4*result/N;Console.OUT.println(“The value of pi is “ + pi);
}}
© 2012 IBM Corporation
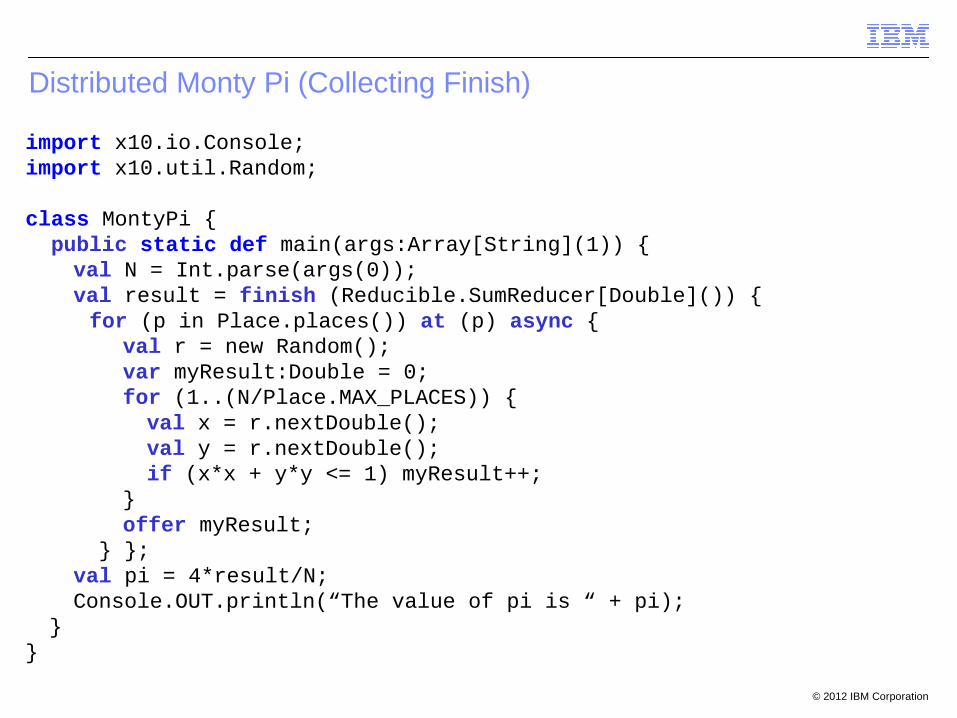
Distributed Monty Pi (Collecting Finish)
import x10.io.Console;import x10.util.Random;
class MontyPi { public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));val result = finish (Reducible.SumReducer[Double]()) {
for (p in Place.places()) at (p) async { val r = new Random(); var myResult:Double = 0; for (1..(N/Place.MAX_PLACES)) { val x = r.nextDouble(); val y = r.nextDouble(); if (x*x + y*y <= 1) myResult++;
} offer myResult;
} };val pi = 4*result/N;Console.OUT.println(“The value of pi is “ + pi);
}}
© 2012 IBM Corporation
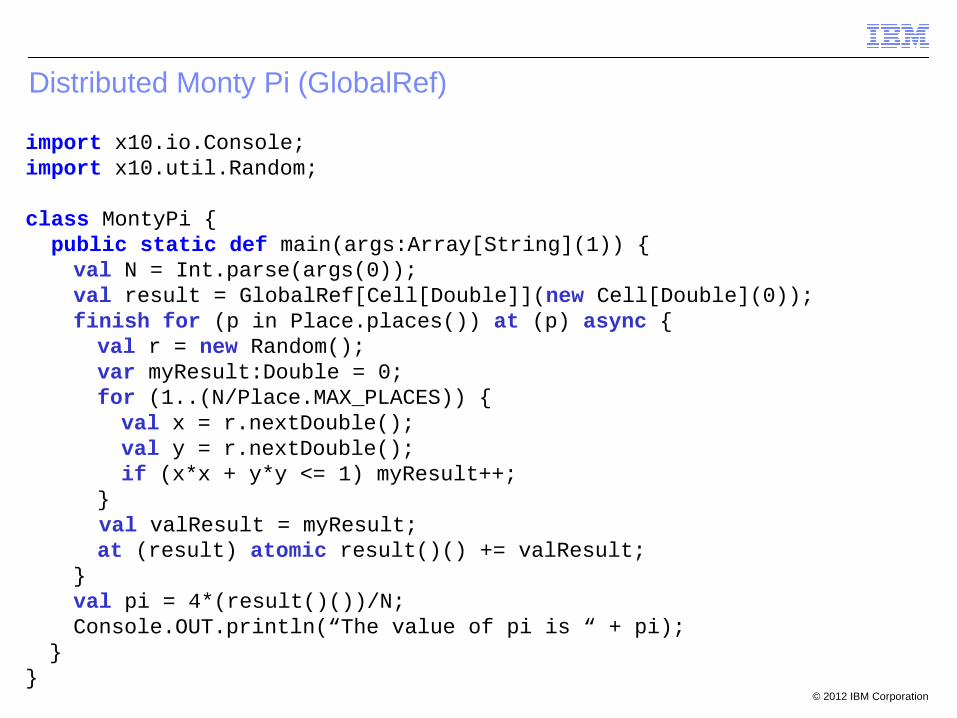
Distributed Monty Pi (GlobalRef)
import x10.io.Console;import x10.util.Random;
class MontyPi { public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));val result = GlobalRef[Cell[Double]](new Cell[Double](0));finish for (p in Place.places()) at (p) async {val r = new Random();var myResult:Double = 0;for (1..(N/Place.MAX_PLACES)) {val x = r.nextDouble(); val y = r.nextDouble();if (x*x + y*y <= 1) myResult++;
} val valResult = myResult;at (result) atomic result()() += valResult;
}val pi = 4*(result()())/N;Console.OUT.println(“The value of pi is “ + pi);
}}

© 2012 IBM Corporation
Overview of Language Features
Many sequential features of Java inherited unchanged
– Classes (single inheritance)– Interfaces (multiple inheritance)– Instance and static fields– Constructors– Overloaded, over-rideable methods– Automatic memory management (GC)– Familiar control structures, etc
Structs– Headerless, inlined, user-defined primitives
Closures– Encapsulate function as code block +
dynamic environment
Type system extensions– Dependent types– Generic types (instantiation-based)– Type inference (local)
Concurrency– Fine-grained concurrency
async S;– Atomicity and synchronization
atomic S; when (c) S;
– Ordering– finish S;
Distribution– Place shifting
at (p) S;– Distributed object model
• Automatic serialization object graphs• GlobalRef[T] to create cross-Place references• PlaceLocalHandle[T] to define objects with distributed state
– Class library support for RDMA, collectives, etc.

© 2012 IBM Corporation16
async
async S
• Creates a new child activity that executes statement S
• Returns immediately
• S may reference variables in enclosing blocks
• Activities cannot be named
• Activity cannot be aborted or cancelled
Stmt ::= async Stmt
cf Cilk’s spawn
// Compute the Fibonacci// sequence in parallel.def fib(n:Int):Int {if (n < 2) return 1; val f1:Int;
val f2:Int;finish { async f1 = fib(n-1);f2 = fib(n-2);
}return f1+f2;
}

© 2012 IBM Corporation17
// Compute the Fibonacci// sequence in parallel.def fib(n:Int):Int {if (n < 2) return 1; val f1:Int;
val f2:Int;finish { async f1 = fib(n-1);f2 = fib(n-2);
}return f1+f2;
}
finish
finish S
Execute S, but wait until all (transitively) spawned asyncs have terminated.
finish is useful for expressing “synchronous” operations on (local or) remote data.
Rooted exception model
– Trap all exceptions thrown by spawned activities.
– Throw an (aggregate) exception if any spawned async terminates abruptly.
implicit finish around program main
Stmt ::= finish Stmt
cf Cilk’s sync

© 2012 IBM Corporation18
// push data onto concurrent // list-stackval node = new Node(data);atomic {node.next = head;head = node;
}
atomic
atomic S Execute statement S atomically
Atomic blocks are conceptually executed in a serialized order with respect to all other atomic blocks: isolation and weak atomicity.
An atomic block body (S) ... must be nonblocking must not create concurrent activities
(sequential) must not access remote data (local) restrictions checked dynamically
// target defined in lexically// enclosing scope.atomic def CAS(old:Object, n:Object) {if (target.equals(old)) {target = n;return true;
}return false;
}
Stmt ::= atomic StatementMethodModifier ::= atomic

© 2012 IBM Corporation19
when
when (E) S
Activity suspends until a state inwhich the guard E is true.
In that state, S is executed atomically and in isolation.
Guard E is a boolean expression must be nonblocking
must not create concurrent activities (sequential)
must not access remote data (local)
must not have side-effects (const)
restrictions mostly checked dynamically; const restriction is not checked.
Stmt ::= WhenStmtWhenStmt ::= when ( Expr ) Stmt | WhenStmt or (Expr) Stmt
class OneBuffer {var datum:Object = null;var filled:Boolean = false;def send(v:Object) { when ( !filled ) {datum = v;filled = true;
}}def receive():Object {when (filled) {val v = datum;datum = null;filled = false;return v;
}}
}

© 2012 IBM Corporation20
at
at (p) S
Execute statement S at place p
Current activity is blocked until S completes
Deep copy of local object graph to target place; the variables referenced from S define the roots of the graph to be copied.
GlobalRef[T] used to create remote pointers across at boundaries
Stmt ::= at (p) Stmt
class C { var x:int;def this(n:int) { x = n; }
}
// Increment remote counterdef inc(c:GlobalRef[C]) {at (c.home) c().x++;
}
// Create GR of Cstatic def make(init:int) {val c = new C(init);return GlobalRef[C](c);
}

© 2012 IBM Corporation
Distributed Object Model
Objects live in a single place
Objects can only be accessed in the place where they live
Implementing at – Compiler analyzes the body of “at” and identifies roots to copy (exposed variables)– Complete object graph reachable from roots is serialized and sent to destination place– A new (unrelated) copy of the object graph is created at the destination place
Controlling object graph serialization– Instance fields of class may be declared transient (won’t be copied)– GlobalRef[T] allows cross-place pointers to be created

© 2012 IBM Corporation
Take a breath…
Whirlwind tour through X10 language– More details will be introduced as we work through the example codes– See http://x10-lang.org for specification, samples, etc.
– Next topic: brief overview of the X10 implementation
Questions so far?

© 2012 IBM Corporation
X10 Target Environments
High-end large HPC clusters– BlueGene/P (since 2010); BlueGene/Q (in progress)– Power7IH (aka PERCS machine)– x86 + InfiniBand, Power + InfiniBand– Goal: deliver scalable performance competitive with C+MPI
Medium-scale commodity systems– ~100 nodes (~1000 core and ~1 terabyte main memory)– Goal: deliver main-memory performance with simple programming model (accessible to
Java programmers)
Developer laptops– Linux, Mac OSX, Windows. Eclipse-based IDE, debugger, etc– Goal: support developer productivity

© 2012 IBM Corporation
X10 Implementation Summary
X10 Implementations– C++ based (“Native X10”)
• Multi-process (one place per process; multi-node)• Linux, AIX, MacOS, Cygwin, BlueGene• x86, x86_64, PowerPC
– JVM based (“Managed X10”)• Multi-process (one place per JVM process; multi-node)• Limitation on Windows to single process (single place)• Runs on any Java 6 JVM
X10DT (X10 IDE) available for Windows, Linux, Mac OS X– Based on Eclipse 3.7– Supports many core development tasks including remote build/execute facilities
IBM Parallel Debugger for X10 Programming– Adds X10 language support to IBM Parallel Debugger– Available on IBM developerWorks (Native X10 on Linux only)
© 2012 IBM Corporation
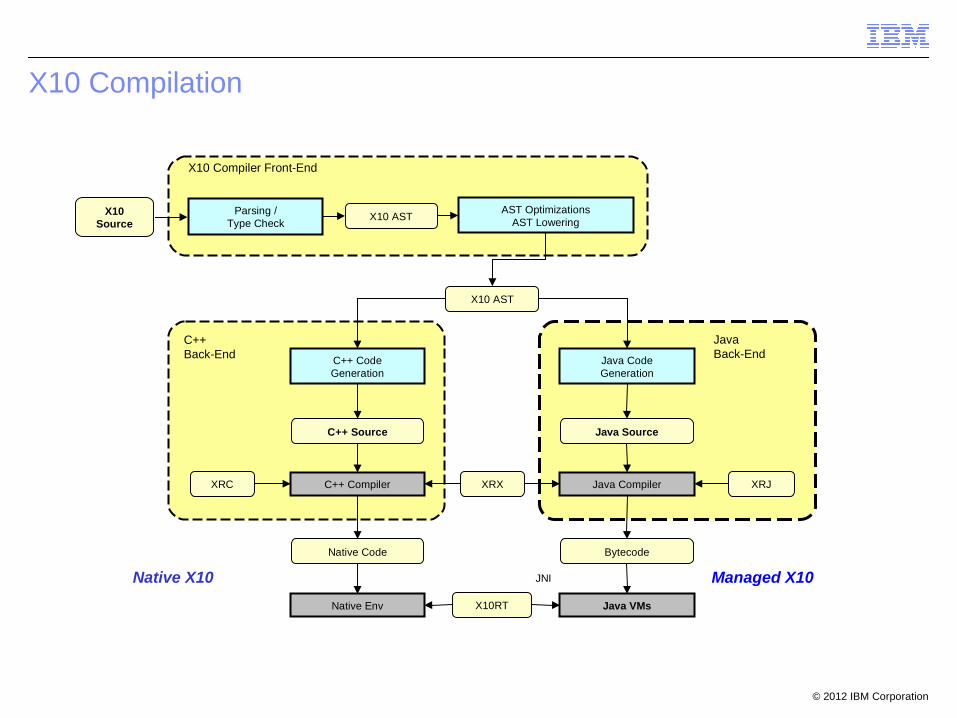
X10 Compilation
X10Source
Parsing /Type Check
AST OptimizationsAST LoweringX10 AST
X10 AST
C++ CodeGeneration
Java CodeGeneration
C++ Source Java Source
C++ Compiler Java CompilerXRC XRJXRX
Native Code Bytecode
X10RT
X10 Compiler Front-End
C++ Back-End
Java Back-End
Java VMsNative Env
JNINative X10 Managed X10

© 2012 IBM Corporation
X10 Runtime Software Stack
Core Class Libraries– Fundamental classes & primitives, Arrays,
core I/O, collections, etc– Written in X10; compiled to C++ or Java
XRX (X10 Runtime in X10)– APGAS functionality
•Concurrency: async/finish (workstealing)•Distribution: Places/at
– Written in X10; compiled to C++ or Java
X10 Language Native Runtime– Runtime support for core sequential X10
language features– Two versions: C++ and Java
X10RT– Active messages, collectives, bulk data
transfer– Implemented in C– Abstracts/unifies network layers (PAMI,
DCMF, MPI, etc) to enable X10 on a range of transports
X10 Application Program
X10 Core Class Libraries
XRX Runtime
X10 Language Native Runtime
X10RT
PAMI DCMF MPI
X10
Ru
ntim
e
TCP/IP

© 2012 IBM Corporation
Performance Model: async, finish, and when
Pool of worker threads in each Place– Each worker maintains a queue of pending asyncs– Worker pops async from its own queue, executes it, repeat…– If worker’s queue empty, steal from another worker’s queue
Finish typically does not block worker (run subtask in queue instead of blocking)
Finish may block because of thieves or remote async– worker 1 reaches end of finish block while worker 2 is still running async
A blocking finish (or a when) incurs OS-level context switch – May incur thread creation cost (maintain set of active workers)
Cost analysis– async
• queue operations (fences, at worst CAS)• heap allocated task object (allocation + GC cost)
– finish (single place)• synchronized counter• heap allocated finish object (allocation + GC cost)

© 2012 IBM Corporation
Performance Model: Places and at
At runtime, each Place is a separate process
Costs of at– Serialization/deserialization (function of size of captured state)– Communication (if destination != here)– Scheduling (worker thread may block) (if destination != here)

© 2012 IBM Corporation
Performance Model: Native X10 vs. Managed X10
Native X10: base performance model is C++
Object-oriented features more expensive– C++ compilers don’t optimize virtual
dispatch, interface invocation, instanceof, etc– Memory management: BDWGC
• Allocation approx like malloc• Conservative GC, (non-moving)• Parallel, but not concurrent
Generics map to C++ templates
Structs map to C++ classes with no virtual methods that are inlined in containing object/array
C++ compilation is mostly file-based, which limits cross-class optimization
More deterministic execution (less runtime jitter)
Managed X10: base performance model is Java
Object-oriented features less expensive– JVMs do optimize virtual dispatch, interface
invocation, instanceof, etc– Memory management
• Very fast allocation• Highly tuned garbage collectors
Generics map to Java generics– Mostly erased– Primitives boxed
Structs map to Java classes (no difference between X10 structs and X10 classes)
JVM dynamically optimizes entire program
Less deterministic execution (more jitter) due to JIT compilation, profile-directed optimization, GC

© 2012 IBM Corporation
Tutorial Outline
X10 Overview (70 minutes)– Programming model concepts– Key language features– Implementation highlights
Scaling SPMD-style computations in X10 (40 minutes)– Scaling finish/async – Scaling communication– Collective operations
Unbalanced computations (20 minutes)– Global Load Balancing & UTS
Application frameworks (20 minutes)– Global Matrix Library– SAT X10
Summary and Discussion (20 minutes)

© 2012 IBM Corporation
Towards a Scalable HelloWholeWorld
Why won’t HelloWholeWorld scale?
1/class HelloWholeWorld {2/ public static def main(args:Rail[String]) {3/ finish 4/ for (p in Place.places()) 5/ at (p) 6/ async 7/ Console.OUT.println(p+" says " +args(0)); 8/ }9/}
1. Using most general (default) implementation of finish
2. Sequential initiation of asyncs
3. Serializing more data than is actually necessary (minor improvement)

© 2012 IBM Corporation
Towards a Scalable HelloWholeWorld (2)
Minor change: optimize serialization to reduce message size
public static def main(args:Rail[String]) { finish for (p in Place.places()) { val arg = args(0); at (p) async Console.OUT.println("(At " + here + ") : " + arg); } }
© 2012 IBM Corporation
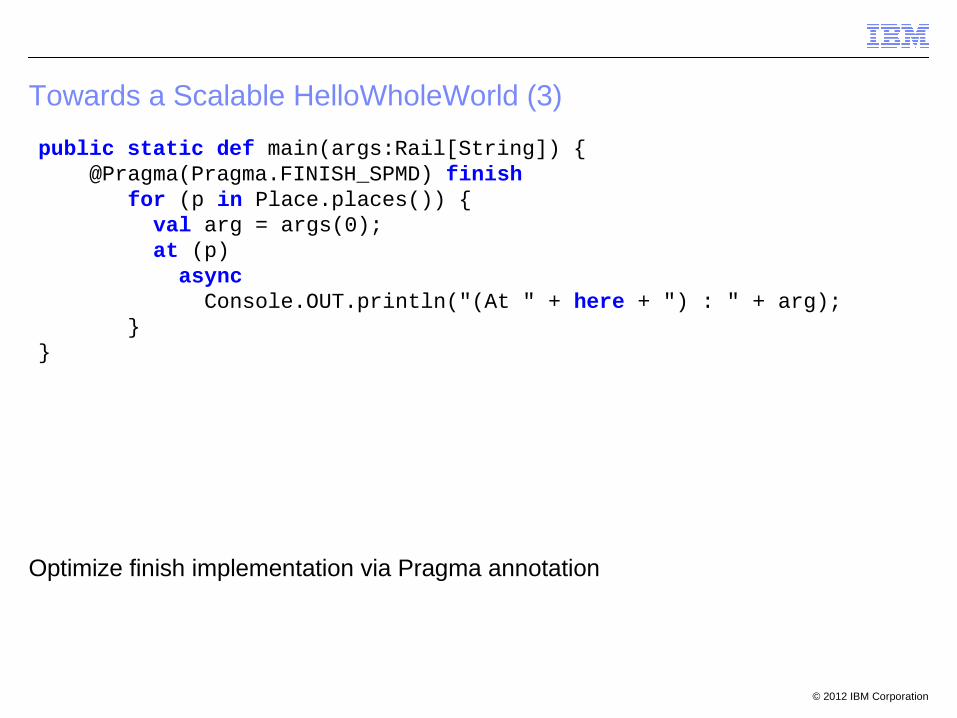
Towards a Scalable HelloWholeWorld (3)
Optimize finish implementation via Pragma annotation
public static def main(args:Rail[String]) { @Pragma(Pragma.FINISH_SPMD) finish for (p in Place.places()) { val arg = args(0); at (p) async Console.OUT.println("(At " + here + ") : " + arg); } }

© 2012 IBM Corporation
Towards a Scalable HelloWholeWorld (4)
Parallelize async initiation … this scales nicely, but it is getting complicated!
public static def main(args:Rail[String]) { @Pragma(Pragma.FINISH_SPMD) finish for(var i:Int=Place.numPlaces()-1; i>=0; i-=32) { at (Place(i)) async { val max = Runtime.hereInt(); val min = Math.max(max-31, 0); @Pragma(Pragma.FINISH_SPMD) finish for (var j:Int=min; j<=max; ++j) { at (Place(j)) async Console.OUT.println("(At "+here+ ") : " + arg); } } }

© 2012 IBM Corporation
Finally: a Simple and Scalable HelloWholeWorld
Put the complexity in the standard library!
broadcastFlat encapsulates the chunked loop & pragma; use a closure (function) to get a clean API
Recurring theme in X10: simple primitives + strong abstraction = new powerful user-defined primitives
public static def main(args:Rail[String]) { val arg = args(0); PlaceGroup.WORLD.broadcastFlat(()=>{ Console.OUT.println("(At " + here + ") : " + arg); }); }

© 2012 IBM Corporation36
K-Means: description of the problem
Given:– A set of points (black dots) in D-dimensional space
(example, D = 2)– Desired number of partitions K
(example, K = 4)
Calculate:– The K cluster locations (red blobs).– Minimize average distance to cluster

© 2012 IBM Corporation37
Lloyd's Algorithm
Computes good (not best) clusters.
Initialize with a guess for the K positions.
Iteratively improve until we reach fixed point.
Algorithm:
while (!bored) {
classify points by nearest cluster
average equivalence classes for improved clusters
}

© 2012 IBM Corporation38
Lloyd's Algorithm
Computes good (not best) clusters.
Initialize with a guess for the K positions.
Iteratively improve until we reach fixed point.
Algorithm:
while (!bored) {
classify points by nearest cluster
average equivalence classes for improved clusters
}

© 2012 IBM Corporation
Summary of Scalable KMeans in X10
Natural formulation as an SPMD-style computation– Evenly distribute data points across Places– Iteratively
• Each Place assigns its points to the closest cluster• Each Place computes new cluster centroids• Global reduction to average together computed centroids
Use X10 Team APIs for scalable reductions
Complete benchmark: 150 lines of X10 code
© 2012 IBM Corporation
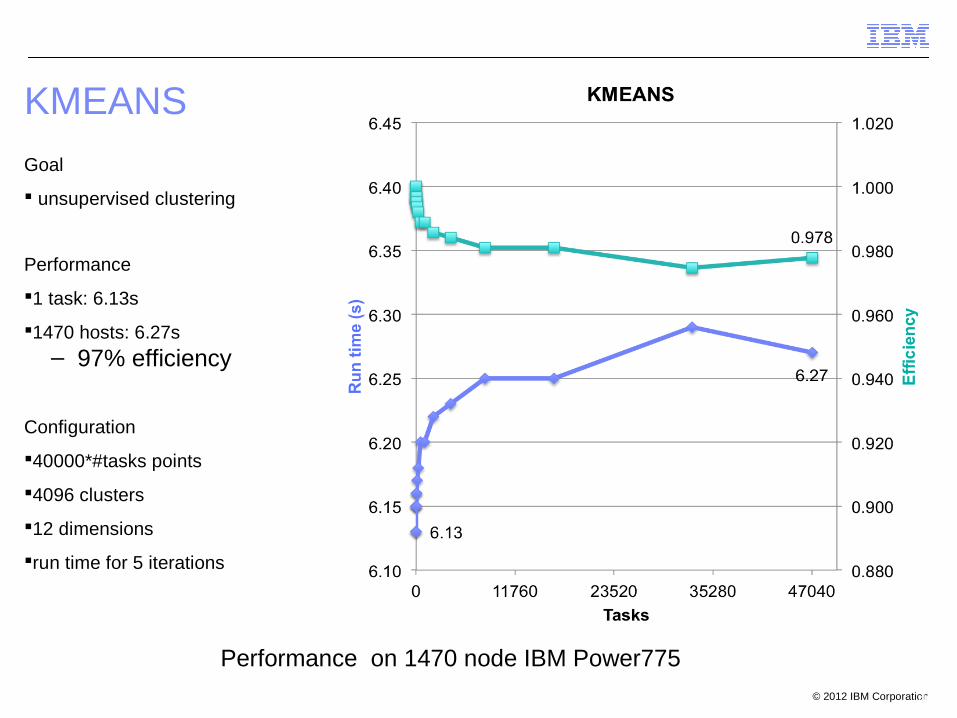
KMEANS
40
Goal
unsupervised clustering
Performance
1 task: 6.13s
1470 hosts: 6.27s
– 97% efficiency
Configuration
40000*#tasks points
4096 clusters
12 dimensions
run time for 5 iterations
Performance on 1470 node IBM Power775

© 2012 IBM Corporation
KMeans initialization
PlaceGroup.WORLD.broadcastFlat(()=>{val role = Runtime.hereInt();val random = new Random(role);val host_points = new Rail[Float](num_slice_points*dim,
(Int)=>random.next()); val host_clusters = new Rail[Float](num_clusters*dim); val host_cluster_counts = new Rail[Int](num_clusters);
val team = Team.WORLD;
if (role == 0)for (k in 0..(num_clusters-1))
for (d in 0..(dim-1))host_clusters(k*dim+d) = host_points(k+d*num_slice_points);
val old_clusters = new Rail[Float](num_clusters*dim);
team.allreduce(role, host_clusters, 0, host_clusters, 0, host_clusters.size, Team.ADD);
... Main loop implementing Lloyd’s algorithm (next slide) ...
});

© 2012 IBM Corporation
KMeans compute kernel
for (iter in 0..(iterations-1)) {Array.copy(host_clusters, old_clusters);host_clusters.clear();host_cluster_counts.clear();
// Assign each point to the closest clusterfor (p in …) {
…sequential compute kernel elided…}
// Compute new clustersteam.allreduce(role, host_clusters, 0, host_clusters, 0,
host_clusters.size, Team.ADD); team.allreduce(role, host_cluster_counts, 0, host_cluster_counts, 0, host_cluster_counts.size, Team.ADD);
for (k in 0..(num_clusters-1))for (d in 0..(dim-1))
host_clusters(k*dim+d) /= host_cluster_counts(k);
team.barrier(role);}
© 2012 IBM Corporation
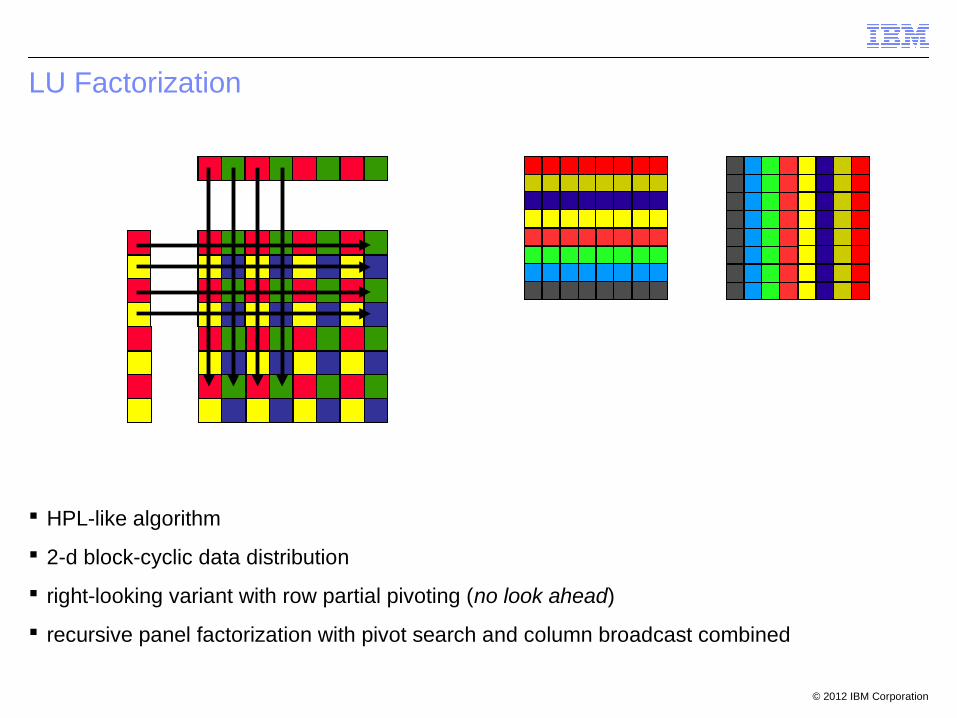
LU Factorization
HPL-like algorithm
2-d block-cyclic data distribution
right-looking variant with row partial pivoting (no look ahead)
recursive panel factorization with pivot search and column broadcast combined

© 2012 IBM Corporation
Summary of Scalable LU in X10
SPMD-style implementation– one top-level async per place (broadcastFlat)– globally synchronous progress
collectives: barriers, broadcast, reductions (row, column, WORLD)
point-to-point RDMAs for row swaps
uses BLAS for local computations
Complete Benchmark: 650 lines of X10 + 160 lines of C++ to wrap native BLAS
© 2012 IBM Corporation
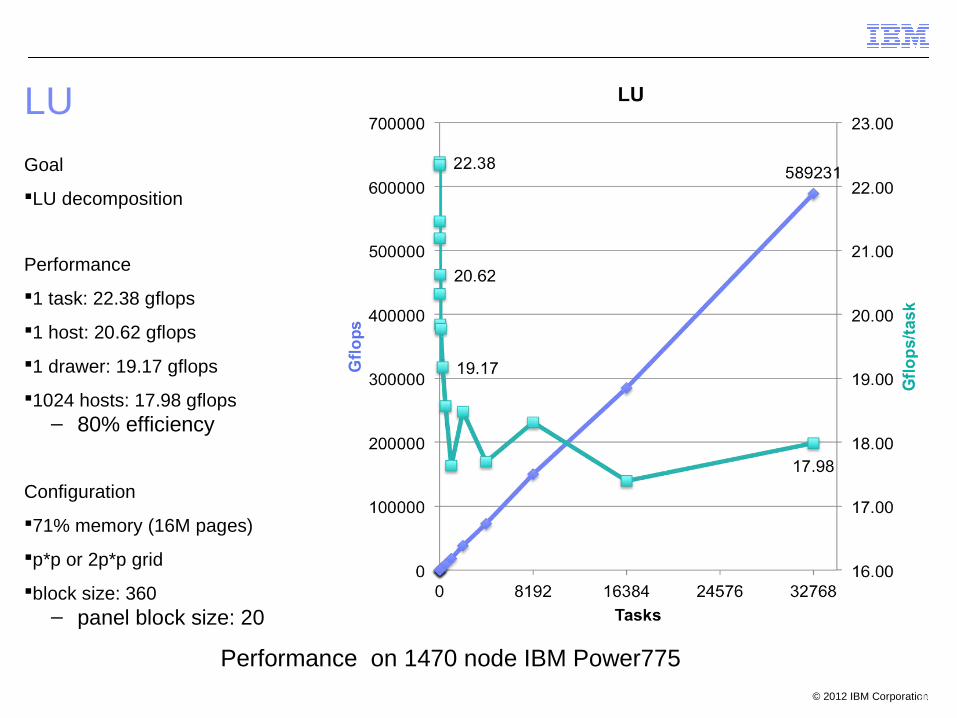
LU
45
Goal
LU decomposition
Performance
1 task: 22.38 gflops
1 host: 20.62 gflops
1 drawer: 19.17 gflops
1024 hosts: 17.98 gflops– 80% efficiency
Configuration
71% memory (16M pages)
p*p or 2p*p grid
block size: 360– panel block size: 20
Performance on 1470 node IBM Power775

© 2012 IBM Corporation
Accessing Native code
import x10.compiler.*;
@NativeCPPInclude("essl_natives.h")@NativeCPPCompilationUnit("essl_natives.cc")class LU {
@NativeCPPExternnative static def blockTriSolve(me:Rail[Double],
diag:Rail[Double], B:Int):void;@NativeCPPExternnative static def blockTriSolveDiag(diag:Rail[Double],
min:Int, max:Int, B:Int):void;
...// Use of blockTriSolve:blockTriSolveDiag(diag, min, max, B);

© 2012 IBM Corporation
Allocation of Distributed BlockedArray (in Huge Pages)
public final class BlockedArray implements (Int,Int)=>Double {
public def this(I:Int, J:Int, bx:Int, by:Int, rand:Random) {min_x = I*bx;min_y = J*by;max_x = (I+1)*bx-1;max_y = (J+1)*by-1;
delta = by; offset = (I*bx+J)*by; raw = new Rail[Double](
IndexedMemoryChunk.allocateZeroed[Double](bx*by, 8, IndexedMemoryChunk.hugePages()));
}
public static def make(M:Int, N:Int, bx:Int, by:Int, px:Int, py:Int) {return PlaceLocalHandle.makeFlat[BlockedArray](Dist.makeUnique(),
()=>new BlockedArray(M, N, bx, by, px ,py)); }}
// In main program: val A = BlockedArray.make(M, N, B, B, px, py);

© 2012 IBM Corporation
Row exchange via asynchronous RDMAs
def exchange(row1:Int, row2:Int, min:Int, max:Int, dest:Int) {val source = here;ready = false;val size = A_here.getRow(row1, min, max, buffer);val _buffers = buffers; // use local variable to avoid serializing this!val _A = A;
val _remoteBuffer = remoteBuffer; // RemoteArray (GlobalRef) wrapping buffer @Pragma(Pragma.FINISH_ASYNC_AND_BACK) finish {
at (Place(dest)) async {@Pragma(Pragma.FINISH_ASYNC) finish {
Array.asyncCopy[Double](_remoteBuffer, 0, _buffers(), 0, size);}
val size2 = _A().swapRow(row2, min, max, _buffers()); Array.asyncCopy[Double](_buffers(), 0, _remoteBuffer, 0, size2);
} }A_here.setRow(row1, min, max, buffer);
}

© 2012 IBM Corporation
Tutorial Outline
X10 Overview (70 minutes)– Programming model concepts– Key language features– Implementation highlights
Scaling SPMD-style computations in X10 (40 minutes)– Scaling finish/async – Scaling communication– Collective operations
Unbalanced computations (20 minutes)– Global Load Balancing & UTS
Application frameworks (20 minutes)– Global Matrix Library– SAT X10
Summary and Discussion (20 minutes)

© 2012 IBM Corporation
Global Load Balancing
A significant class of compute-intensive problems can be cast as “Collecting Finish” (or “Map Reduce”) problems (significantly simpler than Hadoop “Map Shuffle Reduce” problems)
– A parallel “Map” phases spawns work (may be driven by examining data in some shard global data structure)
– Each mapper may contribute 0 or more pieces of information to a “result”.– These pieces can be combined by a commutative, associative “reduction
operator”– Cf collecting finish
Q: How do you efficiently execute such programs if the amount of work associated with each mapper could vary dramatically?
– Example: State-space search, Unbalanced Tree Search (UTS), Branch and Bound Search.

© 2012 IBM Corporation
Global Load Balancing: Central Problem
Goal: Efficiently (~ 90% efficiency) execute collecting finish programs on a large number of node.
Problems to be solved:– Balance work across a large number of places efficiently– Detect termination of the computation quickly.
Conventional Approach: – Worker steals from randomly chosen victim when local work is exhausted.– Key problem: When does a worker know there is no more work?

© 2012 IBM Corporation
Global Load Balance: The Lifeline Solution
Intuition: X0 already has a framework for distributed termination detection – finish. Use it!
But this requires activities terminate at some point!
Idea: Let activities terminate after w rounds of failed steals. But ensure that a worker with some work can “distribute” work (= use at(p) async S) to nodes known to be idle.
– Lifeline graphs. Before a worker dies it creates z lifelines to other nodes. – These form a distribution “overlay” graph.– What kind of graph? Need low out-degree, low diameter graph.
Our paper/implementation uses hyper-cube.

© 2012 IBM Corporation
Algorithm sketch for Lifeline-based GLB Framework
Main activity spawns an activity per place within a finish.
Augment work-stealing with work-distributing:– Each activity processes. – When no work left, steals at most w-times.– (Thief) If no work found, visits at most z-lifelines in turn.
• Donor records thief needs work– (Thief) If no work found, dies.– (Donor) Pushes work to recorded thieves, when it has some.
When all activities die, main activity continues to completion.
Caveat: This scheme assumes that work is relocatable

© 2012 IBM Corporation
UTS: Unbalanced Tree Search
Characteristics– highly irregular => need for global load balancing– geometric fixed law (–t 1 –a 3) => wide tree but shallow depth
Implementation– work queue of SHA1 hash of node + depth + interval of child ids– global work stealing
• n random victims (among m possible targets) then p lifelines (hypercube)• thief steals half of work (half of each node in the local work queue)• finish counts lifeline steals only (25% performance improvement at scale)
– single thread (thief and victim cooperate)
Complete benchmark: 560 lines of X10 (+ 800 lines of sequential C for SHA1 hash)
54
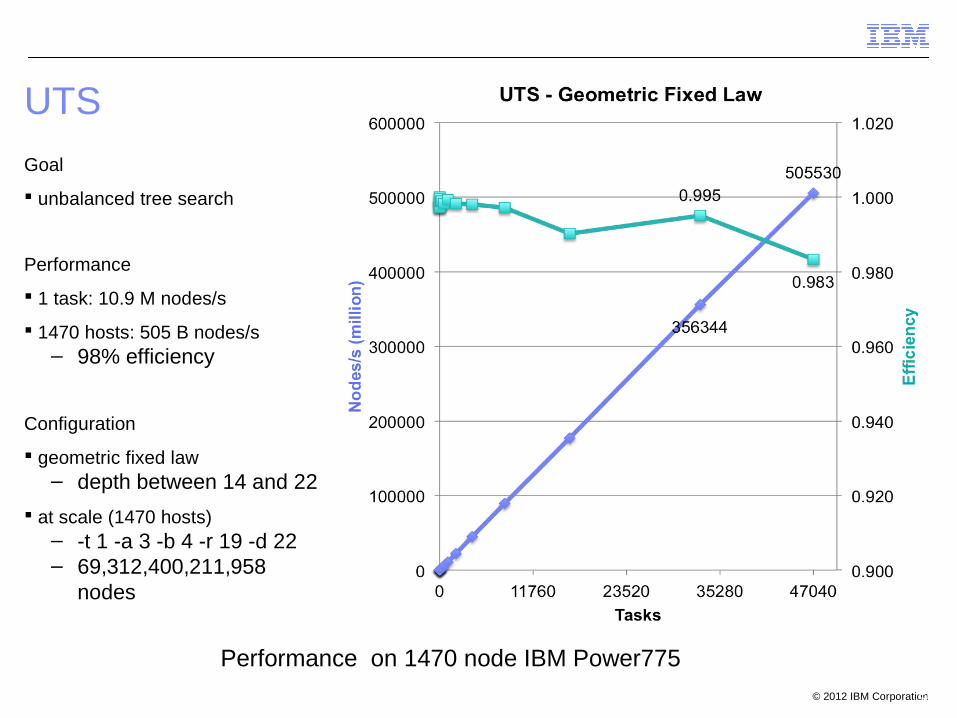
© 2012 IBM Corporation55
Goal
unbalanced tree search
Performance
1 task: 10.9 M nodes/s
1470 hosts: 505 B nodes/s– 98% efficiency
Configuration
geometric fixed law– depth between 14 and 22
at scale (1470 hosts)– -t 1 -a 3 -b 4 -r 19 -d 22– 69,312,400,211,958
nodes
UTS
Performance on 1470 node IBM Power775
© 2012 IBM Corporation
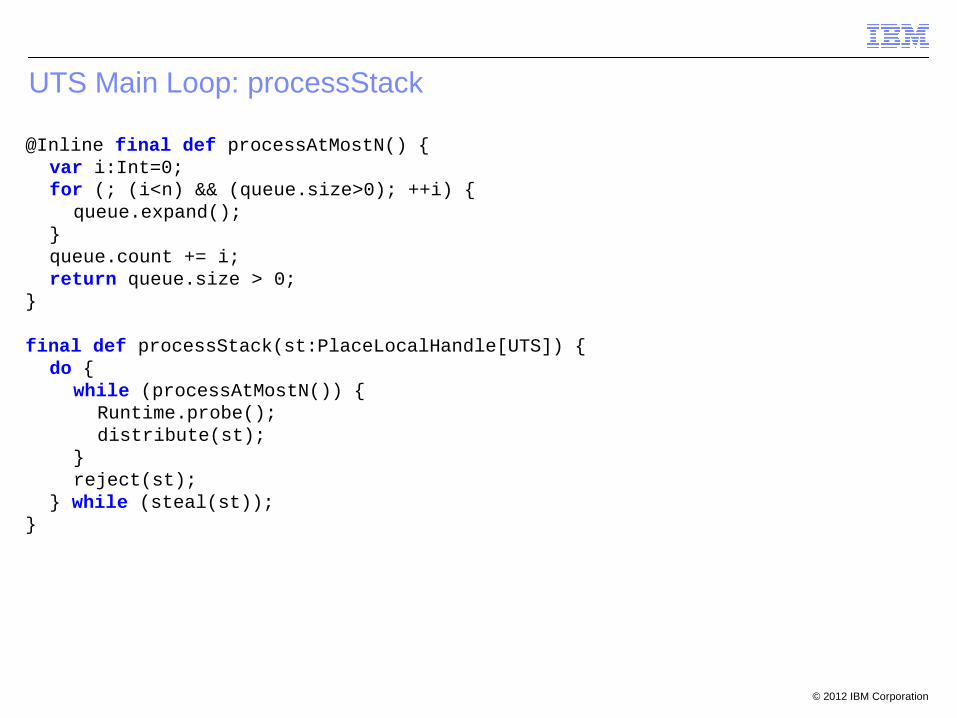
UTS Main Loop: processStack
@Inline final def processAtMostN() {var i:Int=0;for (; (i<n) && (queue.size>0); ++i) {
queue.expand();}queue.count += i;return queue.size > 0;
} final def processStack(st:PlaceLocalHandle[UTS]) {
do {while (processAtMostN()) {
Runtime.probe();distribute(st);
}reject(st);
} while (steal(st));}

© 2012 IBM Corporation
UTS: steal
def steal(st:PlaceLocalHandle[UTS]) {if (P == 1) return false;val p = Runtime.hereInt();empty = true;
for (var i:Int=0; i < w && empty; ++i) {waiting = true;at (Place(victims(random.nextInt(m))))
@Uncounted async st().request(st, p, false);while (waiting) Runtime.probe();
}
for (var i:Int=0; (i<lifelines.size) && empty && (0<=lifelines(i)); ++i) {val lifeline = lifelines(i);if (!lifelinesActivated(lifeline)) {
lifelinesActivated(lifeline) = true;waiting = true;at (Place(lifeline))
@Uncounted async st().request(st, p, true);while (waiting) Runtime.probe();
}}
return !empty;}
© 2012 IBM Corporation
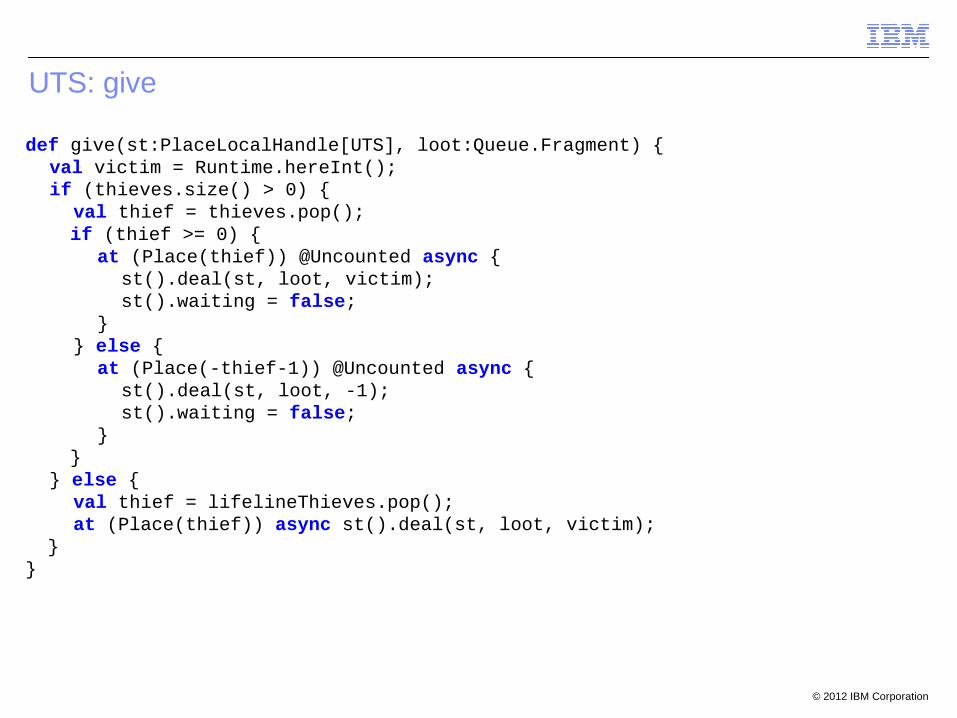
UTS: give
def give(st:PlaceLocalHandle[UTS], loot:Queue.Fragment) {val victim = Runtime.hereInt();if (thieves.size() > 0) {
val thief = thieves.pop(); if (thief >= 0) {
at (Place(thief)) @Uncounted async { st().deal(st, loot, victim); st().waiting = false;
}} else {
at (Place(-thief-1)) @Uncounted async { st().deal(st, loot, -1); st().waiting = false;
} }
} else {val thief = lifelineThieves.pop();at (Place(thief)) async st().deal(st, loot, victim);
}}

© 2012 IBM Corporation
UTS: distribute & reject
def distribute(st:PlaceLocalHandle[UTS]) {var loot:Queue.Fragment;while ((lifelineThieves.size() + thieves.size() > 0) &&
(loot = queue.grab()) != null) {give(st, loot);
} reject(st);}
def reject(st:PlaceLocalHandle[UTS]) {while (thieves.size() > 0) {
val thief = thieves.pop();if (thief >= 0) {
lifelineThieves.push(thief);at (Place(thief)) @Uncounted async { st().waiting = false; }
} else {at (Place(-thief-1)) @Uncounted async { st().waiting = false; }
}}
}
© 2012 IBM Corporation
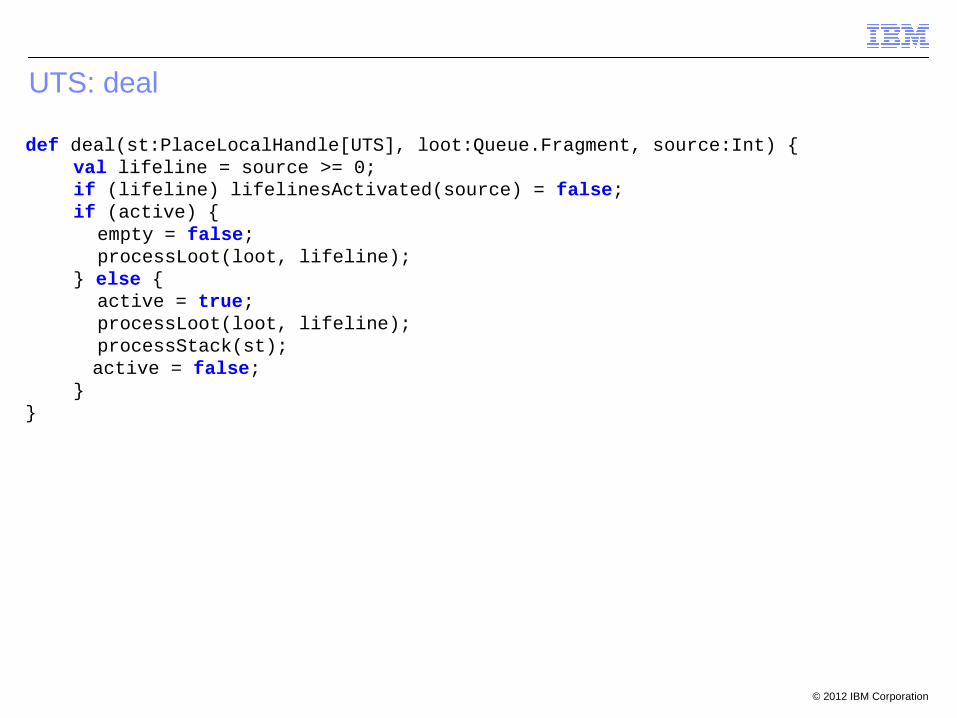
UTS: deal
def deal(st:PlaceLocalHandle[UTS], loot:Queue.Fragment, source:Int) {val lifeline = source >= 0;if (lifeline) lifelinesActivated(source) = false;if (active) {
empty = false;processLoot(loot, lifeline);
} else {active = true;processLoot(loot, lifeline);processStack(st);
active = false;}
}

© 2012 IBM Corporation
Tutorial Outline
X10 Overview (70 minutes)– Programming model concepts– Key language features– Implementation highlights
Scaling SPMD-style computations in X10 (40 minutes)– Scaling finish/async – Scaling communication– Collective operations
Unbalanced computations (20 minutes)– Global Load Balancing & UTS
Application frameworks (20 minutes)– Global Matrix Library– SAT X10
Summary and Discussion (20 minutes)

© 2012 IBM Corporation
X10 Global Matrix Library
Easy-use matrix library in X10 supporting parallel execution on multiple places– Presents standard sequential interface (internal parallelism and distribution).
Matrix data structures:– Dense matrix symmetric and triangular matrix: column-wise storage– Sparse matrix: CSC-LT– Vector, distributed and duplicated vector– Block matrix, distributed and duplicated block matrix
Matrix operations– scaling, cellwise add, subtract, multiply and division– Matrix multiplication– Norm, trace, linear equation solver
Approximately 45,000 lines of X10 code (open source)
© 2012 IBM Corporation
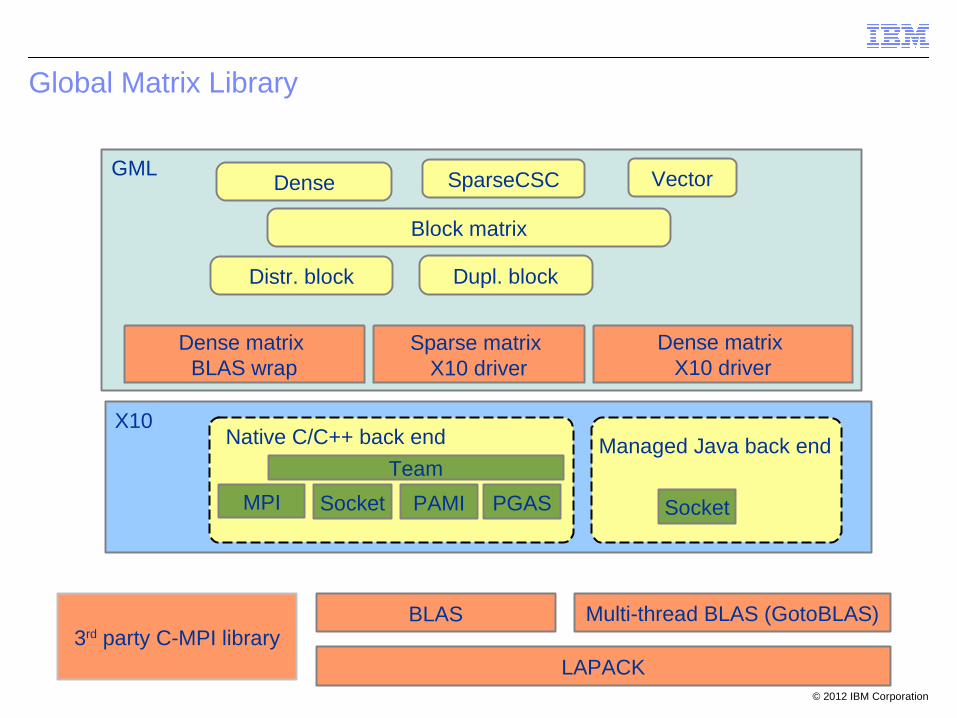
Global Matrix Library
X10
GML
Native C/C++ back end
MPI Socket PAMI PGAS Socket
Managed Java back end
BLAS
LAPACK3rd party C-MPI library
Dense SparseCSC Vector
Block matrix
Sparse matrix X10 driver
Distr. block Dupl. block
Team
Multi-thread BLAS (GotoBLAS)
Dense matrix X10 driver
Dense matrix BLAS wrap
© 2012 IBM Corporation
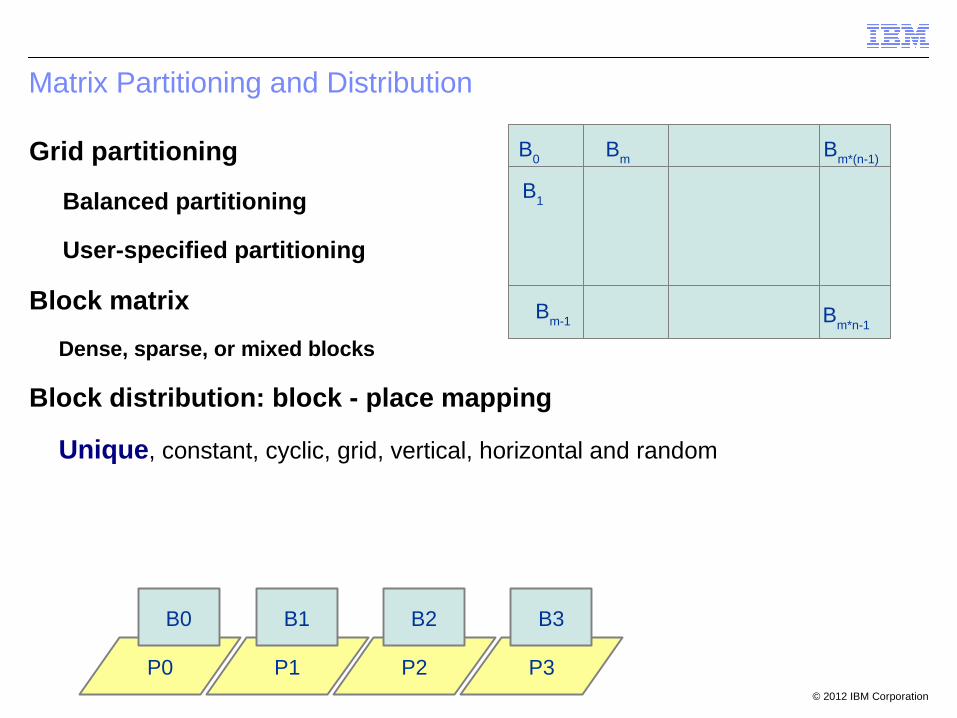
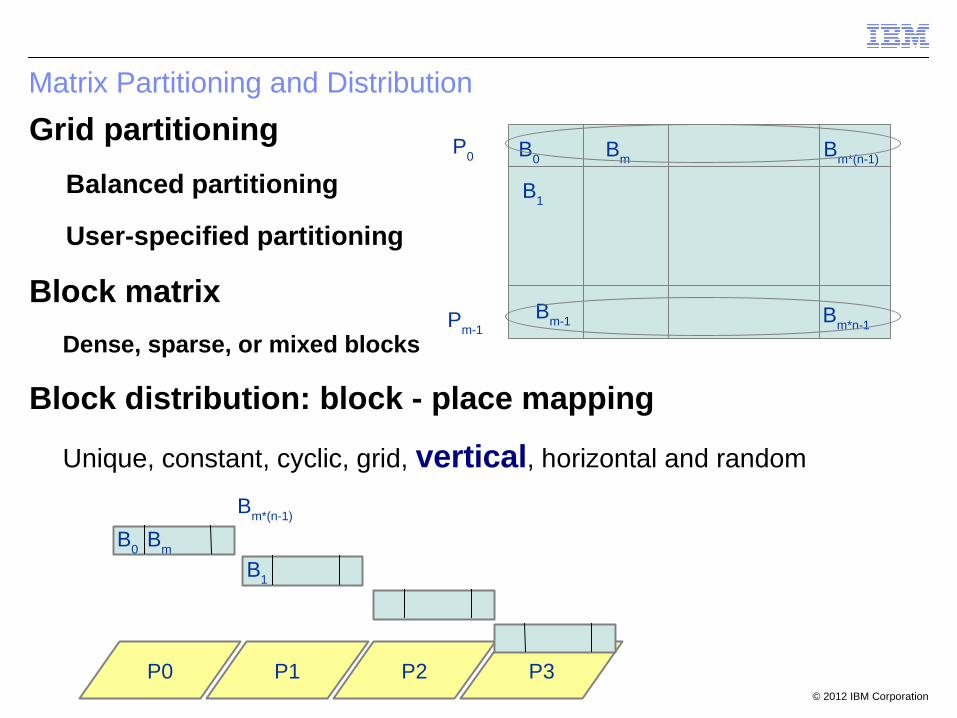
Matrix Partitioning and Distribution
Grid partitioning
Balanced partitioning
User-specified partitioning
Block matrix
Dense, sparse, or mixed blocks
Block distribution: block - place mapping
Unique, constant, cyclic, grid, vertical, horizontal and random
B0
Bm
B1
Bm-1
Bm*(n-1)
Bm*n-1
P0
B0
P1 P2 P3
B1 B2 B3
© 2012 IBM Corporation
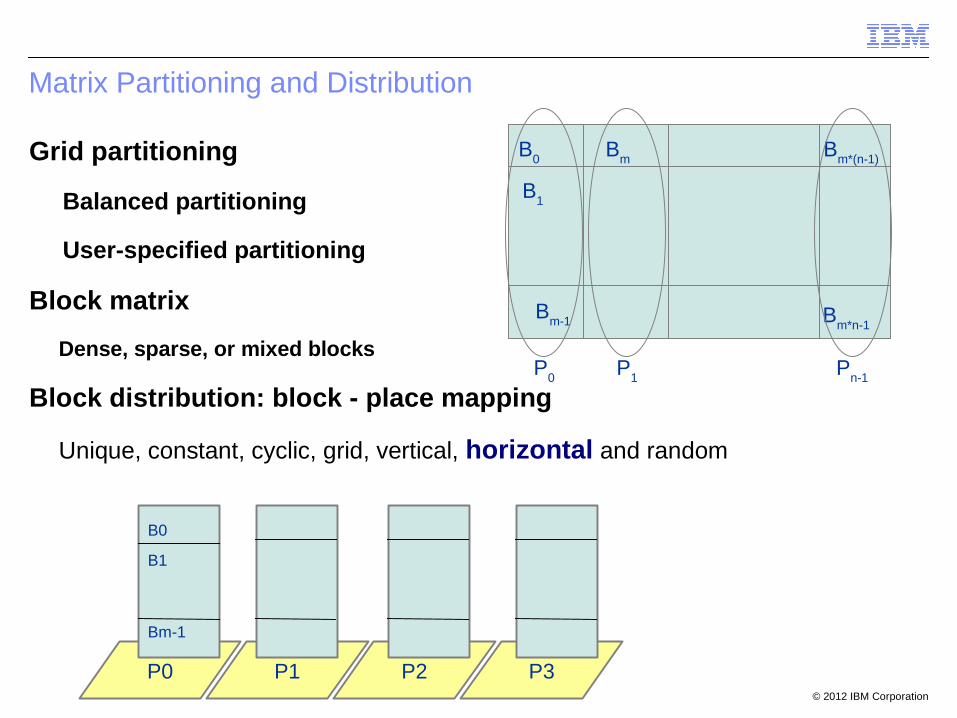
Matrix Partitioning and Distribution
Grid partitioning
Balanced partitioning
User-specified partitioning
Block matrix
Dense, sparse, or mixed blocks
Block distribution: block - place mapping
Unique, constant, cyclic, grid, vertical, horizontal and random
B0
Bm
B1
Bm-1
Bm*(n-1)
Bm*n-1
P0 P1 P2 P3
B0
B1
Bm-1
P0
P1
Pn-1
© 2012 IBM Corporation
Matrix Partitioning and Distribution
Grid partitioning
Balanced partitioning
User-specified partitioning
Block matrix
Dense, sparse, or mixed blocks
Block distribution: block - place mapping
Unique, constant, cyclic, grid, vertical, horizontal and random
B0
Bm
B1
Bm-1
Bm*(n-1)
Bm*n-1
P0 P1 P2 P3
B0
Bm
Bm*(n-1)
B1
P0
Pm-1

© 2012 IBM Corporation
GML Example: PageRank
def step(G:…, P:…, GP:…, dupGP:…,
UP:…, P:…, E, :…) {
for (1..iteration) {
GP.mult(G,P)
.scale(alpha)
.copyInto(dupGP);//broadcast
P.local()
.mult(E, UP.mult(U,P.local()))
.scale(1-alpha)
.cellAdd(dupGP.local())
.sync(); // broadcast
}}
while (I < max_iteration) {
p = alpha*(G%*%p)+(1-alpha)*(e%*%u%*%p);
}
X10
DML Programmer determines distribution of
the data.– G is block distributed per Row
– P is replicated
Programmer writes sequential, distribution-aware code.
Perform usual optimizations – allocate big data-structures outside loop
Could equally well have been in Java.

© 2012 IBM Corporation
PageRank Performance
Triloka x86 cluster (TK)– Managed X10 on socket transport– Native X10 on socket transport
Watson4P (BlueGene/P)– Native X10 on BlueGene DCMF transport
10 40 160 360 640 10000
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Page Rank64-place, G nonzero sparsity 0.001
Java-socket TK
Native-socket TK
Native-pgas BGP
Nonzeros in G (million)
Tim
e(s
ec)
16 32 48 640
2
4
6
8
10
12
14
16
Page Rank1000 million nonzeros in G
Java-socket TK
Native-socket TK
Native-pgas BGP
Number of places (processors)
Tim
e(s
ec)

© 2012 IBM Corporation
GML Example: Gaussian Non-Negative Matrix Multiplication
Key kernel for topic modeling
Involves factoring a large (D x W) matrix
D ~ 100M
W ~ 100K, but sparse (0.001)
Iterative algorithm, involves distributed sparse matrix multiplication, cell-wise matrix operations.
for (1..iteration) { H.cellMult(WV .transMult(W,V,tW) .cellDiv(WWH .mult(WW.transMult(W,W),H))); W.cellMult(VH .multTrans(V,H) .cellDiv(WHH .mult(W,HH.multTrans(H,H))));}
X10
Key decision is representation for matrix, and its distribution. Note: app code is polymorphic in this
choice.
P0
V W
H
H
HH
P1
P2Pn
© 2012 IBM Corporation
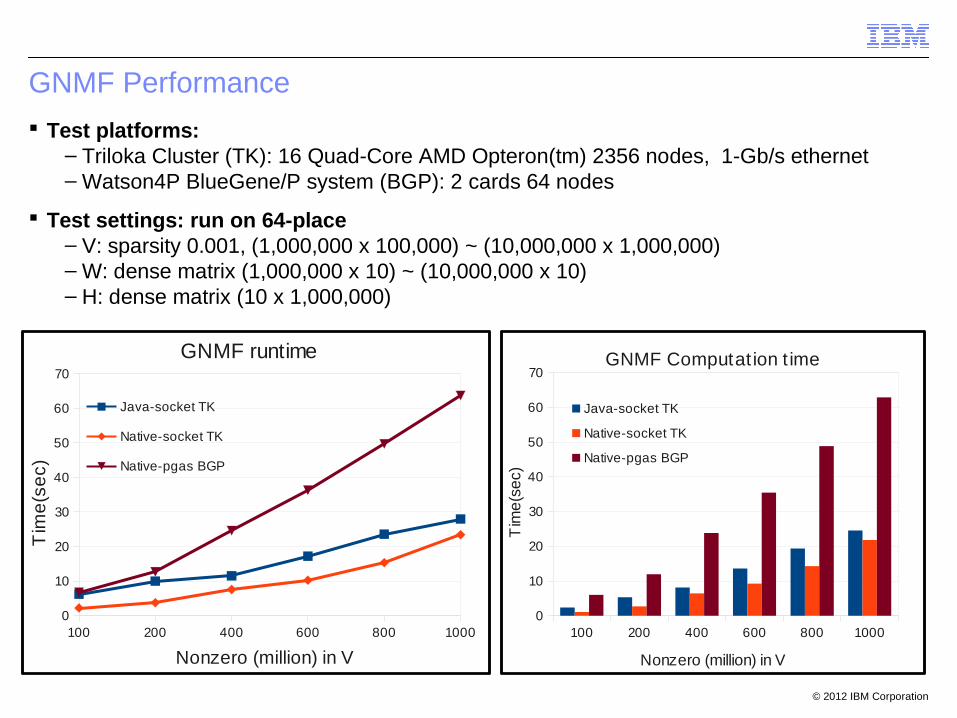
GNMF Performance
Test platforms:– Triloka Cluster (TK): 16 Quad-Core AMD Opteron(tm) 2356 nodes, 1-Gb/s ethernet– Watson4P BlueGene/P system (BGP): 2 cards 64 nodes
Test settings: run on 64-place– V: sparsity 0.001, (1,000,000 x 100,000) ~ (10,000,000 x 1,000,000)– W: dense matrix (1,000,000 x 10) ~ (10,000,000 x 10)– H: dense matrix (10 x 1,000,000)
100 200 400 600 800 10000
10
20
30
40
50
60
70
GNMF runtime
Java-socket TK
Native-socket TK
Native-pgas BGP
Nonzero (million) in V
Tim
e(s
ec)
100 200 400 600 800 10000
10
20
30
40
50
60
70GNMF Computat ion t ime
Java-socket TK
Native-socket TK
Native-pgas BGP
Nonzero (million) in V
Tim
e(s
ec)

© 2012 IBM Corporation
Global Matrix Library Summary
Easy to use– Simplified matrix operation interface– Managed back end simplifies development, while native back end provides high
performance computing capability– Hiding concurrency and distribution details from apps developers
Hierarchical parallel computing capability– Within a node: multi-thread BLAS/LAPACK for intensive computation– Between nodes: collective communication for coarse-grained parallel computing
Adaptability– Data layout compatible to existing specifications (BLAS, CSC-LT).
Portability– Supporting MPI, socket, PAMI and BlueGene transport
Availability– Open source; x10.gml project in X10 project main svn on SourceForge.net

© 2012 IBM Corporation
Sat X10
Framework to combine existing sequential SAT solvers into a parallel portfolio solver– Diversity: small number of base solvers, but different parameterization– Knowledge Sharing: exchange learned clauses between solvers
Structure of SatX10– Minimal modifications to existing solver (add callbacks for knowledge sharing)– Small X10/C++ interoperability wrapper for each solver– Small (100s of lines) X10 program for communication/distribution
Allows parallel solver to run on a single machine with multiple cores and across multiple machines, sharing information such as learned clauses
More information: http://x10-lang.org/satx10
© 2012 IBM CorporationIBM Confidential
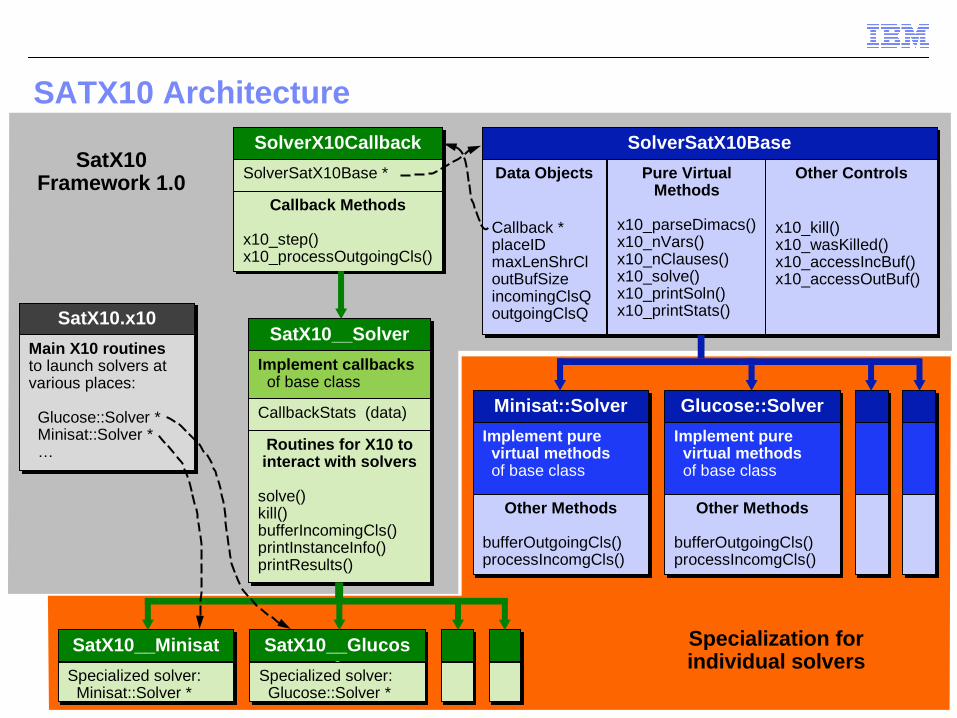
SATX10 Architecture
SolverSatX10BaseSolverSatX10Base
Data Objects
Callback *placeIDmaxLenShrCloutBufSizeincomingClsQoutgoingClsQ
Data Objects
Callback *placeIDmaxLenShrCloutBufSizeincomingClsQoutgoingClsQ
Pure Virtual Methods
x10_parseDimacs()x10_nVars()x10_nClauses()x10_solve()x10_printSoln()x10_printStats()
Pure Virtual Methods
x10_parseDimacs()x10_nVars()x10_nClauses()x10_solve()x10_printSoln()x10_printStats()
Other Controls
x10_kill()x10_wasKilled()x10_accessIncBuf()x10_accessOutBuf()
Other Controls
x10_kill()x10_wasKilled()x10_accessIncBuf()x10_accessOutBuf()
SolverX10CallbackSolverX10Callback
SolverSatX10Base *SolverSatX10Base *
Callback Methods
x10_step()x10_processOutgoingCls()
Callback Methods
x10_step()x10_processOutgoingCls()
SatX10__SolverSatX10__Solver
Implement callbacks of base classImplement callbacks of base class
CallbackStats (data)CallbackStats (data)
Routines for X10 to interact with solvers
solve()kill()bufferIncomingCls()printInstanceInfo()printResults()
Routines for X10 to interact with solvers
solve()kill()bufferIncomingCls()printInstanceInfo()printResults()
SatX10.x10SatX10.x10
Main X10 routinesto launch solvers at various places:
Glucose::Solver * Minisat::Solver * …
Main X10 routinesto launch solvers at various places:
Glucose::Solver * Minisat::Solver * …
SatX10Framework 1.0
Minisat::SolverMinisat::Solver
Implement pure virtual methods of base class
Implement pure virtual methods of base class
Other Methods
bufferOutgoingCls()processIncomgCls()
Other Methods
bufferOutgoingCls()processIncomgCls()
Glucose::SolverGlucose::Solver
Implement pure virtual methods of base class
Implement pure virtual methods of base class
Other Methods
bufferOutgoingCls()processIncomgCls()
Other Methods
bufferOutgoingCls()processIncomgCls()
SatX10__MinisatSatX10__Minisat
Specialized solver: Minisat::Solver *Specialized solver: Minisat::Solver *
SatX10__Glucose
SatX10__Glucose
Specialized solver: Glucose::Solver *Specialized solver: Glucose::Solver *
Specialization forindividual solvers
© 2012 IBM Corporation
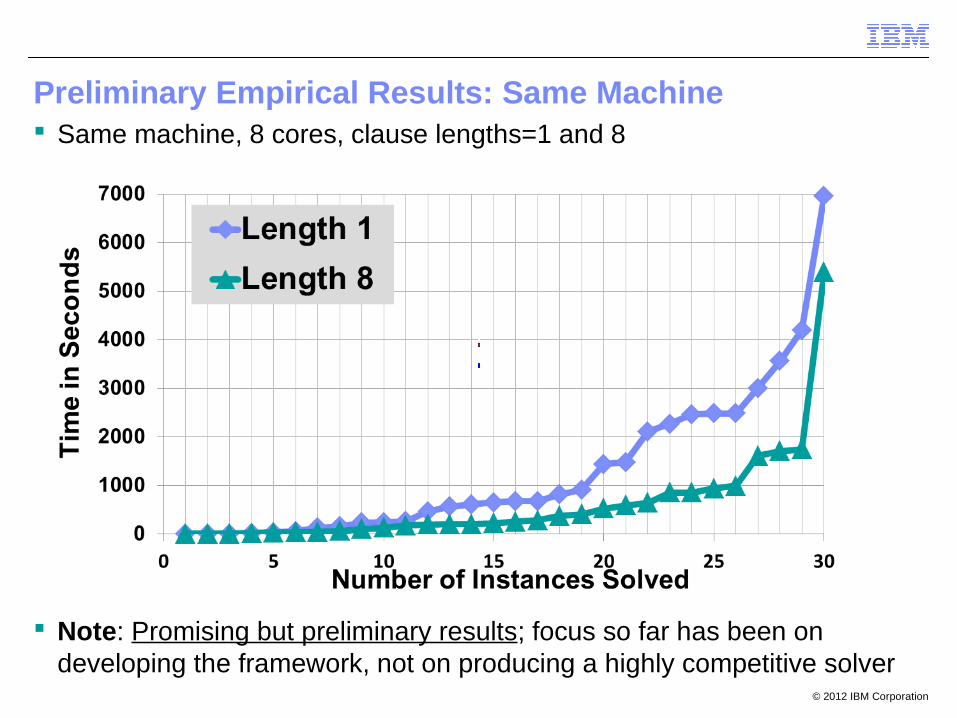
Same machine, 8 cores, clause lengths=1 and 8
Note: Promising but preliminary results; focus so far has been on developing the framework, not on producing a highly competitive solver
Preliminary Empirical Results: Same Machine
© 2012 IBM Corporation
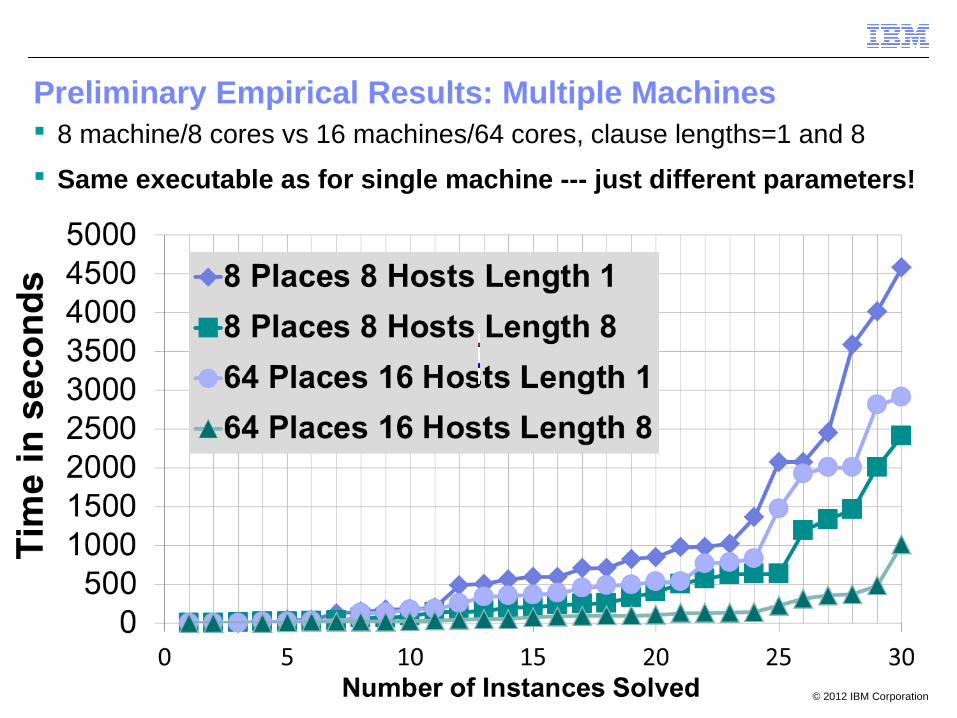
Preliminary Empirical Results: Multiple Machines 8 machine/8 cores vs 16 machines/64 cores, clause lengths=1 and 8
Same executable as for single machine --- just different parameters!

© 2012 IBM Corporation
Tutorial Outline
X10 Overview (70 minutes)– Programming model concepts– Key language features– Implementation highlights
Scaling SPMD-style computations in X10 (40 minutes)– Scaling finish/async – Scaling communication– Collective operations
Unbalanced computations (20 minutes)– Global Load Balancing & UTS
Application frameworks (20 minutes)– Global Matrix Library– SAT X10
Summary and Discussion (20 minutes)

© 2012 IBM Corporation
X10 Project Highlights since SC’11
Three major releases: 2.2.2, 2.2.3, 2.3.0– Maintained backwards compatibility with X10 2.2.0 language (June 2011)– Language backwards compatibility with 2.2.0 will be maintained in future releases
Smooth Java interoperability– Major feature of X10 2.3.0 release
Application work at IBM– M3R: Main Memory Map Reduce (VLDB’12)– Global Matrix Library (open sourced Oct 2011; available in x10 svn)– SatX10 (SAT’12)– HPC benchmarks (for PERCS) run at scale on 47,000 core Power775

© 2012 IBM Corporation
Summary of X10’12 Workshop
Second annual X10 workshop (co-located with PLDI/ECOOP in June 2012)
Papers1. Fast Method Dispatch and Effective Use of Primitives for Reified Generics in Managed
X102. Distributed Garbage Collection for Managed X10,3. StreamX10: A Stream Programming Framework on X10,4. X10-based Massive Parallel Large-Scale Traffic Flow Simulation5. Characterization of Smith-Waterman Sequence Database Search in X106. Introducing ScaleGraph : An X10 Library for Billion Scale Graph Analytics
Invited talks1. A tutorial on X10 and its implementation2. M3R: Increased Performance for In-Memory Hadoop Jobs
X10’13 will be held in June 2013 co-located with PLDI’13

© 2012 IBM Corporation
X10 Community: StreamX10
Slide by Haitao Wei, X10 2012
© 2012 IBM Corporation
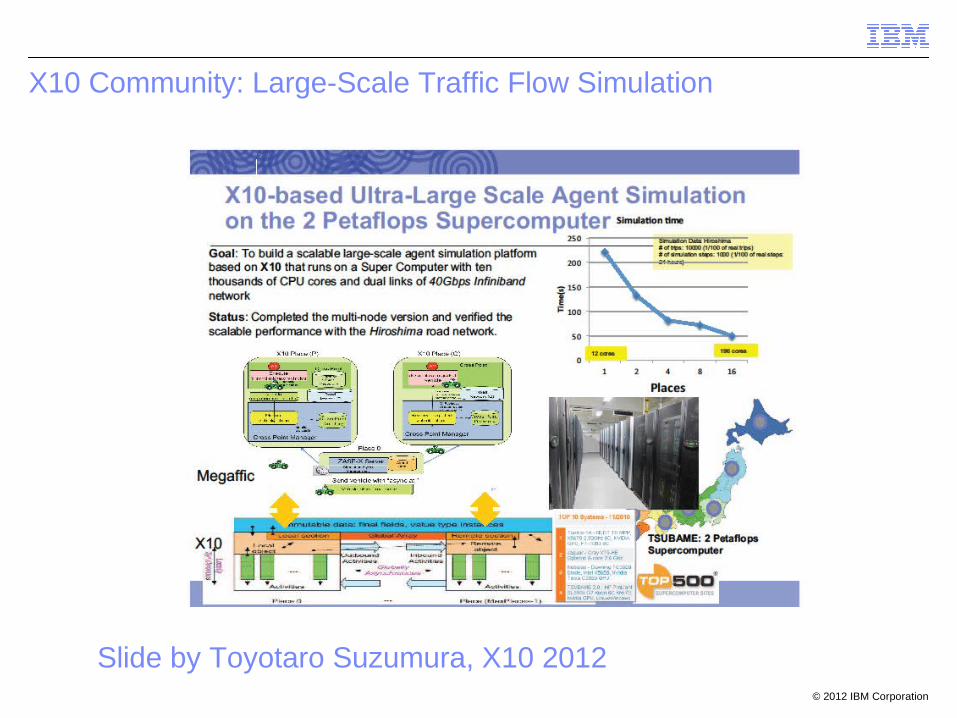
X10 Community: Large-Scale Traffic Flow Simulation
Slide by Toyotaro Suzumura, X10 2012
© 2012 IBM Corporation
X10 Community: ScaleGraph
Slide by Miyuru Dayarathna, X10 2012
© 2012 IBM Corporation
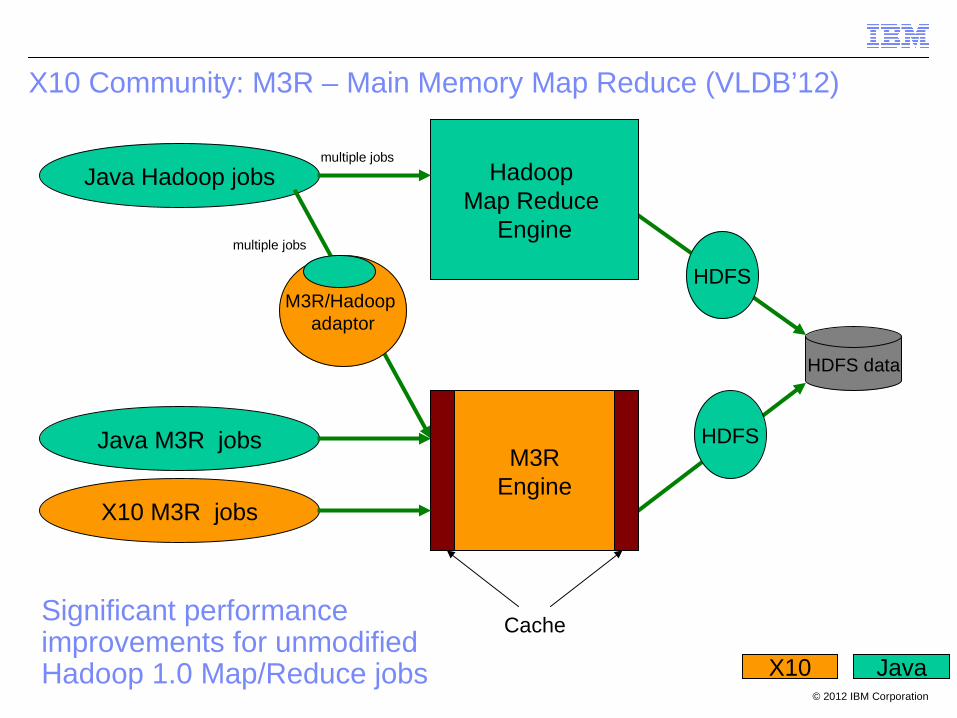
X10 Community: M3R – Main Memory Map Reduce (VLDB’12)
Java Hadoop jobs Hadoop Map Reduce
Engine
HDFS data
M3REngine
HDFS
Java M3R jobs
M3R/Hadoop adaptor
X10 Java
multiple jobs
multiple jobs
Cache
HDFS
X10 M3R jobs
Significant performance improvements for unmodified Hadoop 1.0 Map/Reduce jobs

© 2012 IBM Corporation
X10 Community: ANUChem
• Computational chemistry codes written in X10– FMM: electrostatic calculation using Fast Multipole method– PME: electrostatic calculation using the Smooth Particle Mesh Ewald method– Pumja Rasaayani: energy calculation using Hartree-Fock SCF-method
• Developed by Josh Milthorpe and Ganesh Venkateshwara at ANU– http://cs.anu.edu.au/~Josh.Milthorpe/anuchem.html– Open source (EPL); tracks X10 releases– Around 16,000 lines of X10 code– Overview and initial results in [Milthorpe et al IPDPS 2011]
• Code under active development; significant performance and scalability improvements in current ANUChem 2.2.2 vs. results in IPDPS’11 paper

© 2012 IBM Corporation
Final Thoughts
Give X10 a try– Language definition is stable– Toolchain not production-quality, but good enough for significant application work– Active X10 research & user community
Future X10 Plans– XStack: DSL Technologies for Exascale Computing (D-TEC)
• Building on X10 runtime system• Increase interoperability of X10 and C+MPI+OpenMP (migration path)
– Mixed mode execution • Mix Native X10 and Managed X10 places within single program execution
– For details: see X10 Roadmap at http://x10-lang.org/home/codebase-progress.html
Questions & Discussion
© 2012 IBM Corporation
X10 References
main project web site: http://x10-lang.org
publication list: http://x10-lang.org/x10-community/publications-using-x10.html
language spec: http://x10.sourceforge.net/documentation/languagespec/x10-latest.pdf
releases: http://x10-lang.org/software/download-x10/release-list.html
this tutorial: http://x10-lang.org/tutorials/sc2012