digging into the web archive at the british library 2014-11-27
DESCRIPTION
Status update on how we exploit data mining to support management and exploitation of our web archives. Presented at BL TDM meeting.TRANSCRIPT

Digging into the Web Archive
at the British Library
Andrew Jackson
UK Web Archive Technical Lead

www.bl.uk 2
Collections & Scale
• Three collections:
– By permission (2004-2013)
• c. 200 million URLs
– Legal Deposit (2013 onwards)
• c. 2 billion URLs/year (30TB/y)
– JISC/IA Historical (1996-2013)
• c. 6 billion URLs (57TB)
• Use data-mining to support:
– Access
– Search
– Preservation
– Web science

www.bl.uk 3
Single-Item Retrieval
www.bl.uk 4
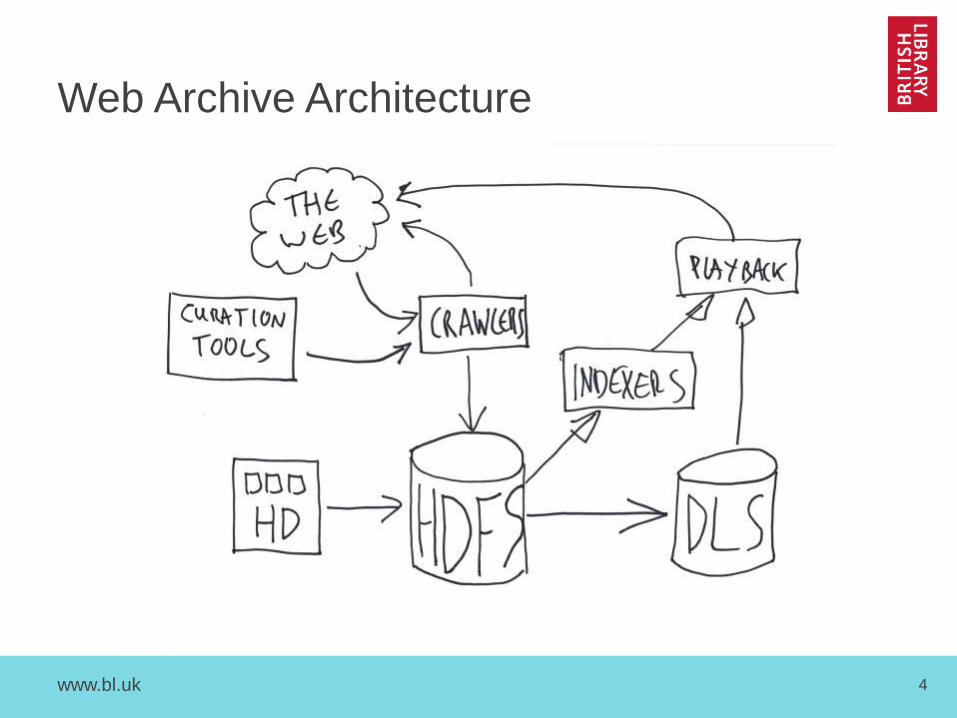
Web Archive Architecture

www.bl.uk 5
Search & Analytical Access
• ‘Title-level’ search:
– Millions of homepages found via metadata
• Full-text search:
– Billions of resources
– Dedicated faceted search service
• Analytical access:
– Combine faceted full-text search with:
• Trend analysis
• Visualisation tools
– Working with modern historians to drive development
www.bl.uk 6
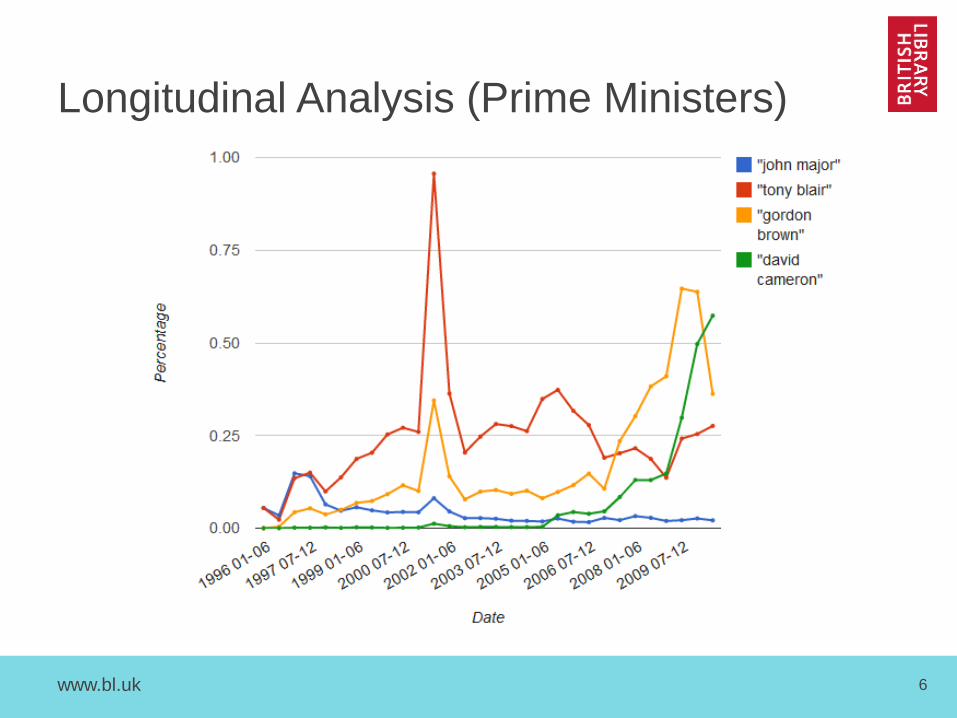
Longitudinal Analysis (Prime Ministers)

www.bl.uk 7
Embedded Licenses

www.bl.uk 8
Secondary Datasets
• Facts about content, including:
– Crawl index
– Geo-index
– Format profiles
– Link graphs
• Facilitate independent research
• Can be made available under CC0
• Hosted at http://data.webarchive.org.uk/opendata/

www.bl.uk 9
Exploring Links Between Hosts
Courtesy of Peter Webster, Rainer Simon and Jules Mataly

www.bl.uk 10
Links From 1996

www.bl.uk 11
Top-Level Links Over Time [here]

www.bl.uk 12
Access Service Spectrum
• Single-item retrieval
• ‘Title-level’ search
• Full-text search
• Analytics & visualisation (at full scale)
• Secondary datasets
• Remote analysis of datasets (an API, e.g. SPARQL)
• Full computational access service (internal only right now)
• Not just the web archive?

www.bl.uk 13
Thank you!
Email: [email protected]
Twitter: @anjacks0n
UK Web Archive:
http://www.webarchive.org.uk
Blog:
http://britishlibrary.typepad.co.uk/webarc
hive/
Twitter: @ukwebarchive