downloading - iam @ cardiff university
TRANSCRIPT

1
RAPTOR Retrieval Analysis, and Presentation Toolkit for usage of Online Resources
Deliverable 5.1: Reporting Options
Information Services
Cardiff University Start Date of Project: January 2010
Duration: 15 Months
Version 1.0
Version History
Version Date Author
0.1 7th May P.Smart
0.2 10th May P.Smart
0.5 10th May P.Smart
0.7 13th May P.Smart
0.8 18th May P.Smart
0.9 14th June P.Smart
1.0 5th July R.Smith, P.Smart

2
Table of Contents
Executive Summary .................................................................................................... 3 1. Introduction.......................................................................................................... 4 2. Authentication and Usage Information.............................................................. 5
2.1. Authentication Information .................................................................................... 5 2.2. Usage Information and Reports .............................................................................. 9 2.3. COUNTER-Complaint Statistics ....................................................................... 11
3. Statistics Harvesting Engines and Protocols.................................................... 14 3.1. Parsing Engines....................................................................................................... 14 3.2. Protocols................................................................................................................... 15
4. Usage Collector and Reporting Engines .......................................................... 17 4.1. Resource Management Systems............................................................................. 17 4.2. Authentication Statistics Reporting Systems........................................................ 19 4.3. Usage Statistics Reporting Systems....................................................................... 21 4.4. General Log File Reporting Systems..................................................................... 22
5. Reporting Options Conclusions ........................................................................ 24 5.1. Raptor Features ...................................................................................................... 29
6. Conclusions ......................................................................................................... 30 References .................................................................................................................. 30 Appendix A - Log File Parser Screenshots ............................................................. 31

3
Executive Summary
• Federated access management technology is becomining more widespread in educational, governmental and commercial organisations. It allows users the convenience of using only one username and password to access any number of electronic resources.
• Another popular way of enabling access to electronic resources for users working outside of the organisation’s premesis is through the use of a proxy system, which tricks the resource into thinking the user is accessing their information from an authorised machine inside the organisation.
• However, the existing state-of-the art in FAM and proxy technology do not provide automated tools for the detailed analysis and reporting of what users are accessing and when they are accessing them, instead only providing raw textual output of the software process, often through log files.
• Without significant manual effort, this reporting gap handicaps an organisation when making key decisions about the value for money of each electronic resource.
• The RAPTOR project aims to help overcome this shortfall by providing the necessary tools to allow automated analysis and reporting.
• In this deliverable we discuss the reporting options of the RAPTOR project by investigating the current raw information captured by existing FAM and Proxy technologies (as well as other existing resource usage reports), surveying existing tools for capturing and processing this information, and then finally highlighting how these tools display this information for human consumption.
• The deliverable is concluded by an enumeration of both the mandatory and desirable reporting options that will be supported by software produced by the RAPTOR project.

4
1. Introduction The RAPTOR project aims to present statistical accounting information from an organisation’s Federated Authentication and Authorisation Infrastructure; particularly its Shibboleth Identity Provider service. It is similar in goal to [5].
Shibboleth is a widely deployed technology in the academic context, and is a part of the wider Federated Identity Management paradigm that is currently being realised across the world’s educational, governmental and commercial sectors. This allows the interfacing of existing user identity management systems within and across organisational boundaries [8], enabling Single Sign On (a user only generally has to authenticate once).
In addition to authorising access to general web systems via federated technologies, access to such systems can be authorised solely on a device level without knowledge of user credentials e.g. by a unique identification number, or IP address. This is particularly common in the case of managing access to library e-resources. Device dependant resource authorisation information is generally not logged at the user’s organisation unless accessed through an on-campus proxy service or on and off-campus URL rewriting proxy service (e.g. EZproxy1), which will by default store harvestable logs detailing each discrete transaction.
Lastly, in addition to authentication and access requests for services, integrating COUNTER-complaint statistics generated by publishers can capture e-resource usage statistics at the journal, book and database level. By auditing these different sources of statistics, service authentication and e-resource usages; reports can be gathered and presented to resource managers. For example, e-resource usage can be reported on per user, resource or organisation over daily, monthly or yearly time periods.
RAPTOR aims to generate statistics within individual federation member institutions. These statistics can then be aggregated to form higher-level reports in a hierarchical monitoring framework. Different views of the hierarchy can be established based on organisation divisions, geographical divisions, or others. RAPTOR will deliver statistics in a graphical and textual form that is suitable for non-technical users, where further breakdown and access to raw statistics will also cater for the needs of technical users. Such statistics will facilitate, where possible, evidence-based managerial decisions to be made on the economical feasibility of subscribing to particular e-resources; the identification of individual users and/or groups of users’ requirements; and finally, any resource misuse that may be occurring undetected.
This report discusses the possible statistics harvesting and reporting options available to the RAPTOR project. We begin by identifying the key sources of raw authentication and usage information available. We then examine the different harvesting methods capable of understanding and retrieving these raw statistics. This is followed by a survey of existing software platforms that can aggregate and generate reports over such information. We conclude by summarising the statistics gathering and reporting lifecycle, and discuss reporting options within the first version of the RAPTOR software package.
1 http://www.oclc.org/ezproxy/

5
2. Authentication and Usage Information
There are two distinct categories of raw information that can be used by the RAPTOR software to create statistical usage summaries: authentication information and usage information. Authentication information essentially details transactional authentications that occur (i.e. an entry for every time a user logs into a service). Usage information shows much finer grained detail about how individual resources are being used (e.g. every single web page retrieved on a service). Authentication information can be harvested from the log files of authentication systems such as Shibboleth or OpenAthens. Usage information can be gathered by consuming existing usage reports produced by information providers (e.g. journal publishers or resource database providers) or by analyzing the log files of proxy software such as EZproxy. Initially, RAPTOR will focus around reporting authentication information, however, both types are described here, as later versions may also include usage information.
2.1. Authentication Information Shibboleth IdP Logs Shibboleth is a federated access management (FAM) technology started in 2000 and developed by Internet2. Shibboleth, as well as other FAM technologies, is born out of the requirements of users that now want the convenience of having to remember only one username and password to access resources and services across more than one domain - a single lifelong identity. A federation is a coalition of organisations that have an established agreement of trust, which includes a global understanding of the policies and rules with which to govern. Users whose organisation is part of a federation can then share resources within that federation or across multiple federations they share agreements with. Key to this is the concept of single sign-on (SSO), which allows users to log into cross-domain resources using a single username and password that only has to be entered once per session (even if multiple resources / services are accessed).
At the heart of the Shibboleth FAM architecture is the service provider (SP), the discovery service (DS) and the identity provider (IdP). A SP provides resources that users can access. An IdP is responsible for authenticating a user against a local identity vault e.g. a directory or database, and releasing attributes about that user back to a SP. A DS is responsible for contacting the correct identity provider for a given user. Authorisation to a resource for a given SP is then obtained by matching user attributes released by an IdP with those authorised by the SP. Attribute release is governed by policies and rules on the IdP.
In practice Shibboleth is an implementation of the standardized Security Assertion Markup Language (SAML) protocol for exchanging authentication and authorization requests – the basis of many access management implementations. In comparison to the popular OpenAthens FAM system, Shibboleth is not a complete identity and access management solution [3], instead delegating identity management to each federation members internal identity management system e.g. a directory services implementation.

6
FAM technology is useful in the following ways. SPs do not need to maintain list of authorised users, instead only requiring policies and rules on which attributes of users they should allow. Users only need one username and password, which can be used once per session. Users can access all resources within or across federations without having to explicitly register with them. Single usernames and passwords are easier to manage and maintain.
In general, log files contain a sequence of lines containing ASCII characters. A line is either a directive or an entry. A directive contains meta information about the logging process, for example, the version of the log file or the fields recorded in each entry line. An entry records concrete information about each log file entry e.g. HTTP request, separated into fields as defined in a directive line. Fields in entries can be separated by a delimiter, for example a white space, tab or comma character.
Within RAPTOR we aim to harvest both Shibboleth 1.3 and 2.x log files to analyse authentication statistics for individual SPs (resources) to allow a better gauging of their impact factor within organisations. Although Shibboleth supports log files on both the IdP and the SP, a realistic use case in many organisations is that one can only guarantee access to their own IdP. Consequently, only authentication information from the IdP can be harvested, and not authorisation information from the SP2. The Tables below shows what information is retrievable from Shibboleth 1.3 shib-access.log file and the Shibboleth 2.0 idp-access.log and idp-audit.log log files. Of note, the shib-access log file is not easily machine parseable i.e. it requires some natural language processing to interpret, whereas the idp-access and idp-audit logs are field delimited and are easier to interpret.
shib-access.log
2008-12-25 00:53:30,156 Attribute assertion issued to provider (https://sdauth.sciencedirect.com/) on behalf of principal (wxxxx1).
Field Description
Request Date/Time The time at which the request was made, which takes the format yyyy-mm-dd hh:mm:ss
Assertion Type Either an authentication assertion, or an attribute release assertion
Provider The name of the requesting SP, e.g. (https://geoshibb.edina.ac.uk/shibboleth
On behalf of The login name used, can be a number of different attributes as taken from the underlying identity datasource, for example username. Akin to the principal name in the Shibboleth 2 logs.
Name Identifier / Named Identifier format
A unique identifier for the session and the format it takes e.g. urn:mace:shibboleth:1.0:nameIdentifier. Links the request and requester for future reference.
2 Although even if the SP logs are available, authorisation is often not controlled by the SP, but by the host resource
7
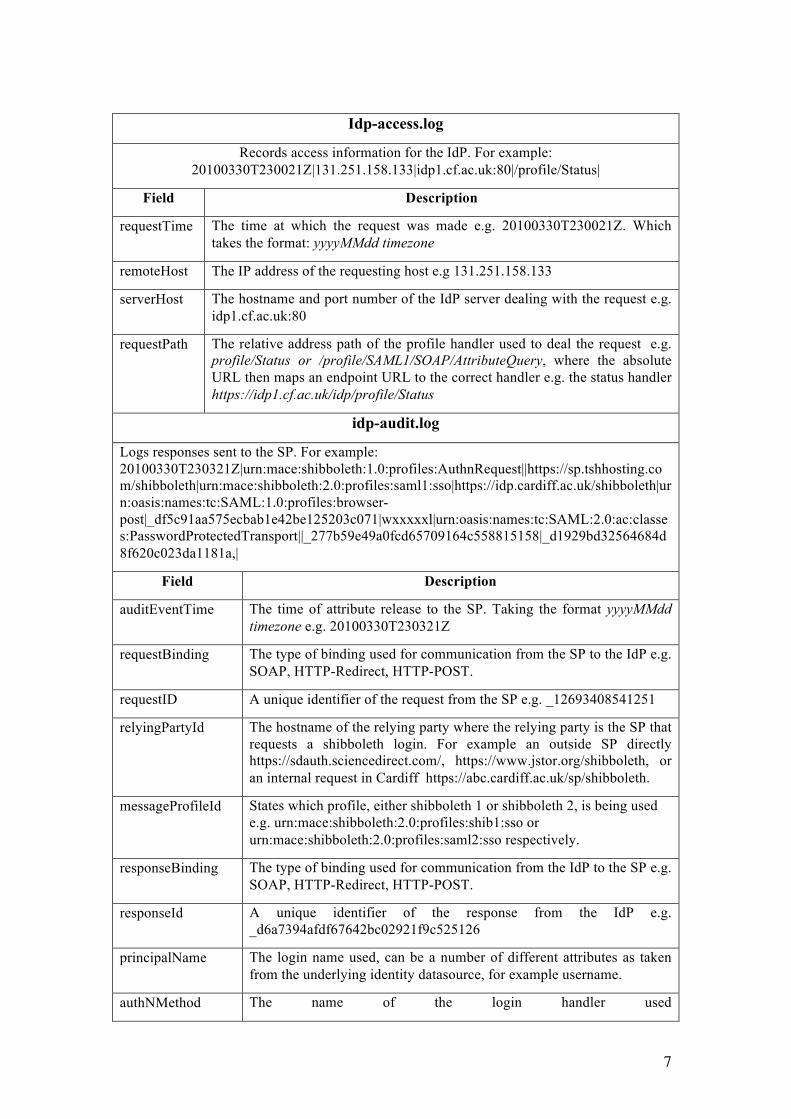
Idp-access.log
Records access information for the IdP. For example: 20100330T230021Z|131.251.158.133|idp1.cf.ac.uk:80|/profile/Status|
Field Description
requestTime The time at which the request was made e.g. 20100330T230021Z. Which takes the format: yyyyMMdd timezone
remoteHost The IP address of the requesting host e.g 131.251.158.133
serverHost The hostname and port number of the IdP server dealing with the request e.g. idp1.cf.ac.uk:80
requestPath The relative address path of the profile handler used to deal the request e.g. profile/Status or /profile/SAML1/SOAP/AttributeQuery, where the absolute URL then maps an endpoint URL to the correct handler e.g. the status handler https://idp1.cf.ac.uk/idp/profile/Status
idp-audit.log
Logs responses sent to the SP. For example: 20100330T230321Z|urn:mace:shibboleth:1.0:profiles:AuthnRequest||https://sp.tshhosting.com/shibboleth|urn:mace:shibboleth:2.0:profiles:saml1:sso|https://idp.cardiff.ac.uk/shibboleth|urn:oasis:names:tc:SAML:1.0:profiles:browser-post|_df5c91aa575ecbab1e42be125203c071|wxxxxxl|urn:oasis:names:tc:SAML:2.0:ac:classes:PasswordProtectedTransport||_277b59e49a0fcd65709164c558815158|_d1929bd32564684d8f620c023da1181a,|
Field Description
auditEventTime The time of attribute release to the SP. Taking the format yyyyMMdd timezone e.g. 20100330T230321Z
requestBinding The type of binding used for communication from the SP to the IdP e.g. SOAP, HTTP-Redirect, HTTP-POST.
requestID A unique identifier of the request from the SP e.g. _12693408541251
relyingPartyId The hostname of the relying party where the relying party is the SP that requests a shibboleth login. For example an outside SP directly https://sdauth.sciencedirect.com/, https://www.jstor.org/shibboleth, or an internal request in Cardiff https://abc.cardiff.ac.uk/sp/shibboleth.
messageProfileId States which profile, either shibboleth 1 or shibboleth 2, is being used e.g. urn:mace:shibboleth:2.0:profiles:shib1:sso or urn:mace:shibboleth:2.0:profiles:saml2:sso respectively.
responseBinding The type of binding used for communication from the IdP to the SP e.g. SOAP, HTTP-Redirect, HTTP-POST.
responseId A unique identifier of the response from the IdP e.g. _d6a7394afdf67642bc02921f9c525126
principalName The login name used, can be a number of different attributes as taken from the underlying identity datasource, for example username.
authNMethod The name of the login handler used

8
urn:oasis:names:tic:SAML:2.0:ac:classes:PasswordProtectedTransport..
releasedAttribute1,…, releasedAttributedn
A comma separated list of the attributes released from the IdP to the SP e.g. eduPersonScopedAffiliation,eduPersonEntitlement,eduPersonTargetedID.old,transientId,eduPersonTargetedID,eduPersonAffiliation
nameIdentifier Used to identify the person that the IdP has issued an assertion about. This is chosen per IdP and could be username, email address or other attribute.
assertion1ID,…, assertionnID
Unique identifiers of each attribute assertion e.g. _277b59e49a0fcd65709164c558825258
OpenAthens Athens is a complete Access Management System (AMS) developed in 1994 by Eduserv for access web-based subscription to e-resources and services. Athens was later developed into a wider access and identity management (AIM) platform under its current name OpenAthens. OpenAthens, like Shibboleth, is a federated access management solution that offers Single Sign On (SSO) to users. However, unlike Shibboleth, it can also be a complete identity management system similar to OpenID3 and Microsoft’s Cardspace4. OpenAthens incorporates the idea of trust (using digital signatures) across federations (meta-organisations), is operating system agnostic, and tries not to compromise a users privacy during attribute release. To achieve this, OpenAthens is meta-AIM software framework that works across and brings together services, resources and access management systems, and supports the following: • Single Sign On including user provisioning, administration and policy
management. • Attribute transformations. • The management of attribute release policies. • Establish standards for communicating between identity providers and service
providers e.g. using SAML. • The integration of different discovery services and access management systems
e.g. CardSpace and Shibboleth could both operate within the OpenAthens framework.
OpenAthens includes three distinct components, namely; OpenAthensMD, OpenAthensLA and OpenAthensSP. OpenAthensMD provides central access (held by Eduserv) to organisations user identifier and attributes, whereas OpenAthensLA provides local authentication of organisations user identifiers and attributes – similar to a Shibboleth IdP. OpenAthensSP allows service providers to connect to the OpenAthens framework – similar to the Shibboleth SP.
OpenAthens statistics show authentication and access information per resource per user. OpenAthens statistics can be produced on request, or by the publisher on a
3 http://www.openid.co.uk/ 4 http://www.microsoft.com/windows/products/winfamily/cardspace/default.mspx

9
regular basis. The period for reporting can also be customized, for example monthly, yearly or for a given time period. Once generated in either PDF, HTML or CSV format, reports can be downloaded from their website or sent to a client via email. The CSV OpenAthens output format used by Cardiff University includes the following information.
OpenAthens Report (CSV)
Field Description
Username / UID The username of the
Administrator Name The Athens username of the administrator
Total Access Total access for all resources
Resource1,…Resourcen Access count for that user per resource (1 to n)
2.2. Usage Information and Reports
EZproxy Logs EZproxy is a middleware proxy referral server, which allows off campus access to web resources that have host based (IP) authentication mechanisms. Off campus access to resources for users with IP address ranges not authorised by the resource is achieved by delegating access to, and passing information through, a proxy - in this case EZproxy - that exists on a server which sits within the authorised IP address range. EZproxy automatically re-writes all URLs of a website so all hyperlinks are directed back through the organisation’s EZproxy server. The EZproxy server logs all resource access requests; in this way information about off campus resource authentications and access to e-resources can be harvested and used in RAPTOR. The EZproxy log structure conforms to the Common Log Format, which is a recognised standard and is described further in the section to follow. The Table below shows what information can be retrieved from the EZproxy log file.

10
EZproxy.log5
Records each URL rewrite request from a client. For example: 94.1.210.120 oNjnvGPYBaisVTy [email protected] [07/Mar/2010:11:43:29 +0000] "GET http://library.cf.ac.uk:80/images/English/UpPatron.gif HTTP/1.1" 200 817
Field Description
IPAddress The IP address of the host routed through EZProxy
Header Header from the browser request e.g. referrer
EZproxy identifier Identifier for the user’s current session
Username The username of the user accessing EZProxy
Date/Time The date and time of the current request.
Request The URL of the request including hostname, port number and the HTTP request method e.g. POST or GET
StatusOfRequest The HTTP numeric status returned from the target website
NumberOfBytesTransferred The number of bytes transferred for this URL request.
Common Log Format (CLF) logs The common log format [1] developed in 1995, is a standardized ASCII text file format typically used by web servers for logging user access. The vast majority of log file parsing software systems can parse the CLF. CLF conformance assumes the following attributes exist in the logfile.
Field Description
IPAddress The IP address of the client machine making a request to the server
Identity The RFC 1413 identity of the client machine (although this information is know to be unreliable6)
User The unique identifier of the requesting user
Date/Time The date and time of the request, with the format day/month/year:hour:minute:second zone
Request The URL of the request including hostname, port number and the HTTP request method e.g. POST or GET
Status The RFC 2616 HTTP status code the server sends back to the client
Bytes The size in bytes of the document sent back to the client
5 See also http://www.oclc.org/support/documentation/ezproxy/cfg/logformat/ 6 For example the HTTP Apache Server does not log this information by default and so is left blank http://httpd.apache.org/docs/2.0/logs.html.

11
The CLF standard was extended in 1996 to handle arbitrary fields of information. The new format, denoted the Extended Log File Format, has the following features [6]:
1. Permit control over the data recorded. 2. Support needs of proxies, clients and servers in a common format 3. Provide robust handling of character escaping issues 4. Allow exchange of demographic data. 5. Allow summary data to be expressed.
Fields are defined at the top (headers) of the file separated by white spaces. Values for entries are then populated in subsequent lines consistent with these headers. The ELFF is widely used in practice, for example it is the default format for Microsoft’s web server and application set, the Internet Information Service (IIS).
2.3. COUNTER-Complaint Statistics
In this section we detail the Counting Online Usage Networked Electronic Resources (COUNTER7) usage reports, which could become an input to RAPTOR for generating, where possible, fine grained resource usage statistics per organisation at the journal and database level. Counter, introduced in 2002, allows for the measurement of electronic resource usage data from the perspective of the information producer e.g. journal publishers or vendors. Statistics generated are sent (typically monthly) to the resource manager of information consumers e.g. a university librarian, where eResource usage can be monitored and renewals and purchase decisions made. Counter is essentially 'a set of agreed standards and protocols for the recording and exchange of online usage data'. COUNTER-compliance from vendors means conformance to the set of standards and protocols defined by the Counter initiative.
COUNTER has a number of different report types to show the access statistics for journals, databases, and books and reference works. Each different report type is now described.
Journal Reports
Report Type Fields Criteria
JR1 – Number of successful full-text article requests by month and journal
Full journal name, publisher, print ISSN and online ISSN, full text requests per month including HTML or PDF breakdown
If full text article requests per month is 0, then this report should be used
JR1a - Number of successful Full-Text articles Requests from an Archive by Month and Journal
Full journal name, publisher, print ISSN and online ISSN, full text requests per month including HTML or PDF
If using report 1a, you must still provide JR1. If vendors provide a separately acquirable journal archive stats as per this report but can not provide JR1a, they
7 http://www.projectcounter.org/

12
breakdown must provide JR5
JR2 - Turnaways by Month and Journal
Journal Name, publisher, print SSN, online ISSN, page type, turnaways per month, total turnaways to date
JR5 - Number of Successful Full-Text Article Requests by Year and Journal
Journal Name, Publisher, Platform, print ISSN, online ISSN, full text requests per month
This report is the converse to JR1a. If this report cannot be used, replace with JRa. This separates total usage from JR1 with per acquired archives similar to JR1a
Database Reports
Report Type Fields Criteria
DB1 - Total Searches and Sessions by Month and Database
Database name, publisher, platform, then for each database: total searches run, searches federated and automated, total sessions, sessions-federated and automated per month and total to date
DB2 - Turnaways by Month and Database
Database name, publisher, platform, page type, turnaways per month, total turnaways to date
DB3 - Total Searches and Sessions by Month and Service
Service name, platform, then for each service: total searches run, searches federated and automated, total sessions, sessions-federated and automated per month and total to date
Books and Reference Works
Report Type Fields Criteria
BR1 - Number of successful title Requests by Month and Title
Title name, publisher, platform, ISBN, ISSN, requests per month, and to date total
Only supplied for titles for which BR2 cannot be provided
BR2 - Number of successful Section Requests by Month and Title
Title name, publisher, platform, ISBN, ISSN, selection requests per month and total to date
If number of section request per month is 0, then this report should be used unless an aggregator or gateway is responsible
BR3 - Turnaway by month and title
Title, publisher, platform, ISBN, ISSN, turnaways per month, turnaways to date
only to be used for titles where turnaways are at the title level, in most cases they are at the level of the service, in which case BR4 applies
BR4 - Turnaways by Month and Service
Title, publisher, platform, turnaways per month, total turnaways to date
13
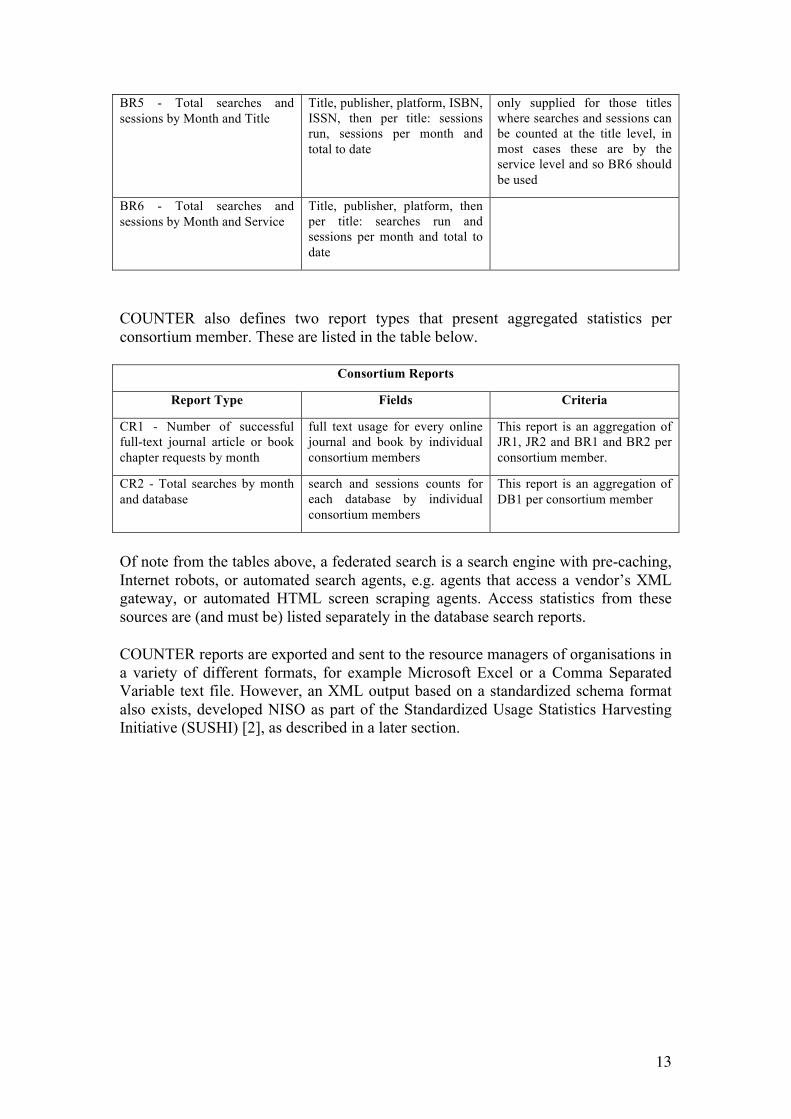
BR5 - Total searches and sessions by Month and Title
Title, publisher, platform, ISBN, ISSN, then per title: sessions run, sessions per month and total to date
only supplied for those titles where searches and sessions can be counted at the title level, in most cases these are by the service level and so BR6 should be used
BR6 - Total searches and sessions by Month and Service
Title, publisher, platform, then per title: searches run and sessions per month and total to date
COUNTER also defines two report types that present aggregated statistics per consortium member. These are listed in the table below.
Consortium Reports
Report Type Fields Criteria
CR1 - Number of successful full-text journal article or book chapter requests by month
full text usage for every online journal and book by individual consortium members
This report is an aggregation of JR1, JR2 and BR1 and BR2 per consortium member.
CR2 - Total searches by month and database
search and sessions counts for each database by individual consortium members
This report is an aggregation of DB1 per consortium member
Of note from the tables above, a federated search is a search engine with pre-caching, Internet robots, or automated search agents, e.g. agents that access a vendor’s XML gateway, or automated HTML screen scraping agents. Access statistics from these sources are (and must be) listed separately in the database search reports. COUNTER reports are exported and sent to the resource managers of organisations in a variety of different formats, for example Microsoft Excel or a Comma Separated Variable text file. However, an XML output based on a standardized schema format also exists, developed NISO as part of the Standardized Usage Statistics Harvesting Initiative (SUSHI) [2], as described in a later section.

14
3. Statistics Harvesting Engines and Protocols
In this section we survey log file parsing engines and communication protocols, with the aim of identifying software libraries capable of reading the raw statistics presented in the previous section.
3.1. Parsing Engines
Log Parser v2.1 (from Microsoft)8 Microsoft’s Log Parser is capable of running SQL style queries over log files and record results into an SQL database. It is part of Microsoft’s IIS recourse toolkit, and supports a number of different formats e.g. IIS, NCSA and W3C log files, as well as the windows event log, CSV and directory information. An SQL style query language provides a generalised way of querying arbitrary log files, an example of which is shown below for returning the IP address, date time and URI from all query logs that have an ex prefix.
SELECT ip, date, time, uri FROM ex*.log
It has a Component Object Model (COM) interface for application interaction. Such tool would be of great benefit to provide a single unified query language for easy access to log file information. However, it does require an input context to be defined in order to understand different log file formats, is not free, and is a .NET project and hence requires a Microsoft Windows environment - which is not the chosen OS on a large number of Shibboleth IdP and EZproxy server configurations.
Java XML Log Analyzer (JXLA)9 JXLA is a Java library for parsing XML based log files. Arbitrary log file formats can be parsed providing the user specifies its format using their developed Regex language. However despite the ease of which it is possible to define parseable log file formats, this approach is little more than a convenience wrapper to a custom regular expression parser. Log Factor 5 Log Factor 5 is a Java Swing interface for Apache Log4J log file inspection. Log4J is a Java logging library that can, amongst others, output to a file handler. Such log files 8 As part of the ISS toolkit http://www.microsoft.com/downloads/details.aspx?familyid=56FC92EE-A71A-4C73-B628-ADE629C89499&displaylang=en 9 http://sourceforge.net/projects/jxla/

15
are then loaded and displayed in Log Factor 5. Its interface provides a hierarchical view of log file entries, where entries can be filtered based on certain attributes and criteria. In order for Log Factor 5 to function, Log4J configurations is required on the host, based on their own standard output format. An example screenshot of Log Factor 5 is shown in Appendix A. Figure 3.
Chainsaw10 v2 (Apache 2006) Chainsaw is another Log4J log file parser inspired by Log Factor 5, created by Apache, and written in Java. It is capable of reading all Log4J files in XML format or from a database (through the Java Database Connectivity driver). It is a complete parsing application with a Java Swing GUI. Dynamic filtering of log files is catered for using custom filter expressions. Of interest, it can receive events from local or remote logging sources through a Log4J Socket Appender and socket receiver on the client. The remote receiver needs to be configured in the output Log4J configuration file which then sends logging information through a socket Appender rather than the standard console or file appender. This allows the application to work in real-time, processing logs entries as they are output by the client program. The parser uses the Log4J configuration itself to understand the log file format. Chainsaw is only compatible with acknowledgeable Log4J parser configurations set up with a socket appender. It requires an XML rather than plain text output and, despite presenting a view of the log file, does not have an analysis option. Chainsaw does come with libraries that could be used with Raptor to achieve backend parsing functionality.
Regular Expression based parsers Many parsing approaches use the regular expression capabilities of programming languages such as Perl, Java and PHP etc. Such approaches are applicable to plain text log files, where the exact format and semantics of log entries need to be understood in order to manually construct appropriate regular expression. A custom regular expression approach may not be robust to subtle changes in the logging format, and would need to be set up for each different log format.
3.2. Protocols
SUSHI
The Standardised Usage Statistics Harvesting Initiative (SUSI) developed a protocol [2] that allows the automatic retrieval of COUNTER-complaint usage statistics in XML format over a SOAP request response web service implementation (on the publisher side). This eliminates the manual effort in acquiring, importing and aggregating Counter statistics, and should improve development of electronic
10 http://logging.apache.org/chainsaw/index.html

16
resource management software. The program has a well defined data model and data interface through XML Schema and the Web Service Description Language respectively. SUSHI is currently being used within digital resource management systems to help automate the auditing of e-resources as described in the section to follow.

17
4. Usage Collector and Reporting Engines In this section we survey a number of existing software systems that either provide full resource management lifecycle solutions e.g. Resource Management Systems, or those that report on service authentication and general usage statistics e.g. OpenAthens authentication statistics or tools for reporting information contained within log files. This survey should provide an insight into the types of reporting options currently available in existing software platforms which could form part of, where applicable, the base Raptor reporting tool. In addition to this, it should highlight any obvious reporting gaps that can be filled by the Raptor reporting tool.
4.1. Resource Management Systems
Electronic Resource Management Systems (ERMS) have become important tools for librarians since their advent in the early 2000’s [4]. An NISO initiative helped standardize ERMS in 2004 [Digital Library Foundation published the Electronic Resource Management Report of DLF and ERM initiative], where an ERMS should support centralised resource auditing and management with the following features: the storage and listing of subscribed e-journals and e-books etc. per resource, management of the e-Resource order and renewal lifecycle, and the reporting of issues from publishers.
In this section we overview the key features of three example ERMS tools, namely; SEMPERTOOL11, Murphy Library’s ERMes12, and EBSCONET ERM Essentials13. This serves to highlight key information and report types that could be used within the Raptor reporting framework.
SEMPERTOOL
Generated Reports Notes
Reports per time period e.g. monthly Monthly, daily or arbitrary time interval
Report based on a simple usage filters Usage filters on different attributes e.g. product name, provider, product type, original price, price in local currency, organization name.
Renewals List subscriptions that need renewing within a given time frame.
11 http://www.sempertool.dk/ 12 http://murphylibrary.uwlax.edu/erm/ 13 http://www2.ebsco.com/en-us/ProductsServices/ERM/Pages/index.aspx

18
Resource Listings
Cancelled subscriptions
Licensed subscriptions
Products per resource Can be listed in a hierarchical-tree view by subject title, publisher etc.
Resources
Resource Lifecycle Management
Trial products from a resource
Renew subscription
Cancel subscription
Create, Edit and Replace resources
Software Features
Open source
Web based user interface
Customisation
ERMes
Generated Reports
Renewals For a given date range
Year to year price comparisons
Access to Counter generated statistics Display of a wide range of Counter statistics as described in Section 2.2. Although manual input required, and no aggregation of statistics.
Database usage by fiscal year
Resource Listings
Vendors Including licensing terms, subscription status
Databases Including subscription terms
Problem logs Access problems
Resource Lifecycle Management
No automatic life order or renewal lifecycle, only subscription reports
19
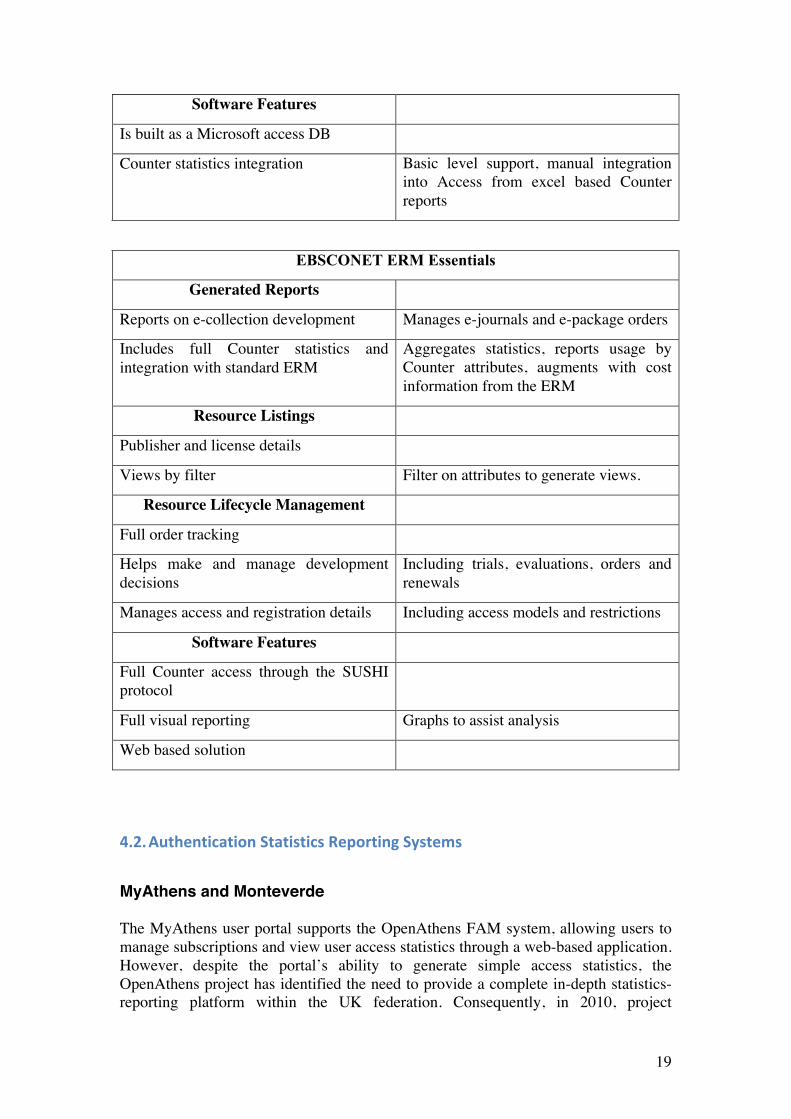
Software Features
Is built as a Microsoft access DB
Counter statistics integration Basic level support, manual integration into Access from excel based Counter reports
EBSCONET ERM Essentials
Generated Reports
Reports on e-collection development Manages e-journals and e-package orders
Includes full Counter statistics and integration with standard ERM
Aggregates statistics, reports usage by Counter attributes, augments with cost information from the ERM
Resource Listings
Publisher and license details
Views by filter Filter on attributes to generate views.
Resource Lifecycle Management
Full order tracking
Helps make and manage development decisions
Including trials, evaluations, orders and renewals
Manages access and registration details Including access models and restrictions
Software Features
Full Counter access through the SUSHI protocol
Full visual reporting Graphs to assist analysis
Web based solution
4.2. Authentication Statistics Reporting Systems
MyAthens and Monteverde The MyAthens user portal supports the OpenAthens FAM system, allowing users to manage subscriptions and view user access statistics through a web-based application. However, despite the portal’s ability to generate simple access statistics, the OpenAthens project has identified the need to provide a complete in-depth statistics-reporting platform within the UK federation. Consequently, in 2010, project

20
Monteverde was started [3]. Project Monteverde is an OpenAthens usage statistics collector, which includes live reporting directly within the OpenAthens LA (as of version 2.1). Project Monteverde strives to provide accurate statistics, operating under the belief that log file parsing is an approximate, interim solution – however they have yet to define a long-term solution to the problem of statistic acquisition. Monteverde will include the following features (taken and adapted from [3]):
• Login events, success and failures • SSO Events to different SPs e.g. ScienceDirect, Oxford English Dictionary. • Diagnostics: using access logs and erroneous login events. • Graphical and or textual report options • Long term trends • Takes inputs from both identity and service providers to give finer grained
knowledge on both user authentication and authorization. • Integration with existing management tools • An open API (Restful [ref-fielding]) for integration into existing projects.
Monteverde only considers resource authentication statistics from the OpenAthens framework, and does not attempt to aggregate such information with other sources of statistics e.g. COUNTER statistics which can be used with fiscal information (like those used by an ERM) to make informed decisions on resource subscriptions.
AMMAIS – the Accounting and Monitoring of Authentication and Authorization Infrastructure
The SWITCH AMMAIS project [5], much like the Monteverde OpenAthens project, hopes to fill the accounting and monitoring gap of the Shibboleth FAM technology. More specifically, they are trying to collect, process and visualise authentication and authorisations requests in Shibboleth. This is an extension of their early work [5] which did not provide a general monitoring solution to the problem. They utilise both the Shibboleth IdP, SP and DS log files for harvesting user authentications, and user authorisations. Using this information, they attempt to monitor 1) user authentication on the IdP, 2) user authorisation on the SP, 3) attribute release from the IdP to the SP, 4) DS interactions (which was already implemented in [5]).
AMMAIS is a usage collection framework that places individual usage collectors on each Shibboleth IdP, SP or DS (denoted meters in their framework) within an organisation. These collectors are then aggregated within or across organisations by an accounting server, and exposed to the user by a suitable interface e.g. a web interface. This framework enables both federation level monitoring as well as a more fine-grained federation member level monitoring.
Currently the AMMAIS project is in its early stages, a general architecture for monitoring has been agreed, and the protocol and interface for communicating between the resource collectors and resource aggregators is under development.

21
4.3. Usage Statistics Reporting Systems
PIRUS2
Publisher and Institutional Repository 214 (PIRUS2) is a JISC sponsored project to collect and analyse usage statistics. The project is lead by the University of Manchester, and started in October 2009 running until the end of December 2010. PIRUS2 is a practical implementation of the more theoretical PIRUS project [7], and aims to develop a suite of open source programs, including a web portal, to consolidate and report COUNTER usage statistics at the article level – where currently, COUNTER statistics are only recorded at the level of individual journals, databases or books.
Finer grained analyses on the access of individual articles is said to be required for a number of reasons15. In overview, the last decade has seen an increase in the number of electronic journal articles that a digital repository hosts, where authors and funding agencies require access statistics at the article level in order to distinguish individual items applicable to them. However, no standard for measuring global article usage currently exists. PIRUS2 are developing a set of open source software services to support this goal based on newly developed COUNTER report types (for article access), which can be exposed using the SUSHI protocol. Of note, how to monitor article level access is still an open question, with initial implementations based around detecting an articles distinct digital object identifier (DOI).
PIRUS2 is a COUNTER only usage collector, and does not integrate with statistics collected with federated access management technologies such as OpenAthens or Shibboleth.
JISC’s Online Usage Statistics Portal
JISC, in collaboration with MIMAS, Cranfield University, and Birmingham University, are developing a Web Portal to provide usage statistics for online journal content. Like the Raptor project, JISC recognized the need to better understand the ‘impact and increase in availability of online journal content’16. Where in the current state, this information is not presented to librarians or resource managers in an easily accessible17 and digestible format. Consequently, the JISC online usage portal will present a unified view of journal usage information through a single web site. In broad, the portal aggregates COUNTER-complaint publisher statistics at the Journal (JR1 and JR1A) level, all of which are access and compiled together autonomously, and presented to the user either in graphical or textual e.g. tabled, format.
14 http://www.cranfieldlibrary.cranfield.ac.uk/pirus2/tiki-index.php 15 see http://www.cranfieldlibrary.cranfield.ac.uk/pirus2/tiki-index.php?page=About for an exhaustive list 16 https://www.jusp.mimas.ac.uk/about.html 17 Access is often through local authentication and authorisation methods, using one-off passwords.

22
IF-MAP
In 2008 the Trusted Network Connection (TNC) started development on IF-MAP (the Interface to Metadata Access Points), a reporting component and protocol to fit within their existing Network Access Control architecture (NAC). IF-MAP was developed to monitor the dynamic state of network infrastructure, helping to diagnose problems and report on usage. IF-MAP defines a client-server architecture, where clients (or sensors) can be any type of network hardware e.g. a DHCP server, and are responsible for collating and publishing events to the IF-MAP server over a secure (e.g. TLS secured) connection using the SOAP protocol. The server specification then supports the mediation, aggregation and retrieval of metadata from a variety of different subscribed clients e.g. linking an IP address with its MAC address from DHCP, and further linking this with username from a radius server and hostname from DNS. The server stores metadata from clients in the Metadata Access Point (MAP) database. IF-MAP logs security events in real-time – where TNC note existing management protocols such as SNMP and Syslog are static.
Although different in purpose to Raptor (reporting on network access as opposed to general resources usage), the client-server reporting architecture is of interest, as well as the IF-MAP v1.1 protocol developed for sending and receiving information over TLS using SOAP. Such protocol defines semantically overlapping metadata types with those required by Raptor e.g. a datatype for logical endpoint access-requests and its associated access-request-ip, and a datatype for representing the authenticated-by hostname or IP address. Consequently, the IF-MAP protocol could either provide a complete implementation from which to work off, or provide a sound base from which to work from.
Despite uptake from a number of commercial company’s, for example Juniper Networks have IF-MAP publishing client and server implementation as part of their Unified Access Control software, open source alternatives are rare, with omapd18 being in a relatively early (beta) stage of development.
4.4. General Log File Reporting Systems
XpoLog19 XpoLog is a commercial software platform for hybrid (servers, applications, security etc) log management. It supports the complete reporting lifecycle from log file parsing to monitoring and reporting. It is principally used for automatic application problem monitoring and analyses. More specifically, the software tries to automatically detected problems from application testing cycles (based on production
18 http://code.google.com/p/omapd/ 19 http://xpolog.com

23
logs). It supports a wide number of input log formats e.g. Log4J, IIS, Syslog. Access Log, but does not provide a public log parsing library
Sawmill20 Sawmill is a paid for, real time universal log file analysis and reporting web application that generates hierarchical, easy to navigate database driven live reporting and graphing views of log files. It’s a complete product covering the full lifecycle of monitoring and reporting. It converts log file data into database relations, which is then used to generate reports e.g. on page views, page hits and sessions. Filtering can be done intrinsically to the web application over the database, or extrinsically using a log filter (using a built in scripting language). There are no API Hooks, the information is not presentable to an external interface. An example screenshot of Sawmill is shown in Appendix A. Figure 1.
AWStats21 AWStats is a free (under the GNU general public license) web based system for viewing log files in real time. It has a large list of input formats it can handle, including: Apache HTTP logs, FTP Logs, mail server logs. A variety of graphical and textual reports (as listed in the table below) can be generated for log files over hourly, daily or monthly time periods.
Report Type Report Type
Requests per country Requests per Host
Number of authenticated users Duration of visit (for web site access)
Requests per file type (e.g. PDF, HTML) Requests per operating system
Requests per browser HTTP Status Codes
Other types of reports are supported for different log file types. For example folders visited and the number and type of file downloads for FTP servers. However AWStats is geared primarily to display web site access statistics. Interestingly, the GeoIP [ref] is used to geocode IP address, allowing the creation of per country statistics – however, typically this is only accurate at a fairly course level of spatial granularity e.g. by Country. An example screenshot from the AWStat is shown in Appendix A. Figure 4.
20 http://www.sawmill.net 21 http://awstats.sourceforge.net/

24
5. Reporting Options Conclusions In this section we will discuss the statistics gathering and reporting lifecycle that will be supported in Raptor, based on the raw input stats and reporting features of existing solutions identified in this document. Raw statistics: As reported in this deliverable, Raptor will have access to four different sources of usage information. The first three provide authentication and access information through the Shibboleth IdP and EZproxy logs and OpenAthens statistisc. The last, COUNTER statistics are provided by publishers and show individual journal, book, and database usage per institution. Both Shibboleth and OpenAthens present FAM authentication statistics, EZproxy presents e-resource access statistics, and COUNTER presents e-resource usage statistics. Consequently, both Shibboleth and OpenAthens can report statistics on the authentications and access to services, be it a library e-resource, project management web site, or virtual learning platforms like Blackboard22. EZproxy and COUNTER on the other hand are tailored to reporting the usage of library e-resources. The Shibboleth IdP has two log files that store access and response information. Access logs record authentication requests to the IdP and contains Shibboleth specific information about the profile handler used on which IdP server, as well as general information about the IP of the requesting host and the time of request. In Raptor we aim to harvest both types of information and, as Raptor is a FAM authentication accounting framework first and foremost, will produce reports on both types. The response logs show Shibboleth specific information about the release of attributes back to the SP. Response logs will also be parsed by Raptor and augmented with the access logs to provide a holistic view of the Shibboleth authentication and attribute release lifecycle. OpenAthens access statistics are pre-processed and output by Eduserv, and can provide individual e-resource usage statistics per user or per service provider if requested. Such statistics are comparable to those provided Shibboleth, which compared to COUNTER-complaint publisher statistics, report at a resource level as opposed to at the individual journal, book or database level. EZproxy logs record off-campus e-resource requests per user for each unique Get or Post request. Consequently, these logs are a good source of user resource access information. However, post processing is needed to distinguish each distinct resource request. For example, in the log fragment below, the user A0001H visited publisher_custom.js shortly followed by publisher_custom_leader.js from the publisher testPub. [email protected]"GET http://testPub.com:80/site/js/publisher_custom.js HTTP/1.1" [email protected]"GET http://testPub.com:80/site/js/publisher_custom_leader.js HTTP/1.1" COUNTER statistics are pre-processed and formatted by the publisher before they are
22 http://www.blackboard.com/Teaching

25
delivered to an organisation. COUNTER provides fine grained usage statistics, showing the frequency of access to individual e-journals, e-books, or e-databases per month and year. However, compared to either EZProxy, OpenAthens or Shibboleth, COUNTER statistics have a low level of granularity at the requester level, showing usage statistics per organisation rather than per user. Combining these statistics within the general framework of Raptor allows a holistic view of e-resource usage in HE or FE institutions. However, resources that provide COUNTER statistics in addition to OpenAthens or Shibboleth IdP and EZproxy information, will overlap. More specifically, a user that signs-on to a publisher through Shibboleth will first be recorded by the Shibboleth IdP then, if that user accesses, for example, and e-journal from that publisher, this usage will also be included in the aggregated COUNTER statistics. Furthermore, Shibboleth can be used to provide authentication to the EZProxy service, in which case from a Shibboleth perspective, this is a reportable service sign-on, but if these logs are combined with EZproxy, such requests should be ignored as the actual resource authentication is taken care of by EZproxy. Such overlap will need to be investigated in depth if useful aggregated statistics are to be generated from the combination authentication and usage information sources. Consequently, the initial stage of Raptor will focus on authentication statistics from the Shibboleth and OpenAthens FAM systems, with an intermediate stage to include EZProxy statistics and a later stage to include COUNTER statistics. Furthermore, in early prototypes of Raptor, even if more than one type of statistics is included they will be reported on separately, leaving their aggregation to the final stages of development. Understanding and reading raw statistics: Numerous log file parsers exist for plain text output files, some e.g. Chainsaw, not only parse, but also display log file entries, and allow ‘live’ reporting from local and remote systems by integrating with Java’s Log4J logging utility. All are capable of reading, in their entirety; the types and formats of Shibboleth and EZproxy log files. COUNTER-complaint statistics are best automatically retrieved through a SUSHI SOAP interface. Thus eliminating the manual effort required to load and aggregate e-journal, e-book and e-database statistics – although a fall back manual loading option should be supported through the correct parsing of CSV or Microsoft Excel files. OpenAthens CSV files are also easily parsable.
Decisions on implementation libraries are left until the RAPTOR architecture has been defined, and so will not be discussed any further here. Suffice to say that machine processing the four different raw statistic types identified in this document is possible with current technologies.
Reporting options: General reporting tools do not understand the specific semantics of the raw access and usage information used by RAPTOR. Consequently, only certain statistics can be reliably generated for with these tools e.g. often just basic frequencies. Furthermore, they are not capable of aggregating different information types, where aggregation must understand the statistical implications of overlapping data sources e.g. access information from COUNTER will often be a superset of the access information that can be obtained from OpenAthens, Shibboleth or EZproxy.
26
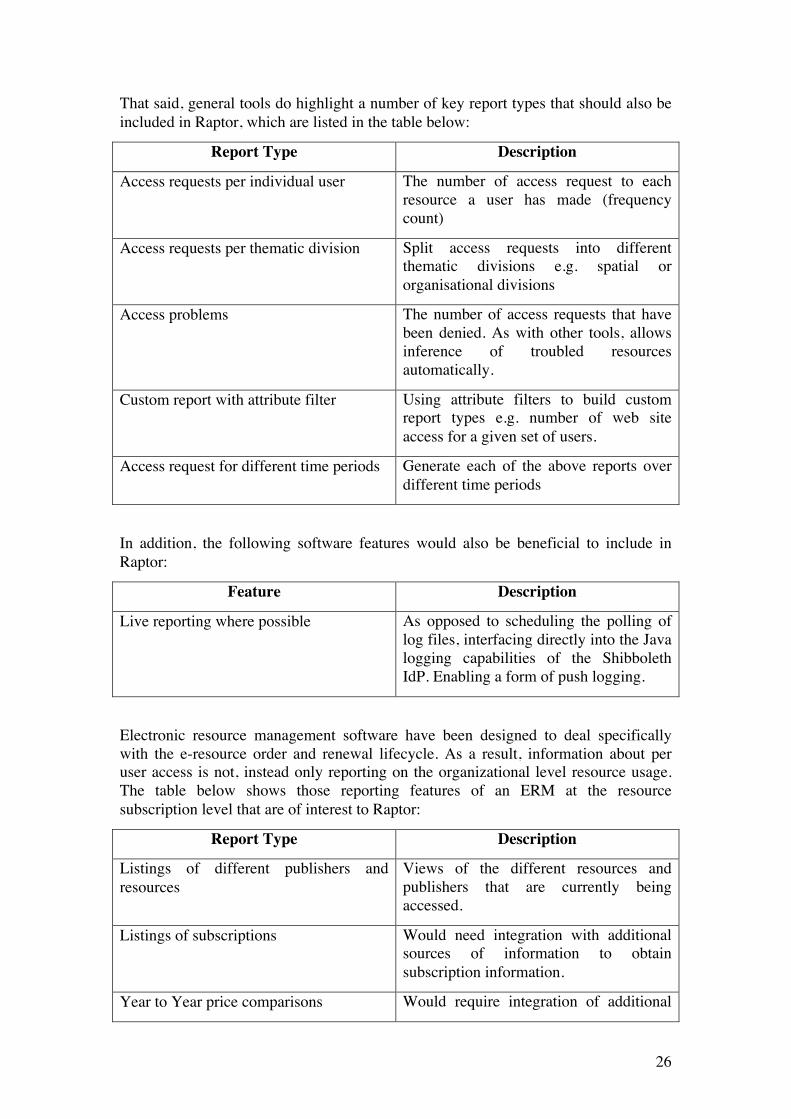
That said, general tools do highlight a number of key report types that should also be included in Raptor, which are listed in the table below:
Report Type Description
Access requests per individual user The number of access request to each resource a user has made (frequency count)
Access requests per thematic division Split access requests into different thematic divisions e.g. spatial or organisational divisions
Access problems The number of access requests that have been denied. As with other tools, allows inference of troubled resources automatically.
Custom report with attribute filter Using attribute filters to build custom report types e.g. number of web site access for a given set of users.
Access request for different time periods Generate each of the above reports over different time periods
In addition, the following software features would also be beneficial to include in Raptor:
Feature Description
Live reporting where possible As opposed to scheduling the polling of log files, interfacing directly into the Java logging capabilities of the Shibboleth IdP. Enabling a form of push logging.
Electronic resource management software have been designed to deal specifically with the e-resource order and renewal lifecycle. As a result, information about per user access is not, instead only reporting on the organizational level resource usage. The table below shows those reporting features of an ERM at the resource subscription level that are of interest to Raptor:
Report Type Description
Listings of different publishers and resources
Views of the different resources and publishers that are currently being accessed.
Listings of subscriptions Would need integration with additional sources of information to obtain subscription information.
Year to Year price comparisons Would require integration of additional
27
resources and COUNTER-Complaint statistics in order to gauge the value for money resources
e-journal, e-book and e-database statistics Generate statistics at this level. Would require COUNTER integration.
Aggregated statistics General frequency statistics as per table ?, combined with e-resource usage statistics show in this table
In addition, the following ERM software features would also be beneficial to include in Raptor:
Feature Description
SUSHI SOAP integration For automatic retrieval of COUNTER statistics from SUSHI compatible publishers.
Visual reporting Graphical reports for easy consumption as opposed to just textual reports
Web based reporting system
The MyAthens user portal, OpenAthens Monteverde statistics collectors and SWITCH accounting framework are an examples of FAM authentication and access reporting tools that are most similar to the initial goals of Raptor, in that they report user resource access statistics. The MyAthens portal is limited with respect to reporting aggregated statistics at the organisation level, instead only reporting individual subscriptions and access information one user at a time. Although Monteverde is in development, its scope and outline highlight the following report types that are of interest to include within Raptor:
Report Type Description
Login events Including success and failures. Similar to problem reporting as mentioned previously.
SSO events per SP How many sign on events per service provider
Long term trends
In addition, Monteverde has a Restful OpenAPI that allows integration into existing projects. Such API may also be beneficial in Raptor, where external services could be allowed access to aggregated statistics.

28
Feature Description
An OpenAPI SOAP or Restful API that allows integration into other systems.
Fully integrated into the OpenAthensLA Statistics can be generated for each Local Authority. Such scenario would be similar to Raptor integrating into a Shibboleth IdP
Web based reporting system
Of note, Monteverde does not aggregate statistics from other sources e.g. EZproxy or COUNTER, instead only considering OpenAthens statistics. Furthermore, statistics are collected and reported on the OpenAthens LA, consequently from this constraint, it remains to be seen whether Monteverde can be used to aggregate statistics from multiple LAs.
PIRUS2 is an interesting project that aims to enable the finest, per article, level of resource access statistics. If the project were successful, its integration into Raptor (through the SUSHI protocol) would add value to the reporting framework. However, adoption of this standard by publishers needs to happen in the short term, before it would be considered.
The AMMAIS project is in an early development stage, hence exact reporting options have yet to be defined. That said, the goals of the project are of interest, and are closely related to those of Raptor, these are: to provide a web interface to authentication and authorisation statistics, collect usage statistics from the federation member level up to the federation level, monitor authentications on the IdP, monitor authorisations on the SP, and monitor any DS interactions.
The development of the JISC Usage Statistics Portal complements the development of Raptor, where a usage and authentication synergy can be established by integrating both statistic types. The Raptor software should therefore provide an Open API, using compatible standards were possible, so as to make it available as an information source to the JISC portal.
Lastly, as noted previously, Raptor can drawn inspiration from the IF-MAP reporting architecture and components, as well as the IF-Map v1.1 protocol used (defined in XSD and passed through SOAP) for communicating between the various components of the architecture.

29
5.1. Raptor Features
From the conclusions drawn in the previous section, the following mandatory reporting features will be incorporated into the Raptor framework:
• Textual views of statistical information • Graphical views of statistical information • Integration of Shibboleth 1.3 and 2.x IdP logs • Integration of OpenAthens IdP usage statistics • Report on (for custom time periods):
o Authentication events per SP and per user (or principalName for Shibboleth)
o Authentications per IP address, geocoding where possible to obtain location specific information.
o Login events – success and failures o Shibboleth specific statistics:
IdP servers used Authentication methods used Message profiles used Response bindings used Type of attributes released, but not actual values for privacy
reasons Shibboleth profiles handlers used
o Access problems on the SP • A web based interface that can present information for technical users (all raw
and processed statistics), and present a subset of processed statistics for non-technical users.
Again from the conclusions drawn in the previous section, the following desirable reporting features will be included, where possible, into the Raptor reporting framework:
• Integration of usage statistics from COUNTER-complaint resources o Including use of the SUSHI protocol o Reporting on:
E-journal, e-database and e-book usage per resource • Integration of EZproxy logs • Aggregation of:
o Authentication information from Shibboleth and OpenAthens o Authentication information from Shibboleth, OpenAthens and
EZproxy o All sources of authentication information with usage information from
COUNTER • An OpenAPI so other software can access Raptor statistics • Live reporting from suitably enable sources e.g. using a socket appender in
Log4J for the Shibboleth IdP.

30
6. Conclusions In this deliverable we documented the reporting options of the Raptor project. Firstly we identified the raw information and statistics that serve as input to the Raptor collection framework. Next, we overviewed existing tools and protocols for harvesting usage information. This was followed by a survey of existing reporting frameworks, which reported on general usage information through to FAM specific usage information. Finally, we concluded on each section, suggesting aspects of existing protocols and tools that would fit within the Raptor reporting framework.
References
[1] A. Luotonen, The Common Logfile Format, 1995, available in 2010 at http://www.w3.org/Daemon/User/Config/Logging.html
[2] Adam Chandler and Tim Jewel, Key Issue: The Standardized Usage Statistics Harvesting Initiative (SUSHI), Serials, 2006, 19:1, 68-70.
[3] David Orrell, OpenAthens roadmap to 2011, presentation, available in 2010 at http://www.slideshare.net/eduserv/openathens-roadmap-to-2011
[4] Jewell, Tim, et al. Electronic Resource Management: Report of the DLF ERM Initiative. (2004). Digital Library Federation. Retrieved 2010.
[5] Patrik Schnellmann and Andre Redard, SWITCH, The Swiss Education & Research Network, Accounting for the Authentication and Authorization Infrastructure (AAI), Pilot Study, available on January 2006, https://www.switch.ch/aai/docs/AAI_Accounting_Pilot_Study.pdf
[6] Phillip M. Hallam-Baker and Brian Behlendorf, Extended Log File Format, World Wide Web Consortium, Working Draft, March 1996, http://www.w3.org/TR/WD-logfile-960323
[7] Peter Shepherd et al., Publisher and Institutional Repository Usage Statistics, Project Report, January 2009, available at http://www.jisc.ac.uk/media/documents/programmes/pals3/pirus_finalreport.pdf
[8] Shibboleth: an Internet 2 Project. Shibboleth in Use, June 2009. Available at: http://shibboleth.internet2.edu/shib-in-use.html. Visited on: Jun. 2009

31
Appendix A -‐ Log File Parser Screenshots
Figure 1 - Sawmill

32
Figure 2 - Chainsaw
Figure 3 - Log Factor 5
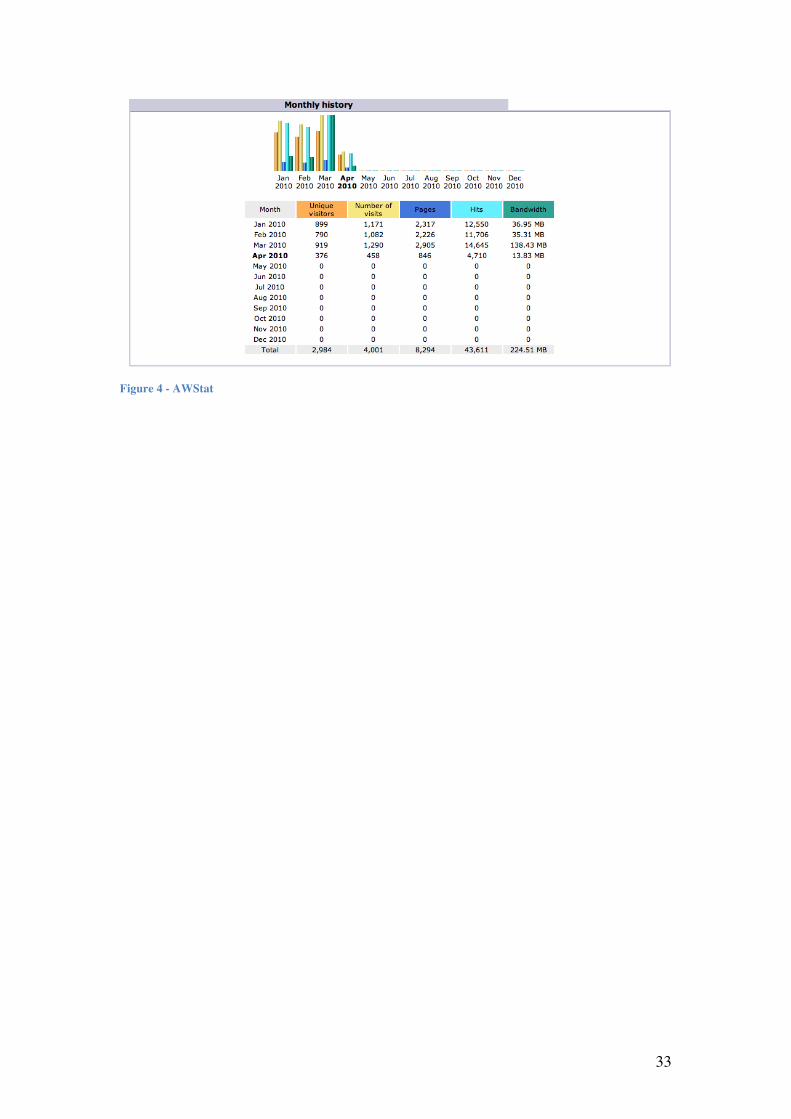
33
Figure 4 - AWStat