family tree of data – provenance and neo4j
TRANSCRIPT

M. David Allen
Family Tree of Data –Provenance and Neo4J
Graph Database Meet up, Arlington
February 10th, 2015
Approved for Public Release; Distribution Unlimited. Case Number 15-0190
The author's affiliation with The MITRE Corporation is provided for identification purposes only, and is not intended to convey or imply MITRE's concurrence with, or support for, the positions, opinions or viewpoints expressed by the author

What?! Where did
that come from?
Says who?
Information is gathered and
fused from many different
sources. Often, it’s lacking
context. How do you know
what to trust?

Intelligence Corroboration
Differentiate independent corroborating reports from multiple reports derived from a single source
– Critical in helping to differentiate between reports of 5 wounded and 5 reports of 1 wounded

Trust Assessment and Warning
Intrusion detection & security
improved assessment and warning

Producers and consumers of
information are often decoupled
(good)
The right hand has no way of
finding out what the left hand is
doing (bad)
Provenance permits taint and
marking propagation
– Add markings to reflect domain-
dependent concerns
Every information resource
becomes its own feed:
producers can keep consumers
up to date, without coupling
Objective: Trust Assessment and Warning

Mission Impact Assessment
What if something breaks? Who
is affected?
Dependencies among information assets improve mission
impact assessment and contingency planning.

Provenance Graphs
• Strong temporal element (left -> right layout)
• Rectangles denote processes or algorithms
• Circles denote data (inputs and outputs to rectangles)
• Graphs can be nested; each item may be further detailed by a separate graph

Storing Provenance in a Relational Database
8
• Previously: MySQL and PostgreSQL
• Storage structure was (simplified):
• “Provenance Object” table
• “Provenance Edge” table
• “from” property (foreign key to objects)
• “to” property (foreign key to objects)
• Discovering graph structure was a process of repeatedly
joining object table to edge table
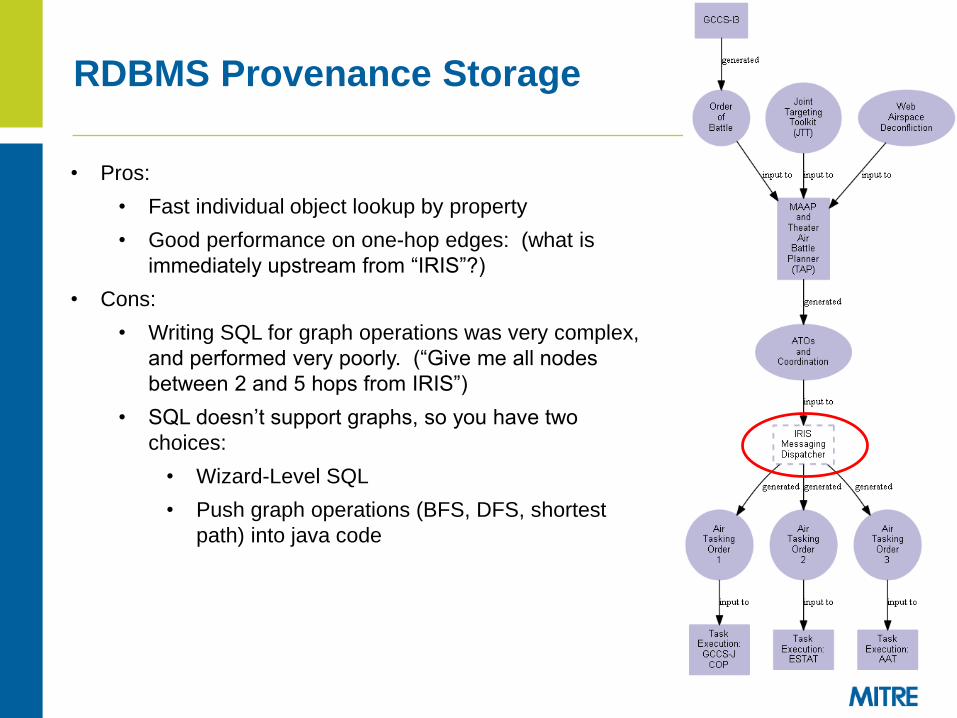
RDBMS Provenance Storage
9
• Pros:
• Fast individual object lookup by property
• Good performance on one-hop edges: (what is
immediately upstream from “IRIS”?)
• Cons:
• Writing SQL for graph operations was very complex,
and performed very poorly. (“Give me all nodes
between 2 and 5 hops from IRIS”)
• SQL doesn’t support graphs, so you have two
choices:
• Wizard-Level SQL
• Push graph operations (BFS, DFS, shortest
path) into java code

Write me a SQL query that finds all paths from node 1 to node 6, and orders the results by path length.
(Requires extra step defining views, sometimes separate T-SQL methods)
Requires re-implementing basic graph concepts (paths) in SQL
Wizard-Level SQL for Graphs: Painful and Error Prone
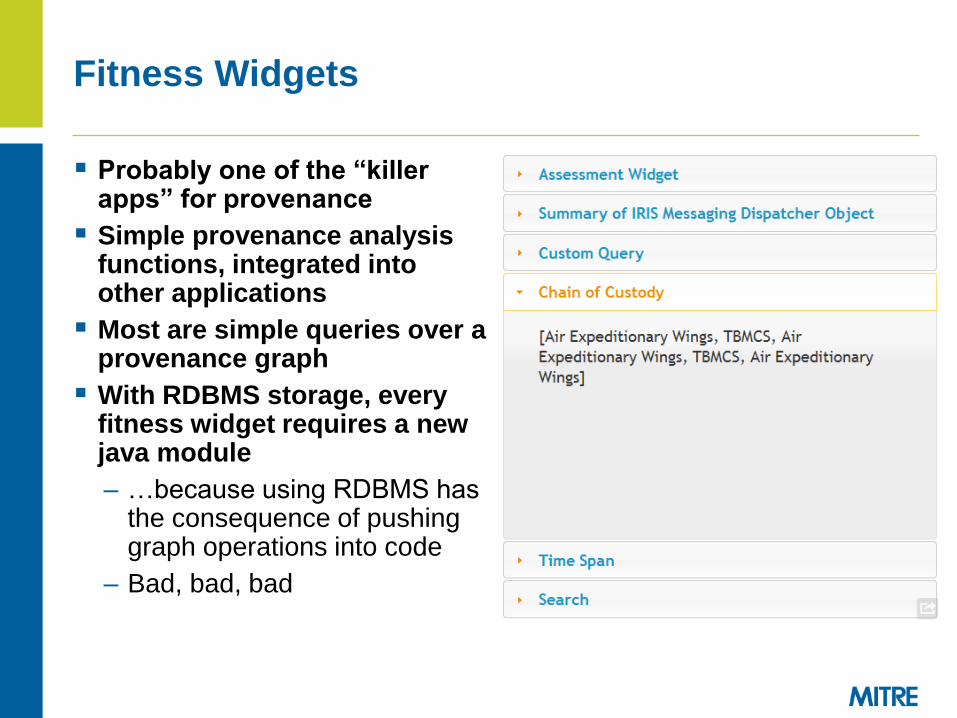
Fitness Widgets
Probably one of the “killer apps” for provenance
Simple provenance analysis functions, integrated into other applications
Most are simple queries over a provenance graph
With RDBMS storage, every fitness widget requires a new java module
– …because using RDBMS has the consequence of pushing graph operations into code
– Bad, bad, bad

An Idea
What if we used a graph database to
store and query our graphs?
(What a concept!)

Declarative graph query language, NOT imperative graph
traversal
– “Here’s what I want. Database, you figure out how to make it
happen”
Flexible schema
– Each new provenance environment has a different collection of
important metadata, and has to be tailored each time
Has to play nice with Java because enterprises trust Java
– Stodgy IT environments don’t care how cool your OCaml
implementation is, they won’t run it.
Top on the Shopping List

https://github.com/plus-provenance/plus
Clone it, “mvn jetty:run”, then hit http://localhost:8080/plus/
PLUS (MITRE’s Research Software)

Provider of “information fitness widgets” – canned analytical
queries over provenance graphs
Basic database for capture, query, reporting over provenance
API for building provenance capture agents in new
environments
Sandbox for advanced applications of provenance
Focused more on capture in distributed systems environments,
more so than “hand curated” provenance data sets
Uses of PLUS

Example Queries (for a taste)
match (n {oid: {oid}})<-[*1..5]-m
where m.type='invocation'
return m;
match (n {oid: {oid}})-[*]->m
where m.name =~ '.*COP.*'
return m;
Get all upstream invocations between 1 and 5 steps away
Does this item flow into any Common Operating Picture? (COP)

Example Queries (for a taste)
match m-[r:*]->(n {oid: {oid}})
where m.name='GCCS-I3'
return length(r);
START n=node:node_auto_index(oid={oid})
match (n {oid: {oid}})<-[r:*]-m,
owner-[r1:owns]->m
where m.type='data' and owner.name='TBMCS'
return count(distinct m);
How many hops away is GCCS-I3?
How many different data items from TBMCS contribute to this node?

What do we give up with Cypher & Neo4J?
Graph databases are said to be “naturally indexed” by
relationships
Nodes can be indexed by label and by properties, but they will
never be as performant as RDBMSs for certain kinds of bulk
queries

How to make neo4j performance look terrible (in comparison): RSS Feeds
MATCH n
WHERE n.type? = 'data' AND
n.created? > (today at midnight) AND
n.created? < (now)
RETURN n
What are the latest reported provenance items?
“Graph Fishing Expeditions” – when you’re not starting from anywhere.
“Bulk Scans” – generic queries that don’t apply to any particular label or index
subset.
“The Table Anti-Pattern” – link everything by ID instead of relationship

How to Think in Graphs: Get all relationships in a workflow
A B C
workflow
instanceinstance
instance
A B C
Workflow
id=1
Node/Table Orientation
relationship
wf=1
relationship
wf=1
Graph Orientation
START r=relationship(*)
WHERE r.workflow = 'SOME WORKFLOW ID'
RETURN r
MATCH (wf:Workflow {oid: ‘foo’})
->[r:instance]->node,
node-[pr:generated|`input to`]->m
RETURN pr
SLOWER(and requires special index on “id” property)
FASTER

Some other Observations on Graph Databases: Good and Bad
Partitioning and sharding graphs is very difficult, and still subject to some research
– Other graph DBs out there (e.g. Apache Giraph) somewhat hide this problem, or make other compromises to get around it (“Bulk Synchronous Parallel” algorithms)
Neo4J presently scales to billions of nodes per machine, and can traverse thousands of relationships very quickly
Much more natural mapping from OO class hierarchies into graph databases than to RDBMS (object/table impedance mismatch)
Graph performance tuning is new thing to most operations people and sysadmins;
– Everybody knows how to make Oracle fly, graph skills are much less common
– Can make for perception problems, compounded by poor graph design (e.g. “table orientation”, designing a graph like it’s a table)

Contact Information
M. David Allen
The MITRE Corporation
Office: (804) 288-0355
The author's affiliation with The MITRE Corporation is provided for identification purposes only, and is
not intended to convey or imply MITRE's concurrence with, or support for, the positions, opinions or
viewpoints expressed by the author

Backups and Additional Materials

PLUS Provenance Service
Provenance Manager
PLUS
Users &
Applications
Administrators
Provenance Store
PLUS
Applications &
Capture Agents
ReportAnnotateRetrieve
Administer
(access control,
archiving, etc.)
API (provenance-aware
applications)
Coordination points for
automatic provenance
capture

Architectural Options for Provenance Capture
“Smart Applications”
– Strategy: Each application calls lineage API to log whatever it
thinks is important
– But, unrealistic for legacy applications
“Interceptors”
– Strategy: Listen in to whatever is happening, and log silently as it
happens
– Requires a small number of points of lineage capture: ESBs are
ideal, since they act as central “routers”
“Wrappers”
– Strategy: Write a transparent wrapper service. Make sure all
orchestrations call the wrapper service with enough information
for the wrapper to invoke the real thing