fast querying indexing for performance (4)
TRANSCRIPT

Fast Querying:Indexing Strategies to Optimize
Performance
Muthu ChinnasamySenior Solutions Architect

Agenda
• Introduction
• What is fast Querying?
• Index Types & Properties
• Index Intersection
• Index Monitoring
• New in MongoDB 3.0

Introduction

MongoDB's unique architecture
• MongoDB uniquely brings the best features of both RDBMS and NoSQL
RDBMS
Strong consistency
Secondary indexes
Rich query language
No SQL
Flexibility
Scalability
Performance

When to use an index?
• Indexes are the single biggest tunable performance factor for an application
• Use for frequently accessed queries• Use when low latency response time needed

How different are indexes in MongoDB?
Compared to NoSQL stores, MongoDB indexes are•Native in the database and not maintained by developers in their code•Strongly consistent - Atomically updated with the data as part of the same write operation

What is Fast Querying?

The query
Question: Find the zip codes in New York city with population more than 100,000. Sort the results by population in descending order
Query: db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}}).sort({pop:-1})
Output:{"zip" : "10021", "city" : "NEW YORK", "pop" : 106564, "state" : "NY" }
{"zip" : "10025", "city" : "NEW YORK", "pop" : 100027, "state" : "NY" }

No Index – Collection Scan
Observations: "cursor" : "BasicCursor"
"n" : 2
"nscannedObjects" : 29470
"nscanned" : 29470
"scanAndOrder" : true
"millis" : 12
29470 documents scanned!29470 documents scanned!

Index on a single field
Create Index:
db.zips.ensureIndex({state:1})
Observations: "cursor" : "BtreeCursor state_1"
"n" : 2
"nscannedObjects" : 1596
"nscanned" : 1596
"scanAndOrder" : true
"millis" : 3
Better. Only 1596 documents scanned for the same result!
Better. Only 1596 documents scanned for the same result!

Compound Index on two fields
Create Index:
db.zips.ensureIndex({state:1, city:1})
Observations: "cursor" : "BtreeCursor state_1_city_1"
"n" : 2
"nscannedObjects" : 40
"nscanned" : 40
"scanAndOrder" : true
"millis" : 0
Much better. Only 40 documents scanned for the same result!
Much better. Only 40 documents scanned for the same result!

Compound Index on three fields
Create Index:
db.zips.ensureIndex({state:1, city:1, pop:1})
Observations: "cursor" : "BtreeCursor state_1_city_1_pop_1 reverse"
"n" : 2
"nscannedObjects" : 2
"nscanned" : 2
"scanAndOrder" : false
"millis" : 0
2 documents scanned for the same result. This is fast querying folks!
2 documents scanned for the same result. This is fast querying folks!

Types of Indexes

Types of Indexes

Be sure to remove unneeded indexes
Drop Indexes:
db.zips.dropIndex({state:1, city:1})
db.zips.dropIndex({state:1})
Why drop those indexes?–Not used by mongo for given queries–Consume space–Affect write operations

• Reduce data sent back to the client over the network• Use the projection clause with a 1 to enable and 0 to disable
– Return specified fields only in a query– Return all but excluded fields– Use $, $elemMatch, or $slice operators to project array fields
Use projection
// exclude _id and include item & qty fields> db.inventory.find( { type: 'food' }, { item: 1, qty: 1, _id:0 } )
// project all fields except the type field> db.inventory.find( { type: 'food' }, { type:0 } )
// project the first two elements of the ratings array & the _id field> db.inventory.find( { _id: 5 }, { ratings: { $slice: 2 } } )

• Returns data from an index only– Not accessing the collection in a query– Performance optimization – Works with compound indexes– Invoke with a projection
Covered (Index only) Queries
> db.users.ensureIndex( { user : 1, password :1 } )
> db.user.find({ user: ”Muthu” }, { _id:0, password:1 } )
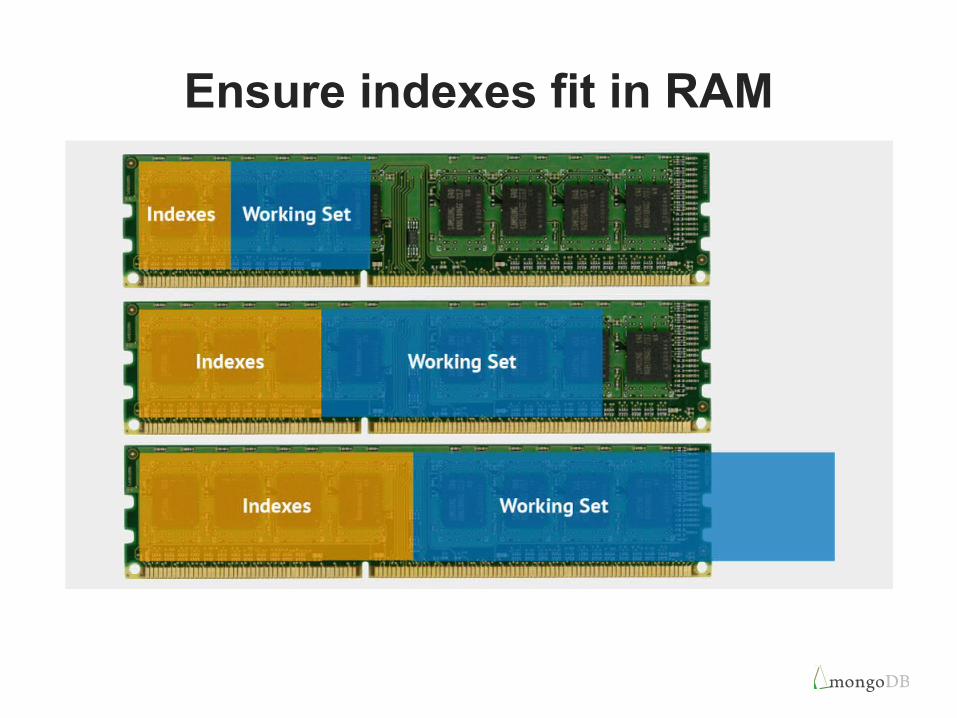
Ensure indexes fit in RAM

Index Types & Properties

Indexing Basics
// Create index on author (ascending)>db.articles.ensureIndex( { author : 1 } )
// Create index on author (descending)>db.articles.ensureIndex( { author : -1 } )
// Create index on arrays of values on the "tags" field – multi key index.>db.articles.ensureIndex( { tags : 1 } )

• Index on sub-documents
– Using dot notation
Sub-document indexes
{‘_id’ : ObjectId(..),
‘article_id’ : ObjectId(..), ‘section’ : ‘schema’,
‘date’ : ISODate(..),‘daily’: { ‘views’ : 45,
‘comments’ : 150 } ‘hours’ : { 0 : { ‘views’ : 10 }, 1 : { ‘views’ : 2 }, … 23 : { ‘views’ : 14,
‘comments’ : 10 } }}
>db.interactions.ensureIndex(
{ “daily.comments” : 1}
}
>db.interactions.find(
{“daily.comments” : { "$gte" : 150} })

• Indexes defined on multiple fields
Compound indexes
//To view via the console> db.articles.ensureIndex( { author : 1, tags : 1 } )
> db.articles.find( { author : Muthu C’, tags : ‘MongoDB’} )//and> db.articles.find( { author : Muthu C’ } )
// you don’t need a separate single field index on "author"> db.articles.ensureIndex( { author : 1 } )

• Sort doesn’t matter on single field indexes– We can read from either side of the btree
• { attribute: 1 } or { attribute: -1 }• Sort order matters on compound indexes
– We’ll want to query on author and sort by date in the application
Sort order
// index on author ascending but date descending
>db.articles.ensureIndex( { ‘author’ : 1, ‘date’ -1 } )

Options
• Uniqueness constraints (unique, dropDups)
• Sparse Indexes
// index on author must be unique. Reject duplicates
>db.articles.ensureIndex( { ‘author’ : 1}, { unique : true } )
// allow multiple documents to not have likes field
>db.articles.ensureIndex( { ‘author’ : 1, ‘likes’ : 1}, { sparse: true } )
* Missing fields are stored as null(s) in the index

Background Index Builds
• Index creation is a blocking operation that can take a long time
• Background creation yields to other operations
• Build more than one index in background concurrently
• Restart secondaries in standalone to build index
// To build in the background> db.articles.ensureIndex(
{ ‘author’ : 1, ‘date’ -1 }, {background : true}
)

Other Index Types
• Geospatial Indexes (2d Sphere)
• Text Indexes
• TTL Collections (expireAfterSeconds)
• Hashed Indexes for sharding

• Indexes on geospatial fields
– Using GeoJSON objects– Geometries on spheres
Geospatial Index - 2dSphere
//GeoJSON object structure for indexing{ name: ’MongoDB Palo Alto’, location: { type : “Point”,
coordinates: [ 37.449157 , -122.158574 ] }}
// Index on GeoJSON objects>db.articles.ensureIndex( { location: “2dsphere” } )
Supported GeoJSON objects:
PointLineStringPolygonMultiPointMultiLineStringMultiPolygonGeometryCollection

//Javascript function to get geolocation.navigator.geolocation.getCurrentPosition();
//You will need to translate into GeoJSON
Extended Articles document
• Store the location article was posted from….
• Geo location from browser
Articles collections>db.articles.insert({
'text': 'Article content…’, 'date' : ISODate(...), 'title' : ’Indexing MongoDB’, 'author' : ’Muthu C’, 'tags' : ['mongodb',
'database', 'geospatial’],
‘location’ : { ‘type’ : ‘Point’,
‘coordinates’ : [37.449, -122.158] }
});

– Query for locations ’near’ a particular coordinate
Geo Spatial Example
>db.articles.find( { location: { $near :
{ $geometry : { type : "Point”, coordinates : [37.449, -122.158] } },
$maxDistance : 5000 }
} )

Text Indexes
• Use text indexes to support text search of string content in documents of a collection
• Text indexes can include any field whose value is a string or an array of string elements
• Text indexes can be very large
• To perform queries that access the text index, use the $text query operator
• A collection can at most have one text index

Text Search
• Only one text index per collection
• $** operator to index all text fields in the collection
• Use weight to change importance of fields
>db.articles.ensureIndex({title: ”text”, content: ”text”}
)
>db.articles.ensureIndex( { "$**" : “text”,
name : “MyTextIndex”} )
>db.articles.ensureIndex( { "$**" : "text”}, { weights :
{ ”title" : 10, ”content" : 5}, name : ”MyTextIndex” }
)
Operators$text, $search, $language, $meta

• Use the $text and $search operators to query
• $meta for scoring results
// Search articles collection> db.articles.find ({$text: { $search: ”MongoDB" }})
> db.articles.find({ $text: { $search: "MongoDB" }}, { score: { $meta: "textScore" }, _id:0, title:1 } )
{ "title" : "Indexing MongoDB", "score" : 0.75 }
Search

Performance best practices
• MongoDB performs best when the working set fits in RAM
• When working set exceeds the RAM of a single server, consider sharding across multiple servers
• Use SSDs for write heavy applications• Use compression features of wiredTiger• Absence of values and negation does not use
index• Use covered queries that use index only

Performance best practices
• Avoid large indexed arrays• Use caution indexing low-cardinality fields• Eliminate unnecessary indexes• Remove indexes that are prefixes of other
indexes• Avoid regex that are not left anchored or rooted• Use wiredTiger feature to place indexes on a
separate, higher performance volumes

We recognize customers need help
Rapid Start Consulting Servicehttps://www.mongodb.com/products/consulting#rapid_start

Index Intersection

Index Intersection
• Consider the scenario with collection having a Compound Index {status:1, order_date: -1} & your query is
a. find({order_date:{'$gt': new Date(…)}, status: 'A'}
MongoDB should be able to use this index as the all fields of the compound index are used in the query

Index Intersection
• Consider the scenario with collection having a Compound Index {status:1, order_date: -1} & your query is
b. find({status: 'A'})
MongoDB should be able to use this index as the leading field of the compound index is used in the query

Index Intersection
• Consider the scenario with collection having a Compound Index {status:1, order_date: -1} & your query is
c. find({order_date:{'$gt': new Date(…)}} //not leading field
MongoDB will not be able to use this index as order_date in the query is not a leading field of the compound index

Index Intersection
• Consider the scenario with collection having a Compound Index {status:1, order_date: -1} & your query is
d. find( {} ).sort({order_date: 1}) // sort order is different
MongoDB will not be able to use this index as sort order on the order_date in the query is different than that of the compound index

Index Intersection
Index intersection should be able to resolve all four query combinations with two separate indexes
a. find({order_date:{'$gt': new Date(…)}, status: 'A'}
b. find({status: 'A'})
c. find({order_date:{'$gt': new Date(…)}} //not leading field
d. find( {} ).sort({order_date: 1}) // sort order is different
Instead of the Compound Index {status:1, order_date: -1}, you would create two single field indexes on {status:1} and {order_date: -1}

Index Intersection – How to check?
db.zips.find({state: 'CA', city: 'LOS ANGELES'})"inputStage" : {
"stage" : "AND_SORTED",
"inputStages" : [
{
"stage" : "IXSCAN",
…
"indexName" : "state_1",
…
{
"stage" : "IXSCAN",
…
"indexName" : "city_1",
…

Index monitoring

The Query Optimizer
• For each "type" of query, MongoDB periodically tries all useful indexes
• Aborts the rest as soon as one plan wins
• The winning plan is temporarily cached for each “type” of query (used for next 1,000 times)
• As of MongoDB 2.6 can use the intersection of multiple indexes to fulfill queries

• Use to evaluate operations and indexes
– Which indexes have been used.. If any.– How many documents / objects have been scanned– View via the console or via code
Explain plan
//To view via the console> db.articles.find({author:’Joe D'}).explain()

Explain() method
• What are the key metrics?– # docs returned– # index entries scanned– Index used? Which one?– Whether the query was covered?– Whether in-memory sort performed?– How long did the query take in millisec?

Explain plan output (no index)
{"cursor" : ”BasicCursor",…"n" : 12,"nscannedObjects" : 25820,"nscanned" : 25820,…"indexOnly" : false,…"millis" : 27,…
}
Other Types:
•BasicCursor• Full collection scan
•BtreeCursor•GeoSearchCursor•Complex Plan•TextCursor

Explain plan output (Index)
{"cursor" : "BtreeCursor author_1_date_-
1",…"n" : 12,"nscannedObjects" : 12,"nscanned" : 12,…"indexOnly" : false,…"millis" : 0,…
}
Other Types:
•BasicCursor• Full collection scan
•BtreeCursor•GeoSearchCursor•Complex Plan•TextCursor

Explain() method in 3.0
• By default .explain() gives query planner verbosity mode. To see stats use .explain("executionStats")
• Descriptive names used for some key fields{ …
"nReturned" : 2,
"executionTimeMillis" : 0,
"totalKeysExamined" : 2,
"totalDocsExamined" : 2,
"indexName" : "state_1_city_1_pop_1",
"direction" : "backward",
…
}

Explain() method in 3.0
• Fine grained query introspection into query plan and query execution – Stages
• Support for commands: Count, Group, Delete, Update
• db.collection.explain().find() – Allows for additional chaining of query modifiers– Returns a cursor to the explain result– var a = db.zips.explain().find({state: 'NY'})– a.next() to return the results

Database Profiler
• Collect actual samples from a running MongoDB instance
• Tunable for level and slowness• Can be controlled dynamically

• Enable to see slow queries
– (or all queries)– Default 100ms
Using Database profiler
// Enable database profiler on the console, 0=off 1=slow 2=all> db.setProfilingLevel(1, 50){ "was" : 0, "slowms" : 50, "ok" : 1 }
// View profile with > show profile
// See the raw data>db.system.profile.find().pretty()

New in MongoDB 3.0

Indexes on a separate storage device
$ mongod --dbpath DBPATH --storageEngine wiredTiger --wiredTigerDirectoryForIndexes
•Available only when wiredTiger configured as the storage engine•With the wiredTigerDirectoryForIndexes storage engine option
• One file per collection under DBPATH/collection• One file per index under DBPATH/index
•Allows customers to place indexes on a dedicated storage device such as SSD for higher performance

Index compression
$ mongod --dbpath DBPATH --storageEngine wiredTiger --wiredTigerIndexPrefixCompression
•Compression is on in wiredTiger by default•Indexes on disk are compressed using prefix compression•Allows indexes to be compressed in RAM

Fine grain control for DBAs
MongoDB 3.0 enhancements allow fine grain control for DBAs•wiredTiger storage engine for wide use cases•Index placement on faster storage devices•Index compression saving disk and RAM capacity•Finer compression controls for collections and indexes during creation time

Register now: mongodbworld.com
Super Early Bird Ends April 3!Use Code MuthuChinnasamy for additional 25% Off
*Come as a group of 3 or more – Save another 25%

MongoDB World is back! June 1-2 in New York.
Use code MuthuChinnasamy for 25% off!Come as a Group of 3 or More & Save Another 25%.

MongoDB can help you!MongoDB Enterprise AdvancedThe best way to run MongoDB in your data center
MongoDB Management Service (MMS)The easiest way to run MongoDB in the cloud
Production SupportIn production and under control
Development SupportLet’s get you running
ConsultingWe solve problems
TrainingGet your teams up to speed.