genome analysis and annotation part ii. the institute for genomic research tigrtigr evidence view...
Post on 20-Dec-2015
218 views
TRANSCRIPT

Genome analysis and annotationGenome analysis and annotationPart IIPart II
THE INSTITUTE FOR GENOMIC RESEARCHTHE INSTITUTE FOR GENOMIC RESEARCHTIGRTIGRTIGRTIGR
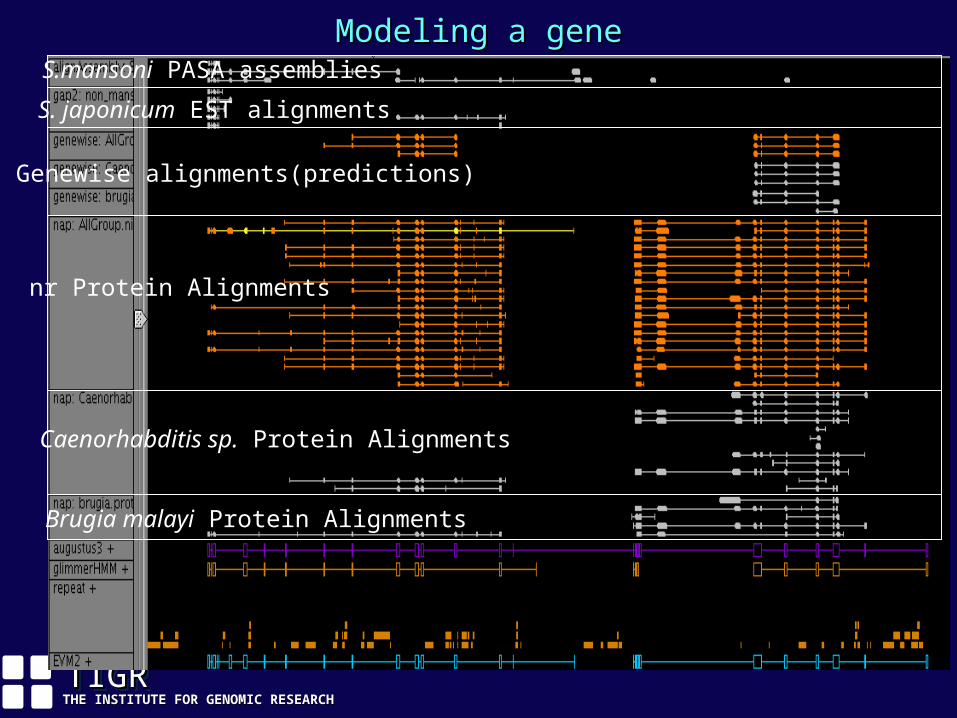
Evidence ViewEvidence ViewS.mansoni PASA assemblies
S. japonicum EST alignments
Genewise alignments(predictions)
nr Protein Alignments
Caenorhabditis sp. Protein Alignments
Brugia malayi Protein Alignments
Modeling a geneModeling a gene
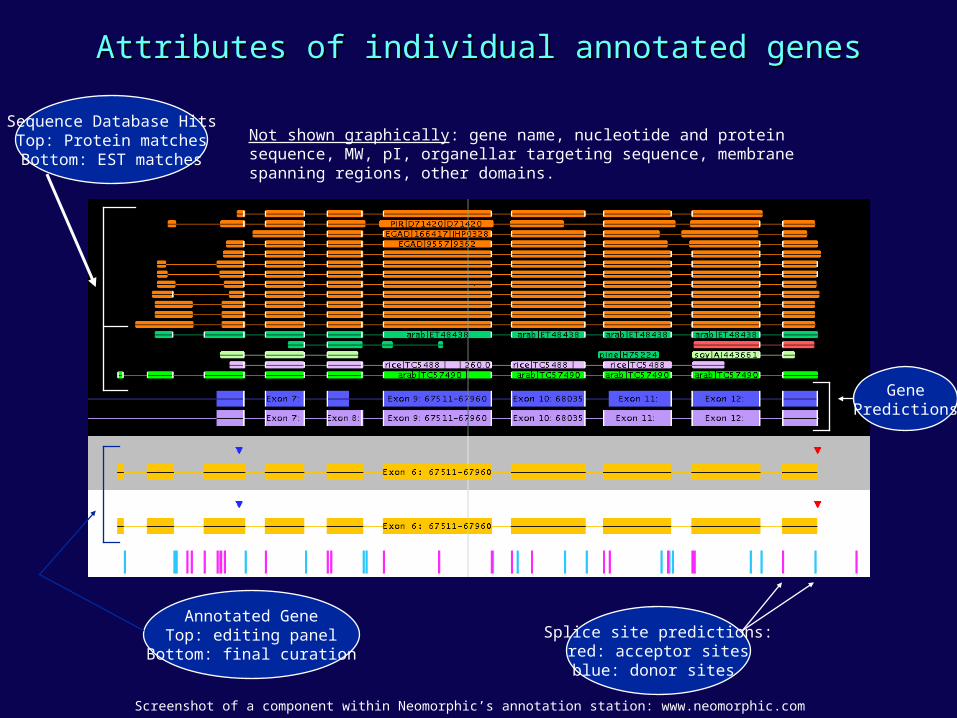
Sequence Database HitsTop: Protein matchesBottom: EST matches
GenePredictions
Annotated GeneTop: editing panel
Bottom: final curation
Splice site predictions:red: acceptor sitesblue: donor sites
Not shown graphically: gene name, nucleotide and protein sequence, MW, pI, organellar targeting sequence, membrane spanning regions, other domains.
Screenshot of a component within Neomorphic’s annotation station: www.neomorphic.com
Attributes of individual annotated genesAttributes of individual annotated genes

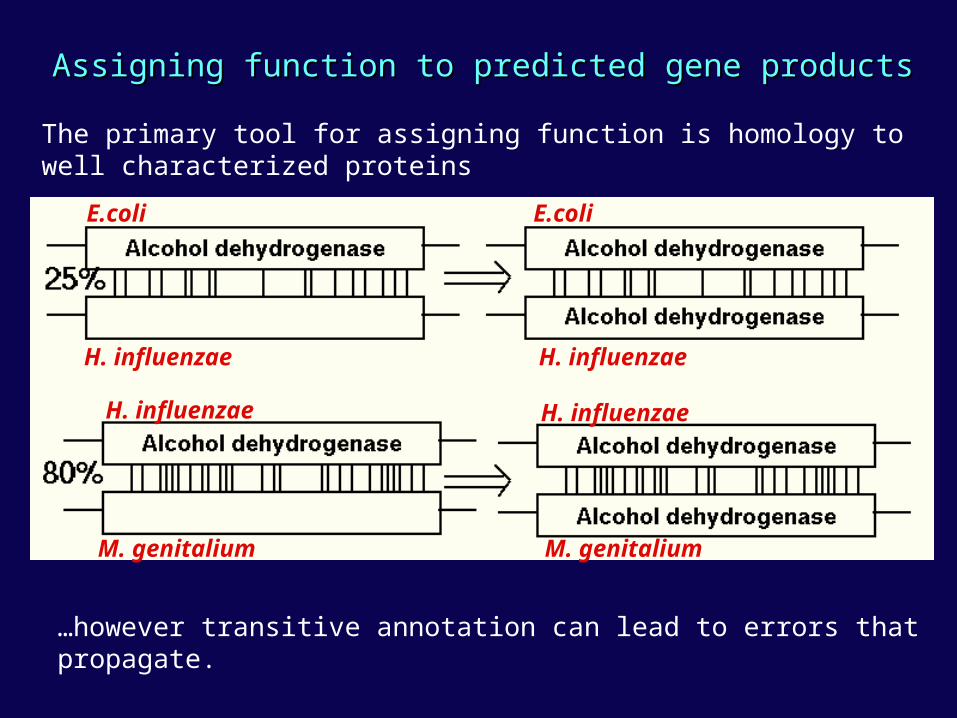
Assigning function to predicted gene productsAssigning function to predicted gene products
E.coli
H. influenzae
M. genitalium
E.coli
H. influenzae
H. influenzae
M. genitalium
H. influenzae
Assigning function to predicted gene productsAssigning function to predicted gene products
The primary tool for assigning function is homology to well characterized proteins
…however transitive annotation can lead to errors that propagate.

The modular nature of proteins can provide the basis for functional annotation
• Proteins may share features that give clues to their structure and/or function
• A domain is a region of a protein that can adopt a particular three-dimensional structure. Together a group of proteins that share a domain is called a family. There are several databases of protein families such as Pfam (http://www.sanger.ac.uk/Software/Pfam/)
• Motifs are short, conserved regions of proteins, typically consisting of a pattern of amino acids that characterizes a prrotein family (http://www.expasy.org/prosite/) EF-hand: D-[DNS]-{ILVFYW}-[DENSTG]-[DNQGHRK]-{GP}-[LIVMC]-[DENQSTAGC]-x(2)- [DE]-[LIVMFYW]
3) HMM domains can also be defined and used to group proteins into families

Top 20 PFAM domains in A. fumigatusCounts in A. nidulans and A. oryzae
PF00400 WD domain, G-beta repeat 532 598 541
PF00023 Ankyrin repeat 368 633 430
PF00083 major facilitator superfamily protein 166 281 219
PF00172 Fungal Zn(2)-Cys(6) binuclear cluster domain 146 179 211
PF00515 TPR Domain 139 142 152
PF00096 Zinc finger, C2H2 type 124 113 142
PF04082 Fungal specific transcription factor domain 110 163 159
PF00153 Mitochondrial carrier protein 106 114 100
PF00069 Protein kinase domain 105 105 101
PF00005 ABC transporter 93 129 86
PF00076 RNA recognition motif. (a.k.a. RRM, RBD, or RNP domain) 93 93 99
PF00106 oxidoreductase, short chain dehydrogenase/reductase family 92 135 129
PF00271 Helicase conserved C-terminal domain 73 80 69
PF00067 Cytochrome P450 63 134 102
PF00107 oxidoreductase, zinc-binding dehydrogenase family 61 107 80
PF00501 AMP-binding enzyme 61 77 83
PF00560 Leucine Rich Repeat 47 50 54
PF00550 Phosphopantetheine attachment site 46 54 60
PF00036 EF hand 10 52 50
Afu Ana Aoa
Protein domain frequencies can yield insights into the biology of an organism
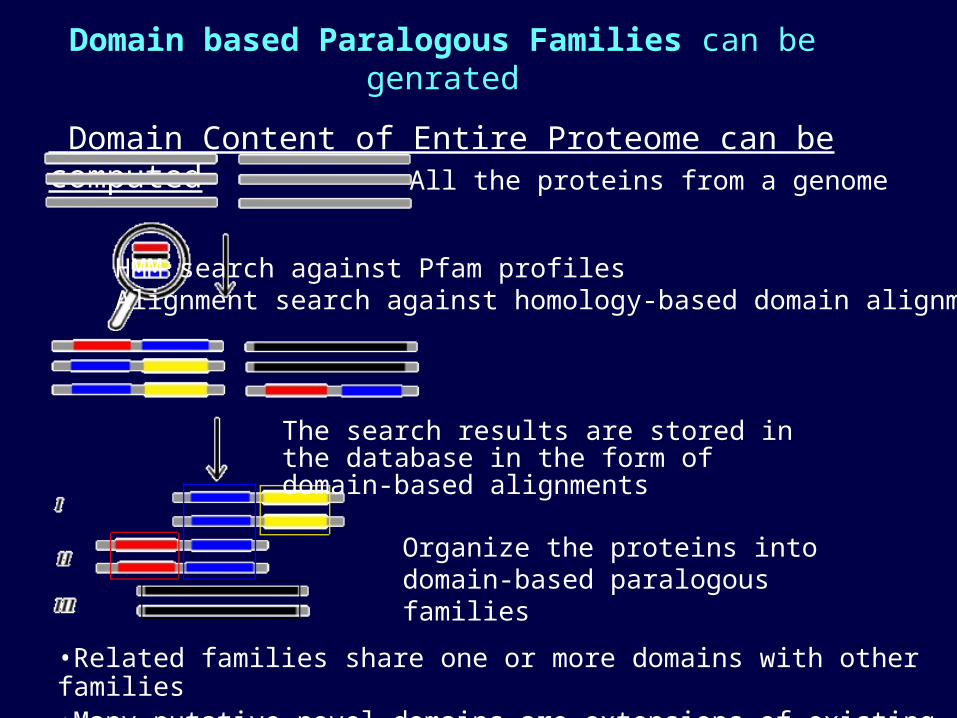
Domain based Paralogous Families can be genrated
Domain Content of Entire Proteome can be computed
All the proteins from a genome
HMM search against Pfam profiles Alignment search against homology-based domain alignments
The search results are stored in the database in the form of domain-based alignments
Organize the proteins into domain-based paralogous families
•Related families share one or more domains with other families•Many putative novel domains are extensions of existing domains
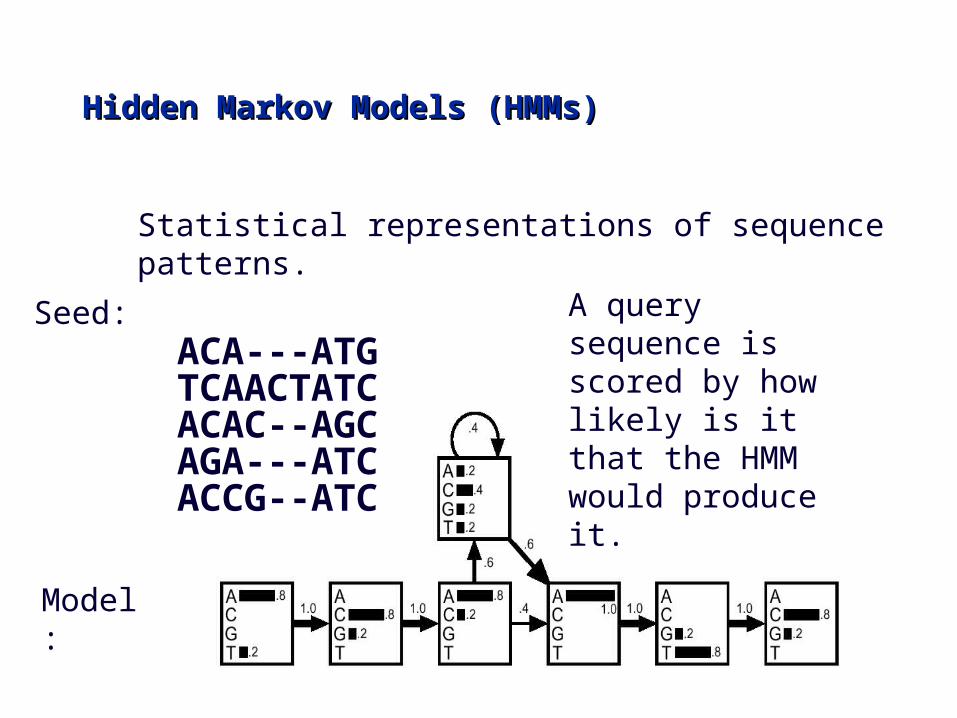
ACA---ATGTCAACTATCACAC--AGCAGA---ATCACCG--ATC
Hidden Markov Models (HMMs)Hidden Markov Models (HMMs)
Seed:
Model:
Statistical representations of sequence patterns.
A query sequence is scored by how likely is it that the HMM would produce it.

Procedure for Preparing a HMM SeedProcedure for Preparing a HMM Seed
Inspect and edit a pairwise aligned group of gene products:Inspect and edit a pairwise aligned group of gene products:
- Eliminate fragments- Eliminate fragments
- Correct the alignment- Correct the alignment
- Remove sequence outside domain- Remove sequence outside domain
- Eliminate redundancy - Eliminate redundancy
- BLAST, annotate and possibly expand the seed.- BLAST, annotate and possibly expand the seed.
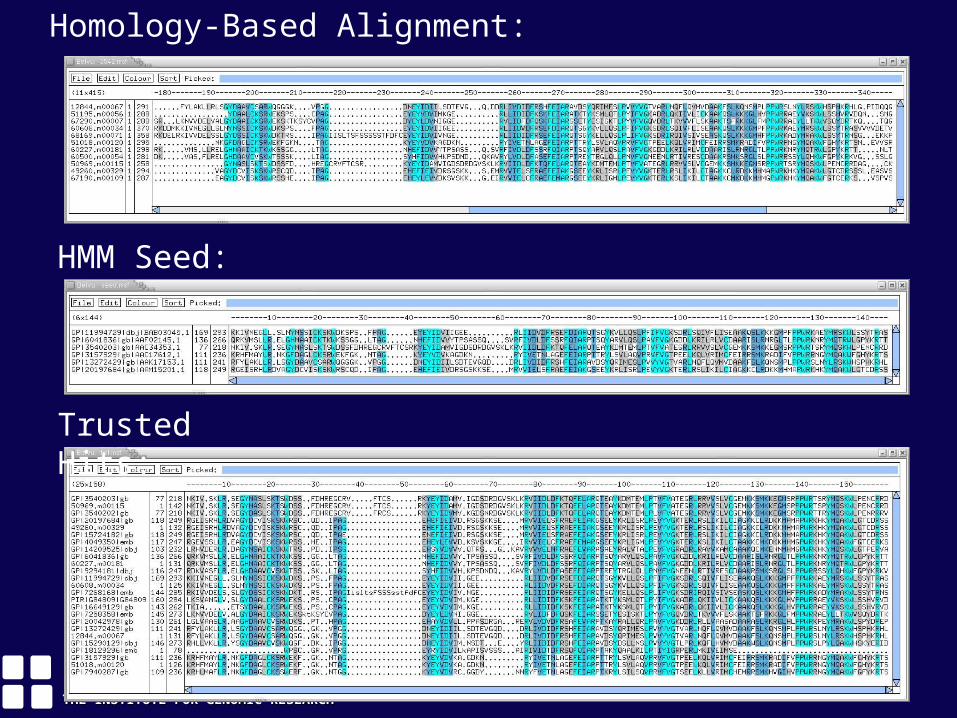
THE INSTITUTE FOR GENOMIC RESEARCHTHE INSTITUTE FOR GENOMIC RESEARCHTIGRTIGRTIGRTIGR
Homology-Based Alignment:
HMM Seed:
Trusted Hits:

What is Gene Ontology (GO)?What is Gene Ontology (GO)?
The Gene Ontology is a set of dynamic controlled vocabularies used to The Gene Ontology is a set of dynamic controlled vocabularies used to describe gene products in terms of their associated biological processes, describe gene products in terms of their associated biological processes, cellular components and molecular functions in a species-independent cellular components and molecular functions in a species-independent manner (www.geneontology.org)manner (www.geneontology.org)
The Three OntologiesThe Three Ontologies
Molecular function, biological process and cellular Molecular function, biological process and cellular component are considered attributes of gene products. component are considered attributes of gene products.
Biological Process (a)Biological Process (a)A biological objectiveA biological objectivehas more than one distinct stephas more than one distinct step
Molecular Function (b)Molecular Function (b)what the gene product does what the gene product does Think ‘activity’Think ‘activity’
Cellular Component (c)Cellular Component (c)location in the cell (or smaller unit)location in the cell (or smaller unit)or part of a complexor part of a complex
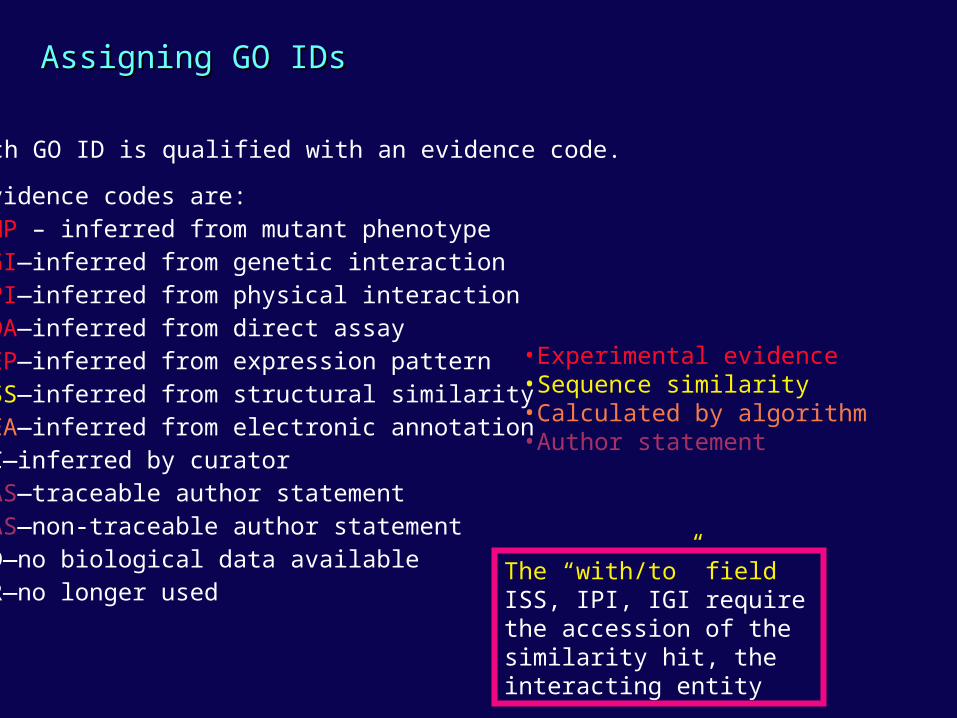
Assigning GO IDsAssigning GO IDs
Each GO ID is qualified with an evidence code.
Evidence codes are:IMP – inferred from mutant phenotypeIGI—inferred from genetic interactionIPI—inferred from physical interactionIDA—inferred from direct assayIEP—inferred from expression patternISS—inferred from structural similarityIEA—inferred from electronic annotationIC—inferred by curatorTAS—traceable author statementNAS—non-traceable author statementND—no biological data available NR—no longer used
•Experimental evidence•Sequence similarity•Calculated by algorithm•Author statement
The “with/to” fieldISS, IPI, IGI require the accession of the similarity hit, the interacting entity
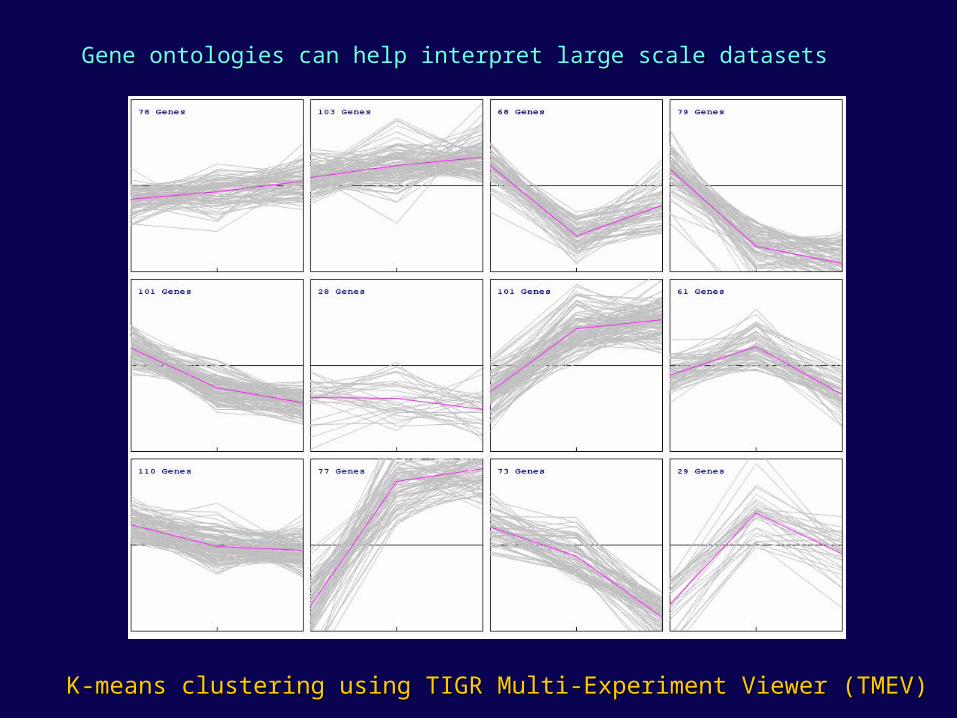
Gene ontologies can help interpret large scale datasetsGene ontologies can help interpret large scale datasets
K-means clustering using TIGR Multi-Experiment Viewer (TMEV)K-means clustering using TIGR Multi-Experiment Viewer (TMEV)

Cluster 4Cluster 4
Cluster 10Cluster 10
methanogenesis
methanogenesis
Translation, transcription
Translation, transcription