getting started with hpc on iceberg - university of...
TRANSCRIPT

Getting Started with HPCGetting Started with HPCGetting Started with HPCGetting Started with HPCOn IcebergOn IcebergOn IcebergOn Iceberg
Michael Griffiths and Deniz SavasMichael Griffiths and Deniz SavasMichael Griffiths and Deniz SavasMichael Griffiths and Deniz Savas
Corporate Information and Computing ServicesCorporate Information and Computing ServicesCorporate Information and Computing ServicesCorporate Information and Computing ServicesThe University of SheffieldThe University of SheffieldThe University of SheffieldThe University of Sheffield
2012201220122012
www.sheffield.ac.uk/wrgridwww.sheffield.ac.uk/wrgridwww.sheffield.ac.uk/wrgridwww.sheffield.ac.uk/wrgrid

• Review of hardware and software
• Accessing
• Managing Jobs
• Building Applications
• Resources
• Getting Help
Outline

•Cluster Grid•Computing clusters ( e.g. iceberg )
•Enterprise Grid, Campus Grid, Intra-Grid
•Departmental clusters, servers and PC network
•Cloud, Utility Grid•Access resources over internet on demand
•Global Grid, Inter-grid•White Rose Grid, National Grid Service, Particle Physics Data Grid
Types of Grids

Iceberg Cluster
HEAD NODE1
Iceberg(1)
HEAD NODE2
Iceberg(2)
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
Worker node
There are 232 worker machines
in the cluster
There are two head-nodes for the iceberg cluster
loginloginlogin
qsh,qsub,qrshqsh,qsub,qrsh
All workers share the same user filestore

iceberg cluster specificationsiceberg cluster specifications
AMD-based nodes containing;
• 96 nodes each with 4 cores and 16 GB of memory
• 31 nodes each with 8 cores and 32 GB of memory
• TOTAL AMD CORES = 632, TOTAL MEMORY = 2528 GBThe 8-core nodes are connected to each other via 16 GBits/sec infiniband for MPI jobsThe 4-core nodes are connected via the much slower "1 Gbits/sec" ethernet connections for MPI jobs. Scratch space on each node is 400 GBytes
Intel Westmere based nodes all infiniband connected, containing;
• 103 nodes each with 12 cores and 24 GB of memory ( i.e. 2 * 6-core Intel X5650 )
• 4 nodes each with 12 cores and 48 GB of memory
• 8 Nvidia Tesla Fermi M2070s GPU units for GPU programming
• TOTAL INTEL CPU CORES = 1152 , TOTAL MEMORY = 2400 GBScratch space on each node is 400 GBTotal GPU memory = 48 GBEach GPU unit is capable of about 1TFlop of single precision floating point performance, or 0.5TFlops at double precision. Hence yielding maximum GPU processing power of upto8 TFlops in total.

Accessing iceberg
Getting an account
All staff and research students are entitled to use iceberg
For Registration See:http://www.shef.ac.uk/wrgrid/register
Staff can have an account by simply emailing [email protected]

Access iceberg
Remote logging in
Terminal access is described at: http://www.shef.ac.uk/wrgrid/using/access
Recommended access is via any browser at: www.shef.ac.uk/wrgridThis uses Sun Global Desktop ( All platforms, Graphics-capable)
Also possible:• Using an X-Windows client ( MS Windows, Graphics-capable)
– Exceed 3D
– Cygwin
• Various ssh clients (MS Windows, Terminal-only )– putty, SSH
Note: ssh clients can also be used in combination with Exceed or Cygwin to enable graphics capability. Above web page describes how this can be achieved.

Access icebergfrom MAC or Linux platforms
• The web browser method of access ( as for Windows platforms) also works on these platforms.
• More customary and efficient method of access is by using the ssh command from a command-shell.Example: ssh –X [email protected]
Note1: -X parameter is needed to make sure that you can use the graphics or gui capabilities of the software on iceberg.Note2: Depending on the configuration of your workstation you may also have to issue the command : xhost + before the sshcommand.
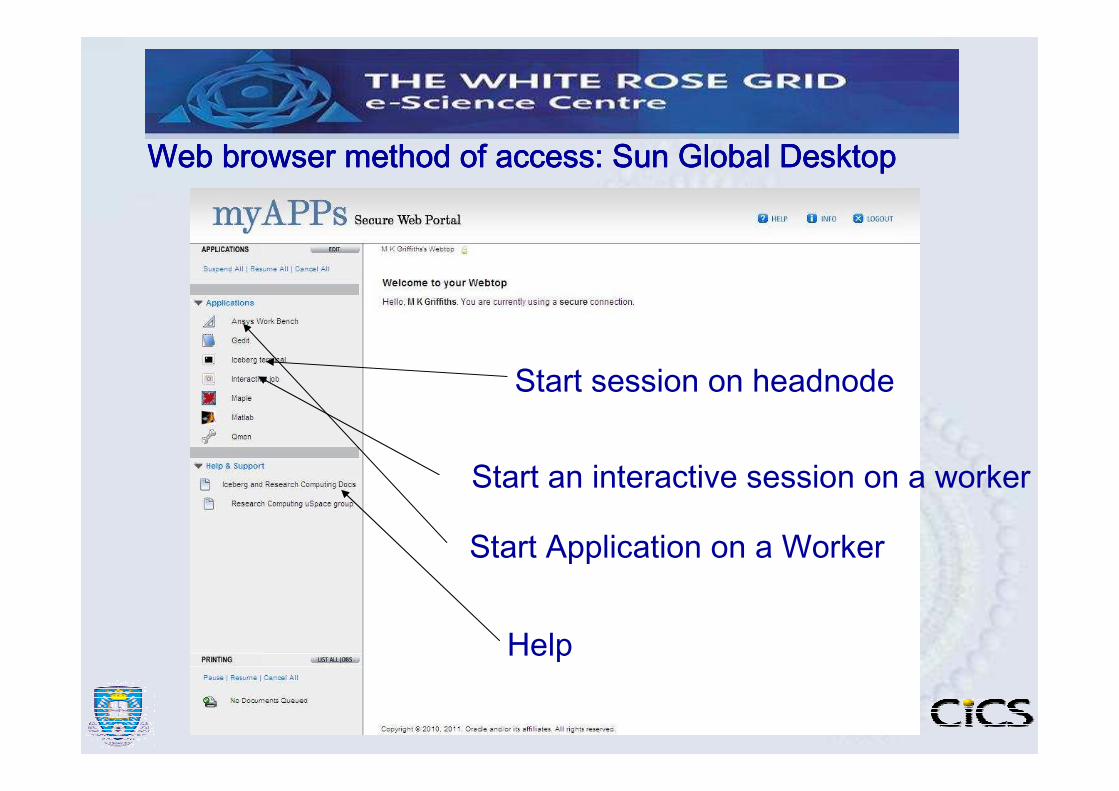
Start session on headnode
Start an interactive session on a worker
Help
Start Application on a Worker
Web browser method of access: Sun Global Desktop Web browser method of access: Sun Global Desktop Web browser method of access: Sun Global Desktop Web browser method of access: Sun Global Desktop

Transferring files to/from iceberg
Summary of file transfer methods as well as links to downloadable tools for file transfers to iceberg are published at:http://www.sheffield.ac.uk/wrgrid/using/access
• Command line tools such as scp, sftp and gftp are available on most platforms.
• Can not use ftp ( non-secure ) to iceberg.
• Graphical tools that transfer files by dragging and dropping files between windows are availablewinscp, coreftp, filezilla, cyberduck

Pitfalls when transferring files
• ftp is not allowed to by iceberg. Only sftp is accepted.
• Do not use spaces ‘ ’ in filenames. Linux do not like it.
• Secure file transfer programs ‘sftp’ classify all files to be transferred as either ASCII_TEXT or BINARY.
• All SFTP clients attempt to detect the type of a file automatically before a transfer starts but also provide advanced options to manually declare the type of the file to be transferred.
• Wrong classification can cause problems particularly when transfers take place between different operating systems such as between Linux and Windows.
• If you are transferring ASCII_TEXT files to/from windows/Linux, to check that transfers worked correctly while on iceberg, type;cat –v journal_file
If you see a ^M at the end of each line you are in trouble !!!
CURE: dos2unix wrong_file on iceberg

Working with files
To copy a file: cp my_file my_new_fileTo move ( or rename ) a file : mv my_file my_new_fileTo delete a file : rm my_fileTo list the contents of a file : less file_name
To make a new directory( i.e. folder) : mkdir new_directory
To copy a file into another directory: cp my_file other_directoryTo move a file into another directory: mv my_file other_directoryTo copy a directory to another location: cp –R directory other_directory
To remove a directory and all its contents!!!: rm –R directory( use with care )
Wildcards : * means matching any sequence of characters.For example: cp *.dat my_directory

Your filestore• Three areas of filestore always available on iceberg
• These areas are available from all headnode and worker nodes.
1. home directory:
• /home/username
• 5 GBytes allocations
• Permanent, secure, backed up area ( deleted files can be recovered )
2. data directory
• /data/username
• 50 GBytes of ollocation
• Not backed but mirrored on another server
3. /fastdata area
• /fastdata
• Much faster access from MPI jobs
• No storage limits but no backup, or mirroring
• Files older than 90 days gets deleted automatically
• Always make a directory under /fastdata and work there.

Scratch area ( only available during a job)
• Located at /scratch
• Used as temporary data storage on the current compute node alone.
• File I/O to /scratch is faster than to NFS mounted /home and /data areas
• File I/O to small files is faster than to /fastdata but …
for large files /fastdata is faster than /scratch
• Data not visible to other worker nodes and expected to exist only during the duration of the job.
HOW TO USE SCRATCH:
• Create a directory using your username under /scratch on a worker and work from that directory
Example: mkdir /scratch/$USER
cp mydata /scratch/$USER
cd /scratch/$USER
( then run your program )

Storage allocations
• Storage allocations for each area are as follows:– On /home 5 GBytes
– On /data 50 GBytes
– No limits on /fastdata
• Check your usage and allocation often to avoid exceeding the quota by typing quota
• If you exceed your quota, you get frozen and the only way out of it is by reducing your filestorage usage by deleting unwanted files via the RM command ( note this is in CAPITALS ).
• Requesting more storage:Email [email protected] to request for more storage.
• Excepting the /scratch areas on worker nodes, the view of the filestore is the same on every worker.

Running tasks on iceberg
• Two iceberg headnodes are gateways to the cluster of worker nodes.
• Headnodes’ main purpose is to allow access to the worker nodes but NOT to run cpu intensive programs.
• All cpu intensive computations must be performed on the worker nodes. This is achieved by;– qsh command for interactive jobs and
– qsub command for batch jobs.
• Once you log into iceberg, taking advantage of the power of a worker-node for interactive work is done simply by typing qsh and working in the new shell window that is opened. The next set of slides assume that you are already working on one of the worker nodes (qsh session).

Where on the cluster ?
• Most of the application packages, compilers and software libraries are only available on the worker_nodes.
• Iceberg headnodes are suitable for only light-weight jobs such as editing files.
• If you are on one of the headnodes, you will need to type qshto get an interactive session to the worker nodes.
• How do you know where you are ? The command prompt will contain your userid@hostnameExample: ch1abc@node-056 $– If you are on one of the headnodes, hostname will be iceberg1 or
iceberg2– If you are on an amd-based worker-node, it will be amd-nodenn
where nn is the number of the amd-node. – If you are on an intel-based worker-node it will be node-nnn
where nnn is the number of the intel node. You can always type echo $HOSTNAME to find out the name of the machine you are currently using.

Software stack on the worker nodes
AMD Opteron/Intel
Westmere
Redhat 64bit Scientific
Linux
Portland, GNU,Intel
OpenMPI
Sun Grid Engine v6
Ganglia

Operating system and utilities
• Linux Operating System version is-
Scientific Linux, which is RedHat Enterprise 5 based
• Default Shell is- bash
• Available editors-Graphical Editors:
– gedit ( not available on headnode)
– emacs
– nedit
Text editors:
– vi
– pico ( not available on headnode)
– nano

Login Environment
• Default shell is bash ( you can request to change your default shell ).
• On login into iceberg many environment variables are setup automatically to provide a consistent interface and access to software.
• Each user has a .bashrc file in their directory to help setup the user environment.
• Type set to get a list of all the environment variables.
• Change all variables that are in CAPITALS with extreme care.
• Modify/enhance your environment by adding commands to the end of your .bashrc file , such as alias commands. (Again do this with care! )

Application packages• Following application packages are available on the worker
nodes via the name of the package.
– maple , xmaple
– matlab
– R
– abaquscae
– abaqus
– ansys
– fluent
– fidap
– dyna
– idl
– comsol
– paraview

Keeping up-to-date with application packages
From time to time the application packages get updated. When this happens;– news articles inform us of the changes via iceberg news. To
read the news- type news on iceberg or check the URL: http://www.wrgrid.group.shef.ac.uk/icebergdocs/news.dat
– The previous versions or the new test versions of software are normally accessed via the version number. For example;
abaqus69 , nagexample23 , matlab2011a

Running application packages in batch queues
icberg have locally provided commands for running some of the popular applications in batch mode. These are;
runfluent , runansys , runmatlab , runabaqus
To find out more just type the name of the command on its own while on iceberg.

Setting up your software development environment
• Excepting the scratch areas on worker nodes, the view of the filestore is identical on every worker.
• You can setup your software environment for each job by means of the module commands.
• All the available software environments can be listed by using the module avail command.
• Having discovered what software is available on iceberg, you can then select the ones you wish to use by using-
module add or module load commands• You can load as many non-clashing modules as you need by
consecutive module add commands.• You can use the module list command to check the list of
currently loaded modules.

Software development environment
• Compilers– PGI compilers
– Intel Compilers
– GNU compilers
• Libraries– NAG Fortran libraries ( MK22 , MK23 )
– NAG C libraries ( MK 8 )
• Parallel programming related– OpenMP
– MPI ( OpenMPI , mpich2 , mvapich )

Managing Your Jobs Sun Grid Engine Overview
SGE is the resource management system, job scheduling and batch
control system. (Others available such as PBS, Torque/Maui, Platform LSF )
• Starts up interactive jobs on available workers
• Schedules all batch orientated ‘i.e. non-interactive’ jobs
• Attempts to create a fair-share environment
• Optimizes resource utilization

Job scheduling on the cluster
SGE workernode
SGE workernode
SGE workernode
SGE workernode
SGE workernode
SGE MASTER node
Queue-A Queue-B Queue-C
AS
lot 1
A S
lot 2
B S
lot 1
C S
lot 1
C S
lot 2
C S
lot 3
B S
lot 1
B S
lot 2
B S
lot 3
B S
lot1
C S
lot1
C S
lot 2
A S
lot 1
B S
lot 1
C S
lot 1
�Queues
�Policies
�Priorities
�Share/Tickets
�Resources
�Users/Projects
JOB Y JOB ZJOB X
JOB U
JOB OJOB N

Job scheduling on the cluster
SGE workernode
SGE workernode
SGE workernode
SGE workernode
SGE workernode
SGE MASTER node
Queue-A Queue-B Queue-C
Slot 1
Slot 2
Slot 3
Slot 1
Slot 2
Slot 3
Slot 1
Slot 2
Slot 3
Slot 1
Slot 2
Slot 3
Slot 1
Slot 2
Slot 3
�Queues
�Policies
�Priorities
�Share/Tickets
�Resources
�Users/Projects
JOB X

Submitting your job
There are two SGE commands submitting jobs;– qsh or qrsh : To start an interactive job
– qsub : To submit a batch job
There are also a list of home produced commands for submitting some of the popular applications to the batch system. They all make use of the qsub command.
These are;
runfluent , runansys , runmatlab , runabaqus
These 4 commands make submitting batch jobs on iceberg for these standard applications much easier than getting to grips with the SGE commands.

Managing Jobsmonitoring and controlling your jobs
• There are a number of commands for querying and modifying the status of a job running or waiting to run. These are;– qstat or Qstat (query job status)
– qdel (delete a job)
– qmon ( a GUI interface for SGE )

Running Jobs Example: Submitting a serial batch job
Use editor to create a job script in a file (e.g. example.sh):#!/bin/bash# Scalar benchmark echo ‘This code is running on’ `hostname`date./linpack
Submit the job:
qsub example.sh

Running Jobsqsub and qsh options
-l h_rt=hh:mm:ss The wall clock time. This parameter must be specified, failure to include this parameter will result in the error message: “Error: no suitable queues”. Current default is 8 hours .
-l arch=intel*-l arch=amd*
Force SGE to select either Intel or AMD architecture nodes. No need to use this parameter unless the code has p rocessor dependency .
-l mem=memory sets the virtual-memory limit e.g. –l mem=10G(for parallel jobs this is per processor and not total).
Current default if not specified is 6 GB .
-l rmem=memory Sets the limit of real-memory required
Current default is 2 GB.Note: rmem parameter must always be less than mem .
-help Prints a list of options
-pe ompigige np-pe openmpi-ib np-pe openmp np
Specifies the parallel environment to be used. np is the number of processors required for the parallel job.

Running Jobs
qsub and qsh options ( continued)
-N jobname By default a job’s name is constructed from the job-script-file-name and the job-id that is allocated to the job by SGE.
This options defines the jobname. Make sure it is unique because the job output files are constructed from the jobna me.
-o output_file Output is directed to a named file. Make sure not to overwrite important files by accident.
-j y Join the standard output and standard error output streams recommended
-m [bea]-M email-address
Sends emails about the progress of the job to the specified email address. If used, both –m and –M must be specified. Select any or all of the b,e and a to imply emailing when the job begins , endsor aborts .
-P project_name Runs a job using the specified projects allocation of resources.
-S shell Use the specified shell to interpret the script rather than the default bash shell. Use with care.
A better option is to specify the shell in the first line of the job script. E.g. #!/bin/bash
-V Export all environment variables currently in effect to the job.

Running Jobsbatch job example
qsub example:
qsub –l h_rt=10:00:00 –o myoutputfile –j y myjob
OR alternatively … the first few lines of the submit script myjobcontains -
$!/bin/bash$# -l h_rt=10:00:00 $# -o myoutputfile$# -j y
and you simply type; qsub myjob

Running JobsInteractive jobs
qsh , qrsh
• These two commands, find a free worker-node and start an interactive session for you on that worker-node.
• This ensures good response as the worker node will be dedicated to your job.
• The only difference between qsh and qrsh is that ;qsh starts a session in a new command window where asqrsh uses the existing window. Therefore, if your terminal connection does not support graphics( i.e. XWindows) than qrsh will continue to work where as qshwill fail to start.

Running JobsA note on interactive jobs
• Software that requires intensive computing should be run on the worker nodes and not the head node.
• You should run compute intensive interactive jobs on the worker nodes by using the qsh or qrsh command.
• Maximum ( and also default) time limit for interactive jobs is 8 hours.

Managing JobsMonitoring your jobs by qstat or Qstat
Most of the time you will be interested only in the progress of your own jobs thro’ the system.
• Qstat command gives a list of all your jobs ‘interactive & batch’ that
are known to the job scheduler. As you are in direct control of your interactive jobs, this command is useful mainly to find out about your batch jobs ( i.e. qsub’ed jobs).
• qstat command ‘note lower-case q’ gives a list of all the executing
and waiting jobs by everyone.
• Having obtained the job-id of your job by using Qstat, you can get further information about a particular job by typing ;
qstat –f -j job_idYou may find that the information produced by this command is far more than you care for, in that case the following command can be used to find out about memory usage for example;
qstat –f -job_id | grep usage

Managing Jobsqstat example output
State can be: r=running , qw=waiting in the queue, E=error state. t=transfering’just before starting to run’ h=hold waiting for other jobs to finish.
job-ID prior name user state submit/start at queue slots ja-task-ID -------------------------------------------------------------------------------------------------------------------------------------------------
206951 0.51000 INTERACTIV bo1mrl r 07/05/2005 09:30:20 [email protected] 1 206933 0.51000 do_batch4 pc1mdh r 07/04/2005 16:28:20 [email protected]. 1 206700 0.51000 l100-100.m mb1nam r 07/04/2005 13:30:14 [email protected]. 1 206698 0.51000 l50-100.ma mb1nam r 07/04/2005 13:29:44 [email protected]. 1 206697 0.51000 l24-200.ma mb1nam r 07/04/2005 13:29:29 [email protected]. 1 206943 0.51000 do_batch1 pc1mdh r 07/04/2005 17:49:45 [email protected]. 1 206701 0.51000 l100-200.m mb1nam r 07/04/2005 13:30:44 [email protected]. 1 206705 0.51000 l100-100sp mb1nam r 07/04/2005 13:42:07 [email protected]. 1 206699 0.51000 l50-200.ma mb1nam r 07/04/2005 13:29:59 [email protected]. 1 206632 0.56764 job_optim2 mep02wsw r 07/03/2005 22:55:30 [email protected] 18 206600 0.61000 mrbayes.sh bo1nsh qw 07/02/2005 11:22:19 [email protected] 24 206911 0.51918 fluent cpp02cg qw 07/04/2005 14:19:06 [email protected] 4

Managing JobsDeleting/cancelling jobs
qdel command can be used to cancel running jobs or remove from the queue the waiting jobs.
• To cancel an individual Job;qdel job_id
Example: qdel 123456
• To cancel a list of jobs
qdel job_id1 , job_id2 , so on …
• To cancel all jobs belonging to a given username
qdel –u username

Managing Jobs
Job output files
• When a job is queued it is allocated a unique jobid (an integer ).
• Once the job starts to run normal output is sent to the output (.o) file and the error o/p is sent to the error (.e) file.
– The default output file name is: <script>.o<jobid>
– The default error o/p filename is: <script>.e<jobid>
• If -N parameter to qsub is specified the respective output files become <name>.o<jobid> and <name>.e<jobid>
• –o or –e parameters can be used to define the output files to use.
• -j y parameter forces the job to send both error and normal output into the same (output) file (RECOMMENDED )

Monitoring the job output files
• The following is an example of submitting a SGE job and checking the output produced
qsub myjob.sh
job <123456> submitted
qstat –f –j 123456 (is the job running ?)
When the job starts to run, type ;
tail –f myjob.sh.o123456

Managing Jobs
Reasons for job failures
– SGE cannot find the binary file specified in the job script
– You ran out of file storage. It is possible to exceed your filestore allocation limits during a job that is producing large output files. Use the quota command to check this.
– Required input files are missing from the startup directory
– Environment variable is not set correctly (LM_LICENSE_FILE etc)
– Hardware failure (eg. mpi ch_p4 or ch_gm errors)

Finding out the memory requirements of a job• Virtual Memory Limits:
– Default virtual memory limits for each job is 6 GBytes– Jobs will be killed if virtual memory used by the job exceeds the
amount requested via the –l mem= parameter.
• Real Memory Limits:– Default real memory allocation is 2 GBytes– Real memory resource can be requested by using –l rmem=– Jobs exceeding the real memory allocation will not be deleted but
will run with reduced efficiency and the user will be emailed about the memory deficiency.
– When you get warnings of that kind, increase the real memory allocation for your job by using the –l rmem= parameter.
– rmem must always be less than memDetermining the virtual memory requirements for a job;
– qstat –f –j jobid | grep mem– The reported figures will indicate
- the currently used memory ( vmem )- Maximum memory needed since startup ( maxvmem)- cumulative memory_usage*seconds ( mem )
– When you run the job next you need to use the reported value of vmem to specify the memory requirement

Managing JobsRunning arrays of jobs
• Add the –t parameter to the qsub command or script file (with #$ at beginning of the line)– Example: –t 1-10
• This will create 10 tasks from one job
• Each task will have its environment variable $SGE_TASK_ID set to a single unique value ranging from 1 to 10.
• There is no guarantee that task number m will start before task number n , where m<n .

Managing Jobs Running cpu-parallel jobs
• Parallel environment needed for a job can be specified by the: -pe <env> nn parameter of qsub command, where <env> is..– openmp : These are shared memory OpenMP jobs and therefore
must run on a single node using its multiple processors.
– ompigige : OpenMPI library- Gigabit Ethernet. These are MPI jobs running on multiple hosts using the ethernet fabric ( 1Gbit/sec)
– openmpi-ib : OpenMPI library-Infiniband. These are MPI jobs running on multiple hosts using the Infiniband Connection ( 32GBits/sec )
– mvapich2-ib : Mvapich-library-Infiniband. As above but using the MVAPICH MPI library.
• Compilers that support MPI. – PGI – Intel– GNU

Setting up the parallel environment in the job script.
• Having selected the parallel environment to use via the qsub –pe parameter, the job script can define a corresponding environment/compiler combination to be used for MPI tasks.
• MODULE commands help setup the correct compiler and MPI transport environment combination needed.
List of currently available MPI modules are;mpi/pgi/openmpi mpi/pgi/mvapich2mpi/intel/openmpi mpi/intel/mvapich2mpi/gcc/openmpi mpi/gcc/mvapich2
• For GPU programming with CUDA libs/cuda
• Example: module load mpi/pgi/openmpi

Summary of module load parameters for parallel MPI environments
TRANSPORTqsub parameter -------------------------COMPILER to use
-pe openmpi-ib-pe ompigige
-pe mvapich2-ib
PGI mpi/pgi/openmpi mpi/pgi/mvapich2
Intel mpi/intel/openmpi mpi/intel/mvapich2
GNU mpi/gcc/openmpi mpi/gcc/mvapich2

Running GPU parallel jobs
GPU parallel processing is supported on 8 Nvidia Tesla Fermi M2070s GPU units attached to iceberg.
• In order to use the GPU hardware you will need to join the GPU project by emailing [email protected]
• You can then submit jobs that use the GPU facilities by using the following three parameters to the qsub command;-P gpu
-l arch=intel*
-l gpu=nn
where 1<= nn <= 8 is the number of gpu-modules to be used by the job.
P stands for project that you belong to. See next slide.

Special projects and resource management
• Bulk of the iceberg cluster is shared equally amongst the users.I.e. each user has the same privileges for running jobs as another user.
• However, there are extra nodes connected to the iceberg cluster that are owned by individual research groups.
• It is possible for new research project groups to purchase theirown compute nodes/clusters and make it part of the iceberg cluster.
• We define such groups as special project groups in SGE parlance and give priority to their jobs on the machines that they have purchased.
• This scheme allows such research groups to use iceberg as ordinary users “with equal share to other users” or to use their privileges ( via the –P parameter) to run jobs on their own part of the cluster without having to compete with other users.
• This way, everybody benefits as the machines currently unused bya project group can be utilised to run normal users’ short jobs.

Job queues on iceberg
Queue name Time Limit (Hours)
System specification
short.q 8
long.q 168 Long running serial jobs
parallel.q 168 Jobs requiring multiple nodes
openmp.q 168 Shared memory jobs using openmp
gpu.q 168 Jobs using the gpu units

Tutorials
On iceberg copy the contents of the tutorial directory to your user area into a directory named sge:
cp –r /usr/local/courses/sge sge
cd sge
In this directory the file readme.txt contains all the instructions necessary to perform the exercises.

Checkpointing Jobs
• Simplest method for checkpointing– Ensure that applications save configurations at regular
intervals so that jobs may be restarted (if necessary) using these configuration files.
• Using the BLCR checkpointing environment– BLCR commands
– Using BLCR checkpoint with an SGE job

Checkpointing jobsUsing BLCR
• BLCR commands relating to checkpointing.cr_run , cr_checkpoint , cr_restart
• Set an environment variable to avoid an errorexport LIBCR_DISABLE_NSCD=1
• Start running the code under the control of the check_pointsystem
cr_run myexecutable [parameters]• Find out it’s process_id (PID)
ps | grep myexecutable
• Checkpoint it and write the state into a filecr_checkpoint -f checkpoint.file PID
If and when my executable fails/crashes runs out of time etc. it can now be restarted from the checkpoint file you specified.
cr_restart checkpoint.file

Using BLCR checkpoint with an SGE Job
• A checkpoint environment has been setup called BLCR - it's accessible using the test cstest.q queue.
• An example of a checkpointing job would look something like:##$ -l h_cpu=168:00:00#$ -q cstest.q#$ -c hh:mm:ss
• #$ -ckpt blcrcr_run ./executable >> output.file
• The -c hh:mm:ss options tells SGE to checkpoint over the specified time interval .
• The -c sx options tells SGE to checkpoint if the queue is suspended, or if the execution daemon is killed.

Building ApplicationsOverview
• The operating system on iceberg provides full facilities for,– scientific code development,
– compilation and execution of programs.
• The development environment includes, – debugging tools provided by the Portland test suite,
– the eclipse IDE.

Compilers
• PGI, GNU and Intel C and Fortran Compilers are installed on iceberg.
• PGI ( Portland Group) compilers are readily available to use as soon as you log into a worker node.
• A suitable module command is necessary to access the Intel or GNU compilers.
• The following modules relating to compilers are available to use with the module add ( or module load) command:
compilers/pgi
compilers/intel
compilers/gcc
• Java compiler and the phyton development environment can also be made available by using the following modules respectively;
apps/java
apps/phyton

Building ApplicationsCompilers
• C and Fortran programs may be compiled using the GNU or Portland Group. The invoking of these compilers is summarized in the following table:
gfortran
g77
g++
gcc
GNU Compilers
Language PGI Compiler
Intel Compiler
C Pggcc icc
C++ pgCC icpc
FORTRAN 77 pg77 ifort
FORTRAN 90/95 pgf90 ifort

Building Applications Compilers
• All of these commands take the filename containing the source to be compiled as one argument followed by a list of optional parameters.
• Example:
pgcc myhelloworld.c –o hello
• The filetype {suffix} usually determines how the syntax of the source file will be treated. For example myprogram.f will be treated as a fixed format (FTN77 style) source where as myprogram.f90 will be assumed to be free format ( Fortran90 style) by the compiler.
• Most compilers have a --help or –help switch that lists the available compiler options.
• -V parameter lists the version number of the compiler you are using.

Help and documentation on compilers
• As well as the –help or --help parameters of the compiler commands there are man ( manual ) pages available for these compilers on iceberg. For example; man pgcc , man icc , man gcc
• Full documentation provided with the PGI and Intel compilers are accessible via your browser from any platform via the page:
http://www.shef.ac.uk/wrgrid/software/compilers

Building ApplicationsA few Compiler Options
Option Effect
-c Compile Compile, do not link.
-o exefile Specifies a name for the resulting executable.
-g Produce debugging information (no optimization).
-Mbounds Check arrays for out of bounds access.
-fast Full optimisation with function unrolling and code reordering.

Building Applications Compiler Options
Option Effect
-Mvect=sse2 Turn on streaming SIMD extensions (SSE) and SSE2 instructions. SSE2 instructions operate on 64 bit floating point data.
-Mvect=prefetch Generate prefetch instructions.
-tp k8-64 -tp k8-64 Specify target processor type to be opteron processor running 64 bit system.
-g77 libs Link time option allowing object files generated by g77 to be linked into programs (n.b. may cause problems with parallel libraries).

Building Applications Sequential Fortran
• Assuming that the Fortran program source code is contained in the file mycode.f90, to compile using the Portland group compiler type:pgf90 mycode.f90
• In this case the code will be output into the file a.out. To run this code issue:./a.out
at the UNIX prompt.
• To add some optimization, when using the Portland group compiler, the –fast flag may be used. Also –o may be used to specify the name of the compiled executable, i.e.:
pgf90 –o mycode –fast mycode.f90
• The resultant executable will have the name mycode and will have been optimized by the compiler.

Building Applications Sequential C
• Assuming that the program source code is contained in the file mycode.c,
• to compile using the Portland C compiler, type:pgcc –o mycode mycode.c
• In this case, the executable will be output into the file mycode which can be run by typing its name at the command prompt:./mycode

Memory Issues
• Programs requiring larger than 2Gigabytes of memory for its data ( i.e. using very large arrays etc. ) may get into difficulties due to addressing issues when pointers can not hold the values of these large addresses.
• It is also advisable that variables that store and use the arrayindices have sufficient number of bytes allocated to them. For example, it is not wise to use short_int (C) or integer*2 (Fortran) for variables holding array indices. Such variables must be re-declared as long_int or integer*4 .
To avoid such problems;
• when using the PGI compilers use the option;
–mcmodel=medium
• when using the Intel compilers use the option;
–mcmodel=medium –shared-intel

Setting other resource limitsulimit
• ulimit provides control over available resources for processes– ulimit –a report all available resource limits
– ulimit –s XXXXX set maximum stacksize
• Sometimes necessary to set the hardlimit e.g.– ulimit –sH XXXXXX

Building Applications 8: Debugging
• The Portland group debugger is a – symbolic debugger for Fortran, C, C++ programs.
• Allows the control of program execution using– breakpoints,
– single stepping and
• enables the state of a program to be checked by examination of– variables
– and memory locations.

Building Applications 9: Debugging
• PGDBG debugger is invoked using– the pgdbg command as follows:
– pgdbg arguments program arg1 arg2.. Argn
– arguments may be any of the pgdbg command line arguments.
– program is the name of the traget program being debugged,
– arg1, arg2,... argn are the arguments to the program.
• To get help from pgdbg use:pgdbg -help

Building Applications 10: Debugging
• PGDBG GUI– invoked by default using the command pgdbg.
– Note that in order to use the debugging tools applications must be compiled with the -g switch thus enabling the generation of symbolic debugger information.

Building Applications 11: Profiling
• PGPROF profiler enables – the profiling of single process, multi process MPI or SMP
OpenMP, or
– programs compiled with the -Mconcur option.
• The generated profiling information enables the identification of portions of the application that will benefit most from performance tuning.
• Profiling generally involves three stages: – compilation
– exection
– analysis (using the profiler)

Building Applications 12: Profiling• To use profiling in is necessary to compile your program with
the following options indicated in the table below:
Option Effect
-Mprof=func Insert calls to produce function level pgrpofoutput.
-Mprof=lines Insert calls to produce line level pgprofoutput.
-Mprof=mpi. Link in mpi profile library that intercepts MPI calls to record message sizes and count message sends and receives. e.g. -Mprof=mpi,func.
-pg Enable sample based profiling.

Building Applications 13: Profiling
• The PG profiler is executed using the command pgprof [options] [datafile]
– Datafile is a pgprof.out file generated from the program execution.

Shared Memory applicationsusing OpenMP
• Fortran and C programs containing OpenMP compiler directives can be compiled to take advantage of parallel processing on iceberg.
• OpenMP model of programming uses a thread-model whereby a number of instances “threads” of a program run simultaneously, when necessary communicating with each other via the memory that is shared by all threads.
• Although any given processor can run multiple threads of the same program via the operating system’s multi-tasking ability, it is more efficient to allocate one thread per processor in a shared memory machine.
• On Iceberg we have the following types of compute nodes;
2 dual-core (= 2*2 = 4 processors) AMD nodes2 quad-core (= 2*4= 8 processor) AMD nodes2 six-core (=2*6 =12 processor ) Intel nodes
Therefore it is usually advisable to restrict OpenMP jobs to about 12 threads when using iceberg.

Shared Memory ApplicationsCompiling OpenMP applications
Source code that contains $OMP pragmas for parallel programming can be compiled using the following flags:– PGI C, C++, Fortran77 or Fortran90
pgf77 , pgf90, pgcc or pgCC -mp [other options] filename - Intel C/C++, Fortran
ifort , icc or icpc –openmp [other options] filename- Gnu C/C++, Fortran
gcc or gfortran –fopenmp [other options] filename
Note that source code compilation does not require working within a job using the openmp environment. Only the execution of an OpenMPparallel executable will necessitate such an environment that has been requested by the use of the –pe openmp flag to qsub or qshcommands.

Shared Memory ApplicationsSpecifying Required Number of Threads
• The number of parallel execution threads at execution time is controlled by setting the environment variable OMP_NUM_THREADS to the appropriate value.
• for the bash or sh shell (which is the default shell on iceberg) use -
export OMP_NUM_THREADS=6
• If you are using the csh or tcsh shell, use -
setenv OMP_NUM_THREADS=6

Shared Memory Applications Starting an OpenMP interactive job
• Short interactive jobs that use OpenMP parallel programming are allowed. Although upto 48 way parallel jobs can theoretically be run such way, due to the high utilisation of the cluster we recommend that you do not exceed 12-way jobs. Here is an example of starting a 12-way interactive job:
qsh -pe openmp 12 or
qrsh -pe openmp 12And in the new shell that starts type:
export OMP_NUM_THREADS=12Alternatively, effect of these two commands can be achieved via the –v
parameter: E.g. qsh –pe openmp 12 –v OMP_NUM_THREADS=12Number of threads to use can later be redefined in the same job to
experiment with hyper-threading for example.
• Important Note: although the number of processors required is specified with the -pe option, it is still necessary to ensure that the OMP_NUM_THREADS environment variable is set to the correct value.

Shared Memory ApplicationsSubmitting an OpenMP Job to Sun Grid Engine
• The job is submitted to a special parallel environment that ensures the job ocupies the required number of slots.
• Using the SGE command qsub the openmp parallel environment is requested using the -pe option as follows;
qsub -pe openmp 12 -v OMP_NUM_THREADS=12 myjobfile.sh
• The following job script, job.sh is submitted using, qsub job.shWhere job.sh is,
#!/bin/bash#$ -cwd#$ -pe openmp 12#$ -v OMP_NUM_THREADS=12
./executable

Parallel Programming with MPI Introduction
• Iceberg is designed with the aim of running MPI (message passing interface ) parallel jobs,
• the sun grid engine is able to handle MPI jobs.
• In a message passing parallel program each process executes the same binary code but,– executes a different path through the code
– this is SPMD (single program multiple data) execution.
• Iceberg uses– openmpi-ib and mvapich2-ib implementation provide by
infiniband (quadrics/connectX), using IB fast interconnect at 32GigaBits/second.

MPI Tutorials
From an iceberg worker, execute the following command:
tar –zxvf /usr/local/courses/intrompi.tgz
The directory which has been created contains some sample MPI applications which you may compile and run.

Set The Correct Environment for MPI
• iceberg cluster supports a variety of MPI environments. A parallel environment can be considered to be composed of threedistinct component, namely;
– Communications hardware: Gigabit-Ethernet or Infiniband
– MPI library : mvapich , mvapich2 , openmpi
– Supporting compiler: PGI , Intel
All supported combinations of these MPI components are made available via the module command.
• On iceberg type module avail to get a list of supported MPI environments.
• Having discovered what is supported you may then use the module loadcommand to make it available. For example:module load mpi/pgi/openmpi will allow use of MPI using the PGI compilers and OpenMPI library on ethernet and infiniband.

Parallel Programming with MPI 2: Hello MPI World!
#include <mpi.h> #include <stdio.h>
int main(int argc,char *argv[]){
int rank; /* my rank in MPI_COMM_WORLD */int size; /* size of MPI_COMM_WORLD */
/* Always initialise mpi by this call before using any mpi functions. */MPI_Init(& argc , & argv);
/* Find out how many processors are taking part in the computations. */MPI_Comm_size(MPI_COMM_WORLD, &size);
/* Get the rank of the current process */ MPI_Comm_rank(MPI_COMM_WORLD, & rank);if (rank == 0)printf("Hello MPI world from C!\n");
printf("There are %d processes in my world, and I have rank %d\n",size, rank);MPI_Finalize();}

Parallel Programming with MPI Output from Hello MPI World!
• When run on 4 processors the MPI Hello World program produces the following output,
Hello MPI world from C!
There are 4 processes in my world, and I have rank 2 There are 4 processes in my world, and I have rank 0 There are 4 processes in my world, and I have rank 3 There are 4 processes in my world, and I have rank 1

Parallel Programming with MPI Compiling MPI Applications Using Infiniband
• To compile C, C++, Fortran77 or Fortran90 MPI code using the portland compiler, type,
mpif77 [compiler options] filename
mpif90 [compiler options] filename
mpicc [compiler options] filename
mpiCC [compiler options] filename

Parallel Programming with MPI Sun Grid Engine MPI Job Script
• The following job script (job.sh) which runs a 16-way MPI job is submitted using,
qsub job.sh
job.sh is the job script file containing the following lines:
#!/bin/bash#$ -pe openmpi-ib 16module load mpi/pgi/openmpimpirun -np 16 ./mpiexecutable

Parallel Programming with MPI 10: Pros and Cons.
• The downside to message passing codes is that they are harder to write than scalar or shared memory codes.
– The system bus on a modern cpu can pass in excess of 4Gbits/sec between the memory and cpu.
– A fast ethernet between PC's may only pass up to 200Mbits/sec between machines over a single ethernet cable and
• this can be a potential bottleneck when passing data between compute nodes.
• The solution to this problem for a high performance cluster suchas iceberg is to use a high performance network solution, such as the 16Gbit/sec interconnect provided by infiniband.
– The availability of such high performance networking makes possible a scalable parallel machine.

Supported Parallel Applications on Iceberg
• Abaqus
• Fluent
• Matlab

Getting help with HPC at Sheffield University
• Web site main page
– http://www.shef.ac.uk/wrgrid/
• Documentation
– http://www.shef.ac.uk/wrgrid/using
• Training (also uses the learning management system)
– http://www.shef.ac.uk/wrgrid/training
• Contacts
– http://www.shef.ac.uk/wrgrid/contacts.html