graph data management lab, school of computer science gdm@fudangdm@fudan put conference information...
TRANSCRIPT

Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cn
Put conference information here
By zerup
Public Opinion Mining on Micro-
blogs

2
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
What is opinion?
An opinion is a subjective belief, and is the result of emotion or interpretation of facts.
An opinion may be supported by an argument or a set of facts.
An opinion may be the result of a person's perspective, understanding, particular feelings, beliefs, and desires.
According to these features, we can make up a dictionary of subjective words to pick up opinions from micro-blogs with lots of facts.

3
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Problem Definition
Given thousands of micro-blogs on the same topic Mining the top-k most popular opinions Solution Framework
• Word partition• Using extracted keywords to calculate similarity• Clustering

4
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Why clustering? Why AP?
In information-theory, an opinion is a set of encoding symbols.
In human recognition, an opinion is made up of subjective, objective and comment.
In semantic network, for a certain topic, opinions sharing common words have similar meanings
According to the three perspectives above, we can construct a graph with every micro-blog as a data point and mutual information as edge. Then we apply a clustering algorithm to the graph to find those opinion exemplars.

5
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Basic Idea of Affinity Propagation (AP)
Data Point i & Exemplar k Responsibility: i->k noted as r(i,k) Availability: k->i noted as a(i,k)

6
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
s(i,k)
ik• For each word w in sentence i, encoding w using words in
sentence k or in the dictionary• s(i,k) is negative sum of the encoding cost
Example:• Sentence i has keywords: A B• Sentence k has keywords: A C D E• Dictionary has keywords: A B C D E F G H• s(i,k) = -(log4 + log8) = -5• s(k,i) = -(log2 + 3*log8) = -10
s(k,k) is set to input preference of k to be a exemplar

7
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
r(i,k)
i = k r(k,k) = s(k,k) – max{s(i,k’)}where
Actually, r(k,k) is fixed.

8
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
a(i,k)
i = k

9
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Result of AP
#iterations is predefined because the convergence of AP is not assured
Finally, we got a matrix M = A + R, where For each >0, we set k to be one exemplar. For , we set k to be i’s exemplar.

10
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Framework of AP
partition
keyword
input
filteredMicro-blogs
word&its property
word with real meaning
return
cluster
Number of clusterCenter&members
output
Word dict.
Semanticnetwork

11
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Preprocessing of Micro-blogs
First, we check all the Micro-blogs and find out that a lot of advertisement share a same embedding URL http://t.cn/agxZ4i. According to this, about 5000 micro-blogs are filtered out of all the total of 165000.
Second, we find that many spam micro-blogs contains lots of unrelated words(so it can occur in many topics), thus it has a lot of spaces in itself.
Third, we hope to develop a subjective word dictionary to pick up those opinion sentences.

12
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Word Partition of AP
Accuracy of Word Partition
• Tool: ICTCLAS
• Limitation: recognizing a person’s name, unsuitable
granularity
Define user’s dictionary and update it
• Store some latest network vocabulary
Which words(w.r.t their properties) are most related with
opinion/sentiment
• We pick up nouns, verbs, adjectives as meaningful keywords
Translate traditional Chinese into simple Chinese

13
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Example of AP
1. 大雾天,但是温度还好,早上起来心情还不错,连续上班11 天,终于休息啊。
2. 很奇怪到十一月的修水竟然还不冷 太阳战胜了大雾 又是个周五 心情莫名的愉悦啊。。。
3. 虽然大雾,心情尚好。4. 大雾中能见度很低,请大家小心驾驶。5. 雾很大,为了保证安全,只能将车速减到最低。6. 大雾天,减速行车,注意安全。
14
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
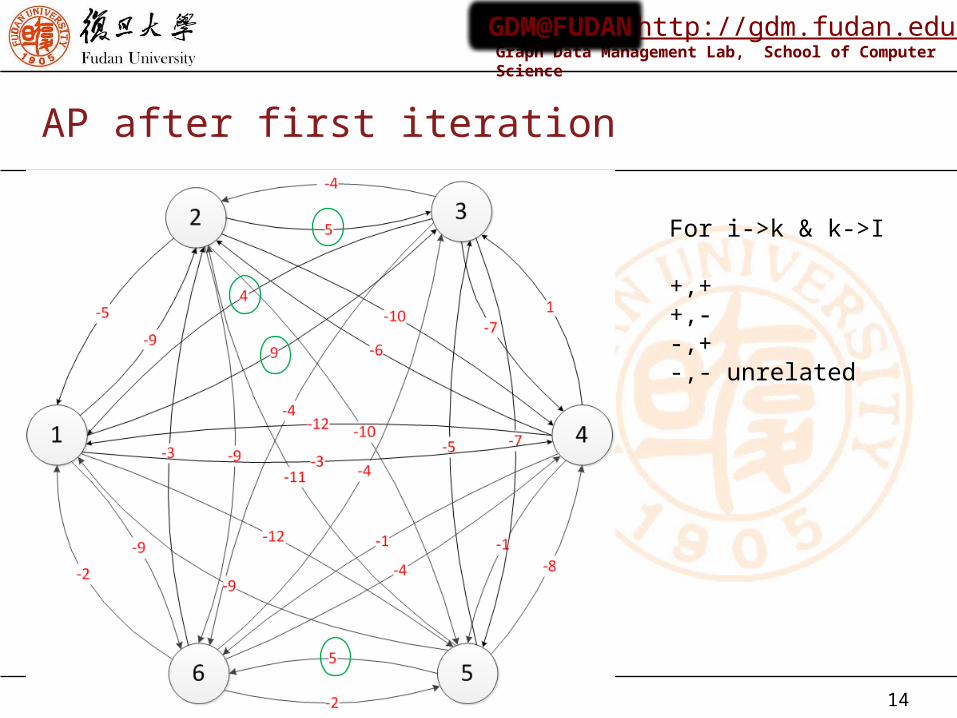
AP after first iteration
For i->k & k->I
+,+ +,- -,+ -,- unrelated

15
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Result of the Example
1. 大雾天,但是温度还好,早上起来心情还不错,连续上班11 天,终于休息啊。
2. 很奇怪到十一月的修水竟然还不冷 太阳战胜了大雾 又是个周五 心情莫名的愉悦啊。。。
3. 虽然大雾,心情尚好。4. 大雾中能见度很低,请大家小心驾驶。5. 雾很大,为了保证安全,只能将车速减到最低。6. 大雾天,减速行车,注意安全。 After three iterations, 3 and 6 become the
exemplars.

16
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Limitations of AP
it is hard to know what value of parameter 'preference' can yield an optimal clustering solution
oscillations cannot be eliminated automatically if occur
Difficult to scale up

18
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Scalability of AP
As Matrix S, A and R are stored, read and written frequently, when #micro-blogs is more than 10,000, AP is much too slow!
To scale up the AP, we have got 3 perspectives:• Sampling or Pruning to reduce #micro-blogs• Give a sketch of the matrix and store those values only
above a predefined threshold• Use a new similarity measurement and make the
similarity symmetric or sparser

19
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Sampling or Pruning
Sampling:• Randomly sample from the set of micro-blogs• Sample over the whole period those micro-blogs are sent• Sample over the social network
Pruning according to specific features of micro-blogs• Lots of comments on a micro-blog means it is a central
opinion, at least a central topic• The more a micro-blog is retweetted, the more people
approve of it• Validation of overlap btw community center and opinion
exemplar

20
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Validation of Overlap between social clusters and micro-blogs clusters
How micro-blogs clusters spread over a social network
If they overlaps a lot, clustering micro-blogs is much easier, cuz the social network is relatively fixed.
If they overlaps a little bit, then we can choose several social communities as our focus.
Check a micro-blogs cluster is coordinated or uncoordinated across the network
The validation is topic-dependent

21
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Focus on the matrix
Divide the similarity matrix into symmetric part and unsymmetric part
Only store those values bigger than a predefined threshold
Use a decomposition of matrix:• M = then we need only store two vectors a and b

22
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
A new similarity measurement
Information encoding (-log) Word Frequency (cos<x,y>)
• Tf-idf (unsuitable)• Bag-of-words
Semantic Network(a long-term work)• A big training data• A big dictionary and Jaccard Coefficient
Social Network• Based on the former validation• If overlap is frequent, we take the relationship of the
senders of two micro-blogs as a factor of similarity

23
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Conclusion
Techniques:• Word Partition• AP• Sampling
Challenges and Solutions:• Filtering spam micro-blogs => build a dict of subjective
word (2)• Word partition => build a user dictionary and improve the
accurancy of partition (4)• Similarity measurement => a semantic network (3)• Sampling and Pruning => leverage the features of social
network and micro-blogs (1)

24
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
The large-scale structure of semantic networks
Stanford, Cognitive Science graph-theoretically analyze three types of
semantic networks: word associations, WordNet, and Roget’s thesaurus
Conclusion: they have a small-world structure, characterized by sparse connectivity, short average path-lengths between words, and strong local clustering. In addition, the distributions of the number of connections follow power laws that suggest a hub structure similar to that found in other natural networks, such as the world wide web.

25
Graph Data Management Lab, School of Computer Science
GDM@FUDAN
http://gdm.fudan.edu.cnGDM@FUDAN
Basic ideas for build such a framework
because new concepts are preferentially attached to rich concepts, the distribution of the connecti-vity follows a power law
Concepts that are learned early in life should show higher connectivity.