hana sql reference manual
DESCRIPTION
HANA SQL Reference ManualTRANSCRIPT

■
■
■

SAP AG
Dietmar-Hopp-Allee 16 69190 Walldorf Germany T +49/18 05/34 34 34 F +49/18 05/34 34 20 www.sap.com
© Copyright 2011 SAP AG. All rights reserved.
No part of this publication may be reproduced or transmitted in any
form or for any purpose without the express permission of SAP AG.
The information contained herein may be changed without prior notice.
Some software products marketed by SAP AG and its distributors
contain proprietary software components of other software vendors.
© Copyright 2011 Sybase, Inc. All rights reserved. Unpublished rights
reserved under U.S. copyright laws.
Sybase, the Sybase logo, Adaptive Server, iAnywhere, Sybase 365,
SQL Anywhere and other Sybase products and services mentioned
herein as well as their respective logos are trademarks or registered
trademarks of Sybase, Inc. All other trademarks are the property of
their respective owners.
Microsoft, Windows, Excel, Outlook, and PowerPoint are registered
trademarks of Microsoft Corporation.
IBM, DB2, DB2 Universal Database, System i, System i5, System p,
System p5, System x, System z, System z10, System z9, z10, z9,
iSeries, pSeries, xSeries, zSeries, eServer, z/VM, z/OS, i5/OS, S/390,
OS/390, OS/400, AS/400, S/390 Parallel Enterprise Server, PowerVM,
Power Architecture, POWER6+, POWER6, POWER5+, POWER5,
POWER, OpenPower, PowerPC, BatchPipes, BladeCenter, System
Storage, GPFS, HACMP, RETAIN, DB2 Connect, RACF, Redbooks,
OS/2, Parallel Sysplex, MVS/ESA, AIX, Intelligent Miner, WebSphere,
Netfinity, Tivoli and Informix are trademarks or registered trademarks
of IBM Corporation.
Linux is the registered trademark of Linus Torvalds in the U.S. and
other countries.
Adobe, the Adobe logo, Acrobat, PostScript, and Reader are either
trademarks or registered trademarks of Adobe Systems Incorporated in
the United States and/or other countries.
Oracle is a registered trademark of Oracle Corporation.
UNIX, X/Open, OSF/1, and Motif are registered trademarks of the Open
Group.
Citrix, ICA, Program Neighborhood, MetaFrame, WinFrame,
VideoFrame, and MultiWin are trademarks or registered trademarks of
Citrix Systems, Inc.
HTML, XML, XHTML and W3C are trademarks or registered
trademarks of W3C®, World Wide Web Consortium, Massachusetts
Institute of Technology.
Java is a registered trademark of Sun Microsystems, Inc
JavaScript is a registered trademark of Sun Microsystems, Inc., used
under license for technology invented and implemented by Netscape.
SAP, R/3, xApps, xApp, SAP NetWeaver, Duet, PartnerEdge,
ByDesign, SAP Business ByDesign, and other SAP products and
services mentioned herein as well as their respective logos are
trademarks or registered trademarks of SAP AG in Germany and in
several other countries all over the world. All other product and service
names mentioned are the trademarks of their respective companies. Data
contained in this document serves informational purposes only. National
product specifications may vary.
These materials are subject to change without notice. These materials
are provided by SAP AG and its affiliated companies ("SAP Group")
for informational purposes only, without representation or warranty of
any kind, and SAP Group shall not be liable for errors or omissions with
respect to the materials. The only warranties for SAP Group products
and services are those that are set forth in the express warranty
statements accompanying such products and services, if any. Nothing
herein should be construed as constituting an additional warranty.
Disclaimer
Some components of this product are based on Java™. Any code
change in these components may cause unpredictable and severe
malfunctions and is therefore expressively prohibited, as is any
decompilation of these components.
Any Java™ Source Code delivered with this product is only to be used
by SAP’s Support Services and may not be modified or altered in any
way.
Documentation in the SAP Service Marketplace
You can find this documentation at the following Internet address:
service.sap.com/hana

SAP HANA Database: SQL Reference Manual
2
Table of Contents
SAP HANA Guides .................................................................................................................................... 9
Notation .............................................................................................................................................. 9
Introduction .......................................................................................................................................... 10
SQL .................................................................................................................................................... 10
Supported Languages and Code Pages ............................................................................................. 10
Comment .......................................................................................................................................... 10
Identifiers .......................................................................................................................................... 10
Single Quotation Mark ...................................................................................................................... 11
Double Quotation Mark .................................................................................................................... 12
SQL Reserved Words ......................................................................................................................... 12
Data Types ............................................................................................................................................. 13
Classification of Data Types .............................................................................................................. 13
Datetime Types ................................................................................................................................. 13
Numeric Types .................................................................................................................................. 13
Character String Types ...................................................................................................................... 15
Binary Types ...................................................................................................................................... 15
Large Object (LOB) Types .................................................................................................................. 15
Supported Formats for Date, Time and Timestamp ......................................................................... 17
Data Type Conversion ....................................................................................................................... 19
Predicates.............................................................................................................................................. 22
Comparison Predicates ..................................................................................................................... 22
Range Predicate ................................................................................................................................ 22
In Predicate ....................................................................................................................................... 22
Exists Predicate ................................................................................................................................. 22
LIKE Predicate ................................................................................................................................... 22
NULL Predicate .................................................................................................................................. 23
Operators .............................................................................................................................................. 24
Unary and Binary Operators ............................................................................................................. 24
Operator Precedence ........................................................................................................................ 24
Arithmetic Operators ........................................................................................................................ 25

SAP HANA Database: SQL Reference Manual
3
String Operator ................................................................................................................................. 25
Comparison Operators ...................................................................................................................... 25
Logical Operators .............................................................................................................................. 26
Set Operators .................................................................................................................................... 26
Expressions............................................................................................................................................ 27
Case Expressions ............................................................................................................................... 27
Function Expressions ........................................................................................................................ 28
Aggregate Expressions ...................................................................................................................... 28
Subqueries in expressions ................................................................................................................. 29
Functions ............................................................................................................................................... 30
Data type conversion functions ........................................................................................................ 30
CAST Function ............................................................................................................................... 30
TO_ALPHANUM Function ............................................................................................................. 30
TO_BIGINT Function ...................................................................................................................... 30
TO_BLOB Function ........................................................................................................................ 31
TO_CLOB Function ........................................................................................................................ 31
TO_DATE Function ........................................................................................................................ 31
TO_DATS Function ........................................................................................................................ 31
TO_DECIMAL Function .................................................................................................................. 31
TO_DOUBLE Function ................................................................................................................... 32
TO_INT Function ........................................................................................................................... 32
TO_INTEGER Function ................................................................................................................... 32
TO_NCLOB Function ...................................................................................................................... 32
TO_NVARCHAR Function .............................................................................................................. 33
TO_REAL Function ......................................................................................................................... 33
TO_SMALLINT Function ................................................................................................................ 33
TO_TINYINT Function .................................................................................................................... 34
TO_TIME Function ......................................................................................................................... 34
TO_TIMESTAMP Function ............................................................................................................. 34
TO_VARCHAR Function ................................................................................................................. 34
DateTime Functions .......................................................................................................................... 36
ADD_DAYS Function ...................................................................................................................... 36
ADD_MONTHS Function ............................................................................................................... 36
ADD_YEARS Function .................................................................................................................... 36

SAP HANA Database: SQL Reference Manual
4
ADD_SECONDS Function ............................................................................................................... 36
DAYS_BETWEEN Function ............................................................................................................. 37
DAYNAME Function ...................................................................................................................... 37
DAYOFMONTH Function ............................................................................................................... 37
DAYOFYEAR Function .................................................................................................................... 37
EXTRACT Function ......................................................................................................................... 38
HOUR Function .............................................................................................................................. 38
LAST_DAY Function ....................................................................................................................... 38
MINUTE Function .......................................................................................................................... 38
MONTH Function .......................................................................................................................... 38
MONTHNAME Function ................................................................................................................ 39
NEXT_DAY Function ...................................................................................................................... 39
NOW Function ............................................................................................................................... 39
SECOND Function .......................................................................................................................... 40
SECONDS_BETWEEN Function ...................................................................................................... 40
CURRENT_DATE Function ............................................................................................................. 40
CURRENT_TIME Function .............................................................................................................. 40
CURRENT_TIMESTAMP Function .................................................................................................. 41
CURRENT_UTCDATE Function ....................................................................................................... 41
CURRENT_UTCTIME Function ....................................................................................................... 41
CURRENT_UTCTIMESTAMP Function............................................................................................ 41
WEEK Function .............................................................................................................................. 42
WEEKDAY Function ....................................................................................................................... 42
YEAR Function ............................................................................................................................... 42
Number Functions............................................................................................................................. 43
ABS Function ................................................................................................................................. 43
ACOS Function............................................................................................................................... 43
ASIN Function ................................................................................................................................ 43
ATAN Function .............................................................................................................................. 43
ATAN2 Function ............................................................................................................................ 44
BITAND Function ........................................................................................................................... 44
CEIL / CEILING Function ................................................................................................................ 44
COS Function ................................................................................................................................. 44
COSH Function .............................................................................................................................. 45

SAP HANA Database: SQL Reference Manual
5
COT Function ................................................................................................................................. 45
EXP Function ................................................................................................................................. 45
FLOOR Function ............................................................................................................................ 45
GREATEST Function ....................................................................................................................... 46
LEAST Function .............................................................................................................................. 46
LN Function ................................................................................................................................... 46
LOG Function ................................................................................................................................. 46
MOD Function ............................................................................................................................... 47
POWER Function ........................................................................................................................... 47
ROUND Function ........................................................................................................................... 47
SIGN Function................................................................................................................................ 48
SIN Function .................................................................................................................................. 48
SINH Function................................................................................................................................ 48
SQRT Function ............................................................................................................................... 48
TAN Function ................................................................................................................................. 49
TANH Function .............................................................................................................................. 49
String Functions ................................................................................................................................ 50
ASCII Function ............................................................................................................................... 50
CHAR Function .............................................................................................................................. 50
CONCAT Function .......................................................................................................................... 50
LEFT Function ................................................................................................................................ 50
LCASE Function.............................................................................................................................. 51
LENGTH Function .......................................................................................................................... 51
LOCATE Function ........................................................................................................................... 51
LOWER Function ........................................................................................................................... 51
LPAD Function ............................................................................................................................... 52
LTRIM Function ............................................................................................................................. 52
NCHAR Function ............................................................................................................................ 52
REPLACE Function ......................................................................................................................... 52
RIGHT Function ............................................................................................................................. 53
RPAD Function .............................................................................................................................. 53
RTRIM Function ............................................................................................................................. 53
SUBSTRING Function ..................................................................................................................... 54
SUBSTR_AFTER Function ............................................................................................................... 54

SAP HANA Database: SQL Reference Manual
6
SUBSTR_BEFORE Function ............................................................................................................ 54
TRIM Function ............................................................................................................................... 55
UCASE Function ............................................................................................................................. 55
UNICODE Function ........................................................................................................................ 55
UPPER Function ............................................................................................................................. 55
Miscellaneous Functions ................................................................................................................... 57
BINTOHEX Function ....................................................................................................................... 57
COALESCE Function ....................................................................................................................... 57
HASANYPRIVILEGES Function ........................................................................................................ 57
HASSYSTEMPRIVILEGE Function ................................................................................................... 58
HEXTOBIN Function ....................................................................................................................... 58
ISAUTHORIZED Function ............................................................................................................... 58
IFNULL Function ............................................................................................................................ 59
NULLIF Function ............................................................................................................................ 59
CURRENT_CONNECTION Function ................................................................................................ 59
CURRENT_SCHEMA Function ........................................................................................................ 60
CURRENT_USER Function ............................................................................................................. 60
GROUPING_ID Function ................................................................................................................ 60
SESSION_CONTEXT Function ......................................................................................................... 61
SYSUUID Function ......................................................................................................................... 62
SQL Statements ..................................................................................................................................... 63
ALTER AUDIT POLICY ..................................................................................................................... 63
ALTER SYSTEM ............................................................................................................................... 64
ALTER TABLE.................................................................................................................................. 69
ALTER USER ................................................................................................................................... 74
CONNECT ....................................................................................................................................... 76
CREATE AUDIT POLICY................................................................................................................... 77
CREATE CALCULATION SCENARIO ................................................................................................. 78
CREATE INDEX ............................................................................................................................... 80
CREATE ROLE ................................................................................................................................. 81
CREATE SCHEMA ........................................................................................................................... 82
CREATE SEQUENCE........................................................................................................................ 83
CREATE SYNONYM ........................................................................................................................ 86
CREATE TABLE ............................................................................................................................... 87

SAP HANA Database: SQL Reference Manual
7
CREATE TYPE ................................................................................................................................. 93
CREATE USER ................................................................................................................................. 94
CREATE VIEW ................................................................................................................................ 95
DELETE ........................................................................................................................................... 96
DROP AUDIT POLICY ...................................................................................................................... 97
DROP CALCULATION SCENARIO .................................................................................................... 98
DROP INDEX .................................................................................................................................. 99
DROP ROLE .................................................................................................................................. 100
DROP SCHEMA ............................................................................................................................ 101
DROP SEQUENCE ......................................................................................................................... 102
DROP SYNONYM ......................................................................................................................... 104
DROP TABLE ................................................................................................................................ 105
DROP TYPE .................................................................................................................................. 106
DROP USER .................................................................................................................................. 107
DROP VIEW.................................................................................................................................. 108
EXPLAIN PLAN ............................................................................................................................. 109
EXPORT ........................................................................................................................................ 114
GRANT ......................................................................................................................................... 115
IMPORT ....................................................................................................................................... 120
IMPORT FROM ............................................................................................................................ 121
INSERT ......................................................................................................................................... 123
LOAD ........................................................................................................................................... 124
MERGE DELTA ............................................................................................................................. 125
RENAME COLUMN ...................................................................................................................... 126
RENAME INDEX ........................................................................................................................... 127
RENAME TABLE ........................................................................................................................... 128
REVOKE ....................................................................................................................................... 129
SELECT ......................................................................................................................................... 130
SET [SESSION] .............................................................................................................................. 141
SET HISTORY SESSION TO ............................................................................................................ 142
SET SCHEMA ................................................................................................................................ 143
SET TRANSACTION AUTOCOMMIT DDL ..................................................................................... 144
SET TRANSACTION ...................................................................................................................... 145
TRUNCATE TABLE ........................................................................................................................ 147

SAP HANA Database: SQL Reference Manual
8
UNLOAD ...................................................................................................................................... 148
UNSET [SESSION] ......................................................................................................................... 149
UPDATE ....................................................................................................................................... 150
UPSERT| REPLACE ....................................................................................................................... 151
Appendix ............................................................................................................................................. 152
Restrictions for SQL Statements ..................................................................................................... 152
SQL Error Codes .............................................................................................................................. 153

SAP HANA Database: SQL Reference Manual
9
SAP HANA Guides For more information about SAP HANA landscape, security, installation and administration, see the
resources listed in the table below.
Topic Guide/Tool Quick Link
SAP HANA
Landscape,
Deployment &
Installation
SAP HANA Knowledge Center on SAP Service Marketplace
https://service.sap.com/hana
SAP HANA 1.0 Master Guide
SAP HANA 1.0 Installation Guide
SAP HANA Administration &
Security
SAP HANA Knowledge Center on SAP Help
Portal
http://help.sap.com/hana
SAP HANA 1.0 Technical Operations Manual
SAP HANA 1.0 Security Guide
Notation This reference use BNF (Backus Naur Form) which is the notation technique used to define
programming languages, to describe SQL. BNF describes the syntax of a grammar using a set of
production rules using a set of symbols.
Symbols used in BNF
Symbol Description
< > Angle brackets are used to surround the name of a syntactic element (BNF
nonterminal) of the SQL language.
::= The definition operator is used to provide definitions of the element appeared
on the left side of the operator in a production rule.
[ ] Square brackets are used to indicate optional elements in a formula. Optional
elements may be specified or omitted.
{ } Braces group elements in a formula. Repetitive elements (zero or more
elements) can be specified within brace symbols.
| The alternative operator indicates that the portion of the formula following
the bar is an alternative to the portion preceding the bar.
... The ellipsis indicates that the element may be repeated any number of times.
If ellipsis appears after grouped elements specifying that the grouped
elements enclosed with braces are repeated. If ellipsis appears after a single
element, only that element is repeated.
!! Introduces normal English text. This is used when the definition of a syntactic
element is not expressed in BNF.

SAP HANA Database: SQL Reference Manual
10
Introduction This chapter describes the SAP HANA Database implementation of Structured Query Language
(SQL). It explains the characteristics of SQL, also how to manage comments and reserve words.
SQL SQL stands for Structured Query Language. It is a standardized language for communicating with a relational database. It is used to retrieve, store or manipulate information in the database.
SAP HANA Database manages tables using SQL statements to create or modify a table and to add or manipulate data within a table. SQL statements can perform the following tasks:
Schema definition and manipulation
Data manipulation System management Session management Transaction management
Supported Languages and Code Pages The SAP HANA Database supports Unicode to allow use of all languages in the Unicode Standard and 7 Bit ASCII code page without restriction.
Comment You can add comments to improve readability and maintainability of your SQL statements.
Comments are delimited in SQL statements as follows: Double hyphens ―—―. Everything after the double hyphen until the end of a line is
considered by the SQL parser to be a comment
"/*" and "*/". This style of commenting is used to place comments on multiple lines. All
text between the opening "/*" and closing "*/" is ignored by the SQL parser.
Identifiers Syntax:
<identifier> ::= <simple_identifier> | <double_quotes><special_identifier><double_quotes>
<simple_identifier> ::= <letter> [{<letter_or_digit>|<underscore>}, ...] <letter> ::= A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S
| T | U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 <letter_or_digit> ::= <letter> | <digit>
<underscore> ::= _ <double_quotes> ::= " <special_identifier> ::= any character Identifiers are used to represent names used in SQL statement including table name, view name,
synonym name, column name, index name, function name, procedure name, user name, role
name, and so on. There are two kinds of identifiers; undelimited identifiers and delimited
identifiers.
Undelimited table and column names must start with a letter and cannot contain any symbols other than digits or an underscore "_".
Delimited identifiers are enclosed in the delimiter, double quotes, then the identifier can
contain any character including special characters. For example, ―AB$%CD‖ is a valid identifier name.
Limitations

SAP HANA Database: SQL Reference Manual
11
o "_SYS_" is reserved exclusively for database engine, hence not allowed at the
beginning of schema object names. o Role name and user name must be specified as undelimited identifiers. o Maximum length for the identifiers is 127 characters.
Single Quotation Mark Single quotation marks are used to delimit string literals and single quotation mark itself can be
represented using two single quotation marks.

SAP HANA Database: SQL Reference Manual
12
Double Quotation Mark Double quotation marks are used to delimit identifiers and double quotation mark itself can be
represented using two double quotation marks.
SQL Reserved Words Reserved words are words which have a special meaning to the SQL parser in the SAP HANA
Database that cannot be used as a user-defined name. Reserved words should not be used in SQL
statements for schema object names. If necessary, you can work around this limitation by
delimiting a table or column name with double quotation marks.
The following table lists all the current and future reserved words for the SAP HANA Database.
Table 1. Reserved Words
ALL ALTER AS BEFORE
BEGIN BOTH CASE CHAR
CONDITION CONNECT CROSS CUBE
CURRENT_CONNECTION CURRENT_DATE CURRENT_SCHEMA CURRENT_TIME
CURRENT_TIMESTAMP CURRENT_USER CURRENT_UTCDATE CURRENT_UTCTIME
CURRENT_UTCTIMESTAMP CURRVAL CURSOR DECLARE
DISTINCT ELSE ELSEIF ELSIF
END EXCEPT EXCEPTION EXEC
FOR FROM FULL GROUP
HAVING IF IN INNER
INOUT INTERSECT INTO IS
JOIN LEADING LEFT LIMIT
LOOP MINUS NATURAL NEXTVAL
NULL ON ORDER OUT
PRIOR RETURN RETURNS REVERSE
RIGHT ROLLUP ROWID SELECT
SET SQL START SYSDATE
SYSTIME SYSTIMESTAMP SYSUUID TOP
TRAILING UNION USING UTCDATE
UTCTIME UTCTIMESTAMP VALUES WHEN
WHERE WHILE WITH
Undelimited table and column names must start with a letter and cannot contain any symbols
other than digits or an underscore "_". If the identifier is enclosed in the delimiter, double quotes,
then the identifier can contain any character including special characters. For example, ―AB$%CD‖
is a valid identifier name. However, "_SYS_" is reserved exclusively for database engine, hence not
allowed at the beginning of schema object names.

SAP HANA Database: SQL Reference Manual
13
Data Types This section describes the data types used in the SAP HANA Database.
Data type specifies the characteristics of a data value. A special value of NULL is included in every data type to indicate the absence of a value. The following table shows the built-in data types in SAP HANA Database.
Classification of Data Types In the SAP HANA Database each data type can be classified by its characteristic as follows:
Table 2. Classification of data types
Classification Data Type
Datetime types DATE, TIME, SECONDDATE, TIMESTAMP
Numeric types TINYINT, SMALLINT, INTEGER, BIGINT, SMALLDECIMAL,
DECIMAL, REAL, DOUBLE, FLOAT
Character string types VARCHAR, NVARCHAR, ALPHANUM
Binary types VARBINARY
Large Object types BLOB, CLOB, NCLOB
Datetime Types
DATE The DATE data type consists of year, month, and day information to represent a date value.
The default format for the DATE data type is 'YYYY-MM-DD'. YYYY represents the year, MM represents the month, and DD represents the day. The range of date value is 0001-01-01 through 9999-12-31.
TIME The TIME data type consists of hour, minute, and second to represent a time value. The default format for the TIME data type is 'HH24:MI:SS'. HH24 represents the hour from 0 to 24, MI represents the minute from 0 to 59, SS represents the second from 0 to 59.
SECONDDATE The SECONDDATE data type consists of year, month, day, hour, minute and second information to represent a date with time value. The default format for the SECONDDATE
data type is 'YYYY-MM-DD HH24:MI:SS'. YYYY represents the year, MM represents the month, DD represents the day, HH24 represents hour, MI represents minute, and SS represents seconds. The range of date value is 0001-01-01 00:00:01 through 9999-12-31 24:00:00.
TIMESTAMP The TIMESTAMP data type consists of date and time information. Its default format is 'YYYY-MM-DD HH24:MI:SS.FF7'. FFn represents the fractional seconds where n indicates the number
of digits in fractional part. . The range of the timestamp value is 0001-01-01 00:00:00.0000000 through 9999-12-31 23:59:59.9999999.
For details on supported formats for datetime types, refer to Table 4, Table 5, Table 6 and Table 7.
Numeric Types
TINYINT The TINYINT data type stores an 8-bit unsigned integer. The minimum value is 0 and the
maximum value is 255 for TINYINT.

SAP HANA Database: SQL Reference Manual
14
SMALLINT The SMALLINT data type stores a 16-bit signed integer. The minimum value is -32,768 and
the maximum value is 32,767 for SMALLINT.
INTEGER The INTEGER data type stores a 32-bit signed integer. The minimum value is -2,147,483,648
and the maximum value is 2,147,483,647 for INTEGER.
BIGINT The BIGINT data type stores a 64-bit signed integer. The minimum value is -
9,223,372,036,854,775,808 and the maximum value is 9,223,372,036,854,775,807 for
BIGINT.
DECIMAL(precision, scale) or DEC(p,s) The DECIMAL (p, s) data type specifies a fixed-point decimal number with precision p and scale s. The precision is the total number of significant digits and can range from 1 to 34. The scale is the number of digits from the decimal point to the least significant digit and can
range from -6,111 to 6,176 which means scale specifies the range of the exponent in the decimal number from 10-6111 to 106176. If the scale is not specified, it defaults to 0. Scale is positive when the number has significant digits to the right of the decimal point and negative when the number has significant digits to the left of the decimal point.
Examples: 0.0000001234 (1234 x 10-10) has the precision 4 and the scale 10. 1.0000001234 (10000001234 x 10-10) has the precision 11 and scale 10.
1234000000 (1234x106) has the precision 4 and scale -6.
When precision and scale are not specified, DECIMAL becomes a floating-point decimal number. In this case, precision and scale can vary within the range described above, 1~34 for precision and -6,111~6,176 for scale depending on the stored value.
SMALLDECIMAL The SMALLDECIMAL is a floating-point decimal number. The precision and scale can vary within the range, 1~16 for precision and -369~368 for scale depending on the stored value. SMALLDECIMAL is supported only on column store.
DECIMAL and SMALLDECIMAL are floating-point types. For instance, a decimal column can store any of 3.14, 3.1415, 3.141592 keeping their precisions. DECIMAL(p, s) is the SQL standard notation for fixed-point decimal. For instance, 3.14, 3.1415,
3.141592 are stored in a decimal(5, 4) column as 3.1400, 3.1415, 3.1416, respectively keeping the specified precision(5) and scale(4).
REAL The REAL data type specifies a single-precision 32-bit floating-point number.
DOUBLE The DOUBLE data type specifies a single-precision 64-bit floating-point number. The minimum value is -1.79769 x 10308 and the maximum value is 1.79769x10308 . The smallest positive DOUBLE value is 2.2207x10-308 and the largest negative DOUBLE value is -2.2207x10-308.
FLOAT(n) The FLOAT(n) data type specifies a 32-bit or 64-bit real number, where n specifies the number of significant bits and can range between 1 and 53.

SAP HANA Database: SQL Reference Manual
15
When you use the FLOAT(n) data type, if n is smaller than 25, it becomes a 32-bit REAL data
type. If n is greater than or equal to 25, it then becomes a 64-bit DOUBLE data type. If n is not declared, it becomes a 64-bit double data type by default.
Character String Types The character string data types are used to store values that contain character strings. While VARCHAR data types contain ASCII character strings, NVARCHAR are used for storing Unicode character strings.
VARCHAR The VARCHAR(n) data type specifies a variable-length ASCII character string, where n
indicates the maximum length and is an integer between 1 and 5000.
NVARCHAR The NVARCHAR(n) data type specifies a variable-length Unicode character set string, where n indicates the maximum length and is an integer between 1 and 5000.
ALPHANUM The ALPHANUM(n) data type specifies a variable-length character string which contains alpha-numeric characters, where n indicates the maximum length and is an integer between 1
and 127.
Binary Types Binary types are used to store bytes of binary data.
VARBINARY The VARBINARY(n) data type is used to store binary data of a specified maximum length in
bytes, where n indicates the maximum length and is an integer between 1 and 5000.
Large Object (LOB) Types LOB (large objects) data types, CLOB, NCLOB and BLOB, are used to store a large amount of data such as text documents and images. The maximum size of an LOB is 2 GB.
BLOB The BLOB data type is used to store large binary data.
CLOB The CLOB data type is used to store large ASCII character data.
NCLOB The NCLOB data type is used to store a large Unicode character object.
LOB types are provided for storing and retrieving such large data. LOB types support the following
operations. The length () function returns the LOB length in bytes. LIKE can be used to search LOB columns. The LOB types have the following restrictions: LOB columns cannot appear in ORDER BY or GROUP BY clauses.
LOB columns cannot appear in FROM clauses as a join predicate. LOB columns cannot appear in WHERE clauses as a predicate except LIKE, CONTAINS, =, or
<>. LOB columns cannot appear in SELECT clauses as an aggregate function argument.
LOB columns cannot appear in SELECT DISTINCT clauses. LOB columns cannot be used in set operations such as EXCEPT. UNION ALL is an exception. LOB columns cannot be used as a primary key.

SAP HANA Database: SQL Reference Manual
16
LOB columns cannot be used in CREATE INDEX statements.
LOB columns cannot be used in statistics update statements.
Table 3: Mapping between SQL Data Type and Column Store Data Type
SQL Type Column Store Type
Integer Types TINYINT, SMALLINT, INT CS_INT
BIGINT CS_FIXED(18,0)
Approximate Types REAL CS_FLOAT
DOUBLE CS_DOUBLE
FLOAT CS_DOUBLE
FLOAT(p) CS_FLOAT, CS_DOUBLE
Decimal Types DECIMAL CS_DECIMAL_FLOAT
DECIMAL(p,s) CS_FIXED(p-s,s)
SMALLDECIMAL CS_SDFLOAT
Character Types VARCHAR CS_STRING,CS_ALPHANUM,CS_UNITDECFLOAT, CS_DATE,CS_TIME
NVARCHAR CS_STRING,CS_ALPHANUM,CS_UNITDECFLOAT
CLOB, NCLOB CS_STRING
ALPHANUM CS_ALPHANUM
Binary Types BLOB CS_RAW
VARBINARY CS_RAW
Date/Time Types DATE CS_DAYDATE, CS_DATE
TIME CS_SECONDTIME, CS_TIME
TIMESTAMP CS_LONGDATE, CS_DATE, CS_SECONDDATE
SECONDDATE CS_SECONDDATE
SAP HANA Database: SQL Reference Manual
17
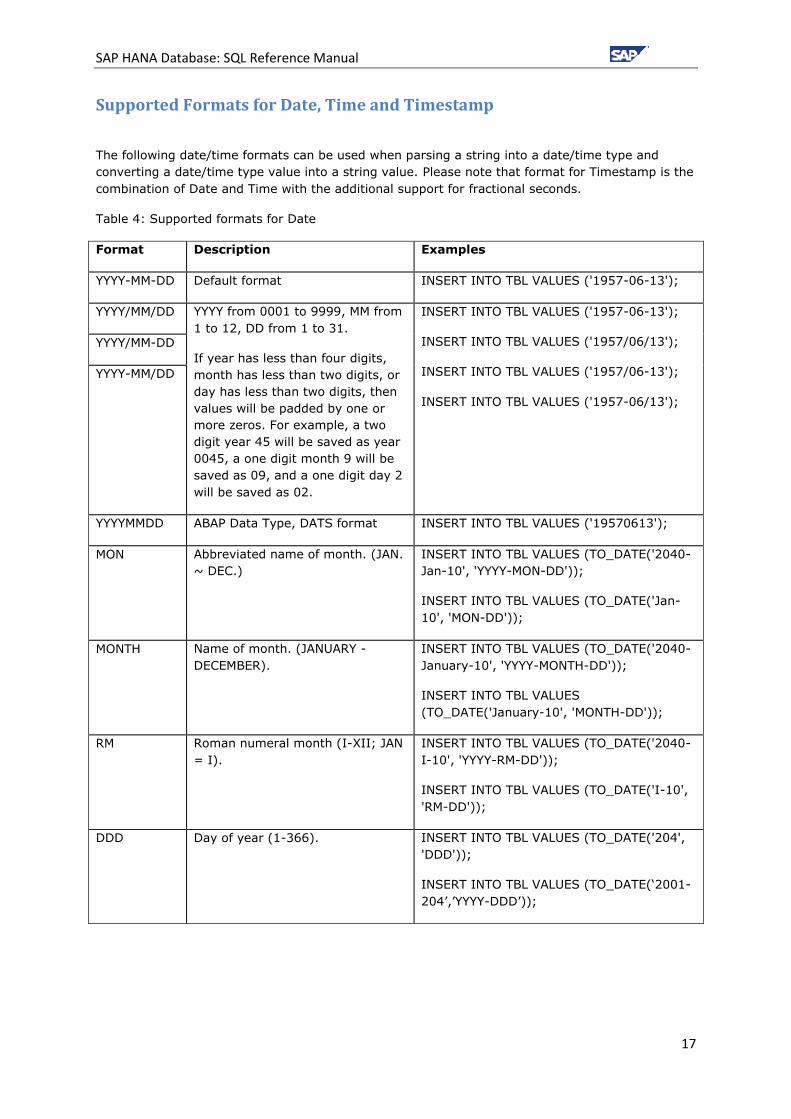
Supported Formats for Date, Time and Timestamp
The following date/time formats can be used when parsing a string into a date/time type and
converting a date/time type value into a string value. Please note that format for Timestamp is the
combination of Date and Time with the additional support for fractional seconds.
Table 4: Supported formats for Date
Format Description Examples
YYYY-MM-DD Default format INSERT INTO TBL VALUES ('1957-06-13');
YYYY/MM/DD YYYY from 0001 to 9999, MM from
1 to 12, DD from 1 to 31.
If year has less than four digits,
month has less than two digits, or
day has less than two digits, then
values will be padded by one or
more zeros. For example, a two
digit year 45 will be saved as year
0045, a one digit month 9 will be
saved as 09, and a one digit day 2
will be saved as 02.
INSERT INTO TBL VALUES ('1957-06-13');
INSERT INTO TBL VALUES ('1957/06/13');
INSERT INTO TBL VALUES ('1957/06-13');
INSERT INTO TBL VALUES ('1957-06/13');
YYYY/MM-DD
YYYY-MM/DD
YYYYMMDD ABAP Data Type, DATS format INSERT INTO TBL VALUES ('19570613');
MON Abbreviated name of month. (JAN.
~ DEC.)
INSERT INTO TBL VALUES (TO_DATE('2040-
Jan-10', 'YYYY-MON-DD'));
INSERT INTO TBL VALUES (TO_DATE('Jan-
10', 'MON-DD'));
MONTH Name of month. (JANUARY -
DECEMBER).
INSERT INTO TBL VALUES (TO_DATE('2040-
January-10', 'YYYY-MONTH-DD'));
INSERT INTO TBL VALUES
(TO_DATE('January-10', 'MONTH-DD'));
RM Roman numeral month (I-XII; JAN
= I).
INSERT INTO TBL VALUES (TO_DATE('2040-
I-10', 'YYYY-RM-DD'));
INSERT INTO TBL VALUES (TO_DATE('I-10',
'RM-DD'));
DDD Day of year (1-366). INSERT INTO TBL VALUES (TO_DATE('204',
'DDD'));
INSERT INTO TBL VALUES (TO_DATE(‗2001-
204‘,‘YYYY-DDD‘));

SAP HANA Database: SQL Reference Manual
18
Table 5: Supported formats for Time
Format Description Examples
HH24:MI:SS Default format
HH:MI[:SS][AM|PM]
HH12:MI[:SS][AM|PM
]
HH24:MI[:SS]
HH from 0 to 23. MI from 0 to 59. SS from
0 to 59. FFF from 0 to 999.
If one digit hour, minute, second is
specified, then 0 will be inserted into the
value. For example, 9:9:9 will be saved as
09:09:09.
HH12 indicates 12 hour clock and HH24
indicates 24 hour clock.
AM or PM can be specified as a suffix to
indicate the time value is before or after
noon.
INSERT INTO TBL VALUES
('23:59:59');
INSERT INTO TBL VALUES
('3:47:39 AM');
INSERT INTO TBL VALUES
('9:9:9 AM');
INSERT INTO TBL VALUES
(TO_TIME('11:59:59','HH1
2:MI:SS');
SSSSS Seconds past midnight (0-86399). INSERT INTO TBL VALUES
(TO_TIME('12345',
'SSSSS'));
Table 6: Supported formats for Timestamp
Format Description Examples
YYYY-MM-DD
HH24:MI:SS.FF7
Default format
FF [1..7] Fractional seconds has the range
1 to 7 after the FF parameter to
specify the number of digits in
the fractional second portion of
the date time value returned.
If a digit is not specified, the
default value is used.
INSERT INTO TBL VALUES
(TO_TIMESTAMP('2011-05-11
12:59.999','YYYY-MM-DD HH:SS.FF3'));
The following date/time formats can additionally be used when converting a date/time type value
into a string value. The following functions can be used when selecting a date/time values with a
specific format.
Table 7: Additional date/time formats
Format Description Example
D Day of week (1-7). TO_CHAR(CURRENT_TIMESTAMP,‘D‘)
DAY Name of day (MONDAY - SUNDAY). TO_CHAR(CURRENT_TIMESTAMP,‘DAY‘)
DY Abbreviated name of day (MON - SUN). TO_CHAR(CURRENT_TIMESTAMP,‘DY‘)

SAP HANA Database: SQL Reference Manual
19
Format Description Example
MON Abbreviated month name (JAN - DEC) TO_CHAR(CURRENT_TIMESTAMP,‘MON‘)
MONTH Full month name (JANUARY - DECEMBER) TO_CHAR(CURRENT_TIMESTAMP,‘MONTH‘)
RM Roman numeral month (I – XII; I is for
January)
TO_CHAR(CURRENT_TIMESTAMP,‘RM‘)
Q Quarter of year (1, 2, 3, 4) TO_CHAR(CURRENT_TIMESTAMP,‘Q‘)
W Week of month (1-5). TO_CHAR(CURRENT_TIMESTAMP,‘W‘)
WW Week of year (1-53). TO_CHAR(CURRENT_TIMESTAMP,‘WW‘)
Data Type Conversion This section describes the data type conversion allowed in SAP HANA Database.
Explicit type conversion The type of an expression result, for example a field reference, a function on fields, or literals can be converted using the following functions: CAST, TO_ALPHANUM, TO_BIGINT, TO_VARBINARY, TO_BLOB, TO_CLOB, TO_DATE, TO_DATS,
TO_DECIMAL, TO_DOUBLE, TO_INTEGER, TO_INT, TO_NCLOB, TO_NVARCHAR, TO_REAL,
TO_SECONDDATE, TO_SMALLINT, TO_TINYINT, TO_TIME, TO_TIMESTAMP, TO_VARCHAR.
Implicit type conversion When a given set of operand/argument types does not match what an operator/function
expects, type conversion is carried out by the SAP HANA Database. This conversion only occurs if a relevant conversion is available and it makes the operation/function executable. For instance, a comparison of BIGINT and VARCHAR is performed by implicitly converting VARCHAR to BIGINT. The entire explicit conversions can be used for implicit conversion except for the TIME and TIMESTAMP data types. TIME and TIMESTAMP can be converted to each other using TO_TIME(TIMESTAMP) and TO_TIMESTAMP(TIME).
Sample examples
Table 8. Implicit Type conversion Examples
Input Expression Transformed Expression with Implicit Conversion
BIGINT > VARCHAR BIGINT > BIGINT(VARCHAR)
BIGINT > DECIMAL DECIMAL(BIGINT) > DECIMAL
TIMESTAMP > DATE TIMESTAMP > TIMESTAMP(DATE)
DATE > TIME Error because there is no conversion available between DATE and TIME
In the table below, Boxes with ―OK‖ mean data type conversions are allowed without any checks.

SAP HANA Database: SQL Reference Manual
20
Boxes with ―CK‖ mean the data type can be converted if the data is valid for the target
type. Boxes with ―-― indicate that data type conversion is not allowed.
The rule is applicable to both implicit and explicit conversion except for Time to Timestamp conversion. Only explicit conversion is allowed for converting the Time data type to Timestamp using the TO_TIMESTAMP or CAST function.
Table 9. Data type conversion table
Target
tinyin
t
sm
allin
t
inte
ger
big
int
decim
al
decim
al(
p,s
)
sm
alld
ecim
al
real
do
ub
le
varch
ar
nvarch
ar
Source
tinyint
OK OK OK OK OK OK OK OK OK OK
smallint CK
OK OK OK OK OK OK OK OK OK
integer CK CK
OK OK OK OK OK OK OK OK
bigint CK CK CK
OK CK CK CK OK OK OK
decimal CK CK CK CK
CK CK CK OK OK OK
decimal(p,s) CK CK CK CK CK Ck CK CK CK OK OK
smalldecimal CK CK CK CK OK CK
CK CK OK OK
real CK CK CK CK OK CK CK
OK OK OK
double CK CK CK CK CK CK CK CK
OK OK
varchar CK CK CK CK CK CK CK CK CK
OK
nvarchar CK CK CK CK CK CK CK CK CK CK
Target time
date seconddate timestamp varchar nvarchar Source
time
- - - OK OK
date -
OK OK OK OK
seconddate time date
timestamp OK OK
timestamp time date seconddate
OK OK
varchar CK CK CK CK
OK
nvarchar CK CK CK CK CK
Target
varbinary alphanum varchar nvarchar Source
varbinary
- - -
alphanum -
OK OK
varchar OK OK
OK
nvarchar OK OK CK

SAP HANA Database: SQL Reference Manual
21
Data Type Precedence This section describes the data type precedence provided by SAP HANA Database. Data type precedence specifies that the data type with lower precedence is converted to the data type with higher precedence.
Highest TIMESTAMP
SECONDDATE
DATE
TIME
DOUBLE
REAL
DECIMAL
SMALLDECIMAL
BIGINT
INTEGER
SMALLINT
TINYINT
NCLOB
NVARCHAR
CLOB
VARCHAR
BLOB
Lowest VARBINARY

SAP HANA Database: SQL Reference Manual
22
Predicates A predicate is specified by combining one or more expressions or logical operators and returns one of the following logical or truth values: TRUE, FALSE, or UNKNOWN.
Comparison Predicates Two values can be compared using comparison predicates and returns true, false, or unknown.
Syntax:
<comparison_predicate> ::= <expression> { = | != | <> | > | < | >= | <= } [ ANY | SOME| ALL ] { <expression_list> | <subquery> }
<expression_list> ::= <expression>, ...
Expressions can be a simple expression such as a character, date, or number. An expression can also be a scalar subquery.
ANY, SOME – When ANY or SOME is specified, a comparison returns true if at least one value returned by subquery or expression_list is true. ALL - When ALL is specified, a comparison returns true if the comparison for all values returned by subquery or expression_list is true.
Range Predicate A value can be compared with the list of values within the provided range. Syntax:
<range_predicate> ::= <expression1> [NOT] BETWEEN <expression2> AND <expression3>
BETWEEN … AND … – When a range predicate is used, it returns true if expression1 is within the range specified by expression2 and expression3. A true will only be returned if expression2 has a lesser value than expression3.
In Predicate A value can be compared with a specified set of values. True will be returned if the value of expression1 is found in the expression_list (or subquery).
Syntax: <In_predicate> ::= <expression> [NOT] IN { <expression_list> | <subquery> }
Exists Predicate Returns true if the subquery returns a result set that is not empty and returns false if the subquery returns an empty result set. Syntax: <exists_predicate> ::= [NOT] EXISTS ( <subquery> )
LIKE Predicate The LIKE predicate is used for string comparisons. A value, expression1, is tested for a pattern,
expression2. Wildcard characters ( % ) and ( _ ) may be used in the comparison string
expression2. LIKE returns true if the pattern specified by expression2 is found.

SAP HANA Database: SQL Reference Manual
23
The percentage sign (%) matches zero or more characters and underscore (_) matches exactly
one character. To match a percent sign or underscore in the LIKE predicate, an escape character must be used.
Using the optional argument, ESCAPE expression3, you can specify the escape character that will be used so that the underscore (_) or percentage sign (%) can be matched. Syntax: <like_predicate> ::= <expression1> [NOT] LIKE <expression2> [ESCAPE <expression3>]
NULL Predicate When IS NULL predicate is specified, a value can be compared with NULL and returns true if a value is NULL. If the IS NOT NULL predicate is specified, it returns true if a value is not NULL.
Syntax: <null_predicate> ::= <expression> IS [NOT] NULL

SAP HANA Database: SQL Reference Manual
24
Operators You can perform arithmetic operations in expressions by using operators. Operators can be used for calculation, value comparison or to assign values.
Unary and Binary Operators Table 10. Unary and binary operators
Operator Operation Format Description
Unary A unary operator
applies to one
operand or a single
value expression.
operator operand
unary plus operator(+)
unary negation operator(-)
logical negation(NOT)
Binary A binary operator
applies to two
operands or two
value expressions.
operand1 operator
operand2
multiplicative operators ( *, / )
additive operators ( +,- )
comparison operators
( =,!=,<,>,<=,>=)
logical operators ( AND, OR )
Operator Precedence
An expression can use several operators, if the number of operators is greater than one, then the
SAP HANA Database will evaluate them in order of operator precedence. You can change this ordering by using parentheses. The SAP HANA Database will always evaluate expressions contained within parentheses first. If parentheses are not used, the operators have the precedence indicated by the table below.
Please note, the SAP HANA Database will evaluate operators with equal precedence from left to right within an expression. Table 11. SQL operator precedence
Precedence Operator Operation
Highest () parentheses
+, - unary positive and negative operation
*, / multiplication, division
+, - addition, subtraction
|| concatenation
=, !=, <, >, <=, >=, IS
NULL, LIKE, BETWEEN
comparison
NOT logical negation
AND conjunction

SAP HANA Database: SQL Reference Manual
25
Precedence Operator Operation
Lowest OR disjunction
Arithmetic Operators You use arithmetic operators to perform mathematical operations such as adding, subtracting, multiplying, dividing and negation of numeric values.
Table 12. Arithmetic operators
Operator Description
-<expression> Negation. If the expression is the NULL value, the result is NULL.
<expression> + <expression> Addition. If either expression is the NULL value, the result is NULL.
<expression> - <expression> Subtraction. If either expression is the NULL value, the result is NULL.
<expression> * <expression> Multiplication. If either expression is NULL, the result is NULL.
<expression> / <expression> Division. If either expression is NULL or if the second expression is 0, an
error is returned.
String Operator A concatenation operator combines two items such as strings, expressions, or constants into one.
Table 13. Concatenation operators
Operator Description
<expression> || <expression> String concatenation (two vertical bars). If either string is NULL, it
returns NULL.
Two string concatenation results in another string. For VARCHAR or NVARCHAR type strings, leading or trailing spaces are kept. If either string is of data type NVARCHAR, the result has data
type NVARCHAR and is limited to 5000 characters. The maximum length for VARCHAR concatenation is also limited to 5000 characters.
Comparison Operators Syntax:
<comparison_operation> ::= <expression1> <comparison_operator> <expression2>
Table 14. Comparison operators
Operator Description Example
= Equal to SELECT * FROM students WHERE id = 25;
> Greater than SELECT * FROM students WHERE id > 25;
< Less than SELECT * FROM students WHERE id < 25;

SAP HANA Database: SQL Reference Manual
26
Operator Description Example
>= Greater than or equal to SELECT * FROM students WHERE id >= 25;
<= Less than or equal to SELECT * FROM students WHERE id <= 25;
!=, <> Not equal SELECT * FROM students WHERE id != 25;
SELECT * FROM students WHERE id <> 25;
Logical Operators Search conditions can be combined using AND or OR operators. You can also negate them using
the NOT operator. Table 15. Logical operators
Operator syntax Notes
AND WHERE condition1 AND condition2 When using AND, the combined condition is TRUE if both conditions are TRUE, FALSE if either condition is FALSE, and UNKNOWN otherwise.
OR WHERE condition1 OR condition2 When using OR, the combined condition is TRUE
if either condition is TRUE, FALSE if both conditions are FALSE, and UNKNOWN otherwise.
NOT WHERE NOT condition The NOT operator is placed before a condition to negate the condition. The NOT condition is TRUE if condition is FALSE, FALSE if condition is TRUE,
and UNKNOWN if condition is UNKNOWN.
Set Operators The operators described in this section perform set operations on the results of two or more
queries.
Table 16. Set operators
Operator Returned Value
UNION Combines the results of two or more select statements or query expressions
UNION ALL Combines the results of two or more select statements or query expressions,
including all duplicate rows.
INTERSECT Combines the results of two or more select statements or query expressions, and
returns all common rows.
EXCEPT Takes output from the first query and then removes rows selected by the second
query.

SAP HANA Database: SQL Reference Manual
27
Expressions An expression is a clause that can be evaluated to return values.
Syntax: expression ::=
<case_expression>
| <function_expression>
| <aggregate_expression>
| (<expression> )
| ( <subquery> )
| - <expression>
| <expression> <operator> <expression>
| <variable_name>
| <constant>
| [<correlation_name>.]<column_name>
Case Expressions A case expression allows the user to use IF ... THEN ... ELSE logic without using procedures in SQL statements.
Syntax:
case_expression ::=
CASE <expression>
WHEN <expression>
THEN <expression>, ...
[ ELSE <expression>]
{ END | END CASE }
If the expression following the CASE statement is equal to the expression following the WHEN
statement, then the expression following the THEN statement is returned. Otherwise the
expression following the ELSE statement is returned, if it exists.

SAP HANA Database: SQL Reference Manual
28
Function Expressions SQL built-in functions can be used as an expression. Syntax:
<function_expression> ::= <function_name> ( <expression>, ... )
Aggregate Expressions
An aggregate expression uses an aggregate function to calculate a single value from the values of multiple rows in a column.
Syntax:
<aggregate_expression> ::= COUNT(*) | <agg_name> ( [ ALL | DISTINCT ] <expression> ) <agg_name> ::= COUNT | MIN | MAX | SUM | AVG | STDDEV | VAR
Aggregate name Description
COUNT Counts the number of rows returned by a query. COUNT(*) returns the
number of rows, regardless of the value of those rows and including duplicate values.COUNT(<expression>) returns the number of non-NULL values for that expression returned by the query.
MIN Returns the minimum value of expression.
MAX Returns the maximum value of expression.
SUM Returns the sum of expression.
AVG Returns the arithmetical mean of expression.
STDDEV Returns the standard deviation of given expression as the square root of VARIANCE function.
VAR Returns the variance of expression as the square of standard deviation.

SAP HANA Database: SQL Reference Manual
29
Subqueries in expressions A subquery is a SELECT statement enclosed in parentheses. The SELECT statement can contain one and only one select list item. When used as an expression, a scalar subquery is allowed to
return only zero or one value.
Syntax: <scalar_subquery_expression> ::= (<subquery>)
Within the SELECT list of the top level SELECT, or in the SET clause of an UPDATE statement, you can use a scalar subquery anywhere that you can use a column name. However, scalar_subquery cannot be used inside GROUP BY clause.
Example:
For example, the following statement returns the number of employees in each department,
grouped by department name: SELECT DepartmentName, COUNT(*), ‗out of‘, (SELECT COUNT(*) FROM Employees) FROM Departments AS D, Employees AS E WHERE D.DepartmentID = E.DepartmentID GROUP BY DepartmentName;

SAP HANA Database: SQL Reference Manual
30
Functions Functions are used to return information from the database. They are allowed anywhere an expression is allowed. Functions use the same syntax conventions used by SQL statements.
Data type conversion functions Data type conversion functions are used to convert arguments from one data type to another, or to test whether they can be converted.
CAST Function Syntax:
CAST (expression AS data_type)
Description:
Returns the value of an expression converted to a supplied data type. Parameters:
expression - The expression to be converted. data type - The target data type.
TINYINT | SMALLINT | INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE |
ALPHANUM | VARCHAR | NVARCHAR | DAYDATE | DATE | TIME | SECONDDATE | TIMESTAMP
Example:
SELECT CAST (7 AS VARCHAR) "cast" FROM DUMMY;
Retrieves: cast 7
TO_ALPHANUM Function Syntax:
TO_ALPHANUM (expression)
Description:
Converts the expression of a data type into a value of alphanum data type. Example:
SELECT TO_ALPHANUM ('10') "to alphanum" FROM DUMMY;
Retrieves: to alphanum
10
TO_BIGINT Function Syntax:
TO_BIGINT (expression)
Description:
Converts the expression of a data type into a value of bigint data type. Example:
SELECT TO_BIGINT ('10') "to bigint" FROM DUMMY;
Retrieves: to bigint
10

SAP HANA Database: SQL Reference Manual
31
TO_BLOB Function Syntax:
TO_BLOB (expression)
Description:
Converts the expression of a data type into a value of blob type. expression must be a binary string. Example:
SELECT TO_BLOB (TO_BINARY('abcde')) "to blob" FROM DUMMY;
Retrieves: to blob
abcde
TO_CLOB Function Syntax:
TO_CLOB (expression) Description:
Converts the expression of a data type into a value of CLOB data type. Example:
SELECT TO_CLOB ('TO_CLOB converts an expression into a value of CLOB data type') "to clob" FROM DUMMY;
Retrieves: to clob
TO_CLOB converts an expression into a value of CLOB data type
TO_DATE Function Syntax:
TO_DATE (expression [, format]) Description:
Converts the expression of a data type into a value of DATE data type.
Example:
SELECT TO_DATE('2010-01-12', 'YYYY-MM-DD') "to date" FROM DUMMY; Retrieves: to date
2010-01-12
TO_DATS Function Syntax:
TO_DATS (expression) Description:
Converts the expression of a data type into a value of ABAP DATE string with format ‗YYYYMMDD‘.
Example:
SELECT TO_DATS ('2010-01-12') "abap date" FROM DUMMY; Retrieves: abap date
20100112
TO_DECIMAL Function

SAP HANA Database: SQL Reference Manual
32
Syntax:
TO_DECIMAL (expression [, precision, scale]) Description:
Converts the expression of a data type into a value of DECIMAL (precision, scale) data type. Example:
SELECT TO_DECIMAL(7654321.89, 9, 2) "to decimal" FROM DUMMY; Retrieves: to decimal
7654321.89
TO_DOUBLE Function Syntax:
TO_DOUBLE (expression) Description:
Converts the expression of a data type into a value of DOUBLE (double precision) data type.
Example:
SELECT 3*TO_DOUBLE ('15.12') "to double" FROM DUMMY; Retrieves: to double
45.36
TO_INT Function Syntax:
TO_INT (expression) Description:
Converts the expression of a data type into a value of INTEGER data type. Example:
SELECT TO_INT('10') "to int" FROM DUMMY; Retrieves: to int
10
TO_INTEGER Function Syntax:
TO_INTEGER (expression) Description:
Converts the expression of a data type into a value of INTEGER data type. Example:
SELECT TO_INTEGER ('10') "to int" FROM DUMMY; Retrieves: to int
10
TO_NCLOB Function Syntax:

SAP HANA Database: SQL Reference Manual
33
TO_NCLOB (expression) Description:
Converts the expression of a data type into a value of NCLOB data type. Example:
SELECT TO_NCLOB ('TO_NCLOB converts an expression into a value of NCLOB data type') "to
nclob" FROM DUMMY; Retrieves: to nclob
TO_NCLOB converts an expression into a value of NCLOB data type
TO_NVARCHAR Function Syntax:
TO_NVARCHAR (expression [,format]) Description:
Converts the expression of a data type into a value of unicode character data type.
If format is omitted, it converts to the corresponding format using the date format model. Example:
SELECT TO_NVARCHAR(TO_DATE('2009/12/31'), 'YY-MM-DD') "to nchar" FROM DUMMY;
Retrieves: to nchar
09-12-31
TO_REAL Function Syntax:
TO_REAL (expression) Description:
Converts the expression of a data type into the value of REAL (single precision) data type. Example:
SELECT 3*TO_REAL ('15.12') "to real" FROM DUMMY; Retrieves: to real
45.36
TO_SMALLINT Function Syntax:
TO_SMALLINT (expression) Description:
Converts the expression of a data type into a value of SMALLINT data type. Example:
SELECT TO_SMALLINT ('10') "to smallint" FROM DUMMY; Retrieves: to smallint
10

SAP HANA Database: SQL Reference Manual
34
TO_TINYINT Function Syntax:
TO_TINYINT (expression) Description:
Converts the expression of a data type into a value of TINYINT data type. Example:
SELECT TO_TINYINT ('10') "to tinyint" FROM DUMMY;
Retrieves: to tinyint
10
TO_TIME Function Syntax:
TO_TIME (expression [, format]) Description:
Converts the expression of a data type into a value of TIME data type. If format is omitted, it converts expression into the corresponding format using the date format
model as explained in Table 5. Example:
SELECT TO_TIME ('08:30 AM', ‗HH:MI AM‘) "to time" FROM DUMMY; Retrieves: to time
08:30:00
TO_TIMESTAMP Function Syntax:
TO_TIMESTAMP (expression [, format]) Description:
Converts the expression of a data type into the TIMESTAMP data type.
If format is omitted, it converts expression into the corresponding format using the date format
model as explained in Table 5. Example:
SELECT TO_TIMESTAMP ('2010-01-11 13:30:00', 'YYYY-MM-DD HH24:MI:SS') "to timestamp" FROM DUMMY;
Retrieves: to timestamp
2010-01-11 13:30:00.0000000
TO_VARCHAR Function Syntax:
TO_VARCHAR (expression [, format]) Description:
Converts the expression of a data type into a value of character data type. Example:
SELECT TO_VARCHAR (TO_DATE('2009-12-31'), 'YYYY/MM/DD') "to char" FROM DUMMY;

SAP HANA Database: SQL Reference Manual
35
Retrieves: to char
2009/12/31

SAP HANA Database: SQL Reference Manual
36
DateTime Functions
ADD_DAYS Function Syntax:
ADD_DAYS (d, n) Description:
Computes the date d plus n days. Example:
SELECT ADD_DAYS (TO_DATE ('2009-12-05', 'YYYY-MM-DD'), 30) "add days" FROM DUMMY;
Retrieves: add days
2010-01-04
ADD_MONTHS Function Syntax:
ADD_MONTHS (d, n) Description:
Computes the date d plus n months. Example:
SELECT ADD_MONTHS (TO_DATE ('2009-12-05', 'YYYY-MM-DD'), 1) "add months" FROM DUMMY; Retrieves: add months
2010-01-05
ADD_YEARS Function Syntax:
ADD_YEARS (d, n) Description:
Computes the date d plus n years. Example:
SELECT ADD_YEARS (TO_DATE ('2009-12-05', 'YYYY-MM-DD'), 1) "add years" FROM DUMMY; Retrieves: add years
2010-12-05
ADD_SECONDS Function Syntax:
ADD_SECONDS (t, n) Description:
Computes the time t plus n seconds. Example:
SELECT ADD_SECONDS (TO_TIME ('23:30:45'), 60*30) "add seconds" FROM DUMMY; Retrieves: add seconds
00:00:45.000

SAP HANA Database: SQL Reference Manual
37
DAYS_BETWEEN Function Syntax:
DAYS_BETWEEN (date1, date2) Description:
Computes the number of days between date1 and date2. Example:
SELECT DAYS_BETWEEN (TO_DATE ('2009-12-05', 'YYYY-MM-DD'), TO_DATE('2010-01-05',
'YYYYMM-DD')) "days between" FROM DUMMY; Retrieves: days between
31
DAYNAME Function Syntax:
DAYNAME (expression) Description:
Returns the name of the weekday in English. Example:
SELECT DAYNAME ('2011-05-30') "dayname" FROM DUMMY; Retrieves: dayname
MONDAY
DAYOFMONTH Function Syntax:
DAYOFMONTH (expression) Description:
Returns the day of the month in integer. Example:
SELECT DAYOFMONTH ('2011-05-30') "dayofmonth" FROM DUMMY;
Retrieves: dayofmonth
30
DAYOFYEAR Function Syntax:
DAYOFYEAR (expression) Description:
Returns the day of the year in integer. Example:
SELECT DAYOFYEAR ('2011-05-30') "dayofyear" FROM DUMMY;
Retrieves: dayofyear
150

SAP HANA Database: SQL Reference Manual
38
EXTRACT Function Syntax:
EXTRACT ({YEAR | MONTH | DAY | HOUR | MINUTE | SECOND} FROM datetime_value) Description:
Finds and returns the value of a specified datetime field from a datetime_value. Example:
SELECT EXTRACT (YEAR FROM TO_DATE ('2010-01-04', 'YYYY-MM-DD')) "extract" FROM DUMMY;
Retrieves: extract
2010
HOUR Function Syntax:
HOUR (expression) Description:
Extract hour from expression. Example:
SELECT HOUR ('12:34:56‘) "hour" FROM DUMMY;
Retrieves: hour
12
LAST_DAY Function Syntax:
LAST_DAY (d) Description:
Returns the date of the last day of the month that contains d. Example:
SELECT LAST_DAY (TO_DATE('2010-01-04', 'YYYY-MM-DD')) "last day" FROM DUMMY; Retrieves: last day
2010-01-31
MINUTE Function Syntax:
MINUTE (expression) Description:
Extract minute from expression. Example:
SELECT MINUTE ('12:34:56‘) "minute" FROM DUMMY; Retrieves: minute
34
MONTH Function

SAP HANA Database: SQL Reference Manual
39
Syntax:
MONTH(expression) Description:
Returns the number of the month from a given date. Example:
SELECT MONTH ('2011-05-30‘) "month" FROM DUMMY; Retrieves: month
5
MONTHNAME Function Syntax:
MONTHNAME(expression) Description:
Returns the name of the month in English. Example:
SELECT MONTHNAME ('2011-05-30‘) "monthname" FROM DUMMY; Retrieves: monthname
MAY
NEXT_DAY Function Syntax:
NEXT_DAY (d) Description:
Returns the date of the next day of d. Example:
SELECT NEXT_DAY (TO_DATE ('2009-12-31', 'YYYY-MM-DD')) "next day" FROM DUMMY; Retrieves: next day
2010-01-01
NOW Function Syntax:
NOW () Description:
Returns the current timestamp. Example:
SELECT NOW () "now" FROM DUMMY; Retrieves: now
2010-01-01 16:34:19

SAP HANA Database: SQL Reference Manual
40
SECOND Function Syntax:
SECOND (t) Description:
Returns the second number of a given time t. Example:
SELECT SECOND (‘12:34:56‘) "second" FROM DUMMY; Retrieves: second
56
SECONDS_BETWEEN Function Syntax:
SECONDS_BETWEEN (d1, d2) Description:
Computes the number of seconds between d1 and d2, which is semantically equal to d2 – d1. Example:
SELECT SECONDS_BETWEEN ('2009-12-05', '2010-01-05') "seconds between" FROM DUMMY; Retrieves: Seconds between
2678400
CURRENT_DATE Function Syntax:
CURRENT_DATE Description:
Returns the current local system date. Example:
SELECT CURRENT_DATE "current date" FROM DUMMY; Retrieves: current date
2010-01-11
CURRENT_TIME Function Syntax:
CURRENT_TIME Description:
Returns the current local system time. Example:
SELECT CURRENT_TIME "current time" FROM DUMMY; Retrieves: current time
17:37:37.279

SAP HANA Database: SQL Reference Manual
41
CURRENT_TIMESTAMP Function Syntax:
CURRENT_TIMESTAMP Description:
Returns the current local system timestamp information. Example:
SELECT CURRENT_TIMESTAMP "current timestamp" FROM DUMMY;
Retrieves:
current timestamp
2010-01-11 17:38:48.802
CURRENT_UTCDATE Function Syntax:
CURRENT_UTCDATE
Description:
Returns the current UTC date. The UTC stands for Coordinated Universal Time, also known as Greenwich Mean Time (GMT). Example:
SELECT CURRENT_UTCDATE "Coordinated Universal Date" FROM DUMMY; Retrieves: Coordinated Universal Time
2010-01-11
CURRENT_UTCTIME Function Syntax:
CURRENT_UTCTIME Description:
Returns the current UTC time. Example:
SELECT CURRENT_UTCTIME "Coordinated Universal Time" FROM DUMMY; Retrieves: Coordinated Universal Time
08:41:19.267
CURRENT_UTCTIMESTAMP Function Syntax:
CURRENT_UTCTIMESTAMP Description:
Returns the current UTC timestamp. Example:
SELECT CURRENT_UTCTIMESTAMP "Coordinated Universal Timestamp" FROM DUMMY; Retrieves: Coordinated Universal Timestamp
2010-01-11 08:41:42.484

SAP HANA Database: SQL Reference Manual
42
WEEK Function Syntax:
WEEK (d) Description:
Returns the week number of a given date d. Example:
SELECT WEEK (TO_DATE('2011-05-30', 'YYYY-MM-DD')) "week" FROM DUMMY;
Retrieves: week
22
WEEKDAY Function Syntax:
WEEKDAY (d) Description:
Returns the day of week of a given date d. The return value ranges from 0 to 6, each of which
represents Monday to Sunday. Example:
SELECT WEEKDAY (TO_DATE ('2010-12-31', 'YYYY-MM-DD')) "week day" FROM DUMMY; Retrieves: week day
4
YEAR Function Syntax:
YEAR (d) Description:
Returns the year number of a given date d. Example:
SELECT YEAR (TO_DATE ('2011-05-30', 'YYYY-MM-DD')) "year" FROM DUMMY; Retrieves: year
2011

SAP HANA Database: SQL Reference Manual
43
Number Functions Number functions take numeric values or strings with numeric characters as inputs and returns numeric values. When strings with numeric characters are given as inputs, implicit conversion from string to number is performed automatically before computing the result values.
ABS Function Syntax :
ABS (n) Description:
Returns the absolute value of a numeric expression n.
Example:
SELECT ABS (-1) "absolute" FROM DUMMY;
Retrieves: absolute
1
ACOS Function Syntax:
ACOS (n) Description:
Returns the arc-cosine, in radians, of a numeric expression n between -1 and 1. Example:
SELECT ACOS (0.5) "acos" FROM DUMMY; Retrieves: acos
1.0471975511965979
ASIN Function Syntax:
ASIN (n)
Description:
Returns the arc-sine, in radians, of a number n between -1 and 1. Example:
SELECT ASIN (0.5) "asin" FROM DUMMY;
Retrieves: asin
0.5235987755982989
ATAN Function Syntax :
ATAN (n) Description:
Returns the arc-tangent, in radians, of a number n. The argument is a number and the range of n
is unlimited.
Example:

SAP HANA Database: SQL Reference Manual
44
SELECT ATAN (0.5) "atan" FROM DUMMY;
Retrieves: atan
0.4636476090008061
ATAN2 Function Syntax :
ATAN2 (n, m)
Description:
Returns the arc-tangent, in radians, of the ratio of two numbers n and m. This is the same result as ATAN(n/m). Example:
SELECT ATAN2 (1.0, 2.0) "atan2" FROM DUMMY; Retrieves: atan2
0.4636476090008061
BITAND Function Syntax:
BITAND (expression1, expression2) Description:
Calculates an AND operation on the bits of expression1 and expression2. Both expression1 and expression2 must be non-negative integers. The BITAND function returns a result with BIGINT type.
Example:
SELECT BITAND (255, 123) "bitand" FROM DUMMY; Retrieves: bitand
123
CEIL / CEILING Function Syntax :
CEIL (n) Description:
Returns the first integer that is greater or equal to a given value n. For positive numbers, this is known as rounding up. Example:
SELECT CEIL (14.5) "ceiling" FROM DUMMY; Retrieves: ceiling
15
COS Function Syntax:
COS (n)
Description:
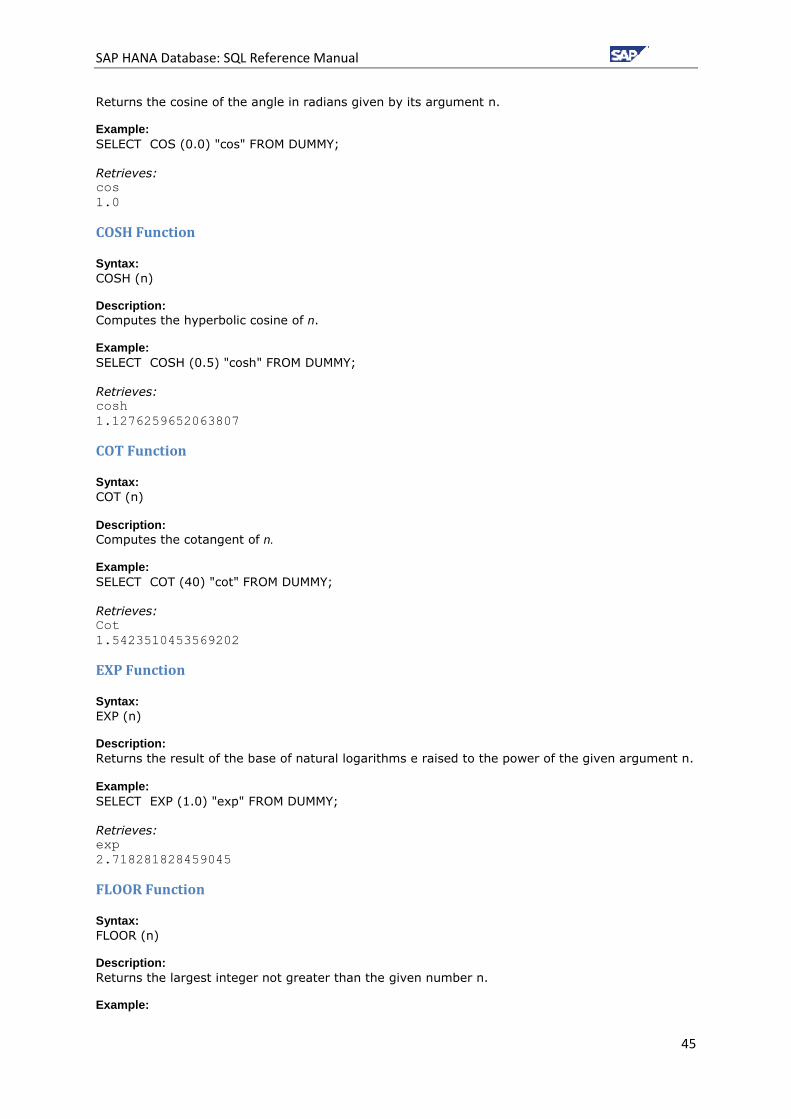
SAP HANA Database: SQL Reference Manual
45
Returns the cosine of the angle in radians given by its argument n. Example:
SELECT COS (0.0) "cos" FROM DUMMY; Retrieves: cos
1.0
COSH Function Syntax:
COSH (n) Description:
Computes the hyperbolic cosine of n. Example:
SELECT COSH (0.5) "cosh" FROM DUMMY; Retrieves: cosh
1.1276259652063807
COT Function Syntax:
COT (n)
Description:
Computes the cotangent of n. Example:
SELECT COT (40) "cot" FROM DUMMY; Retrieves: Cot
1.5423510453569202
EXP Function Syntax:
EXP (n) Description:
Returns the result of the base of natural logarithms e raised to the power of the given argument n. Example:
SELECT EXP (1.0) "exp" FROM DUMMY; Retrieves: exp
2.718281828459045
FLOOR Function Syntax:
FLOOR (n) Description:
Returns the largest integer not greater than the given number n. Example:

SAP HANA Database: SQL Reference Manual
46
SELECT FLOOR (14.5) "floor" FROM DUMMY;
Retrieves: floor
14
GREATEST Function Syntax:
GREATEST (n1 [, n2]...) Description:
Returns the greatest value among the arguments: n1, n2, ... Example:
SELECT GREATEST ('aa', 'ab', 'ba', 'bb') "greatest" FROM DUMMY; Retrieves: greatest
bb
LEAST Function Syntax:
LEAST (n1 [, n2]...) Description:
Returns the least value among the arguments: n1, n2... Example:
SELECT LEAST('aa', 'ab', 'ba', 'bb') "least" FROM DUMMY;
Retrieves: least
aa
LN Function Syntax:
LN (n) Description:
Returns the natural logarithm of the specified number. Example:
SELECT LN (9) "ln" FROM DUMMY; Retrieves: ln
2.1972245773362196
LOG Function Syntax :
LOG (m, n) Description:
Returns the natural logarithm of n base m. The base m must be a positive value other than 1 and n
must be any positive value. Example:
SELECT LOG (10, 2) "log" FROM DUMMY;

SAP HANA Database: SQL Reference Manual
47
Retrieves: log
0.30102999566398114
MOD Function Syntax:
MOD (n, d)
Description:
Returns the remainder of a number n divided by a divisor d.
When n is negative this function acts differently dto the standard computational modulo operation.
The following explains example of what MOD functions returns as the result.
If d is zero, then this function returns n.
If n is greater than 0 and n is less than d, then this function returns n. If n is less than 0 and n is greater than d, then this function returns n. Otherwise, this function calculates the remainder of the absolute value of n divided by the
absolute value of d to calculate the absolute value of the remainder. If m is less than 0, then the returned remainder from MOD is a negative number, and if m is greater than 0, then the returned remainder from MOD is a positive number.
Example:
SELECT MOD (15, 4) "modulus" FROM DUMMY;
Retrieves: modulus
3
POWER Function Syntax:
POWER (b, e)
Description:
Calculates the base number b raised to the power of an exponent e.
Example:
SELECT POWER (2, 10) "power" FROM DUMMY;
Retrieves: power
1024.0
ROUND Function Syntax:
ROUND (n [, pos]) Description:
Rounds n to the specified pos amount of places after the decimal point.
Example:
SELECT ROUND (16.16, 1) "round" FROM DUMMY;
Retrieves: round
16.2
SELECT ROUND (16.16, -1) "round" FROM DUMMY;

SAP HANA Database: SQL Reference Manual
48
Retrieves: round
20
SIGN Function Syntax:
SIGN (n) Description:
Returns the sign (positive or negative) of the given number.n. Returns 1 if n is a positive value, -1
if n is a negative value, and 0 if n is equal to zero.
Example:
SELECT SIGN (-15) "sign" FROM DUMMY;
Retrieves: sign
-1
SIN Function Syntax:
SIN (n) Description:
Returns the sine of n, where the argument is an angle expressed in radians.
Example:
SELECT SIN ( 3.141592653589793/2) "sine" FROM DUMMY; Retrieves: sine
1.0
SINH Function Syntax:
SINH (n) Description:
Returns the hyperbolic sine of n, where the argument is an angle expressed in radians. Example:
SELECT SINH (0.0) "sinh" FROM DUMMY;
Retrieves: sinh
0.0
SQRT Function Syntax:
SQRT (n) Description:
Returns the square root of a number n.

SAP HANA Database: SQL Reference Manual
49
Example:
SELECT SQRT (2) "sqrt" FROM DUMMY;
Retrieves: sqrt
1.4142135623730951
TAN Function Syntax:
TAN (n) Description:
Returns the tangent of an angle in radians.
Example:
SELECT TAN (0.0) "tan" FROM DUMMY;
Retrieves: tan
0.0
TANH Function Syntax:
TANH (n) Description:
Returns the hyperbolic tangent of a number n. Example:
SELECT TANH (1.0) "tanh" FROM DUMMY; Retrieves: tanh
0.7615941559557649

SAP HANA Database: SQL Reference Manual
50
String Functions
ASCII Function Syntax:
ASCII(c) Description:
Returns the integer ASCII value of the first byte in a string c. Example:
SELECT ASCII('Ant') "ascii" FROM DUMMY; Retrieves: ascii
65
CHAR Function Syntax:
CHAR (n)
Description:
Returns the character with the ASCII value of a number n. Example:
SELECT CHAR (65) || CHAR (110) || CHAR (116) "character" FROM DUMMY; Retrieves: character
Ant
CONCAT Function Syntax:
CONCAT (str1, str2) Description:
Returns a combined string which consists of str1 followed by str2. The concatenation operator (||)
is identical to this function. Example:
SELECT CONCAT ('C', 'at') "concat" FROM DUMMY;
Retrieves: concat
Cat
LEFT Function Syntax:
LEFT (str, n) Description:
Returns n characters from the beginning of a string str. Example:
SELECT LEFT ('Hello', 3) "left" FROM DUMMY;
Retrieves: left

SAP HANA Database: SQL Reference Manual
51
Hel
LCASE Function Syntax:
LCASE(s) Description:
Converts all characters in a string s to lowercase. The LCASE function is identical to the LOWER
function. Example:
SELECT LCASE ('Test') "lcase‖ FROM DUMMY;
Retrieves: lcase
test
LENGTH Function Syntax:
LENGTH(s) Description:
Returns the number of characters in the specified string.s. For LOB types, it returns the length in bytes. Example:
SELECT LENGTH ('length in char') "length" FROM DUMMY;
Retrieves: length
14
LOCATE Function Syntax:
LOCATE (haystack, needle) Description:
Returns the position of sub-string needle within string haystack. Returns 0 if needle is not found from haystack. Example:
SELECT LOCATE ('length in char', ‗char‘) "locate" FROM DUMMY; Retrieves: Locate
11
LOWER Function Syntax
LOWER(s) Description
Converts all characters in a string s to lowercase. The LOWER function is identical to the LCASE function.

SAP HANA Database: SQL Reference Manual
52
Example
SELECT LOWER ('Ant') "lower" FROM DUMMY;
Retrieves: lower
ant
LPAD Function Syntax:
LPAD (target, n [, pattern]) Description:
Pad the left side of a target string with spaces or pattern to make the target n characters in length.. Example:
SELECT LPAD ('end', 15, '12345') "lpad" FROM DUMMY; Retrieves: lpad
123451234512end
LTRIM Function Syntax:
LTRIM (target [, remove_set]) Description:
Removes from the leftmost of target all of the characters that appear in remove_set until reaching a
character not in remove_set and then returns the result. If remove_set is not specified, a single blank space is used. Please note that remove_set is treated as a set of characters and not a search string. Example:
SELECT LTRIM ('babababAabend','ab') "ltrim" FROM DUMMY;
Retrieves: ltrim
Aabend
NCHAR Function Syntax:
NCHAR (n) Description:
This function returns the Unicode character with the specified integer code number n.
Example:
SELECT NCHAR (65) "nchar" FROM DUMMY; Retrieves: nchar
A
REPLACE Function Syntax:
REPLACE (original_string, search_string, replace_string) Description:

SAP HANA Database: SQL Reference Manual
53
Searches in original_string for all occurrences of search_string and replaces them with
replace_string. If original_string is an empty string, then the result will also be an empty string.
If two overlapping substrings match the search_string in the original_string, then only the first occurrence will be replaced with the replace_string.
If original_string does not contain any occurrence of search_string, then the function returns the original_string unchanged. If original_string, search_string, or replace_string is NULL, then the function returns NULL.
Example:
SELECT REPLACE ('DOWNGRADE DOWNWARD','DOWN', 'UP') "replace" FROM DUMMY; Retrieves: replace
UPGRADE UPWARD
RIGHT Function Syntax:
RIGHT(target, n) Description:
Returns the rightmost n characters of a string target. Example:
SELECT RIGHT('HI0123456789', 3) "right" FROM DUMMY; Retrieves: right
789
RPAD Function Syntax:
RPAD (target, n [, pattern]) Description:
Pad the right side of a target string with spaces or pattern to make the target n characters in length. Example:
SELECT RPAD ('end', 15, '12345') "right padded" FROM DUMMY; Retrieves: right padded
end123451234512
RTRIM Function Syntax:
RTRIM (target [,remove_set ]) Description:
Removes from the rightmost of target all of the characters that appear in remove_set until reaching
a character not in remove_set and then returns the result. If remove_set is not specified, a single blank space is used. Please note that remove_set is treated as a set of characters and not a search string.
Example:
SELECT RTRIM ('endabAabbabab','ab') "rtrim" FROM DUMMY;
Retrieves: rtrim

SAP HANA Database: SQL Reference Manual
54
endabA
SUBSTRING Function Syntax:
SUBSTRING (target, start_position [, string_length]) Description:
Returns a substring of a string target starting from the start_position of the string. SUBSTRING
can either return the remaining part of a string from the start_position or, optionally, a number of characters set by the string_length parameter. If start_position is less than 0, then it is considered as 1. If string_length is less than 1, then an empty string is returned as the result. Example:
SELECT SUBSTRING ('1234567890',4,2) "substring" FROM DUMMY;
Retrieves: substring
45
SUBSTR_AFTER Function Syntax:
SUBSTR_AFTER (target, pattern) Description:
Returns a substring of the target string that follows the first occurrence of the pattern argument in the target string.
If target does not contain a substring which is the same as pattern, then an empty string is
returned.
If pattern is an empty string, then target is returned. If target or pattern is NULL, then NULL is returned. Example:
SELECT SUBSTR_AFTER ('Hello My Friend','My ') "substr after" FROM DUMMY;
Retrieves: substr after
Friend
SUBSTR_BEFORE Function Syntax:
SUBSTR_BEFORE (target, pattern) Description:
Returns a substring of the target string before the first occurrence of the pattern argument in the target string. If target does not contain a substring which is the same as pattern, then an empty string is
returned. If pattern is an empty string, then target is returned. If target or pattern is NULL, then NULL is returned. Example:
SELECT SUBSTR_BEFORE ('Hello My Friend','My') "substr before" FROM DUMMY; Retrieves: substr before
Hello

SAP HANA Database: SQL Reference Manual
55
TRIM Function Syntax:
TRIM ([[LEADING | TRAILING | BOTH] trim_char FROM] target_string ) Description:
Returns a string after trimming a trim_char from target_string string. The trimming operation is carried out either from the start (LEADING), end (TRAILING) or both(BOTH) ends of the target_string. If either target_string or trim_char is a null value, then a NULL is returned. If no option is specified, it removes both the leading and trailing substring trim_char from
target_string string.
If trim_char is not specified, then a single blank space will be used. Example:
SELECT TRIM (‗a‘ FROM ‗aaa123456789aa‘) "trim both" FROM DUMMY; Retrieves: trim both
123456789
SELECT TRIM (LEADING ‘a‘ FROM ‗aaa123456789aa‘) "trim leading" FROM DUMMY; Retrieves: trim leading
123456789aa
UCASE Function Syntax:
UCASE (target) Description:
Converts all characters in the target string to uppercase. Example:
SELECT UCASE ('Ant') "ucase" FROM DUMMY;
Retrieves: ucase
ANT
UNICODE Function Syntax :
UNICODE(c) Description:
Returns an integer containing the Unicode code point of the first character in the string, or NULL if the first character is not a valid encoding. Example:
SELECT UNICODE ('#') "unicode" FROM DUMMY;
Retrieves: unicode
54620
UPPER Function Syntax:
UPPER (target)

SAP HANA Database: SQL Reference Manual
56
Description:
Converts all characters in the target string to uppercase.
Example:
SELECT UPPER ('Ant') "uppercase" FROM DUMMY; Retrieves: uppercase
ANT

SAP HANA Database: SQL Reference Manual
57
Miscellaneous Functions
BINTOHEX Function Syntax:
BINTOHEX (expression) Description:
Returns the hexidecimal string of expression. Example:
SELECT BINTOHEX('AB') "bintohex" FROM DUMMY;
Retrieves: bintohex
4142
COALESCE Function Syntax :
COALESCE (expression_list) Description:
Returns the first non-NULL expression from a list. At least two expressions must be passed into the function, and all expressions must be comparable. The result will be NULL if all the arguments are NULL. Example:
SELECT * FROM tab;
Retrieves: ID A B
1 100.0 80.0
2 NULL 63.0
3 NULL NULL
SELECT id, a, b, COALESCE (a, b*1.1, 50.0) "coalesce" FROM tab; Retrieves: ID A B coalesce
1 100.0 80.0 100
2 NULL 63.0 69.3
3 NULL NULL 50
HASANYPRIVILEGES Function Syntax:
HASANYPRIVILEGES (<user_name>, <object_oid>, <schema_name>, <object_type> [,
<subobjecttype>]) Description:
Returns 1 in case the given user has any privilege on the specified object. <object_type> is for example: TABLE, VIEW, PROCEDURE Users having system privilege DATA ADMIN or CATALOG READ are allowed to use this function
with any user given as first parameter. Other users are only allowed to use their own user_name
as first parameter.

SAP HANA Database: SQL Reference Manual
58
Example:
SELECT HASANYPRIVILEGES (CURRENT_USER, 12345, ‗MY_SCHEMA‘, ‗TABLE‘) HAS_PRIV FROM
DUMMY;
Retrieves: HAS_PRIV
1
HASSYSTEMPRIVILEGE Function Syntax:
HASSYSTEMPRIVILEGE (<user_name>, <systemprivilege>) Description:
Returns 1 if the given user has the specified systemprivilege.
<systemprivilege> is ‗CATALOG READ‘ for example
DATA ADMIN or CATALOG READ – With DATA ADMIN or CATALOG READ privilege, users are allowed to check for all users. Normal users are only allowed to check for themselves, if they do have any privilege on that object. Example:
SELECT HASSYSTEMPRIVILEGE (CURRENT_USER, 'INIFILE ADMIN') HAS_INI_ADMIN FROM
DUMMY;
Retrieves: HAS_INI_ADMIN
0
HEXTOBIN Function Syntax:
HEXTBIN (expression) Description:
Returns the binary value of expression where expression is a hexadecimal value. Example:
SELECT HEXTOBIN ('1a') "hextobin" FROM DUMMY;
Retrieves: hextobin
1A
ISAUTHORIZED Function Syntax:
ISAUTHORIZED (<user_name>, <SQL-privilege>, <schema_name>, <object_name>, <object_type> [, <subobjecttype>]) Description:
Returns 1 if the given user has the specified SQL-privilege on the specified object. <SQL-privilege> is ‗SELECT‘ or ‗EXECUTE‘ for example. <object_type> is for example: TABLE, VIEW, PROCEDURE Example:
SELECT ISAUTHORIZED (CURRENT_USER, ‗SELECT‘, ‗MY_SCHEMA‘, ‗MY_TABLE‘, ‗TABLE‘)
HAS_PRIV FROM DUMMY;

SAP HANA Database: SQL Reference Manual
59
Retrieves: HAS_PRIV
1
IFNULL Function Syntax:
IFNULL (expression1, expression2) Description:
Returns expression1 if expression1 is not NULL and expression2 if expression1 is NULL. Example:
SELECT IFNULL ('diff', 'same') "ifnull" FROM DUMMY;
Retrieves: ifnull
diff
NULLIF Function Syntax:
NULLIF (expression1, expression2) Description:
NULLIF compares the values of the two expressions. If the first expression equals the second expression, NULLIF returns NULL. If the first expression does not equal the second expression, or if the second expression is NULL,
NULLIF returns the first expression.
The NULLIF function provides a short way to write some CASE expressions. Example:
SELECT NULLIF ('diff', 'same') "nullif" FROM DUMMY;
Retrieves: nullif
Diff
SELECT NULLIF('same', 'same') "nullif" FROM DUMMY; Retrieves: nullif
NULL
CURRENT_CONNECTION Function Syntax:
CURRENT_CONNECTION
Description:
Returns the current connection id. Example:
SELECT CURRENT_CONNECTION "current connection" FROM DUMMY; Retrieves: current connection
2

SAP HANA Database: SQL Reference Manual
60
CURRENT_SCHEMA Function Syntax:
CURRENT_SCHEMA
Description:
Returns the current schema name in the string. Example:
SELECT CURRENT_SCHEMA "current schema" FROM DUMMY; Retrieves: current schema
SYSTEM
CURRENT_USER Function Syntax:
CURRENT_USER
Description:
Returns the current user name in the string. Example:
SELECT CURRENT_USER "current user" FROM DUMMY; Retrieves: current user
SYSTEM
GROUPING_ID Function Syntax:
GROUPING_ID(column_name_list)
Description:
GROUPING_ID function can be used with GROUPING SETS to return multiple levels of aggregations in a single result set. GROUPING_ID returns an integer value to identify which grouping set each row belongs to. Each column in GROUPING_ID must be an element of the GROUPING SETS. GROUPING_ID is assigned by converting the bit vector generated from GROUPING SETS to a
decimal number by treating the bit vector as a binary number. When a bit vector is composed, 0 is assigned to each column specified in the GROUPING SETS and 1 otherwise in the order it appears in the GROUPING SETS. By treating the bit vector as a binary number, this function returns an integer value as the output. Example:
SELECT customer, year, product, SUM(sales), GROUPING_ID(customer, year, product) FROM guided_navi_tab GROUP BY GROUPING SETS ( (customer, year, product), (customer, year),
(customer, product), (year, product), (customer), (year), (product));

SAP HANA Database: SQL Reference Manual
61
Retrieves:
CUSTOMER YEAR PRODUCT SUM(SALES) GROUPING_ID(CUSTOMER,YEAR,PRODUCT)
1 C1 2009 P1 100 0
2 C1 2010 P1 50 0
3 C2 2009 P1 200 0
4 C2 2010 P1 100 0
5 C1 2009 P2 200 0
6 C1 2010 P2 150 0
7 C2 2009 P2 300 0
8 C2 2010 P2 150 0
9 C1 2009 ? 300 1
10 C1 2010 ? 200 1
11 C2 2009 ? 500 1
12 C2 2010 ? 250 1
13 C1 ? P1 150 2
14 C2 ? P1 300 2
15 C1 ? P2 350 2
16 C2 ? P2 450 2
17 ? 2009 P1 300 4
18 ? 2010 P1 150 4
19 ? 2009 P2 500 4
20 ? 2010 P2 300 4
21 C1 ? ? 500 3
22 C2 ? ? 750 3
23 ? 2009 ? 800 5
24 ? 2010 ? 450 5
25 ? ? P1 450 6
26 ? ? P2 800 6
SESSION_CONTEXT Function Syntax:
SESSION_CONTEXT(session_parameter)
Description:
Returns the value of session_parameter assigned to the current user or the value of a personal
setting. The parameter can be set when the session is created. Currently available read only
session variables are ‗locale‘, ‗locale_sap‘, ‗client‘, ‗conn_id‘, ‗applicationname‘, ‗clientuser‘,
‗clienthostname‘.
Example:
SELECT SESSION_CONTEXT(‗conn_Id‘) ―session context‖ FROM DUMMY;
Retrieves: session context
4

SAP HANA Database: SQL Reference Manual
62
SYSUUID Function Syntax:
SYSUUID
Description:
Returns the SYSUUID. Example:
SELECT SYSUUID FROM DUMMY; Retrieves: SYSUUID
4DE3CD576C79511BE10000000A3C2220

SAP HANA Database: SQL Reference Manual
63
SQL Statements This chapter describes the SQL statements that are supported by the SAP HANA Database.
ALTER AUDIT POLICY SQL Syntax: ALTER AUDIT POLICY <policy_name> <on_off>
Parameters: <policy_name> :: = <identifier>
<on_off> ::= ENABLE | DISABLE
Description: Enables or disables an audit policy. Information on AUDIT POLICY is available in the system view,
PUBLIC.AUDIT_POLICIES.

SAP HANA Database: SQL Reference Manual
64
ALTER SYSTEM SQL Syntax: ALTER SYSTEM <alter_system_options>
Parameters:
Parameters for ALTER SYSTEM: alter_system_options ::= ALTER CONFIGURATION (<ini_set_parameter>, ...) SET | UNSET <parameter_key_value_list>
[ WITH RECONFIGURE] | ALTER SESSION <session_id> SET | UNSET <session_variable_name>=<session_variable_value> | CANCEL [WORK IN] SESSION <session_id>
| CLEAR SQL PLAN CACHE | CLEAR TRACES (<trace_file_name_list>)
| DELETE ALL HANDLED EVENTS | DELETE HANDLED EVENT [<host_port>] <event_id> | DISCONNECT SESSION <session_id>
| LOGGING <on_off> | RECLAIM DATAVOLUME [SPACE] <host_port> <payload_size> <shrink_mode> | RECLAIM LOG [<log_part>]
| RECLAIM VERSION SPACE | RECONFIGURE SERVICE (<service_name>, <host_name>, <port_no>) | REMOVE TRACES (<host_name>, <trace_file_name_list>) | RESET MONITORING VIEW <view_name>
| SAVE PERFTRACE [INTO FILE <file_name>]
| SAVEPOINT | SET EVENT HANDLED [<event_type>] <event_id>
| START PERFTRACE [<user_name>] [PLAN_EXECUTION] [DURATION <duration>]
| STOP PERFTRACE | STOP SERVICE (<service_name>,<host_name>,<port_no>) [IMMEDIATE [WITH COREFILE]]
Description:
ALTER CONFIGURATION
Sets or Removes configuration parameters in the ini file. Ini file configuration is used for the layered configuration for DEFAULT, SYSTEM, HOST layers. The following is an example of ini file locations:
DEFAULT: /usr/sap/<SYSTEMNAME>/HDB<INSTANCENUMBER>/exe/config/indexserver.ini SYSTEM: /usr/sap/<SYSTEMNAME>/SYS/global/hdb/custom/config/indexserver.ini
HOST: /usr/sap/<SYSTEMNAME>/ HDB<INSTANCENUMBER>/<HOSTNAME>/indexserver.ini The priority of configuration is defined as DEFAULT < SYSTEM < HOST, meaning the priority of HOST layer has the highest priority. Configuration with the available highest
priority will be applied to the running environment. If the highest priority level configuration is removed, then the configuration with the next highest priority will be applied. DEFAULT layer configuration cannot be changed or removed. You can configure remote host configurations if you use HOST layer.
Currently available ini files are listed in M_INIFILES and current configuration is available in M_INIFILE_CONTENTS.
Syntax Elements: <parameter_key_value_list> ::=

SAP HANA Database: SQL Reference Manual
65
{(<section_name>,<parameter_name>) = <parameter_value>},…
<section_name> ::= <string_literal>
<parameter_name> ::= <string_literal> <parameter_value> ::=<string_literal>
Example syntax to change system layer configuration is as follows:
ALTER SYSTEM ALTER CONFIGURATION ('filename', 'layer') SET ('section1',
'key1') = 'value1', ('section2', 'key2') = 'value2', ... [WITH RECONFIGURE];
ALTER SYSTEM ALTER CONFIGURATION ('filename', 'layer', 'layer_name' ) UNSET
('section1', 'key1'), ('section2'), ...[WITH RECONFIGURE];
'layer' can be 'SYSTEM' or 'HOST'. In case of HOST layer, 'layer_name' is either its target
tenant name or target host name; for example, 'selxeon12' for host. 'filename' is 'indexserver.ini' in case of row-store engine configuration. 'filename' must be
one of the ini files located on the 'default' layer. The set command will update the value of a key if the key already exists, but insert it otherwise. If 'filename' does not exist on the 'layer', the 'filename' file will be created first.
Without ―with reconfigure‖, the new configuration is written to the ini file, but the new value is not applied to runtime on the fly and will be applied at the next startup of the server. This means that there could be inconsistencies between the ini file contents and the actual configuration value in memory.
ALTER SESSION SET|UNSET
You can set session variables of any session by providing key and value pairs. If you have
session administration privileges, you can change session variables of other sessions by specifying the session ID. <session_id> ::= connection ID number <session_variable_name> ::= <string_literal>
<session_variable_value> ::= <string_literal>
There are several available read-only session variables and they are LOCALE, LOCALE_SAP, CLIENT, CONN_ID, APPLICATIONNAME, CLIENTUSER, and CLIENTHOSTNAME.
CANCEL [WORK IN] SESSION
Cancels the currently executed operation by the specified session, however, the session is
not disconnected.
CLEAR SQL PLAN CACHE
Resets sql plan cache. It tries to remove all the plans that are not currently running. CLEAR|REMOVE TRACES

SAP HANA Database: SQL Reference Manual
66
CLEAR TRACES clears trace contents from trace files and all files that were opened by a
service will be removed or reset to size 0. On distributed system, the command will clear all traces on all hosts. <trace_filename_list> :: = <trace_file_name>, … <trace_file_name> ::= <string_literal>
It can clear different types of files:
Name Files
ALERT <service>alert...trc
CLIENT localclient_....trc
CRASHDUMP *.crashdump....trc
* open *.trc files of all active services
INDEXSERVER,NAMESERVER,...,DAEMON open *.trc files of a single service type
REMOVE TRACES deletes the trace files on specified hosts. When a service has a trace file open, then it cannot be deleted, so ―CLEAR‖ command should be used in that case. The trace files can be monitored using M_TRACEFILES and trace file contents can be monitored using M_TRACEFILE_CONTENTS.
DELETE ALL HANDLED EVENTS Delete all events with status ―HANDLED‖.
DELETE HANDLED EVENT
Delete the event with given ID. <host_port> ::= (‗<host_name>:<port_number>‘) | (<host_name>, <port_number>) <host_name> ::= <string_literal> <port_number> ::= Port Number <event_id> ::= event ID number
DISCONNECT SESSION
Disconnects the specified session from the database. The specified session will be disconnected but the current operation will be continued until it is completed.
LOGGING <on_off>
Logging is enabled or disabled.
<on_off>::= ON | OFF
RECLAIM DATA VOLUME Reduces data volume size to a N% of payload size; it works like defragmenting a hard disk, pages scattered around the data volume will be moved to the front of the data volume and the free space at the end of the data volume will be truncated. <host_port>::= ‗host:port‘
<payload_size>::= % of payload size (should be > 110%) <opt_shrink_mode>::= either ―defragment‖ or ―sparsify‖, default value is ―defragment‖
RECLAIM LOG
Reclaim disk space of unused log segments. <log_part>::= Log part number

SAP HANA Database: SQL Reference Manual
67
RECLAIM VERSION SPACE
Performs MVCC version garbage collection for resource reuse. RECLONFIGURE SERVICE
RECONFIGURE SERVICE reconfigures the service with current parameters. Depending on service, host, port, different services can be reconfigured: Service Host port
n.a. not empty not 0 Reconfigure single service on host y with port z
not empty not empty 0 Reconfigure all services of type x on host y
not empty empty 0 Reconfigure all services of type x
empty empty 0 Reconfigure all services
The information on service status is available at M_SERVICES.
RESET MONITORING VIEW
Resets statistics data for the specified monitoring view.
START|STOP|SAVE PERFTRACE
ALTER SYSTEM START PERFTRACE [USER name] [APPLICATIONUSER name]
[PLAN_EXECUTION] [FUNCTION_PROFILER] [DURATION seconds]
START Starts performance trace. It can be restricted to a specific SQL user by providing user_name. Also, plan execution details can be recorded with PLAN_EXECUTION option. If
the duration is specified, then it automatically stops after the specified duration.
ALTER SYSTEM STOP PERFTRACE
STOP Stops performance trace.
ALTER SYSTEM SAVE PERFTRACE [INTO FILE 'filename']

SAP HANA Database: SQL Reference Manual
68
SAVE
Collect performance trace data and save the information into a file. The file is located on the server in the trace directory. If no file name is specified, then ‗perftrace.tpt' is used. The file can be downloaded from ‗SAP HANA Computing Studio‘->Diagnosis-Files and then
the performance trace can be loaded and analyzed with HDBAdmin in any HDB instance. The status of performance trace can be monitored from M_PERFTRACE.
SAVEPOINT Executes a savepoint on the persistence manager. A savepoint is a point in time when a complete consistent image of the database is persisted on the disk. The consistent image can be used to restart the database.
SET EVENT HANDLED
Set event with given ID and type to state ―HANDLED‖
STOP SERVCE
STOP SERVICE stops the service. HOST and PORT information should be specified to stop a service. STOP SERVICE with IMMEDIATE option kills the running service. HOST and PORT information should be specified to kill a running service.
Service Host port
n.a. not empty not 0 Reconfigure single service on host y with port z
not empty not empty 0 Reconfigure all services of type x on host y
not empty empty 0 Reconfigure all services of type x
empty empty 0 Reconfigure all services

SAP HANA Database: SQL Reference Manual
69
ALTER TABLE
SQL Syntax:
ALTER TABLE <table_name> {<add_column_clause> | < drop_column_clause> | < alter_column_clause> | <add_primary_key_clause> | < drop_primary_key_clause> | <preload_clause> | <add_statistics_clause> | <drop_statistics_clause> | < table_conversion_clause> | <move_clause> | <add_range_partition_clause> | <move_partition_clause> | <drop_partition_clause>
| <partition_by_clause> | <merge_partition_clause> | <create_history_clause> | <drop_history_clause>} [WITH PARAMETERS (<parameter_key_value_list>)]
Parameters:
<table_name> ::= [<schema_name>.]<identifier>
<add_column_clause> ::= ADD ( <column_definition> <column_constraint>, ... )
<drop_column_clause> ::=DROP ( <column_name>, ... )
<alter_column_clause> ::= ALTER ( <column_definition>, ... )
ALTER Increasing the length of a column can be done. When modifying column definition is tried in column store, no error is returned because no check is done inside the database yet. An error may be returned if the data does not fit in the new data type defined when selecting the column. ALTER does not follow data type conversion rules yet.
<add_primary_key_clause> ::= ADD [CONSTRAINT <constraint_name>] PRIMARY KEY (<column_name>,... )
CONSTRAINT Specifies the name of a constraint.
PRIMARY KEY A primary key constraint is a combination of a NOT NULL constraint and a UNIQUE constraint. It prohibits multiple rows from having the same value in the same column.
<drop_primary_key_clause> ::= DROP PRIMARY KEY
<preload_clause> ::= PRELOAD ALL | PRELOAD ( <column_name> ) | PRELOAD NONE
PRELOAD sets/removes the preload flag of the given tables or columns. As a consequence, these tables are automatically loaded into memory after an index server start. The current
status of the preload flag is visible in the system table TABLES, column PRELOAD, possible
values ('FULL', 'PARTIALLY', ‗NO‘) and in system table TABLE_COLUMNS, column PRELOAD, possible values ('TRUE', 'FALSE').
<add_statistics_clause> ::= ADD STATISTICS FOR QUERY OPTIMIZER [ (<column_name>,… ) ]
ADD STATISTICS FOR QUERY OPTIMIZER Creates statistics for the columns of a table. If a column list is not specified, the statistics for all columns of the table are created. System view statistics has the statistics of columns of a table. Statistics are min, max, count, distinct count, null count values.
<update_statistics_clause> ::=
UPDATE STATISTICS FOR QUERY OPTIMIZER [(<column_name>,… ) ]
UPDATE STATISTICS FOR QUERY OPTIMIZER Update statistics for the columns of a table. If a column list is not specified, the statistics
for all columns of the table are updated. System view statistics has the statistics of
columns of a table. Statistics are min, max, count, distinct count, null count values.

SAP HANA Database: SQL Reference Manual
70
<drop_statistics_clause> ::=
DROP STATISTICS FOR QUERY OPTIMIZER [(<column_name>,… ) ]
DROP STATISTICS FOR QUERY OPTIMIZER Drops statistics for the columns of a table. If a column list is not specified, all existing statistics of the table are dropped.
<table_conversion_clause> ::= [ALTER TYPE] { ROW [THREADS <number_of_threads>]
| COLUMN [THREADS <number_of_threads> [BATCH <batch_size>]]}
ALTER TYPE ROW | COLUMN This command is used to convert the table storage from ROW to COLUMN or from COLUMN
to ROW. THREADS <number_of_threads>
Specifies how many threads should be used in parallel for table conversion. The optimal value for number of threads should set to the number of available CPU cores.
Default: The default value is TABLE_CONVERSION_PARALLELISM that is, the number of CPU cores specified in the indexserver.ini file. BATCH <batch_size>
Specifies the number of rows inserted in batch, and the default value is 2,000,000 which is
the optimal value. Insert into column table will be immediately committed after every int_const records insertion, which may reduce memory consumption. BATCH option can be used only when the table is converted from ROW to COLUMN. However, the batch size more than 2,000,000 might cause high memory consumption, thus it is not recommended to change this value.
A new table with a different storage type can be created from an existing table by copying the existing table's columns and data. This command is used to convert the table storage from ROW to COLUMN or from COLUMN to ROW. If the source table was in ROW storage, then the created table will be in COLUMN storage.
<move_clause> ::= MOVE TO LOCATION <host_port>
MOVE TO LOCATION A table can be moved to the specified location in a distributed environment.
<add_range_partition_clause> ::= ADD <range_partition_clause>
ADD adds a partition for tables partitioned with RANGE, HASH RANGE, ROUNDROBIN RANGE.
<range_partition_clause> ::= PRTITION <min_value> <= VALUES < <max_value> | PARTITION <value_or_values> = <target_value>
| PARTITION OTHERS <min_value> ::= <string_literal> | <numeric_literal> <max_value> ::= <string_literal> | <numeric_literal>
<target_value> ::= <string_literal> | <numeric_literal>
<move_partition_clause> ::= MOVE PARTITION <partition_number> TO <host_port>
MOVE PARTITION moves a partition to another host.
The port number is the internal indexserver port number, 3xx03.
<drop_partition_clause> ::= DROP PARTITION <range_partition_clause>
DROP PARTITION drops a partition for tables partitioned with RANGE, HASH RANGE, ROUNDROBIN RANGE.

SAP HANA Database: SQL Reference Manual
71
<partition_clause> ::= PARTITION BY <hash_partition> [,<range_partition> | ,<hash_partition>]
| PARTITION BY <range_partition> | PARTITION BY <roundrobin_partition> [,<range_partition>]
<hash_partition> ::= HASH (<partition_expression>[, ...]) PARTITIONS { <num_partitions> | GET_NUM_SERVERS()}
<range_partition> ::= RANGE (<partition_expression>) ( <range_spec>)
<roundrobin_partition> ::= ROUNDROBIN PARTITIONS {<num_partitions> | GET_NUM_SERVERS() }
<range_spec> ::=
{<from_to_spec> | <single_spec>[,…] } [, PARTITION OTHERS]
<from_to_spec> ::=
PARTITION <lower_value> <= VALUES < <upper_value>
<single_spec> ::= PARTITION VALUE <single_value>
<partition_expression> ::= <column_name> | YEAR (<column_name> ) | MONTH ( <column_name> )
PARTITION BY creates partitions for a non-partitioned table.

SAP HANA Database: SQL Reference Manual
72
<merge_partition_by_clause> ::= MERGE PARTITIONS
MERGE PARTITIONS merges all parts of a partitioned table into a non-partitioned table.
<create_history_clause> ::= CREATE HISTORY
Changes session type from SIMPLE to HISTORY and creates history-main and history-delta part of a table.
<drop_history_clause> ::= DROP HISTORY
Changes session type from HISTORY to SIMPLE and drops history-main and history-delta part of a table.
WITH PARAMETERS ( <parameter_key_value_list>, ... )
Column store-specific options can be passed in using the "WITH PARAMETERS" clause.
• Keys and single values can be any string literal
• Duplicate keys are allowed • Keys are automatically mapped into their uppercase representation
<parameter_key_value_list> ::= <parameter_key_value>, …
<parameter_key_value> ::=
<string_literal> = <string_literal> | <identifier> = <string_literal> | <string_literal> = (<string_literal>, ... )
Current parameters
‗AUTO_MERGE‘ = 'ON' | 'OFF' Default=ON Automatic delta merge triggered by memwatcher.
‗CONCAT_ATTRIBUTE‘ = (new_att, exist_att_list) Creating concatenated attributes:
new_att:= ‗string_literal‘ exist_att_list = 'string_literal' | exist-att-list ',' 'string_literal'
‗DELETE_CONCAT_ATTRIBUTE‘ := exist_att
Deleting concatenated attributes:
exist_att := 'string_literal'
‗TREX_FLAGS‘ = ('column_name','flags'), Flags are the implementation flags; the integer value is currently between 0 and 67108864. ‗INDEX_PROPERTY‘ = ('prop#', 'value')
Changing column table properties
ALTER TABLE <table_name> WITH PARAMETERS (‗INDEX_PROPERTY‘ = ('prop#', 'value') )
‗DSO_ACTIVATE_REQUESTS‘ = (rid_list) dso-activation of the given request IDs in the corresponding DSO index. rid_list has to be a comma-separated list of strings. Activation in the DSO sense means
changing the active data of the DSO index by applying the changes of the given requests residing in the Activation Queue. This parameter will only work for DSO indexes.

SAP HANA Database: SQL Reference Manual
73
‗DSO_ROLLBACK_REQUESTS‘ = (rid_list)
dso-rollback of the given RequestIds in the corresponding DSO index.
rid_list has to be a comma-separated list of strings. Rollback in the DSO sense means
removing the changes in the active data of the DSO that were caused by the given
requests. This parameter will only work for DSO indexes.
Description:
The ALTER TABLE statement allows you to perform the following actions:
Add, drop or alter columns Create or drop a primary key Preload or unload columns Add or drop statistics for sql optimizer
Convert table types Move a table
Add, drop or move partitions Example 1: ALTER TABLE T1 ADD (column_a VARCHAR(10));
ALTER TABLE T1 WITH PARAMETERS('CONCAT_ATTRIBUTE'=('A$B','A','B'));

SAP HANA Database: SQL Reference Manual
74
ALTER USER SQL Syntax: ALTER USER <user_name> <set_user_settings> | <external_identity> | <reset_attempts> | <drop_attempts> | <disable_password> | <force_change> | <deactive>
Parameters: <set_user_settings> ::= <set_user_password> | <set_user_parameter> | <clear_user_parameter>
<set_user_password> ::= PASSWORD <password>[<set_user_parameter> | <clear_user_parameter>]
<set_user_parameter>::= SET PARAMETER CLIENT= <string_literal>
<clear_user_parameter>::=CLEAR PARAMETER CLIENT | CLEAR ALL PARAMETERS
<external_identity> ::= IDENTIFIED EXTERNALLY AS <string_literal>
<reset_attempts> :: = RESET CONNECT ATTEMTPS
<drop_attempts> ::= DROP CONNECT ATTEMPTS
<disable_password> ::= DISABLE PASSWORD LIFETIME
<force_change> ::= FORCE PASSWORD CHANGE
<deactive> ::= DEACTIVE USER NOW | AT <string_literal>
Description: The ALTER USER statement modifies the database user.
Users created with PASSWORD cannot be changed to EXTERNALLY and vice versa, the users
created with EXTERNALLY cannot be changed to PASSWORD. System view USER_PARAMETERS shows all the user parameters and their values.
PASSWORD You can change a user‘s password with this command. SET PARAMETER CLIENT= <string_literal> <string_literal>::= param_value
Can be used to set a user parameter when a user is created in the database. CLEAR PARAMETER CLIENT, CLEAR ALL PARAMETERS This statement can be used to set/unset a parameter for an existing user. For this, the USER ADMIN system privilege is required.
IDENTIFIED EXTERNALLY You can change the external authentication. For information about external identities, contact your system administrator. RESET CONNECT ATTEMPTS If the number of MAXIMUM_INVALID_CONNECT_ATTEMPTS is reached before a successful (correct user/password-combination) connect is done, then this user is locked for some minutes before
being allowed to connect (even with correct user/password-combination) again. With the SQL command ALTER USER user_name RESET CONNECT ATTEMPTS an administrator can reset the
number of invalid attempts to 0 and therefore allow the user to connect immediately. DROP CONNECT ATTEMPTS

SAP HANA Database: SQL Reference Manual
75
Using this command, an administrator or the user himself can delete the information of invalid
connect attempts happened. DISABLE PASSWORD LIFETIME
With this option, an administrator (not the user himself) can exclude that user from all password-life-time-checks. This should be used only for technical users, not for normal database users. FORCE PASSWORD CHANGE With this option an administrator can force that user to change his password directly after the next connect before being allowed to work any further.
DEACTIVATE USER NOW The administrator can deactivate a user account using this command. After the user account is deactivated, the user cannot log on to the SAP HANA database until the administrator resets the user‘s password.
Example:
ALTER USER my_user PASSWORD myUserPass1;

SAP HANA Database: SQL Reference Manual
76
CONNECT SQL Syntax: CONNECT <user_name> PASSWORD <password>
Description: Connect to the database instance by specifying user_name and password.
Example: CONNECT my_user PASSWORD myUserPass1;

SAP HANA Database: SQL Reference Manual
77
CREATE AUDIT POLICY SQL Syntax: CREATE AUDIT POLICY <policy_name> AUDITING <action_status> <action_list> LEVEL <audit_level>
Parameters: <action_status> ::= SUCCESSFUL | UNSUCCESSFUL | ALL <action_list> ::= GRANT PRIVILEGE | REVOKE PRIVILEGE | GRANT STRUCTURED PRIVILEGE | REVOKE
STRUCTURED PRIVILEGE | GRANT ROLE | REVOKE ROLE | GRANT ANY | REVOKE ANY | CREATE USER | DROP USER | CREATE ROLE | DROP ROLE | CONNECT | SYSTEM CONFIGURATION CHANGE| ENABLE AUDIT POLICY | DISABLE AUDIT POLICY | SET SYSTEM LICENSE | CREATE STRUCTURED PRIVILEGE | DROP STRUCTURED PRIVILEGE <action_level> ::= EMERGENCY | ALERT | CRITICAL | WARNING | INFO
Description: Creates an audit policy describing which events to audit. Each policy has a name and can be
enabled or disabled by the administrator. Audit policies are owned by the system. They are not
dropped when the creating user is removed. The policy has several further attributes, which are
used to narrow the number of events that are audited.
The action list describes the list of database actions triggering this particular audit policy.
The possible action status are SUCCESSFUL, UNSUCCESSFUL, and ALL and UNSUCCESSFUL means
the current user is not authorized to execute the current action.
An audit level is assigned to each policy. Possible levels are EMERGENCY, ALERT, CRITICAL,
WARNING, INFO.

SAP HANA Database: SQL Reference Manual
78
CREATE CALCULATION SCENARIO SQL Syntax:
CREATE CALCULATION SCENARIO <scenario_name> USING <xml> [WITH PARAMETERS (<parameter_key_value>, ... ) ]
Parameters: <scenario_name> ::= <identifier> <xml> ::= <string_literal>
parameter_key_value ::= 'DEFAULT_SCHEMA' = <schema_name>
|'INMEMORY_SCENARIO' = '0'
|'INMEMORY_SCENARIO' = '1' |'EXPOSE_NODE' = ( <node_name>, <view_name> ) |'EXPOSE_NODE' = ( <node_name>, <schema_name>, <view_name> )
Description: The CREATE CALCULATION SCENARIO statement creates a calculation scenario.
Please note that a calculation scenario is not a default catalog object, so it cannot be accessed via a SELECT statement after its creation. A column view of type calculation is required on top of the scenario to query it. As it is not a catalog object, it is also not linked to a catalog schema. The first part of the name can be rather seen as a package in which the scenario is created. This implies that a drop of a
(database) schema does not drop the calculation scenarios. The scenario is defined with the used XML-string which has to be formatted as described in the XSD. The default schema defines on the one hand the package in which the scenario is created (if not defined explicitly), and the schema for the views on top listed in the expose nodes on the other.
It can be either in-memory only (set optional parameter value 'INMEMORY_SCENARIO' = '1') or persistent. The default scenario is persistent and stored in the repository. With an expose node item it is possible to directly create a column view of type calculation on top of a specified node on top of the scenario. The view name is defined in 'view_name'. The referenced node has to be specified in 'node_name'. Note that sub-transactions have started (and committed) in order to create the
views.
Note: For application development, a column view of type calculation should be used. Example
DROP TABLE TEST1;
CREATE COLUMN TABLE TEST1(A INTEGER, B DOUBLE);
insert into test1 values ( 1, 2);
insert into test1 values ( 11, 22);
insert into test1 values ( 111, 222);
DROP CALCULATION SCENARIO SYSTEM.DEMO_PROJECTION_OP cascade;
CREATE CALCULATION SCENARIO SYSTEM.DEMO_PROJECTION_OP USING '
<?xml version="1.0" encoding="utf-8"?>
<cubeSchema version="2" operation="createCalculationScenario">
<calculationScenario schema="SYSTEM" name="DEMO_PROJECTION_OP">
<dataSources>

SAP HANA Database: SQL Reference Manual
79
<tableDataSource name="demo_projection_datasource" schema="SYSTEM"
table="TEST1">
<attributes>
<allAttribute/>
</attributes>
</tableDataSource>
</dataSources>
<calculationViews>
<projection name="demo_projection" defaultViewFlag="true">
<inputs>
<input name="demo_projection_datasource" />
</inputs>
<attributes>
<allAttribute />
<calculatedAttribute name="C" datatype="double" isViewAttribute="true">
<formula>"A" * "B"</formula>
</calculatedAttribute>
</attributes>
<filter>"C" > 1</filter>
</projection>
</calculationViews>
</calculationScenario>
</cubeSchema>'
;
DROP VIEW SYSTEM.MYCALCVIEW;
CREATE COLUMN VIEW SYSTEM.MYCALCVIEW TYPE CALCULATION
WITH PARAMETERS
('PARENTCALCINDEXPACKAGE'='SYSTEM',
'PARENTCALCINDEX'='DEMO_PROJECTION_OP',
'PARENTCALCNODE'='demo_projection');
SELECT * FROM SYSTEM.MYCALCVIEW;
DROP CALCULATION SCENARIO SYSTEM.DEMO_PROJECTION_OP CASCADE;

SAP HANA Database: SQL Reference Manual
80
CREATE INDEX
SQL Syntax:
CREATE [UNIQUE] [BTREE | CPBTREE] INDEX <index_name> ON <table_name> (<column_name>, ...) [ ASC | DESC ]
Parameters: UNIQUE Used to create unique indexes. Check for duplicates will occur when an index is created and when a record is added to the table. BTREE | CPBTREE
Used to select the kind of index to use.
When column data types are character string types, binary string types, decimal types, or when the constraint is a composite key, or a non-unique constraint, the default index type is CPBTREE; otherwise, BTREE is used. If neither BTREE nor CPBTREE keyword is specified, then SAP HANA Database chooses the
appropriate index type. ASC | DESC Specifies whether the index should be created in ascending or descending order. These keywords can be only used in the btree index.
Description: The CREATE INDEX statement creates an index.
Example:
CREATE INDEX idx ON A(B);

SAP HANA Database: SQL Reference Manual
81
CREATE ROLE SQL Syntax: CREATE ROLE <role_name>
Description:
A role is a named collection of privileges and can be granted to either a user or a role. If you want to allow several database users to perform the same actions, you can create a role, grant the needed privileges to this role, and grant the role to the different database users. The default role is PUBLIC, every database user has been granted this role implicitly. Users who have system privilege ROLE ADMIN can CREATE, or DROP roles. The standard roles that are delivered with the SAP HANA database are:
MODELING Contains all privileges required for using the information modeler in the SAP HANA studio. MONITORING
Contains privileges for full read-only access to all meta data, the current system status in system and monitoring views, and the data of the statistics server. PUBLIC Contains privileges for filtered read-only access to the system views. Only objects for which the users have access rights are visible. By default, this role is assigned to each user.
CONTENT_ADMIN Contains the same privileges as the MODELING role, but with the extension that this role is allowed to grant these privileges to other users. In addition, it contains the repository privileges to
work with imported objects.
Example: CREATE ROLE my_role;

SAP HANA Database: SQL Reference Manual
82
CREATE SCHEMA SQL Syntax: CREATE SCHEMA <schema_name> [OWNED BY <user_name>]
Parameters:
OWNED BY Specifies the name of the schema owner. Description:
The CREATE SCHEMA statement creates a schema in the current database.
Example: CREATE SCHEMA my_schema OWNED BY system;

SAP HANA Database: SQL Reference Manual
83
CREATE SEQUENCE
SQL Syntax:
CREATE SEQUENCE <sequence_name> [<sequence_parameter_list>] [RESET BY <subquery>]
Parameters: <sequence_parameter_list> ::= <sequence_parameter>, ...
<sequence_parameter> ::=
INCREMENT BY integer
| START WITH integer | MAXVALUE integer | NO MAXVALUE
| MINVALUE integer | NO MINVALUE | CYCLE | NO CYCLE
INCREMENT BY Defines the amount the next sequence value is incremented from the last value assigned. The default is 1. Specify a negative value to generate a descending sequence. An error is returned if the INCREMENT BY value is 0
START WITH Defines the starting sequence value. If you do not specify a value for the START WITH clause, MINVALUE is used for ascending sequences and MAXVALUE is used for descending sequences.
MAXVALUE Defines the largest value generated by the sequence and must be between 0 and
4611686018427387903. NO MAXVALUE When MAXVALUE is not specified, the maximum value for an ascending sequence is 4611686018427387903 and the maximum value for a descending sequences is -1. MINVALUE
The minimum value of a sequence can be specified after MINVALUE and is between 0 and 4611686018427387903. NO MINVALUE When MINVALUE is not specified, the minimum value for an ascending sequence is 1 and the minimum value for a descending is -4611686018427387903.
CYCLE The sequence number will be reused after it reaches its maximum or minimum value. NO CYCLE Default option. The sequence number will not be reused after it reaches its maximum or minimum value.
RESET BY During the restart of the database, database automatically executes the RESET BY statement and the sequence value is restarted with the specified value from the statement after RESET BY. If RESET BY is not specified, the sequence value is stored persistently in database. During the restart of the database, the next value of the sequence is generated from the saved sequence
value.
Description:

SAP HANA Database: SQL Reference Manual
84
The CREATE SEQUENCE statement is used to create a sequence.
A sequence is used to generate unique integers by multiple users. CURRVAL is used to get the current value of the sequence and NEXTVAL is used to get the next value of the sequence. Example 1: sequence_name.CURRVAL
sequence_name.NEXTVAL
Example 2:
If the sequence s is used to create a unique key on column A in the table R, then after a database
is restarted, a UNIQUE key value can be created by automatically assigning the maximum value of column A to the sequence value using a RESET BY statement as follows: CREATE SEQUENCE s RESET BY SELECT IFNULL(MAX(a), 0) + 1 FROM r;

SAP HANA Database: SQL Reference Manual
85
CREATE STRUCTURED PRIVILEGE
SQL Syntax: CREATE STRUCTURED PRIVILEGE <structured_privilege_name>
Parameters: <structured_privilege_name>::= the name of the structured privilege
Description: An analytical privilege (based on a generic structured privilege) is uniquely identified by its name and contains a collection of relevant restrictions to restrict user access from different perspectives, such as accessible cubes and an accessible value range of dimension attributes.

SAP HANA Database: SQL Reference Manual
86
CREATE SYNONYM SQL Syntax: CREATE [PUBLIC] SYNONYM <synonym_name> FOR <schema_object_name>
Description: The CREATE SYNONYM creates an alternate name for a table, view, procedure or sequence.
You can use a synonym to re-point functions and stored procedures to differing tables, views or sequences without needing to re-write the function or stored procedure.
The optional PUBLIC element allows for the creation of a public synonym.
Example: CREATE SYNONYM a_synonym FOR a;

SAP HANA Database: SQL Reference Manual
87
CREATE TABLE SQL Syntax:
CREATE [<table_type>] TABLE <table_name> <table_contents_source> [<table_create_option_list>] [WITH PARAMETERS (<parameter_key_value_list>)]
Parameters:
<table_type> ::= COLUMN | ROW | HISTORY COLUMN | GLOBAL TEMPORARY | LOCAL TEMPORARY
ROW, COLUMN If the majority of access is through a large number of tuples but with only a few selected attributes, COLUMN-based storage should be used. If the majority of access involves selecting a few records with all attributes selected, ROW-based storage is preferable. The
SAP HANA Database uses a combination to enable storage and interpretation in both forms. You can define the type of organization for each table. The default value is ROW.
HISTORY COLUMN Creates a table with a particular transaction session type called ‗HISTORY‘. Tables with
session type HISTORY support time travel; the execution of queries against historic states
of the database is possible.
Timetravel can be done in the following ways.
Session-level timetravel:
SET HISTORY SESSION TO UTCTIMESTAMP =<timestamp yyyy:mm:dd hh:mm:ss>
SET HISTORY SESSION TO COMMIT ID =<commitid>
A database session (=database connection) can be set back to a certain point-in-time. The
COMMIT ID variant of the statement takes a commitid as a parameter. The value of the
commitid parameter must occur in COMMIT_ID column of the system table
SYS.TRANSACTION_HISTORY, otherwise an exception will be thrown. The COMMIT ID is
useful when using user defined snapshots. A user defined snapshot can be taken by simply
storing the commitid which is assigned to a transaction during the commit phase. The
commitid can be retrieved by executing the following query directly after a transaction
commit:
SELECT LAST_COMMIT_ID FROM M_TRANSACTIONS WHERE CONNECTION_ID = CURRENT_CONNECTION; The TIMESTAMP-variant of the statement takes a timestamp as parameter. Internally, the
timestamp is used to look up a (commit_time,commit_id)-pair inside the system-
table SYS.TRANSACTION_HISTORY where the commit_time is close to the given
timestamp (to be more precisely: choose pair where maximal COMMIT_TIME is smaller or
equal to the given timestamp; if no such pair is found an exception will be raised). The
session then will be restored with the determined commit-id as in the COMMIT ID variant.
To terminate a restored session to switch back to the current session, an explicit
COMMIT or ROLLBACK has to be executed on the DB connection.
Statement-level timetravel:
<subquery> AS OF UTCTIMESTAMP <timestamp yyyy:mm:dd hh:mm:ss> <subquery> AS OF COMMIT ID <commitid>

SAP HANA Database: SQL Reference Manual
88
In order to be able to relate the commitid with the commit time, a system table
SYS.TRANSACTION_HISTORY is maintained which stores additional information for each transaction which commits data for history table.
Remarks:
Autocommit has to be turned off when a session should be restored (otherwise an
exception will be thrown with an appropriate error message)
Non-history tables in restored sessions always show their current snapshot
Only data query statement (select) is allowed inside restored sessions.
A history table must have a primary key The session type can be checked from the column, SESSION_TYPE of the system
table SYS.TABLES.
GLOBAL TEMPORARY Table definition is globally available while data is visible only to the current session. The table is truncated at the end of the session. Metadata in a global temporary table is persistent meaning the metadata exists until the
table is dropped and the metadata is shared across sessions. Data in a global temporary table is session-specific meaning only the owner session of the global temporary table is allowed to insert/read/truncate the data, exists for the duration of the session and data from the global temporary table is automatically dropped when the session is terminated. Global temporary table can be dropped only when the table does not have any record in it. Supported operations on Global Temporary Table:
1. Create without a primary key 2. Rename table 3. Rename column
4. Truncate 5. Drop 6. Create or Drop view on top of global temporary table 7. Create synonym
8. Select 9. Select into or Insert 10. Delete 11. Update 12. Upsert or Replace
LOCAL TEMPORARY The table definition and data is visible only to the current session. The table is truncated at the end of the session. Metadata exists for the duration of the session and is session-specific meaning only the
owner session of the local temporary table is allowed to see. Data in a local temporary table is session-specific meaning only the owner session of the local temporary table is
allowed to insert/read/truncate the data, exists for the duration of the session and data from the local temporary table is automatically dropped when the session is terminated. Supported operations on Global Temporary Table: 1. Create without a primary key 2. Truncate 3. Drop
4. Select 5. Select into or Insert 6. Delete 7. Update 8. Upsert or Replace
<table_contents_source>:

SAP HANA Database: SQL Reference Manual
89
<table_contents_source>::= ( <table_element>,… )|[ (column_name,...) ]
[<like_table_clause> | <as_table_subquery>] [ WITH [NO] DATA ] ]
<table_element> ::= <column_definition> <column_constraint> | <table_constraint> ( <column_name>, ... )
<column_definition> ::= <column_name> <data_type>
[<column_store_data_type>] [<ddic_data_type>] [DEFAULT <default_value>] [GENERATED ALWAYS AS <expression> ]
DEFAULT
Default specifies a value to be assigned to the column if an INSERT statement does not provide a value for the column.
DATA TYPE in column definition Available column store data types are CS_ALPHANUM, CS_INT, CS_FIXED,
CS_FLOAT, CS_DOUBLE, CS_DECIMAL_FLOAT, CS_FIXED(p-s,s), CS_SDFLOAT, CS_STRING, CS_UNITEDECFLOAT, CS_DATE, CS_TIME, CS_FIXEDSTRING, CS_RAW, CS_DAYDATE, CS_SECONDTIME, CS_LONGDATE, and CS_SECONDDATE.
Available DDIC data types are DDIC_ACCP, DDIC_ALNM, DDIC_CHAR,
DDIC_CDAY, DDIC_CLNT, DDIC_CUKY, DDIC_CURR, DDIC_D16D, DDIC_D34D, DDIC_D16R, DDIC_D34R, DDIC_D16S, DDIC_D34S, DDIC_DATS, DDIC_DAY, DDIC_DEC, DDIC_FLTP, DDIC_GUID, DDIC_INT1, DDIC_INT2, DDIC_INT4, DDIC_INT8, DDIC_LANG, DDIC_LCHR, DDIC_MIN, DDIC_MON, DDIC_LRAW, DDIC_NUMC, DDIC_PREC, DDIC_QUAN, DDIC_RAW, DDIC_RSTR, DDIC_SEC, DDIC_SRST, DDIC_SSTR,
DDIC_STRG, DDIC_STXT, DDIC_TIMS, DDIC_UNIT, DDIC_UTCM, DDIC_UTCL, DDIC_UTCS, DDIC_TEXT, DDIC_VARC, DDIC_WEEK.
GENERATED ALWAYS AS Specifies the expression to generate the column value in runtime.
<column_constraint> ::= NULL | NOT NULL | UNIQUE [BTREE | CPBTREE]
|PRIMARY KEY [BTREE | CPBTREE] NULL | NOT NULL The NOT NULL constraint prohibits a column value from being NULL.
If NULL is specified it is not considered a constraint, it represents a column that may contain a null value. The default is NULL.
UNIQUE Specifies a column as a unique key. A composite unique key enables the specification of multiple columns as a
unique key. With a unique constraint, multiple rows cannot have the same value in the same column.
PRIMARY KEY A primary key constraint is a combination of a NOT NULL constraint and a UNIQUE constraint. It prohibits multiple rows from having the same value in the same column.
BTREE | CPBTREE Specifies the index type. When column data types are character string types, binary string types, decimal types, or when the constraint is a composite key, or non-unique constraint, the default index type is CPBTREE. Otherwise, BTREE is used.
BTREE keyword has to be used in order to use B+-tree index and the
CPBTREE keyword has to be used for the CPB+-tree index. If the index type is omitted, the SAP HANA Database chooses the appropriate index considering the column data types.

SAP HANA Database: SQL Reference Manual
90
<table_constraint> ::=UNIQUE [BTREE | CPBTREE] | PRIMARY KEY [BTREE |
CPBTREE] This defines a table constraint which can be used on one or more columns of a table. There are two kinds of a table constraint. They are: UNIQUE Specifies a uniqueness constraint for a column. This prevents multiple rows
from having the same values in the same column list.
PRIMARY KEY A primary key constraint is a combination of the NOT NULL and UNIQUE constraints. It creates a unique column that can be always be used to
locate rows uniquely within a table.
BTREE | CPBTREE Specifies the index type. When column data types are character string types, binary string types, decimal types, or when the constraint is a composite key, or non-unique constraint, the default index type is CPBTREE, BTREE is used in all other cases.
BTREE keyword has to be used in order to use the B+-tree index and the CPBTREE keyword has to be used for the CPB+-tree index. If the index type is omitted, the SAP HANA Database chooses the appropriate index considering the column data types.
<like_table_clause> ::= LIKE <like_table_name>
Creates a table that has the same definition as like_table_name. All the column definitions with constraints and default values are copied from like_table_name. Data is filled from the specified table when WITH DATA option is provided, however, the default value is WITH NO DATA.
<as_table_subquery> ::=AS (<select_query>)
Creates a table and fills it with the data computed by the <select_query>. Only NOT NULL constraints are copied by this clause. If <column_names> are specified,
specified <column_names> override the column names from <select_query>.
WITH [NO] DATA
Specifies whether the data is copied from <select_query> or <like_table_clause>. The
default value is WITH DATA.
<table_create_option_list> ::= <table_create_option>,…
<table_create_option> ::=
[<logging_option> | <auto_merge_option> | <partition_caluse>| <location_clause>]
<logging_option> ::= LOGGING | NO LOGGING [RETENTION <retention_period>]
LOGGING | NO LOGGING LOGGING (default value) specifies that table logging is activated.
NO LOGGING specifies that logging is deactivated. A NO LOGGING table means that the definition of the table is persistent and globally available, data is temporary and global. RETENTION Specifies the retention time in seconds of the column table created by NOLOGGING. After
the specified retention period has elapsed, the table will be dropped if used physical
memory of the host reaches above 80%.

SAP HANA Database: SQL Reference Manual
91
<auto_merge_option> ::= AUTO MERGE | NO AUTO MERGE
AUTO MERGE | NO AUTO MERGE AUTO MERGE (default value) specifies that automatic delta merge is triggered by memwacher.
<partition_clause>::= PARTITION BY <hash_partition> [,<range_partition> | ,<hash_partition>]
| PARTITION BY <range_partition> | PARTITION BY <roundrobin_partition> [,<range_partition>]
<hash_partition> ::= HASH (<partition_expression>[, ...]) PARTITIONS { <num_partitions> |
GET_NUM_SERVERS() }
<range_partition> ::= RANGE (<partition_expression>) ( <range_spec>)
<roundrobin_partition> ::= ROUNDROBIN PARTITIONS {<num_partitions> | GET_NUM_SERVERS()}
<range_spec> ::= {<from_to_spec> | <single_spec>[,…] } [, PARTITION OTHERS]
<from_to_spec> ::=
PARTITION <lower_value> <= VALUES < <upper_value>
<single_spec> ::= PARTITION VALUE <single_value>
<partition_expression> ::= <column_name> | YEAR ( <column_name> ) | MONTH ( <column_name> )

SAP HANA Database: SQL Reference Manual
92
It is possible to determine the index servers on which the partitions are created. If you specify the LOCATION, the partitions will be created on these instances using round robin. Duplicates in the list will be removed. If you specify exactly the same number of instances
as partitions in the partition specification, then each partition will be assigned to the respective instance in the list. All index servers in the list have to belong to the same instance. If no locations are specified, the partitions will be created randomly. If the number of partitions matches the number of servers – for example by using GET_NUM_SERVERS() – it is ensured that multiple CREATE TABLE calls distribute the partitions in the same way. In case of a multi-level partitioning, this applies for the number of partitions of the first level.
This mechanism is useful if several tables are to be created which have a semantic relation to each other.
<location_clause> ::= AT [LOCATION] ‗<host:port>‘ | ( ‗<host:port>‘, … )
AT LOCATION A column store table can be created in the specified location with host:port. Location list can be specified when creating partitioned tables that are distributed on multiple instances. When location list is provided without partition_clause, the table is created on the first
location specified. If location information is not provided, the table will be automatically assigned to one node.
This option can be used for both row store and column store tables in a distributed environment.
<parameter_key_value_list>::= <parameter_key_value>, …
<parameter_key_value>::= <string_literal> = <string_literal> |
<identifier> = <string_literal> |
<string_literal> = (<string_literal>, ... )
Options that can be used only for column store tables can be passed in using "WITH PARAMETERS" clause. Parameter keys and string values can be any string literal. Duplicate keys are allowed. Keys are automatically mapped into their upper-case form.
parameter_key_value
'TREX_FLAGS' = ('column_name','flags'), Flags are the implementation flags, integer value is currently between 0 and 67108864.
Description:
The CREATE TABLE statement creates a table. Tables are created without data except when as_table_subquery or like_table_clause is used with the WITH DATA option.
Example:
CREATE TABLE A (A INT PRIMARY KEY, B INT);

SAP HANA Database: SQL Reference Manual
93
CREATE TYPE SQL Syntax: CREATE TYPE <type_name> AS TABLE (<table_element>, ... )
Parameters:
<table_element> ::= <column_definition> <column_constraint> | <table_constraint> ( <column_name>, ... )
Description: The CREATE TYPE statement creates a user-defined type.
A user can create tables that have the same specifications as a user-defined table type.
Example: CREATE TYPE my_type AS TABLE ( column_a DOUBLE );

SAP HANA Database: SQL Reference Manual
94
CREATE USER SQL Syntax: CREATE USER <user_name> <password_clause> | <external_identity> [set_parameter]
Parameters:
<password_clause> ::= PASSWORD <password>
<password> ::= <string_literal>
<external_identity> ::= IDENTIFIED EXTERNALLY AS [<external_identity_name>] <external_identifty_name> ::= <string_literal>
<set_parameter> ::= SET PARAMETER CLIENT= <param_value>
<param_value> ::= <string_literal>
Description: The CREATE USER statement creates a new database user.
The specified user name must not be identical to the name of an existing user, role, or schema. PASSWORD password In the SAP HANA Database there are two kinds of users, internally and externally authenticated users. Internally authenticated users are authenticated using a user name and a password. The password for a user has to be changed regularly.
Password must follow the rules defined for the current database. The password rules include the minimal password length and the definition which of the character types ( lower, upper, digit, special characters ) that have to be part of the password.
IDENTIFIED EXTERNALLY AS [external_identity] External users are authenticated using an external system, e.g. a Kerberos system. Such users do not have a password. For detailed information about external identities, contact your domain administrator.
SET PARAMETER CLIENT= param_value Can be used to set a user parameter when a user is created in the database.
Example: CREATE USER my_user PASSWORD Aa123456;

SAP HANA Database: SQL Reference Manual
95
CREATE VIEW
SQL Syntax:
CREATE VIEW <view_name> [(<column_name>,...) ] AS <subquery>
Description: The CREATE VIEW statement effectively creates virtual table based on the results of an SQL
statement. It is not a table in a real sense as it does not contain data in itself. When a column name is specified along with the view name, a query result is displayed with that column name. If a column name is omitted, a query result gives an appropriate name to the column automatically. The number of column names has to be the same as the number of columns
returned from select_statement.
Update operations on views are supported if the following conditions are met:
Each column in the view must map to a column of a single table If a column in the base table has NOT NULL constraint without default value, the column
must be included in view columns to be an insertable view. Update operation on a view is
allowed without this condition. Must not contain an aggregate or analytic function in a SELECT list for example, the
followings are not allowed: TOP, SET, DISTINCT operator in a SELECT list GROUP BY, ORDER BY clause
Must not contain a subquery in a SELECT list
Must not contain a sequence value(CURRVAL, NEXTVAL) Must not contain a column view as the base view
If base views or tables are updatable, a view on the base views or tables can be updatable if the above conditions are met.
Example:
CREATE VIEW v_name AS SELECT * FROM a;

SAP HANA Database: SQL Reference Manual
96
DELETE SQL Syntax: DELETE [HISTORY] FROM <table_name> [WHERE <predicate>]
Description:
The DELETE statement deletes records from a table where the predicates are met. If the WHERE
clause is omitted, then it removes all records from a table.
DELETE HISTORY DELETE HISTORY will mark the chosen records of the history-part of the history-table for deletion. This means that after executing this command, timetravel queries referencing the deleted rows may still see these rows. In order to physically delete these rows the following statements
have to be executed:
ALTER SYSTEM RECLAIM VERSION SPACE; MERGE HISTORY DELTA of <table_name>;
Please note that in some cases even the execution of the two statements above may not lead
to physical deletion. To check whether the rows are physically deleted, the following statement can be helpful: SELECT * FROM <table_name> WHERE <predicate>
WITH PARAMETERS ('REQUEST_FLAGS'= ('ALLCOMMITTED','HISTORYONLY'));
Example:
DELETE FROM table_a WHERE a = 1;

SAP HANA Database: SQL Reference Manual
97
DROP AUDIT POLICY SQL Syntax: DROP AUDIT POLICY <policy_name>
Description:
Drops an audit policy.
Example:
DROP AUDIT POLICY policy_name;

SAP HANA Database: SQL Reference Manual
98
DROP CALCULATION SCENARIO SQL Syntax: DROP CALCULATION SCENARIO name [<drop_option> ]
Parameters:
<drop_option> ::= CASCADE
Default = CASCADE Cascaded drop drops the calculation scenario and dependent column views of type calculation.
Non-cascaded drop behavior prevents dropping the scenario if there are any column views of type calculation referencing the scenario.
Description: The DROP CALCULATION SCENARIO statement deletes a calculation scenario.
Example: DROP CALCULATION SCENARIO SYSTEM.DEMO_PROJECTION_OP CASCADE;

SAP HANA Database: SQL Reference Manual
99
DROP INDEX
SQL Syntax:
DROP INDEX <index_name>
Description: The DROP INDEX statement removes an index.
Example:
DROP INDEX idx ;

SAP HANA Database: SQL Reference Manual
100
DROP ROLE SQL Syntax: DROP ROLE <role_name>
Description:
Users with system privilege ROLE ADMIN can DROP roles. If a role was granted to a user, it is revoked when the role is dropped. Revoking a role may lead to making some views inaccessible. This will occur if a view, or procedures using those views, depends on any privilege that the role has.
Example:
DROP ROLE my_role;

SAP HANA Database: SQL Reference Manual
101
DROP SCHEMA SQL Syntax: DROP SCHEMA <schema_name> [<drop_option>]
Parameters:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
Restrict drop behavior will drop the object when there is no dependent object. If there is a
dependent object, an error will be thrown. Cascaded drop drops the object and dependent objects.
Non-Cascaded drop option is not supported for dropping SCHEMA.
Description: The DROP SCHEMA statement removes a schema.
Example:
DROP SCHEMA my_schema;

SAP HANA Database: SQL Reference Manual
102
DROP SEQUENCE SQL Syntax: DROP SEQUENCE <sequence_name> [ <drop_option> ]
Parameters:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT Cascaded drop drops the object and dependent objects. When CASCADE option is not specified,
non-cascaded drop behavior drops the object and does not drop the dependent objects, but invalidates the dependent objects (VIEW, PROCEDURE).
The invalidated object can be revalidated when an object that has same schema and object name is created. Object ID, schema name, and object name pair is reserved for revalidating dependent objects.
Restrict drop behavior will drop the object when there is no dependent object. If there is a dependent object, an error will be thrown. Description: The DROP SEQUENCE statement removes a sequence.
Example: DROP SEQUENCE s;

SAP HANA Database: SQL Reference Manual
103
DROP STRUCTURED PRIVILEGE
SQL Syntax: DROP STRUCTURED PRIVILEGE <structured_privilege_name>
Description:
An analytical privilege (based on a generic structured privilege) is uniquely identified by its name and contains a collection of relevant restrictions to restrict user access from different perspectives. You can revoke these restrictions in the SAP HANA Database using the DROP STRUCTURED PRIVILEGE statements. As the owner (creator) of an analytical privilege, you can also revoke the analytical privilege to or from another user to restrict user access to analytic data (cubes) using the REVOKE statement.

SAP HANA Database: SQL Reference Manual
104
DROP SYNONYM SQL Syntax: DROP SYNONYM <synonym_name> [<drop_option>]
Parameters:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
Cascaded drop drops the object and dependent objects. When CASCADE option is not specified,
non-cascaded drop behavior drops the object and does not drop the dependent objects, but invalidates the dependent objects (VIEW, PROCEDURE).
The invalidated object can be revalidated when an object that has same schema and object name is created. Object ID, schema name, and object name pair will be reserved for revalidating dependent objects.
Restrict drop behavior will drop the object when there is no dependent object. If there is a dependent object, an error will be thrown. Description: The DROP SYNONYM statement removes a synonym.
Example: DROP SYNONYM a_synonym;

SAP HANA Database: SQL Reference Manual
105
DROP TABLE
SQL Syntax:
DROP TABLE <table_name> [<drop_option>]
Parameters: <drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT Cascaded drop drops the object and dependent objects. When CASCADE option is not specified, non-cascaded drop behavior drops the object and does not drop the dependent objects, but invalidates the dependent objects (VIEW, PROCEDURE).
The invalidated object can be revalidated when an object that has the same schema and object name is created. The object ID, schema name, and object name pair will be reserved for revalidating dependent objects. Restrict drop behavior drops the object when there is no dependent object. If there is a dependent object, an error is thrown.
Description: The DROP TABLE statement deletes a table.
Example:
DROP TABLE A;

SAP HANA Database: SQL Reference Manual
106
DROP TYPE SQL Syntax: DROP TYPE <type_name> [<drop_option>]
Parameters: <drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
Cascaded drop drops the object and dependent objects. When CASCADE option is not specified, non-cascaded drop behavior drops the object and does not drop the dependent objects, but
invalidates the dependent objects (VIEW, PROCEDURE). When a table type is dropped with non-cascaded drop option, the dependent SQLScript procedure
will be invalidated but will not be dropped. When the underlying object of SQLScript procedure is recreated, the validity of the procedure is checked again and revalidated.
Restrict drop behavior will drop the object when there is no dependent object. If there is a dependent object, an error will be thrown.
Description: The DROP TYPE statement removes a user-defined table type.
Example: DROP TYPE my_type;

SAP HANA Database: SQL Reference Manual
107
DROP USER SQL Syntax:
DROP USER user_name [<drop_option>]
Parameters: <drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT If CASCADE is specified (or used as the default), all schemas, synonyms and tables of the user are
dropped, including indexes, privileges, view tables and everything based on these objects, is also deleted along with the user.
If RESTRICT is specified, and the user to be dropped is the owner of synonyms or tables, then the DROP USER statement will fail.
Description: The DROP USER statement deletes a database user. The schema with the user's name and the
schemas belonging to the user, together with all objects in them (even if they are created by different users), are deleted. Objects owned by the user, even if they are part of another schema,
are deleted. Objects that are dependent on deleted objects are deleted. Privileges on these deleted objects are also deleted. It is possible to delete a user even if a there is a current user session existing.
Example: DROP USER my_user;

SAP HANA Database: SQL Reference Manual
108
DROP VIEW
SQL Syntax:
DROP VIEW <view_name> [<drop_option>]
Parameter: <drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT Cascaded drop drops the object and dependent objects. When CASCADE option is not specified, non-cascaded drop behavior drops the object and does not drop the dependent objects, but invalidates the dependent objects (VIEW, PROCEDURE).
The invalidated object can be revalidated when an object that has same schema and object name is created. Object ID, schema name, and object name pair will be reserved for revalidating dependent objects. Restrict drop behavior will drop the object when there is no dependent object. If there is a dependent object, an error will be thrown.
Description: The DROP VIEW statement removes a view.
Example:
DROP VIEW v_name;

SAP HANA Database: SQL Reference Manual
109
EXPLAIN PLAN SQL Syntax: EXPLAIN PLAN [SET STATEMENT_NAME = <statement_name>] FOR SELECT <subquery>
Parameters:
<statement_name> ::= string literal used to identify the name of a specific execution plan in the
output table for a given SQL statement. It is set to NULL if the SET STATEMENT_NAME is not specified.
<subquery> ::= an SQL statement
Description: The EXPLAIN PLAN statement is used to evaluate the execution plan that the SAP HANA Database
follows to execute an SQL statement. The result of the evaluation is stored into the EXPLAIN_PLAN_TABLE view for later user examination. The SQL statement must be data manipulation statement, thus a schema definition language statement cannot be used with the EXPLAIN PLAN command.
You can obtain SQL plan from EXPLAIN_PLAN_TABLE view. The view is shared by all users. Here is an example of reading an SQL plan from the view.
SELECT * FROM EXPLAIN_PLAN_TABLE;
Columns in EXPLAIN_PLAN_TABLE view:
Table 19: Column name and description
Column Name Description
STATEMENT_NAME The string specified as STATEMENT_NAME on executing the EXPLAIN PLAN command. This is used to distinguish plans from each other when there are multiple plans in the EXPLAIN_PLAN_TABLE view.
OPERATOR_NAME Name of an operator. Details are described in the following section.
OPERATOR_DETAILS Details of an operator. Predicates and expressions used by the operator are shown here.
SCHEMA_NAME Name of the schema of the accessed table.
TABLE_NAME Name of the accessed table.
TABLE_TYPE Type of the accessed table. One of the following options: COLUMN TABLE, ROW TABLE, MONITORING VIEW, JOIN VIEW, OLAP VIEW, CALCULATION VIEW and HIERARCHY VIEW.
TABLE_SIZE Estimated number of rows in the accessed table
OUTPUT_SIZE
Estimated number of rows produced by an operator

SAP HANA Database: SQL Reference Manual
110
Column Name Description
SUBTREE_COST Estimated cost of executing the subtree starting from an operator. This value is only for relative comparison.
OPERATOR_ID ID of an operator unique in a plan. IDs are integers starting from 1.
PARENT_OPERATOR_ID OPERATOR_ID of the parent of an operator. The shape of an SQL plan is a tree and the topology of the tree can be reconstructed using OPERATOR_ID and PARENT_OPERATOR_ID. PARENT_OPERATOR_ID of the root operator is shown as NULL.
LEVEL Level from the root operator. Level of the root operator is 1, level of a child of the root operator is 2 and so on. This can be utilized for output indentation.
POSITION Position in the parent operator. Position of the first child is 1, position of the second child is 2 and so on.
HOST The hostname where an operator was executed
PORT The TCP/IP port used to connect to the host
TIMESTAMP Date and time when the EXPLAIN PLAN command was executed.
CONNECTION_ID ID of the connection where the EXPLAIN PLAN command was executed.
EXECUTION_ENGINE Type of the execution engine where an operator is executed: COLUMN or ROW
OPERATOR_NAME column in EXPLAIN_PLAN_TABLE view: Table 20. List of column engine operators shown in the OPERATOR_NAME column.
Operator Name Description
COLUMN SEARCH Starting position of column engine operators. OPERATOR_DETAILS lists projected columns.
LIMIT Operator for limiting the number of output rows
ORDER BY Operator for sorting output rows
HAVING Operator for filtering with predicates on top of grouping and aggregation
GROUP BY Operator for grouping and aggregation
DISTINCT Operator for duplicate elimination
FILTER Operator for filtering with predicates
JOIN Operator for joining input relations
COLUMN TABLE Information about accessed column table
MULTIPROVIDER Operator for producing union-all of multiple results having the same grouping and aggregation
Table 21. List of row engine operators shown in the OPERATOR_NAME column.
Operator Name Description
ROW SEARCH Starting position of row engine operators. OPERATOR_DETAILS lists projected columns.
LIMIT Operator for limiting number of output rows
ORDER BY Operator for sorting output rows
HAVING Operator for filtering with predicates on top of grouping and aggregation
GROUP BY Operator for grouping and aggregation
MERGE AGGREGATION Operator for merging the results of multiple parallel grouping and aggregations
DISTINCT Operator for duplicate elimination
FILTER Operator for filtering with predicates

SAP HANA Database: SQL Reference Manual
111
Operator Name Description
UNION ALL Operator for producing union-all of input relations
MATERIALIZED UNION ALL Operator for producing union-all of input relations with intermediate result materialization
BTREE INDEX JOIN Operator for joining input relations through B-tree index searches. Join type suffix can be added. For example, B-tree index join for left outer join is shown as BTREE INDEX JOIN (LEFT OUTER). Join without join type suffix means inner join.
CPBTREE INDEX JOIN Operator for joining input relations through CPB-tree index searches. Join type suffix can be added.
HASH JOIN Operator for joining input relations through probing hash table built on the fly. Join type suffix can be added.
NESTED LOOP JOIN Operator for joining input relations through nested looping. Join type suffix can be added.
MIXED INVERTED INDEX JOIN
Operator for joining an input relation of row store format with a column table without format conversion using an inverted index of the column table. Join type suffix can be added.
BTREE INDEX SEARCH Table access through B-tree index search
CPBTREE INDEX SEARCH Table access through CPB-tree index search
TABLE SCAN Table access through scanning
AGGR TABLE Operator for aggregating base table directly
MONITOR SEARCH Monitoring view access through search
MONITOR SCAN Monitoring view access through scanning
COLUMN SEARCH is a mark for the starting position of column engine operators and ROW SEARCH is a mark for the starting position of row engine operators.
In the example below, the intermediate result produced by a COLUMN SEARCH (ID 10) is
consumed by a ROW SEARCH (ID 7), and the intermediate result produced by the ROW SEARCH (ID 7) is consumed by another COLUMN SEARCH (ID 1). The operators below the lowest COLUMN SEARCH (ID 10) explain how the COLUMN SEARCH (ID 10) is executed. The operators between the ROW SEARCH (ID 7) and the COLUMN SEARCH (ID 10) explain how the ROW SEARCH (ID 7) processes the intermediate result produced by the COLUMN SEARCH (ID 10). The operators between the top COLUMN SEARCH (ID 1) and the ROW SEARCH
(ID 7) explain how the top COLUMN SEARCH (ID 1) processes the intermediate result produced by the ROW SEARCH (ID 7). Table 22. Operators
OPERATOR_NAME OPERATOR_ID PARENT_OPERATOR_ID LEVEL POSITION
COLUMN SEARCH 1 NULL 1 1
LIMIT 2 1 2 1
ORDER BY 3 2 3 1
GROUP BY 4 3 4 1
JOIN 5 4 5 1
COLUMN TABLE 6 5 6 1
ROW SEARCH 7 5 6 2
BTREE INDEX JOIN 8 7 7 1
BTREE INDEX JOIN 9 8 8 1
COLUMN SEARCH 10 9 9 1
FILTER 11 10 10 1

SAP HANA Database: SQL Reference Manual
112
OPERATOR_NAME OPERATOR_ID PARENT_OPERATOR_ID LEVEL POSITION
COLUMN TABLE 12 11 11 1
Example of SQL plan explanation Here is an example of SQL plan explanation of a query. The query is from TPC-H Benchmark. In the example, all tables are located on row store.
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';
EXPLAIN PLAN SET STATEMENT_NAME = 'TPC-H Q10' FOR
SELECT TOP 20
c_custkey,
c_name,
SUM(l_extendedprice * (1 - l_discount)) AS revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
FROM
customer,
orders,
lineitem,
nation
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate >= '1993-10-01'
AND o_orderdate < ADD_MONTHS('1993-10-01',3)
AND l_returnflag = 'R'
AND c_nationkey = n_nationkey
GROUP BY
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
ORDER BY
revenue DESC;
SELECT operator_name, operator_details, table_name
FROM explain_plan_table
WHERE statement_name = 'TPC-H Q10';
The following is the plan explanation of the above query.
OPERATOR_NAME OPERATOR_DETAILS TABLE_NAM
E ROW SEARCH CUSTOMER.C_CUSTKEY, CUSTOMER.C_NAME,
SUM(LINEITEM.L_EXTENDEDPRICE * (1 - LINEITEM.L_DISCOUNT)),
CUSTOMER.C_ACCTBAL, NATION.N_NAME, CUSTOMER.C_ADDRESS,
CUSTOMER.C_PHONE, CUSTOMER.C_COMMENT
None
LIMIT NUM RECORDS: 20
ORDER BY SUM(LINEITEM.L_EXTENDEDPRICE * (1 - LINEITEM.L_DISCOUNT))
DESC
None
MERGE AGGREGATION NUM PARTITIONS: 4 None
GROUP BY GROUPING: NATION.N_NAME, R_CUSTOMER.C_CUSTKEY, AGGREGATION:
SUM(LINEITEM.L_EXTENDEDPRICE * (1 - LINEITEM.L_DISCOUNT))
None
CPBTREE INDEX JOIN INDEX NAME: _SYS_TREE_RS_279_#0_#P0,
INDEX CONDITION: ORDERS.O_ORDERKEY = LINEITEM.L_ORDERKEY,
INDEX FILTER: 'R' = LINEITEM.L_RETURNFLAG
LINEITEM

SAP HANA Database: SQL Reference Manual
113
OPERATOR_NAME OPERATOR_DETAILS TABLE_NAM
E BTREE INDEX JOIN INDEX NAME: _SYS_TREE_RS_285_#0_#P0,
INDEX CONDITION: CUSTOMER.C_NATIONKEY = NATION.N_NATIONKEY
NATION
BTREE INDEX JOIN INDEX NAME: _SYS_TREE_RS_283_#0_#P0,
INDEX CONDITION: ORDERS.O_CUSTKEY = CUSTOMER.C_CUSTKEY
CUSTOMER
TABLE SCAN FILTER CONDITION: ORDERS.O_ORDERDATE < '1994-01-01' AND
ORDERS.O_ORDERDATE >= '1993-10-01'
ORDERS
This means that:
1. TABLE SCAN will be executed on ORDERS with the FILTER CONDITION. 2. BTREE INDEX JOIN will be executed with the B-tree index of CUSTOMER and the result
of the below TABLE SCAN. 3. BTREE INDEX JOIN will be executed with the B-tree index of NATION and the result of
the below BTREE INDEX JOIN. 4. CPBTREE INDEX JOIN will be executed with the CPB-tree index of LINEITEM and the
result of the below BTREE INDEX JOIN. 5. GROUP BY will be executed with the result of the below CPBTREE INDEX JOIN, with 4
threads. 6. MERGE AGGREGATION will be executed with the result of the GROUP BY below.

SAP HANA Database: SQL Reference Manual
114
EXPORT SQL Syntax:
EXPORT <table_name_list> AS <export_format> INTO <path> [WITH <option_name_list>] [THREADS <number_of_threads>]
Parameters: <table_name_list> ::= <table_name>,… | ALL <export_format> ::= BINARY | CSV <option_name_list> ::= <option_name>,…
<option_name> ::= REPLACE | CATALOG ONLY | SCRAMBLE [BY <password>] <path> :: = A string literal to specify the path <number_of_threads> ::= Integer to specifiy the number of threads
Description: The EXPORT command exports tables, views, column views, synonyms, sequences, or procedures
in the specified format as BINARY or CSV. Data for temporary tables and ―no logging‖ tables
cannot be exported using EXPORT. REPLACE With REPLACE option, previously exported data will be removed and newly exported data will be saved. If REPLACE option is not specified, an error will be thrown if there exists a previously exported data already in the specified directory.
CATALOG ONLY With CATALOG ONLY option, only database catalog will be exported without data. SCRAMBLE
Export in CSV format has an additional option to scramble sensitive customer data using SCRAMBLE [BY '<password>']. When the optional password is not specified, a default scramble password is used. Only character string data can be scrambled. When imported, scrambled data
will be imported as scrambled so that end users cannot read the data and it is not possible to unscramble the data. To export all tables you should use the keyword ALL. If you want to export/import tables of a specific schema, you should use the schema name with the asterisk: EXPORT "SCHEMA"."*" AS BINARY INTO <path> [WITH <option_name>,… ] [THREADS <number_of_threads>]
You can monitor the progress of the export using M_EXPORT_BINARY_STATUS system views.
You can abort the export session using the connection ID from the corresponding view in the following command: ALTER SYSTEM CANCEL [WORK IN] SESSION 'connectionId' The detailed result of the export is stored in session-local temporary tables. #EXPORT_BINARY_RESULT.

SAP HANA Database: SQL Reference Manual
115
GRANT SQL Syntax: GRANT <system_privilege>,... TO <grantee> [WITH ADMIN OPTION] | GRANT <schema_privilege>,... ON SCHEMA <schema_name> TO <grantee> [WITH GRANT OPTION]
| GRANT <object_privilege>,... ON <object_name> TO <grantee> [WITH GRANT OPTION] | GRANT <role_name>,... TO <grantee> [WITH ADMIN OPTION] | GRANT STRUCTURED PRIVILEGE <privilege_name> TO <grantee>
Parameters:
<system_privilege> ::=
AUDIT ADMIN | BACKUP ADMIN | CATALOG READ | CREATE SCENARIO | CREATE SCHEMA | CREATE STRUCTURED PRIVILEGE | DATA ADMIN | EXPORT | IMPORT | INIFILE ADMIN | LOGGING
ADMIN | MONITOR ADMIN | OPTIMIZER ADMIN | RESOURCE ADMIN | ROLE ADMIN | SAVEPOINT ADMIN | SCENARIO ADMIN | SERVICE ADMIN | SESSION ADMIN | STRUCTUREDPRIVILEGE ADMIN | TENANT ADMIN | TRACE ADMIN | USER ADMIN | VERSION ADMIN <schema_privilege> ::= CREATE ANY | DELETE | DROP | EXECUTE | INDEX | INSERT | SELECT |
UPDATE
<object_privilege> ::= ALL PRIVILEGES | ALTER | DELETE | DROP | EXECUTE | INDEX | INSERT |
SELECT |UPDATE <grantee> :: = <user_name> | <role_name>
Description:
GRANT is used to grant privileges to users and roles. GRANT is also used to grant roles to users. All System Privileges can be granted using the GRANT command. With the WITH ADMIN OPTION clause, the granted user or user with the granted role can further grant the System Privileges to other users and roles. GRANT <system_privilege>,... TO <grantee> [WITH ADMIN OPTION]
GRANT <schema_privilege>,... ON SCHEMA <schema_name> TO <grantee> [WITH GRANT OPTION]
Object privileges need to be granted on individual objects. This can be done in SQL as follows: GRANT <object_privilege>,... ON <object_name> TO <grantee> [WITH GRANT OPTION]
The SCHEMA keyword is needed when privileges are being granted to or revoked from a schema. With the WITH GRANT OPTION clause, the granted user or user with the granted role can further
grant the privileges on the corresponding object to other users and roles.
The table below explains the types of privileges used by the SAP HANA database.
Type of Privilege Description
System Privileges Used for administrative tasks. System Privileges are assigned to users and roles.
SQL Privileges Used to restrict the access to and modification of database objects, such as tables. Depending on the object type (for example, table, view), actions (for example, CREATE ANY, ALTER, DROP) can be authorized per object. SQL Privileges are assigned to users and roles.
For SQL Privileges in the SAP HANA database, the SQL standard behavior is applied.
Analytic Privileges Used to restrict the access for read operations to certain data in Analytic, Attribute, and Calculation Views by
filtering the attribute values.
Only applied at processing time of the user query. Analytic Privileges need to be defined and activated before

SAP HANA Database: SQL Reference Manual
116
Type of Privilege Description
they can be granted to users and roles.
Package Privileges Used to restrict the access to and the use of packages in the repository of the SAP HANA database. Packages contain design-time versions of various objects, such as Analytic, Attribute, and Calculation Views, Analytic
Privileges, and functions. To be able to work with packages, the respective Package Privileges must be granted.
SQL Privileges
In the SAP HANA database, a number of privileges are available to control the authorization of SQL commands. Following the principle of least privilege, users should be given only the smallest set of privileges they require for their role. Thus, this chapter gives a complete overview of the privileges
supported at the SQL level, so that they can be assigned appropriately to the respective database users.
The SQL Privileges can be divided as follows: System Privileges These are system-wide privileges that control some general system activities mainly for administrative purposes, such as creating schema, creating and changing users and roles.
Object Privileges These privileges are bound to an object, for example, to a table, and control activities that are possible on this particular object, such as SELECT, UPDATE, or DELETE on database tables. The following sections describe all supported privileges in these two groups, together with the list of SQL commands they authorize.
System Privileges
Users and Roles USER ADMIN This privilege authorizes the creation and changing of users using the CREATE USER, ALTER USER, and DROP USER SQL commands.
ROLE ADMIN This privilege authorizes the creation and deletion of roles using the CREATE ROLE and DROP ROLE SQL commands. It also authorizes the granting and revocation of roles using the GRANT and REVOKE SQL commands. Catalog and Schema Management
CREATE SCHEMA This privilege authorizes the creation of database schemas using the CREATE SCHEMA SQL command. DATA ADMIN This powerful privilege authorizes to read all data in the system and monitoring views as well as
execute all DDL (Data Definition Language) – and only DDL – commands in the SAP HANA database. CATALOG READ This privilege authorizes all users to have unfiltered read-only access to all system and monitoring views. Normally, the content of those views is filtered based on the privileges of the accessing user.
The CATALOG READ privilege enables users to have read-only access to the full content of all system and monitoring views.
Analytics

SAP HANA Database: SQL Reference Manual
117
CREATE SCENARIO
This privilege controls the creation of calculation scenarios and cubes (calculation database). SCENARIO ADMIN
This privilege authorizes all calculation scenario-related activities (including creation). CREATE STRUCTURED PRIVILEGE This privilege authorizes the creation of Structured Privileges (Analytic Privileges). Note that only the owner of an Analytic Privilege can further grant it to other users or roles and revoke it again. STRUCTUREDPRIVILEGE ADMIN
This privilege authorizes the creation, reactivation, and dropping of Structured Privileges. Auditing AUDIT ADMIN
This privilege controls the execution of the following auditing-related SQL commands:
CREATE AUDIT POLICY DROP AUDIT POLICY ALTER AUDIT POLICY System Management These privileges authorize the various system activities that can be performed using the ALTER
SYSTEM SQL commands. Because of the high level of impact on the system, these privileges are not relevant to a normal database user and shall only be granted with care (for example, only to a support user or role.) A short overview on the relevant privileges is given in the following:
BACKUP ADMIN
This privilege authorizes the ALTER SYSTEM BACKUP command to define and initiate a backup process or to perform a recovery process. SAVEPOINT ADMIN This privilege authorizes the execution of a checkpoint process using the ALTER SYSTEM SAVEPOINT command.
INIFILE ADMIN This privilege authorizes different methods to change system settings. LOGGING ADMIN This privilege authorizes the ALTER SYSTEM LOGGING [ON|OFF] commands to enable or disable the log flush mechanism.
MONITOR ADMIN This privilege authorizes monitoring all activities done using the various ALTER SYSTEM MONITOR commands as well as the ALTER SYSTEM SET MONITOR LEVEL <level> command. RESOURCE ADMIN This privilege authorizes the utilization of the management console via the stored procedure
MANAGEMENT_CONSOLE_PROC. For more information, see Authorization for the Management Console. OPTIMIZER ADMIN This privilege authorizes the ALTER SYSTEM CLEAR SQL PLAN CACHE and ALTER SYSTEM UPDATE STATISTICS commands, which influence the behavior of the query optimizer.
SERVICE ADMIN This privilege authorizes the ALTER SYSTEM [START|KILL|RECONFIGURE] commands, intended for
administering system services of the database. SESSION ADMIN

SAP HANA Database: SQL Reference Manual
118
This privilege authorizes the ALTER SYSTEM ALTER SESSION commands to stop or disconnect a
user session. TRACE ADMIN
This privilege authorizes the ALTER SYSTEM [CLEAR|REMOVE] TRACES commands for operations on database trace files. VERSION ADMIN This privilege authorizes the ALTER SYSTEM RECLAIM VERSION SPACE command of the multi-version concurrency control (MVCC) mechanism. This privilege authorizes system activities to restart and set the run level of the engine.
Data Import and Export The following System Privileges are available for the authorization of the data import and export in the database:
IMPORT
This privilege authorizes the import activity in the database using the IMPORT SQL commands. Note that, beside this privilege, the user still needs the INSERT privilege on the target tables to be imported. EXPORT This privilege authorizes the export activity in the database via the EXPORT TABLE SQL commands. Note that, beside this privilege, the user still needs the SELECT privilege on the source tables to be
exported. Obsolete Privileges Object Privileges Object privileges are bound to objects they provide authorization for. The table below lists the
different object privileges supported by the SAP HANA database and the object types, for which
the privileges can be employed (OK: applicable; -: not applicable; ?: dynamically evaluated, see Note below). Object Privileges
Privilege
Schema Table View Sequence Synonym Function/
Procedure
CREATE ANY OK - - - - -
ALL PRIVILEGES
- OK OK - ? -
DROP OK OK OK OK ? OK
ALTER OK OK - - ? OK
SELECT OK OK OK OK ? -
INSERT OK OK OK - ? -
UPDATE OK OK OK - ? -
DELETE OK OK OK - ? -
INDEX OK OK - - ? -
EXECUTE OK - - - ? OK
CREATE ANY This privilege allows the creation of all kinds of objects, in particular, tables, views, sequences,
synonyms, SQL Script functions, or database procedures in a schema. This privilege can only be granted on a schema. ALL PRIVILEGES This is a collection of all DDL and DML (Data Manipulation Language) privileges that on the one hand, the grantor currently has and is allowed to grant further and on the other hand, can be
granted on this particular object. This collection is dynamically evaluated for the given grantor and object. ALL PRIVILEGES is not applicable to a schema, but only a table, view, or table type.
DROP and ALTER are DDL privileges and authorize the DROP and ALTER SQL commands. While the DROP privilege is valid for all kinds of objects, the ALTER privilege is not valid for sequences and synonyms as their definitions cannot be changed after creation.

SAP HANA Database: SQL Reference Manual
119
INDEX This special DDL privilege authorizes the creation, changing, or dropping of indexes for an object using the CREATE INDEX, DROP INDEX, and ALTER INDEX commands. This privilege can only be
applied to a schema, table, and table type. SELECT, INSERT, UPDATE, and DELETE These are DML privileges and authorize respective SQL commands. While SELECT is valid for all kinds of objects, except for functions and procedures, INSERT, UPDATE, and DELETE are valid for schemas, tables, table types, and updatable views only.
EXECUTE This special DML privilege authorizes the execution of an SQL Script function or a database procedure using the CALLS or CALL command, respectively.
All DDL and DML privileges are valid for schemas in the sense that they authorize applicable activities on the objects created in this schema.
Synonyms can be created for tables, views, sequences, database procedures, but not for schemas and SQL Script functions. The privileges that can be granted and revoked on a synonym are determined by the actual object the synonym stands for.

SAP HANA Database: SQL Reference Manual
120
IMPORT SQL Syntax: IMPORT <table_name_list> AS <import_format> FROM <path> [WITH <option_name_list>] [THREADS <number_of_threads>]
Parameters: <table_name_list> ::= <table_name>,… | ALL <import_format> :: = BINARY | CSV
<option_name_list> ::= <option_name>,… <option_name> ::= REPLACE | CATALOG ONLY <path> :: = ‗full_path‘ <number_of_threads> ::= Integer to indicate the number of threads
Description: The IMPORT statement imports tables, views, column views, synonyms, sequences, or procedures.
Data for temporary tables and ―no logging‖ tables cannot be imported using IMPORT command. REPLACE With REPLACE option, the specified table will be dropped and created and data will be imported. If REPLACE option is not specified, an error will be thrown if there exists a table with the same name in the same schema.
CATALOG ONLY With CATALOG ONLY option, only database catalog will be imported without data. To import all tables you should use the keyword ALL. If you want to import tables of a specific
schema, you should use the schema name with the asterisk: IMPORT "SCHEMA"."*" AS BINARY FROM <path> [WITH option_name,… ] [THREADS N]
You can monitor the progress of the import using M_IMPORT_BINARY_STATUS system views. Also, you can abort the import session using the connection ID from the corresponding view in the following command:
ALTER SYSTEM CANCEL [WORK IN] SESSION 'connectionId' The detailed result of the import is stored in session-local temporary tables. #IMPORT_BINARY_RESULT.

SAP HANA Database: SQL Reference Manual
121
IMPORT FROM SQL Syntax: IMPORT FROM <control_file> WITH [THREADS <number_of_threads>] [BATCH <batch_size>] [<import_from _option>]
Parameters: <import_from_option> ::= WITH TABLE LOCK [ WITHOUT TYPE CHECK ] <control_file> ::= ‘full_path_of_control_file’
<number_of_threads> ::= Integer literal that specifies the number of threads
Description: The IMPORT FROM statement imports external data from a csv file into an existing table.
THREADS Indicates the number of threads that can be used for concurrent import. Default value is 1 and maximum allowed value is 256. BATCH
Indicates the number of records to be inserted in each commit. THREADS and BATCH can be used to achieve high loading performance by enabling parallel loading and committing many records at once. In general, for column tables, a good setting is to use 10 parallel loading threads, with a commit frequency of 10.000 records or greater. Example:
IMPORT FROM '/home/myself/reposrc.ctl' WITH THREADS 10 BATCH 50000
WITH TABLE LOCK Locks table for fast import into column store tables. If WITHOUT TYPE CHECK option is specified, then the record is inserted without checking the type of each field. Control file format
[] means optional. field specs: a comma separated list of column specifications. When not specified, the
whole fields are assumed. eor: end of row. When not specified, the new-line character is used. eoc: end of column. When not specified, the comma character is used. moq: mark of quotation. When not specified, the double-quotation mark is used.
[IMPORT DATA]
INTO TABLE <tablename> [(<field specs>)]
FROM <os_data_filename> [RECORD DELIMITED BY '<eor>'] [FIELDS [DELIMITED BY
'<eoc>'] [OPTIONALLY ENCLOSED BY '<moq>']]
[ERROR LOG <os_bad_filename>]
Upon an error, either a parsing error or a SQL error, the erroneous rows are written to the error log file. In the case of a parsing error, the error position is marked with the carrot character. The following is how a column is parsed from CSV files.
//
// Note on the Current Implementation
//
// Common
// - The null value cannot be enclosed.
// - Leading whilte spaces are not ignored.
// - Most of the limitations are tradeoff for the performance.

SAP HANA Database: SQL Reference Manual
122
//
// Char (Max: 8192B)
// - Buffer overflow: truncate by ignoring subsequent characters.
// - Error: Unmatched quotation mark in the C-style mode
// No delimiter in the Oracle-style verbatim mode
// - Strings that start with "null" must be enclosed or escaped.
// - In the Oracle-like verbatim mode,
// a string must be followed by a delimiter and
// - When a string starts with a quotation mark in the verbatim mode,
// the last character is ignored without checking it is a quotation mark
// - In the ordinary mode, a string cannot go beyond the new-line character
// I assume such a situation is abnormal. If the new-line character is
// needed, the corresponding escape sequence should be used.
//
// Binary (Max: 8192B)
// - Buffer overflow: truncate by ignoring subsequent characters
// - Error: No digit to read, An odd number of digits, Unmatched encloser
//
// BigInt
// - Number overflow: undefined values
// - Error: No digit to read, Unmatched encloser
//
// Double
// - Number overflow: undefined values
// - Error: No digit to read, Unmatched encloser
// - No support for exponents
//
// Decimal (Max: 40B)
// - Buffer overflow:
// Report an error on the overflow at a whole digit
// Otherwise, truncate subsequent fractional digits
// - Number overflow: depend on the ODBC driver used
// - Error: No digit to read, Unmatched encloser
//
// Date/Time/Timestamp
// - Number overflow: undefined values
// - Error: No digit to read for a field, Not a month name, Unmatched encloser
The sample control file below shows how to give column specifications, which are a comma-separated list of name-type pairs. The "reposrc.csv" file should have two columns per line. The first column in the file is stored into the PROGNAME field of the REPOSRC table and the second column in the file is stored into the DATA field of the table. IMPORT DATA
INTO TABLE "SYSTEM"."TEST"
FROM 'data_file_name.csv'
RECORD DELIMITED BY '\n'
FIELD DELIMITED BY ','
OPTIONALLY ENCLOSED BY '"'
ERROR LOG 'error_file_name.err'
Example:
IMPORT FROM ‘home/myself/reposrc.ctl’ WITH THREADS 10 BATCH 50000;

SAP HANA Database: SQL Reference Manual
123
INSERT SQL Syntax: INSERT INTO <table_name> [(<column_name_list>)] {VALUES (<expression_list>) | <subquery>} [WITH PARAMETERS (<parameter_key_value_list>)]
Parameters: <column_name_list> ::= <column_name>,… <expression_list> ::= <expression>,… <parameter_key_value_list> ::= <parameter_key_value>, …
<parameter_key_value>::= <string_literal> = <string_literal> |
<identifier> = <string_literal> | <string_literal> = (<string_literal>, ... )
Description:
The INSERT statement adds records to a table.
A subquery that returns records can be used to insert records into the table. If the subquery does not return any records, then the database will not insert any records into the table.
The column list can be specified with the INSERT statement. If the column list is omitted, the
database inserts all columns in the table.
Example:
CREATE TABLE table_a (A INT);
INSERT INTO table_a VALUES (1);

SAP HANA Database: SQL Reference Manual
124
LOAD SQL Syntax: LOAD <table_name> {DELTA | ALL | (<column_name_list>)}
Parameters: <column_name_list> ::= <column_name>,…
Description:
The LOAD statement loads the column store table data to memory.
DELTA - DELTA part of the column store table is loaded into memory. Since the column store is read optimized and compressed, deltas are introduced to optimize insert or updates. All insertions are passed to a delta. ALL – ALL data of the column store table in main and delta is loaded into memory.
column_name, … – Columns specified in the column list are loaded into memory. Example:
LOAD a_table all;

SAP HANA Database: SQL Reference Manual
125
MERGE DELTA SQL Syntax:
MERGE [HISTORY] DELTA OF <table_name> [PART <part_number>]
[WITH PARAMETERS ( <parameter_key_value_list>) ]
WITH PARAMETERS (parameter_key_value):
Column store-specific options can be passed in using the "WITH PARAMETERS" clause. • Keys and single values can be any string literal • Duplicate keys are allowed • Keys are automatically mapped into their uppercase representation
<parameter_key_value_list> ::= <parameter_key_value>, …
<parameter_key_value>::= <string_literal> = <string_literal> |
<identifier> = <string_literal> | <string_literal> = (<string_literal>, ... )
Current parameters
'SMART_MERGE' = 'ON' | 'OFF' When SMART_MERGE is ON, the database does a smart merge, this means database decides whether to merge or not based on merge criteria specified in automerge section of indexserver configuration
‗PASSPORT‘=‘<string>‘
Merge request call tag to identify the request in related traces
‗MEMORY_MERGE‘=‘ON‘|‘OFF‘ Database merges delta index in memory only, it will not be persisted.
Description The MERGE DELTA statement merges deltas to main column store table. Since the column store is
read optimized and compressed, deltas are introduced to optimize insert or updates in the optimized way. All insertions are passed to a delta. At a certain point in time, deltas can be merged into the main column table. Deltas will be merged into main column table. HISTORY – Can be specified to merge history deltas into the history main on column store history
tables.
PART – Can be specified to merge a delta of a partition to main column table. Example: MERGE DELTA OF A;
MERGE DELTA OF A PART 1;
MERGE HISTORY DELTA OF A;
MERGE HISTORY DELTA OF A PART 1;

SAP HANA Database: SQL Reference Manual
126
RENAME COLUMN
SQL Syntax:
RENAME COLUMN <table_name>.<old_column_name> TO <new_column_name>
Description: The RENAME COLUMN statement changes the name of a column.
Example: CREATE TABLE B (A INT PRIMARY KEY, B INT);
RENAME COLUMN B.A TO C;

SAP HANA Database: SQL Reference Manual
127
RENAME INDEX
SQL Syntax:
RENAME INDEX <old_index_name> TO <new_index_name>
Description: The RENAME INDEX statement changes the name of an index.
Example:
RENAME INDEX idx TO new_idx;

SAP HANA Database: SQL Reference Manual
128
RENAME TABLE
SQL Syntax:
RENAME TABLE <table_name> TO <new_table_name>
Description: The RENAME TABLE statement changes the name of a table to new_table_name in the same
schema.
Example: RENAME TABLE A TO B;
RENAME TABLE mySchema.A TO B;

SAP HANA Database: SQL Reference Manual
129
REVOKE SQL Syntax: REVOKE <system_privilege>,... FROM <grantee> | REVOKE <schema_privilege>,... ON SCHEMA <schema_name> FROM <grantee>
| REVOKE <object_privilege>,... ON <object_name> FROM <grantee>
| REVOKE <column_privilege>,... (<column_name>,... ) ON <object_name> FROM <grantee> | REVOKE <role_name>,... FROM <grantee>
| REVOKE STRUCTURED PRIVILEGE <structured_privilege_name> FROM <grantee>
<system_privilege> ::= CREATE SCHEMA | DATA ADMIN | ROLE ADMIN | USER ADMIN |
BACKUP ADMIN | CHECKPOINT ADMIN | CHECKPOINT EXEC | CREATE SCENARIO | CREATE
STRUCTURED PRIVILEGE | INIFILE ADMIN | LOGFLUSH ADMIN | MONITOR ADMIN | OPTIMIZER ADMIN | RESOURCE ADMIN | SESSION ADMIN |SERVICE ADMIN | TENANT ADMIN | TRACE ADMIN
| VERSION ADMIN | INDEX | ALTER <schema_privilege> ::= CREATE ANY | DELETE | DROP | EXECUTE | INSERT | SELECT | UPDATE
<object_privilege> ::= ALL PRIVILEGES | ALTER | DELETE | DROP | EXECUTE | INDEX | INSERT |
SELECT | UPDATE <column_privilege> ::= INSERT | SELECT | UPDATE
<grantee> :: = <user_name> | <role_name>
Description: The REVOKE statement revokes the specified privileges or roles for the specified objects from the
specified users or roles. Revoking may cause views, procedures to become inaccessible.

SAP HANA Database: SQL Reference Manual
130
SELECT SQL Syntax:
<subquery> [<order_by_clause>] [<for_update_clause>] [<time_travel_clause>]
<subquery> ::= <select_clause> <from_clause > [<where_clause>]
[<group_by_clause>]
[<having_clause>] { <set_operator subquery>,… }
[<limit_clause>]
<select_clause> ::= SELECT [TOP <number> ] [ ALL | DISTINCT ] <select_list>
<select_list> ::= {<select_item>, …}
<select_item> ::=
[[<schema_name>.] <table_name>.] <asterisk> | <expression> [ AS ] <column_alias>
<asterisk> ::= *
<from_clause> ::= FROM {<table>, … }
<table> ::= <table_name> [ [AS] <table_alias> ]
| <subquery> [ [AS] <table_alias> ] | <joined_table>
<joined_table> ::= <table> [<join_type>] JOIN <table> ON <predicate>
| <table> CROSS JOIN <table> | <joined_table>
<join_type> ::= INNER | {LEFT | RIGHT | FULL } [OUTER]
<where_clause> ::= WHERE <condition>
<condition> ::= <condition> OR <condition> | <condition> AND <condition>
| NOT <condition> | ( <condition> ) | <predicate>
<predicate> ::= <comparison_predicate>
| <range_preciate>
| <in_predicate> | <exist_predicate> | <like_predicate> | <null_predicate>
<comparison_predicate> ::= <expression> { = | != | <> | > | < | >= | <= }
[ ANY | SOME| ALL ] ({<expression_list> | <subquery>})
<range_predicate> ::= <expression> [NOT] BETWEEN <expression> AND <expression>
<in_predicate> ::= <expression> [NOT] IN ( {<expression_list> | <subquery>} )
<exist_predicate> ::= [NOT] EXISTS ( <subquery> )

SAP HANA Database: SQL Reference Manual
131
<like_predicate> ::= <expression> [NOT] LIKE <expression> [ESCAPE <expression>]
<null_predicate> ::= <expression> IS [NOT] NULL
<group_by_clause> ::= GROUP BY { <group_by_expression_list> | <grouping_set> }
<group_by_expression_list> ::= { <expression>, ... }
<grouping_set> ::= { GROUPING SETS | ROLLUP | CUBE }
[BEST number] [LIMIT number [OFFSET number] ] [WITH SUBTOTAL] [WITH BALANCE] [WITH TOTAL] [TEXT_FILTER <filterspec> [FILL UP [SORT MATCHES TO TOP]]]
[STRUCTURED RESULT [WITH OVERVIEW] [PREFIX value] | MULTIPLE RESULTSETS] ( <grouping_expression_list> )
<grouping_expression_list> ::= { <grouping_expression>, ... }
<grouping_expression> ::= <expression> | ( <expression>, ... ) | ( ( <expression>, ... ) <order_by_clause> )
<having_clause> ::= HAVING <predicate>
<set_operator> ::= UNION [ALL] | INTERSECT | EXCEPT
<order_by_clause> ::= ORDER BY {{<expression> | <position> } [ASC | DESC] }, ...
<limit_clause> ::= LIMIT <expression> [OFFSET <expression> ]
<for_update_clause> ::= FOR UPDATE [OF <column_name>, … ]
<time_travel_clause> ::= AS OF [COMMIT ID|TIMESTAMP] [ <commit_id> | <timestamp>]
<group_by_expression_list> ::= { <expression>, … }
Description: <select_clause> ::= SELECT [TOP n] [ ALL | DISTINCT ] <select_list>
<select_list> ::= { <select_item>, …}
<select_item> ::=
[ [<schema_name>.] <table_name>.] <asterisk>
| <expression> [ AS ] <column_alias>
<asterisk> ::= *

SAP HANA Database: SQL Reference Manual
132
The SELECT statement retrieves data from one or more tables in the database.
TOP
TOP can be used to return the fist n records from the SQL statement. DISTINCT, ALL DISTINCT can be used to return only one copy of each set of duplicate rows
selected. ALL can be used to return all rows selected, including all copies of duplicates. The default is ALL.
select_list The select list allows users to specify the columns they want to retrieve from the database.
asterisk
Asterisk (*) can be used to select all the data in all columns from all tables or views listed in the FROM clause. If a schema name and a table name or a table name is provided with asterisk(*), it is used to limit the scope of the result set to the specified table. column_alias, table_alias
The user may rename the existing column or table name.
<from_clause> ::= FROM {<table>, … }
<table> ::= <table_name> [ [AS] <table_alias> ]
| <subquery> [ [AS] <table_alias> ] | <joined_table>
<joined_table> ::= <table> [<join_type>] JOIN <table> ON <predicate>
| <table> CROSS JOIN <table> | <joined_table>
<join_type> ::= INNER | {LEFT | RIGHT | FULL } [OUTER]
The join_type specifies the types of join being performed. RIGHT indicates a
right outer join, LEFT indicates a left outer join, and FULL indicates a full outer join. The OUTER keyword may or may not be used when an outer
join is being performed.
ON <predicate>
The ON clause specifies a join predicate.
CROSS JOIN The CROSS keyword indicates that a cross join is being performed. A cross join produces the cross-product of two relations and is identical with the comma-delimited (,) notation.
<where_clause> ::= WHERE < condition >
The WHERE condition is used to specify a predicate on the records to be selected and the user therefore can retrieve the desired data.
<having_clause> ::=HAVING <predicate>
The HAVING keyword is used to select the specified groups that satisfy the predicates. If this keyword is omitted, all groups are selected.
<order_by_clause> ::=ORDER BY {{ <expression> | <position> } [ASC | DESC] }, ...

SAP HANA Database: SQL Reference Manual
133
The ORDER BY clause is used to sort the records by the field specified in SELECT statement.
The ASC keyword is used to sort the result in ascending order and the DESC keyword is used to sort the result in descending order. The default value is DESC.
<set_operator> ::= UNION [ALL| DISTINCT] | INTERSECT [DISTINCT] | EXCEPT [DISTINCT]
Set operators enable more than one select statement to be combined and only one result set is returned. UNION ALL – Selects all rows from all select statements.
UNION [DISTINCT] – Selects all unique rows from all select statements by removing duplicate rows found from different select statements. UNION is the same as UNION DISTINCT.
INTERSECT [DISTINCT] – Returns all unique rows that exist in all select statements in
common.
EXCEPT [DISTINCT] – Returns all unique rows from the first select statements after removing the duplicates in the following select statements.
<for_update_clause> ::= FOR UPDATE [OF <column_name>, …]
The FOR UPDATE keyword locks the selected rows so that other users cannot lock or update the rows until end of this transaction.
<limit_clause> ::=LIMIT n1 [OFFSET n2]
LIMIT - Returns the first n1 records from the SQL statement. When OFFSET n2 is specified, the database skips the number of rows specified by n2 before returning the results set.
<group_by_clause> ::= GROUP BY { <group_by_expression_list> | <grouping_set> }
<group_by_expression_list> ::= { <expression>, ... }
<grouping_set> ::= { GROUPING SETS | ROLLUP | CUBE }
[BEST number] [LIMIT number [OFFSET number] ] [WITH SUBTOTAL] [WITH BALANCE] [WITH TOTAL] [TEXT_FILTER <filterspec> [FILL UP [SORT MATCHES TO TOP]]]
[STRUCTURED RESULT [WITH OVERVIEW] [PREFIX value] | MULTIPLE RESULTSETS] ( <grouping_expression_list> )
<grouping_expression_list> ::= { <grouping_expression>, ... }
<grouping_expression> ::= <expression>
| ( <expression>, ... )
| ( ( <expression>, ... ) <order_by_clause> )
The GROUP BY keyword is used to group the selected rows based on the values in the
specified columns.
GROUPING SETS
Generates results with specified multiple groupings of data in a single statement. If no
additional options such as best and limit are set, the result is the same as UNION ALL of
the aggregation of each specified group. For example, "select col1, col2, col3, count(*)
from t group by grouping sets ( (col1, col2), (col1, col3) )" is equivalent to "select col1,
col2, NULL, count(*) from t group by col1, col2 union all select col1, NULL, col3, count(*)
from t group by col1, col3". In the grouping-sets query each of (col1, col2) and (col1, col3)
specifies the grouping.

SAP HANA Database: SQL Reference Manual
134
ROLLUP
Generates results with multiple levels of aggregation in a single statement. For example,
"rollup (col1, col2, col3)" is equivalent to "grouping sets ( (col1, col2, col3), (col1, col2),
(col1) )" with an additional aggregation without grouping. Thus, the number of grouping
that result set contains is the number of columns in ROLLUP list plus one for last
aggregation if there is no additional option.
CUBE
Generates results with multiple levels of aggregations in a single statement. For example,
"cube (col1, col2, col3)" is equivalent to "grouping sets ( (col1, col2, col3), (col1, col2),
(col1, col3), (col2, col3), (col1), (col2), (col3) )" with an additional aggregation without
grouping. Thus, the number of grouping that result set contains is the same as all possible
permutations of columns in the CUBE list plus one for the last aggregation if there is no
additional option.
BEST n
Returns only the top-n grouping sets sorted in descending order of the number of rows
aggregated in each grouping set. n can be any of zero, positive, and negative. When n is
zero, it is the same with no BEST option. When n is negative, it means sorting in ascending
order.
LIMIT n1 [OFFSET n2]
Returns the first n1 grouped records after skipping n2 ones for each grouping set.
WITH SUBTOTAL
Returns for each grouping set an additional subtotal of the returned results as controlled
by OFFSET or LIMIT. Unless OFFSET and LIMIT is set, the value is the same as the one for
WITH TOTAL.
WITH BALANCE
Returns for each grouping set an additional aggregated value of the remaining values not
returned as controlled by OFFSET or LIMIT.
WITH TOTAL
Returns for each grouping set an additional row that is the aggregated total value. OFFSET
and LIMIT options cannot change this value.
TEXT_FILTER <filterspec>
Performs text filtering or highlighting on the grouping columns with <filterspec>, which is
a single-quoted string that follows the below syntax.
<filterspec> ::= '[<prefix>]<element>{<subsequent>…}'
<prefix> ::= + | - | NOT <element> ::= <token> | <phrase> <token> ::= !! Unicode letters or digits <phrase> ::= !! double-quoted string that does not contain double quotations inside <subsequent> ::= [<prefix_subsequent>]<element> <prefix_subsequent> ::= + | - | NOT | AND | AND NOT | OR
A filter defined by <filterspec> is a token/phrase or tokens/phrases connected with logical
operators such as AND, OR and NOT. A token matches a string that contains its

SAP HANA Database: SQL Reference Manual
135
corresponding word case-insensitively. For example, ‗ab‘ matches ―ab cd‖ and ―cd Ab‖, but
does not match ―abcd‖. A token can contain wildcard characters ‗*‘ that matches any string
and ‗?‘ that matches any character. Inside phrase, however, ‗*‘ and ‗?‘ do not work as
wildcard characters. With tokens and phrases logical operators AND, OR and NOT may be
used together. Since OR is the default operator, ‗ab cd‘ is the same as ‗ab OR cd‘. Note
that logical operators should be written in uppercase characters. As a kind of logical
operators, prefixes ‗+‘ and ‗-‘ mean inclusion (AND) and exclusion (AND NOT), respectively.
For example, ‗+ab -cd‘ is the same as ‗ab AND NOT cd‘.
If there is no FILL UP option, only grouped records that have matching values are returned.
Note that a filter is applied to only the first grouping column in each grouping set.
FILL UP
Returns not only matched grouped records, but also non-matched ones. Function
text_filter ( <grouping column> ) is useful to identify which one is matched. Refer to
‗Related Functions‘ below.
SORT MATCHES TO TOP
Returns matching values before non-matching ones for each grouping set. This option
cannot be used with SUBTOTAL, BALANCE and TOTAL.
STRUCTURED RESULT
Returns results as temporary tables. For each grouping set a single temporary table is
created. If WITH OVERVIEW option is set, an additional temporary table is created for the
overview of grouping sets. The names of temporary tables are specified by PREFIX option.
MULTIPLE RESULTSETS
Returns results in multiple result sets.
WITH OVERVIEW
Returns the overview in a separate table additionally.
PREFIX value
Specifies a prefix for naming the temporary tables. It must start with ―#‖, which means
the temporary table. If omitted, the default prefix is ―#GN‖. Then, the concatenation of
this prefix value and a nonnegative integer number is used as the name of temporary
tables; for example, ―#GN0‖, ―#GN1‖ and ―#GN2‖. Refer to ‗Return Format‘ below.
The projection clause must include all grouping columns used in the GROUPING SETS
specification.
Related Functions
grouping_id ( <grouping column1, …, grouping columnn> ) function returns an
integer number to identify which grouping set each grouped record belongs to.
text_filter ( <grouping column> ) function, which is used with TEXT_FILTER, FILL
UP, and SORT MATCHES TO TOP, displays matching values or NULL. NULL is
displayed for non-matching values when FILL UP option is specified.
Return Format

SAP HANA Database: SQL Reference Manual
136
If neither STRUCTURED RESULT nor MULTIPLE RESULTSETS is set, the unioned
result of all grouping sets is returned, with NULL values filling up attributes that are not included in a specific grouping set.
With STRUCTURED RESULT, temporary tables are created additionally which can be
queried using ―SELECT * FROM <table name>‖ in the same session. The name of the tables follows the form
o <PREFIX>0: this table will contain the overview if WITH OVERVIEW is specified
o <PREFIX>n: n-th grouping set subject to re-ordering by the BEST parameter
With MULTIPLE RESULTSETS, multiple result sets are returned. Grouped records
for each grouping set are in a single result set.
<time_travel_clause> ::= AS OF [COMMIT ID|TIMESTAMP] [<commit_id> | <timestamp>]
Can be used for statement level time travel to go back to the snapshot specified by
commit_id or timestamp.
Example: Here is t1 table.
drop table t1;
create column table t1 ( id int primary key, customer varchar(5), year int,
product varchar(5), sales int );
insert into t1 values(1, 'C1', 2009, 'P1', 100);
insert into t1 values(2, 'C1', 2009, 'P2', 200);
insert into t1 values(3, 'C1', 2010, 'P1', 50);
insert into t1 values(4, 'C1', 2010, 'P2', 150);
insert into t1 values(5, 'C2', 2009, 'P1', 200);
insert into t1 values(6, 'C2', 2009, 'P2', 300);
insert into t1 values(7, 'C2', 2010, 'P1', 100);
insert into t1 values(8, 'C2', 2010, 'P2', 150);
The following GROUPING SETS query is equivalent to the second below group-by query. Note that
two groups inside grouping sets in the first query are specified at each group by in the second
query.
select customer, year, product, sum(sales)
from t1
group by GROUPING SETS
(
(customer, year),
(customer, product)
);
select customer, year, NULL, sum(sales)
from t1
group by customer, year
union all
select customer, NULL, product, sum(sales)
from t1
group by customer, product;
ROLLUP and CUBE are concise representations of grouping sets that are used frequently. The
following ROLLUP query is equivalent to the second below grouping-set query.

SAP HANA Database: SQL Reference Manual
137
select customer, year, sum(sales)
from t1
group by ROLLUP(customer, year);
select customer, year, sum(sales)
from t1
group by grouping sets
(
(customer, year),
(customer)
)
union all
select NULL, NULL, sum(sales)
from t1;
The following CUBE query is equivalent to the second below grouping-set query.
select customer, year, sum(sales)
from t1
group by CUBE(customer, year);
select customer, year, sum(sales)
from t1
group by grouping sets
(
(customer, year),
(customer),
(year)
)
union all
select NULL, NULL, sum(sales)
from t1;
BEST 1 specifies that the following query returns only top-1 best group. In this example, 4 records
exist for (customer, year) group and 2 records exist for (product) group, so the former 4 records
are returned. For 'BEST -1' instead of 'BEST 1', the latter 2 records are returned.
select customer, year, product, sum(sales)
from t1
group by grouping sets BEST 1
(
(customer, year),
(product)
);
LIMIT 2 limits the number of records to maximum 2 for each group. For (customer, year) group,
the number of its records are 4, then only first 2 records will be returned. For (product) group, the
number of its records are 2, so all the records will be returned.
select customer, year, product, sum(sales)
from t1
group by grouping sets LIMIT 2
(
(customer, year),
(product)
);

SAP HANA Database: SQL Reference Manual
138
WITH SUBTOTAL produces additional one record for each group to display subtotal of returned
records. These subtotal records get NULL for each of customer, year, product columns and the
sum of sum(sales) values in the select list.
select customer, year, product, sum(sales)
from t1
group by grouping sets LIMIT 2 WITH SUBTOTAL
(
(customer, year),
(product)
);
WITH BALNACE produces additional one record for each group to display subtotal of unreturned
records.
select customer, year, product, sum(sales)
from t1
group by grouping sets LIMIT 2 WITH BALANCE
(
(customer, year),
(product)
);
WITH TOTAL produces additional one record for each group to display total of all grouped records
without regard that the records are returned or not.
select customer, year, product, sum(sales)
from t1
group by grouping sets LIMIT 2 WITH TOTAL
(
(customer, year),
(product)
);
TEXT_FILTER allows users to retrieve the first column of each group with a given <filterspec>. The
following query will search columns ending with '2': customers for the first grouping set and
products for the second one. Only matched three records will be returned. TEXT_FILTER function
in the select list is useful to see which values are matched.
select customer, year, product, sum(sales), text_filter(customer),
text_filter(product)
from t1
group by grouping sets TEXT_FILTER '*2'
(
(customer, year),
(product)
);
FILL UP is used to return both matched and non-matched records with <filterspec>. Therefore, the
following query returns six records whereas the previous query does three ones.

SAP HANA Database: SQL Reference Manual
139
select customer, year, product, sum(sales), text_filter(customer),
text_filter(product)
from t1
group by grouping sets TEXT_FILTER '*2' FILL UP
(
(customer, year),
(product)
);
SORT MATCHES TO TOP is used to raise matched records up. For each grouping set, its grouped
records will be sorted.
select customer, year, product, sum(sales), text_filter(customer),
text_filter(product)
from t1
group by grouping sets TEXT_FILTER '*2' FILL UP SORT MATCHES TO TOP
(
(customer, year),
(product)
);
STRUCTURED RESULT creates temporary tables: one for each grouping set and one more for the
overview table optionally. "#GN1" table is for (customer, year) grouping set and "#GN2" table is
for (product) one. Note that each table contains only related columns. That is, "#GN1" table does
not have "product" column and "#GN2" table does not have "customer" and "year" columns.
select customer, year, product, sum(sales)
from t1
group by grouping sets STRUCTURED RESULT
(
(customer, year),
(product)
);
select * from "#GN1";
select * from "#GN2";
WITH OVERVIEW creates a temporary table "#GN0" for the overview table.
drop table "#G1";
drop table "#G2";
select customer, year, product, sum(sales)
from t1
group by grouping sets structured result WITH OVERVIEW
(
(customer, year),
(product)
);
select * from "#GN0";
select * from "#GN1";
select * from "#GN2";
Users can change the names of temporary tables by using PREFIX keyword. Note that the names
still must start with '#', which is the prefix of temporary tables.

SAP HANA Database: SQL Reference Manual
140
select customer, year, product, sum(sales)
from t1
group by grouping sets STRUCTURED RESULT WITH OVERVIEW PREFIX '#MYTAB'
(
(customer, year),
(product)
);
select * from "#MYTAB0";
select * from "#MYTAB1";
select * from "#MYTAB2";
Temporary tables are dropped when the corresponding session is closed or when a user executes a drop command. A list of temporary tables are seen in m_temporary_tables.
select * from m_temporary_tables;
MULTIPLE RESULTSETS returns resultsets as multiple resultsets. In SAP HANA Studio, the
following query will return three resultsets: one is for the overview table and two are for grouping
sets.
select customer, year, product, sum(sales)
from t1
group by grouping sets MULTIPLE RESULTSETS
(
(customer, year),
(product)
);

SAP HANA Database: SQL Reference Manual
141
SET [SESSION] SQL Syntax: SET [SESSION] <key> = <value>
Parameters: <key> ::= string literal that indicates the key of a session variable <value> ::= string literal that indicates the value of a session variable
Description: You can set session variables by providing key and value pairs. With this command, session variables of the current session can be set. If you have session administration privileges, you can change session variables of other sessions by specifying the session ID using ALTER SYSTEM
ALTER SESSION [session_id] SET command. There are several available read-only session variables and they are LOCALE, LOCALE_SAP,
CLIENT, CONN_ID, APPLICATIONNAME, CLIENTUSER, CLIENTHOSTNAME. Session variables can be retrieved using SESSION_CONTEXT() function. Session variables can be unset using UNSET command. Example:
SET ‘my_var’ = ‘dummy’;
SELECT session_context(‘my_var’) FROM dummy;
Unset ‘my_var’;

SAP HANA Database: SQL Reference Manual
142
SET HISTORY SESSION TO SQL Syntax: SET HISTORY SESSION TO <restore_options>
Parameters:
<restore_options>::=
NOW | COMMIT ID <commit_id>
| UTCTIMESTAMP <timestamp>
Description:
A database session can be set back to a certain point-in-time using SET HISTORY SESSION
statements The session will restore the transaction snapshot to the point in time corresponding to the provided option to allow a history search.
NOW – Session will restore the snapshot to the current time from the history search. COMMIT ID – Session will restore the snapshot corresponding to the specified commit ID
(COMMIT ID). UTCTIMESTAMP – Session will restore the snapshot of the specified timestamp.
The COMMIT ID-variant of the statement takes a commit-id as parameter. The value of the commit-id parameter must occur inside the COMMIT_ID column of the system-table
SYS.TRANSACTION_HISTORY, otherwise an exception will be thrown.
The COMMIT ID-variant is mainly useful when using user defined snapshots. A user defined snapshot can be taken by simply storing the commit-id which is assigned to a transaction during the commit-phase (of course this does only make sense when history tables are updated by the transaction). The commit-id may be retrieved by executing the following query directly after a transaction commit:
SELECT LAST_COMMIT_ID FROM M_HISTORY_INDEX_LAST_COMMIT_ID WHERE SESSION_ID = CURRENT_CONNECTION The UTCTIMESTAMP-variant of the statement takes a timestamp as parameter. Internally, the
timestamp is used to look up a (commit_time,commit_id)-pair inside the system-table
SYS.TRANSACTION_HISTORY where the commit_time is close to the given timestamp. To be more precisely: choose pair where maximal COMMIT_TIME is smaller or equal to the given timestamp; if no such pair is found an exception will be raised. The session then will be restored with the determined commit-id as in the COMMIT ID-variant. NOTE:
Autocommit has to be turned off when a session should be restored (otherwise an exception will be thrown with an appropriate error message)
Non-history tables in restored sessions always show their current snapshot Execution of data manipulation statements and data definition statements are not allowed
inside restored sessions. Only select statements are allowed. Besides SET HISTORY SESSION TO NOW, a history session can als obe terminated by an
explicit COMMIT or ROLLBACK on the DB connection.

SAP HANA Database: SQL Reference Manual
143
SET SCHEMA SQL Syntax: SET SCHEMA <schema_name>
Parameters:
<schema_name> ::= string literal which specifies schema name
Description: You can change the current schema of the session. The current schema is used when database
object names such as table names are not prefixed with the schema name.

SAP HANA Database: SQL Reference Manual
144
SET TRANSACTION AUTOCOMMIT DDL SQL Syntax: SET TRANSACTION AUTOCOMMIT DDL <on_off>
Parameters:
<on_off> ::= ON | OFF Description: You can specify the auto commit property for DDL statements specific to the session.
Normal row and column table: DDLs except for truncate and table conversion can be rollbacked, and rollbacks on DMLs are supported.
Global temporary table: DDLs can be rollbacked, but rollbacks on DMLs are not supported.
Local temporary table: rollbacks on DDLs and DMLs are not supported. No logging column table: DDLs are not supported when ddl autocommit is off, whereas
rollbacks on DMLs are supported.

SAP HANA Database: SQL Reference Manual
145
SET TRANSACTION SQL Syntax: SET TRANSACTION <isolation_level> | <transaction_access_mode>
Parameters:
<isolation_level> ::= ISOLATION LEVEL <level> <level> ::= READ COMMITTED | REPEATABLE READ | SERIALIZABLE <transaction_access_mode> ::= READ ONLY | READ WRITE
READ COMMITTED
Default
This isolation level corresponds to the statement level read consistency. With statement level snapshot isolation, different statements in a transaction may see
different snapshots of the system. The statement in a transaction sees consistent snapshots of the system. Each statement sees the changes that were committed when the execution of the statement started. Reading a row does not set any locks. When rows are inserted, updated or deleted, the system sets exclusive locks on the affected rows for the duration of the transaction. The system releases these locks at the end of the transaction. When rows are inserted,
updated or deleted, the system also sets shared locks on the affected tables for the duration of the transaction. This guarantees that the table is not dropped or altered while some rows of the table are being updated.
REPEATABLE READ/ SERIALIZABLE
This isolation level corresponds to transaction level snapshot isolation.
All statements of a transaction see the same snapshot of the database. This snapshot contains all changes that were committed at the time the transaction started with the changes made by the transaction itself. Reading a row does not set any locks. When rows are inserted, updated or deleted, the system sets exclusive locks on the affected rows for the duration of the transaction. The
system releases these locks at the end of the transaction. When rows are inserted, updated or deleted, the system also sets shared locks on the affected tables for the duration of the transaction. This guarantees that the table is not dropped or altered while some rows of the table are being updated.
READ WRITE Default
An SQL-transaction access mode may be explicitly set by a SET TRANSACTION statement;
otherwise, it is implicitly set to the default access mode. READ ONLY
When read only access mode is set, then only read operation with SELECT statement is allowed and exceptions will be thrown if any update is tried.
Description: The system uses multi-version concurrency control (MVCC) to ensure consistent read operations. Concurrent read operations see a consistent view of the system without blocking concurrent write operations. Updates are implemented not by overwriting existing records, but by inserting new
versions. The isolation level specification determines the lock operation type. The system supports both
statement level snapshot isolation and transaction level snapshot isolation. For statement snapshot isolation use level READ COMMITTED.

SAP HANA Database: SQL Reference Manual
146
For transaction snapshot isolation use REPEATABLE READ or SERIALIZABLE.
DDL statements always run in READ COMMITTED isolation level.

SAP HANA Database: SQL Reference Manual
147
TRUNCATE TABLE SQL Syntax: TRUNCATE TABLE <table_name>
Description: Deletes all rows from a table. TRUNCATE is faster than DELETE FROM when deleting all records
from a table, but TRUNCATE cannot be rollbacked. To rollback from deleting records, ―DELETE
FROM <table_name>‖ should be used.
HISTORY tables can also be truncated just like normal tables by executing this command. All parts
of the history table (main, delta, history main and history delta) will be deleted and the content
will be lost.

SAP HANA Database: SQL Reference Manual
148
UNLOAD SQL Syntax: UNLOAD <table_name>
Description The UNLOAD statement unloads the column store table data from memory to disk.
Example:
UNLOAD a_table;

SAP HANA Database: SQL Reference Manual
149
UNSET [SESSION] SQL Syntax: UNSET [SESSION] <key>
Parameters: <key> ::= key of a session variable
Description: You can unset session variables by providing key. With this command, session variables of the current session can be unset. If you have session administration privileges, you can change session variables of other sessions by specifying the session ID using ALTER SYSTEM ALTER
SESSION [session_id] UNSET command.
There are several available read-only session variables and they are LOCALE, LOCALE_SAP, CLIENT, CONN_ID, APPLICATIONNAME, CLIENTUSER, CLIENTHOSTNAME. Session variables can be retrieved using SESSION_CONTEXT() function.
Example: SET ‘my_var’ = ‘dummy’;
SELECT session_context(‘my_var’) FROM dummy;
Unset ‘my_var’;

SAP HANA Database: SQL Reference Manual
150
UPDATE SQL Syntax:
UPDATE <table_name> [[AS] <alias_name> ] <set_clause> [WHERE <predicate>]
[WITH PARAMETERS ( <parameter_key_value_list> ) ]
Parameters:
<set_clause>::= SET { <column_name> = <expression>} , …
<parameter_key_value_list> ::= <parameter_key_value>,…
<parameter_key_value> ::=
<string_literal> = <string_literal> |
<identifier> = <string_literal> | <string_literal> = (<string_literal>, ... )
Description:
The UPDATE statement changes the values of the records of a table where the predicate is met.
If the WHERE clause predicate is true, the result of expression is assigned to that column.
If the WHERE clause is omitted, then it updates all records of a table. Example:
UPDATE table_a SET a = 2 WHERE a = 1;

SAP HANA Database: SQL Reference Manual
151
UPSERT| REPLACE SQL Syntax: UPSERT <table_name> [(<column_name>,...) ] { <values_list_clause> | <subquery> }
REPLACE <table_name> [(<column_name>,...) ] { <values_list_clause> | <subquery> }
<values_list_clause> ::= VALUES ( <expression>,... ) [ WHERE <predicate> | WITH PRIMARY KEY ]
Description:
The UPSERT/REPLACE statement without a subquery is similar to the UPDATE statement. The only
difference is when the WHERE clause predicate is false, it adds a new record to the table like the INSERT statement.
In case of a table which has a PRIMARY KEY, the PRIMARY KEY column must be included in the column list. Columns defined with NOT NULL without default specification have to be included in the column list as well. Other columns are filled with default value or NULL if not specified. The UPSERT/REPLACE statement with a subquery works like the INSERT statement, except that if
an old row in the table has the same value as a new row for a PRIMARY KEY, then the old row is
changed by values of the returned record from a subquery. Unless the table has a PRIMARY KEY, it becomes equivalent to INSERT because there is no index to be used to determine whether or not a new row duplicates another. The UPSERT/REPLACE statement with a 'WITH PRIMARY KEY' is same as one with the subquery. It
works based on the PRIMARY KEY.
Example:
CREATE TABLE A (A INT PRIMARY KEY, B INT);
UPSERT A VALUES (1, 1);
UPSERT A SELECT A + 1, B FROM A;

SAP HANA Database: SQL Reference Manual
152
Appendix
Restrictions for SQL Statements
Database
Maximum number of locks Unlimited for record locks, 16384 for table locks
Maximum number of maximum sessions 8192
Database size limit Limited by storage size RS: 1TB
Schemas
Maximum number of tables in a schema 131072
Length of an identifier 127 characters
Length of an alias name 128 characters
Maximum length of a constant string literal 32767 bytes
maximum number of hex characters in a binary
literal
8192
Tables and Views
Maximum number of columns in a table 1000
Maximum number of columns in a view 1000
Maximum number or partitions of a column table 1000
Maximum number of rows in each table Limited by storage size RS: 1TB/sizeof(row),
CS: 2^31 * number of partitions
Maximum length of a row Limited by RS storage size ( 1TB )
Maximum size of a non-partitioned table Limited by RS storage size ( 1TB )
Indexes and Constraints
Maximum number of indexes for each table 1023
Maximum number of primary key columns in each
table
16
Maximum number of columns in an index 16
Maximum number of columns in a UNIQUE
constraint
16
Maximum size of sum of primary key, index, UNIQUE
constraint
16384
SQL
Maximum length of an SQL statement 2GB
Maximum depth of SQL view nesting 128
Maximum depth of SQL parse tree 255
Maximum number of joined tables in an SQL
statement or view
255
Maximum number of columns in an ORDER BY, GROUP BY or SELECT clause
65536
SQLScript
Maximum size of all stored procedures Limited by RS storage size ( 1TB )

SAP HANA Database: SQL Reference Manual
153
SQL Error Codes
Error Code Description
1 general warning
2 general error
3 fatal error
4 cannot allocate enough memory
5 initialization error
6 invalid data
7 feature not supported
8 invalid argument
9 index out of bounds
10 invalid username or password
11 invalid state
12 cannot open file
13 cannot create/write file
14 cannot allocate enough disk space
15 cannot find file
16 statement retry
17 metadata schema version incompatible between database and executable file
18 service shutting down
19 invalid license
128 transaction error
129 transaction rolled back by an internal error
130 transaction rolled back by integrity constraint violation
131 transaction rolled back by lock wait timeout
132 transaction rolled back due to unavailable resource
133 transaction rolled back by detected deadlock
134 failure in accessing checkpoint file
135 failure in accessing anchor file
136 failure in accessing log file
137 failure in accessing archive file
138 transaction serialization failure
139 current operation cancelled by request and transaction rolled back
140 invalid write-transaction identifier
141 failure in accessing invisible log file
142 exceed max num of concurrent transactions
143 transaction serialization failure until timeout expires
144 transaction rollback, unique constraint violated
145 transaction distribution work failure
146 resource busy and acquire with NOWAIT specified
147 inconsistency between data and log
148 transaction start is blocked until Master_Restart finishes
149 distributed transaction commit failure
150 statement cancelled due to old snapshot

SAP HANA Database: SQL Reference Manual
154
256 sql processing error
257 sql syntax error
258 insufficient privilege
259 invalid table name
260 invalid column name
261 invalid index name
262 invalid query name
263 invalid alias name
264 invalid datatype
265 expression missing
266 inconsistent datatype
267 specified length too long for its datatype
268 column ambiguously defined
269 too many values
270 not enough values
271 duplicate alias
272 duplicate column name
273 not a single character string
274 inserted value too large for column
275 aggregate function not allowed
276 missing aggregation or grouping
277 not a GROUP BY expression
278 nested group function without GROUP BY
279 group function is nested
280 ORDER BY item must be the number of a SELECT-list
281 outer join not allowed in operand of OR or IN
282 two tables cannot be outer-joined to each other
283 a table may be outer joined to at most one other table
284 join field does not match
285 invalid join condition
286 identifier is too long
287 cannot insert NULL or update to NULL
288 cannot use duplicate table name
289 cannot use duplicate index name
290 cannot use duplicate query name
291 argument identifier must be positive
292 wrong number of arguments
293 argument type mismatch
294 cannot have more than one primary key
295 too long multi key length
296 replicated table must have a primary key
297 cannot update primary key field in replicated table
298 cannot store DDL
299 cannot drop index used for enforcement of unique/primary key

SAP HANA Database: SQL Reference Manual
155
300 argument index is out of range
301 unique constraint violated
302 invalid CHAR or VARCHAR value
303 invalid DATE, TIME or TIMESTAMP value
304 division by zero undefined
305 single-row query returns more than one row
306 invalid cursor
307 numeric value out of range
308 column name already exists
309 correlated subquery cannot have TOP or ORDER BY
310 sql error in procedure
311 cannot drop all columns in a table
312 sequence is exhausted
313 invalid sequence
314 numeric overflow
315 invalid synonym
316 wrong number of arguments in function invocation
317 P_QUERYPLANS not exists nor valid format
318 decimal precision specifier is out of range
319 decimal scale specifier is out of range
320 cannot create index on expression with datatype LOB
321 invalid view name
322 cannot use duplicate view name
323 duplicate replication id
324 cannot use duplicate sequence name
325 invalid escape sequence
326 CURRVAL of given sequence is not yet defined in this session
327 cannot explain plan of given statement
328 invalid name of function or procedure
329 cannot use duplicate name of function or procedure
330 cannot use duplicate synonym name
331 user name already exists
332 invalid user name
333 column not allowed
334 invalid user privilege
335 field alias name already exists
336 invalid default value
337 INTO clause not allowed for this SELECT statement
338 zero-length collumns are not allowed
339 invalid number
340 not all variables bound
341 numeric underflow
342 collation conflict
343 invalid collate name

SAP HANA Database: SQL Reference Manual
156
344 parse error in data loader
345 not a replication table
346 invalid replication id
347 invalid option in monitor
348 invalid datetime format
349 cannot CREATE UNIQUE INDEX
350 cannot drop columns in the primary-key column list
351 column is referenced in a multi-column constraint
352 cannot create unique index on cdx table
353 update log group name already exists
354 invalid update log group name
355 the base table of the update log table must have a primary key
356 exceed maximum number of update log group
357 the base table already has a update log table
358 update log table can not have a update log table
359 concatenated string is too long
360 view WITH CHECK OPTION where-clause violation
361 data manipulation operation not legal on this view
362 invalid schema name
363 number of index columns exceeds its maximum
364 invalid partial key size
365 no matching unique or primary key for this column list
366 referenced table does not have a primary key
367 number of referencing columns must match referenced columns
368 unique constraint not allowed on temporary table
369 exceed maximum view depth limit
370 cannot perform DIRECT INSERT operation on table with unique indexes
371 invalid XML document
372 invalid XPATH
373 invalid XML duration value
374 invalid XML function usage
375 invalid XML index operation
376 Python stored procedure error
377 JIT operation error
378 invalid column view
379 table schema mismatch
380 fail to change run level
381 fail to restart
382 fail to collect all version garbage
383 invalid identifier
384 constant string is too long
385 could not restore session
386 cannot use duplicate schema name
387 table ambiguously defined

SAP HANA Database: SQL Reference Manual
157
388 role already exists
389 invalid role name
390 invalid user type
391 invalidated view
392 can't assign cyclic role
393 roles must not receive a privilege with grant option
394 error revoking role
395 invalid user-defined type name
396 cannot use duplicate user-defined type name
397 invalid object name
398 cannot have more than one order by
399 role tree too deep
400 primary key not allowed on insert-only table
401 unique constraint not allowed on insert-only table
402 the user was already dropped before query execution
403 internal error
404 invalid (non-existent) structured privilege name
405 cannot use duplicate structured privilege name
406 INSERT, UPDATE and UPSERT are disallowed on the generated field
407 invalid date format
408 password or parameter required for user
409 multiple values for a parameter not supported
410 invalid privilege namespace
411 invalid table type
412 invalid password layout
413 last n passwords can not be reused
414 user is forced to change password
415 user is deactivated
416 user is locked
417 can't drop without CASCADE specification
418 invalid view query for creation
419 can't drop with RESTRICT specification.
420 password change currently not allowed
421 cannot create fulltext index
422 privileges must be either all SQL or all from one namespace
423 liveCache error
424 invalid name of package
425 duplicate package name
426 number of columns mismatch
427 can not reserve index id any more
428 invalid query plan id
429 integrity check failed
430 invalidated procedure
431 user's password will expire within few days

SAP HANA Database: SQL Reference Manual
158
432 this syntax has been deprecated and will be removed in next release
433 null value found
434 invalid object ID
435 invalid expression
436 could not set system license
437 only commands for license handling are allowed in current state
438 invalid user parameter value
439 composite error
440 table type conversion error
441 this feature has been deprecated and will be removed in next release
442 number of columns exceeds its maximum
443 invalid calculation scenario name
444 package manager error
512 replication error
513 cannot execute ddl statement on replication table while replicating
514 failure in accessing anchor file
515 failure in accessing log file
516 replication table has not conflict report table
517 conflict report table already enabled
518 conflict report table already disabled
576 api error
577 cursor type of forward is not allowed
578 invalid statement
579 exceed maximum batch size
580 Server rejected the connection(protocol version mismatch)
581 this function can be called only in the case of single statement
582 this query does not have result set
583 connection does not exist
584 no more lob data
585 operation is not permitted
586 invalid parameter is received from server
587 result set is currently invalid
588 next() is not called for this result set
589 too many parameters are set
590 some paramters are missing
591 internal error
592 not supported type conversion
593 remote-only function
594 no more result row in result set
595 Specified parameter is not output parameter
596 LOB streaming is not permitted in auto-commit mode
597 session context error
598 failed to execute the external statement
599 session layer is not initialized yet

SAP HANA Database: SQL Reference Manual
159
600 failed routed execution
601 too many session variables are set
602 cannot set readonly session variable
603 invalid LOB
604 remote temp table access failure
605 invalid xa join request
606 exceed maximum LOB size
607 failed to cleanup resources
608 exceed maximum number of prepared statements
1024 session error
1025 communication error
1026 cannot bind a communication port
1027 communication initialization error
1028 I/O control error
1029 connection failure
1030 send error
1031 receive error
1032 cannot create a thread
1033 error while parsing protocol
1034 exceed maximum number of sessions
1035 not supported version
1036 invalid session id
1037 unknown hostname
1280 sqlscript error
1281 wrong number or types of parameters in call
1282 output parameter not a variable
1283 OUT and IN OUT parameters may not have default expressions
1284 duplicate parameters are not permitted
1285 at most one declaration is permitted in the declaration section
1286 cursor must be declared by SELECT statement
1287 identifier must be declared
1288 expression cannot be used as an assignment target
1289 expression cannot be used as an INTO-target of SELECT/FETCH statement
1290 expression is inappropriate as the left hand side of an assignment statement
1291 expression is of wrong type
1292 illegal EXIT statement, it must be appear inside a loop
1293 identifier name must be an exception name
1294 an INTO clause is expected in SELECT statement
1295 EXPLAIN PLAN and CALL statement are not allowed
1296 identifier is not a cursor
1297 wrong number of values in the INTO list of a FETCH statement
1298 unhandled user-defined exception
1299 no data found
1300 fetch returns more than requested number of rows

SAP HANA Database: SQL Reference Manual
160
1301 numeric or value error
1302 parallelizable function cannot have OUT or IN OUT parameter
1303 user-defined exception
1304 cursor is already opened
1305 return type is invalid
1306 return type mismatch
1307 unsupported datatype is used
1308 illegal single assignment
1309 invalid use of table variable
1310 scalar type is not allowed
1311 Out parameter is not specified
1312 At most one output parameter is allowed
1313 output parameter should be a table or a table variable
1314 inappropriate variable name: do not allow "" for the name of variable or parameter
1315 return result set from select stmt exist when result view is defined
1316 some out table var is not assigned
1317 Function name exceedes max. limit
1318 Built-in function not defined
1319 Parameter must be a table name
1320 Parameter must be an attribute name without a table name upfront
1321 Parameter must be an attribute name without an alias
1322 CE_CALC not allowed
1323 Parameter must be a vector of columns or aggregations
1324 Join attribute must be available in projection list
1325 Parameter must be a vector of sql identifiers
1326 Duplicate attribute name
1327 Parameter has a non supported type
1328 Attribute not found in column table
1329 Duplicate column name
1330 Syntax Error for calculated Attribute
1331 Syntax Error in filter expression
1332 Parameter must be a valid column table name
1333 Join attributes not found in variable
1334 Input parameters do not have the same table type
1335 Cyclic dependency found in a runtime procedure
1336 Unexpected internal exception caught in a runtime procedure
1337 Variable depends on an unassigned variable
1338 CE_CONVERSION: customizing table missing
1339 Too many parameters
1340 The depth of the nested call is too deep
1536 swapx error
1537 this table has no swap space
1538 swap already activated
1539 swap not yet activated

SAP HANA Database: SQL Reference Manual
161
1540 swap space is not created
1541 failure in unpinning a swap page
1542 failure in swap file
1543 failure in accessing swap data file
1544 failure in accessing swap log file
1545 swap buffer overflow
1546 swap buffer reservation failure
1792 shared memory error
1793 invalid key or invalid size
1794 the segment already exists
1795 exceed the system-wide limit on shared memory
1796 no segment exists for the given key, and IPC_CREAT was not specified
1797 the user does not have permission to access the shared memory segment
1798 no memory could be allocated for segment overhead
1799 invalid shmid
1800 allow read access for shmid
1801 shmid points to a removed identifier
1802 the effective user ID of the calling process is not the creator
1803 the gid or uid value is too large to be stored in the structure
1804 the user does not have permission to access the shared memory segment
1805 invalid shmid
1806 no memory could be allocated for the descriptor or for the page tables
1807 unknown shared memory error
2048 column store error
2049 primary key is not specified for column table
2050 not supported ddl type for column table
2051 not supported data type for column table
2052 not supported dml type for column table
2053 invalid returned value from attribute engine
2304 python dbapi error
2305 interface failure
2306 programming mistake
2307 invalid query parameter
2308 not supported encoding for string
2560 distributed metadata error
2561 DDL redirect error
2562 DDL notification error
2563 DDL invalid container id
2564 DDL invalid index id
2565 distributed environment error
2566 network error
2567 metadata update not supported in slave
2568 metadata update of master indexserver is failed
2816 SqlScript Error

SAP HANA Database: SQL Reference Manual
162
2817 SqlScript Builtin Function
2818 SqlScript
2819 SqlScript
2820 SqlScript
2821 SqlScript
2822 SqlScript
2823 SqlScript
2824 SqlScript
2825 SqlScript
2826 SqlScript
2827 SqlScript
2828 SqlScript
2829 SqlScript
2830 SqlScript
2831 SqlScript
2832 SqlScript
2833 SqlScript
2834 SqlScript
2835 SqlScript
2836 SqlScript
2837 SqlScript
2838 SqlScript
2839 SqlScript
2840 SqlScript
2841 SqlScript
2842 SqlScript
2843 SqlScript
2844 SqlScript
2845 SqlScript
2846 SqlScript
2847 SqlScript
2848 SqlScript
2849 SqlScript
2850 SqlScript
2851 SqlScript
2852 SqlScript
2853 SqlScript
2854 SqlScript
2855 SqlScript
2856 SqlScript
2857 SqlScript
2858 SqlScript
2859 SqlScript
2860 SqlScript

SAP HANA Database: SQL Reference Manual
163
2861 SqlScript
2862 SqlScript
2863 SqlScript
2864 SqlScript
2865 SqlScript
2866 SqlScript
2867 SqlScript
2868 SqlScript
2869 SqlScript
2870 SqlScript
2871 SqlScript
2872 SqlScript
2873 SqlScript
2874 SqlScript
2875 SqlScript
2876 SqlScript
2877 SqlScript
2878 SqlScript
2879 SqlScript
2880 SqlScript
2881 SqlScript
2882 SqlScript
2883 SqlScript
2884 SqlScript
2885 SqlScript
2886 SqlScript
2887 SqlScript
2888 SqlScript
2889 SqlScript
3584 distributed SQL error
3585 expression shipping failure
3586 operator shipping failure
3587 invalid protocol or indexserver (statisticsserver) shutdown during distributed query execution
3588 sequence shipping failure
3589 remote query exuectuion failure
110002 Something went wrong ($errtxt$)
110006 $number$, $errtxt$
110007 No source defined which should be backed up
110008 The file '$filename$' already exists and must not be overwritten
110009 No destination defined for restore
110010 Unable to read $readItem$ information from backup '$filename$'
110011 Invalid value <$value$> for $readItem$
110012 Expected tag <$expected$> but found <$readItem$>
110013 Unexpected end of backup

SAP HANA Database: SQL Reference Manual
164
110015 Command not allowed
110016 BackupExecutor: Unexpected state <$value$> for <$name$>
110017 Another backup operation is already running
110018 The error <$errtxt$> occurred
110019 An object has the unexpected state <$value$>
110021 Object <$type$> with the value <$id$> does not exist.
110024 TREX Net exception caught: <$errtxt$>
110025 BackupExecutor: $errtxt$ ($number$)
110026 The state '$value$' of the BackupManager does not allow the requested operation
110028 Orphaned volume with the number '$volume$' found in the topology
110029 Backup ist not possible because the volume '$volume$' is not assigned to a service
110030 The service '$name$' at '$host$:$port$' responsible for the volume '$volume$' has the wrong state '$state$'
110032 Recovery of the instance is not possible
110033 The volume with the number '$volume$' does not exist in the topology
110034 Error while reading the topology ('$errtxt$')
110035 No recovery information available for the service '$name$' at '$host$:$port$' responsible for the volume '$volume$'
110036 The recover information for the service '$name$' at '$host$:$port$' responsible for the volume '$volume$' has been already requested
110037 The recover information for the service '$name$' at '$host$:$port$' responsible for the volume '$volume$' has the state '$state$'
110038 $errtxt$
110039 The recover statement file '$name$' older than $number$ seconds will not be used
110040 The recover statement file '$name$' larger than $number$ bytes will not be used
110041 An error has been occurred while checking or reading the recover statement file '$name$'
110042 The recover statement file '$name$' is empty
110043 Can not start the service '$name$' at '$host$:$port$' responsible for the volume '$volume$' because an error during recovery before
110044 The service '$name$' at '$host$:$port$' responsible for the volume '$volume$' does crash
110045 Backup is not possible because the service '$name$' at '$host$:$port$' responsible for the volume '$volume$' does not run
110046 Communication failure with service '$name$' at '$host$:$port$' responsible for the volume '$volume$'
110048 Service is not in recovery state
110049 Volume with volId: <$vol$> was already registered.
110201 Expect invalid snapshotid but got $sid$.
110301 Unknown request method '$id$' with name '$name$' can not be handled.
110401 Requested backup destination ($dest$) has not necessary size of $size$.
110402 Requested backup destination is NULL.
120001 Data with name '$name$' not found.
120001 Something wents wrong.

SAP HANA Database: SQL Reference Manual
165
120002 Memory allocation error.
120003 Can not create object '$NAME$'.
120004 Error during excution of SAX parser.
120005 Error in document '$FILENAME$' (row: $ROWNO$ column: $COLUMNNO$).
120006 SAX error: $ERRORTEXT$.
120007 Invalid name or directory for the document specified.
120008 Name '$FILENAME$' or directory '$PATHNAME$' for the document to long.
120009 Can not open document '$FILENAME$'
120010 Can not determine properties of document '$FILENAME$'.
120011 Can not read document '$FILENAME$'.
120012 Operating system error: $ERRORTEXT$ ($ERROR_NUMBER$).
120013 Object '$NAME$' does not exist.
120014 Sorry XML feature '$NAME$' not supported.
300001 Invalid SSL configuration: $ErrorText$
300002 OpenSSL is not available: $ErrorText$
300003 OpenSSL is not available
300005 SAP crypto lib is not available: $ErrorText$
300006 Cannot create certificate store
300007 Cannot create certificate store
300008 Certificate store import error
300010 Cannot create SSL context: $ErrorText$
300012 Cannot create SSL engine: $ErrorText$
300013 SSL handshake failed: $ErrorText$
300014 SSL handshake failed
300015 SSL certificate validation failed: $ErrorText$
1000000 Assertion failed: $condition$
1000001 Unknown unhandled exception in critical scope detected
1000002 Out of memory $REASON$
1000003 Index $IDX$ out of range [$BEG$, $END$)
1000004 Registered exception not registered on current thread
1000005 Invalid critical exception scope detected (in: uncaught $ADDR$, out: no exc)
1000006 Incompatible or invalid iterator
1000007 Conversion to $TYPE$ type failed. Value: $VALUE$
1000008 Invalid sorting
1000009 Bad cast $REASON$
1000010 Invalid argument
1000011 RValue change: $STR$
1000012 Range error
1000013 Runtime error
1000014 Logic error
1000015 Domain error
1000016 Length error
1000017 Underflow error
1000018 Null pointer in typeid $REASON$

SAP HANA Database: SQL Reference Manual
166
1000019 Unexpected enum type $TYP$: $DESRC$
1000020 Iterators point to different $CLS$ containers
1000021 Null pointer dereference
1000022 Unexpected exception $REASON$
1000024 Integer overflow
1000025 Time overflow "$MSG$": $VAL$
1000026 Time conversion $SEC$:$MIN$:$HRS$ $DAY$.$MNT$.$YRS$
1000027 Memory corruption: "$CURRENT$", expected: "$EXPECT$"
1000032 Invalid unicode character
1000033 Corrupted compressed data
1000034 Initialization error
1000035 Buffer overflow
1000036 Buffer alignment too low
1000087 IO stream failed
1000088 Locale error: $DESRC$
1000089 Object not initialized
1000090 Reached unreachable code
1000091 Not yet implemented
2000001 Generic file error
2000002 Cannot create root directory $root$, rc=$sysrc$: $sysmsg$
2000003 Cannot remove file $fn$, rc=$sysrc$: $sysmsg$
2000004 Cannot open file $file$, rc=$sysrc$: $sysmsg$
2000005 Mode $mode$ not allowed when trying to $action$ file
2000006 Short write, $ws$ of $s$ bytes written at $ofs$, file $file$
2000007 Invalid read, $rs$ of $s$ bytes read at $ofs$, file $file$
2000008 Error during asynchronous file transfer, rc=$sysrc$: $sysmsg$
2000009 Error calling io_setup, rc=$sysrc$: $sysmsg$
2000010 Cannot close file $file$, rc=$sysrc$: $sysmsg$
2000011 Unaligned buffer
2000012 Unaligned offset
2000014 Cannot lock file $file$ for write access, rc=$sysrc$: $sysmsg$
2000015 Cannot assign type "$ntype$" to file factory with type "$otype$"
2000016 File $fn$ is currently not open
2000017 InMemory files don't support paths
2000018 $msg$
2000019 Cannot resize $file$ from $os$ to $ns$
2000020 Cannot rename file $src$ into $tgt$, rc=$sysrc$: $sysmsg$
2000021 Cannot fsync() file $file$, rc=$sysrc$: $sysmsg$
2000022 Cannot append to file opened in write mode
2010001 Error in SystemMutex generic: rc=$sysrc$: $sysmsg$
2010002 Error in SystemMutex init: rc=$sysrc$: $sysmsg$
2010003 Error in SystemMutex lock: rc=$sysrc$: $sysmsg$
2010004 Error in SystemMutex unlock: rc=$sysrc$: $sysmsg$
2010005 Error in SystemMutex locked by other thread/task $m_pOwner$ $m_lockCount$

SAP HANA Database: SQL Reference Manual
167
2010006 Error in TimedSystemMutex timedlock: rc=$sysrc$: $sysmsg$
2010007 Error in TimedSystemMutex the mutex is already locked by this thread
2010011 Error in SystemSemaphore generic: rc=$sysrc$: $sysmsg$
2010012 Error in SystemSemaphore init: rc=$sysrc$: $sysmsg$
2010013 Error in SystemSemaphore destroy: rc=$sysrc$: $sysmsg$
2010014 Error in SystemSemaphore wait: rc=$sysrc$: $sysmsg$
2010015 Error in SystemSemaphore signal: rc=$sysrc$: $sysmsg$
2010016 Error in SystemCondVariable init: rc=$sysrc$: $sysmsg$
2010017 Error in SystemCondVariable destroy: rc=$sysrc$: $sysmsg$
2010018 Error in SystemCondVariable wait: rc=$sysrc$: $sysmsg$
2010019 Error in SystemCondVariable signal: rc=$sysrc$: $sysmsg$
2010022 Error in Mutex wrong owner for wake up
2010024 Error in Mutex destructor: waiters unexpected
2010025 Error in Mutex destructor: locked unexpected $m_Futex$ $m_LockCount$
2010042 Error in RWLock not locked shared
2010043 Error in RWLock not locked intend
2010044 Error in RWLock not locked exclusive
2010045 Error in RWLock destructor: waiters unexpected
2010046 Error in RWLock destructor: locked unexpected
2010047 Error in RWLock not enough shared locks to unlock
2010048 Error in RWLock too many shared locks, counter overflow
2010050 Error in NamedProcessMutex create: rc=$sysrc$: $sysmsg$
2010051 Error in NamedProcessMutex close: rc=$sysrc$: $sysmsg$
2010052 Error in NamedProcessMutex lock: rc=$sysrc$: $sysmsg$
2010053 Error in NamedProcessMutex unlock: rc=$sysrc$: $sysmsg$
2010054 Error in NamedProcessMutex timedlock: rc=$sysrc$: $sysmsg$
2010055 Error in NamedProcessMutex trylock: rc=$sysrc$: $sysmsg$
2010056 Error in NamedProcessMutex Invalid Handle
2010057 Error in NamedProcessSemaphore create: rc=$sysrc$: $sysmsg$
2010058 Error in NamedProcessSemaphore close: rc=$sysrc$: $sysmsg$
2010059 Error in NamedProcessSemaphore wait: rc=$sysrc$: $sysmsg$
2010060 Error in NamedProcessSemaphore signal: rc=$sysrc$: $sysmsg$
2010061 Error in NamedProcessSemaphore timedWait: rc=$sysrc$: $sysmsg$
2010062 Error in NamedProcessSemaphore tryWait: rc=$sysrc$: $sysmsg$
2010063 Error in NamedProcessSemaphore Invalid Handle
2010064 Error in SharedMemorySemaphore create: rc=$sysrc$: $sysmsg$
2010065 Error in SharedMemorySemaphore close: rc=$sysrc$: $sysmsg$
2010066 Error in SharedMemorySemaphore wait: rc=$sysrc$: $sysmsg$
2010067 Error in SharedMemorySemaphore signal: rc=$sysrc$: $sysmsg$
2010070 Error in SharedMemorySemaphore Invalid Handle
2010071 Error in SharedMemoryMutex create: rc=$sysrc$: $sysmsg$
2010080 Error in SystemReadWriteLock rc=$sysrc$: $sysmsg$
2010081 Error in SystemReadWriteLock locked unexpected $m_pOwner$ $m_Counter$
2010085 Error in InterProcessMutex create: rc=$sysrc$: $sysmsg$

SAP HANA Database: SQL Reference Manual
168
2010086 Error in InterProcessMutex unlock: rc=$sysrc$: $sysmsg$
2010087 Error in InterProcessMutex timedLock: rc=$sysrc$: $sysmsg$
2010088 Error in InterProcessMutex timedLock: $timeout$ $ts$
2010090 Error in SystemEvent rc=$sysrc$: $sysmsg$
2020001 Resource $res$ not found
2020002 Resource $res$ already managed
2020003 Resource $res$ not managed
2020004 Resource $res$ is in invalid state
2020005 Resource $res$ reference count overflow or underflow
2020006 Resource $res$ already deallocated, cannot modify/delete
2020007 Resource $res$ still loading, cannot modify/delete
2020008 Resource $res$ is not flushable, cannot modify/delete
2020009 Resource $res$ still loading, cannot flush or evict
2020010 Resource $res$ not in I/O, cannot finish flush
2020011 ReleaseTime of Resource $res$ has most significant bit
2020012 Error in creation of Header Heap: $msg$
2020013 Owner of Resource Header Container already set
2020014 Resource has wrong size $size$
2020015 Resource has wrong refcounter of $ref$
2020016 Resource statistics error
2020017 Internal error while booking or changing resource size. size1: $size1$, size2: $size2$
2020018 Error with disposition NonEscalatingTemorary of Resource $res$
2030001 Block $head$/$ptr$+$size$/$bsize$ fence before block changed
2030002 Block $head$/$ptr$+$size$/$bsize$ fence after block changed
2030003 Block $head$/$ptr$+$size$/$bsize$ dealloc pattern changed after dealloc at offset $offset$
2030004 Block $head$/$ptr$+$size$/$bsize$ dealloc pointer $userptr$ invalid
2030005 Block of size $size$ cannot be allocated, RC=$sysrc$: $sysmsg$
2030006 Block $ptr$+$size$ cannot be deallocated, RC=$sysrc$: $sysmsg$
2030007 Block $ptr$+$size$ cannot be decommitted, RC=$sysrc$: $sysmsg$
2030008 Deallocating not-in-use memory block at $ptr$
2030009 Trying to get size of not-in-use memory block at $ptr$
2030010 Destroying allocator '$name$' with $inuse$ used blocks
2030011 Trying to access free memory at $ptr$
2030012 Cannot delete Block $head$/$ptr$+$size$/$bsize$ (maybe double delete)
2030013 Parent allocator $name$ is not composite
2030014 Composite statistics size incompatible
2030015 Internal error of memory management: $err$
2030016 Functionality '$func$' not yet implemented
2030017 Out of memory occured during initialization of memory management: $msg$
2030018 Overflow in allocation status: $newSize$
2030019 Allocation status: compare less or equal of two values failed: $val1$ !<= $val2$
2030020 Thread specific shrink counter has wrong value: ctr=$ctr$
2030021 Compaction thread is not running

SAP HANA Database: SQL Reference Manual
169
2030022 Wrong decomitted size: decomitted=$decomitted, precharge=$precharge$, size=$size$
2030023 Alignment error: val=$val$
2030024 Null pointer not expected: name=$name$
2030025 Null pointer expected: name=$name$, val=$val$
2030026 Null expected: name=$name$, val=$val$
2030027 Too many compactors
2030028 Could not find compactor
2030029 Wrong allocation size, size1=$size1$, size2=$size2$
2030030 Internal IPMM error: $msg$
2030031 Too many IPMM processes
2030032 Corrupt IPMM process slot vector
2030033 Could not open shared memory for IPMM, rc=$rc$
2030034 Error in IPMM shared memory handling, val1=$val1, val2=$val2$
2040001 Cannot start first job worker
2040002 Thread join error: $reason$
2040003 Thread not started: $what$
2040004 Stack protection error $what$ for stack ($base$-base, $size$-size) at $addr$: rc=$sysrc$ ($sysmsg$)
2040005 Stack management error: $reason$
2040006 Error suspending thread $id$ ($name$) for asynchronous request, rc=$sysrc$: $sysmsg$
2040007 Error getting context of thread $id$ ($name$) for asynchronous request, rc=$sysrc$: $sysmsg$
2040008 Target context $name$ is not suspended, but called operation requires it
2040009 Error waiting for next async operation in context $name$: rc=$sysrc$ ($sysmsg$)
2040010 Cannot register thread init function, maximum already registered ($max$)
2040011 Successor job has other predecessors
2040012 Job wait called before execute
2040013 Job released without wait() or forget()
2040014 Errors have occurred in other jobs of the same job net (error_no=$error_no$)
2040015 Generic error in job execution
2040016 Wrong waiter state $waiter$ on job
2040017 Job executor shutting down
2040018 Connection context not assigned
2040019 setNextJob not allowed
2040020 Connection context already has an ID ($oid$) while trying to set ID $nid$
2040021 Statement context already has an ID ($oid$) while trying to set ID $nid$
2040022 Statement context not assigned
2050001 System error: $msg$, rc=$sysrc$: $sysmsg$
2050002 No free physical processor available
2050003 Parse error in UKT/CPU relationship, invalid parameter UKTCPU-Relationship, value '$VALUE$'
2050004 Missing shared library name to load
2050005 Error loading shared library $name$, rc=$sysrc$: $sysmsg$
2050006 Error resolving symbols: $loadlibrary$, $loadlibraryex$, $freelibrary$
SAP HANA Database: SQL Reference Manual
170
2050007 Error unknown op code for replacement
2050008 Error could not find shared library $name$
2050010 Error while handling security descriptions, rc=$sysrc$: $sysmsg$
2050020 Error open shared memory segment $name$, rc=$sysrc$: $sysmsg$
2050021 Error map view of file shared memory segment $name$, rc=$sysrc$: $sysmsg$
2050023 Error shared memory $name$ size differ requestedSize=$reqSize$ > isSize=$isSize$, rc=$sysrc$: $sysmsg$
2050024 Error shared memory $name$ could not set group: $groupname$-$groupid$, rc=$sysrc$: $sysmsg$
2050030 Error open memory mapping $name$, rc=$sysrc$: $sysmsg$
2050031 Error close memory mapping $base$ $length$, rc=$sysrc$: $sysmsg$
2050032 Error flush memory mapping $base$ $length$, rc=$sysrc$: $sysmsg$
2050033 Error try to flush private or not writeable memory mapping $base$ , $length$ , $flags$
2050034 Error while retrieving info for system shared memory rc=$sysrc$: $sysmsg$
2090001 Invalid message type $type$ registered, maximum is $max$
2090002 Message type $type$ already registered
2100001 Timer error: $condition$ ==> $message$
2100002 $reason$
2100003 $reason$ ($detail$)
2110000 Unexpected stream size: $size$ bytes
2110001 Generic stream error: $msg$ - , rc=$sysrc$: $sysmsg$
2110002 Stream in wrong state $state$ when trying to $action$ stream
2110003 Error during asynchronous stream request, rc=$sysrc$: $sysmsg$
2110004 Error invalid address: $msg$, rc=$sysrc$: $sysmsg$
2110005 Error during stream send: $msg$, rc=$sysrc$: $sysmsg$
2110006 Error during stream receive: $msg$, rc=$sysrc$: $sysmsg$
2110007 Error reading wraparound buffer
2110008 Error address in use: $msg$, rc=$sysrc$: $sysmsg$
2120001 External command error
2120002 Cannot open file $file$, rc=$sysrc$: $sysmsg$
2120003 Duplicate Topic: $topic$
2120004 Unknown TraceLevel: $level$
2120005 Unknown TraceLevel String: $level$
2120006 Unknown TraceTopic: $topic$
2120007 Unknown CheckLevel: $level$
2120008 Unknown CheckLevel String: $level$
2120009 Unknown CheckTopic: $topic$
2120010 RotationMode: $mode$
2120011 Profiler: $msg$
2120012 External command $cmd$ not available in sql
2120013 External subcommand $subcmd$ not available in sql
2120014 Need special privileges to execute subcommand $subcmd$ via sql
2120015 No value with name $name$ found
2120016 Duplicate value with name $name$ found

SAP HANA Database: SQL Reference Manual
171
2120017 Error parsing value '$value$' for $name$: $reason$
2120018 Structure element $name$ ends past available data
2120019 Structure collection element $name$ at index $index$ ends past available data
2120020 Generic error parsing structure around element $name$
2120021 Value $name$ not an integer
2120022 Invalid integer data size in $name$
2120023 Error checking value $name$: $reason$
2120024 Error checking structure $name$: $reason$
2120025 Structure too complex, maximum nesting depth exhausted
2150001 Event type $type$ already registered as $name$
2150002 Event type name $name$ already registered as $type$
2150003 Event type $type$ not found
2160001 Generic configuration error
2160002 Default configuration handler already set
2160003 Configuration network error: $msg$
2160004 Invalid $id$ $val$ for server connection
2160005 Configuration directory: $msg$
2160006 Ambiguous units "$node$", expected "$param$"
2160007 Unexpected type "$node$", required "$expect$"
3000003 Consistent change is already active on thread/session $sess$
3000004 Consistent change is not active on thread/session $sess$
3000005 Consistent change session $sess$ is in invalid state
3000006 Too many savepoint callbacks registered, maximum is $max$
3000007 Invalid lock state of savepoint lock
3000008 Invalid non-logged scope nesting on session $sess$
3000009 Invalid PersistenceManager state
3000010 Missing pre-commit callback on session $sess$
3000011 Cannot shutdown session registry, since sessions still open
3000012 Persistency shutting down, cannot open sessions
3000013 Invalid state for UNDO file in session $sess$
3000014 Invalid iterator state for UNDO file iterator in session $sess$
3000015 Invalid restart data for persistent space
3000016 Page $res$ has an unassigned physical page number
3000017 Anchor page corrupted
3000018 Restart page corrupted
3000019 Missing savepoint/snapshot record for savepoint/snapshot ID $snapshot$
3000020 Log partition count mismatch (expected $exp$, got $count$)
3000021 Invalid restart data for redo log position
3000022 Transaction ID $tidold$ already assigned when assigning TID $tidnew$ in session $sess$
3000023 Session $sess$ has no TID assigned
3000024 History queue is in invalid state
3000026 Consistent change cannot be rolled back in parallel mode on session $sess$
3000027 Cannot activate or terminate no-log scope on parallel session $sess$
3000028 Closing not owned consistent change on session $sess$

SAP HANA Database: SQL Reference Manual
172
3000029 Exactly one consistent change on session $sess$ required to execute this operation
3000030 Cannot create consistent change on session $sess$ during COMMIT/ROLLBACK processing
3000031 History manager already in shutdown phase, cannot add new history
3000032 Cannot grow savepoint record (current size $current$, free $free$, needed $needed$)
3000033 Maximum subtransaction nesting depth reached on session $sess$
3000034 No subtransaction active on session $sess$
3000035 Cannot start subtransaction when consistent change already active on session $sess$
3000036 Subtransaction still active on session $sess$
3000037 Cannot release consistent change on session $sess$ during COMMIT/ROLLBACK processing (stray exception?)
3000038 Invalid RemoteAccessor handle in PersistenceManager for volume $volume$
3000039 Cannot abort savepoint at this time
3000040 Distributed savepoint already running
3000041 Distributed savepoint is not running
3000042 Distributed savepoint already synchronized
3000043 Distributed savepoint running
3000044 Savepoint is disabled
3000045 Transaction with TID $tid$ not found
3000046 Consistent change cannot be rolled back since REDO already written on session $sess$
3000047 Uncommitted data left on destroyed session $sess$
3000050 RemoteAccessor failed for $volume$ on $server$: error code: $error_code$ error message $error_text$
3000051 RemoteOperation failed for $volume$: $error_text$
3000052 Could not read anchor page(s), read $rsz$ out of $esz$ bytes, data missing
3000053 Could not read anchor page, none of $count$ found copies contains valid data
3000054 Cannot backup with a snapshot $snapshotid$ created before restart of the database
3000055 Cannot find snapshot directory entry for snapshot $snapshotid$
3000056 Rollback forced on session $sess$
3000057 Global sync callback already set
3000058 Replay transaction callback already set
3000059 Unknown REDO log record type $type$ encountered
3000060 Parent session $sess$ has no TID assigned - creation of nested session not possible
3000061 Parent session $sess$ has no consistent view assigned - creation of nested session not possible
3000062 $command$ not allowed on nested subtransaction $sess$
3000063 $command$ not allowed on parent session $sess$ because started nested subtransaction is still open
3000064 Parent session $sess$ requires more than maximum of nested sessions in parallel
3000065 Nested session $sess$ has already been closed. Operation not allowed
3000066 Slave volume $volume$ is inconsistent with master (last commit position on slave:

SAP HANA Database: SQL Reference Manual
173
$slave$, last known position on master: $master$)
3000067 Volume $volume$ is not a slave volume ID
3000068 Slave position set: $set$
3000070 Prepare of distributed transaction failed
3000071 Transaction ID is invalid when assigning TID $tid$ in session $sess$
3000072 No-log scope on session $sess$ still active, cannot end transaction
3000073 Volume ID $volume$ is invalid, valid range [0..$max$]
3000074 Operation $op$ on volume ID $volume$ invalid
3000075 No-log scope expected on session $sess$!
3000076 Savepoint not possible at this time (no known restart log position)
3010001
3010002 Invalid ContainerID.
3010004 Invalid PageNo.
3010005 Page $pno$ already deleted.
3010006 Invalid container type $ct$.
3010008 ContainerName $ns$ - $n$ not found.
3010009 ContainerName $ns$ - $n$ already assigned.
3010013 Entry $eid$ not found.
3010014 Error ($msg$) trying to assign $len$-char string $strg$ that exceeds it's maximum length of $max$.
3010015 Inconsistent size of virtual file $res$.
3010016 Data write is not active on session $sess$ when trying to write file $res$
3010017 BTree internal error.
3010018 BTree wrong page type.
3010019 Page $pno$ has wrong owner $owner$, expected $cont$
3010020 Trying to overwrite file $res$ in two or more parallel transactions in session $sess$
3010021 BTree invalid root PageNo.
3010022 Entry $eid$ already deleted.
3010023 Cannot overwrite virtual file $res$ (older overwrite not visible - commit missing?).
3010024 Empty $type$ string.
3010025 Continuation container with v0 has size $size$.
3010026 Continuation container with v$version$ has size $size$ instead of $expsize$.
3010027 Invalid backward migration $oldver$ => $newver$ of continuation container.
3010028 No consistent view for implicit reads in $meth$.
3010029 Continuation container with invalid version $ver$.
3010030 Invalid file ID $cid$.
3010031 Invalid entry ID $eid$.
3010032 Invalid container ID $cid$, expected entry-based.
3010033 Invalid container ID $cid$, expected file ID-based.
3010034 Container $cid$ not found.
3010035 Seek failed on virtual file $res$.
3010036 Invisible append found in optimized write on virtual file $res$.
3010037 Stream not closed at destruction time on virtual file $res$.
3010038 Cannot decrement external refcounter on container $cid$.

SAP HANA Database: SQL Reference Manual
174
3010039 Nonzero external refcounter on container $cid$.
3010040 Invalid input parameter specified. $msg$.
3010041 Forbidden operation for container created by ContainerNameDirectory. $cid$.
3010042 Error buffer is to small for entry data.
3010043 Too many moves, exceeds $num_partlinks$.
3010044 Invalid virtual file (already deleted). $msg$.
3010045 ContainerName $ns$ - $n$ already deleted in parallel transaction.
3010046 Container $cid$ already deleted.
3010047 Key already exists
3010048 Key is in doubt
3010050 BTree marked as deleted
3010051 Invalid virtual file stream. $msg$.
3010052 VirtualFile error occurred.
3010053 $type$ string "$str$" has length $len$ != $cmplen$.
3010054 Invalid entry (length).
3010055 Duplicate entry.
3010056 Operation $op$ only for VirtualFiles.
3010057 ContainerType $type$ already registered.
3010058 ContainerType $type$ not registered.
3010059 Invalid ref count in virtual file $res$.
3010060 VirtualFile with invalid character size.
3010061 Operation $op$ not allowed in Redo.
3010062 Operation $op$ must be logged.
3010063 Must be FileID-based.
3010064 Invalid part link.
3010065 Invalid user data.
3010066 Wrong page disposition! pno= $pno$, cID= $cid$.
3010067 Invalid entry! pno= $pno$, cID= $cid$.
3020001 Invalid LogicalPageAccess.
3020002 Invalid PageIO.
3020004 Invalid Volume.
3020005 Invalid FreeBlockManager.
3020006 Invalid PageHandle.
3020007 Invalid logical page number $pno$.
3020008 Invalid physical page number $pno$.
3020009 Invalid physical page SizeClass.
3020011 FBM blockNo $bn$ is invalid.
3020012 Volume $inx$ has size $fs$, but should be $is$.
3020013 Page 0 of 8K volume 0 has type $type$.
3020014 Operation '$op$' not allowed in $phase$ phase.
3020015 FBM $level$ level in inconsistent state.
3020016 Cannot switch back to tree mode.
3020017 Shrink mode $mode$ not supported $detail$.
3020018 Cannot shrink DataVolume to $percent$% of payload.

SAP HANA Database: SQL Reference Manual
175
3020019 Converter: Incorrect state.
3020020 Converter: Operation not allowed.
3020021 PageIO: batch overflow with $nb$ of $mb$ batches.
3020022 PageIO: size class $sz$ invalid or missing.
3020023 PageIO: invalid volume index $vol$.
3020024 Converter: Maximum size reached.
3020027 ConverterLeafPage: Invalid EntryIndex.
3020028 PageIO: trying to $act$ $size$ bytes on page with $psize$ bytes.
3020029 PageIO: expected checksum $exp$, found $cs$.
3020030 PageIO: unknown checksum algorithm $csa$.
3020031 PageIO: expected SizeClass $exp$ but found $sz$.
3020032 Page $res$ is not managed, cannot flush
3020033 PageIO: page $pno$ is marked as $stat$.
3020034 PageIO: Cannot $act$ $off$ + $sz$ bytes from $fsz$ bytes.
3020037 PageIO: invalid PageNo: $pno$.
3020038 PageIO: page read failed.
3020039 PageIO: invalid savepoint phase in $meth$.
3020041 Invalid page type.
3020042 Failed bitvector operation.
3020043 FBM error.
3020044 Allocate page failed.
3020045 SavepointVersion $spVersion$ repeated.
3020046 SavepointVersion $spVersion$ repeated.
3020047 PageIO: status invalid.
3020048 PageIO: status invalid.
3020049 PageIO: invalid page type.
3020050 PageIO: no volumes.
3020051 PageIO: prealloc size too small.
3020052 Invalid shrink superblock.
3020053 Invalid shrink pages.
3020054 Invalid payload.
3020055 Invalid superblock.
3020061 ConverterLeafPage expected but found pagetype $pt$.
3020062 ConverterIndexPage expected but found pagetype $pt$.
3020063 PageIO: $sz$ bytes of $pgsz$ read.
3020064 PageIO: $sz$ bytes of $pgsz$ written.
3020065 PageIO: superblock read failed.
3030001 Maximum number of callback factories already registered
3030002 Too many consistent views open based on same minTID
3030003 Invalid minTID $tid$
3040001 No log partitions given when instantiating new logger
3040002 Too many log partitions given when instantiating new logger, maximum is $max$
3040003 Duplicate log partition root $root$
3040004 No memory for allocating $count$ initial log buffers of size $size$

SAP HANA Database: SQL Reference Manual
176
3040005 Cannot execute log backups in mode $mode$
3040006 Log partition on raw device $dev$ cannot start at offset $offset$ past end of device $end$
3040007 Log partition on raw device $dev$ at offset $offset$ has too small size $size$, at least $min$ required
3040008 Log partition on raw device $dev$ at offset $offset$ cannot be created with size $size$, only $rem$ remaining
3040009 Cannot start log segment manager worker thread
3040010 Invalid partition index $idx$
3040020 Trying to read on log segment recovery channel $id$
3040021 Got too much data for log segment recovery channel $id$, expected $exp$, got $offset$+$size$
3040022 Got too few data for log segment recovery channel $id$, expected $exp$, got $act$
3040023 Cannot start log recovery manager thread
3040024 Cannot start log recovery queue worker thread
3040025 Log end positions already set or a log segment already pushed to recovery
3040050 Physical size $size$ of segment directory $name$ exceeeds maximum available space $max$
3040051 Error reading segment directory $name$, configuration mismatch (expected/found entry count $ecnt$/$fcnt$, max changes $emax$/$fmax$)
3040052 Error reading segment directory $name$, expected $esize$, read $rsize$ bytes
3040053 Error reading segment directory $name$, invalid header for page $page$ at position $idx$
3040054 Error reading segment directory $name$, inconsistency found at page $page$
3040055 Error reading segment directory $name$, missing page $idx$
3040056 Error reading segment directory $name$, freelist contains $fcnt$ items, expecting $ecnt$
3040057 Error formatting log segment directory $name$, wrote $wsize$ bytes, expected $esize$
3040058 Cannot start log formatter thread
3040100 Unknown REDO log entry type $type$
3040101 REDO log is out of sync at position $pos$
3040102 REDO log history lost at position $pos$
3040103 REDO log entry at position $pos$ is non-transactional, but enqueued as transactional
3040104 Invalid point-in-time $point$ specified for REDO replay, last point-in-time was already $pos$
3040105 Invalid point-in-time $point$ in the middle of log entry ending at $pos$ specified for REDO replay
3040106 REDO log entry at position $pos$ is invalid, it contains position $epos$
3040107 Invalid log hole start $start$ in the middle of log entry ending at $pos$
3040108 Found overlapping log hole $start1$-$end1$, conflicts with $start2$-$end2$
3040109 Overlapping holes found
3040110 Found overlapping buffer $start$-$end$, current position is already $pos$
3040111 Duplicate log buffer with start position $start$ found
3040112 Log position $pos$ doesn't point to a log entry, previous entry invalid
3040113 Log entry at position $pos$ invalid

SAP HANA Database: SQL Reference Manual
177
3040114 Log replay start at position $pos$ requested, but data ends at position $epos$
3040115 Invalid part $pos$+$size$ of partial entry $id$, expected end $size$, computed $csize$
3040116 Found duplicate start of partial log entry $id$ at $pos$
3040117 Partial entry $id$ continuation found at $pos$, but no beginning found
3040118 Invalid buffer header found at position $pos$ in segment $id$
3040119 Buffer size $size$ at position $pos$ in segment $id$ invalid, maximum $rest$ expected
3040120 Buffer checksum at position $pos$ in segment $id$ invalid
3040121 Buffer at position $pos$ doesn't belong to segment $id$
3040122 Buffer $start$ with size $size$ at position $pos$ starts before current position $cpos$ in segment $id$
3040123 Error in parallel worker thread prevents continuing recovery in this worker
3040124 Transaction for $sess$ already prepared for COMMIT or ROLLBACK
3040125 Invalid log partition index $idx$ found for local log segment $seg$
3040126 Invalid log segment replay sequence (trying to push $seg$, expected $exp$)
3040127 Invalid log segment replay sequence (trying to push unknown $seg$)
3040128 Invalid log partition index $idx$ found for backed up log segment $seg$
3040129 Inconsistent log segment information (already known $old$, newly-added $new$)
3040130 Segment $seg$ is already loading
3040131 Known log segments already set or a segment already pushed
3040132 All known log segments were already loaded for log partition when trying to load $seg$
4010001 Invalid authorization mode change
4010003 Unknown authorization mode
4010004 Adding dependencies under objects that do not have any restrictions on DML-privileges is not allowed.
4010005 Granting privilege on object that is not enabled for that kind of operation.
4010006 OUTDATED ERROR
4010007 Invalid principal id type found on current dependency.
4010008 Not authorized
4010009 Cycles in dependency graph not allowed
4010010 Change ownership can only be applied to root node of consists-of dependency graph.
4010011 Consists-of dependencies can only be created between objects owned by the same user.
4010012 Changing validity on objects that are either unrestricted or restricted but impossible is not allowed.
4010013 Object found that is either unrestricted but has dependencies or that is impossible to use with a certain privilege, but has dependencies for that privilege.
4010014 A handler is already registered for object type $type$
4010015 No handler registered for object type $type$
4020001 There can be only on type of dependencies under the same object
4020002 Dependency must be of valid type
4020003 Trying to insert a structured privilege twice
4020004 Trying to fetch a non-existing structured privilege
4020005 Trying to delete a non-existing dependency with DepObj=$depoid$

SAP HANA Database: SQL Reference Manual
178
4020006 Trying to delete a dependency from the catalog failed. DepObj=$depoid$
4020007 Trying to add a dependency that already exists. DepObj=$depoid$
4020008 Adding owner $owner$ for object ($objectType$,$objectSubType$,$objectId$) to catalog failed.
4020011 Adding an authorization to the catalog failed. Granter=$granter$
4020012 Removing an authorization to the catalog failed. Revoker=$revoker$
4020014 Adding a DML restriction to the catalog failed. Object=($objectType$,$objectSubType$,$objectId$)
4020015 Removing an existing DML restriction from the catalog failed. Object=($objectType$,$objectSubType$,$objectId$)
4020016 Retrieving a certain DML restriction from the catalog failed. Object=($objectType$,$objectSubType$,$objectId$)
4020017 Adding a new dependency to the catalog failed. DepObj=$depoid$
4020018 Removing an DML restriction from the catalog failed. PrivilegeId=$privilegeId$
4020019 Could not connect
4030001 Invalid type
4030002 Invalid ID type
4030003 Duplicate object ID
4030004 Duplicate type
4030005 Duplicate sub type
4035001 Adding new type $typename$ to the catalog failed.
4035002 Adding new subtype $subtypename$ for $type$ to the catalog failed.
4035003 Trying to look up internal object id ($type$,$subtype$,$id$) via id instead via name.
4035004 Failing to add object id ($type$,$subtype$,$name$) to the catalog. [Temporary=$temporary$]
4035006 Failing to look up object type $type$ in the catalog.
4035007 Failing to look up object subtype $subtype$ in the catalog.
4035008 Trying to access non existing Object ($type$,$subtype$,$id$).
4040001 User was already initialized
4040002 Assigning this role would create an cycle
4040003 Removing granted role (revokee=$revokee$, role=$role$) from catalog failed
4040004 Adding granted role (assignee=$assignee$, role=$role$) to catalog failed
4040005 Principal $principal$ not found in the catalog.
4040006 Unexpected principal type for principal $principalId$.
4040007 Invalid principal id for principal $principalName$.
4040008 Principal tree would exceed height limit of $heightLimit$ with a height of $height$.
4050001 Duplicate privilege
4050002 Privilege '$privilege$' not found.
4050003 Privilege '$privilege$' already exists.
4050004 Creation of privilege '$privilege$' failed.
4060001 Illegal string input of data type [$value$]
4060002 Invalid integer value [$value$]
4060003 Invalid double value [$value$]
4060004 Invalid timestamp value [$value$]

SAP HANA Database: SQL Reference Manual
179
4060005 Invalid string value [$value$]
4060006 Invalid operator in value filter
4060007 Illegal data type of operand in value filter
4060008 Invalid data type in value filter
4060009 Invalid operands of given filter operator
4060010 Invalid restriction id
4060011 Invalid value filters in restriction
4060012 Invalid structured privilege subtype name [$name$]
4060013 Invalid restriction subtype name [$name$]
4060014 Invalid structured privilege subtype id
4060015 Invalid restriction subtype id
4060016 Structured privilege name already exists [$name$]
4060017 Restriction name already exists [$name$]
4060018 Failed to add structured privilege -> restriction dependency
4060019 Failed to retrieve structured privilege from catalog
4060020 Failed to remove structured privilege from catalog
4060021 Failed to save structured privilege to catalog
4060022 Failed to update structured privilege in catalog
4070001 Invalid cube name [$name$]
4070002 No dimension attributes specified
4070003 Invalid dimension attribute name [$name1$/$name2$]
4070004 No operator in value filter
4070005 Invalid operator in value filter
4070006 No operands in value filter
4070007 Invalid operand in value filter [$name$]
4070008 Illegal number of operands for an unary operator
4070009 Illegal number of operands for a binary operator
4070010 Invalid restricted object name [$name$]
4070011 No value filters provided for dimension attribute
4070012 No value filters expected for ALL dimension attribute
4070013 Invalid value filters in restriction
4070015 Invalid analytical privilege name [$name$]
4070016 No cube restriction in analytical privilege
4070017 Invalid cube restriction in analytical privilege [$name$]
4070018 No activity restriction in analytical privilege
4070019 Invalid activity restriction in analytical privilege [$name$]
4070020 Invalid validity restriction in analytical privilege
4070021 No dimension restriction in analytical privilege
4070022 Invalid dimension restriction in analytical privilege
4070023 Invalid generated restriction name [$name$]
4070028 Unknown cube name [$name$]
4070030 Unknown analytical privilege name [$name$]
4070031 Cube name already exists [$name$]
4070033 Analytical privilege name already exists [$name$]

SAP HANA Database: SQL Reference Manual
180
4070034 User not allowed to grant analytical privilege [$name$]
4070035 User not allowed to revoke analytical privilege [$name$]
4070040 Failed to add cube -> dim attr dependency
4070041 Failed to add dim attr -> analytical privilege dependency
4080001 No handler registered for namespace $name$
4080002 A handler is already registered for namespace $name$
5000001 Internal Error.
5001001 Error during commit handling
5001002 Provoked error during commit handling
5001003 Assert/Crash triggered.
5001004 Internal Error.
5001005 Commit trap
6000001 Invalid policy name: $policyName$.
6000002 Policy with name $policyName$ already exists.
6000003 Adding new policy with name $policyName$ to the catalog storage failed.
6000004 Adding new audited object ($objectId_type$,$objectId_subType$,$objectId_oid$) to audit policy ($policyId_type$,$policyId_subType$,$policyId_oid$) failed.
6000005 Adding new audited user ($userId$) to audit policy ($policyId_type$,$policyId_subType$,$policyId_oid$) failed.
6000006 Adding new audited action ($actionId$) to audit policy ($policyId_type$,$policyId_subType$,$policyId_oid$) failed.
6000007 Audit policy with id ($policyId_type$,$policyId_subType$,$policyId_oid$) not found in catalog storage.
6000008 No policy name found for policy id ($policyId_type$,$policyId_subType$,$policyId_oid$).
6000009 Unkown action
6000010 Unkown policy type
6000011 Unkown level
7000001 Failed to install a permanent license.
7000003 Failed to retrieve a valid license.
7000004 Internal likey error.
7000005 No valid license available.
7000006 Failed to obtain a hardware key.
10000000 The CreateTableEntry is missing for $index$
10000001 Can't write log entry. DocAction is invalid for $index$
10000002 Could not add Attribute $attribute$ for $index$: $message$
10000003 Could not create delta $index$: $msg$
10000004 Could not change Attribute $attribute$ for $index$: $message$
10000005 Could not drop Attribute $attribute$ for $index$: $message$
10000006 Create file for $index$ does not exist
10000007 Could not create concat attribute $concat$ for $index$: $message$
10000008 Failed to write data into $index$: $message$
10000009 Failed to lookup udivs for $index$: $message$
10000010 Could not get new udivs for $index$: $message$
10000011 Found invalid deindex data
10000012 The InvalidateMainUdivsEntry is missing for index $index$

SAP HANA Database: SQL Reference Manual
181
10000013 DeltaLog general error for index $index$
10000014 Found an invalid log entry with $id$ for $index$
10000015 Found an invalid row id '$rowid$'
10000016 Could not rename Attribute from $oldName$ to $newName$ for $index$: $message$
10000017 Attribute $attribute$ does not exist for $index$: $message$
10000018 Canceling DeltaLog Replay for $index$ because Table is not valid
10000019 Could not determine max row ID for $index$
10000020 Could not open log for $index$
10000021 Merge failed for $index$
10000022 Out of memory
10000023 Udiv Lookup failed for $index$ and rowid '$rowid$'
10000024 Unknown SessionType for $index$
10000025 Field $field$ not valid for $index$
10000026 Statement rollback failed for $index$
10000027 Found an invalid log entry version with $id$ and $version$ for $index$
10000028 Replay canceled due to transaction abort
10000029 Runtime data not valid for $index$
10000030 Delta already exists: $index$
73000001 Invalid column $COL$.
73000002 Invalid value type $TYPE$: $VAL$.
73000003 Column $COL1$ does not match with $COL2$.
73000004 $VAL$, $MSG$.
73000005 Invalid column type:$VAL$.
73000006 Invalid column size:$VAL$.
73000007 Invalid table:$TAB$.
73000008 Memory allocation failed:$VAL$.
73000009 Function executes failed:$MSG$.
73001001 Invalid column $COL$.
73001002 Invalid value type $TYPE$: $VAL$.
73001003 Column $COL1$ does not match with $COL2$.
73001004 $VAL$, $MSG$.
73001005 Invalid column type:$VAL$.
73001006 Invalid column size:$VAL$.
73001007 Invalid table:$TAB$.
73001008 Memory allocation failed:$VAL$.
73001009 Function executes failed:$MSG$.
73001010 Parameter not found:$MSG$.
73001011 LOGIC ERROR:$MSG$.