ht'061 evaluation of crawling policies for a web-repository crawler frank mccown & michael...
TRANSCRIPT

HT'06 1
Evaluation of Crawling Policies for a Web-Repository Crawler
Frank McCown & Michael L. NelsonOld Dominion UniversityNorfolk, Virginia, USA
Odense, DenmarkAugust 23, 2006

HT'06 2
Alternate Models of Preservation
• Lazy Preservation– Let Google, IA et al. preserve your website
• Just-In-Time Preservation– Find a “good enough” replacement web page
• Shared Infrastructure Preservation– Push your content to sites that might preserve it
• Web Server Enhanced Preservation– Use Apache modules to create archival-ready resources
image from: http://www.proex.ufes.br/arsm/knots_interlaced.htm

HT'06 3
Outline
• Web page threats• Web Infrastructure• Warrick
– architectural description– crawling policies– future work

HT'06 4Black hat: http://img.webpronews.com/securitypronews/110705blackhat.jpgVirus image: http://polarboing.com/images/topics/misc/story.computer.virus_1137794805.jpg Hard drive: http://www.datarecoveryspecialist.com/images/head-crash-2.jpg
HT'06 5
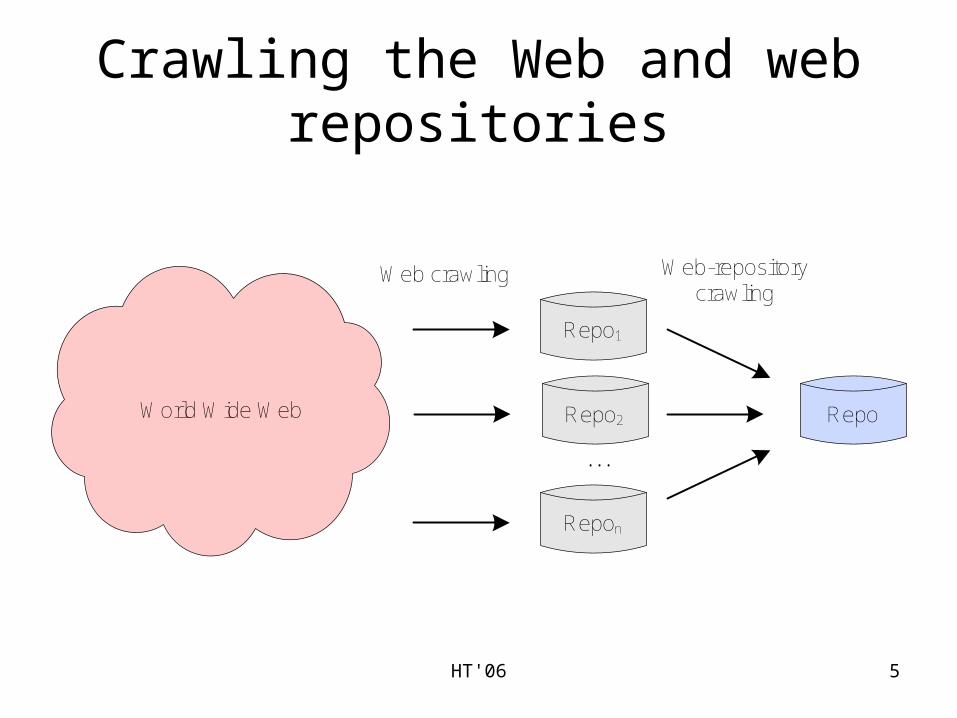
Crawling the Web and web repositories
World Wide Web
Repo1
Repo2
Repon
...
Web crawling
Repo
Web-repository crawling

HT'06 6
How much of the Web is indexed?
• GYM intersection less than 43%
Figure from “The Indexable Web is More than 11.5 billion pages” by Gulli and Signorini (WWW’05)

HT'06 7
Traditional Web Crawler
Init
Download resource
Extract URLs
Seed URLs
Frontier
Visited URLs
Web
Repo

HT'06 8
Web-Repository Crawler
Init
Download resource
Extract URLs
Seed URLs
Frontier
Visited URLs Repo
Web repos

HT'06 9

HT'06 10

HT'06 11
Cached Image

Cached PDF
http://www.fda.gov/cder/about/whatwedo/testtube.pdf
MSN version Yahoo version Google version
canonical

Web Repository CharacteristicsType MIME type File ext Google Yahoo MSN IA
HTML text text/html html C C C C
Plain text text/plain txt, ans M M M C
Graphic Interchange Format image/gif gif M M ~R C
Joint Photographic Experts Group
image/jpegjpg
M M ~R C
Portable Network Graphic image/png png M M ~R C
Adobe Portable Document Format
application/pdfpdf
M M M C
JavaScript application/javascript js M M C
Microsoft Excel application/vnd.ms-excel xls M ~S M C
Microsoft PowerPoint application/vnd.ms-powerpoint
pptM M M C
Microsoft Word application/msword doc M M M C
PostScript application/postscript ps M ~S C
C Canonical version is storedM Modified version is stored (modified images are thumbnails, all others are html conversions)~R Indexed but not retrievable~S Indexed but not stored

HT'06 14
Limitations
Web crawling• Limit hit rate per host• Websites periodically
unavailable • Portions of website off-
limits (robots.txt, passwords)
• Deep web• Spam• Duplicate content• Flash and JavaScript
interfaces• Crawler traps
Web-repo crawling• Limit hit rate per repo• Limited hits per day (API
query quotas)• Repos periodically
unavailable• Flash and JavaScript
interfaces• Can only recover what
repos have stored• Lossy format conversions
(thumb nail images, HTMLlized PDFs, etc.)

HT'06 15
Warrick
• First developed in fall of 2005• Available for download at
http://www.cs.odu.edu/~fmccown/warrick/ • www2006.org – first lost website reconstructed
(Nov 2005)• DCkickball.org – first website someone else
reconstructed without our help (late Jan 2006)• www.iclnet.org – first website we reconstructed
for someone else (mid Mar 2006)• Internet Archive officially endorses Warrick (mid
Mar 2006)

HT'06 16
How Much Did We Reconstruct?
A
“Lost” web site Reconstructed web site
B C
D E F
A
B’ C’
G E
F
Missing link to D; points to old resource G
F can’t be found
Four categories of recovered resources:
1) Identical: A, E2) Changed: B, C3) Missing: D, F4) Added: G

HT'06 17
Reconstruction Diagram
added 20%
identical 50%
changed 33%
missing 17%

HT'06 18
Initial Experiment - April 2005
• Crawl and reconstruct 24 sites in 3 categories:1. small (1-150 resources) 2. medium (150-499 resources)3. large (500+ resources)
• Calculate reconstruction vector for each site• Results: mostly successful at recovering HTML• Observation: many wasted queries, disconnected
portions of websites are unrecoverable• See:
– McCown et al. Reconstructing websites for the lazy webmaster. Tech Report, 2005. http://arxiv.org/abs/cs.IR/0512069
– Smith et al. Observed web robot behavior on decaying web subsites. D-Lib Magazine, 12(2), Feb 2006.

HT'06 19
Missing Disconnected Resources

HT'06 20
Lister Queries
• Problem with initial version of Warrick: wasted queries– Internet Archive: Do you have X? No– Google: Do you have X? No– Yahoo: Do you have X? Yes– MSN: Do you have X? No
• What if we first ask each web repository “What resources do you have?” We call these “lister queries”.
• How many repository requests will this save?• How many more resources will this discover?• What other problems will this help solve?

HT'06 21
Lister Queries cont.
• Search engines– site:www.foo.org– Limited to first 1000 results or less
• Internet Archive– http://web.archive.org/web/*/http://www.foo.org/*– Not all URLs reported are actually accessible
• Results are given in groups of 100 or less

HT'06 22
URL Canonicalization
• How do we know if URL X is pointing to the same resource as URL Y?
• Web crawlers use several strategies that we may borrow:– Convert to lowercase– Remove www prefix– Remove session IDs– etc.
• All web repositories have different canonicalization policies which lister queries can uncover

HT'06 23
Missing ‘www’ Prefix

HT'06 24
Case Sensitivity
• Some web servers run on case-insensitive file systems (e.g., IIS on Windows)
• http://foo.org/bar.html is equivalent to http://foo.org/BAR.html
• MSN always ignores case, Google and Yahoo do not

HT'06 25

HT'06 26
Crawling Policies
1. Naïve Policy - Do not issue lister queries; only recover links that are found in recovered pages.
2. Knowledgeable Policy - Issue lister queries but only recover links that are found in recovered pages.
3. Exhaustive Policy - Issue lister queries and recover all resources found in all repositories. (Repository dump)

HT'06 27
Web-Repository Crawler using Lister Queries
Init
Download resource
Extract URLs
Frontier
Visited URLs Repo
Web repos
Seed URLs
Stored URLs
Lister queries
ExhaustivePolicy

HT'06 28
Experiment
• Download all 24 websites (from first experiment)
• Perform 3 reconstructions for each site using the 3 crawling policies
• Compute reconstruction vectors for each reconstruction


Reconstruction Statistics
Efficiency ratio = total recovered resources / total repository requests

Efficiency Ratio
All resources
Efficiency ratio = total recovered resources /
total repository requests

Efficiency Ratio
Not including ‘added’ resources
Efficiency ratio = total recovered resources /
total repository requests

HT'06 33
Summary of Findings
• Naïve policy– Recovers nearly as many non-added resources as
the knowledgeable and exhaustive policies– Issues highest number of repository requests
• Knowledgeable policy – Issues fewest number of requests per reconstruction – Has highest efficiency ratio for only non-added
resources• Exhaustive policy
– Recovers significantly more added resources than the other two policies
– Highest efficiency ratio

Website “Hijacking”

Soft 404 “Cache
poisoning”
Warrick should detect soft 404s

HT'06 36
Other Web Obstacles
• Effective “do not preserve” tags:– Flash– AJAX– http POST– session ids, cookies, etc.– cloaking– URLs that change based on traversal patterns
• Lutkenhouse, Nelson, Bollen, Distributed, Real-Time Computation of Community Preferences, Proceedings of ACM Hypertext 05
– http://doi.acm.org/10.1145/1083356.1083374

HT'06 37
Conclusion
• Web sites can be reconstructed by accessing the caches of the Web Infrastructure– Some URL canonicalization issues can be tackled
using lister queries– multiple policies available depending on
reconstruction requirements
• Much work to be done– capturing server-side information– moving from descriptive model to proscriptive &
predictive model