idit keidar, topics in reliable distributed systems, technion ee, winter 2004-2005 1 topics in...
Post on 20-Dec-2015
218 views
TRANSCRIPT

1Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Topics in Reliable Distributed Systems
048961 Winter 2004-2005
Dr. Idit Keidar

2Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Course Overview
• Graduate level
• Format: reading group & seminar
• Discussion and evaluation of research papers

3Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Prerequisite
• An introductory course on distributed computing• You need to be familiar with:
– Failure models: crash, Byzantine, …– Asynchronous and synchronous message-passing and
shared memory models– Safety and liveness properties– Reasoning about distributed systems,
indistinguishability arguments– Byzantine agreement/consensus/atomic commit– State machine replication, linearizability

4Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
This Term’s Focus: Distributed Storage
• Data-centric replication– Distributed shared memory
• Byzantine fault-tolerance
• Peer-to-peer storage systems
• Distributed and federated file systems
• Security

5Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Requirements and Grading
• Reading the papers (one a week)
• Handing in short paper summaries – 15%
• Participating in class discussions – 10%
• Presenting one of the papers – 75%– Select a paper within the next 2 weeks

6Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Reading The Papers
• This is a reading group.• This means that you should read each paper before it is
being discussed. • Read the entire paper and be familiar with all its content.
– Most will be conference papers.
• You don’t need to understand everything, check previous work, or memorize details.
• Hand in a short summary of the paper (unless you are presenting it) by e-mail to me the night before the lecture.– Any time before 8:00am the morning of the lecture is considered
part of the night before.

7Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Paper Summaries
• Total of ½ a page to 1 page long (no more!!). • One paragraph overview
– What question is the paper is trying to answer?– What are the main results?
• One paragraph on your experience– What did you learn?– What questions remain unanswered?– What didn’t you understand?
• Short discussion of the paper’s strengths and weaknesses.

8Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Evaluating A Paper’s Strengths and Weaknesses
• Is the paper answering the “right” question?– Does it make reasonable assumptions?
• How novel is the solution?• Is the solution technically sound?• How well is the solution evaluated?• Expected impact. (Hard to guess).• Writing level: is the paper clearly written?
Is it self-contained?

9Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Paper Presentations
• You should fully understand the paper, be familiar with previous work, and be able to compare the paper with other similar work.
• The presentation should include:– Summary and evaluation.– Comparison with other work.– List of topics to discuss in class.
• It is highly recommended to discuss the presentation with me beforehand.

10Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Contact Me
• Idit Keidar <idish@ee>– Please send me e-mail with 048961 in the subject,
and I’ll add you to the course mailing list. – Warning: Technion spam filter may block email from
company addresses. • Office hours: Tue 10:30-11:30 Mayer 960.• Let me know in the coming two weeks what you
would like to present.– See bibliography on course web page:
http://www.ee.technion.ac.il/people/idish/048961/
• Schedule will be posted on the course web page.

11Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Background: Reliable Distributed Data

12Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
How Does one Achieve…
• Reliability with unreliable components? – Fault-tolerance
• Availability in the presence of failures?– Disconnects in a wide-scale system
• Disaster recovery?
• Fast local access in a wide-scale system?

13Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Primary-Backup (Passive) Replication
• “Hot” standby• Client talks to primary server• Primary updates backup(s)• Client detects server failure using timeout
– performs “fail-over” to backup server
– may need to repeat last operation(s)
• Pros?• Cons?

14Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
State Machine (Active) Replication
• Model service as deterministic state machine– Sorry, no non-deterministic servers allowed
• Implement using a collection of servers, each running a copy of the state machine– Start at same initial state– Perform operations in the same order w/out gaps
a a ab b
c

15Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Notes on Active and Passive Replication
• Support objects of arbitrary type
• Not always possible– State machine replication uses consensus to
agree on order of operations– Not solvable in failure-prone asynchronous
systems [FLP]
• Primary-backup needs accurate failue detection

16Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
R/W Registers
• Only methods are read and write– No RMW
• Typically what disks support– Should be good enough for file systems…
• Consistent replication possible even when consensus is unsolvable
First, let us define consistency…

17Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Operations Take Time
time
invocation 12:00
read(x)
response 12:01
7
7x

18Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Concurrent Operations Take Overlapping Time
time
write(x,8) write(x,9)
read(x)

19Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Consistency Semantics
• Sequential specification for register:– read returns last value written before the read
• What does it mean for a concurrent object to be correct? – Intuition: the object should “look like” a non-
concurrent one

20Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Split Operations into Two Events
• Invocation– read(x)– write(x,v)
• Response– result or exception
– read(x) returns v– write(x,v) returns ack

21Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Linearizability
• Each operation should –– “take effect”– instantaneously– between its invocation and response events
• Such a concurrent execution is linearizable
• Such a concurrent object is atomic

22Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Example
time
read(1)write(0)
write(1)
time
linearizable

23Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Example
time
read(1)write(0)
write(1)
time
read(0)
write(1) happened
after write(0) not
linearizable
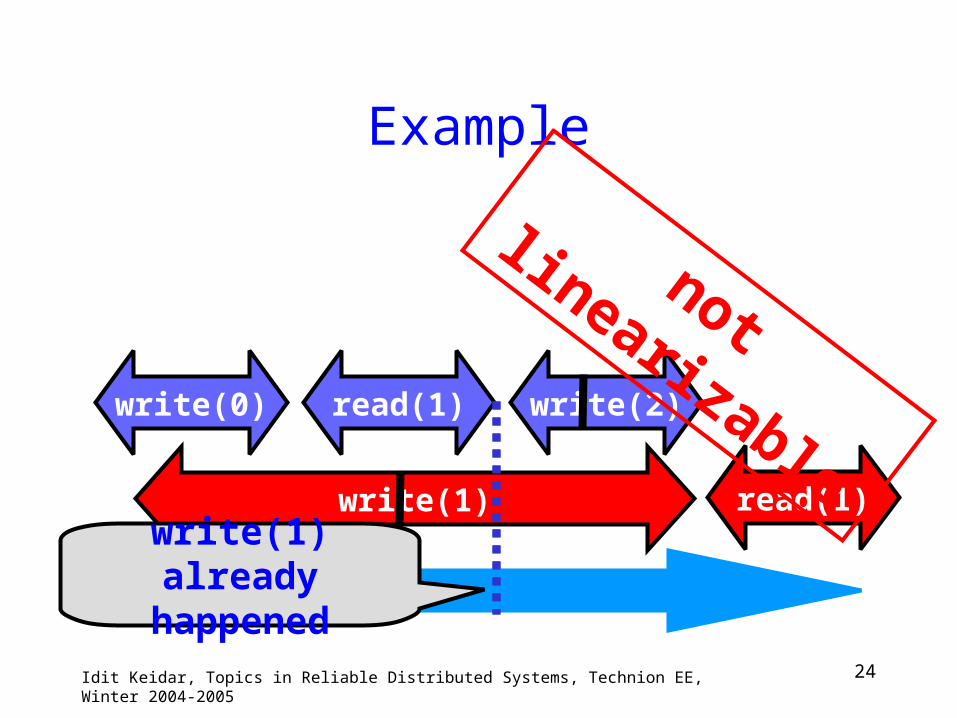
24Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Example
time
read(1)write(0)
write(1)
write(2)
time
read(1)
not
linearizablewrite(1) already
happened

25Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Example
time
read(1)write(0)
write(1)
write(2)
time
read(2)
linearizable

26Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Linearizability
• See formal definition in– Attiya &Welch, Distributed Computing, Ch. 9 – 046272 Lecture 11
• Definition applicable for any object type
• Easy to reason about

27Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Weaker Alternative: Sequential Consistency
• No need to preserve real-time order

28Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Weaker Consistency Conditions for Registers

29Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Safe Register
write(1001)
read(1001)
OK if reads and writes
don’t overlap

30Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Safe Register
write(1001)
read(????)
Effects undefined if reads and writes
do overlap

31Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Regular Register
write(0)
read(1)
Safe + Concurrent read returns either old or new value(Assume single writer)
write(1)
read(0)
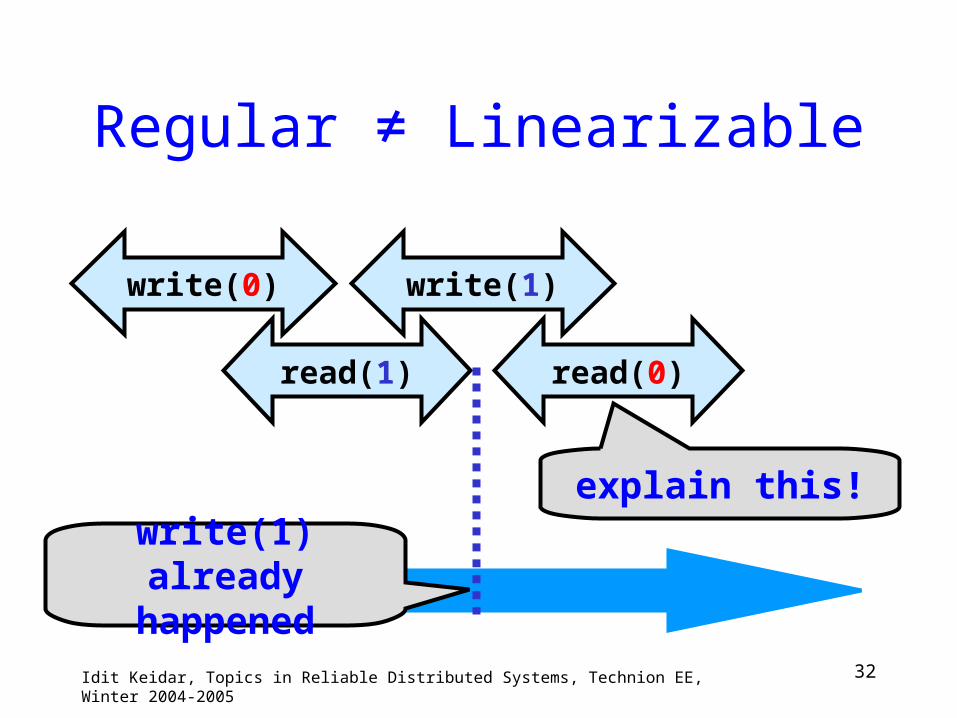
32Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Regular ≠ Linearizable
write(0)
read(1)
write(1)
read(0)
write(1) already
happened
explain this!

33Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Liveness Requirement
• Wait-freedom (wait-free termination): every operation by a correct process p completes in a finite number of p’s steps.
• Regardless of steps taken by other processes– In particular, the other processes may fail
or take any number of steps between p’s steps
– But p must be given a chance to take as many steps as it needs

34Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Implementing Shared R/W Registers

35Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Distributed Shared Memory (DSM)
• Goal: provide the elusion of atomic/regular shared-memory registers in a message-passing system

36Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Data-Centric Replication
• A fixed collection of persistent data items accessed by transient clients
• Data items have limited functionality– E.g., read/write registers, or– an object of a certain type.
• Cannot communicate with one another.

37Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
What is it Good For?
• Storage Area Networks (SAN)– disk functionality is limited (R/W)– disks cannot communicate
• Large scale client/server systems– simple servers that do not communicate with
each other scale better, manage load better
• Peer-to-peer storage

38Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Replicated Register Take I: Write-All-Read-One
• Data replicated at all servers– Every write goes to all of them
x = 0
write(x,3) write(x,5)
x = 3x = 5
x = 0x = 3x = 5
x = 0x = 5x = 3

39Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Take II: Add Timestamps
x = 0, t=0
write(x,3) write(x,5)
x = 3, t=1x = 5, t=2
x = 0, t=0x = 5, t=2ignore x = 3
• Ignore writes with old timestamps
x = 0, t=0x = 3, t=1x = 5, t=2
• Timestamp must be unique.. how?• Timestamps must be monotonically increasing... how?

40Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
R/W Replicated Register Write-All-Read-One
• How are reads/queries handled?– For regular register?– For atomic register?
• Pros?
• Cons?

42Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Fault Tolerant Data Centric Systems
• System consists of n fault-prone shared-memory objects– called base objects– really n servers or disks storing base objects

43Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Failure Models
• Clients: any number of crash failures.– Aka wait-free.– No Byzantine failures: assume authentication.
• Base objects: up to a threshold t.– Crash or Byzantine failures.
• We now discuss crash.
– A faulty object may stop responding to clients.– A Byzantine object can send bogus responses.

44Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Take III: Quorum-Based Replication
• A quorum system over a universe U of n processes is a collection of subsets of U (called quorums) such that every two quorums intersect– E.g., all sets including a majority of U
• Write to quorum– As before, with unique increasing timestamp
• Read from a quorum– Choose highest timestamped read value

45Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Fault-Tolerant Register Emulation
x = 0, t=0
write(x,3) read(x)
x = 3, t=1x = 0, t=0x = 0, t=0
x = 3, t=1
return 3

46Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Variants
• Single write round for single-writer• Read before write for multi-writer• Single read round for regular register• Write-back for multi-reader• Based on [Attiya, Bar-Noy, Dolev], see:
– Attiya & Welch, Distributed Computing, Ch. 9 & 10
– Nancy Lynch, Distributed Algorithms, Ch. 13 & 17
– 046272 Lectures 12 and 13

47Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
What if Servers can be Penetrated?
• Byzantine fault-tolerance: threshold of servers can be faulty
• Can clients be faulty? – Benign faults: yes (crash, slow, message loss)– Byzantine faults: no
• Employ access control
• If bypassed, who cares? – A malicious client can mess up the data anyway

48Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Byzantine quorum systems: example [Malkhi and Reiter 98]
• At most one server can be penetrated
x = 7, t = 1
x = 7
x = 0t = 0
x = 2t = 5
x = 7t = 1
x = 7t = 1

49Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Byzantine quorum systems: example [Malkhi and Reiter 98]
x = 7, t = 1
x = 7
x = 0t = 0
x = 0t = 0
x = 7t = 1
x = 7t = 1
• Why timestamps?

50Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2004-2005
Later in the Course
• More on Byzantine fault-tolerance
• Error-correcting codes
• Various optimizations– For server-based systems– For SAN-based systems
• Peer-to-peer storage
• Distributed file systems