information theory and learning theory: twin aspects of shannon engineering jay bhatnagar
TRANSCRIPT

Information Theory and Learning Theory:
Twin Aspects of Shannon Engineering
Jay Bhatnagar

TRIBUTE - SECTION

Tribute Section : Robert G. Gallager
Robert G. Gallager Professor Emeritus, EECS, Massachusetts Institute of Technology
RLE & LIDS. ‘53 (BSEE), ‘57(SM), ‘60(D.Sc.)
Modern Classics: Discrete Stochastic-Graph Theory-Analysis, Communication networks, Information Theory, Coding Theory
• Gallager, R. G., "Low Density Parity Check Codes", Transac. of the IRE Professional Group on Information Theory, Vol. IT-8, pp. 21-28,January 1962.
• Gallager, R. G., "A Simple Derivation of the Coding Theorem and Some Applications", IEEE Trans. on Information Theory, Vol. IT-11, No. 1, pp. 3-18, January 1965.
Archives: Information Theory and Reliable Communication (Wiley 1968); Data Networks; Principles of Digital Communication; Stochastic Processes, Theory for Applications;

Some of the famous Quotes
Jay : My e-mail in feeling wasted with Pattern Recognition during PhD
phase
RGG: “ Being asked to switch areas can be a boon in disguise, to go
back and forth between simple math models and real
systems/problems in pattern recognition”
“On simple Toy models of fundamental problems than versions
of enhancements more like marketing gimmick – heaps of case
studies ignoring a simple general theory or collection of simple
themes put together neatly in mathematical structure for
attacking a more complex problem”
“ Research on early theories is more reflection of a community’s
effort”

Tribute Section : Thomas M. Cover ‘
Caption : Thomas Cover, one of the Caption: Portrait of Tom shared by Young-Han Kim world's top Information Theorists
’60 (BS- Physics MIT ), ‘61 (MS- EE, Stanford), ‘64(PhD-EE, Stanford) Trailblazing work: Statistics, Combinatorics, Information theory,
Communication, Complexity, Investment theory, Pattern recognition, Statistical signal processing.
• T.M. Cover, Geometrical and Statistical Properties of Linear Inequalities with Applications in Pattern Recognition, IEEE Transac. on Electronic Computers, 326-334, 1965
• T.M. Cover and P.E. Hart, Nearest Neighbor Pattern Classification, IEEE Transac. On IT-13, 21-27, 1967
• T.M Cover, Estimation by Nearest neighborhood, IEEE Transac. on IT, 1968

Famous Coverian Quotes• On being asked by one of his Colleagues at an ISIT retreat –
Why do we do Theoretical Research
Tom’s Response:
Why does my Dog raise its leg when it pees ……..
….. Because it Can
“ Theory is the First Term in the Taylor Series of Practice” – Tom Cover
“ Tom was perhaps second to only Shannon in terms of his choice of
Research Problems and the Elegant results, in writing a Text book or Chapter or With the profound impact in the genesis of several key fundamentals in Statistics, Investment, Information Theory, Pattern Classification and Communication Networks” - 2012 ISIT Memorial

Information Theory

Information Theory (IT)• C E. Shannon, “A Mathematical Theory of
Communication”, 1948• C E. Shannon, “A Mathematical Theory of Cryptography”,
1945 • Built on theorems that sit on the cusp of several
celestial signs - Algebra, Statistics, Analysis, Measure theory & Probability, Lie groups & manifolds, Convexity – Topology
• Information model with physical /architectural &
algorithmic rules typifying role of information via logarithms and exponents :
- Efficient Representation for Data Compression
- Reliable Representation for Error Control
- Secure Representation for Cryptography

Information Theory (IT)• Binary interface in systems (modular algebra) for
data sources and, decisions that are also functions on modular Group, Field, Ring
• Shannon engg. gives performance limits and fundamental insights on these roles in building/modeling comm. systems, but does not tell how to achieve it
• Modern day Coding (signal level) and Protocols (architectural level) details that push Comm. Design

Information Theory (IT)• Almost all major early works at Bell labs, RLE/
LIDS (MIT) , ISL (Stanford), CSL (UIUC), JPL (CalTech)
• Major action now at EECS/CS/ECE/EE Depts. – Information Architectures to process Digital media like - Doc., Audio, Video, Image etc. types of Information for Communication
• We have data standards due to Information Theory

INFORMATION THEORY ..
.. Shannon Principles

Principle - 1• Unify all types of sources into Bits• Unify Data and Decision in terms of Bits (digital)
Unlike, the Tukey bit, Shannon bit is a measure of information
Wherein Data (information) & Decision (measure) described in bits
Decision was probabilistic, now even data a function of probabilistic
• Basic information model for Digital Communication:
source (X = 0,1) – channel (Y= 0,1) – sink ( = 0,1)
• Entropy: H(x) or H(p(x)) bits, as sort of information – meter
• Keep your Expectations (low) at the minimum ….. Anonymous
thX

Principle - 1
• Avg. length of sequences in book (L) ≥ Hd(p) = (logd 2)H2(p)
• minimum average length of code words to describe X given its
component distribution /p.m.f p(x) for, DMS is given as:
;
)) /1 (log()log()min()( 1xx
xxx
xxx pEppplpH
1x
xp
integer)-(non boundlower , w.r.t differ. ;2 xx x
lxx llp x

Discrete Entropy: H(X) case study of Avg. randomness• Say, i.i.d Bernoulli trials: p(X=1) = p, q (X=0) = (1 – p)
• Each trial conveys information measure Binary Entropy:
Plot, H(p) as a function of px € [0,1] and notice H(p)is concave in p. Notice: max {H(p)} = 1 bit, for p = q = 0.5 ; under constraint :
)1log()1(log)( pppppH
1x
xp

Entropy and Physics of Information
Given n joint trials, avg. information conveyed is ≈ n H(p)
(Asymptotic Equipartition Principle)
(a) ( ∏ Xi ) Probabilistic macro state made up of several Pr. micro states
Ensemble Avg. of product terms or macro state converges to some micro state denoted by H(X)
(b) Observations described by countable probabilistic states in this ε-typical set. All sequences of length close to H(X) called typical sequences
(c) Not concerned with relation of underlying distribution of H(X)
w.r.t Xi’s. Therefore, n.H (X) is the stochastic/avg. complexity of ( ∏ Xi ).
n H(X) may not be as useful for accurate data generation, perhaps useful for min. complexity model generation (MDL – J. Rissanen, Polya, Renyi)
(d) What if: ‘n’ is small (Verdu), Xi’s distributed in heavy tails (LDP), local neighbor behavior dominant in large sample case (k-NN)
XHXXXpnP
n ],....,,[log1 21

Principle 1 – Entropy (contd…)
Differential Entropy ~ has no practical use.
If variance , max [h(X)] implies X ~ Gaussian• Define, Distortion: • Define, Mutual information:
• Performance governed by, min. and max. of I(X;Y) for p(X),• A rate distortion pair (R,D) is said to be achievable if there exists a
sequence of (2nR,n) rate-distortion codes (f n ,g n) with:
or, min R(D)=
Multiple ways to construct codes with rates strictly approaching H(X)
or R (D),referred to as achievability of the rate region
x
xx ffXh log)(
],[ nnn
n xfgxdED
XXHXHXXHXHXXI //;
XXp ,
function decoding : ;function encoding: nn gf
DXfgXdE nnn
n )](,([ exists ),();(min
xxpXXI

Principle 2 – Information Capacity
• is defined as the Channel Capacity
• Typical Communication terms: ‘C’ Indicates maximum achievable rate of some generating system ( X ), when received (Y ) conveys enough meaning/inference about X; given finite access to resources like Bandwidth & Power. Noise is the difference between Y and X
• When transmitting information at rates R < C, the transmission reliability is almost perfect, i.e. there is no loss of information or information and X that can be recovered from ( Y ) with Perror → 0
(Again, making room for encoding methods to achieve rate regions for varying asymptotes of reliability by so called error control coding)
• A more popular version due to Shannon-Nyquist:
C = (0.5) log [ 1 + S-N-R] bits per dimension or bits per transmission
Also, can be derived from the maximization above or the packing lemma
Given a finite sample size database to quantify Recognition capacity defined by Signal-to-Noise ratio of the database (for some metric), the S-N-R plugged in to give Constrained capacity of Recognition system ~ Bhatnagar et al.
Quantify recognition capacity as sample size grows to infinity ~ Sullivan et al.
);( max)(
YXICxp

Relative Entropy : K - L divergence• A very useful Information measure for applications in Statistics first arising in
Sequential tests of Hypotheses due to A. Wald, coined much later as Relative Entropy ~ D (p x // q x)
• Observe some random data ~ X and formulate hypotheses/models: and
then,
as the Kullback - Leibler divergence
D(p x // q x) ≠ D(q x // p x) ; Asymmetric
- Given empirical models , how much is the mean discrimination offered in one pdf w.r.t the other over varying size of X [Mean Information for Discrimination]
- How much do same elements of measurable spaces statistically deviate after being characterized by different empirical descriptions [Divergence]
- [Cross Entropy],
- [Information gain]
Given continuity arguments and Radon-Nikodym derivate of p x w.r.t q x exixts
;Xp ;Xq
x x
xxxx q
ppqpD log //
)(),()log( )log( log 11- pHqpHqpppq
pp xxxx
x x
xx
dQdQ
dP
dQ
dPqpD
X
xx
log //

K-L Divergence: Story continues• Properties of Entropy: H (X) ≥ 0; Conditioning reduces Entropy: H(X/Y)≤ H(X)• Define - Joint Entropy/Chain rule ~ H(X,Y) = H(Y, X) = H(X) + H(Y/X)
(Triangle inequality) ≤ H(X) + H (Y)
Generalizing:
Recall, mutual-information: I (X;Y) is also given as follows -
= D ((p x,y // p x. . p y)) ≥ 0; {non-neg. of D(p//q)}
= H(X) – H(X/Y) ≥ 0
thereby, H(X) ≥ H(X/Y)
• If we know the true description or hypothesis of the r.v, then we could construct a code with avg. length close to H(p x), in using any other hypothesis q x for r.v., we incur a loss or unreliability in bits given by D(p x // q x) on the avg.
iintoi
iin XHXXXHXXXH
1
1121 ,....,,....,,

Sufficient Statistics – (Neyman - Fisher Test)• Note that from the data processing inequality if, ϴ → X → T(X)
I(ϴ; T(X)) ≤ I (ϴ ;X)
• A function T(X) is said to be a Sufficient statistic relative to the family ,
if X is independent of ϴ given T(X), i.e. , ϴ → T(X) → X forms Markov chain
I(ϴ; T(X)) ≥ I (ϴ ;X)
Based on these inequalities, we may conclude that : I(ϴ; T(X)) = I (ϴ ;X)
Implying that, Sufficient Statistics preserve Mutual Information, for all
Fano’s inequality:
Suppose we know a random variable Y and wish to guess another correlated random
variable X, then Fano’s inequality relates the probability of error in guessing the
random variable X to its conditional entropy H(X/Y)
---------------------------------------------------------------------------------------------------
;xf
;xf

Competitive Optimality: Tom Cover• ON THE COMPETITIVE OPTIMALITY OF THE HUFFMAN CODE
Entropy provides a n Optimality rule which is min. in Expectation ,in the sense that -
for, Code book C(X) is Optimal w.r.t another Code book C(X`) given the respective
code words of length { l(x)} and { l(x`)}; iff : E [l(X)] < E [l`(X)] which signifies
optimality in large sample or long run case…… min. avg.
We now ask if, Pr [ l(x) < l(x`) ] > Pr [ l(x) > l(x`) ] ?
That is evaluating/testing for Optimality in short run case.
For ex: consider two phrases in Spanish and its corresponding Translation in English.
English - NO SMOKING Spanish- NO FUMAR
English - FASTEN SEAT BELTS Spanish- ABROCHARSE EL CINTURON
Apparently, based on this small comparison -
Short phrases: Spanish is Competitively optimal, Long phrases: English wins
Conclusion: English and Spanish are Competitively Equal !

Some points on NN Pattern Classification - Estimation
• In non-parametric sampling or decision theory, one knows some pre-classified points; say, , the NN rule determines a category/class
based on learning from the nearest neighbors or detecting a bin for some observed sample x by majority-voting from k out of the n known x i ’s (called k n from ) in some appropriate metric.
Call,
In absence of parametric formulations, best bet (max neighbors – min. sample size sense ) is to learn from close points. In fact, 50% information for classification is in the k - nearest neighbor or associated pattern
Invoke, k large implies good learning window for large N
k small no. of points , guarantees accuracy as greater conditional Pr. That points in the k-NN are really close
Convergence or monotonic convergence of information in the sequence (fitting learning) requires, k n → ∞ (monotonic increase of close neighbors) and,
(k n / n) → 0 (the learning of close neighbors grows at a bounded finite rate)
Entropy rate, defines, how much novelty in an ensemble of size n :
)},(,,.........,{( )11 nnxx ~nx
nixxdxxdxxxx ii
nnn ...,2,1);,(min, :if toNN as},.....,{ ~1
~
errorBayesNNkerror PP )( .2
}{ process stochasticfor ;,.....,1
lim 1 inn
XXXHn
H

Example - Nearest neighborhood (contd.)
• For 2-category problem, M = 2: {D 1, D 2} Let the priors be,
if, error in NN rule if,
Let,
In Algebraic Coding Theory, there is a Sphere Packing Bound (Hamming)
which states that, for a (n,q,d) error control code perfect packing of n-bit long code words in some d-separable space occurs with number of code words given by,
5.021 1Dx 22
~ or, DxDx in n
error nP
2
1),1(
12 okk
0
02
1),(
k
j
n
error j
nnkP
)( 2let ;
)1(
),(21
0
minmin
binaryq
qk
nq
dnCk
d
k
n

Large Deviations Principle (LDP)
• Large Deviations (LD) reported due to Chernoff, Ellis, Cover, Csiszàr
• LD is mainly associated with Probab. of rare events, like errors or events like behavior of Probab. of sample mean on tails that can be asymptotically formulated on an exponential scale
• We do not mean P (A) ≈ 0, instead we mean the Probabilities for which,
is moderately sized
with ‘n’ point masses (say, i.i.d) contributing to Pr (A) that is moderately sized when n grows to be very large
)](log[Pr1
lim An n
n

LDP (contd ….)
• By viewing this through A.E.P, in this case - (a) we claim to sit on the tails that results in divergence from Central Limit for estimating E, the only change being that of using ‘+’ sign outside the logarithm
- Exponential family as a parametric form of probability density function
So, where; , uniformly for all A
- I is a rate function and basic properties that I must satisfy include: non-negativity and some x € A that minimizes I whenever A is compact.
Note: ; where is the distribution
in A that is closest to q in relative entropy and,
q is the distribution of the n i.i.d r.v’s
)]()[exp(()( AnIAgAP nn 0)(1
lim
Agn n
n
)//( *
2)( qpnDerrorP )]//([minarg* qpDPAP

LEARNING THEORY
(STATISTICAL COMPUTING)
“STATISTICS DEALS WITH THE IMPERFECTIONS OF THE MORE PERFECT PROBABILITY THEORY”

Ground work of ML
• PATTERN RECOGNITION
DATA ---- DECISION BOUNDARY/SURFACE ---- DECISION/CLASSIFIER
Some observations:
(a) Draws from areas: Statistics, Topology &elements of simple & complex Geometries
(b) Pattern Classification is the detailed study of the Decision functionality.
Creating classifier is mostly an adaptive task where we start with some model that can be tuned (min. sum of costs, scale with i/p samples) to classify with new data OR Training – viewed as estimating the model (bias / under fitting in small sample case & variance /over fitting in large sample case)
(c) For a long time, research was based on acquiring Database and validating the
algorithm on several Classifiers

Ground work of ML (contd…)
(d) Shannon developed series of experiments at Bell Labs & then MIT to demonstrate the concept of Artificial Intelligence, more so from Game Theory (dynamic ability)
AI: Class of Algorithms that teach to perform tasks {Ti} by rewards or penalties, to give desired outcomes that improve with Experience {Ei}
(e) Shannon’s famous random coding argument: Averages on large classes of methods perform statistically better than any one given method

(contd….)
SOME OBSERVATIONS:
Point (c) leads to –
(1) Consensus from several classifiers, (Fusion, improves Efficiency - CRLB)
(2) Data driven Classification, (some Classifiers performed better than the others, for a different datasets) and questions the Efficiency of classification
Or ,
hints at the need to view PR using Machine Intelligence or Machine Learning …….…
• Machine Learning: Classification ability of data is stored in the data generative model (like DNA code stores evolutionary characteristics of Human)
• Simple view, Principle of Mathematical Induction where a function or rule
fn on elements of a sequence is shown to be Generalized with ‘n’
• Bagging (Breiman), Boosting (Schapire), NN(Cover) form class of
non-parametric estimation methods, learning or Generalizing from data
(Refer: Tom Cover’s PhD Thesis (’65), Write up given in the last section)

Picture ML• Significant challenges lie in how a system{method} Learns rather than Only
Classifies better. Thereby classification is subsumed /assisted by some uncanny Learning ability typical of the end goal {classification/domain}
Fig.1: ML from PR
Learning Module(Predict or (re -) generate
samples & properties)DIRECT CLASSIFIER FOR THE
NOVELTIES
Classifier (Conventional); Perf. dependent on
training & classifier
Training Module i) communicate known
samples/properties)ii) often test multiple classifiers for a database
Replaced by
PERFORMANCE ISSUES:
(i)Training + Testing for Error Analysis of Training Phase
(ii) Training + Learning and Error Analysis for
Learning/Generalization phase
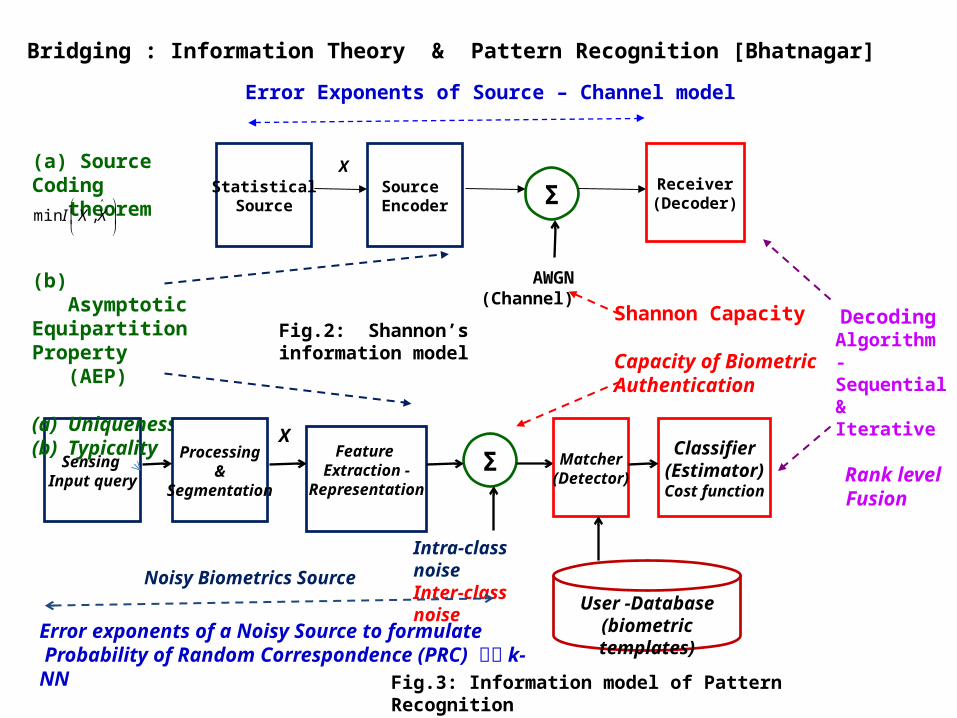
Bridging : Information Theory & Pattern Recognition [Bhatnagar]
Sensing Input query
Feature Extraction -
Representation
X
Σ
Intra-class noiseInter-class noise
Classifier(Estimator)Cost function
(a) Source Coding theorem
(b) Asymptotic EquipartitionProperty (AEP)
(a) Uniqueness(b) Typicality
Shannon Capacity
Capacity of Biometric Authentication
Error Exponents of Source – Channel model
Error exponents of a Noisy Source to formulate Probability of Random Correspondence (PRC) k-NN
Decoding Algorithm -Sequential &Iterative
Rank level Fusion
StatisticalSource
Source Encoder
X
Σ
AWGN (Channel)
Receiver(Decoder)
Processing&
Segmentation
Noisy Biometrics Source
Matcher(Detector)
User -Database(biometric templates)
Fig.2: Shannon’s information model
Fig.3: Information model of Pattern Recognition
XXI ,min

Exploring IT towards ML - Sense/sample and collect a time series of events (simple,
composite) observations, not stop here, measure & process the data (call it as learning)
- Detect, what is new and How much is new, calling this as Source and, how best can it be Generalized with high reliability as Learning Capacity ?
- Rate at which the novelty arrives in the collected input data or the pattern (a measure that is often statistical).
It may so work out that all datasets act like natural code words that have intrinsic measures of novelty
Pose a question, estimate the rate of learning, specific data driven properties/measures (statistical )

Exploring IT towards ML - Rate at which the novelty in input data/pattern is
transferred or converted into a learning output (novelty as an information source and a decision process that spots this giving a final label as an inf. sink) ?
- Source-channel separation ?
- Overall system complexity in terms of learning can be given by input rate and output rate or in normalized ratio terms. Importantly, since the learning function is not fully reliable, it can make sense to define capacity/rate of reliable learning under various constraints?

Some of my Current Interests• IEEE Transac. on ETC
(2013)
“Estimating Random correspondence of Iris biometrics Using Coding Exponents: An Information Theoretic Framework for Big Data Performance Models”
Some more problems:
- On Error Probability bound based on the Output of Similarity Checks
(Checks based on Matcher outputs, learning Errors from low density clusters)
- On a data fitting test based on the Capacity metric
( under fitting – optimal fitting – over fitting)
- Learning quality of samples using Lloyd-Max
- A generalized framework for information fusion based on Capacity

End of Slides