informs is located in maryland, usa publisher: institute
TRANSCRIPT

This article was downloaded by: [73.154.135.173] On: 28 September 2020, At: 08:38Publisher: Institute for Operations Research and the Management Sciences (INFORMS)INFORMS is located in Maryland, USA
Information Systems Research
Publication details, including instructions for authors and subscription information:http://pubsonline.informs.org
Content Growth and Attention Contagion in InformationNetworks: Addressing Information Poverty on WikipediaKai Zhu, Dylan Walker, Lev Muchnik
To cite this article:Kai Zhu, Dylan Walker, Lev Muchnik (2020) Content Growth and Attention Contagion in Information Networks: AddressingInformation Poverty on Wikipedia. Information Systems Research 31(2):491-509. https://doi.org/10.1287/isre.2019.0899
Full terms and conditions of use: https://pubsonline.informs.org/Publications/Librarians-Portal/PubsOnLine-Terms-and-Conditions
This article may be used only for the purposes of research, teaching, and/or private study. Commercial useor systematic downloading (by robots or other automatic processes) is prohibited without explicit Publisherapproval, unless otherwise noted. For more information, contact [email protected].
The Publisher does not warrant or guarantee the article’s accuracy, completeness, merchantability, fitnessfor a particular purpose, or non-infringement. Descriptions of, or references to, products or publications, orinclusion of an advertisement in this article, neither constitutes nor implies a guarantee, endorsement, orsupport of claims made of that product, publication, or service.
Copyright © 2020, INFORMS
Please scroll down for article—it is on subsequent pages
With 12,500 members from nearly 90 countries, INFORMS is the largest international association of operations research (O.R.)and analytics professionals and students. INFORMS provides unique networking and learning opportunities for individualprofessionals, and organizations of all types and sizes, to better understand and use O.R. and analytics tools and methods totransform strategic visions and achieve better outcomes.For more information on INFORMS, its publications, membership, or meetings visit http://www.informs.org

INFORMATION SYSTEMS RESEARCHVol. 31, No. 2, June 2020, pp. 491–509
http://pubsonline.informs.org/journal/isre ISSN 1047-7047 (print), ISSN 1526-5536 (online)
Content Growth and Attention Contagion in Information Networks:Addressing Information Poverty on WikipediaKai Zhu,a Dylan Walker,b Lev Muchnikc
aDesautels Faculty of Management, McGill University, Montreal, Quebec H3A 1G5, Canada; bQuestrom School of Business, BostonUniversity, Boston, Massachusetts 02215; c Jerusalem School of Business Administration, The Hebrew University of Jerusalem, 91905Jerusalem, IsraelContact: [email protected] (KZ); [email protected], https://orcid.org/0000-0002-1354-4969 (DW); [email protected] (LM)
Received: November 7, 2018Revised: July 19, 2019Accepted: September 23, 2019Published Online in Articles in Advance:June 10, 2020
https://doi.org/10.1287/isre.2019.0899
Copyright: © 2020 INFORMS
Abstract. Open collaboration platforms have fundamentally changed the way thatknowledge is produced, disseminated, and consumed. In these systems, contributionsarise organically with little to no central governance. Although such decentralizationprovides many benefits, a lack of broad oversight and coordination can leave questions ofinformation poverty and skewness to the mercy of the system’s natural dynamics. Un-fortunately, we still lack a basic understanding of the dynamics at play in these systemsand specifically, how contribution and attention interact and propagate through in-formation networks.We leverage a large-scale natural experiment to study how exogenouscontent contributions to Wikipedia articles affect the attention that they attract and howthat attention spills over to other articles in the network. Results reveal that exogenouslyadded content leads to significant, substantial, and long-term increases in both contentconsumption and subsequent contributions. Furthermore, we find significant attentionspillover to downstream hyperlinked articles. Through both analytical estimation andempirically informed simulation, we evaluate policies to harness this attention contagion toaddress the problem of information poverty and skewness. We find that harnessing at-tention contagion can lead to as much as a twofold increase in the total attention flow toclusters of disadvantaged articles. Our findings have important policy implications foropen collaboration platforms and information networks.
History: Anandasivam Gopal, Senior Editor; Maytal Saar-Tsechansky, Associate Editor.Funding: L. Muchnik acknowledges financial support from the Israel Science Foundation [Grant 1777/
17]. D. Walker acknowledges the NVIDIA Corporation for their donation of GPU hardware usedin this research.
Supplemental Material: The online appendix is available at https://doi.org/10.1287/isre.2019.0899.
Keywords: user-generated content • open collaboration platform • information consumption • attention contagion • spillover effect
1. IntroductionWikipedia is one of the most successful examples ofopen collaboration platforms, serving millions of in-formation seekers daily. It is both a repository of freeknowledge and the most visited educational resourceon the planet.1 By the end of 2017, a mere 16 years sinceits inception, the English language Wikipedia alonecontained over 5.5 million articles and a total of over3.1 billion words, over 60 times as many as the nextlargest English language encyclopedia, EncyclopediaBritannica.2 It consists of millions of articles writtenby a global network of volunteers and is accessible toanyone with an internet connection. Wikipedia rep-resents a new generation of internet-based collabo-rative tools that strive to be open, accessible, andegalitarian.
However, Wikipedia’s reliance on open and dis-tributed collaboration as well as community gover-nance is not without its problems. As noted by Wiki-pedia itself, volunteers do not always contribute to the
content that people need the most.3 Large proportionsof articles are incomplete or insufficiently supportedwith references.4 Because of Wikipedia’s open anddistributed production model, it is difficult to directcontributors’ attention to articles that most need im-provement. Hence, not only are these articles incom-plete, but they are likely to remain so. As a consequence,the coverage and depth of knowledge in Wikipediaarticles are uneven. Although well-developed articlesare considerably longer than their analogues in Ency-clopedia Britannica, many articles are still of poorquality, and they are on average half as long as theirprofessionally edited analogues.5 Importantly, cov-erage also seems to be uneven across both geographicalareas and knowledge domains (Halavais and Lackaff2008, Kittur et al. 2009, Graham et al. 2014). For ex-ample, Wikipedia has strong coverage of militaryhistory and political events in America, but articles onbiology, law, medicine, and information on developingcountries are often absent or underdeveloped.6
491

Left unchecked, the societal implications of unevencoverage are deeply troubling. Despite the opennessof Wikipedia, there are growing concerns that geo-graphical areas and knowledge domains that areleft out or underrepresented will remain so or be-come even further underrepresented relative to thegrowing knowledge base in a kind of poor-get-poorerphenomenon. Geographical informational skews canact to further limit our understandings of, attentionto, and interactions with impoverished areas in termsof regional economic, social, political, and culturalconcerns (Norris 2001, Yu 2006, Forman et al. 2012,Graham et al. 2014). Knowledge domain informationskews can compound insularity, lead to domain-based siloing, and push information seekers towardalternative, domain-specific information platforms thatare less open and are not free. Informational skew mayreinforce or even compound existing biases in world-views and exacerbate information poverty. Existingresearch has shown that information (un-)availabilityhas a surprisingly strong impact on real-worldoutcomesin financial markets, scientific advancement, and thetourist industry (Xu and Zhang 2013, Xiaoquan andLihong 2015, Hinnosaar et al. 2017, Thompson andHanley 2017). These studies further emphasize thesalience of the skewed coverage problem in Wiki-pedia. Importantly, although we focus onWikipedia,concerns of uneven coverage exist in a variety of plat-forms that facilitate collaborative content production,including open source software (e.g., GitHub), knowl-edge markets (e.g., Stack Overflow or Quora), andproduct reviews (e.g., Amazon or Steam).
It is unclear whether Wikipedia’s uneven coverageis driven by selection effects on the part of Wikipediaeditors owing to their intrinsic interests (Kuznetsov2006, Nov 2007), natural emerging trends and ex-ogenous factors (Kampf et al. 2012, 2015; Keegan et al.2013), or a systematic tendency for well-developedarticles to continue to receive more attention via the“rich-get-richer” dynamic (Barabasi and Albert 1999,Aaltonen and Seiler 2016). Most existing work onknowledge contribution behavior on Wikipedia hasfocused primarily on the motivation of its editors(Harhoff et al. 2003, Nov 2007, Zhang and Zhu 2011,Lampe et al. 2012, Zhu et al. 2013, Gallus 2017).However, it is critical that we understand the factorsthat govern the evolution and lifecycle of articles,which are central to the dynamics of Wikipedia as asystem. Such factors are also likely important de-terminants of uneven coverage. Unfortunately, ourunderstanding of how open collaboration platformsevolve and attract attention is still very limited.
There are three streams of research in the literaturethat are relevant to our study.Thefirst streamof researchemphasizes the dynamic coevolution of knowledgeconsumption and knowledge production. The open
collaboration model allows consumers of knowledge toreact to existing content and potentially, also becomecontributors. However, how do production and con-sumption of knowledge interact in this complex dy-namic system (Wilkinson andHuberman 2008, Kampfet al. 2012)? Aaltonen and Seiler (2016) find thatlongerWikipedia articles tend to receivemore editingin the future. Kummer (2019) studied how attentionshocks arising from natural disasters affect contri-butions. Kane and Ransbotham (2016) investigate thefeedback loop between consumption and contribu-tion of articles in WikiProject Medicine and find thatthe state of content moderates this feedback loop. It isnoteworthy that they argue that this feedback loop inopen collaboration platforms has been underresearchedand that a deeper understanding is warranted.The second stream of research emphasizes the
network perspective by recognizing that, similar tothe web as a whole, Wikipedia is an informationnetwork of hyperlinked articles. This has importantimplications: at least some of the traffic (attention)arriving at a particular article flows outward alonglinks to other downstream articles. The importance ofthis network perspective derives from a long traditionof relating a node’s relative importance to its networkproperties—an assumption that is implicit to thewell-known PageRank algorithm. The overall exposure ofan article in Wikipedia is determined by the variousways that an information seeker can arrive at it viaboth external (e.g., search engines) and internal sources(upstream Wikipedia articles). Previous research hasshown that the network position of an article is corre-lated with its content consumption and production(Kane 2009, Ransbotham et al. 2012, Kummer et al.2016). Moreover, the structural embeddedness ofan article in the content-contributor network is pos-itively related to its viewership and information quality(Ransbotham et al. 2012, Kane andRansbotham2016).Beyond information networks, Lin et al. (2017) ex-amined a product recommendation network and foundthat both network diversity and stability are signifi-cantly associated with product demand. These findingssuggest that articles that are disadvantaged in terms ofnetwork position may receive less attention, furtherlimiting their future evolution.The third stream of research focuses on attention
flow or spillover in information networks and policiesto optimally leverage spillover. West and Leskovec(2012) used an experimental game to study the dy-namics of attention flow in Wikipedia through thelens of goal-oriented search. Kummer (2014) studiedspillovers from articles that are featured on the homepage of German Wikipedia. Wu and Huberman(2007) study the dynamics of attention to articleson the news aggregator Digg.com and show howattention to articles decays with their novelty. Several
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia492 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

works have focused on how content and particularly,perception of its importance can drive attention.Salganik et al. (2006) conducted a series of random-ized online experiments to determine the impact ofmusic track ranking on consumption. Muchnik et al.(2013a) demonstrated that perceived popularity ofcomments not only attracts attention and additionalvotes but can lead to herding phenomena, where“likes” beget additional “likes.” Carmi et al. (2017)carried this idea further and studied how demandshocks generate not only attention but also, attentionspillover in the product recommendation networks ofAmazon.com, yielding substantial benefits to down-stream recommended products. Finally, Aral et al.(2013) studied seeding strategies for policies that le-verage spillover in the context of social networks.These studies suggest that attention spillover has asignificant impact on real-world outcomes and thatpolicies that leverage spillover can be beneficial.
Although all three streams of research have enrichedour understanding of knowledge production and con-sumption in information networks, much of the workon open collaboration platforms, like Wikipedia, relieson endogenous observational data, making it difficultto draw valid causal conclusions. In addition, existingwork has focused only on the local direct effect ofattention spillover. It has not addressed how hetero-geneous characteristics of articles moderate spillover.Additionally, it has not considered the systemic effectof spillover and its broader policy implications.
Yet, a rigorous understanding of the dynamics atplay in the Wikipedia network and collaborativeinformation systems in general is indispensable forunderstanding how information evolves in these sys-tems. Such an understanding is vital to the mission ofglobal empowerment through open knowledge pro-duction and dissemination.Moreover, it is an importantprecursor to the development of sound policies, suchas incentivizing contributions to achieve more robustcoverage.7 Randomized, controlled experiments arethe gold standard for causal inference, but they aredifficult to conduct on platforms like Wikipedia. Apartfrom the technical challenges and ethical concerns as-sociated with experiments in this context, the continuedsurvival and operations of these platforms dependcompletely on the community of contributors, who arehighly sensitive to sudden andunvetted policy changes.However, natural experiments that create exogenousvariation in otherwise endogenous relationships canalso permit valid causal inference.
In this study, we leverage a natural experiment toexamine how exogenous content contributions to aWikipedia article affect future activities surroundingthe article in terms of both pageview dynamics andediting behavior. More interestingly, we examinehow the attention that an article attracts can spill over
to other articles that it links to and hence, furtherpropagate through the network. Furthermore, weconsider the broader policy implications of spillover.We conduct policy simulations to understand howspillovers concentrated in the clusters of the network,which we term attention contagion, could impact theevolution of Wikipedia as a system and how it couldbe harnessed and incorporated into policies to ad-dress impoverished regions in information networks.The goal of the policy simulation is to integrate our
findings into an empirically calibrated attention dif-fusion model and guide policy decisions through theanalysis of counterfactuals. Although the platformcan answer some policy questions through analysisof observational data and through experimentation,many relevant counterfactuals for policy recommen-dation are not directly recoverable from direct esti-mates. They may be too costly or even impossibleto test. In our context, interpreting the spillover effectof individual articles on the whole system is notstraightforward. In particular, the effect of spilloversmight be amplified when editorial efforts are directedat a group of interconnected articles. The key ideabehind the policy simulation approach is that reducedformanalysis is used to estimate parameters of amodelof the system so that the model can be used to ex-trapolate findings tomore complex ormore interestingpolicies at the cost of imposing additional model as-sumptions (Taylor and Eckles 2018).Our study provides three major contributions. First,
we confirm and obtain causal estimates of the feedbackloop between contribution and attention. We find thatcontribution drives sustained increase in future atten-tion (12% on average, with stronger impact for moresignificant contributions) and future contributions (3.6more edits and two more unique editors over a six-month period). Second, we determine the article andnetwork characteristics that most amplify spillover orattention contagion. We find that spillovers have themost impact (as much as 22%) for less popular articlesthat are hyperlinked from focal articles through newlycreated links. Third, we provide insights from compar-isons of policies to address information-impoverishedregions of the network based on analytic derivation andempirically calibrated simulations. We demonstrate thata policy designed to leverage attention contagion canyield substantial increases in attention (as much astwofold) to impoverished regions of information net-works. These results are directly relevant to concerns ofsocietal equity and have managerial importance forcollaborative information platforms.
2. Natural Experiment and DataSince 2010, the Wikipedia Education Foundation hasbeen collaborating with university course instructorsto encourage students in the United States and Canada
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 493

to expand and improve Wikipedia articles throughcourse assignments. The mission of this endeavor isto cultivate students’ skills, such as media literacy,writing, and critical thinking, while leveraging stu-dent effort to fill content gaps on Wikipedia. Since itslaunch, university instructors participating in theprogram have guided their students to add content toapproximately 46,000 course-related articles on Wiki-pedia. About 35,000 students have contributed morethan 35 million words to Wikipedia, equivalent to 22volumes of a printed encyclopedia. These student-editedarticles have collectively received 282 million views bythe end of 2017.8
In this study, we leverage the exogenous contentcontributions that result from this campaign to enrichour understanding of the dynamics in open collab-oration platforms. The identification derives from theassumption that the content contributions by studentsare exogenous to the natural evolution of the articlesand would not have occurred during the same timeperiod in the absence of theWiki Education campaign.This is likely to hold for two reasons. First, many ofthe treated articles pertain to topics that do not nat-urally relate to current events (e.g., detailed topics infundamental sciences, such as properties of molecules,etc.). Second, the timing of contribution is exogenous.The content addition occurs during a fixed time periodthat corresponds to an arbitrary class period—that is tosay, that the contribution would not have occurredduring the same time period in the absence of theassignment. We seek to learn three things from thisnatural experiment: first, whether efforts that focus ondeveloping underdeveloped pages can lead to long-term, sustained impact; second and more generally,how contribution and attention dynamically interactand how this interaction depends on article attributes;and third, whether and to what extent attention prop-agates through the information network (that is, thephenomenon of attention contagion). Finally, we seekto combine insights in order to synthesize and assesspolicies that address informationpoverty and skewness.
For this study, we collected all of the articles thatreceived content contribution from students throughthis campaign in the year of 2016.9 For each article, weretrieved its title, URL, the time period of the course(i.e., the shock period), and the number of charactersadded to the article by the assigned student from thewebsite of Wiki Education Dashboard.10 In our analy-sis, we retain only articles that existed prior to thecampaign (excluding new articles created by students)and those that received substantive contributions (of atleast 500 added characters during the shockperiod). Thisleaves uswith 3,296unique treated articles in the sample.
To assess the impact of the content shock,we considerthe number of pageviews of an article, a widely usedmeasure of information consumption. In addition, we
parse the complete revision history of each article toobtain the time series of edits and authorship (i.e.,the number of unique editors who worked on the ar-ticle over time). Both the pageviews and revisions arecollected through the public Application Program-ming Interface (API) developed andmaintained by theWikimedia Foundation.11
2.1. Matching and Control GroupRates ofWikipedia content creation and consumptionare subject to seasonality and other temporal patterns.A simple comparison of quantities of interest (forexample, pageviews and revisions) before and afterthe content shock may, therefore, be misleading.Observed changes can be attributed to alteration ofthe page content but also, to naturally occurringtrends. Statistical modeling techniques alone are of-ten insufficient to fully account for seasonality andother complex temporal patterns of article activity.We address this issue by constructing a sample oftreated and control articles matched across multipleattributes. The control group is used to identify theaverage outcomes corresponding to the counterfac-tual state that would have occurred for articles in thetreatment group had they not received the contentcontribution during the shock period.The control group is chosen via the following pro-
cedure. First, we pick candidates for the control groupby choosing a random sample of 100,000 Wikipediaarticles that did not receive content contribution fromstudents. Second, we define the hypothetical shockperiod for each control article by randomly samplingfrom the pool of shock periods of treated articles andmeasure the preshock article characteristics for controlarticles. Third, we use coarsened exact matching (CEM)(Iacus et al. 2012) based on each article’s preshockcharacteristics of tenure, size, and popularity (cal-culated based on average historical pageviews) toobtain a matched sample by pruning articles thathave no close match in the treated and control groups.We opt for a k-to-k matching solution (i.e., an equalnumber of treated and control units), which is ac-complished by pruning observations from a CEMsolution within each stratum until the solution con-tains the same number of treated and control units inall strata. Pruning occurs within a stratum throughnearest neighbor selection using a Euclidean distancefunction.Matching is a frequently used technique for drawing
causal conclusions from observational data based on theassumption of selection on observables (Rosenbaumand Rubin 1983, Ho et al. 2007). It emulates a ran-domized experiment after the data have been col-lected by constructing a balanced data set in whichsamples in the control group are similar to the sam-ples in the treated set in observed characteristics. We
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia494 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

confirm that the constructed control group closely mir-rors the treatment group in seasonality and natural timetrends. This can be verified in the model-free plots ofpageviews over time in Section 2.3 and by comparingarticle attributes in each group as displayed in Table 1.The averages of all three covariates are very close acrossgroups, and t tests fails to reject the null hypothesisthat they have the same mean value. In addition, thisbetween-group panel research design lends itself neatlyto a standard difference-in-difference estimation of theeffect of content contribution.
The above procedure yields 2,766 pairs of matchedtreated and control articles. For each article, weconstruct a panel of weekly pageviews from 26 weeksbefore the shock to 26 weeks after (excluding theshock period itself). Our final sample consists of abalanced panel of 52 periods for 5,532 articles or287,664 observations at the article-week level. Our re-sults are robust to other matching procedure choices.For example, we evaluated an alternative matchingprocedure that incorporates matching on article topicand find that the direct effect results are qualitativelysimilarwithonly small changes in themagnitude of effectsizes. In addition, we also demonstrate that our resultsare robust to matching based on network characteristicsof articles (see the online appendix for further details).
2.2. Links and Hyperlink ArticlesBecause we are also interested in attention spilloversfrom treated articles to downstream hyperlinked arti-cles, we parse content revisions to retrieve the outgoinghyperlinks from focal articles. Following the links, weretrieve all articles linked to by treated and control ar-ticles. There aremillions of such hyperlinked articles. Toavoid confounds that may arise from multiple expo-sures to the treatment, we retain only hyperlinked ar-ticles that are linked to from one and only one treatedarticle (Walker and Muchnik 2014). For parity, wetreat articles downstream of control articles in the samemanner. This allows us to obtain a clean estimate of thespillover effect from each link. This procedure yields131,974 hyperlinked articles that are downstream fromdirectly treated articles. The spillover treated and spill-over control articles constitute our sample for analyzingthe spillover effect of the content contribution. This isillustrated in Figure 1.
2.3. Model-free EvidenceIn this section, we present model-free evidence re-garding the direct and spillover impact of the contentshock in terms of both pageview dynamics and editingbehavior. A model-free examination of the evidencecan reveal important effects while avoiding modelingassumptions.
2.3.1. Pageviews Dynamic. Because articles are highlyheterogeneous, they experienced a large variance inactivities (such as pageviews) even prior to treatment,a phenomenon that is typical for complex social systems(Muchnik et al. 2013b). To compensate for large base-line variation, we scaled pageviews for each articlerelative to its own preshock popularity, which is com-puted as average weekly pageviews over 26 weeks(about six months)12 prior to its shock period:
scaledPageviewi, t � pageviewi,t
preShockPopularityi, (1)
where preShockPopularityi�1/26∑26
µ�1pageviewi,τ−µ andτ is the weekwhen the content shock begins for articlei. Because courses in our sample begin at differentweeks and have different durations, we align theirstart dates and exclude the duration of shock perioditself from the analysis. We consider relative timebefore or after the shock. Figure 2 plots the mean andstandard deviation of weekly scaled pageviews in thesix months prior to and after the shock period fortreated and control articles.This model-free view of the data displays a clear
seasonal trend for both treatment and control grouparticles, indicating the need for careful construction ofa control group as a counterfactual. Prior to the shock,articles in the control group mimic the time trendof those in the treatment group well, highlightingthe success of our CEMprocedure.We can also see thesignificant and relatively long-lasting impact of thetreatment on postshock pageviews. Treated articlesreceived approximately 10%more traffic than controlarticles, and this effect persisted for at least 26 weeksafter the contribution shock. Evidently, Wikimedia’scampaign efforts to develop underdeveloped pagesboth worked and had a relatively long-term impact,suggesting the potential for a policy approach to
Table 1. Balanced Check for Matched Sample
Size (characters) Popularity (weekly pageviews) Tenure (weeks)
Control 16,228 1,575 506Treatment 16,255 1,574 506t test (p-value) 0.70 0.93 0.51
Notes. This table illustrates the quality of our matching procedure. It compares preshock characteristicsof articles in the matched groups; t tests indicate that we cannot reject the null hypothesis that articles intreatment and control groups have the same mean across all three characteristics.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 495

fill impoverished regions in Wikipedia’s informationnetwork.
Figure 3 plots the mean and standard deviation ofweekly scaled pageviews in the 26 weeks prior toand after the shock period for articles in the spillovertreated and spillover control groups. Although page-views of spillover treated articles seem to exceed those
of spillover control articles after week 10, it is unclearfrom this model-free evidence alone whether the effectis significant. It should be noted that there is little doubtthat spillover of attention occurs on Wikipedia—thiscan be seen explicitly from published clickstreamdata of actual traffic flowing over hyperlinks fromone article to another (see Section 3.1.3 for further
Figure 1. (Color online) Research Design—Direct Effect and Spillover Effect
Notes. This figure illustrates the direct treated and direct control articles, which constitute our matched sample for analyzing the direct effect ofthe treatment. Similarly, the spillover treated and spillover control articles constitute our sample for analyzing the spillover effect of the contentcontribution.
Figure 2. (Color online) Impact of Content Shock on Pageviews
Notes. This figure displays the pageviews dynamics for articles in the treatment and control groups. Time is measured relative to the shockperiod (which is excluded) up to 26 weeks before and after. Dots and whiskers represent the means and standard deviations, respectively. ofscaled pageviews in each bin.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia496 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS
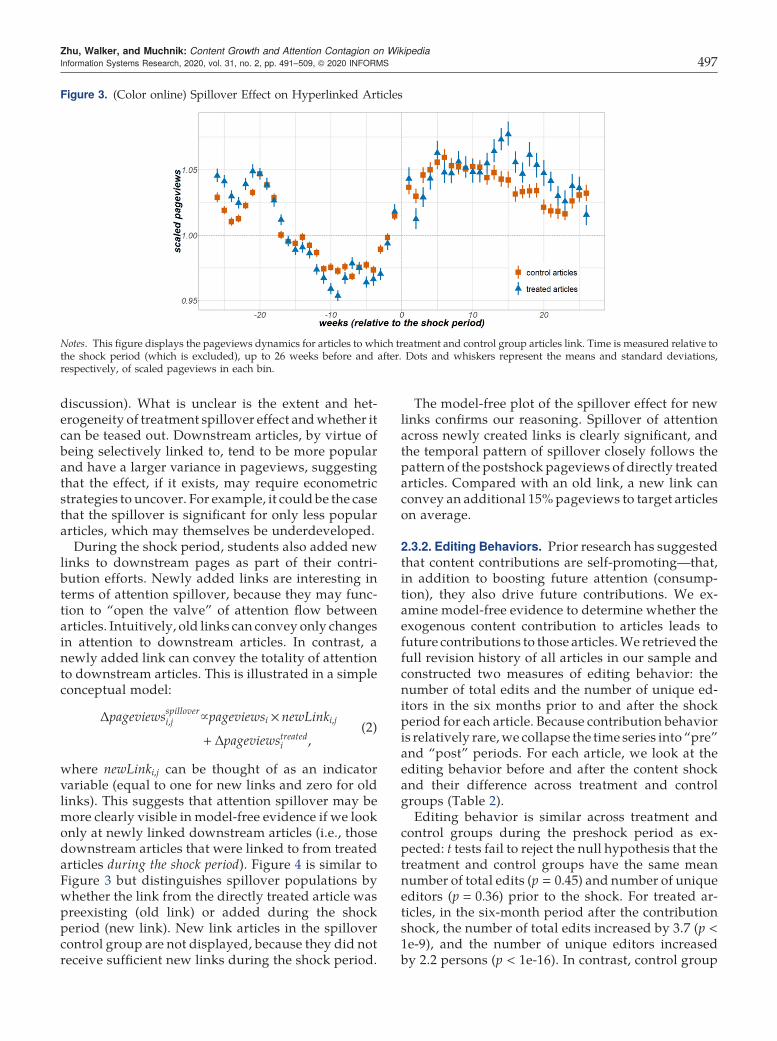
discussion). What is unclear is the extent and het-erogeneity of treatment spillover effect andwhether itcan be teased out. Downstream articles, by virtue ofbeing selectively linked to, tend to be more popularand have a larger variance in pageviews, suggestingthat the effect, if it exists, may require econometricstrategies to uncover. For example, it could be the casethat the spillover is significant for only less populararticles, which may themselves be underdeveloped.
During the shock period, students also added newlinks to downstream pages as part of their contri-bution efforts. Newly added links are interesting interms of attention spillover, because they may func-tion to “open the valve” of attention flow betweenarticles. Intuitively, old links can convey only changesin attention to downstream articles. In contrast, anewly added link can convey the totality of attentionto downstream articles. This is illustrated in a simpleconceptual model:
Δpageviewsspilloveri,j }pageviewsi × newLinki,j
+ Δpageviewstreatedi ,(2)
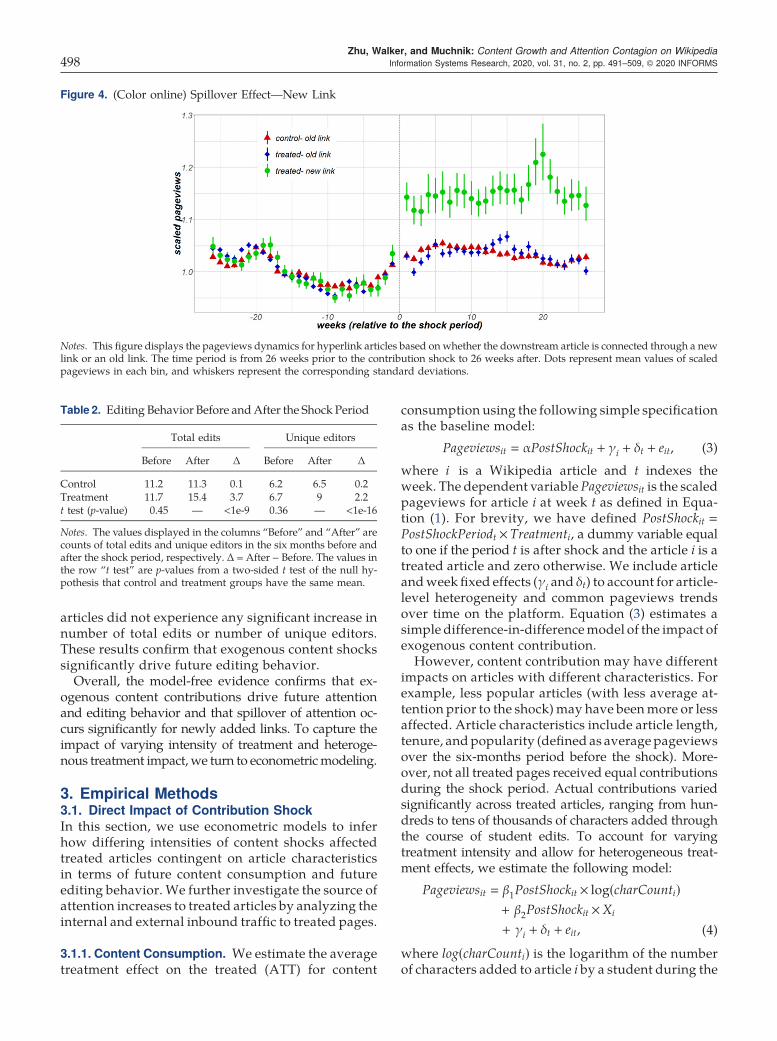
where newLinki,j can be thought of as an indicatorvariable (equal to one for new links and zero for oldlinks). This suggests that attention spillover may bemore clearly visible in model-free evidence if we lookonly at newly linked downstream articles (i.e., thosedownstream articles that were linked to from treatedarticles during the shock period). Figure 4 is similar toFigure 3 but distinguishes spillover populations bywhether the link from the directly treated article waspreexisting (old link) or added during the shockperiod (new link). New link articles in the spillovercontrol group are not displayed, because they did notreceive sufficient new links during the shock period.
The model-free plot of the spillover effect for newlinks confirms our reasoning. Spillover of attentionacross newly created links is clearly significant, andthe temporal pattern of spillover closely follows thepattern of the postshock pageviews of directly treatedarticles. Compared with an old link, a new link canconvey an additional 15% pageviews to target articleson average.
2.3.2. Editing Behaviors. Prior research has suggestedthat content contributions are self-promoting—that,in addition to boosting future attention (consump-tion), they also drive future contributions. We ex-amine model-free evidence to determine whether theexogenous content contribution to articles leads tofuture contributions to those articles.We retrieved thefull revision history of all articles in our sample andconstructed two measures of editing behavior: thenumber of total edits and the number of unique ed-itors in the six months prior to and after the shockperiod for each article. Because contribution behavioris relatively rare,we collapse the time series into “pre”and “post” periods. For each article, we look at theediting behavior before and after the content shockand their difference across treatment and controlgroups (Table 2).Editing behavior is similar across treatment and
control groups during the preshock period as ex-pected: t tests fail to reject the null hypothesis that thetreatment and control groups have the same meannumber of total edits (p � 0.45) and number of uniqueeditors (p � 0.36) prior to the shock. For treated ar-ticles, in the six-month period after the contributionshock, the number of total edits increased by 3.7 (p <1e-9), and the number of unique editors increasedby 2.2 persons (p < 1e-16). In contrast, control group
Figure 3. (Color online) Spillover Effect on Hyperlinked Articles
Notes. This figure displays the pageviews dynamics for articles to which treatment and control group articles link. Time is measured relative tothe shock period (which is excluded), up to 26 weeks before and after. Dots and whiskers represent the means and standard deviations,respectively, of scaled pageviews in each bin.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 497
articles did not experience any significant increase innumber of total edits or number of unique editors.These results confirm that exogenous content shockssignificantly drive future editing behavior.
Overall, the model-free evidence confirms that ex-ogenous content contributions drive future attentionand editing behavior and that spillover of attention oc-curs significantly for newly added links. To capture theimpact of varying intensity of treatment and heteroge-nous treatment impact, we turn to econometricmodeling.
3. Empirical Methods3.1. Direct Impact of Contribution ShockIn this section, we use econometric models to inferhow differing intensities of content shocks affectedtreated articles contingent on article characteristicsin terms of future content consumption and futureediting behavior. We further investigate the source ofattention increases to treated articles by analyzing theinternal and external inbound traffic to treated pages.
3.1.1. Content Consumption. We estimate the averagetreatment effect on the treated (ATT) for content
consumption using the following simple specificationas the baseline model:
Pageviewsit � αPostShockit + γi + δt + eit, (3)
where i is a Wikipedia article and t indexes theweek. The dependent variable Pageviewsit is the scaledpageviews for article i at week t as defined in Equa-tion (1). For brevity, we have defined PostShockit �PostShockPeriodt ×Treatmenti, a dummy variable equalto one if the period t is after shock and the article i is atreated article and zero otherwise. We include articleandweekfixed effects (γi and δt) to account for article-level heterogeneity and common pageviews trendsover time on the platform. Equation (3) estimates asimple difference-in-differencemodel of the impact ofexogenous content contribution.However, content contribution may have different
impacts on articles with different characteristics. Forexample, less popular articles (with less average at-tention prior to the shock) may have beenmore or lessaffected. Article characteristics include article length,tenure, and popularity (defined as average pageviewsover the six-months period before the shock). More-over, not all treated pages received equal contributionsduring the shock period. Actual contributions variedsignificantly across treated articles, ranging from hun-dreds to tens of thousands of characters added throughthe course of student edits. To account for varyingtreatment intensity and allow for heterogeneous treat-ment effects, we estimate the following model:
Pageviewsit � β1PostShockit × log(charCounti)+ β2PostShockit ×Xi
+ γi + δt + eit, (4)
where log(charCounti) is the logarithm of the numberof characters added to article i by a student during the
Figure 4. (Color online) Spillover Effect—New Link
Notes. This figure displays the pageviews dynamics for hyperlink articles based on whether the downstream article is connected through a newlink or an old link. The time period is from 26 weeks prior to the contribution shock to 26 weeks after. Dots represent mean values of scaledpageviews in each bin, and whiskers represent the corresponding standard deviations.
Table 2. Editing Behavior Before andAfter the Shock Period
Total edits Unique editors
Before After Δ Before After Δ
Control 11.2 11.3 0.1 6.2 6.5 0.2Treatment 11.7 15.4 3.7 6.7 9 2.2t test (p-value) 0.45 — <1e-9 0.36 — <1e-16
Notes. The values displayed in the columns “Before” and “After” arecounts of total edits and unique editors in the six months before andafter the shock period, respectively. Δ = After − Before. The values inthe row “t test” are p-values from a two-sided t test of the null hy-pothesis that control and treatment groups have the same mean.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia498 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

shock period.13 It represents the variation of treat-ment intensity. Xi is a vector of article characteristicsmeasured before the content shock, including articletenure, size, and popularity. To provide better in-terpretability of model estimates and avoid the as-sumption of linearity, we bin these three continuousvariables to low and high levels by their median valueand include dummy variables that are equal to onewhen the value is high and zero otherwise (i.e., olderarticle, longer article, and more popular article) in thevector Xi. Diagnostic tests show that two bins for ourcontinuous variable are a reasonable choice (see theonline appendix formore detail). The interaction termof PostShockit and Xi allows us to investigate hetero-geneous treatment effects. We retain article fixedeffects and week fixed effects. The parameters of in-terest are β1 and β2.
We use linear regression to estimate the abovemodels, and results are reported in Table 3.14 Becausewe scale the pageviews of each article with respect toits average pageviews over the six months prior to theshock, all estimates can be conveniently interpreted asthe percentage changes of pageviews relative to theirpreshock average. Following the suggestion of Bertrandet al.(2004), all reported standard errors allow forarbitrary serial correlation across time and hetero-scedasticity across articles to properly gauge theuncertainty around the estimates for serially corre-lated outcomes in panel data.
Overall, we find that postshock pageviews fortreated article increased by 12% on average. The
magnitude of the treatment effect is positively cor-related with treatment intensity, and the impact isstronger for articles that are younger and less pop-ular. The effect is both economically and statisticallysignificant. Based on the model estimates in (3), arelatively young and less popular article with 6,000characters added (the average number of charactersadded for treated articles in our sample) during theshock period experienced a 25% boost in postshockpageviews. The impact is even larger for similar ar-ticles that received a more intense treatment.We perform diagnostics to assess our modeling
assumptions in terms of linear interaction effects andcommon support. Results show that both assump-tions are satisfied. For robustness, we also estimatedalternative specifications. Using linear regression, wedrop article fixed effects γi and retain only a simpletreatment indicator, and all estimates are similar (seethe online appendix for more details).
3.1.2. Editing Behavior. Beyond the impact on atten-tion, we are also interested in whether exogenouscontent contributions spur future editing behavior.Because editing behavior is typically sparse for aWikipedia article, formodeling purposes,we collapsethe time series into just “pre” and “post” periods forthe six months prior to and after the contributionshock. For each article, this yields two six-month timeperiods, during which we count the number of totaledits and number of unique editors, and these comprisethe dependent variables. Compared with alternativeapproaches (such as multistage, zero-inflated models),this transformation permits a simpler linear model,which retains interpretability andavoidsmore restrictivemodeling assumptions (such as distributional assump-tions on the error term that are required by Poisson ornegative binomial regression). In addition, as suggestedby Bertrand et al. (2004), the “pre” and “post” timeseries collapse allows us to obtain a consistent esti-mator for the standard errors of the treatment effectin the difference-in-difference model. The modelsestimated here are similar to models in Equations (3)and (4) for content consumption, apart from the timeperiod collapse and the exchange of the dependentvariable for editing behavior. For the sake of in-terpretability, we report the results from a linear re-gression, but results from Poisson regression andnegative binomial regression are qualitatively similar(see the online appendix for details).As we can see from Table 4, the contribution shock
has a significant impact on future editing behavior interms of both number of total edits and number ofunique editors. Based on model estimates from col-umns (1) and (4) in Table 4, an article that receivedcontent contribution in the shock period had ap-proximately 3.6 more edits and two more unique
Table 3. The Impact of Content Contribution onConsumption
Scaled pageviews
(1) (2) (3)
PostShock 0.119***(0.017)
PostShock × log(charCount) 0.035*** 0.065***(0.005) (0.008)
PostShock × old article −0.041*(0.024)
PostShock × popular article −0.142***(0.025)
PostShock × long article −0.015(0.025)
Article fixed effect Yes Yes YesTime fixed effect Yes Yes YesObservations 287,664 287,664 287,664Adjusted R2 0.122 0.122 0.124
Notes. In Models (2) and (3), we include PostShock × log(charCount)and exclude a bare PostShock term, because log(charCount) capturesthe intensity of a treatment (and every article that received acontribution as a consequence of treatment had some number ofcharacters added).
*Significant at the 10% level; ***significant at the 1% level.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 499

editors in the six months after the shock periodcomparedwith articles that did not receive exogenouscontent contribution. Similar to our findings for contentconsumption, the magnitude of the treatment effectincreases with treatment intensity. Based on the esti-mates from columns (2) and (4) in Table 4, an articlewith 6,000 characters added during the shock periodattracts 4.5more edits and 2.5 editors in the six-monthpostshock period. As for heterogeneous treatmenteffects, the most significant factor was weaker impactfor articles that already have a substantial amount ofcontent.
3.1.3. Sources of IncreasedAttention. Bothmodel-freeresults and estimates from statistical models con-firm that exogenous contributions to articles drivefuture attention. However, from where does this in-creased attention originate? In general, articles canreceive attention directly from external sources (e.g.,traffic arriving to an article from outside of the in-formation network, such as through search enginediscovery or links from external websites) and in-ternal sources (e.g., traffic flowing to an article fromanother upstream article). This distinction is inter-esting and meaningful from a policy perspective,because some articles may act to pull attention intothe information network from external sources, therebyincreasing the overall attention to the platform. Arti-cles also play a role in the redistribution of attentionthroughout the platform, which is relevant from thestandpoint of information equity. An article’s role inthe flow of attention on the information network isillustrated in Figure 5.
For many large-scale real-world information sys-tems, we cannot directly observe the detailed flow ofattention (traffic). However, recently released data of
monthly Wikipedia clickstream15 snapshots provideexactly this level of detail for all Wikipedia articles.The clickstream data show how users arrive at anarticle and what links they click on within the articleover the course of a given month aggregated at thearticle level. They contain counts of (referrer, re-source) pairs extracted from the Wikipedia HTTPrequest logs, where a referrer is an HTTP header fieldthat identifies the address of the web page that linkedto the resource being requested. In other words, theclickstream data give a weighted network of articlesand external sites, where the weight of each edgecorresponds to the traffic flow along that edge. Thesecounts are aggregated at the monthly level, and any(referrer, resource) pair with greater than 10 obser-vations in amonth is included in the data set. To give asense of the scale of the data, the August 2016 releasecontains 25.8 million (referrer, resource) pairs from atotal of 7.5 billion requests for about 4.4 million En-glishWikipedia articles. Figure 6 displays an examplefrom the Wikimedia website, which illustrates in-coming and outgoing traffic to the page “London” onEnglish Wikipedia.We leverage these data to shed light on the sources
from which increased attention originates. The click-stream data snapshots are only available for a limitednumber of months during the period of our naturalexperiment. To look at the change of traffic flow, weneed to compare snapshots before and after the shockperiod. Fortunately, theWikimedia Foundation releasedclickstream snapshots for both August 2016 and Janu-ary 2017, which are just before and after articles weretreated in the fall semester of 2016.For each article, we calculate its total inbound
traffic (combined internal and external traffic arrivingat the article), total outbound traffic (traffic leaving
Table 4. The Impact of Contribution Shock on Future Editing Behavior
Number of total edits Number of unique editors
(1) (2) (3) (4) (5) (6)
PostShock 3.596*** 1.996***(0.855) (0.243)
PostShock × log(charCount) 1.173*** 1.186*** 0.640*** 0.606***(0.229) (0.234) (0.068) (0.065)
PostShock × old article 1.446 0.691**(0.957) (0.339)
PostShock × long article −1.840** −0.829***(0.926) (0.305)
PostShock × popular article 0.241 0.333(0.856) (0.326)
Article fixed effect Yes Yes Yes Yes Yes YesTime fixed effect Yes Yes Yes Yes Yes YesObservations 10,964 10,964 10,964 10,964 10,964 10,964Adjusted R2 0.63 0.63 0.63 0.82 0.82 0.82
**Significant at the 5% level; ***significant at the 1% level.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia500 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

the article), internal inbound traffic16 (traffic flow tothe article from other articles in the network), andexternal inbound traffic (trafficflow to the article froma search engine or other external website). We useCEM to ensure that articles in the treatment groupand control group are comparable across all trafficmeasures prior to the start of the natural experiment(i.e., in the August 2016 snapshot). The k-to-k CEMprocedure leaves us with 1,017 articles in both thetreatment and control groups (see the online appendixfor distribution and balance checks for clickstream data).
We first look at changes in network structure interms of newly created incoming links. During theshock period, it is likely that links to articles in eitherthe treatment or control group were created either bystudent editors or as part of the natural evolution of the
information network. Matching the 2,024 treatment andcontrol articles in our sample with the clickstream datasnapshots (for August 2016 and January 2017), we findthat the number of active incoming links17 for treatedarticles grew significantly faster compared with controlgroup articles. As we see in Table 5, articles in thetreatment group received on average 0.9 more activelinks during the shock period (compared with 0.4 forarticles in control group). New incoming links make anarticle more discoverable by creating new channels tocapture attention flow within the network. These in-creased channels may explain how contributions ul-timately drive attention.Attention from external sources can also explain the
attention increases that we observed. To determine theextent to which observed attention increases derive from
Figure 5. (Color online) Flow of Attention on Information Networks with Respect to a Particular Article in Terms of Flow In(Internal and External) and Flow Out
Figure 6. (Color online) Sources of Incoming andOutgoing Traffic for the “London”Wikipedia Article as Determined from theClickstream Monthly Data Snapshots Provided by the Wikimedia Foundation
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 501

internal or external sources, we compare pre-/postshockchanges in internal, external, and total incoming trafficacross treatment and control articles in Table 6. Thecontrol group serves as a counterfactual to accountfor natural fluctuations arising from seasonal orother pageview trends, leading to a simple DID styleestimator.
From Table 6, we see that the total incoming trafficincreased by 14.6 pageviews per article per day for thetreatment group relative to 8.2 for the control group.The extra 6.4 pageviews can be interpreted as theATT, which is about a 14% increase relative to thepreshock average. This result is consistent with ourprior estimates, which were based on article-levelpageviews data. Hence, we demonstrate the impactof content shock using two different data sources(clickstream data and pageviews data) and find similareffect sizes. We can also see that both internal and ex-ternal sources conveyed increased attention, indicatingthat content contributions yield attention gains fromwithin the information network and from without. Wesuggest that attention gains from external sources arelikely the result of increased visibility of the articles insearch engine results.18 Modern search engine algo-rithms are clearly sensitive to the recency of contentchanges. Although we do not know the actual detailsof search engine ranking algorithms (proprietaryinformation), more incoming hyperlinks to a pageconvey a higher ranking in ordinary PageRank. Wedefine the ratio of internal to external traffic asR(T) � Tinternal/Texternal. New traffic has a higher ratio
(R(ΔT) � 0.4) relative to the preshock ratio (R(TBefore) �0.3), indicating that new traffic originates slightlymore from internal sources.
3.2. Attention SpilloverThe impact of content shocks is not limited to directlytreated articles. Attention resulting from the shockcan also spill over onto other downstream articlesthrough the hyperlink network. Conceptually, we canthink of the spillover as a dyadic relationship betweeneach source (directly treated or control) and targetarticle. As our consideration of model-free evidenceshowed, new links, which build bridges betweensource and target articles, seem to play a critical rolein facilitating spillover. It also seems plausible thatthe popularity of source and target articles maymoderate the extent of the spillover. We test thesehypotheses with the following model:
Pageviewsit � β0PostShockit + β1PostShockit× stPopularityi + β2PostShockit× newLinki + β3PostShockit× stPopularityi × newLinki+ γi + δt + eit, (5)
where i is a target article and t is the week. stPopularityiis a two-dimensional vector (sourcePopularityi, targetPopularityi) representing the popularity of the sourcearticle (i.e., the treated article that received an exog-enous content contribution) and the target article(that was linked to from the treated article), re-spectively. The indicator newLinki is equal to one if thelink between source article and target article wasadded during the treatment period and zero other-wise. The parameters of interest are β1, β2, β3. Weinclude each term in successive models gradually toinvestigate how they parcel out the overall spillovereffect. The results are displayed in Table 7.We can see from column (1) of Table 7 that the
overall effect (i.e., when averaged over all articles) issmall but significant. This result is consistent with themodel-free evidence and our intuition given the largeheterogeneity across articles. Column (2) of Table 7
Table 5. Number of Incoming Links
Number of incoming links per articles
Before After Δ
Control 6.6 7.0 0.4Treatment 6.6 7.5 0.9t test (p-value) 0.96 — <1e-15
Notes. The values displayed in the columns “Before” and “After” arethe average numbers of incoming links per articles in the six monthsbefore and after the shock period, respectively.Δ =After − Before. Thevalues in the row “t test” are p-values from a two-sided t test of the nullhypothesis that control and treatment groups have the same mean.
Table 6. Incoming Traffic Breakdown
Total incoming traffic Internal traffic (Tinternal) External traffic (Texternal)
Before After Δ Before After Δ Before After Δ
Control 45.4 53.6 8.2 10.2 12.2 2.0 35.2 41.4 6.0Treated 44.7 59.3 14.6 10.2 14.0 3.8 34.4 45.2 10.8t test (p-value) 0.85 — 0.01 0.97 — 0.05 0.80 — 0.03
Notes. The values displayed in the columns “Before” and “After” are the average traffic per article perday in the sixmonths before and after the shock period, respectively.Δ=After − Before. The values in therow “t test” are p-values from a two-sided t test of the null hypothesis that control and treatment groupshave the same mean.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia502 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

shows how the treatment effect varies with the popu-larity of source and target articles. Evidently, spilloverfrom low-popularity source articles to low-popularitytarget articles yielded a 2.7% increase in pageviews(p < 0.01). Although this effect size may initially seemsmall, it is measured with respect to a single outgoinglink from the treated article to one target article.In general, treated articles link to multiple downstreamtarget articles, suggesting that the overall collectiveeffect of spillover can be quite substantial. Interestingly,spillover is enhanced when both source and target ar-ticles are less popular, which is a typical scenario forunderdeveloped pages, particularly in informationallyimpoverished regions in the Wikipedia network.
A more interesting insight emerges when we con-sider whether the link between source and targetarticles was new. Surprisingly, for new links, theimpact of the spillover can be as large as around 13%,which is close in magnitude to the average directeffect. As illustrated in our discussion of model-freeevidence, the rationale is that a new link can “open thevalve” between source and target articles and conveyboth the preexisting and increased attention from thesource to the target. We note that old links clearlyconvey attention (as the clickstream data illustrate).However, they convey only increased attention fromthe source to the target, and we lack the statisticalpower to see it directly in this model. Finally, theattention spillover is even larger (14.8%) for new linksbetween less popular source and target articles. Be-cause underdeveloped regions of information net-works likely satisfy all of these criteria (i.e., lowpopularity of articles and lack of preexisting linkstructures between articles), policies that focus on
promoting such regions can benefit from strategiesthat harness spillover.
4. Policy Simulation ofAttention Contagion
Our spillover results indicate that attention shocks inWikipedia have a local network effect. Articles in thesystem benefit when upstream articles receive atten-tion. Some spillovers direct attention to downstreamarticles that already receive significant exposure.However, some of this attentionmay increase exposureto underdeveloped articles. This begs the followingquestion: by focusing attention on connected sets ofunderdeveloped articles, can we optimally harnessspillovers in order to redirect attention to articles thatwould benefit the most from increased exposure?To better understand this question, we conduct
policy simulations in which we integrate our findingsfrom the econometric estimates into an empiricallycalibrated attention diffusion model to guide policydecisions through the analysis of counterfactuals. Wepropose a policy in which editors are encouraged tofocus their editorial efforts on a set of targeted un-derdeveloped articles that are intimately related toone another in order to harness attention contagionand maximize joint exposure. Targeted sets of relatedarticles either will be well connected at the outset(i.e., a set of stub articles that are already well con-nected but remain underdeveloped) or will becomewell connected as a consequence of directed editorialefforts. That is, the links between sets of related ar-ticles need not exist prior to being edited but can ariseas a consequence. The rationale is that attention spill-overs to underdeveloped articles are more valuable to
Table 7. The Attention Spillover of Contribution Shock
Scaled pageviews
(1) (2) (3) (4)
PostShock 0.008*** 0.027*** −0.006 −0.005(0.003) (0.006) (0.004) (0.007)
PostShock × popularTargetArticle −0.013** −0.004(0.005) (0.005)
PostShock × popularSourceArticle −0.016** 0.000(0.007) (0.007)
PostShock × newLink 0.129*** 0.148***(0.012) (0.018)
PostShock × popularTargetArticle × newLink −0.138***(0.023)
PostShock × popularSourceArticle × newLink 0.073***(0.023)
Article fixed effect Yes Yes Yes YesTime fixed effect Yes Yes Yes YesObservations 6,862,648 6,862,648 6,862,648 6,862,648Adjusted R2 0.104 0.104 0.104 0.104
**Significant at the 5% level; ***significant at the 1% level.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 503

the platform (in terms of the information equity thatthey convey) than spillovers to articles that are alreadywell developed.
4.1. Intuition—A Mean Field EstimationWe begin by providing an intuition for how networkstructure can impact attention spillover using a meanfield estimation. To represent a set of related and highlyconnected articles in a manner that is simple, we con-sider network cliques defined as a set of n completelyconnected nodes in a network. To demonstrate ourintuition, we analytically calculate the spillover incliques of size n using mean field assumptions.
For an n clique, assuming that each node receivesdirect traffic T and where spillover over a single stepis given by Tspillover � f T, the total spillover exposuregain is given by
∑nk�2 n!/(n − k)! * f k−1 . The summand
represents all partial permutations of a set of k nodes,describing the paths of length k − 1 that successivespillovers take (each contributing a multiplicativefactor of f ) from each starting node to each otherending node. Figure 7 displays the total spillover gainfor all articles in the clique (i.e., the total additionalexposure gained from spillover from each article inthe clique onto all other articles).
For example, for amean spillover of f � 0.10 and forcliques of sizes n = 3, 4, and 5, the total spilloverexposure gain is 0.66, 1.46, and 2.73, respectively, asmeasured in units of proportion of incident directtraffic. This estimate assumes constant spillover ( f )and equal traffic from any node in the clique to anyother, which is unlikely to hold in the real world.Fortunately, we can relax these assumptions by usingexact and fine-grained data on traffic flowing on alllinks in Wikipedia and traffic to all pages from ex-ternal sources (e.g., traffic from search engines thatarrive at Wikipedia pages) from the monthly click-stream snapshots.19 We leverage these data to esti-mate spillover and assess policies designed to capturespillover through empirically calibrated simulations.
4.2. Diffusion SimulationOur mean field estimation is useful to obtain stylizedestimates of policies that focus attention on clusters of
well-connected articles and develop an intuition aboutwhy this might work, but it does not account for real-world heterogeneity in actual traffic flow on the linksbetween articles. To address this, we test policies morerealistically and comprehensively through simulationsof traffic flow that arise from attention perturbations.We define perturbations as increases in incident trafficfrom external sources. These policy simulations makeuse of highly detailed clickstream data for calibration toensure that traffic flow changes follow pathways inproportion to real-world patterns on Wikipedia. Toaccomplish this, we use a generalization of the per-sonalized PageRank algorithm.20 PageRank is widelyrecognized as one of themost important algorithmsusedfor network-based information retrieval. It representstraffic flow as a randomwalk process on the informationnetwork, and it is given in the iterative form by
r.t+1 � (1 − α) r.0 + αG · r.t, (6)
where r.t is a vector of the traffic (attention) landingon article i for the tth iteration of the diffusion process;r.0 is a vector of the initial distribution of trafficor whenever the process involves “hopping” ratherthan following a hyperlink from an article to a down-stream article. The “hopping” occurs with probability(1 − α)—the so-called damping factor. G is a matrix ofnormalized outflow of traffic from any article i thathyperlinks to an article j. Convergence of the iterativeform of PageRank is achieved for some r. ≡ r.t+1 when| r.t+1 − r.t | < ε for a small choice of ε. The convergedvector r. represents the normalized accumulated trafficto each article i that results from the simulated randomwalk process. We represent this simulation processfunctionally as r. � PR( r.0,G,α, ε).Ordinary PageRank assumes an equal initial dis-
tribution of traffic, r.0 � 1/N, and equal probabilityof outflow along all links, Gij � Aij/kj, where Aij is theadjacency matrix and kj is the degree of article j. Thedamping factor is conventionally chosen as (1 − α) �0.15. Personalized PageRank relaxes the assumptionof equal initial distribution of traffic for an arbitrarynormalized r.0. To guarantee realism, we relax theseassumptions even further and leverage the clickstream
Figure 7. Mean Field Estimate of Total Spillover to a Clique
Note. For each clique shown, we calculate the mean field estimate of the total spillover to all nodes in the clique under the dynamic processdescribed in the text.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia504 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

data (see Section 3.1.3 for a description) to empiricallycalibrate internal and external traffic flows in thesimulation.21 In personalized PageRank, we set thevector r.0 to the normalized empirical distribution ofexternal incident traffic on each article i and thematrixG to the normalized empirical distribution of outflowtraffic from article i to article j. Having defined thesimulation process, we are now in a position to assesshowperturbations to attention (i.e., increases in incidenttraffic fromexternal sources—e.g., arising from contentcontribution shocks) drive accumulated attention toall articles in the network. We represent a generalperturbation to some set of articles S as r.
S0p � r.0 + δr
. S
0pand set the perturbation according to
(δr0p)i � (r0)i{p, for i εS0, otherwise, (7)
where p> 0 represents a constant percentage increaseof attention shock to affected articles (those in thechosen perturbed set S). In other words, we createrelative perturbations of attention that are correlatedacross a set S of chosen articles. For each perturba-tion, we calculate the resultant PageRank vectorr.Sp � PR( r.S
0p,G,α, ε) and compare it with the un-perturbed PageRank vector r. � PR( r.0,G,α, ε). Spe-cifically, we are interested in the resultant excess at-tention (EA) received by underdeveloped articles,which comprise the articles in the perturbed set:
EA(S, p) � ∑i ε S
rSp,i − riri
. (8)
Because any perturbation of a set of articles will re-sult in those articles receiving excess attention, we
compare excess attention across two different poli-cies: (i) an attention contagion policy (ACP), whereeditorial efforts are focused on clusters of well-connected, underdeveloped articles, and (ii) an un-directed attention policy (UAP), where editorial effortsare focused on randomly chosen underdevelopedarticles that are not necessarily (but may incidentallybe) connected to one another. The random selection ofunderdeveloped articles under this latter UAP willlead to contributions to articles that are more spreadout across the information network compared withthe ACP.22 The two policies are illustrated in Figure 8.The UAP represents a simple and useful baseline forcomparison. It may be that, without guidance, editorsalready cluster their editorial focus to some extent.However, we do not parametrize clustering underUAP to avoid introducing unnecessary assumptionsand additional complexity.To compare these two policies, we first need to
identify sets of well-connected articles in Wikipediathat appear in clickstream data and are good em-pirical proxies for underdeveloped articles. Impor-tantly, many actual sets of related, underdevelopedarticles will likely lack the linking structure thatwould naturally arise from directed editorial focus.That is to say, although these underdeveloped pagesare related to one another, they do not yet possess thelinking structure to connect them. To avoid makingunnecessary and potentially ill-informed assump-tions about unobserved network structure and itsrelationship to content, we instead focus only onactual links that appear in the clickstream data andthat experienced actual traffic flow. To accomplishthis, we use the weighted directed graph of traffic
Figure 8. (Color online) Concentration of Attention Across Network Communities or Cliques for the Two Policies
Notes. Red nodes receive increased attention (perturbed). Panel (a) illustrates the ACP, where attention to red nodes (which constitute theperturbed set SACPc for a given clique or community, c) is clusteredwithin a community or clique. Panel (b) illustrates the UAP, where attention isspread out randomly across communities or cliques in the network. To compare policies fairly, red nodes in panel (a) are matched one to one tored nodes in panel (b) (comprising the set SUAP
mcas described in the text).
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 505

flow between articles and seek tightly connected setsof nodes in the form of both cliques and communities.To find cliques, we computed a large sample ofmaximal cliques via depth-first search with Bron–Kerbosh-style pruning (Tomita et al. 2006). To findcommunities, we modify the well-known label propa-gation algorithm (LBA) (Raghavan et al. 2007): to ad-dress the instability of the original LBA, we performthe algorithm 200 times and assign articles to the samecommunity if and only if they were assigned to thesame community in at least 95% of the runs. Thisapproach produces stable, tightly connected com-munities with minimal noise. It is also efficient, fast,and able to cope with networks of millions of nodes.Wefiltermaximal cliques and communities and retainonly those of small to moderate size (2≤ n≤ 6). Foreach such clique or community, wematch each articleto another article in a different clique or communitywith the closest external incident traffic. This yieldeda set of well-connected articles to perturb according tothe attention contagion policy, SACP
c , and a corre-sponding matched set of articles to be used in theundirected attention policy, SUAP
mc, where c labels the
clique or community and mc labels the matched set.Note that the articles in SACPc belong to the same cliqueor community (c), whereas articles in SUAP
mccan belong
to many different cliques or communities. Becausetesting large numbers of perturbations is computa-tionally intense, we select a random subset of 600cliques and communities, and for each clique orcommunity, we simulate the perturbations for bothpolicies and compare the distribution of excess at-tention EA(SACPc , p) with EA(SUAP
mc, p). The results are
displayed in Figure 9 for cliques (Figure 9(a)) andcommunities (Figure 9(b)) for simulation with p � 0.1.
The attention contagion policy clearly leads to signif-icant excess attention directed toward underdevelopedpages compared with the undirected attention policy,
yielding a relative increase of mean excess attention(ACP over UAP) of 106% for cliques and 44.2% for com-munities (p < 1e-71 from two-sided t test).23 Becauseeditors may already cluster their editorial attention tosome extent even without a guidance policy, our resultsshould be interpreted as an upper bound to the valueconveyed by the attention contagion policy. Excessattention scales linearly with the size of the pertur-bation, which follows from the definition of excessattention and the expansion of the iterative perturbedPageRank equation. The shape of the distributions ofexcess attention for either policy is determined entirelyfrom the network structure around the perturbation set,implying that the results are identical up to a scale factor(p) for different choices of perturbation size. Resultsare also robust to different random samples of cliquesor communities (see the online appendix for details).
5. ConclusionOpen collaborative platforms have fundamentallychanged the way that knowledge is produced, dis-seminated, and consumed in the digital era. Thisstudy directly contributes to our understanding of theinteraction between production and consumption ofinformation and the phenomenon of attention con-tagion on Wikipedia, arguably the largest and mostsuccessful example of such platforms. To conductvalid causal inference so that we can inform policywith high confidence, we used a battery of methods,including natural experiment, matching, econometricmodeling, and empirically informed simulation. Wefound that real-world exogenous contributions in-crease future attention by 12% on average, withstronger impact for more significant contributions.They also increase future contribution by 3.6 moreedits and two more unique editors to affected articlesover a six-month period. This impact is both eco-nomically significant and persists for a long time. In
Figure 9. (Color online) Distribution and Kernel Density Estimates of Excess Attention for Perturbative Simulations (p = 0.1) ofthe ACP and UAP for 600 Cliques and Communities
Notes. (a) Cliques. (b) Communities. The ACP leads to significantly more excess attention.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia506 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

addition, we obtained causal estimates of the extent ofspillover impact and identified characteristics of ar-ticles and links between them that receive the mostbenefit from spillovers. Specifically, we find that spill-over is greatest across new links that point to lesspopular target articles, yieldingan impact ashighas 22%for new links from popular source articles to unpopulartarget articles and 15% for new links from less popularsource articles to less popular target articles.
Overall, our results confirm the existence of posi-tive feedback loops of production and consumptionof information on Wikipedia. This, unfortunately,also implies that underdeveloped articles experiencea poor-get-poorer phenomenon and are, therefore,naturallydisadvantaged in the cumulativedevelopmentprocess. This observation is deeply troubling, because itsuggests that impoverished regions in collaborativeinformation systems will remain impoverished in theabsence of policies that are specifically designed toaddress this problem. More importantly, because in-formation poverty is often correlated with economicpoverty (Norris 2001, Yu 2006, Forman et al. 2012,Graham et al. 2014), this phenomenon can act to ex-acerbate economic, social, political, and cultural in-equalities. Fortunately, our findings suggest that lessdeveloped regions of information networks can benefitsubstantially from spillovers. We carry this insightfurther and propose and compare policies that driveeditorial attention using diffusion simulations that arebased on real-world traffic flows on Wikipedia. Weevaluate the attention contagion policy that leveragesspillovers to stimulate development of impoverishedregions.Wefind that thispolicy canyieldup to a twofoldincrease in excess attention relative to the baselineundirected attention policy. These results are directlyrelevant to concerns of information equity and havemanagerial implication for collaborative informationplatforms. Although we focus on Wikipedia, our find-ings are relevant to the uneven coverage problem thatexists in many platforms that facilitate collaborativecontent production in domains, such as open sourcesoftware creation (e.g., GitHub), knowledge markets(e.g., Stack Overflow or Quora), and product reviews(e.g., Amazon or Steam).
Our results suggest that two policies can be effectivefor encouraging the development of underdevelopedarticles or impoverished regions in the informationnetwork. First, editors may be encouraged to identifypopular articles that should naturally (semantically)link to a focal underdeveloped article. Our resultsshow that creating such a link can harness the largestattention spillover (as much as 22%), although careshould be taken to ensure that added links are seman-tically meaningful. Second and perhaps, more impor-tantly, Wikipedia should consider encouraging coher-ent development of impoverished regions. Our results
show that underdeveloped regions,which typically lackboth attention and the linking structure to connect re-lated articles, are precisely positioned to benefit fromattention contagion policies. Currently, the quality andimportance ofWikipedia articles are assessed through atagging system implemented on talk pages. Tools existthat use these metrics to allow editors to search forspecific articles that are both important and in need ofattention. Additional features could be added to thesetools to encourage a coherent focus for individual edi-tors or even groups of editors.This work is not without limitations. This work
tackles causality by leveraging a natural experiment,matching, econometric techniques, and empiricallyinformed simulation. However, cleaner causal in-ference could be achieved in future work throughcontrolled, randomized experiments. As we examineattention spillover owing to a second-order shock toattention (that itself is driven by a contribution shock),we may miss subtle heterogeneous spillover effects.Future work could consider perturbations to link struc-ture and real-world experimental tests of attention con-tagion policies. Furthermore, Wikipedia is subject toother natural experiments that may be discoverable. Inparticular, examination of clickstream data may permitthe discovery of natural experiments that can help us bet-ter understand attention flow in information networks.
Endnotes1 It is the fifth most visited website in the world according to Alexa.2 See https://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia,accessed November 7, 2019.3 See https://wikiedu.org/changing/wikipedia/, accessed Novem-ber 7, 2019.4 See http://time.com/4180414/wikipedia-15th-anniversary/, accessedNovember 7, 2019.5 See https://en.wikipedia.org/wiki/Wikipedia:Size_comparisons,accessed November 7, 2019.6 See https://en.wikipedia.org/wiki/Criticism_of_Wikipedia, accessedNovember 7, 2019.7 See https://meta.wikimedia.org/wiki/Research:Increasing_article_coverage, accessed November 7, 2019.8 See https://wikiedu.org/changing/wikipedia/, accessed Novem-ber 7, 2019.9Wikimedia changed their measurement of pageviews in May 2015to better filter out bot traffic and incorporate the visits from mobiledevices. Looking at the articles edited in 2016 guarantees thatwe havea consistent measure of pageviews in the six months before and afterthe content shock.10 See https://dashboard.wikiedu.org/, accessed November 7, 2019.11 See https://www.mediawiki.org/wiki/API:Main_page, accessedNovember 7, 2019.12Note that this normalization simply scales the time series ofpageviews of each article by a constant. Examination of the model-free evidence for scaled and unscaled pageviews reveals that thisscaling is appropriate.13For articles in the control group, the value of log(charCounti) is setto zero.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 507

14Note that, in Models (2) and (3) in Table 3, we include PostShock ×log(charCount) and exclude a barePostShock term, because log(charCount)captures the intensity of a treatment (and every article that receiveda contribution as a consequence of treatment had some number ofcharacters added).15 See https://meta.wikimedia.org/wiki/Research:Wikipedia_clickstream,accessed November 7, 2019.16The link traffic only includes links from other Wikipedia articles.The link traffic from other websites outside of the ecosystem ofWikipedia was classified under the external traffic category.17We define an active incoming link as one that conveys at least 10pageviews in a month. The monthly clickstream data snapshots filterout any (referrer, resource) pairs that do not meet this criterion.18 Search engines traffic dominates other external sources, such asexternal websites, in external traffic.19 See Ellery Wulczyn and Dario Taraborelli (2015) Wikipedia click-stream at https://meta.wikimedia.org/wiki/Research:Wikipedia_clickstream, accessed November 7, 2019.20Personalized PageRank has recently been formally related to thetask of community detection in networks (Kloumann et al. 2016).21 In prior research, others have calibrated PageRank with internaltraffic from Wikipedia clickstream data (Dimitrov et al. 2017) buthave not accounted for variation in external traffic.22 In fact, because UAP spreads out editorial focus through the net-work, it conveys excess attention to more unique articles. However,under ACP, more articles receive a larger share of excess attention.For more details, see Figure A11 and the related discussion in theonline appendix.23Alternatively, two-sample Kolmogorov-Smirnov tests reject thenull hypothesis that the distributions are equal with p < 1e-63
ReferencesAaltonen A, Seiler S (2016) Cumulative growth in user-generated
content production: Evidence from Wikipedia. Management Sci.62(7):2054–2069.
Aral S, Muchnik L, Sundararajan A (2013) Engineering social con-tagions: Optimal network seeding in the presence of homophily.Network Sci. 1(2):125–153.
Barabasi AL, Albert R (1999) Emergence of scaling in random net-works. Science 286(5439):509–512.
Bertrand M, Duflo E, Mullainathan S (2004) How much should wetrust differences-in-differences estimates? Quart. J. Econom.119(1):249–275.
Carmi E, Oestreicher-Singer G, Stettner U, Sundararajan A (2017) IsOprah contagious? The depth of diffusion of demand shocks ina product network. Management Inform. Systems Quart. 41(1):207–221.
Dimitrov D, Singer P, Lemmerich F, Strohmaier M (2017) Whatmakes a link successful on Wikipedia? Proc. 26th Internat. Conf.World Wide Web—WWW ’17 (ACM Press, New York), 917–926.
Forman C, Goldfarb A, Greenstein S (2012) The internet and localwages: A puzzle. Amer. Econom. Rev. 102(1):556–575.
Gallus J (2017) Fostering public good contributions with symbolicawards: A large-scale natural field experiment at Wikipedia.Management Sci. 63(12):3999–4446.
Graham M, Hogan B, Straumann RK, Medhat A (2014) Unevengeographies of user-generated information: Patterns of in-creasing informational poverty. Ann. Assoc. Amer. Geographers104(4):746–764.
Halavais A, Lackaff D (2008) An analysis of topical coverage ofWikipedia. J. Comput.-Mediated Comm. 13(2):429–440.
Harhoff D, Henkel J, Von Hippel E (2003) Profiting from voluntaryinformation spillovers: How users benefit by freely revealingtheir innovations. Res. Policy 32(10):1753–1769.
Hinnosaar M, Hinnosaar T, Kummer M, Slivko O (2017) Wikipediamatters. Preprint, submittedOctober 3, http://dx.doi.org/10.2139/ssrn.3046400.
Ho DE, Imai K, King G, Stuart EA (2007) Matching as nonparametricpreprocessing for reducing model dependence in parametriccausal inference. Political Anal. 15(3):199–236.
Iacus SM, King G, Porro G (2012) Causal inference without balancechecking: Coarsened exact matching. Political Anal. 20(1):1–24.
Kampf M, Tessenow E, Kenett DY, Kantelhardt JW (2015) The de-tection of emerging trends using Wikipedia traffic data andcontext networks. PLoS One 10(12):e0141892.
Kampf M, Tismer S, Kantelhardt JW, Muchnik L (2012) Fluctuationsin Wikipedia access-rate and edit-event data. Phys. A 391(23):6101–6111.
Kane GC (2009) It’s a network, not an encyclopedia: A social networkperspective on Wikipedia collaboration. Acad. Management J.2009(1):1–6.
Kane GC, Ransbotham S (2016) Research note—content and col-laboration: An affiliation network approach to informationquality in online peer production communities. Inform. SystemsRes. 27(2):219–470.
Keegan B, Gergle D, Contractor N (2013) Hot off the Wiki: Structuresand dynamics of Wikipedia’s coverage of breaking news events.Amer. Behav. Sci. 57(5):595–622.
Kittur A, Chi EH, Suh B (2009) What’s in Wikipedia? Proc. 27thInternat. Conf. Human Factors Comput. Systems—CHI 09 (ACMPress, New York), 1509–1512.
Kloumann I, Ugander J, Kleinberg J (2016) Block models and per-sonalized PageRank. Proc. Natl. Acad. Sci. USA 114(1):33–38.
KummerME (2014) Spillovers in networks of user generated content:Evidence from 93 pseudo-experiments on Wikipedia. Preprint,submitted December 29, https://ssrn.com/abstract=2567179.
KummerME (2019) Attention in the peer production of user generatedcontent: Evidence from 93 pseudo-experiments onWikipedia. Pre-print, submitted August 2, https://ssrn.com/abstract=3431249.
Kummer ME, SaamM, Halatchliyski I, Giorgidze G (2016) Centralityand content creation in networks: The case of economic topics onGerman Wikipedia. Inform. Econom. Policy 36:36–52.
Kuznetsov S (2006) Motivations of contributors to Wikipedia. ACMSIGCAS Comput. Soc. 36(2):1.
Lampe C, Obar J, Ozkaya E, Zube P, Velasquez A (2012) ClassroomWikipedia participation effects on future intentions to contribute.Proc. ACM2012Conf. Comput. Supported CooperativeWork—CSCW’12 (ACM, New York), 403–406.
Lin Z, Goh KY, Heng CS (2017) The demand effects of productrecommendation networks: An empirical analysis of networkdiversity and stability. Management Inform. Systems Quart. 41(2):397–426.
Muchnik L, Aral S, Taylor SJ (2013a) Social influence bias: A ran-domized experiment. Science 341(6146):647–651.
Muchnik L, Pei S, Parra LC, Reis SDS, Andrade JS Jr, Havlin S, MakseHA (2013b) Origins of power-law degree distribution in theheterogeneity of human activity in social networks. Sci. Rep. 3(1):1783.
Norris P (2001) Digital Divide: Civic Engagement, Information Poverty,and the Internet Worldwide (Cambridge University Press, Cam-bridge, UK).
Nov O (2007) What motivates Wikipedians? Comm. ACM 50(11):60–64.
Raghavan UN, Albert R, Kumara S (2007) Near linear time algo-rithm to detect community structures in large-scale networks.Physical Rev. E: Statist. Nonlinear Soft Matter Physics 76(3 Pt 2):036106.
Ransbotham S, Kane G, Lurie NH (2012) Network characteristics andthe value of collaborative user generated content. Marketing Sci.31(3):387–405.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on Wikipedia508 Information Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS

Rosenbaum PR, Rubin DB (1983) The central role of the propensityscore in observational studies for causal effects. Biometrika 70(1):41–55.
Salganik MJ, Dodds PS, Watts DJ (2006) Experimental study of in-equality and unpredictability in an artificial cultural market.Science 311(5762):854–856.
Taylor SJ, Eckles D (2018) Randomized experiments to detect andestimate social influence in networks. Lehmann S, Ahn YY, eds.Complex Spreading Phenomena in Social Systems (Springer In-ternational Publishing, Cham, Switzerland), 289–322.
Thompson NC, Hanley D (2017) Science is shaped by Wikipedia:Evidence from a randomized control trial. Preprint, submittedSeptember 20, http://dx.doi.org/10.2139/ssrn.3039505.
Tomita E, Tanaka A, Takahashi H (2006) The worst-case time com-plexity for generating all maximal cliques and computationalexperiments. Theoret. Comput. Sci. 363(1):28–42.
Walker D, Muchnik L (2014) Design of randomized experiments innetworks. Proc. IEEE 102(12):1940–1951.
West R, Leskovec J (2012) Human wayfinding in information net-works. Proc. 21st Internat. Conf. World Wide Web—WWW ’12(ACM, New York), 619–628.
Wilkinson D, Huberman B (2008) Assessing the value of cooperationinWikipedia. Preprint, submitted February 1, https://arxiv.org/pdf/cs/0702140.pdf.
Wu F, Huberman BA (2007) Novelty and collective attention. Proc.Natl. Acad. Sci. USA 104(45):17599–17601.
Xiaoquan Z, Lihong Z (2015) How does the internet affect the fi-nancial market? An equilibrium model of internet-facilitatedfeedback trading.Management Inform. SystemsQuart. 39(1):17–38.
Xu SX, Zhang MX (2013) Impact of Wikipedia on market informa-tion environment: Evidence on management disclosure and inves-tor reaction. Management Inform. Systems Quart. 37(4):1043–1068.
Yu L (2006) Understanding information inequality: Making sense ofthe literature of the information and digital divides. J. LibrarianshipInform. Sci. 38(4):229–252.
Zhang X, Zhu F (2011) Group size and incentive to contribute:A natural experiment at Chinese Wikipedia. Amer. Econom. Rev.101(June):1–17.
Zhu H, Zhang A, He J, Kraut RE, Kittur A (2013) Effects of peerfeedback on contribution: A field experiment in Wikipedia.CHI ’13 Proc. SIGCHI Conf. Human Factors Comput. Systems(ACM, New York), 2253–2262.
Zhu, Walker, and Muchnik: Content Growth and Attention Contagion on WikipediaInformation Systems Research, 2020, vol. 31, no. 2, pp. 491–509, © 2020 INFORMS 509