initiation à la reconstruction phylogénétique - edu.upmc.fr€¦ · initiation à la...
TRANSCRIPT

Initiation à la reconstruction phylogénétique
Yves DesdevisesUniversité Pierre et Marie Curie
Observatoire Océanologique de Banyuls04 68 88 73 13
[email protected]://desdevises.free.fr
Références• Darlu P. et Tassy P. 1993. Reconstruction phylogénétique :
concepts et méthodes. Masson.
• Perrière G. et Brochier C. 2010. Concepts et méthodes en phylogénie moléculaire. Springer.
• Felsenstein J. 2004. Inferring phylogenies. Sinauer.
• Hall B. 2007. Phylogenetic trees made easy. Third Edition. Sinauer.
• Lemey P, Salemi M. et Vandamme A.-M. 2009. The phylogenetic handbook. Second Edition. Cambridge University Press.
• Page R. et Holmes E. 1998. Molecular evolution: a phylogenetic approach. Blackwell.
• But : proposer une hypothèse des liens de parenté entre plusieurs taxons
• Phylogénie = arbre évolutif (≠ échelle)
• Spéciation : binaire
• Basé sur l’homologie : similarité résultant de l’héritage d’un ancêtre commun
• Indication de l’existence d’un ancêtre commun
• Identifiable à l’aide d’un arbre phylogénétique, peut également servir à le construire
• Multiples utilisations des phylogénies
• Découvrir l’origine des organismes
• Classification et biodiversité
• Inférence des états de caractères ancestraux
• Etude de l’évolution corrélée et de l’adaptation
• Evolution moléculaire
• Taux de diversification et “key innovations”
• Dates de divergence
• Biogéographie et phylogéographie
• Cospéciation
1
2
3
4

Arbres phylogénétiques
Symphodus roissali
Symphodus cinereus
Symphodus tinca
Symphodus ocellatus
Symphodus mediterraneus
Symphodus melanocercus
Ctenolabrus rupestris
Labrus merulaLabrus viridis
Cheilinus trilobatusCheilinus chlorourus
Epibulus incidiator
Stetojulis albovittataStetojulis bandanensis
Halichoeres hortulanus
Halichoeres margaritaceus
Labropsis australis
Halichoeres marginatus
Anampses geographicusAnampses caeruleopunctatus
Labroides dimidiatus
Labrichthys unilineatusCoris julis
Hemigymnus melapterusHemigymnus fasciatus
Thalassoma bifasciatum
Thalassoma lunare
Thalassoma lutescens
Pictilabrus laticlaviusNotolabrus tetricus
Bodianus rufusClepticus parrae
Pagrus major
Symphodus roissali
Symphodus cinereus
Symphodus tinca
Symphodus ocellatus
Symphodus mediterraneus
Symphodus melanocercus
Ctenolabrus rupestris
Labrus merula
Labrus viridis
Cheilinus trilobatus
Cheilinus chlorourus
Epibulus incidiator
Stetojulis albovittata
Stetojulis bandanensis
Halichoeres hortulanus
Halichoeres margaritaceus
Labropsis australis
Halichoeres marginatus
Anampses geographicus
Anampses caeruleopunctatus
Labroides dimidiatus
Labrichthys unilineatus
Coris julis
Hemigymnus melapterus
Hemigymnus fasciatus
Thalassoma bifasciatum
Thalassoma lunare
Thalassoma lutescens
Pictilabrus laticlavius
Notolabrus tetricus
Bodianus rufus
Clepticus parrae
Pagrus majorSymphodus roissali
Symphodus cinereus
Symphodus tinca
Symphodus ocellatus
Symphodus mediterraneus
Symphodus melanocercus
Ctenolabrus rupestris
Labrus merula
Labrus viridis
Cheilinus trilobatus
Cheilinus chlorourus
Epibulus incidiator
Stetojulis albovittata
Stetojulis bandanensis
Halichoeres hortulanus
Halichoeres margaritaceus
Labropsis australis
Halichoeres marginatus
Anampses geographicus
Anampses caeruleopunctatus
Labroides dimidiatus
Labrichthys unilineatus
Coris julis
Hemigymnus melapterus
Hemigymnus fasciatus
Thalassoma bifasciatum
Thalassoma lunare
Thalassoma lutescens
Pictilabrus laticlavius
Notolabrus tetricus
Bodianus rufus
Clepticus parrae
Pagrus major
Stetojulis albovittataStetojulis bandanensis
Cheilinus chlorourus
Cheilinus trilobatus
Epibulus incidiatorLabrus viridisLabrus merula
Ctenolabrus rupestris
Symphodus roissali
Symphodus cinereus
Symphodus tinca
Symph
odus
ocell
atus
Symphodus mediterraneus
Symphodus melanocercu
s
Pagrus
majo
r
Bodianus rufus
Clepticus parrae
Notolabrus tetricus
Pictilabrus laticlaviusThalassoma lunare
Thalassoma bifasciatum
Thalassoma lutescensHemigymnus melapterus
Hemigymnus fasciatus
Coris julis
Labrichthys unilineatus
Labr
oides
dim
idiatu
s
Anam
pses
caer
uleop
uncta
tus
Anampses geographicus
Labr
opsis
aus
tralis
Halicho
eres m
argina
tus
Halicho
eres h
ortula
nus
Halichoeres margaritaceus
Symphodus roissaliSymphodus cinereusSymphodus tinca
Symphodus ocellatus
Symphodus mediterraneus
Symphodus melanocercus
Ctenolabrus rupestris
Labrus merula
Labrus viridis
Chei
linus
trilo
batu
s
Cheil
inus c
hloro
urus
Epibu
lus in
cidiat
or
Stetoju
lis alb
ovitta
ta
Stetojulis bandanensis
Halichoeres hortulanusHalichoeres margaritaceus
Labropsis australis
Halichoeres marginatus
Anampses geographicus
Anampses caeruleopunctatus
Labroides dimidiatus
Labrichthys unilineatusCoris julis
Hemigym
nus melapterus
Hemigym
nus fasciatus Thala
ssom
a bif
ascia
tum
Thala
ssom
a lun
are
Thala
ssom
a lute
scen
s
Pictila
brus l
aticla
vius
Notolab
rus te
tricus
Bodianus rufus
Clepticus parrae
Pagrus major
• Cladogrammes
• Pas de longueurs de branches
• Clades
• Phylogrammes
• Longueurs de branches
Arbre additif Arbre ultramétrique
Feuilles = taxons terminaux
Racine
Branches terminales
Noeud
Branches intérieures
Polytomie
A B C D E F G H I J
• Spéciation
5
6
7
8

Hypothèse
A CB
• Pour orienter l’arbre
• Utilisation d’un extra-groupe (hors-groupe = groupe extérieur = outgroup)
• Reste = groupe intérieur (ingroup)
ajout d’un extra-groupe
Arbre non enracinéextra-groupe
Arbre enraciné
Enracinement
• Extra-groupe : taxon frère hors de l’ingroup
• Caractères partagés entre outgroup et ingroup = caractères ancestraux
• Parfois pas d’extra-groupe : enracinement au point équidistant des extrémités de l’arbre (suppose longueurs de branches) = midpoint rooting
A
BC
D
E
F
AB C D EF
• Groupe
• Monophylétique : clade
• Mammifères
• Paraphylétique
• Reptiles
• Polyphylétique
• Algues, protozoaires
9
10
11
12

Caractères• Organismes composés de différentes
caractéristiques
• Ces caractéristiques prennent des formes différentes selon les taxons : états de caractères
• L’ensemble des états d’un caractère constituent un caractère
• Ces états sont produits par des changements héritables
• L’inférence phylogénétique se fait à partir des différences entre états de caractères
• On cherche à établir le lien entre ancêtre et descendant par la présence/absence d’un état de caractère
• On cherche l’apparition de nouveaux états de caractères dans les descendants
• Les différents états de caractères sont par définition des homologies
• Les taxons qui partagent ce nouvel état de caractère (dérivé) forment des clades
• Exemple : les poils chez les mammifères, noyau chez les Eucaryotes, ...
Homologies
• Les homologies sont supposées montrer des similarités en :
• position
• structure
• développement
• Un critère reconnu pour supporter les homologies est la congruence avec d’autres caractères
Lézard
Grenouille Humain
Chien
Changement
POILS
AbsentsPrésents
13
14
15
16

Homoplasies
• Ce sont les similarités non homologues
• Résultat d’une évolution indépendante
• Convergence
• Parallélisme
• Réversion
• Brouillent le signal phylogénétique : peuvent conduire à l’établissement de fausses relations de parenté
Convergence
Réversion
Parallélisme
17
18
19
20

Lézard
Grenouille
Humain
Chien
QUEUE
AbsentePrésente
Humain
Grenouille Lézard
ChienQUEUE
AbsentePrésente
• Sans homoplasies, l’inférence phylogénétique serait facile
• Problème fondamental de la reconstruction phylogénétique : distinguer les homoplasies (= bruit) du signal
• Corollaire : la qualité des données (un “bon” signal phylogénétique) est plus importante que la méthode utilisée
• Si il y a un seul arbre correct, quand des caractères supportent des arbres différents, l’un au moins est forcément homoplasique
Humain
Grenouille Lézard
ChienQUEUE
AbsentePrésente
Lézard
Grenouille Humain
ChienPOILS
AbsentsPrésents
Congruence• L’arbre choisi est celui qui maximise le nombre de
caractères congruents
Lézard
Grenouille Humain
Chien
Changements
POILSLACTATION...
MAMMIFERES
21
22
23
24

Cas des données moléculaires
• L’homoplasie est généralement plus commune avec des données moléculaires que morphologiques
• Peu d’états (4 pour l’ADN : A G C T)
• Chimiquement proches
• Taux d’évolution parfois élevé
• Pas d’identification de l’homoplasie par structure ou développement
Données
• Fossiles : rares
• Caractères morphologiques
• Caractères moléculaires : ADN, protéines, ...
• De loin les plus utilisés : modèles, nombreux caractères, moins subjectifs, ...
• Phylogénie du fragment d’ADN (≠ espèce)
• Futur : génomes ➙ phylogénomique
Données moléculaires
• Nucléotides ou acides aminés (pour divergences plus anciennes)
• Caractères = positions des bases (ou AA)
• Etats de caractères = nature des bases ou AA
• Etape primordiale : alignement
• Parfois manuel
• Méthodes automatiques : retouchage manuel
• Peut utiliser information sur la structure secondaire
• Nucléotides : 4 états seulement (2 types)
• Modélisable
• Homoplasie “facile”
25
26
27
28

• Acides aminés
• 20 états
• 5 catégories
• Modélisation beaucoup plus difficile
• Codons
• 61 états !
• Arbre des gènes ≠ arbre des espèces
• Gènes orthologues ou paralogues
A*C*b*
Arbre
Orthologues Orthologues
Paralogues
a A*b* c BC*
Duplication
Gène ancestral
Alignement<---------------(--------------------HELIX 19---------------------)<---------------(22222222-000000-111111-00000-111111-0000-22222222Thermus ruber UCCGAUGC-UAAAGA-CCGAAG=CUCAA=CUUCGG=GGGU=GCGUUGGATh. thermophilus UCCCAUGU-GAAAGA-CCACGG=CUCAA=CCGUGG=GGGA=GCGUGGGAE.coli UCAGAUGU-GAAAUC-CCCGGG=CUCAA=CCUGGG=AACU=GCAUCUGAAncyst.nidulans UCUGUUGU-CAAAGC-GUGGGG=CUCAA=CCUCAU=ACAG=GCAAUGGAB.subtilis UCUGAUGU-GAAAGC-CCCCGG=CUCAA=CCGGGG=AGGG=UCAUUGGAChl.aurantiacus UCGGCGCU-GAAAGC-GCCCCG=CUUAA=CGGGGC=GAGG=CGCGCCGAmatch ** *** * ** ** * **
• Hypothèse d’homologies positionnelles entre nucléotides ou AA
• Méthodes
• Manuelle (Seaview, BioEdit, Se-Al, ...)
• Automatique (ClustalX, MAFFT, POY, MUSCLE, T-Coffee, PRANK...)
• Combinaison des deux (ce qu’on fait en général)
• Alignement plus ou moins facile
• Séquence codante ou pas
• Utiliser les AA (codons) pour alignement
• Considérer les types d’AA (taille, polarité, hydrophobicité)
• On peut parfois utiliser la structure secondaire
• Séquences plus ou moins divergentes
• Homologie variable selon région
• Alignement atteint par ajout d’événements d’insertion-délétion (indels) à l’aide de gaps : limités par pénalités (sauf aux extrémités)
29
30
31
32

• But de l’alignement automatique : maximiser le score de l’alignement
• Exemple
GATTCGAATTC
On définit :Match = +1Mismatch = 0Indel = -1
Dot Plot
GATTC-GAATTCScore = 2
GA-TTCGAATTCScore = 4
1
1
-1
1
1
1
1
-1
1
1
1
1
G-ATTCGAATTCScore = 4
2 alignements optimaux
1
1
0
1
0
-1
• En plus de la pénalité d’introduction des gaps (gap opening penalty), on définit une pénalité pour l’extension des gaps (gap extension penalty), moins élevée (encourage extension, pas des trous partout)
• GOP et GEP peuvent varier le long des séquences, en fonction de la présence de gaps et de caractéristiques biochimiques (e.g. AA hydrophiles)
• On peut aussi pondérer différemment les substitutions (certaines sont plus faciles que d’autres ; e.g. pour AA : matrice BLOSUM 62)
• Problème complexe analytiquement : on ne peut garantir le “meilleur” alignement quand le nombre de séquences augmente (alignement multiple)
• Alignement progressif (e.g. Clustal)
• Calcul d’un arbre-guide basé sur un alignement par paires
• Aligne d’abord les séquences les plus proches et ainsi de suite
• Rapide mais pas de critère d’optimalité
33
34
35
36

• Alignement global ou local
• Global : considère toute la longueur des séquences. Bien si divergence faible et taille similaire
• Local : par région. Mieux si régions variables
• Hybride (semiglobal ou glocal)
• Après alignement, possibilité de sélection automatique des régions informatives, en éliminant les régions mal alignées
• GBlocks
• Choix de différents critères modifiant la stringence de la sélection
• Multiple hits
• Substitutions multiples au même site
• Affecte les sites qui évoluent rapidement
Seq 1 AGCGAGSeq 2 GCGGAC
C AC G T A
1 2 3
1
Seq 1
Seq 2
Saturation
• 3 changements visibles
• 12 changements réels
37
38
39
40
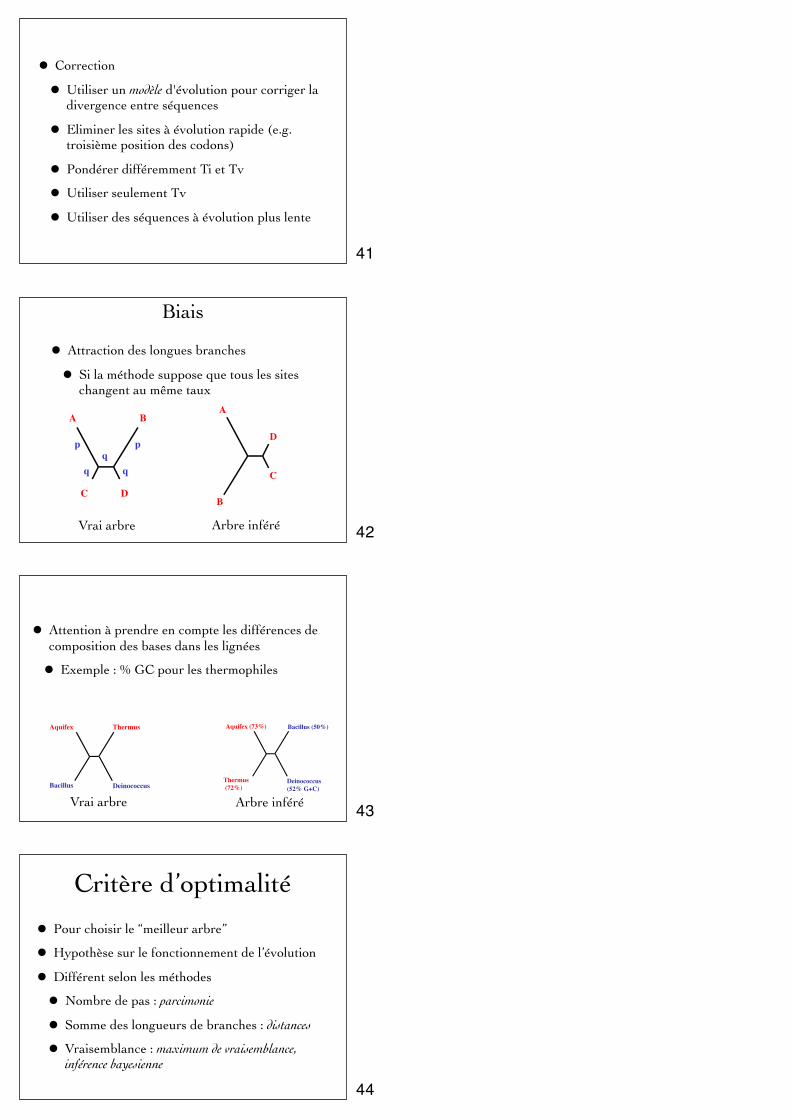
• Correction
• Utiliser un modèle d'évolution pour corriger la divergence entre séquences
• Eliminer les sites à évolution rapide (e.g. troisième position des codons)
• Pondérer différemment Ti et Tv
• Utiliser seulement Tv
• Utiliser des séquences à évolution plus lente
• Attraction des longues branches
• Si la méthode suppose que tous les sites changent au même taux
A B
C D
ppq
A
B
C
D
Vrai arbre Arbre inféré
Biais
• Attention à prendre en compte les différences de composition des bases dans les lignées
• Exemple : % GC pour les thermophiles
Aquifex Thermus
Bacillus Deinococcus
Aquifex (73%)
Thermus (72%)
Bacillus (50%)
Deinococcus(52% G+C)
Vrai arbre Arbre inféré
Critère d’optimalité
• Pour choisir le “meilleur arbre”
• Hypothèse sur le fonctionnement de l’évolution
• Différent selon les méthodes
• Nombre de pas : parcimonie
• Somme des longueurs de branches : distances
• Vraisemblance : maximum de vraisemblance, inférence bayesienne
41
42
43
44

Topologies : nombre• Nombre d’arbres non enracinés (pour n taxons)
= (2n-5)(2n-7)...(3)(1)
• Nombre d’arbres enracinés
= (2n-3)(2n-5)...(3)(1)
• Exemples
• 5 taxons : 105 arbres enracinés
• 8 taxons : 135 135
• 10 taxons : 34 459 425
• 50 taxons : 3 1074 (> atomes dans l’univers !!)
∏ (2i-5)i= 3
i= n
∏ (2i-3)i= 2
i= t
Algorithmes1. Calculer les topologies
2. Optimiser tous les caractères et calculer les longueurs
• Long si beaucoup de taxons
• Algorithmes
• Recherche exhaustive si peu de taxons (environ 10) : examine toutes les topologies
• Branch and Bound : explore une partie de l’espace des arbres, pour environ 20 taxons, efficace
• Algorithme heuristique, moins efficace, plus rapide : trouver des “bons” arbres et les réarranger
Treespace
“Treespace”
Suboptimal island oftrees
Global optimum
Starting trees
Parcimonie
45
46
47
48

Cladistique
• Deux lignées sont plus proches entre elles que d’une autre si elles partagent un ancêtre commun plus récent
• Hypothèses phylogénétiques = hypothèse d’un ancêtre commun
• Associée à reconstruction par parcimonie
• MP = Maximum de Parcimonie
Principe de parcimonie
• Favoriser la solution la plus simple
• Permet de choisir entre plusieurs hypothèses phylogénétiques
• Maximiser les congruences et minimiser les homoplasies
• Mesure de l’ajustement des caractères aux arbres
• Méthode basée sur les caractères individuels
Ajustement (fit) des caractères
• Nombre minimum de pas (passage d’un état à l’autre) requis pour expliquer la distribution observée des états de caractères
• Cela est déterminé par l’optimisation de caractères par parcimonie (mapping)
• Cette optimisation est différente sur différents arbres
• Position des changements parfois non unique pour un même arbre et un même nombre de pas : longueurs de branches pas toujours définies
Exemple
Gre
noui
lle
Cro
codi
le
Ois
eau
Kan
gour
ou
Cha
uve-
sour
is
Hum
ain
1 pas PoilsAbsentsPrésents
2 pas
Gre
noui
lle
Cro
codi
le
Ois
eau
Kan
gour
ou
Cha
uve-
sour
is
Hum
ain
49
50
51
52

Analyse par parcimonie• Pour un ensemble de caractères, détermination de
l’ajustement (nombre de pas) de chaque caractère à l’arbre
• La somme pour tous les caractères (X pondération éventuelle) est appelée la longueur de l’arbre
• Les arbres les plus parcimonieux (MPT = most parsimonious trees) sont ceux qui ont la longueur la plus petite
• Caractère informatif : au moins 2 états dans 2 taxons
• Critère d’optimalité (= fonction objective) : nombre de pas = longueur de l’arbre
• On peut obtenir un ou plusieurs MPT
• Plusieurs arbres : consensus
• Les arbres donnent en même temps des séquences (hypothèses) évolutives des caractères
• Longueurs de branches : nombre de changements. Généralement sous-estimées. Pas un but de ce type de méthode (longueurs souvent non considérées)
• Plusieurs mesures pour les arbres et les caractères estiment l’ajustement entre arbre et données : degré d’homoplasie (CI, RI, ...)
Types de caractères
• Différences des coûts pour les changements d’états
• Wagner (ordonné, additif) : morphologie
0 → 1 → 2
• Fitch (non ordonné, non additif, coûts égaux) : ADN, protéines, morphologie
A ⎯ G
T ⎯ C
53
54
55
56

• Sankoff (généralisée)
A ⎯ G 1 pas
T ⎯ C 5 pas
• Exemple typique : poids différent des transitions et des transversions
• Coûts symétriques ou asymétriques
Stepmatrices
Purines (Pu)
Pyrimidines (Py)
A G
T C
dedededede
à
A C G T
à
A 0 5 1 5
à C 5 0 5 1à
G 1 5 0 5
à
T 5 1 5 0Tra
nsve
rsio
ns (
Tv)
Py
P
u
Transitions (Ti)Py PyPu Pu Transitions plus faciles
Transversions plus nombreuses
Parcimonie - Avantages
• Simple
• Pas de modèle explicite d’évolution
• Arbre et évolution des caractères
• Bien si homoplasie rare
• Bien pour caractères morphologiques
Parcimonie - Inconvénients
• Problème si beaucoup d’homoplasies, ou concentrées dans certaines régions
• Attraction des longues branches (Felsenstein Zone)
• Sous-estime la longueur des branches
• Modèle d’évolution implicite : comportement pas toujours clair
• Justifié sur bases plus philosophiques que numériques
57
58
59
60

Maximum de vraisemblance
• Maximum Likelihood = ML
• Méthode basée sur les caractères individuels
• Utilise un modèle d’évolution explicite
• MP est parfois considéré comme un cas particulier du ML
• Méthode la plus complexe au niveau des calculs
• Très grande importance du modèle : uniquement pour données moléculaires
Principe• Répond à la question :
Quelle est la probabilité d’observer les données considérant un modèle particulier d’évolution des séquences (processus et arbre) ?
• Pr(D|T)
• Estimation de la valeur des paramètres du modèle pour maximiser cette probabilité : vraisemblance
• Dans la pratique, on cherche bien sûr l’arbre (topologie et longueurs)
• Calcul de la vraisemblance pour toutes les topologies : algorithme heuristique obligatoire
π = [A, C, G, T]
Sachant
A : AACGB : ACCGC : AACAD : AATG
A
B
C
DProbabilité de
€
a b c db a e fc e a gd c f a
⎧
⎨
⎪ ⎪
⎩
⎪ ⎪
⎫
⎬
⎪ ⎪
⎭
⎪ ⎪
A C G T
ACGT
P =
Nucléotides
61
62
63
64

Paramètres• Fréquences des bases : π
• Somme = 1
• Taux de substitution : matrice P
• Somme des lignes = 1
• Fonction des bases et du temps (branches)
• Hétérogénéité : Γ
• Arbre
• Topologie
• Longueurs de branches
π = [A, C, G, T]
€
a b c db a e fc e a gd c f a
⎧
⎨
⎪ ⎪
⎩
⎪ ⎪
⎫
⎬
⎪ ⎪
⎭
⎪ ⎪
A C G T
ACGT
P =
A
B
C
D
Hétérogénéité du taux de substitution
Paramètre : α
- élevé : taux = 1 partout- faible (0,5) : la plupart des sites changent peu- 0 : taux tous différents
En pratique, une distribution discrète avec 4 classes donne de bons résultats
• La probabilité d’observer une séquence donnée est le produit des fréquences (composition) par les taux de substitution (tenant compte de la longueur des branches)
Exemple
CCAT CCGT
Vraisemblance = πCPC→CπCPC→CπAPA→GπTPT→T
= 0.4X0.983X0.4X0.983X0.1X0.007X0.3X0.979= 0.00003
€
P =
0.976 0.01 0.007 0.0070.002 0.983 0.005 0.010.003 0.01 0.979 0.0070.002 0.013 0.005 0.979
⎧
⎨
⎪ ⎪
⎩
⎪ ⎪
⎫
⎬
⎪ ⎪
⎭
⎪ ⎪
π = [0.1, 0.4, 0.2, 0.3]
(pour une longueurde branche donnée b)
b
• La vraisemblance L change en fonction des longueurs de branches
00.000020.000040.000060.000080.0001
0.000120.000140.000160.000180.0002
0 0.1 0.2 0.3 0.4 0.5 0.6
L
Longueur de la branche b
ML pour une longueur de 0.330614
65
66
67
68

• Nombre généralement très petit : on prend le log de la vraisemblance (L)
• Nombre négatif (0<L<1)
• Il faut faire la même chose pour tout l’arbre
• Pour toutes les topologies et longueurs possibles
• Pour toutes les séquences de longueur donnée, dont les séquences aux noeuds internes
• Tout en estimant les meilleurs paramètres
• C’est très long...
• Sans compter que les changements ne se produisent généralement pas de la même façon à différents endroits de la séquence
• Contraintes de structure
• Position dans le codon
• Site actif
• etc...
• Et ce taux de changement varie en fonction du temps pour une position donnée : hétérotachie
Modèles de baseJukes-Cantor (JC)πA= πC = πG = πT
α = β
α : transitionsβ : transversions
Kimura 2 paramètres (K2P)πA= πC = πG = πT
α ≠ β
Kimura 3 paramètres (K3P)πA= πC = πG = πT
α ≠ β1 ≠ β2
Symétrique (SYM)πA= πC = πG = πT
6 taux différents
Hasegawa-Kishino-Yano 85 (HKY 85)πA≠ πC ≠ πG ≠ πT
α ≠ β
Tamura-Nei (TrN)πA≠ πC ≠ πG ≠ πT
α ≠ β1 ≠ β2General Time Reversible (GTR)
πA≠ πC ≠ πG ≠ πT
6 taux différents
Felsenstein 81 (F81)πA≠ πC ≠ πG ≠ πT
α = β
Séquences codantes
• Différentes contraintes sur différentes positions sur le codon
• Partitionner la séquence par rapport à la position sur le codon et attribuer à chaque partition un modèle et ses paramètres. Différentes possibilités
• Utiliser un codon model
• Utilisation de l’information sur le code génétique
69
70
71
72

Protéines (acides aminés)
• Modèle : probabilité de changement d’un AA en un autre (PhyML, PhyloWin, Puzzle, Phylip)
• 20 AA : beaucoup plus de possibilités que les nucléotides, estimation difficile
• Beaucoup de modèles empiriques (Dayhoff, JTT, WAG, Blosum, ...), issus de grands jeux de séquences, comparées par paires ou basés sur des arbres (par MP ou ML)
Choix du modèle• Plus un modèle comporte de paramètres
• Plus il s’ajuste aux données
• Plus le problème est long à calculer
• Plus l’estimation est incertaine (= augmentation de la variance = baisse du nombre de degrés de liberté)
• Besoin d’un compromis
• A un moment, passer au modèle plus complexe ne produit pas une amélioration significative
• Une solution : hLRT ou AIC (ModelTest, ProtTest)
• hLRT (hierarchical likelihood ratio test) : compare les modèles entre eux (doivent être emboîtés)
• AIC (Akaike information criterion) : estime l’ajustement du modèle aux données en tenant compte du nombre de paramètres
• Choisir un modèle avec AIC le plus bas
ML - Avantages• Prend en compte la saturation
• Bonnes longueurs de branches
• Consistent : si le modèle est bon, convergence vers le bon arbre quand le nombre de données augmente
• Non sujet à l’attraction des longues branches si bon modèle
• Utilise toutes les données (pas de “sites informatifs”)
• Processus d’évolution et séquences ancestrales
• Assez robuste
73
74
75
76

ML - Inconvénients
• Inconsistant si le modèle n’est pas le bon
• Même le modèle le plus complexe est une simplification de la réalité
• Encore très lourd en calculs : besoin d’heuristiques donc de compromis
Inférence Bayesienne
• Technique la plus récente, de plus en plus utilisée (MrBayes, PhyloBayes, BayesPhylogenies)
• Mêmes modèles qu’en ML (MrModelTest)
• Basée sur la notion de probabilité postérieure, qui se base sur la connaissance des données à l’avance : probabilité a priori (prior) (sujet controversé)
• Quelle est la probabilité du modèle/arbre considérant les données ?
• Pr(T|D) = (Pr(T)Pr(D|T))/Pr(D)
probabilité posterieure
prior vraisemblance probabilité des données
• La formule de Bayes combine la probabilité a priori et la vraisemblance pour générer une probabilité postérieure : prior choisi comme non informatif (e.g. plat), ainsi la probabilité postérieure (pp) dépend essentiellement de la vraisemblance
• Ne cherche pas “le” meilleur arbre (idem pour tous les paramètres), mais explore l’espace des possibilités à l’aide d’une chaîne de Markov Monte Carlo (MCMC) et échantillonne les topologies obtenues dans le plateau des choix optimaux (e.g. hautes vraisemblances pour arbres) : intervalles de confiance, quantification du support des clades (pp)
77
78
79
80

• Pas d’étape de validation nécessaire : un très grand nombre d’arbres est généré, le consensus de l’échantillon donne les probabilités d’apparition des clades (si le modèle est le bon !) : plus rapide que le ML
• Problème : utiliser des chaînes de calculs assez longues. Utilisation de plusieurs chaînes afin de mieux explorer le treespace (MCMCMC = Metropolis coupled MCMC) et éviter de rester bloqué sur des pics suboptimaux
MCLong !
Approche traditionnelle(ML, MP)
Inférence Bayesienne
Tendance à accepter les arbres avec une meilleure
probabilité postérieure
Après un délai : échantillon d’arbres
de hautes probabilités postérieures
Distances
• Estimation du nombre moyen de changements entre paires de taxons
• Basée sur distances et non caractères individuels
• Données parfois uniquement sous forme de distances (hybridation ADN/ADN, sérologie, morphométrie, ...)
• Sinon transformation des données en matrice de distance
• Surtout pour données moléculaires
81
82
83
84

• Le simple pourcentage de différences entre séquences (p-distance) sous-estime généralement la vraie distance à cause de la saturation
• D’autant plus vrai que les séquences sont éloignées
• Utilisation d’un modèle corrigeant les distances (mêmes modèles et paramètres qu’en ML : JC, K2P, GTR, ...)
• Distances de départ ≠ distances patristiques (calculées à partir de l’arbre)
• Distances de départ (pairwise distances, éventuellement avec correction par un modèle)
• Distances patristiques
• pij ≠ dij
• Principal algorithme : Neighbor-Joining (NJ)
• Arbres additifs
• Dérivés : BioNJ, ...
• Il faut un critère pour l’ajustement des données d’origine à l’arbre (topologie et longueurs)
• Minimum evolution (ME) : minimise la longueur de l’arbre
• L’algorithme ne garantit pas lui-même d’atteindre un tel critère d’optimalité, même si le NJ s’en approche : mieux d’ajouter une étape d’optimisation
• NJ : part d'un arbre en étoile et forme séquentiellement les paires qui minimisent la longueur de l'arbre (somme des longueurs de branches)
• Tend à donner l'arbre le plus court mais pas d'optimisation pendant la procédure, qui est une simple agglomération (donc très rapide)
8 7
6
5 4
1
2
3
8
7
6
5
2 3
4
1
85
86
87
88

Distances - Avantages
• Rapide : seule méthode si nombre de taxons très élevé
• Beaucoup de modèles, testables par ML
Distances - Inconvénients
• Perte d’information : impossible de revenir aux séquences avec les distances
• Pas de scénarios évolutifs des caractères
• Souvent moins efficace que ML (simulations)
Validation
• Avec n’importe quelles données, on obtient un arbre, même s’il n’y a pas de signal phylogénétique dans ces données
• Pas moyen de tester si l’arbre est “le bon” (pas d’hypothèse nulle intéressante)
• On peut néanmoins estimer la confiance qu’on peut avoir dans un arbre
• Beaucoup de méthodes basées sur la randomisation (destruction ou altération du signal phylogénétique)
• La plupart de ces méthodes sont indépendantes de la méthode de reconstruction choisie
89
90
91
92

Bootstrap (non paramétrique)• Technique de ré-échantillonnage
• Création de nouveaux jeux de données (100, 1000,...) à partir de l’original : sélection aléatoire des caractères (colonnes) avec remise (sans remise : jacknife)
• Bruit dans la structure phylogénétique = estimation de la variance de l’échantillonnage
• Inférence de l’arbre à partir de chaque jeu
• Consensus majoritaire de tous arbres obtenus
• Pourcentage d’apparition des clades = support
• Très utilisé
• Suppose l’indépendance des caractères
• Suppose qu’ils sont “identiquement distribués”
• Pas un test statistique
• Souvent trop conservateur (proportions trop faibles)
Pour résumerDonnées
ADN, AA, morphologie, ...
Arbre(s)
Caractères Distances
Modèle ?Pondérations ?
(sites, changements)
AlignementLogiciel + yeux
Qualité des donnéesSaturation, homogénéité, ...
MéthodeType de données, nombre de taxons
Critère d’optimalité
ME...Oui
NJ...Non
ValidationBootstrap, PTP, Bremer, ...
DistancesModèle ?
MPMLBI
Logiciels• Pleins !!... et souvent gratuits !
• ... mais presque tous pour des données moléculaires, et implémentant des méthodes variées (MEGA, SeaView, DAMBE, FastDNAml, PhyML, MrBayes, Tree-Puzzle, ...).
• Pour les données morphologiques (et moléculaires) : Phylip (gratuit mais pas simple), PAUP (le meilleur, mais payant) qui contient le plus de méthodes et tests en tous genres
• Nombreux logiciels pour dessiner et modifier les arbres (TreeView, TreeEdit, NJ-Plot, FigTree, TreeDyn...)
• Aussi pour consensus (RadCon, PAUP, Component, ...), superarbres (RadCon, Rainbow, Clann, SuperTree, ...)
93
94
95
96