innodb physical replication-simplify - percona · n redo log and undo log ... n create a new file...
TRANSCRIPT

zhai weixiangDatabase Engineer
RDS department, Alibaba
Physical Replication Based on InnoDB

Who Am I
Ø MynameisZhai Weixiang
Ø Database Engineer at Alibaba, since 2011n Weprovide various ofdatabase services:MySQL,MariaDB, MongoDB, PostgreSQL, Redis,etcn Eachbackedwith a kernel maintaining teamn https://www.aliyun.com/
Ø My jobn Developnew features && fix bugs && performance tuning, mainlyfocus on InnoDB
Ø You can find me vian http://bugs.mysql.com/search.php?cmd=display&status=all&reporter=5698040n Filed 100+ bug reports since 2012
n https://www.facebook.com/weixiang.zhain Email: [email protected]
2

Agenda
• BackgroundKnowledge• High Level Architecture• ReplicateChangesofServerLayer• MVCConSlave• ReplicateChangeBuffer• PlannedandUnplannedFailover• Test Results• Q/A
3

BackgroundKnowledge
4

Background: Basic Concepts
5
Ø Somebasicconceptsyoumustknowbeforethetalk:n TransactionIDn ReadViewn MinitransactionandLSNn RedologandUndologn Binarylog

Background: Lifecycle of Transaction
Example:Createtablet1(aint,bint,primarykey(a),key(b));Insertsomedata…….
Time
GlobalState:Activerw_trx ids(3,6,8)Max_trx_id:10,maxunallocatedid
(1)BEGIN;
(2)SELECT*FROMt1;
Ø Createreadview
Ø Checkifdataisvisible
Ø Startaread-only transaction
3 4 5 6 7 8 9 10low_limit_id =max_trx_id =10Up_limit_id =3Copy read-writetransactionidsarraytolocaltrx_ids set(3,6,8)
a DB_TRX_ID DB_ROLL_PTR b Visibility
1 2 2 Y trx id<up_limit_id
2 5 3 Y up_limit_id<= trx_id <low_limit_id&&Notinlocaltrx_ids set
3 6 Roll_ptr 4 N Reside intrx_ids array
4 10 Roll_ptr 5 N >= low_limit_id
UndoPage
(3,2,PTR,2)Datachangesmadebytrx 2isvisible
Ø Finish thestatement1.RC:Closethereadviewimmediately2.RR:Keepreadviewopenuntiltransactioniscommitted
6

Background: Lifecycle of Transaction
7
time
GlobalState:Activerw_trx ids(3,6,8)Max_trx_id:10
(1)BEGIN;(2)SELECT*FROMt1;
(3)UPDATEt1setb=b+1wherea=1
GlobalState:Activerw_trx ids(3,6,8,10)Max_trx_id:11
Example:Createtablet1(aint,bint,primarykey(a));Insertsomedata…….
Ø Assign aundo slotforupdate_undo;Ø Writetrx_id(10)totheundoheader
page;Ø Storetherecordintoundopage
beforechangingit;Ø Storedatachangesintoredolog
Ø Settrx toread-writemodeØ Assign trx_id 10,andadditto
globaltrx arrayØ Assign arollbacksegment

Background: Lifecycle of Transaction
8
time
(1)BEGIN;
(2)SELECT*FROMt1;
(3)UPDATEt1setb=b+1wherea=1
(4)COMMIT
Example:Createtablet1(aint,bint,primarykey(a));Insertsomedata…….
EnginePrepare:Ø Setundo stateto
TRX_UNDO_PREPARED
Binlog GroupCommit:
Ø Flush StageCollectaqueueoftransactionsifpossibleWrite/syncalllogsfrom logbufferintofileWritebinarylogintofileØ SyncStageSyncbinarylogifneededØ EngineCommitSetundo stateasCOMMITTEDReleaserecordlockRemovetrx_id fromglobalarray
Iflog-bin is disabled,andonlyone transactionalstorageengine isinvolved,aread-writetransaction only need to be committed insideengine.

Pros and Cons
Ø Prosn Binarylogismorereadablecomparingtoredologandcouldbeusedforvariousscenarios.n Replicatedatabetweendifferentstorageenginesn Canbuildaverycomplicatedreplicationtopologywithcarefuldesign
Ø Consn Needtwofsync tomaketransactiondurablen Morediskwrittenincreasesresponsetimeoftransactionn Replicationdelayn Send log to slave only after the transaction is committed on mastern Sometimes multi-thread replication doesn’t work well for DDL or big transaction
9

Why Physical Replication
Ø Betterperformance:higherthroughputandlowerresponse timen Write less data(turnoffbinarylogandgtid),and only onefsync tomake
transactiondurablen Lessrecoverytime
Ø Replicationn Lessreplicationlatencyn Ensuredataconsistency(mostimportantforsomesensitiveclients)
Ø BasedonInnoDBn InnoDB isthemost mature and general purposestorageenginen Andbeactively developed/optimizedby oracle and the community
10

High Level Architecture
11

Requirement
n Mastern Norestriction
n Slaven Onlyallowread only workloadn Supportedisolation:RepeatableRead,ReadCommitted,ReadUncommitted
n BasedonaheavilypatchedMySQL5.6n Removereadonlytransactionlist,anddon’tallocatetrx_id forreadonlytransaction.
(upstream)n Useglobaltrx_ids arraytobuildsnapshot(Percona)n AllsystemtableshavetouseInnoDBEngine;(upstream)
12

Rearrange log file layout
13
Ø Logfilecanbearchived
Ib_logfile0 Ib_logfile1 Ib_logfile2 Ib_logfile3
Ib_logfile0 Ib_logfile1Ib_logfile
N……Ib_logfile2
Ø Logfilecanbepurged
Ib_checkpoint
innodb_log_files_in_group=4
Ib_logfile0
n PURGEINNODBLOGSTO$filenamen Orautomaticallypurgedbyabackground
threadifn Not exceedthefilewherelatest
checkpointwasmadein.n Notexceedthefilewheresome
connecteddumpthreadshaven’tshipittoslave
8 bytes LOG_CHECKPOINT_NO
8bytes LOG_CHECKPOINT_LSN
4bytes LOG_CHECKPOINT_FIL_NUM
4bytes LOG_CHECKPOINT_FIL_OFFSET
n Createanewfiletostorecheckpoint information
Activelywriteto

Rearrange log file layout
14
Ib_logfile0 Ib_logfile1Ib_logfile
N……Ib_logfile2
Ø Allocatingnewfilewithout affectingperformance
Ib_checkpoint
Ib_logfile0
n Purgedfilecanbereusedtodecrease diskload ofextendingfile
Logpurgethread
LogFileAllocatethread
n LogfileAllocatethreadisresponsibleforpreparingnextlogfilen Obtainfilefromrecyclepoolandrenameitn Orcreateanewfileifthepool isempty purge
Renameandaddtopool
Purged_0
Purged_1Getpurged_0
Ib_logfileN+1Ib_logfile1
Renameto
Activelywriteto
Recycle_pool

Architecture Of Physical Replication
15Master Slave
IO_Thread
STARTINNODBSLAVE
Log_dump
Connect tomaster&&
DumpRequest(Master_uuid,Start_lsn)
Logbuffer
Ib_logfileIb_logfile
Log_apply_coordinator
SyshashUserhash
Logworker
….
Read
Send
Copy to
log_write_up_to
ReadParse&&distributevia:fold(spaceid,pageno)%(n_workers +1)
Logworker
SyshashUserhash
SyshashUserhash
Checkiftherequestisvalid
Redologofsystemtablespace
Redologofusertablespace

How do slave know it’s slave ?
Ø Requirementn Slaveshouldalwaysbeaslaveaftereveryrestarting,unlessafailoverhappensn Slaveshouldalwaysread logsfromaconsistentsource server.
Ø A servermay change among threestatesn MASTERn SLAVEn UPGRADABLE-SLAVE,middle statebetweenmasterandslave
Ø Addanewfile(innodb_repl.info)topersistthe server staten Everyfailoverisrecorded in the formatof “server_uuid,start_lsn”n server_uuid of the serverwherethelatest logisoriginallygenerated
16

17
Master
uuid=1……“1,0”“2,200”“1,300”
Server_uuid =1Innodb_repl.info
Slave
uuid=1……“1,0”“2,200”“1,300”
Server_uuid =2
Innodb_repl.info
UpgradableSlaveuuid=0
……“1,0”“2,200”
Server_uuid =3
innodb_repl.info
Equaltostoreduuid, treatitasMASTER
Notequaltostoreduuid,
treatitasSlave
aplanned failoverjusthappened andthisserverhasn’tchangeit’s stateafterserver1ispromotedtomaster
uuid=1……“1,0”“2,200”“1,300”
Slave
update
How do slave know it’s slave ?
0~200,generatedbyserver1200~300,generatedbyserver2300~,generatedbyserver1

Background threads on slave
Ø Don’tstartpurgethread anditsco-workerthreadsØ Themasterthreadisonlyresponsibleformakinglazycheckpointeveryone
secondØ dict_stats threadshouldonlybeallowedtoupdatetablestatisticsinmemoryØ Thepagecleanerthreadhastocountinthereplicationstatetodecidetorun
idletaskorbusytask
18

ReplicateChangesofServerLayer
19

Ø Problem:n ThemetadatafilesonserverlayerincludesFRM,PAR,DB.OPT,TRG,TRNanddatabase
directoryn Andoperationsonthesefilesarenotstoredinredolog
Ø Solution:n Newlyaddedlogtypes:n MLOG_METAFILE_CREATE: [FIL_NAME | CONTENT]n MLOG_METAFILE_RENAME: [ORIGINAL_NAME | TARGET_NAME]n MLOG_METAFILE_DELETE: [FIL_NAME]
n Don’treplicatetemporarytable
20
Replicate file-level operation

Replicate DDL
Ø Problemn Userclientsshouldn’taccessatablethatmetadataisbeingchangedn Andalsoneedtoinvalidsomecachedobjectsn Table define cache, table open cache, dict cache inside InnoDB
Ø Solution:Markthestartpointandendpointwhilechangingthetable’smetadata
Ø Alwayschooseuserclientasavictimifdeadlockofmdlhappens
21
WriteonMaster ReplayonSlave
MLOG_METACHANGE_BEGINAfter acquiringexclusivemdllock
AcquireMDL_EXCLUSIVElockontableandinvalidallrelevanttablecacheobjects
MLOG_METACHANGE_END BeforereleasingmdllockApply allhashed logentriesandreleaseMDLlockontable

Replicate DDL
l CREATETABLEt1(aINTPRIMARYKEY,bINT);
l ALTERTABLEt1ADDKEY(b);
Ø MLOG_METACHANGE_STARTØ MLOG_METAFILE_CREATE(test/t1.frm)Ø MLOG_METACHANGE_END
Ø PreparePhasen MLOG_METACHANGE_STARTn MLOG_METAFILE_CREATE(test/#sql-
3c36_1.frm)n MLOG_METACHANGE_END
Ø In-placebuild…slowpartofDDLØ CommitPhasen MLOG_METACHANGE_STARTn MLOG_METAFILE_RENAME(./test/#sql-
3c36_1.frmto./test/t1.frm)n MLOG_METACHANGE_END
22
Example: Redologfromserverlayer

Incomplete Log Group
Ø Problem1: MLOG_METACHANGE_ENDmaybelostifthemasteriscrashedduringexecutionofDDLn WriteaMLOG_META_RELEASElogaftercrashingrecovery,andslavewillreleaseall
acquiredmdllockswhileparsingthiskindoflog.
Ø Problem2: Parse MLOG_METACHANGE_START on slave, thenmake a checkpoint, and crash theserver ? MDL Locks must also be recovered!!!n The checkpoint LSN shouldn’texceed the oldest start point of uncompletedmetadata
changesn Collect all table names thatmetadata changes haven’t beenfinished after crash recovery
and then resurrect MDL Locks
23

Extend tablespace file
Ø Problem:n ibd/ibdata fileisphysicallyextendedwithoutwritinglog
Ø Solution:n Newlogtype:[MLOG_FILE_EXTEND|space_id |new_size]n ExtendfiletodesiredsizeifdetectingMLOG_FILE_EXTENDonslave
24

Refresh cache
25
OnMaster On Slave
Grant Privileges reload_acl_and_cache
Create/Dropprocedure sp_cache_invalidate
Update tablestatistics Add table idtorecalc_pool andwakeupdict_stats threadtoupdatethein-memory tablestatistics
n Weusenewtypesofredologtonotifyallconnectedslavesthattheyshouldupdatethecacheddatainmemory

MVCConSlave
26

The boundary of a transaction’s lifecycle
Ø ConsistentReadn Rebuildtheglobaltransactionstateonslaven Weneedtoknowstateofeachtransaction(activeorcommitted)viaredolog
Ø Addtwologtypestohelprebuildingtransactionscenariosonslaven MLOG_TRX_START:Markthestartpointofaread-writetransactionafterassigning
atrx_id,loggedinordern MLOG_TRX_COMMIT:Marktheendpointofatransactionaftermarkingundostate
ascommitted
27
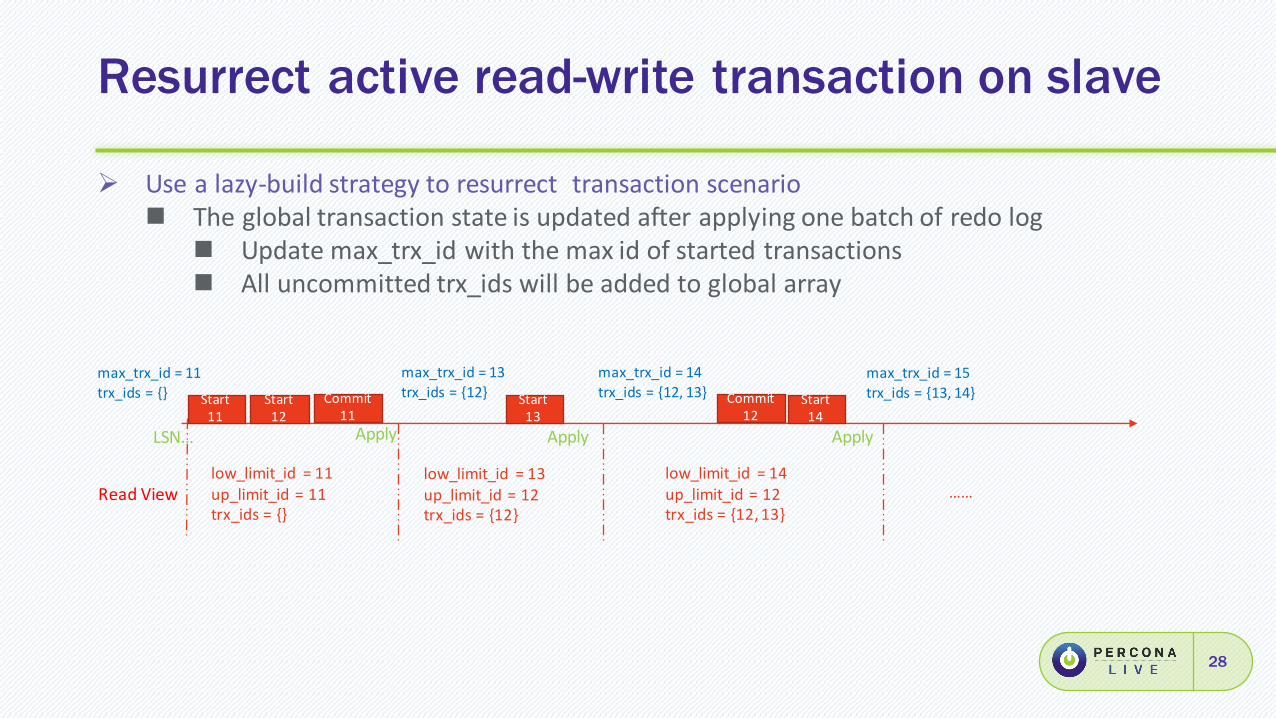
Ø Usealazy-buildstrategytoresurrecttransactionscenarion Theglobaltransactionstateisupdatedafterapplyingonebatchofredolog
n Updatemax_trx_id withthemaxidofstartedtransactionsn Alluncommittedtrx_ids willbeaddedtoglobalarray
Resurrect active read-write transaction on slave
28
LSN…
max_trx_id =13trx_ids ={12}Start
11Start12
Commit11Apply
max_trx_id =11trx_ids ={} Start
13Apply
max_trx_id =14trx_ids ={12,13} Start
14Commit
12Apply
max_trx_id =15trx_ids ={13,14}
low_limit_id =11up_limit_id =11trx_ids ={}
low_limit_id =13up_limit_id =12trx_ids ={12}
low_limit_id =14up_limit_id =12trx_ids ={12,13}
……ReadView

Purge ControlØ Problem:
n Shouldn’tpurgetheundologsthatmaybereferencedbyanactivereadview
Ø Option1:Controlpurgeprogress onslave
Ø Shortcoming:Thissolutionmayleadtoreplicationdelayiftherearelong-timerunningtransactiononslave
29
Master Slave
Ø Create areadviewfordatapurgingØ Writethereadviewintoredolog,with
newtypeMLOG_PURGE_SNAPSHOTØ Startpurging….
Ø ParseMLOG_PURGE_SNAPSHOTandbuildareadview
Ø Checkifthesnapshot overlapswithanyactivereadview,waituntilthesereadviewsareclosed.Thenupdatepurgereadviewonslave.
Ø Orupdatepurgeviewdirectlyifwaitingtoolong(configurable),anduserclientsmaygetDB_MISSING_HISTORYerrorcode.

Purge Control
Ø Option2: Control the purge progress on masterbysending feedbackataperiodicintervals(bydefault,onceevery0.5s)
30
Master Slave1 Slave2
Slave3
lowest_trx_no =3lowest_trx_no =7lowest_trx_no =6
lowest_trx_no =4
Send3Sendmin(3,7)
Send4
purge_view->low_limit_no=min(3,4,6)=3
Shortcoming: undo logmaygrowextremelylargeifthereisalongtimerunning transactioninsidethereplicationtopology
lowest_trx_no standsforthelowwatermarkbefore which undo page canbe safely truncated, and it’s not a exact number

Replicate structure change of B-TREE
Ø Problem:n It’snotsafetosearchB-treewhileits structureisbeingchanged(pagesplitor
merge)
Ø Solution:n AppendMLOG_INDEX_LOCK_ACQUIREtothelogcacheofmtr ifitholdsxlockon
indexandchangesmorethanonepagen Onslave:AcquireXlockonindex,applyingtheloggroup,andthenreleasethe
indexlock
31

ReplicateChangeBuffer
32

What’s Change buffer
Ø Changebuffer (aka,insertbuffer,oribuf forshort)isaspecialb-treethatcachemodificationsonsecondaryindexleafpageiftherequestedpagedoesn’tresideinbufferpool,inordertoreducerandomI/O
n INSERT,DELETE,DELETE-MARK
Ø Eachpageoccupies4bitsonchangebufferbitmappagetoindicateiftherearependingchanges
n IBUF_BITMAP_FREE(2bits), IBUF_BITMAP_BUFFERED(1bit), IBUF_BITMAP_IBUF(1bit)
Ø Changebufferentriesaremergedwhentherelevantindexpagesarereadfromdiskorperiodicallybymasterthread
n Change buffer Mergingcanbetriggeredbya read-onlytransaction!!!
33

Merge Change Buffer On Slave
Ø Bufferedchangesmustbemergedwithoutchanginganyphysicaldataonslave
Ø Steps:n Allocateanadditionalmemory(calledshadowpage)frombufferpool,andstoreunchanged
dataintoitbeforemergingn Mergebufferedoperationsintothepage (setmtr_t::log_mode toMTR_LOG_NONE)n Changebufferbitmappageandpagesofchangebufferb-treekeepunchangedduringthe
process
Ø Shadowpagewillbefreedwhiletheblockn Beevictedfrombufferpooln Orbeaccessedbylogapplythread
34

Merge Change Buffer On Slave
Ø Ifanewmodificationhasbeencached,buttherelevantpageisalreadyinbufferpoolonslave,thenewlybufferedchangeneedtobemerged
Ø OnMaster:n Appendanewlogentry(MLOG_IBUF_INSERT) totheminitransactionthatinsertanew
changebufferentry,anditconsistsoftherelevantsecondaryindexspaceidandpageno
Ø OnSlave:n Tag thepageifit’sinbufferpooln Ifitistouchedbyuserclientslater,restoreunmodifieddatafromshadowpage,and
remergeallbufferedchangesagain
35

Replicate Change buffer Merging
Ø Problem:Logisappliedinparallelvia(space,page),butachangebuffermergingconsistsofmultipleminitransactions
n Shouldn’t resetthecorresponding bitonbitmappagebeforemergingn Whateverchangingsecindexpagebeforedeleting changebufferentry,orinreverseorder,user
clientsmayread inconsistentdata
Ø OnMastern WriteMLOG_IBUF_MERGE_STARTbeforemergingbufferedchangesn WriteMLOG_IBUF_MERGE_ENDafterupdating changebufferbitmap
Ø OnSlaven ParseMLOG_IBUF_MERGE_START:Apply all hashed log; GettherelevantpageandXlockit;Restore
the originaldata from shadow page ifexists,andthenfreeshadowpagen ParseMLOG_IBUF_MERGE_END:Applyallhashedlogentriesandreleasexlockontheblock
36

Replicate Change buffer Merging
Ø Ifthereareconcurrentchangebuffermergingonsameindex,latchordermaybebrokenn Forexample:STARTpage1,STARTPage2,STARTPage3….Thelogapplythreadmay
acquirexlocksonPage1,2,3.n ButInnoDBonlyallowstolockleafpages fromlefttorightnode
Ø Solutionn Checkifthereareanylockedneighbornodebeforelockinganewblock; If yes,
release x lock on the block and then re-lock them in order.
37

Failover
38

39
MasterUpgradableslave
Planned Failover
Slave
Ø Step1:Demotemastertoupgradable-slaven ALTERINNODBTOSLAVE
Ø KeyAction:n Exitallactivereadwritetransactionsn Suspendorexitbackground threadsthatmay
changedatan WriteMLOG_DEMOTEn ChangeserverstatetoUpgradableSlaven Createread-blacktreewhichisusedtospeed
upinsertions intotheflush_listSlave
Ø Step2:ParseMLOG_DEMOTEonslaven ChangeserverstatetoUpgradableSlave
MLOG_PROMOTE
MLOG_PROMOTE
Upgradableslave
Upgradableslave
Allinstancesarereadyforpromoting

40
Upgradableslave
Upgradableslave
Upgradableslave
Planned Failover
Ø Step3:Pickoneinstanceandexecute:n ALTERINNODBTOMASTER
Ø KeyAction:n WritelogMLOG_PROMOTEwhichconsistsofcurrent
server’sserver_uuidn Add<serveruuid, currentlsn>toinnodb_repl.info filen Reinitializesomein-memoryobjects:purgesystem,
ibuf,max_trx_id,row_id,AUTO_INCREMENT, etc.n ChangeserverstatetoMaster
Ø Step4:ParseMLOG_PROMOTEn Changeserverstatetoslaven Add thenewfailoverrecordintolocal
innodb_repl.info file
PromoteMaster
MLOG_PROMOTE
MLOG_PROMOTE
Slave
Slave

Unplanned Failover
Ø Toreducedowntime,we have to allowa slave server to take over quickly if themaster server isfoundtobeofflineorunreachable
Ø Promoteslavetonewmastern Applyallstoredlogentriesn ALTERINNODBFORCE TOMASTERn Rollbackalluncommittedtransactionsbytraversingundoslots.
Ø Demoteoldmastertoslaven ALTERINNODBTOSLAVEn Rollbackinconsistentdataifnecessary
41

Unplanned Failover
Ø Rollbackinconsistentdataonnewmaster
42
Server1
Server1 Server2
LogonServer1
LogonServer2
Failover!!
Ø STARTINNODBRECOVERFROM$RECV_LSNn Step 1: Disable all requests from user clientsn Step2:Collectallaffected<space,page>that
needtoberecovered.ButgiveupifthereisDDLinvolved
n Step3:Getthesepagesfromserver2andtransmittoserver1vianetwork
n Step4:Overwriteallaffectedpagesonserver1n Step5:Truncateredologandmakeanew
checkpointn Step 6: Start replication and enable requests
from user clients
Recv_lsn
Server1
More Log
Enablerequests
Server2

TestResults
43

Test Results
Ø MySQLVersionn ALI_56_redo:usephysicalreplicationandlog-binisdisabledn ALI_56:aheavilypatchedMySQL,basedonupstream5.6n MySQL5629:Upstream5.6.29
Ø TestEnvironmentn Sysbench 0.5n 50tables,eachwith200,000recordsn Bufferpoolsize:16GB,8 buffer pool instance, alldatafitinmemoryn innodb_thread_concurrency= 32n Log file group is big enough, so no sharp checkpoint will happenn 2 threads per core; 6 cores per socket; 2 CPU sockets;
44

0100002000030000400005000060000700008000090000
1 4 8 16 32 64 128 256
TPS
Threads
Sync_binlog = 1Innodb_flush_log_at_trx_commit = 1
Ali56_redo Ali56 mysql5629
45
Update_non_index (TPS)

Update_non_index (RT)
46
012345678910
1 4 8 16 32 64 128 256
RT(m
s)
Threads
Sync_binlog = 1Innodb_flush_log_at_trx_commit = 1
Ali56_redo Ali56 mysql5629

Update_non_index(TPS)
47
0100002000030000400005000060000700008000090000100000
1 4 8 16 32 64 128 256
TPS
Threads
Sync_binlog = 1000Innodb_flush_log_at_trx_commit = 2
Ali56_redo Ali56 mysql5629

Update_non_index(RT)
48
012345678910
1 4 8 16 32 64 128 256
RT(m
s)
Threads
Sync_binlog = 1000Innodb_flush_log_at_trx_commit = 2
Ali56_redo Ali56 mysql5629

Conclusion
Ø Nodoubtthatyou can always gain a better performance if binary log is disabled (andoptimize group commit for writing/syncing redo)
Ø Ali56 performs better than thelatest MySQL 5.6, what’s the secret ?
Check out these reportsJhttp://bugs.mysql.com/bug.php?id=73202http://bugs.mysql.com/bug.php?id=75299http://bugs.mysql.com/bug.php?id=76686http://bugs.mysql.com/bug.php?id=76728http://bugs.mysql.com/bug.php?id=77094http://bugs.mysql.com/bug.php?id=77827http://bugs.mysql.com/bug.php?id=79005
49

ThankyouQ/A
Ifthere’snotime, please feel free to sendme your [email protected]
Join my colleague and friend Yinqiang Zhang’s talk ”20 April 01:00 PM - 01:50 PM @ Ballroom C”to learn more about how Alibaba changes MySQL to build the most powerful e-commerce system !!!!
50