input modeling aslı sencer graduate program in engineering and technology management simulation-4
TRANSCRIPT

INPUT MODELİNGAslı Sencer
Graduate Program in
Engineering and Technology Management
Simulation-4

2
STEPS OF İNPUT MODELİNG
1) Collect data from real system of interest Requires substantial time and effort Use expert opinion in case of no sufficient data
2) Identify a probability distribution to represent the input process
Draw frequency distribution, histograms Choose a family of theoretical distribution
3) Estimate the parameters of the selected distribution4) Apply goodness-of-fit tests to evaluate the chosen
distribution and the parameters Chi-square tests Kolmogorov Smirnov Tests
5) If these tests are not justified, choose a new theoretical distribution and go to step 3! If all theoretical distributions fail, then either use emprical distribution or recollect data.

3
STEP 1: DATA COLLECTİON İNCLUDES LOTS OF DİFFİCULTİES
Nonhomogeneous interarrival time distribution; distribution changes with time of the day, days of the week, etc. You can’t merge all these data for distribution fitting!
Two arrival processes might be dependent; like demand for washing machines and dryers. You shouldn’t treat them seperately!
Start and end of service durations might not be clear; You should split the service into well defined processes!
Machines may breakdown randomly; You should collect data for up and down times!

4
STEP 2.1: IDENTİFY THE PROBABİLİTY DİSTRİBUTİON
Histogram with Discrete Data
Arrivals per period Frequency
0 121 102 193 174 105 86 77 58 59 3
10 311 1
10 8 5 1 6 0 4 6 2 32 3 5 9 2 0 2 4 2 35 1 8 9 1 9 3 7 4 02 6 3 1 4 5 0 3 3 22 10 0 3 6 0 6 5 7 08 2 3 7 0 2 2 1 0 40 2 4 1 2 5 1 5 3 28 6 3 4 6 11 3 2 8 02 4 2 4 1 3 1 2 1 23 10 0 7 3 5 3 7 3 4
Raw Data
0 1 2 3 4 5 6 7 8 9 10 110
2
4
6
8
10
12
14
16
18
20
Histogram of Arrivals per Period
Frequency

5
STEP 2.1: IDENTİFY THE PROBABİLİTY DİSTRİBUTİON
3 6 9 12 15 18 21 24 27 30 33 360
5
10
15
20
25
Histogram of Component Life
Frequency
Histogram with Continuous DataComponent Life
(days) Frequency[0-3) 23[3-6) 10[6,9) 5
[9-12) 1[12-15) 1[15-18) 2[18-21) 0[21-24) 1[24-27) 1[27-30) 0[30-33) 1[33-36) 1
... ...[42-45) 1
... ...[57-60) 1
... ...[78-81) 1
... ...[144-147) 1
79.919 3.081 0.062 1.961 5.8453.027 6.505 0.021 0.013 0.1236.769 59.899 1.192 34.760 5.009
18.387 0.141 43.565 24.420 0.433144.695 2.663 17.967 0.091 9.003
0.941 0.878 3.148 2.157 7.5790.624 5.380 3.371 7.078 23.9600.590 1.928 0.300 0.002 0.5437.004 31.764 1.005 1.147 0.2193.217 14.382 1.008 2.336 4.562
Raw Data

6
STEP 2.2: SELECTİNG THE FAMİLY OF DİSTRİBUTİONS
The purpose of preparing a histogram is to infer a known pdf or pmf.
This theoretical distribution is used to generate random variables like interarrival times and service times during simulation runs.
Exponential, normal and poisson ditributions are frequently encountered and are not difficult to analyze.
Yet there are beta, gamma and weibull families that provide a wide variety of shapes.

7
Applications of Exponential Distribution
Used to model time between independent events,like arrivals or breakdowns
Inappropriate for modeling process delay times
8

9
Applications of Poisson Distribution
•Discrete distribution, used to model the number of independent events occuring per unit time, Eg. Batch sizes of customers and items
•If the time betweeen successive events is exponential,then the number of events in a fixed time intervalsis poisson.

10

11

12
Applications of Beta Distribution:
•Often used as a rough model in the absence of data•Represent random proportions•Can be transformed into scaled beta sample Y=a+(b-a)X

13

14
Applications of Erlang Distribution
•Used to represent the time required to complete a taskwhich can be reprsented as the sum of k exponentially distributed durations.
•For large k, Erlang approaches normal distribution.
•For k=1, Erlang is the exponential distribution withrate=1/β.
•Special case of gamma distribution in which α, theshape parameter of gamma distribution is k.

15
Applications of Gamma Distribution
•Used to represent time required to complete a task
•Same as Erlang distribution when the shape parameterα is an integer.

16
Applications of Johnson Dist.Flexible domain being bounded or unbounded allows it to fit many data sets.If δ>0, the domain is boundedIf δ<0, the domain is unbounded

17
Applications of Lognormal DistributionUsed to represent quantities which is the product of large number of random quantitiesUsed to represent task times which are skewed to right. If X~LOGN( ), then lnX ~NORM(μ,σ)
ll ,

18

19
Applications of Weibull Distribution
•Widely used in reliability models to represent lifetimes.
•If the system consists of large number of parts that failindependently, time between successive failures can beWeibull.
•Used to model nonnegative task times that are skewed to left.
•It turns out to be exponential distribution when =1.

20
Applications of Continuous Empirical Distribution
•Used to incorporate empirical data as an alternative totheoretical distribution, when there are multimodes,significant outliers, etc.

21
Applications of Discrete Empirical Distribution
•Used for discrete assignments such as job type, visitation sequence or batch size

22
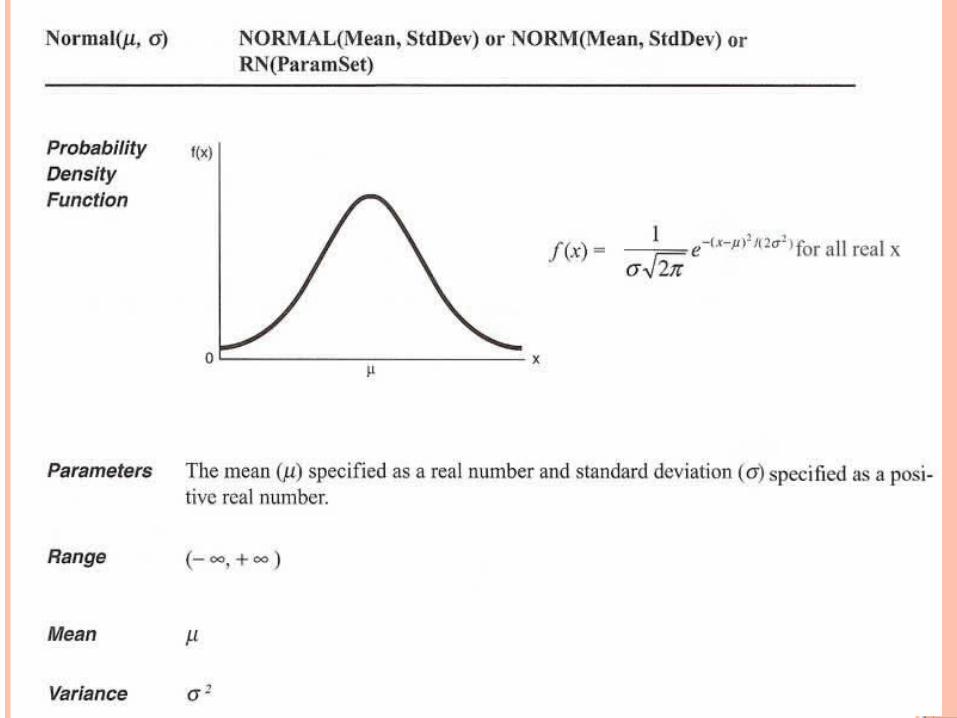
STEP 3: ESTİMATE THE PARAMETERS OF THE SELECTED DİSTRİBUTİON A theoretical distribution is specified by its parameters that
are obtained from the whole population data.Ex: Let V,W,X,Y,Z be random variables, thenV~N(µ,σ2), where µ is the mean and σ2 is the variance.W~Poisson (λ), where λ is the meanX~Exponential (β), where β is the mean Y~Triangular (a,m,b), where a, m,b are the minimum,mod and the maximum of the dataZ~Uniform (a,b), where a and b are the minimum and maximum of the data
These parameters are estimated by using the point estimators defined on the sample data

23
STEP 3: ESTİMATE THE PARAMETERS OF THE SELECTED DİSTRİBUTİON Sample mean and the sample variance are the point estimators for
the population mean and population variance
Let Xi; i=1,2,...,n iid random variables (raw data are known) , then
the sample mean and sample variance s2 are calculated as
10 8 5 1 6 0 4 6 2 32 3 5 9 2 0 2 4 2 35 1 8 9 1 9 3 7 4 02 6 3 1 4 5 0 3 3 22 10 0 3 6 0 6 5 7 08 2 3 7 0 2 2 1 0 40 2 4 1 2 5 1 5 3 28 6 3 4 6 11 3 2 8 02 4 2 4 1 3 1 2 1 23 10 0 7 3 5 3 7 3 4
Discrete Raw Data79.919 3.081 0.062 1.961 5.8453.027 6.505 0.021 0.013 0.1236.769 59.899 1.192 34.760 5.009
18.387 0.141 43.565 24.420 0.433144.695 2.663 17.967 0.091 9.003
0.941 0.878 3.148 2.157 7.5790.624 5.380 3.371 7.078 23.9600.590 1.928 0.300 0.002 0.5437.004 31.764 1.005 1.147 0.2193.217 14.382 1.008 2.336 4.562
Continuous Raw Data

24
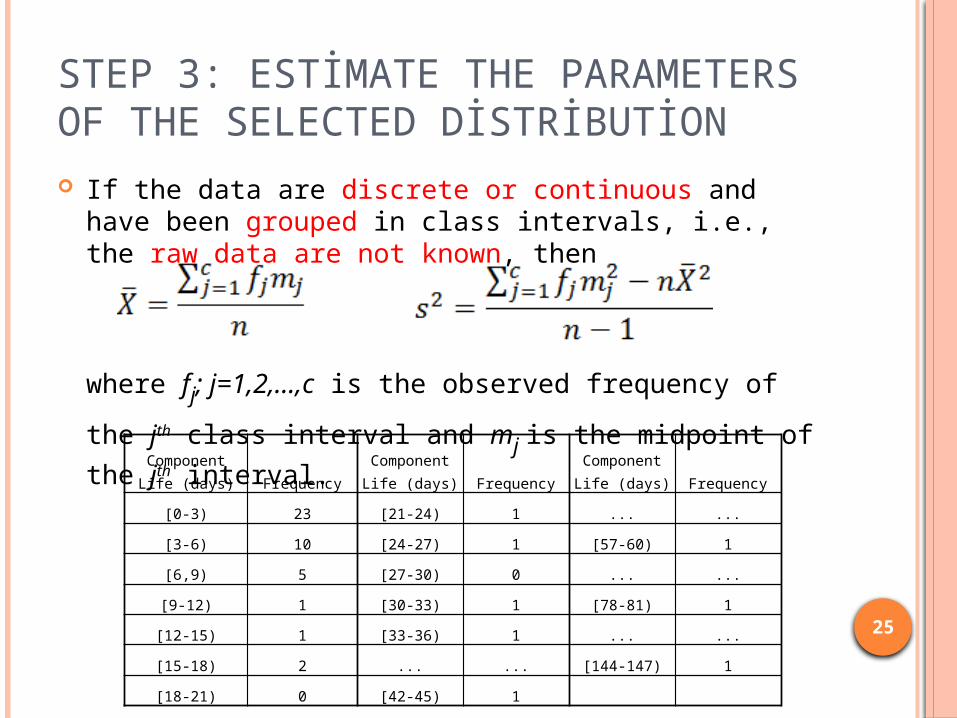
STEP 3: ESTİMATE THE PARAMETERS OF THE SELECTED DİSTRİBUTİON If the data are discrete and have been grouped in a
frequency distribution, i.e., the raw data are not known, then
where k is the number of distinct values of X and fj; j=1,2,...,k is the observed frequency of the value Xj of X.
Arrivals per period Frequency Arrivals per period Frequency
0 12 6 7
1 10 7 5
2 19 8 5
3 17 9 3
4 10 10 3
5 8 11 1
25
STEP 3: ESTİMATE THE PARAMETERS OF THE SELECTED DİSTRİBUTİON If the data are discrete or continuous and have been
grouped in class intervals, i.e., the raw data are not known, then
where fj; j=1,2,...,c is the observed frequency of the jth
class interval and mj is the midpoint of the jth interval.Component Life
(days) FrequencyComponent Life
(days) FrequencyComponent Life
(days) Frequency
[0-3) 23 [21-24) 1 ... ...
[3-6) 10 [24-27) 1 [57-60) 1
[6,9) 5 [27-30) 0 ... ...
[9-12) 1 [30-33) 1 [78-81) 1
[12-15) 1 [33-36) 1 ... ...
[15-18) 2 ... ... [144-147) 1
[18-21) 0 [42-45) 1

26
STEP 3: ESTİMATE THE PARAMETERS OF THE SELECTED DİSTRİBUTİON
The minimum, mod (i.e., data value with the highest frequency) and maximum of the population data are estimated from the sample data as
Xt is the data value that has the highest frequency.

27
STEP 4: GOODNESS OF FİT TEST
Goodness of fit tests (GFTs) provide helpful guidance for evaluating the suitability of the selected input model as a simulation input.
GFTs check the discrepancy between the emprical and the selected theoretical distribution to decide whether the sample is taken from that theoretical distribution or not.
The role of sample size, n: If n is small, GFTs are unlikely to reject any theoretical
distribution, since discrepancy is attributed to the sampling error!
If n is large, then GFTs are likely to reject almost all distributions.

28
STEP 4: GOODNESS OF FİT TESTSCHİ SQUARE TEST Chi square test is valid for large sample sizes and for both
discrete and continuous assumptions when parameters are estimated with maximum likelihood.
Hypothesis test:
Ho: The random variable X conforms to the theoretical distribution with the estimated parameters
Ha: The random variable does NOT conform to the theoretical distribution with the estimated parameters
We need a test statistic to either reject or fail to reject Ho. This test statistic should measure the discrepency between the theoretical and the emprical distribution.
If this test statistic is high, then Ho is rejected, Otherwise we fail to reject Ho! (Hence we accept Ho)

29
STEP 4: GOODNESS OF FİT TESTSCHİ SQUARE TEST
Test statistic:Arrange n observations into a set of k class intervals or cells. The test statistic is given by
where Oi is the observed frequency in the ith class interval and Ei is the expected frequency in the ith class interval.
where pi is the theoretical probability associated with the ith class, i.e., pi =P(random variable X belongs to ith class).

30
STEP 4: GOODNESS OF FİT TESTSCHİ SQUARE TEST
Recommendations for number of class intervals for continuous data
It is suggested that . In case it is smaller, then that class should be combined with the adjacent classes. Similarly the corresponding Oi values should also be combined and k should be reduced by every combined cell.
Sample Size,
n
Number of Class Intervals
k
20 Do not use chi-square test
50 5-10
100 10 to 20
>100 to n/5

31
STEP 4: GOODNESS OF FİT TESTSCHİ SQUARE TEST Evaluation
Let α =P(rejecting Ho when it is true); the significance level is 5%.
If probability of the test statistic < α, reject Ho and the distribution
otherwise, fail to reject Ho.
follows the chi-square distribution with k-s-1 degress
of freedom, where s is the number of
estimated parameters.
Reject HoFail to Reject Ho

32
CHİ-SQUARE DİSTRİBUTİON TABLE
α(k-s-1)
𝜒𝛼 ,𝑘− 𝑠− 12

33
STEP 4: GFT - CHİ SQUARE TEST EX: POİSSON DİSTRİBUTİON
Consider the discrete data we analyzed in step 2.Ho: # arrivals, X~ Poisson (λ=3.64)Ha: owλ is the mean rate of arrivals, =3.64
The following probabilities are found by using the pmf
P(0)=0.026 P(6)=0.085
P(1)=0.096 P(7)=0.044
P(2)=0.174 P(8)=0.020
P(3)=0.211 P(9)=0.008
P(4)=0.192 P(10)=0.003
P(5)=0.140 P(>11)=0.001

34
STEP 4: GFT - CHİ SQUARE TEST EX: POİSSON DİSTRİBUTİON Calculation of the chi-square test statistic with k-s-1=7-1-
1=5 degrees of freedom and α=0,05.
So, Ho is rejected!

35
STEP 4: GFT - CHİ SQUARE TEST EX: ARENA İNPUT ANALYZER
Distribution Summary
Distribution: Normal
Expression: NORM(225, 89)
Square Error: 0.037778
Chi Square Test
Number of intervals = 12
Degrees of freedom = 9
Test Statistic = 1.22e+004
Corresponding p-value < 0.005
Data Summary
Number of Data Points = 27009
Min Data Value = 1
Max Data Value = 1.88e+003
Sample Mean = 225
Sample Std Dev = 89
Histogram Summary
Histogram Range = 0.999 to 1.88e+003
Number of Intervals = 40
Fit all summaryFunction Sq Error-----------------------Normal 0.0506Gamma 0.0625Beta 0.0639Erlang 0.0673Weibull 0.079Lognormal 0.0926Exponential 0.286Triangular 0.311Uniform 0.36
Reject Normal distribution at 5% significance level!

36
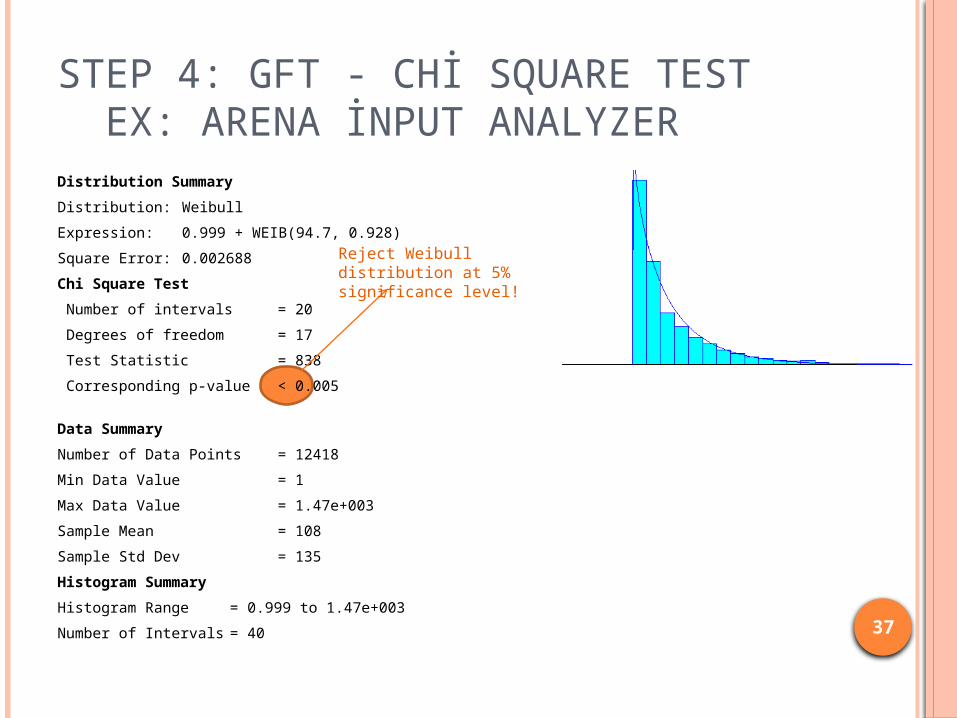
STEP 4: GFT - CHİ SQUARE TEST EX: ARENA İNPUT ANALYZERDistribution Summary
Distribution: Lognormal
Expression: 2 + LOGN(145, 67.9)
Square Error: 0.000271
Chi Square Test
Number of intervals = 4
Degrees of freedom = 1
Test Statistic = 207
Corresponding p-value < 0.005
Data Summary
Number of Data Points = 21547
Min Data Value = 2
Max Data Value = 6.01e+003
Sample Mean = 146
Sample Std Dev = 79.5
Histogram Summary
Histogram Range = 2 to 6.01e+003
Number of Intervals = 40
Reject Lognormal distribution at 5% significance level!
37
STEP 4: GFT - CHİ SQUARE TEST EX: ARENA İNPUT ANALYZERDistribution Summary
Distribution: Weibull
Expression: 0.999 + WEIB(94.7, 0.928)
Square Error: 0.002688
Chi Square Test
Number of intervals = 20
Degrees of freedom = 17
Test Statistic = 838
Corresponding p-value < 0.005
Data Summary
Number of Data Points = 12418
Min Data Value = 1
Max Data Value = 1.47e+003
Sample Mean = 108
Sample Std Dev = 135
Histogram Summary
Histogram Range = 0.999 to 1.47e+003
Number of Intervals = 40
Reject Weibull distribution at 5% significance level!

38
STEP 4: GOODNESS OF FİT TESTSDRAWBACKS OF CHİ-SQUARE GFT The Chi-square test uses the estimates of the
parameters obtained from the sample that decreases the degrees of freedom.
Chi-square test requires the data to be placed in class intervals in the continuous distributions where these classes are arbitrary and affects the value of the chi-square test statistic.
The distribution of the chi-square test statistic is known approximately and the power of the test (probability of rejecting an incorrect theoretical distribution) is sometimes low.
Hence other GFTs are also needed!

39
STEP 4: GOODNESS OF FİT TESTSKOLMOGOROV-SMİRNOV TEST
Useful when the sample sizes are small and when no parameters are estimated from the sample data.
Compares the cdf of the theoretical distribution, F(x) with the emprical cdf, SN(x) of the sample of N observations.
Hypothesis test:
Ho: Data follow the selected pdf
Ha: Data do NOT follow the selected pdf
Test Statistic:
The largest deviation, D between F(x) and SN(x).

40
STEP 4: GOODNESS OF FİT TESTSKOLMOGOROV-SMİRNOV TEST
Steps of K-S Test:
1. Rank the data so that
2. Calculate the maximum discrepancy D between F and SN,
𝑋(1) ≤ 𝑋(2) ≤ ⋯ ≤ 𝑋(𝑁)
𝐹൫𝑋(𝑖)൯= 𝑃(𝑋≤ 𝑋(𝑖))
𝑆𝑁൫𝑋(𝑖)൯= # 𝑜𝑓 𝑠𝑎𝑚𝑝𝑙𝑒𝑑 𝑟𝑎𝑛𝑑𝑜𝑚 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒𝑠≤ 𝑋(𝑖)𝑁 = 𝑖𝑁

41
STEP 4: GOODNESS OF FİT TESTSKOLMOGOROV-SMİRNOV TEST
If F is discrete , where
If F is continuous
𝐷+ = max0≤𝑖≤𝑁൛𝑆𝑁൫𝑋ሺ𝑖ሻ൯− 𝐹൫𝑋ሺ𝑖ሻ൯ൟ= max0≤𝑖≤𝑁൜𝑖𝑁− 𝐹൫𝑋ሺ𝑖ሻ൯ൠ 𝐷− = max0≤𝑖≤𝑁൛𝐹൫𝑋ሺ𝑖ሻ൯− 𝑆𝑁൫𝑋ሺ𝑖−1ሻ൯ൟ= max0≤𝑖≤𝑁൜𝐹൫𝑋ሺ𝑖ሻ൯− 𝑖 − 1𝑁 ൠ
𝐷= 𝑚𝑎𝑥ሼ𝐷+,𝐷−ሽ
𝐷= max0≤𝑖≤𝑁ห𝐹൫𝑋ሺ𝑖ሻ൯− 𝑆𝑁൫𝑋ሺ𝑖ሻ൯ห

42
STEP 4: GOODNESS OF FİT TESTSKOLMOGOROV-SMİRNOV TEST
3. Evaluation 𝐼𝑓 𝐷> 𝐷∝,𝑁,𝑡ℎ𝑒𝑛 𝑟𝑒𝑗𝑒𝑐𝑡 𝐻𝑜 𝐼𝑓 𝐷≤ 𝐷∝,𝑁,𝑡ℎ𝑒𝑛 𝑓𝑎𝑖𝑙 𝑡𝑜 𝑟𝑒𝑗𝑒𝑐𝑡 𝐻𝑜

43
STEP 4: GOODNESS OF FİT TESTSEXAMPLE: KOLMOGOROV-SMİRNOV TEST
Consider the data: 0.44, 0.81, 0.14, 0.05, 0.93
Ho: Data are uniform between (0,1)Ha: ow
i 1 2 3 4 5
0.05
0.14
0.44
0.81
0.93
0.05
0.14
0.44
0.81
0.93
0.20
0.40
0.60
0.80
1.00
0.15
0.26
0.16
- 0.07
0.05
- 0.04
0.21
0.13
𝑋ሺ𝑖ሻ
𝑆𝑁൫𝑋ሺ𝑖ሻ൯= 𝑖/𝑁
𝐹൫𝑋ሺ𝑖ሻ൯= 𝑋ሺ𝑖ሻ
𝑖/𝑁− 𝐹൫𝑋ሺ𝑖ሻ൯ 𝐹൫𝑋ሺ𝑖ሻ൯= (𝑖 − 1)/𝑁
Since D=0.26 < = 0.565
Ho is not rejected!Data are uniform between
(0,1)
𝐷0.05,5