language processing & scheduling for linux based …gtu.ac.in/uploads/synopsis - 119997493006 -...
TRANSCRIPT

Language Processing & Scheduling for Linux
based Mobile Operating System
In Regional Language
Ph.D. Synopsis
Submitted To
Gujarat Technological University
For the Degree
of
Doctor of Philosophy
In
Computer Science
Researcher
Milan Sanjaykumar Bhatt
Enrolment No: 119997493006
(Computer Science)
Supervisor
Dr. Prashant M. Dolia Associate Professor
Department of Computer Science
Maharaja Krishnakumar Sinhji Bhavnagar University
Bhavnagar

2 | P a g e
Content
1. Abstract …………………………………………………………………………………… ..3..
2. Brief description on the state of the art of the research topic …………………………….. ..3..
3. Motivation in research ……………………………………………………………………. ..4..
4. Descriptive Research ……………………………………………………………………... ..5..
5. Definition of Problem …………………………………………………………………….. ..5..
6. Objective and Scope of Work …………………………………………………………….. ..6..
7. Methodology of Research ………………………………………………………………… ..6..
8. Original Contribution by the thesis ……………………………………………………….. ..6..
9. Proposed RELAN Algorithm …………………………………………………………… ..7..
10. Result ……………………………………………………………………………………. ..13..
11. Achievements with respect to objectives ………………………………………………... ..14..
12. Conclusion ………………………………………………………………………………. ..14..
13. Copies of papers published and a list of all publications arising from the thesis ……….. ..15..
14. References ……………………………………………………………………………….. ..16..

3 | P a g e
1. ABSTRACT
An immense cultural transition and transformation is taking place today in the way of Gujarati
regional people, how to access, learn, and interact with information. The density of mobile phone
usage among the rural people has also increased noticeably. In the devices available in the market
today, there is a total absence of Gujarati language characters in the processes of booting of the
Linux based devices. The researcher has focused on the introduction of at-least minimum of one
suffix and one stem of Gujarati language displaying in booting screen while booting process in
Linux based mobile operating system. This research will, without doubt, greatly contribute to the
village people's working experiences with the mobile operating system which functions with their
own vernacular language.
2. BRIEF DESCRIPTION ON THE STATE OF THE ART OF THE RESEARCH TOPIC
The Information Technology, without doubt, has enormous power to improve how people live and
work. Thousands of tools – hardware, software, and embedded – are developed to make life of
mankind an efficient and convenient experience. A revolution is taking place today in the way of
people, how to access, learn, and interact with information in own regional language.
At the starting of the configuration of some new mobile devices, mobile operating systems give the
message to the user in English language. So, rural area people or specific domain regional
language people can’t understand English language and may not understand the different messages
properly at the starting of mobile at first time which is given by the mobile operating system. Most
people are working with the mobile technology in different way, they use the different mobile with
specific operating system like Android, Windows, Asha, and Blackberry etc. But now a day almost
booting process of operating systems are in English Language.
If this booting process is supported by the local vernacular language, this will enable the rural user
to understand and proceed with the Linux device more smoothly and friendly, as against the start-
up with the English language.
The proposed booting process and its component and its process (different messages) offers the
start-up process of the Linux based mobile device in regional language.
Researcher has also concentrated on the language processing of the system with platform for
Mobile Devices with Linux Kernel, this operating system concentrates Linux Kernel 2.6.28 and its

4 | P a g e
system calls and relates to booting processing file of the kernel on Linux based mobile with
regional language.
Therefore, further research work is required to develop more assistive system in areas like what
you see, is what you get (WYSIWYG) concept in the system, fast processing speed, as well as
language processing with regional language.
This research work focuses on the introduction of the new booting process in regional language,
and further suggests exercise on the introduction of all the application, entire operating system and
its processes in regional language.
3. MOTIVATION IN RESEARCH
The possible motives for doing research are following.
o Desire to get a research degree along with its consequential benefits;
This research has awarded the researcher with the understanding of the problem of non-
availability of regional language in mobile operating system at booting processes and there
by motivated to work upon the problem and creation of booting process in regional
language in devices.
o Desire to face the challenge in solving the unsolved problems, i.e., concern over practical
problems initiates’ research;
During this research phase, the researcher came across many problems like: now a day
mobile devices already have regional language application, but there is a total absence of
regional language in booting process. This research addresses this problem and tries to find
out possible solution for an operating system in regional languages as well as booting
processes messages for mobile devices in regional language.
o Desire to get intellectual joy of doing some creative work
In this research work, the researcher tries to make creative work i.e. a new booting
processes messages in regional language as well as all the applications in regional
language, entire operating systems and its process (different messages) in regional
language.

5 | P a g e
o Desire to be of service to society
Ultimate objective of technology is to facilitate human being. If same thought is viewed for
specific domains (replacing technology with information technology and human being with
use of the mobile), then objective would be to facilitate Indian people using the Linux
based mobile and its system. The base of the research work is to materialize the concept of
what you see is what you get in regional language.
4. DESCRIPTIVE RESEARCH
o How many users use mobile with Linux based operating system?
In current scenario there are only 0.92 % users use mobile with Linux based operating
system. (Not Android based Mobile Phone)
o How many users use regional language in Mobile devices?
Today approximately 2 % of users use regional language applications in mobile devices.
o Price of Linux based mobile phones.
Approximately 25,000 Rs. to 50,000 Rs. i.e. Costlier than Android, Windows based and
Symbian OS mobile. Whereas the Linux Operating Systems are totally free.
o How many mobile company use booting process in regional language?
Save some exceptional cases, there is no operating system that offers any regional
languages in mobile for booting process.
5. DEFINITION OF PROBLEM
Understanding a start-up information of first time of using mobile devices are available only in
English language, so regional people may not understand how to use a mobile. Interfaces for
mobile information access need to allow users flexibility in their choice of modes and interaction
style in accordance with their preferences, the task at hand, and their physical and social
environment. There are no any regional language characters to display on booting screen in Linux
based hand held devices.
So researcher found that very meagre attention has been paid to this type of problem. Facing the
challenge in solving the unsolved problem, the researcher focused on introducing a new proposed
booting process and its component and its process (different messages) given in regional language.
During this solution, many problems are there like: now a day mobile devices already have
regional language application, but there is a total absence of regional language in booting process.
This research addresses this problem and tries to find out possible solution for an operating system
in regional languages as well as booting processes messages for mobile devices in regional
language.

6 | P a g e
6. OBJECTIVE AND SCOPE OF WORK
Ultimate objective of technology is to facilitate human being. If same thought is viewed for
specific domains (replacing technology with information technology and human being with use of
the mobile), then objective would be to facilitate Indian people using the Linux based mobile and
its system. The base of the research work is to materialize the concept of what you see is what you
get in regional language.
7. METHODOLOGY OF RESEARCH
In approach, a problem is identified, and solved by using available technologies and/or extension
of technologies. This approach is problem centric. In another approach, technology is extended /
invented, which is useful in solving, completely or partially, many problems related to use of the
Linux based technology in India. This approach is technology centric.
This research work is carried out by technology centric approach, and many applications were
developed based on the outcome of the work, i.e. programming tools. The researcher developed a
brand new algorithm and terminated it as RELAN (REgional LANguage). On linking it with the
Maemo operating system’s kernel, it was tested upon the booting process with a view to getting
the desired result of getting booting messages in regional language. However, the practical
application borne garbage value. Upon this, the researcher tried to develop an alteration in RELAN
algorithm. When this modified RELAN algorithm was linked with the Maemo operating system’s
kernel and provided with the build of booting process in regional language, it yielded the desired
result.
8. ORIGINAL CONTRIBUTION BY THE THESIS
The entire work in this synopsis, as well as thesis is the original work, with research papers as the
back bone. The proposed applying algorithm has been visualized as a collection of various
modules, system calls each of which with relevant publications. The details of the associated
papers are as follows:
Paper Published:
1. Altered RELAN Algorithm to Display a Minimum of One Suffix and One Stem of Gujarati
Language in Booting Screen at Booting Process in Linux based Mobile Operating System.
IJCSN International Journal of Computer Science and Network, Volume 4, Issue 5, October
2015.

7 | P a g e
2. A Proposed to Display any One Character of Regional Language for Booting Screen of Linux
Based Mobile Operating System Using RELAN Algorithm. International Journal of Computer
Science and Technology [IJCST], IJCST Vol. 6, Issue 2, April - June 2015, pp: 314-317.
3. A Proposed RELAN Algorithm for Booting Process in Regional Language for Linux Based
Mobile Operating System. Indian journal of applied research, Vol. 5, No. 2, 2015, pp: 203-207.
4. Proposed Booting screen and Architecture in regional language for Linux based mobile devices.
International Journal of Computer Applications, NCETICT 2013, pp.: 28-33.
5. “Linux સચંાલિત Mobile માટે ગજુરાતી ભાષાનુ ં સલૂચત સ્થાપત્ય (Architecture) તથા ગજુરાતી
ભાષામા ં સલૂચત Desktop અન ે વિવિધ Software”. Shabd Braham-International Research
Journal of Indian Languages, Vol. 1, No.9, pp.: 67-73.
9. PROPOSED RELAN ALGORITHM
Step 1: Generate an object of obtain the optimal split position for each only two stem and
only one suffix Gujarati word in the word list provided for training face data input stream
and buffer_reader classes respectively ''data_input_stream', 'buff_read'.
file_writer guj_char= new File_writer(“/usr/src/linux-source—2.6.8/kernel/guj_char.c”;
buffer_writer guj_char = new buffer_writer(guj_char);
{ stem1 + suffix1, stem2 + suffix2, stem3 + suffix3, ................ , steml + suffixl }
guj_char -> guj_word [2] [N] array // separating character from text
STEP 2: Repeat Step 1 until the optimal split positions of all the words remain unchanged.
Loop { f(i) = s * log (freq(stems)) + (Lw – s) * log (freq(suffixs)) }
// s : Split position (Varies from 1 to Lw)
// Lw : Length of the Word
STEP 3: Generate signatures using the stems and suffixes generated from the training
phase.
1St Loop { // To get every character from string [ f(i) ]
2nd Loop { // To get suffix from the string [ f(i) ]
} // 2nd Loop
} // 1st Loop

8 | P a g e
STEP 4: Discard the signatures which contain either only one stem or only one suffix.
class buff_read closed
char stem;
char suffix;
write to “guj_char.c ”;
if ( guj_char==”stem”);
write to “guj_char.c ”
else if ( guj_char==”suffix”);
write to “guj_char.c ”
close();
During the RELAN phase, I try to obtain the optimal split position for each word present in the
Gujarati word list provided for training. I obtain the optimal split for only one word and only two
suffixes by taking all possible splits of the word and choosing the split which maximizes the
function given in equation as the optimal split position. The suffix corresponding to the optimal
split position is verified against the list of 59 Gujarati suffixes created by me. If it cannot be
generated by agglutination of the hand crafted suffixes, then the length of the word is chosen as the
optimal split position. i.e. the entire word is treated as a stem with no suffix.
{ stem1 + suffix1, stem2 + suffix2, stem3 + suffix3,………. stemL + suffixL }
માત ૃ= { મા + ત,ૃ મ + ાા + ત + ાૃ, માત ૃ+ NULL }
ગતા = { ગ + તા, ગ + ત + ાા, ગતા + NULL }
file_name>.c = guj_char.c
#include <linux/stdio.h>
#include <linux/linkage.h>
#include <linux/kernel.h>
#include <asm/uaccess.h>
#include <asm/locale.h>
#define MAX_BUF_SIZE 4
asmlinkage int sys_guj_char(char _ _ usr *buff, int len){
char tmp[MAX_BUF_SIZE]; // tmp buffer to copy user's string into

9 | P a g e
int guj_stem_len; // find how many stems in a string
int guj_suffix_len; // find how many suffixes in a string
a:
if ( guj_char==”stem”); then
write to “guj_char.c ”
elif ( guj_char==”suffix”); then
write to “guj_char.c ”
close(); fi
File_writer guj_char = new File_writer(“/usr/src/linux-source—2.6.8/kernel/guj_char.c”;
Buffer_writer guj_char = new buffer_writer(guj_char);
class buff_read closed
// Now Apply RELAN algorithm
char suffix;
char stem;
guj_char = { stem1 + suffix1, stem2 + suffix2, stem3 + suffix3, ................ , steml + suffixl } ;
guj_char -> guj_word [2] [N] array;
guj_char = s * log (freq(stems)) + (Lw – s) * log (freq(suffixs));
printk(KERN_EMERG “Entering guj_char(). The len is %d\n”, len);
char guj_char_list;
if (len <= 2 || (len > MAX_BUF_SIZE)); then
printk((KERN_EMERG “Entering guj_char() failed: illegal len (%d) !”, len);
return (-1);
return a; fi
// copy buff from user space into a kernel buffer
if (copy_from_user(tmp, buff, len); then
printk(KERN_EMERG “Entering guj_char() fail: copy_from_user() error”);
return (-1);
return a; fi
tmp[len] = '\0';
printk( KERN_EMERG “ guj_char() from %s. \n”, tmp);
if (!setlocale(LC_CTYPE, "")) {
fprintf(stderr, "Can't set the specified locale! " "Check LANG, LC_CTYPE, LC_ALL.\n");
return 1 }

10 | P a g e
printf("%ls\n", L "Bhatru – ascii(0AC3) ");
return 0;
return (0);
close()
}
The bootloader is the first software program that runs when a computer starts. It is responsible for
loading and transferring control to the Linux kernel. The grub.conf file is available in
/boot/grub/grub.conf.
Also the /boot/grub/grub.conf file can also be referenced via the symbolic link file named
/etc/grub.conf. In this boot loader the default font is unicode.pf2. Now set the Gujarati fonts in the
boot loader your first check the Unicode of Gujarati fonts. Gujarati Lohit font’s Unicode number is
set within 0A80 – 0AFF. There are 128 different character and suffixes.
The bootloader is the first software program that runs when a computer starts. It is responsible for
loading and transferring control to the Linux kernel.
The grub.conf file is available in /boot/grub/grub.conf. Also the /boot/grub/grub.conf file can also
be referenced via the symbolic link file named /etc/grub.conf.
Below the how to apply a proposed algorithm in particular kernel 2.6.8. The kernel in the /boot
directory is named vmlinuz-2.6.8-1.521, its RAM disk image file is named initrd-2.6.8-1.521.img,
and the root partition.
1. Configuring Kernel: Configuring the kernel with the used of terminal as a sudo or root user.
$ make gconfig: - X windows (Gtk) based configuration tool, works best under Gnome Desktop.
2. Compiling Kernel
$ make
$ make modules
$ make modules_install (check user is root or su)
3. Install Kernel
$ make install
It will install three files into /boot directory as well as modification to your kernel grub
configuration file.

11 | P a g e
1. system.map, 2.6.8 2. config-2.6.8 3. vmlinuz-2.6.8
4. Create an initrd image
$ cd /boot
$ mkinitrd -o initrd.img-2.6.8
5. Creating a Custom Kernel
In this step you can create a new system calls in under kernel.h file and this file is available in
/usr/src/linux
source—2.6.8/kernel/<file_name>.c
Now generate the simple Gujarati character with the kernel file and linkage with the <file_name>.c
with kernel.h
<file_name>.c = guj_char.c
#include <linux/linkage.h>
#include <linux/kernel.h>
#include <asm/uaccess.h>
#define MAX_BUF_SIZE 4
asmlinkage int sys_guj_char(char _ _ usr *buff, int len)
{
char tmp[MAX_BUF_SIZE]; // tmp buffer to copy user's
string into
int guj_stem_len; // find how many stems in a string
int guj_suffix_len; // find how many suffixes in a string
a:
if ( guj_char==”stem”);
write to “guj_char.c ”
else if ( guj_char==”suffix”);
write to “guj_char.c ”
close();
File_writer guj_char = new File_writer(“/usr/src/linux-source—2.6.8/kernel/guj_char.c”;
Buffer_writer guj_char = new buffer_writer(guj_char);
class buff_read closed

12 | P a g e
// Apply RELAN algorithm
guj_char = { stem1 + suffix1, stem2 + suffix2, stem3 + suffix3, ................ , steml + suffixl } ;
guj_char -> guj_word [2] [N] array;
guj_char = i * log (freq(stemi)) + (L – i) * log (freq(suffixi));
boolean suffix;
boolean stem;
printk(KERN_EMERG “Entering guj_char(). The len is %d\n”, len);
char guj_char_list;
if (len <= 2 || (len > MAX_BUF_SIZE))
{
printk((KERN_EMERG “Entering guj_char() failed: illegal len (%d) !”, len);
return (-1);
} goto (a);
// copy buff from user space into a kernel buffer
if (copy_from_user(tmp, buff, len)
{
printk(KERN_EMERG “Entering guj_char() fail: copy_from_user() error”);
return (-1);
} goto (a)
tmp[len] = '\0';
printk( KERN_EMERG “ guj_char() from %s. \n”, tmp);
return (0);
close()
}
6. Edit the Makefile to compile your new system call
Add guj_char.o to the definition of obj-y, like
obj-y = sched.o fork.o printk.o
cpu.o exit.o resource.o
guj_char.o
7. Add your system call to the unistd kernel header files by editing
/usr/src/linux-source-2.6.8/arch/x86/include/asm/unistd_32.h. and add the line:

13 | P a g e
# define _ _ NR guj_char 337 // unique system call number
8. Add your system call to the syscalls kernel header files by editing
/usr/src/linux-source-2.6.8/arch/x86/include/asm/syscalls.h. and add the lines
/* kernel/guj_char.c */
asmlinkage int sys_guj_char(char _ _ usr *buff, int len)
9. Now recompile and load your kernel
# Move to the root of the linux source code
cd /usr/src/linux-source-2.6.8
make bzImage
make install
# Move to the boot directory
cd /boot
mkinitramfs -o initrd.img-2.6.8.1-cs470p2 2.6.31.9-cs470p2
update-grub
/sbin/reboot
10. Now reboot and load new kernel for booting process in your Linux
10. RESULT (OUTPUT)
The following output is originally defining in Qt Designer with original linux kernel 2.6.8

14 | P a g e
11. ACHIEVEMENTS WITH RESPECT TO OBJECTIVES
1. The outcomes of the first phase clearly indicated that our proposed algorithm which is
applying Linux kernel 2.6.8 and displaying an ASCII code. And some time displaying an
error code which is generated by computer processor.
2. In second phase modifying algorithm applying a kernel and displaying at-least one stem
and one suffix of the Gujarati language character at the time of booting process of Maemo
Operating system in Nokia N900 device.
12. CONCLUSION
Specific domain people cannot understand English language at the time of booting process in
mobile devices. So, researcher made creative work i.e. a new booting process in regional language.
Now a day the mobile devices already have regional language application installed. But all the
operating systems offer the booting process in English language only. So, viewed in this way, the
introduction of booting process in regional language is an unsolved problem.
So during my entire research process the researcher focused to solve specific domain people can
understand at the start up (booting process) the Nokia N900 Linux mobile in regional language.
Using this entire work based on Linux operating system and MAEMO operating system which is
based on Debian series as well as kernel programming. During this work the researcher developed
RELAN Algorithm and applied to the Nokia N900 mobile device. It did not function properly and
mobile phone used to crash. Then, the researcher focused on some required modifications in
RELAN algorithm and imparted some changes in guj_char.c file.
This research work is benefiting to the specific domain people like village people who do not
understand English language. The introduction of the outcome of this research will definitely help
them understand the instruction of booting process of the mobile devices as it will be in Gujarati
language, which they understand.
The limitation of this research is that since it is pedagogical and carried out with the limited
resources and funds, it has been limited only to the introduction of two character and two suffixes.
The researcher is confident enough to work upon fully developed RELAN algorithm which might
lead to the introduction of whole setup of Gujarati language in booting process.
15 | P a g e
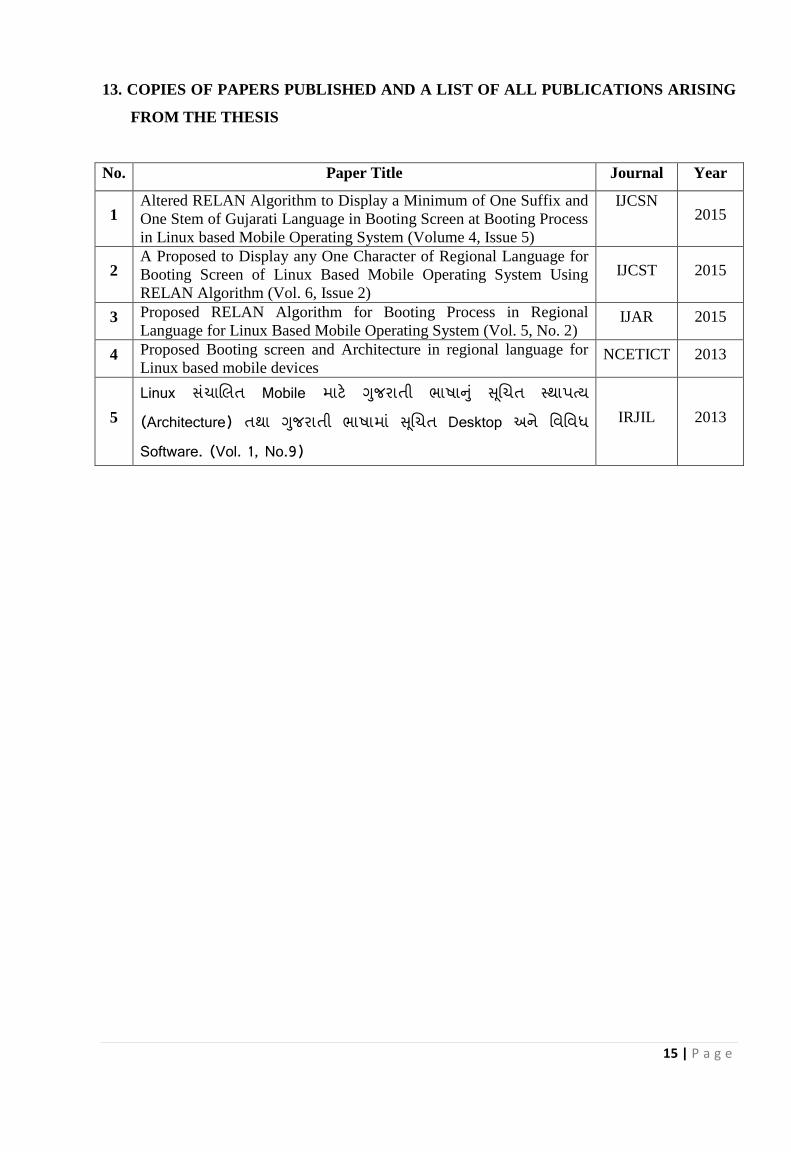
13. COPIES OF PAPERS PUBLISHED AND A LIST OF ALL PUBLICATIONS ARISING
FROM THE THESIS
No. Paper Title Journal Year
1 Altered RELAN Algorithm to Display a Minimum of One Suffix and
One Stem of Gujarati Language in Booting Screen at Booting Process
in Linux based Mobile Operating System (Volume 4, Issue 5)
IJCSN
2015
2 A Proposed to Display any One Character of Regional Language for
Booting Screen of Linux Based Mobile Operating System Using
RELAN Algorithm (Vol. 6, Issue 2)
IJCST 2015
3 Proposed RELAN Algorithm for Booting Process in Regional
Language for Linux Based Mobile Operating System (Vol. 5, No. 2) IJAR 2015
4 Proposed Booting screen and Architecture in regional language for
Linux based mobile devices NCETICT 2013
5
Linux સચંાલિત Mobile માટે ગજુરાતી ભાષાનુ ં સલૂચત સ્થાપત્ય (Architecture) તથા ગજુરાતી ભાષામા ં સલૂચત Desktop અને વિવિધ Software. (Vol. 1, No.9)
IRJIL 2013

16 | P a g e
14. REFERENCE
1. Altered RELAN Algorithm to Display a Minimum of One Suffix and One Stem of Gujarati
Language in Booting Screen at Booting Process in Linux based Mobile Operating System.
IJCSN International Journal of Computer Science and Network, Volume 4, Issue 5, October
2015 (SCOPUS Indexing)
2. A Proposed to Display any One Character of Regional Language for Booting Screen of Linux
Based Mobile Operating System Using RELAN Algorithm. International Journal of Computer
Science and Technology [IJCST], IJCST Vol. 6, Issue 2, April - June 2015, pp: 314-317.
3. A Proposed RELAN Algorithm for Booting Process in Regional Language for Linux Based
Mobile Operating System. Indian journal of applied research, Vol. 5, No. 2, 2015, pp: 203-207.
4. Proposed Booting screen and Architecture in regional language for Linux based mobile
devices. International Journal of Computer Applications, NCETICT 2013, pp.: 28-33. (Scopus
Indexing)
5. “Linux સચંાલિત Mobile માટે ગજુરાતી ભાષાનુ ં સલૂચત સ્થાપત્ય (Architecture) તથા ગજુરાતી
ભાષામા ંસલૂચત Desktop અન ેવિવિધ Software”. Shabd Braham-International Research Journal
of Indian Languages, Vol. 1, No.9, pp.: 67-73.
6. Jin Zhou, Brian Demsky, “Memory Management for Many-Core Processors with Software
Configurable Locality Policies”, International Symposium on Memory Management, 2012.
7. Vivek D., Vijay W., Helonde J., “Characterizing the Memory Management for Improving the
Performance of Embedded system used in Wireless Sensor Networks”, IJCA Proceedings on
International Conference in Computational Intelligence, 2012.
8. Raghavan S., Mooney, R. J., Ku. H, “Learning to read between the lines using Bayesian Logic
Programs”, ACL 2012.
9. Savvas G., Nicholas B., “Joint Transmitter Power Control and Mobile Cache Management in
Wireless Computing”, IEEE Transactions on Mobile Computing, Vol. 7, No. 4.
10. Prasenjit M., Madar M., Swapan P., Gobinda K., Pabitra M., Kalyankumar D., "YASS: Yet
another suffix stripper", ACM Transactions on Information Systems, Vol. 25, No. 4, pp 18-38,
2007.
11. Dagan I., Greental I., and Shnarch E., “Semantic inference at the lexical-syntactic level Bar-
aim”, 22nd AAAI Conference on Artificial Intelligence, 2007.
12. Creutz, Mathis, Krista L., “Unsupervised models for morpheme segmentation and morphology
learning. Association for Computing Machinery Transactions on Speech and Language
Processing”, 2007.
13. John G., "An algorithm for unsupervised learning of morphology", Natural Language
Engineering, Vol. 12, No. 4, pp 353-371, 2006.