lecture-7 - pennsylvania state university · the$structure$of$the$fastq$file$...
TRANSCRIPT

2012$%$BMMB$597D:$Analyzing$Next$Genera;on$Sequencing$Data$
$
$Week$4,$Lecture$7$
István'Albert'
'
Biochemistry$and$Molecular$Biology$$
and$Bioinforma;cs$Consul;ng$Center$
$
Penn$State$

Sequencing$Technologies$%$perspec;ve$
1st''genera0on:$Frederic$Sanger$develops$DNA$sequencing$technology.$Latest$versions$3$million$bases/day,$1500bp$long$reads$$
2nd'genera0on:$(next%gen)$sequencing$started$2005$with$the$release$of$the$454$sequencing$plaXorm.$600$billion$bases/week,$150bp$long$reads$
$
3rd'genera0on:$single$molecule$(no$DNA$amplifica;on$required),$these$are$not$replacing$but$augumen;ng$2nd$genera;on$systems,$longer$reads,$shorter$turnarounds$
$
$
$

Sequencing$Technology$Reviews$

Sequencing$Instruments$

NGS$sequencing$read$formats$
Reads:$$short$sequences$produced$by$the$instrument$
$
Illumina$!$FastQ$format$(.fastq$or$.fq)$
Solid$!$colorspace$fasta$(.xsq$or$.csfasta$+$.qual)$
454$$$!$standard$flowgram$format$(.sff)$

Numerical$value$of$a$character$(ord)$

Integer$value$of$$character$(chr)$

Encoding$
One$character$!$one$byte$space$ABCa$=$$4$bytes$long$
65$66$67$97$=$11$bytes$long$$
Good:'The$space$savings$are$of$about$3$;mes$Bad:'not$readable,$hinders$understanding,$different$decoding$op;ons$

Quality$Scores$
• A$quality$score$is$a$number$that$usually$has$limits,$a$low$(say$0)$to$a$high$(say$40)$
• A$quality$score$represents$an$error$probability.$
• It$characterizes$a$single$step$of$the$process$and$the$NOT$the$en;re$experimental$procedure$
• Quality$scores$are$used$to$represent$base$calling$accuracy,$alignment$accuracy$$and$other$probabili;es$

Remapping$an$encoding$• Only$some$types$of$characters$can$be$printed.$
• So$the$encoding$must$start$at$a$character$that$can$be$printed,$but$we$also$want$that$value$to$be$the$low$end$of$the$scale$=$0$
$
• Say$character$“A”$has$a$code$of$65.$If$we$choose$“A”$as$the$minimum$of$our$scale$then$$$$$$$$$$$$$$$

PHRED$Quality$Scores$
For$a$quality$score$Q$the$error$probability$is$
$
P'='10'–Q/10'$
Examples:$
$
Q'='10$!$P$=$10$–1$=$1/10$=$0.1$=$10%$
Q'='40$!$P$=$10$–4$=$1/10000$=$$0.0001$=$0.01%$
$

There$are$mul;ple$encodings$
• Illumina$used$to$switch$around$the$encoding$every$once$in$a$while.$$
• Finally$they$seiled$on$the$Sanger$for$encoding/Phred$quality$representa;on.$
• There$are$datasets/tools$out$there$with$different$encodings!$

Sanger$Encoding$(+33)$
• Quality$Value$range$between$0$and$93$$
• Start$the$scale$at$character$33$
• End$the$scale$at$character$33$+$93$=$126$
(currently$most$instruments$only$produce$quali;es$in$the$range$is$0$to$40)$

Illumina$1.3$encoding$(+64)$$(obsolete$but$s;ll$olen$observed$in$the$wild)$
• Quality$range$between$0$to$62$
• Start$scale$at$character$64$$
• End$scale$at$character$64$+$62$=$126$

Understanding$encodings$
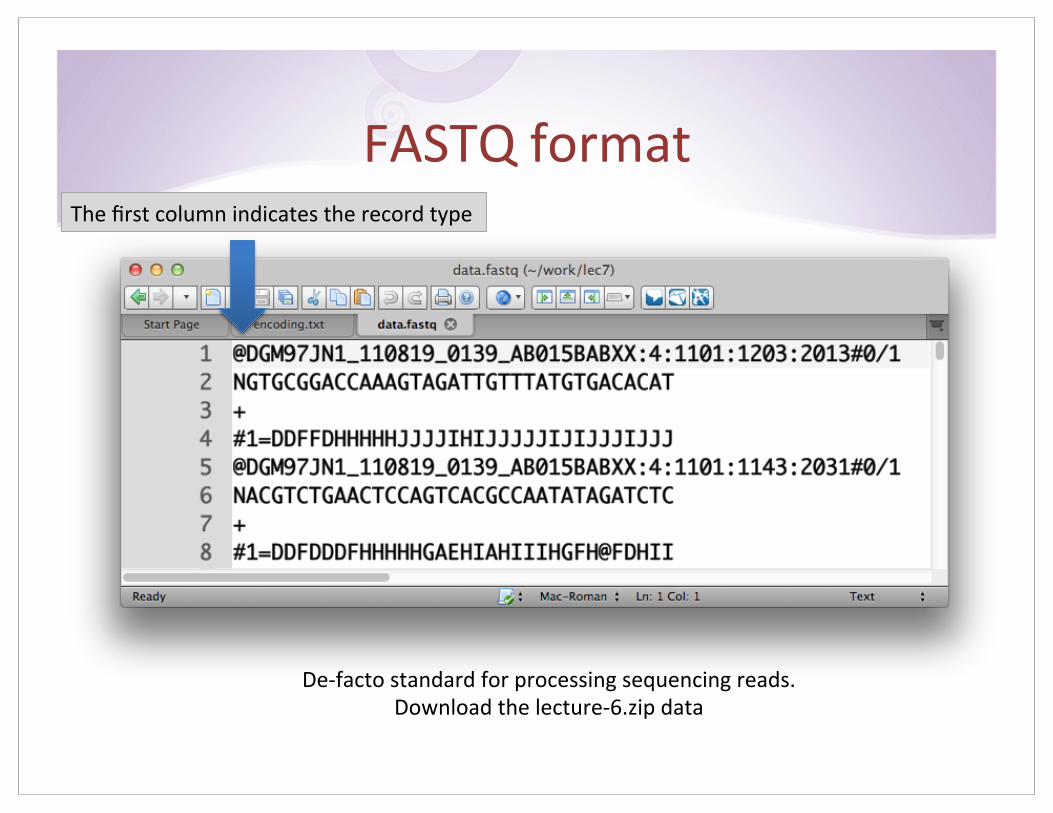
FASTQ$format$The$first$column$indicates$the$record$type$
De%facto$standard$for$processing$sequencing$reads.$$Download$the$lecture%6.zip$data$

The$structure$of$the$FASTQ$file$
Four'lines'per'FASTQ'record''
1. @$indicates$the$sequence$id$(above$is$longer$than$the$sequence$itself!)$2. the$sequence$content$of$the$read$3. $+$op;onally$repeat$the$sequence$id$(olen$lel$empty)$4. quality$string$
Paper:'The$Sanger$FASTQ$file$format$for$sequences$with$quality$scores,$$and$the$Solexa/Illumina$FASTQ$variants$%$$Nucl.&Acids&Res.&(2010)&38&(6):&176771771.&$

Other$formats$
• Some$instruments$generate$files$in$different$formats.$Occasionally$two$files:$
1. $A$sequence$file$in$FASTA$format$
2. A$FASTA$like$quality$file$that$lists$numerical$
quali;es$
Convert$them$to$FASTQ$

FASTA$and$Quality$Files$
First$step$is$to$convert$to$FASTQ$format.$

Homework$7$
• What$characters$in$the$Sanger$encoding$represent$base$calling$error$probabili;es$of:$$– 100%$$
– 0.01%$$$
– 0.001%$$
• Create$a$Sanger$encoded$FASTQ$file$that$contains$the$sequence$ATGC$and$has$the$quali;es$of$32,$51,$38$and$34'