leibniz: a digital scientific notation
TRANSCRIPT

Leibniz: A Digital Scientific Notation
Konrad HINSEN
Centre de Biophysique Moléculaire, Orléans, Franceand
Synchrotron SOLEIL, Saint Aubin, France
24 November 2016
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 1 / 38
Computational science today
B Y Z E E Y A M E R A L I
Z. Merali, Nature 467, 775 (2010)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 2 / 38

Embarassing bugs
1856
NEWS>>
THIS WEEK A dolphin’s
demise
Indians wary of
nuclear pact
1860 1863
Until recently, Geoffrey Chang’s career was ona trajectory most young scientists only dreamabout. In 1999, at the age of 28, the proteincrystallographer landed a faculty position atthe prestigious Scripps Research Institute inSan Diego, California. The next year, in a cer-emony at the White House, Chang received aPresidential Early Career Awardfor Scientists and Engineers, thecountry’s highest honor for youngresearchers. His lab generated astream of high-prof ile papersdetailing the molecular structuresof important proteins embedded incell membranes.
Then the dream turned into anightmare. In September, Swissresearchers published a paper inNature that cast serious doubt on aprotein structure Chang’s grouphad described in a 2001 Science
paper. When he investigated,Chang was horrified to discoverthat a homemade data-analysis pro-gram had flipped two columns ofdata, inverting the electron-densitymap from which his team hadderived the final protein structure.Unfortunately, his group had usedthe program to analyze data forother proteins. As a result, on page 1875,Chang and his colleagues retract three Science
papers and report that two papers in other jour-nals also contain erroneous structures.
“I’ve been devastated,” Chang says. “I hopepeople will understand that it was a mistake,and I’m very sorry for it.” Other researchersdon’t doubt that the error was unintentional,and although some say it has cost them timeand effort, many praise Chang for setting therecord straight promptly and forthrightly. “I’mvery pleased he’s done this because there hasbeen some confusion” about the original struc-tures, says Christopher Higgins, a biochemistat Imperial College London. “Now the fieldcan really move forward.”
The most influential of Chang’s retractedpublications, other researchers say, was the
2001 Science paper, which described the struc-ture of a protein called MsbA, isolated from thebacterium Escherichia coli. MsbA belongs to ahuge and ancient family of molecules that useenergy from adenosine triphosphate to trans-port molecules across cell membranes. Theseso-called ABC transporters perform many
essential biological duties and are of great clin-ical interest because of their roles in drug resist-ance. Some pump antibiotics out of bacterialcells, for example; others clear chemotherapydrugs from cancer cells. Chang’s MsbA struc-ture was the first molecular portrait of an entireABC transporter, and many researchers saw itas a major contribution toward figuring out howthese crucial proteins do their jobs. That paperalone has been cited by 364 publications,according to Google Scholar.
Two subsequent papers, both now beingretracted, describe the structure of MsbA fromother bacteria, Vibrio cholera (published inMolecular Biology in 2003) and Salmonella
typhimurium (published in Science in 2005).The other retractions, a 2004 paper in theProceedings of the National Academy of
Sciences and a 2005 Science paper, describedEmrE, a different type of transporter protein.
Crystallizing and obtaining structures offive membrane proteins in just over 5 yearswas an incredible feat, says Chang’s formerpostdoc adviser Douglas Rees of the Califor-nia Institute of Technology in Pasadena. Suchproteins are a challenge for crystallographersbecause they are large, unwieldy, and notori-ously diff icult to coax into the crystalsneeded for x-ray crystallography. Rees saysdetermination was at the root of Chang’s suc-cess: “He has an incredible drive and workethic. He really pushed the field in the sense
of getting things to crystallize thatno one else had been able to do.”Chang’s data are good, Rees says,but the faulty software threweverything off.
Ironically, another former post-doc in Rees’s lab, Kaspar Locher,exposed the mistake. In the 14 Sep-tember issue of Nature, Locher,now at the Swiss Federal Instituteof Technology in Zurich, describedthe structure of an ABC transportercalled Sav1866 from Staphylococcus
aureus. The structure was dramati-cally—and unexpectedly—differ-ent from that of MsbA. Afterpulling up Sav1866 and Chang’sMsbA from S. typhimurium on acomputer screen, Locher says herealized in minutes that the MsbAstructure was inverted. Interpretingthe “hand” of a molecule is alwaysa challenge for crystallographers,
Locher notes, and many mistakes can lead toan incorrect mirror-image structure. Gettingthe wrong hand is “in the category of monu-mental blunders,” Locher says.
On reading the Nature paper, Changquickly traced the mix-up back to the analysisprogram, which he says he inherited fromanother lab. Locher suspects that Changwould have caught the mistake if he’d takenmore time to obtain a higher resolution struc-ture. “I think he was under immense pressureto get the first structure, and that’s what madehim push the limits of his data,” he says. Oth-ers suggest that Chang might have caught theproblem if he’d paid closer attention to bio-chemical findings that didn’t jibe well with theMsbA structure. “When the first structurecame out, we and others said, ‘We really
A Scientist’s Nightmare: Software
Problem Leads to Five Retractions
SCIENTIFIC PUBLISHING
CR
ED
IT: R
. J. P.
DA
WS
ON
AN
D K
. P.
LO
CH
ER
, N
AT
UR
E4
43
, 1
80
( 2
00
6)
22 DECEMBER 2006 VOL 314 SCIENCE www.sciencemag.org
Flipping fiasco. The structures of MsbA (purple) and Sav1866 (green) overlap
little (left) until MsbA is inverted (right).
▲
Published by AAAS
on
Nov
embe
r 8, 2
016
http
://sc
ienc
e.sc
ienc
emag
.org
/D
ownl
oade
d fr
om
G. Miller, Science 314 1856 (2007)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 3 / 38

Unexpected behavior
The Effects of FreeSurfer Version, Workstation Type, andMacintosh Operating System Version on AnatomicalVolume and Cortical Thickness MeasurementsEd H. B. M. Gronenschild1,2*, Petra Habets1,2, Heidi I. L. Jacobs1,2,3, Ron Mengelers1,2, Nico Rozendaal1,2,
Jim van Os1,2,4, Machteld Marcelis1,2
1Department of Psychiatry and Neuropsychology, School for Mental Health and Neuroscience, Maastricht University Medical Center, Maastricht, Alzheimer Center
Limburg, The Netherlands, 2 European Graduate School of Neuroscience (EURON), Maastricht University, Maastricht, The Netherlands, 3Cognitive Neurology Section,
Institute of Neuroscience and Medicine-3, Research Centre Julich, Julich, Germany, 4 King’s College London, King’s Health Partners, Department of Psychosis Studies
Institute of Psychiatry, London, United Kingdom
Abstract
FreeSurfer is a popular software package to measure cortical thickness and volume of neuroanatomical structures. However,little if any is known about measurement reliability across various data processing conditions. Using a set of 30 anatomicalT1-weighted 3T MRI scans, we investigated the effects of data processing variables such as FreeSurfer version (v4.3.1, v4.5.0,and v5.0.0), workstation (Macintosh and Hewlett-Packard), and Macintosh operating system version (OSX 10.5 and OSX10.6). Significant differences were revealed between FreeSurfer version v5.0.0 and the two earlier versions. These differenceswere on average 8.866.6% (range 1.3–64.0%) (volume) and 2.861.3% (1.1–7.7%) (cortical thickness). About a factor twosmaller differences were detected between Macintosh and Hewlett-Packard workstations and between OSX 10.5 and OSX10.6. The observed differences are similar in magnitude as effect sizes reported in accuracy evaluations andneurodegenerative studies. The main conclusion is that in the context of an ongoing study, users are discouraged toupdate to a new major release of either FreeSurfer or operating system or to switch to a different type of workstationwithout repeating the analysis; results thus give a quantitative support to successive recommendations stated by FreeSurferdevelopers over the years. Moreover, in view of the large and significant cross-version differences, it is concluded thatformal assessment of the accuracy of FreeSurfer is desirable.
Citation: Gronenschild EHBM, Habets P, Jacobs HIL, Mengelers R, Rozendaal N, et al. (2012) The Effects of FreeSurfer Version, Workstation Type, and MacintoshOperating System Version on Anatomical Volume and Cortical Thickness Measurements. PLoS ONE 7(6): e38234. doi:10.1371/journal.pone.0038234
Editor: Satoru Hayasaka, Wake Forest School of Medicine, United States of America
Received January 12, 2012; Accepted May 1, 2012; Published June 1, 2012
Copyright: ! 2012 Gronenschild et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permitsunrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Funding: This work was supported by the Geestkracht program of the Dutch Health Research Council (ZON-MW, grant number 10-000-1002), and the EuropeanCommunity’s Seventh Framework Program under grant agreement No. HEALTH-F2-2009-241909 (Project EU-GEI). The funders had no role in study design, datacollection and analysis, decision to publish, or preparation of the manuscript.
Competing Interests: The authors have declared that no competing interests exist.
* E-mail: [email protected]
Introduction
FreeSurfer (Athinoula A. Martinos Center for BiomedicalImaging, Harvard-MIT, Boston) comprises a popular and freelyavailable set of tools for deriving neuroanatomical volume andcortical thickness measurements from automated brain segmenta-tion (http://surfer.nmr.mgh.harvard.edu), recently summarised byFischl [1]. A number of reported studies discussed the accuracy ofthe technique by comparing the volume of specific brainstructures, such as the hippocampus or amygdala, with manuallyderived volumes [2–5]. The measurement of cortical thickness wasvalidated against histological analysis [6] and manual measure-ments [7,8]. Also the reliability of the measurements was subject ofa number of investigations. Some of these studies addressed theeffect of scanner-specific parameters, including field strength, pulsesequence, scanner upgrade, and vendor (cortical thickness: [9,10];volume: [11]). In addition, the scan-rescan variability of a numberof subcortical brain volumes was assessed [12–14]. Finally, it hasbeen shown that Freesurfer is capable of reliably capturing (subtle)morphological and pathological changes in the brain (e.g., [5,13]).
Since FreeSurfer is CPU-intensive (20–30 hours per brain for afull segmentation is not exceptional), it is common practice todistribute the computational load among the available centralprocessor units (CPUs) on a single workstation and/or amongseveral workstations. Given this context, a number of questionssuggest themselves: (1) does every CPU produce the same results;(2) is there any interaction between the processes runningsimultaneously on the same workstation; (3) does every workstationproduce the same results?Just like similar neuroimaging packages, new releases of
FreeSurfer are issued regularly, fixing known bugs and improvingexisting tools and/or adding new ones. Each release is accompa-nied with documentation describing the changes relative to theprevious release (http://surfer.nmr.mgh.harvard.edu/fswiki/ReleaseNotes). However, transition to a new release during thecourse of a study may affect the results and is thereforediscouraged by the developers of FreeSurfer. This potential sourceof variation in outcome may invalidate comparisons betweendifferent studies. As yet, the sources and effect sizes of thesevariations have never been investigated in detail.
PLoS ONE | www.plosone.org 1 June 2012 | Volume 7 | Issue 6 | e38234
E. Gronenschild et al., PLoS ONE 7(6) e38234 (2012)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 4 / 38

Misuse of black-box software
Cluster failure: Why fMRI inferences for spatial extenthave inflated false-positive ratesAnders Eklunda,b,c,1, Thomas E. Nicholsd,e, and Hans Knutssona,c
aDivision of Medical Informatics, Department of Biomedical Engineering, Linköping University, S-581 85 Linköping, Sweden; bDivision of Statistics andMachine Learning, Department of Computer and Information Science, Linköping University, S-581 83 Linköping, Sweden; cCenter for Medical ImageScience and Visualization, Linköping University, S-581 83 Linköping, Sweden; dDepartment of Statistics, University of Warwick, Coventry CV4 7AL, UnitedKingdom; and eWMG, University of Warwick, Coventry CV4 7AL, United Kingdom
Edited by Emery N. Brown, Massachusetts General Hospital, Boston, MA, and approved May 17, 2016 (received for review February 12, 2016)
The most widely used task functional magnetic resonance imaging(fMRI) analyses use parametric statistical methods that depend on avariety of assumptions. In this work, we use real resting-state dataand a total of 3 million random task group analyses to computeempirical familywise error rates for the fMRI software packages SPM,FSL, and AFNI, as well as a nonparametric permutation method. For anominal familywise error rate of 5%, the parametric statisticalmethods are shown to be conservative for voxelwise inferenceand invalid for clusterwise inference. Our results suggest that theprincipal cause of the invalid cluster inferences is spatial autocorre-lation functions that do not follow the assumed Gaussian shape. Bycomparison, the nonparametric permutation test is found to producenominal results for voxelwise as well as clusterwise inference. Thesefindings speak to the need of validating the statistical methods beingused in the field of neuroimaging.
fMRI | statistics | false positives | cluster inference | permutation test
Since its beginning more than 20 years ago, functional magneticresonance imaging (fMRI) (1, 2) has become a popular tool
for understanding the human brain, with some 40,000 publishedpapers according to PubMed. Despite the popularity of fMRI as atool for studying brain function, the statistical methods used haverarely been validated using real data. Validations have insteadmainly been performed using simulated data (3), but it is obviouslyvery hard to simulate the complex spatiotemporal noise that arisesfrom a living human subject in an MR scanner.Through the introduction of international data-sharing initia-
tives in the neuroimaging field (4–10), it has become possible toevaluate the statistical methods using real data. Scarpazza et al.(11), for example, used freely available anatomical images from396 healthy controls (4) to investigate the validity of parametricstatistical methods for voxel-based morphometry (VBM) (12).Silver et al. (13) instead used image and genotype data from 181subjects in the Alzheimer’s Disease Neuroimaging Initiative(8, 9), to evaluate statistical methods common in imaging ge-netics. Another example of the use of open data is our previouswork (14), where a total of 1,484 resting-state fMRI datasets fromthe 1,000 Functional Connectomes Project (4) were used as nulldata for task-based, single-subject fMRI analyses with the SPMsoftware. That work found a high degree of false positives, up to70% compared with the expected 5%, likely due to a simplistictemporal autocorrelation model in SPM. It was, however, notclear whether these problems would propagate to group studies.Another unanswered question was the statistical validity of otherfMRI software packages. We address these limitations in thecurrent work with an evaluation of group inference with the threemost common fMRI software packages [SPM (15, 16), FSL (17),and AFNI (18)]. Specifically, we evaluate the packages in theirentirety, submitting the null data to the recommended suite ofpreprocessing steps integrated into each package.The main idea of this study is the same as in our previous one
(14). We analyze resting-state fMRI data with a putative taskdesign, generating results that should control the familywise error
(FWE), the chance of one or more false positives, and empiricallymeasure the FWE as the proportion of analyses that give rise toany significant results. Here, we consider both two-sample andone-sample designs. Because two groups of subjects are randomlydrawn from a large group of healthy controls, the null hypothesisof no group difference in brain activation should be true. More-over, because the resting-state fMRI data should contain noconsistent shifts in blood oxygen level-dependent (BOLD) activity,for a single group of subjects the null hypothesis of mean zeroactivation should also be true. We evaluate FWE control for bothvoxelwise inference, where significance is individually assessed ateach voxel, and clusterwise inference (19–21), where significanceis assessed on clusters formed with an arbitrary threshold.In brief, we find that all three packages have conservative
voxelwise inference and invalid clusterwise inference, for bothone- and two-sample t tests. Alarmingly, the parametric methodscan give a very high degree of false positives (up to 70%, com-pared with the nominal 5%) for clusterwise inference. By com-parison, the nonparametric permutation test (22–25) is found toproduce nominal results for both voxelwise and clusterwise in-ference for two-sample t tests, and nearly nominal results for one-sample t tests. We explore why the methods fail to appropriatelycontrol the false-positive risk.
ResultsA total of 2,880,000 random group analyses were performed tocompute the empirical false-positive rates of SPM, FSL, andAFNI; these comprise 1,000 one-sided random analyses repeatedfor 192 parameter combinations, three thresholding approaches,and five tools in the three software packages. The tested parameter
Significance
Functional MRI (fMRI) is 25 years old, yet surprisingly its mostcommon statistical methods have not been validated using realdata. Here, we used resting-state fMRI data from 499 healthycontrols to conduct 3 million task group analyses. Using this nulldata with different experimental designs, we estimate the in-cidence of significant results. In theory, we should find 5% falsepositives (for a significance threshold of 5%), but instead wefound that the most common software packages for fMRI anal-ysis (SPM, FSL, AFNI) can result in false-positive rates of up to70%. These results question the validity of some 40,000 fMRIstudies and may have a large impact on the interpretation ofneuroimaging results.
Author contributions: A.E. and T.E.N. designed research; A.E. and T.E.N. performed re-search; A.E., T.E.N., and H.K. analyzed data; and A.E., T.E.N., and H.K. wrote the paper.
The authors declare no conflict of interest.
This article is a PNAS Direct Submission.
Freely available online through the PNAS open access option.1To whom correspondence should be addressed. Email: [email protected].
This article contains supporting information online at www.pnas.org/lookup/suppl/doi:10.1073/pnas.1602413113/-/DCSupplemental.
www.pnas.org/cgi/doi/10.1073/pnas.1602413113 PNAS Early Edition | 1 of 6
NEU
ROSC
IENCE
STATIST
ICS
A. Eklund, T.E. Nichols, H. Knutsson, PNAS 113(28) 7900 (2016)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 5 / 38

Why can’t we fix this?
Insufficient software engineering
Testing numerical software is very difficult.
Most scientific software has no specification.
Most scientific software is badly documented.
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 6 / 38

Testing floating-point code
Reliable tests check for equality...
... but exact equality never happens with floats.
... but exact equality never happens with floats. Why ???
... therefore we must introduce tolerances ...
... but nobody knows how to choose them.
Full discussion:K. Hinsen, The Approximation Tower in Computational Science: Why TestingScientific Software Is Difficult, Comp. Sci. Eng. 17(4) 72-77 (2015)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 7 / 38

Specifications and documentation
Informal specifications / documentationTheory: should be published in journal articles etc.
Practice: complexity of models and methods prevents a fulldescription
Formal specificationsUnknown to most computational scientists
No domain-specific languages and tools
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 8 / 38
Climate models
66 COMPUTING IN SCIENCE & ENGINEERING
meteorological research and development (Met R&D) effort. The two groups primarily occupy a single, open-plan office space on the second floor of the Met Office’s Exeter headquarters and have built a single unified code base. This close relationship with an operational weather forecasting center is unusual for a climate mod-eling group, as is use of a unified code base. The results we present here focus primarily on cli-mate research, but our interviews—and the de-velopment practices we observed—cover both groups.
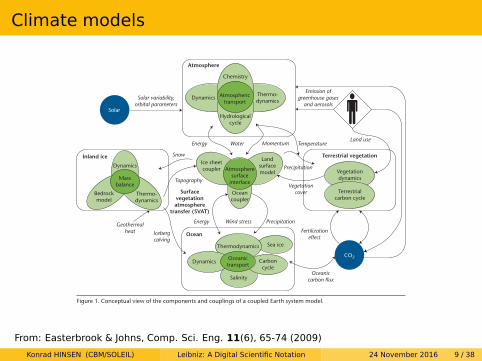
Climate Modeling BasicsClimate scientists use a range of computational models in their research. The most sophisticated are general circulation models (GCMs), which represent the atmosphere and oceans using a 3D grid and solve the equations for fluid mo-tion to calculate energy transfer between grid points. GCMs are designed so that the various subsystems (atmosphere, ocean, ice sheets, veg-etation, and so on) can run either independent-ly or coupled, with a coupler handling energy
and mass transfers between subsystems (see Figure 1). Researchers can run the models at dif-ferent resolutions, depending on the available computing power. Coarse-resolution GCMs can simulate large-scale phenomena, such as mid-latitude weather systems, while finer-resolution models are needed to simulate smaller-scale phe-nomena, such as tropical cyclones.10
Scientists make many trade-offs when build-ing climate models. It’s not computationally fea-sible to simulate all relevant climate processes (to the level they’re currently understood), so climate scientists must decide which processes to resolve explicitly and which to parameterize. They de-velop parameter schemes from observational data or from uncoupled runs of models that do resolve the phenomena. For example, they can use a sepa-rate cloud-resolving model to generate aggregate cloud formation data for use as GCM parameters. Judgment is needed to determine which processes and resolutions are relevant to a given research question.
The Earth’s climate is a complex system, ex-hibiting chaotic behavior. The models might
Figure 1. Conceptual view of the components and couplings of a coupled Earth system model.
Sea ice
Chemistry
Atmospherictransport
Dynamics
Ice sheetcoupler Atmosphere
surfaceinterface
Landsurfacemodel
Oceancoupler
Dynamics
Inland ice
Dynamics
Massbalance
Bedrockmodel
Thermo-dynamics
Surfacevegetationatmosphere
transfer (SVAT)
Ocean
Atmosphere
SolarHydrological
cycle
Thermo-dynamics
Thermodynamics
Oceanictransport
Carboncycle
Salinity
CO2
Terrestrialcarbon cycle
Vegetationdynamics
Terrestrial vegetation
From: Easterbrook & Johns, Comp. Sci. Eng. 11(6), 65-74 (2009)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 9 / 38

Protein models
A small protein (lysozyme) in the Amber99 force field
1960 atoms (1001 shown)
183 distinct atom types
interaction energy: afunction of 5880 variables,with a few thousandnumerical parameters
Remember that this is a smallprotein!
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 10 / 38

Biomolecular force fields (1/2)
This is how a typical research paper describes the AMBER force field:
U =X
bonds ij
kij⇣rij � r(0)ij
⌘2
+X
angles ijk
kijk⇣�ijk � �(0)
ijk
⌘2
+X
dihedrals ijkl
kijkl cos (nijkl✓ijkl � �ijkl)
+X
all pairs ij
4✏ij
�12ijr12
��6ijr6
!
+X
all pairs ij
qiqj4⇡✏0rij
U =X
bonds ij
kij⇣rij � r(0)ij
⌘2
+X
angles ijk
kijk⇣�ijk � �(0)
ijk
⌘2
+X
dihedrals ijkl
kijkl cos (nijkl✓ijkl � �ijkl)
+X
all pairs ij
4✏ij
�12ijr12
��6ijr6
!
+X
all pairs ij
qiqj4⇡✏0rij
missing details
not quite true common approximationsnot mentioned
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 11 / 38

Biomolecular force fields (2/2)
Protein parameter files for Amber 12, in somewhat documentedformats:
lines filename984 amino12.in814 aminoct12.in782 aminont12.in533 frcmod.ff12SB744 parm99.dat
For the details... read the source code!
For the algorithms that select the parameters for a given proteinstructure... read the source code!
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 12 / 38

Read the source code!
10 Computing in Science & Engineering 1521-9615/14/$31.00 © 2014 IEEE Copublished by the IEEE CS and the AIP May/June 2014
Streamlining Development of a Multimillion-Line Computational Chemistry Code
Robin M. Betz and Ross C. Walker | San Diego Supercomputer Center
Software engineering methodologies can be helpful in computational science and engineering projects. Here, a continuous integration software engineering strategy is applied to a multimillion-line molecular dynamics code; the implementation both streamlines the development and release process and unifies a team of widely distributed, academic developers.
The needs of computational science and en-gineering (CSE) projects greatly differ from those of more traditional business enterprise software, especially in terms of code valida-
tion and testing. Although software engineers have expended considerable effort to simplify and stream-line the development and testing process, such ap-proaches often encounter problems when applied to the scientific software domain. Testing is a notorious example of this difference between the two fields. Although business applications with a well-defined usage are easily testable, scientific applications are quite a different story. When the desired outcome of a program is an unknown subject of research, the traditional measurements of software validity used by software engineers are difficult or even impossible to define or establish. Tools designed to simplify the development process often don’t mesh readily with the goals and development timescale of CSE codes, and as a result, test suites are typically written from scratch or not at all.
CSE codes are also typically developed quite dif-ferently from other applications. Developers work-ing on scientific code usually have backgrounds that are quite different from those of software en-gineers, approaching the discipline primarily from a scientific background, and as such they’re often unfamiliar with good development practices. This is further complicated by the fact that groups are often distributed among many universities and even countries, making collaboration and group deci-sion making complicated compared to a group of software engineers working in the same office. CSE
developers are also researchers first and foremost, and their goal is primarily to generate publication-quality research, rather than develop maintainable, extensible code using the latest development meth-odologies. This frequently results in a developer cul-ture that’s resistant to change, as the time required to implement and understand a new methodology can be prohibitive in a research environment.
Although the tools and methods used in soft-ware engineering can be difficult to apply to sci-entific projects, they provide significant benefits to the development of scientific software. In this case study, we adapt the software engineering practice of continuous integration to assist in the validation and testing of the molecular dynamics code pack-age, Assisted Model Building with Energy Refine-ment (Amber; http://ambermd.org).1 Although there were several challenges in applying this meth-odology to Amber’s complex and diverse code base, the introduction of software engineering tools to Amber has proven to be extremely useful in unify-ing a geographically separated group of developers with different computer and science backgrounds, and ultimately has provided considerable benefits to the project as a whole.
BackgroundAmber is a package of molecular simulation pro-grams that’s widely used within the computational chemistry and computational molecular biology communities. It includes a wide variety of programs that enable the simulation of molecular systems at the atomic level. It includes tools for all stages of
SOFTWARE ENGINEERING FOR CSE
CISE-16-03-Betz.indd 10 28/05/14 4:50 PM
Betz & Walker, Comp. Sci. Eng. 16(3), 10-17 (2014)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 13 / 38

Can we do science with computers?
Science requires verifiability of all findings, but:
We cannot discuss computational models and methods... because we cannot write them down.
We cannot compare different models and methods... for the same reason.
We cannot test scientific software... because we have no specifications.
Users don’t understand their software... because it’s too complex ...
... and there is no specification.
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 14 / 38

Similar issues elsewhere (1/2)
Reports and Articles
Social Processes and Proofs of Theorems and Programs Richard A. De Millo Georgia Institute of Technology
Richard J. Lipton and Alan J. Perlis Yale University
It is argued that formal verifications of programs, no matter how obtained, will not play the same key role in the development of computer science and software engineering as proofs do in mathematics. Furthermore the absence of continuity, the inevitability of change, and the complexity of specification of significantly many real programs make the formal verification process difficult to justify and manage. It is felt that ease of formal verification should not dominate program language design.
Key Words and Phrases: formal mathematics, mathematical proofs, program verification, program specification
CR Categories: 2.10, 4.6, 5.24
Permission to copy without fee all or part of this material is granted provided that the copies are not made or distributed for direct commercial advantage, the ACM copyright notice and the title of the publication and its date appear, and notice is given that copying is by permission of the Association for Computing Machinery. To copy otherwise, or to republish, requires a fee and/or specific permission.
This work was supported in part by the U.S. Army Research Office on grants DAHC 04-74-G-0179 and DAAG 29-76-G-0038 and by the National Science Foundation on grant MCS 78-81486.
Authors' addresses: R.A. De Millo, Georgia Institute of Technol- ogy, Atlanta, GA 30332; A.J. Perlis and R.J. Lipton, Dept. of Computer Science, Yale University, New Haven, CT 06520. © i 979 ACM 0001-0782/79/0500-0271 $00.75.
271
I should like to ask the same question that Descartes asked. You are proposing to give a precise definition of logical correctness which is to be the same as my vague intuitive feeling for logical correctness. How do you intend to show that they are the same? ... The average mathematician should not forget that intuition is the final authority.
J. Barkley Rosser
Many people have argued that computer program- ming should strive to become more like mathematics. Maybe so, but not in the way they seem to think. The aim of program verification, an attempt to make pro- gramming more mathematics-like, is to increase dramat- ically one's confidence in the correct functioning of a piece of software, and the device that verifiers use to achieve this goal is a long chain of formal, deductive logic. In mathematics, the aim is to increase one's con- fidence in the correctness of a theorem, and it's true that one of the devices mathematicians could in theory use to achieve this goal is a long chain of formal logic. But in fact they don't. What they use is a proof, a very different animal. Nor does the proof settle the matter; contrary to what its name suggests, a proof is only one step in the direction of confidence. We believe that, in the end, it is a social process that determines whether mathematicians feel confident about a theorem--and we believe that, because no comparable social process can take place among program verifiers, program verification is bound to fail. We can't see how it's going to be able to affect anyone's confidence about programs.
Communications May 1979 of Volume 22 the ACM Number 5
Communications of the ACM, 1979
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 15 / 38
Similar issues elsewhere (2/2)4XDQWD�0DJD]LQH
KWWSV���ZZZ�TXDQWDPDJD]LQH�RUJ����������LQ�FRPSXWHUV�ZH�WUXVW� )HEUXDU\���������
,Q�&RPSXWHUV�:H�7UXVW"$V�PDWK�JURZV�HYHU�PRUH�FRPSOH[��ZLOO�FRPSXWHUV�UHLJQ"
,OOXVWUDWLRQ�E\�6LPRQV�6FLHQFH�1HZV
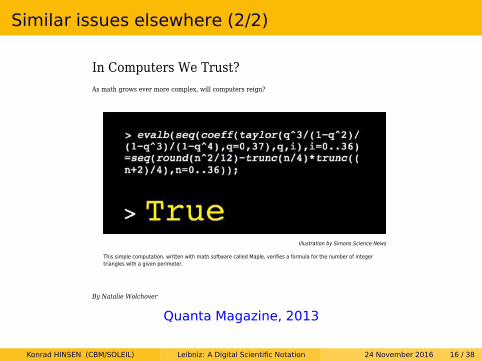
7KLV�VLPSOH�FRPSXWDWLRQ��ZULWWHQ�ZLWK�PDWK�VRIWZDUH�FDOOHG�0DSOH��YHULILHV�D�IRUPXOD�IRU�WKH�QXPEHU�RI�LQWHJHUWULDQJOHV�ZLWK�D�JLYHQ�SHULPHWHU�
%\�1DWDOLH�:ROFKRYHU
6KDORVK�%��(NKDG��WKH�FR�DXWKRU�RI�VHYHUDO�SDSHUV�LQ�UHVSHFWHG�PDWKHPDWLFV�MRXUQDOV��KDV�EHHQNQRZQ�WR�SURYH�ZLWK�D�VLQJOH��VXFFLQFW�XWWHUDQFH�WKHRUHPV�DQG�LGHQWLWLHV�WKDW�SUHYLRXVO\�UHTXLUHGSDJHV�RI�PDWKHPDWLFDO�UHDVRQLQJ��/DVW�\HDU��ZKHQ�DVNHG�WR�HYDOXDWH�D�IRUPXOD�IRU�WKH�QXPEHU�RILQWHJHU�WULDQJOHV�ZLWK�D�JLYHQ�SHULPHWHU��(NKDG�SHUIRUPHG����FDOFXODWLRQV�LQ�OHVV�WKDQ�D�VHFRQG�DQGGHOLYHUHG�WKH�YHUGLFW��e7UXH�f
6KDORVK�%��(NKDG�LV�D�FRPSXWHU��2U��UDWKHU��LW�LV�DQ\�RI�D�URWDWLQJ�FDVW�RI�FRPSXWHUV�XVHG�E\�WKHPDWKHPDWLFLDQ�'RURQ�=HLOEHUJHU��IURP�WKH�'HOO�LQ�KLV�1HZ�-HUVH\�RIILFH�WR�D�VXSHUFRPSXWHU�ZKRVHVHUYLFHV�KH�RFFDVLRQDOO\�HQOLVWV�LQ�$XVWULD��7KH�QDPH�b�+HEUHZ�IRU�eWKUHH�%�RQHf�b�UHIHUV�WR�WKH$77��%���(NKDGdV�HDUOLHVW�LQFDUQDWLRQ�
e7KH�VRXO�LV�WKH�VRIWZDUH�f�VDLG�=HLOEHUJHU��ZKR�ZULWHV�KLV�RZQ�FRGH�XVLQJ�D�SRSXODU�PDWKSURJUDPPLQJ�WRRO�FDOOHG�0DSOH�
Quanta Magazine, 2013
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 16 / 38

Digital Scientific Notations
Informal language programming language
DigitalScientificNotation
formal
embedded intoscholarly discourse
automated(partial) validation
verifiable byhuman readers
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 17 / 38

Full story
K. Hinsen, The Self-Journal of Science, 2016
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 18 / 38

Commented summary
630 NATURE PHYSICS | VOL 12 | JULY 2016 | www.nature.com/naturephysics
thesis
Digital scienceTechnology is transforming science. We can calculate faster than ever before, and gather more precise data, of an ever-expanding variety. We now store staggering volumes of information, and draw on it ever more creatively. Communication between scientists is changing too, even if the scientific paper still remains the standard element of information transfer and recording. The web, e-mail and blogs, as well as social media including Facebook and Twitter, have completely altered how we exchange thoughts.
The standard scientific paper increasingly offers only a limited glimpse of today’s scientific process. After all, computer software of innumerable kinds has established itself implicitly within the fabric of scientific practice — in the structuring of databases, and in computer algorithms used to process such data, or to carry out mathematical analyses. How the intricate details of software and algorithms influence results isn’t always clear.
Indeed, one might worry that the standards of science are quietly being eroded. Can we trust the results of a new paper if they depend on calculations carried out by proprietary software with non-public source code? Just recently, mathematicians reported the proof of a long-standing conjecture — the Boolean Pythagorean triples problem. The proof resides in some 200 terabytes of computer-generated output. If only computers running other algorithms can check the result, how can we really know it’s all ok?
These issues have been raised recently by biophysicist Konrad Hinsen (preprint at https://arxiv.org/abs/1605.02960; 2016), who has drawn motivation from years of relying on software to run biomolecular simulations. As he points out, computing applications have become so utterly familiar to all of us that we treat them as practical tools not requiring further analysis. We see tools for integrating, simulating, sorting and transforming as the equivalent of forks, spoons and other tableware; as unquestioned things to be used and judged only by their capacity to produce results.
Yet beyond results, science aims to record the process of logic and argument that leads to a deduction or interpretation. Scientists judging work need to scrutinize the path leading to results. An experiment, for example, only leads to new understanding if we understand all the details of how the
apparatus was set up and used; we accept theoretical arguments only if each step is made explicit. Likewise, Hinsen argues, trusting the results of any calculation run on scientific software requires full understanding of the functioning of that software. Unfortunately, most software used today never gets any peer review.
Hinsen offers an illustration of the problem. Consider using Newton’s equations to calculate the celestial mechanics of planets and predict their future trajectories. The scientific knowledge relevant to the problem is embodied in Newton’s laws of motion and gravitation, the mathematics of calculus, as well as a considerable body of astronomical observation and experimental knowledge (on telescopes and the interpretation of their output, for example) that yields accurate initial conditions for the bodies in question at some moment. The calculation of future motion can then be carried forward, in principle using only pencil and paper.
In practice, we use computers, as otherwise we could calculate little of practical interest. This introduces another layer of required specification, for the numerical algorithm used to approximate the continuous dynamical equations with finite difference analogues, as well as for the software that determines how real numbers get approximated by floating point operations. Calculations relying on software need to be explicit on such details if they are to fully describe the pathway to a set of results, so other scientists can reproduce them. Today, this is often — probably even typically — not the case. Our casual familiarity with software is partially to blame.
But the nature of software, Hinsen argues, makes the problem worse. The programming languages behind it all aren’t anything like human languages, and only permit writing instructions for a computer, and nothing else. This disrupts the ordinary process by which scientists record what they’re doing in a way that can be easily understood by others, as anything scientific has to be
reduced to numerics. The result is a series of diabolical tendencies all too familiar to computational scientists. As he notes, scientists can develop software using the best practices of software engineering and the result may still compute something different from what its users think it computes. Of course, concerned users can in principle consult the documentation, but how do they know that documentation is complete and accurate?
All of this would be avoided if computing source code were intelligible to human readers, but that’s very far from the case. At the moment, Hinsen suggests, “most scientific software source code is unintelligible to its users, and sometimes it even becomes unintelligible to its developers over time.”
Hinsen got concerned about the issue after having to abandon a research project when he could not reproduce the most important prior work on the topic, which relied on software that no longer existed. He wrote his own software, obtained very different results, yet couldn’t explore where the differences might come from. He couldn’t publish on the topic, given the lack of real information to make any comparisons.
What’s the solution? Hinsen doesn’t offer any specific solution, but merely raises the question and outlines possible routes to better practice. At the moment, many people don’t even realize that there is a problem. It can be solved, he suggests, if scientists relying on computation — and this is increasingly just about everyone — take the issue seriously. Yet it will require insight from computer science itself to find the right techniques. Hinsen has started an open science project in the hope of finding collaborators to start working toward better practices (see https://www.guaana.com/ projects/scientific-notations-for-the-digital-era).
Scientists haven’t learned yet that software represents more than just tools for doing things; it’s part of the precious repository of knowledge. It’s currently being built up out of language that the majority of human scientists can’t read or understand, and this is a big problem, even if it is largely invisible. There’s no guarantee that the cumulative and self-correcting history of science will automatically continue. ❐
MARK BUCHANAN
Computer software of innumerable kinds has established itself implicitly within the fabric of scientific practice.
M. Buchanan, Nature Physics 12 630 (2016)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 19 / 38

Leibniz - a digital notation for the physical sciences
My first attempt at a Digital Scientific Notation
Still in a very early stage
Any feedback welcome:Open Science project on Digital Scientific Notations in generalLeibniz on GitHub
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 20 / 38

Gottfried Wilhelm Leibniz (1646-1716)
Leibniz attributed all his discov-eries in mathematics to the de-velopment and use of good no-tations.
Ideas most relevant to DigitalScientific Notations:
Leibniz’s notation incalculus: dy/dx,
Retc.
Calculus ratiocinator:computing, formal logic,etc.
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 21 / 38
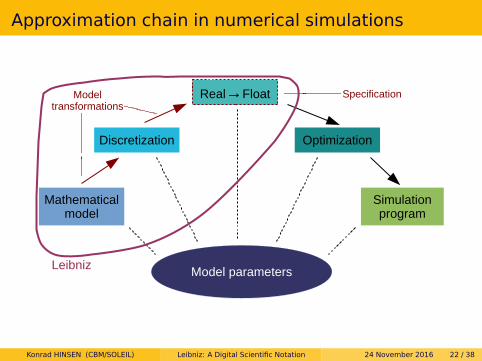
Approximation chain in numerical simulations
Mathematicalmodel
Simulationprogram
Discretization
Real→Float
Optimization
Model parameters
Modeltransformations
Specification
Leibniz
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 22 / 38

Leibniz syntax
<context id="point-kinematics"><sorts><sort id="point_system" /><sort id="velocities" /><sort id="a_trajectory" /><sort id="positions" /><sort id="velocity" /><sort id="position" /><sort id="v_trajectory" /><sort id="accelerations" /><sort id="acceleration" /><sort id="trajectory" /><sort id="point" /><sort id="time" />
</ sorts><subsorts><subsort sort="point" sort="point_system" />
</ subsorts><ops><op id="at">
<arity><sort id="a_trajectory" /><sort id="time" />
</ ar i ty><sort id="accelerations" />
</op>
. . .
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 23 / 38

Software tools around Leibniz
Leibniz
Authoringtools
Manipulationtools
Numericaltools
Visualizationtools
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 24 / 38

Leibniz authoring environment (just a demo for now)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 25 / 38

Output for human readers
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 26 / 38

“Development” syntax (works now)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 27 / 38

Leibniz in a nutshell
An algebraic specification language
based on equational logic
... and term rewriting
Today, Leibniz is a subset of Maude with different syntax.
In the future, Leibniz will further diverge from Maude.
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 28 / 38

Order-sorted term algebra
A Leibniz term is either a standard term or a special term.
A standard term has the form op(arg1 arg2 . . .),or just op for zero arguments.
Special terms are integers, rationals, and floats.
Each term has an associated sort.
Sorts have a partial order, defined by subsort relations.
Subsort relations form a directed acyclic graph.
The connected components of this graph are called kinds.
All terms must be kind-correct (“static typing”)
Sort errors within a kind can be resolved during rewriting(“dynamic typing”)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 29 / 38
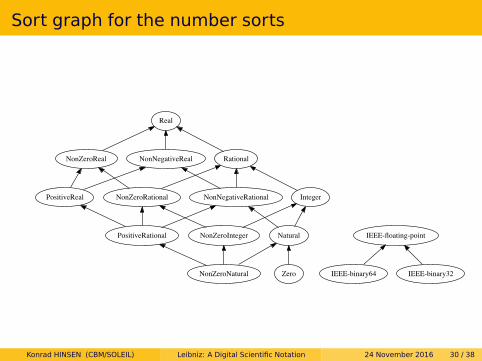
Sort graph for the number sorts
NonZeroNatural
NonZeroIntegerPositiveRational Natural
NonNegativeRational
NonNegativeReal Rational
IEEE-binary64
IEEE-floating-point
NonZeroRational
NonZeroReal
Real
IntegerPositiveReal
Zero IEEE-binary32
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 30 / 38

A very simple example
define-context mass;include real-numbers;sort Mass;; The sum of two masses is a mass.op {Mass + Mass} Mass; The product of a positive number with a mass is a mass.op {PositiveReal * Mass} Mass; A mass divided by a positive number is a mass.op {Mass / PositiveReal} Mass; The quotient of two masses is a positive number.op {Mass / Mass} PositiveReal
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 31 / 38

Using subsorts
define-context distance;include real-numbers;sort Distance;sort NonZeroDistance ; an important special case for divisionsubsort NonZeroDistance Distance;op {Distance + Distance} Distanceop {Distance - Distance} Distance;op {Real * Distance} Distanceop {NonZeroReal * NonZeroDistance} NonZeroDistanceop {Distance / NonZeroReal} Distance;op {Distance / NonZeroDistance} Realop {NonZeroDistance / NonZeroDistance} NonZeroReal
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 32 / 38
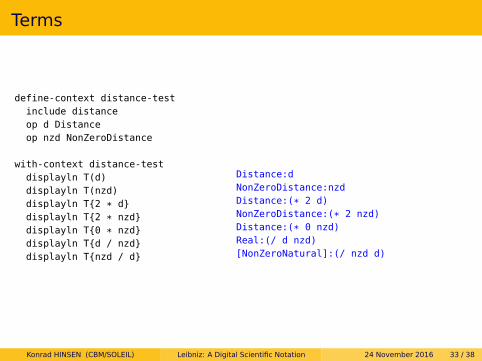
Terms
define-context distance-testinclude distanceop d Distanceop nzd NonZeroDistance
with-context distance-testdisplayln T(d)displayln T(nzd)displayln T{2 * d}displayln T{2 * nzd}displayln T{0 * nzd}displayln T{d / nzd}displayln T{nzd / d}
Distance:dNonZeroDistance:nzdDistance:(* 2 d)NonZeroDistance:(* 2 nzd)Distance:(* 0 nzd)Real:(/ d nzd)[NonZeroNatural]:(/ nzd d)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 33 / 38

Rewrite rules
define-context distance-with-rules;include distance;=> D : Distance
{1 * D}D
=> F1 : RealF2 : RealD : Distance
{{F1 * D} + {F2 * D}}{{F1 + F2} * D}
=> F : NonZeroRealD : Distance
{D / F}{{1 / F} * D}
=> F1 : RealF2 : RealD : Distance
{F1 * {F2 * D}}{{F1 * F2} * D}
define-context distance-testinclude distance-with-rulesop d Distance
with-context distance-testdisplayln T{{2 * d} + {3 * d}}displayln RT{{2 * d} + {3 * d}}displayln RT{{2 * d} + {d / 2}}
Distance:(+ (* 2 d) (* 3 d))Distance:(* 5 d)Distance:(* 5/2 d)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 34 / 38

Equations and transformations
define-context distance-with-equations;include distance-with-rules;op d1 Distanceop d2 NonZeroDistance;eq #:label eq-1
d1{2 * d2}
with-context distance-with-equations;displayln eq(eq-1);displayln
Atr #:var (D Distance) D {D / 2}eq(eq-1)#:label eq-2
(eq #:label eq-1 d1 (* 2 d2))
(eq #:label eq-2 (* 1/2 d1) d2)
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 35 / 38

Unusual features
Embedding code into scholarly discourse leads to different prioritiesfrom software development.
No namespaces, no scopes, no modularity.
Use explicit renaming instead (supported by the authoringenvironment).
Minimal built-in contexts: just numbers and booleans.
No “standard library”.
Re-use and adapt published libraries instead.
Prevents the creation of large black-box code libraries.
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 36 / 38

Play with it yourself
All the code is on GitHub.
Written in Racket, which provides excellent support for this kindof project.
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 37 / 38

Future work
LeibnizAssociative/commutative operators
Built-in collections: lists, sets, maybe more
Interfaces to external data (files, databases, ...)
Support toolsAuthoring environment
Manipulation tools for numerical work (real ! float etc.)
Libraries for popular programming languages
Find fundingProject outside of every funding agency’s categories
Suggestions welcome!
Konrad HINSEN (CBM/SOLEIL) Leibniz: A Digital Scientific Notation 24 November 2016 38 / 38