machine learning real life applications by examples - mario cartia
TRANSCRIPT

DATADRIVENINNOVATIONRome 2017 | Open Summit
MACHINE LEARNING REAL LIFE APPLICATIONS BY EXAMPLES
SPEAKERMARIO CARTIA

DDIR O M E | 2 0 1 7M A RI O C A RT I A
Canmachinesthink?Computingmachinery andintelligence.Mind,59,433-460(1950)Turing A.M.

DDIR O M E | 2 0 1 7M A RI O C A RT I A
19682001:ASpaceOdyssey
“I'm sorry Dave, I'm afraid I can't do that”

DDIR O M E | 2 0 1 7M A RI O C A RT I A
1982Supercar

DDIR O M E | 2 0 1 7M A RI O C A RT I A
1983Wargames

DDIR O M E | 2 0 1 7M A RI O C A RT I A
1996Kasparovvs.Deep Blue

DDIR O M E | 2 0 1 7M A RI O C A RT I A
Does Deep Blue use artificial intelligence?The short answer is "no." Earlier computer designs that triedto mimic human thinking weren't very good at it. No formula exists for intuition. So Deep Blue's designers have gone"back to the future." Deep Blue relies more on computationalpower and a simpler search and evaluation function.
The long answer is "no." "Artificial Intelligence" is more successful in science fiction than it is here on earth, and youdon't have to be Isaac Asimov to know why it's hard to design a machine to mimic a process we don't understandvery well to begin with.
Source: https://www.research.ibm.com/deepblue/meet/html/d.3.3a.shtml

DDIR O M E | 2 0 1 7M A RI O C A RT I A
Decision Tree (IF...THEN)

DDIR O M E | 2 0 1 7M A RI O C A RT I A
“Machine learning is the subfield of computer sciencethat gives computers the ability to learn without beingexplicitly programmed.”
Arthur Samuel, 1959

DDIR O M E | 2 0 1 7M A RI O C A RT I A
SpamEmailFiltering
DDIR O M E | 2 0 1 7M A RI O C A RT I A
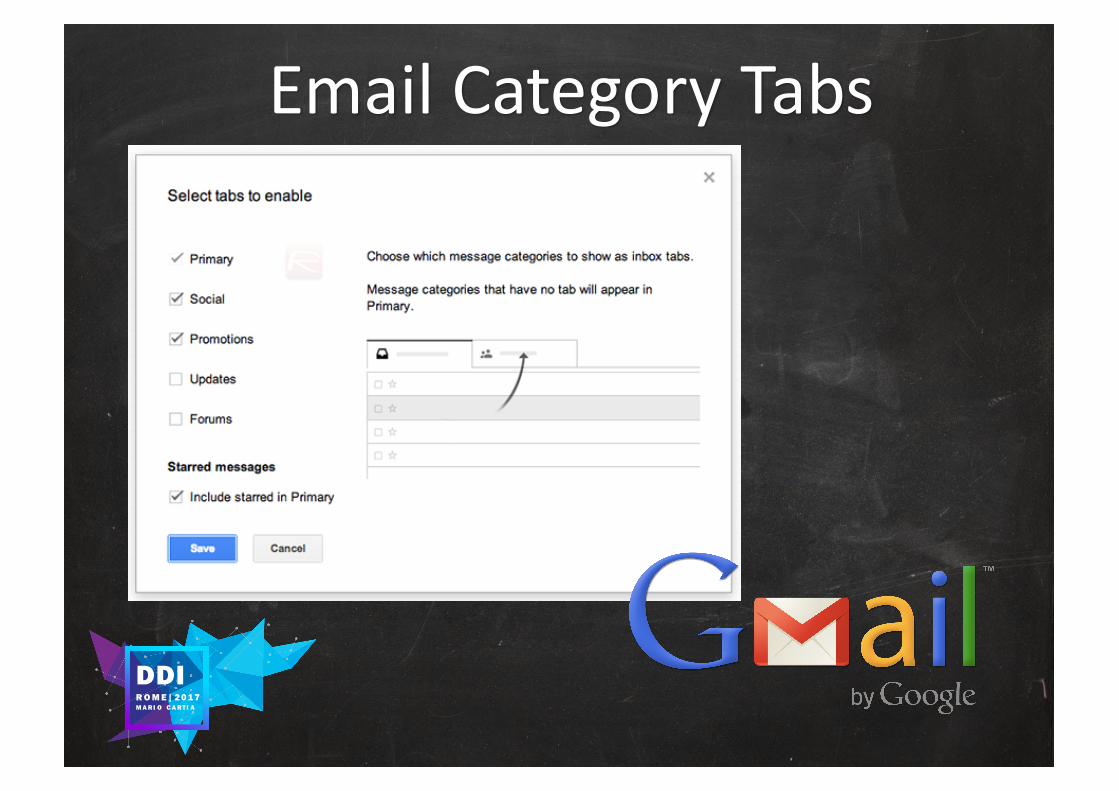
EmailCategory Tabs

DDIR O M E | 2 0 1 7M A RI O C A RT I A
“If you can'texplain it simplyyou don'tunderstandit well enough”

DDIR O M E | 2 0 1 7M A RI O C A RT I A
SUPERVISEDLEARNINGSupervised learning is where youhave input variables (x) and anoutput variable (y) and you use analgorithm to learn the mappingfunction from the input to theoutput
y=f(x)

DDIR O M E | 2 0 1 7M A RI O C A RT I A
SUPERVISEDLEARNINGClassification is a general processrelated to categorization, the processin which ideas and objects arerecognized, differentiated, andunderstood
A classification system is an approachto accomplishing classification

DDIR O M E | 2 0 1 7M A RI O C A RT I A
CLASSIFICATIONIn Machine Learning, NaiveBayes Classifiers are a family ofsimple probabilistic classifiersbased on applying Bayes'theorem with strong (naive)independence assumptionsbetween the features

DDIR O M E | 2 0 1 7M A RI O C A RT I A
NAIVEBAYESCLASSIFIERSNaive Bayes has been studiedextensively since the 1950s andremains a popular (baseline) method fortext categorization, the problem ofjudging documents as belonging to onecategory or the other (such as spam orlegitimate, sports or politics, etc.) withword frequencies as the features

DDIR O M E | 2 0 1 7M A RI O C A RT I A
TEXT CATEGORIZATION
SUPERVISED LEARNING
CLASSIFICATION
NAIVE BAYES CLASSIFIER
?
DDIR O M E | 2 0 1 7M A RI O C A RT I A
DDIR O M E | 2 0 1 7M A RI O C A RT I A
DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A
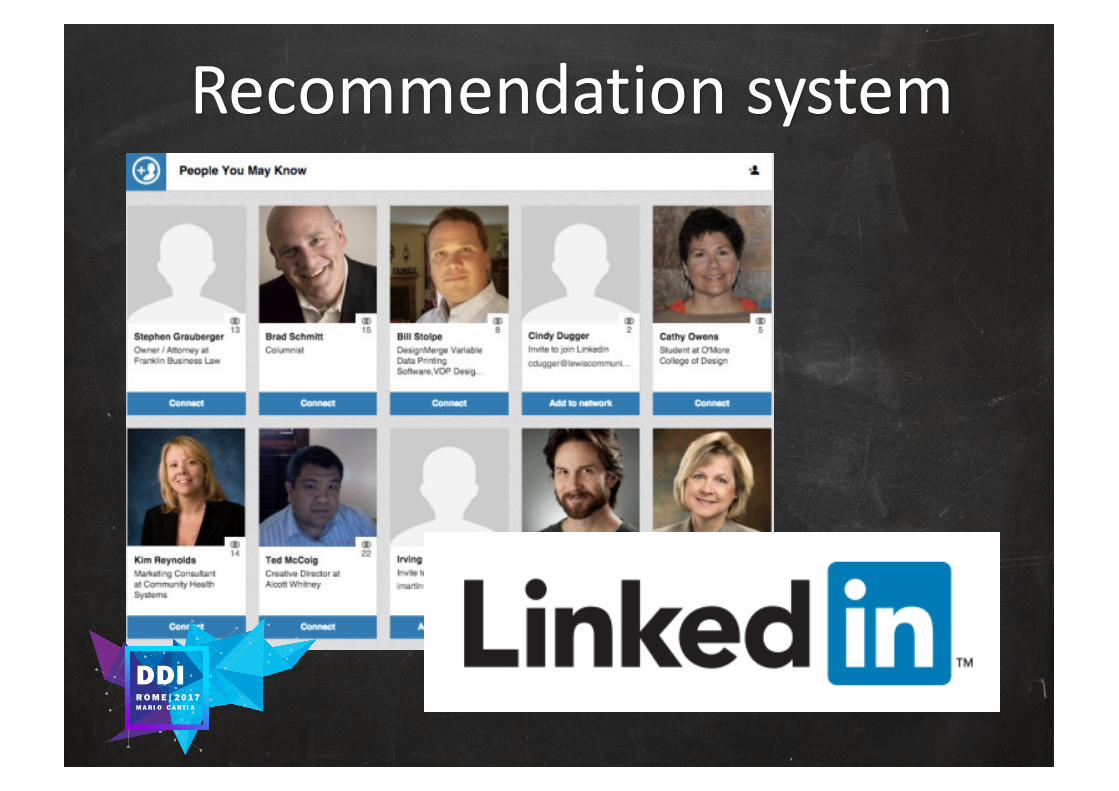
Recommendation system

DDIR O M E | 2 0 1 7M A RI O C A RT I A
Recommendation system
DDIR O M E | 2 0 1 7M A RI O C A RT I A
Recommendation system

DDIR O M E | 2 0 1 7M A RI O C A RT I A
Recommendation system

DDIR O M E | 2 0 1 7M A RI O C A RT I A
Recommendation system

DDIR O M E | 2 0 1 7M A RI O C A RT I A
UNSUPERVISEDLEARNINGUnsupervised learning algorithmsare machine learning algorithmsthat work without a desired outputlabel
Essentially, the algorithm attemptsto estimate the underlying structureof the population of input data

DDIR O M E | 2 0 1 7M A RI O C A RT I A
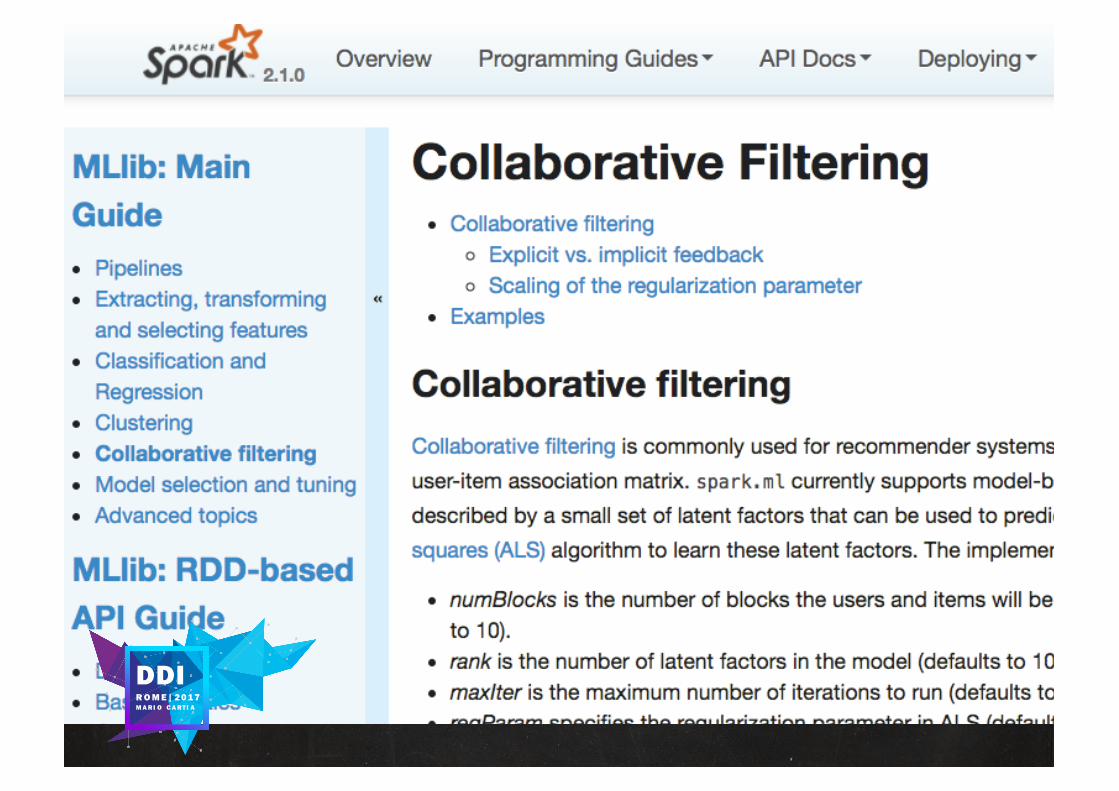
UNSUPERVISEDLEARNINGCollaborative Filtering is a method of makingautomatic predictions (filtering) about theinterests of a user by collecting preferences ortaste information from many users(collaborating)
In the more general sense, CollaborativeFiltering is the process of filtering forinformation or patterns using techniquesinvolving collaboration among multiple agents,viewpoints, data sources, etc.

DDIR O M E | 2 0 1 7M A RI O C A RT I A
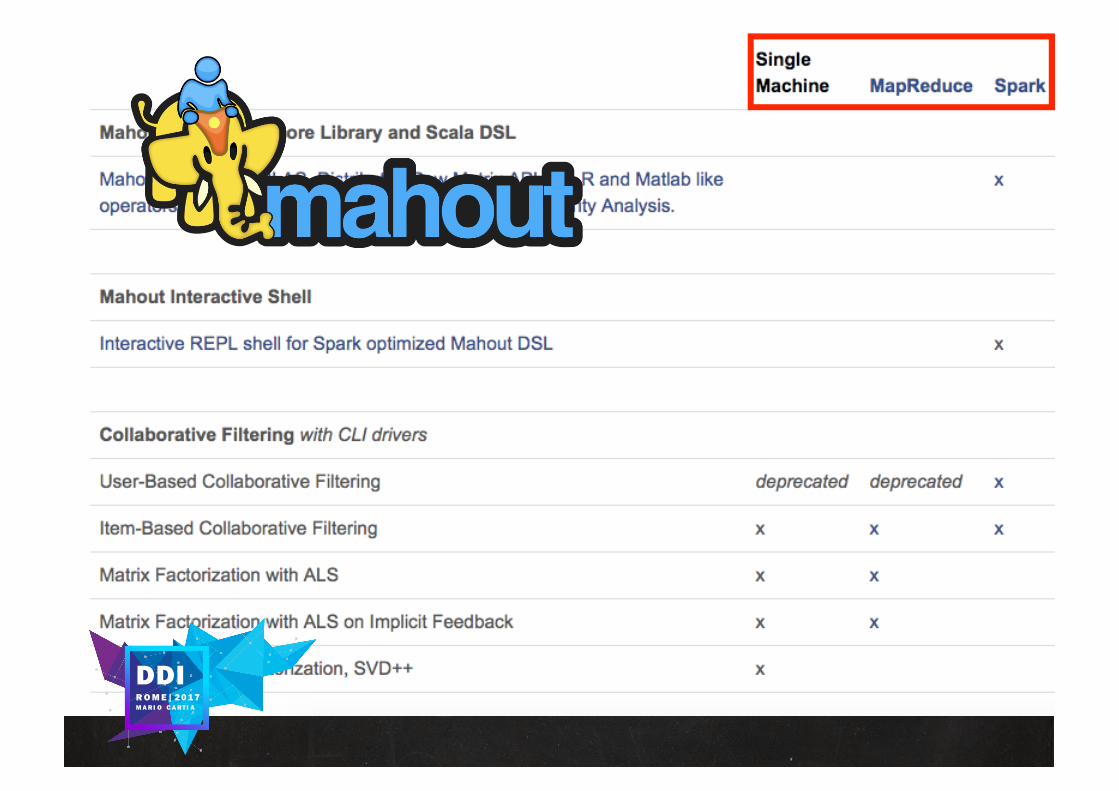
COLLABORATIVEFILTERINGApplications of Collaborative Filtering typicallyinvolve very large data sets
As the numbers of users and items grow,traditional CF algorithms will suffer seriousscalability problems
Large web companies use clusters ofmachines to scale recommendations for theirmillions of users

DDIR O M E | 2 0 1 7M A RI O C A RT I A
RECOMMENDATION SYSTEM
UNSUPERVISED LEARNING
COLLABORATIVE FILTERING
USER BASED / ITEM BASED / OTHER
?
DDIR O M E | 2 0 1 7M A RI O C A RT I A
DDIR O M E | 2 0 1 7M A RI O C A RT I A
DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A
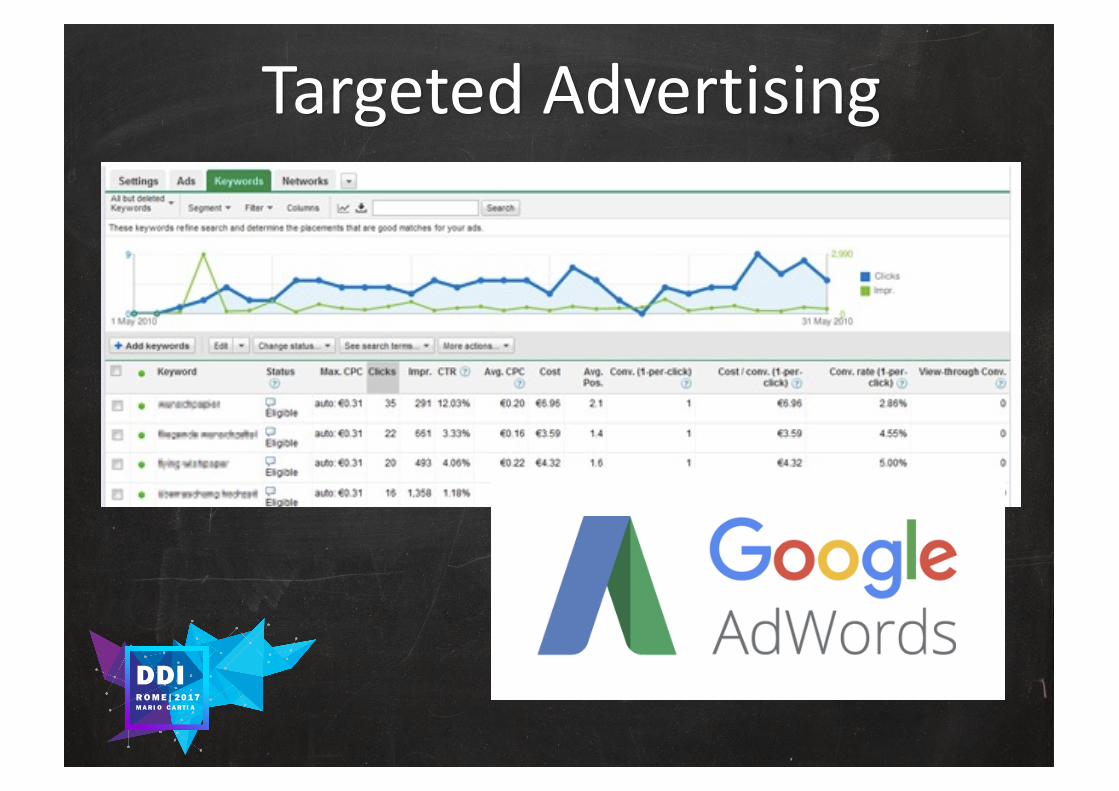
Targeted Advertising
DDIR O M E | 2 0 1 7M A RI O C A RT I A
Targeted Advertising

DDIR O M E | 2 0 1 7M A RI O C A RT I A
UNSUPERVISEDLEARNINGCluster analysis or Clustering is thetask of grouping a set of objects insuch a way that objects in the samegroup (called a cluster) are moresimilar (in some sense or another)to each other than to those in othergroups (clusters)

DDIR O M E | 2 0 1 7M A RI O C A RT I A
CLUSTERINGK-means clustering is a method of vectorquantization, originally from signalprocessing, that is popular for clusteranalysis in data mining
K-means clustering aims to partition nobservations into k clusters in which eachobservation belongs to the cluster withthe nearest mean

DDIR O M E | 2 0 1 7M A RI O C A RT I A
TARGETED ADVERTISING
UNSUPERVISED LEARNING
CLUSTERING
K-MEANS CLUSTERING
?

DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A
DDIR O M E | 2 0 1 7M A RI O C A RT I A
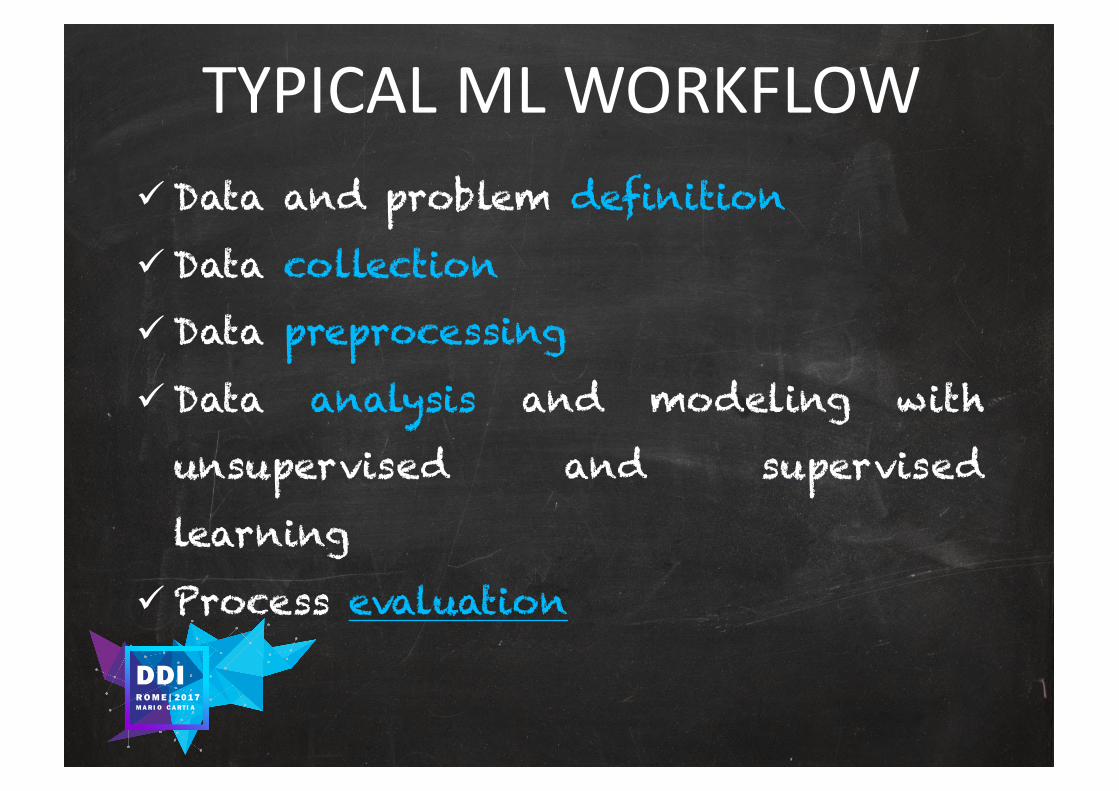
TYPICALMLWORKFLOWü Data and problem definition
ü Data collection
ü Data preprocessing
ü Data analysis and modeling with
unsupervised and supervised
learning
ü Process evaluation

DDIR O M E | 2 0 1 7M A RI O C A RT I A
EVALUATIONMETRICSThe root-mean-square deviation(RMSD) or root-mean-square error(RMSE) is a frequently usedmeasure of the differences betweenvalues (sample and populationvalues) predicted by a model or anestimator and the values actuallyobserved

DDIR O M E | 2 0 1 7M A RI O C A RT I A
BEYONDMLDeep learning is a branch ofmachine learning based on a set ofalgorithms that attempt to modelhigh level abstractions in data
Deep learning is part of a broaderfamily of machine learning methodsbased on learning representations

DDIR O M E | 2 0 1 7M A RI O C A RT I A
BEYONDMLOne of the promises of Deep Learningis replacing handcrafted features withefficient algorithms for unsupervisedor semi-supervised feature learningand hierarchical feature extraction
Some of the representations areinspired by advances in neuroscience

DDIR O M E | 2 0 1 7M A RI O C A RT I A
BEYONDMLVarious Deep Learning architecturessuch as deep neural networks havebeen applied to fields like computervision, automatic speech recognition,natural language processing, audiorecognition and bioinformatics wherethey have been shown to produce state-of-the-art results on various tasks

DDIR O M E | 2 0 1 7M A RI O C A RT I A
DDIR O M E | 2 0 1 7M A RI O C A RT I A

DDIR O M E | 2 0 1 7M A RI O C A RT I A
ML&BIGDATA
“We don’t have better algorithms.We just have more data.”
Peter NorvigGoogle’s Research Director

DDIR O M E | 2 0 1 7M A RI O C A RT I A
ML&BIGDATAApache Hadoop is an open-sourcesoftware framework used for distributedstorage and processing of big data setsusing clusters built from commodityhardware

DDIR O M E | 2 0 1 7M A RI O C A RT I A
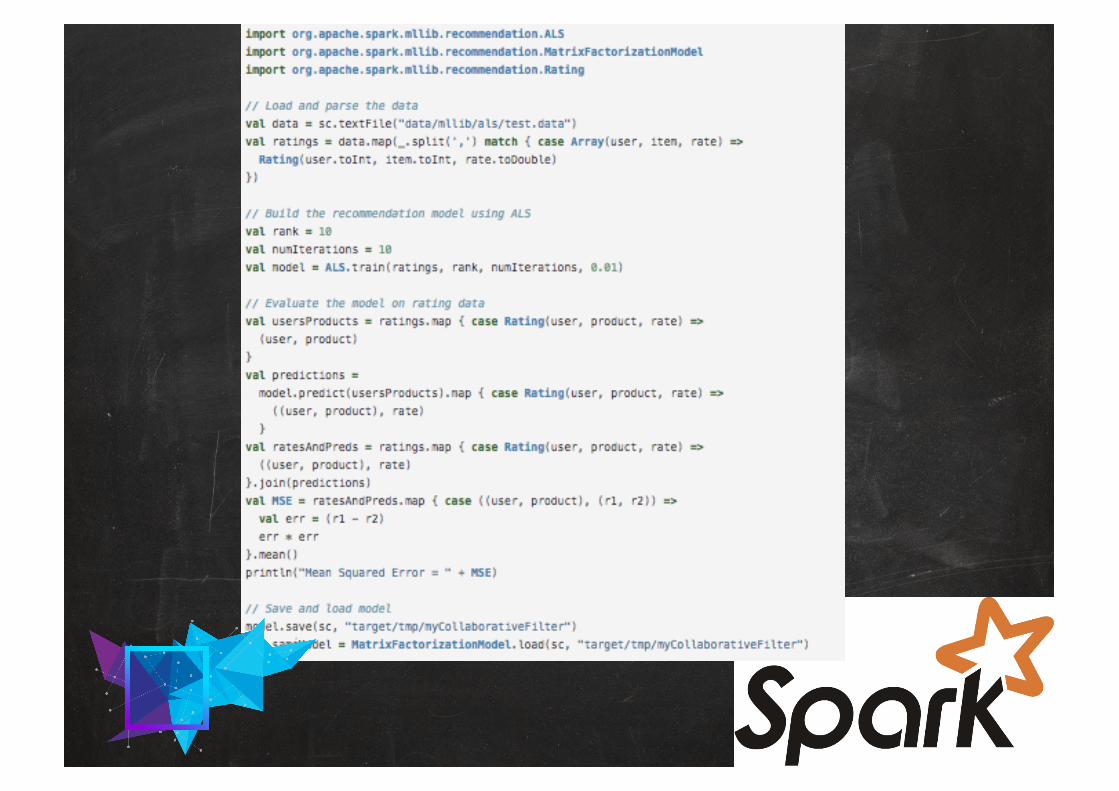
ML&BIGDATAApache Spark is a fast and general-purposecluster computing system
It provides high-level APIs in Scala, Java, Pythonand R, and an optimized engine that supportsgeneral execution graphs
It also supports a rich set of higher-level toolsincluding Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphXfor graph processing, and Spark Streaming

DDIR O M E | 2 0 1 7M A RI O C A RT I A
ML&BIGDATA

DDIR O M E | 2 0 1 7M A RI O C A RT I A
WHYTOUSESCALA?Spark Survey 2016

DDIR O M E | 2 0 1 7M A RI O C A RT I A
WHYTOUSESCALA?Scala is one of the most exciting languages to be created in the 21st century. It is a multi-paradigm language that fully supports functional, object-oriented, imperative and concurrent programming. It also has a strong type system, and from our point of view, strong type is a convenient form of self-documenting code.
Scala works on the JVM and has access to the riches of the Java ecosystem, but it is less verbose than Java. As we employ it for ND4J, its syntax is strikingly similar to Python, a language that many data scientists are comfortable with. Like Python, Scala makesprogrammers happy, but like Java, it is quite fast.
Finally, Apache Spark is written in Scala, and any library that purportsto work on distributed run times should at the very least be able to interface with Spark
Source: https://deeplearning4j.org/scala
