memories: advanced cacheszshi/course/cse5302/files/memory1_caches.pdf · memories: advanced caches...
TRANSCRIPT

Memories: Advanced Caches
Z. Jerry ShiAssistant Professor of Computer Science and Engineering
University of ConnecticutUniversity of Connecticut
* Slides adapted from Blumrich&Gschwind/ELE475’03, Peh/ELE475’*

Speed gap
Q. How do architects address this gap?
A Put smaller faster “cache” memories between CPU
μProc:
A. Put smaller, faster cache memories between CPU and DRAM. Create a “memory hierarchy”.
60% / year2x in 1.5 years
DRAM: 7% / year
2 i 102x in 10 yrs

1977: DRAM faster than microprocessors
Apple ][ (1977)
CPU: 1000 nsCPU: 1000 nsDRAM: 400 ns
Steve WozniakSteve
Jobs

Levels of the Memory Hierarchy
CPU Registers
CapacityAccess TimeCost Staging
Xfer Unit
Upper Level
fasterCPU Registers100s Bytes<10s ns
CacheK B
Registers
Instr. Operands prog./compiler1-8 bytes
K Bytes10-100 ns1-0.1 cents/bit
M i M
Cache
Blocks cache cntl8-128 bytes
Main MemoryM Bytes200ns- 500ns0.0001-.00001 cents /bitDisk
Memory
Pages OS512-4K bytes
G Bytes, 10 ms (10,000,000 ns)
10-5- 10-6 cents/bit
Disk
Files user/operatorMbytes
Tapeinfinitesec-min10 -8
Tape
y
Lower LevelLarger

What is a cache?
• Small, fast storage used to improve average access time to slow memoryy
• Hold subset of the instructions and data used by program• Exploits spatial and temporal locality
– Temporal locality: If an item is referenced, it will tend to be referenced again soon
– Spatial locality: If an item is referenced nearby items will tend toSpatial locality: If an item is referenced, nearby items will tend to be referenced soon
• Last 15 years, HW relied on locality for speed– It is a property of programs which is exploited in machine design

Memory Hierarchy: Apple iMac G5
Managed by compiler
Managed by hardware
Managed by OS,hardware,
07 Reg L1 Inst L1 Data L2 DRAM Disk
by hardware hardware,application
iMac G5
07 Reg L1 Inst L1 Data L2 DRAM Disk
Size 1K 64K 32K 512K 256M 80G
Latency1 3 3 11 88 107
1.6 GHzy
Cycles, Time
1,0.6 ns
3,1.9 ns
3,1.9 ns
11,6.9 ns
88,55 ns
107,12 ms
G l Ill i f l f hLet programs address a memory space that
scales to the disk size at a speed that is usually
Goal: Illusion of large, fast, cheap memory
scales to the disk size, at a speed that is usually as fast as register access

Memory hierarchy specs
Type Capacity Latency BandwidthType Capacity Latency Bandwidth
Register <2KB 1ns 150GB/s
L1 Cache <64KB 4ns 50GB/s
L2 Cache <8MB 10ns 25GB/s
L3 Cache <64MB 20ns 10GB/s
Memory <4GB 50ns 4GB/sMemory <4GB 50ns 4GB/s
Disk >1GB 10ms 10MB/s

iMac’s PowerPC 970: All caches on-chipL1 (64K Instruction)
Registers
512KL2s (1K
)
L1 (32K Data)

Programs with locality cache well ...
B d l lit b h iBad locality behavior
ddre
ss
acce
ss)
Temporal
mor
y A
ddo
t per
Locality
Mem
(one
SpatialLocality
Donald J. Hatfield, Jeanette Gerald: Program Restructuring for Virtual Memory. IBM Systems Journal 10(3): 168-192 (1971)
Time

Caches are everywhere
• In computer architecture, almost everything is a cache!– Registers “a cache” on variables – software managedRegisters a cache on variables software managed– First-level cache a cache on second-level cache– Second-level cache a cache on memory– Memory a cache on disk (virtual memory)– TLB a cache on page table– Branch-prediction a cache on prediction information– Branch-prediction a cache on prediction information– Branch Target Buffer a cache on the PC of instructions following
branches

Terminology
• Higher levels in the hierarchy are closer to the CPU• At each level a block is the minimum amount of data whoseAt each level a block is the minimum amount of data whose
presence is checked at each level– Blocks are also often called lines– Block size is always a power of 2– Block sizes of the lower levels are usually fixed multiples of
the block sizes of the higher levelsthe block sizes of the higher levels• A reference is said to hit at a particular level if the block is found
at that level– Hit Rate (HR) = Hits/References– Miss Rate (MR) = Misses/References
• Access time of a hit is the hit time

Terminology (2)
• The additional time to fetch a block from lower levels on a miss is called the miss penaltyon a miss is called the miss penalty– Time to replace a block in the upper level – Hit time << Miss penalty (500 instructions on 21264!)
• Miss Penalty = Access Time + Transfer Time– Access time is a function of latency
“Ti f d i ”• “Time for memory to get request and process it”– Transfer time is a function of bandwidth
• “Time for all of block to get back”
Miss Penalty Access Time
TransferTime
Penalty Access TimeBlock Size

Access vs. Transfer Time
Cache Memory
AA
BD
• Miss penalty = A + B + C
C
Miss penalty A B C– Access Time = A + B– Transfer Time to the upper level = C
• Transfer Time to the processor core = D

Latency vs. Bandwidth
• “There is an old network saying: Bandwidth problems can be cured with money. Latency problems are harder because the y y pspeed of light is fixed --- you can’t bribe God.”
» David Clark, MIT
• Recall pipelining: We improved instruction bandwidth but• Recall pipelining: We improved instruction bandwidth, but actually made latency worse
• With memory, for bandwidth we can:– Wider buses, larger block sizes, new DRAM organizations
(RAMBUS)• Latency is still much harder:• Latency is still much harder:
– Have to get request from cache to memory (off chip)– Have to do memory lookup– Have to have bits travel on wire back on-chip to cache

Caching Basics: Four Questions
• Block placement policy?– Where does a block go when it is fetched?Where does a block go when it is fetched?
• Block identification policy?– How do we find a block in the cache?
• Block replacement policy?– When fetching a block into a full cache, how do we decide what
other block gets kicked out?other block gets kicked out?• Write strategy?
– Does any of this differ for reads vs. writes?

Cache organization
• Direct mapped– A block has only one
l it iplace it can appear in the cache
• Fully associativeA block can be placed– A block can be placed anywhere in the cache
• n-way set associative– A block can be placedA block can be placed
in a restricted set of places

Simple Cache Example
• Direct-mapped cache: Each block has a specific spot in the cache. If it is in the cache, only one place for it, y p
• Makes block placement, ID, and replacement policies easy– Block Placement: Where does a block go when fetched?
• It goes to its one assigned spot– Block ID: How do we find a block in the cache?
• We look at the tags for that one assigned spotg g p– Block replacement: What gets kicked out?
• Whatever is in its assigned spotW i– Write strategy:
• “Allocate on write” More on write strategies later`

Direct-mapped cache
Memory address
n bits Cache line/block
2nCache 2

Fetching data from cache
state bits: valid, dirty, etc.Memory address
data blocktag
= ? MUX
Hit? Word

Memory address
0 3127 2818 190 3127 2818 19
4919
tag block address offsettag block address offset
Line size = 24 = 16 bytesLine size 2 16 bytes
Number of lines = 29 = 512
Number of bits in a line = 16 * 8 + 19 + 2 = 149
Number of bits in the cache = 149 * 512 = 76288

Direct Mapped Caches
• Partition Memory Address into three regions– C = Cache Size– M = Numbers of bits in memory address– B = Block Size
Tag Index Block OffsetM - log C log C/B log B
Tag Index Block Offset
Tag Memory
Data Memory
= Hit/Miss D tData

Set Associative Caches
• Partition Memory Address into three regions– C = Cache Size, B=Block Size, A=number of members per set, , p– A block can be placed any of the A locations in a set
M-log C/A log C/(B*A) log BTag Index Block Offset
Tag Memoryway0 way1
Data Memory=
way0 way1
=Hit/Miss
=
OR DataHit/MissOR Data

Cache size example
• 32-bit machine• 64KB 32B Block 2-Way Set Associative64KB, 32B Block, 2 Way Set Associative• Compute Total Size of Tag Array
– 64KB/ 32B blocks => 2K Blocks– 2K Blocks / 2-way set-associative => 1K Sets– 32B Blocks => 5 Offset Bits
1K S t > 10 i d bit– 1K Sets => 10 index bits– 32-bit address – 5 offset bits – 10 index bits = 17 tag bits– 17 tag bits * 2K Blocks => 34Kb => 4.25KBg

Summary of set associativity
• Direct Mapped– One place in cache, One Comparator, No Muxes
• Set Associative Caches– Restricted set of places
n way set associativity– n-way set associativity– Number of comparators = number of blocks per set– n:1 MUX
• Fully Associative– Anywhere in cache– Number of comparators = number of blocks in cacheNumber of comparators number of blocks in cache– n:1 MUX needed

Cache miss
flag bits: valid, dirty
data blocktag
Miss

Direct-mapped Cache Example
• 8 locations in our cache• Block Size = 1 byte
Lower order bits Block Size 1 byte
• Data reference stream:References to memory locations:
0 00001 00012 0010y
– 0,1,2,3,4,5,6,7,8,9,0,0,0,2,2,2,4,9,1,9,1• Entry = address mod cache size
2 00103 00114 01005 01016 01107 01117 01118 10009 1001

Cache Examples: Cycles 1 - 5
0 1 2 3 4 5 6 7 8 9 0 0 0 2 2 2 4 9 1 9 10,1,2,3,4,5,6,7,8,9,0,0,0,2,2,2,4,9,1,9,1
Miss Miss Miss Miss Miss0 0
1012
012
012
3 34

Cache Examples: Cycles 6-10
0 1 2 3 4 5 6 7 8 9 0 0 0 2 2 2 4 9 1 9 10,1,2,3,4,5,6,7,8,9,0,0,0,2,2,2,4,9,1,9,1
Miss Miss Miss Miss Miss012
012
012
812
892
345
345
345
345
3455 5
6567
567
567

Cache Examples: Cycles 11-15
0 1 2 3 4 5 6 7 8 9 0 0 0 2 2 2 4 9 1 9 10,1,2,3,4,5,6,7,8,9,0,0,0,2,2,2,4,9,1,9,1
Miss Hit (0) Hit (0) Hit (2) Hit (2)092
092
092
092
092
345
345
345
345
3455
67
567
567
567
567

Cache Examples: Cycles 16-21
0 1 2 3 4 5 6 7 8 9 0 0 0 2 2 2 4 9 1 9 10,1,2,3,4,5,6,7,8,9,0,0,0,2,2,2,4,9,1,9,1
Hit(2) Hit (4) Hit(9) Miss Miss Miss092
092
092
012
092
012
345
345
345
345
345
3455
67
567
567
567
567
567

Example summary
• Hit Rate = 7/21 = 1/3• Miss Rate = 14/21 = 2/3Miss Rate 14/21 2/3
Now, what if the block size = 2 bytes?yEntry = (Address / Block Size) mod Cache Size
How about 2-way set associative cache?
H b t f ll i ti h ?How about fully associative cache?

Cache misses: three C’s
• Compulsory– The first access to a block can NOT be in the cacheThe first access to a block can NOT be in the cache– Also called cold start misses or first reference misses– Misses even in an infinite cache
• Capacity– The cache is too small to hold all the blocks needed by a program
Blocks being discarded and later retrieved– Blocks being discarded and later retrieved– Misses in fully associative cache
• Conflict– The cache has sufficient space, but a block can not be kept because
of the conflict with another blockAlso called collision misses or interference misses– Also called collision misses or interference misses

Summary: Block Placement + ID
• Placement– Invariant: block always goes in exactly one setInvariant: block always goes in exactly one set– Fully-Associative: Cache is one set, block goes anywhere– Direct-Mapped: Block goes in exactly one frame– Set-Associative: Block goes in one of a few frames
• IdentificationFind Set– Find Set
– Search ways in parallel (compare tags, check valid bits)

Block Replacement
• Cache miss requires a replacement• No decision needed in direct mapped cacheNo decision needed in direct mapped cache• More than one place for memory blocks in set-associative
– Easy for direct mapped• Replacement Strategies
– OptimalR l Bl k d f th t h d i ti ( l )• Replace Block used furthest ahead in time (oracle)
– Least Recently Used (LRU)• Optimized for temporal locality
– (Pseudo) Random• Nearly as good as LRU, simpler

Replacement Strategy
A randomly chosen block?Easy to implement, how
The Least Recently Used (LRU) block? Appealing, y p ,
well does it work?(LRU) block? Appealing,but hard to implement for high associativity
Miss Rate for 2-way Set Associative CacheAlso,Size Random LRU
tryotherLRU
16 KB 5.7% 5.2%
64 KB 2.0% 1.9%approx.
256 KB 1.17% 1.15%

Miss rate
Assoc: 2-way 4-way 8-waySize LRU Ran LRU Ran LRU Ran16 KB 5.2% 5.7% 4.7% 5.3% 4.4% 5.0%64 KB 1.9% 2.0% 1.5% 1.7% 1.4% 1.5%256 KB 1.15% 1.17% 1.13% 1.13% 1.12% 1.12%

Write Policies
• Writes are only about 21% of data cache traffic• Optimize cache for reads do writes “on the side”Optimize cache for reads, do writes on the side
– Reads can do tag check/data read in parallel– Writes must be sure we are updating the correct data and the correct
amount of data (1-8 byte writes)– Serial process => slow
• What to do on a write hit?What to do on a write hit?• What to do on a write miss?

Write Hit Policies
• Q1: When to propagate new values to memory?• Write back – Information is only written to the cacheWrite back Information is only written to the cache.
– Next lower level only updated when it is evicted (dirty bits say when data has been modified)
– Can write at speed of cache – Caches become temporarily inconsistent with lower-levels of
hierarchy. y– Uses less memory bandwidth/power (multiple consecutive writes
may require only 1 final write)M ltiple rites ithin a block can be merged into one rite– Multiple writes within a block can be merged into one write
– Evictions are longer latency now (must write back)

Write Hit Policies
• Q1: When to propagate new values to memory?• Write through – Information is written to cache and to the lower-Write through Information is written to cache and to the lower
level memory– Main memory is always “consistent/coherent”– Easier to implement – no dirty bits– Reads never result in writes to lower levels (cheaper)– Higher bandwidth needed– Higher bandwidth needed– Write buffers used to avoid write stalls

Write buffers
• Small chunks of memory to buffer outgoing writesCPU to buffer outgoing writes
• Processor can continue when data written to
CPU
when data written to buffer
• Allows overlap of Cache Write Buffer ows ove p o
processor execution with memory updateLower Levels of MemoryLower Levels of Memory
W it b ff ti l f it th h hWrite buffers are essential for write-through caches

Write buffers
• Writes can now be pipelined (rather than serial)Check tag + Write store data into Write Buffer– Check tag + Write store data into Write Buffer
– Write data from Write buffer to L2 cache (tags ok)• Loads must check write buffer for St O• Loads must check write buffer for
pending stores to same address• Loads Check:
Address| DataStore Op
• Loads Check:– Write Buffer– Cache
Address| DataWrite Buffer Entry
Cache– Subsequent Levels of Memory Tag Data
Data Cache

Write buffer policies: Performance/Complexity Tradeoffs
Stores L2 CacheL2 Cache
Loads
• Allow merging of multiple stores? “coalescing”• Flush Policy – How to do flushing of entries?
L d S i i P li Wh t h h l d t• Load Servicing Policy – What happens when a load occurs to data currently in write buffer?

Write merging
Non-merging Buffer• Except for multi-word
write operations, extra slots are unused
Merging Write Buffer• More efficient writes
R d b ff f ll• Reduces buffer-full stalls

Write Buffer Flush Policies
• When to flush?– Aggressive flushing:Aggressive flushing:
Reduce chance of stall cycles due to full write buffer– Conservative flushing:
Write merging more likely (entries stay around longer) reducesWrite merging more likely (entries stay around longer) reduces memory traffic
– On-chip L2’s More aggressive flushing• What to flush?
– Selective flushing of particular entries?Fl sh e er thing belo a partic lar entr– Flush everything below a particular entry
– Flush everything

Write Buffer Load Service Policies
• Load op’s address matches something in write buffer• Possible policies:Possible policies:
– Flush entire write buffer, service load from L2– Flush write buffer up to and including relevant address, service
from L2– Flush only the relevant address from write buffer, service from L2– Service load from write buffer don’t flushService load from write buffer, don t flush
• What if a Read miss doesn’t hit in the Write buffer?– Give priority for the Read L2 accesses over the Write L2 Accesses

Write misses?
• Write Allocate– Block is allocated on a write missBlock is allocated on a write miss– Standard write hit actions follow the block allocation– Write misses = Read Misses– Goes well with write-back
• No-write AllocateWrite misses do not allocate a block– Write misses do not allocate a block
– Only update lower-level memory– Blocks only allocate on Read misses!– Goes well with write-through

Summary of Write Policies
Write Policy Hit/Miss Writes to
WriteBack/Allocate Both L1 Cache
WriteBack/NoAllocate Hit L1 CacheWriteBack/NoAllocate Hit L1 Cache
WriteBack/NoAllocate Miss L2 Cache
WriteThrough/Allocate Both Both
WriteThrough/NoAllocate Hit Both
WriteThrough/NoAllocate Miss L2 Cache

Cache performance
• Average memory access time (AMAT):AMAT = Hit Time + Miss Rate × Miss PenaltyAMAT Hit Time + Miss Rate × Miss Penalty
Misleading indicator of cache performance is miss rateExample:
i i 1 i l 20 i 0 1Hit Time = 1ns, Miss Penalty = 20ns, Miss Rate = 0.1AMAT = 1 + 0.1 * 20 = 3ns
• CPU time = (CPU execution cycles + Memory Stall Cycles) × Cycle TimeCPU time (CPU execution cycles + Memory Stall Cycles) Cycle Time
• To improve cache performance, we can1. Reduce the miss rate, 2. Reduce the miss penalty, or3. Reduce the time to hit in the cache.
• Out-of-order processors can hide some of the miss penalty

1. Reduce Miss Rate via Larger Block Size
20%
25%
1K
Miss Rate 10%
15%4K
16K
5%
10%64K
256K
0%
16 32 64
128
256
Block Size (bytes) Miss penaltyCompulsory (spatial locality)Conflict? (fewer blocks in cache)Capacity? (fewer blocks in cache)

2: Reduce Miss Rate via Larger Cache
0.12
0.14 1-wayConflict
0.08
0.12-way
4-way
8
• Old rule of thumb: 2x size => 25% cut in miss rate
• What does it reduce?
0.04
0.068-way
Capacity
• What does it reduce?
0
0.02
1 2 4 8 6 2 4 8
Cache Size (KB)
1 2 4 8
16 32 64
128
Compulsory
Hit time (wire delay)Cost

2. Reduce Miss Rate via Larger Cache
100%1
80%1-way
2-way4-way
Conflict
40%
60%y
8-way
Capacity
20%
Capacity
0%
1 2 4 8
16 32 64
128
Cache Size (KB)
1
Compulsory

3. Reduce Miss Rate via Higher Associativity
• 2:1 Cache Rule: Miss Rate of a Direct-Mapped cache of size N pp= Miss Rate of a 2-way cache of size N/2
• Works up to 128K...
B E ti ti i th l fi l !• Beware: Execution time is the only final measure!– Will Clock Cycle time increase?– Hill [1988] suggested hit time for 2-way vs. 1-way [ ] gg y y
external cache +10%, internal + 2%
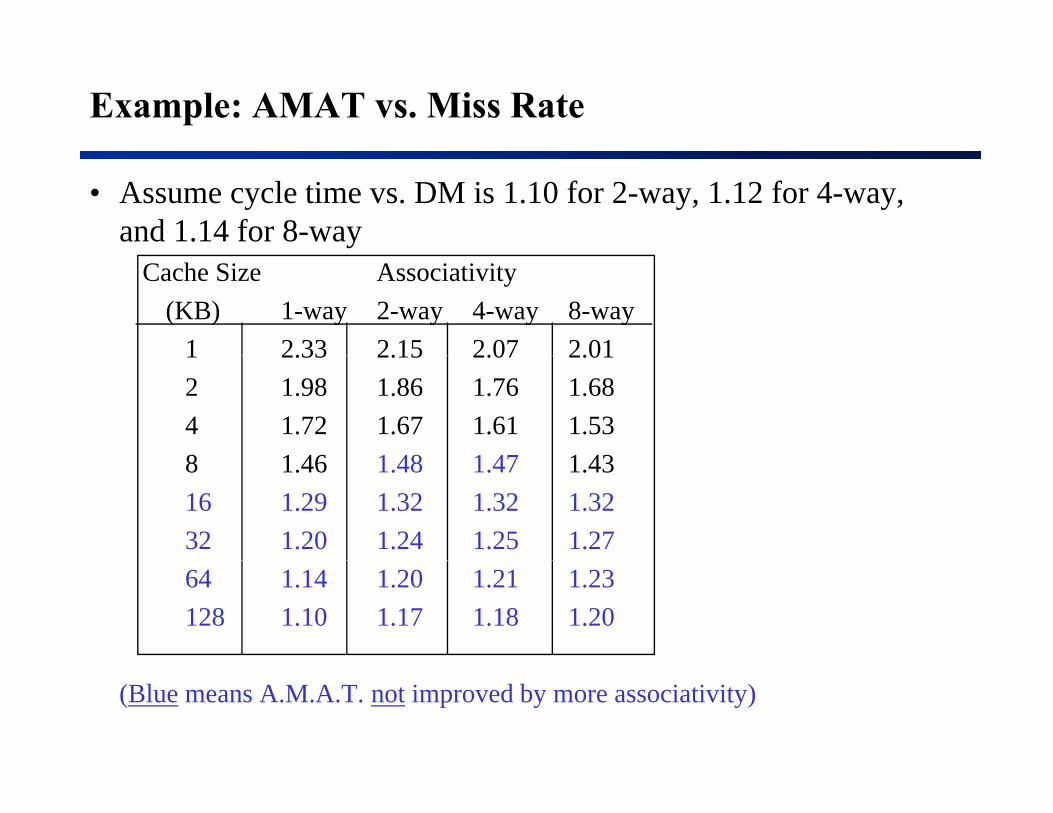
Example: AMAT vs. Miss Rate
• Assume cycle time vs. DM is 1.10 for 2-way, 1.12 for 4-way, and 1.14 for 8-way
Cache Size Associativity(KB) 1-way 2-way 4-way 8-way
1 2.33 2.15 2.07 2.011 2.33 2.15 2.07 2.012 1.98 1.86 1.76 1.684 1.72 1.67 1.61 1.538 1 46 1 48 1 47 1 438 1.46 1.48 1.47 1.4316 1.29 1.32 1.32 1.3232 1.20 1.24 1.25 1.2764 1.14 1.20 1.21 1.23128 1.10 1.17 1.18 1.20
(Blue means A.M.A.T. not improved by more associativity)

4. Reduce Miss Rate via Way Prediction and Pseudoassociativity
• How to combine fast hit time of Direct Mapped and have the lower conflict misses of 2-way SA cache? y
• Way Prediction: Predict which way will hit– 2-way: 50% chance
• Data Multiplexer set in advance– If wrong, check every block
• Example: 21264• Example: 21264– 1 cycle if right– 3 cycles if wrongy g– 85% accuracy on SPEC95
• Pseudoassociativity: On a miss, check the other half of the cache– Invert the highest bit of the index

Way Prediction

Pseudoassociativity
• Divide cache: on a miss, check other half of cache to see if there (invert most significant index bit), if so have a pseudo-hit (slow hit)
Hit Time
Pseudo Hit Time Miss Penalty
D b k CPU i li i h d if hit t k 1 2 l
Time
• Drawback: CPU pipeline is hard if hit takes 1 or 2 cycles– Better for caches not tied directly to processor (L2)– Used in MIPS R10000 L2 cache, similar in UltraSPARC

5. Reduce Miss Rate by Hardware Prefetching of Instructions & Data
• Example of instruction prefetching– Alpha 21064 fetches 2 blocks on a miss: the requested one is placed in
cache and the prefetched block is in “stream buffer”– If the requested instruction is in the stream buffer, cancel the original
request to the cache– 1 stream buffer catches 15% to 25% of the misses from a 4KB direct-
mapped instruction cache (Jouppi 1990). Four got 50%• Works with data blocks too:
– 1 data stream buffer got 25% misses from 4KB cache (Jouppi 1990); 4 buffers got 43%
– Palacharla & Kessler [1994] for scientific programs forPalacharla & Kessler [1994] for scientific programs for – 8 streams got 50% to 70% of misses from two 64KB, 4-way set
associative caches for scientific programs (Palacharla et al 1994)• Prefetching relies on having extra memory bandwidth that can be used without• Prefetching relies on having extra memory bandwidth that can be used without
penalty• Cache blocks are a form of prefetching

6. Reduce Miss Rate by Software Prefetching of Data
• Prefetching comes in two flavors:– Register prefetch will load the value into a register (PA-RISC)Register prefetch will load the value into a register (PA RISC)
• Must be correct address and register• The value is bound at the time the prefetch is performed
C h f t h L d i t h (MIPS IV P PC t )– Cache prefetch Load into cache (MIPS IV, PowerPC, etc.)• Can be incorrect. Frees HW/SW to guess!• The data value is not bound until the real load operation
• Either of these can be faulting or nonfaulting– Nonfaulting prefetches turn into no-ops if they would result in an
exceptionexception– A normal load is a “faulting register prefetch” instruction
• Issuing Prefetch Instructions takes timeg– Is cost of prefetch issues < savings in reduced misses?– Higher superscalar reduces difficulty of issue bandwidth

Software prefetch example
for (i=0;i<3;i++)for (j=0;j<100,j++)
a[i][j] = b[j][0] * b[j+1][0]
All elements 8 bytes longAll elements 8 bytes longCache: 8KB direct mapped, 16 byte blocks, write allocateArray a[3][100]: 3*100*8 bytes = 2400BArray b[101][3]: 3*101*8 bytes = 2424B What happens at each Array a access?a[0][0] a[0][1] a[0][2] a[0][3]a[0][0], a[0][1], a[0][2], a[0][3], …What happens for Array b?b[0][0], b[1][0], b[1][0], b[2][0], … for each i

Code with software prefetching
For (j=0;j<100;j++) { //prefetch setupprefetch(b[j+7][0]); //for 7 iterations laterprefetch(a[0][j+7]);a[0][j] = b[j][0] * b[j+1][0];
}For (i=1;i<3;i++) //use the prefetch
for (j=0;j<100;j++) {prefetch(a[i][j+7]);a[i][j] = b[j][0] * b[j+1][0];
}
Number of misses? 19 misses vs. 251
Number of prefetch instructions?

7. Reduce Miss Rate by Compiler Optimizations
• McFarling [1989] reduced caches misses by 75% on 8KB direct mapped cache, using software!pp , g
• Instructions– Reorder procedures in memory so as to reduce conflict misses– Profiling to look at conflicts (using tools they developed)
• DataMerging Arrays: improve spatial locality by single array of– Merging Arrays: improve spatial locality by single array of compound elements vs. 2 arrays
– Loop Interchange: change nesting of loops to access data in order d istored in memory
– Loop Fusion: Combine 2 independent loops that have same looping and some variables overlapp
– Blocking: Improve temporal locality by accessing “blocks” of data repeatedly vs. going down whole columns or rows

Padding and Offset Changes
• Cache size of 8KB
Before:int a[2048];
After:int a[2064];int b[2064];int b[2048];
int c[2048];
int b[2064];int c[2064];
for(i=0;i<2048;i++)C[i]=A[i]+B[i]
for(i=0;i<2048;i++)C[i]=A[i]+B[i]
Programmer should do this!

Merging Arrays
/* Before: 2 sequential arrays */int val[SIZE];int key[SIZE];
/* After: 1 array of stuctures */struct merge {struct merge {
int val;int key;
};};struct merge merged_array[SIZE];
Reduce conflicts between val & key; improve spatial locality

Loop Interchange
/* Before */for (j = 0; j < 100; j = j+1)for (j 0; j < 100; j j+1)
for (i = 0; i < 5000; i = i+1)x[i][j] = 2 * x[i][j];
/* After *// After /for (i = 0; i < 5000; i = i+1)
for (j = 0; j < 100; j = j+1)x[i][j] = 2 * x[i][j];x[i][j] = 2 * x[i][j];
/* C: Row-major order */
Sequential accesses instead of striding through memory every 100 words; improved spatial locality

Loop Fusion
/* Before */for (i = 0; i < N; i = i+1)for (j = 0; j < N; j = j+1)
a[i][j] = 1/b[i][j] * c[i][j];for (i = 0; i < N; i = i+1)for (j = 0; j < N; j = j+1)
d[i][j] = a[i][j] + c[i][j];/* After */for (i = 0; i < N; i = i+1)for (j = 0; j < N; j = j+1){ a[i][j] = 1/b[i][j] * c[i][j];
d[i][j] = a[i][j] + c[i][j];}
2 misses per access to a & c vs one miss per access;2 misses per access to a & c vs. one miss per access; improve spatial locality
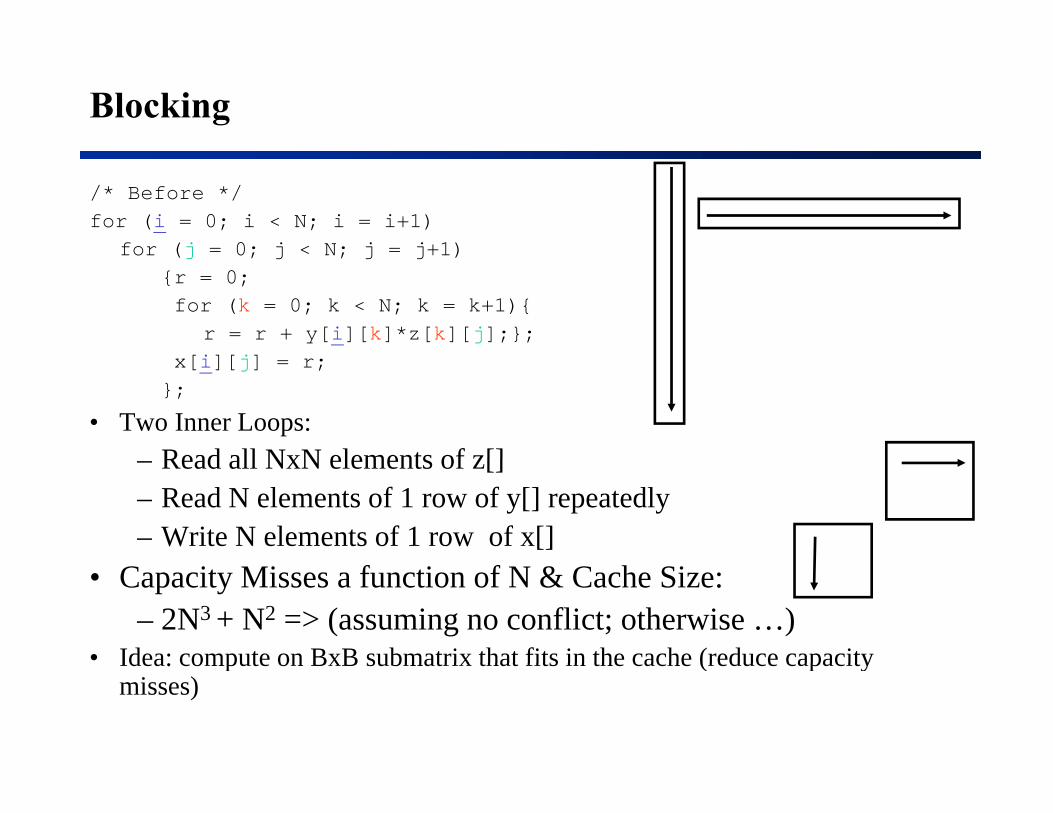
Blocking
/* Before */for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)for (j 0; j < N; j j+1){r = 0;for (k = 0; k < N; k = k+1){
r = r + y[i][k]*z[k][j];};[i][j]x[i][j] = r;
};
• Two Inner Loops:Read all NxN elements of z[]– Read all NxN elements of z[]
– Read N elements of 1 row of y[] repeatedly– Write N elements of 1 row of x[]
• Capacity Misses a function of N & Cache Size:– 2N3 + N2 => (assuming no conflict; otherwise …)
• Idea: compute on BxB submatrix that fits in the cache (reduce capacityIdea: compute on BxB submatrix that fits in the cache (reduce capacity misses)

Blocking
/* After */for (jj = 0; jj < N; jj = jj+B)(jj jj jj jj )for (kk = 0; kk < N; kk = kk+B)for (i = 0; i < N; i = i+1)
for (j = jj; j < min(jj+B 1 N); j = j+1)for (j = jj; j < min(jj+B-1,N); j = j+1){r = 0;
for (k = kk; k < min(kk+B-1,N); k = k+1) {
r = r + y[i][k]*z[k][j];};x[i][j] = x[i][j] + r;
};};
• B called Blocking Factor• Capacity Misses from 2N3 + N2 to N3/B+2N2

Blocking

Reducing Conflict Misses by Blocking
0.1
0.05 Direct Mapped Cache
Fully Associative Cache
00 50 100 150
• Conflict misses in non-FA-caches vs. Blocking sizeLam et al [1991] a blocking factor of 24 had a fifth the
Blocking Factor
– Lam et al [1991] a blocking factor of 24 had a fifth the misses vs. 48 despite both fitting in cache

Summary of Compiler Optimizations to Reduce Cache Misses (by hand)
t ( 7)
vpenta (nasa7)
btrix (nasa7)
tomcatv
gmty (nasa7)
h l kspice
mxm (nasa7)
btrix (nasa7)
compress
cholesky(nasa7)
Performance Improvement
1 1.5 2 2.5 3
mergedarrays
loopinterchange
loop fusion blocking

Summary: Miss Rate Reduction
CPUtime = IC × CPI Execution +Memory accesses
Instruction× Miss rate × Miss penalty⎛
⎝ ⎞ ⎠ × Clock cycle time
• 3 Cs: Compulsory, Capacity, Conflict1. Reduce Misses via Larger Block Size2 R d Mi i Hi h A i ti it2. Reduce Misses via Higher Associativity3. Reduce Misses via Way Prediction and Pseudoassociativity5. Reduce Misses by HW Prefetching Instr, Data6. Reduce Misses by SW Prefetching Data7. Reduce Misses by Compiler Optimizations

Cache Optimization Summary
Techniques MR MP HT ComplexityLarger Block Size + – 0Larger Caches + – 1M
iss Rat
gHigher Associativity + – 1Way Prediction + 2Pseudoassociative Caches + 2HW P f t hi f I t /D t + + 2/3e HW Prefetching of Instr/Data + + 2/3Compiler Controlled Prefetching + + 3Compiler Reduce Misses + 0

Reducing Miss Penalty
• Have already seen two examples of techniques to reduce miss penaltyp y– Write buffers give priority to read misses over writes– Merging write buffers
l i d i f h i l d i• Multiword writes are faster than many single word writes
• Now we consider several more– Victim CachesVictim Caches– Critical Word First/Early Restart– Multilevel caches– Non-blocking cache– Load bypassing/forwarding

Write Buffer Refresher
• Usually many more reads than writes– 20% of data cache traffic20% of data cache traffic– 7% of overall traffic (I + D)
• Read stalls until data arrives; write stalls until data is taken– Writes can be buffered and written later
• What about RAW?D i th b ff– Drain the buffer
– Search the buffer• Write-allocate
– Turn write miss into read miss, then write

1. Reduce Miss Penalty: Read Priority
• Naive write-back cache:– Read miss requiring evictionRead miss requiring eviction– Write dirty victim block to memory– Read new block from memory– Return read to CPU– Miss penalty = 2 memory accesses
• Improvement:• Improvement:– Read miss requiring eviction– Move dirty victim block to write buffer while reading new block
from memory– Return read to CPU
Empty write buffer when memory is available– Empty write buffer when memory is available– Miss penalty = 1 memory access

2. Reduce Miss Penalty: Early Restart and Critical Word First
• CPU normally just needs one word at a time• Large cache blocks have long transfer timesg g• Don’t wait for full block to be loaded before restarting CPU
– Early restart — As soon as the requested word of the block arrives, send it to the CPU and let the CPU continuesend it to the CPU and let the CPU continue
– Critical Word First — Request the missed word first from memory and send it to the CPU as soon as it arrives; let the CPU continue execution while filling the rest of the words in the block Alsoexecution while filling the rest of the words in the block. Also called wrapped fetch and requested word first.
• Generally useful only with large blocks
block

3. Reduce Miss Penalty: Load bypassing/forwarding
Load bypassing Load forwarding
Store X Store X
Store Y Store Y
Load Z (Execute this before the Stores)
Load X (Forward Store X)Stores)
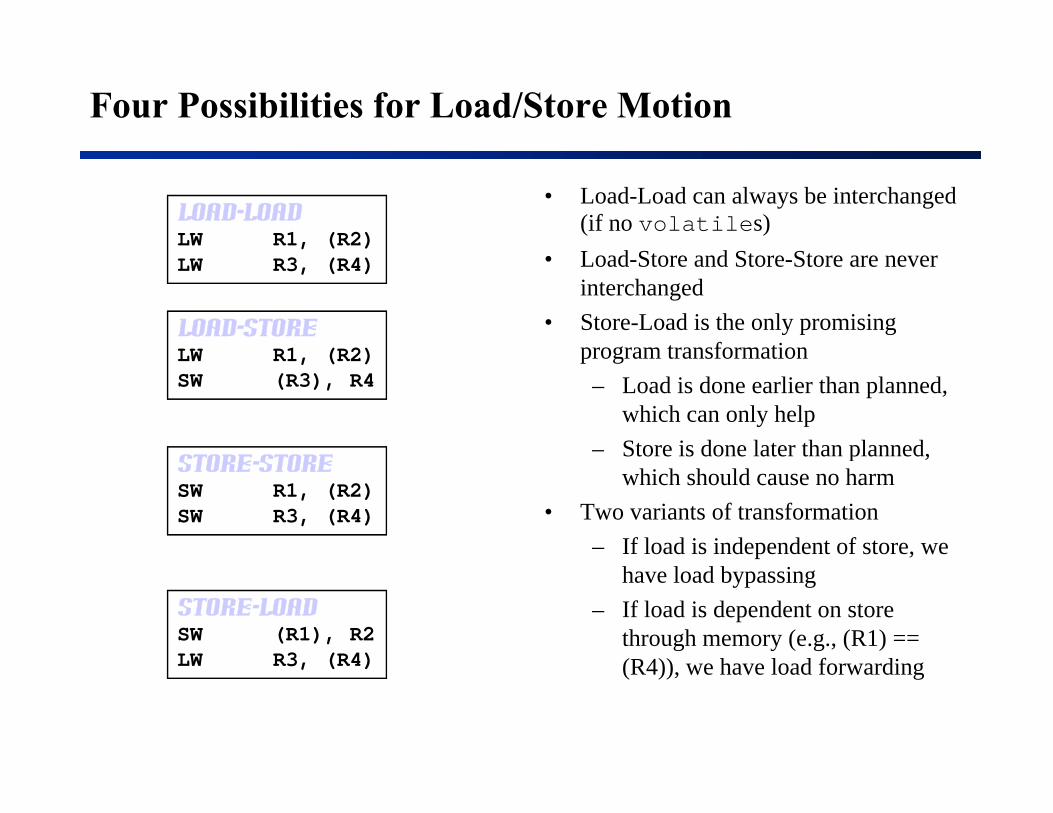
Four Possibilities for Load/Store Motion
Load-LoadLW R1, (R2)
• Load-Load can always be interchanged (if no volatiles)L d St d St StLW R3, (R4) • Load-Store and Store-Store are never interchanged
• Store-Load is the only promising program transformation
Load-StoreLW R1 (R2) program transformation
– Load is done earlier than planned, which can only help
– Store is done later than planned,
LW R1, (R2)SW (R3), R4
Store Storep ,
which should cause no harm• Two variants of transformation
– If load is independent of store, we
Store-StoreSW R1, (R2)SW R3, (R4)
have load bypassing– If load is dependent on store
through memory (e.g., (R1) == (R4)) h l d f di
Store-LoadSW (R1), R2LW R3, (R4) (R4)), we have load forwardingLW R3, (R4)

Load/store processing pipeline

Reduce Miss Penalty via Load bypassing/forwarding
Load forwardingLoad bypassing

Reduce Miss Penalty via Load bypassing/forwarding
• In-order issue of loads/stores -> Out-of-order issue
• Problem: Load may alias with in-transit store that’s not yet in store buffer
• Solution: Finished load buffer -> complete in program order. If alias detected, reissue load

4. Reduce Miss Penalty: Non-blocking Caches
• Non-blocking cache or lockup-free cache allows data cache to continue to supply cache hits during a miss
i F/E bit i t t f d ti– requires F/E bits on registers or out-of-order execution– requires multi-bank memories– “hit under miss” reduces the effective miss penalty by working during
miss vs. ignoring CPU requests• “hit under multiple miss” or “miss under miss” may further lower the
effective miss penalty by overlapping multiple misses– Significantly increases the complexity of the cache controller as there can
be multiple outstanding memory accesses– Requires the main memory can service multiple missesq y p– Pentium Pro allows 4 outstanding memory misses

Non-blocking caches
• Dual-ported, non-blocking cache
• Non-blocking: Missed load queue stores missed load instructions

Value of Hit Under Miss for SPEC
Figure 5.23

5. Reducing Miss Penalty: Victim Caches
• Direct mapped caches => many conflict misses• Solution 1: More associativity (expensive)Solution 1: More associativity (expensive)• Solution 2: Victim Cache• Victim Cache
– Small (4 to 8-entry), fully-associative cache between L1 cache and refill pathHolds blocks discarded from cache because of evictions– Holds blocks discarded from cache because of evictions
– Checked on a miss before going to L2 cache– Hit in victim cache => swap victim block with cache block– 4-entry victim cache removed 20% to 95% of conflicts for a 4 KB
direct mapped data cache (Jouppi [1990])Used in Alpha HP machines– Used in Alpha, HP machines

Victim Cache
• Even one entry helps some benchmarks!
• Helps more for smaller caches larger blockcaches, larger block sizes

6: Reduce Miss Penalty via a Second-Level Cache
• Q: Why a second cache level?– A: same reason as before!A: same reason as before!
• L1 is cache for memory; L2 is cache for L1• L1 can be small and fast to match the clock cycle time of the CPU
L2 i l t t th t ld t i• L2 is large to capture many accesses that would go to main memory
• Considerations– L2 not tied to CPU
• Can have its own clock• Likely to be set-associative
L2 d i f tl b l– L2 accessed infrequently: can be more clever– L2 is not free ($$$)– L2 increases miss penalty for DRAM accessesp y

Second-Level Cache Performance
• L2 EquationsAMAT = Hit TimeL1 + Miss RateL1 × Miss PenaltyL1Miss Penalty = Hit Time + Miss Rate × Miss PenaltyMiss PenaltyL1 = Hit TimeL2 + Miss RateL2 × Miss PenaltyL2AMAT = Hit TimeL1 +
Miss RateL1 × (Hit TimeL2 + Miss RateL2 × Miss PenaltyL2)
• Definitions:– Local miss rate — misses in this cache divided by the total number of
memory accesses to this cache (Miss rateL2)y ( L2)• Number of misses / Number of refs to cache• Local miss rate of L2 cache is usually not very good because most locality has
been filtered out by the L1 CacheGl b l i i hi h di id d b h l b f– Global miss rate — misses in this cache divided by the total number of memory accesses generated by the CPU (Miss RateL1 × Miss RateL2)
• Number of misses / Number of refs of CPU• Global Miss Rate is what matters• Global Miss Rate is what matters

Comparing Local and Global Miss Rates
• Global miss rate close to single level cache rate provided L2 >> L1 (32KB)• Local cache rate is not a good measure of secondary cache

Another Graph To Stare At...
Base performance is 8192 byte L2 cache with a hit time of 1 cycleWhat do you see?y

L2 Cache Performance
• For L2 Caches– Low latency, high bandwidth is less importantLow latency, high bandwidth is less important– Low miss rate is very important– Why?
• L2 Caches design for– Unified (I+D)
Larger Size (4 8MB) at the expense of latency– Larger Size (4-8MB) at the expense of latency– Larger block sizes (128Byte lines!) – High associativity: 4, 8, 16 at the expense of latency

Multilevel inclusion
• Inclusion is said to hold between level i and level i+1 if all data in level i is also in level i+1
• Desirable because for I/O and multiprocessors only have to keep 2nd level consistent
• Difficult when different block sizes at various levels– When a block in L2 is to be replaced, all related blocks in L1 have
to be invalidated A slightly higher miss rateo be v d ed s g y g e ss e• Multilevel exclusion: L1 data is never found in L2
– Do not waste space to keep multiple copies– L1 misses result in a swap of blocks between L1 and L2– AMD Athlon has only 256 KB L2 cache (two 64KB L1 cache)

7. Reduce Miss Penalty: Write Buffer Merging

Summary: Miss Penalty Reduction
CPUtime = IC × CPI Execution +Memory accesses
Instruction× Miss rate × Miss penalty⎛
⎝ ⎞ ⎠ × Clock cycle time
• Five techniques– Read priority over write on miss
E l R t t d C iti l W d Fi t– Early Restart and Critical Word First– Victim Caches– Non-blocking Caches (Hit under Miss, Miss under Miss)
S d L l C h– Second Level Cache• Can be applied recursively to Multilevel Caches
– Danger is that time to DRAM will grow with multiple levels in betweenFi L2 h k hi i i d– First attempts at L2 caches can make things worse, since increased worst case is worse

Cache Optimization Summary
Techniques MR MP HT ComplexityLarger Block Size + – 0Larger Caches + – 1M
iss Ra
Larger Caches + – 1Higher Associativity + – 1Way Prediction + 2Pseudoassociative Caches + 2te HW Prefetching of Instr/Data + + 2/3Compiler Controlled Prefetching + + 3Compiler Reduce Misses + 0Priority to Read Misses + 1
Miss Pen
Priority to Read Misses 1Early Restart & Critical Word 1st + 2Victim cache + + 2Load bypassing/forwarding + 3nalty
Non-Blocking Caches + 3Second Level Caches + 2Write buffer merging + 1

Improving Cache Performance
1. Reduce the miss rate, 2 Reduce the miss penalty or2. Reduce the miss penalty, or3. Reduce the time to hit in the cache.
i lii iA A yMissPenaltMissRateHitTimeAMAT ×+=

1. Reduce Hit time via Small and Simple Caches
• Always need to read the tag array– Direct mapping: can read data in parallel (why?)Direct mapping: can read data in parallel (why?)
• Speed up external L2 by keeping tags on-chip

2. Reduce Hit Time by Avoiding Address Translation
• Conventional organization:
– translate on every access
CPU TLB $ MEMVA PA PA
• Virtually addressed cache:
CPU $ TLB MEMVA VA PA
– translate only on a miss– Looks great! But...

Virtually Addressed Cache
• Aliasing: Different virtual addresses can map to the same physical addressp y– H/W can check all aliases and invalidate on a miss
• Example: 21264 uses 64K I$ with 8K page, so there are 8 possible aliasesaliases.
– Page coloring: set-associative mapping applied to VM page mapping, so that aliases match in their low-order address bits
• Aliases will always have the same index and offset
Tag Index Offset VAPA
012301223

Virtually Addressed Cache
• Multiprocessing– Processes use the same virtual addresses for their own physicalProcesses use the same virtual addresses for their own physical
addresses• Flush the cache on a context switch
Ouch! Cost = flush + compulsory misses– Ouch! Cost = flush + compulsory misses• Extend tag with Process Identifier (PID)
– Page-Level protection is enforced during VA->PA address l itranslation
• Copy protection info from TLB to cache on miss– Adds a datapath
– Input/Output direct memory access• DMA uses physical addresses. How to invalidate?

Multiprocessing Impact
Figure 5.25

Virtually Indexed, Physically Tagged Cache
• Best of both worlds?– Start cache read immediatelyStart cache read immediately– Only need PA for tag compare
CPU$
TLBMEM
VA PA
• But index+offset limited to VM page size– Increase cache size through higher associativity

3. Reduce Hit Time by Pipelining Cache Access
• Pipeline access split into multiple cycles so faster cycle time• Increase throughput rather than decrease latencyIncrease throughput rather than decrease latency

4. Reduce Hit Time With A Trace Cache
• Predict instruction sequences and fetch them into the instruction cache– Fold branch predictor into cache– Fragmentation: small basic blocks not aligned to large cache blocks– Multiple copies: same instruction can be part of several traces

Cache Optimization Summary
Techniques MR MP HT ComplexityLarger Block Size + – 0Larger Caches + – 1M
iss Ra
Larger Caches + – 1Higher Associativity + – 1Way Prediction + 2Pseudoassociative Caches + 2te HW Prefetching of Instr/Data + + 2/3Compiler Controlled Prefetching + + 3Compiler Reduce Misses + 0Priority to Read Misses + 1
Miss Pen
Priority to Read Misses 1Early Restart & Critical Word 1st + 2Victim cache + + 2Load bypassing/forwarding + 3nalty
Non-Blocking Caches + 3Second Level Caches + 2Write buffer merging + 1Small & Simple Caches – + 0H
itTim
e
Small & Simple Caches + 0Avoiding Address Translation + 2Pipelining Caches + 1