memory networks, neural turing machines, and question answering
TRANSCRIPT

1/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Memory Networks, Neural Turing Machines,and Question Answering
Akram El-Korashy1
1Max Planck Institute for Informatics
November 30, 2015Deep Learning Seminar.
Papers by Weston et al. (ICLR2015), Graves et al. (2014), andSukhbaatar et al. (2015)

2/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Outline
1 IntroductionIntuition and resemblance to human cognitionHow does it look like?
2 QA Experiments, End-to-EndArchitecture - MemN2NTrainingBaselines and Results
3 QA Experiments, Strongly SupervisedArchitecture - MemNNTrainingResults
4 NTM code induction experiments

3/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Intuition and resemblance to human cognition
Why memory?
Human’s working memory is a capacity for short-term storageof information and its rule-based manipulation. . .
Therefore, an NTM1resembles a working memory system, as itis designed to solve tasks that require the application ofapproximate rules to “rapidly-created variables”.
1Neural Turing Machine. I will use it interchangeably with MemoryNetworks, depending on which paper I am citing.

4/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Intuition and resemblance to human cognition
Why memory? Why not RNNs and LSTM?
The memory in these models is the state of the network, whichis latent (i.e., hidden; no exlpicit access) and inherentlyunstable over long timescales. [Sukhbaatar2015]
Unlike a standard network, NTM interacts with a memory matrixusing selective read and write operations that can focus on(almost) a single memory location. [Graves2014]

5/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Intuition and resemblance to human cognition
Why memory networks? How about attention models with RNNencoders/decoders?
The memory model is indeed analogous to the attentionmechanisms introduced for machine translation.

5/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Intuition and resemblance to human cognition
Why memory networks? How about attention models with RNNencoders/decoders?
The memory model is indeed analogous to the attentionmechanisms introduced for machine translation.
Main differencesIn a memory network model, the query can be made overmultiple sentences, unlike machine translation.The memory model makes several hops on the memorybefore making an output.The network architecture of the memory scoring is asimple linear layer, as opposed to a sophisticated gatedarchitecture in previous work.

6/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Intuition and resemblance to human cognition
Why memory? What’s the main usage?
Memory as non-compact storageExplicitly update memory slots mi on test time by making use ofa “generalization” component that determines “what” is to bestored from input x , and “where” to store it (choosing amongthe memory slots).
Storing stories for Question AnsweringGiven a story (i.e., a sequence of sentences), training of theoutput component of the memory network can learn scoringfunctions (i.e., similarity) between query sentences and existingmemory slots from previous sentences.

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
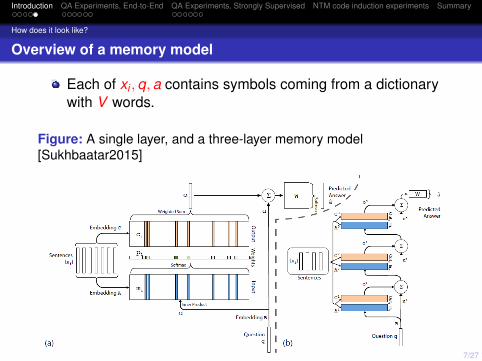
A memory model that is trained only end-to-end.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
Trained model takes a set of inputs x1, ..., xn to be stored inthe memory, a query q, and outputs an answer a.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]
7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
Each of xi ,q,a contains symbols coming from a dictionarywith V words.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
All x is written to memory up to a fixed buffer size, then finda continuous representation for the x and q.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
The continuous representation is then processed viamultiple hops to output a.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
This allows back-propagation of the error signal throughmultiple memory accesses back to input during training.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]
7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
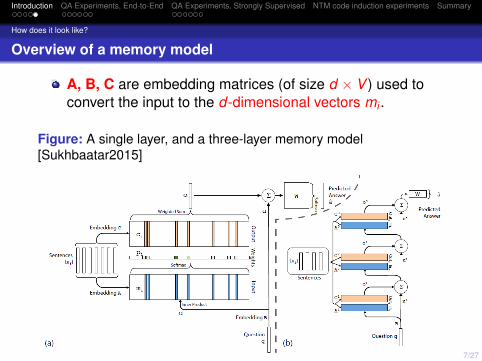
A, B, C are embedding matrices (of size d × V ) used toconvert the input to the d-dimensional vectors mi .
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
A match is computed between u and each memory mi bytaking the inner product followed by a softmax.
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
The response vector o from the memory is the weightedsum: o =
∑i pici .
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

7/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
How does it look like?
Overview of a memory model
The final prediction (answer to the query) is computed withthe help of a weight matrix as: a = Softmax(W (o + u)).
Figure: A single layer, and a three-layer memory model[Sukhbaatar2015]

8/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Plan
1 IntroductionIntuition and resemblance to human cognitionHow does it look like?
2 QA Experiments, End-to-EndArchitecture - MemN2NTrainingBaselines and Results
3 QA Experiments, Strongly SupervisedArchitecture - MemNNTrainingResults
4 NTM code induction experiments

9/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Synthetic QA tasks, supporting subset
There are a total of 20 different types of tasks that testdifferent forms of reasoning and deduction.
Figure: A given QA task consists of a set of statements, followed by aquestion whose answer is typically a single word. [Sukhbaatar2015]

9/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Synthetic QA tasks, supporting subset
Note that for each question, only some subset of thestatements contain information needed for the answer, andthe others are essentially irrelevant distractors (e.g., thefirst sentence in the first example).
Figure: A given QA task consists of a set of statements, followed by aquestion whose answer is typically a single word. [Sukhbaatar2015]

9/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Synthetic QA tasks, supporting subset
In the Memory Networks of Weston et al., this supportingsubset was explicitly indicated to the model during training.
Figure: A given QA task consists of a set of statements, followed by aquestion whose answer is typically a single word. [Sukhbaatar2015]

9/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Synthetic QA tasks, supporting subset
In what is called end-to-end training of memory networks,this information is no longer provided.
Figure: A given QA task consists of a set of statements, followed by aquestion whose answer is typically a single word. [Sukhbaatar2015]

9/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Synthetic QA tasks, supporting subset
20 QA tasks. A task is a set of example problems. Aproblem is a set of I sentences xi where I ≤ 320, aquestion q and an answer a.
Figure: A given QA task consists of a set of statements, followed by aquestion whose answer is typically a single word. [Sukhbaatar2015]

9/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Synthetic QA tasks, supporting subset
The vocabulary is of size V = 177! Two versions of thedata are used, one that has 1000 training problems pertask, and one with 10,000 per task.
Figure: A given QA task consists of a set of statements, followed by aquestion whose answer is typically a single word. [Sukhbaatar2015]

10/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Architecture - MemN2N
Model ArchitectureK = 3 hops were used.Adjacent weight sharing was used to ease training and reducethe number of parameters.
Adjacent weight tying1 The output embedding of a layer is input to the layer
above. (Ak+1 = Ck )2 Answer prediction is the same as the final output.
(W T = CK )3 Question embedding is the same as the input to the first
layer. (B = A1)

11/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Architecture - MemN2N
Sentence Representation, Temporal Encoding
Two different sentence representations: bag-of-words(BoW), and Position Encoding (PE)
BoW embeds each words, and sums the resulting vectors,e.g., mi =
∑j Axij .
PE encodes the position of the word using a column vectorlj where lkj = (1 − j/J)− (k/d)(1 − 2j/J), where J is thenumber of words in the sentence.

11/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Architecture - MemN2N
Sentence Representation, Temporal Encoding
Two different sentence representations: bag-of-words(BoW), and Position Encoding (PE)
BoW embeds each words, and sums the resulting vectors,e.g., mi =
∑j Axij .
PE encodes the position of the word using a column vectorlj where lkj = (1 − j/J)− (k/d)(1 − 2j/J), where J is thenumber of words in the sentence.
Temporal Encoding: Modify the memory vector with aspecial matrix that encodes temporal information. 2
Now, mi =∑
j Axij + TA(i), where TA(i) is the i th row of aspecial temporal matrix TA.All the T matrices are learned during training. They aresubject to the sharing constraints as between A and C.
2There isn’t enough detail on what constraints this matrix should besubject to, if any.

12/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Training
Loss function and learning parameters
Embedding Matrices A, B and C, as well as W are jointlylearnt.Loss function is a standard cross entropy between a andthe true label a.Stochastic gradient descent is used with learning rate ofη = 0.01, with annealing.

13/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Training
Parameters and TechniquesRN: Learning time invariance by injecting random noise toregularize TA
LS: Linear start: Remove all softmax except for the answerprediction layer. Apply it back when validation loss stopsdecreasing. (LS learning rate of η = 0.005 instead of 0.01for normal training.)LW: Layer-wise, RNN-like weight tying. Otherwise,adjacent weight tying.BoW or PE: sentence representation.joint: training on all 20 tasks jointly vs independently.
[Sukhbaatar2015]

14/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
RN: Learning time invariance by injecting random noise toregularize TA
Figure: All variants of the end-to-end trained memory modelcomfortably beat the weakly supervised baseline methods.[Sukhbaatar2015]

14/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
LS: Linear start: Remove all softmax except for the answer prediction layer. Apply it back when validation loss stopsdecreasing. (LS learning rate of η = 0.005 instead of 0.01 for normal training.)
Figure: All variants of the end-to-end trained memory modelcomfortably beat the weakly supervised baseline methods.[Sukhbaatar2015]

14/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
LW: Layer-wise, RNN-like weight tying. Otherwise, adjacentweight tying.
Figure: All variants of the end-to-end trained memory modelcomfortably beat the weakly supervised baseline methods.[Sukhbaatar2015]

14/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
BoW or PE: sentence representation.
Figure: All variants of the end-to-end trained memory modelcomfortably beat the weakly supervised baseline methods.[Sukhbaatar2015]

14/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
take-home msg: More memory hops give improvedperformance.
Figure: All variants of the end-to-end trained memory modelcomfortably beat the weakly supervised baseline methods.[Sukhbaatar2015]

14/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
take-home msg: Joint training on various tasks sometimeshelps.
Figure: All variants of the end-to-end trained memory modelcomfortably beat the weakly supervised baseline methods.[Sukhbaatar2015]

15/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Baselines and Results
Set of Supporting Facts
Figure: Instances of successful prediction of the supportingsentences.

16/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Plan
1 IntroductionIntuition and resemblance to human cognitionHow does it look like?
2 QA Experiments, End-to-EndArchitecture - MemN2NTrainingBaselines and Results
3 QA Experiments, Strongly SupervisedArchitecture - MemNNTrainingResults
4 NTM code induction experiments

17/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Architecture - MemNN
IGOR
The memory network consists of a memory m and 4 learnedcomponents
1 I: (input feature map) - converts the incoming input to theinternal feature representation.
2 G: (generalization) - updates old memories given the newinput.
3 O: (output feature map) - produces a new output, given thenew input and the current memory state.
4 R: (response) - converts the output into the responseformat desired.

18/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Architecture - MemNN
Model Flow
The core of inference lies in the O and R modules. The Omodule produces output features by finding k supportingmemories given x .For k = 1, the highest scoring supporting memory isretrieved: o1 = O1(x ,m) = argmax
i=1,...,NsO(x ,mi).
For k = 2, a second supporting memory is additionallycomputed: o2 = O2(x ,m) = argmax
i=1,...,NsO([x ,mo1 ],mi).
In the single-word response setting, where W is the set ofall words in the dict., then r = argmax
w∈WsR([x ,mo1 ,mo2 ],w).

19/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Training
Max-margin, SGD
Supporting sentences annotations are available as part of the trainingdata. Thus, scoring functions are trained by minimizing a marginranking loss over the model parameters UO and UR using SGD.
Figure: For a given question x with true response r and supportingsentences mO1 , mO2 (i.e., k = 2), this expression is minimized overparameters UO and UR :
where f , f ′ and r are all other choices than the correct labels, and γ is the margin.
20/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Results
large-scale QA
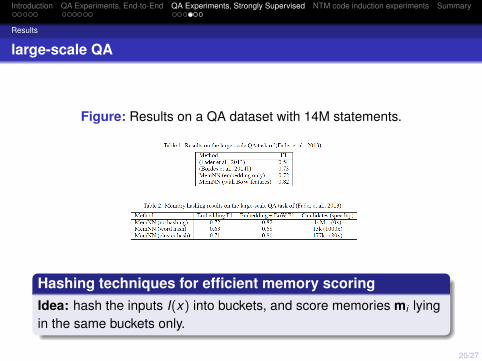
Figure: Results on a QA dataset with 14M statements.
Hashing techniques for efficient memory scoringIdea: hash the inputs I(x) into buckets, and score memories mi lyingin the same buckets only.

20/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Results
large-scale QA
Figure: Results on a QA dataset with 14M statements.
Hashing techniques for efficient memory scoringword hash: a bucket per dict. word, containing all sentences thatcontain this word.

20/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Results
large-scale QA
Figure: Results on a QA dataset with 14M statements.
Hashing techniques for efficient memory scoringcluster hash: Run K-means to cluster word vectors (UO)i , giving Kbuckets. Hash sentence to all buckets in which its words belong.

21/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Results
simulation QA
Figure: The task is a simple simulation of 4 characters, 3 objects and5 rooms - with characters moving around, picking up and droppingobjects. (Similar to the 10k dataset of MemN2N)

22/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Results
simulation QA - sample test rseults
Figure: Sample test set predictions (in red) for the simulation in thesetting of word-based input and where answers are sentences and anLSTM is used as the R component of the MemNN.

23/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Plan
1 IntroductionIntuition and resemblance to human cognitionHow does it look like?
2 QA Experiments, End-to-EndArchitecture - MemN2NTrainingBaselines and Results
3 QA Experiments, Strongly SupervisedArchitecture - MemNNTrainingResults
4 NTM code induction experiments

24/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Architecture
More sophisticated memory “controller”.
Figure: Content-addressing is implemented by learning similaritymeasures, analogous to MemNN. Additionally, the controller offerssimulation of location-based addressing by implementing a rotationalshift of a weighting.

25/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
NTM learns a Copy task
Figure: The networks were trained to copy sequences of eight bitrandom vectors, where the sequence lengths were randomizedbetween 1 and 20. NTM with LSTM controller was used.

25/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
... on which LSTM fails
Figure: The networks were trained to copy sequences of eight bitrandom vectors, where the sequence lengths were randomizedbetween 1 and 20. NTM with LSTM controller was used.

26/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Summary
Intuition of memory networks vs standard neural networkmodels.MemNN is successful through strongly-supervised learningin QA tasksMemN2N is used with more realistic end-to-end training,and is competent enough on the same tasks.NTMs can learn simple memory copy and recall tasks frominput-memory, output-memory training data.

26/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
Summary
Intuition of memory networks vs standard neural networkmodels.MemNN is successful through strongly-supervised learningin QA tasksMemN2N is used with more realistic end-to-end training,and is competent enough on the same tasks.NTMs can learn simple memory copy and recall tasks frominput-memory, output-memory training data.
Thank you!

27/27
Introduction QA Experiments, End-to-End QA Experiments, Strongly Supervised NTM code induction experiments Summary
References
End-To-End Memory Networks, Sainbayar Sukhbaatar,Arthur Szlam, Jason Weston, Rob Fergus, 2015.Memory Networks, Jason Weston, Sumit Chopra, AntoineBordes, 2015Neural Turing Machines, Alex Graves, Greg Wayne, IvoDanihelka, 2014Deep learning at Oxford 2015, Nando de Freitas