modeling learning trajectories with batch gradient descent
TRANSCRIPT

Modeling Learning Trajectories with BatchGradient Descent
Joe Pater and Robert Staubs
Department of Linguistics
NECPhon, MIT, 10/26/2013
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 1 / 1

Overview
1 A gradual batch model: replication of Jaeger’s (2007)replication of Boersma and Levelt (2000)
2 Comparison with on-line models
3 Derivation of MaxEnt gradient descent
4 Regularization and hidden structure
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 2 / 1

Gradient descent: a gradual batch model
There seems to be a general assumption in the phonologicalliterature that ‘batch’ implies ‘non-gradual’.
From our soon-to-be-revised unpublished ms.:
‘Another important avenue for further research is the developmentof on-line learning algorithms in this framework. Such methodsmay be more cognitively plausible than the batch method we haveexplored and would certainly be more useful in modeling the courseof human language acquisition.’
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 3 / 1

Gradient descent: a gradual batch model
In using gradient ascent/descent for the modeling of humanlearning trajectories, we are following a suggestion ofGoldwater and Johnson’s (2003):
‘Gradient ascent is a popular but not very efficient optimizationalgorithm which may produce human-like learning curves, althoughwe have not investigated this here’
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 4 / 1

Gradient descent: a gradual batch model
In this we are preceded by Jaeger (2007), who shows that asampling version of Stochastic Gradient Ascent is nearlyidentical to Boersma’s (1998) Gradual Learning Algorithm forStochastic OT.
Jaeger’s (2007) model samples from the training data(on-line/‘Stochastic’) and from the probability distributiondefined by the grammar (‘sampling version’)
The version of gradient descent that we are using eliminatesboth of these kinds of sampling, which has great practicalconsequences for the modeler (see also Moreton, Pater andPertsova 2013)
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 5 / 1

Gradient descent: a gradual batch modelWe’ll start with the familiar on-line update (=HG-GLA,Perceptron), and show how the two kinds of sampling can bestraightforwardly eliminated in a MaxEnt modelThe update takes the difference between the vectors ofconstraint violations of two representations, and scales it bythe learning rate (multiplies it by a small number)Constraints, violations with negative integers, and differencevector:
! !! ! "#$#%&! '&()*!+,&(-(-.!%&)&!!/0(--1,2! 34&()35!64&()7! 89! !
:1&,-1,;<!.,&==&,!/:#<1,2! 34&()35!64&(7! ! 89!
>(??1,1-@1!/!"#"$2! 89! A9!!!34&()3!
"#$#%&!B!
'&()*!C!
%" &%" '"
64&()7! 89! ! 8B! DEDDF! DE99G!64&(7! ! 89! 8C! DED9H! DEHH9!! 8DE99G! 8DEHH9! ! ! !!!!34&()3! ! "#$#%&! '&()*!64&()7! DEG! 89! !64&(7! DE9! ! 89!! ! 8DEG! 8DE9!!! !! "#$#%&! '&()*!+,&(-(-.!%&)&!! 8DEG! 8DE9!:1&,-1,;<!.,&==&,! 8DE99G! 8DEHH9!>(??1,1-@1!/!"#"$2! !"#$%&' ("#$%&'!!!!! "#$#%&!
9D!'&()*!D!
%" &%" '"
34&()35!64&()7! 89! ! 89D! I!EDD9! I!EDD9!34&()35!64&(7! ! 89! D! 9! 9!!! "#$#%&!
B!'&()*!C!
%" &%" '"
34&()35!64&()7! 89! ! 8B! EDDF! E99G!34&()35!64&(7! ! 89! 8C! ED9H! EHH9!!!!! "#$#%&!
B!'&()*!C!
%" &%" '"
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 6 / 1

Gradient descent: a gradual batch model
Jaeger (2007) gets the output of the learner’s grammar, a‘Loser’, by sampling. We instead take the probability weightedsum of violation vectors to represent the learner’s expectation.
! !! ! "#$#%&! '&()*!+,&(-(-.!%&)&!!/0(--1,2! 34&()35!64&()7! 89! !
:1&,-1,;<!.,&==&,!/:#<1,2! 34&()35!64&(7! ! 89!
>(??1,1-@1!/!"#"$2! 89! A9!!!34&()3!
"#$#%&!B!
'&()*!C!
%" &%" '"
64&()7! 89! ! 8B! DEDDF! DE99G!64&(7! ! 89! 8C! DED9H! DEHH9!! 8DE99G! 8DEHH9! ! ! !!!!34&()3! ! "#$#%&! '&()*!64&()7! DEG! 89! !64&(7! DE9! ! 89!! ! 8DEG! 8DE9!!! !! "#$#%&! '&()*!+,&(-(-.!%&)&!! 8DEG! 8DE9!:1&,-1,;<!.,&==&,! 8DE99G! 8DEHH9!>(??1,1-@1!/!"#"$2! !"#$%&' ("#$%&'!!!!! "#$#%&!
9D!'&()*!D!
%" &%" '"
34&()35!64&()7! 89! ! 89D! I!EDD9! I!EDD9!34&()35!64&(7! ! 89! D! 9! 9!!! "#$#%&!
B!'&()*!C!
%" &%" '"
34&()35!64&()7! 89! ! 8B! EDDF! E99G!34&()35!64&(7! ! 89! 8C! ED9H! EHH9!!!!! "#$#%&!
B!'&()*!C!
%" &%" '"
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 7 / 1

Gradient descent: a gradual batch model
Jaeger (2007) also gets the training datum, a ‘Winner’, bysampling. We instead take the probability weighted sum ofviolation vectors to represent the training data.
! !! ! "#$#%&! '&()*!+,&(-(-.!%&)&!!/0(--1,2! 34&()35!64&()7! 89! !
:1&,-1,;<!.,&==&,!/:#<1,2! 34&()35!64&(7! ! 89!
>(??1,1-@1!/!"#"$2! 89! A9!!!34&()3!
"#$#%&!B!
'&()*!C!
%" &%" '"
64&()7! 89! ! 8B! DEDDF! DE99G!64&(7! ! 89! 8C! DED9H! DEHH9!! 8DE99G! 8DEHH9! ! ! !!!!34&()3! ! "#$#%&! '&()*!64&()7! DEG! 89! !64&(7! DE9! ! 89!! ! 8DEG! 8DE9!!! !! "#$#%&! '&()*!+,&(-(-.!%&)&!! 8DEG! 8DE9!:1&,-1,;<!.,&==&,! 8DE99G! 8DEHH9!>(??1,1-@1!/!"#"$2! !"#$%&' ("#$%&'!!!!! "#$#%&!
9D!'&()*!D!
%" &%" '"
34&()35!64&()7! 89! ! 89D! I!EDD9! I!EDD9!34&()35!64&(7! ! 89! D! 9! 9!!! "#$#%&!
B!'&()*!C!
%" &%" '"
34&()35!64&()7! 89! ! 8B! EDDF! E99G!34&()35!64&(7! ! 89! 8C! ED9H! EHH9!!!!! "#$#%&!
B!'&()*!C!
%" &%" '"
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 8 / 1

Gradient descent: a gradual batch model
And then we just do the same update, but now it’s over all ofthe training data, and over the learner’s entire expectation,rather over a sample of each.
! !! ! "#$#%&! '&()*!+,&(-(-.!%&)&!!/0(--1,2! 34&()35!64&()7! 89! !
:1&,-1,;<!.,&==&,!/:#<1,2! 34&()35!64&(7! ! 89!
>(??1,1-@1!/!"#"$2! 89! A9!!!34&()3!
"#$#%&!B!
'&()*!C!
%" &%" '"
64&()7! 89! ! 8B! DEDDF! DE99G!64&(7! ! 89! 8C! DED9H! DEHH9!! 8DE99G! 8DEHH9! ! ! !!!!34&()3! ! "#$#%&! '&()*!64&()7! DEG! 89! !64&(7! DE9! ! 89!! ! 8DEG! 8DE9!!! !! "#$#%&! '&()*!+,&(-(-.!%&)&!! 8DEG! 8DE9!:1&,-1,;<!.,&==&,! 8DE99G! 8DEHH9!>(??1,1-@1!/!"#"$2! 8DEIH9! ADEIH9!!!!!! "#$#%&!
9D!'&()*!D!
%" &%" '"
34&()35!64&()7! 89! ! 89D! J!EDD9! J!EDD9!34&()35!64&(7! ! 89! D! 9! 9!!! "#$#%&!
B!'&()*!C!
%" &%" '"
34&()35!64&()7! 89! ! 8B! EDDF! E99G!34&()35!64&(7! ! 89! 8C! ED9H! EHH9!!!!! "#$#%&!
B!'&()*!C!
%" &%" '"
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 9 / 1

Gradient descent: a gradual batch model
There’s also no need to sample from the set of tableaux. Weagain take the probability weighted sum, for both the trainingdata and the learner’s expectation.
Probabilities of syllable types in Dutch (Boersma and Levelt2000 via Jaeger 2007)
5 Order of acquisition 7
empirical expectation value of each constraint is replaced by the observed value.Adapted to ME, the update rule thus is
(�rk+1)j = (�rk)j + η · (cj(ik, ok) − E�r[cj ])
Recall that the distribution p�r is a product of the theoretical conditionalprobability distribution p�r(o|i) and the marginal empirical probabilities of theinputs pemp(i). The latter cannot be calculated analytically. Therefore E�r[cj ]has to be estimated as well. We thus replace it by a random variable that hasE�r[cj ] as its expected value. This can be done by drawing a sample hk fromthe distribution p�r(·|i) corresponding to the current rankings �r. This leads usto the revised update rule
(�rk+1)j = (�rk)j + η · (cj(ik, ok) − cj(ik, hk))
For the special case that all constraints are binary, this is the Gradual Learn-ing Algorithm, and for the general case it is very closely related to it.
Let us consider the consequences of this finding. Both the GLA for StOTand SGA for ME are on-line algorithms. They both converge iff the empiricaland the acquired expectation value for each constraint coincide, i.e. if for allconstraints Cj :
Eemp[cj ] − E�r[cj ] = 0
Under the ME interpretation, among all distributions sharing this property,the learning algorithm finds the one with the highest entropy. If the GLAunder the StOT interpretation converges towards a different distribution for thesame training corpus, it will be one with lower entropy, i.e. a less parsimonioushypothesis.
5 Order of acquisition
Boersma and Levelt (2000) report an experiment where the acquisition of Dutchsyllable structures was simulated using StOT and the GLA. I repeated theexperiment with a ME model and SGA and obtained almost identical results.
The attested frequency of Dutch syllable types in child directed speech is asin table 1 (taken from Boersma and Levelt (2000) who attribute it to Joost vande Weijer, personal communication).
CV 44.81% CCVC 1.98%CVC 32.05% CCV 1.38%VC 11.99% VCC 0.42%V 3.85% CCVCC 0.26%
CVCC 3.25%
Tab. 1: Frequency of syllable types in Dutch
Following the optimality theoretic acquisition study Levelt and van de Vi-jver (1998), Boersma and Levelt (2000) assume the following five constraintspertaining to syllable structure:Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 10 / 1
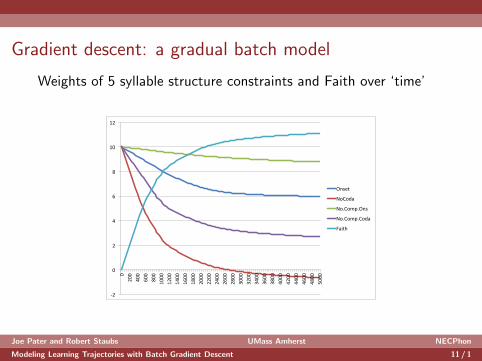
Gradient descent: a gradual batch model
Weights of 5 syllable structure constraints and Faith over ‘time’
!"#
$#
"#
%#
&#
'#
($#
("#$#
"$$#
%$$#
&$$#
'$$#
($$$
#("
$$#
(%$$
#(&
$$#
('$$
#"$
$$#
""$$
#"%
$$#
"&$$
#"'
$$#
)$$$
#)"
$$#
)%$$
#)&
$$#
)'$$
#%$
$$#
%"$$
#%%
$$#
%&$$
#%'
$$#
*$$$
#
+,-./#
012134#
01521675+,-#
015216752134#
849/:#
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 11 / 1
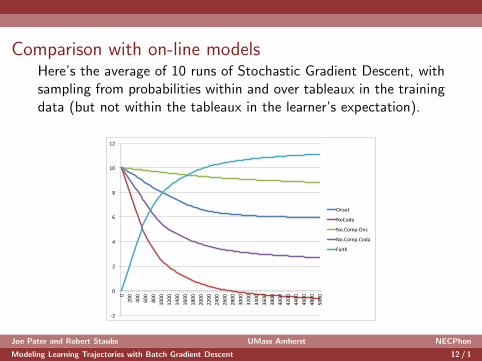
Comparison with on-line modelsHere’s the average of 10 runs of Stochastic Gradient Descent, withsampling from probabilities within and over tableaux in the trainingdata (but not within the tableaux in the learner’s expectation).
!"#
$#
"#
%#
&#
'#
($#
("#
$#"$
$#%$
$#&$
$#'$
$#($
$$#
("$$
#(%
$$#
(&$$
#('
$$#
"$$$
#""
$$#
"%$$
#"&
$$#
"'$$
#)$
$$#
)"$$
#)%
$$#
)&$$
#)'
$$#
%$$$
#%"
$$#
%%$$
#%&
$$#
%'$$
#*$
$$#
+,-./#
012134#
01521675+,-#
015216752134#
849/:#
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 12 / 1

Where’s the gradient?
Gradient descent finds a minimum according to some lossfunction
The gradient we use here corresponds to negative loglikelihood loss
The exponential form of MaxEnt grammar gives a simplegradient analogous to the perceptron rule or HG-GLA(Boersma & Pater 2014)
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 13 / 1

Deriving the gradientStart with form of likelihood, applying properties of logarithms.
∂
∂wlogL(w ; y) =
∂
∂wlog
∏i
P(yi |w)
=∂
∂w
∑i
logP(yi |w)
=∂
∂w
∑i
logew
T vi∑j e
wT vj
=∑i
∂
∂wlog ew
T vi − ∂
∂wlog
∑j
ewT vj
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 14 / 1

Gradient breaks into a numerator term and denominator term. Thedenominator contains a model probability in it.
∂
∂wlogL(w ; y) =
∑i
[vi −
∂∂w
∑j e
wT vj∑j e
wT vj
]
=∑i
vi −∑j
vjewT vj∑
j ewT vj
=
∑i
vi −∑j
vjP(yj |w)
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 15 / 1

The denominator term has the form of an expectation.
∂
∂wlogL(w ; y) =
∑i
vi −∑j
vjP(yj |w)
=
∑i
vi − EP [vj ]
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 16 / 1

As the examples we started with showed, gradient descent canhandle non-categorical distributions
K-L divergence loss (error minimization) is a generalization ofnegative log likelihood loss
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 17 / 1

Regularization
Regularization imposes restrictions on solutions beyond fit todata
This type of restriction is implemented slightly differently indifferent types of learning:
1 Priors for learning from likelihood2 Regularization terms for batch learning by maximum likelihood3 Decay terms for gradual learning
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 18 / 1

L(w ; y) ∝∏i
e− (wi−µi )
2
2σ2i Gaussian prior (1)
logL(w ; y) ∝ −∑i
(wi − µi )22σ2i
L2 regularization (2)
∂
∂wjlogL(w ; y) ∝ −(wj − µj)
σ2jdecay (3)
Encourages weights close to set values – penalizes sum of squareddifferences.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 19 / 1

L(w ; y) ∝∏i
e−|wi−µi |
λ Laplacian prior (4)
logL(w ; y) ∝ −∑i
|wi − µi |λi
L1 regularization (5)
∂
∂wjlogL(w ; y) ∝ −λj sgn(wj) decay (6)
Encourages weights to equal set values – penalizes sum of absolutedifferences.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 20 / 1
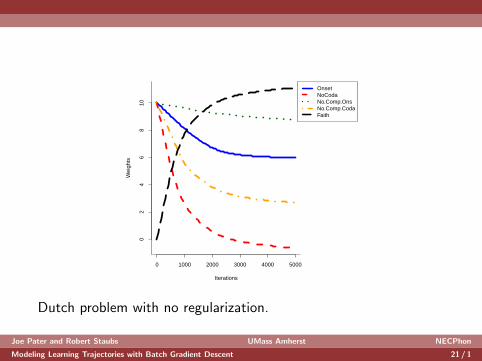
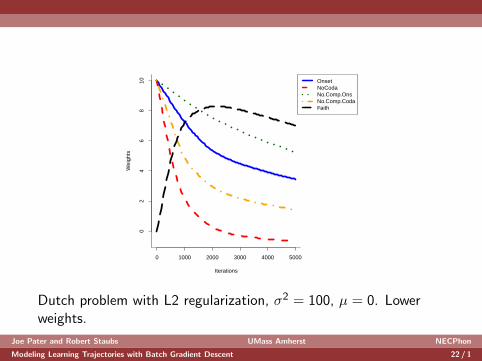
0 1000 2000 3000 4000 5000
02
46
810
Iterations
Wei
ghts
OnsetNoCodaNo.Comp.OnsNo.Comp.CodaFaith
Dutch problem with no regularization.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 21 / 1
0 1000 2000 3000 4000 5000
02
46
810
Iterations
Wei
ghts
OnsetNoCodaNo.Comp.OnsNo.Comp.CodaFaith
Dutch problem with L2 regularization, σ2 = 100, µ = 0. Lowerweights.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 22 / 1
0 1000 2000 3000 4000 5000
02
46
810
Iterations
Wei
ghts
OnsetNoCodaNo.Comp.OnsNo.Comp.CodaFaith
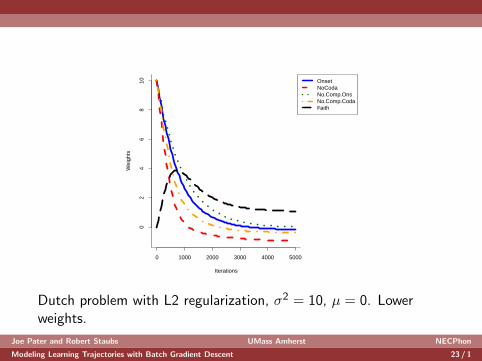
Dutch problem with L2 regularization, σ2 = 10, µ = 0. Lowerweights.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 23 / 1
0 1000 2000 3000 4000 5000
02
46
810
Iterations
Wei
ghts
OnsetNoCodaNo.Comp.OnsNo.Comp.CodaFaith
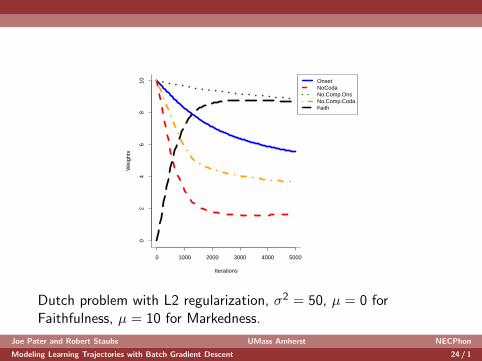
Dutch problem with L2 regularization, σ2 = 50, µ = 0 forFaithfulness, µ = 10 for Markedness.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 24 / 1

0 1000 2000 3000 4000 5000
02
46
810
Iterations
Wei
ghts
OnsetNoCodaNo.Comp.OnsNo.Comp.CodaFaith
Dutch problem with L1 regularization, λ = 0.1, µ = 0. Moresparsity (zero weights).
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 25 / 1

Hidden structure
The probability of an overt structure y is the sum of theprobabilities of the hidden structures z that correspond to it(e.g. Eisenstat NECPhon 2; Pater et al. NECPhon 3; Pater etal. 2012)
Recall: the gradient without hidden structure is the differencebetween the violations of the observed forms and the expectedviolations under the model
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 26 / 1

With hidden structure the observed violations are not known
One strategy is to use the expected violations of hiddenstructures for the observed structure under the model’sprobabilities
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 27 / 1

No hidden structure:
∑i
vi − EP [vj ]
Hidden structure:
∑i
EP [v |yi ]− EP [vj ]
This approach thus has the form of Expectation-Maximization.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 28 / 1

We replicate an example from Pater et al. (2012) of a languagewith final devoicing.
SR Meaninga. [bet] catb. [beda] catsc. [mot] dogd. [mota] dogs
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 29 / 1

The hidden structure here is the assumed UR for the alternatingword.
UR options SR Meaning
a./bed/
[bet] cat/bet/
b./bed+a/
[beda] cats/bet+a/
c. /mot/ [mot] dogd. /mot+a/ [mota] dogs
These URs are controlled by constraints which motivate theirchoice.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 30 / 1

0 1000 2000 3000 4000 5000
−1.
0−
0.5
0.0
0.5
1.0
1.5
2.0
Iterations
Wei
ghts
cat /bed/cat /bet/Id.VoiceCoda.VcelessInter.Vce
Devoicing problem with L2 regularization, σ2 = 10, µ = 0.Starting weights at 0.
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 31 / 1

Hidden structure introduces non-convexity—local minima—tothe learning problem
Different starting weights may end up in different optima
Gradient descent for hidden structure still needs somesampling—but only over starting weights (or some othermethod for avoiding local minima)
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 32 / 1

Conclusions
Why use a batch model?
Because there is no sampling, there is a single learning curvegiven an initial set of weights
An on-line model requires multiple runs and averaging to geta representative learning curve
Multiple runs and averaging are inconvenient, and require adecision on an appropriate number of runs
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 33 / 1

Conclusions
Why use on-line learning?
Because you know the order of the data, and want to modelits effects (though a sliding batch window is also a possibility)
Because your problem is very large, in which case samplingcan be more efficient
Or because you need to sample because you aren’t usingMaxEnt
Cognitive plausibility arguments are questionable
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 34 / 1
Resources
Scripts and example files to be available at Harmonic Grammar inR site:http://blogs.umass.edu/hgr/
Software for Elliott Moreton’s related weightless MaxEnt algorithm:http://www.unc.edu/~moreton/Software/Weightless/
Joe Pater and Robert Staubs UMass Amherst NECPhon
Modeling Learning Trajectories with Batch Gradient Descent 35 / 1