morpheme-specific phonology: constraint indexation and inconsistency resolution joe pater, 2008; in...
Post on 21-Dec-2015
231 views
TRANSCRIPT

Morpheme-specific Phonology: Constraint Indexation and Inconsistency Resolution
Joe Pater, 2008; in Steve Parker (ed.) Phonological Argumentation: Essays
on Evidence and Motivation

Organisation of the Paper
• Exceptional triggering and blocking of syncope in Yine – illustrating markedness and faithfulness indexing.
• The Locality question: morpheme-specific indexing versus other approaches
• Indexing and learning viz., indexing as a tool of inconsistency resolution.
• Conclusions

Introduction
• The different tacks to handle morpheme-specific phonology (MSI hereafter) in OT:– A theory in which individual
morphemes select separate rankings viz., the “cophonology” approach (Anttila 2002)
– Faithfulness-only indexing (Fuzakawa 1999 and Ito and Mester 1999 & 2001)
– Indexing of faithfulness AND markedness constraints (the present approach)
• As will be observed, the present approach is better than the other two for the following reasons:– Its ease in incorporating
locality considerations which play a definitive role in MSP’s.
– Its ability to distinguish exceptional triggering (through markedness-indexing) and blocking (through faithfulness-indexing).
– Its separation of exceptionality and variation which Anttila’s (2002) approach wrongly conflates.

Predecessors of Indexing in OT
• Alignment (McCarthy and Prince 1993) and Edgemost (Prince and Smolensky 1993/2004) represent indexation in that edges of morphological categories/specific morphemes are identified as being governed by specific alignment considerations .
• Fuzukawa (1999), Ito and Mester (1999, 2001), Kraska-Szelenk (1997, 1999) and Pater (2000) extend morphological indexation from Alignment to other constraints as well.

Morpheme-specific Indexing (MSI): the Basics
• Every constraint has a general instantiation • Some constraints may have a specific
instantiation which will be indexed to (or “co-indexed” with) the morphemes responsible for exceptional behaviour.
• Crux: The indexed and unindexed variants of a constraint are essentially different constraints in the overall hierarchy.

Hypothetical Case 1:
• NoCoda >> Max: Coda consonants always deleted.
• Max >> NoCoda: Coda consonants always retained.
• MaxL >> NoCoda >> Max: Indexed morphemes (e.g., [tak]L /tak/) will retain their coda consonant (MaxL >> NoCoda) but unindexed ones (e.g., [pak] /pak/) will not (NoCoda >> Max).

Hypothetical Case 1 contd…
• Assume the language bans complex onsets completely: *Complex >> MaxL >> NoCoda >> Max.– (i) When there is external
evidence for exceptionality (coda retention) the indexing approach captures it with the ranking MaxL >> NoCoda.
– (ii) When there is no such evidence (consonant clusters) for exceptionality, the indexing approach disallows it: *Complex >> MaxL
• Cophonology: In this approach, which has only one instantiation of a constraint, exceptional and impossible patterns cannot be teased apart.– (i) Exceptional coda retention:
reversing the general ranking NoCoda >> Max (viz., Max >> NoCoda).
– (ii) Clusters cannot be banned because the system allows just about any sort of re-ranking: there is nothing “inherent” in the system to prevent *Complex >> Max Max >> *Complex.

The Subregularity Convention
• Because the cophonology approach cannot readily prevent rankings yielding impossible patterns, Anttila (2002) invokes this convention.
• As per this, only (pairs of) constraints which are unranked w. r. t one another (i.e. those in charge of the variation) can be re-ranked whereas the rest of the ranking remains inalterable:– In the hypothetical example therefore, *Complex >>
Max would be fixed whereas Max, NoCoda can choose different rankings for different morphemes.

Differences between MSI and Cophonology
• MSI(i) Filters out a rich base based on
positive evidence.(ii) Separates variation from
exceptionality without stipulation.
(iii) Distinguishes exceptional triggering from blocking
(iv) Addresses locality effects
• Cophonology(i) Requires a stipulation (like
SBC) to rule out spurious rankings.
(ii) Conflates exceptionality and variation in that pairs of constraints which are unranked underlie both variation and exceptional patterns .
(iii) Cannot distinguish exceptional triggering from blocking.
(iv) Cannot deal with locality

A Demonstration of MSI: Syncope in Yine
Kisseberth (1970) (c.f Matteson (1965)
reviews suffix-based syncope in Yine
(formerly Piro) for its implications for a
theory of exceptions in rule-based Phonology.

Classes of Suffixes Involved:
(a) Those which trigger syncope on the preceding morpheme (details of suffix class omitted): [-lu], [-nu] and [-ya].
(b) Those which fail to trigger syncope: [-ta], (another) [-nu] and [-wa] but themselves undergo it before class (a) suffixes.
(c) Exceptional [-wa] which neither conditions nor undergoes syncope; a homophonous [-wa], however, undergoes syncope when placed before class (a) suffixes.

The MSI Analysis:
• Constraint conditioning syncope: Align-Suf-C (Align Suffix, L, Consonant, R)
• Align-Suf-C >> Max: syncope• To distinguish the syncope-
triggering suffixes from non-triggers, Align-Suf-C (L1) (the indexed version) is created and the triggering suffixes share the index (L1).
• Align-Suf-C (L1) >> Max >> Align-Suf-C: Indexed morphemes trigger syncope (Align-Suf-C (L1) >> Max) and unindexed ones do not (Max >> Align-Suf-C).
• To distinguish suffixes which undergo syncope from those that do not Max (L2) is created.
• Max (L2) >> Align-Suf-C (L1) >> Max >> Align-Suf-C: Morphemes indexed with L2 do not undergo syncope when they follow L1 suffixes but otherwise do.

Tableau 1
Align-Suf-C (L1) >> Max >> Align-Suf-C
Input Output Align-Suf-(L1)C
MAX Align-Suf-C
a. heta+ya(L1)
hetaya *! *
☞hetya *
b. heta+wa ☞hetawa *
hetwa *!

Tableau 2
MAX-L2 >> ALIGN-SUF(L1)-C >> MAX >> ALIGN-SUF-C
Input Output MAX(L2) Align-Suf(L1)-C MAX
a.heta+nu+lu(L1)
☞hetanru *
hetanulu *!
b.heta+wa(L2)+lu(L1)
☞hetawalu *
hetawlu *! *

Yine Syncope (contd…)
• Syncope is also avoided just in case it would create a tri-consonant cluster (*CCC).
• The overall constraint hierarchy (under the MSI approach) for Yine syncope is: *CCC, Max (L2) >> Align-Suf(L1)-C >> Max >> Align-Suf-C

Yine Syncope under the Cophonology Approach: Drawbacks • This approach can handle syncope triggering (Align-Suf-C >> Max
for triggering morphemes) and blocking (Max >> Align-Suf-C for syncope blocking).
• But forms like /hetanru/ (from /heta+nu+lu/) will demand Max>> Align Suf-C for heta+nu /hetan…/ but will demand the opposite for nu+lu /nru/. There is no way to get blocking and triggering within different morphemes of the same word under this approach.
• Cophonology cannot also tackle the two instances of homophonous [-wa], one which undergoes syncope and the other which does not. In MSI, the [-wa] indexed to Max will not undergo syncope and the unindexed one will. Under the re-ranking approach, either both [-wa]’s will be predicted to undergo syncope or neither will.

Finnish [a+i] allomorphy (Anttila 2002)
• In Finnish, a stem-final /a/ preceding an [-i] in the plural/past suffix: deletes: [jumala+i+ssa] /jumalissa/;or mutates to /o/: [tavara+i+ssa] /tavaroissa/;or displays free variation: [itara+i+ssa] /itaroissa/ ~ /itarissa/.
• [a+i] configurations are allowed morpheme-internally so deletion/mutation is a DE effect.
• Anttila’s (2002) analysis focuses on the interplay between morphological and phonological factors conditioning the allomorphy.
• This paper, however, directly appeals to the (tentative, markedness) constraint driving the alternation: *[ai].

MSI Analysis and Locality:
• *[ai] is indexed to the [-i] in the relevant suffixes.• *[ai](L) – indexed – outranks both Max and Ident inducing repair (violating
faithfulness).• Locality convention *[X]L: “Assign a violation mark to any instance of X that
contains a phonological exponent of a morpheme specified as L.” (p. 10)• Indexed constraints apply if and only if the locus of violation contains the
indexed morpheme (or parts of it or conjunctions thereof): the locality convention therefore gives MSI an edge over alternative theories in that it is able to pick out sub-parts of morphemes which are active in triggering/blocking.
• *[ai](L) >> Max, Ident >> *[ai] will ensure that stem-final /a/ preceding [-i] undergoes mutation or gets deleted.
• If the stem is indexed for Max, mutation will take place: [tavara+i+ssa] /tavaroissa/. If it is indexed for Ident deletion would be the result: [jumala+i+ssa] /jumalissa/. Unindexed stems such as /itara--/ will display free variation (tableaux later).

Assamese ATR Harmony (Mahanta 2009) and MSI:
(1) In Assamese, the front and back mid vowels surface as [e] and [o] (viz., [+ATR]) when followed by high + ATR vowels /u/ or /i/. Elsewhere, the vowels come out as [-ATR] [ɛ] and [ɔ].
(2) The low vowel /a/ is generally opaque to ATR harmony except before the suffixes [-iya] and [-uwa]: While /a/ normally becomes /o/ before these suffixes (e.g., /sal/ ~ /sol-iya/; /dal/ ~ /dol-iya/), it becomes /e/ when preceded by another /e/ (e.g., /dhemel-iya/).
(3) Mahanta makes use of the markedness constraint*[-ATR][+ATR] to account for general ATR harmony and *[-ATR][+ATR] (L) to account for the exceptional harmonising of /a/ before [-iya] and [-uwa].
(4) Ident (Low) >> *[-ATR][+ATR]: /a/ does not “generally” undergo harmony. (5) *[-ATR][+ATR](L) >> Ident (Low) >> [-ATR][+ATR]: before [-iya] and [-
uwa] which are indexed for *[-ATR][+ATR](L), even /a/ undergoes harmony.

Tableau 3
Input Output *[-ATR][+ATR](L) Ident-Low
*[-ATR][+ATR]
/alax-
uwa/
alax-uwa *! *
☞ alox-uwa* *
olox-uwa **!

Local exceptional triggering: MSI and other approaches – a comparison• If [a+i] sequences in Finnish occur only at morpheme junctures, Cophonology,
MSI and faithfulness-only indexing can all account for it.• But when such strings occur tautomorphemically and heteromorphemically
(e.g., /taitta-i/) only MSI with its locality convention gets the right output: /taittoi/ or /taitti/; never */titti/ or *taittai/.
– Cophonology will demand the ranking FAITH >> *[ai] for the stem-internal [ai] and the opposite for the one at the stem+suffix juncture. There is no way to reconcile the rankings in such a way that the stem-internal [ai] is retained and the morpheme-junctural one is repaired.
– In the faithfulness-only indexing approach, if the stem is indexed for FAITH (and FAITH (L) >> *[ai] >> FAITH), then the stem-final /a/ that precedes suffixal [-i] will never be repaired; if not, then both [ai] sequences will be repaired, contrary to expectation.
• Faithfulness-only indexing and Cophonology can get /taittoi/ or /taitti/ only by resorting to a sub-theory of Derived Environment, a result obtained without additional machinery in MSI.

The problem:
• What MSI has and the other approaches do not is the facility to pick out parts of morphemes within a larger string through indexed constraints, making the constraints in turn apply to sub-word components and successfully.
• In other words, MSI’s locality convention *[X]L enables it to deal with cases like Finnish allomorphy, Assamese vowel harmony etc all of which are triggered locally.
• Faithfulness-indexing and Cophonology on the other hand, because their constraints are defined over entire morpho-phonological strings cannot handle inter-morphemic patterns of exceptional triggering and blocking which are in some sense local in nature.

Finnish [a+i] Allomorphy again:
• Recall: (i) *[a+i] is the marked configuration and is repaired in
Finnish when the /i/ is part of the plural or past suffix.(ii) The repair choice varies: when the stem is indexed for
Max, the /a/ preceding the suffix undergoes mutation; when it is indexed for Ident, it is deleted; when unindexed, either option may be chosen.
(iii) This is the general picture and holds of tri-syllabic stems (more generally those with odd parity of syllables).
Note: Double lines in the tableaux below indicate that the constraints separated by them are not ranked w. r. t each other.

Tableau 4
Input Output *[ai](L1)
MAX(L2)
IDENT(L3)
MAX IDENT
/itara-i(L1)-ssa/
itaraissa *!
☞itaroissa *
☞itarissa *
/tavara(L2)-i(L1)-ssa/
tavaraissa *!
☞tavaroissa *
tavarissa *! *
/jumala(L3)-i(L1)-ssa/
jumalaissa *!
jumaloissa *! *
☞jumalissa *

Finnish [a+i]: stems with an even number of syllables (Cophonology
and MSI treatments )1) For disyllabic stems, Anttila (2002) attributes the obligatory deletion of
(mutation does not occur in this context) stem-final /a/, when there is an /o/ preceding it, to a ban on the co-occurrence of foot-internal round vowels (constraint: OCP/V[rd]φ (OCP for short)).
2) Anttila (2002) – OCP >> Max (his *Del): mutation is not a possibility in this context.
3) MSI - Ident (L3), OCP >> Max (L2) >> Max, Ident: Even if a disyllabic stem is indexed for Max (L2), the stem-final /a/ will undergo deletion (and not mutate to /o/) if there is a preceding /o/ due to the ranking of the constraints in boldface.
4) Tableau below shows that a final /a/ in a disyllabic stem is bound by OCP and is therefore deleted; however, the final vowel in a tri-syllabic stem does not have a foot-internal /o/ preceding it whence it mutates to /o/.
5) Double lines indicate mutual lack of ranking.

Tableau 5
Input Output IDENT(L3)
OCP/V[rd]φ
MAX(L2)
MAX
IDENT
/tota (L2)-i(L1)/
☞ (toti) * *
(totoi) *! *
/itota(L2)-i(L1)/
(ito)ti *! *
☞ (ito)(toi) *

Finnish [a+i]: stems with an even number of syllables (contd)
6) When the foot-internal vowel preceding /a/ is not /o/, mutation (based on the tri-syllabic case in tableau 5) is expected to be the norm because OCP is irrelevant . However, there is actually free variation in this case: /taita+i/ /taiti/ ~ /taitoi/.
7) To derive default mutation in even-numbered stems (the contra case of OCP-driven deletion), one needs a constraint that applies only to even numbered stems: Pater adopts the constraint OO-Maxφ.
8) OCP/V[rd]φ >> OO-Maxφ, Ident (L3) >> Max (L2) >> Ident, Max: (a) without pressure from OCP, unindexed (even-numbered) stems will choose mutation (since Ident (L3) is irrelavant) which is the ‘default’ repair in this context; (b) stems indexed to Ident (L3) will involve free variation (never categorical deletion because of lack of ranking between OO-Maxφ, Ident (L3));(c) as for tri-syllabic stems, they will choose mutation if they are indexed for Max (L2), deletion if they are indexed for Ident (L3) and free variation when they are unindexed.
Note: 8 (a) and (b) are illustrated in tableau 6 below; 8 (c) in tableau 5 above.
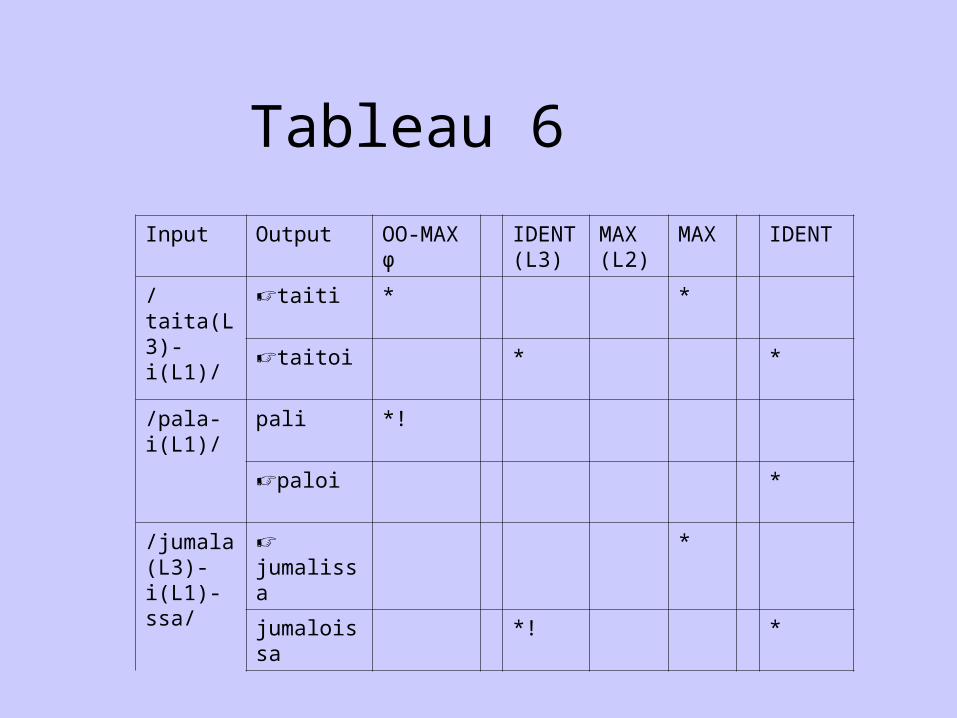
Tableau 6
Input Output OO-MAX φ
IDENT(L3)
MAX(L2)
MAX
IDENT
/taita(L3)-i(L1)/
☞taiti * *
☞taitoi * *
/pala-i(L1)/
pali *!
☞paloi *
/jumala(L3)-i(L1)-ssa/
☞jumalissa *
jumaloissa *! *

A comparison of approaches
• Anttila (2002) does not handle even-numbered cases without foot-internal round vowels viz., cases like /pala+i/ /paloi/ which involve mutation.
• The overall analysis cannot anyway be translated into his morpheme-specific re-ranking approach:– For instance, free variation for /taita-i/ requires Ident and Max to
be unranked (as per the Subregularity Convention whose outcome is the conflation of exceptionality and variation as noted earlier).
– But this would mean that stems are (also) free to pick the ranking Max >> Ident leading to consistent mutation in this environment which runs contrary to the empirical fact.

Constraint-indexing as Inconsistency Resolution:
• Exceptions to phonological patterns result in inconsistent data sets (Tesar, Alderete, Horwood, Merchant, Nishitani and Prince (2003)) with which the prevalent constraint rankings are incompatible: that is, some parts of the data may demand one ranking and others a different one.
• Tesar and Smolensky’s (1998) Constraint Demotion Algorithm is a tool devised to deduce this type of inconsistency.
• In a hypothetical language, for instance, which has /pa/~/pak/, /lo/ ~ lok/ and /tak/ ~ /ta/ as the winner loser-pairs, NoCoda >> Max will pick the winner in the first two instances but the loser in the third. The CDA “will fail to rank these constraints” and “declare the data inconsistent.” (Prince 2002) as discussed in Pater (2008: p. 19).
• The Recursive Constraint Demotion Algorithm (RCD) (Tesar and Smolensky 1998) is useful in picking out the locus of inconsistency:

Operation of the Recursive Constraint Demotion Algorithm
Constraints preferring only winners installed in a stratum|
Winner ~ loser data pairs covered by installed constraints removed
|Constraints preferring only winners in the remaining data installed in the
next stratum|
Process repeated until all data are covered; or there are no more constraints preferring only winners in the residue.
|Residue the locus of inconsistency.

RCD and Indexing
• In the case of lexical stress, location of inconsistency is ensued by alteration to the underlying representation (Tesar et al 2003) called “lexical surgery”.
• However, the search space of possible lexical changes is huge for other morpheme-specific phonological patterns and “surgery” therefore seems unlikely in these cases.
• In this context, indexing can be brought in (only) where “consistency” ends: (a) once the RCD deduces inconsistency, a constraint selecting winners for all instances of some morpheme is indexed with all such morphemes and is installed in a stratum;(b) the RCD now iterates again, indexing other constraints if required with morphemes for which they choose only winners, until the entire dataset is accounted for.

Indexing as inconsistency resolution: a re-look at syncope in Yine
• Max and Align-Suf-C, the crucial constraints, both pick winners and losers as seen below:
Input W~L Max Align-Suf-C
heta+lu hetlu~hetalu L (heta) W (lu)
heta+nu hetanu~hetnu W (heta) L (nu)
heta+wa+lu hetawalu~hetawlu W (wa) L (lu)
heta+nu+lu hetanru~hetanulu L (nu) W (lu)

Indexing and RCD:
• At first blush, Max can be indexed only for [-wa] because it prefers Ws and Ls for /heta/ as does Align-Suf-C for [-lu] and [-nu].
• Once the data pairs where Max (L1) chooses only winners are removed, Align-Suf-C chooses only winners for [-lu] with which it can be indexed.
• The next slide shows the installation of constraints in stratified fashion:

Stratified installation of indexed constraints:
Max (L1) >>
Input W~
L
Max Align-Suf-C
heta+lu hetlu ~
hetalu
L
(heta)
W
(lu)
heta+nu hetanu ~
hetnu
W
(heta)
L
(nu)
heta+nu+lu
hetanlu ~
hetanulu
L
(nu)
W
(lu)
Max (L1) >> Align-Suf-C (L2)
Input W~L Max Align-Suf-C
heta+ nu hetanu ~ hetnu
W (heta) L (nu)

Overall ranking and implications:
• *CCC >>> Max (L1) >> Align-Suf-C (L2) >> Max >> Align-Suf-C • *CCC is ranked on top because syncope never creates tri-consonant
clusters and its inviolability is definitive even before indexing begins (viz., inconsistency is deduced).
• Viewed as an algorithm for inconsistency resolution, indexing as a “meta-construct” will always be subordinated to the general constraint ranking which will always hold primacy in generating the non-exceptional phonological patterns:– E.g., /terka+lu/ /terkalu/ (*terklu) is decided even before inconsistency
is located because of high-ranking *CCC; so there is no way that the learner will delay learning this phonological pattern till inconsistency is detected by indexing /terka--/ with Max.

Representational Alternatives
• Matteson (1965): non-triggering morphemes in Yine accounted for by postulation of an empty V-slot before the suffix-initial consonant (e.g., Vta) (see Wolf 2006 for an OT derivation of the account).
• Morphemes which do not undergo syncope (exceptionally) may be subject to faithfulness to some aspect of syllable structure (e.g., Max-mora) which blocks syncope.
• The problem is threefold:(i) How does the learner choose the correct representation?(ii) And how does one know that this representation is indeed (in some
cases) a mora when the entire vowel alternates (viz., vowel quality is not predictable)?
(iii) Even if it is plausible for the learner to restructure the input such that a faithfulness constraint is allowed to then choose the correct output, no currently extant learnability proposal accommodates such a provision.

Representational versus Diacritic Theories
• See Inkelas (1994) for a version of Lexicon Optimisation resulting in underspecified representations;
• See Tesar et al (2003) for comments on the grammar-blind nature of lexical “surgery” (Tesar and Smolensky 1998) and Tesar (2006) for contrast analysis.
• Ultimately, the criterion to assess the merit of diacritic theories and representational ones should be related to learnability and not some abstract/aesthetic principle (p.23).
• Although “diacritics” seem the way to go for the cases discussed, not all cases of exceptionality can or should be handled by indexing (see Ito and Mester 2001, Albright 2002 and Becker 2004 for more arguments favouring diacritic theories) :– Mutation processes whose markedness motivation has disappeared are
more amenable to representational analyses;– However, even proponents of representational tacks in OT also see a place
for some variant of morpheme-specific indexing (Inkelas 1999).

Among diacritic approaches
• Though faithfulness-only indexing seems prima facie too restrictive a model to handle all co-occurring patterns of lexically idiosyncratic phonological patterns (Inkelas and Zoll 2003), it is difficult to find examples that cannot be handled by faithfulness-only indexing given the M&F interactions in OT.
• As for markedness-indexing (Pater 2000, 2006, Ota 2004, and Flack to appear; see also Gelbart 2005) proposed here, it could run into one problem: relativised to a category like Affix, markedness-indexing can subvert the meta-ranking Root-Faith >>Affix-Faith (McCarthy and Prince 1995) by allowing contrasts in affixes and neutralising them in roots.
• Cophonology (Anttila 2002) can account for virtually all types of exceptionality that a theory accommodating M&F indexing (the one proposed here) handles. It cannot, however, translate a grammar like the following where the indexed constraint is more than one stratum away from its unindexed counterpart:– Con1-L >> Con2 >> Con3 >> Con1

Alternatives and intermediate positions
• A marriage of approaches or intermediate positions between strictly representational and diacritic standpoints is possible: e.g., indexing of only certain markedness constraints or “structural hypotheses limited to surface observable forms”.
• Alternative accounts of morphology-based phonological exceptionality include Alderete’s (2001) antifaithfulness theory, Kurisu’s (2001) Realize Morpheme theory and Zuraw’s (2000) extension of Boersma and Hayes’ (1998) Stochastic OT.