multi-layer perceptron - university of wisconsin–madison
TRANSCRIPT

Multi-Layer Perceptron
Generated by Doxygen 1.5.6
Fri Dec 19 11:53:34 2008


Contents
1 Multi-Layer Perceptron Project Report 1
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 MLP Implementations 3
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Common Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3 Common Training Algorithm . . . . . . . . . . . . . . . . . . . . . . 4
2.3.1 Training Data . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3.2 Feed Forward . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3.3 Back-Propagation . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3.4 Weight Updates . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 BLAS Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.5 cuBLAS Implementation . . . . . . . . . . . . . . . . . . . . . . . . 7
2.6 cuBLAS and CUDA Implementation . . . . . . . . . . . . . . . . . . 8
2.7 CUDA Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.7.1 Feed Forward . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.7.1.1 apply_act_fun() . . . . . . . . . . . . . . . . . . . 9
2.7.1.2 copy_plus_bias() . . . . . . . . . . . . . . . . . . . 10
2.7.2 Back-Propagation . . . . . . . . . . . . . . . . . . . . . . . . 10
2.7.2.1 compute_output_delta() . . . . . . . . . . . . . . . 10
2.7.2.2 transform_delta() . . . . . . . . . . . . . . . . . . 10
2.7.3 Weight Updates . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.7.3.1 add_transpose() . . . . . . . . . . . . . . . . . . . 11

ii CONTENTS
3 Results 13
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1 Test Platform . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.2 Compiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.3 Data Sets . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.3.1 srfData . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.3.2 examData . . . . . . . . . . . . . . . . . . . . . . 14
3.2.3.3 forestData . . . . . . . . . . . . . . . . . . . . . . 15
3.2.4 Training Settings . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2.5 Performance Measurement . . . . . . . . . . . . . . . . . . . 16
3.3 Performance Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3.1 srfData Results . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3.2 Exam Data Results . . . . . . . . . . . . . . . . . . . . . . . 17
3.3.3 Forest Data Results . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.4 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4 Software Design 21
4.1 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1.1 Documentation . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1.2 Libraries . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1.3 The Graphical User Interface . . . . . . . . . . . . . . . . . . 22
4.1.4 Cross Platform Support . . . . . . . . . . . . . . . . . . . . . 24
5 Conclusion 27
6 Namespace Index 29
6.1 Namespace List . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
7 Class Index 31
7.1 Class Hierarchy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
8 Class Index 33
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

CONTENTS iii
8.1 Class List . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
9 File Index 35
9.1 File List . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
10 Namespace Documentation 37
10.1 anonymous_namespace{blas_mlp.cpp} Namespace Reference . . . . 37
10.2 anonymous_namespace{cublas_cuda_mlp.cpp} Namespace Reference 38
10.3 anonymous_namespace{cublas_mlp.cpp} Namespace Reference . . . 39
10.4 anonymous_namespace{training_panel.cpp} Namespace Reference . 40
10.5 anonymous_namespace{training_results_panel.cpp} Namespace Ref-erence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
10.6 mlp Namespace Reference . . . . . . . . . . . . . . . . . . . . . . . 42
10.6.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 42
10.6.2 Typedef Documentation . . . . . . . . . . . . . . . . . . . . 44
10.6.2.1 dev_ptr_list_t . . . . . . . . . . . . . . . . . . . . 44
10.6.2.2 layer_weights_t . . . . . . . . . . . . . . . . . . . 45
10.6.2.3 vector_t . . . . . . . . . . . . . . . . . . . . . . . 45
10.6.3 Enumeration Type Documentation . . . . . . . . . . . . . . . 45
10.6.3.1 activation_function_t . . . . . . . . . . . . . . . . 45
10.6.4 Function Documentation . . . . . . . . . . . . . . . . . . . . 45
10.6.4.1 get_impl_title . . . . . . . . . . . . . . . . . . . . 45
11 Class Documentation 47
11.1 anonymous_namespace{training_panel.cpp}::layer_gui_t Class Refer-ence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
11.1.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 48
11.2 mlp::basic_layer_t< Ptr > Struct Template Reference . . . . . . . . . 50
11.2.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 50
11.3 mlp::basic_matrix_t< Type > Class Template Reference . . . . . . . 52
11.3.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 53
11.3.2 Constructor & Destructor Documentation . . . . . . . . . . . 56
11.3.2.1 basic_matrix_t . . . . . . . . . . . . . . . . . . . . 56
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

iv CONTENTS
11.4 mlp::blas_mlp_t Class Reference . . . . . . . . . . . . . . . . . . . . 57
11.4.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 58
11.4.2 Member Function Documentation . . . . . . . . . . . . . . . 61
11.4.2.1 get_debug_stream . . . . . . . . . . . . . . . . . . 61
11.4.2.2 get_weights . . . . . . . . . . . . . . . . . . . . . 61
11.4.2.3 run_training_epoch . . . . . . . . . . . . . . . . . 62
11.4.2.4 set_training_data . . . . . . . . . . . . . . . . . . . 62
11.4.2.5 set_tuning_data . . . . . . . . . . . . . . . . . . . 62
11.5 mlp::cublas_cuda_mlp_t Class Reference . . . . . . . . . . . . . . . 63
11.5.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 64
11.5.2 Member Function Documentation . . . . . . . . . . . . . . . 67
11.5.2.1 get_debug_stream . . . . . . . . . . . . . . . . . . 67
11.5.2.2 get_weights . . . . . . . . . . . . . . . . . . . . . 68
11.5.2.3 run_training_epoch . . . . . . . . . . . . . . . . . 68
11.5.2.4 set_training_data . . . . . . . . . . . . . . . . . . . 69
11.5.2.5 set_tuning_data . . . . . . . . . . . . . . . . . . . 69
11.6 mlp::cublas_mlp_t Class Reference . . . . . . . . . . . . . . . . . . 70
11.6.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 71
11.6.2 Member Typedef Documentation . . . . . . . . . . . . . . . 75
11.6.2.1 host_layer_t . . . . . . . . . . . . . . . . . . . . . 75
11.6.3 Member Function Documentation . . . . . . . . . . . . . . . 75
11.6.3.1 back_prop . . . . . . . . . . . . . . . . . . . . . . 75
11.6.3.2 feed_forward . . . . . . . . . . . . . . . . . . . . . 76
11.6.3.3 get_debug_stream . . . . . . . . . . . . . . . . . . 77
11.6.3.4 get_weights . . . . . . . . . . . . . . . . . . . . . 77
11.6.3.5 run_training_epoch . . . . . . . . . . . . . . . . . 78
11.6.3.6 set_training_data . . . . . . . . . . . . . . . . . . . 78
11.6.3.7 set_tuning_data . . . . . . . . . . . . . . . . . . . 78
11.6.3.8 update_weights . . . . . . . . . . . . . . . . . . . 79
11.7 mlp::error_t Class Reference . . . . . . . . . . . . . . . . . . . . . . 80
11.7.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 80
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

CONTENTS v
11.8 mlp::gui::main_form_t Class Reference . . . . . . . . . . . . . . . . 82
11.8.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 83
11.9 mlp::gui::training_panel_t Class Reference . . . . . . . . . . . . . . 84
11.9.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 85
11.10mlp::gui::training_results_panel_t Class Reference . . . . . . . . . . 88
11.10.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 89
11.11mlp::input_handler_t Class Reference . . . . . . . . . . . . . . . . . 92
11.11.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 92
11.12mlp::mlp_t Class Reference . . . . . . . . . . . . . . . . . . . . . . . 94
11.12.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 96
11.12.2 Member Function Documentation . . . . . . . . . . . . . . . 97
11.12.2.1 classify . . . . . . . . . . . . . . . . . . . . . . . . 97
11.12.2.2 create_mlp . . . . . . . . . . . . . . . . . . . . . . 97
11.12.2.3 get_debug_stream . . . . . . . . . . . . . . . . . . 98
11.12.2.4 get_weights . . . . . . . . . . . . . . . . . . . . . 98
11.12.2.5 run_training_epoch . . . . . . . . . . . . . . . . . 99
11.12.2.6 set_activation_function . . . . . . . . . . . . . . . 99
11.12.2.7 set_training_data . . . . . . . . . . . . . . . . . . . 100
11.12.2.8 set_tuning_data . . . . . . . . . . . . . . . . . . . 100
11.12.2.9 set_weights . . . . . . . . . . . . . . . . . . . . . 100
11.12.2.10tune . . . . . . . . . . . . . . . . . . . . . . . . . 100
11.13RNG_rand48 Class Reference . . . . . . . . . . . . . . . . . . . . . 102
11.13.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 102
11.13.2 Member Function Documentation . . . . . . . . . . . . . . . 104
11.13.2.1 get . . . . . . . . . . . . . . . . . . . . . . . . . . 104
11.13.2.2 get_random_numbers . . . . . . . . . . . . . . . . 104
11.13.3 Member Data Documentation . . . . . . . . . . . . . . . . . 104
11.13.3.1 A0 . . . . . . . . . . . . . . . . . . . . . . . . . . 104
12 File Documentation 105
12.1 blas_mlp.cpp File Reference . . . . . . . . . . . . . . . . . . . . . . 105
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

vi CONTENTS
12.1.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 105
12.2 blas_mlp.hpp File Reference . . . . . . . . . . . . . . . . . . . . . . 107
12.2.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 107
12.3 cublas_cuda_mlp.cpp File Reference . . . . . . . . . . . . . . . . . . 109
12.3.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 109
12.4 cublas_cuda_mlp.cu File Reference . . . . . . . . . . . . . . . . . . 111
12.4.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 111
12.4.2 Function Documentation . . . . . . . . . . . . . . . . . . . . 113
12.4.2.1 add_transpose . . . . . . . . . . . . . . . . . . . . 113
12.4.2.2 apply_act_fun . . . . . . . . . . . . . . . . . . . . 114
12.4.2.3 compute_output_delta . . . . . . . . . . . . . . . . 114
12.4.2.4 copy_plus_bias . . . . . . . . . . . . . . . . . . . 114
12.4.2.5 transform_delta . . . . . . . . . . . . . . . . . . . 115
12.5 cublas_cuda_mlp.hpp File Reference . . . . . . . . . . . . . . . . . . 117
12.5.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 117
12.5.2 Function Documentation . . . . . . . . . . . . . . . . . . . . 119
12.5.2.1 add_transpose . . . . . . . . . . . . . . . . . . . . 119
12.5.2.2 apply_act_fun . . . . . . . . . . . . . . . . . . . . 120
12.5.2.3 compute_output_delta . . . . . . . . . . . . . . . . 120
12.5.2.4 copy_plus_bias . . . . . . . . . . . . . . . . . . . 121
12.5.2.5 transform_delta . . . . . . . . . . . . . . . . . . . 121
12.6 cublas_mlp.cpp File Reference . . . . . . . . . . . . . . . . . . . . . 123
12.6.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 123
12.7 cublas_mlp.hpp File Reference . . . . . . . . . . . . . . . . . . . . . 125
12.7.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 125
12.8 error.hpp File Reference . . . . . . . . . . . . . . . . . . . . . . . . 127
12.8.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 127
12.9 input_handler.cpp File Reference . . . . . . . . . . . . . . . . . . . . 129
12.9.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 129
12.10input_handler.hpp File Reference . . . . . . . . . . . . . . . . . . . . 130
12.10.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 130
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

CONTENTS vii
12.11layer.hpp File Reference . . . . . . . . . . . . . . . . . . . . . . . . 132
12.11.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 132
12.12main_form.cpp File Reference . . . . . . . . . . . . . . . . . . . . . 134
12.12.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 134
12.13main_form.hpp File Reference . . . . . . . . . . . . . . . . . . . . . 135
12.13.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 135
12.14matrix.hpp File Reference . . . . . . . . . . . . . . . . . . . . . . . 137
12.14.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 137
12.15mlp.cpp File Reference . . . . . . . . . . . . . . . . . . . . . . . . . 139
12.15.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 139
12.16mlp.hpp File Reference . . . . . . . . . . . . . . . . . . . . . . . . . 140
12.16.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 140
12.17mlp_types.hpp File Reference . . . . . . . . . . . . . . . . . . . . . 142
12.17.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 142
12.18mlpGUI.cpp File Reference . . . . . . . . . . . . . . . . . . . . . . . 145
12.18.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 145
12.19training_panel.cpp File Reference . . . . . . . . . . . . . . . . . . . 146
12.19.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 146
12.20training_panel.hpp File Reference . . . . . . . . . . . . . . . . . . . 148
12.20.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 148
12.21training_results_panel.cpp File Reference . . . . . . . . . . . . . . . 150
12.21.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 150
12.22training_results_panel.hpp File Reference . . . . . . . . . . . . . . . 152
12.22.1 Detailed Description . . . . . . . . . . . . . . . . . . . . . . 152
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen


Chapter 1
Multi-Layer Perceptron ProjectReport
1.1 Introduction
A Multi-Layer Perceptron (MLP) is an artificial neural network generally used for clas-sification or approximation. The MLP consists of a feed-forward network of neuronswhich map input vectors to output vectors. Each artificial neuron consists of a linearcombination of weighted inputs which is passed though a non-linear activation functionto produce the neuron’s output.
Since their introduction over a decade ago, consumer Graphics Processing Units(GPUs) have steadily increased in processing power. The current generation of GPUscontain a large number of independent processing cores and large memories in orderto execute highly parallel 3D graphics visualization. These resources are generallyapplicable to a large range of highly parallel workloads outside the real-time graphicsspace. This project takes advantage of nVidia’s CUDA general-purpose GPU (GPGPU)framework to implement a Multi-Layer Perceptron which executes on the GPU.
This report describes a CPU based MLP implementation, a GPU based MLP imple-mentation and a hybrid implementation. The design of the MLP implementations aredescribed and performance characteristics are discussed.
This project was undertaken as the semester project for ECE 539 for the fall 2008semester at the University of Wisconsin – Madison. All work described was done byScott Finley who holds the copyright to the source code documented here.
Chapters 1-5 of this report consist of the project report. The remainder of this reportis documentation of the source code produced. The entire text of this report residesin the project source code itself and the pdf and html formatted reports are generatedautomatically by a documentation tool called Doxygen. The result of this literate pro-

2 Multi-Layer Perceptron Project Report
gramming style is that the resulting documents contain high-level design information aswell as the low-level code documentation. A further advantage is that all the high-leveldesign information is available directly in the documentation along with normal codecomments. Engineers working with the code have this information easily available tomake understanding the code easier.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 2
MLP Implementations

4 MLP Implementations
2.1 Introduction
The purpose of this project is to compare the implementation of a MLP on the CPUand GPU. To accomplish this, the following three implementations were done:
1. BLAS: A CPU-only implementation using the boost::BLAS linear algebra li-brary.
2. cuBLAS: A hybrid CPU/GPU implementation using the nVidia cuBLAS linearalgebra library.
3. cuBLAS + CUDA: A GPU-only implementation using nVidia’s cuBLAS libraryand CUDA C language extensions.
2.2 Common Interface
The mlp_t abstract base class implements the common user interface for all MLP im-plementations. Each of the concrete MLP implementations inherit from this interfaceand implement the required public functions. This common interface makes it easy toallow the user to decide at run time which MLP implementation to use.
The main operations provided by an MLP implementation are running a training epoch,estimating current error, and classifying data. The MLP runs a single training epoch ata time. Before this operation completes, the internal neuron weights are updated. Theuser typically runs many epochs until the resulting error is acceptable. The error at anygiven time can be estimated by computing the output using the tuning data and currentweights. This results in a classification rate (percentage of inputs that are correctlyclassified) and a mean-squared error. This error calculation does not change the neuronweights, but the MLP does save the neuron weights each time the error or classificationrate improves. Once training is complete the user can pass real data to the MLP. TheMLP classifies this data using the best set of neuron weights.
The details of the mlp_t class interface are described the class reference chapter.
2.3 Common Training Algorithm
All three MLP implementations use the same general strategy of expressing the MLPtraining algorithm as series of matrix and vector operations. This simplifies the im-plementation by allowing the use of well known and highly optimized linear algebralibraries. It also allows the performance characteristics of the CPU and GPU basedcode to be directly compared because the algorithms used are as similar as possible.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

2.3 Common Training Algorithm 5
2.3.1 Training Data
The training epoch starts by inserting the user provided training data as the input matrixto layer 0, denoted X0. Each column of X0 is a data sample and each row representsa single feature. A row of 1s is inserted as the first row to allow for a bias weight tobe learned by each neuron in each layer. Thus if the user provides N samples with Kfeatures, X0 will be have dimension [(K + 1)×N ].
2.3.2 Feed Forward
The first stage of an MLP training epoch (and the only stage of data classification) iscalled “feed forward”. The output (denoted Zl) for each layer is computed accordingto the following formula:
Zl = ul(WTl Xl)
Xl is the layer input (or user input for the first layer) and has dimensions [Kl × N ]where N is the number of input samples provided by the user and Kl = Ml−1 + 1 isone more than the number of neurons of the previous layer. The added input row is setto all 1s to allow each neuron to learn a bias weight. Wl is the weight matrix for thelayer and has dimension [Kl ×Ml], where Ml is the user specified number of neuronsfor the layer. ul() is the user-chosen non-linear activation function (either hyperbolictangent or sigmoidal function). The output of each layer is used as the input to the nextlayer and has dimension [Ml × N ]. The output of the final layer is the output of theMLP for the epoch.
2.3.3 Back-Propagation
The second stage of MLP training is “back-propagation”. This begins by computingthe error delta (denoted ∆EL) at the output layer according to the following formula:
∆EL = u′L(ZL)∑i,j
[(ZL(i, j)− Y (i, j))2]
Y is the desired output for this training data provided by the user and has the samedimension as ZL : [ML × N ]. ∆El denotes the error delta for a given layer and hasone element per output so that it also has the same dimension as Zl. Once the outputlayer error delta has been computed, the delta error matrix for each proceeding layer iscalculated according to the following formula:
∆El = W(l+1)∆E(l+1) · u′l(Zl)
The result of the matrix-matrix product W(l+1)∆E(l+1) has one more row than Zl
because an extra bias row is added to the input at each layer. This extra row musttherefore be removed before multiplying with Zl. Note that the · operator denotes anelement-wise multiplication, not a matrix-matrix product. In this way the output layeris propagated back into an error delta matrix at each layer.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

6 MLP Implementations
2.3.4 Weight Updates
The final stage of MLP training is computing the new neuron weights. The changefor the weights at each layer (denoted ∆Wl) is computed according to the followingformula:
∆Wl(t) = η(∆ElXTl ) + µ∆Wl(t− 1) +R
∆Wl is shown with a time index t to indicate that the delta value at the current epoch(∆Wl(t)) depends on the value at the previous epoch (∆Wl(t− 1)). η is the user pro-vided learning rate. The learning rate must be greater than 0 and is used to control howfast the neuron weights change from epoch to epoch. µ is the user provided momentumterm. This must be greater than or equal to zero and is used to stabilize convergence.R is a matrix of random noise with the same dimensions as Wl. Adding noise helpsto avoid converging to local error minimums which are far from the global minimum.Once the weight delta has been computed it is saved for use in the next epoch andadded to the current weights to perform the weight update:
Wl(t) = Wl(t− 1) + ∆Wl
2.4 BLAS Implementation
blas_mlp_t is a class which implements the mlp_t inteface using the CPU only.The boost::blas library is used to represent matrix objects and for matrix operations.boost::blas is a modern object-oriented implementation of the well known Basic Lin-ear Algebra Subprograms library. More information about boost::blas and the otherboost C++ libraries can be found at http://www.boost.org .
The purpose of this implementation is to serve as a baseline withwhich to compare the GPU based implementations. The use of theboost::blas libraries provides competitive performance (performance compar-isons can be found at http://www.boost.org/doc/libs/1_37_-0/libs/numeric/ublas/doc/overview.htm . The rest of the blas_mlp_tcode has not undergone performance tuning and large improvements are no doubtpossible. Most notably, the code is single-threaded. A multi-threaded approach shouldbe able provide large performance improvements on modern multi-core processors.
The results presented later in this report focus on an analysis of performance differenceswhich vary by orders of magnitude. Optimization of this class would be important fordeployment in a production setting, but is not relevant for the purposes of this research.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

2.5 cuBLAS Implementation 7
2.5 cuBLAS Implementation
cublas_mlp_t is a class which implements the mlp_t interface using a hybrid ap-proach of CPU and GPU. In this class the high-cost matrix-matrix product calcula-tions are done using nVidia’s cuBLAS library. Details about this library can be foundon nVidia’s CUDA website: http://www.nvidia.com/object/cuda_-home.html .
The cuBLAS library allows significant performance increases by utilizing an nVidiaGPU without requiring the programmer to write GPU based code directly. The libraryprovides a API in C which which the user can perform the standard BLAS linear alge-bra operations.
The drawback to this approach is that it requires duplication and frequent synchroniza-tion of data between main CPU memory and device memory on the GPU. This problemis exacerbated by the fact that the cuBLAS library doesn’t provide trivial operationssuch as matrix subtraction and addition. The result is that these simple operations mustbe performed by the CPU requiring many extra memory copies between CPU and GPUmemory. These copy operations have very high latency relative to CPU and GPU clockspeeds which makes them a bottleneck for overall performance. The results section ofthis report investigates this further.
The following sections provide details about how the MLP training phases are per-formed on the CPU and GPU:
cuBLAS Feed Forward
For each layer the following steps must be done:
1. Copy neuron weights and layer input to GPU
2. Perform matrix product: Zl = WTl Xl
3. Copy layer output to CPU
4. Apply activation function to each element of layer output
5. Copy layer output to GPU
6. Set next layer input to current layer output
cuBLAS Back-Propagation
• Compute the output layer error delta on the CPU:
∆EL = u′L(ZL)∑i,j
[(ZL(i, j)− Y (i, j))2]
• Copy the output layer error delta to the GPU
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

8 MLP Implementations
• For each layer hidden layer:
1. Compute the matrix product: W(l+1)∆E(l+1)
2. Copy the result to the CPU
3. Apply the non-linear activation function derivative to the current layer out-put on the CPU
4. Element by element multiplication to produce layer delta:
∆El = W(l+1)∆E(l+1) · u′l(Zl)
5. Copy layer error delta to GPU
cuBLAS Weight Update
For each layer the following steps are needed:
1. Copy the previous epoch weight update to the GPU
2. calculate weight delta on GPU with single cuBLAS call:
∆Wl(t) = η(∆ElXTl ) + µ∆Wl(t− 1)
3. Copy the result to the CPU
4. Add random noise on the CPU
5. Add the weight update to the current weight on the CPU. Copy to the GPU is notneeded here because it will be done during feed-forward of the next epoch
These summaries illustrate that each training epoch requires multiple CPU-GPU mem-ory copies.
2.6 cuBLAS and CUDA Implementation
The cublas_cuda_mlp_t class implements the mlp_t interface using a combination ofcuBLAS and CUDA. CUDA is nVidia’s framework allowing programs to be writtenfor execution on an nVidia GPU. More details about CUDA can be found at nVidia’sCUDA website: http://www.nvidia.com/object/cuda_home.html.
This implementation directly addresses the performance bottleneck of frequent CPU toGPU memory copies. The cuBLAS library is still used to perform the high-cost matrixproduct operations in exactly the same was as is done in the cublas_mlp_t implemen-tation. Instead of performing the other operations on the CPU as cublas_mlp_t does,this class uses CUDA code to perform them on the GPU.
Effective use of CUDA requires that algorithms be expressed as a single program flowwhich is then applied to many pieces of data in parallel. This allows a dramatic speedup
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

2.7 CUDA Functions 9
for operations in which the data is used independently. For example, a matrix-matrixsubtraction can be expressed as many threads in which each does a single subtractionof one element in the arrays.
Some operations are a challenge to express in a massively parallel program. Computingthe sum of all the elements in a matrix does not have an obvious solution in the sameway that a matrix-matrix subtraction does. This is because a summation of this kindwould traditionally be done by accumulating the sum into a single memory location (orregister) by serial additions of each element into the running sum. There is no benefitto using more than one thread to do this because their operations would need to becompletely serialized.
There was not sufficient time during this project to research and implement efficientparallel algorithms for all the operations done on the GPU using CUDA. As a resultthe performance of this class in some cases may be quite sub-optimal. However, it doesserve as a good proof of concept for implementing a Multi-Layer Perceptron on a GPU.Certainly order-of-magnitude comparisons to the CPU implementation are appropriate.
2.7 CUDA Functions
This section describes the functions which are implemented using CUDA to be runon the GPU. Functions which take one or more matrices as arguments require thatthe matrix row and column dimensions be supplied, even when they can be inferredfrom other arguments. This allows error checks that would otherwise be impossible.Buffer overruns are a problem in C in general and are especially hard to detect in coderunning on the GPU. Extra argument checks are an attempt to minimize this kind oferror. Incorrect argument values result in a failed assertion, which halts the program onmost system. The assertion check may also be compiled out depending on the compilersettings.
Matrix arguments are always accompanied by row and column dimensions. Matricesare in column major format in order to be compatible with cuBLAS.
2.7.1 Feed Forward
2.7.1.1 apply_act_fun()
Does an in-place application of the chosen activation function to each element of thevector or matrix. If the function choice argument is 0 f(x) = tanh(x) is applied. Ifthe argument is 1, the sigmoidal function f(x) = 1
1+ex is applied. This operation iscompletely parallelizable so as many threads as possible are run in parallel. When thefunction returns the values in the input matrix have been changed.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

10 MLP Implementations
2.7.1.2 copy_plus_bias()
Used to copy the output of one layer to the input of the next layer. A simple memorycopy is not sufficient for this because the dimensions of the matrices are not the same.The change in dimension is due to the addition of a row of inputs with the value 1.0.This added constant input to each neuron of a layer allows the neurons to learn a biasvalue.
This function takes pointers to the source and destination arrays as well as the numberof rows and columns in each matrix. The number of columns in each matrix much bethe same, and the number of rows in the destination must be exactly one more than thenumber of rows in the source.
This operation is completely parallelizable so as many threads as possible are run inparallel. When this function returns the destination matrix will be filled with contentsof the source matrix plus an extra row which is filled with 1s.
2.7.2 Back-Propagation
2.7.2.1 compute_output_delta()
This function takes the desired output and the actual output and computes the outputlayer error delta as described in the algorithms section.
This operation is completely parallelizable so as many threads as possible are run inparallel. When this function returns the destination matrix will be filled with computederror delta.
2.7.2.2 transform_delta()
Takes the intermediate layer delta value as an argument. This has already been com-puted using cuBLAS as:
W(l+1)∆E(l+1)
Also takes the current layer output as an argument. Computes the final layer delta bypassing the layer output through the derivative of the layer activation function and thenmultiplying it current delta. This computation is not done in place because the removalof the extra bias row from the source delta is done at the same time as the calculation.This requires that output matrix have one fewer rows than the input.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

2.7 CUDA Functions 11
2.7.3 Weight Updates
2.7.3.1 add_transpose()
This function is used to add the neuron weight update to the current neuron weightvalue. It also adds the random noise if the user specified any. The formula for thisupdate is shown below:
Wl(t) = Wl(t− 1) + ∆Wl +R
Because of the way cuBLAS expects the arguments for the operation used previouslyin the weight update phase ∆Wl is stored transposed, as compared toWl. This functiontakes that fact into account so it causes no computational overhead. The neuron weightsfor each epoch are not stored separately. Instead the weight matrix from the previousepoch is passed to this function which overwrites it with the resulting new weights.
The random values passed to this function is a matrix generated previously by a call toa CUDA random number generator. This is the RNG_rand48 generator by A. Arnoldand J. A. van Meel , FOM institute AMOLF, Amsterdam. Their work is availableat http://www.amolf.nl/∼vanmeel/mdgpu/ and is described in the article"Harvesting graphics power for MD simulations" by J.A. van Meel, A. Arnold, D.Frenkel, S. F. Portegies Zwart and R. G. Belleman, arXiv:0709.3225. This randomnumber generator was found to have a serious bug which caused buffer overruns if thenumber of random number request changed from request to request. It also failed tofree its memory buffer when exiting which caused a memory leak. I was able to fix orwork around these problems but the use of another random number generator would bepreferred if time permitted.
The random numbers passed to add_transpose() are integers and there must be the samenumber of them as there are elements in the weight matrix. The integers are convertedto floating point numbers and scaled so that the absolute value is less than the thresholdprovided by the user.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12 MLP Implementations
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 3
Results

14 Results
3.1 Introduction
One of the main objectives of this project is to evaluate the performance of the GPUbased MLP implementations versus the CPU. This chapter presents performance com-parisons of the three MLP implementations being trained on a variety of datasets.
3.2 Methodology
3.2.1 Test Platform
The test platform was configured as follows:
• CPU: Intel Core 2 Duo Q6600 Quad Core
• RAM: 4 GB
• GPU: GeForce 8800 GT, 256 MB RAM
• OS: Windows Vista Ultimate 64-bit
3.2.2 Compiler
The code was compiled on the test platform using Microsoft Visual Studio 2005 Profes-sional. It was compiled as a 64-bit application in release mode with debug informationturned off and optimization set to favor speed. The CUDA code was compiled withnVidia’s nvcc compiler from version 2.0 of the CUDA SDK.
3.2.3 Data Sets
The three MLP implementation were tested with the following three data sets:
3.2.3.1 srfData
This is a small, synthetic data set that was created while developing this application. Itconsists of nine training samples. The inputs have three features with which they areclassified into one of three outputs. It does not have separate testing data.
3.2.3.2 examData
This is a moderately sized data set with 150 training samples. Inputs have three featuresand there are two output classes. This data set was provided as part of the final exam
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

3.2 Methodology 15
for ECE 539 at the UW-Madison in the Fall 2008 semester. The source and nature ofthe data was not specified. There is no separate testing set.
3.2.3.3 forestData
This is a section taken from a very large data set provided by the US Forest Service.The data is taken from satellite imagery along with other sources of informationabout forest coverage. Each training sample represents data about a 30 by 30 squaremeter cell of forest. These inputs map onto one of 7 forest coverage classifica-tions. Inputs have 54 features. More information about this data set can be found athttp://kdd.ics.uci.edu/databases/covertype/covertype.data.html.
Although this data set is very large (over 500,000 training samples are available) onlya small subset was used for performance testing. 500 training samples were used alongwith 500 different tuning samples.
3.2.4 Training Settings
MLP training was performed varying the following key setting:
• MLP implementation: blas_mlp_t, cublas_mlp_t and cublas_cuda_mlp_t wereused.
• Data sets: The srf, exam and forestry data sets were used. The data set beingused determined the dimensions of the input matrix and output matrices for eachtraining epoch. All available training samples were used as input for each epoch.
• Neurons per layer: The MLP was always configured with two hidden layers,but the number of neurons in each layer was varied between 1 and 1000 (bothhidden layers always had the same number of neurons). This had a direct effecton the size of the neuron weight matricies and caused wide variation in the costof operations involving data passing between the two hidden layers.
Other settings have no effect on calculation complexity (although they have a directeffect on the training result) and were kept constant across all tests. These included:
• Learning Rate: 0.1 for all tests
• Momentum: 0.8 for all tests
• Number of epochs between error estimations by classifying tuning data. Thiscould certainly effect performance. The purpose of this testing was to focus ontraining performance, so this number was kept high (100 epochs) so that tuningtime would be negligible.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

16 Results
• Input data scaling: Scaling is done on the CPU before training begins, so it wouldnot effect training performance. It was enabled during testing.
• Output data scaling: Scaling is done on the CPU before training begins, so itwould not effect training performance. It was enabled during testing.
3.2.5 Performance Measurement
Performance was measured using the system clock. A timer was started just before thefirst training epoch began and stopped just after the last training epoch. The total timein milliseconds was then divided by the number of epochs to produce the performancemetric of milliseconds per epoch. Most tests were allowed to run for at least 1000epochs. In the cases of tests in which a single epoch took a long time at least 3 epochwere run and the test ran for at least 10 minutes.
3.3 Performance Data
This section presents the performance data for the three data sets.
3.3.1 srfData Results
The following table shows performance results when training was done using the srfdata set.
Hidden Neurons BLAS cuBLAS cuBLAS + CUDA1 0.04 19 4.283 0.07 17.57 4.6910 0.26 22.01 3.9350 3.22 23.4 4.97100 11.57 19.73 5.36200 43.5744 43.08 27.84500 265.549 67.25 35.381000 1064.8 103.7 54.62
The same data is shown in the following figure:
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

3.3 Performance Data 17
Figure 3.1: srf data
3.3.2 Exam Data Results
The following table shows performance results when training was done using the examdata set.
Hidden Neurons BLAS cuBLAS cuBLAS + CUDA1 0.436 23.7583 6.1310 3.69474 46.9615 29.7350 49.7333 57.3412 30.7917100 181.267 60.8571 32.6767200 686.1 71.2053 34.55500 6200 136.167 52.651000 26584 227.9 86.6625
The same data is shown in the following figure:
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen
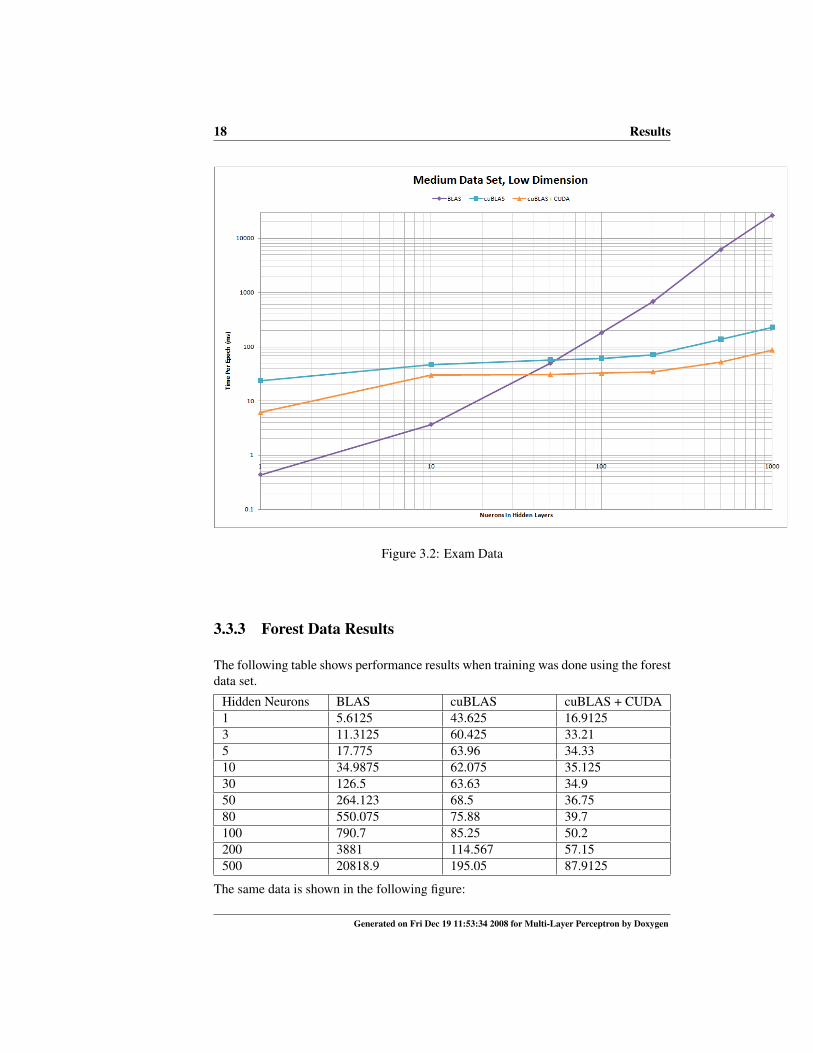
18 Results
Figure 3.2: Exam Data
3.3.3 Forest Data Results
The following table shows performance results when training was done using the forestdata set.
Hidden Neurons BLAS cuBLAS cuBLAS + CUDA1 5.6125 43.625 16.91253 11.3125 60.425 33.215 17.775 63.96 34.3310 34.9875 62.075 35.12530 126.5 63.63 34.950 264.123 68.5 36.7580 550.075 75.88 39.7100 790.7 85.25 50.2200 3881 114.567 57.15500 20818.9 195.05 87.9125
The same data is shown in the following figure:
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

3.3 Performance Data 19
Figure 3.3: Forest Data
3.3.4 Analysis
All three data sets show similar results. The CPU data points graph to a line (or perhapsa slight rising curve) indicating something like quadratic growth in computation timeas the number of neurons increases. The CPU computation time grows by up to fiveorders of magnitude while the neuron count changes by three orders of magnitude. TheGPU based implementations show much flatter curves. GPU computation time changesby about one order of magnitude over the same three order of magnitude change in theneuron count.
Another similarity across all three data sets is that the CPU does much better (up toan order of magnitude) on small computations, while the GPU does much better (upto three orders of magnitude) on large computations. This is to be expected due tothe long latency of data transfers between main CPU memory and GPU memory. Ifactual computation times are small the GPU implementation run times are dominatedby memory transfers. The CPU has a tremendous advantage in this case because it hasto work with the data while preparing for training so it is very likely that all the neededdata will be cached and ready to go once training starts.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

20 Results
At the other extreme, the CPU is at a tremendous disadvantage once execution timebecome dominated by matrix-matrix product operations. When this is the case CPUcomputations will increase with the square (or worse) of the amount of data added,while GPU memory copying only scales linearly with the amount of data. Further-more, modern GPU have hundreds of stream processors, (the GeForce 8800GT usedfor testing has 112) which means that GPU computation time does not increase at alluntil all the processors are saturated and then scales much more slowly as data is added.
The main difference between the data sets is the point at which the CPU performanceline cross the GPUs. This point corresponds to the point at which the faster computationon the GPU overcomes the overhead of memory latency. The happens later for thecublas_mlp_t implementation than for the cublas_cuda_mlp_t implementation becauseit performs many more memory transfers.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 4
Software Design

22 Software Design
4.1 Approach
A major focus of this project was utilizing sound software engineering techniques.
4.1.1 Documentation
Thorough documentation is a key to understanding and maintaining software throughits usable life. All the interfaces and classes in this projected were documented as theywere implemented. In addition a literate programming style was chosen in order toembed higher-level design and algorithm information directly in the code. The doxygendocumenting tool was used for this purpose. The full text of this report is writtendirectly in the project source code. Special tags understood by the doxygen tool allowthe portions of this report relating to specific code objects (the blas_mlp_t class forexample) to be inserted as code comments in the code for the objects. As a result,anyone reading and trying to understand the code has full and immediate access to allthe relevant information without referring to an external document.
Doxygen also produces an html version of this report and reference which can be moreconvenient in some cases.
4.1.2 Libraries
The use of good libraries make successful development much easier. This project makeextensive use of the C++ Standard Template Library (STL) and of the Boost Libraries(far beyond just boost::blas).
The boost::shared_ptr object, for example made correct handling of GPU memorypointers much easier. Storing CUDA pointers to GPU memory in boost’s smart pointerallowed the CUDA C-style deallocation function to be registered with the smart pointeras a deallocator. This meant that CUDA pointers did not need to be manually deallo-cated, but would automatically be deallocated when they went out of scope. This ishelpful not only to prevent an error in which the programmer simply forgets to deal-locate the memory, but also automatically handles complicated cases in which pointerownership is transferred from one object to another or an exception is thrown.
4.1.3 The Graphical User Interface
A good portion of the time on this project was put into developing a graphical userinterface. Although this is not particularly interesting from a reseach point of view, itgoes a long way to making the MLP software accessible.
The user interface makes configuring and training the MLP much quicker than it wouldotherwise have been. Immediate graphical feedback about the progress of MLP train-ing is particularly nice. This is accomplished through the use of a graphing widget that
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

4.1 Approach 23
updates in real time as the MLP training run in another thread.
The interface also provides a text-based log and status windows which displays detailsand data that might not always be needed. The makes saving log data to disk and/orcopying it to the clipboard quite easy.
Finally, the tab based interface allows the results of multiple training runs to be avail-able at the same time for comparison, tweeking and further classification runs.
The following figures show the main portions of the GUI:
Figure 4.1: Training Setup Screen
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

24 Software Design
Figure 4.2: Training Progress Screen
4.1.4 Cross Platform Support
A design goal from the start of this project was to allow it to run on multiple platforms.This is important because it makes the software available to a wider range of users. Italso improves the software quality because different platforms exercise the code andexpose errors and other problems in different ways.
This design goal was achieved by the use of two key cross platform libraries. The firstis boost, which provides versions of its libraries for all major platforms. These librariesare well tested and provide a consistent API and behavior characteristics on all systems.
The second library that enabled cross platform use was wxWidgets. This library wasused for all the GUI code. Like boost, wxWidgets is available on all major platformsand abstracts away the very significant differences between GUI toolkits. It also usesthe platform’s native widgets on every system so the application doesn’t look out ofplace to the user.
Finally, it should be mentioned that it was possible to do this project in a cross platformway because nVidia released its CUDA framework and drivers for both Linux and
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

4.1 Approach 25
Windows.
The result of using cross platform libraries is that the cudaMLP application compilesand runs well on both Linux and Windows. Development was done on both Ubuntu8.10 32-bit and Windows Vista Ultimate 64-bit. Binaries for both of these platformsare included with this package. Compiling and running on other versions of Windowsand Linux should be possible as long as boost, wxWidgets and the CUDA SDK anddrivers are available.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

26 Software Design
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 5
Conclusion

28 Conclusion
This report describes the implementation of a Multi-Layer Perceptron on a GPU. Thealgorithms used to train an MLP are described along with the methods of implementa-tion for use on a CPU and GPU.
Performance results of two GPU based implementations are compared to a baselineimplementation using the CPU. For large workloads, up to two orders of magnitudeimprovement in performance is possible. For smaller workload the GPU implementa-tions cannot overcome the overhead of copying data to the GPU.
The source code for this project is in 25 files containing about 6000 lines of code.
This project was done during the Fall semester of 2008 for ECE 539 at the Universityof Wisconsin—Madison, by Scott Finley. Questions and comments can be sent [email protected] .
This chapter concludes the body of the main project report. The remainder of thisdocument contains the detailed documentation of the source code. Those chaptersare mainly useful when reading and using the code. The html versions of the sourcecode reference material is likely to be easier to navigate when referring to source codedocumentation.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 6
Namespace Index
6.1 Namespace List
Here is a list of all documented namespaces with brief descriptions:
anonymous_namespace{blas_mlp.cpp} . . . . . . . . . . . . . . . . . . . . 37anonymous_namespace{cublas_cuda_mlp.cpp} . . . . . . . . . . . . . . . . 38anonymous_namespace{cublas_mlp.cpp} . . . . . . . . . . . . . . . . . . . 39anonymous_namespace{training_panel.cpp} . . . . . . . . . . . . . . . . . 40anonymous_namespace{training_results_panel.cpp} . . . . . . . . . . . . . 41mlp (Holds mlp code ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42

30 Namespace Index
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 7
Class Index
7.1 Class Hierarchy
This inheritance list is sorted roughly, but not completely, alphabetically:
mlp::basic_layer_t< Ptr > . . . . . . . . . . . . . . . . . . . . . . . . . . . 50mlp::basic_matrix_t< Type > . . . . . . . . . . . . . . . . . . . . . . . . . 52mlp::error_t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80mlp::input_handler_t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92mlp::mlp_t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
mlp::blas_mlp_t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57mlp::cublas_cuda_mlp_t . . . . . . . . . . . . . . . . . . . . . . . . . . 63mlp::cublas_mlp_t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
RNG_rand48 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102wxFrame
mlp::gui::main_form_t . . . . . . . . . . . . . . . . . . . . . . . . . . . 82wxPanel
anonymous_namespace{training_panel.cpp}::layer_gui_t . . . . . . . . . 47mlp::gui::training_panel_t . . . . . . . . . . . . . . . . . . . . . . . . . 84mlp::gui::training_results_panel_t . . . . . . . . . . . . . . . . . . . . . 88
wxThreadHelpermlp::gui::training_results_panel_t . . . . . . . . . . . . . . . . . . . . . 88

32 Class Index
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 8
Class Index
8.1 Class List
Here are the classes, structs, unions and interfaces with brief descriptions:
anonymous_namespace{training_panel.cpp}::layer_gui_t (A panel for theuse to input the configuration of a single layer ) . . . . . . . . . . . 47
mlp::basic_layer_t< Ptr > (Holds the data for a layer of the MLP ) . . . . . . 50mlp::basic_matrix_t< Type > (Represents a matrix in a way that is compat-
able with cublas ) . . . . . . . . . . . . . . . . . . . . . . . . . . . 52mlp::blas_mlp_t (CPU-only MLP implementation using boost::blas ) . . . . . 57mlp::cublas_cuda_mlp_t (Implements the mlp_t inteface using cuBLAS and
CUDA ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63mlp::cublas_mlp_t (Implements the mlp_t interface using nVidia’s cublas li-
brary ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70mlp::error_t (Thrown by MLP functions to indicate and error ) . . . . . . . . 80mlp::gui::main_form_t (Main form for GUI ) . . . . . . . . . . . . . . . . . 82mlp::gui::training_panel_t (Main form for GUI ) . . . . . . . . . . . . . . . . 84mlp::gui::training_results_panel_t (Dialog that displays training progress ) . . 88mlp::input_handler_t (Reads and handles MLP input data ) . . . . . . . . . . 92mlp::mlp_t (Common interface for MLP implementations ) . . . . . . . . . . 94RNG_rand48 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102

34 Class Index
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 9
File Index
9.1 File List
Here is a list of all documented files with brief descriptions:
blas_mlp.cpp (Implements the MLP using just the boost::blas library ) . . . . 105blas_mlp.hpp (Implements the MLP using just the boost::blas library ) . . . . 107cublas_cuda_mlp.cpp (Implements the MLP using just the cublas library ) . . 109cublas_cuda_mlp.cu (CUDA code for cublas_cuda_mlp_t ) . . . . . . . . . . 111cublas_cuda_mlp.hpp (Implements the MLP using just the cublas library
with CUDA glue ) . . . . . . . . . . . . . . . . . . . . . . . . . . . 117cublas_mlp.cpp (Implements the MLP using just the cublas library ) . . . . . 123cublas_mlp.hpp (Implements the MLP using just the cublas library ) . . . . . 125cudaMLP.cpp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ??error.hpp (Holds error type ) . . . . . . . . . . . . . . . . . . . . . . . . . . 127input_handler.cpp (Reads and handles MLP input data ) . . . . . . . . . . . . 129input_handler.hpp (Reads and handles MLP input data ) . . . . . . . . . . . . 130layer.hpp (Template for holding MLP layer data ) . . . . . . . . . . . . . . . 132main_form.cpp (Main form class for the GUI ) . . . . . . . . . . . . . . . . . 134main_form.hpp (Main form class for the GUI ) . . . . . . . . . . . . . . . . 135matrix.hpp (Template for a matrix type ) . . . . . . . . . . . . . . . . . . . . 137mlp.cpp (Holds base mlp stuff ) . . . . . . . . . . . . . . . . . . . . . . . . . 139mlp.hpp (Holds base mlp stuff ) . . . . . . . . . . . . . . . . . . . . . . . . 140mlp_types.hpp (Holds basic simple types for mlp ) . . . . . . . . . . . . . . 142mlpGUI.cpp (Creates the front end GUI ) . . . . . . . . . . . . . . . . . . . 145random.cu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ??random.hpp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ??training_panel.cpp (Main form class for the GUI ) . . . . . . . . . . . . . . . 146training_panel.hpp (Main training panel class for the GUI ) . . . . . . . . . . 148training_results_panel.cpp (Training dialog implementation ) . . . . . . . . . 150

36 File Index
training_results_panel.hpp (Panel that displays training progress ) . . . . . . 152
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 10
Namespace Documentation
10.1 anonymous_namespace{blas_mlp.cpp} Names-pace Reference
Functions
• mlp::float_t activation_function (mlp::activation_function_t type, mlp::float_tval)
• mlp::float_t activation_function_derivative (mlp::activation_function_t type,mlp::float_t val)

38 Namespace Documentation
10.2 anonymous_namespace{cublas_cuda_mlp.cpp}Namespace Reference
Functions
• mlp::float_t activation_function (mlp::activation_function_t type, mlp::float_tval)
• mlp::float_t activation_function_derivative (mlp::activation_function_t type,mlp::float_t val)
• template<typename Type>boost::shared_ptr< Type > cuda_alloc (unsigned int num_elements)
• template<typename Type>void free_wrapper (Type ∗p)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

10.3 anonymous_namespace{cublas_mlp.cpp} Namespace Reference 39
10.3 anonymous_namespace{cublas_mlp.cpp} Names-pace Reference
Functions
• mlp::float_t activation_function (mlp::activation_function_t type, mlp::float_tval)
• mlp::float_t activation_function_derivative (mlp::activation_function_t type,mlp::float_t val)
• mlp::dev_ptr cuda_alloc (unsigned int num_elements, unsigned int element_-size)
• void free_wrapper (mlp::float_t ∗p)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

40 Namespace Documentation
10.4 anonymous_namespace{training_panel.cpp}Namespace Reference
Classes
• class layer_gui_tA panel for the use to input the configuration of a single layer.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

10.5 anonymous_namespace{training_results_panel.cpp} Namespace Reference41
10.5 anonymous_namespace{training_results_-panel.cpp} Namespace Reference
Functions
• float_t find_classification_rate (output_set_t const &result, output_set_t const&desired)
• float_t find_error (output_set_t const &result, output_set_t const &desired)Computes the sum-of-squares error between the result and desired output sets.
• unsigned int max_index (output_t const &data)returns the index of the element with the highest value
• input_set_ptr scale (input_set_ptr p_data, float_t min_bound, float_t max_-bound)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

42 Namespace Documentation
10.6 mlp Namespace Reference
10.6.1 Detailed Description
Holds mlp code.
Classes
• class application_t• struct basic_layer_t
Holds the data for a layer of the MLP.
• class basic_matrix_t
Represents a matrix in a way that is compatable with cublas.
• class blas_mlp_t
CPU-only MLP implementation using boost::blas.
• class cublas_cuda_mlp_t
Implements the mlp_t inteface using cuBLAS and CUDA.
• class cublas_mlp_t
Implements the mlp_t interface using nVidia’s cublas library.
• class error_t
Thrown by MLP functions to indicate and error.
• class input_handler_t
Reads and handles MLP input data.
• class mlp_t
Common interface for MLP implementations.
Typedefs
• typedef std::vector< activation_function_t > activation_functions_t
Defines a list of activation functions.
• typedef boost::shared_ptr< float_t > dev_ptr
type of a cublas device memory pointer
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

10.6 mlp Namespace Reference 43
• typedef std::vector< dev_ptr > dev_ptr_list_t
Function object for the activation function.
• typedef float float_t
Defines a float type used in this program.
• typedef boost::shared_ptr< input_handler_t > input_handler_ptr
Pointer to input handler.
• typedef boost::shared_ptr< input_t > input_ptr
A pointer to a training data sample.
• typedef boost::shared_ptr< input_set_t > input_set_ptr
Pointer to a training set.
• typedef std::vector< input_ptr > input_set_t
Holds a set of training data.
• typedef std::vector< float_t > input_t
Defines a training data sample.
• typedef std::vector< neuron_weights_t > layer_weights_t
Pointer to weights for a layer.
• typedef boost::shared_ptr< mlp_t > mlp_ptr
Pointer to an mlp instance.
• typedef std::vector< layer_weights_t > mlp_weights_t
Holds the mlp weights.
• typedef std::vector< unsigned int > neuron_counts_t
Array holding the number of neurons in each layer.
• typedef std::vector< float_t > neuron_weights_t
Array of weights for a single neuron.
• typedef boost::shared_ptr< output_t > output_ptr
A pointer to a training data sample.
• typedef boost::shared_ptr< output_set_t > output_set_ptr
Pointer to a target output set.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

44 Namespace Documentation
• typedef std::vector< output_ptr > output_set_t
Holds a set of target output values.
• typedef std::vector< float_t > output_t
Defines a target output value.
• typedef std::vector< float_t > vector_t
Enumerations
• enum activation_function_t { ACT_FUN_TANH = 0, ACT_FUN_SIGMOID,ACT_FUN_INVALID }
Pointer to weights for the whole MLP.
• enum implementation_t {
MLP_IMPL_BLAS = 0, MLP_IMPL_CUBLAS, MLP_IMPL_CUDA_-BLAS, MLP_IMPL_CUDA,
MLP_IMPL_INVALID }
Defines the mlp implementations available.
Functions
• std::string get_impl_title (implementation_t impl)
Returns a string describing the mlp implementation. Good for showing to the user.
• std::ostream & operator<< (std::ostream &ostr, mlp::matrix_t const &m)
10.6.2 Typedef Documentation
10.6.2.1 typedef std::vector< dev_ptr > mlp::dev_ptr_list_t
Function object for the activation function.
Function object for the activation function derivative Array holding pointers to matriceson the device
Definition at line 37 of file mlp_types.hpp.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

10.6 mlp Namespace Reference 45
10.6.2.2 typedef std::vector< neuron_weights_t > mlp::layer_weights_t
Pointer to weights for a layer.
Holds the weights for a layer
Definition at line 49 of file mlp_types.hpp.
10.6.2.3 typedef std::vector<float_t> mlp::vector_t
This type is used for both vectors and matrices on the host. Everything is column-majorand indexed starting 1 (the 0 element is wasted).
Definition at line 25 of file mlp_types.hpp.
10.6.3 Enumeration Type Documentation
10.6.3.1 enum mlp::activation_function_t
Pointer to weights for the whole MLP.
Defines the possible activation functions
Definition at line 58 of file mlp_types.hpp.
10.6.4 Function Documentation
10.6.4.1 std::string mlp::get_impl_title (implementation_t impl)
Returns a string describing the mlp implementation. Good for showing to the user.
Returns:
A description of the implementation
Parameters:
impl The implemenation to describe
Definition at line 41 of file mlp.cpp.
Here is the caller graph for this function:
mlp::get_impl_title
mlp::gui::training_results_panel_t::Entry
mlp::gui::training_results_panel_t::training_results_panel_t
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

46 Namespace Documentation
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 11
Class Documentation
11.1 anonymous_namespace{training_-panel.cpp}::layer_gui_t Class Reference
Inheritance diagram for anonymous_namespace{training_panel.cpp}::layer_gui_t:
anonymous_namespace{training_panel.cpp}::layer_gui_t
- m_layer- mp_act_fun_choice- mp_neuron_count
+ activation_function()+ disableNuerons()+ enableNuerons()+ layer_gui_t()+ nuerons()
wxPanel

48 Class Documentation
Collaboration diagram for anonymous_namespace{training_panel.cpp}::layer_gui_t:
anonymous_namespace{training_panel.cpp}::layer_gui_t
- m_layer- mp_act_fun_choice- mp_neuron_count
+ activation_function()+ disableNuerons()+ enableNuerons()+ layer_gui_t()+ nuerons()
wxPanel
wxChoice *
mp_act_fun_choice
wxSpinCtrl *
mp_neuron_count
unsigned int
m_layer
11.1.1 Detailed Description
A panel for the use to input the configuration of a single layer.
Definition at line 29 of file training_panel.cpp.
Public Member Functions
• mlp::activation_function_t activation_function () const
get activation function
• void disableNuerons (unsigned int val)
Disables neuron input.
• void enableNuerons ()
Enables the neuron input.
• layer_gui_t (unsigned int layer, wxWindow ∗parent, unsigned int neurons)
Constructor.
• unsigned int nuerons () const
Returns the number of neurons in the layer.
Private Attributes
• unsigned int m_layer
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.1 anonymous_namespace{training_panel.cpp}::layer_gui_t Class Reference49
• wxChoice ∗ mp_act_fun_choice• wxSpinCtrl ∗ mp_neuron_count
The documentation for this class was generated from the following file:
• training_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

50 Class Documentation
11.2 mlp::basic_layer_t< Ptr > Struct Template Ref-erence
#include < 539/project/src/layer.hpp>
Collaboration diagram for mlp::basic_layer_t< Ptr >:
mlp::basic_layer_t< Ptr >
+ p_delta+ p_dW+ p_W+ p_X+ p_Z
+ ~basic_layer_t()
Ptr
p_Wp_X
p_dWp_Z
p_delta
11.2.1 Detailed Description
template<typename Ptr> struct mlp::basic_layer_t< Ptr >
Holds the data for a layer of the MLP.
Definition at line 25 of file layer.hpp.
Public Attributes
• Ptr p_delta
"delta" error values. (M+1)xN, one for each output value, plus the bias into next level
• Ptr p_dW
Change in W. Begins epoch with change from last epoch (init to 0!) and is updatedevery epoch. Must be held transposed to get math right with cu blas.
• Ptr p_W
Layer weights. KxM, each column is a neuron, M neurons.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.2 mlp::basic_layer_t< Ptr > Struct Template Reference 51
• Ptr p_XLayer input data. KxN, each column is a sample, N samples.
• Ptr p_ZLayer output. MxN, each column is the output of all neurons for a single sample.
The documentation for this struct was generated from the following file:
• layer.hpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

52 Class Documentation
11.3 mlp::basic_matrix_t< Type > Class TemplateReference
#include < 539/project/src/matrix.hpp>
Inheritance diagram for mlp::basic_matrix_t< Type >:
mlp::basic_matrix_t< Type >
- m_columns- m_data- m_rows
+ add_transposed()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ columns()+ copy_from_device()+ copy_plus_bias()+ copy_to_device()+ operator()()+ operator()()+ operator*=()+ operator-()+ operator-=()+ operator=()+ raw_data()+ rows()+ sub_matrix()+ sum_of_squares()+ transform()- check_dim()- check_index()- get_index()
mlp::basic_matrix_t< float >
- m_columns- m_data- m_rows
+ add_transposed()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ columns()+ copy_from_device()+ copy_plus_bias()+ copy_to_device()+ operator()()+ operator()()+ operator*=()+ operator-()+ operator-=()+ operator=()+ raw_data()+ rows()+ sub_matrix()+ sum_of_squares()+ transform()- check_dim()- check_index()- get_index()
< float >
mlp::basic_matrix_t< float_t >
- m_columns- m_data- m_rows
+ add_transposed()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ columns()+ copy_from_device()+ copy_plus_bias()+ copy_to_device()+ operator()()+ operator()()+ operator*=()+ operator-()+ operator-=()+ operator=()+ raw_data()+ rows()+ sub_matrix()+ sum_of_squares()+ transform()- check_dim()- check_index()- get_index()
< float_t >
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.3 mlp::basic_matrix_t< Type > Class Template Reference 53
Collaboration diagram for mlp::basic_matrix_t< Type >:
mlp::basic_matrix_t< Type >
- m_columns- m_data- m_rows
+ add_transposed()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ basic_matrix_t()+ columns()+ copy_from_device()+ copy_plus_bias()+ copy_to_device()+ operator()()+ operator()()+ operator*=()+ operator-()+ operator-=()+ operator=()+ raw_data()+ rows()+ sub_matrix()+ sum_of_squares()+ transform()- check_dim()- check_index()- get_index()
std::vector< Type >
- elements
m_data
Type
elements
std::vector< T >
- elements
< Type >
T
elements
int
m_rowsm_columns
11.3.1 Detailed Description
template<typename Type> class mlp::basic_matrix_t< Type >
Represents a matrix in a way that is compatable with cublas.
Definition at line 33 of file matrix.hpp.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen
54 Class Documentation
Public Member Functions
• basic_matrix_t< Type > const & add_transposed (basic_matrix_t< Type >const &other)
adds the other matrix to this one after transposing
• basic_matrix_t (std::vector< boost::shared_ptr< std::vector< Type>>> const&other)
constructor from vector of vectors
• basic_matrix_t (unsigned int r, unsigned int c, dev_ptr dp)
constructor from device data
• basic_matrix_t (basic_matrix_t< Type > const &other, Type init)
Constructor from another matrix, adds a const val to the "extra" element at the top ofeach column.
• basic_matrix_t (unsigned int r=0, unsigned int c=0, Type init=0.f)
Constructor.
• unsigned int columns () const
Number of columns.
• void copy_from_device (dev_ptr p_dev_matrix)
copies data from device pointer to matrix of this size
• void copy_plus_bias (basic_matrix_t< Type > const &other, Type bias)
Copies data from other and addes first row of bias.
• void copy_to_device (dev_ptr p_dev_matrix)
copies matrix values to pre-allocated device pointer
• Type & operator() (unsigned int r, unsigned int c)
Read/write access to an element.
• Type const & operator() (unsigned int r, unsigned int c) const
Read-only access to an element.
• basic_matrix_t< Type > const & operator∗= (basic_matrix_t< Type > const&rhs)
Multiply-equals operator.
• basic_matrix_t< Type > operator- (basic_matrix_t< Type > const &rhs) const
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.3 mlp::basic_matrix_t< Type > Class Template Reference 55
Matrix subtraction.
• basic_matrix_t< Type > const & operator-= (basic_matrix_t< Type > const&rhs)
Subtract-equals.
• basic_matrix_t< Type > const & operator= (basic_matrix_t< Type > const&other)
assignment operator
• Type ∗const raw_data ()
Returns a cublas compatable pointer to the data.
• unsigned int rows () const
Number of rows.
• basic_matrix_t< Type > sub_matrix (unsigned int start_row, unsigned int end_-row, unsigned int start_column, unsigned int end_column) const
Creates a sub-marix.
• Type sum_of_squares () const
Returns the sum of the squares of all elements.
• basic_matrix_t< Type > const & transform (boost::function< Type(Type) > f)
Applies the function to each element.
Private Member Functions
• void check_dim (basic_matrix_t< Type > const &rhs) const
checks that the given matrix has the same dimensions as this one. Throws error_t ifnot
• void check_index (unsigned int r, unsigned int c) const
Checks row and column values.
• unsigned int get_index (unsigned int row, unsigned int col) const
Returns the naked array index given the row and column.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

56 Class Documentation
Private Attributes
• unsigned int m_columnsNumber of columns.
• std::vector< Type > m_dataArray holding the data. Data is column major and the 0 element of each column isnot used.
• unsigned int m_rowsNumber of rows.
11.3.2 Constructor & Destructor Documentation
11.3.2.1 template<typename Type> mlp::basic_matrix_t< Type>::basic_matrix_t (basic_matrix_t< Type > const & other, Type init)[inline]
Constructor from another matrix, adds a const val to the "extra" element at the top ofeach column.
Definition at line 128 of file matrix.hpp.
The documentation for this class was generated from the following file:
• matrix.hpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.4 mlp::blas_mlp_t Class Reference 57
11.4 mlp::blas_mlp_t Class Reference
#include < 539/project/src/blas_mlp.hpp>
Inheritance diagram for mlp::blas_mlp_t:
mlp::blas_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_host_layers- m_last_N- m_layers- m_rng- m_target- m_update_max- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ blas_mlp_t()+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~blas_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

58 Class Documentation
Collaboration diagram for mlp::blas_mlp_t:
mlp::blas_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_host_layers- m_last_N- m_layers- m_rng- m_target- m_update_max- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ blas_mlp_t()+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~blas_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
float
m_update_maxm_best_errorm_best_crate
matrix< float_t, boost::numeric::ublas::column_major >
m_target
shared_ptr< matrix_t >
mp_tuning_setmp_target_set
mp_training_setmp_tuning_target_set
vector< matrix_t >
m_best_w
vector< host_layer_t >
m_host_layers
int
m_layersm_last_N
std::stringstream
m_debug_stream
std::basic_stringstream< char >
std::basic_iostream< Char >
std::basic_istream< Char >
std::basic_ios< Char >
std::basic_ostream< Char >
std::ios_base
vector< activation_function_t >
m_act_fun
mt19937
m_rng
11.4.1 Detailed Description
CPU-only MLP implementation using boost::blas.
blas_mlp_t is a class which implements the mlp_t inteface using the CPU only.The boost::blas library is used to represent matrix objects and for matrix operations.boost::blas is a modern object-oriented implementation of the well known Basic Lin-ear Algebra Subprograms library. More information about boost::blas and the otherboost C++ libraries can be found at http://www.boost.org .
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.4 mlp::blas_mlp_t Class Reference 59
The purpose of this implementation is to serve as a baseline withwhich to compare the GPU based implementations. The use of theboost::blas libraries provides competitive performance (performance compar-isons can be found at http://www.boost.org/doc/libs/1_37_-0/libs/numeric/ublas/doc/overview.htm . The rest of the blas_mlp_tcode has not undergone performance tuning and large improvements are no doubtpossible. Most notably, the code is single-threaded. A multi-threaded approach shouldbe able provide large performance improvements on modern multi-core processors.
The results presented later in this report focus on an analysis of performance differenceswhich vary by orders of magnitude. Optimization of this class would be important fordeployment in a production setting, but is not relevant for the purposes of this research.
Definition at line 37 of file blas_mlp.hpp.
Public Member Functions
• blas_mlp_t (unsigned int input_dim, neuron_counts_t const &neuron_counts,float_t randomize_weights, float_t randomize_updates)
Constructor.
• virtual void classify (input_set_t const &input, output_set_t &output)
Classifies the given input using the current weights.
• virtual std::stringstream & get_debug_stream ()
Gets the debug printouts.
• virtual mlp_weights_t get_weights () const
Gets the current weights.
• virtual float_t run_training_epoch (unsigned int num_samples, float_t learning_-rate, float_t momentum)
Runs a training epoch.
• virtual void set_activation_function (unsigned int layer, activation_function_tact_fun)
Chooses which activation function to use for the given layer.
• virtual void set_training_data (input_set_ptr p_training_set, output_set_ptr p_-target_set)
Sets the data to use when running MLP training.
• virtual void set_tuning_data (input_set_ptr p_tuning_set, output_set_ptr p_-tuning_target_set)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

60 Class Documentation
Sets the data to use when checking for convergence.
• virtual void set_weights (mlp_weights_t const &weights)Sets the weights for use in classification.
• virtual void tune (float_t &error, float_t &classification_rate)Uses the tuning data to estimate the current error and classification rate. Does notchange the neuron weights.
• virtual ∼blas_mlp_t ()Destructor.
Private Types
• typedef basic_layer_t< matrix_ptr > host_layer_tData for a single MLP layer.
• typedef std::vector< host_layer_t > host_layers_tData for all layers.
• typedef boost::shared_ptr< matrix_t > matrix_ptrPointer to a batrix.
• typedef boost::numeric::ublas::matrix< float_t,boost::numeric::ublas::column_major > matrix_t
matrix type used for data and calculations
Private Member Functions
• float_t back_prop ()• void check_and_init_layers (unsigned int num_samples)• void feed_forward ()• void randomize_input (unsigned int num_samples)• void update_weights (float_t learning_rate, float_t momentum)
Private Attributes
• std::vector< activation_function_t > m_act_fun• float_t m_best_crate• float_t m_best_error
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.4 mlp::blas_mlp_t Class Reference 61
• std::vector< matrix_t > m_best_w• std::stringstream m_debug_stream• host_layers_t m_host_layers• unsigned int m_last_N• unsigned int const m_layers• boost::mt19937 m_rng• matrix_t m_target• float_t m_update_max• matrix_ptr mp_target_set• matrix_ptr mp_training_set• matrix_ptr mp_tuning_set• matrix_ptr mp_tuning_target_set
11.4.2 Member Function Documentation
11.4.2.1 virtual std::stringstream& mlp::blas_mlp_t::get_debug_stream ()[inline, virtual]
Gets the debug printouts.
Returns:
A stringstream object holding all the debug output since the last time it was cleared.
For debug/development use only. Requires a debug build to generate much usefulinformation.
Implements mlp::mlp_t.
Definition at line 97 of file blas_mlp.hpp.
11.4.2.2 mlp::mlp_weights_t mlp::blas_mlp_t::get_weights () const[virtual]
Gets the current weights.
Returns:
The current weights
Implements mlp::mlp_t.
Definition at line 712 of file blas_mlp.cpp.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

62 Class Documentation
11.4.2.3 mlp::float_t mlp::blas_mlp_t::run_training_epoch (unsigned intnum_samples, float_t learning_rate, float_t momentum) [virtual]
Runs a training epoch.
Returns:
Error found after passing the training samples through the MLP before updatingweights.
This function does a single feed-forward and back-propagation pass which results inan update of the neuron weights. If the number of samples requested is less that thetotal number available (the number of samples given to set_training_data()) a randomset of samples is taken from the training data.
This function must not be called until after training data has been supplied via a call toset_training_data().
Implements mlp::mlp_t.
Definition at line 297 of file blas_mlp.cpp.
11.4.2.4 void mlp::blas_mlp_t::set_training_data (input_set_ptr p_training_set,output_set_ptr p_target_set) [virtual]
Sets the data to use when running MLP training.
This data is used by the run_training_epoch() function
Implements mlp::mlp_t.
Definition at line 165 of file blas_mlp.cpp.
11.4.2.5 void mlp::blas_mlp_t::set_tuning_data (input_set_ptr p_tuning_set,output_set_ptr p_tuning_target_set) [virtual]
Sets the data to use when checking for convergence.
This data is used by the tune() function and so only results in a measure of the currenterror and classification rate. This data is never used to change the MLP weights.
Implements mlp::mlp_t.
Definition at line 231 of file blas_mlp.cpp.
The documentation for this class was generated from the following files:
• blas_mlp.hpp• blas_mlp.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.5 mlp::cublas_cuda_mlp_t Class Reference 63
11.5 mlp::cublas_cuda_mlp_t Class Reference
#include < 539/project/src/cublas_cuda_mlp.hpp>
Inheritance diagram for mlp::cublas_cuda_mlp_t:
mlp::cublas_cuda_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_dev_layers- m_last_N- m_layers- m_rng- m_update_max- mp_target- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ classify()+ cublas_cuda_mlp_t()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~cublas_cuda_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

64 Class Documentation
Collaboration diagram for mlp::cublas_cuda_mlp_t:
mlp::cublas_cuda_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_dev_layers- m_last_N- m_layers- m_rng- m_update_max- mp_target- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ classify()+ cublas_cuda_mlp_t()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~cublas_cuda_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
vector< basic_matrix_t< float_t > >
m_best_w
float
m_update_maxm_best_errorm_best_crate
shared_ptr< matrix_t >
mp_tuning_setmp_target_set
mp_training_setmp_target
mp_tuning_target_set
std::stringstream
m_debug_stream
std::basic_stringstream< char >
std::basic_iostream< Char >
std::basic_istream< Char >
std::basic_ios< Char >
std::basic_ostream< Char >
std::ios_base
vector< activation_function_t >
m_act_fun
vector< dev_layer_t >
m_dev_layers
unsigned int
m_layersm_last_N
mt19937
m_rng
11.5.1 Detailed Description
Implements the mlp_t inteface using cuBLAS and CUDA.
The cublas_cuda_mlp_t class implements the mlp_t interface using a combination of
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.5 mlp::cublas_cuda_mlp_t Class Reference 65
cuBLAS and CUDA. CUDA is nVidia’s framework allowing programs to be writtenfor execution on an nVidia GPU. More details about CUDA can be found at nVidia’sCUDA website: http://www.nvidia.com/object/cuda_home.html.
This implementation directly addresses the performance bottleneck of frequent CPU toGPU memory copies. The cuBLAS library is still used to perform the high-cost matrixproduct operations in exactly the same was as is done in the cublas_mlp_t implemen-tation. Instead of performing the other operations on the CPU as cublas_mlp_t does,this class uses CUDA code to perform them on the GPU.
Effective use of CUDA requires that algorithms be expressed as a single program flowwhich is then applied to many pieces of data in parallel. This allows a dramatic speedupfor operations in which the data is used independently. For example, a matrix-matrixsubtraction can be expressed as many threads in which each does a single subtractionof one element in the arrays.
Some operations are a challenge to express in a massively parallel program. Computingthe sum of all the elements in a matrix does not have an obvious solution in the sameway that a matrix-matrix subtraction does. This is because a summation of this kindwould traditionally be done by accumulating the sum into a single memory location (orregister) by serial additions of each element into the running sum. There is no benefitto using more than one thread to do this because their operations would need to becompletely serialized.
There was not sufficient time during this project to research and implement efficientparallel algorithms for all the operations done on the GPU using CUDA. As a resultthe performance of this class in some cases may be quite sub-optimal. However, it doesserve as a good proof of concept for implementing a Multi-Layer Perceptron on a GPU.Certainly order-of-magnitude comparisons to the CPU implementation are appropriate.
Definition at line 42 of file cublas_cuda_mlp.hpp.
Public Types
• typedef boost::shared_ptr< matrix_t > matrix_ptr
Public Member Functions
• virtual void classify (input_set_t const &input, output_set_t &output)
Classifies the given input using the current weights.
• cublas_cuda_mlp_t (unsigned int input_dim, neuron_counts_t const &neuron_-counts, float_t randomize_weights, float_t randomize_update)
Constructor.
• virtual std::stringstream & get_debug_stream ()
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen
66 Class Documentation
Gets the debug printouts.
• virtual mlp_weights_t get_weights () const
Gets the current weights.
• virtual float_t run_training_epoch (unsigned int num_samples, float_t learning_-rate, float_t momentum)
Runs a training epoch.
• virtual void set_activation_function (unsigned int layer, activation_function_tact_fun)
Chooses which activation function to use for the given layer.
• virtual void set_training_data (input_set_ptr p_training_set, output_set_ptr p_-target_set)
Sets the data to use when running MLP training.
• virtual void set_tuning_data (input_set_ptr p_tuning_set, output_set_ptr p_-tuning_target_set)
Sets the data to use when checking for convergence.
• virtual void set_weights (mlp_weights_t const &weights)
Sets the weights for use in classification.
• virtual void tune (float_t &error, float_t &classification_rate)
Uses the tuning data to estimate the current error and classification rate. Does notchange the neuron weights.
• virtual ∼cublas_cuda_mlp_t ()
Destructor.
Private Types
• typedef basic_layer_t< matrix_ptr > dev_layer_t
layer on the device
• typedef std::vector< dev_layer_t > dev_layers_t
Layer list on device.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.5 mlp::cublas_cuda_mlp_t Class Reference 67
Private Member Functions
• float_t back_prop ()• void check_and_init_layers (unsigned int num_samples)• void feed_forward ()• void randomize_input (unsigned int num_samples)• void update_weights (float_t learning_rate, float_t momentum)
Private Attributes
• std::vector< activation_function_t > m_act_fun• float_t m_best_crate• float_t m_best_error• std::vector< basic_matrix_t< float_t > > m_best_w• std::stringstream m_debug_stream• dev_layers_t m_dev_layers• unsigned int m_last_N• unsigned int m_layers• boost::mt19937 m_rng• float_t m_update_max• matrix_ptr mp_target• matrix_ptr mp_target_set• matrix_ptr mp_training_set• matrix_ptr mp_tuning_set• matrix_ptr mp_tuning_target_set
Classes
• class matrix_t
11.5.2 Member Function Documentation
11.5.2.1 virtual std::stringstream& mlp::cublas_cuda_mlp_t::get_debug_-stream () [inline, virtual]
Gets the debug printouts.
Returns:
A stringstream object holding all the debug output since the last time it was cleared.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

68 Class Documentation
For debug/development use only. Requires a debug build to generate much usefulinformation.
Implements mlp::mlp_t.
Definition at line 119 of file cublas_cuda_mlp.hpp.
11.5.2.2 mlp::mlp_weights_t mlp::cublas_cuda_mlp_t::get_weights () const[virtual]
Gets the current weights.
Returns:
The current weights
Implements mlp::mlp_t.
Definition at line 255 of file cublas_cuda_mlp.cpp.
Here is the call graph for this function:
mlp::cublas_cuda_mlp_t::get_weights
mlp::basic_matrix_t::columns
mlp::basic_matrix_t::rows
11.5.2.3 mlp::float_t mlp::cublas_cuda_mlp_t::run_training_epoch (unsignedint num_samples, float_t learning_rate, float_t momentum)[virtual]
Runs a training epoch.
Returns:
Error found after passing the training samples through the MLP before updatingweights.
This function does a single feed-forward and back-propagation pass which results inan update of the neuron weights. If the number of samples requested is less that thetotal number available (the number of samples given to set_training_data()) a randomset of samples is taken from the training data.
This function must not be called until after training data has been supplied via a call toset_training_data().
Implements mlp::mlp_t.
Definition at line 415 of file cublas_cuda_mlp.cpp.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.5 mlp::cublas_cuda_mlp_t Class Reference 69
11.5.2.4 void mlp::cublas_cuda_mlp_t::set_training_data (input_set_ptrp_training_set, output_set_ptr p_target_set) [virtual]
Sets the data to use when running MLP training.
This data is used by the run_training_epoch() function
Implements mlp::mlp_t.
Definition at line 311 of file cublas_cuda_mlp.cpp.
11.5.2.5 void mlp::cublas_cuda_mlp_t::set_tuning_data (input_set_ptrp_tuning_set, output_set_ptr p_tuning_target_set) [virtual]
Sets the data to use when checking for convergence.
This data is used by the tune() function and so only results in a measure of the currenterror and classification rate. This data is never used to change the MLP weights.
Implements mlp::mlp_t.
Definition at line 363 of file cublas_cuda_mlp.cpp.
The documentation for this class was generated from the following files:
• cublas_cuda_mlp.hpp• cublas_cuda_mlp.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

70 Class Documentation
11.6 mlp::cublas_mlp_t Class Reference
#include < 539/project/src/cublas_mlp.hpp>
Inheritance diagram for mlp::cublas_mlp_t:
mlp::cublas_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_dev_layers- m_host_layers- m_last_N- m_layers- m_rng- m_target- m_update_max- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ classify()+ cublas_mlp_t()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~cublas_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.6 mlp::cublas_mlp_t Class Reference 71
Collaboration diagram for mlp::cublas_mlp_t:
mlp::cublas_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_dev_layers- m_host_layers- m_last_N- m_layers- m_rng- m_target- m_update_max- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ classify()+ cublas_mlp_t()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~cublas_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
shared_ptr< input_set_t >
mp_training_set
float
m_update_maxm_best_errorm_best_crate
shared_ptr< matrix_t >
mp_tuning_setmp_tuning_target_set
vector< matrix_t >
m_best_w
vector< host_layer_t >
m_host_layers
std::stringstream
m_debug_stream
std::basic_stringstream< char >
std::basic_iostream< Char >
std::basic_istream< Char >
std::basic_ios< Char >
std::basic_ostream< Char >
std::ios_base
vector< activation_function_t >
m_act_fun
vector< dev_layer_t >
m_dev_layers
basic_matrix_t< float_t >
m_target
unsigned int
m_layersm_last_N
shared_ptr< output_set_t >
mp_target_set
mt19937
m_rng
11.6.1 Detailed Description
Implements the mlp_t interface using nVidia’s cublas library.
cublas_mlp_t is a class which implements the mlp_t interface using a hybrid ap-proach of CPU and GPU. In this class the high-cost matrix-matrix product calcula-tions are done using nVidia’s cuBLAS library. Details about this library can be foundon nVidia’s CUDA website: http://www.nvidia.com/object/cuda_-home.html .
The cuBLAS library allows significant performance increases by utilizing an nVidiaGPU without requiring the programmer to write GPU based code directly. The libraryprovides a API in C which which the user can perform the standard BLAS linear alge-bra operations.
The drawback to this approach is that it requires duplication and frequent synchroniza-tion of data between main CPU memory and device memory on the GPU. This problemis exacerbated by the fact that the cuBLAS library doesn’t provide trivial operations
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

72 Class Documentation
such as matrix subtraction and addition. The result is that these simple operations mustbe performed by the CPU requiring many extra memory copies between CPU and GPUmemory. These copy operations have very high latency relative to CPU and GPU clockspeeds which makes them a bottleneck for overall performance. The results section ofthis report investigates this further.
The following sections provide details about how the MLP training phases are per-formed on the CPU and GPU:
cuBLAS Feed Forward
For each layer the following steps must be done:
1. Copy neuron weights and layer input to GPU
2. Perform matrix product: Zl = WTl Xl
3. Copy layer output to CPU
4. Apply activation function to each element of layer output
5. Copy layer output to GPU
6. Set next layer input to current layer output
cuBLAS Back-Propagation
• Compute the output layer error delta on the CPU:
∆EL = u′L(ZL)∑i,j
[(ZL(i, j)− Y (i, j))2]
• Copy the output layer error delta to the GPU
• For each layer hidden layer:
1. Compute the matrix product: W(l+1)∆E(l+1)
2. Copy the result to the CPU
3. Apply the non-linear activation function derivative to the current layer out-put on the CPU
4. Element by element multiplication to produce layer delta:
∆El = W(l+1)∆E(l+1) · u′l(Zl)
5. Copy layer error delta to GPU
cuBLAS Weight Update
For each layer the following steps are needed:
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.6 mlp::cublas_mlp_t Class Reference 73
1. Copy the previous epoch weight update to the GPU
2. calculate weight delta on GPU with single cuBLAS call:
∆Wl(t) = η(∆ElXTl ) + µ∆Wl(t− 1)
3. Copy the result to the CPU
4. Add random noise on the CPU
5. Add the weight update to the current weight on the CPU. Copy to the GPU is notneeded here because it will be done during feed-forward of the next epoch
These summaries illustrate that each training epoch requires multiple CPU-GPU mem-ory copies.
Definition at line 43 of file cublas_mlp.hpp.
Public Member Functions
• virtual void classify (input_set_t const &input, output_set_t &output)Classifies the given input using the current weights.
• cublas_mlp_t (unsigned int input_dim, neuron_counts_t const &neuron_counts,float_t randomize_weights, float_t randomize_updates)
Constructor.
• virtual std::stringstream & get_debug_stream ()Gets the debug printouts.
• virtual mlp_weights_t get_weights () constGets the current weights.
• virtual float_t run_training_epoch (unsigned int num_samples, float_t learning_-rate, float_t momentum)
Runs a training epoch.
• virtual void set_activation_function (unsigned int layer, activation_function_tact_fun)
Chooses which activation function to use for the given layer.
• virtual void set_training_data (input_set_ptr p_training_set, output_set_ptr p_-target_set)
Sets the data to use when running MLP training.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

74 Class Documentation
• virtual void set_tuning_data (input_set_ptr p_tuning_set, output_set_ptr p_-tuning_target_set)
Sets the data to use when checking for convergence.
• virtual void set_weights (mlp_weights_t const &weights)Sets the weights for use in classification.
• virtual void tune (float_t &error, float_t &classification_rate)Uses the tuning data to estimate the current error and classification rate. Does notchange the neuron weights.
• virtual ∼cublas_mlp_t ()Destructor.
Private Types
• typedef basic_layer_t< dev_ptr > dev_layer_tlayer on the device
• typedef std::vector< dev_layer_t > dev_layers_tLayer list on device.
• typedef basic_layer_t< matrix_ptr > host_layer_tList of matrices.
• typedef std::vector< host_layer_t > host_layers_tLayer list on host.
• typedef boost::shared_ptr< matrix_t > matrix_ptrpointer to a matrix
• typedef basic_matrix_t< float_t > matrix_tMatrix for MLP use.
Private Member Functions
• float_t back_prop ()cuBLAS Back-Propagation
• void check_and_init_layers (unsigned int num_samples)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.6 mlp::cublas_mlp_t Class Reference 75
• void feed_forward ()cuBLAS Feed Forward
• void randomize_input (unsigned int num_samples)• void update_weights (float_t learning_rate, float_t momentum)
cuBLAS Weight Update
Private Attributes
• std::vector< activation_function_t > m_act_fun• float_t m_best_crate• float_t m_best_error• std::vector< matrix_t > m_best_w• std::stringstream m_debug_stream• dev_layers_t m_dev_layers• host_layers_t m_host_layers• unsigned int m_last_N• unsigned int m_layers• boost::mt19937 m_rng• matrix_t m_target• float_t m_update_max• output_set_ptr mp_target_set• input_set_ptr mp_training_set• matrix_ptr mp_tuning_set• matrix_ptr mp_tuning_target_set
11.6.2 Member Typedef Documentation
11.6.2.1 typedef basic_layer_t< matrix_ptr > mlp::cublas_mlp_t::host_layer_t[private]
List of matrices.
layer on the host
Definition at line 56 of file cublas_mlp.hpp.
11.6.3 Member Function Documentation
11.6.3.1 mlp::float_t mlp::cublas_mlp_t::back_prop () [private]
cuBLAS Back-Propagation
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

76 Class Documentation
• Compute the output layer error delta on the CPU:
∆EL = u′L(ZL)∑i,j
[(ZL(i, j)− Y (i, j))2]
• Copy the output layer error delta to the GPU
• For each layer hidden layer:
1. Compute the matrix product: W(l+1)∆E(l+1)
2. Copy the result to the CPU
3. Apply the non-linear activation function derivative to the current layer out-put on the CPU
4. Element by element multiplication to produce layer delta:
∆El = W(l+1)∆E(l+1) · u′l(Zl)
5. Copy layer error delta to GPU
Definition at line 545 of file cublas_mlp.cpp.
Here is the call graph for this function:
mlp::cublas_mlp_t::back_prop mlp::basic_matrix_t::transform
Here is the caller graph for this function:
mlp::cublas_mlp_t::back_prop mlp::cublas_mlp_t::run_training_epoch
11.6.3.2 void mlp::cublas_mlp_t::feed_forward () [private]
cuBLAS Feed Forward
For each layer the following steps must be done:
1. Copy neuron weights and layer input to GPU
2. Perform matrix product: Zl = WTl Xl
3. Copy layer output to CPU
4. Apply activation function to each element of layer output
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.6 mlp::cublas_mlp_t Class Reference 77
5. Copy layer output to GPU
6. Set next layer input to current layer output
Definition at line 464 of file cublas_mlp.cpp.
Here is the caller graph for this function:
mlp::cublas_mlp_t::feed_forward
mlp::cublas_mlp_t::classify
mlp::cublas_mlp_t::run_training_epoch
mlp::cublas_mlp_t::tune
11.6.3.3 virtual std::stringstream& mlp::cublas_mlp_t::get_debug_stream ()[inline, virtual]
Gets the debug printouts.
Returns:
A stringstream object holding all the debug output since the last time it was cleared.
For debug/development use only. Requires a debug build to generate much usefulinformation.
Implements mlp::mlp_t.
Definition at line 113 of file cublas_mlp.hpp.
11.6.3.4 mlp::mlp_weights_t mlp::cublas_mlp_t::get_weights () const[virtual]
Gets the current weights.
Returns:
The current weights
Implements mlp::mlp_t.
Definition at line 207 of file cublas_mlp.cpp.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

78 Class Documentation
11.6.3.5 mlp::float_t mlp::cublas_mlp_t::run_training_epoch (unsigned intnum_samples, float_t learning_rate, float_t momentum) [virtual]
Runs a training epoch.
Returns:
Error found after passing the training samples through the MLP before updatingweights.
This function does a single feed-forward and back-propagation pass which results inan update of the neuron weights. If the number of samples requested is less that thetotal number available (the number of samples given to set_training_data()) a randomset of samples is taken from the training data.
This function must not be called until after training data has been supplied via a call toset_training_data().
Implements mlp::mlp_t.
Definition at line 347 of file cublas_mlp.cpp.
Here is the call graph for this function:
mlp::cublas_mlp_t::run_training_epoch
mlp::cublas_mlp_t::back_prop
mlp::cublas_mlp_t::feed_forward
mlp::cublas_mlp_t::update_weights
mlp::basic_matrix_t::transform
11.6.3.6 void mlp::cublas_mlp_t::set_training_data (input_set_ptrp_training_set, output_set_ptr p_target_set) [virtual]
Sets the data to use when running MLP training.
This data is used by the run_training_epoch() function
Implements mlp::mlp_t.
Definition at line 264 of file cublas_mlp.cpp.
11.6.3.7 void mlp::cublas_mlp_t::set_tuning_data (input_set_ptr p_tuning_set,output_set_ptr p_tuning_target_set) [virtual]
Sets the data to use when checking for convergence.
This data is used by the tune() function and so only results in a measure of the currenterror and classification rate. This data is never used to change the MLP weights.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.6 mlp::cublas_mlp_t Class Reference 79
Implements mlp::mlp_t.
Definition at line 305 of file cublas_mlp.cpp.
11.6.3.8 void mlp::cublas_mlp_t::update_weights (float_t learning_rate, float_tmomentum) [private]
cuBLAS Weight Update
For each layer the following steps are needed:
1. Copy the previous epoch weight update to the GPU
2. calculate weight delta on GPU with single cuBLAS call:
∆Wl(t) = η(∆ElXTl ) + µ∆Wl(t− 1)
3. Copy the result to the CPU
4. Add random noise on the CPU
5. Add the weight update to the current weight on the CPU. Copy to the GPU is notneeded here because it will be done during feed-forward of the next epoch
Definition at line 639 of file cublas_mlp.cpp.
Here is the caller graph for this function:
mlp::cublas_mlp_t::update_weights mlp::cublas_mlp_t::run_training_epoch
The documentation for this class was generated from the following files:
• cublas_mlp.hpp• cublas_mlp.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

80 Class Documentation
11.7 mlp::error_t Class Reference
#include < 539/project/src/error.hpp>
Inheritance diagram for mlp::error_t:
mlp::error_t
- m_msg
+ error_t()+ what()+ ~error_t()
std::exception
Collaboration diagram for mlp::error_t:
mlp::error_t
- m_msg
+ error_t()+ what()+ ~error_t()
std::exception
std::string
m_msg
std::basic_string< char >
11.7.1 Detailed Description
Thrown by MLP functions to indicate and error.
Definition at line 22 of file error.hpp.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.7 mlp::error_t Class Reference 81
Public Member Functions
• error_t (char const ∗file, int line, std::string const &msg)• const char ∗ what () const throw ()
Private Attributes
• std::string m_msg
The documentation for this class was generated from the following file:
• error.hpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

82 Class Documentation
11.8 mlp::gui::main_form_t Class Reference
#include < 539/project/src/main_form.hpp>
Inheritance diagram for mlp::gui::main_form_t:
mlp::gui::main_form_t
- mp_log_window- mp_notebook- mp_redirector- mp_training_panel
+ main_form_t()- on_about()- on_quit()
wxFrame
Collaboration diagram for mlp::gui::main_form_t:
mlp::gui::main_form_t
- mp_log_window- mp_notebook- mp_redirector- mp_training_panel
+ main_form_t()- on_about()- on_quit()
wxFrame
mlp::gui::training_panel_t
- m_layers- mp_add_layer_button- mp_epoch_count- mp_epoch_size- mp_epochs_per_test- mp_failure_threshold- mp_frame_with_status- mp_impl_choice- mp_in_dim_spin- mp_layer_cfg_sizer- mp_learning_rate_text- mp_momentum_text- mp_rand_update_max- mp_randomize_updates- mp_randomize_weights- mp_rem_layer_button- mp_scale_input- mp_scale_output- mp_train_button- mp_training_data- mp_training_load_status_text- mp_training_picker- mp_tuning_data- mp_tuning_load_status_text- mp_tuning_picker- mp_use_training_radio- mp_use_tuning_file_radio- mp_weight_max
+ training_panel_t()- build_convergance_box()- build_impl_box()- build_layer_config_box()- build_training_box()- build_training_data_box()- build_tuning_data_box()- on_add_layer()- on_rem_layer()- on_train()- on_training_open()- on_tuning_open()- SetStatusText()
mp_training_panel
wxPanel
wxFilePickerCtrl *
mp_tuning_pickermp_training_picker
wxChoice *
mp_impl_choice
wxBoxSizer *
mp_layer_cfg_sizer
wxSpinCtrl *
mp_failure_thresholdmp_epoch_countmp_epoch_size
mp_epochs_per_testmp_in_dim_spin
wxStaticText *
mp_tuning_load_status_textmp_training_load_status_text
wxCheckBox *
mp_randomize_weightsmp_scale_outputmp_scale_input
mp_randomize_updates
shared_ptr< input_handler_t >
mp_training_datamp_tuning_data
unsigned int
m_layers
wxRadioButton *
mp_use_training_radiomp_use_tuning_file_radio
wxTextCtrl *
mp_weight_maxmp_momentum_text
mp_learning_rate_textmp_rand_update_max
wxButton *
mp_rem_layer_buttonmp_add_layer_button
mp_train_button
wxFrame *
mp_frame_with_status
wxLogWindow *
mp_log_window
shared_ptr< wxStreamToTextRedirector >
mp_redirector
wxNotebook *
mp_notebook
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.8 mlp::gui::main_form_t Class Reference 83
11.8.1 Detailed Description
Main form for GUI.
Definition at line 33 of file main_form.hpp.
Public Member Functions
• main_form_t (const wxString &title, const wxPoint &pos, const wxSize &size)Constructor.
Private Member Functions
• void on_about (wxCommandEvent &event)Displays the about window.
• void on_quit (wxCommandEvent &event)Handles quit event.
Private Attributes
• wxLogWindow ∗ mp_log_window• wxNotebook ∗ mp_notebook• boost::shared_ptr< wxStreamToTextRedirector > mp_redirector• training_panel_t ∗ mp_training_panel
The documentation for this class was generated from the following files:
• main_form.hpp• main_form.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

84 Class Documentation
11.9 mlp::gui::training_panel_t Class Reference
#include < 539/project/src/training_panel.hpp>
Inheritance diagram for mlp::gui::training_panel_t:
mlp::gui::training_panel_t
- m_layers- mp_add_layer_button- mp_epoch_count- mp_epoch_size- mp_epochs_per_test- mp_failure_threshold- mp_frame_with_status- mp_impl_choice- mp_in_dim_spin- mp_layer_cfg_sizer- mp_learning_rate_text- mp_momentum_text- mp_rand_update_max- mp_randomize_updates- mp_randomize_weights- mp_rem_layer_button- mp_scale_input- mp_scale_output- mp_train_button- mp_training_data- mp_training_load_status_text- mp_training_picker- mp_tuning_data- mp_tuning_load_status_text- mp_tuning_picker- mp_use_training_radio- mp_use_tuning_file_radio- mp_weight_max
+ training_panel_t()- build_convergance_box()- build_impl_box()- build_layer_config_box()- build_training_box()- build_training_data_box()- build_tuning_data_box()- on_add_layer()- on_rem_layer()- on_train()- on_training_open()- on_tuning_open()- SetStatusText()
wxPanel
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.9 mlp::gui::training_panel_t Class Reference 85
Collaboration diagram for mlp::gui::training_panel_t:
mlp::gui::training_panel_t
- m_layers- mp_add_layer_button- mp_epoch_count- mp_epoch_size- mp_epochs_per_test- mp_failure_threshold- mp_frame_with_status- mp_impl_choice- mp_in_dim_spin- mp_layer_cfg_sizer- mp_learning_rate_text- mp_momentum_text- mp_rand_update_max- mp_randomize_updates- mp_randomize_weights- mp_rem_layer_button- mp_scale_input- mp_scale_output- mp_train_button- mp_training_data- mp_training_load_status_text- mp_training_picker- mp_tuning_data- mp_tuning_load_status_text- mp_tuning_picker- mp_use_training_radio- mp_use_tuning_file_radio- mp_weight_max
+ training_panel_t()- build_convergance_box()- build_impl_box()- build_layer_config_box()- build_training_box()- build_training_data_box()- build_tuning_data_box()- on_add_layer()- on_rem_layer()- on_train()- on_training_open()- on_tuning_open()- SetStatusText()
wxPanel
wxFilePickerCtrl *
mp_tuning_pickermp_training_picker
wxChoice *
mp_impl_choice
wxBoxSizer *
mp_layer_cfg_sizer
wxSpinCtrl *
mp_failure_thresholdmp_epoch_countmp_epoch_size
mp_epochs_per_testmp_in_dim_spin
wxStaticText *
mp_tuning_load_status_textmp_training_load_status_text
wxCheckBox *
mp_randomize_weightsmp_scale_outputmp_scale_input
mp_randomize_updates
shared_ptr< input_handler_t >
mp_training_datamp_tuning_data
unsigned int
m_layers
wxRadioButton *
mp_use_training_radiomp_use_tuning_file_radio
wxTextCtrl *
mp_weight_maxmp_momentum_text
mp_learning_rate_textmp_rand_update_max
wxButton *
mp_rem_layer_buttonmp_add_layer_button
mp_train_button
wxFrame *
mp_frame_with_status
11.9.1 Detailed Description
Main form for GUI.
Definition at line 28 of file training_panel.hpp.
Public Member Functions
• training_panel_t (wxWindow ∗parent, wxFrame ∗p_frame_with_status)
Constructor.
Private Member Functions
• wxStaticBoxSizer ∗ build_convergance_box ()• wxStaticBoxSizer ∗ build_impl_box ()• wxStaticBoxSizer ∗ build_layer_config_box ()• wxStaticBoxSizer ∗ build_training_box ()• wxStaticBoxSizer ∗ build_training_data_box ()• wxStaticBoxSizer ∗ build_tuning_data_box ()• void on_add_layer (wxCommandEvent &event)
Adds a layer.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

86 Class Documentation
• void on_rem_layer (wxCommandEvent &event)Removes a layer.
• void on_train (wxCommandEvent &event)Runs training.
• void on_training_open (wxFileDirPickerEvent &event)Opens the training file.
• void on_tuning_open (wxFileDirPickerEvent &event)• void SetStatusText (wxString const &msg)
Sets the status text in the parent.
Private Attributes
• unsigned int m_layers• wxButton ∗ mp_add_layer_button• wxSpinCtrl ∗ mp_epoch_count• wxSpinCtrl ∗ mp_epoch_size• wxSpinCtrl ∗ mp_epochs_per_test• wxSpinCtrl ∗ mp_failure_threshold• wxFrame ∗ mp_frame_with_status• wxChoice ∗ mp_impl_choice• wxSpinCtrl ∗ mp_in_dim_spin• wxBoxSizer ∗ mp_layer_cfg_sizer• wxTextCtrl ∗ mp_learning_rate_text• wxTextCtrl ∗ mp_momentum_text• wxTextCtrl ∗ mp_rand_update_max• wxCheckBox ∗ mp_randomize_updates• wxCheckBox ∗ mp_randomize_weights• wxButton ∗ mp_rem_layer_button• wxCheckBox ∗ mp_scale_input• wxCheckBox ∗ mp_scale_output• wxButton ∗ mp_train_button• input_handler_ptr mp_training_data• wxStaticText ∗ mp_training_load_status_text• wxFilePickerCtrl ∗ mp_training_picker• input_handler_ptr mp_tuning_data• wxStaticText ∗ mp_tuning_load_status_text• wxFilePickerCtrl ∗ mp_tuning_picker• wxRadioButton ∗ mp_use_training_radio
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.9 mlp::gui::training_panel_t Class Reference 87
• wxRadioButton ∗ mp_use_tuning_file_radio• wxTextCtrl ∗ mp_weight_max
The documentation for this class was generated from the following files:
• training_panel.hpp• training_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

88 Class Documentation
11.10 mlp::gui::training_results_panel_t Class Refer-ence
#include < 539/project/src/training_results_panel.hpp>
Inheritance diagram for mlp::gui::training_results_panel_t:
mlp::gui::training_results_panel_t
- m_activation_functions- m_best_weights- m_epoch_size- m_fail_thresh- m_graph_crate- m_graph_error- m_graph_x- m_impl- m_input_dimension- m_layers- m_learning_rate- m_max_epoch- m_momentum- m_neuron_counts- m_randomize_updates- m_randomize_weights- m_run- m_scale_target_data- m_scale_training_data- m_status_data- m_test_interval- mp_best_crate- mp_best_error- mp_classify_button- mp_classify_data- mp_classify_picker- mp_convergence_error- mp_crate- mp_crate_layer- mp_done_button- mp_elapsed_time- mp_epoch_error- mp_epoch_text- mp_error_layer- mp_failure- mp_graph_window- mp_percent_complete- mp_progress_gauge- mp_time_per_epoch- mp_training_data- mp_tuning_data- mp_updates_missed
+ training_results_panel_t()- Entry()- on_classify()- on_data_open()- on_epoch_done()- on_stop()
wxPanel
wxThreadHelper
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.10 mlp::gui::training_results_panel_t Class Reference 89
Collaboration diagram for mlp::gui::training_results_panel_t:
mlp::gui::training_results_panel_t
- m_activation_functions- m_best_weights- m_epoch_size- m_fail_thresh- m_graph_crate- m_graph_error- m_graph_x- m_impl- m_input_dimension- m_layers- m_learning_rate- m_max_epoch- m_momentum- m_neuron_counts- m_randomize_updates- m_randomize_weights- m_run- m_scale_target_data- m_scale_training_data- m_status_data- m_test_interval- mp_best_crate- mp_best_error- mp_classify_button- mp_classify_data- mp_classify_picker- mp_convergence_error- mp_crate- mp_crate_layer- mp_done_button- mp_elapsed_time- mp_epoch_error- mp_epoch_text- mp_error_layer- mp_failure- mp_graph_window- mp_percent_complete- mp_progress_gauge- mp_time_per_epoch- mp_training_data- mp_tuning_data- mp_updates_missed
+ training_results_panel_t()- Entry()- on_classify()- on_data_open()- on_epoch_done()- on_stop()
wxPanel
wxThreadHelper
wxFilePickerCtrl *
mp_classify_picker
mpWindow *
mp_graph_window
implementation_t
m_impl
mpFXYVector *
mp_crate_layermp_error_layer
float
m_randomize_updatesm_momentum
m_learning_ratem_randomize_weights
std::vector< float >
- elements
elements
mlp::gui::training_results_panel_t::status_data_t
+ best_crate+ best_error+ convergance_error+ crate+ elapsed_ms+ epoch+ epoch_error+ fail_cnt+ processed+ updates_missed
convergance_errorbest_cratebest_error
epoch_errorcrate
wxStaticText *
mp_epoch_errormp_epoch_text
mp_time_per_epochmp_updates_missed
mp_convergence_errormp_failuremp_crate
mp_best_cratemp_elapsed_time
mp_percent_complete...
vector< layer_weights_t >
m_best_weights
shared_ptr< input_handler_t >
mp_training_datamp_tuning_data
mp_classify_data
bool
m_runm_scale_target_data
m_scale_training_data
processed
m_graph_errorm_graph_crate
m_graph_x
std::vector< T >
- elements
< float >
std::vector< unsigned int >
- elements
< unsigned int >
T
elements
vector< activation_function_t >
m_activation_functions
wxGauge *
mp_progress_gaugem_status_data
int
epochupdates_missed
fail_cnt
long
elapsed_ms
unsigned int
m_test_intervalm_layers
m_epoch_sizem_max_epoch
m_input_dimensionm_fail_thresh
elements
m_neuron_counts
wxButton *
mp_classify_buttonmp_done_button
11.10.1 Detailed Description
Dialog that displays training progress.
Definition at line 31 of file training_results_panel.hpp.
Public Member Functions
• training_results_panel_t (wxWindow ∗parent, implementation_t impl, un-signed int input_dimension, unsigned int layers, neuron_counts_t const&neuron_counts, activation_functions_t activation_functions, input_handler_-ptr training_data, input_handler_ptr tuning_data, bool scale_training_data, boolscale_target_data, float_t randomize_weights, float_t randomize_updates, float_tlearning_rate, float_t momentum, unsigned int max_epoch, unsigned int epoch_-size, unsigned int test_interval, unsigned int fail_thresh)
Constructor.
Private Member Functions
• void ∗ Entry ()
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

90 Class Documentation
Background thread work.
• void on_classify (wxCommandEvent &event)• void on_data_open (wxFileDirPickerEvent &event)• void on_epoch_done (wxCommandEvent &event)• void on_stop (wxCommandEvent &event)
Handles user click on cancel/done button.
Private Attributes
• activation_functions_t m_activation_functions• mlp_weights_t m_best_weights• unsigned int m_epoch_size• unsigned int m_fail_thresh• std::vector< float > m_graph_crate• std::vector< float > m_graph_error• std::vector< float > m_graph_x• implementation_t m_impl• unsigned int m_input_dimension• unsigned int m_layers• float_t m_learning_rate• unsigned int m_max_epoch• float_t m_momentum• neuron_counts_t m_neuron_counts• float_t m_randomize_updates• float_t m_randomize_weights• bool m_run• bool m_scale_target_data• bool m_scale_training_data• status_data_t m_status_data• unsigned int m_test_interval• wxStaticText ∗ mp_best_crate• wxStaticText ∗ mp_best_error• wxButton ∗ mp_classify_button• input_handler_ptr mp_classify_data• wxFilePickerCtrl ∗ mp_classify_picker• wxStaticText ∗ mp_convergence_error• wxStaticText ∗ mp_crate• mpFXYVector ∗ mp_crate_layer• wxButton ∗ mp_done_button• wxStaticText ∗ mp_elapsed_time
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.10 mlp::gui::training_results_panel_t Class Reference 91
• wxStaticText ∗ mp_epoch_error• wxStaticText ∗ mp_epoch_text• mpFXYVector ∗ mp_error_layer• wxStaticText ∗ mp_failure• mpWindow ∗ mp_graph_window• wxStaticText ∗ mp_percent_complete• wxGauge ∗ mp_progress_gauge• wxStaticText ∗ mp_time_per_epoch• input_handler_ptr mp_training_data• input_handler_ptr mp_tuning_data• wxStaticText ∗ mp_updates_missed
Classes
• struct status_data_t
The documentation for this class was generated from the following files:
• training_results_panel.hpp• training_results_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

92 Class Documentation
11.11 mlp::input_handler_t Class Reference
#include < 539/project/src/input_handler.hpp>
Collaboration diagram for mlp::input_handler_t:
mlp::input_handler_t
- m_in_dim- m_out_dim- mp_target- mp_training
+ input_dimension()+ input_handler_t()+ output_dimension()+ sample_count()+ target_set()+ training_set()
shared_ptr< input_set_t >
mp_training
int
m_in_dimm_out_dim
shared_ptr< output_set_t >
mp_target
11.11.1 Detailed Description
Reads and handles MLP input data.
Definition at line 26 of file input_handler.hpp.
Public Member Functions
• unsigned int input_dimension () const• input_handler_t (unsigned int in_dim, std::string path)
Constructor.
• unsigned int output_dimension () const• unsigned int sample_count () const• output_set_ptr target_set () const• input_set_ptr training_set () const
Private Attributes
• unsigned int m_in_dim• unsigned int m_out_dim• output_set_ptr mp_target
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.11 mlp::input_handler_t Class Reference 93
• input_set_ptr mp_training
The documentation for this class was generated from the following files:
• input_handler.hpp• input_handler.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

94 Class Documentation
11.12 mlp::mlp_t Class Reference
#include < 539/project/src/mlp.hpp>
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.12 mlp::mlp_t Class Reference 95
Inheritance diagram for mlp::mlp_t:
mlp::mlp_t
+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ create_mlp()
mlp::blas_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_host_layers- m_last_N- m_layers- m_rng- m_target- m_update_max- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ blas_mlp_t()+ classify()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~blas_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::cublas_cuda_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_dev_layers- m_last_N- m_layers- m_rng- m_update_max- mp_target- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ classify()+ cublas_cuda_mlp_t()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~cublas_cuda_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
mlp::cublas_mlp_t
- m_act_fun- m_best_crate- m_best_error- m_best_w- m_debug_stream- m_dev_layers- m_host_layers- m_last_N- m_layers- m_rng- m_target- m_update_max- mp_target_set- mp_training_set- mp_tuning_set- mp_tuning_target_set
+ classify()+ cublas_mlp_t()+ get_debug_stream()+ get_weights()+ run_training_epoch()+ set_activation_function()+ set_training_data()+ set_tuning_data()+ set_weights()+ tune()+ ~cublas_mlp_t()- back_prop()- check_and_init_layers()- feed_forward()- randomize_input()- update_weights()
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

96 Class Documentation
11.12.1 Detailed Description
Common interface for MLP implementations.
The mlp_t abstract base class implements the common user interface for all MLP im-plementations. Each of the concrete MLP implementations inherit from this interfaceand implement the required public functions. This common interface makes it easy toallow the user to decide at run time which MLP implementation to use.
The main operations provided by an MLP implementation are running a training epoch,estimating current error, and classifying data. The MLP runs a single training epoch ata time. Before this operation completes, the internal neuron weights are updated. Theuser typically runs many epochs until the resulting error is acceptable. The error at anygiven time can be estimated by computing the output using the tuning data and currentweights. This results in a classification rate (percentage of inputs that are correctlyclassified) and a mean-squared error. This error calculation does not change the neuronweights, but the MLP does save the neuron weights each time the error or classificationrate improves. Once training is complete the user can pass real data to the MLP. TheMLP classifies this data using the best set of neuron weights.
The details of the mlp_t class interface are described the class reference chapter.
Definition at line 317 of file mlp.hpp.
Public Member Functions
• virtual void classify (input_set_t const &input, output_set_t &output)=0Classifies the given input using the current weights.
• virtual std::stringstream & get_debug_stream ()=0Gets the debug printouts.
• virtual mlp_weights_t get_weights () const =0Gets the current weights.
• virtual float_t run_training_epoch (unsigned int num_samples, float_t learning_-rate, float_t momentum)=0
Runs a training epoch.
• virtual void set_activation_function (unsigned int layer, activation_function_tact_fun)=0
Chooses which activation function to use for the given layer.
• virtual void set_training_data (input_set_ptr p_training_set, output_set_ptr p_-target_set)=0
Sets the data to use when running MLP training.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.12 mlp::mlp_t Class Reference 97
• virtual void set_tuning_data (input_set_ptr p_tuning_set, output_set_ptr p_-tuning_target_set)=0
Sets the data to use when checking for convergence.
• virtual void set_weights (mlp_weights_t const &weights)=0Sets the weights for use in classification.
• virtual void tune (float_t &error, float_t &classification_rate)=0Uses the tuning data to estimate the current error and classification rate. Does notchange the neuron weights.
Static Public Member Functions
• static boost::shared_ptr<mlp_t> create_mlp (implementation_t impl, unsignedint input_dim, neuron_counts_t const &neuron_counts, float_t randomize_-weights, float_t randomize_updates)
Factory for mlp implementations.
11.12.2 Member Function Documentation
11.12.2.1 virtual void mlp::mlp_t::classify (input_set_t const & input,output_set_t & output) [pure virtual]
Classifies the given input using the current weights.
Parameters:
input The data to classifyoutput The results of classification will be appended to this argument
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.2 mlp::mlp_ptr mlp::mlp_t::create_mlp (implementation_t impl,unsigned int input_dim, neuron_counts_t const & neuron_counts,float_t randomize_weights, float_t randomize_updates) [static]
Factory for mlp implementations.
Returns:
A pointer to the requested MLP implementation
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

98 Class Documentation
Acts as a virtual constructor, allowing the user to easily construct an MLP with theexact implemenation determined at run time.
Parameters:
impl The MLP implementation to use
input_dim The dimension of input vectors.
neuron_counts The number of neurons in each hidden layer. The number of en-tries determines the number of layers. The size of the last (output) layer mustmatch the dimension of the output data.
randomize_weights Set to 0.f to disable randomizing initial neuron weights. Inthis case all neuron weights will be initialized to zero. A non-zero value isinterpreted as a maximum absolute value of random noise added to 1.0 togenerate random initial weights.
randomize_updates Set to 0.f to disable adding random noise to weight updatesduring error back-propagation. A non-zero value is interpreted as the maxi-mum absolute value of the noise added to weight updates.
Definition at line 18 of file mlp.cpp.
Here is the caller graph for this function:
mlp::mlp_t::create_mlp mlp::gui::training_results_panel_t::Entry
11.12.2.3 virtual std::stringstream& mlp::mlp_t::get_debug_stream () [purevirtual]
Gets the debug printouts.
Returns:
A stringstream object holding all the debug output since the last time it was cleared.
For debug/development use only. Requires a debug build to generate much usefulinformation.
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.4 virtual mlp_weights_t mlp::mlp_t::get_weights () const [purevirtual]
Gets the current weights.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.12 mlp::mlp_t Class Reference 99
Returns:
The current weights
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.5 virtual float_t mlp::mlp_t::run_training_epoch (unsigned intnum_samples, float_t learning_rate, float_t momentum) [purevirtual]
Runs a training epoch.
Returns:
Error found after passing the training samples through the MLP before updatingweights.
This function does a single feed-forward and back-propagation pass which results inan update of the neuron weights. If the number of samples requested is less that thetotal number available (the number of samples given to set_training_data()) a randomset of samples is taken from the training data.
This function must not be called until after training data has been supplied via a call toset_training_data().
Parameters:
num_samples The number of training samples to use
learning_rate The learing rate. Must be between 0 and 1.
momentum The momentum value. Must be between 0 and 1.
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.6 virtual void mlp::mlp_t::set_activation_function (unsigned int layer,activation_function_t act_fun) [pure virtual]
Chooses which activation function to use for the given layer.
Parameters:
layer The layer for which to set the activation function
act_fun The activation function to use
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

100 Class Documentation
11.12.2.7 virtual void mlp::mlp_t::set_training_data (input_set_ptrp_training_set, output_set_ptr p_target_set) [pure virtual]
Sets the data to use when running MLP training.
This data is used by the run_training_epoch() function
Parameters:
p_training_set Pointer to the training data, each element of the set is a singletraining sample
p_target_set Pointer to the correct output. Each entry holds the output vector forthe corresponding training input vector.
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.8 virtual void mlp::mlp_t::set_tuning_data (input_set_ptr p_tuning_set,output_set_ptr p_tuning_target_set) [pure virtual]
Sets the data to use when checking for convergence.
This data is used by the tune() function and so only results in a measure of the currenterror and classification rate. This data is never used to change the MLP weights.
Parameters:
p_tuning_set The tuning data.p_tuning_target_set Each entry is the desired output for the corresponding input
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.9 virtual void mlp::mlp_t::set_weights (mlp_weights_t const & weights)[pure virtual]
Sets the weights for use in classification.
Parameters:
weights The new weights
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
11.12.2.10 virtual void mlp::mlp_t::tune (float_t & error, float_t &classification_rate) [pure virtual]
Uses the tuning data to estimate the current error and classification rate. Does notchange the neuron weights.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.12 mlp::mlp_t Class Reference 101
Parameters:
error The sum-of-squares error between the tuning data MLP output and the cor-rect output
classification_rate The fraction of tuning samples which were correctly classified
Implemented in mlp::blas_mlp_t, mlp::cublas_cuda_mlp_t, and mlp::cublas_mlp_t.
The documentation for this class was generated from the following files:
• mlp.hpp• mlp.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

102 Class Documentation
11.13 RNG_rand48 Class Reference
#include < 539/project/src/random.hpp>
Collaboration diagram for RNG_rand48:
RNG_rand48
- A0- A1- blocksX- C0- C1- res- state- stride- threadsX- a- c
+ generate()+ get()+ get_random_numbers()+ RNG_rand48()+ ~RNG_rand48()- cleanup()- init()
static const unsigned long long
ac
int
A0A1
stridethreadsXblocksX
C0C1
void *
resstate
11.13.1 Detailed Description
a rand48 random number generator. The random number generator works similar tothe standard lrand48. The seed, which is normally set by srand48, here a parameter of
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

11.13 RNG_rand48 Class Reference 103
the constructor. Random numbers are drawn in two steps:
• first, random numbers are generated via the generate function, and then
• then, they can be retrieved via the get function Alternatively, you can use themdirectly on the GPU. A pointer to the random number array can be retrievedby get_random_numbers. This functions returns a void ∗, to avoid CUDA datatypes in this header file. The true type is however int ∗.
Definition at line 41 of file random.hpp.
Public Member Functions
• void generate (int n)generate n random numbers as 31-bit integers like lrand48
• void get (int ∗r, int n)• void ∗ get_random_numbers ()• RNG_rand48 (int seed)
initialize the RNG with seed, just as the standard srand48-function
Private Member Functions
• void cleanup ()CUDA-safe destructor.
• void init (int seed)CUDA-safe constructor.
Private Attributes
• unsigned int A0• unsigned int A1• int blocksX
number of blocks of threads
• unsigned int C0• unsigned int C1• void ∗ res
generated random numbers
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

104 Class Documentation
• void ∗ statecurrent random numbers per thread
• int stride• int threadsX
number of threads
Static Private Attributes
• static const unsigned long long a = 0x5DEECE66DLLmagic constants for rand48
• static const unsigned long long c = 0xB
11.13.2 Member Function Documentation
11.13.2.1 void RNG_rand48::get (int ∗ r, int n)
get the first n of the previously generated numbers into array r. r must be large enoughto contain all the numbers, and enough numbers have to be generated before.
Definition at line 191 of file random.cu.
11.13.2.2 void∗ RNG_rand48::get_random_numbers () [inline]
return a GPU pointer to the generated random numbers, for using them in other GPUfunctions.
Definition at line 81 of file random.hpp.
11.13.3 Member Data Documentation
11.13.3.1 unsigned int RNG_rand48::A0 [private]
strided iteration constants (48-bit, distributed on 2x 24-bit)
Definition at line 56 of file random.hpp.
The documentation for this class was generated from the following files:
• random.hpp• random.cu
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Chapter 12
File Documentation
12.1 blas_mlp.cpp File Reference
12.1.1 Detailed Description
Implements the MLP using just the boost::blas library.
Author:
Scott Finley
Date:
December 02, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file blas_mlp.cpp.
#include <boost/numeric/ublas/matrix_proxy.hpp>
#include <boost/format.hpp>
#include <iostream>
#include <vector>
#include <algorithm>
#include "blas_mlp.hpp"

106 File Documentation
Include dependency graph for blas_mlp.cpp:
blas_mlp.cpp
boost/numeric/ublas/matrix_proxy.hpp
boost/format.hpp
iostream
vector
algorithm
blas_mlp.hpp
sstream
boost/shared_ptr.hpp
boost/random.hpp boost/numeric/ublas/matrix.hpp boost/numeric/ublas/io.hpp
mlp.hpp
layer.hpp
string
mlp_types.hpp error.hpp
exception
matrix.hpp
numeric boost/lambda/lambda.hpp boost/function.hppcublas.h
Namespaces
• namespace anonymous_namespace{blas_mlp.cpp}
Functions
• mlp::float_t anonymous_namespace{blas_mlp.cpp}::activation_function(mlp::activation_function_t type, mlp::float_t val)
• mlp::float_t anonymous_namespace{blas_mlp.cpp}::activation_function_-derivative (mlp::activation_function_t type, mlp::float_t val)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.2 blas_mlp.hpp File Reference 107
12.2 blas_mlp.hpp File Reference
12.2.1 Detailed Description
Implements the MLP using just the boost::blas library.
Author:
Scott Finley
Date:
December 02, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file blas_mlp.hpp.
#include <sstream>
#include <boost/shared_ptr.hpp>
#include <boost/random.hpp>
#include <boost/numeric/ublas/matrix.hpp>
#include <boost/numeric/ublas/io.hpp>
#include "mlp.hpp"
#include "layer.hpp"
Include dependency graph for blas_mlp.hpp:
blas_mlp.hpp
sstream
boost/shared_ptr.hpp
boost/random.hpp boost/numeric/ublas/matrix.hpp boost/numeric/ublas/io.hpp
mlp.hpp
layer.hpp
string boost/format.hpp
mlp_types.hpperror.hpp
vectorexception
matrix.hpp
algorithm numeric boost/lambda/lambda.hpp boost/function.hpp cublas.h
This graph shows which files directly or indirectly include this file:
blas_mlp.hpp
blas_mlp.cpp mlp.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

108 File Documentation
Namespaces
• namespace mlp
Classes
• class mlp::blas_mlp_tCPU-only MLP implementation using boost::blas.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.3 cublas_cuda_mlp.cpp File Reference 109
12.3 cublas_cuda_mlp.cpp File Reference
12.3.1 Detailed Description
Implements the MLP using just the cublas library.
Author:
Scott Finley
Date:
November 22, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file cublas_cuda_mlp.cpp.
#include <boost/format.hpp>
#include <boost/foreach.hpp>
#include <boost/function.hpp>
#include <boost/array.hpp>
#include <boost/lambda/bind.hpp>
#include <exception>
#include <vector>
#include <ctime>
#include <algorithm>
#include <iostream>
#include <cmath>
#include <cutil.h>
#include <vector_types.h>
#include "cublas_cuda_mlp.hpp"
#include "error.hpp"
#include "cublas.h"
#include "cuda.h"
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

110 File Documentation
Include dependency graph for cublas_cuda_mlp.cpp:
cublas_cuda_mlp.cpp
boost/format.hpp
boost/foreach.hpp
boost/function.hpp
boost/array.hpp boost/lambda/bind.hpp
exception vector
ctime
algorithm
iostream cmath cutil.h vector_types.hcublas_cuda_mlp.hpp
error.hpp cublas.h
cuda.h
sstream
boost/random.hpp
boost/shared_ptr.hpp
mlp.hpp
mlp_types.hpp
layer.hpprandom.hpp
string
matrix.hpp
numeric boost/lambda/lambda.hpp
Namespaces
• namespace anonymous_namespace{cublas_cuda_mlp.cpp}
Functions
• mlp::float_t anonymous_namespace{cublas_cuda_mlp.cpp}::activation_-function (mlp::activation_function_t type, mlp::float_t val)
• mlp::float_t anonymous_namespace{cublas_cuda_mlp.cpp}::activation_-function_derivative (mlp::activation_function_t type, mlp::float_t val)
• template<typename Type>boost::shared_ptr< Type > anonymous_namespace{cublas_cuda_-mlp.cpp}::cuda_alloc (unsigned int num_elements)
• template<typename Type>void anonymous_namespace{cublas_cuda_mlp.cpp}::free_wrapper (Type∗p)
• std::ostream & operator<< (std::ostream &ostr, mlp::cublas_cuda_mlp_-t::matrix_t &m)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.4 cublas_cuda_mlp.cu File Reference 111
12.4 cublas_cuda_mlp.cu File Reference
12.4.1 Detailed Description
CUDA code for cublas_cuda_mlp_t.
Author:
Scott Finley
Date:
November 28, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file cublas_cuda_mlp.cu.
#include <math.h>
#include <assert.h>
Include dependency graph for cublas_cuda_mlp.cu:
cublas_cuda_mlp.cu
math.h assert.h
Defines
• #define MAX_RAND 0x8FFFFFFF
Functions
• __global__ void act_fun_sigmoidal (float ∗M, int elements)Sigmoidal activation function.
• __global__ void act_fun_tanh (float ∗M, int elements)tanh activation function
• void add_transpose (float ∗p_A, int A_rows, int A_cols, float const ∗p_B, intB_rows, int B_cols, int ∗p_rand, float rand_max)
Adds transpose of matrix B to matrix A.
• void apply_act_fun (int fun, float ∗p_data, int data_size)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

112 File Documentation
Applies an activation function to a GPU matrix or vector.
• __device__ float apply_fun_p (int fun, float val)• void compute_output_delta (float ∗p_desired, float ∗p_got, float ∗p_delta, float∗p_E, int elements, int fun)
Computes the error delta of the output layer.
• void copy_plus_bias (float ∗p_src, int src_rows, int src_cols, float ∗p_dst, intdst_rows, int dst_cols)
Copies the matrix and adds a bias row filled with 1.0f.
• __global__ void dev_add_transpose (float ∗p_A, int A_rows, int A_cols, floatconst ∗p_B, int B_rows, int B_cols, int ∗p_rand, float rand_max)
• __global__ void dev_compute_error (float ∗p_desired, float ∗p_got, float ∗p_-delta, float ∗p_E, int elements, int fun)
• __global__ void dev_copy_plus_bias (float ∗p_src, int src_cols, int src_rows,float ∗p_dst, int dst_cols, int dst_rows)
copies a matrix but adds an extra row initialized to 1.
• __global__ void dev_randomize_training (int ∗p_index, float ∗p_train, inttrain_rows, int train_cols, float ∗p_X, int X_rows, int X_cols, float ∗p_tar_in,int tar_in_rows, int tar_in_cols, float ∗p_tar_out, int tar_out_rows, int tar_out_-cols)
• __global__ void dev_transform_delta (float ∗p_in, int in_rows, int in_cols,float ∗p_Z, int Z_rows, int Z_cols, float ∗p_out, int out_rows, int out_cols, intfun)
• __global__ void dev_tune_error (float ∗p_Z, float ∗p_d, int rows, int columns,float ∗p_error, float ∗p_crate)
• void randomize_training (int ∗p_index, float ∗p_train, int train_rows, int train_-cols, float ∗p_X, int X_rows, int X_cols, float ∗p_tar_in, int tar_in_rows, inttar_in_cols, float ∗p_tar_out, int tar_out_rows, int tar_out_cols)
• void transform_delta (float ∗p_in, int in_rows, int in_cols, float ∗p_Z, int Z_-rows, int Z_cols, float ∗p_out, int out_rows, int out_cols, int fun)
Applies transformation to delta and copies to smaller buffer, leaving off the unneededfirst row.
• void tune_error (float ∗p_Z, float ∗p_d, int rows, int columns, float ∗p_error,float ∗p_crate)
Variables
• __shared__ char data [ ]
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.4 cublas_cuda_mlp.cu File Reference 113
12.4.2 Function Documentation
12.4.2.1 void add_transpose (float ∗ p_A, int A_rows, int A_cols, float const ∗p_B, int B_rows, int B_cols, int ∗ p_rand, float rand_max)
Adds transpose of matrix B to matrix A.
This function is used to add the neuron weight update to the current neuron weightvalue. It also adds the random noise if the user specified any. The formula for thisupdate is shown below:
Wl(t) = Wl(t− 1) + ∆Wl +R
Because of the way cuBLAS expects the arguments for the operation used previouslyin the weight update phase ∆Wl is stored transposed, as compared toWl. This functiontakes that fact into account so it causes no computational overhead. The neuron weightsfor each epoch are not stored separately. Instead the weight matrix from the previousepoch is passed to this function which overwrites it with the resulting new weights.
The random values passed to this function is a matrix generated previously by a call toa CUDA random number generator. This is the RNG_rand48 generator by A. Arnoldand J. A. van Meel , FOM institute AMOLF, Amsterdam. Their work is availableat http://www.amolf.nl/∼vanmeel/mdgpu/ and is described in the article"Harvesting graphics power for MD simulations" by J.A. van Meel, A. Arnold, D.Frenkel, S. F. Portegies Zwart and R. G. Belleman, arXiv:0709.3225. This randomnumber generator was found to have a serious bug which caused buffer overruns if thenumber of random number request changed from request to request. It also failed tofree its memory buffer when exiting which caused a memory leak. I was able to fix orwork around these problems but the use of another random number generator would bepreferred if time permitted.
The random numbers passed to add_transpose() are integers and there must be the samenumber of them as there are elements in the weight matrix. The integers are convertedto floating point numbers and scaled so that the absolute value is less than the thresholdprovided by the user.
Parameters:
p_A Input A, result is written hereA_rows Rows in AA_cols Columns in Ap_B Input B, not changedB_rows Rows in BB_cols Columns in Bp_rand Ponter to random noise matrixrand_max Maximum absolute value allowed for noise.
Definition at line 255 of file cublas_cuda_mlp.cu.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

114 File Documentation
12.4.2.2 void apply_act_fun (int fun, float ∗ p_data, int data_size)
Applies an activation function to a GPU matrix or vector.
Does an in-place application of the chosen activation function to each element of thevector or matrix. If the function choice argument is 0 f(x) = tanh(x) is applied. Ifthe argument is 1, the sigmoidal function f(x) = 1
1+ex is applied. This operation iscompletely parallelizable so as many threads as possible are run in parallel. When thefunction returns the values in the input matrix have been changed.
Parameters:
fun Determines which activation function to apply. 0 == tanh, 1 == sigmoidal
p_data Pointer to the array on the GPU
data_size Number of elements in the array
Definition at line 193 of file cublas_cuda_mlp.cu.
12.4.2.3 void compute_output_delta (float ∗ p_desired, float ∗ p_got, float ∗p_delta, float ∗ p_E, int elements, int fun)
Computes the error delta of the output layer.
This function takes the desired output and the actual output and computes the outputlayer error delta as described in the algorithms section.
This operation is completely parallelizable so as many threads as possible are run inparallel. When this function returns the destination matrix will be filled with computederror delta.
Parameters:
p_desired Array holding the desired values
p_got Array holding the actual values
p_delta Error delta is written here. Must be pre-allocated by caller.
p_E The sum-of-squares error is written here. Must be pre-allocated by caller.
elements Size of all three arrays.
fun The activation function for this layer. 0 == tanh, 1 == sigmoidal
Definition at line 215 of file cublas_cuda_mlp.cu.
12.4.2.4 void copy_plus_bias (float ∗ p_src, int src_rows, int src_cols, float ∗p_dst, int dst_rows, int dst_cols)
Copies the matrix and adds a bias row filled with 1.0f.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.4 cublas_cuda_mlp.cu File Reference 115
Used to copy the output of one layer to the input of the next layer. A simple memorycopy is not sufficient for this because the dimensions of the matrices are not the same.The change in dimension is due to the addition of a row of inputs with the value 1.0.This added constant input to each neuron of a layer allows the neurons to learn a biasvalue.
This function takes pointers to the source and destination arrays as well as the numberof rows and columns in each matrix. The number of columns in each matrix much bethe same, and the number of rows in the destination must be exactly one more than thenumber of rows in the source.
This operation is completely parallelizable so as many threads as possible are run inparallel. When this function returns the destination matrix will be filled with contentsof the source matrix plus an extra row which is filled with 1s.
Parameters:
p_src Pointer to source array
src_rows Source rows
src_cols Source columns
p_dst Pointer to destination array
dst_rows Destination rows
dst_cols Destination columns
Definition at line 205 of file cublas_cuda_mlp.cu.
12.4.2.5 void transform_delta (float ∗ p_in, int in_rows, int in_cols, float ∗ p_Z,int Z_rows, int Z_cols, float ∗ p_out, int out_rows, int out_cols, intfun)
Applies transformation to delta and copies to smaller buffer, leaving off the unneededfirst row.
Takes the intermediate layer delta value as an argument. This has already been com-puted using cuBLAS as:
W(l+1)∆E(l+1)
Also takes the current layer output as an argument. Computes the final layer delta bypassing the layer output through the derivative of the layer activation function and thenmultiplying it current delta. This computation is not done in place because the removalof the extra bias row from the source delta is done at the same time as the calculation.This requires that output matrix have one fewer rows than the input.
Parameters:
p_in Pointer to current delta matrix
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

116 File Documentation
in_rows Rows in current delta
in_cols Columns in current delta
p_Z Pointer to Layer output
Z_rows Rows in layer output
Z_cols Columns in layer ouput
p_out result is written here. Must be pre-allocated by caller
out_rows output rows
out_cols output columns
fun Activation function for the layer. 0 == tanh, 1 == sigmoidal
Definition at line 230 of file cublas_cuda_mlp.cu.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.5 cublas_cuda_mlp.hpp File Reference 117
12.5 cublas_cuda_mlp.hpp File Reference
12.5.1 Detailed Description
Implements the MLP using just the cublas library with CUDA glue.
Author:
Scott Finley
Date:
November 22, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file cublas_cuda_mlp.hpp.
#include <vector>
#include <sstream>
#include <boost/random.hpp>
#include <boost/shared_ptr.hpp>
#include "mlp.hpp"
#include "layer.hpp"
#include "mlp_types.hpp"
#include "random.hpp"
Include dependency graph for cublas_cuda_mlp.hpp:
cublas_cuda_mlp.hpp
vector
sstream
boost/random.hpp
boost/shared_ptr.hpp
mlp.hpp
mlp_types.hpp
layer.hpp random.hpp
string boost/format.hpp
error.hpp
exception
matrix.hpp
algorithm numeric boost/lambda/lambda.hpp boost/function.hpp cublas.h
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

118 File Documentation
This graph shows which files directly or indirectly include this file:
cublas_cuda_mlp.hpp
cublas_cuda_mlp.cpp mlp.cpp
Namespaces
• namespace mlp
Classes
• class mlp::cublas_cuda_mlp_t
Implements the mlp_t inteface using cuBLAS and CUDA.
• class mlp::cublas_cuda_mlp_t::matrix_t
Functions
• void add_transpose (float ∗p_A, int A_rows, int A_cols, float const ∗p_B, intB_rows, int B_cols, int ∗p_rand, float rand_max)
Adds transpose of matrix B to matrix A.
• void apply_act_fun (int fun, float ∗p_data, int data_size)
Applies an activation function to a GPU matrix or vector.
• void compute_output_delta (float ∗p_desired, float ∗p_got, float ∗p_delta, float∗p_E, int elements, int fun)
Computes the error delta of the output layer.
• void copy_plus_bias (float ∗p_src, int src_rows, int src_cols, float ∗p_dst, intdst_rows, int dst_cols)
Copies the matrix and adds a bias row filled with 1.0f.
• void randomize_training (int ∗p_index, float ∗p_train, int train_rows, int train_-cols, float ∗p_X, int X_rows, int X_cols, float ∗p_tar_in, int tar_in_rows, inttar_in_cols, float ∗p_tar_out, int tar_out_rows, int tar_out_cols)
• void transform_delta (float ∗p_in, int in_rows, int in_cols, float ∗p_Z, int Z_-rows, int Z_cols, float ∗p_out, int out_rows, int out_cols, int fun)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.5 cublas_cuda_mlp.hpp File Reference 119
Applies transformation to delta and copies to smaller buffer, leaving off the unneededfirst row.
• void tune_error (float ∗p_Z, float ∗p_d, int rows, int columns, float ∗p_error,float ∗p_crate)
12.5.2 Function Documentation
12.5.2.1 void add_transpose (float ∗ p_A, int A_rows, int A_cols, float const ∗p_B, int B_rows, int B_cols, int ∗ p_rand, float rand_max)
Adds transpose of matrix B to matrix A.
This function is used to add the neuron weight update to the current neuron weightvalue. It also adds the random noise if the user specified any. The formula for thisupdate is shown below:
Wl(t) = Wl(t− 1) + ∆Wl +R
Because of the way cuBLAS expects the arguments for the operation used previouslyin the weight update phase ∆Wl is stored transposed, as compared toWl. This functiontakes that fact into account so it causes no computational overhead. The neuron weightsfor each epoch are not stored separately. Instead the weight matrix from the previousepoch is passed to this function which overwrites it with the resulting new weights.
The random values passed to this function is a matrix generated previously by a call toa CUDA random number generator. This is the RNG_rand48 generator by A. Arnoldand J. A. van Meel , FOM institute AMOLF, Amsterdam. Their work is availableat http://www.amolf.nl/∼vanmeel/mdgpu/ and is described in the article"Harvesting graphics power for MD simulations" by J.A. van Meel, A. Arnold, D.Frenkel, S. F. Portegies Zwart and R. G. Belleman, arXiv:0709.3225. This randomnumber generator was found to have a serious bug which caused buffer overruns if thenumber of random number request changed from request to request. It also failed tofree its memory buffer when exiting which caused a memory leak. I was able to fix orwork around these problems but the use of another random number generator would bepreferred if time permitted.
The random numbers passed to add_transpose() are integers and there must be the samenumber of them as there are elements in the weight matrix. The integers are convertedto floating point numbers and scaled so that the absolute value is less than the thresholdprovided by the user.
Parameters:
p_A Input A, result is written here
A_rows Rows in A
A_cols Columns in A
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

120 File Documentation
p_B Input B, not changed
B_rows Rows in B
B_cols Columns in B
p_rand Ponter to random noise matrix
rand_max Maximum absolute value allowed for noise.
Definition at line 255 of file cublas_cuda_mlp.cu.
12.5.2.2 void apply_act_fun (int fun, float ∗ p_data, int data_size)
Applies an activation function to a GPU matrix or vector.
Does an in-place application of the chosen activation function to each element of thevector or matrix. If the function choice argument is 0 f(x) = tanh(x) is applied. Ifthe argument is 1, the sigmoidal function f(x) = 1
1+ex is applied. This operation iscompletely parallelizable so as many threads as possible are run in parallel. When thefunction returns the values in the input matrix have been changed.
Parameters:
fun Determines which activation function to apply. 0 == tanh, 1 == sigmoidal
p_data Pointer to the array on the GPU
data_size Number of elements in the array
Definition at line 193 of file cublas_cuda_mlp.cu.
12.5.2.3 void compute_output_delta (float ∗ p_desired, float ∗ p_got, float ∗p_delta, float ∗ p_E, int elements, int fun)
Computes the error delta of the output layer.
This function takes the desired output and the actual output and computes the outputlayer error delta as described in the algorithms section.
This operation is completely parallelizable so as many threads as possible are run inparallel. When this function returns the destination matrix will be filled with computederror delta.
Parameters:
p_desired Array holding the desired values
p_got Array holding the actual values
p_delta Error delta is written here. Must be pre-allocated by caller.
p_E The sum-of-squares error is written here. Must be pre-allocated by caller.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.5 cublas_cuda_mlp.hpp File Reference 121
elements Size of all three arrays.fun The activation function for this layer. 0 == tanh, 1 == sigmoidal
Definition at line 215 of file cublas_cuda_mlp.cu.
12.5.2.4 void copy_plus_bias (float ∗ p_src, int src_rows, int src_cols, float ∗p_dst, int dst_rows, int dst_cols)
Copies the matrix and adds a bias row filled with 1.0f.
Used to copy the output of one layer to the input of the next layer. A simple memorycopy is not sufficient for this because the dimensions of the matrices are not the same.The change in dimension is due to the addition of a row of inputs with the value 1.0.This added constant input to each neuron of a layer allows the neurons to learn a biasvalue.
This function takes pointers to the source and destination arrays as well as the numberof rows and columns in each matrix. The number of columns in each matrix much bethe same, and the number of rows in the destination must be exactly one more than thenumber of rows in the source.
This operation is completely parallelizable so as many threads as possible are run inparallel. When this function returns the destination matrix will be filled with contentsof the source matrix plus an extra row which is filled with 1s.
Parameters:
p_src Pointer to source arraysrc_rows Source rowssrc_cols Source columnsp_dst Pointer to destination arraydst_rows Destination rowsdst_cols Destination columns
Definition at line 205 of file cublas_cuda_mlp.cu.
12.5.2.5 void transform_delta (float ∗ p_in, int in_rows, int in_cols, float ∗ p_Z,int Z_rows, int Z_cols, float ∗ p_out, int out_rows, int out_cols, intfun)
Applies transformation to delta and copies to smaller buffer, leaving off the unneededfirst row.
Takes the intermediate layer delta value as an argument. This has already been com-puted using cuBLAS as:
W(l+1)∆E(l+1)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

122 File Documentation
Also takes the current layer output as an argument. Computes the final layer delta bypassing the layer output through the derivative of the layer activation function and thenmultiplying it current delta. This computation is not done in place because the removalof the extra bias row from the source delta is done at the same time as the calculation.This requires that output matrix have one fewer rows than the input.
Parameters:
p_in Pointer to current delta matrix
in_rows Rows in current delta
in_cols Columns in current delta
p_Z Pointer to Layer output
Z_rows Rows in layer output
Z_cols Columns in layer ouput
p_out result is written here. Must be pre-allocated by caller
out_rows output rows
out_cols output columns
fun Activation function for the layer. 0 == tanh, 1 == sigmoidal
Definition at line 230 of file cublas_cuda_mlp.cu.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.6 cublas_mlp.cpp File Reference 123
12.6 cublas_mlp.cpp File Reference
12.6.1 Detailed Description
Implements the MLP using just the cublas library.
Author:
Scott Finley
Date:
November 22, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file cublas_mlp.cpp.
#include <boost/format.hpp>
#include <boost/foreach.hpp>
#include <boost/function.hpp>
#include <boost/array.hpp>
#include <boost/lambda/bind.hpp>
#include <exception>
#include <vector>
#include <ctime>
#include <algorithm>
#include <iostream>
#include "cublas_mlp.hpp"
#include "error.hpp"
#include "cublas.h"
Include dependency graph for cublas_mlp.cpp:
cublas_mlp.cpp
boost/format.hpp
boost/foreach.hpp
boost/function.hpp
boost/array.hpp boost/lambda/bind.hpp
exception vector
ctime
algorithm
iostreamcublas_mlp.hpp
error.hpp cublas.hsstream
boost/random.hpp
boost/shared_ptr.hpp
mlp.hpp
layer.hpp
string
mlp_types.hpp
matrix.hpp
numeric boost/lambda/lambda.hpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

124 File Documentation
Namespaces
• namespace anonymous_namespace{cublas_mlp.cpp}
Functions
• mlp::float_t anonymous_namespace{cublas_mlp.cpp}::activation_function(mlp::activation_function_t type, mlp::float_t val)
• mlp::float_t anonymous_namespace{cublas_mlp.cpp}::activation_-function_derivative (mlp::activation_function_t type, mlp::float_t val)
• mlp::dev_ptr anonymous_namespace{cublas_mlp.cpp}::cuda_alloc (un-signed int num_elements, unsigned int element_size)
• void anonymous_namespace{cublas_mlp.cpp}::free_wrapper (mlp::float_-t ∗p)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.7 cublas_mlp.hpp File Reference 125
12.7 cublas_mlp.hpp File Reference
12.7.1 Detailed Description
Implements the MLP using just the cublas library.
Author:
Scott Finley
Date:
November 22, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file cublas_mlp.hpp.
#include <vector>
#include <sstream>
#include <boost/random.hpp>
#include <boost/shared_ptr.hpp>
#include "mlp.hpp"
#include "layer.hpp"
Include dependency graph for cublas_mlp.hpp:
cublas_mlp.hpp
vector
sstream
boost/random.hpp
boost/shared_ptr.hpp
mlp.hpp
layer.hpp
string boost/format.hpp
mlp_types.hpperror.hpp
exception
matrix.hpp
algorithm numeric boost/lambda/lambda.hpp boost/function.hpp cublas.h
This graph shows which files directly or indirectly include this file:
cublas_mlp.hpp
cublas_mlp.cpp cudaMLP.cpp mlp.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen
126 File Documentation
Namespaces
• namespace mlp
Classes
• class mlp::cublas_mlp_tImplements the mlp_t interface using nVidia’s cublas library.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.8 error.hpp File Reference 127
12.8 error.hpp File Reference
12.8.1 Detailed Description
Holds error type.
Author:
Scott Finley
Date:
November 20, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file error.hpp.
#include <exception>
#include <string>
#include <boost/format.hpp>
Include dependency graph for error.hpp:
error.hpp
exception string boost/format.hpp
This graph shows which files directly or indirectly include this file:
error.hpp
mlp.hpp
cublas_cuda_mlp.cpp cublas_mlp.cpp
matrix.hpp
layer.hpp input_handler.hpp
blas_mlp.hpp
mlp.cpp
cublas_cuda_mlp.hpp cublas_mlp.hpp main_form.hpp training_panel.hpp training_results_panel.hpp
blas_mlp.cpp cudaMLP.cpp main_form.cppmlpGUI.cpp training_panel.cpp training_results_panel.cpp
input_handler.cpp
Namespaces
• namespace mlp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen
128 File Documentation
Classes
• class mlp::error_tThrown by MLP functions to indicate and error.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.9 input_handler.cpp File Reference 129
12.9 input_handler.cpp File Reference
12.9.1 Detailed Description
Reads and handles MLP input data.
Author:
Scott Finley
Date:
November 23, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file input_handler.cpp.
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include <boost/format.hpp>
#include <boost/foreach.hpp>
#include <boost/algorithm/string.hpp>
#include <boost/lexical_cast.hpp>
#include "input_handler.hpp"
Include dependency graph for input_handler.cpp:
input_handler.cpp
iostream fstream sstream
string vectorboost/format.hpp
boost/foreach.hpp boost/algorithm/string.hpp boost/lexical_cast.hppinput_handler.hpp
boost/shared_ptr.hpp
mlp_types.hpperror.hpp
exception
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

130 File Documentation
12.10 input_handler.hpp File Reference
12.10.1 Detailed Description
Reads and handles MLP input data.
Author:
Scott Finley
Date:
November 23, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file input_handler.hpp.
#include <vector>
#include <string>
#include <boost/shared_ptr.hpp>
#include "mlp_types.hpp"
#include "error.hpp"
Include dependency graph for input_handler.hpp:
input_handler.hpp
vector stringboost/shared_ptr.hpp
mlp_types.hpp error.hpp
exceptionboost/format.hpp
This graph shows which files directly or indirectly include this file:
input_handler.hpp
cudaMLP.cpp input_handler.cpp training_panel.hpp training_results_panel.hpp
main_form.cpp training_panel.cpp training_results_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.10 input_handler.hpp File Reference 131
Namespaces
• namespace mlp
Classes
• class mlp::input_handler_tReads and handles MLP input data.
Typedefs
• typedef boost::shared_ptr< input_handler_t > mlp::input_handler_ptrPointer to input handler.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

132 File Documentation
12.11 layer.hpp File Reference
12.11.1 Detailed Description
Template for holding MLP layer data.
Author:
Scott Finley
Date:
November 20, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file layer.hpp.
#include <vector>
#include "matrix.hpp"
#include "error.hpp"
Include dependency graph for layer.hpp:
layer.hpp
vector
matrix.hpp
error.hppalgorithm numeric
boost/shared_ptr.hpp boost/format.hpp
boost/lambda/lambda.hpp boost/function.hppmlp_types.hpp cublas.h
exception string
This graph shows which files directly or indirectly include this file:
layer.hpp
blas_mlp.hpp cublas_cuda_mlp.hpp cublas_mlp.hpp
blas_mlp.cpp mlp.cppcublas_cuda_mlp.cpp cublas_mlp.cppcudaMLP.cpp
Namespaces
• namespace mlp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.11 layer.hpp File Reference 133
Classes
• struct mlp::basic_layer_t< Ptr >Holds the data for a layer of the MLP.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

134 File Documentation
12.12 main_form.cpp File Reference
12.12.1 Detailed Description
Main form class for the GUI.
Author:
Scott Finley
Date:
November 24, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file main_form.cpp.
#include <boost/format.hpp>
#include <iostream>
#include <vector>
#include <wx/notebook.h>
#include <wx/aboutdlg.h>
#include "main_form.hpp"
#include "training_panel.hpp"
Include dependency graph for main_form.cpp:
main_form.cpp
boost/format.hpp
iostream
vector
wx/notebook.h wx/aboutdlg.h main_form.hpptraining_panel.hpp
wx/wx.hwx/filepicker.h wx/spinctrl.h mlp.hpp
string
sstream
boost/shared_ptr.hpp
mlp_types.hpp error.hpp
exception
input_handler.hpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.13 main_form.hpp File Reference 135
12.13 main_form.hpp File Reference
12.13.1 Detailed Description
Main form class for the GUI.
Author:
Scott Finley
Date:
November 24, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file main_form.hpp.
#include <wx/wx.h>
#include <wx/filepicker.h>
#include <wx/spinctrl.h>
#include "mlp.hpp"
Include dependency graph for main_form.hpp:
main_form.hpp
wx/wx.h wx/filepicker.h wx/spinctrl.h mlp.hpp
string
sstream
boost/shared_ptr.hpp boost/format.hpp
mlp_types.hpp error.hpp
vector exception
This graph shows which files directly or indirectly include this file:
main_form.hpp
main_form.cpp mlpGUI.cpp
Namespaces
• namespace mlp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen
136 File Documentation
• namespace mlp::gui
Classes
• class mlp::gui::main_form_tMain form for GUI.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.14 matrix.hpp File Reference 137
12.14 matrix.hpp File Reference
12.14.1 Detailed Description
Template for a matrix type.
Author:
Scott Finley
Date:
November 20, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file matrix.hpp.
#include <vector>
#include <algorithm>
#include <numeric>
#include <boost/shared_ptr.hpp>
#include <boost/format.hpp>
#include <boost/lambda/lambda.hpp>
#include <boost/function.hpp>
#include "mlp_types.hpp"
#include "error.hpp"
#include "cublas.h"
Include dependency graph for matrix.hpp:
matrix.hpp
vector
algorithm numeric
boost/shared_ptr.hpp boost/format.hpp
boost/lambda/lambda.hpp boost/function.hppmlp_types.hpp error.hpp cublas.h
exceptionstring
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

138 File Documentation
This graph shows which files directly or indirectly include this file:
matrix.hpp
layer.hpp
blas_mlp.hpp cublas_cuda_mlp.hpp cublas_mlp.hpp
blas_mlp.cpp mlp.cppcublas_cuda_mlp.cpp cublas_mlp.cppcudaMLP.cpp
Namespaces
• namespace mlp
Classes
• class mlp::basic_matrix_t< Type >Represents a matrix in a way that is compatable with cublas.
Functions
• template<typename Type>std::ostream & operator<< (std::ostream &ostr, mlp::basic_matrix_t< Type >const &m)
prints a matrix to an ostream
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.15 mlp.cpp File Reference 139
12.15 mlp.cpp File Reference
12.15.1 Detailed Description
Holds base mlp stuff.
Author:
Scott Finley
Date:
November 22, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file mlp.cpp.
#include "mlp.hpp"
#include "cublas_mlp.hpp"
#include "cublas_cuda_mlp.hpp"
#include "blas_mlp.hpp"
Include dependency graph for mlp.cpp:
mlp.cpp
mlp.hpp
cublas_mlp.hpp cublas_cuda_mlp.hpp blas_mlp.hpp
string
sstream
boost/shared_ptr.hpp boost/format.hpp
mlp_types.hpperror.hpp
vectorexception
boost/random.hpp layer.hpp
matrix.hpp
algorithm numeric boost/lambda/lambda.hppboost/function.hpp cublas.h
random.hpp boost/numeric/ublas/matrix.hppboost/numeric/ublas/io.hpp
Functions
• std::string mlp::get_impl_title (implementation_t impl)Returns a string describing the mlp implementation. Good for showing to the user.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

140 File Documentation
12.16 mlp.hpp File Reference
12.16.1 Detailed Description
Holds base mlp stuff.
Author:
Scott Finley
Date:
November 22, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file mlp.hpp.
#include <string>
#include <sstream>
#include <boost/shared_ptr.hpp>
#include <boost/format.hpp>
#include "mlp_types.hpp"
#include "error.hpp"
Include dependency graph for mlp.hpp:
mlp.hpp
string
sstream
boost/shared_ptr.hpp boost/format.hpp
mlp_types.hpp error.hpp
vector exception
This graph shows which files directly or indirectly include this file:
mlp.hpp
blas_mlp.hpp
mlp.cpp
cublas_cuda_mlp.hpp cublas_mlp.hpp main_form.hpp training_panel.hpp training_results_panel.hpp
blas_mlp.cpp cublas_cuda_mlp.cpp cublas_mlp.cppcudaMLP.cpp main_form.cppmlpGUI.cpp training_panel.cpp training_results_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.16 mlp.hpp File Reference 141
Namespaces
• namespace mlp
Classes
• class mlp::mlp_tCommon interface for MLP implementations.
Typedefs
• typedef boost::shared_ptr< mlp_t > mlp::mlp_ptrPointer to an mlp instance.
Enumerations
• enum mlp::implementation_t {
MLP_IMPL_BLAS = 0, MLP_IMPL_CUBLAS, MLP_IMPL_CUDA_-BLAS, MLP_IMPL_CUDA,
MLP_IMPL_INVALID }Defines the mlp implementations available.
Functions
• std::string mlp::get_impl_title (implementation_t impl)Returns a string describing the mlp implementation. Good for showing to the user.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

142 File Documentation
12.17 mlp_types.hpp File Reference
12.17.1 Detailed Description
Holds basic simple types for mlp.
Author:
Scott Finley
Date:
November 20, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file mlp_types.hpp.
#include <vector>
#include <boost/shared_ptr.hpp>
Include dependency graph for mlp_types.hpp:
mlp_types.hpp
vector boost/shared_ptr.hpp
This graph shows which files directly or indirectly include this file:
mlp_types.hpp
mlp.hpp
cublas_cuda_mlp.hpp
training_results_panel.cpp
matrix.hpp
input_handler.hpp
blas_mlp.hpp
mlp.cpp
cublas_mlp.hpp main_form.hpp training_panel.hpp training_results_panel.hpp
blas_mlp.cppcublas_cuda_mlp.cpp cublas_mlp.cpp cudaMLP.cpp main_form.cppmlpGUI.cpp training_panel.cpp
layer.hpp
input_handler.cpp
Namespaces
• namespace mlp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.17 mlp_types.hpp File Reference 143
Typedefs
• typedef std::vector< activation_function_t > mlp::activation_functions_tDefines a list of activation functions.
• typedef boost::shared_ptr< float_t > mlp::dev_ptrtype of a cublas device memory pointer
• typedef std::vector< dev_ptr > mlp::dev_ptr_list_tFunction object for the activation function.
• typedef float mlp::float_tDefines a float type used in this program.
• typedef boost::shared_ptr< input_t > mlp::input_ptrA pointer to a training data sample.
• typedef boost::shared_ptr< input_set_t > mlp::input_set_ptrPointer to a training set.
• typedef std::vector< input_ptr > mlp::input_set_tHolds a set of training data.
• typedef std::vector< float_t > mlp::input_tDefines a training data sample.
• typedef std::vector< neuron_weights_t > mlp::layer_weights_tPointer to weights for a layer.
• typedef std::vector< layer_weights_t > mlp::mlp_weights_tHolds the mlp weights.
• typedef std::vector< unsigned int > mlp::neuron_counts_tArray holding the number of neurons in each layer.
• typedef std::vector< float_t > mlp::neuron_weights_tArray of weights for a single neuron.
• typedef boost::shared_ptr< output_t > mlp::output_ptrA pointer to a training data sample.
• typedef boost::shared_ptr< output_set_t > mlp::output_set_ptrPointer to a target output set.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

144 File Documentation
• typedef std::vector< output_ptr > mlp::output_set_tHolds a set of target output values.
• typedef std::vector< float_t > mlp::output_tDefines a target output value.
• typedef std::vector< float_t > mlp::vector_t
Enumerations
• enum mlp::activation_function_t { ACT_FUN_TANH = 0, ACT_FUN_-SIGMOID, ACT_FUN_INVALID }
Pointer to weights for the whole MLP.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.18 mlpGUI.cpp File Reference 145
12.18 mlpGUI.cpp File Reference
12.18.1 Detailed Description
Creates the front end GUI.
Author:
Scott Finley
Date:
November 24, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file mlpGUI.cpp.
#include <wx/wx.h>
#include <wx/textctrl.h>
#include "main_form.hpp"
Include dependency graph for mlpGUI.cpp:
mlpGUI.cpp
wx/wx.h
wx/textctrl.h main_form.hpp
wx/filepicker.hwx/spinctrl.h mlp.hpp
string
sstream
boost/shared_ptr.hpp boost/format.hpp
mlp_types.hpp error.hpp
vector exception
Namespaces
• namespace mlp
Classes
• class mlp::application_t
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

146 File Documentation
12.19 training_panel.cpp File Reference
12.19.1 Detailed Description
Main form class for the GUI.
Author:
Scott Finley
Date:
November 24, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file training_panel.cpp.
#include <boost/format.hpp>
#include <iostream>
#include <vector>
#include <wx/notebook.h>
#include "training_panel.hpp"
#include "training_results_panel.hpp"
Include dependency graph for training_panel.cpp:
training_panel.cpp
boost/format.hpp
iostream
vector
wx/notebook.htraining_panel.hpptraining_results_panel.hpp
wx/wx.h wx/filepicker.h wx/spinctrl.hinput_handler.hpp mlp.hpp
stringboost/shared_ptr.hpp
mlp_types.hpp error.hpp
exception
sstream
Namespaces
• namespace anonymous_namespace{training_panel.cpp}
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.19 training_panel.cpp File Reference 147
Classes
• class anonymous_namespace{training_panel.cpp}::layer_gui_tA panel for the use to input the configuration of a single layer.
Enumerations
• enum {
ID_Open_Training_File = 1, ID_Rem_Layer, ID_Add_Layer, ID_Train,
ID_Open_Tuning_File }defines event ids
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

148 File Documentation
12.20 training_panel.hpp File Reference
12.20.1 Detailed Description
Main training panel class for the GUI.
Author:
Scott Finley
Date:
December 01, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file training_panel.hpp.
#include <wx/wx.h>
#include <wx/filepicker.h>
#include <wx/spinctrl.h>
#include "input_handler.hpp"
#include "mlp.hpp"
Include dependency graph for training_panel.hpp:
training_panel.hpp
wx/wx.h wx/filepicker.h wx/spinctrl.h input_handler.hpp mlp.hpp
vector stringboost/shared_ptr.hpp
mlp_types.hpp error.hpp
exception boost/format.hpp
sstream
This graph shows which files directly or indirectly include this file:
training_panel.hpp
main_form.cpp training_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.20 training_panel.hpp File Reference 149
Namespaces
• namespace mlp• namespace mlp::gui
Classes
• class mlp::gui::training_panel_tMain form for GUI.
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

150 File Documentation
12.21 training_results_panel.cpp File Reference
12.21.1 Detailed Description
Training dialog implementation.
Author:
Scott Finley
Date:
November 27, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file training_results_panel.cpp.
#include <iostream>
#include <wx/notebook.h>
#include <mathplot.h>
#include <cmath>
#include <boost/foreach.hpp>
#include <iterator>
#include <string>
#include "training_results_panel.hpp"
#include "mlp_types.hpp"
Include dependency graph for training_results_panel.cpp:
training_results_panel.cpp
iostream wx/notebook.h mathplot.h cmath boost/foreach.hpp iterator
string
training_results_panel.hpp
mlp_types.hpp
wx/wx.h
vector
wx/filepicker.hmlp.hpp input_handler.hpp
sstream
boost/shared_ptr.hppboost/format.hpp
error.hpp
exception
Namespaces
• namespace anonymous_namespace{training_results_panel.cpp}
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.21 training_results_panel.cpp File Reference 151
Enumerations
• enum { ID_Done = 1, ID_Results_Panel, ID_Open_Data_File, ID_Classify }
Functions
• float_t anonymous_namespace{training_results_panel.cpp}::find_-classification_rate (output_set_t const &result, output_set_t const &desired)
• float_t anonymous_namespace{training_results_panel.cpp}::find_error(output_set_t const &result, output_set_t const &desired)
Computes the sum-of-squares error between the result and desired output sets.
• unsigned int anonymous_namespace{training_results_panel.cpp}::max_index(output_t const &data)
returns the index of the element with the highest value
• input_set_ptr anonymous_namespace{training_results_panel.cpp}::scale(input_set_ptr p_data, float_t min_bound, float_t max_bound)
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

152 File Documentation
12.22 training_results_panel.hpp File Reference
12.22.1 Detailed Description
Panel that displays training progress.
Author:
Scott Finley
Date:
November 27, 2008 Copyright (c) 2008 by Scott Finley. All rights reserved.
Definition in file training_results_panel.hpp.
#include <wx/wx.h>
#include <vector>
#include <wx/filepicker.h>
#include "mlp.hpp"
#include "input_handler.hpp"
Include dependency graph for training_results_panel.hpp:
training_results_panel.hpp
wx/wx.h
vector
wx/filepicker.hmlp.hppinput_handler.hpp
string
sstream
boost/shared_ptr.hpp boost/format.hpp
mlp_types.hpp error.hpp
exception
This graph shows which files directly or indirectly include this file:
training_results_panel.hpp
training_panel.cpp training_results_panel.cpp
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

12.22 training_results_panel.hpp File Reference 153
Namespaces
• namespace mlp• namespace mlp::gui
Classes
• class mlp::gui::training_results_panel_tDialog that displays training progress.
• struct mlp::gui::training_results_panel_t::status_data_t
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

Index
A0RNG_rand48, 104
activation_function_tmlp, 45
add_transposecublas_cuda_mlp.cu, 113cublas_cuda_mlp.hpp, 119
anonymous_namespace{blas_mlp.cpp},37
anonymous_namespace{cublas_cuda_-mlp.cpp}, 38
anonymous_namespace{cublas_-mlp.cpp}, 39
anonymous_namespace{training_-panel.cpp}, 40
anonymous_namespace{training_-panel.cpp}::layer_gui_t, 47
anonymous_namespace{training_-results_panel.cpp}, 41
apply_act_funcublas_cuda_mlp.cu, 113cublas_cuda_mlp.hpp, 120
back_propmlp::cublas_mlp_t, 75
basic_matrix_tmlp::basic_matrix_t, 56
blas_mlp.cpp, 105blas_mlp.hpp, 107
classifymlp::mlp_t, 97
compute_output_deltacublas_cuda_mlp.cu, 114cublas_cuda_mlp.hpp, 120
copy_plus_biascublas_cuda_mlp.cu, 114
cublas_cuda_mlp.hpp, 121create_mlp
mlp::mlp_t, 97cublas_cuda_mlp.cpp, 109cublas_cuda_mlp.cu, 111
add_transpose, 113apply_act_fun, 113compute_output_delta, 114copy_plus_bias, 114transform_delta, 115
cublas_cuda_mlp.hpp, 117add_transpose, 119apply_act_fun, 120compute_output_delta, 120copy_plus_bias, 121transform_delta, 121
cublas_mlp.cpp, 123cublas_mlp.hpp, 125
dev_ptr_list_tmlp, 44
error.hpp, 127
feed_forwardmlp::cublas_mlp_t, 76
getRNG_rand48, 104
get_debug_streammlp::blas_mlp_t, 61mlp::cublas_cuda_mlp_t, 67mlp::cublas_mlp_t, 77mlp::mlp_t, 98
get_impl_titlemlp, 45
get_random_numbersRNG_rand48, 104

INDEX 155
get_weightsmlp::blas_mlp_t, 61mlp::cublas_cuda_mlp_t, 68mlp::cublas_mlp_t, 77mlp::mlp_t, 98
host_layer_tmlp::cublas_mlp_t, 75
input_handler.cpp, 129input_handler.hpp, 130
layer.hpp, 132layer_weights_t
mlp, 44
main_form.cpp, 134main_form.hpp, 135matrix.hpp, 137mlp, 42
activation_function_t, 45dev_ptr_list_t, 44get_impl_title, 45layer_weights_t, 44vector_t, 45
mlp.cpp, 139mlp.hpp, 140mlp::basic_layer_t, 50mlp::basic_matrix_t, 52
basic_matrix_t, 56mlp::blas_mlp_t, 57
get_debug_stream, 61get_weights, 61run_training_epoch, 61set_training_data, 62set_tuning_data, 62
mlp::cublas_cuda_mlp_t, 63get_debug_stream, 67get_weights, 68run_training_epoch, 68set_training_data, 68set_tuning_data, 69
mlp::cublas_mlp_t, 70back_prop, 75feed_forward, 76get_debug_stream, 77
get_weights, 77host_layer_t, 75run_training_epoch, 77set_training_data, 78set_tuning_data, 78update_weights, 79
mlp::error_t, 80mlp::gui::main_form_t, 82mlp::gui::training_panel_t, 84mlp::gui::training_results_panel_t, 88mlp::input_handler_t, 92mlp::mlp_t, 94
classify, 97create_mlp, 97get_debug_stream, 98get_weights, 98run_training_epoch, 99set_activation_function, 99set_training_data, 99set_tuning_data, 100set_weights, 100tune, 100
mlp_types.hpp, 142mlpGUI.cpp, 145
RNG_rand48, 102A0, 104get, 104get_random_numbers, 104
run_training_epochmlp::blas_mlp_t, 61mlp::cublas_cuda_mlp_t, 68mlp::cublas_mlp_t, 77mlp::mlp_t, 99
set_activation_functionmlp::mlp_t, 99
set_training_datamlp::blas_mlp_t, 62mlp::cublas_cuda_mlp_t, 68mlp::cublas_mlp_t, 78mlp::mlp_t, 99
set_tuning_datamlp::blas_mlp_t, 62mlp::cublas_cuda_mlp_t, 69mlp::cublas_mlp_t, 78
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen

156 INDEX
mlp::mlp_t, 100set_weights
mlp::mlp_t, 100
training_panel.cpp, 146training_panel.hpp, 148training_results_panel.cpp, 150training_results_panel.hpp, 152transform_delta
cublas_cuda_mlp.cu, 115cublas_cuda_mlp.hpp, 121
tunemlp::mlp_t, 100
update_weightsmlp::cublas_mlp_t, 79
vector_tmlp, 45
Generated on Fri Dec 19 11:53:34 2008 for Multi-Layer Perceptron by Doxygen