musical mosaicing with high level descriptors - music technology
TRANSCRIPT

Master in Sound & Music Computing
Musical Mosaicing with High LevelDescriptors
John O'Connell
Supervisors:
Perfecto HerreraJordi Janer

John O'Connell, 2011
Some Rights Reserved.
This work is licensed under a Creative CommonsAttribution-NonCommercial-ShareAlike 3.0 Unported License.http://creativecommons.org/licenses/by-nc-sa/3.0/

Contents
1 Introduction 1
2 Motivation 4
3 State of the Art 53.1 Music Content Description . . . . . . . . . . . . . . . . . . . . . . 5
3.1.1 A Brief History . . . . . . . . . . . . . . . . . . . . . . . . 53.1.2 Low level - The signal . . . . . . . . . . . . . . . . . . . . 63.1.3 High level - Machine Learning . . . . . . . . . . . . . . . . 63.1.4 Musical moods . . . . . . . . . . . . . . . . . . . . . . . . 7
3.2 Origins of Mosaicing . . . . . . . . . . . . . . . . . . . . . . . . . 83.2.1 The birth of sampling . . . . . . . . . . . . . . . . . . . . 93.2.2 Musical freedom . . . . . . . . . . . . . . . . . . . . . . . 93.2.3 Towards music content description . . . . . . . . . . . . . 103.2.4 Musical mosaicing . . . . . . . . . . . . . . . . . . . . . . 113.2.5 Tiny grains of sound . . . . . . . . . . . . . . . . . . . . . 123.2.6 Speech synthesis . . . . . . . . . . . . . . . . . . . . . . . 133.2.7 Data driven grains . . . . . . . . . . . . . . . . . . . . . . 13
3.3 Mosaicing Software . . . . . . . . . . . . . . . . . . . . . . . . . . 143.4 Practical Applications of Mosaicing . . . . . . . . . . . . . . . . . 15
3.4.1 Soundscapes and Installations . . . . . . . . . . . . . . . . 153.4.2 Live Performance . . . . . . . . . . . . . . . . . . . . . . . 163.4.3 Smart Sampling . . . . . . . . . . . . . . . . . . . . . . . 163.4.4 Composing with a Mosaicing application . . . . . . . . . . 17
3.5 Anatomy of a Mosaicing Application . . . . . . . . . . . . . . . . 183.5.1 Database . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.5.2 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.5.3 Segmentation . . . . . . . . . . . . . . . . . . . . . . . . . 203.5.4 Unit Selection . . . . . . . . . . . . . . . . . . . . . . . . . 203.5.5 Transformation . . . . . . . . . . . . . . . . . . . . . . . . 21
3.6 Music made using CSS techniques . . . . . . . . . . . . . . . . . 223.7 Evaluation of a Mosaicing System . . . . . . . . . . . . . . . . . . 22
4 Research Goals 25
1

5 Methodology 275.1 Software Development . . . . . . . . . . . . . . . . . . . . . . . . 275.2 High Level Descriptor Evaluation . . . . . . . . . . . . . . . . . . 285.3 Musical Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6 Contributions 306.1 An Extensible Framework for Mosaicing . . . . . . . . . . . . . . 30
6.1.1 Extensibility of existing systems . . . . . . . . . . . . . . 306.1.2 Prototyping . . . . . . . . . . . . . . . . . . . . . . . . . . 316.1.3 Implementation . . . . . . . . . . . . . . . . . . . . . . . . 326.1.4 Description of algorithm . . . . . . . . . . . . . . . . . . . 356.1.5 Framework Applications . . . . . . . . . . . . . . . . . . . 36
6.2 The Evolution of a Hierarchical Mosaicing Model . . . . . . . . . 426.2.1 Tackling the time resolution issue . . . . . . . . . . . . . . 426.2.2 Derivation of the Time Resolution of a Binary Classi�er . 43
6.3 An Evaluation of a Hierarchical Model for Mood Mosaicing . . . 466.3.1 Mood Mosaicing with the Beatles . . . . . . . . . . . . . . 466.3.2 Further Evaluation of the Mood Descriptors . . . . . . . . 50
6.4 Musical Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.4.1 The Loop-based Paradigm . . . . . . . . . . . . . . . . . . 546.4.2 Integrating Mosaics into a Composition: A personal ex-
perience . . . . . . . . . . . . . . . . . . . . . . . . . . . . 566.4.3 The Signi�cance of Performance issues . . . . . . . . . . . 57
7 Conclusions 60
8 Future Work 62
References 64
A Glossary 70
B System Documentation 72B.1 Module hmosaic.control . . . . . . . . . . . . . . . . . . . . . . . 73
B.1.1 Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . 73B.1.2 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 73B.1.3 Class Target . . . . . . . . . . . . . . . . . . . . . . . . . 74B.1.4 Class HighLevelControl . . . . . . . . . . . . . . . . . . . 75B.1.5 Class Gridder . . . . . . . . . . . . . . . . . . . . . . . . . 79B.1.6 Class Context . . . . . . . . . . . . . . . . . . . . . . . . . 80B.1.7 Class RepeatUnitCost . . . . . . . . . . . . . . . . . . . . 81
B.2 Module hmosaic.settings . . . . . . . . . . . . . . . . . . . . . . . 83B.2.1 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
B.3 Module hmosaic.utils . . . . . . . . . . . . . . . . . . . . . . . . . 85B.3.1 Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . 85B.3.2 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
B.4 Module hmosaic.analyse . . . . . . . . . . . . . . . . . . . . . . . 87B.4.1 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 87B.4.2 Class EssentiaError . . . . . . . . . . . . . . . . . . . . . 87B.4.3 Class EssentiaAnalyser . . . . . . . . . . . . . . . . . . . . 88
B.5 Module hmosaic.segment . . . . . . . . . . . . . . . . . . . . . . . 89
2

B.5.1 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 89B.5.2 Class AudioSegmenter . . . . . . . . . . . . . . . . . . . . 89B.5.3 Class NoteOnsetSegmenter . . . . . . . . . . . . . . . . . 89
B.6 Module hmosaic.models . . . . . . . . . . . . . . . . . . . . . . . 92B.6.1 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 92B.6.2 Class DBSong . . . . . . . . . . . . . . . . . . . . . . . . . 92B.6.3 Class DBSegment . . . . . . . . . . . . . . . . . . . . . . 93B.6.4 Class SegmentAudio . . . . . . . . . . . . . . . . . . . . . 94B.6.5 Class Unit . . . . . . . . . . . . . . . . . . . . . . . . . . . 94B.6.6 Class Mosaic . . . . . . . . . . . . . . . . . . . . . . . . . 95B.6.7 Class MosaicUnit . . . . . . . . . . . . . . . . . . . . . . . 97B.6.8 Class DataUnit . . . . . . . . . . . . . . . . . . . . . . . . 98
B.7 Module hmosaic.corpus . . . . . . . . . . . . . . . . . . . . . . . 99B.7.1 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 99B.7.2 Class CorpusManager . . . . . . . . . . . . . . . . . . . . 99B.7.3 Class Corpus . . . . . . . . . . . . . . . . . . . . . . . . . 100B.7.4 Class CorpusDoesNotExistException . . . . . . . . . . . . 102B.7.5 Class CorpusExistsException . . . . . . . . . . . . . . . . 103B.7.6 Class FileExistsException . . . . . . . . . . . . . . . . . . 104B.7.7 Class FileNotFoundException . . . . . . . . . . . . . . . . 105B.7.8 Class FileCorpusManager . . . . . . . . . . . . . . . . . . 105B.7.9 Class FileCorpus . . . . . . . . . . . . . . . . . . . . . . . 107
C System Scripts Documentation 111C.1 Module hmosaic.scripts.convertAudio . . . . . . . . . . . . . . . . 112
C.1.1 Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . 112C.1.2 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
C.2 Module hmosaic.scripts.createHighLevelChops . . . . . . . . . . . 113C.2.1 Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . 113C.2.2 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
C.3 Module hmosaic.scripts.processTestData . . . . . . . . . . . . . . 114C.3.1 Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . 114C.3.2 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
C.4 Module hmosaic.scripts.plotResults . . . . . . . . . . . . . . . . . 117C.4.1 Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . 117C.4.2 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
3

List of Figures
1.1 A Photomosaic of a seagull . . . . . . . . . . . . . . . . . . . . . 1
3.1 Diemo Schwarz's taxonomy of applications . . . . . . . . . . . . . 143.2 An alternative taxonomy of applications . . . . . . . . . . . . . . 153.3 Anatomy of a mosaicing application . . . . . . . . . . . . . . . . 18
6.1 First prototype of a mosaicing application . . . . . . . . . . . . . 326.2 Second prototype of a mosaicing application . . . . . . . . . . . . 336.3 System Architecture Diagram . . . . . . . . . . . . . . . . . . . . 346.4 Block Diagram of hierarchical algorithm . . . . . . . . . . . . . . 366.5 Mosaicing Control GUI . . . . . . . . . . . . . . . . . . . . . . . 376.6 Corpus Selection GUI . . . . . . . . . . . . . . . . . . . . . . . . 376.7 Segmenter GUI . . . . . . . . . . . . . . . . . . . . . . . . . . . . 386.8 Hierarchical Similarity Search GUI . . . . . . . . . . . . . . . . . 406.9 Transformations, Tracking & Settings GUI . . . . . . . . . . . . . 416.10 Increased classi�er accuracy with increased time resolution . . . 456.11 Classi�cation results for 2 and 4 second segments . . . . . . . . . 466.12 LastFM user tags for In My Life . . . . . . . . . . . . . . . . . . 476.13 Motown mosaicing mood curves . . . . . . . . . . . . . . . . . . . 506.14 Sunra mosaicing mood curves . . . . . . . . . . . . . . . . . . . . 516.15 Aggressive mood comparisons . . . . . . . . . . . . . . . . . . . . 526.16 Sad mood comparisons . . . . . . . . . . . . . . . . . . . . . . . . 526.17 Relaxed mood comparisons . . . . . . . . . . . . . . . . . . . . . 536.18 Happy mood comparisons . . . . . . . . . . . . . . . . . . . . . . 536.19 Mosaic Looping Application . . . . . . . . . . . . . . . . . . . . . 556.20 Average performance of extractor routines . . . . . . . . . . . . . 59
4

List of Tables
6.1 Onset detection descriptors . . . . . . . . . . . . . . . . . . . . . 396.2 Similarity Search: Summary of Low level Descriptors . . . . . . . 406.3 Similarity Search: Summary of High level descriptors . . . . . . . 416.4 Chosen acapellas for gender classi�cation . . . . . . . . . . . . . 436.5 Acapella segment classi�cation results . . . . . . . . . . . . . . . 446.6 Emotion of Beatles excerpts and Frankenstein Target . . . . . . . 486.7 Distances between target and mosaics . . . . . . . . . . . . . . . 506.8 Empirical comparison of mood mosaicing models . . . . . . . . . 546.9 T-test results for mood comparison experiment . . . . . . . . . . 546.10 Mosaic smoothness comparison . . . . . . . . . . . . . . . . . . . 546.11 Feature extraction performance testing . . . . . . . . . . . . . . . 59
5

Abstract
This thesis investigates the use of high level descriptors (like genre, mood, in-strumentation, singer's gender, etc.) in audio mosaicing, a form of data drivenconcatenative sound synthesis (CSS). The document begins by discussing theadvances made in the �eld of music content description over the last 10 years, ex-plaining the meaning of high level music content description and highlighting therelevance of automatic music content description in general, to the �eld of audiomosaicing. It proceeds, tracing the origins of mosaicing from its beginnings asa time consuming manual process, through to modern e�orts to automate mo-saicing and enhance the productivity of artists seeking to create mosaics. Theessential components of a mosaicing system are described. Existing mosaicingsystems are dissected and categorised into a taxonomy based on their potentialapplication area. The time resolution of high level descriptors is investigatedand a new hierarchical framework for incorporating high level descriptors intomosaicing applications is introduced and evaluated. This framework is writ-ten in Python and utilises pure data as both user interface and audio engine.Descriptors, stemming from Music Information Retrieval (MIR) research arecalculated using an in-house analysis extraction tool. In-house audio-matchingsoftware is used as the similarity search engine. Many other libraries have alsobeen integrated to aid the research, in particular Aubio for note detection, andRubberband, for time stretching. The high level descriptors included in thisproject are; mood (happy, sad, relaxed or happy), gender (male or female), key,scale (major or minor), instrumental, vocal. A mini application for augmentingaudio loops with mosaics is presented. This is used to show how the frame-work can be extended to cater for a given mosaicing paradigm. The musicalapplications of mosaics in the traditional song-based composition are also ex-plored. Finally, conclusions are drawn and directions for future work postulated.
Keywords: concatenative sound synthesis, mosaicing, high level, semantic de-scriptors, pure data, Python, MIR, mood description, composition

Acknowledgements
I'd like to thank Xavier Serra for giving me the opportunity to come to Barcelonaand study at the Music Technology Group in the �rst place. I also wish tothank Vincent Akkermans for granting me a 6 month internship, which notonly helped to pay the bills but also gave me a fascinating insight into theworking life of a university research group. To all my friends from the master,I consider myself blessed to have been gifted with such a sound group of peopleto share this experience with. This is my �rst research project and as such Iam indebted to my supervisors; Perfecto Herrera and Jordi Janer. Your adviceand direction was invaluable to me, not merely for navigating the murky watersof musical mosaicing, but for understanding how one goes about researchinga topic in general. I wish to thank Cyril Laurier for allowing me to use hismusical moods dataset and Nicholas Wack for patiently explaining how to usethe MTG technology I was researching with. Finally, and most importantly, Iwant to thank Po-Heng for putting up with me during this rather intense yearof learning, and my family for supporting my decisions.

Chapter 1Introduction
Mosaicing may be best understood through a simple example presented belowin Figure 1.1
Figure 1.1: A Photomosaic of a seagull, comprised of many small photos ofbirds and humans. This �le was found in the wikimedia commons where it wasoriginally uploaded by the user: J2thawiki
1

In this photo mosaic it is easy to perceive the image of a bird, we can make outits yellow beak and white feathers against a blue background. However it is alsoeasy to see, upon closer inspection, how the image is composed of a multitudeof smaller images, like a collage. Audio mosaicing seeks to replicate the sameperceptual illusion in the auditory domain, however it is not quite as easily doneas with photo mosaicing.
Photo mosaicing works by reducing each of the source library images to a sin-gle RGB colour value (a triple of values for red, green and blue). The targetimage is then segmented and each segment, again reduced to a single averagedcolour value, is replaced by the closest matching source image, thus creatingthe mosaic. A more accurate match may be made by comparing the source andtarget segments pixel by pixel to �nd the closest match. This approach is morecomputationally intensive but the search space is still 3 dimensional - a singleRGB colour value.
Audio mosaicing lacks this single feature with which to describe all audio gen-erally and facilitate a similar perceptual trick. The temporal aspect must alsobe contended with - the audio changes over time, while a photo-mosaic remainsstatic . Additionally, with a photomosaic, the observer moves closer to the photoin order to see the individual images of which it is comprised. If they stand backfrom the mosaic, they see the bigger picture once again. It is di�cult to imaginehow this stepping back can be accomplished in the auditory domain.
The �eld of music description has, in lieu of a single global feature, producedmany descriptions of di�erent aspects of sound and music. Called descriptors,these measures range from �le metadata, e.g. length, to timbral descriptors ordescriptions of the pitch, harmonic content, perceptual loudness or energy. Akey problem with many of these descriptors is the lack of a perceptual correlate.Ordinary people might speak about a photo in terms of its colour and the RGBvalue of the photo describe this colour, however few people would discuss a pieceof music in terms of its zero-crossing rate or spectral centroid. Despite the lackof a perceptual correlate, most audio-mosaicing systems use combinations ofthese descriptors, which may be thought of as low level descriptors.
One might draw a comparison between the high level features of the seagullidenti�able in Figure 1.1, and high level musical features which might be dis-tinguished in a piece of audio, e.g. instrumentation or genre, even mood. Thisis where high level descriptions of music come in. These descriptors are oftencalled semantic as they seek to relate to certain concepts which ordinary peoplemight use in the discussion of music, like mood or genre. We can also includemore technical semantic concepts, for example; the key of a piece and whetherit is major or minor. These high level descriptors have not thus far been in-corporated into any audio-mosaicing system. It is the purpose of this thesis toexplore the integration of high-level audio descriptions into a such a system,thereby bringing a measure of semantic control to the mosaicing process.
My personal motivation for taking on this project is discussed in the next sec-tion. Following that, a state of the art review is conducted which surveys the�eld of music content description tracing the development of high level audiodescriptors, highlighting the fuzziness of the semantic categories they seek tode�ne using musical mood as a case study, before delving into the origins of mo-
2

saicing and �nishing up in the modern age of mosaicing research and mosaicingart. A taxonomy of mosaicing based on area of application is contributed. Myresearch goals are speci�ed and my methodology is outlined prior to describ-ing some useful contributions; an extensible framework for audio-mosaicing, aninvestigation into the time resolution of the high level descriptors and an in-vestigation into musical approaches using mosaics. Afterwards, conclusions aredrawn and directions for future research pointed out.
For more detailed information on the di�erence between terms such as audio-mosaicing, musical-mosaicing, concatenative-sound synthesis, etc. please see theglossary Appendix A at the end of this document
3

Chapter 2Motivation
My motivation for taking on this project stems from a personal interest increating music. I write songs and compose music and I was interested in thecompositional applications of mosaicing. It seems like a miraculous idea - tobe able to resynthesise audio from tiny segments of other audio and attain aperceptual correlate at the end of the process. Furthermore to do so with highlevel descriptors, to be able to produce a mosaic which corresponds to the targetin terms of genre, mood, even danceability, is an even more enticing prospect.This miracle is however, a long way o� and yet I think the challenging natureof this topic also appealed to me. High level descriptors are still a very newcommodity outside of research and there are still many outstanding problems in�elds related to this project (e.g. onset detection, pitch detection in polyphonicaudio, multimedia database technology, etc.). Finally, when researching theproject proposals, this was the subject area which captured my interest themost and I was more keen on reading the literature on this topic than on anyother.
4

Chapter 3State of the Art
3.1 Music Content Description
3.1.1 A Brief History
Music Content Description, often called Music Information Retrieval (MIR)is a young discipline, whose origin as a research community, can be tracedback to the International Conference on Music Information Retrieval in 2000[1]. There are many potential applications for this kind of research, includingmusical search, musical identi�cation and copyright enforcement.
At the moment social tagging, on sites such as last.fm is helping navigate thehuge amount of music now available online, however this su�ers from issuessuch as inaccuracy and even malicious tagging; e.g. the application of 558 BrutalDeath Metal tags to Paris Hilton [2]. Searching for music by using automaticallyextracted descriptions of its audio-musical content rather than manually enteredmetadata (tags) precludes these kinds of problems It also opens up possibilitiesfor recommender systems to help users to �nd music on the long tail, i.e. musicthat is not commercially successful and would not be recommended to you byother contextual systems which work based on what other people have boughtor recommended or what is selling well.
Another application for this kind of research was demonstrated by the phenom-enal success of Shazam [3]. Shazam identi�es music based on the processingof a few seconds of audio followed by a lighting fast search in a huge databaseof audio �ngerprints in an attempt to �nd a match. Its speed and robustnessto noise contributed to it's popularity in the smartphone applications market.Cover detection systems have also been developed, and it has been suggested bySerrà [4] that one day, they may even be used in court cases to help determinewhether one song plagiarises another or infringes its copyright.
All of these potential applications are based upon descriptions of the signal thatare automatically extracted using signal processing and/or machine learning
5

techniques. The following sections outline the types of descriptions availableand discusses how they are extracted from the audio.
3.1.2 Low level - The signal
Music description always begins with low level features extracted from the audiocontent using signal processing techniques. The key ingredient in many of thesetechniques is the fast Fourier transform (FFT), an e�cient implementation ofthe discrete Fourier transform, which provides a representation of the audio sig-nal in the frequency domain. The features subsequently extracted may includeRMS, spectral centroid, spectral �atness, etc. These features can be di�cultfor humans to understand or relate them to anything meaningful (without someprior knowledge of signal processing), however their mathematical descriptioncan be quite simple and is calculated using only the signal. A good descriptionof these low level features and how to calculate them may be found in [5]
The usefulness of low level descriptors can be extended by applying a percep-tual model. Perceptual feature extraction generally requires some additionalpreprocessing of the spectrum e.g. a �lter which simulates the attenuation ofthe human middle ear could be applied to the FFT data into order to weightit's constituent frequency bands in a way which directly relates to human per-ception e.g. Bark bands or the Mel scale. The Harmonic Pitch Class Pro�les(HPCP) described in [6] might also be classed as perceptual descriptors. Thesedescriptions are less abstract in concept and relate more closely to semanticmusical features. In general, mid level descriptors rely, not just on the signal,but also on a supporting data model to apply a meaningful label, e.g. a note,from information extracted from the signal (e.g. pitch)
A feature described by a single low-level descriptor is not typically a semanticfeature. Normally these low level descriptors are combined to form mid-level orhigh-level descriptors which aim towards a more semantic, higher level featuredescription.
3.1.3 High level - Machine Learning
The semantic gap in music description has been widely discussed, e.g. [7, 8]Generally speaking it refers to the gap between the low level features of theaudio and the higher level semantic concepts used by humans to describe soundand music. For example, two experts in signal processing might discuss an audio�le in terms of it's low level features (e.g. spectral centroid, RMS, MFCCs). It issafe to say, that two people on the street or in a bar, with no knowledge of signalprocessing, discussing the latest hit single by some pop group, will not use theseterms. They might however, speak of mood, genre or instrumentation, which areall high-level, semantic categories. Mid and high-level descriptors are an attemptto bridge this gap by combining more traditional techniques, derived from signalprocessing, with machine learning, music theory, statistical modelling, etc. inorder to extract content objects from the audio. These content objects are a setof labels which relate more closely to how humans might describe music; e.g.genre, melody, key, rhythm, etc. There is much research which investigates the
6

correlation between low-level audio features and high-level semantic concepts inan attempt to narrow this gap, e.g. [9], [10], [11]. We will �rstly discuss thetypical approach to building a high level descriptor, then we will examine musicalmood more closely, describing how research in music perception informed thecreation of the mood descriptions used in this thesis.
Out of the limitations of signal processing, was born a new approach, usingmachine learning. This approach can be simpli�ed by breaking it into a 2 stepprocess. In the �rst, audio examples which are considered representative of aparticular semantic category are collected into a training dataset, e.g. musicwhich is sad. In the second step, this dataset is used to train the classi�er and amodel is built. The model identi�es patterns in large collections of descriptors,extracted for each audio �le in the training dataset, based on the underlyingassumption that the songs in the dataset are all similar, they have all beenlabelled as belonging to a particular category. Commonalities or patterns aresought within this analysis, in order to classify an unseen audio example asbeing a member of the given category or not.
Many di�erent machine learning algorithms exist for building the models. Oneof the most popular approaches is to use Support Vector Machines (SVM), whichworks by separating the examples into two categories divided by a hyperplane.The Support Vectors are the examples which lie closest to the hyperplane andthe objective is to orient this hyperplane in the N dimensional descriptor spacesuch that those Support Vectors on either side of the hyperplane are as far awayfrom each other as possible [12] For more details on how to create a semanticclassi�er using support vector machines, the interested reader is referred to [13],which describes the implementation of a gender classi�er. Please see [14] for amore comprehensive review of statistical techniques in general.
3.1.4 Musical moods
This section explores the di�culty of deriving mathematical models to describethe fuzzy, subjective categories which humans use to classify music, by selectingone of these descriptors and analysing the research behind it. Musical mood,or emotion in music has been chosen because, in the experience of the author,it tends, somewhat ironically, to stir up strong emotions in people, with manybelieving that it is too subjective a quality to be categorised by an algorithm.
The association of a mood label to an audio signal, or segment thereof is certainlya daunting task. The signal alone cannot tell us the emotion of a piece of audio, amachine learning approach will have to be utilised. Research in music cognitioncan help us to fathom the types of moods which music can express or induceand the factors which in�uence our emotional response. This research can bedrawn upon when designing models for mood classi�cation of audio.
Vieillard, et al. in [15], in the course of validating 56 musical excerpts (intendedto convey 4 di�erent emotional states - Happy, Sad, Scared, Peaceful) found thatHappy and Sad excerpts were identi�ed after the presentation of fewer than 3musical events. This is in line with other research e.g. [16] which suggeststhat basic emotions are more easily expressed by music. This expression ofemotion in the music is distinct from the induction of emotion in the listener.
7

Induced emotions can be much more complex, depending on the context and theassociations which people hold for particular pieces of music, related to memoryof events in their lives.
Laurier, et al. in [17] work o� the premise that emotional responses to musicare not so subjective as to make them unsuitable for mathematical modelling,and by choosing basic emotions for their categories they derive a simpler andmore accurate model. This mood model is revised and improved in [18], whichuses a small selection of mutually exclusive categories; Angry, Sad, Happy andRelaxed. A binary classi�cation approach is used to allow songs to inhabitmore than one category e.g. a song might be classi�ed as either Angry or NotAngry and Sad or Not Sad, etc. For each mood category a set of semanticallyrelated words was created usingWordnet1 The audio data comprising the groundtruth was assembled by searching the last.fm2 social network for songs labelledby users of the network with tags matching members of the set of words foreach category. A set of songs was thus created for each category and this setwas subsequently validated by a group of expert listeners. The �nal selectioncomprised of 1000 songs spread evenly across the 8 categories. Descriptors wereextracted and an SVM model was built and the classi�cation results are verygood with accuracies above 80% for each category, and in the case of the Angrycategory, even reaching 98% accuracy. The mood classi�cation scheme used inthis thesis is derived from this work , it was chosen as one of the primary focusesof this investigation into mosaicing with high level descriptors.
3.2 Origins of Mosaicing
In this section, an attempt is made to shed some light on where mosaicing camefrom. Firstly, it is required to clarify some terms which are used throughout theliterature:
• Concatenative Sound Synthesis (CSS) is a process whereby audiois created by the concatenation of many small segments of audio, calledunits, from a source unit database, called a corpus.
• Musical Mosaicing is a process whereby a piece of music, called a targetand represented by a score or an audio �le, is approximated through theamalgamation of many small snippets of audio drawn from sources distinctfrom the source of the target.
• Audio Mosaicing is the same as musical mosaicing except that it neednot neccessarily be musical e.g. Sound texture mosaicing as in [19] or [20]might be better classi�ed as audio mosaicing.
Idealogically, musical mosaicing owes a lot to sampling, the idea of taking anexisting sound and reusing it, as an instrument, a texture, etc. in a new pieceof music. After we trace the historical, technological and social aspects leadingto the �rst musical mosaics, we show how automatic audio content description
1http://wordnet.princeton.edu2www.last.fm
8

applies and we investigate the technological developments in two very di�er-ent research areas; speech synthesis and granular synthesis, which allowed thedevelopment of the �rst automatic musical mosaicing systems.
3.2.1 The birth of sampling
Some people may believe that sampling began with hip hop, however the dreamof capturing sound, and storing it somehow, for later reproduction or manipula-tion, is not a new one. In fact Fowler, claims the origins of mechanical objects,capable of reproducing sound, can be traced back to the invention of a hy-dropowered organ by the Banu Musa brothers 3 of Bagdad, in the 9th centuryAD. [21]
He describes the organ as a device with interchangeable cylinders whose mech-anism provided the basis for music boxes, automatic piano players and othermechanical musical devices until Thomas Edison's invention of the phonographin the nineteenth century.
Composers down through the years had written for these mechanical musicaldevices however, once stored, the data was generally �xed, a�ording little pos-sibility to transform it and allow it to become part of the creative compositionprocess.
This all began to change in the 20th century with the proliferation of the phono-graph and devices like it. This change accelerated rapidly with the introductionof magnetic tape as an audio storage medium. The new medium of tape providedincreased possibilities for sound transformation and manipulation. Manipula-tions, such as cutting and splicing, which were possible with wax discs, werenow much less laborious [22] and new transformations could be wrought withtape, e.g. the tape delay e�ect.
This opened the door on the practice of creating tape loops through the cut-ting, splicing and manipulating of audio recorded onto tape. By the mid 1960s,this art had found its way into the heart of global popular music , featuringprominently in The Beatles song, Tomorrow Never Knows [23]. Nowadays peo-ple understand a musical sample as being "an excerpt from a musical recordingthat is used in another artists recording", however the basic meaning of the wordsample is simply "A representative part from a larger whole".4 Composers werelooking for new sounds, sampling material from real world soundscapes and andmanipulating found objects provided such sounds.
3.2.2 Musical freedom
We must break out of this narrow circle of pure musical sounds and
conquer the in�nite variety of noise sounds - Russolo, 1913
From the beginning of the 20th Century composers had begun to dream ofnew forms of music and to break free, not only from the shackles of traditional
3http://www-history.mcs.st-andrews.ac.uk/Biographies/Banu_Musa.html4De�nitions of sample were taken from http://www.merriam-webster.com/dictionary/
sample
9

orchestration, but also from the rigid classical score paradigm of describingmusic. In 1913 Luigi Rossolo, the Italian futurist painter, wrote a letter to thecomposer Balilla Pratella in which he outlined his manifesto - the Art of Noises -a vision of expansion beyond the restrictive timbres of traditional orchestras byutilising the strange new sounds of the industrial age [24]. Curtis Roads tracesthe composed manipulation of recorded sounds back to the early 1920's whenpeople like Ernst Toch were experimenting with variable speed phonographsin live performance. [25] By the 1950's many composers were abandoning thetraditional score e.g. Schae�er and Pierre Henry with Orpheè53 [26] or IannisXenakis, the �rst composer to adopt a granular theory of music, who progressedbeyond the traditional score in the course of his development of stochastic musicthrough works like Metastasis (premiered in 1955 in Donaueschingen) [27, p. 1-12]
It has been suggested that an increased desire for completely new forms of musicsprang from the aftermath of two world wars and the devastation that waswrought. It is certainly true that a more favourable climate existed in Europeafter the war, there was more interest and the advances in technology broughtby the war led to the setting up of two studios in Europe, one in Cologne becamethe birthplace of synthesised electronic music, while the other in Paris provideda home for Pierre Schae�er and the Musique Concrète movement. These twostudios represented two very di�erent approaches to electronic music and it isthe aesthetic of the Parisian school which interests us most here.
Radiodi�usion Television Francaise (RTF) were the broadcasting company em-ploying Pierre Schae�er, pioneer of concrete music. They invested more moneyinto his research and by the early 1950's he was working alongside composerslike Pierre Henry and scientists like Andrè Moles in a purpose-built studio withmany specially made machines for composing and performing concrete music.e.g. the Phonogène, a tape based transposer and time stretcher.
In Musique Concrète sounds are recorded onto shellac or tape and through thisprocess they are abstracted from their real world source and converted intoObjets Sonores or sound objects. These sound objects are then manipulatedand sequenced in such a way that the listener may not be easily able to identifythe real-world sources of the original sound material. This is known as theacousmatic situation [28] and the intention is to lead the listener to concentrateon the intrinsic qualities of the sounds themselves, the "in-itself" (en-soi) ofthese sound objects.
For a comprehensive treatment on Pierre Schae�er and the genesis of concretemusic, the reader is referred to Manning's history of electronic music. [26].
3.2.3 Towards music content description
In electronic music the basic sound material must �rst be discovered
and then a research made to �nd out what these sounds can do - John
Baker, BBC Radiophonic orchestra
The pioneering vision of Schae�er must have provided at least some of theinspiration for the foundation of the BBC radiophonic orchestra in England.The radiophonic orchestra, in its early years, provided a home for many talented
10

young composers working with the medium of tape, e.g. Maddalena Fagandini,John Baker, Delia Derbyshire, etc. The quote from John Baker at the beginningof this section illustrates well the analysis requirements of the new generationof composers who were inspired by the philosophy of musique concrete.
These attempts to classify sound into categories based solely on the perceptualqualities of the sound itself, disregarding our knowledge of how the sound hasbeen generated, had begun with Pierre Scahe�er's attempts to increase themusicality of his early concrète compositions, like Ètude aux chemins de fer. Herealised that a study would have to be made of the properties of the soundsthemselves irrespective of their sources, he called this 'reduced listening', andhe used it in the development of his classi�cation scheme for sound objects. Hisresearch and observations were eventually synthesised into his Traitè des objetsmusicaux [29], published in 1966.
Schae�er considered, not only the sound objects themselves, but individual partsof such sound objects (e.g. attack, decay) and techniques and harmonic plans forcomposing concrete music. The resultant document was therefore very complex,however the text by Chion [[30]] provides a welcome elucidation of Schae�er'sideas
These classi�cation schemes at �rst appear quite primitive, unscienti�c even,next to the current state of the art in music content description. However, theyare semantic categories which is something that cutting edge music similaritysystems are only just beginning to achieve, e.g. [31], where a high level semanticdistance measure is derived for music similarity tasks. Attempts have been madeto automatically classify sounds according to Schae�er's taxonomy e.g. [32] Itmakes good sense to try and leverage these techniques to approximate thosesemantic categories required by composers, thus automating much of the boringwork of building your own personalised sonic palette.
3.2.4 Musical mosaicing
Artists have been deluding themselves for centuries with the notion
that they create. In fact they do nothing of the sort. They discover.
Spider Robinson - Melancholy Elephants
The possibility of creating new music from existing music by sampling the ex-isting music is an enticing one. However artists seeking to work within thisparadigm will �nd it fraught with issues of copyright. Our patent laws allowpeople to copyright musical progressions, lyrics, recorded audio, etc. as theirexclusive property which others may not appropriate for their own use withoutspecial permission (i.e. payment). While a thorough discussion of the social andlegal issues surrounding sampling is beyond the scope of this thesis, the originsof musical mosaicing are intrinsically tied to these questions and the interestedreader is referred to this summary [33].
John Oswald's plunderphonics project 5 was not merely about music, but soughtalso to challenge our society's beliefs on ownership and creation, with special
5www.plunderphonics.com
11

regard to western music - whose �nite melodic, harmonic and rhythmic spacespreclude the possibility of ever creating anything genuinely new.
If creativity is a �eld, copyright is the fence. - John Oswald
This was a manual labour of love, with each mosaic assembled by hand fromtiny samples of source audio �les. It was only with the development of musiccontent description that such a process could be attempted automatically. Theidea of mosaicing, inherited from the visual realm and the work of Robert Silvers6, was applied to musical audio, in an attempt to automate that which Oswaldcreated by hand, in the musical mosaicing system of Zils and Pachet. [34].
3.2.5 Tiny grains of sound
It's very much like the pointillist painters, thousands and thousands
of brush strokes - Curtis Roads 7
The concept of granular synthesis stems from a theory of hearing proposed bythe nobel prize winning physicist Dennis Gabor in 1947 [35]. Gabor spoke aboutsound as being composed of acoustical quanta and proposed that this granularor quantum representation was powerful enough to describe any sound.
As mentioned previously the �rst to apply this Einstein inspired classi�cation ofsound to music creation was Iannis Xenakis, in his composition Analogique A-Bfor string orchestra and tape. Xenakis created the grains by splicing segments oftape together, however the sounds themselves were synthetic. Xenakis details,in [27, p. 79-109], how these compositions were evolved using his own screenssystem (similar to fourier and wavelet grids, and describes his methodology asMarkovian Stochostic music.
There are many systems for granular synthesis. Curtis Roads, the �rst to im-plement granular synthesis in the digital domain identi�ed 5 di�erent categoriesin [25, p. 172-184]
• Fourier and wavelet grids
• Pitch synchronous overlapping streams
• Quasi-synchronous streams
• Asynchronous clouds
• Time granulated streams
The last category is of particular interest to us as in this category, the grainmaterial, is extracted from audio sound �les. The process of grain selection isquite arbitrary. Grains are randomly selected from an audio �le or from severalaudio �les. A single grain may be extracted and turned into a roll throughrepeated playback. Automated musical mosaicing has become a data drivenform of the time granulated stream method described by Roads, where thegrain selection is not arbitrary but rather determined by the features of theaudio itself.
6http://www.photomosaic.com7http://www.youtube.com/watch?v=ajdRGF5NHIs
12

3.2.6 Speech synthesis
Concatenative Sound Synthesis (CSS) techniques have their origins in the �eldof Speech Research. Over 20 years ago, the �rst Text to Speech (TTS) programsbegan appear e.g. NTT in 1989 for Japanese or CHATR in 1994 for English[36] The idea behind a TTS application is that the system receives textual inputand generates an audio signal, sonifying the text, as output.
CSS is not the only means by which the output speech may be generated in aTTS, other systems use parameteric sysnthesis systems like source �lter - basedon signal processing or articulatory - based on physical modelling.
These other systems are both rule-based, rather than data driven. This presentsa huge disadvantage as the rules engines in these systems must be hugely com-plex in order to model natural speech and such systems are very in�exible, e.g.changing the voice might require rewriting a signi�cant part of the rules.
Within the concatenative synthesis approach there are 2 variants; �xed-inventoryand non-uniform. Only non-uniform is fully data driven as the �xed inventoryapproach breaks the source audio into small units based on speech research e.g.diphones, triphones, etc. thus requiring rule based transformations of the unitsin order to achieve the required prosodic variations to produce natural soundingspeech. In non-uniform concatenative synthesis the unit size is not �xed and theunits themselves tend to be drawn from continuously read audio, so that chunkwhich best matches a portion of the target is chosen as a source unit. Thesechunks therefore have an arbitrary length. Concatenation quality is improvedthrough the use of Pitch Synchronous overlap add synthesis (PSOLA) duringthe concatenation process. [37]
Lately these techniques have been adapted to singing voice synthesis as in [38]where the sample based concatenative synthesis approach described above ismarried to a set of spectral models in a performance modelling system. Theidea is to circumvent the problem of realistically sampling a continuously excitedinstrument (in this case the human voice) without dramatically increasing thesize of the sample database.
3.2.7 Data driven grains
Schwarz coined the term 'data-driven concatenative sound synthesis' in his phdthesis[36]. He imagined this as being a data-driven extension of granular synthe-sis. By data-driven he meant that the grain selection process was not arbitrarybut rather driven by analysis data extracted from the audio. The idea of acousti-cal quanta [35]is still relevant, except that the duration of the acoustical quantaought to be that of the smallest possible fragment of audio from which the se-lected audio content descriptors can reliably extract information. These ideasemerged out of the intersection between speech synthesis, granular synthesis andmusic content description. The work done by John Oswald on the plunderphon-ics project or by the BBC Radiophonic Orchestra, prior to the introduction ofsynthesisers, could accurately be described as data driven concatenative soundsynthesis. However in these cases the data was not derived automatically using
13

music content analysis techniques, but rather manually, through listening to theaudio.
3.3 Mosaicing Software
In this section we present the software applications which fall into the categoryof concatenative sound synthesis or musical/audio mosaicing. Diemo Schwarzcompiled a taxonomy of applications in [39] This taxonomy is still relevant, hasthe advantage of being updated continually on his webpage 8 and is shown inFigure 3.1
Figure 3.1: Schwarz's taxonomy of applications - note that high level descriptorshere are not high level as we are de�ning high level (semantic)
What this diagram does not illustrate are CSS use cases, e.g. Ringomatic sharesits corner of the application space with Catapillar and they are both very dif-ferent propositions. One is a real time drum loop creator, the other is designedfor non-real time building of a mosaic from a target and is very well optimisedtowards working with speech signals.
An alternative taxonomy would try and identify some use cases for this researchby analysing the existing research and categorising it by potential applicationareas as shown in Figure 3.2. We will discuss these categories in more detail inthe next section and in addition we will examine the use of mosaics in compo-sition.
8http://imtr.ircam.fr/imtr/Corpus-Based_Sound_Synthesis_Survey
14

Figure 3.2: A taxonomy of mosaicing research applications by potential uses.CataRT is the only real multipurpose application.
3.4 Practical Applications of Mosaicing
3.4.1 Soundscapes and Installations
CataRT dominates the sphere of applications, due to its maturity and extensi-bility. It is developed on top of Max/MSP 9, a very popular visual programming10 application. In CataRT [40], an audio target is not utilised to create theaudio output but rather the target is speci�ed by tracing a path through a 2-dimensional descriptor space. This corpus browsing experience feels much closerto granular synthesis from a sonic point of view. The user can adjust parame-ters like grain size and duration and once the grains become small enough, thehigher level features that need a greater time resolution become lost and you �ndyourself listening to microsounds, tiny acoustical quanta, as discussed by CurtisRoads in [41] It might be contended that because it enables free mosaicing inan n-dimensional descriptor space, it is very easy to map a whole database ofsound to a physical space, like in nuvolet [42] which allows the performer to ex-plore sound databases using 3D gestural control by marrying the output of themicrosoft kinect camera 11 to the CataRT descriptor space, which concatenatesthe source units based on the performers navigation of the descriptor space.
9http://cycling74.com/products/maxmspjitter/10http://en.wikipedia.org/wiki/Visual_programming_language11http://en.wikipedia.org/wiki/Kinect
15

Another example is plumage [43], which uses a custom 3D interface to controlCataRT. Many more artistic projects utilising CataRT are to be found listed onSchwarz's webpage12.
3.4.2 Live Performance
As previously mentioned, CataRT [40] introduced the concept of deriving thetarget speci�cation by allowing the user to trace a path through the corpusof source units. This paradigm presents many rich possibilities for musicalapplications of concatenative sound synthesis, particularly with regard to realtime synthesis through corpus navigation. For example, a musician's outputmight be recorded in real time, added to the corpus and used by a laptopperformer in order to jam with the musician not on the basis of sequencingloops but by drawing paths through musical units arranged along descriptor axis,e.g. pitch or loudness, thus allowing a certain level of semantic improvisationwith the recorded audio rather than relying on random, stochastic processes toresequence the audio. [44]. The creator of CataRT, Diemo Schwarz, has beenexploring real time improvisation with CataRT by doing exactly this - analysingand segmenting live audio captured onstage from a musician and exploring thesesounds as the musician(s) continues to play. 13 More recently, another CataRTbased musical project, uses an electric bass guitar to navigate the source corpus[45]. In this project the bass is not an extended instrument as the instrumentsacoustic sound is not ampli�ed. Rather, it is a controller of sorts with the audioit produces being used to navigate through the source-corpus descriptor space,driving the concatenation.
Most live performance with mosaicing is avant garde in nature, however I havehad the good fortune to see the creators of loop mash improvising live with theirCubase plug-in. This is a di�erent type of experience; electronic, rhythmical.It would not sound out of place on a nightclub dance�oor. The Loopmashtechnology, o�ers a powerful, loop-based step sequencer engine, for layeringup slices of concatenated audio and mixing them in real time. It features anintuitive, semantic interface for interpolating the source audio units and the stepbased model of playback ensures a synced rhythmic output, while also allowingthe user the possibility to randomise events to a certain extent, thus creatinga less predictable output. The integration of this engine with a voice operatedcontroller produced some very impressive results14 as described in [[46]]
3.4.3 Smart Sampling
Sampler instruments which utilise real audio sound much more realistic than amidi representation of the same music. The problem with sampler instrumentsis the vast quantity of audio data required to attain this similitude. All pos-sible articulations and dynamics for all of the notes in the instrument's rangeought to be recorded in order to achieve maximum realism. A small subset of
12http://catart.concatenative.net13http://www.youtube.com/theconcatenator14http://www.dtic.upf.edu/~jjaner/presentations/smc08/vosaicing.mov
16

the mosaicing applications which have been reviewed could be used as a kindof smart sampler application. It must be conceded at this point that this au-thor has not had the opportunity to try any of these applications as they allrequire a signi�cant monetary investment. The exception is the Audio Analo-gies project [47] which has not yet produced an application, however Microsoftown a patent which stemmed from this research (US Patent #7,737,354), sothe likelihood of an application based on this technology being freely availablein the future is slim! What these applications all have in common is their usecase, which overlaps to some extent, with that of samplers. Although they useconcatenated audio data for the output, the input is either a midi score (Synful,Audio Analogies) or, in the case of Loopmash, a loop quantised into a discretenumber of samples, any of which may be replaced by something similar, in adynamic fashion. The output is a realistic approximation of the score using realaudio, which may or may not have been annotated. These applications are thusunencumbered by state of the art issues in music description, e.g. onset detec-tion, pitch detection. They seem broadly similar to samplers with the advantagethat they need much less actual audio sample data; Synful transforms its sourceunits to better meet the target speci�cation, while Audio Analogies produces itsoutput using an example of a monophonic audio performance, the source audio,and its corresponding score to determine how to synthesise a monophonic audiorepresentation of a new score, using this same source audio. The advantage ofthis again, is that very little audio data is needed by the system. Loopmash isa little bit di�erent. It seems to have been conceived more as an instrumentfor live performance, particularly for rhythmic, electronic music. It organisesthe music into a series of quantised loops, the source database is pre-segmentedso individual units in any given loop can be dynamically replaced according todata driven comparisons of similarity.
3.4.4 Composing with a Mosaicing application
CataRT seems to be well suited for composition, it even includes a recordingfacility for saving the generated mosaics to disk. Paths drawn through thedescriptor space using its lcd functionality are easily repeated and there is alsothe possibility to create a mosaic based on an audio target or real time input.In CataRT some additional metadata such as the original temporal position ofthe unit within its source �le is included. This allows for browsing throughthe corpus automatically in sequence when idle, with playback jumping to thenearest unit in the descriptor space when the mouse is moved. CataRT alsocontains a beat mode whereby source units are selected in a metronomic fashion.This is quite a similar approach to that employed by the Loopmash technology,which is built around a loop based step sequencer paradigm. These two toolsare both designed more for realtime use but they could be incorporated into acomposers setup. Both applications present the di�culty that you may have tobuy expensive third party software in order to run them Loopmash is a pluginand is available exclusively with Cubase VST. If you do not have a copy ofCubase you will not be able to use Loopmash. There is an iphone/ipad app butthis is also limited by the proprietary hardware and software environment inwhich it runs. CataRT runs in Max/MSP, however it may not be necessary tobuy the software as it could potentially be used in Max Runtime, which is free.
17

The author has not tested this, so there may be issues with this approach and ofcourse, it becomes a completely standalone tool in this scenario as it cannot beextended without purchasing Max/MSP. Beyond these technical and �nancialissues, it is not yet clear how exactly one might compose with mosaics. Thiswill be treated in more depth later.
3.5 Anatomy of a Mosaicing Application
All mosaicing applications share certain common qualities
The diagram in Figure 3.3 shows the �ow of data through a mosaicing appli-cation. The target is provided to the application in the form of constraints,these can be derived from a score, or an audio �le, or speci�ed manually or semimanually. The system then queries a source audio database - which is typicallypre-analysed and pre-segmented. The best matching units are returned and theconcatenated audio output is assembled. In some systems the mosaicing sys-tem may transform the selected source unit to better match the target, or thecontext, prior to concatenation e.g. [48].
Figure 3.3: Essential components and data �ow in a generic CSS application.
The following subsections discuss typical mosaicing components in more detail
3.5.1 Database
A mosaicing application must store the analysis data for the source unit corpusin such a way that allows for searching the corpus descriptor space and retrievingthe most suitable units. The problem of managing hierarchial constraints, and
18

organising the analysis data for each audio �le and its constituent units in thesource corpus is well addressed by a relational database model.
In his phd thesis,[36], Shwarz describes a PostgreSQL 15 relational databasemanagement system (RDBMS), which was employed for managing the analy-sis data. For his real time corpus browsing system CataRT, as described in[40], Schwarz uses SQLlite 16 instead, which is a much lighter system, strippeddown and portable. It provides the relational models useful for encapsulatingthe analysis data, excellent portability and performance and sacri�ces only theadvanced enterprise functionality of PostgreSQL (which is not required in amusical context).
A �le based 'informal database' was used in work such as MATConcat [49] whereconcatenation quality was not a concern, units were uniformly segmented andonly basic low level descriptors were utilised (Spectral centroid, RMS, etc.).
The creator of the soundspotter application [19] has a created a feature vectordatabase management system, called audioDB 17, speci�cally geared towardscontent based retrieval of multimedia. The system uses a proprietary analysisdata format, supported features include chroma and mel cepstrum, note or beatonsets may be provided by the system in order to retrieve analysis output foreach segment. In this way, when searching within the database, only semanticsubdivisions of audio are returned.
Freesound is a large online sound repository where users can search for creativecommons 18 licensed audio. At the time of writing a revamped version of thesite has just been launched19 and all the audio hosted by the freesound project(over 100,000 audio �les) has been analysed using the music analysis technolo-gies developed at the MTG[50]. The full list of descriptors calculated for eachaudio �le was available here20 at time of writing. The descriptor values can beretrieved via the api and a similarity search feature is o�ered. This works byusing certain preset combinations of descriptors and allows the user to submitan audio track and search for similar sounds using a given preset, e.g. rhythmor music. So far, arbitrary combinations of descriptors may not be speci�ed inthis search. On the backend, freesound itself uses MongoDB which is a �lestoredatabase and very e�cient.
3.5.2 Analysis
From the early days of concrete music, right through to modern real-time corpusbrowsing, mosaicing has always depended on analysis of the both the source au-dio data and the target, the sound at which you aim. Modern music descriptiono�ers hundreds of descriptors, from low level information about the signal tohigh level semantic classi�cations of audio into categories of genre, mood, etc.Most mosaicing systems focus on low level descriptors.
15http://www.postgresql.org/16http://www.sqlite.org/17http://www.omras2.org/audioDB18http://creativecommons.org/19http://www.freesound.org20http://freesound.org/docs/api/analysis_docs.html
19

MATConcat [[49]], as mentioned above uses basic low level descriptions of thesound, CataRT is only slightly more advanced, expanding the used descriptorsto include pitch and also temporal information relating to the original positionof a given unit within the source audio �le it was extracted from. Soundspotteruses LFCC's (log frequency cepstral coe�cients) which are a very abstract de-scription of the timbre of a sound. TimbreID as described in [51] is again focusedon timbre characteristics. Bark bands and MFCCs (mel frequency cepstral co-e�cients) are extracted alongside lower level features like spectral centroid, zerocrossing rate, etc.
Some systems which use higher level descriptors include Ringomatic [52] whichaims at being a real time interactive drum sequencer. In this case, the descrip-tors used are speci�c to drum sounds. Temporal aspects of each unit can bemodelled, as mentioned in [36]. This allows us to label our unit semantically asa note, a dinote, an attack of a note, a release of a note, etc.
3.5.3 Segmentation
CataRT allows for a wide variety of segmentation strategies; yin note basedsegmentation, segmentation based on silence, score based segmentation, e.g.from a set of markers loaded into CataRT from a text �le or SDIF 21 �le. Filescan also be imported in their entirety to use as source units. This approach issimilar to that used in Synful, a commercial CSS application. By applying theconstraint that source units shall be whole musical phrases, they increase themusicality of the output. In Synful 22 the target is derived from the user's midiinput and a process called Reconstructive Phrase Modeling is used in order toselect the best matching phrases and combine them or transform them to meetthe target speci�cation. Reconstructive Phrase modelling could be thought ofas a combination of harmonic plus stochastic spectral synthesis as describedin [[22]] and concatenative sound synthesis. In e�ect, Synful is a data drivensampler, and constitutes an attempt to circumvent the lack of expressiveness oftraditional midi controllers or samplers, as described in [53]
3.5.4 Unit Selection
The CHATR application discussed above has been hugely in�uential and intro-duced the concept of a path search algorithm for unit selection in [[54]]. Ap-plications like this were the inspiration for Diemo Schwarz's Caterpillar systemwhich uses a Viterbi path search algorithm to �nd the most optimal sequence ofsource units which matches the target units, given two costs, the target cost, aeuclidean distance indicating the proximity of the target unit and the potentialsource units, and a concatenation cost, which attempts to smooth the outputby indicating how well the lower level descriptors of contiguous units match attheir join points.
A breakthrough was made in [34]. They addressed the problem of selectingthe samples with which to build the mosaic by modelling it as a constraint
21http://sdif.sourceforge.net/22http://www.synful.com/AboutUs.htm
20

satisfaction problem (CSP). Constraints are used to calculate cost functions foreach mosaic unit at each point in time. They employ a hierarchical system,di�erentiating between segment constraints and sequence constraints. Segmentconstraints are based on descriptors of the audio content, however sequenceconstraints may be statistical in nature e.g. 90% of the segments selected musthave a pitch of 440 Hz. Their system allows the user to specify the constraintsmanually or allow the constraints to be derived automatically from target audio.
The target feature vectors for the unit selection process may be derived in anumber of di�erent ways. Traditional musical mosaicing might be considered toderive its target speci�cation from a score, or an audio �le as in Caterpillar. Alot of current research takes its inspiration from CataRT and focuses on real timeinteractive corpus browsing. These real time approaches have led to the adoptionof CSS techniques in live electronic performance and sound installations [55]Previous research has also investigated using the voice to drive the mosaicedoutput like ScambledHackz23 or the more sophisticated implementation in [46]which also extracts tonal information from the voice signal and implements amulti-track, near real-time, loop based approach which allows the layering ofmosaics in a multitrack environment. Other approaches which utilise a realtime timbral similarity based approach are [19, 51]
3.5.5 Transformation
Sometimes you may not have a source unit which perfectly matches the targetsdescription at every point in time. One solution to this problem is to utilisea huge corpus database e.g. Freesound. There would obviously be e�ciencyissues to be overcome in searching such a huge descriptor space. Commercialapplications like Synful and Loopmash24 employ signal processing techniques,especially pitch transposition and time stretching, in order to match the target.Coleman proposes breaking the link between analysis and transformation whichnormally exist in short time fast fourier (STFT) based analysis-resynthesis sys-tems. The aim of this research is to create a transformation descriptor spacecontaining the feature vectors of all source units, after all possible transforma-tions. This is the space which is searched for the best matching target. Thisapproach allows for a good similarity between the input target and the outputmosaic without the need for a huge source unit corpus to �nd a good match.Please see [[56, 48]] for the mathematical details.
A similar approach is to use Feature Modulation Synthesis [57] In feature mod-ulation synthesis the source unit is transformed to match the target througha process of selecting the best transformation to modify its descriptor values,the tricky part is modifying one descriptor value without changing any of theothers. Recent work has begun to address this problem [58]
23http://www.popmodernism.org/scrambledhackz/24http://www.steinberg.net/en/products/cubase/cubase6_instruments_fx.html
21

3.6 Music made using CSS techniques
Granular synthesis has been widely used in music, �rst by avant garde com-posers and researchers such as Barry Truax and Curtis roads, later by morepopular electronic musicians like Aphex Twin and Squarepusher who took thesetechniques and brought strange new music to a much wider audience. Plunder-phonics 25 was one of the �rst projects to produce musical mosaics, the creationof new music through the rearrangement of existing audio. This di�ers fromgranular synthesis in that the composer is not really working at the level ofmicrosound [41], the segments of audio are long enough for the listener to beable to identify high level, semantic features e.g. the instrumentation. Thiswas a painstaking manual process much like the work of the musique concretemovement and the BBC radiophonic orchestra prior to the introduction of syn-thesisers. The technology now being developed aims to automate this process.The �rst mosaicing application used in order to create music was MATConcat[49] In recent years, as the technologies become more accessible to composersand musicians, we have seen an increase in artistic work which explores thesenew possibilities, e.g. Junkspace for banjo and electronics by Sam Britton whichuses CataRT as a compositional tool to resequence and rearrange recorded audio[59].
In the course of this research, very few obvious examples of an audio mosaic werefound. By obvious, I mean that, as with most photomosaics, there is no needfor explanation, no need for concentration on the part of the observer, in orderto spot the similarities between the target audio and the mosaiced audio. Thoseoutstanding examples which exist, either placed severe constraints on the target(e.g. by using a midi target, like Audio Analogies[47]), or source audio (allow-ing only certain types of audio which the system has been explicitly designed tohandle e.g. Synful [53]). CataRT has seen many applications in soundscaping,live improvisation and installations as evinced by the large quantity of workslisted on Schwarz's website26. However, as alluded to previously, it must benoted that for several of these applications it is di�cult to say whether what ishappening is mosaicing or granular synthesis, as in CataRT it is possible to re-duce the grain size to durations where the analysis makes no sense. For examplein [5] a window size of 60 milliseconds was utilised for the fast fourier transform.This was necessary in order to allow an accurate harmonic description of pitchesas low as 50 Hz. Therefore, if you are mosaicing with pitch descriptors and youallow the unit size to become less than 60 ms, is it really still mosaicing? Onecan no longer claim that it is a data driven process so this type of activity wouldbe more accurately described as granular synthesis
3.7 Evaluation of a Mosaicing System
Literature is scant on the topic of evaluation of mosaicing systems. One ofthe primary references in mosaicing is Diemo Schwarz's phd thesis of 2004.In this document he explains that his system was expressly designed to be
25www.plunderphonics.com26http://imtr.ircam.fr/imtr/Corpus-Based_Sound_Synthesis_Survey
22

�exible enough to support many di�erent approaches to mosaicing, and that anyevaluation ought to be linked to a speci�c mosaicing use-case. He describes howhe evaluated an example of re-synthesis of an audio target through mosaicing(the approach of this thesis). He evaluates the quality of the re-synthesis bycomparing the descriptor values over time for each unit of the original targetand its corresponding unit in the resultant mosaic. From these comparisons anerror curve can be extrapolated. These kind of evaluations certainly indicateshortcomings in a given source corpus. If there is a large error, it may mean thatthere are not enough source units which closely match the search criteria. Ingeneral, the larger the source corpus, the better the results of this evaluation.The degree of dimensionality of the search space would also play a part. Ifone is using only a few low level descriptors then the errors will be less as thesearch criteria are more easily satis�ed in any given source unit database. Inany case, the results may not correlate with people's perception of the quality ofthe mosaic. This is a very subjective thing and the quality of the mosaic woulddepend in great part upon its intended use.
Schwarz goes on to describe his experience using the system for artistic speechsynthesis. In this way, the �exibility, or extensibility of his system was evalu-ated, albeit by the author of the system himself, however more importantly, thesystem was evaluated based on the output it produced for this speci�c artisticwork. This is the most important function of the system; to produce satisfactoryoutput. However, this is also the most di�cult thing to assess as the qualityor goodness depends on the context. He suggests that a systematic evaluationof which descriptors are the most useful in a particular use-case would be wel-come. As mentioned before, the more descriptors that are used, the bigger thesearch space needs to be to produce satisfactory results, it is therefore normallythe case, that for any given application only a small subset of the available de-scriptors (there could be hundreds of these) will be commonly used. Schwarzcomments that for speci�c mosaicing applications, e.g. an application gearedtowards composition, the only quality criterion is how useful the application isin the creative process, and that it's almost impossible to test this in a con-trolled manner. Equally, neither is it clear how to set up a listening test. Ina listening test for a speech synthesis application one might ask the subjectsabout the intelligibility or naturalness of the results. However for a mosaicingapplication, it may not be so clear what constitutes a good result.
Many mosaicing applications are evaluated based on certain speci�c attributes ofgiven examples. In the musaicing project [34], a set of examples are presentedand evaluated in terms of how well the mosaic adheres over time to a set ofconstraints derived from the target, e.g. pitch or percussivity. The evaluationis done by comparing the resultant audio waveforms. A similar approach wasadopted for the evaluation of Ringomatic[52], a real time data driven drummachine, where the energy curves over time were compared to see how well thedrum machine's dynamics matched the target's dynamics. In these cases, whatis really being evaluated is the quality of the analysis process combined with thedistance function, whether it be a single low level signal attribute, e.g. spectralcentroid, or a more complicated combination of features e.g. percussivity. Ifthe time and frequency resolution of the analysis is su�ciently high and if theanalysis itself is su�ciently accurate then the mosaic and target features willmatch and with an optimal distance function the best match may be found.
23

This is no di�erent from an evaluation of any generic information retrieval sys-tem, however if the purpose of mosaicing is to make artistic works (and it isdi�cult to see what else it would be useful for), then a mosaicing system can beproperly evaluated only within the context of a practice based research. Someconference papers are beginning to take this approach e.g. [45], and Schwarzhas reviewed some recent artistic projects [59]. Ultimately though, the �eld ofmosaicing lacks a de�nitive overview of artistic research such as Curtis Road'sMicrosounds [41], which describes computer programs, artistic works and ap-proaches to composition within the �eld of granular synthesis.
24

Chapter 4Research Goals
The following research goals are aimed at:
1. Find a way of incorporating high-level music content descriptions into amusical-mosaicing system.
2. Develop an extensible, reusable code-base for musical-mosaicing.
3. Investigate processes of musical creation with the system.
High-level music descriptions build upon lower level descriptions of the signal inorder to approximate semantic classi�cations like genre, mood, etc. These highlevel concepts are the ones used by humans to talk about music, for us they areperceptual features of the music. In this thesis, the primary research goal is to�nd a way of incorporating high-level music content descriptions into a musical-mosaicing system. In this way, it is hoped to produce semantic mosaics whichre�ect some high-level, semantic features of their target. High-level descriptorsare not typically built on the signal alone and common-sense indicates that adi�erent approach may be needed.
The following questions are posed:
1. Are existing high-level descriptors suitable for mosaicing?
2. How can they best be incorporated into a mosaicing system?
3. How may the results be evaluated?
The creation of a multi-platform library for mosaicing could provide a valuableresource for students investigating data-driven music making. In order to satisfythis goal the code must be clear, understandable and fully documented. Ourgoal is also to make the library extensible and we test the ful�lment of this goalby extending it, by creating a new musical application to cater for a musicalmosaicing paradigm. This goal overlaps with the broader goal of evaluatingthis new system's merits for musical mosaicing. A practice based research of anestablished mosaicing paradigm is conducted using this musical application de-veloped on top of the mosaicing framework. The goal is to evaluate the creative
25

possibilities of such a tool and suggest potential application areas. Finally wewish to use the high-level descriptors to develop a composition based aroundmosaicing. In the next section we outline the methodology which was followedin order to achieve these goals.
26

Chapter 5Methodology
5.1 Software Development
In order to begin, a system must �rst be built to perform the mosaicing andthis requires a lot of work. As described in section 3.5 the following componentswill be required:
• A database system for managing �les and analysis
• Analysis (using Essentia[50])
• Segmentation engine (using Aubio1 and/or Essentia[50])
• Unit Selection (Incorporating Gaia[50])
• Transformations (e.g. crossfading or timestretching (using rubberband2))
An Extreme Programming (XP) methodology was adopted in order to allowcontinuous revision of the structure of the framework, to test di�erent mosaic-ing algorithms, di�erent transformations, di�erent segmentation schemes, etc.This methodology stems from modern corporate software development and isan example of an agile software development process[60]. It was designed in re-sponse to the limitations of the waterfall model [61], whereby the client speci�estheir requirements at the beginning of the software development process and thesystem would be built and tested based on these requirements. The waterfallmodel has the drawback that the code is not tested 'in the wild' by the clientuntil the end of a long development cycle at which point change may be verycostly. XP is designed to prevent this by scheduling frequent releases to allowthe client to assess the progress, after each release more planning and refactoringis carried out and new code is continuously integrated into the main codebase.It was felt that XP was an appropriate methodology for a project in which theoutcome was very unclear. There were many open questions, that could onlyreally be answered by using the system e.g. How much control is required over
1http://aubio.org2http://breakfastquay.com/rubberband/
27

the mosaicing algorithm, which transformations work from a creative point ofview, etc. Even more pertinently, which use cases work for mosaicing and howcan this be facilitated? Can we come up with some user stories? In this processthe author was e�ectively wearing two 'hats', being both development team andclient. The bulk of the work was done in a series of sprints, each sprint addingnew features. The sprints were then followed by periods of using the system,informal testing, documentation and redesign. Best practice guidelines, howeverinformal, were adhered to as much as possible e.g. the o�cial Python codingstyle guidelines: PEP8 3. This proved to be an e�cient process for creatinga framework which was enjoyable to experiment with and which had severalcompelling use cases (see section 6.4).
5.2 High Level Descriptor Evaluation
It is important to evaluate the appropriateness of high level descriptors for amosaicing system without evaluating the descriptors themselves. Most of thehigh level descriptors included are calculated by training SVM models. Thelengths of the audio �les they are trained with would not generally be shorterthan 10 seconds. This is optimised for searching for other similar pieces of mu-sic, it is not designed for the matching of tiny segments, such as those usedby a mosaicing system. A simple solution would be to retrain the classi�ersusing smaller segments of audio, however the problem is not merely a techno-logical one and may not be solvable in this manner. Humans have been ableto identify the pitch of a segment of audio given only 10 ms [62], however itis reported that at least 4 seconds is required for the identi�cation of mood ina piece of audio [63]. The word mosaic implies the use of small segments ofaudio, so in order to determine the suitability of existing high-level descriptorsfor a mosaicing system, their accuracy in labelling small segments of audio wastested. In subsection 6.2.2 a gender classi�er is shown to be inaccurate in la-belling small segments of audio. From these initial experiments, the conceptof a descriptors time resolution was developed. The time resolution of a de-scriptor is the minimum length of audio for which it maintains an acceptableaccuracy. The time resolution of the gender classi�er is explored and generalmethod for determining the time resolution of a descriptor is described. A hi-erarchical model for mosaicing, based around this concept of a time resolution,is proposed. A hierarchical system might circumvent time resolution issues byanalysing large segments of audio, corresponding to the chosen time resolution,using high-level descriptors. The small segments which comprise each of thelarger high-level segments are then analysed using low-level descriptors. Botha hierarchical mosaicing algorithm (dual segment sizes) and a non-hierarchicalmosaicing algorithm (one segment size) were implemented using the framework.The two systems were compared in a series of experiments and the results wereanalysed statistically in order to try and provide an objective measure of evalu-ation as to which system is superior. A surprising property of high-level mosaicscreated using the hierarchical system was discovered and investigated.
3www.Python.org/dev/peps/pep-0008
28

5.3 Musical Evaluation
The framework was extended by building a musical application for augmentingloops with mosaics. This is an example of a mosaicing the paradigm (likeLoopmash). The experience of trying to make music within this paradigm,using the software developed during this thesis, was discussed and a video wascreated, showcasing music making with mosaics in real-time.
The evaluation of the system, or the mosaics produced by the system is a di�cultproblem. In Microsound [41], Curtis Roads has the following to say about theevaluation of new synthesis techniques:
"Scienti�c tests help us to estimate the potential of a technique ofsynthesis or sound transformation. They may even suggest how tocompose with it, but the ultimate test is artistic. The aestheticproof of any signal processing technique is its use in a successfulcomposition"
This was taken as the inspiration to research mosaicing by trying to make musicwith mosaics. A composition was created and placed in the public domain asan example of how to incorporate high-level mosaics into traditional song-basedcomposition. These evaluation of this composition was purely subjective andwas conducted by the author himself. The only criteria for success was theauthor's satisfaction with the results.
A major drawback of using the high-level mosaics was the time required to createthem. This made them unsuitable for use in the mosaic looping applicationdescribed in subsection 6.4.1. The performance issues associated with high-level mosaics are therefore explored in the �nal part of the Musical Resultssection
29

Chapter 6Contributions
6.1 An Extensible Framework for Mosaicing
6.1.1 Extensibility of existing systems
In conducting the state of the art review some of those mosaicing systems whichare freely available were experimented with
• CataRT
• Soundspotter
• TimbreID
All of these systems are implemented in visual patch �ow languages Max/MSP(CataRT) and Pure Data (TimbreID, Soundspotter) and were designed for realtime operation.
Of these systems CataRT is the most mature and has gained widespread adop-tion, particularly for installations and experimental, improvisational music. Itdepends on the FTM1 and Gabor2 libraries which extend Max/MSP3 with someadvanced data structures and objects designed for granular synthesis. It hasbeen widely used in art installations and avant garde music, especially live im-provisation scenarios where the performer analyses live audio from a musician,stores it in the corpus and then browses this corpus in an n-dimensional descrip-tor space (composed of low level descriptors derived from signal processing, ormetadata e.g. length of �le, position in original source audio, etc.) It would havebeen good to extend this software as it o�ers a solution to many of the issuesassociated with mosaicing systems - e.g. performance of huge source corpora,segmentation, concatenation and a n-dimensional descriptor space for browsingsource units. The primary obstacle for this research was the software's lack of
1http://ftm.ircam.fr/index.php/Main_Page2http://ftm.ircam.fr/index.php/Gabor3http://cycling74.com/products/maxmspjitter/
30

stability on the Windows 7 platform (issues with FTM and Gabor) and the�nancial investment required to use Max/MSP.
A secondary issue was uncertainty about how to incorporate high level descrip-tors into a real time framework like Max/MSP or Pure Data in general. Theauthor of TimbreID designed his own real time descriptors running in pure datacalculating timbre features. Creating descriptors is outside the scope of thisproject and there were already doubts as to the feasibility of running the highlevel descriptors in real time.
6.1.2 Prototyping
The aim of building this system was to explore high level mosaicing in an uncon-strained way. It was therefore crucial to design a modular system which can beeasily modi�ed as the research progresses and ideas for incorporating the highlevel descriptors take shape. It was decided early on that coding descriptors andimplementing a similarity search engine were outside the scope of this project.Creating a high level descriptor would be a masters project in itself.
The Canoris project 4 was an attempt by the Music Technology Group (MTG)to make available the fruits of their research into music description, similaritysearch and singing voice synthesis, via a web service. The web service wasREST5 compliant. Canoris allowed the user to create collections of audio �les,for which a large amount of low, mid and high level analysis was extracted usingessentia. This analysis could then be retrieved for each audio �le in the json6
�le format via a request to the web service. This system appealed as it was freeand worked over the web which simpli�ed the technological aspects of creatinga mosaicing system and allowed the heavy lifting (analysis) to be done on thewebserver. It also provided a possibility to port the new mosaicing system tothe web itself rather than have it tied to the desktop. The �rst prototype wasdeveloped in Python 7, a high level programming language, and implementeda rudimentary, �xed length, segmentation engine to segment several audio �les.These segments were then uploaded to Canoris using a Canoris api client codedin Python and the analysis data was retrieved by issuing periodic requests to thewebservice in an attempt to procure it as soon as the analysis process �nishedon the server.
A simple gui was then built using PyQt4 8 to visualise the analysis data ina style very similar to CataRT, where the source units are visualised in a 2-dimensional descriptor space. The protoype is shown in Figure 6.1 and allowedvery limited audio playback of the units. Some inconsistencies discovered inthe analysis data at this point provided early indications that the high leveldescriptors were not consistent for very short segments of audio.
A second prototype allowed the generation of rudimentary mosaics based on asingle mood value. These mosaics could then be linked together and played in
4http://canoris.com5http://en.wikipedia.org/wiki/Representational_State_Transfer6http://www.json.org/7www.Python.org8http://www.riverbankcomputing.co.uk/software/pyqt/intro
31
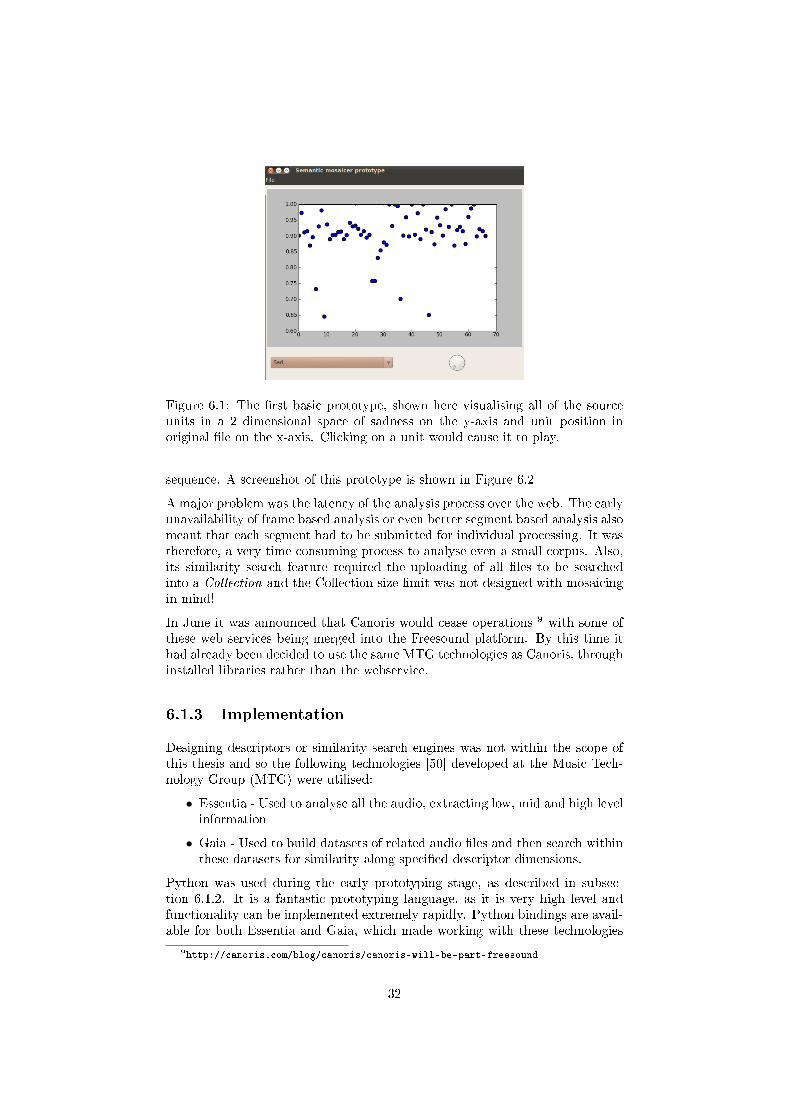
Figure 6.1: The �rst basic prototype, shown here visualising all of the sourceunits in a 2 dimensional space of sadness on the y-axis and unit position inoriginal �le on the x-axis. Clicking on a unit would cause it to play.
sequence. A screenshot of this prototype is shown in Figure 6.2
A major problem was the latency of the analysis process over the web. The earlyunavailability of frame based analysis or even better segment based analysis alsomeant that each segment had to be submitted for individual processing. It wastherefore, a very time consuming process to analyse even a small corpus. Also,its similarity search feature required the uploading of all �les to be searchedinto a Collection and the Collection size limit was not designed with mosaicingin mind!
In June it was announced that Canoris would cease operations 9 with some ofthese web services being merged into the Freesound platform. By this time ithad already been decided to use the same MTG technologies as Canoris, throughinstalled libraries rather than the webservice.
6.1.3 Implementation
Designing descriptors or similarity search engines was not within the scope ofthis thesis and so the following technologies [50] developed at the Music Tech-nology Group (MTG) were utilised:
• Essentia - Used to analyse all the audio, extracting low, mid and high levelinformation
• Gaia - Used to build datasets of related audio �les and then search withinthese datasets for similarity along speci�ed descriptor dimensions.
Python was used during the early prototyping stage, as described in subsec-tion 6.1.2. It is a fantastic prototyping language, as it is very high level andfunctionality can be implemented extremely rapidly. Python bindings are avail-able for both Essentia and Gaia, which made working with these technologies
9http://canoris.com/blog/canoris/canoris-will-be-part-freesound
32

Figure 6.2: This gui prototype was used to generate rudimentary mosaics basedon a given mood and a threshold. The mosaics could then be chained togetherto form a sequence.
easier, although the analysis process itself was coded in C++ due to performanceconsiderations. Python is not so wonderful for developing interactive graphicalinterfaces, but more crucially, it is an unsuitable choice for real time audio. It'sunsuitability is due to it's Global Interpreter Lock (GIL). The GIL ensures thatonly 1 thread can run inside the Python interpreter at any one time, beforeany piece of code can be executed, the GIL must �rst be acquired [64]. Thismay cause a problem for an audio application where one wishes to allow theuser to play audio and use the GUI at the same time for example. After someexperimentation it was decided to segment the system into two processes whichwould communicate via OSC.
1. A thin GUI client in pure data which also handles audio playback.
2. A backend Python daemon process which handles everything else
This system architecture can be conceptualised as a model-view-controller (MVC)style architecture, as illustrated graphically in Figure 6.3. An MVC architectureis one in which the application code is split into 3 logical packages. [65]
1. Model - Contains system components which actually do the work
2. Controller - Used to pass messages between Model and View
3. View - The information which is displayed to the user
33

Figure 6.3: This diagram illustrates the Model View Controller paradigm im-plicit in the system architecture.
In order to maintain �exibility, it was wished to develop the codebase as inde-pendent modules. These logical modules are listed below:
• Segmentation
• Analysis
• File management
• Utilities
• Models
• Settings
• Mosaicing engine listening on OSC(the central control)
Interdependencies between modules were avoided whenever possible. This wasachieved by using a using an object oriented programming (OOP) paradigm.Abstract base classes were de�ned with skeleton methods to be overridden insubclasses and thus provide a generic interface for inter-object communication.A scripting interface was also developed so that the modules in the model partof the architecture can be used programatically, independent of the view or thecontroller.
For a detailed description of the codebase and the scripting interface pleaseconsult the system documentation in Appendix B.
34

6.1.4 Description of algorithm
In this section the �nal hierarchical algorithm, responsible for assembling themosaic is described. At this point the target has already been segmented intoboth high-level and low-level units and all the analysis information has beenextracted. The block diagram in Figure 6.4 illustrates the iterative processof selecting the best matching source unit. The steps of the algorithm are asfollows:
• Create gaia dataset from high-level target units
• Create high level distance measure (a linear combination of weighted eu-clidean distances for each chosen descriptor and corresponding weight)
• For each high level target unit create a gaia Point
• Use each target point, along with the high-level distance measure to searchfor the nearest matches in the source corpus' high-level unit dataset. (Thenumber of segments retrieved depends on the high-level scope setting)
• Assemble the constituent units comprising each high-level source corpusmatch into a single gaia dataset
• Each high-level target unit is now mapped to a gaia dataset of low-levelsource corpus units
• Each low-level target unit in each high level target unit is combined withthe low-level distance measure (also a linear combination of weighted eu-clidean distances for each chosen descriptor and corresponding weight)and matches are sought in the high-level unit's corresponding dataset oflow-level source units derived from the high level source unit matches.
• The results are then processed by the context cost and the repeat unitcost objects and the highest valued unit is then added to the mosaic afterapplying selected transformations like cross-fading or time-stretching.
35

Figure 6.4: This diagram illustrates the iterative process of selecting a suitablesource unit for each target unit
6.1.5 Framework Applications
Once the system was working via a scripting interface, several pure data guiabstractions were created in order to invoke its functionality. These guis en-capsulate all the functionality which has been developed as a byproduct of thisresearch into semantic descriptors. They allowed the easy, nearly interactive, in-vestigation of di�erent parameters and approaches. They are an example of howa modular approach to system design facilitates rapid development of new func-tionality or new work�ows or even new mini applications (e.g. the segmenter).Each of these GUI bundles of functionality is treated in this chapter.
36

Figure 6.5: This gui is used to connect to the Python daemon process, sendmessages, control the audio and save mosaics
Control
This gui abstraction conceals all the message sending logic for the gui framework.All framework applications send global messages here to be routed to the Pythondaemon via OSC. It also receives response messages from the Python daemonand routes them to the correct application. This module contains a control foradjusting the volume of the target and the mosaic and a button to allow theirchorusing, in order to hear how well the target and mosaic sound layered on topof each other. There is also a button labelled Save Mosaic which saves, not onlythe mosaic, but the target, onset marked target and an informational text �lecontaining the current state of the OSCControl object, all settings are writtenhere. This functionality was included for research purposes, i.e. to be able tosee which parameters created a particular e�ect. Overall DSP audio control isalso provided in this gui.
Corpus selection
Figure 6.6: Select a source corpus with which to mosaic - or re-analyse a sourcecorpus.
Choose a corpus of source material with which to mosaic. A corpus can also bere-analysed, based on a speci�c segmentation scheme (e.g. `onsets' or 500 or
37

1000 ) derived from the global parameters set in the SegmentationGui. This isnot recommended as it is very slow. See section 6.4.3 for more details. Newsource corpora must be added manually to this module.
Segmenter
Figure 6.7: Test segmentation of target and set global segmentation parameters.
The settings here are utilised, not only to perform the segmentation of theincoming target audio, but also to determine which segmentation scheme of theselected corpus will be (re)analysed if the user selects the Analyse option in theCorpus Gui.
The most important use of the segmenter is to preview the e�ects of di�erentsegmentation schemes on the target. In this respect it could be considered amini application in its own right. The calculation of onsets using either aubioor essentia is supported, as is basic �xed length segmentation (which requiresno analysis), and bpm based segmentation.
The Mark Audio button takes the target, analyses it (according to the selectedsegmentation scheme) and marks the audio �le with beeps where it will becut. This allows the user to preview the accuracy of the selected segmentationscheme, adjust its parameters, preview the results and readjust or choose an-other segmentation scheme, etc. When the user is satis�ed that the target hasbeen marked correctly, the Reprocess Target button can be pressed in order tore-segment the target, according to the newly selected scheme.
The available segmentation schemes are described below:
Aubio Note Segmentation In aubio mode, the command line utility aubionoteis used and the minimum note length parameter is used to a�ord the user a mea-sure of control over the granularity of the onsets, e.g. if they wish to count avery fast trill as just one note instead of many notes, the minimum note lengthparameter can enable them to achieve this.
Essentia Onsets Segmentation In essentia mode, the following descriptorsare calculated for each frame of target audio:
38

Table 6.1: Onset detection descriptorsName DescriptionHigh Frequency Content (HFC) Calculates the high frequency content of the spectrum
as described in [66]Complex Domain Detects changes in both energy and phase for each
frame of the signalRoot Mean Square (RMS) Can be thought of as representing the energy in each
frame
Research has shown that combinations of HFC (good for percussive events)and Complex (good for reacting to more tonal onsets) perform better than anapproach utilising only one or the other [67]. It is with this in mind, that weallow the user to pick any combination of these 3 features and a weighting foreach feature selected. This is submitted to the OnsetDetection algorithm inessentia which picks the peaks and returns onset times.
BPM based segmentation In this scheme, the target is �rst analysed, andthe BPM is extracted. From the BPM, it is trivial to calculate the beat lengthin milliseconds. e.g. providing the BPM of the target is fairly constant, thismethod of segmentation approximates the pace of the original, so the mosaicssound more in sync with the target.
One problem with this approach is that the BPM beat length is rarely 500msor 1000ms or 1250ms. This raises an issue where it may be di�cult to �ndenough di�erent onsets of the same length in the source corpus. The solutionwas to introduce a length tracking mechanism (as discussed in Settings, Trans-formations and Tracking below). Initially, the time stretching approach alonewas employed, however the deterioration in quality of the audio can be verynoticeable in places, especially if the stretch is large. For this reason, a secondmode of length constraint satisfaction was devised which simply cuts the soundto make it shorter, or pads it with silence to make it longer.
Fixed Length segmentation This is the simplest scheme. The user picksbetween 500ms, 1000ms and 1250ms and the audio is segmented into equal sizepieces. any left over samples are discarded.
Similarity Search
When mosaicing, each of the target units is input into the similarity searchmodule, in order to �nd the most similar units. The similarity search gui,shown in Figure 6.8, is split across two panels. The high level similarity searchis used to match high level chunks of audio of length greater than or equal to thechosen time resolution (5 seconds). The low level similarity search is then usedto search for similar units within the pool of de�ned low level segments (whichmay be of a �xed length or variable length (based on onsets)). This gui allowsthe user to select descriptors and weights. From each descriptor a euclideandistance measure is used to �nd the most similar units to it. The weightsare then used to create a linear combination of euclidean distances, where the
39

weight determines the importance attached to that particular descriptor whensearching for similar units. The high-level descriptor weighting is used to searchfor longer segments, while the low-level descriptor weighting is used to searchthrough the smaller source units comprising each segment.
Figure 6.8: Select descriptors and corresponding weights to utilise when search-ing the source corpus for matching units.
Table 6.2: Similarity Search: Summary of Low level DescriptorsDescriptor Summary
Length The duration of the audioSpectral Flatness An indication of percussivity in the Spectrum [5]Spectral RMS The root mean square of the signal calculated in the
frequency domain.Spectral Centroid The barycenter of the spectrum [5]Spectral Spread The spread of the spectrum around the centroid [5]Spectral Decrease Similar to Spectral Rollo� as described in [5]Spectral Flux A measure of the overall, frame by frame, change in
magnitude of the frequency bins [68]Spectral Energy Another measure of the energy of the signal calculated
in the frequency domain.Zero Crossing Rate A measure of how often the signal crosses the zero axis
[5]Pitch An estimation of the fundamental frequency of the
spectrumSpectral Contrast A modi�ed version [69] of the Octave Based Spectral
Contrast feature described in [70]HPCP The tone chroma of the audio signal as described in
[6]MFCC Calculates the coe�cients of the mel-frequency cep-
strum according to the MFCC-FB40 implementationdescribed in [71]
Barkbands Divides the frequency range into perceptually derivedbands and calculates the energy in each band.
All of the high level descriptors mentioned involve the use of libsvm, whichprecludes their realtime calculation.
For more information on how these descriptors are calculated, the interestedreader is referred to [10] or [18] for more speci�c details on the mood descriptors.
40

Table 6.3: Similarity Search: Summary of High level descriptorsDescriptor Summary
Happiness A single value describing the happiness of the analysedmusic. [18]
Sadness A single value describing the sadness of the analysedmusic. [18]
Relaxedness A single value describing the relaxedness of the anal-ysed music. [18]
Aggressiveness A single value describing the aggressiveness of theanalysed music. [18]
Male A single value describing the probability of the malegender in the audio. [10]
Female A single value describing the probability of the femalegender in the audio. [10]
Instrumental A single value describing the probability that the audiois instrumental. [72]
Vocal A single value describing the probability that the audiois vocal. [72]
Figure 6.9: Track certain properties of the target and implement global settingsa�ecting unit search and unit selection.
Settings, Transformations and Tracking
This gui is split into two sections
1. Target Tracking
2. Settings
Target Tracking Three di�erent target tracking mechanisms have been im-plemented:
Key is another semantic descriptor, the idea is to choose units in the same keyas the target and keep the whole thing semantically linked. As key is a label(i.e. F#, A, etc.), the problem of not having enough source units to �nd onematching the target key must be contended with. Similarly there may be toofew source units of a particular key, such that units get repeatedly selected,which can sound jarring. These selection problems are not as pronounced asfor scale where the target unit will have one or two values - major or minor.This is a much broader classi�cation than key, where many di�erent values areavailable. Both key and scale thresholds apply only during the high level unitselection process.
41

The track length feature stemmed from repeated use of the length descriptor asthe highest weighted feature in similarity search during testing. It was felt thatthe unit length was so important for maintaining some kind of temporal/rhyth-mic identity with the target, that it should be treated separately. Using thetrack length feature a�xes the source unit to a grid based on the target's bpm.
Depending on the selected mode, units which do not exactly �t, will be ei-ther time-stretched or padded with silence or simply cut. The time-stretchingfunctionality is provided by the rubberband commandline utility 10 which isan open-source phase vocoder implementation providing time-stretching andpitch-shifting.
Settings The settings application is where control over the concatenation al-gorithm is pro�ered. The user can toggle high level mosaicing on or o� and alsochoose a crossfade time in milliseconds for overlapping the units and eliminat-ing concatenation artefacts caused by sudden changes in energy and/or phasebetween adjacent units in the mosaic. High level scope indicates how many ofthe closest matching source segments are included in order to generate the poolof available units for the low level search process. Low level scope indicates howmany low level unit search results are returned. This could have an impact ifthe results are processed by either or both of the two cost functions which mayreorder the results. Both cost functions can be activated/deactivated from thissettings module. Unit Context is a cost based on how similar each low level re-sult is to the other low level results (based on the low level search parameters).Repeat Cost is a cost which penalises those units which are repeatedly selected.It can be useful in situations where the same unit is getting repeatedly selectedto the extent that the mosaic sounds like a broken record.
6.2 The Evolution of a Hierarchical Mosaicing
Model
6.2.1 Tackling the time resolution issue
The hierarchical mosaicing model discussed in the previous section is examinedin more detail here. Firstly, the issue of how to �nd a suitable time resolu-tion is treated. We know that the ideal time resolution ought to vary fromdescriptor to descriptor as research shows us that this is the case for humans.Gender classi�cation is possible with just 200ms of audio[73]. It is reported byKrumhansl[74] that subjects were able to name both artist and title from just400ms of audio in 25% of cases. Research into emotion in music [63] claims thatlengths of 4, 8, and 16 seconds are optimal for humans to perceive the mood ofthe audio. It was predicted that because the classi�ers have been trained usinglonger segments of audio, their performance in analysing very short audio �leswill be sub-optimal.
Two possible solutions are postulated:
10http://breakfastquay.com/rubberband/
42

1. Retrain the classi�er using instances of shorter durations.
2. Find an acceptable time resolution for a selection of high level descriptorsand implement a hierarchical mosaicing system.
Retraining the SVM models was ruled out of scope, given the time span allottedto this thesis. In the next section we describe a method to determine the timeresolution of a speci�c binary classi�er and we show how this was done for thegender SVM model, included in Essentia.
6.2.2 Derivation of the Time Resolution of a Binary Clas-si�er
In this section an attempt is made to �nd the time resolution of an SVM based,binary classi�er. A binary SVM classi�er is used to group examples into oneof two categories, in this case we chose the Gender classi�er, which categorisesexamples as either Male or Female. Note that the results returned by theclassi�er are the probability (between 0 and 1) of the example being a memberof the Male category, together with the probability of the example belonging tothe Female category. Both category membership probabilities, when combined,add up to 1. This means that there is a possibility of the example havingan equal membership of both categories (0.5 Male, 0.5 Female) The datasetused comprises of a series of 136 acapellas, both male and female vocalists,singers and rappers. This dataset was analysed using and classi�ed into Gendercategories by the classifer. An initial experiment was run in order to assessthe performance of the classi�er when used to classify very short segments ofaudio, as might be typically used in a mosaicing context, ranging from 200 msto 1250 ms. The entire dataset was not utilised for this task but rather a smallerselection of handpicked examples, which exhibited very strong membership ofa given category, were chosen to conduct the tests. The acapellas which wereselected, their actual gender and the results of the classi�cation routine arepresented in Table 6.4. The selection was split equally betweenMale and Femaleexamples and only those examples which were classi�ed as having a very strongprobability of belonging to the correct Gender, were selected.
Table 6.4: List of used "a capella" vocal examples, with actual gender and prob-abilities yielded by the classi�er
Song Name Gender Female Male
RickAstley Male 0.0293809194118 0.970619082451JayZ Male 0.0240641832352 0.975935816765TheCenturions Male 0362716279924 0.963728368282LLCoolJ Male 0.00459884805605 0.995401144028OlDirtyBastard Male 0.0191408805549 0.980859100819ToriAmos Female 0.964695572853 0.0353044383228Madonna Female 0.980607867241 0.0193921606988Robyn Female 0.925979971886 0.0740200504661LisaStans�eld Female 0.896858751774 0.103141263127BelindaCarlisle Female 0.990210652351 0.00978936441243
The experiment was carried out as follows:
43
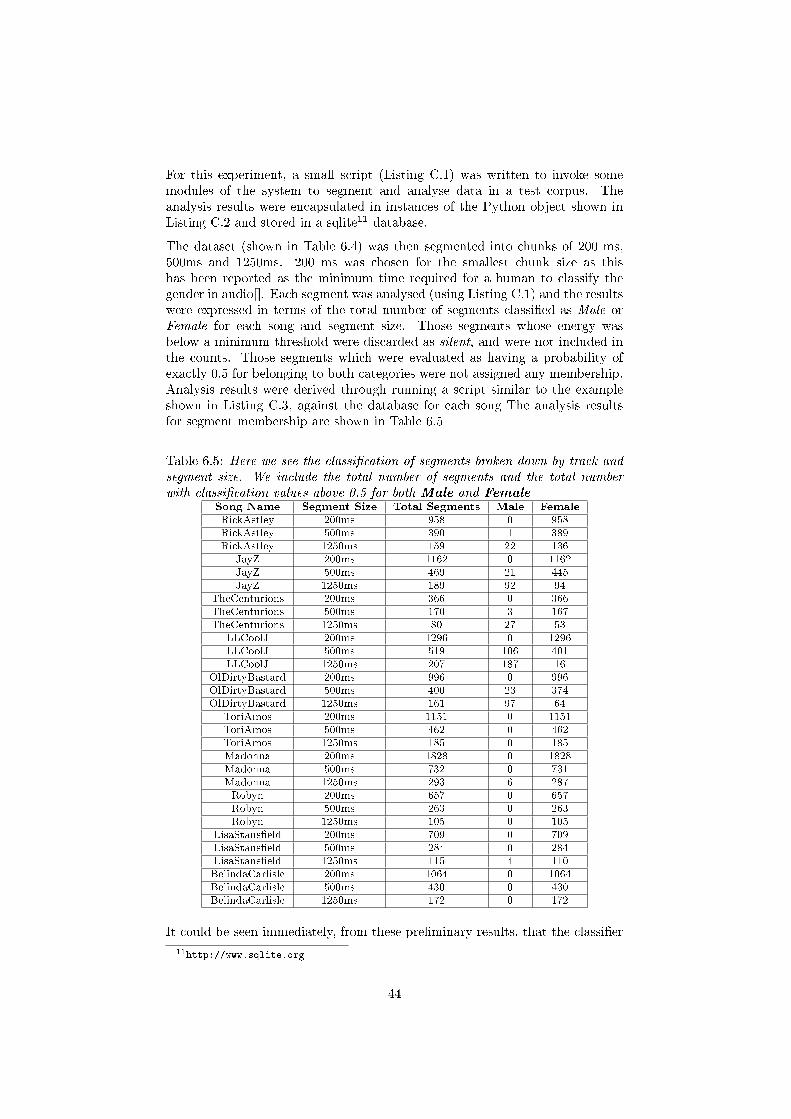
For this experiment, a small script (Listing C.1) was written to invoke somemodules of the system to segment and analyse data in a test corpus. Theanalysis results were encapsulated in instances of the Python object shown inListing C.2 and stored in a sqlite11 database.
The dataset (shown in Table 6.4) was then segmented into chunks of 200 ms,500ms and 1250ms. 200 ms was chosen for the smallest chunk size as thishas been reported as the minimum time required for a human to classify thegender in audio[]. Each segment was analysed (using Listing C.1) and the resultswere expressed in terms of the total number of segments classi�ed as Male orFemale for each song and segment size. Those segments whose energy wasbelow a minimum threshold were discarded as silent, and were not included inthe counts. Those segments which were evaluated as having a probability ofexactly 0.5 for belonging to both categories were not assigned any membership.Analysis results were derived through running a script similar to the exampleshown in Listing C.3, against the database for each song The analysis resultsfor segment membership are shown in Table 6.5
Table 6.5: Here we see the classi�cation of segments broken down by track andsegment size. We include the total number of segments and the total numberwith classi�cation values above 0.5 for both Male and Female
Song Name Segment Size Total Segments Male Female
RickAstley 200ms 958 0 958RickAstley 500ms 390 1 389RickAstley 1250ms 159 22 136
JayZ 200ms 1162 0 1162JayZ 500ms 469 21 445JayZ 1250ms 189 92 94
TheCenturions 200ms 366 0 366TheCenturions 500ms 170 3 167TheCenturions 1250ms 80 27 53
LLCoolJ 200ms 1296 0 1296LLCoolJ 500ms 519 106 401LLCoolJ 1250ms 207 187 16
OlDirtyBastard 200ms 996 0 996OlDirtyBastard 500ms 400 23 374OlDirtyBastard 1250ms 161 97 64
ToriAmos 200ms 1151 0 1151ToriAmos 500ms 462 0 462ToriAmos 1250ms 185 0 185Madonna 200ms 1828 0 1828Madonna 500ms 732 0 731Madonna 1250ms 293 6 287Robyn 200ms 657 0 657Robyn 500ms 263 0 263Robyn 1250ms 105 0 105
LisaStans�eld 200ms 709 0 709LisaStans�eld 500ms 284 0 284LisaStans�eld 1250ms 115 4 110BelindaCarlisle 200ms 1064 0 1064BelindaCarlisle 500ms 430 0 430BelindaCarlisle 1250ms 172 0 172
It could be seen immediately, from these preliminary results, that the classi�er
11http://www.sqlite.org
44

tends towards female for lengths of less than 1250 ms. Therefore, it does notmake much sense, to use it to analyse those segments which are to be mosaiced.An informal sanity check was conducted on the segments of 200ms. It was trivialfor the author to classify the segments correctly.
In an e�ort to �nd that length where the classi�er achieves good performance,a further test was run, this time using segments of 2 seconds and 4 secondsagainst the full dataset of 136 examples. The objective here was to �nd anacceptable minimum length for a high level segment. In Figure 6.10, we visu-alise the entire dataset, split into segments of 2 seconds and 4 seconds. Thesegments of 2 seconds are represented by blue circles, while segments of 4 sec-onds are represented by green circles. The x-axis represents the analysed valuesof the segments themselves, from male (0 -> 0.5) to female (0.5 -> 1), the y-axis represents the values of the full length acapellas, from which the segmentswere extracted, in the same way. It can be easily seen that there is a greaterconcentration of 4 second segments in the top-right and bottom-left corners ofthe graph, which indicates that these segment values correlate with the valuescalculated for the original �le.
In Figure 6.11 we have a more concise summary by way of a barchart showingthe number of correctly and incorrectly classi�ed segments for each duration.
Figure 6.10: Here we see the relationship between the segment analysis and thesong analysis. The blue circles represent segments of 2 seconds in length, andthe green represents 4 second segments.
45

Figure 6.11: This chart shows how many segments were correctly classi�ed,i.e. their classi�cation matches the classi�cation of the �le they were extractedfrom. The number of correctly and incorrectly classi�ed segments are groupedby duration.
6.3 An Evaluation of a Hierarchical Model for
Mood Mosaicing
In this section the results from mood-mosaicing with a hierarchical model arecompared to those results derived from mood-mosaicing with a non-hierarchicalmodel. Firstly, a subjective account of mood mosaicing with the Beatles, isoutlined. A small selection of mosaics from this investigation are then analysedto see how closely they match the target's mood and whether the hierarchicalor non-hierarchical models produced the 'best' mosaics, objectively speaking.Finally, a more rigorous test is carried out using audio from the dataset describedin [18] and the results are analysed to determine which of the mosaics adheremost closely to the mood of the target.
6.3.1 Mood Mosaicing with the Beatles
Initial experiments involved selecting some of these excerpts and creating mo-saics from them using just the mood descriptors in a non-hierarchical system.Subjectively speaking, it's di�cult to judge whether such mosaics preserve theemotional content of their targets as they have lost most of their musical mean-ing. The results were much improved by using the hierarchical system, as thelow level constraints can then be used to target low level source units in termsof pitch or tone chroma or other musical features, thus improving the musicality
46

of the resultant mosaic, while the high-level constraints take care of the moodmatching. With polyphonic source audio, for example; the Motown source cor-pus, the e�ect of the mosaics were at times, akin to that of scanning throughradio stations at high speed. It was felt that it would be more instructive to cre-ate an arti�cial target comprised of many di�erent snippets of audio exhibitingdi�erent emotional characteristics. In this way it might be possible to perceivethe change in mood of the mosaic, as we do when we listen to the target.
Experiment Setup
A frankenstein was therefore created, a target, synthesised from clips of severaldi�erent Beatles songs, which were felt (subjectively) to be representative ofeach of the moods (happy, sad, relaxed, aggressive). It was wished, to createa mosaic, from this target, where the mood of the mosaic would evolve overtime, just as in the original. The target and it's constituent audio �les areshown, along with their lengths and analysed mood values in Table 6.6 It wasfelt that the analysed values for the constituent audio are pretty accurate. Seefor example, the correlation between the analysed results for the InMyLife.wavexcerpt and the user submitted tags for In My Life on the Last.fm12 socialnetwork as shown in Figure 6.12
Figure 6.12: User submitted tags for In My Life, retrieved from LastFM. Notethe presence of relaxed, mellow, melancholy, etc.
Four source corpora were used during the investigations:
1. A selection of 20 Motown 'hits'. It was felt to be apt, to try and reconstructthe emotions of the Beatles by sampling the emotions of Motown, as theBeatles borrowed heavily from Motown.
2. 1972 Sun Ra album 'Space is the Place'13
12http://www.last.fm13http://www.allmusic.com/album/r399111
47

3. 397 'classic breaks' - the drum loops most commonly sampled by hip hopartists.
4. 90 minutes of mono-timbral piano music by Satie.
Table 6.6: Emotion of Beatles excerpts and Frankenstein TargetName Length agg hap sad relMotherNaturesSon.wav 10.992 0.005 0.037 0.937 0.984ObLaDi.wav 8.809 0.083 0.873 0.227 0.658InMyLife.wav 8.773 0.000 0.056 0.953 0.993YerBlues.wav 12.228 0.980 0.513 0.005 0.163BeatlesFrankenstein.wav 40.394 0.059 0.342 0.197 0.597
The target audio and source corpus were both segmented using onset detectionbased on a generic weighting of high frequency content, complex domain andRMS. The audio was also segmented using the following �xed unit-size segmen-tation schemes: 200ms, 500ms, 1000ms. The only transformation used duringthese experiments was a short cross-fade of 15ms, in order to reduce concatena-tion artefacts.
Experimenting with the Non-Hierarchical Model
Initially linear combination of equally weighted euclidean distances based onthe happy, sad, relaxed and aggressive descriptors was utilised for the simi-larity search. and the 'onsets' segmentation scheme was chosen to start with.The results, did not make much sense musically but an emotional trajectorycould be perceived in the mosaics as they imitated the target's transitionsfrom InMyLife.wav to YerBlues.wav and again from MotherNaturesSon.wav toObLaDi.wav.
Further mosaics were derived after balancing the mood constraints with somelow/mid level descriptors (HPCP, Spectral Energy, Length), in order to takeinto account more 'musical' features of the target. These mosaics made moresense musically but less sense emotionally. The feeling of transition betweenemotions was not as clear.
The results were somehow better with the Sun Ra source corpus and surpris-ingly good results were achieved using the 'classic breaks' source corpus. Thechanges between the di�erent segments of the target may be perceived. Espe-cially striking is the transition from toms to cymbals as the mood changes fromrelaxed to aggressive.
Some experiments were run using �xed length segmentation. Those mosaicsutilising a unit size of 200 ms were di�cult to relate to their targets in terms ofemotional content. With a unit size of 500ms or 1000ms the results were muchbetter.
The �nal experiment used the piano corpus , which while still polyphonic, ismono-timbral and certain interesting problems were noted with the results Itwas felt that with the piano corpus, the problem of repeatedly picking the samesource unit was evident, and while one might call the section corresponding to
48

the YerBlues.wav portion of the target aggressive, it was di�cult to distinguishfrom the �nal happy section, corresponding to ObLaDi.wav.
This leads to the interesting suspicion that for mood mosaicing, polyphonicaudio works better and �xed-unit segmentation schemes with unit-sizes greaterthan 500 ms perform well.
Experimenting with the Hierarchical Model
We used the same musical frankenstein as shown in Table 6.6 and the samesource corpora as described above for experimenting with the hierarchical model.Some additional features of the hierarchical model were utilised, including keytracking, and the dedication of the low level constraints to low level musical pa-rameters like tone chroma, energy, bpm, pitch, etc. These features contributedto an increased musicality in the mosaic output, while still maintaining an emo-tional trajectory as in the previous experiments. This illustrates a strong advan-tage of the hierarchical model in that high level features can be abstracted fromthose lower level features which govern musicality. In this way it is possible totrack the emotion of the target whilst also producing audio which adheres to thetarget musically. This was not easy using only a single level of constraints. Themore constraints which are set at any given level, the more general the resultsbecome. This can be overcome by increasing the size of the source corpus, orby using a hierarchical system, such as that described here.
The results seemed to exhibit a higher quality from the start, using an onsetssegmentation scheme augmented with time-stretching. It was noted that byincreasing the highlevel scope, the high level search space is widened and theemotional trajectory becomes more di�cult to perceive as more error is intro-duced.
Analysis of the results
Of the mosaics which emerged during the early investigations into mood mo-saicing two of the most impressive were �xed unit size mosaicing with SunRaand Motown. These mosaics were repeated using the revised hierarchical model.The original target and the four mosaics were segmented into equal chunks ofat least 5 seconds, which was the chosen time resolution for the investigationsinto high level mood mosaicing. In order to increase the resolution of the resultsan overlap factor of 25% was chosen. In Figure 6.13 and Figure 6.14 we cansee how well the hierarchical and non-hierarchical mosaic examples match eachother and the target in terms of their analysed mood.
In Table 6.7 the mean of absolute di�erence between the target mood valuesand the mosaic mood values are shown for each mood. For the 8 cases shownthe hierarchical system achieves better results in 6 out of 8 cases.
49

Figure 6.13: Here we see the Motown mood curves
Table 6.7: Distance between targets and mosaics. Those mosaics with a pre�xof H were created using the hierarchical system, while those with a pre�x ofNH were created using the non-hierarchical system. In all cases, the lower thevalue, the closer the match
HMotown NHMotown HSunra NHSunraSAD 0.119 0.570 0.196 0.165HAPPY 0.230 0.083 0.873 0.140RELAXED 0.198 0.440 0.164 0.240AGGRESSIVE 0.055 0.608 0.085 0.119
6.3.2 Further Evaluation of the Mood Descriptors
Goal of the Experiment
This investigation into mood mosaicing attempts to discern whether the im-plementation of a hierarchical system for high level mood mosaicing, whichimplements a dual-size segmentation scheme presents a signi�cant advantageover a system utilising only a single segmentation scheme.
Experiment Data
The experiment data was derived from the dataset created in [18]. It comprisestwenty-eight audio �les, with seven audio �les derived randomly from each of thefour mood categories 14 using the following script Listing C.4. The script utilises
14sad, happy, relaxed and aggressive
50

Figure 6.14: Here we see the Sunra mood curves
the Mersenne Twister algorithm [75] for random number generation in order tomake the selection randomly. This dataset combines both the wisdom of thecrowds and the wisdom of the few, in that the songs were preselected based onlast.fm15 tags entered by users of this social network and then the categoriesassigned to each song were validated by a selection of expert listeners.
Experiment Conditions
The two systems were set-up identically. The same constraints were used forboth levels of the hierarchy - a linear combination of evenly weighted euclideandistances for each of the four moods. The only di�erence being that high-levelconstraints are ignored when mosaicing in a non-hierarchical manner. The onlytransformation employed was a short cross-fade of 15ms between units, in orderto smooth the concatenation, along with time-stretching to ensure that themosaics adhered to the target in the time domain.
Description of Experiment
The script shown in Listing C.5 was run on the dataset and the mean of theabsolute di�erence between the target mood values and the mosaic mood valueswere calculated for each mood. The barcharts shown in Figure 6.15, Figure 6.18,Figure 6.16 and Figure 6.17 shows the % accuracy with which the mosaic's mood
15www.last.fm
51

mirrors that of the target for each of the four moods. Both target and mosaicsare analysed using a sliding window of 5 seconds with a 25% overlap. Mo-saics created using the hierarchical system are displayed in green, while mosaicscreated using the non-hierarchical model are displayed in yellow.
Figure 6.15: Performance of the hierarchical model vs the non-hierarchicalmodel in the aggressive mood
Figure 6.16: Performance of the hierarchical model vs the non-hierarchicalmodel in the sad mood
Conclusions
In Table 6.8 we see the number of cases in which each model performed better,broken down by mood. For the aggressive and sad moods the results are strongerin favour of the hierarchical model, however for happy and relaxed moods thedi�erence in the results is negligible. An average distance was calculated fromeach mosaic to its target and the hierarchical values were compared to the non-hierarchical values using a t-Test in order to see if there is a signi�cant statisticaldi�erence between the results. A t-Test is a way of evaluating the di�erence inmeans between two groups. A function 16 from the scipy project 17 was used torun the test and obtain the t-statistic and a two tailed p-value for each mood.The p-value is a measure of statistical signi�cance which represents the proba-bility that the results were obtained through pure chance. A p-value of 0.05 is
16http://www.scipy.org/doc/api_docs/SciPy.stats.stats.html#ttest_rel17http://www.scipy.org/
52

Figure 6.17: Performance of the hierarchical model vs the non-hierarchicalmodel in the relaxed mood
generally considered as borderline statistically signi�cant, while a value < .01is signi�cant and a p-value of < 0.005 or < 0.001 are sometimes called highlysigni�cant [76]. The results are shown in Table 6.9. The p-values are muchgreater than 0.05 and as such do not indicate a signi�cant statistical advantagefor the hierarchical system over the non-hierarchical system. Having said this,a listening test showed a signi�cant general di�erence between the mosaics pro-duced by the two systems. The hierarchical mosaics are more consistent, whilethe non-hierarchical mosaics tend to exhibit much more variation in energy -the scanning radio stations e�ect.
Further Analysis and Final Conclusions
This apparent smoothing e�ect was veri�ed experimentally by calculating theenergy in 6 bands (between 100 Hz and 10000Hz) and summing them to cre-ate a crude perceptual loudness descriptor. This loudness value was calculatedfor each frame of 1024 samples in each of the mosaics produced. The stan-dard deviation of the perceptual loudness over time in each of the mosaics wasthen calculated. The average standard deviation for both hierarchical and non-hierarchical mosaics is shown in Table 6.10, together with a t-statistic and ap-value of 0.0024 which indicates that the di�erence in loudness deviation be-
Figure 6.18: Performance of the hierarchical model vs the non-hierarchicalmodel in the happy mood
53

tween hierarchical and non-hierarchical mosaics can be claimed to be highlysigni�cant (statistically speaking). Thus we can conclude that the hierarchicalsystem, in the case of the mood descriptors at least, has a smoothing e�ect onthe loudness of the mosaic output. The script used to calculate these �gures isshown in Listing C.6.
Table 6.8: Empirical performance comparison of hierarchical and non-hierarchical models for mood-mosaicing showing the % of cases in which themodels produced a mosaic closest to the target
Mood Hierarchical Model Non-hierarchical
Aggressive 71.43 28.57Sad 85.71 14.29Happy 53.57 46.43Relaxed 46.43 53.57
Table 6.9: T-test results for mood comparison experimentMood T-statistic P-value
Aggressive 0.429 0.672Sad 0.853 0.402Happy 0.068 0.946Relaxed -0.107 0.915
Table 6.10: Statistical analysis of the deviation of the perceptual loudness ofthe mosaics over time.
Average loudness deviation of hierarchical mosaics 33.275Average loudness deviation of non-hierarchical mosaics 27.69T-statistic -3.367P-value 0.0024
6.4 Musical Results
6.4.1 The Loop-based Paradigm
One of the stated research goals was to explore a selection of use cases forcomposing with mosaics. In this section the framework which has been createdis extended in order to experiment with composition and music-making withmosaics. The inspiration was the Loopmash project where the user can createlayers of mosaics in a loop playing in real time. The pure data 4 track loopershown in Figure 6.19 is a crude imitation, but with the chosen targets pre-segmented and pre-analysed it proved to be quite a lot of fun to use.
54

It allows the user to control:
• 3 mosaics playing in real time with the target
• Mosaics can be muted and unmuted in real time and can also be playedindividually.
• New mosaics can be processed in the background and copied to the looperwhen ready or auditioned to see how they �t with the rest of the audio.
• Using the 'Record' function a portion of the mosaic can be copied into abu�er whilst looping audio.
Figure 6.19: This mini-application is used to build mosaic-augmented loops
The creation of this looper took no more than a couple of hours and requiredno changes to the framework in order to implement. This in no way constitutesa strong validation of the extensibility of the framework as the author of theframework was the one who extended it. Having said this, the author was rea-sonably satis�ed as to the ease of the extension process. It required a knowledgeof pure data but only a little knowledge of the internal message structure of theframework was required in order to retrieve target and mosaics.
Like Loopmash it worked well with drumloops, it is possible to augment them,creating heavy syncopated beats, reminiscent of dubstep or wonky hiphop, etc.
An example video of the looper in action was uploaded to youtube: http:
//www.youtube.com/watch?v=0Q3SMwPAuKM
The current implementation is just a proof of concept, and there are glitches inthe audio when loading new mosaics from disk or using the record function (ascan be heard in the video). These errors would have to be resolved in order tomake this looper a useful tool, however the promise of this paradigm is evident,not only for composition but even for live performance.
55

Unfortunately, the hierarchical model did not allow the same level of spontaneityand fun as the analysis takes too long.
6.4.2 Integrating Mosaics into a Composition: A personalexperience
Background
Glitch music is a genre of electronic music which arose from the exploration offailure [77]. Extreme time stretching and bit-crushing (resampling at a muchlower sample rate) are examples of glitch techniques. It is the deliberate placingof musical focus on digital imperfections. Audio-mosaicing is inherently glitchy.It is founded on technologies which do not yet work perfectly and so errors inthe analysis (e.g. pitch detection in polyphonic audio, onset detection in non-percussive material), produce glitchy mosaics. This composition evolved as anattempt to use digital glitches (imperfect mosaics of imperfect takes) to evokehuman glitches (imperfect memory) by integrating mosaics into a fairly typicallystructured acoustic song (ABABC).
Technical details
The material for this composition was captured in a lo-� manner. One can hearmany clicks and discontinuities in the source audio, which was recorded on aTascam DR-2D digital �eld recorder18. Four tracks were recorded - Bodhran19,Nylon String Guitar, Lead Vocals, Backing Vocals. The tracks were sequenced ina digital audio workstation called Ardour2. The main 4 tracks were compressedand the lead vocal was treated with the Gong Model plugin by Steve Harris.This is a weird and wonderful e�ect which imparts a fabulous sibilance to thehigher frequencies in the spectrum. The �nished track has been left roughintentionally, even the song itself is somehow un�nished. It was not masteredas such, just normalised and compressed in Audacity 20, a digital audio editor.The mosaics were realised using the hierarchical model primarily due to thesmoothing e�ect it produces as discussed in section 6.3.2, but also to allow thesetting of high level target-tracking constraints like key and scale as described insection 6.1.5. The performance issues discussed in subsection 6.4.3 were avoidedby generating the mosaics in batch mode using a script.
Selection of Mosaic Source Audio
The out-takes, those takes which were deemed as not good enough for inclusionin the �nished song, were compiled into source corpora, where they were seg-mented and analysed. These out-takes contain errors or glitches, which meantthey were discarded. The aim of this exercise was to try and use this glitchymaterial and incorporate it into the �nished project, rather than discarding it.
18http://tascam.com/product/dr-2d19The bodhran is an irish frame drum20http://audacity.sourceforge.net
56

The theme of the song is nostalgic to a certain extent. Nostalgia implies a rose-tinted view of some past period in time and it arises out of glitches in humanmemory. It is not an objective recollection of how things really were. In thisway, it felt suitable to ornament the song with musical glitches, to imitate whathappens in our brain when we indulge ourselves in nostalgic recollections of a'better' time.
Integrating the Mosaics
The targets for the mosaic were the �nal four tracks selected for the composition.The �rst appearance of the mosaic is in the solo, the material here was createdby mosaicing guitar out-takes from the lead vocal target and mosaicing vocalout-takes from the guitar target. After this solo, the mosaics begin to be wovenin and out of the audio, an additional mosaic draws from the bodhran out-takeswith the guitar track as a target. This creates a bodhran rhythm synced to thebeat of the guitar, which produces some interesting syncopations when mixedin with the main bodhran track. The mosaic audio was not processed, withthe exception of the bodhran mosaic, which was treated with Barry's SatanMaximiser plug-in, in order to make it a little more aggressive. Volume andpanning automation in ardour was utilised in order to weave the mosaic audioin and out of the mix.
Conclusions
The author has a sneaking suspicion that the song is not actually that good,however he still likes the idea and considers that the e�ect of these mosaics wouldnot be so easy to create by alternative means. The interested reader can listento the song here: http://soundcloud.com/greenguerilla/out-take-mosaic
6.4.3 The Signi�cance of Performance issues
An important aspect of the creative process when composing music in a tradi-tional manner, is feedback from the instrument it is being composed on. Thisfeedback will be almost always instantaneous, which allows the composer toquickly follow a musical idea, make adjustments which produce instant results,etc. When mosaicing with high level descriptors, the user experience is muchless immediate, and the most signi�cant impediment is the analysis process.This is not a major issue for the source databases, as these can be pre-analysed,however the target must be analysed while the user waits and the delay betweenmaking some parameter changes and hearing the results can be signi�cant.
The High-level Analysis Process
The high level classi�ers which have been used in this research were created bytraining an SVM model. This has the following disadvantages when it comes tothe speed of the analysis process:
57

• The models are typically built with a large number of low level and midlevel descriptors, many more than would be needed for a simple low levelmosaicing system.
• Each SVM model must be loaded and computed when a candidate ispresented for classi�cation, this incurs a cost which depends on the numberof dimensions of the model (i.e. the number of extracted descriptors),rather than the length of the audio �le.
This last point is particularly pertinent for a mosaicing system as the audio �lesare normally very short but this does not o�er the advantage that one mightthink it would. This is not generally an issue for a music retrieval system as allof this data can be pre-calculated.
A small experiment was run, in order to contrast the extraction speed of highlevel analysis, versus the extraction speed of low level analysis. Two extractorswere written:
1. streaming_extractor - extracts high level analysis and low level analysis
2. streaming_extractor_lowlevel - extracts low level analysis only
The extractors were coded in C++ and called in a separate process from themain Python program. The extractor code uses Essentia, which in turn invokeslibsvm 21 in order to handle the SVM related work.
The timing was calculated as shown in Listing 6.1:
Listing 6.1: "Timing the feature extraction"
#s t a r t the t imingsnap_start = time ( )for f in a . ana lyse ( wav_f i l e s ) :
snap_end = time ( )print ( "Analysing %s took %f seconds "
% ( f , snap_end−snap_start ) )snap_start = time ( )
This script was run against an arbitrary selection of audio �les of di�erentlengths The results in the table show that the performance di�erences are sig-ni�cant, especially for very short audio �les. With greater �le length the per-formance becomes more equitable. All lengths and processing times are in sec-onds. This is shown more succinctly in Figure 6.20, where the average of all theprocessing times normalised by the length of the audio �les is shown for eachextractor. The error bars represent the standard deviation of the normalisedprocessing times. The large error bar for the high level extractor exposes it'snon-linearity for processing times with respect to length.
21http://www.csie.ntu.edu.tw/~cjlin/libsvm/
58

Table 6.11: Comparison of processing time for full extractor vs. low-level ex-tractor routines.
name length low-level extractor full extractor
07_5.wav 0.128 0.292 2.79706_5.wav 0.151 0.302 2.75210_6.wav 0.174 0.310 2.80502_1.wav 0.221 0.316 2.80208_5.wav 0.372 0.351 2.77512_7.wav 0.441 0.358 2.78609_6.wav 0.453 0.357 2.80811_7.wav 0.557 0.385 2.82601_1.wav 0.569 0.367 2.91100_0.wav 0.789 0.407 2.90604_3.wav 1.057 0.464 2.94903_2.wav 1.103 0.477 2.945tibet.wav 1.255 0.512 2.99005_5.wav 1.382 0.532 2.958loop2.wav 8.641 1.818 4.394polyphonicloop1.wav 9.764 2.071 4.533loop3.wav 15.041 2.971 5.712Rhubarb.wav 464.267 82.964 90.099
Figure 6.20: Average processing time normalised by audio �le length for each ofthe extraction routines.
59

Chapter 7Conclusions
Our primary research goal was to �nd a way of incorporating high-level musiccontent descriptions into a mosaicing system. We have shown that these de-scriptions may not be trustworthy for very short segments of audio and that anew approach is required to integrate existing high-level descriptors. The con-cept of a time resolution for high level descriptors was introduced and exploredand a hierarchical model was proposed for integrating high-level descriptors intoa mosaicing system. A general method was devised for the derivation of a timeresolution for an arbitrary high-level label classi�er. We explored some methodsof evaluating the hierarchical model versus the non-hierarchical model. Whilethe results showed no statistical advantage for using the high-level descriptors interms of classi�er accuracy, we have shown that the hierarchical system producesmore cohesive and coherent mosaics with much less variation in loudness. Thishelps to minimise the impression of the mosaic being a recording of somebodyscanning radio stations at high speed. Additionally, with two levels of descriptorsearch, mosaics can be built which adhere to high-level constraints like mood atthe top level of the hierarchy, while adhering to more musical characteristics; likepitch or tone chroma, at the bottom level of the hierarchy. This a�ords a greaterlevel of control over the mosaic and allows better results with smaller databases.The main disadvantage of using high-level descriptors is the time required toextract the high-level labels from the audio segments. We showed showed howthe performance of the high-level descriptors improved when analysing longersegments of audio. A hierarchical system can therefore minimise performanceissues by extracting high-level analysis only from the larger segments whose sizeis determined by the time resolution of the given descriptor.
A secondary goal of developing an extensible library of functions was also re-alised. In this project a new modular framework for musical mosaicing incorpo-rating high-level descriptors was presented. Its extensibility was demonstratedthrough the creation of a looper application to explore a paradigm for makingmusic with mosaics. A serious attempt was made to write documentation tocover every function in the code-base. The current version of this documenta-tion is included in Appendix B. It is intended to make the source code for this
60

framework available online in order to ful�l our goals of providing a resource forlearning about mosaicing, exploring mosaicing techniques and building musicalmosaicing applications.
The broader goal of exploring musical processes with mosaicing was explored.Two di�erent use-cases were presented and a composition was created to add tothe body of music made with mosaics.
61

Chapter 8Future Work
The following items are general suggestions for future investigations into mo-saicing with high-level classifers.
• Retrain the high-level classi�ers with smaller segments of audio, whoseduration is determined by recent research into the minimum duration re-quired for human identi�cation of the related semantic concept in audio.Implement a dynamic hierarchy whereby the segment length depends onthe descriptors being used.
• An alternative approach might examine the bene�ts of using smarter seg-mentation combined with existing descriptors. For example, segmentingmusical audio in terms of its higher level musical structure [78]
• Utilise existing descriptors but employ an active learning approach [79]whereby the user can improve the system by labelling selected instancesfrom the segmented source corpus.
The following suggestions describe potential ways to extend and improve theframework introduced in this document.
• Expand the system with more descriptors, the most desirable of whichwould be (in the author's opinion); An instrument classi�er and a robustperceptual loudness descriptor (perhaps based on Bark bands)
• Use the choice of source corpus as an additional high-level descriptor, inthis way an incoming audio target would be analysed to see which sourcecorpus it is most similar to and the most closely matching corpus wouldbe used to derive the mosaic audio.
• Migrate the framework's �le based database model to a relational databasemodel. This would allow easier abstraction of the analysis and audiomatching components. It would also aid in the future extension of theframework.
• Explore the musical side of the framework by building more innovative in-terfaces geared towards speci�c use-cases, like the looper described previ-
62

ously. Software libraries such as Processing1 or Open Frameworks2 mightaid in the creation of a more interactive, a more satisfying user experience.
In general, mosaicing o�ers rich artistic possibilities and the most im-portant future work ought to be a practice-based research exploring thecreation of music using mosaics.
1http://processing.org/2http://www.openframeworks.cc/
63

References
[1] P. Herrera, J. Serrà, C. Laurier, E. Guaus, E. Gómez, and X. Serra, �TheDiscipline Formerly Known as MIR,� tech. rep., Universitat Pompeu Fabra,2009.
[2] P. Lamere, �Social Tagging and Music Information Retrieval,� Journal ofNew Music Research, vol. 37, pp. 101�114, June 2008.
[3] A. Wang, �The Shazam music recognition service,� Communications of theACM, vol. 49, p. 44, Aug. 2006.
[4] J. Serrà, Identi�cation of Versions of the Same Musical Composition byProcessing Audio Descriptions. PhD thesis, Universitat Pompeu Fabra,2011.
[5] G. Peeters, �A large set of audio features for sound description (similarityand classi�cation) in the CUIDADO project,� tech. rep., IRCAM, 2004.
[6] E. Gomez, Tonal Description of Music Audio Signals. PhD thesis, Univer-sitat Pompeu Fabra, 2006.
[7] O. Celma, P. Herrera, and X. Serra, �A multimodal approach to bridgethe Music Semantic Gap,� in ESWC 2006 Workshop on Mastering theGap: From Information Extraction to Semantic Representation, (Athens,Greece), June 2006.
[8] G. A. Wiggins, �Semantic Gap?? Schemantic Schmap!! MethodologicalConsiderations in the Scienti�c Study of Music,� International Symposiumon Multimedia, vol. 0, pp. 477�482, 2009.
[9] F. Fuhrmann and P. Herrera, �Polyphonic Instrument Recognition For Ex-ploring Semantic Similarities In Music,� in proceedings of the 13th Inter-national Conference on Digital Audio E�ects (DAFX), (Graz, Austria),pp. 1�8, 2010.
[10] N. Wack, C. Laurier, O. Meyers, R. Marxer, D. Bogdanov, J. Serrà,E. Gómez, and P. Herrera, �Music classi�cation using high-level models,�tech. rep., Universitat Pompeu Fabra, 2010.
64

[11] M. Haro, A. Xambó, F. Fuhrmann, D. Bogdanov, E. Gómez, and P. Her-rera, �The Musical Avatar - A visualization of musical preferences by meansof audio content description,� (Pitea, Sweden), ACM New York, NY, USA,Sept. 2010.
[12] T. Fletcher, �Support Vector Machines Explained,� 2009.
[13] M. Kotti and C. Kotropoulos, �Gender classi�cation in two EmotionalSpeech databases,� 19th International Conference on Pattern Recognition,pp. 1�4, Dec. 2008.
[14] C. M. Bishop, Pattern Recognition and Machine Learning. New York:Springer, 2007.
[15] S. Vieillard, I. Peretz, N. Gosselin, S. Khalfa, L. Gagnon, and B. Bouchard,�Happy, sad, scary and peaceful musical excerpts for research on emotions,�Cognition & Emotion, vol. 22, pp. 720�752, June 2008.
[16] P. Juslin and P. Laukka, �Expression, Perception, and Induction of MusicalEmotions: A Review and a Questionnaire Study of Everyday Listening,�Journal of New Music Research, vol. 33, pp. 217�238, Sept. 2004.
[17] C. Laurier, O. Lartillot, T. Eerola, and P. Toiviainen, �Exploring Relation-ships between Audio Features and Emotion in Music,� in proceedings of the7th Triennial Conference of European Society for the Cognitive Sciences ofMusic (ESCOM)., 2008.
[18] C. Laurier, O. Meyers, J. Serra, M. Blech, and P. Herrera, �Music MoodAnnotator Design and Integration,� 2009 Seventh International Workshopon Content-Based Multimedia Indexing, pp. 156�161, June 2009.
[19] M. Casey and M. Grierson, �Soundspotter/Remix-TV: fast approximatematching for audio and video performance,� in proceedings of the Inter-national Computer Music Conference (ICMC), (Copenhagen, Denmark),2004.
[20] D. Schwarz and N. Schnell, �Descriptor-Based Sound Texture Sampling,�in proceedings of the 7th Sound and Music Computing Conference (SMC),(Barcelona, Spain), 2010.
[21] C. B. Fowler, �The Museum of Music: A History of Mechanical Instru-ments,� Music Educators Journal, vol. 54, no. 2, pp. 45�49, 1967.
[22] Xavier Serra, A System for Sound Analysis/Transformation/SynthesisBased On A Deterministic plus Stochastic Decomposition. PhD thesis, Oct.1989.
[23] I. MacDonald, Revolution in the Head: the Beatles' Records and the Sixties.Vintage, 2005.
[24] L. Russolo, �The Art of Noises,� Jan. 1913.
[25] C. Roads, The Computer Music Tutorial. Cambridge, MA, USA: MITPress, 1996.
[26] P. Manning, Electronic and Computer Music. Oxford University Press,2004.
65

[27] I. Xenakis, Formalized music: thought and mathematics in composition.Pendragon Press, 1971.
[28] J. Dack, �Technology and the Instrument,� in Musik Netz Werke: Kon-turen der neuen Musikkultur (L. Grün and F. Wiegand, eds.), pp. 39�54,Transcript, 2002.
[29] P. Schae�er, Traité des objets musicaux. Paris: Seuil, 1966.
[30] M. Chion, Guide des objets sonores. Paris: Buchet/Chastel, 1983.
[31] D. Bogdanov, J. Serrà, N. Wack, and P. Herrera, �From Low-Level to High-Level: Comparative Study of Music Similarity Measures,� 2009 11th IEEEInternational Symposium on Multimedia, pp. 453�458, 2009.
[32] J. Ricard and P. Herrera, �Morphological sound description : computa-tional model and usability,� in proceedings of the 116th convention of theAudio Engineering Society (AES), (Berlin), 2004.
[33] B. Sturm, �Concatenative sound synthesis and intellectual property: Ananalysis of the legal issues surrounding the synthesis of novel sounds fromcopyright-protected work,� Journal of New Music Research, vol. 35, pp. 23�33, Mar. 2006.
[34] A. Zils and F. Pachet, �Musical Mosaicing,� in proceedings of the Cost-G6conference on Digital Audio E�ects (DAFX), (Limerick, Ireland), 2001.
[35] D. Gabor, �Acoustical quanta and the theory of hearing,� Nature, vol. 159,pp. 591�594, 1947.
[36] D. Schwarz, Data-driven concatenative sound synthesis. PhD thesis, 2004.
[37] J. van Santen, R. . Sproat, J. Olive, and J. Hirschberg, Progress in SpeechSynthesis. New York, USA: Spinger-Verlag, 1996.
[38] J. Bonada and X. Serra, �Synthesis of the Singing Voice by PerformanceSampling and Spectral Models,� IEEE Signal Processing Magazine, vol. 24,pp. 67�69, 2007.
[39] D. Schwartz, �Concatenative sound synthesis: The early years,� Journal ofNew Music Research, vol. 35, no. 1, p. 3, 2006.
[40] D. Schwarz, �Real-time Corpus-based Concatenative Synthesis withCataRT,� in proceedings of the 9th international conference on digital audioe�ects (DAFX), (Montreal), pp. 1�7, 2006.
[41] C. Roads, Microsound. Cambridge, Massachusetts: MIT Press, 2001.
[42] J. M. Comajuncosas, A. Barrachina, J. O'Connell, and E. Guaus, �Nuvolet: 3D Gesture-driven Collaborative Audio Mosaicing,� in New Interfaces forMusical Expression (NIME), pp. 252�255, 2011.
[43] C. Jacquemin and R. Cahen, �Plumage : Design d'une interface 3D pour leparcours d'echantillons sonores granularises,� in In IHM, (Paris, France),2007.
[44] D. Schwarz, �Corpus-based concatenative synthesis,� Signal ProcessingMagazine, IEEE, vol. 24, no. 2, pp. 92�104, 2007.
66

[45] P. A. Tremblay, �Sur�ng the Waves : Live Audio Mosaicing of an ElectricBass Performance as a Corpus Browsing Interface,� in proceedings of the2010 Conference on New Interfaces for Musical Expression (NIME 2010),pp. 15�18, 2010.
[46] J. Janer and M. D. Boer, �Extending voice-driven synthesis to audio mo-saicing,� in proceedings of the 5th Sound and Music Computing Conference(SMC), (Berlin), 2008.
[47] I. Simon and D. Salesin, �Audio Analogies : Creating New Music Froman Existing Performance by Concatenative Synthesis,� in Proceeding of theInternational Computer Music Conference (ICMC), 2005.
[48] J. B. Graham Coleman , Esteban Maestre, �Augmenting Sound MosaicingWith Descriptor-Driven Transformation,� in proceedings of the 13th Int.Conference on Digital Audio E�ects (DAFx), pp. 1�4, 2010.
[49] B. Sturm, �MATConcat: an application for exploring concatenative soundsynthesis using MATLAB,� in Proceedings of Digital Audio E�ects (DAFX),(Naples, Italy), 2004.
[50] �Essentia & Gaia: audio analysis and music matching C++ libraries.�
[51] W. Brent, �A timbre analysis and classi�cation toolkit for pure data,� inproceedings of the International Computer Music Conference, pp. 224�229,2010.
[52] J.-j. Aucouturier and F. Pachet, �Ringomatic : A Real-Time InteractiveDrummer Using Constraint-Satisfaction and Drum Sound Descriptors,� inproceedings of the International Conference on Music Information Retrieval(ISMIR), pp. 412�419, 2005.
[53] E. Lindemann, �Music Synthesis with Reconstructive Phrase Modelling,�IEEE Signal Processing Magazine, pp. 80�91, 2007.
[54] A. J. Hunt and A. W. Black, �Unit selection in a concatenative speechsynthesis system using a large speech database.,� in proceedings of theIEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP), (Atlanta, Georgia), 1996.
[55] G. Leslie, D. Schwarz, O. Warusfel, F. Bevilacqua, B. Zamborlin, P. Jod-lowski, N. Schnell, and I. Cnrs, �Grainstick : A Collaborative , InteractiveSound Installation,� in proceedings of the International Computer MusicConference (ICMC), (New York), pp. 3�6, 2010.
[56] G. Coleman and J. Bonada, �Sound Transformation by Descriptor Usingan Analytic Domain,� in proceedings of the 11th International Conferenceon Digital Audio E�ects (DAFx), (Espoo, Finland), Jan. 2008.
[57] M. Ho�man and P. R. Cook, �Feature-Based Synthesis : Mapping Acousticand Perceptual Features onto Synthesis Parameters,� in proceedings of theICMC, (Copenhagen, Denmark), 2006.
[58] T. H. Park, J. Biguenet, Z. Li, C. Richardson, and T. Scharr, �Featuremodulation synthesis (FMS),� in proceedings of the ICMC, (Copenhagen,Denmark), pp. 368�372, 2007.
67

[59] D. Schwarz, R. Cahen, and S. Britton, �Principles and Applications ofInteractive Corpus-based Concatenative Synthesis,� in JIM, GMEA, (Albi,France), 2008.
[60] K. Beck, Extreme programming explained: Embrace change. Addison-Wesley, 1999.
[61] W. Royce, �Managing the development of large software systems,� proceed-ings of IEEE, no. 26, pp. 1�9, 1970.
[62] J. Plazak and D. Huron, �The �rst three seconds: Listener knowledgegained from brief musical excerpts,� Musicae Scientiae, vol. 15, pp. 29�44, Mar. 2011.
[63] Z. Xiao, E. Dellandrea, W. Dou, L. Chen, G. D. Collongue, E. Cedex, andE. Engineering, �What is the Best Segment Duration For Music Mood Anal-ysis?,� in International Workshop on Content-Based Multimedia Indexing(CBMI), pp. 17�24, 2008.
[64] D. Beazley, �Understanding the Python GIL. [Presentation],� in PyCon,(Atlanta, Georgia), 2010.
[65] G. E. Krasner and S. T. Pope, �A Description of the Model-View-ControllerUser Interface Paradigm in the Smalltalk-80 System,� tech. rep., ParcPlaceSystems, Mountain View, California, 1988.
[66] P. Masri and A. Bateman, �Improved Modelling of Attack Transients in Mu-sic Analysis-Resynthesis,� in proceedings of International Computer MusicConference (ICMC), (Hong Kong), pp. 100�103, 1996.
[67] P. M. Brossier, J. P. Bello, and M. D. Plumbley, �Fast labelling of notes inmusic signals,� in proceedings of the 5th International Conference on MusicInformation Retrieval (ISMIR-04), (Barcelona), 2004.
[68] Simon Dixon, �Onset Detection Revisited,� In Proc. of the Int. Conf. onDigital Audio E�ects (DAFx-06), pp. 1�6, 2006.
[69] V. Akkermans, J. Serrà, and P. Herrera, �Shape-based Spectral ContrastDescriptor,� in proceedings of the SMC 2009 - 6th Sound and Music Com-puting Conference, no. July, (Porto), pp. 23�25, 2009.
[70] L. Lu, H.-j. Zhang, J.-h. Tao, and L.-h. Cui, �Music type classi�cation byspectral contrast feature,� in Proceedings. IEEE International Conferenceon Multimedia, pp. 113�116, Ieee, 2002.
[71] T. Ganchev, N. Fakotakis, and G. Kokkinakis, �Comparative Evaluationof Various MFCC Implementations on the Speaker Veri�cation Task,� inproceedings of the 10th International Conference on Speech and Computers,vol. 1, (Patras, Greece), pp. 191�194, 2005.
[72] D. Bogdanov, J. Serrà, N. Wack, and P. Herrera, �Semantic SimilarityMeasure For Music Recommendation (A Pharos whitepaper).� 2009.
[73] H. Harb and L. Chen, �A general audio classi�er based on human perceptionmotivated model,� Multimedia Tools and Applications, vol. 34, pp. 375�395,Mar. 2007.
68

[74] C. L. Krumhansl, �"Thin Slices" of Music,� Music Perception: An Inter-disciplinary Journal, vol. 27, no. 5, pp. 337�354, 2010.
[75] M. Matsumoto and T. Nishimura, �Mersenne twister: a 623-dimensionallyequidistributed uniform pseudo-random number generator,� ACM Trans-actions on Modeling and Computer Simulation, vol. 8, pp. 3�30, Jan. 1998.
[76] T. Hill and P. Lewicki, Statistics: Methods and Applications. Tulsa, Okla-homa: StatSoft, 2007.
[77] K. Cascone, �The Aesthetics of Failure: "Post-Digital" Tendencies in Con-temporary Computer Music.,� Computer Music Journal, vol. 24, no. 4,2000.
[78] M. Levy and M. Sandler, �New methods in structural segmentation of mu-sical audio,� in Proceedings of the European Signal Processing Conference.,2006.
[79] B. Settles, �Active Learning Literature Survey,� tech. rep., University ofWisconsin�Madison, 2009.
69

Appendix AGlossary
As the following terms are somewhat interchangeable in the literature we willattempt to draw some distinctions between them before we begin. All processesrefer to the creation of a large segment of audio from many smaller segments ofaudio.
Concatenative Sound Synthesis (CSS) is a process whereby audio is createdby the concatenation of many small segments of audio, called units, from asource unit database, called a corpus.
Musical Mosaicing is a process whereby a piece of music, called a target andrepresented by a score or an audio �le, is approximated through the amalga-mation of many small snippets of audio drawn from sources distinct from thesource of the target.
Audio Mosaicing is the same as musical mosaicing except that it need notnecessarily be musical e.g. Sound texture mosaicing as in [19] or [20] might bebetter classi�ed as audio mosaicing.
Both audio mosaicing and musical mosaicing may be considered as sub-categorieswithin concatenative sound synthesis, however the concatenation quality orsmoothness/naturalness of the output audio may not be as much of a concernin creative applications as it is in speech synthesis applications.
In this document descriptors/analysis/classi�ers are commonly split into twocategories:
Low-level - Low-level analysis is grounded in signal processing and employsmathematics to describe certain attributes of the signal e.g. spectral centroid,rms, etc.
High-level - High-level analysis aims at a more semantic description of theaudio. High-level descriptors may also be called label-classi�ers as they applya semantic label to a piece of audio. This label typically corresponds to aterm which a human might choose to describe the audio e.g. the mood of the
70

audio, the instrumentation used, the musical key of the piece, etc. A high-leveldescriptor is typically created using a combination of many low-level descriptors
71

Appendix BSystem Documentation
This section includes the source code documentation as of September 2011.The most up-to-date version of the source code may be downloaded from here:https://github.com/jgoconnell/hmosaic.
The full documentation, including software requirements and installation in-structions is available online here: http://greenguerilla.alwaysdata.net/
hmosaic/docs/
72

B.1 Module hmosaic.control
B.1.1 Functions
extract_from_list(func)
This decorator is intended to manipulate a list argument tofunctions, returning the function without the argument whenthe list is empty and with the value stripped from its list whenthe list has one value. Designed to allow seamlessness betweencalling methods in daemon mode (using OSCMessages) orcalling them in programmatic mode. i.e. So you don't have toput arguments in a list when calling methods programatically
strip_arguments(func)
Decorator to strip the arguments and keyword arguments froma function call,
validate_setting(setting)
Makes sure that the given **setting** exists in `settings.py`.
equalise_datasets(tds, sds)
Takes two Gaia datasets and makes sure they have the samelayout.
get_unused_descriptors()
Returns a set of descriptors which are not used and whichoccasionaly cause problems with gaia due to their values.
get_mood_distance(unit_db)
Returns a hard coded mood distance. A linear combination ofeuclidean distances for all 4 moods.
get_low_level_distance(unit_db)
Returns a hard coded low level distance based on length, pitchand spectral energy
gaia_transform(points)
Takes a dict of point names and �lepaths Creates a DataSet andperforms the standard transformations
B.1.2 Variables
Name Description__package__ Value: 'hmosaic'
continued on next page
73

Name Description__warningregistry__ Value: {('Not importing
directory
\'/home/john/thesis/hmosaic/es...
B.1.3 Class Target
object
hmosaic.control.Target
Simple model of a target with a �lepath and some useful analysis data likelength and bpm
Methods
__init__(self, �lepath)
Sets the basic item of info: the targets �lepath.
Overrides: object.__init__
__repr__(self )
Makes sure the target �lepath is returned as the objects stringrepresentation
Overrides: object.__repr__
set_props(self, analysis)
Loads the analysis of the complete target �le into a gaia pointand extracts certain high level features/classi�ers. The featuresare then stored in a dictionary for later retrieval.
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __setattr__(), __sizeof__(), __str__(), _-_subclasshook__()
Properties
Name DescriptionInherited from object
__class__
74

B.1.4 Class HighLevelControl
object
hmosaic.control.HighLevelControl
Methods
__init__(self, source_manager, daemon=True)
All the default values for the mosaicing session areinitialised here. A OSC client is created in order totalk to the audio engine. Designed with pure data inmind but is actually agnostic where the audioplayback mechanism is concerned.
Overrides: object.__init__
listen(self, pattern, tags, data, client_address)
OSC server method - all valid OSC requests getpassed in here and are delegated to functions of theclass from here. Some basic input validation may bedone prior to calling functions. Exceptions raised willnot cause the program to bomb out, so error handlingis minimal and logging is maximal. I have groupedacceptable message types by component wherepossible e.g. target, analysis, context, etc.
setSourceCorpus(*args)
Loads a new source corpus, from which to search formosaic units.
analyseCorpus(self )
Analyses the currrent corpus, using �self.chop� todetermine the segmentation scheme to search for.
setTarget(*args)
Adds the target to the database and sets self.target.Target name in db is based on its original �lename butif that already exists then it uses a pattern based onthe timestamp. Target is analysed to extractinformation like BPM, length, etc.
75

processTarget(*args, **kwargs)
Processes the target for mosaicing. Segment it intounits based on the chosen segmentation scheme.Analyse the units.
process_target_hl(self )
Processes the target for high level mosaicing. The ideais to take a preanalysed, presegmented target andprocess it in a high level manner - 5 second chunksCreate a gaia unit-db for each chunk.
setCrossfade(*args)
Sets the concatenation crossfade.
toggleFixed(*args)
This function sets `self.chop`, it can be used to togglethe segmentation style, either *onsets* or *�xedlength*. If `chop` is 0 then we used onset basedsegmentation, otherwise we chop the audio up into`chop` sized chunks.
toggleBPM(*args)
This function is used to activate **BPM** relatedsegmentation. It sets �self.bpm� to **True** or**False**. If set to **TRUE**, it means that�self.chop� is calculated dynamically, based on thebpm of the target.
setOnsets(self, onsets_array)
Used to set the onsets weights parameter. Convertspairs in a sequence to a dict representation.
setAubio(*args)
This function can be used to switch between**aubio** and **essentia** onset detection routines.
76
setAubioLength(*args)
This function sets a minimum note length for the**aubio** based note segmentation routine. It willmerge together note events till the minimum length isexceeded. **TO DO** : Improve the note selectionalgorithm by adjusting the aubio threshold instead,rather than the convoluted minimum length logic thatis currently being used.
getMarkedAudio(*args, **kwargs)
This function calls a method of the corpus whichmarks the target with beeps indicated by the positionof the onsets in the list and saves this as an audio �le,the location of which is sent to the audio engine.
trackLength(*args)
Activates the gridder object to �t units to the targetsrhythmic grid.
trackLengthType(*args)
Sets gridder to silence or stretch. 1 means stretch,anything else means silence
useLabel(*args)
Sets a label to be used during high level mosaicing.
useLabelThreshold(self, data)
Sets a label and threshold to be used during high levelmosaicing.
setConstraints(self, constraints_array)
This sets **self.constraints**. These are thedescriptors and weights used during the low level unitsearch process.
setHLConstraints(self, constraints_array)
This sets **self.chl_onstraints**. These are thedescriptors and weights used during the high level unitsearch process.
77

toggleHighLevel(*args)
A simple switch for bypassing high level mosaicing.
setHighScope(*args)
De�nes the number of results returned during highlevel search.
setLowScope(*args)
De�nes the number of results returned during lowlevel search.
saveMosaic(*args)
Saves the target, the mosaic and a beep demarcatedtarget (where beeps sound at the locations of thedetected onsets). The �les are saved into the**mosaic** corpus of the target repository. If�save_name� is **None** then the �lename isautogenerated based on the timestamp, else�save_name� is used as the root name for saving the�les, using the following convention: **save_nameMOSAIC.wav* **save_nameONSETS.wav* **save_nameTARGET.wav* * *save_nameINFO.txt*
send_mosaic_path(self )
Simple method to copy the �le at �self.mosaic.�lepath�to some prede�ned location where PureData or anyother audio engine can �nd it. An OSC message isthen sent to the engine to notify it that the �le isready.
loadLastTarget(*args)
This �nds the most recently processed target and setsit for use here.
createMosaic(*args, **kwargs)
This is the main method of this class. It checks all thesettings and creates the mosaic accordingly. It sendsthe �lepath to the �nished mosaic back to the guiclient at the end if running in daemon mode.
78

Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
B.1.5 Class Gridder
object
hmosaic.control.Gridder
Transforms Mosaic Units to match the length of the target unit.
Methods
__init__(self, strategy=1)
Two possible strategies * timestretch (default) * Cutor pad with silence The �rst strategy is selfexplanatory, the second operates di�erently dependingon the length of the unit. If the target unit is longer,it pads the mosaic unit with silence, if the target unitis shorter it simply cuts the mosaicUnit.
Overrides: object.__init__
set_active(self, switch)
Turn this gridder object on or o�.
�t(self, unit, tlength)
The �t method takes two params * *unit* - The unitto be modi�ed * *tlength* - The target length Thismethod simply applies the current strategy andreturns a new unit of the correct length.
79

Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
B.1.6 Class Context
object
hmosaic.control.Context
This class keeps track of a certain number of previous units It canbe used to weight the gaia results based on similarity between eachresult and the audio in the context.
Methods
__init__(self, length=20)
Sets the �length� of the context.
Overrides: object.__init__
append(self, key)
Appends an entry to the dictionary, changes behaviourwhen full This was inspired by the Python CookbookRingBu�er recipe.
reset(self )
Helper method to reset the cost function every time.
80

get_results(self, results)
Creates a GaiaDB of the previous context andsearches for each point in the resultset. Returnsresults updated with the local distance factored in.The simplest way is to calculate the total distancefrom each point for each result and add that to theresult score. That way, those which are very di�erentwill be penalised.
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
B.1.7 Class RepeatUnitCost
object
hmosaic.control.RepeatUnitCost
This should accept a gaia result set as input and return a single unitas output. Cost is based on gaia similarity score, if the result hasalready been selected and (maybe) the similarity of the result to thecontext. This Cost object ought to be con�gurable...
81

Methods
__init__(self, factor=0.02, context=20)
�factor� is multiplied by the number of times the unitappears in the context. This number is then added tothe score for that unit in the current search results.This incresases its distance and thus a di�erent unitmay be selected if the units are quite similar to eachother.
Overrides: object.__init__
reset(self )
helper method to reset the cost function
get_results(self, results)
check_repeats(unit)
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
82

B.2 Module hmosaic.settings
This �le contains settings for the project. e.g. * Ip addresses, portsand allowable address strings for OSC communication. * Filepathsto target corpus, test_corpus. * shortcuts for analysis keys andpaths to Essentia Binaries.
B.2.1 Variables
Name DescriptionCLIENT_IP Value: 'localhost'CLIENT_PORT Value: 8000SERVER_IP Value: 'localhost'SERVER_PORT Value: 8001TARGET_REPO Value:
'$HOME/target_corpus'SAVE_TMP_NA-ME
Value: 'saved_mosaic.wav'
HAPPY Value: 'highlevel.mood_-happy.all.happy'
SAD Value: 'highlevel.mood_-sad.all.sad'
RELAXED Value: 'highlevel.mood_-relaxed.all.relaxed'
AGGRESSIVE Value: 'highlevel.mood_-aggressive.all.aggressive'
BPM Value: 'rhythm.bpm'LIVE Value: 'highlevel.live_-
studio.all.live'STUDIO Value: 'highlevel.live_-
studio.all.studio'VOCAL Value: 'highlevel.voice_-
instrumental.all.voice'INSTRUMENTAL Value: 'highlevel.voice_-
instrumental.all.instrumental'MALE Value:
'highlevel.gender.all.male'FEMALE Value:
'highlevel.gender.all.female'LOUDNESS Value:
'lowlevel.spectral_-rms.mean'
continued on next page
83

Name DescriptionLENGTH Value: 'metadata.audio_-
properties.length'PITCH Value:
'lowlevel.pitch.mean'SCALE Value: 'tonal.key_scale'KEY Value: 'tonal.key_key'ESSENTIA_BIN_-DIR
Value: ''
TARGET_ANAL-YSER
Value: 'streaming_-extractor_target'
DEFAULT_ANA-LYSER
Value:'streaming_extractor'
SOURCE_REPO Value: '$HOME/AudioCorpus'TEST_DATA_DI-R
Value: '$HOME/test_data'
TEST_CORPUS_-REPO
Value:'$HOME/test_corpus_repo'
TEST_CORPUS Value: 'test_corpus'ADDRESS_STRI-NGS
Value: ['setSourceCorpus','analyseCorpus','setTarget', 'proces...
CHOP_SIZES Value: [500, 1000, 1250,'onsets']
FILE_LOGGING Value: NoneSCREEN_LOGGI-NG
Value: 'DEBUG'
__package__ Value: 'hmosaic'
84

B.3 Module hmosaic.utils
Contains functions which are repeatedly used by di�erent parts ofthe framework.
B.3.1 Functions
to_mono(audio_data)
Accepts an array of audio data and converts it tomono, ensuring that it is represented as an array of32bit �oating point numbers.
calc_chop_from_bpm(bpm)
secs_to_samps(time, sr)
chop_to_ms(sr, chop)
get_�xed_onsets(chop, length)
get_directories(path)
most_recent_�rst(paths)
Orders a list of �lepaths by most recently modi�ed�rst.
get_�les_recursive(directory, ext='.wav')
Generator to �nds all �les with extension 'ext'
wav_timestamp(�lename)
Returns a �lename or path renamed to contain atimestamp, unique to the minute...
switch_ext(name, ext)
load_yaml(self, analysis_�lepath)
Uses yaml to return a dictionary of analysis valuesgiven an �analysis_�lepath�
85

prepare_thresholds(func, *args)
A decorator to clean the thresholds string and pass itto the function.
get_db_connection(dbname)
Opens a connection to the database. The db isassumed to be in the same directory. Returns a�Store� interface to the db.
get_gaia_point(�lepath)
Tries to load an essentia yaml analysis �le (speci�ed in`�lepath`) as a gaia point.
timestretch(unit, length, sr)
Stretches a `hmosaic.models.MosaicUnit` to the given**length** for the speci�ed sample rate, **sr**.
B.3.2 Variables
Name Description__package__ Value: 'hmosaic'
86

B.4 Module hmosaic.analyse
Di�erent music content analysers are stored here. The system wasbuilt on top of Essentia, however in order to use some other analyseryou just need to provide
B.4.1 Variables
Name Description__package__ Value: 'hmosaic'
B.4.2 Class EssentiaError
object
exceptions.BaseException
exceptions.Exception
hmosaic.analyse.EssentiaError
Methods
Inherited from exceptions.Exception
__init__(), __new__()
Inherited from exceptions.BaseException
__delattr__(), __getattribute__(), __getitem__(),__getslice__(), __reduce__(), __repr__(), __setattr_-_(), __setstate__(), __str__(), __unicode__()
Inherited from object
__format__(), __hash__(), __reduce_ex__(), __-sizeof__(), __subclasshook__()
Properties
Name DescriptionInherited from exceptions.BaseException
args, messagecontinued on next page
87

Name DescriptionInherited from object
__class__
B.4.3 Class EssentiaAnalyser
Is used for invoking the binary essentia analyser. It may be run inbatch mode or for a single �le. The extracted analysis is alwayswritten to a .yaml �le with the same �lepath as the original .wav�le which was presented for analysis.
Methods
__init__(self )
Sets the essentia binary to the path stored in settings.
analyse(self, audio_�les)
Parameter is a list of audio �les. A generator isreturned with the analysis data for each �le.
set_bin(self, bin_name)
Allows dynamic switching of binary analysers, e.g. foranalysing solely low level features one can enjoy amuch faster analysis process by switching the analyserbinary. The only constraint is that the new binarymust be stored in the same directory as the defaultsetting (read from settings.py)
analyse_audio(self, audio_�lepath)
This function invokes the essentia binary. Reads in theoutput �le, deletes the �le and returns a dictionary.
88

B.5 Module hmosaic.segment
Contains all models related to segmentation. Aubio and Essentiaare both utilised by di�erent routines.
B.5.1 Variables
Name Description__package__ Value: 'hmosaic'__warningregistry-__
Value: {('Not importingdirectory\'/home/john/thesis/hmosaic/es...
B.5.2 Class AudioSegmenter
Basic �xed length segmenter. Is initialised with a given �chop� size(in ms) and provides methods to retrieve an array of marked audiodata and a generator function to yield units of segmented audio,which can be written to the corpus. This class may be consideredthe base class for a segmenter. Any subclasses ought to overridethese 3 object functions
Methods
__init__(self, chop=500, hop=None)
Set the chop time and/or hopsize here.
segment(self, �lepath)
Tries to create an Audio instance here. Yieldssegments of sample data.
mark_audio(self, �lepath)
B.5.3 Class NoteOnsetSegmenter
object
hmosaic.segment.NoteOnsetSegmenter
89

This is a pure essentia segmenter. I have found that hfc and rmsgive better result so that's why the defaults are as they are. Weightsare evaluated as 1. complex, 2. hfc, 3. rms
Methods
__init__(self, sr=44100, frame_size=4096,hop_size=512, onset_weights={'complex': 1,'flux': 0.0, 'hfc': 1, 'rms': 1},�lter_audio=False, aubio=False,�xedlength=False)
x.__init__(...) initializes x; seex.__class__.__doc__ for signature
Overrides: object.__init__
set_weights(self, weights)
Expects weights to be a valid onset_weightsdictionary
segment(self, �lepath)
mark_audio(self, �lepath)
write_aubio_onsets(self, onset_list, �lepath)
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
Class Variables
90

Name Descriptiondefaults Value: {'complex': 1,
'flux': 0.0, 'hfc': 1,'rms': 1}
91

B.6 Module hmosaic.models
This module contains most of the models used in the framework.This includes **storm** ORM models, as well as quite sophisticatedMosaic models which keep track of their constituent units and canapply global crossfades and timestretching.
B.6.1 Variables
Name Description__package__ Value: 'hmosaic'
B.6.2 Class DBSong
object
hmosaic.models.DBSong
Information about the full source audio �les
Methods
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __init__(), __new__(), __reduce__(),__reduce_ex__(), __repr__(), __setattr__(), __-sizeof__(), __str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
Class Variables
Name Description__storm_table_-_
Value: 'song'
id Value: Int(primary= True)
continued on next page
92

Name Descriptionsong_name Value: Unicode()male Value: Float()female Value: Float()vocal Value: Float()instrumental Value: Float()
B.6.3 Class DBSegment
object
hmosaic.models.DBSegment
Information about segments drawn from the *DBSongs* Containshigh level analysis data like *male*, *female* *vocal*, *instrumen-tal*, etc.
Methods
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __init__(), __new__(), __reduce__(),__reduce_ex__(), __repr__(), __setattr__(), __-sizeof__(), __str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
Class Variables
Name Description__storm_table_-_
Value: 'segment'
id Value: Int(primary= True)song_name Value: Unicode()
continued on next page
93

Name Descriptionsong Value:
Reference(song_name,DBSong.song_name)
segment_name Value: Unicode()segment_duration Value: Int()vocal Value: Float()instrumental Value: Float()male Value: Float()female Value: Float()
B.6.4 Class SegmentAudio
Very simple audio class - encapsulates the following informationabout an audio �le: * ��lepath� - location of original �le. * �au-dio_array� - 32bit �oating point array of audio signal. * �sample_-rate� - Sampling rate of the audio. * �format� - format of the wav�le. * �name� - basename from the �lepath * �samples� - number ofsamples in the array * �length� - Length of the audio in seconds.
Designed to be used with a segmenter but it is generic enough to beused elsewhere (or as a base class)
Methods
__init__(self, �lepath)
B.6.5 Class Unit
This class is also designed to be used with segmenters, it is intendedto be the �unit� which is yielded in the �segment� routine. Unlikethe SegmentAudio class, this Unit class does not read an audio �le.All parameters are passed to it in the initialiser.
It stores only the following attributes: * �data� - 32bit �oating pointarray of audio signal. * �sample_rate� - Sampling rate of the audio.* �length� - Length of the audio in seconds.
94

Methods
__init__(self, data, sample_rate, length)
Set parameters to be instance attributes forencapsulation of unit data.
B.6.6 Class Mosaic
A Mosaic object containing methods to concatenate units, crossfadeunits, persist to disk, play the units, etc.
Methods
__init__(self, �lepath=None, units=None)
Can be initialised from a ��lepath� or from an array ofUnit objects, or with no default audio - an emptycontainer. If initialised with units or �lepath, the datais parsed and �self._calculate_metadata� is called topopulate �Mosaic� attributes.
add_unit(self, unit)
Adds a �unit� of type �Unit� to the Mosaic.
crossfade(self, overlap=50)
Apply fade in and FADE OUT AND overlap theresults.
New approach applies a fade to the �rst and last'overlap' ms.
normalise(self, factor=0.99)
Normalise the data array and scale by �factor� Thisoperation acts on the �data� attribute of the mosaic,so it should be performed after crossfading andtimestretching.
95

timestretch(self, length=None, crossfade=None)
Timestretch each unit to match the given length (inms). If �crossfade� is not **None** then take thecrossfade into account for the stretch. This functionuses the **Rubberband** timestretching library. Ifthe stretch is extreme then the sound may beextremely degraded. For each unit - we write it to anaudio�le, perform the timestretch and read back in theaudio �le and then we crossfade.
persist(self, �lepath=None)
Saves the mosaic to that location on disk indicated bythe `�lepath` parameter.
play(self )
Convenience wrapper for the �play� function, importedas �play_array� from �scikits.audiolab�
merge_mosaics(self, mosaic)
Accepts a �mosaic� of type �Mosaic� as a parameterand merges the units from this mosaic into the currentone.
add_audio_samples(self, data)
Public accessor method for the private�self._append_data� function. Allows arrays ofsample data to be added directly to the mosaic.
export(self, �lepath)
Exports the mosaic to the given ��lepath�
play_units(self, no_units=None, start_unit=0)
Convenience method to create and play a submosaicin one function call.
create_submosaic(self, no_units, start_unit=0)
Create a submosaic starting from the given�start_unit�, with a length of �no_units�.
96

get_submosaic(self, no_units=None, start_unit=0)
Convenience method to get a submosaic.
B.6.7 Class MosaicUnit
object
hmosaic.models.MosaicUnit
Another bare bones audio class - practially identical to SegmentAu-dio, except that it can be marked as silent, and it can also recalculateits own properties.
Methods
__init__(self, �lepath)
Sets the �lepath and calculates the attributes of the�MosaicUnit�
Overrides: object.__init__
recalculate(self )
If unit is set to silent then this method should becalled. It recalculates length and no of samples.
set_�lepath(self, path)
When passed a valid wav �le into �path�, this �le isread and the current data is replaced by this new data.
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
97

B.6.8 Class DataUnit
Simplest represenation - just an array of mono signal.
Methods
__init__(self, data)
98

B.7 Module hmosaic.corpus
Contains all code related to database and �le management aspectsGaia similarity search is also encapsulated in here. . Base classesare de�ned and a �le based database management system is imple-mented.
B.7.1 Variables
Name Description__package__ Value: 'hmosaic'
B.7.2 Class CorpusManager
object
hmosaic.corpus.CorpusManager
Known Subclasses: hmosaic.corpus.FileCorpusManager
Abstract base class for a CorpusManager. A corpus manager knowsabout all existing corpuses. It can create and delete corpuses, listall the available corpuses and return a corpus instance. This baseclass has been kept very abstract so as to allow maximum �exibility.All of the below methods ought to be implemented in a subclass, soas to allow modularity and interchangeable components.
Methods
__init__(self )
Initialsise the manager.
Overrides: object.__init__
list_corpuses(self )
Returns a list of available corpuses.
create_corpus(self, corpus_name)
Creates a corpus.
99

load_corpus(self, corpus_name)
Returns an instance of the corpus indicated bycorpus_name.
delete_corpus(self, corpus_name)
Deletes the corpus indicated by corpus_name!!!
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
B.7.3 Class Corpus
object
hmosaic.corpus.Corpus
This is a corpus, it can yield units based on supplied constraints.This base class has been kept very abstract so as to allow maximum�exibility. All of the below methods ought to be implemented in asubclass, so as to allow modularity and interchangeable components.
Methods
__init__(self, �lepath)
Initialiser for the base class.
Overrides: object.__init__
100

list_audio_�les(self )
Returns �lepaths for all audio �les. The criteria forwhich units to select would be implemented byoverriding this function.
list_audio_units(self )
Returns �lepaths for all units. The criteria for whichunits to select would be implemented by overridingthis function.
store_audio(self )
Provides a means to add audio to the corpus ...
segment_audio(self, name)
Segments the audio into units. This function mayinstantiate an object from �hmosaic.segment� to takecare of the segmentation details.
save_marked_audio(self, name)
Returns the audio �le requested.
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
101

B.7.4 Class CorpusDoesNotExistException
object
exceptions.BaseException
exceptions.Exception
hmosaic.corpus.CorpusDoesNotExistException
Thrown when loading or deleting a corpus which does not exist.
Methods
Inherited from exceptions.Exception
__init__(), __new__()
Inherited from exceptions.BaseException
__delattr__(), __getattribute__(), __getitem__(),__getslice__(), __reduce__(), __repr__(), __setattr_-_(), __setstate__(), __str__(), __unicode__()
Inherited from object
__format__(), __hash__(), __reduce_ex__(), __-sizeof__(), __subclasshook__()
Properties
Name DescriptionInherited from exceptions.BaseException
args, messageInherited from object
__class__
102

B.7.5 Class CorpusExistsException
object
exceptions.BaseException
exceptions.Exception
hmosaic.corpus.CorpusExistsException
Thrown when attempting to create a corpus which already exists.
Methods
Inherited from exceptions.Exception
__init__(), __new__()
Inherited from exceptions.BaseException
__delattr__(), __getattribute__(), __getitem__(),__getslice__(), __reduce__(), __repr__(), __setattr_-_(), __setstate__(), __str__(), __unicode__()
Inherited from object
__format__(), __hash__(), __reduce_ex__(), __-sizeof__(), __subclasshook__()
Properties
Name DescriptionInherited from exceptions.BaseException
args, messageInherited from object
__class__
103

B.7.6 Class FileExistsException
object
exceptions.BaseException
exceptions.Exception
hmosaic.corpus.FileExistsException
Thrown when the �le already exists in the corpus.
Methods
Inherited from exceptions.Exception
__init__(), __new__()
Inherited from exceptions.BaseException
__delattr__(), __getattribute__(), __getitem__(),__getslice__(), __reduce__(), __repr__(), __setattr_-_(), __setstate__(), __str__(), __unicode__()
Inherited from object
__format__(), __hash__(), __reduce_ex__(), __-sizeof__(), __subclasshook__()
Properties
Name DescriptionInherited from exceptions.BaseException
args, messageInherited from object
__class__
104

B.7.7 Class FileNotFoundException
object
exceptions.BaseException
exceptions.Exception
hmosaic.corpus.FileNotFoundException
Thrown when a �le cannot be found.
Methods
Inherited from exceptions.Exception
__init__(), __new__()
Inherited from exceptions.BaseException
__delattr__(), __getattribute__(), __getitem__(),__getslice__(), __reduce__(), __repr__(), __setattr_-_(), __setstate__(), __str__(), __unicode__()
Inherited from object
__format__(), __hash__(), __reduce_ex__(), __-sizeof__(), __subclasshook__()
Properties
Name DescriptionInherited from exceptions.BaseException
args, messageInherited from object
__class__
B.7.8 Class FileCorpusManager
object
hmosaic.corpus.CorpusManager
hmosaic.corpus.FileCorpusManager
105

Methods
__init__(self, �lepath)
For now keep corpus discovery simple. A corpus is justa directory indicated by �lepaths It containssubdirectories �lled with wav �les, which contain theaudio and json �les which contain the analysis.
Overrides: object.__init__
list_corpuses(self )
All the subdirectories in self.repository are assumed tobe �le corpuses.
Overrides:hmosaic.corpus.CorpusManager.list_corpuses
create_corpus(self, corpus_name)
Creates an empty corpus by creating a directory in therepository. Raises an exception if the corpus of thatname already exists.
Overrides:hmosaic.corpus.CorpusManager.create_corpus
load_corpus(self, corpus_name)
Raises an exception if the corpus indicated bycorpus_name doesn't exist. Returns an instance of aFileCorpus otherwise.
Overrides:hmosaic.corpus.CorpusManager.load_corpus
delete_corpus(self, corpus_name)
Will delete the corpus!!! Returns True upon successfuldeletion, False otherwise
Overrides:hmosaic.corpus.CorpusManager.delete_corpus
Inherited from object
__delattr__(), __format__(), __getattribute__(), _-_hash__(), __new__(), __reduce__(), __reduce_-
106

ex__(), __repr__(), __setattr__(), __sizeof__(), _-_str__(), __subclasshook__()
Properties
Name DescriptionInherited from object
__class__
B.7.9 Class FileCorpus
This is a corpus, it can yield units based on supplied constraints.All analysis is stored as a yaml file and is produced by Essentia.Whole files can be analysed using high level analysis, while unitsare analysed using a stripped down version of the analysis as it ismuch faster.Gaia is used to build DataSets of the analysed units. Eachsegmentation of the source audio file (e.g. based on detected onsets orusing a fix length chop size for segmentation like 500 ms,1000 ms,etc.)It is recommended to keep these Datasets relatively smalle.g. 15000 units.Performance issues have been encountered using larger DataSets(> 30000 units)A file corpus looks like this
corpus_name---> unit_ds_onsets.db---> unit_ds_500.db---> unit_ds_1000.db---> audio1.wav---> audio1.yaml---> audio1
---> 500---> 1.wav---> 2.wav---> 3.wav
---> 1000---> 1.wav
---> onsets---> 1_0.wav
107

---> 1_0.yaml---> 2_1.wav---> 2_1.yaml---> 3_1.wav---> 3_1.yaml---> 4_2.wav---> 4_2.yaml
Methods
__init__(self, �lepath)
Initialises itself to the �lepath. This is where all theaudio and analysis is.
store_audio(self, audio_�lepath, �lename=None)
Adds audio to the corpus. If ��lename� is supplied,then the source audio is added to the corpus using that�lename. Otherwise the basename of �audio_�lepath�is used. Source �les must be unique in the corpus, soan exception is raised if this name already exists. The�le is then converted to monophonic, 44.1 kHz wavformat before being stored in the corpus.
delete_audio(self, �lename)
Deletes the given audio at ��lename� and all it'sassociated units. ��lename� can be the basename ofthe audio in the corpus or the full �lepath to the audioin the corpus.
list_audio_�les(self )
Lists those audio �les all audio �les in the corpus. 1big assumption: Audio �les are *.wav always!!
list_audio_units(self, audio_�lename=None,chop=None)
Return full �lepaths for all units
108
get_�lepath(self, �lename)
Given the name of a �le, ��lename� which was addedto the corpus, this function returns the full �lepath ofthe �le inside the corpus or **None** if ��lename�cannot be found.
search_audio_�les(self, pattern)
Accepts a regular expression and returns those�lenames which match.
get_most_recent(self )
Gets the most recently created segment and returnsthe corresponding audio �le. This can be used to setthe most recently target - useful for testing!
store_info(self, info_dict, �lename)
Stores information in the `info_dict` to disk atlocation indicated by �lename.
segment_audio(self, audio_�lepath, chop=500,hop=None, onset_weights={}, aubio=False)
Takes an audio �le and segments it according to thechop value (milliseconds). A subfolder is created, samename as the audio �le, inside this folder, we haveanother folder with the chop time and the units areheld in there.
save_marked_audio(self, �lename,onset_weights={}, aubio=None, chop=None)
Looks for a name - which should be in the db andmarks the current onsets and saves the �le to thecorpus.
create_gaia_db(self, chop='onsets')
Creates Gaia datasets for all units of the given �chop�segmentation scheme from all the .yaml �les producedby the essentia analysis.
109

get_gaia_unit_db(self, chop='onsets')
Returns a gaia db instance for similarity searching.Gaia databases are composed of all units from a givenchop size, although in the case of onsets basedsegmentation unit size is variable. The �chop�argument is therefore required as it will be present inthe �lename of the Gaia DataSet on disk.
110

Appendix CSystem Scripts Documentation
111

C.1 Module hmosaic.scripts.convertAudio
This is a commandline script for checking the test_data directoryfor mp3s and �acs and converting them to wav �les. Takes care ofdodgy �lenames too!
C.1.1 Functions
execute_�ac_convert()
Cycles through test_data, converting all �ac to wavScript includes a utility remove spaces and problemcharacters from �le name
execute_mp3_convert()
Cycles through test_data, converting all mp3 to wavScript includes a utility remove spaces and problemcharacters from �le name. **WARNING** - Thisroutine uses �mpeg to convert the mp3s. It will fail if�mpeg is not installed *or* if �mpeg is installedwithout mp3 support.
rename_wavs()
Short utility script to rename the wav �les.
strip_all(input_string)
Remove problem characters from �lenames. Minimisesannoying errors later on. Better safe than sorry!!
C.1.2 Variables
Name Description__package__ Value: 'hmosaic.scripts'
112

C.2 Module hmosaic.scripts.createHighLevelChops
C.2.1 Functions
gaia_transform(points)
Takes a dict of point names and �lepaths. Creates aDataSet and performs the standard transformations
get_unused_descriptors()
Gets some descriptors which are not commonly usedin order to remove them from the analysis
process_highlevel(corpus, �lepath, chop)
Utility method used to test the hierarchical systemand create high level segments along with analysis andconstituent units stored in a gaia dataset for a given�corpus� and �le from that �corpus� .
highlevel_mosaic(target, tcorpus, scorpus, scope=5)
This will be used to test the highlevel mosaicingprocess. The scope variable controls the number ofresults which are returned for each target unit whichis sought.
initial_test()
Helper method used for analysing a couple of corpusesat once.
process_corpus_highlevel(corpus_name, chop)
Wrapper for the **process_highlevel** method inorder to process all �les in a given **corpus** for agiven **chop**
C.2.2 Variables
Name Description__package__ Value: 'hmosaic.scripts'
113

C.3 Module hmosaic.scripts.processTestData
This is a commandline script for processing the test data. It callssegementation routines, analysis routines, etc. and stores all outputin the test corpus. This module also contains some functions forgathering data during experiments.
C.3.1 Functions
segment(chop)
Segment all audio �les in the test corpus according to�chop�.
analyse_essentia_units(chop)
Analyse all essentia units of segmentation type: �chop�in the test corpus.
analyse_essentia_�les(corpus_name='test_-corpus')
Analyse all essentia units of segmentation type: �chop�in the test corpus.
create_and_populate()
Recreates **settings.TEST_CORPUS** from the setof �les in **settings.TEST_DATA_DIR**, converts
run_tasks()
Very rough and ready set of instructions to process.Delete the test_corpus and start over, segment andanalyse di�erent chop sizes.
display_�le_values(*args)
Display an aribitrary set of descriptor values fromanalysis contained in **settings.TEST_CORPUS**.The descriptor keys ought to be passed in �args�
create_db()
Recreates the database with the segment information
114

add_to_db()
Recreates the song table in the database.
gather_csv_data(*args)
This function gets given a corpus and extracts thedescriptors given in the *args* to the function. Itrecords this data, audio �le name and segmentduration.
gather_db_data()
This function gets given a corpus and extracts thedescriptors for male, female, vocal and instrumental.It encapsulates this data, along with audio �le name,segment �lepath and segment duration in a`hmosaic.models.DBSegment object and then stores itin a sqlite database.
create_mood_mosaics(*args)
Given a path to some mood music this function loadsup the moods, creates a mosaic with each mood andsaves them.
check_gender(*args)
Checks the analysis in *TEST_CORPUS* in order toascertain the male/female values of each one. Thosewhich score higher than 0.85 are added to a list whichis returned
run_gender_analysis()
Analyse the �les in a corpus called **gender** in**settings.TEST_CORPUS_REPO**.
run_gender_report(*args)
Checks the database and runs a report. We includevocal/instrumental and male/female. Actual genderwill have to be entered manually.
gender_breakdown()
Process the results of the gender analysis experiments
115

add_gender(*args)
Checks the analysis in *TEST_CORPUS* in order toascertain the male/female values of each one. Thosewhich score higher than 0.85 have their values plustheir name added to the db.
map_mosaics(corpus_name, chop,from_scratch=False, hop=False)
Returns dictionary containing mood values over timefor all audio �les in the test corpus. The resolution ofthe graphs can be increased using the **hop**parameter (a value between 0 and 1 indicating overlapfactor).
C.3.2 Variables
Name Description__package__ Value: 'hmosaic.scripts'
116

C.4 Module hmosaic.scripts.plotResults
C.4.1 Functions
scatterPlotIt()
Makes scatterplots based on the results of the genderanalysis for songs and segments.
barChartIt()
Makes a bar chart based on the results of the genderanalysis for songs and segments.
plot_mosaic_curves(g, key, tune)
Takes the graph from**hmosaic.scripts.processTestData.map_mosaics**,along with values for mood key and tune and plots thegraphs.
C.4.2 Variables
Name Description__package__ Value: 'hmosaic.scripts'
117

Listing C.1: "Extracting analysis information"
def gather_db_data ( ) :"""
This f unc t i on e x t r a c t s the d e s c r i p t o r va l u e sf o r male , female , voca l and ins t rumenta l c l a s s i f i e r s .I t encap su l a t e s t h i s data , a long wi th audio f i l e name ,segment f i l e p a t h and segment dura t ion in a` semanticmosaic . models . DBSegment o b j e c t and then s t o r e si t in a s q l i t e database .
"""cm = FileCorpusManager ( s e t t i n g s .TEST_CORPUS_REPO)corpus = cm. load_corpus ( s e t t i n g s .TEST_CORPUS)create_db ( )s t o r e = get_db_connection ( )
for f in corpus . l i s t_aud i o_ f i l e s ( ) :for s in corpus . l i s t_aud io_uni t s (
audio_fi lename=os . path . basename ( f ) ) :try :
a = get_gaia_point ( switch_ext ( s , ' . yaml ' ) )except Exception , e :
l og . e r r o r ( ' Ana lys i s not found . Must be s i l e n t ' )continue
seg = DBSegment ( )seg . song_name = unicode ( os . path . basename ( f ) )seg . segment_name = unicode ( s )seg . segment_duration = in t ( os . path . basename (
os . path . dirname ( s ) ) )seg . voca l = f l o a t ( a [ s e t t i n g s .VOCAL] )seg . in s t rumenta l = f l o a t ( a [ s e t t i n g s .INSTRUMENTAL] )seg . male = f l o a t ( a [ s e t t i n g s .MALE] )seg . female = f l o a t ( a [ s e t t i n g s .FEMALE] )s t o r e . add ( seg )
s t o r e . commit ( )s t o r e . f l u s h ( )s t o r e . c l o s e ( )
Listing C.2: "DBSegment object"
class DBSegment( ob j e c t ) :"""
A segment wi th ana l y s i s i n f o .
"""__storm_table__ = "segment"id = Int ( primary=True )song_name = Unicode ( )segment_name = Unicode ( )segment_duration = Int ( )voca l = Float ( )
118

i n s t rumenta l = Float ( )male = Float ( )female = Float ( )
Listing C.3: "Example SQL statement to extract analysis results from the DB"
select count (∗ ) from segment where
song_name=' RickAst l eyS l eep ingAcape l l a . wav ' and
segment_duration=200;select count (∗ ) from segment where
song_name=' RickAst l eyS l eep ingAcape l l a . wav 'and segment_duration=200 and male > 0 . 5 ;select count (∗ ) from segment where
song_name=' RickAst l eyS l eep ingAcape l l a . wav 'and segment_duration=200 and f emale > 0 . 5 ;
Listing C.4: "Function to randomly pick 7 audio �les from each mood category"
def pick_mood_collection ( ) :
for f in os . l i s t d i r ( s e t t i n g s .MOOD_COLLECTION) :os . remove ( f )
sad_songs = f i l t e r ( lambda x : x . s p l i t ( ' . ' ) [ 1 ] == 'wav ' ,[ os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' sad ' , x ) for x in
os . l i s t d i r ( os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' sad ' ) ) ] )happy_songs = f i l t e r ( lambda x : x . s p l i t ( ' . ' ) [ 1 ] == 'wav ' ,
[ os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' happy ' , x ) for x in
os . l i s t d i r ( os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' happy ' ) ) ] )re laxed_songs = f i l t e r ( lambda x : x . s p l i t ( ' . ' ) [ 1 ] == 'wav ' ,
[ os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' r e l axed ' , x ) for x in
os . l i s t d i r ( os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' r e l axed ' ) ) ] )aggress ive_songs = f i l t e r ( lambda x : x . s p l i t ( ' . ' ) [ 1 ] == 'wav ' ,
[ os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' a gg r e s s i v e ' , x ) for x in
os . l i s t d i r ( os . path . j o i n ( s e t t i n g s .MOOD_DATASET, ' a gg r e s s i v e ' ) ) ] )for i in range ( 7 ) :
s h u t i l . c o p y f i l e ( sad_songs [ randint ( 0 , 1 11 ) ] ,os . path . j o i n ( s e t t i n g s .MOOD_COLLECTION,
'SADTARGET%d .wav ' % ( i +1)))s h u t i l . c o p y f i l e ( happy_songs [ randint ( 0 , 1 11 ) ] ,
os . path . j o i n ( s e t t i n g s .MOOD_COLLECTION,'HAPPYTARGET%d .wav ' % ( i +1)))
s h u t i l . c o p y f i l e ( re laxed_songs [ randint ( 0 , 1 11 ) ] ,os . path . j o i n ( s e t t i n g s .MOOD_COLLECTION,
'RELAXEDTARGET%d .wav ' % ( i +1)))s h u t i l . c o p y f i l e ( aggress ive_songs [ randint ( 0 , 1 11 ) ] ,
os . path . j o i n ( s e t t i n g s .MOOD_COLLECTION,'AGGRESSIVETARGET%d .wav ' % ( i +1)))
Listing C.5: "Function to create barcharts to compare hierarchical and non-hierarchical systems."
def moodBarChart (mood , met r i c s=None ) :N = 28width = 0 .2ind = np . arange (N)#hlp = re . compi le ( ' h l .+MOSAIC. wav ' )#l l p = re . compi le ( ' l l .+MOSAIC. wav ' )map( l i s t . sor t , [ met r i c s [mood ] [ t ]
for t in metr i c s [mood ] ] )l l S c o r e s = [ met r i c s [mood ] [ t ] [ 1 ]
for t in metr i c s [mood ] ]h lS co r e s = [ met r i c s [mood ] [ t ] [ 0 ]
for t in metr i c s [mood ] ]l a b e l s = [ k for k in metr i c s [mood ] . keys ( ) ]map( l i s t . sor t , [ l a b e l s , h lScores , l l S c o r e s ] )combscores = z ip ( [ f l o a t ((1− s [ 1 ] ) ∗ 1 0 0 )
119

for s in l l S c o r e s ] ,[ f l o a t ((1− s [ 1 ] ) ∗ 1 0 0 ) for s in h lSco r e s ] )
b e t t e r = 0for p in combscores :
i f p [ 0 ] < p [ 1 ] :b e t t e r += 1
f i g = f i g u r e ( )ax = f i g . add_subplot (111)r e c t s 1 = ax . bar ( ind , [ f l o a t ((1− s [ 1 ] ) ∗ 1 0 0 )
for s in h lSco r e s ] , width , c o l o r=' red ' )r e c t s 2 = ax . bar ( ind+width , [ f l o a t ((1− s [ 1 ] ) ∗ 1 0 0 )
for s in l l S c o r e s ] , width , c o l o r=' blue ' )ax . s e t_y labe l ( ' S im i l a r i t y to Target (%) ' )ax . s e t_ t i t l e ( 'Model Comparison f o r %s mood va lue s : \
H i e r a r c h i c a l b e t t e r in %d out o f 28 ca s e s ' % be t t e r )ax . s e t_xt i ck s ( ind+width )ax . s e t_x t i c k l ab e l s ( l a b e l s )ax . l egend ( ( r e c t s 1 [ 0 ] , r e c t s 2 [ 0 ] ) ,
( ' H i e r c h i c a l Model ' , 'Non−Hi e r a r c h i c a l Model ' ) )
Listing C.6: "Function to compare perceptual loudness of mosaics produced byhierarchical and non-hierarchical means"
#!/ usr / b in /env pythonimport os
import s c ipy . s t a t s as s t a t simport numpy as np
from hmosaic . ana lyse import LoudnessAnalyserfrom hmosaic . corpus import FileCorpusManagerfrom hmosaic import s e t t i n g s
def compare_loudness ( ) :cm = FileCorpusManager ( s e t t i n g s .TEST_CORPUS_REPO)corpus = cm. load_corpus ( ' moodexperiment ' )l = LoudnessAnalyser ( )
h l_ f i l e s = f i l t e r (lambda f : os . path . basename ( f ) . s t a r t sw i t h ( ' h l ' )
and os . path . basename ( f ) . endswith ( 'MOSAIC.wav ' ) ,corpus . l i s t_aud i o_ f i l e s ( )
)h l_ f i l e s . s o r t ( )l l _ f i l e s = f i l t e r (
lambda f : os . path . basename ( f ) . s t a r t sw i t h ( ' l l ' )and os . path . basename ( f ) . endswith ( 'MOSAIC.wav ' ) ,
corpus . l i s t_aud i o_ f i l e s ( ))
hl_edev= [ ]l l_edev = [ ]# get_loudness re turns 10 l o g a r i t hm i c a l l y spaced bands .
120

# Here we take 5 bands from the f requency reg ion# in which the human ear i s most s e n s i t i v e .for f in h l_ f i l e s :
hl_edev . append (np . array ([ reduce (lambda x , y : x+y , frame [ 1 : 6 ] )
for frame in l . get_loudness ( f ) ] ) . s td ( ) )for f in l l _ f i l e s :
l l_edev . append (np . array ([ reduce (lambda x , y : x+y , frame [ 1 : 6 ] )
for frame in l . get_loudness ( f ) ] ) . s td ( ) )
print ( "Average dev i a t i on in perceptua l loudness \ f o r non−h i e r a r c h i c a l mosaics : %f "
% np . array ( l l_edev ) . mean ( ) )print ( "Average dev i a t i on in perceptua l loudness \
f o r h i e r a r c h i c a l mosaics : %f "% np . array ( hl_edev ) . mean ( ) )
t s t a t , pvalue = s t a t s . t t e s t_ r e l ( hl_edev , l l_edev )print ( " t s t a t i s t i c i s %f " % t s t a t )print ( "p−value i s %f " % pvalue )
i f __name__ == '__main__ ' :compare_loudness ( )
121