new approaches to web personalization
DESCRIPTION
New Approaches to Web PersonalizationTRANSCRIPT

Magdalini P. Eirinaki
NEW APPROACHES
TO WEB PERSONALIZATION
Ph.D. THESIS
ATHENS UNIVERSITY OF ECONOMICS AND BUSINESS Dept. of Informatics
May 2006

i
© Copyright by Magdalini P. Eirinaki
2006

ii
ACKNOWLEDGEMENTS
“...And if you find her poor, Ithaka won't have fooled you. Wise as you will have
become, so full of experience, you will have understood by then what these Ithakas
mean." Constantine P. Cavafis (1863-1933)
There are many people that I need to thank for making this long journey so
memorable. First of all, I thank my advisor, Michalis Vazirgiannis, for believing in me
and supporting me all these years, providing me with valuable advice, and giving me the
opportunity to travel to several places and meet very interesting people during project
meetings or conferences.
I would also like to thank the members of my PhD examination committee, namely,
professors Ioannis Milis, Gerhard Weikum, Emmanouil Yakoumakis, Emmanouil
Yannakoudakis, Martha Sideri and Vassilis Vassalos.
I would like to extend my sincerest thanks to my collaborators during my PhD. First
of all, Iraklis Varlamis, for our fruitful discussions that constituted my first steps in
research. Also, Giorgos Tsatsaronis, Dimitris Kapogiannis, and especially Charalampos
Lampos and Stratos Pavlakis, that worked really hard as undergraduate students offering
their excellent implementation skills, as well as valuable insights concerning our work. I
also thank Sarabjot S. Anand and Joannis Vlachakis, my collaborators during a European
project.
As a member of the DB-NET group, I had the chance to meet and befriend many
people. My thanks go to Maria Halkidi, Yannis Batistakis, Christos Pateritsas, Euripides
Vrachnos, Christoforos Ververidis, Christos Doulkeridis, Giorgos Tsatsaronis, Dimitris
Mavroeidis, our wonderful secretary Viky Sambani, and my good friends, Iraklis
Varlamis and Stratis Valavanis, for making these years fun and carefree, even during our
numerous moves, or our deadlines.
“A friend is one who believes in you when you have ceased to believe in yourself”.
There are many times during one’s PhD when one wants to give up. My gratitude goes to
all my friends (thankfully too many to be mentioned individually), especially Elena

iii
Avatagelou, Nikos Karelos, Matoula Kalyveza, my brother Pavlos Eirinakis and my very
best friend, Foteini Glykou, for being there for me.
I should thank the person that motivated me to become a computer scientist, my
uncle, professor Panagiotis Varelas. Throughout the years, he was always challenging me
with brain-teasing mathematical problems, introducing me to the fascinating world of
logic, algorithms, and, eventually, Informatics.
Special thanks to Alkis Polyzotis. He is the one that inspired and motivated me to
start this journey. His insights and advices during all these years enabled me to set higher
standards for my research. He has been a true friend and mentor, and I am very happy
that we have started a new “journey” together.
Finally, I come to the ones I thank the most for their constant love, support, and
encouragement, my parents Kyriaki and Pantelis Eirinakis. They believe in me and
always do everything in their power to let me pursue my dreams. I owe to them
everything that I have accomplished to this day. This thesis is dedicated to them.

iv
TABLE OF CONTENTS
LIST OF FIGURES ........................................................................................................ vii
LIST OF TABLES ........................................................................................................... ix
ABSTRACT...................................................................................................................... xi
1 Introduction.................................................................................................................... 1
1.2 Contributions........................................................................................................ 6
1.3 Thesis Outline ...................................................................................................... 9
2 Preliminaries & Related Work................................................................................... 11
2.1 Usage Data Pre-processing ................................................................................ 11
2.2 Web Usage Mining and Personalization............................................................ 14
2.3 Integrating Content Semantics in Web Personalization..................................... 15
2.4 Integrating Structure in Web Personalization .................................................... 16
3 Semantic Web Personalization ................................................................................... 19
3.1 Motivating Example........................................................................................... 20
3.2 SEWeP System Architecture ............................................................................. 23
3.3 Similarity of Ontology Terms............................................................................ 25
3.3.2 THESUS Similarity Measure.................................................................... 26
3.4 Content Characterization ................................................................................... 26
3.4.1 Keyword Extraction .................................................................................. 27
3.4.2 Keyword Translation ................................................................................ 28
3.4.3 Semantic Characterization ........................................................................ 30
3.5 C-Logs Creation & Mining................................................................................ 32
3.6 Document Clustering ......................................................................................... 32
3.7 Recommendation Engine ................................................................................... 33
3.7.1 Semantic Recommendations..................................................................... 34

v
3.7.2 Category-based Recommendations........................................................... 35
3.8 Experimental Evaluation.................................................................................... 36
3.8.1 Methodology............................................................................................. 37
3.8.2 Experimental Results ................................................................................ 38
3.9 System Prototypes.............................................................................................. 42
3.9.1 SEWeP Prototype...................................................................................... 42
3.9.2 The I-KnowUMine Project ....................................................................... 46
3.9.3 The Greek Web Archiving Project ........................................................... 47
3.10 Conclusions...................................................................................................... 49
4 Link Analysis for Web Personalization ..................................................................... 51
4.1 Motivating Example........................................................................................... 52
4.2 Preliminaries ...................................................................................................... 54
4.2.1 The Navigational Graph............................................................................ 54
4.2.2 Markov Models......................................................................................... 57
4.3 Usage-based PageRank...................................................................................... 60
4.3.1 PageRank .................................................................................................. 60
4.3.2 UPR: Link Analysis on the Navigational Graph ...................................... 62
4.4 Localized UPR (l-UPR) ..................................................................................... 64
4.4.1 The Personalized Navigational Graph (prNG) ......................................... 65
4.4.2 UPR-based Personalized Recommendations ............................................ 68
4.5 Web Path Prediction using hybrid Probabilistic Predictive Models.................. 68
4.5.1 Popular Path Prediction............................................................................. 69
4.5.2 Reconsidering Prior Probabilities’ Computation ...................................... 70
4.6 Experimental Evaluation.................................................................................... 72
4.6.1 Experimental Setup................................................................................... 72
4.6.2 l-UPR Recommendations’ Evaluation...................................................... 74
4.6.3 h-PPM Recommendations’ Evaluation..................................................... 77
4.6.4 Comparison of l-UPR and h-PPM ............................................................ 82
4.7 System Prototype ............................................................................................... 83
4.8 Conclusions........................................................................................................ 87

vi
5 Conclusions and Future Research.............................................................................. 88
5.1 Thesis Summary................................................................................................. 88
5.2 Discussion .......................................................................................................... 90
LIST OF REFERENCES............................................................................................... 95
APPENDIX A................................................................................................................ 103
APPENDIX B ................................................................................................................ 105

vii
LIST OF FIGURES
Figure 1. The web personalization process......................................................................... 3
Figure 2. SEWeP architecture........................................................................................... 24
Figure 3. The keyword translation procedure ................................................................... 30
Figure 4. The semantic characterization process .............................................................. 31
Figure 5. The semantic recommendation method............................................................. 35
Figure 6. The category-based recommendation method .................................................. 36
Figure 7. Experiment #1: Recommendation sets’ evaluation ........................................... 39
Figure 8. Experiment #2: Original vs. Hybrid Recommendations................................... 40
Figure 9. Experiment #3: Semantic vs. Hybrid Recommendations .................................. 41
Figure 10. Experiment #4: Category-based vs. Hybrid Recommendations ..................... 41
Figure 11. SEWeP screenshot: The Logs Preprocessing module ..................................... 44
Figure 12. SEWeP screenshot: the Session Management module.................................... 45
Figure 13. SEWeP screenshot: the Semantic Association Rules Mining module ............ 45
Figure 14. The IKUM system architecture ....................................................................... 46
Figure 15. The Greek Web Archiving system architecture .............................................. 48
Figure 16. PageRank-based example................................................................................ 53
Figure 17. Usage-based PageRank (UPR) example ......................................................... 53
Figure 18. NG Creation Algorithm ................................................................................... 56
Figure 19. Navigational Graph ......................................................................................... 57
Figure 20. NG synopsis (Markov Chain) .......................................................................... 59
Figure 21. prNG of Markov Chain NG synopsis .............................................................. 66
Figure 22. prNG of 2nd order Markov model NG synopsis ............................................. 66
Figure 23. Construction of prNG ...................................................................................... 67
Figure 24. Path expansion subroutine............................................................................... 67
Figure 25. Average OSim and KSim of top-n rankings for msnbc data set....................... 76
Figure 26. Average OSim and KSim of top-n rankings for cti data set............................. 76
Figure 27. OSim for msnbc data set, Markov Chain NG synopsis ................................... 78
Figure 28. KSim for msnbc data set, Markov Chain NG synopsis ................................... 78
Figure 29. OSim for cti data set, Markov Chain NG synopsis.......................................... 79

viii
Figure 30. KSim for cti data set, Markov Chain NG synopsis.......................................... 79
Figure 31. OSim for msnbc data set, 2nd-order Markov model NG Synopsis ................... 81
Figure 32. KSim for msnbc data set, 2nd-order Markov model NG Synopsis ................... 81
Figure 33. Comparison of l-UPR and h-PPM, Markov Chain NG synopsis .................... 83
Figure 34. The Prior Probabilities Computation module.................................................. 85
Figure 35. The Path Probabilities Computation module................................................... 86
Figure 36. The l-UPR Path Prediction module ................................................................. 86

ix
LIST OF TABLES
Table 1: Related Work ...................................................................................................... 18
Table 2. URIs and related concept hierarchy terms.......................................................... 22
Table 3. User Sessions ...................................................................................................... 56
Table 4. Path Frequencies ................................................................................................ 59
Table 5. Top-10 Frequent Paths...................................................................................... 105
Table 6. Top-10 ranking for Start setup.......................................................................... 106
Table 7. Top-10 ranking for Total setup......................................................................... 106


xi
ABSTRACT
The impact of the World Wide Web as a main source of information acquisition is
increasing dramatically. The existence of such abundance of information, in combination
with the dynamic and heterogeneous nature of the web, makes web site exploration a
difficult process for the average user. To address the requirement of effective web
navigation, web sites provide personalized recommendations to the end users. Most of the
research efforts in web personalization correspond to the evolution of extensive research
in web usage mining, i.e. the exploitation of the navigational patterns of the web site’s
visitors. When a personalization system relies solely on usage-based results, however,
valuable information conceptually related to what is finally recommended may be
missed. Moreover, the structural properties of the web site are often disregarded.
In this thesis, we propose novel techniques that use the content semantics and the
structural properties of a web site in order to improve the effectiveness of web
personalization. In the first part of our work we present SEWeP (standing for SEmantic
Web Personalization), a personalization system that integrates usage data with content
semantics, expressed in ontology terms, in order to compute semantically enhanced
navigational patterns and effectively generate useful recommendations. To the best of our
knowledge, SEWeP is the only semantic web personalization system that may be used by
non-semantic web sites.
In the second part of our work, we present a novel approach for enhancing the quality
of recommendations based on the underlying structure of a web site. We introduce UPR
(Usage-based PageRank), a PageRank-style algorithm that relies on the recorded usage
data and link analysis techniques. UPR is applied on an abstraction of the user sessions
termed Navigational Graph in order to determine the importance of a web page. We
develop l-UPR, a recommendation algorithm based on a localized variant of UPR that is
applied to the personalized navigational sub-graph of each user. Moreover, we integrate
UPR and its variations in a hybrid probabilistic predictive model as a robust mechanism
for determining prior probabilities of page visits. Overall, we demonstrate that our

xii
proposed hybrid personalization framework results in more objective and representative
predictions than existing techniques that rely solely on usage data.

1
CHAPTER 1
Introduction
During the past few years the World Wide Web has become the biggest and most
popular way of communication and information dissemination. It serves as a platform for
exchanging various kinds of information, ranging from research papers, and educational
content, to multimedia content, software and personal logs (blogs). Every day, the web
grows by roughly a million electronic pages, adding to the hundreds of millions pages
already on-line. Because of its rapid and chaotic growth, the resulting network of
information lacks of organization and structure. Users often feel disoriented and get lost
in that information overload that continues to expand. On the other hand, the e-business
sector is rapidly evolving and the need for web market places that anticipate the needs of
their customers is more than ever evident. Therefore, the ultimate need nowadays is that
of predicting the user needs in order to improve the usability and user retention of a web
site. This thesis presents novel methods and techniques that address this requirement. We
elaborate on the problems that motivated our work in Section 1.1, and we outline our
contribution in Section 1.2. A rough plan of this thesis is included in Section 1.3.
1.1 Motivation
Imagine a user that navigates through the pages of a web portal, specializing in sports.
We will refer to it (hypothetically) as the “Sportal”, residing on the imaginary site
“www.theSportal.com”. This user is a fan of winter ski and would like to visit a ski resort

2
for the holidays. He therefore searches to find any related information available, ranging
from winter resort hotels to weather reports and ski equipment. Since the amount of
information in the “Sportal” is very big, this information is not necessarily organized as a
single thematic module. Based on this user’s navigation, however, in combination with
previous users’ visits focusing on the same subject (winter ski vacation), the system
makes recommendations to the user.
Assume, for example, that many users in the past have seen the pages
www.theSportal.com/events/ski.html, www.theSportal.com/travel/ski_resorts.html, and
www.theSportal.com/equipment/ski_boots.html during the same visit. If the current user
visits the first two, the system can recommend the third one, based on the assumption that
people with similar interests present similar navigational behavior. Moreover, since the
current visitor seems to be interested in pages concerning the winter, ski, and resorts
thematic areas of the portal, the system may recommend other pages that are related with
these categories, such as a page about ski equipment that is on sale
(www.theSportal.com/equipment/ski_boot_sale.html) or a page about hotels suited for
winter holidays (www.theSportal.com/travel/winter/hotels.html). Finally, we also note
that some pages of the “Sportal” are more important than others in terms of previous
users’ navigation and their position in the web site’s graph. Consider, for example, a page
that provides information on the snow and weather conditions on all the ski resorts
(www.theSportal.com/weather/snowreport.html). If many users have visited this page
before, either by following links from other pages, or by directly “jumping” to it (using a
bookmark, for example), then this page seems important, and can also be recommended
to the current user. What is more, if the “Sportal” has registered users, and therefore can
explicitly collect information concerning their interests and topic preferences, it can
provide related recommendations to each individual visitor.
In brief, web personalization can be defined as any action that customizes the
information or services provided by a web site to an individual user, or a set of users,
based on knowledge acquired by their navigational behavior, recorded in the web site’s
logs, in other words, its usage. This information is often combined with the content and
the structure of the web site, as well as the interests/preferences of the user, if they are

3
available. The web personalization process is illustrated in Figure 1. Using the four
aforementioned sources of information as input to pattern discovery techniques, the
system tailors the provided content to the needs of each visitor of the web site. The
personalization process can result in the dynamic generation of recommendations, the
creation of index pages, the highlighting of existing hyperlinks, the publishing of targeted
advertisements or emails, etc. In this thesis we focus on personalization systems that aim
at providing personalized recommendations to the web site’s visitors. Furthermore, since
the personalization algorithms we propose in this work are generic and applicable to any
web site, we assume that no explicit knowledge involving the users’ profiles, such as
ratings or demographic information, is available.
Figure 1. The web personalization process
The problem of providing recommendations to the visitors of a web site has received
a significant amount of attention in the related literature. Most of the research efforts in
web personalization correspond to the evolution of extensive research in web usage
mining, taking into consideration only the navigational behavior of the (anonymous or
registered) visitors of the web site [ADW02, AP+04, BS04, HEK03, JF+97, KS04,
MD+00a, MPG03, MPT99, NM02, NP03, NP04, SK+00, SK+01]. Pure usage-based

4
personalization, however, presents certain shortcomings. This may happen when, for
instance, there is not enough usage data available in order to extract patterns related to
certain navigational actions, or when the web site’s content changes and new pages are
added but are not yet included in the web logs. Moreover, taking into consideration the
temporal characteristics of the web in terms of its usage, such systems are very
vulnerable to the training data used to construct the predictive model. As a result, a
number of research approaches integrate other sources of information, such as the web
content [AG03, DM02, EGP02, GKG05, JZM04b, JZM05, MD+00b, ML+04, MSR04,
OB+03, PE00] or the web structure [BL06, HLC05, NM03, ZHH02b] in order to enhance
the web personalization process.
As already implied, the users’ navigation is largely driven by semantics. In other
words, in each visit, the user usually aims at finding information concerning a particular
subject. Therefore, the underlying content semantics should be a dominant factor in the
process of web personalization. The web site’s content characterization process involves
the feature extraction from the web pages. Usually these features are keywords
subsequently used to retrieve similarly characterized content. Several methods for
extracting keywords that characterize web content have been proposed [BP98, CD+99,
HG+02]. The similarity between documents is usually based on exact matching between
these terms. This way, however, only a binary matching between documents is achieved,
whereas no actual semantic similarity is taken into consideration. The need for a more
abstract representation that will enable a uniform and more flexible document matching
process, imposes the use of semantic web structures, such as ontologies1 [BHS02,
HN+03]. By mapping the keywords to the concepts of an ontology, or topic hierarchy,
the problem of binary matching can be surpassed through the use of the hierarchical
relationships and/or the semantic similarities among the ontology terms, and therefore,
the documents.
Finally, we should take into consideration that the web is not just a collection of
documents browsed by its users. The web is a directed labeled graph, including a plethora
1 In this work we focus on the hierarchical part of an ontology. Therefore, in the rest of this work we use
the terms concept hierarchy, taxonomy and ontology interchangeably.

5
of hyperlinks that interconnect its web pages. Both the structural characteristics of the
web graph, as well as the web pages’ and hyperlinks’ underlying semantics are important
and determinative factors in the users’ navigational process. We briefly discuss the most
important research studies2 based on the aforementioned intuitions below, while a more
detailed overview of related work is given in Chapter 2.
Several research studies proposed frameworks that express the users’ navigational
behavior in terms of an ontology and integrate this knowledge in semantic web sites
[OB+03], Markov model-based recommendation systems [AG03], or collaborative
filtering systems [DM02]. Overall, all the aforementioned approaches are based on the
same intuition: enhance the web personalization process with content semantics,
expressed using the terms of a domain-ontology. The extracted web content features are
mapped to ontology terms and this abstraction enables the generalizations/specializations
of the derived patterns and/or user profiles. In all proposed models, however, the
ontology-term mapping process is performed manually or semi-automatically (needing
the manual labeling of the training data set). As far as the content characterization
process is concerned, the features characterizing the web content are extracted from the
web page itself, ignoring semantics arising from the connectivity features of the web
[BP98, CD+98]. Some approaches are based on collaborative filtering systems, which
assume that some kind of user ratings are available, or on semantic web sites, which
assume that an existing underlying semantic annotation of the web content is available a
priori. Finally, none of the aforementioned approaches fully exploits the underlying
semantic similarities of terms belonging to an ontology, apart from the straightforward
“is-a” or “parent-child” hierarchical relationships.
As far as the exploitation of the connectivity features of the web graph is concerned,
even though they have been extensively used for personalizing web search results
[ANM04, H02, RD02, WC+02], only a few approaches exist for enhancing the web
recommendation process, either using the degree of link connectivity for switching
among different recommendation models [NM03] or using citation network analysis for
clustering related pages in a recommendation system based on Markov models
2 At this point, we focus on research studies that appeared prior, or in parallel to our work.

6
[ZHH02b]. None of the aforementioned systems, however, exploits the notion of a web
page’s importance in the web graph and fully integrates link analysis techniques in the
web personalization process.
1.2 Contributions
The main contribution of this thesis is a set of novel techniques and algorithms aimed
at improving the overall effectiveness of the web personalization process through the
integration of the content and the structure of the web site with the users’ navigational
patterns.
In the first part of our work we present the semantic web personalization system
SEWeP that integrates usage data with content semantics in order to compute
semantically enhanced navigational patterns and effectively generate useful
recommendations. Similar to previously proposed approaches, the proposed
personalization framework uses ontology terms to annotate the web content and the
users’ navigational patterns. The key departure from earlier approaches, however, is that
SEWeP is the only web personalization framework that employs automated keyword-to-
ontology mapping techniques, while exploiting the underlying semantic similarities
between ontology terms. Apart from the novel recommendation algorithms we propose,
we also emphasize on a hybrid structure-enhanced method for annotating web content.
To the best of our knowledge, SEWeP is the only semantic web personalization system
that can be used by any web site, given only its web usage logs and a domain-specific
ontology.
Our key contributions regarding this framework are:
• A methodology for semantically annotating the content of a web site using
ontology terms. The feature extraction is performed using an integration of
various techniques used in Information Retrieval that exploit both the content and
the connectivity features of the web pages. The mapping of these features to
ontology terms is a fully automated process, using appropriate similarity metrics
and a thesaurus. This characterization enables further processing (clustering,

7
association rules mining etc.) relying on the semantic similarity between web
documents.
• An algorithm for processing multilingual content. All web documents, without
regard to the language they are written in, should be characterized by a set of
terms belonging to a domain-ontology. Therefore, prior to the ontology mapping,
an intermediate step is needed where all the keywords that characterize a
document are translated to a common language. We propose an automated
keyword translation algorithm based on the document’s context.
• Two recommendation algorithms which integrate web content semantics with the
users’ navigational behavior. The web pages are characterized by a set of domain-
ontology terms. This uniform characterization enables the categorization of the
web pages into semantically coherent clusters, as well as the semantic
enhancement of the web logs. These two enhanced sources of knowledge are then
used by the proposed methods to generate recommendations that are semantically
relevant to the current navigational behavior of each user. The first method
generates recommendations by expanding the association rules derived by mining
the web logs, using the most similar document cluster. The second method
generates a new type of association rules, named category-based association rules,
which are computed by mining the semantically enhanced logs (called C-logs)
and expanding the recommendation set based on the most similar document
cluster.
• An extensive set of user-based experiments (blind tests) which demonstrate the
effectiveness of the proposed methods, when integrated in a web personalization
framework, and support our initial intuition that content semantics enhance the
web personalization process.
In the second part of our work, we encompass the notion of authority transfer, as
defined in the most popular link analysis algorithm, PageRank [BP98]. The underlying
assumption is that a web page is considered to be important (in other words is an
authority) if other important pages have a link pointing it. In other words, authority pages
transfer some of their “importance” to the pages they link to, and so on. Motivated by the

8
fact that in the context of navigating a web site, a page/path is important if many users
have visited/followed it before, we propose a novel algorithm, named UPR, that assigns
importance rankings (and therefore visit probabilities) to the web site’s pages. UPR
(Usage-based PageRank) is a PageRank-style algorithm that is applied on an abstraction
of the user sessions termed the Navigational Graph (NG). Based on this generalized
personalization framework, we specialize it in two different contexts. We develop l-UPR,
a recommendation algorithm based on a localized variant of UPR that is applied to the
personalized navigational sub-graph of each user for providing fast, online
recommendations. Moreover, we integrate UPR and its variations in a hybrid
probabilistic predictive model (h-PPM) as a robust mechanism for determining prior
probabilities of page visits. To the best of our knowledge, this is the first integrated
solution addressing the problem of web personalization using a page ranking approach.
More specifically, our key contributions are:
• A unified personalization framework integrating web usage mining with link
analysis techniques for assigning probabilities to the web pages based on their
importance in the web site's navigational graph. We define UPR, a usage-based
personalized PageRank-style algorithm used for ranking the web pages of a site
based on previous users’ navigational behavior.
• The introduction of l-UPR, a localized version of UPR which is applied to
personalized sub-graphs of the web navigational graph in order to provide fast,
online rankings of probable “next” pages of interests to current users. We describe
how these personalized sub-graphs are generated online, based on the current visit
of each user.
• The application of UPR for extending and enhancing standard web usage mining
and personalization probabilistic models such as Markov models. We present a
hybrid probabilistic prediction framework (h-PPM) where UPR, as well as its
variations, are used for assigning prior probabilities to the nodes (pages) of any
Markov model based on the topology (structure) and the navigational patterns
(usage) of the web site.

9
• An extensive set of experiments proving UPR’s effectiveness in both proposed
frameworks. We apply UPR and its variations for assigning priors to be used by
different order Markov models and show that the recommendation accuracy is
better than pure-usage based approaches. Moreover, we apply l-UPR to localized
sub-graph synopses for generating online recommendations and again support our
claim for the need of enhancing the prediction process with information based on
the link structure in combination with the usage of a site.
1.3 Thesis Outline
The rest of this thesis is organized as follows. Chapter 2 presents a brief introduction
to several data preprocessing issues that should be addressed prior to applying any web
personalization techniques. It also reviews related work on the web usage mining and
personalization areas, emphasizing on web personalization methods that integrate content
or structure. All related efforts, including our work are summarized in Table 1, which is
included in the end of this Chapter. In Chapter 3 we present in detail the proposed
semantic web personalization framework. In Chapter 4 we demonstrate how link analysis
can be integrated in the web personalization process. Finally, Chapter 5 concludes this
Thesis and outlines directions for future work.

10

CHAPTER 2
Preliminaries & Related Work
In this Chapter we start by briefly presenting the data preprocessing issues that should
be taken into consideration prior to applying any web mining and personalization
techniques to the usage data. We then provide a review of related research efforts,
ranging from the earlier approaches that focus on web usage mining, to the ones focusing
on web personalization. We then present those that integrate content and/or structure data
in the web personalization process, emphasizing on the research efforts (previous and
subsequent) that are more similar to our work3. We provide a summarized overview of all
related research efforts categorized by the web mining method employed and their
application area in Table 1. The areas covered by our work are depicted by highlighted
cells.
2.1 Usage Data Pre-processing
The main data source in the web usage mining and personalization process is the
information residing on the web site’s logs. Web logs record every visit to a page of the
web server hosting it. The entries of a web log file consist of several fields which
represent the date and the time of the request, the IP number of the visitor’s computer
(client), the URI requested, the HTTP status code returned to the client, and so on. The
web logs’ file format is based on the so called “extended” log format, proposed by W3C
3 A more detailed overview of the related work, as well as references to related commercial products can be
found in [EV03, E04].

12
[W3Clog]. In general, the extended log format consists of a list of prefixes and
identifiers, some of which can be found in Table such as c (client), s (server), r (remote),
cs (client to server), sc (server to client), sr (server to remote server, used by proxies), rs
(remote server to server, used by proxies), x (application-specific identifier), and a list of
identifiers such as date, time, ip (records the IP of the client generating the page hit),
bytes (records the number of bytes transferred), cached (records whether a cache hit
occurred), status (records the status code returned by the web server), comment (comment
returned with status code), method (method used to retrieve data), uri (the URI
requested), uri-stem and uri-query. Using a combination of some of the aforementioned
prefixes and identifiers, additional information such as referrer, that is the web page the
client was visiting before requesting that page, user_agent, that is the software the client
is using, or keyword, that is the keywords used when visiting that page after a search
engine query, can be recorded. Except for the web server logs, which are the main source
of information in the web usage mining and personalization processes, useful information
can be acquired from proxy server logs, browser logs, registration data, cookies, user
ratings etc. Since in this thesis we present a generic personalization framework which can
be applied on any web site, requiring only the anonymous usage data recorded in its web
usage logs, we do not elaborate on such data sources.
Prior to processing the usage data using web mining or personalization algorithms,
the information residing in the web logs should be preprocessed. The web log data pre-
processing is an essential phase in the web usage mining and personalization process. An
extensive description of this process can be found in [CMS99]. In the sequel, we provide
a brief overview of the most important pre-processing techniques, providing in parallel
the related terminology.
The first issue in the pre-processing phase is data preparation. Depending on the
application, the web log data may need to be cleaned from entries involving page
accesses that returned, for example, an error or graphics file accesses. Furthermore,
crawler activity usually should be filtered out, because such entries do not provide useful
information about the site’s usability. A very common problem to be dealt with has to do
with web pages’ caching. When a web client accesses an already cached page, this access

13
is not recorded in the web site’s log. Therefore, important information concerning web
path visits is missed. Caching is heavily dependent on the client-side technologies used
and therefore cannot be dealt with easily. In such cases, cached pages can usually be
inferred using the referring information from the logs and certain heuristics, in order to
re-construct the user paths, filling out the missing pages.
After all page accesses are identified, the pageview identification should be
performed. According to [WCA] a pageview is defined as “the visual rendering of a web
page in a specific environment at a specific point in time”. In other words, a pageview
consists of several items, such as frames, text, graphics and scripts that construct a single
web page. Therefore, the pageview identification process involves the determination of
the distinct log file accesses that contribute to a single pageview. Again such a decision is
application-oriented.
In order to personalize a web site, the system should be able to distinguish between
different users or groups of users. This process is called user profiling. In case no other
information than what is recorded in the web logs is available, this process results in the
creation of aggregate, anonymous user profiles since it is not feasible to distinguish
among individual visitors. However, if the user’s registration is required by the web site,
the information residing on the web log data can be combined with the users’
demographic data, as well as with their individual ratings or purchases. The final stage of
log data pre-processing is the partition of the web log into distinct user and server
sessions. A user session is defined as “a delimited set of user clicks across one or more
web servers”, whereas a server session, also called a visit, is defined as “a collection of
user clicks to a single web server during a user session” [WCA]. If no other means of
session identification, such as cookies or session ids is used, session identification is
performed using time heuristics, such as setting a minimum timeout and assume that
consecutive accesses within it belong to the same session, or a maximum timeout,
assuming that two consecutive accesses that exceed it belong to different sessions. More
details on the user and session identification process can be found in [EV03].

14
2.2 Web Usage Mining and Personalization
Web usage mining is the process of identifying representative trends and browsing
patterns describing the activity in the web site, by analyzing the users’ behaviour. Web
site administrators can then use this information to redesign or customize the web site
according to the interests and behavior of its visitors, or improve the performance of their
systems. Moreover, the managers of e-commerce sites can acquire valuable business
intelligence, creating consumer profiles and achieving market segmentation.
There exist various methods for analyzing the web log data [CMS97, SC+00]. Some
research studies use well known data mining techniques such as association rules
discovery [CPY96], sequential pattern analysis [B02, BB+99, BS00, SFW99], clustering
[KJ+01, NC+03, YZ+96], probabilistic models [BL99, DK04, JZM04a, LL03, S00,
ZB04, ZHH02a], or a combination of them [CH+00, YH03]. Since web usage mining
analysis was initially strongly correlated to data warehousing, there also exist some
research studies based on OLAP cube models [HN+01, ZXH98]. Finally some proposed
web usage mining approaches that require registered user profiles [HF04, SZ+97], or
combine the usage data with semantic meta-tags incorporated in the web site’s content
[ML+04, OB+03].
Furthermore, this knowledge can be used to automatically or semi-automatically
adjust the content of the site to the needs of specific groups of users, i.e. to personalize
the site. As already mentioned, web personalization may include the provision of
recommendations to the users, the creation of new index pages, or the generation of
targeted advertisements or product promotions. The usage-based personalization systems
use association rules and sequential pattern discovery [MPT99], clustering [AP+04,
BS04], Markov models [ADW02], machine learning algorithms [HEK03, NP04], or are
based on collaborative filtering [MD+00a, NM02, NP03, SK+00, SK+01] in order to
generate recommendations. Some research studies also combine two or more of the
aforementioned techniques [JF+97, KS04, MPG03].

15
2.3 Integrating Content Semantics in Web Personalization
Several frameworks supporting the claim that the incorporation of information related
to the web site’s content enhances the web personalization process have been proposed
prior [MD+00b, EGP02, PE00] or subsequent [JZM04b, JZM05, GKG05] to our work. In
this Section we overview in detail the ones that are more similar to ours, in terms of using
a domain-ontology to represent the web site’s content.
Dai and Mobasher [DM02] proposed a web personalization framework that uses
ontologies to characterize the usage profiles used by a collaborative filtering system.
These profiles are transformed to “domain-level” aggregate profiles by representing each
page with a set of related ontology objects. In this work, the mapping of content features
to ontology terms is assumed to be performed either manually, or using supervised
learning methods. The defined ontology includes classes and their instances therefore the
aggregation is performed by grouping together different instances that belong to the same
class. The recommendations generated by the proposed collaborative system are in turn
derived by binary matching of the current user visit, expressed as ontology instances, to
the derived domain-level aggregate profiles, and no semantic similarity measure is used.
The idea of semantically enhancing the web logs using ontology concepts is
independently described by Oberle et. al. [OB+03]. This framework is based on a
semantic web site built on an underlying ontology. The authors present a general
framework where data mining can then be performed on these semantic web logs to
extract knowledge about groups of users, users’ preferences, and rules. Since the
proposed framework is built on a semantic web knowledge portal, the web content is
already semantically annotated (through the existing RDF annotations), and no further
automation is provided. Moreover, the proposed framework focuses solely on web
mining and thus does not perform any further processing in order to support web
personalization.
Acharyya and Ghosh [AG03] also propose a general personalization framework based
on the conceptual modeling of the users’ navigational behavior. The proposed
methodology involves mapping each visited page to a topic or concept, imposing a
concept hierarchy (taxonomy) on these topics, and then estimating the parameters of a

16
semi-Markov process defined on this tree based on the observed user paths. In this
Markov models-based work, the semantic characterization of the content is performed
manually. Moreover, no semantic similarity measure is exploited for enhancing the
prediction process, except for generalizations/specializations of the ontology terms.
Finally, in a subsequent work, Middleton et. al [MSR04] explore the use of ontologies
in the user profiling process within collaborative filtering systems. This work focuses on
recommending academic research papers to academic staff of a University. The authors
represent the acquired user profiles using terms of a research paper ontology (is-a
hierarchy). Research papers are also classified using ontological classes. In this hybrid
recommender system which is based on collaborative and content-based recommendation
techniques, the content is characterized with ontology terms, using document classifiers
(therefore a manual labeling of the training set is needed) and the ontology is again used
for making generalizations/specializations of the user profiles.
2.4 Integrating Structure in Web Personalization
Although the connectivity features of the web graph have been extensively used for
personalizing web search results [ANM04, H02, RD02, WC+02], only a few approaches
exist that take them into consideration in the web site personalization process. Zhu et. al.
[ZHH02b] use citation and coupling network analysis techniques in order to conceptually
cluster the pages of a web site. The proposed recommendation system is based on
Markov models. Nakagawa and Mobasher [NM03] use the degree of connectivity
between the pages of a web site as the determinant factor for switching among
recommendation models based on either frequent itemset mining or sequential pattern
discovery. Nevertheless, none of the aforementioned approaches fully integrates link
analysis techniques in the web personalization process by exploiting the notion of the
authority or importance of a web page in the web graph.
In a very recent work, Huang et. al. [HLC05] address the data sparsity problem of
collaborative filtering systems by creating a bipartite graph and calculating linkage
measures between unconnected pairs for selecting candidates and make

17
recommendations. In this study the graph nodes represent both users and rated/purchased
items.
Finally, subsequent to our work, Borges and Levene [BL06] proposed independently
two link analysis ranking methods, SiteRank and PopularityRank which are in essence
very much like the proposed variations of our UPR algorithm (PR and SUPR
respectively). This work focuses on the comparison of the distributions and the rankings
of the two methods rather than proposing a web personalization algorithm. The authors’
concluding remarks, that the topology of the web site is very important and should be
taken into consideration in the web personalization process, further support our claim.

18
Table 1: Related Work
AREA
METHOD
WUM WUM
& Profile
WUM &
ContentWP
WP &
Profile
WP &
Content
WP &
Structure
General framework/ architecture
[CMS97, SC+00] [ML+04,
OB+03*]
Association Rules Mining
(AR) [CPY96]
Sequential Pattern
Discovery (SP)
[BB+99, BS00,
SFW99] [HF04]
Clustering (Cl) [KJ+01, NC+03, YZ+96]
[SZ+97] [AP+04, BS04] [PE00] [ZHH02b]
OLAP cube – based model
[HN+01, ZXH98]
Collaborative Filtering (CF) N/A N/A N/A N/A
[MD+00a, NM02,
NP03,SK+00, SK+01]
[MD+00b, MSR04*, DM02*]
[HLC05]
Markov models (MM)
[BL99, DK04,
LL03,S00, ZHH02a,]
[ADW02] [AG03*]
Probabilistic models (PM)
[ZB04, JZM04a] [JZM04b]
Machine Learning
methods (ML) [HEK03,
NP04] [EGP02]
Link Analysis algorithms (LA) [BL06]
MM & Cl [CH+00, YH03] [MPG03]
AR & SP [MPT99] [NM03]
AR & Cl N/A N/A N/A N/A [GKG05]
ML & CF N/A N/A N/A N/A [JF+97] MM & CF N/A N/A N/A N/A [KS04]
PM & CF N/A N/A N/A N/A [JZM05]
Met
hod
Com
bina
tions
LA&MM
*: Systems/Approaches that use ontologies N/A: Not applicable method for this area

19
CHAPTER 3
Semantic Web Personalization
The users’ navigation in a web site is typically content-driven. The users usually
search for information or services concerning a particular topic. Therefore, the underlying
content semantics should be a dominant factor in the process of web personalization. In
this thesis we present SEWeP (standing for Semantic Enhancement for Web
Personalization), a web personalization framework that integrates content semantics with
the users’ navigational patterns, using ontologies to represent both the content and the
usage of the web site.
In our proposed framework we employ web content mining techniques to derive
semantics from the web site’s pages. These semantics, expressed in ontology terms, are
used to create semantically enhanced web logs, called C-logs (concept logs).
Additionally, the site is organized into thematic document clusters. The C-logs and the
document clusters are in turn used as input to the web mining process, resulting in the
creation of a broader, semantically enhanced set of recommendations. The whole process
bridges the gap between Semantic Web and Web Personalization areas, to create a
Semantic Web Personalization system. To the best of our knowledge, SEWeP is the only
system that provides an integrated solution for semantic web personalization and can be
used by any (semantic or not) web site, fully exploiting the underlying semantic
similarities of ontology terms. Parts of this chapter have appeared at [EVV03, EL+04].

20
In the Sections that follow we motivate the integration of content semantics in the
web personalization process using an illustrative example, and then present in more detail
the components of the SEWeP system. We conclude with an extensive experimental
evaluation of the system, as well as a brief description of system prototypes based (or
partly based) on the SEWeP framework.
3.1 Motivating Example
A web site can be personalized in various ways, such as the creation of new index
pages, personalized search services, or dynamic recommendations’ generation. In this
thesis, we deal with the latter case, that of “predicting” links that might be of interest for
each specific visitor.
Resuming from the example presented in the first Chapter, we assume that there
exists a web portal, specializing on sports activities, called (hypothetically) “Sportal”, and
residing on the imaginary site “www.theSportal.com”. This portal contains various
information resources about sports, ranging from sport news to advertisements on sport
events and equipment. The personalization system of “Sportal” applies association rules
mining on its web logs in order to generate recommendations to its visitors, based on the
assumption that users with similar interests have similar navigational behavior. Assume
that one of the discovered patterns is the following:
www.theSportal.com/events/ski.html,
www.theSportal.com/travel/ski_resorts.html
www.theSportal.com/equipment/ski_boots.html.
One may easily “interpret” this pattern as: “people that are interested in ski events and
search for winter vacations will probably be interested in purchasing ski boots”. Based on
the assumption that this user is interested in finding a ski resort to spend her holidays and
using pure usage-based personalization, the next time a user U navigates through
“Sportal” and visits the first two web pages, the personalized site will dynamically
recommend to U the page included in the right hand side (RHS) of the rule.

21
The “Sportal’s” content, however, is continuously updated. Suppose that the ski
equipment department has just announced a sale on all ski boots:
www.theSportal.com/equipment/ski_boot_sale.html.
Since this is a new web page, it isn’t included in the web logs, or is included in very low
ratio (no one or only a few users have visited this page), therefore is definitely not
included in the derived association rules comprising our navigational model. As a
consequence, if we follow the “traditional” usage-based personalization process, it will
never be recommended to U, even though it is apparent that it is very “similar” to their
search intentions.
Moreover, assume that “Sportal” also hosts another service, about the snow
conditions in several ski resorts, in the web page:
www.theSportal.com/weather/snowreport.html.
Again, the information residing in this page is very relevant with U’s interests, but it is
not included in the association rules derived. This may occur, for example, if the web
administrator hasn’t add a link from the ski-related pages to the weather page, therefore
not many users have followed this path before.
As a third scenario, consider the case when U, instead of following the previous path,
visits the web pages
www.theSportal.com/sports/winter_sports/ski.html,
www.theSportal.com/travel/winter/hotels.html.
It is obvious that this visit is semantically similar to the previous one and the objective of
the user the same. The system however, will not provide the same recommendations to U,
since it won’t “recognize” this similarity. Moreover, in case these two web pages are not
included in an association rule in the knowledge base, for any of the aforementioned
reasons, the system will recommend nothing to him!
Based on the aforementioned example, it is evident that pure usage-based
personalization is problematic in several cases. We claim that information conceptually
related to the users’ visit should not be “missed”, and introduce the SEWeP
personalization system that addresses the aforementioned shortcomings by generating
semantically enhanced recommendations.

22
Before getting into more technical details, we demonstrate SEWeP’s functionality
through a use-case scenario based on the aforementioned example. The users’ visits to the
web pages of “Sportal” are recorded in the web server logs. These logs, after being
preprocessed, are used along with the web site’s semantics as input in the process of C-
Logs creation. In other words, the content of the web site is processed in order to be
semantically characterized by the categories of a related ontology. Table 2 shows some
URIs along with the respective domain-ontology terms that semantically characterize
them.
Table 2. URIs and related concept hierarchy terms
URI Concept hierarchy terms
www.theSportal.com/events/ski.html sport, event, ski, schedule
www.theSportal.com/sports/winter_sports/ski.html sport, winter, ski
www.theSportal.com/travel/ski_resorts.html travel, ski, resort
www.theSportal.com/travel/winter/hotels.html travel, winter, hotel, sport
www.theSportal.com/equipment/ski_boots.html snow, ski, equipment
www.theSportal.com/equipment/ski_boot_sale.html snow, ski, equipment
www.theSportal.com/weather/snowreport.html weather, snow, ski
Based on the semantic similarity between these terms, the respective web pages are
categorized in semantic clusters (since the terms are hierarchically correlated). SEWeP
recommendation engine generates both URI-based (as any usage-based personalization
system does) and category-based association rules (e.g. snow, winter, hotel travel,
equipment). These rules are then expanded to include documents that fall under the most
similar semantic cluster.
Returning to our scenario, assume that the user visits the web pages:
www.theSportal.com/events/ski.html, and
www.theSportal.com/travel/ski_resorts.html.

23
The system, based on the URI-based association rules derived from web log mining,
finds the most relevant rule and recommends its RHS to him. This recommendation set
will be referred to as original recommendations:
www.theSportal.com/events/ski.html,
www.theSportal.com/travel/ski_resorts.html
www.theSportal.com/equipment/ski_boots.html.
Moreover, it expands the recommendation set by including documents that belong to the
same thematic cluster as the URI proposed, generating semantic recommendations:
www.theSportal.com/equipment/ski_boot_sale.html
www.theSportal.com/weather/snowreport.html.
Assume now that another user navigates through the web site, visiting the web pages
www.theSportal.com/sports/winter_sports/ski.html,
www.theSportal.com/travel/winter/hotels.html.
Based on the derived URI-based association rules, a usage-based personalization system
would not find a matching association rule and wouldn’t recommend anything. SEWeP,
however, based on the category-based association rules it generates, abstracts the user’s
visit and matches it with the category-based rule:
ski, winter, travel
snow, equipment
It then recommends documents that belong to the cluster which is characterized by the
RHS terms. This recommendation set will be referred to as category-based
recommendations. In what follows, we describe in detail how SEWeP implements the
aforementioned process.
3.2 SEWeP System Architecture
SEWeP uses a combination of web mining techniques to personalize a web site. In
short, the web site’s content is processed and characterized by a set of ontology terms
(categories). The visitors’ navigational behavior is also updated with this semantic

24
knowledge to create an enhanced version of web logs, C-logs, as well as semantic
document clusters. C-Logs are in turn mined to generate both a set of URI and category-
based association rules. Finally, the recommendation engine uses these rules, along with
the semantic document clusters in order to provide the final, semantically enhanced set of
recommendations to the end user.
Figure 2. SEWeP architecture
As illustrated in Figure 2, SEWeP consists of the following components:
• Content Characterization. This module takes as input the content of the web site
as well as a domain-specific ontology and outputs the semantically annotated
content to the modules that are responsible for creating the C-Logs and the
semantic document clusters. The content characterization process consists of the
keyword extraction, keyword translation and semantic characterization sub-
processes which are described in more detail in Section 3.4.
• Semantic Document Clustering. The semantically annotated pages created by the
previous component are grouped into thematic clusters. This categorization is
achieved by clustering the web documents based on the semantic similarity
between the ontology terms that characterize them. This process is described in
Section 3.5.
• C-Logs Creation & Mining. This module takes as input the web site’s logs as well
as the semantically annotated web site content. It outputs the semantically

25
enhanced C-logs (concept logs) which are in turn used to generate both URI and
category-based frequent itemsets and association rules. These rules are
subsequently matched to the current user’s visit by the recommendation engine.
We overview this process in Section 3.6.
• Recommendation Engine. This module takes as input the current user’s path and
matches it with the semantically annotated navigational patterns generated in the
previous phases. The recommendation engine generates three different
recommendation sets, namely, original, semantic and category-based ones,
depending on the input patterns used. In Section 3.7 we overview the two novel
recommendation algorithms that are employed by SEWeP.
The creation of the ontology as well as the semantic similarity measures used as input
in the aforementioned web personalization process are orthogonal to the proposed
framework. We assume that the ontology is descriptive of the web site’s domain and is
provided/created by a domain expert. In what follows we describe the key components of
our architecture, starting by introducing the similarity measures we used in our work.
3.3 Similarity of Ontology Terms
As already mentioned, SEWeP exploits the expressive power of content semantics,
them being represented by ontology terms. Using such a representation, the similarity
between documents is deduced to the distance between terms that are part of a hierarchy.
The need for such a similarity measure is encountered throughout the personalization
process, namely, during content characterization, keyword translation, document
clustering and recommendations’ generation. In our approach, we adopt the Wu &
Palmer similarity measure [WP94] for calculating the distance between terms that belong
to a tree (hierarchy). Moreover, we use its generalization, proposed by Halkidi et. al.
[HN+03] to compute the similarity between sets of terms that belong to a concept
hierarchy. Henceforth, we will refer to these metrics as WPsim and THEsim respectively.
We should stress that the choice of the similarity measure is orthogonal to the rest system
functionality, as long as it serves for calculating the distance between hierarchically

26
organized terms [EM+06, MT+05]. The definitions of the two similarity measures are
given in what follows.
3.3.1 Wu&Palmer Similarity Measure
Given a tree, and two nodes a, b of this tree, their similarity is computed as follows:
)(*2
)()(),(
cdepthbdepthadepth
baWPsim+
= (1)
where the node c is their deepest (in terms of tree depth) common ancestor.
3.3.2 THESUS Similarity Measure
Given a concept hierarchy O and two sets of weighted terms A={(wi, ki)} and B={(vi,
hi)}, with wi, vi ∈ O, their similarity is defined as:
( )( ) ( )( ) ⎥⎦
⎤⎟⎟⎠
⎞⎜⎜⎝
⎛×+⎢
⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛×= ∑∑
= ∈= ∈
||
1,|]|,1[
||
1,|]|,1[
,max1,max121)(
B
A
A
BBA,
ijijiji
jijijkhWPsim
HhkWPsim
KTHEsim µλ (2)
where ( )ji
jiji vw
vw,max, ×
+=
2λ and ∑
=
=||
)(,
A
iixiK
1
λ ,with
( ) ( )( )jixiBjxixi hkWPsimhkWPsimxix ,max,|)( ,|]|,1[, ×=×=∈
λλ .
3.4 Content Characterization
A fundamental component of the SEWeP architecture is the automated content
characterization process. SEWeP is the only web personalization framework enabling the
automated annotation of web content with ontology terms without needing any human
labeling or prior training of the system. The keywords’ extraction is based both on the
content of the web pages, as well as their connectivity features. What is more, SEWeP
enables the annotation of multilingual content, since it incorporates a context-sensitive
translation component which can be applied prior to the ontology mapping process. In the
subsections that follow we describe in detail the aforementioned processes, namely, the
keyword extraction, keyword translation and semantic characterization modules.

27
3.4.1 Keyword Extraction
There exists a wealth of methods for representing web documents, most of which
have emerged from the area of searching and querying the web [BP98, CD+99, HG+02].
The most straightforward approach is to perform text mining in the document itself
following standard Information Retrieval (IR) techniques. This approach, however, has
been shown insufficient for the web content, since it relies solely on the information
included in the document ignoring semantics arising from the connectivity features of the
web [BP98, CD+98]. It is difficult to extract keywords from web documents that contain
images, programs etc. Additionally, many web pages do not include words that are the
most descriptive ones for their content (for example rarely a portal web site includes the
word “portal” in its home page). Therefore, in many approaches information contained in
the links that point to the document and the text near them - defined as “anchor-window”
[CD+97] - is used for characterizing a web document [CD+99, HG+02, PW00, VV+04].
This approach is based on the hypothesis that the text around the link to a page is
descriptive of the page’s contents and overcomes the problems of the content-based
approach, since it takes into consideration the way others characterize a specific web
page. In our work, we adopt and extend this approach, by also taking into consideration
the content of the pages that are pointed by the page that is processed, based on the
assumption that in most web pages the authors include links to topics that are of
importance in the page’s context.
More specifically, the keywords that characterize a web page p are extracted using:
1. raw term frequency of p
2. raw term frequency of a selected fraction (anchor-window) of the web pages that
point to p (inlinks)
3. raw term frequency of the web pages that are pointed by p (outlinks)
The three keyword extraction methods can be applied interchangeably or in combination.
We should explain at this point the decision concerning term weighting phase, when
the extracted keywords are given weights in order to use the most important ones. Term
weighting, extensively used in the vector space model for document clustering, is carried
out using several methods, such as raw term frequency, or algorithms belonging to the

28
Tf*Idf family [SB98]. Raw term frequency is based on the term statistics within a
document and is the simpler way of assigning weights to terms. Tf*Idf is a method used
for collections of documents, i.e. documents that have similar content. In the case of a
Web site however, this assumption is not always true since a Web site may contain
documents that refer to different thematic categories (especially in the case of Web
portals) and this was the reason for choosing raw term frequency as the term weighting
method of our approach.
At the end of this phase, each document d is characterized by a weighted set of
keywords d = {(ki,wi)}, where wi is the weight representing the summed (over the
combination of methods) word frequency of keyword ki. Before proceeding with
mapping the extracted keywords to related ontology terms, all non-English keywords
should be translated. In our approach, we determine the most suitable synonym using a
context-sensitive automated translation method, which is described in detail in the
Section that follows.
3.4.2 Keyword Translation
As already mentioned, the recommendation process is based on the characterization
of all web documents using a common representation. Since many web sites contain
content written in more than one language, this raises the issue of mapping keywords
from different languages to the terms of a common domain-ontology.
Consider, for example, the web site of a Computer Science department, or of a
research group in Greece. This site will contain information addressed to the students,
which will be written in Greek, research papers, which will be written in English, and
course material, which will be written in both languages. Since the outcome of the
keyword extraction process is a mixed set of English and Greek words, the translation of
all Greek keywords to English should be performed, prior to selecting the most frequent
ones. By using any dictionary, each Greek word (after stemming and transforming to the
nominative) will be mapped to a set of English synonyms; the most appropriate synonym,
however, depends on the context of the web page’s content. A naive approach would be
to keep all possible translations, or a subset of them, but this would result in a high
number of keywords and would lead to inaccurate results. Another less computationally

29
intensive approach would be to keep the “first” translation returned by the dictionary,
which is the most common one. The “first” translation, however, is not always the best.
For example the words “plan”, “schedule” and “program” are some of the translations of
the same Greek word (“πρόγραµµα”), however in the Informatics context the word
“program” is the one that should be selected.
To address this important issue, we propose to determine the most precise synonym
based on the content of the web page it was extracted from. Assuming that the set of
keywords will be descriptive of the web page’s content, we derive the best synonym set
by comparing their semantics. This context-sensitive automated translation method is
applicable for any language, provided that a dictionary and its inflection rules are
available. In our system implementation we applied it for the Greek language.
Since all words in the Greek language (nouns, verbs, adverbs) can be inflected, we
perform stemming and transformation to the nominative of each Greek word prior to
applying the actual translation method. For this purpose, we used the inflection rules of
Triantafillidis Grammar [Tria]. The translation algorithm is depicted in Figure 3. The
input is the set of English and Greek keywords (En(D) and Gr(D) respectively) of
document D. The output is a set of English keywords K that “best” characterize the web
page. Let En(g) = {english translations of g, g ∈ Gr(D)} and Sn(g) = {Wordnet senses of
keywords in En(g)}. For every translated word’s sense (as defined by Wordnet), the
algorithm computes the sum of the maximum similarity between this sense and the senses
of the remaining keywords (let WPsim denote the Wu&Palmer distance between two
senses). Finally, it selects the English translation with the maximum scored sense. The
algorithm has complexity O(kn2) for every Greek keyword, where n is the number of
senses for every keyword and k is the number of remaining words w. Since this algorithm
is applied off-line once for every document D, it does not constitute a bottleneck in the
system’s online performance.

30
An initial experimental evaluation [LE+04] has shown promising results for the
proposed approach, but several issues remain open. For instance, our technique makes an
implicit assumption of “one sense per discourse”, i.e., that multiple appearances of the
same word will have the same meaning within a document. This assumption might not
hold in several cases, thus leading to erroneous translations. Our technique constitutes a
first step toward the automated mapping of keywords to the terms of a common concept
hierarchy; clearly, a more extensive study is required in order to provide a complete and
more precise solution.
Figure 3. The keyword translation procedure
3.4.3 Semantic Characterization
In order to assist the remainder of the personalization process (C-logs creation,
semantic document clustering, semantic recommendations) the n most frequent
(translated) keywords that where extracted in the previous phase, are mapped to the terms
O = {c1, …, ck.} of a domain ontology (in our approach we need the concept hierarchy
part of the ontology). This mapping is performed using a thesaurus4. If the keyword
belongs to the ontology, then it is included as it is. Otherwise, the system finds the
“closest” (i.e. most similar) term (category) to the keyword through the mechanisms
4 In our system implementation, we use WordNet [WN] for this purpose.
Procedure translateW(Gr,En)1. K ← Ø ; 2. for all g ∈ Gr(D) do
3. for all s ∈ Sn(g) do 4. score[s] = 0;
5. for all w ∈ En(D)U Gr(D)-{g} do 6. sim = max(WPsim(s, Sn(w))); 7. score[s] += sim; 8. done 9. done 10. smax = s’;
(score[s’] = max(score[s]), s ∈ Sn(g)) 11. K ← e, e ∈ En(g), e contains smax; 12. done

31
provided by the thesaurus. Since the keywords carry weights according to their
frequency, the categories’ weights are also updated.
We should stress here that the selection of the ontology influences the outcome of the
mapping process. For this purpose, it should be semantically relevant to the content to be
processed. In order to find the closest term in the ontology O for a keyword k that
describes a document, we compute the Wu & Palmer similarity [WP94] between all
senses of k, Sn(k) and all senses of all the categories c in O, Sn(ci). At the end of this
process, each keyword is mapped to every category with a similarity s respectively. We
select the (k,c) pair that gives the maximum similarity s. This process is shown in Figure
4.
Figure 4. The semantic characterization process
If more than one keywords are mapped to the same category ci, the relevance ri
assigned to it is computed using the following formula:
∑
∑
→
→
⋅=
ij
ij
ckj
ckjj
i w
swr
)( (3)
where wj is the weight assigned to keyword kj for document d and sj the similarity with
which kj is mapped to ci. At the end of this process, each document d is represented as a
set d = {(ci, ri)}, where ri ∈[0,1] since sj ∈[0,1]. Even though the aforementioned process
has complexity O(|c|n2), where n is the number of senses of a word, it doesn’t aggravate
the system’s performance, since it is performed offline once, and is repeated only when
the content of a web page changes or when new web pages are added in the web site.
Procedure CategoryMapping(k, O)
1. for all sns ∈ Sn(k) do 2. for all ci ∈ O do 3. scsimmax ← maxargsc ∈ Sn(ci)(WPsim(sns, sc)); 4. done 5. ssimmax = max({scsimmax}); 6. cmax = c ∈ O, for which (scsimmax == ssimmax); 7. done 8. sim = max({ssimmax}); 9. cat = c’∈ {cmax}, for which (ssimmax == sim); 10. return(cat, sim); 11. done

32
3.5 C-Logs Creation & Mining
C-Logs are in essence the web site’s logs enhanced with content semantics. The C-
Logs creation process involves the association of each web logs’ record with the ontology
terms that represent the respective URI. C-logs are processed using the same statistical
and data mining techniques applied to web logs, such as association rules, clustering or
sequential pattern discovery.
The web mining algorithms currently supported by SEWeP is frequent itemsets’ and
association rules’ discovery. Both algorithms are based on a variation of the Apriori
algorithm [AS94], used to extract patterns that represent the visitors’ navigational
behavior in terms of pages often visited together. The input to the algorithm is the
recorded users’ sessions expressed both in URI and category level. The output is a set of
URI and category-based frequent itemsets or association rules respectively. Since no
explicit user/session identification data are available, we assume that a session is defined
by all the pageview visits made by the same IP, having less than a maximum threshold
time gap between consecutive hits.
3.6 Document Clustering
After the content characterization process, all web documents are semantically
annotated with terms belonging to a concept hierarchy. This knowledge is materialized
by grouping together documents that are characterized by semantically similar terms, i.e.
neighboring categories in the hierarchy. This categorization is achieved by clustering the
web documents based on the similarity among the ontology terms that characterize each
one of them. The generated clusters capture semantic relationships that may not be
obvious at first sight, for example documents that are not “structurally” close (i.e. under
the same ‘root’ web site’s path).
The problem of document clustering is considerably different from the case of
clustering points in a metric space. In SEWeP the objects to be clustered are sets of
(weighted) terms of a concept hierarchy that correspond to the extracted categories for
each document. In this space, there are no coordinates and ordering as in a Euclidean
metric space. We can only compute the similarity between documents given an

33
appropriate similarity measure between sets of weighted categories, therefore we use
THEsim, as defined earlier, with a modification of the density-based algorithm DBSCAN
[EK+98] for clustering the documents. After the document clustering, each cluster is
labeled by the most descriptive categories of the documents it contains, i.e. the categories
that characterize more than t% of the documents. Modification details and the algorithm
itself are described in [HN+03, VV+04]. The semantic document clusters are used in turn
in order to expand the recommendation set with semantically similar web pages, as we
describe in Section 3.7.
3.7 Recommendation Engine
As already mentioned, after the document characterization and clustering processes
have been completed, each document d is represented by a set of weighted terms
(categories) that are part of the concept hierarchy: d = {(ci, ri)}, ci ∈ O, ri ∈ [0,1] (O is
the concept hierarchy, ri is ci’s weight). In the motivating example, we presented how this
knowledge can be transformed into three different types of recommendations, depending
on the rules that are used as input (association rules between URIs or between categories)
and the involvement of semantic document clusters: original, semantic, and category-
based recommendations.
Original recommendations are the “straightforward” way of generating
recommendations, simply relying in the usage data of a web site. They are generated
when, for each incoming user, a sliding window of her past n visits is matched to the
URI-based association rules in the database, and the m most similar ones are selected.
The system recommends the URIs included in the rules, but not visited by the user so far.
The intuition behind semantic recommendations is that, useful knowledge
semantically similar to the one originally proposed to the users, is omitted for several
reasons (updated content, not enough usage data etc.) Those recommendations are in the
same format as the original ones but the web personalization process is enhanced by
taking into account the semantic proximity of the content. In this way, the system's
suggestions are enriched with content bearing similar semantics. In short, they are
generated when, for each incoming user, a sliding window of their past n visits is

34
matched to the URI-based association rules in the database, and the single most similar
one is selected. The system finds the URIs included in the rule but not yet visited by the
user (let A) and recommends the m most similar documents that are in the same semantic
cluster as A.
Finally, the intuition behind category-based recommendations is the same as the one
of semantic recommendations: incorporate content and usage data in the recommendation
process. This notion, however, is further expanded by expressing the users’ navigational
behavior in a more abstract, yet semantically meaningful way. Both the navigational
patterns’ knowledge database and the current user’s profile are expressed by categories.
Therefore, pattern matching to the current user’s navigational behavior is no longer exact
since it utilizes the semantic relationships between the categories, as expressed by their
topology in the domain-specific concept hierarchy. The final set of recommendations is
generated when, for each incoming user, a sliding window of the user’s past n visits is
matched to the category-based association rules in the database, and the most similar is
selected. The system finds the most relevant document cluster (using similarity between
category terms) and recommends the documents that are not yet visited by the user.
In what follows, we describe in detail the semantic and category-based
recommendations’ algorithms. The description of the generation of original
recommendations is omitted, since it is a straightforward application of the Apriori
algorithm to the sessionized web logs.
3.7.1 Semantic Recommendations
Navigational patterns. We use the Apriori algorithm [AS94] to discover frequent
itemsets and/or association rules from the C-Logs, CLg. We consider that each distinct
user session represents a different transaction. We will use S = { Im }, to denote the final
set of frequent itemsets/association rules, where Im = {(urii)}, urii ∈ CLg.
Recommendations. In brief, the recommendation method takes as input the user’s
current visit, expressed a set of URIs: CV = {(urij)}, urij ∈ WS, (WS is the set of the web
site’s URIs. Note that some of these may not be included in CLg). The method finds the
itemset in S that is most similar to CV, and recommends the documents (labeled by
related categories) belonging to the most similar document cluster Clm ∈ Cl (Cl is the set

35
of document clusters). In order to find the similarity between URIs, we perform binary
matching (denoted as SIM). This procedure is shown in Figure 5.
Figure 5. The semantic recommendation method
3.7.2 Category-based Recommendations
Navigational patterns. We use an adaptation of the Apriori algorithm [AS94] to
discover frequent itemsets and/or association rules including categories. We consider that
each distinct user session represents a different transaction. Instead of using as input the
distinct URIs visited, we replace them with the respective categories. We keep the most
important ones, based on their frequency (since the same category may characterize more
than one documents). We then apply the Apriori algorithm using categories as items. We
will use C = { Ik }, to denote the final set of frequent itemsets/association rules, where Ik
= {(ci,, ri)}, ri ∈ O, ri ∈ [0,1] (ri reflects the frequency of ci).
Recommendations. In short, the recommendation method takes as input the user’s
current visit, expressed in weighted category terms: CV = {(cj, fj)}, cj ∈ O, fj ∈ [0,1] (fj is
the normalized frequency of cj in the current visit). The method finds the itemset in C that
is most similar to CV, creates a generalization of it and recommends the documents
(labeled by related categories) belonging to the most similar document cluster Cln ∈ Cl
(Cl is the set of document clusters). To find the similarity between categories we use the
Wu & Palmer metric, whereas in order to find similarity between sets of categories, we
Procedure SemanticRec(CV)1. CM ← Ø ; 2. Im = maxargI∈S SIM(I,CV); 3. for all d ∈ Im do 4. for all cj ∈ d do 5. if cj ∈ CM then 6. rj’ += rj; 7. CM ← (cj,rj’); 8. else 9. CM ← (cj,rj); 10. done 11. done 12. return D = {d}, {d} ∈ Clm, maxargCln∈Cl WPsim(CLm,CM);

36
use the THESUS metric (denoted as WPsim and THEsim respectively), defined in Section
3. This procedure is shown in Figure 6.
Figure 6. The category-based recommendation method
The same procedure can be run by omitting the weights in one or all the phases of the
algorithm. On the other hand, in case weights are used, an extension of the Apriori
algorithm, which incorporates weights in the association rules mining process, such as
[SA95], can be used. Let us also stress that even though this description of the method
focuses on sets’ representation (derive frequent itemsets and use them in the
recommendation method), it can also be applied (with no further modification) to the
association rules that can be derived by those sets. If association rules are derived, then
the user’s activity is matched to the LHS of the rule (step 2), and recommendations are
generated using the RHS of the rule (step 7).
3.8 Experimental Evaluation
So far, we have described the framework for enhancing the recommendation process
through content semantics. Our claim, that the process of semantically annotating web
content using terms derived from a domain-specific taxonomy prior to the
recommendation process enhances the results of web personalization, is intuitive. Since
the objective of the system is to provide useful recommendations to the end users, we
performed an experimental study, based on blind testing with 15 real users, in order to
validate the effectiveness of our approach. The results indicate that the effectiveness of
each recommendation set (namely, Original, Semantic, Category), depends on the
context of the visit and the users’ interests. What is evident, however, is that a hybrid
Procedure CategoryRec(CV)1. Ik = maxargI∈S THEsim(I,CV); 2. for all cj ∈ CV do 3. ci = maxargc∈Ik WPsim(c,cj); 4. cn = least_common_ancestor(ci,cj), rn = max(ri,rj); 5. CI ← (cn, rn); 6. done 7. return D = {d}, {d} ∈ Cln, maxargCln∈Cl WPsim(CLn,CI);

37
model, incorporating all three types of recommendations, generates the most effective
results.
3.8.1 Methodology
Data Set. We used the web logs of the DB-NET web site [DBN]. This is the site of a
research team, which hosts various academic pages, such as course information, research
publications, as well as members’ home pages. The two key advantages of using this data
set are that the web site contains web pages in several formats (such as pdf, html, ppt,
doc, etc.), written both in Greek and English and a domain-specific concept hierarchy is
available (the web administrator created a concept-hierarchy of 150 categories that
describe the site’s content). On the other hand, its context is rather narrow, as opposed to
web portals, and its visitors are divided into two main groups: students and researchers.
Therefore, the subsequent analysis (e.g. association rules) uncovers these trends: visits to
course material, or visits to publications and researcher details. It is essential to point out
that the need for processing online (up-to-date) content, made it impossible for us to use
other publicly available web log sets, since all of them were collected many years ago
and the relevant sites’ content is no longer available. Moreover, the web logs of popular
web sites or portals, which would be ideal for our experiments, are considered to be
personal data and are not disclosed by their owners. To overcome these problems, we
collected web logs over a 1-year period (1/11/02 – 31/10/03). After preprocessing, the
total web logs’ size was approximately 105 hits including a set of over 67.500 distinct
anonymous user sessions on a total of 357 web pages. The sessionizing was performed
using distinct IP & time limit considerations (setting 20 minutes as the maximum time
between consecutive hits from the same user).
Keyword Extraction – Category Mapping. We extracted up to 7 keywords from each
web page using a combination of all three methods (raw term frequency, inlinks,
outlinks). We then mapped these keywords to ontology categories and kept at most 5 for
each page.
Document Clustering. We used the clustering scheme described in [HN+03], i.e. the
DBSCAN clustering algorithm and the THESim similarity measure for sets of keywords.

38
However, other web document clustering schemes (algorithm & similarity measure) may
be employed as well.
Association Rules Mining. We created both URI-based and category-based frequent
itemsets and association rules. We subsequently used the ones over a 40% confidence
threshold.
3.8.2 Experimental Results
In our experiments, we chose three popular paths followed by users in the past, each
one having a different “objective”; one (A) containing visits to contextually irrelevant
pages (random surfer), a second (B) including a small path to very specialized pages
(information seeking visitor), and a third one (C) including visits to top-level, yet
research-oriented pages (topic-oriented visitor). We then conducted a series of 4
experiments. These paths, along with the recommendations generated for Experiment #2
are included in Appendix A.
Experiment #1. For the first experiment, we created three different sets of
recommendations named Original, Semantic, and Category (the sets are named after the
respective recommendation methods). We presented the users with the paths and the
three sets (unlabeled) in random order and asked them to rate them as “indifferent”,
“useful” or “very useful”. The outcome is shown in Figure 7.
The results of the first experiment revealed the fact that depending on the context and
purpose of the visit the users profit from different source of recommendations. More
specifically, in visit A, both Semantic and Category sets are mostly evaluated as
useful/very useful. The Category recommendation set performs better, and this can be
explained by the fact that it’s the one that recommends 3 “hub” pages, which seems to be
the best after a “random walk” on the site. On the other hand, in visits B and C, Semantic
performs better. In visit B, the path was focused to specific pages and the same held for
the recommendations’ preferences. In visit C the recommendations that were more
relevant to the topics previously visited were preferred.

39
Original
Semantic
CategoryIndifferent
UsefulVery Useful
0102030405060
70
Path A
Original
Semantic
CategoryIndifferent
UsefulVery Useful
0102030405060
70
Path B
Original
Semantic
Category
IndifferentUseful
Very Useful
010203040506070
Path C
Figure 7. Experiment #1: Recommendation sets’ evaluation

40
For that reason, we decided to evaluate the performance of a hybrid method that
incorporates all three types of recommendations. We run a set of experiments comparing,
for each path, each one of the proposed recommendation sets with a Hybrid
recommendation set, containing the top recommended URIs from each of the three
methods (Original, Semantic, Category). We then asked the users to choose the
recommendation set they preferred more.
Experiment #2: In the second experiment, we asked the users to choose between the
Hybrid and the Original recommendations’ set. The outcome is shown in Figure 8.
Original vs. Hybrid Recommendations
01020304050607080
Path A Path B Path C
Use
r Pre
fere
nces
(%)
Original Hybrid
Figure 8. Experiment #2: Original vs. Hybrid Recommendations
The results of this experiment verify our intuition that the users benefit from the
semantic enhancement of the recommendations. Again, this depends on each visit’s
purpose, but in total users rate the Hybrid SEWeP outcome as equal as or better than the
pure usage-based one.
Experiment #3: In the third experiment, we presented the users with the Semantic and
the Hybrid recommendation set and asked them to rank them in terms of their usefulness
in navigation. The outcome is shown in Figure 9.
We observe that Hybrid recommendation set seems to perform better in the case of
the “random” path Α, whereas the Semantic recommendation set prevails in the case of
the more “specialized” paths B and C. Hence, we cannot conclude on which
recommendation set is better, since it depends on the path and therefore the users’

41
specific interests, even though the Semantic recommendation set seems to prevail in the
case of specialized information seeking visits.
Semantic vs. Hybrid Recommendations
0102030405060708090
Path A Path B Path C
Use
r pre
fere
nces
(%)
Semantic Hybrid
Figure 9. Experiment #3: Semantic vs. Hybrid Recommendations
Experiment #4: In the fourth experiment, users had to select between the Category-
based recommendation set and the Hybrid one. The outcome is shown in Figure 10. The
results of this experiment demonstrate the dominance of the Hybrid recommendation set
over the Category-based one. One explanation for this would be that in the second case,
important information may be lost during the generalization (convert user’s current path
to categories) back to specialization (convert categories to URIs) process.
Category-based vs. Hybrid Recommendations
0
20
40
60
80
100
Path A Path B Path C
Use
r pre
fere
nces
(%)
Category-based Hybrid
Figure 10. Experiment #4: Category-based vs. Hybrid Recommendations

42
Based on these experimental results, we observe that what is characterized as useful
by the users depends on the objective of each visit. Out of the three possible
recommendation sets, the Semantic recommendation set, generated after the semantic
expansion of the most popular association rule performs better. Comparing all three
recommendation sets with the Hybrid one, we observe that it dominates the other three,
since the hybrid recommendations are preferred by the users in most cases (7 out of 9).
Therefore, we conclude that SEWeP’s semantic enhancement of the personalization
process improves the quality of the recommendations in terms of complying with the
users’ needs.
A general observation that was made after examining each user’s preferences
individually is that the recommendations’ usefulness is a very subjective issue.
Depending on the circumstances, each user’s preferences differ from the other users, and
sometimes even from his own. Thus, an “objective” qualitative evaluation of such
systems is quite difficult.
3.9 System Prototypes
In this Section we present the SEWeP prototype [PL+04], emphasizing on some
implementation details. We also briefly present two prototypes partly based on some of
the proposed framework’s components, namely, the IKUM and the Greek Web Archive.
More details on the personalized content delivery platform IKUM [VEA03, EVA05], as
well as the Greek Web Archiving framework [LE+04] can be found in the respective
publications.
3.9.1 SEWeP Prototype
The SEWeP system prototype is entirely based on Java (JDK 1.4 or later). For the
implementation of SEWeP we utilized the following third party tools & algorithms: PDF
Box Java Library, Jacob Java-Com Bridge Library, and swf2html library (for text
extraction); Xerces XML Parser; Wordnet v1.7.1 Ontology; JWNL and JWordnet 1.1
java interfaces for interaction with Wordnet; Porter Stemming Algorithm [P80] for
English; Triantafillidis Greek Grammar [Tria]; Apache Tomcat 4.1 and Java Servlets for

43
the recommendation engine; JDBC Library for MS SQL Server. The main functionalities
of the prototype are described below:
Logs Preprocessing: The system provides full functionality for preprocessing any
kind of web logs, by enabling the definition of new log file templates, filters
(including/excluding records based on field characteristics), etc. The “clean” logs are
stored in new files. A screenshot of the log preprocessing module is shown in Figure 11.
Content Retrieval: The system crawls the web and downloads the web site’s pages,
extracting the plain text from a variety of crawled file formats (html, doc, php, ppt, pdf,
flash, etc.) and stores them in appropriate database tables.
Keyword Extraction & Translation: The user selects among different methods for
extracting keywords. Prior to the final keywords selection, all non-English keywords are
translated using an automated process (the system currently also supports Greek content).
All extracted keywords are stored in a database table along with their relevant frequency.
Keyword – Category Mapping: The extracted keywords are mapped to categories of a
domain-specific ontology. The system finds the “closest” category to the keyword
through the mechanisms provided by a thesaurus (WordNet [WN]). The weighted
categories are stored in XML files and/or in a database table.
Session Management: SEWeP enables anonymous sessionizing based on distinct IPs
and a user-defined time limit between sessions. The distinct sessions are stored in XML
files and/or database tables. Figure 12 includes a screenshot of this module.
Semantic Association Rules Mining: SEWeP provides a version of the Apriori
algorithm [AS94] for extracting frequent itemsets and/or association rules (confidence
and support thresholds set by the user). Apart from URI-based rules, the system also
provides functionality for generating category-based rules. The results are stored in text
files for further analysis or use by the recommendation engine. Figure 13 includes a
screenshot of this module.
Clustering: SEWeP integrates clustering facilities for organizing the documents into
meaningful semantic clusters. Currently SEWEP capitalizes on the clustering tools
available in the THESUS system [VV+04].

44
Recommendations: The (semantic) association rules/frequent itemsets created feed a
client-side application (servlet) in order to dynamically generate recommendations to the
visitor of the personalized site.
Figure 11. SEWeP screenshot: The Logs Preprocessing module

45
Figure 12. SEWeP screenshot: the Session Management module
Figure 13. SEWeP screenshot: the Semantic Association Rules Mining module

46
3.9.2 The I-KnowUMine Project
The objective of the I-KnowUMine (IKUM) project is the development of a content
delivery platform based on content, knowledge and behavioral data in order to present
personalized content to the users. This approach benefits from the combination and
integration of technology advances in areas such as web mining, content management,
personalization and portals. The IKUM system modules are classified into four main
layers: the Content Management Layer, Web Mining Layer, Knowledge Management
Layer, and Interaction Layer, as illustrated in the block diagram of Figure 14.
Figure 14. The IKUM system architecture
The Content Management Layer is based on the content characterization component
of the SEWeP architecture. It incorporates the Content Management Module, the
Taxonomy Management Module and the Content Classification Module. The main
functionalities implemented in this layer are the support for consistent authoring and
storage of the content of the web site, its enrichment with semantic information,
generated automatically or corrected/provided by a domain expert, the support for

47
creating or importing taxonomies as well as the support for administrative functions such
as workflow and user management.
The Web Mining Layer is based on the C-logs creation & mining components of the
SEWeP architecture, enabling the semantic enhancement of web logs in order to create
the C-logs, which are in turn used as input to the Web Mining Module.
The Knowledge Management Layer is responsible for managing the knowledge
generated by the Web Mining layer and includes its deployment through various
recommendation engines (Recommendation Module).
Apart from these three general layers there is also an Interaction Layer, which
includes the Publishing Module and the web server, which will present the corresponding
personalized page to every user, by combining possibly “fixed” parts of the web page
with parts where the personalized information should be presented. More details on the
IKUM project can be found in [VEA03, EVA05].
3.9.3 The Greek Web Archiving Project
The objective of this project is to propose a framework for archiving the Greek Web.
This process involves the creation of an archive containing as many “Greek” web pages
as possible as well as the knowledge extraction from this collection. What should be
characterized as “Greek” Web is not solid since there exist many Greek web sites that are
not under the .gr top-level domain. Therefore, the main criteria we use in order to define
the Greek perimeter, apart from the domain name, are the Greek language and the
Hellenic-oriented content. In addition to collecting the data though, we also perform a
semantic characterization of the pages in order to group them into thematic clusters.
These clusters can subsequently be used to accelerate the search in the Web Archive and
enable the keyword-based search without human intervention.
The Greek Web Archiving system architecture is depicted in Figure 15. The system
consists of three main components: the Web Crawler, the Content Manager and the
Clustering Module. The Web Crawler searches the web using the aforementioned criteria
in order to gather as many “Greek” web pages as possible. The collected URIs are stored
in a database along with the date and time the crawling was performed, to enable
updating of the archive in the future. Some additional information such as the web pages

48
that point to, or are pointed by the URI can also be included for future use. The Content
Manager is in essence the Content characterization component of the SEWeP
architecture. Finally, the Clustering Module uses the K-means or the DBSCAN algorithm
and generates a label for each created cluster, taking the cluster centroids into account.
The system also integrates a Cluster Validation sub-module, in order to evaluate the
quality of the created clusters. Since the structure of the data was not known a-priori, we
used relative cluster validation criteria [HBV02], including the Dunn index, modified
Hubert Statistics and Davies-Boudlin index for this purpose. More information on this
project can be found in [LE+04].
Figure 15. The Greek Web Archiving system architecture

49
3.10 Conclusions
In this Chapter we presented the key concepts and algorithms underlying SEWeP, a
novel semantic web personalization system. SEWeP is based on the integration of content
semantics with the users’ navigational behaviour in order to generate recommendations.
The web site’s documents are automatically mapped to ontology terms, enabling further
processing (clustering, association rules mining, recommendations’ generation) to be
performed based on the semantic similarity between these terms. Using this
representation, the final recommendation set presented to the user is semantically
enhanced, overcoming problems emerging when pure usage-based personalization is
performed. Experimental results with real users have verified our claim that the semantic
enrichment of the personalization process improves the quality of the recommendations
in terms of complying with the users’ needs. Nevertheless, the recommendations’
usefulness is a very subjective issue and therefore very difficult to evaluate. A general
observation that can be made is that out of the three possible recommendation sets the
system generates, the Semantic recommendation set, generated after semantic expansion
of the most popular association rule performs better, yet comparing all three
recommendation sets with the Hybrid one, we can conclude that this setup is the most
useful than the other three.


CHAPTER 4
Link Analysis for Web Personalization
The connectivity features of the web graph play important role in the process of web
searching and navigating. Several link analysis techniques, based on the popular
PageRank algorithm [BP98], have been largely used in the context of web search
engines. The underlying intuition of these techniques is that the importance of each page
in a web graph is defined by the number and the importance of the pages linking to it.
In this thesis, we introduce link analysis in a new context, that of web personalization.
Motivated by the fact that in the context of navigating a web site, a page/path is
important if many users have visited it before, we propose a new algorithm UPR (Usage-
based PageRank). UPR is based on a personalized version of PageRank, “favoring” pages
and paths previously visited by many web site users. We apply UPR to a representation
of the web site’s user sessions, termed Navigational Graph in order to rank the web site’s
pages. This ranking may then be used in several contexts:
• Use it as a “global ranking” of the web site’s pages. The computed rank
probabilities can serve as the prior probabilities of the pages when
recommendations are generated using probabilistic predictive models such as
Markov Chains, higher-order Markov models, tree synopses etc.
• Apply UPR to small subsets of the web site’s navigational graph (or its
approximations), which are generated based on each current user’s visit. This

52
localized version of UPR (named l-UPR) provides localized personalized
rankings of the pages most likely to be visited by each individual user.
In what follows we illustrate our approach through a motivating example. We then
provide the required theoretical background on link analysis before presenting the
proposed algorithm. We prove that this hybrid algorithm can be applied to any web site’s
navigational graph as long as the graph satisfies certain properties. We then proceed with
describing the two proposed frameworks in which UPR can be applied, namely, the
localized personalized recommendations with l-UPR and the hybrid probabilistic
predictive models (h-PPM). We conclude with an extensive experimental evaluation we
performed on both frameworks (l-UPR and h-PPM), proving our claim that the
underlying link structure of the web sites should be taken into consideration in the web
personalization process, and details on the system prototype we used. Parts of this chapter
have appeared at [EV05, EVK05].
4.1 Motivating Example
Assume that the graph of Figure 16 represents a fraction of the web. The nodes
represent the web pages and the edges represent the links between them. Suppose that a
user U has already visited pages a and b. We want to predict which is the most probable
path U will follow next, namely, c d or c e. We notice from this small fraction of the
web graph, that d is linked to by more pages than e. Based on the assumption that a web
page is important if it is pointed to by many other (important) pages, it seems that d is
more important, therefore the most probable path is the one ending on this page.
This simple example shows in brief how PageRank works. PageRank is an iterative
algorithm which assigns visit probabilities (authority scores) to the pages of a web graph.
In each iteration the authority score of a page is distributed evenly to the pages it points
to. The more authority a page has, the more authority its out-linked pages will receive.
Conversely, the more the incoming links of a page, the more authority it accumulates. By
applying PageRank to the entire web graph, we get an importance ranking of all the
pages it includes. This ranking has been very useful in the context of web search.

53
Figure 16. PageRank-based example
Assume now that the graph of Figure 17 represents a fraction of a web site’s graph.
The weights on the edges represent the number of one-step user transitions between the
connected nodes (pages). Based on these weights, we observe that page e has been visited
by more people have than page d, therefore we may claim that in this “navigational
graph” c e seems to be more important than c d in terms of users’ interest. We may
therefore extend the PageRank assumption and claim that, in the web navigation context,
a page is considered important if many users have visited it before.
Figure 17. Usage-based PageRank (UPR) example

54
This is the intuition behind the hybrid algorithm we propose in this thesis, UPR. UPR
is in essence a usage-based variation of PageRank which is applied to the web site’s
navigational graph, and provides us with authority scores that represent the importance of
the web site’s pages both in terms of link connectivity, as well as their visit frequency.
In what follows we present some preliminaries concerning the navigational graph in
Section 4.2. Section 4.3 includes a detailed analysis of both the PageRank and UPR
algorithms. The two proposed personalization frameworks in which UPR can be applied
are presented in Sections 4.4 and 4.5. The experimental study is detailed in Section 4.6
whereas an overview of the prototype system implementing the proposed frameworks is
included in Section 4.7.
4.2 Preliminaries
The input to our proposed algorithm is the Navigational Graph (NG). NG is a
weighted directed graph representation of the user sessions. NG can be used in order to
discover page and path probabilities and support popular path prediction, since it contains
all the distinct user sessions, therefore is a full representation of the actual user paths
followed in the past. This structure, however, can become large, especially when
modeling the user sessions of big web sites. Therefore, the processing of NG may become
very intensive computationally. The need for reduced complexity and online availability
imposes the creation of approximations of the NG, referred to as NG synopses. An NG
synopsis may be a Markov model of any order (depending on the simplicity/accuracy
trade-off that is required), or any other graph synopsis, such as those proposed in [PG02,
PGI04]. We should stress at this point that our approach is orthogonal to the type of
synopsis one may choose. In what follows we present in more detail the NG structure and
its synopses, emphasizing on Markov models, since these are the NG synopses we are
using in the second framework we propose in this thesis as well as in the experimental
study we performed.
4.2.1 The Navigational Graph
As already mentioned, the Navigational Graph (NG) is a weighted directed graph
which represents the user sessions of a web site. In its simplest form, NG is a node- and

55
edge-labeled tree, that has as root a special node R and the labels of the nodes identify the
M web pages of the web site WS. Another option would be to encode the data as a graph
using a bisimulation of the tree-based representation. We stress that this choice is
orthogonal to the techniques that we introduce. The edges of NG represent the links
between the web pages (i.e. the paths followed by the users), and the labels (weights) on
edges represent the number of link traversals. The weighted paths from the root towards
the leaves represent all the user sessions’ paths that are included in the web logs. All tree
paths terminate in a special leaf-node E denoting the end of a path. The NG resembles to
the web site’s graph, it may, however, include page links that do not physically exist (if,
for example a user jumps to a page from another following a bookmark), or, on the other
hand, may not include existing hyperlinks, if they were never followed in the past. Since
NG is a complete representation of the information residing on the web logs, there is a
high degree of replication of states in different parts of this structure.
The NG creation algorithm is as follows: For every user session US in the web logs,
we create a path starting from the root of the tree. If a subsequence of the session already
exists we update the weights of the respective edges, otherwise we create a new branch,
starting from the last visited common page in the path. We note that any consecutive
pages’ repetitions have been removed from the user sessions during the data cleaning
process; on the other hand, we keep any pages that have been visited more than once, but
not consecutively. We also denote the end of a session using a special exit node. The
algorithm for creating the NG is detailed in Figure 18.

56
Figure 18. NG Creation Algorithm
In order to make this process clearer, we present a simple example. Assume that the
user sessions of a web site are those included in Table 3. The Navigational Graph created
after applying the aforementioned algorithm is depicted in Figure 19.
Table 3. User Sessions
User Session # Path
1 a b c d 2 a b e d 3 a c d f 4 b c b g 5 b c f a
Procedure CreateTree(U)Input: User Sessions U Output: Navigational Tree *NG 1. root <- NG; 2. tmpP <- root; 3. for every US∈U do 4. while US ≠ ∅ do 5. si = first_state(US); 6. if parent(tmpP,si) then 7. wtmpP,I = wtmpP,I + 1; 8. tmpP <- si; 9. US <- remove(US, si); 10. else 11. addchild(tmpP,si); 12. wtmpP,I = 1; 13. tmpP <- si; 14. US <- remove(US, si); 15. endif 16. if parent(tmpP,E) then 17. wtmpP,E = wtmpP,E + 1; 18. else 19. addchild(tmpP,E); 20. wtmpP,E = 1; 21. endif 22. done 23. tmpP <- NG; 24.done

57
Figure 19. Navigational Graph
4.2.2 Markov Models
As already stated, NG can become large as it contains redundant information (such as
recurring sub-paths). As a consequence, performing computations directly over the NG
can become prohibitively expensive. The need for reduced complexity and online
availability imposes the creation of NG synopses, for reducing the NG structure size.
These synopses capture the sequential dependence between visits up to some level, while
preserving their most important statistical characteristics. The more detailed the synopsis
is, the more accurate will the representation of NG be. On the other hand, the construction
of a less detailed synopsis will save time and computational power. In this thesis we
elaborate on Markov models since these are the synopses used in our proposed
frameworks and experimental study.
Every node in NG may be considered as a state in a discrete Markov model, and may
be defined as a tuple <S, TP, L>, where S is the state space, which includes all nodes in
the transition graph, TP is the one-step transition probability matrix, and L is the initial
probability distribution regarding the states in S. In that model, the navigation of a user

58
may be represented as a stochastic process {Xn}, that has S as state space. If )(,
mjiP is the
bounded probability of visiting page j in the next step, and is based on the last m pages,
then {Xn} is called an mth-order Markov model [Kij97].
The simplest synopsis of NG is a Markov Chain. The Markov Chain is built upon the
Markov Property, which states that each “next” visit to a page depends only on the
current one and is independent of the previous ones. Therefore, a Markov Chain is a 1st-
order Markov model, and the bounded probability of visiting page xj in the next step is
given by Equation 4:
( ) )|(,...,,| 1011)1(
, 01 injniininjnji xXxXPxXxXxXxXPPn
======== +−+ − (4)
This representation is simple to construct, depends, however, on the assumption that
the navigation is “memoryless”, in other words that the next page to be visited by a user
only depends on the user’s current location. NG synopses that take into consideration the
“long-term memory” aspects of web surfing are higher order Markov models, which can
easily be constructed from NG by computing the k-step path frequencies (where k is the
order of the model). In essence, higher-order Markov models “relax” the Markov
property. Therefore, given that the user is currently at page xi and has already visited
pages01
,..., ii xxn−
, then )(,
mjiP is based only on pages
11,...,,
+−− mnn iii xxx and is given by
Equation 5:
( ) ( )101 11011
)(, ,...,|,...,,|
+−−========= +−+−+ mnn imninjniininjn
mji xXxXxXPxXxXxXxXPP (5)
where the bounded probability of {Xn+1}, given all the previous events, equals the
bounded probability of {Xn+1} given the m previous events, for an mth – order Markov
model.
The transition probabilities are easily computed using the information residing on
NG. We define the one-step transition probability matrix TP as follows: each item TPi,j
represents the probability of transitioning from page(s) xi to page xj in one step. In other
words,
i
ijijji w
wxxPTP == )|(, (6)

59
where wi represents the total number of visits to page(s) xi, and wij represents the number
of consecutive visits from xi to xj. Note that in case of paths having length l>1, we denote
as xi the prefix containing the first l-1 pages.
Table 4. Path Frequencies
l = 1 l = 2 l = 3 xi wi xi → xj wij xi → xj wij a 4 a → b 2 a → b → c 1 b 5 a → c 1 a → b → e 1 c 4 b → c 3 a → c → d 1 d 3 b → e 1 b → c → b 1 e 1 b → g 1 b → c → d 1 f 2 c → b 1 b → c → f 1 g 1 c → d 1 b → e → d 1
c → f 1 c → b → g 1 d → f 1 c → d → f 1 e → d 1 c → f → a 1
f → a 1
Table 4 includes the paths of length l ≤ 3 corresponding to the user sessions included
in Table 3. Using this information, and based on the previous analysis, we can compute
the transition probabilities for 1st and 2nd order Markov models NG synopses. The
respective 1st order Markov model (Markov Chain) synopsis is depicted in Figure 20. The
numbers in parentheses in the nodes denote the number of visits to a page whereas the
edges’ weights denote the times the respective link was followed. Nodes S and E
represent the paths’ start and end points respectively.
Figure 20. NG synopsis (Markov Chain)

60
In the analysis that follows we use Markov models in two different frameworks. In
the first, we apply them in order to synopsize NG prior to applying the proposed localized
personalized ranking algorithm l-UPR. In the second, we propose Markov model-based
hybrid predictive models that incorporate link analysis techniques.
4.3 Usage-based PageRank
So far, link analysis has been largely used in the context of web search. In this thesis,
we introduce link analysis techniques in the web personalization process. We propose
UPR, a hybrid PageRank-style algorithm for ranking the pages of a web site based on its
links’ connectivity as well as its usage, in order to assist the recommendation process. In
what follows we present the original PageRank algorithm as proposed by Brin and Page
[BP98]. We then provide the formal definition of the proposed algorithm, Usage-based
PageRank (UPR).
4.3.1 PageRank
The PageRank algorithm is the most popular link analysis algorithm, used for
assigning numerical weightings to web documents that are used from web search engines
in order to rank the retrieved results. The algorithm models the behavior of a random
surfer, who either chooses an outgoing link from the page he is currently visiting, or
“jumps” to a random page. Each choice bears a probability. The PageRank of a page is
defined as the probability of the random surfer visiting this page at some particular time
step k > K. This probability is correlated with the importance of this page, as it is defined
based on the number and the importance of the pages linking to it. For sufficiently large
K this probability is unique, as illustrated in what follows.
Consider the web as a directed graph G, where the N nodes represent the web pages
and the edges represent the links between them. The random walk on G induces a
Markov Chain where the states are given by the nodes in G, and M is the stochastic
transition matrix with mij describing the one-step transition from page xj to page xi. The
adjacency function mij is 0 if there is no direct link from xj to xi, and normalized such that,
for each j:

61
11
=∑=
N
iijm (7)
As stated by the Perron-Frobenius theorem, if M is irreducible (i.e. G is strongly
connected) and aperiodic, then Mk (i.e. the transition matrix for the k-step transition)
converges to a matrix in which each column is the unique stationary distribution *RPr
,
independent of the initial distribution RPr
. The stationary distribution is the vector which
satisfies the Equation:
** RPMRPrr
×= (8)
in other words *RPr
is the dominant eigenvector of the matrix M.
Since M is the stochastic transition matrix over the web graph G, PageRank is in
essence the stationary probability distribution over pages induced by a random walk on
G. As already implied, the convergence of PageRank is guaranteed only if M is
irreducible and aperiodic [MR95]. The latter constraint is guaranteed in practice in the
web context, since the visits to a web page do not usually follow a periodic pattern. The
irreducibility is satisfied by adding a damping factor (1-ε) to the rank propagation (the
damping factor is a very small number, usually set to 0.15), in order to limit the effect of
rank sinks and guarantee convergence to a unique vector. We therefore define a new
matrix M’ by adding low-probability transition edges between every pair of nodes in G:
UMM εε +−= )1(' (9)
In other words, the user may follow an outgoing link, or choose a random destination
(usually referred to as random jump) based on the probability distribution of U. The latter
process is also known as teleportation. PageRank can then be expressed as the unique
solution to Equation 8, if we substitute M with M’:
pRPMRP rrrεε +×−= )1( (10)
where pr is a non-negative N-vector whose elements sum to 1.

62
Usually ∑
∈
=
)(
1
jk xOutxk
ij xm , where Out(xj) is the set of pages pointed to by xj, and
NNNU
×⎥⎦⎤
⎢⎣⎡= 1 , i.e. the probability of teleporting to another page is uniform. In that case
1
1
×⎥⎦⎤
⎢⎣⎡=
NNpr .
By choosing, however, U, and consequently pr , to follow a non-uniform distribution,
we can bias the PageRank vector computation to favor certain pages (therefore the
“random” jump is no longer random!) Thus, pr is usually referred to as the
personalization vector. This approach is largely used in the web search engines’ context,
where the ranking of the retrieved results are biased by favoring pages relevant to the
query terms, or the user preferences to certain topic categories [ANM04, H02, RD02,
WC+02]. In what follows, we present UPR, a usage-based personalized version of
PageRank algorithm, used for ranking the pages of a web site based on the navigational
behavior of previous visitors.
4.3.2 UPR: Link Analysis on the Navigational Graph
Based on the intuition that a page is important in a web site if many users have visited
it before, we introduce the hybrid link analysis algorithm UPR. UPR extends the
traditional link analysis algorithm PageRank, by biasing the page ranking with
knowledge acquired from previous user visits, as they are recorded in the user sessions.
In order to perform this, we define both the transition matrix M and the personalization
vector pr in such way that the final ranking of the web site’s pages is strongly related to
the frequency of visits to them.
Recapitulating from Section 4.2, we define the directed navigational graph NG, where
the nodes represent the web pages of the web site WS and the edges represent the
consecutive one-step paths followed by previous users. Both nodes and edges carry
weights. The weight wi on each node represents the number of times page xi was visited
and the weight wj i on each edge represents the number of times xi was visited

63
immediately after xj. We denote the set of pages pointed to by xj (outlinks) as Out(xj), and
the set of pages pointing to xj (inlinks) as In(xj).
Following the aforementioned properties of the Markov theory and the PageRank
computation, the Usage-based PageRank vector RPUr
is the solution to the following
Equation:
pRPUMRPU rrrεε +×−= )1( (11)
The transition matrix M on NG is defined as the square N x N matrix whose elements mij
equal to 0 if there does not exist a link (i.e. visit) from page xj to xi and
∑
∈→
→=
)( jk xOutxkj
ijij w
wm (12)
otherwise. The personalization vector pr is defined as
1×∈⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=∑
NWSxj
i
j
wwpr (13)
Using the aforementioned formulas, we bias the PageRank calculation to assign a
higher rank to the pages that were visited more often by users in the past. We then use
this hybrid ranking, combining the structure and the usage data of the site, to provide a
ranked recommendation set to current users, as we describe in the subsequent sections.
Note that Equation 7 holds, that is, M is normalized such that the sum of each column
equals to 1, therefore M is a stochastic transition matrix, as required for the convergence
condition of the algorithm to hold. M is, as already mentioned, aperiodic in the web
context and irreducible since we have included the damping factor (1-ε). It is therefore
guaranteed that Equation 11 will converge to a unique vector, *RPUr
.
Definition (UPR): We define the usage-based PageRank UPRi of a web page xi as the n-
th iteration of the following recursive formula:
∑∑ ∑∈
∈∈
→
→− −+⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
×=
WSxj
i
xInxxOutx
kj
ijnj
ni
j
ij
jk
ww
ww
UPRUPR )1()(
)(
1 εε (14)

64
Each iteration of UPR has complexity O(n2). The total complexity is thus determined
by the number of iterations, which in turn depends on the size of the dataset. In practice,
however, PageRank (and accordingly UPR) gives good approximations after 50 iterations
for ε=0.85 (which is the most commonly used value, recommended in [BP98]). The
computations can be accelerated by applying techniques such as those described in
[KHG03, KH+03] even though it is not necessary in the proposed frameworks since UPR
is applied to a single web site, therefore it converges after a few iterations.
In the Sections that follow, we present how UPR can be applied in different
personalization frameworks in order to assist the recommendations process.
4.4 Localized UPR (l-UPR)
The UPR algorithm can be applied to a web site in order to rank its web pages taking
into consideration both its link structure and the paths followed by users, as recorded in
the web logs. This process results in a “global” usage-based ranking of the web site’s
pages. In the context of web site personalization, however, we want to “bias” this
algorithm further, focusing on the path the current visitor has followed and the most
probable “next” pages he might visit, i.e. generating a “localized” personalized ranking.
We select a small subset of the NG synopsis we have modeled the user sessions with,
based on the current user’s path. This sub-graph includes all the subsequent (to the
current visit) pages visited by users with similar behavior in the past, until a predefined
path depth d. Therefore, it includes all the potential “next” pages of the current user’s
visit. l-UPR (localized UPR) is in essence the application of UPR on this small,
personalized fraction of the navigational graph. The resulting ranking is used in order to
provide recommendations to the current visitor. This approach is much faster than
applying UPR to the NG synopsis since the size of the graph is dramatically reduced,
therefore enabling online computations. Moreover, the ranking results are personalized
for each individual user, since they are based on the current user’s visit and similar users’
behavior in the past. We present the process of creating the personalized sub-graph,
termed prNG, and the recommendation process in more detail below.

65
4.4.1 The Personalized Navigational Graph (prNG)
In short, the process of constructing the personalized sub-graph is as follows: We
expand (part of) the path already visited by the user, including all the outgoing links (i.e.
the pages and the respective weighted edges) existing in the NG synopsis. The length of
the path taken into consideration when expanding the graph depends on the NG synopsis
we have used (in the case of Markov model synopses this represents the desired
“memory” of the system). We subsequently perform this operation for the new pages (or
paths), until we reach a predefined expansion depth. We then remove any pages that
already have been visited by the user, since these don’t need to be included in the
generated recommendations. The children of the node (page) that is removed are linked
to its parent. This ensures that all the previously visited pages by users having similar
behavior will be kept in the final sub-graph, without including any higher-level pages
they might have used as hubs for their navigation. After reaching the final set of nodes,
we normalize each node’s outgoing edge weights.
Before proceeding with the technical details of this algorithm, we illustrate its
functionality using two examples, based on the sessions included in Table 3, and the
respective path frequencies of Table 4. In both examples we create the prNGs for two
user visits including the paths {a → b} and {b → c}. In the first example, we assume that
the sessions are modeled using a Markov Chain NG synopsis. Using the path frequencies
for l=2 (i.e. the one-step transitions), we expand the two paths, {a → b} and {b → c}, to
create the respective prNGs, as shown in Figure 21. The second example is based on a
2nd-order Markov model NG synopsis. Note that in this case we use the path frequencies
for l=3. The corresponding prNGs for the two paths are illustrated in Figure 22. The
outgoing edge weights of each node are normalized so that they sum to 1. We also
observe that the nodes included in each prNG depend on the NG synopsis we choose to
model the user sessions with.

66
Figure 21. prNG of Markov Chain NG synopsis
Figure 22. prNG of 2nd order Markov model NG synopsis
The prNG construction algorithm is presented in Figures 23 and 24. The algorithm
complexity depends on the synopsis used, since the choice of the synopsis affects the
time needed for locating the successive pages for expanding the current path. It also
depends on the number of outgoing links of each sub-graph’s page and the expansion
depth, d. Therefore, if the complexity of locating successive pages in a synopsis is k, the
complexity of the prNG creation algorithm is ( )1)(* −dNGfanoutkO , where fanout(NG)
is the maximum number of a node’s outgoing links in NG. In the case of Markov model
synopses, k=1 since the process of locating the outgoing pages of a page or path reduces
to the lookup in a hash table.

67
Figure 23. Construction of prNG
Figure 24. Path expansion subroutine
Since the resulting prNG includes all possible “next” page visits of the user, we then
apply UPR in order to rank them and generate personalized recommendations. The
personalized navigational sub-graph prNG should be built so as to retain the desirable
attributes for UPR to converge. The irreducibility of the sub-graph is always satisfied
since we have added the damping factor (1-ε) in the rank propagation. Moreover,
Equation 7 which states that the sum of all outgoing edges’ weights of every node in the
Procedure Create_prNG(CV, NG)Input: Current User Visit CV, Navigational Graph NG Output: Subset of NG prNG 1. start 2. CV = {vp}; 3. cp = lastVisitedPath(CV); 4. expand(cp, NG, depth, expNG); 5. removeVisited(expNG, CV); 6. updateEdges(expNG); 7. prNG = normalize(expNG); 8. end
Procedure expand(cp, NG, d, eNG)Input: last page/path visited cp, navigational graph synopsis NG, depth of expansion d Output: expanded navigational graph eNG 1. start 2. P := cp; 3. R:= rootNode(eNG); 4. tempd = 0; 5. addNode(eNG, R, cp); 6. while (tempd <= d)do 7. for every (p∈P of same level)do 8. forevery np = linksto(NG, p, np, w)do 9. addNode(enG, p, np, w); 10. P += np; 11. done; 12. done; 13. tempd +=1; 14.done; 15.end

68
sub-graph equals to 1, is satisfied since we normalize them. Note here that prNG does not
include any previously visited pages.
Definition (l-UPR): We define l-UPRi of a page xi as the UPR rank value of this page in
the personalized sub-graph prNG.
These l-UPR rankings of the candidate pages are subsequently used to generate a
personalized recommendation set to each user. This process is explained in more detail in
the following Section.
4.4.2 UPR-based Personalized Recommendations
The application of UPR or l-UPR to the navigational graph results in a ranked set of
pages which are subsequently used for recommendations. As already presented, the final
set of candidate recommendation pages can be either personalized or global, depending
on the combination of algorithm - navigational graph chosen:
1) Apply l-UPR to prNG. Since prNG is a personalized fraction of the NG synopsis,
this approach results in a “personalized” usage-based ranking of the pages most
likely to be visited next, based on the current user’s path.
2) Apply UPR to NG synopsis. This approach results in a “global” usage-based
ranking of all the web site’s pages. This global ranking can be used as an
alternative in case personalized ranking does not generate any recommendations.
It can also be used for assigning page probabilities in the context of other
probabilistic prediction frameworks, as we will describe in the Section that
follows.
Finally, another consideration would be to have a pre-computed set of
recommendations for all popular paths in the web site, in order to save time during the
online computations of the final recommendation set.
4.5 Web Path Prediction using hybrid Probabilistic Predictive Models
One of the most popular web usage mining methods is the use of probabilistic
models. Such models represent the user sessions as a graph whose nodes are the web

69
site’s pages and edges are the hyperlinks between them, and are in essence based in what
we have already described as NG synopses. Using the transitional probabilities between
pages as defined by the probabilistic model, a path prediction is made by selecting the
most probable path among candidate paths, based on each user’s visit. Such purely usage-
based probabilistic models, however, present certain shortcomings. Since the prediction
of users' navigational behavior is solely based on the usage data, the structural properties
of the web graph are ignored. Thus important paths may be underrated. Moreover, as we
will also see in the experimental study we performed, such models are often shown to be
vulnerable to the training data set used.
In this Section we present a hybrid probabilistic predictive model (h-PPM) that
extends Markov models by incorporating link analysis methods. More specifically, we
choose the Markov models as NG synopses and use UPR and two more PageRank-style
variations of it, for assigning prior probabilities to the web pages based on their
importance in the web site's web and navigational graph.
4.5.1 Popular Path Prediction
As already presented, Markov models provide a simple way to capture sequential
dependence when modeling the navigational behavior of the users of a web site. The
order of the Markov model indicates the “memory” of the prediction, i.e. denotes the
number of previous user steps which are taken into consideration in the process of
calculating the path probabilities. For example, in Markov Chains the probability of
visiting a page depends only on the previous one, in 2nd-order Markov models depends on
the previous two, and so on. The selection of the order influences both the prediction
accuracy and the complexity of the model while heavily depends on the application/data
set. After building the model, i.e. computing the transition probabilities, the path
probabilities are computed using the chain rule. More specifically, for an m-th order
Markov model, the path probability of following the path kxxx →→→ ...21 equals to:
∏=
−−=→→→k
iimiik xxxPxPxxxP
21121 )...|(*)()...( (15)

70
For example, using a Markov Chain as the prediction model, the probability of the path
{a b c} reduces to)(
)()(
)()()|()|()()(bP
cbPaP
baPaPbcPabPaPcbaP →→==→→ .
Based on Equation 15, the prediction of the next most probable page visit of a user is
performed by computing the probabilities of all existing paths having the pages visited so
far by the user as prefix and choosing the most probable one. The bounded probabilities’
computation is straightforward since it reduces to a lookup on the transition probability
matrix TP. On the other hand, the prior probability assignment is an open issue, and we
deal with it in the sequel.
4.5.2 Reconsidering Prior Probabilities’ Computation
There are three approaches used commonly for assigning initial probabilities (priors)
to the nodes of a Markov model. The first one assigns equal probabilities to all nodes
(pages). The second estimates the initial probability of a page p as the ratio of the number
of visits on p as a first page in a path, to the total number of user sessions. In the case of
modeling web navigational behavior, however, neither of the aforementioned approaches
provides accurate results. The first approach assumes a uniform distribution, favoring
non-important web pages. On the other hand, the second does exactly the opposite: favors
only top-level “entry” pages. Furthermore, in the case of a page that was never visited
first, its prior probability equals to zero. The third approach is more “objective” with
regards to the other two, since it assigns prior probabilities proportionally to the
frequency of total visits to a page. This approach, however, does not handle important,
yet new (i.e. not included in the web usage logs) pages. Finally, as shown in the
experimental evaluation, all approaches are very vulnerable to the training data used for
building the predictive model.
In the literature, only a few approaches exist where the authors claim that these
techniques are not accurate enough and define different priors. Sen and Hansen [SH03]
use Dirichlet priors, whereas Borges and Levene [BL04] define a hybrid formula which
combines the two options (taking into consideration the frequency of visits to a page as
the first page, or the total number of visits to the page). For this purpose, they define the
variable α, which ranges from 0 (for page requests as first page) to 1 (for total page

71
requests). In their experimental study, however, they don’t explicitly refer to the optimal
value they used for a.
In this thesis, we address such shortcomings following an alternative approach. Our
motivation draws from the fact that the initial probability of a page should reflect the
importance of this page in the web navigation. We propose the integration of the web
site’s topological characteristics, as represented by its link structure, with the navigational
patterns of its visitors used for computing these probabilities. More specifically, we
propose the use of three PageRank-style ranking algorithms for assigning prior
probabilities. The first (PR) is the PageRank algorithm applied on the web site’s graph,
and computes the page prior probabilities based solely on the link structure of the web
site. The second is UPR, which, as already described, is applied on the web site’s
navigational graph and “favors” pages previously visited by many users. The third
algorithm (SUPR) is a variation of UPR, which assigns uniform probabilities to the
random jump instead of biasing it as well.
Definition (PageRank-based Prior Probability): We define the prior probability P(xi)
of a page xi as:
( ) ( )( )∑∈
−+−==)(
1 ),(*)()(*)1()()(ik xInx
ikkn
iin
i xxpxPxpxPxP εε (16)
with (1-ε) being the damping factor (usually set to 0.15) and for
(i) PR (PageRank):
M
xp i1)( = and
∑∈
=
)(
1),(
kj xOutxj
ik xxxp (17)
(ii) SUPR (Semi-Usage PageRank):
M
xp i1)( = and
∑∈
=
)(
),(
kj xOutxkj
kiik w
wxxp (18)
(iii) UPR (Usage PageRank):
∑∈
=
WSxj
ii
j
wwxp )( and
∑∈
=
)(
),(
kj xOutxkj
kiik w
wxxp (19)

72
Any of the aforementioned ranking schemes can be applied on the web site’s web or
navigational graph (or its synopsis), resulting in a probability assignment for each one of
its pages. These probabilities can subsequently be used instead of the commonly used
priors for addressing the aforementioned problems. As we present in the experimental
study we have performed, this approach provides more objective and precise predictions
than the ones generated from the pure usage-based approaches.
4.6 Experimental Evaluation
In this Section we present a set of experiments we performed in order to evaluate the
performance of both recommendation frameworks proposed in this thesis. In the case of
l-UPR, since there is no previous related work to compare it with, we use two different
setups of Markov Chains, which is the NG synopsis we used in l-UPR setup too. Using all
three setups, we generate top-3 and top-5 recommendation sets for 10 different user
paths, and compare them to the actual paths the users followed. In order to evaluate the
incorporation of page ranking in the hybrid probabilistic predictive models (h-PPM), we
compare the top-n path rankings generated by five different setups with the n most
frequent paths. For our experiments, we use two different data sets in order to examine
how the proposed methods behave in various types of web sites.
4.6.1 Experimental Setup
In our experiments we used two publicly available data sets. The first one includes
the page visits of users who visited the “msnbc.com” web site on 28/9/99 [MSN]. The
visits are recorded at the level of URL category (for example sports, news, etc.). It
includes visits to 17 categories (i.e. 17 distinct pageviews). We selected 96.000 distinct
sessions including more than one and less than 50 page visits per session and split them
in two non-overlapping time windows to form a training (65.000 sessions) and a test
(31.000 sessions) data set. The second data set includes the sessionized data for the
DePaul University CTI web server, based on a random sample of users visiting the site
for a two week period during April 2002 [CTI]. The data set includes 683 distinct
pageviews and 13.745 distinct user sessions of length more than one. We split the
sessions in two non-overlapping time windows to form a training (9.745 sessions) and a

73
test (4.000 sessions) data set. We will refer to these data sets as msnbc and cti data set
respectively. We chose to use these two data sets since they present different
characteristics in terms of web site context and number of pageviews5. More specifically,
msnbc includes the visits to a very big portal. That means that the number of sessions, as
well as the length of paths is very large. This data set has however the characteristic of
very few pageviews, since the visits are recorded at the level of page categories. We
expect that the visits to this web site are almost homogeneously distributed among the 17
different categories. On the other hand, cti data set refers to an academic web site. Visits
to such sites are usually categorized in two main groups: visits from students looking for
information concerning courses’ or administrative material, and visits from researchers
seeking information on papers, research projects, etc. We expect that the recorded visits
will imply this categorization.
Since in all the experiments we created top-n rankings, in the evaluation step we used
two metrics commonly used for comparing two top-n rankings r1 and r2. The first one,
denoted as OSim(r1,r2) [H02] indicates the degree of overlap between the top-n elements
of two sets A and B (each one of size n) to be:
n
BArrOSim
∩=),( 21 (20)
The second, KSim(r1,r2) is based on Kendall’s distance measure [KG90] and indicates the
degree to which the relative orderings of two top-n lists are in agreement and is defined
as:
( )1),,(',':),(
),( 2121 −∩∩
≠=
BABAvuvuoforderingsamehaverrvu
rrKSim (21)
where r1’ is an extension of r1, containing all elements included in r2 but not r1 at the end
of the list (r2’ is defined analogously) [H02]. In other words, KSim takes into
consideration only the common items of the two lists, and computes how many pairs of
them have the same relative ordering in both lists. It is obvious that OSim is more
important (especially in small rankings) since it indicates the concurrence of predicted
5 We should note at this point that there does not exist any benchmark for web usage mining and
personalization. We therefore chose these two publicly available datasets which have been used again in the past for experimentation in the web usage mining and personalization context.

74
pages with the actual visited ones. On the other hand, KSim must be always evaluated in
conjunction with the respective OSim since it can take high values even when only a few
items are common in the two lists.
At this point, we should discuss the methodology we chose for evaluating the
generated recommendations. There exist several related research efforts that propose a
general personalization architecture, without supporting their work with any experimental
evaluation [DM02, GKG05, ML+04, MPT99, OB+03, ZHH02b]. In this work we used a
commonly used methodology, dividing the data set into training and test data
respectively. According to this evaluation methodology, the training data are used in
order to generate the predictive model. The generated recommendations are in turn
compared to the “actual” user paths, as derived from the test data, using various metrics
[AG03, HLC+05, JPT03, JZM04b, JZM05, MD+00b, MPG03, NP03, SK+01]. Since,
however, the recommendations are compared to paths that have already been followed by
the users, it is questionable whether such a comparison evaluates the quality of
recommendations that include “new” paths. This issue is partially addressed by most
predictive models, since the generated recommendations include pages that are two or
more steps away. In real-life systems, this problem is addressed when the predictive
model is based on data extracted from an already personalized web site.
4.6.2 l-UPR Recommendations’ Evaluation
As already mentioned, the choice of the NG synopsis we use to model the user
sessions is orthogonal to the l-UPR framework. In this Section, we present results
regarding the impact of using our proposed method instead of pure usage-based
probabilistic models, focusing on Markov Chains.
We used 3 different setups for generating recommendations. The first two, referred to
as Start and Total, are the ones commonly used in Markov models for computing prior
probabilities. More specifically, Total assigns prior page probabilities proportional to the
total page visits, whereas Start assigns prior page probabilities proportional to the visits
beginning with this page. The third setup, referred to as l-Upr, is in essence our proposed
algorithm applied to a Markov Chain-based prNG. For the l-Upr setup, we set the

75
damping factor (1-ε) to 0.15 and the number of iterations to 100 to ensure convergence.
We expand each path to depth d=2.
The experimental scenario is as follows: We select the 10 most popular paths
comprising of two or more pages from the test data set. For each such path p, we make
the assumption that it is the current path of the user and generate recommendations
applying the aforementioned approaches on the training data set. Using the first two
setups, we find the n pages having higher probability to be visited after p. On the other
hand, using our approach, we expand p to create a localized sub-graph and then apply l-
UPR to rank the pages included in it. We then select the top-n ranked pages. This process
results in three recommendation sets for each path p. At the same time, we identify, in the
test data set, the n most frequent paths that extend p by one more page. We finally
compare, for each path p, the generated top-n page recommendations of each method
(Start, Total, l-Upr) with the n most frequent “next” pages, using the OSim and KSim
metrics.
We run the experiments generating top-3 and top-5 recommendation lists for each
setup. We performed the experiments using small recommendation sets because this
resembles more to what happens in reality, i.e. the system recommends only a few “next”
pages to the user. The diagrams presented here, show the average OSim and KSim
similarities over all 10 paths.
Figure 25 depicts the average OSim and KSim values for the top-3 and top-5 rankings
generated for the msnbc data set. In the first case (top-3 page predictions) we observe that
l-Upr behaves slightly worse in terms of prediction accuracy (OSim) but all methods
achieve around 50% accuracy. The opposite result is observed in the second case (top-5
page predictions), where l-Upr behaves better in prediction accuracy than the other two
methods, and the overall prediction accuracy is more than average. In both cases we
observe a lower KSim, concluding that l-Upr managed to predict the “next” pages but not
in the same order (as they were actually visited). As we mentioned earlier, however, the
presentation order is not so important in such a small recommendation list. Overall, the
differences between the three methods are insignificant. This can be justified if we take
into account the nature of the data set used. As already mentioned, the number of distinct
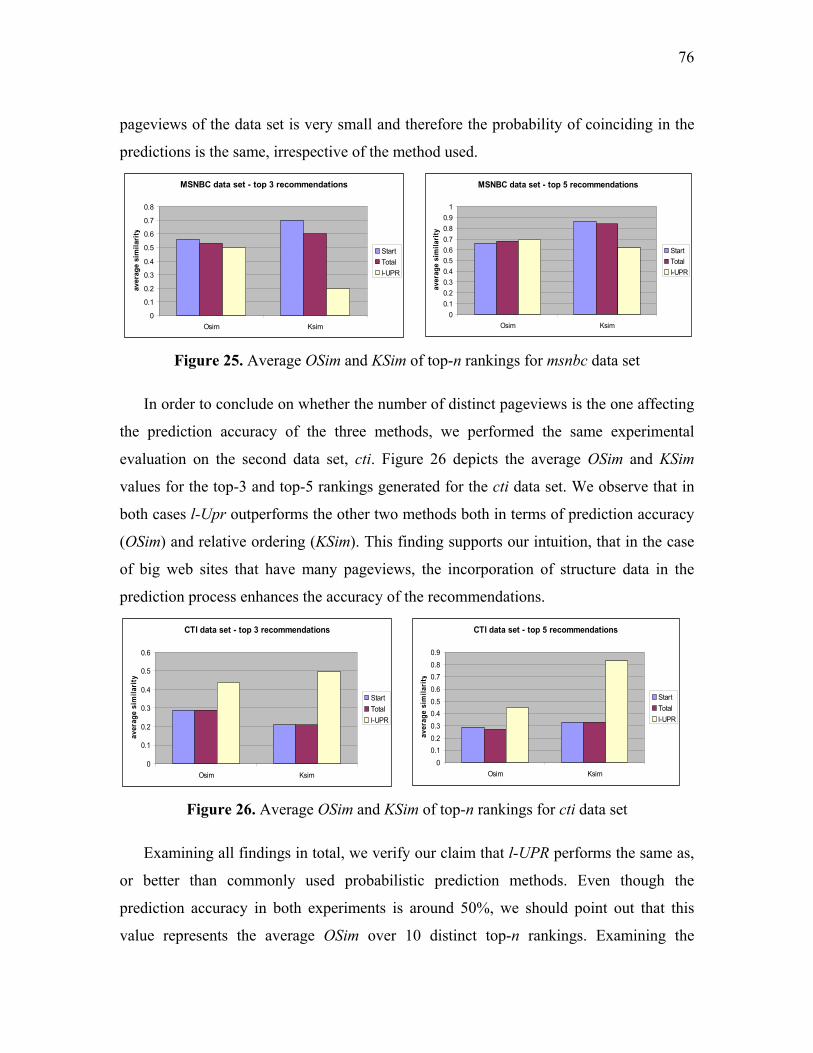
76
pageviews of the data set is very small and therefore the probability of coinciding in the
predictions is the same, irrespective of the method used.
MSNBC data set - top 3 recommendations
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Osim Ksim
aver
age
sim
ilari
ty
StartTotall-UPR
MSNBC data set - top 5 recommendations
00.10.20.30.40.50.60.70.80.9
1
Osim Ksim
aver
age
sim
ilari
ty
StartTotall-UPR
Figure 25. Average OSim and KSim of top-n rankings for msnbc data set
In order to conclude on whether the number of distinct pageviews is the one affecting
the prediction accuracy of the three methods, we performed the same experimental
evaluation on the second data set, cti. Figure 26 depicts the average OSim and KSim
values for the top-3 and top-5 rankings generated for the cti data set. We observe that in
both cases l-Upr outperforms the other two methods both in terms of prediction accuracy
(OSim) and relative ordering (KSim). This finding supports our intuition, that in the case
of big web sites that have many pageviews, the incorporation of structure data in the
prediction process enhances the accuracy of the recommendations.
CTI data set - top 3 recommendations
0
0.1
0.2
0.3
0.4
0.5
0.6
Osim Ksim
aver
age
sim
ilari
ty
StartTotall-UPR
CTI data set - top 5 recommendations
00.10.20.30.40.50.60.70.80.9
Osim Ksim
aver
age
sim
ilari
ty
StartTotall-UPR
Figure 26. Average OSim and KSim of top-n rankings for cti data set
Examining all findings in total, we verify our claim that l-UPR performs the same as,
or better than commonly used probabilistic prediction methods. Even though the
prediction accuracy in both experiments is around 50%, we should point out that this
value represents the average OSim over 10 distinct top-n rankings. Examining the

77
rankings individually, we observed a big variance in the findings, with some
recommendation sets being very similar to the actually visited pages (OSim > 70%),
whereas others being very dissimilar (OSim < 20%). Moreover, the NG synopsis used in
all three setups is the Markov Chain, which is the simplest synopsis model, yet the less
accurate one. We expect better prediction accuracy if the algorithm is applied over a
more accurate NG synopsis and leave this open for future work.
Overall, taking into consideration the low complexity of the proposed algorithm that
enables the fast, online generation of personalized recommendations, we conclude that it
is a very efficient alternative to pure usage-based methods.
4.6.3 h-PPM Recommendations’ Evaluation
In order to evaluate the impact of incorporating link analysis methods in the
probabilistic prediction process, we used 5 setups of the prediction model, differing in
terms of the prior probabilities’ computation. The first two setups, termed Start and Total,
are the ones used in previous approaches for computing prior probabilities, as we already
explained in the previous Section. More specifically, Start assigns probabilities
proportional to the visits of a page in the beginning of the sessions, whereas Total assigns
probabilities proportional to the total visits to a page. We do not include the approach of
assigning uniform prior probabilities to all nodes, since it is shown to perform worse than
the other two. The other three setups, termed PR, SUPR, and UPR, assign probabilities
using the respective proposed algorithms defined in Section 4.5.2. We use two NG
synopses for approximating the Navigational Graph NG, namely, the Markov Chain and
the 2nd-order Markov model. For the PageRank-style algorithms, the damping factor (1-ε)
was set to 0.15 and the number of iterations was set to 100.
Applying the five setups on the training data, we generated a list including the top-n
most probable paths for n∈{3, 5, 10, 20}. We then compared these results with the top-n
most frequent paths (i.e. the actual paths followed by the users), as derived from the test
data.
The diagrams of Figures 27 and 28 depict the OSim and KSim similarities for the top
3, 5, 10, and 20 rankings of the msnbc data set, using a Markov Chain as NG synopsis and
prediction model. We observe that OSim is around 60% for the two pure usage-based
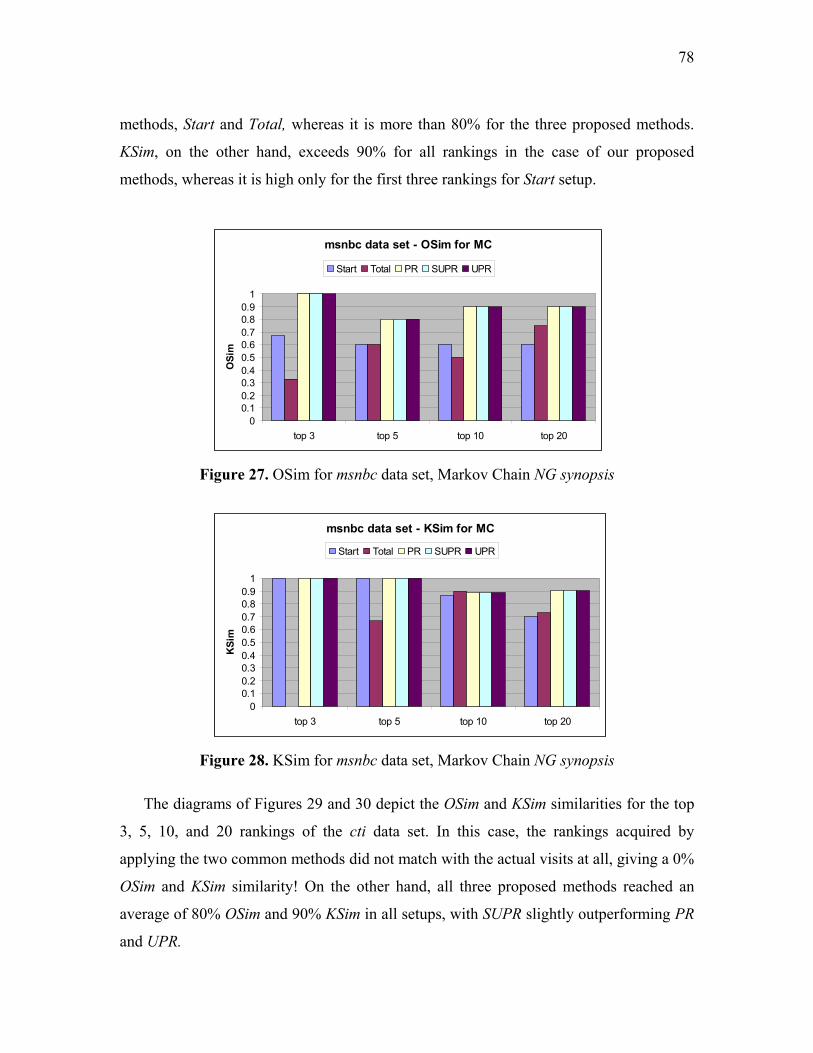
78
methods, Start and Total, whereas it is more than 80% for the three proposed methods.
KSim, on the other hand, exceeds 90% for all rankings in the case of our proposed
methods, whereas it is high only for the first three rankings for Start setup.
msnbc data set - OSim for MC
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5 top 10 top 20
OSi
m
Start Total PR SUPR UPR
Figure 27. OSim for msnbc data set, Markov Chain NG synopsis
msnbc data set - KSim for MC
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5 top 10 top 20
KSi
m
Start Total PR SUPR UPR
Figure 28. KSim for msnbc data set, Markov Chain NG synopsis
The diagrams of Figures 29 and 30 depict the OSim and KSim similarities for the top
3, 5, 10, and 20 rankings of the cti data set. In this case, the rankings acquired by
applying the two common methods did not match with the actual visits at all, giving a 0%
OSim and KSim similarity! On the other hand, all three proposed methods reached an
average of 80% OSim and 90% KSim in all setups, with SUPR slightly outperforming PR
and UPR.

79
cti data set - OSim for MC
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5 top 10 top 20
OSi
m
Start Total PR SUPR UPR
Figure 29. OSim for cti data set, Markov Chain NG synopsis
cti data set - KSim for MC
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5 top 10 top 20
KSi
m
Start Total PR SUPR UPR
Figure 30. KSim for cti data set, Markov Chain NG synopsis
At this point, we should analyze the behavior of the Start and Total setups, which
represent the straightforward Markov model implementation. The outcomes of the
experiments verify our claim that Markov models are very vulnerable to the training data
used, and several pages may be overrated or underestimated in certain circumstances. In
the case of the msnbc data set, where the number of distinct pages was very small and
therefore the navigational paths were evenly distributed, the pure usage-based models
seem to behave fairly (but, again, worse than the hybrid models). On the other hand, in
the case of the cti data set, where hundreds of distinct pages (and therefore distinct paths)
existed, the prediction accuracy of usage-based models was disappointing! We examined

80
the produced top-n rankings of the two usage-based approaches, and observed that they
include only the visits of students to course material. Since probably many students
visited the same pages and paths in that period of time, accessing the pages directly
(probably using a bookmark), these visits overlapped any other path visited by any other
user. On the other hand, by taking into consideration the “objective” importance of a
page, as conveyed by the link structure of the web site, such temporal influences are
reduced. The reader may refer to Appendix B that includes the top-10 ranked paths which
were generated using the Start and Total setups, as well as the 10 most frequent ones,
which were used as the test data set on our experiments.
The framework proposed in this Chapter can be directly applied for computing the
prior probabilities of visiting the pages of a web site. In other words, this framework can
be directly applied to Markov Chain NG synopses. In the case of higher-order Markov
models, however, our intuition was that this framework should be extended for
supporting the computation of prior probabilities for path visits (up to some length,
depending on the order). For instance, a 2nd-order Markov model is based on the
assumption that we have prior knowledge concerning the visit probabilities of all paths
including up to 3 pages. Indeed, the results from applying the proposed algorithms to the
cti dataset indicated the need for this model extension. In the case of the msnbc dataset,
however, we did not observe any significant deviation of the results. This can be
explained by the fact that msnbc has only a few distinct nodes, hence a small number of
different distinct paths a user can follow. As already mentioned, in this data set the users’
visits were almost uniformly distributed across all web site’s page categories. Therefore
the probability of visiting two pages consecutively is very well approximated by the
probability of visiting the last page (almost independent of the page the user was
previously visiting). In what follows, we present the results of this experiment. We
present some preliminary ideas concerning possible extensions of this framework in the
final Chapter.
The results of the set of experiments we performed using the 2nd-order Markov
models as NG synopsis on the msnbc data set are included in the diagrams of Figures 31
and 32. We observe that in the case of 2nd-order Markov models the winner is UPR
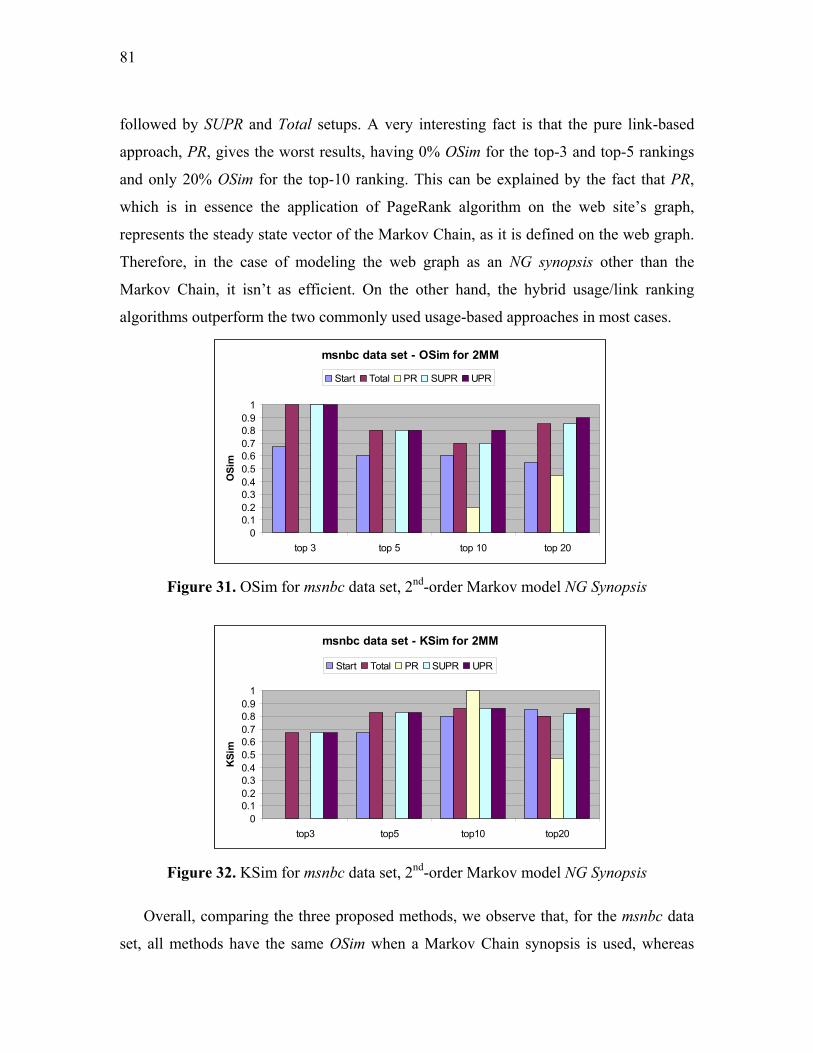
81
followed by SUPR and Total setups. A very interesting fact is that the pure link-based
approach, PR, gives the worst results, having 0% OSim for the top-3 and top-5 rankings
and only 20% OSim for the top-10 ranking. This can be explained by the fact that PR,
which is in essence the application of PageRank algorithm on the web site’s graph,
represents the steady state vector of the Markov Chain, as it is defined on the web graph.
Therefore, in the case of modeling the web graph as an NG synopsis other than the
Markov Chain, it isn’t as efficient. On the other hand, the hybrid usage/link ranking
algorithms outperform the two commonly used usage-based approaches in most cases.
msnbc data set - OSim for 2MM
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5 top 10 top 20
OSi
m
Start Total PR SUPR UPR
Figure 31. OSim for msnbc data set, 2nd-order Markov model NG Synopsis
msnbc data set - KSim for 2MM
00.10.20.30.40.50.60.70.80.9
1
top3 top5 top10 top20
KSi
m
Start Total PR SUPR UPR
Figure 32. KSim for msnbc data set, 2nd-order Markov model NG Synopsis
Overall, comparing the three proposed methods, we observe that, for the msnbc data
set, all methods have the same OSim when a Markov Chain synopsis is used, whereas

82
UPR outperforms the other two when a 2nd-order Markov model synopsis is used. On the
other hand, in the case of the cti data set, we observe that SUPR outperforms the other
two methods. Nevertheless, there is no prevalent underlying pattern between the number
of recommendations and OSim/KSim. Therefore, we cannot conclude on the superiority
of one of the proposed methods, other than that it strongly depends both on the data set
and the NG synopsis used.
4.6.4 Comparison of l-UPR and h-PPM
In the last part of the experimental evaluation, we compared the two proposed
frameworks, namely, l-UPR and h-PPM. For this purpose, we used the same
methodology we followed when evaluating the l-UPR framework, as described in Section
4.6.2: we build the navigational graph from the test data set and select the 10 most
popular paths comprising of two or more pages. For each such path p, we make the
assumption that it is the current path of the user and generate recommendations applying
the aforementioned approaches on the training data set. Using l-UPR, we expand p to
create a localized sub-graph and then apply the algorithm to rank the pages included in
the sub-graph. Using h-PPM, we find the n pages having higher probability to be visited
after p. We then select the top-n ranked pages. At the same time, we identify in the test
data set the n most frequent paths that extend p by one more page. We finally compare,
for each path p, the generated top-n page recommendations of each method (l-UPR, h-
PPM) with the n most frequent “next” pages, using the OSim metric. We omit the KSim
results here, since, as already mentioned, they are not very important for such small
recommendation sets.
We applied this methodology to both data sets, generating top-3 and top-5
recommendation sets. For generating recommendations using the h-PPM framework, we
present here the variation that behaved better in the previous experiments, namely, UPR
for the msnbc data set and SUPR for the cti data set. We should point out, however, that
all variations produce almost the same recommendations for such small sets, as already
implied in Section 4.6.3. The experimental results are depicted in Figure 33.

83
msnbc data set
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5
OSi
ml-UPR h-PPM
cti data set
00.10.20.30.40.50.60.70.80.9
1
top 3 top 5
OSi
m
l-UPR h-PPM
Figure 33. Comparison of l-UPR and h-PPM, Markov Chain NG synopsis
We observe that the relevant prediction accuracy of each method depends on the size
of the recommendation set and the data set that is used. Therefore, h-PPM has better
prediction accuracy for small recommendation sets, whereas l-UPR is slightly better for
the bigger recommendation sets. Nevertheless, the differences between the two methods
are minor and we cannot draw any conclusions, other than repeating that the final choice
heavily depends on the data set we want to model.
4.7 System Prototype
In this Section we present the prototype system implementing the aforementioned
approaches, namely, the l-UPR and h-PPM recommendation frameworks. Both
frameworks are integrated in the same prototype as they share the same infrastructure and
some algorithms. Apart from the proposed frameworks, this prototype system implements
Markov models of any order supporting path prediction and recommendations.
The system prototype is entirely based on C# (Microsoft Visual Studio .Net). No
database was used since all the inputs/outputs to the system are files. Anything created
on-the-fly was stored in hash tables. The main functionalities of the prototype are
described below. The names in the parentheses next to the modules’ names show the
framework each module is used in.
Web Graph Reconstruction (h-PPM & l-UPR): Since this framework implements link
analysis-based algorithms (PageRank (PR) and semi-Usage PageRank (SUPR)), the
knowledge of the web site’s link structure is essential. The web structure, however, is not

84
always known. The system provides the web graph reconstruction module, which takes as
input the web site’s user sessions and reconstructs the web site’s graph based on this
information. The output of this process is an XML file.
Navigational Graph Creation (h-PPM): The proposed algorithm, UPR, is based on
the application of link analysis over the web site’s Navigational Graph, NG. This module
enables the creation of NG from the web site’s user sessions in order to be used in
subsequent computations. The NG is stored in a hash file.
Prior Probabilities Computation (h-PPM): This module enables the computation of
the prior probabilities defined on Section 4.5.2, namely, PR, SUPR and UPR. The system
also provides the functionality for computing probabilities based on the page visits’
frequencies, used by Markov models, namely, Start and Total (prior probabilities are
proportional to the number of visits to a page as the first page in the session or to the total
number of visits to a page, respectively). This process takes as input the parameters of the
chosen probability computation method. The prior probabilities computed using either
one of the five alternative methods are stored in a hash table and used by the Path
Probability Computation module. The results, as well as a log including all the iterations
of the link analysis-based algorithms are also saved in files. A screenshot of this module
is shown in Figure 34.
Path Probabilities Computation (h-PPM): The system enables the popular path
prediction using either the h-PPM framework, or Markov models. The priors used in each
method are pre-computed by the Prior Computation module. This module enables the
prediction of the n most probable “next” visits for any sub-path of NG, along with the
respective probabilities. It also enables the prediction of the top-n popular paths. This
information is output to files for further analysis. Figure 35 includes a screenshot of this
module.
l-UPR Path Prediction (l-UPR): This module implements the l-UPR recommendation
framework. It incorporates functionality for creating the NG using the web site’s user
sessions, whereas the NG synopsis can be a Markov model of any order. The module
takes as input the path (current visitor’s path) and the parameters of the l-UPR algorithm
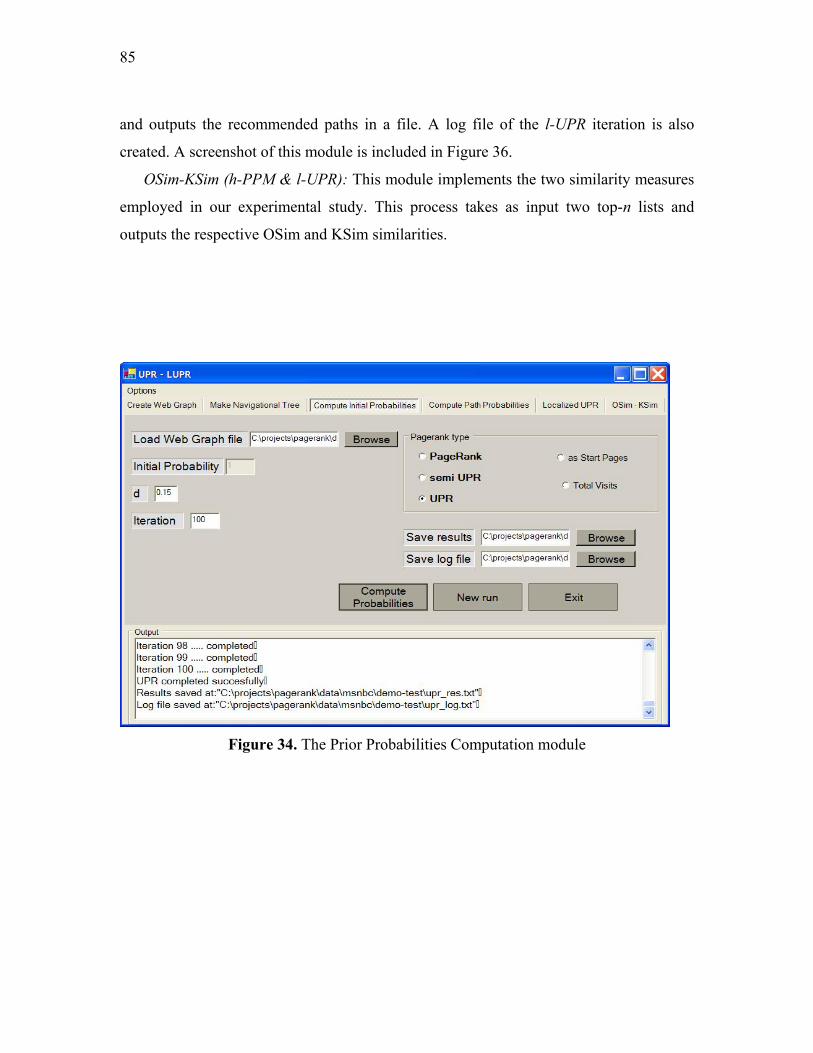
85
and outputs the recommended paths in a file. A log file of the l-UPR iteration is also
created. A screenshot of this module is included in Figure 36.
OSim-KSim (h-PPM & l-UPR): This module implements the two similarity measures
employed in our experimental study. This process takes as input two top-n lists and
outputs the respective OSim and KSim similarities.
Figure 34. The Prior Probabilities Computation module

86
Figure 35. The Path Probabilities Computation module
Figure 36. The l-UPR Path Prediction module

87
4.8 Conclusions
There is a wealth of recommendation models for personalizing a web site based on
the navigational behavior of past users. Most of the models, however, are solely based on
the web site’s usage data ignoring the link structure of the web graph visited. In this
Chapter we presented how link analysis can be integrated in the web personalization
process. We propose a novel algorithm, UPR, which is applicable to any navigational
graph synopsis, and provides ranked recommendations to the visitors of a web site,
capitalizing on the structural properties of the navigation graph. We presented UPR in the
context of two different personalization frameworks, l-UPR and h-PPM. In the first
framework, a localized version of UPR is applied to a personalized sub-graph of the NG
synopsis and is used to create online personalized recommendations to the visitors of the
web site. The second approach addresses several shortcomings of pure usage-based
probabilistic predictive models, by incorporating link analysis techniques in such models
in order to support popular paths’ prediction. The experiments we have performed for
both frameworks are more than promising, outperforming existing approaches.

88
CHAPTER 5
Conclusions and Future Research
5.1 Thesis Summary
The World Wide Web grows at a tremendous pace, and its impact as the main source
of information acquisition is increasing dramatically. Because of its rapid and chaotic
growth, the resulting network of information lacks organization and structure, making
web site exploration difficult. To address the requirement of effective web navigation, the
web sites provide personalized recommendations to the end users.
Most of the research efforts in web personalization correspond to the evolution of
extensive research in web usage mining, i.e. the exploitation of the navigational patterns
of the web site’s visitors. When a personalization system relies only on usage-based
results, however, valuable information conceptually related to what is finally
recommended may be missed. Moreover, the structural properties of the web site are
often disregarded. In this thesis, we present novel techniques that incorporate the content
semantics and the structural properties of a web site in the web personalization process.
In the first part of our work we present a semantic web personalization system.
Motivated by the fact that if a personalization system is only based on the recorded
navigational patterns, important information that is semantically similar to what is
recommended might be missed, we propose a web personalization framework (SEWeP)
that integrates usage data with content semantics, expressed in ontology terms, in order to

89
compute semantically enhanced navigational patterns and effectively generate useful
recommendations.
To support this framework, we developed various techniques for managing web
content. The web document annotation is performed using both the content of the page,
as well as its connectivity features, thus providing a more objective characterization of
the text. Moreover, the mapping of the extracted features to ontology terms is performed
automatically, as opposed to related research efforts which require manual labeling of the
documents. This uniform representation of the content using ontology terms enables
further processing (clustering, association rules mining, recommendations’ generation) in
an abstract, semantic level. Therefore, the resulting recommendations are semantically
enhanced and evaluated to be more useful during the users’ navigation. To the best of our
knowledge, SEWeP is the only semantic web personalization system that performs
automated content characterization and ontology mapping, therefore can be used by any
web site.
In the second part of our work, we propose the incorporation of the underlying
structure of a web site in the web personalization process. We present the novel algorithm
UPR (Usage-based PageRank), a PageRank-style algorithm that relies on the recorded
usage data and link analysis techniques in order to determine the importance of a web
page. We demonstrate how UPR can be applied to any web site in order to rank its web
pages. We then specialize the proposed personalization framework, comprising of the
UPR algorithm as well as an abstraction of the user sessions termed Navigational Graph
in two different contexts.
We introduce l-UPR, a personalized recommendation algorithm. l-UPR is a localized
variant of UPR that is applied to the personalized navigational sub-graph of each user.
We present the algorithm for creating personalized navigational sub-graphs using the
current visit of each user. This sub-graph includes all the possible “next visits” of the
user, maintaining the properties required for the algorithm to converge. Since l-UPR is
applied only to a small fraction of the actual web graph, its computation is not time-
consuming. Therefore it can be applied online, providing fast and accurate personalized
recommendations to each web site’s visitor.

90
Based on the same motivation and framework, we propose a hybrid probabilistic
predictive model, in order to address the pure usage-based probabilistic models’
shortcomings. In this model, we use UPR and its variations as a robust mechanism for
determining prior probabilities of page visits. Using this approach, the probabilistic
predictive models are enriched with usage data-independent information, resulting in
more objective and representative predictions than existing techniques that rely solely on
usage data.
The diversity of the two specializations verifies the potential of our approach in
providing an integrated framework for applications of link analysis to web
personalization.
5.2 Discussion
SEWeP was introduced in a time when the Semantic Web vision was rather new, and
people were just starting to exploit some of its principal ideas, structures, languages and
protocols. Since then, some of them were shown to be insufficient and were abandoned,
whereas others, with ontologies being one of them, are now broadly accepted and used in
many different applications. SEWeP exploits ontologies in order to represent web content
and the users’ navigational behavior. The exploitation of content semantics (either using
ontologies or not) in the web usage mining or the web personalization process has been
the subject of many studies that followed (or were carried on in parallel to) SEWeP
[AG+03, OB+03, ML+04, MSR04, GKG05].
There exist, however, several open issues in this area. Since most of the existing web
sites do not have an underlying semantic infrastructure, and due to the size of most web
sites, it is very difficult to annotate the content by hand, as most approaches imply. It is
evident that the content characterization process should be performed automatically. One
of the most crucial parts of this process is the mapping of the extracted features to
ontology terms, since an inappropriate mapping would eventually result in inaccurate
recommendations. Therefore, one of the most important updates to the SEWeP system
would be to incorporate even more effective semantic similarity measures, such as those
proposed in [MTV04, MT+05].

91
Another important issue concerning the content characterization process is the
processing of multilingual content. Even though all systems are based on the implicit
assumption that the web content is annotated in the same language (usually English), this
is not the case for the majority of web pages. In this thesis we proposed a preliminary
solution for bilingual web sites, focusing on Greek web sites. A possible extension would
be to generalize this framework for multilingual sites, enhancing the translation process
with more effective similarity measures, such as those proposed above.
The semantic web personalization framework presented in this thesis is solely based
on the recorded usage data and the content of the web site. Since knowledge about the
users’ profiles, as used in the collaborative filtering systems, has been shown to be
valuable in the recommendation process, we would like to extend the proposed
architecture to incorporate such information regarding users’ ratings, preferences etc. If,
for example, the users’ preferences are expressed in ontology terms and are available
apriori, the recommendation algorithm could be tuned to “promote” relevant pages.
Moreover, we should consider the hidden (or deep, or invisible) web, in other words
the pages that are dynamically created as results to queries on underlying databases. In
the last few years, the size of the hidden web pages is rapidly increasing. It cannot,
however, be indexed and processed easily. This is a major problem in the web search
context nowadays, and should be taken into consideration by future personalization
frameworks.
In general, we believe that the incorporation of content semantics in the web
personalization process has been shown to be very useful and this is verified by the fact
that it is nowadays used commonly in real-life recommendation systems. The same holds
for the combination of more than one web usage mining techniques in the web
personalization process.
As far as the second part of this thesis is concerned, we see much potential in the
integration of link analysis in web personalization. Even though link analysis algorithms
have been largely used in other contexts, especially in web searching, in the past few
years, only lately they have been introduced in similar [BG+04] or the same [BL06]
application, that of web usage mining and personalization.

92
In this thesis we have supported the initial intuition that link analysis can be used in
several different contexts in order to support web personalization through an extensive
experimental evaluation process. As we have already pointed out, the priors defined in h-
PPM framework are directly applicable to Markov Chains, but do not always work for
higher-order Markov models. UPR and its variations compute probabilities for the
navigational graph’s nodes, i.e. the web site’s pages. In higher order Markov models, we
need such probabilities for the web site’s paths too. One solution would be to create
summarizing nodes including all the paths, or only the most popular ones, and then apply
UPR on this aggregate navigational graph. This would result in UPR values for paths
which could subsequently be used in the h-PPM context. This issue remains open for
future work.
Our future plans involve the application of l-UPR on different NG synopses. As
shown in the experimental evaluation, l-UPR is a very promising recommendation
algorithm. In our study we applied it on the Markov Chain NG synopsis. We expect better
results in the case of more complex NG synopses, which approximate more accurately the
navigational graph.
Another issue that should be taken into consideration in the process of assigning
importance scores in the web pages of a web site is the “freshness” and “trends” in the
web navigation context. We believe that pages/paths with more recent visits, or
increasing rate of visits should be favored in the recommendation process [BVW04] and
aim to incorporate this intuition in our future work.
Moreover, we plan to investigate how this hybrid usage-structure ranking can be
applied to a unified web/navigational graph which expands out of the limits of a single
web site. Such approach would enable a “global” importance ranking over the web,
enhancing both web search results and the recommendation process.
Finally, we conclude with our vision for web personalization systems. This thesis has
shown how the integration of content semantics or link analysis techniques can improve
the recommendation process. We believe that the next step would be to exploit all these
data, namely, usage, content and structure, in a single, unified framework. This
framework need not be specifically focused on generating personalized

93
recommendations, but should cover many web applications such as web search results
ranking, or web content (blogs/bookmarked pages/multimedia etc.) categorization.


95
LIST OF REFERENCES
[ADW02] C. Anderson, P. Domingos, D. S. Weld, Relational Markov Models and their Application to Adaptive Web Navigation, in Proc. of the 8th ACM SIGKDD Conference, Canada (2002)
[AG03] S. Acharyya, J. Ghosh, Context-Sensitive Modeling of Web Surfing Behaviour Using Concept Trees, in Proc. of the 5th WEBKDD Workshop, Washington DC (2003)
[ANM04] M.S. Aktas, M.A. Nacar, F. Menczer, Personalizing PageRank Based on Domain Profiles, in Proc. of the 6th WEBKDD Workshop, Seattle (2004)
[AP+04] M. Albanese, A. Picariello, C. Sansone, L. Sansone, A Web Personalization System based on Web Usage Mining Techniques, in Proc. of WWW2004, New York (2004)
[AS94] R. Agrawal, R. Srikant, Fast Algorithms for Mining Association Rules, in Proc. of 20th VLDB Conference (1994)
[B02] B. Berendt, Using site semantics to analyze, visualize and support navigation, in Data Mining and Knowledge Discovery Journal, 6: 37-59 (2002)
[BB+99] A.G. Buchner, M. Baumgarten, S.S. Anand, M.D. Mulvenna, J.G. Hughes, Navigation pattern discovery from Internet data, in Proc. of the 1st WEBKDD Workshop, San Diego (1999)
[BG+04] V. Bacarella, F. Giannoti, M. Nannni, D. Pedrsechi, Discovery of Ads Web Hosts through Traffic Data Analysis, in Proc. of the 9th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD ’04), Paris, France (2004)
[BHS02] B. Berendt, A. Hotho, G. Stumme, Towards Semantic Web Mining, in Proc. of the 1st Intl. Semantic Web Conference (ISWC 2002)
[BL99] Jose Borges, Mark Levene, Data Mining of User Navigation Patterns, in Web Usage Analysis and User Profiling, published by Springer-Verlag as Lecture Notes in Computer Science, 1836: 92-111
[BL04] J. Borges, M. Levene, A Dynamic Clustering-Based Markov Model for Web Usage Mining, Technical Report, available at http://xxx.arxiv.org/abs/cs.IR/0406032 (2004)
[BL06] J. Borges, M. Levene, Ranking Pages by Topology and Popularity within Web Sites, accepted for publication in World Wide Web Journal (2006)
[BP98] S. Brin, L. Page, The anatomy of a large-scale hypertextual Web search engine, Computer Networks, 30(1-7): 107-117 (1998)
[BS00] B. Berendt, M. Spiliopoulou, Analysing navigation behaviour in web sites integrating multiple information systems, The VLDB Journal 9(1):56-75 (2000)
[BS04] R. Baraglia, F. Silvestri, An Online Recommender System for Large Web Sites, in Proc. of ACM/IEEE Web Intelligence Conference (WI’04), China (2004)

96
[BVW04] K. Berberich, M. Vazirgiannis, G. Weikum, T-Rank: Time-aware Authority Ranking, 3rd Workshop on Algorithms and Models for the Web-Graph (WAW 2004), Rome, Italy (2004)
[CD+97] S. Chakrabarti, B. Dom, R. Agrawal, P. Raghavan, Using taxonomy, discriminants, and signatures for navigation in text databases, in Proc. of the 23rd VLDB Conference, Athens, Greece (1997)
[CD+98] S. Chakrabarti, B. Dom, P. Raghavan, S. Rajagopalan, D. Gibson, J. Kleinberg, Automatic Resource Compilation by Analyzing Hyperlink Structure and Associated Text, in Proc. of WWW7 (1998)
[CD+99] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, R. Kumar, P. Raghavan, S. Rajagopalan, A. Tomkins, Mining the Link Structure of the World Wide Web, IEEE Computer 32(6), (1999)
[CH+00] I.Cadez, D.Heckerman, C.Meek, P. Smyth, S. White, Visualization of Navigation Patterns on a Web Site Using Model Based Clustering, in Proc. of ACM KDD2000 Conference, Boston MA (2000)
[CMS97] R. Cooley, B. Mobasher, J. Srivastava, Web Mining: Information and Pattern Discovery on the World Wide Web, in Proc. of the 9th IEEE International Conference on Tools with Artificial Intelligence (ICTAI '97)
[CMS99] Robert Cooley, Bamshad Mobasher, Jaideep Srivastava, Data preparation for mining world wide Web browsing patterns, Knowledge and Information Systems,1(1), (1999)
[CPY96] M.S. Chen, J.S. Park, P.S. Yu, Data Mining for Path Traversal Patterns in a Web Environment, in Proc. of the 16th Intl. Conference on Distributed Computing Systems (1996)
[CTI] CTI DePaul web server data, http://maya.cs.depaul.edu/~classes/ect584/data/cti-data.zip
[DBN] DB-NET web server data, http://www.db-net.aueb.gr [DK04] M. Deshpande, G. Karypis, Selective Markov Models for Predicting Web-Page
Accesses, in ACM Transactions on Internet Technology, 4(2):163-184, (2004) [DM02] H. Dai, B. Mobasher, Using Ontologies to Discover Domain-Level Web Usage
Profiles, in Proc. of the 2nd Workshop on Semantic Web Mining, Helsinki, Finland (2002)
[E04] M. Eirinaki, Web Mining: A Roadmap, IST/NEMIS Technical Report, 2004, http://www.db-net.aueb.gr
[EK+98] M. Ester, H. P. Kriegel, J. Sander, M. Wimmer, X. Xu, Incremental Clustering for Mining in a Data Warehousing Environment, in Proc. of the 24th VLDB Conference (1998)
[EL+04] M. Eirinaki, C. Lampos, S. Paulakis, M. Vazirgiannis, Web Personalization Integrating Content Semantics and Navigational Patterns, in Proc. of ACM WIDM 2004, Washington D.C. (2004)

97
[EM+06] M. Eirinaki, D. Mavroeidis, G. Tsatsaronis, M. Vazirgiannis, Semantic Web Personalization: The role of Ontologies, book chapter in “Semantics, Web, and Mining”, (working title), eds. M. Ackermann, B. Berendt, M. Grobelnik, A. Hotho, D. Mladenic, G. Semeraro, M. Spiliopoulou, G. Stumme, V. Svatek, M. van Someren, to be published by Springer, LNCS/LNAI
[EV03] M. Eirinaki, M. Vazirgiannis, Web Mining for Web Personalization, in ACM Transactions on Internet Technologies (ACM TOIT), 3(1):1-27 (2003)
[EV05] M. Eirinaki, M. Vazirgiannis, ‘Usage-based web personalization”, in Proceedings of 5th IEEE International Conference on Data Mining (ICDM 2005), Houston, Texas, (2005)
[EVA05] M.Eirinaki, J.Vlahakis, S. S. Anand, An Integrated Web Personalization Platform Based on Content Structures and Usage Behaviour, Book Chapter in "Intelligent Techniques in Web Personalization", eds. B.Mobasher, S.S.Anand, LNAI 3169, pp. 272-288, Springer Verlag, (2005)
[EVK05] M. Eirinaki, M. Vazirgiannis, D. Kapogiannis, “Web path recommendations based on Page Ranking and Markov Models”, in Proc. of ACM WIDM 2005, Bremen, Germany (2005)
[EVV03] M.Eirinaki, M. Vazirgiannis, I. Varlamis, "SEWeP: Using Site Semantics and a Taxonomy to Enhance the Web Personalization Process", in Proc. of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD2003), Washington DC (2003)
[EGP02] P. Edwards, G.A. Grimnes, A. Preece, An Empirical Investigation for Learning from the Semantic Web, in Proc. of the 2nd Semantic Web Mining Workshop, Helsinki, Finland (2002)
[GKG05] J. Guo, V. Keselj, Q. Gao, Integrating Web Content Clustering into Web Log Association Rule Mining, In Proc. of Canadian AI 2005 (2005)
[H02] T. Haveliwala, Topic-Sensitive PageRank, in Proc. of WWW2002 Conference, Hawaii (2002)
[HBV02] M. Halkidi, Y. Batistakis, M. Vazirgiannis, Cluster Validity Methods: Part II, SIGMOD Record, September 2002
[HEK03] S. Holland, M. Ester, W. Kiebling, Preference Mining: A Novel Approach on Mining User Preferences for Personalized Applications, in Proc. of the 7th PKDD Conference (2003)
[HF04] G. Hooker, M. Finkelman, Sequential Analysis for Learning Modes of Browsing, in Proc. of the 6th WEBKDD Workshop, Seattle (2004)
[HG+02] T.H. Haveliwala, A. Gionis, D. Klein, P. Indyk, Evaluating Strategies for Similarity Search on the Web, in Proc. of WWW11, Hawaii (2002)
[HLC05] Z. Huang, X. Li, H. Chen, Link Prediction Approach to Collaborative Filtering, in Proc. of ACM JCDL’05, (2005)

98
[HN+01] Zhexue Huang, Joe Ng, David W. Cheung, Michael K. Ng, Wai-Ki Ching, A Cube Model for Web Access Sessions and Cluster Analysis, in Proc. of the 3rd WEBKDD Workshop (2001)
[HN+03] M. Halkidi, B. Nguyen, I. Varlamis, M. Vazirgiannis, THESUS: Organizing Web Documents into Thematic Subsets using an Ontology, VLDB journal, 12(4): 320-332, (2003)
[JF+97] T. Joachims, D. Freitag, T. Mitchell, WebWatcher: A Tour Guide for the World Wide Web, in Proc. of IJCAI97, (1997)
[JPT03] S. Jespersen, T.B. Pedersen, J. Thorhauge, Evaluating the Markov Assumption for Web Usage Mining, in Proc. of ACM WIDM 2003, Lousiana, (2003)
[JZM04a] X. Jin, Y. Zhou, B. Mobasher, Web Usage Mining Based on Probabilistic Latent Semantic Analysis, in Proc. of the 10th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'04), Seattle, (2004)
[JZM04b] X. Jin, Y. Zhou, B. Mobasher, A Unified Approach to Personalization based on Probabilistic Latent Semantic Models of Web usage and Content, in Proceedings of AAAI Workshop on Semantic Web Personalization (SWP’04), (2004)
[JZM05] X. Jin, Y. Zhou, B. Mobasher, A Maximum Entropy Web Recommendation System: Combining Collaborative and Content Features, in Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'05), Chicago (2005)
[Kij97] M. Kijima, Markov Processes for Stochastic Modeling, Chapman & Hall, London, (1997)
[KS04] J. Kleinberg, M. Sandler, Using Mixture Models for Collaborative Filtering, in Proc. of ACM Symposium on Theory of Computing (STOC’04), (2004)
[KG90] M. Kendall, J.D.Gibbons, Rank Correlation Methods, Oxford University Press, (1990)
[KHG03] S.D. Kamvar, T.H. Haveliwala, and G.H. Golub, Adaptive Methods for the Computation of PageRank, in Proc. of the Intl. Conference on the Numerical Solution of Markov Chains, (2003)
[KH+03] S.D. Kamvar, T.H. Haveliwala, C.D. Manning, and G.H. Golub, Extrapolation Methods for Accelerating PageRank Computations, in Proc. of the 12th Intl. World Wide Web Conference, (2003)
[KJ+01] R. Krishnapuram, Anupam Joshi, Olfa Nasraoui, Liyu Yi, Low-Complexity Fuzzy Relational Clustering Algorithms for Web Mining, in IEEE Transactions of Fuzzy Systems, (2001)
[LE+04] C. Lampos, M. Eirinaki, D. Jevtuchova, M. Vazirgiannis, Archiving the Greek Web, in Proc. of the 4th Intl. Web Archiving Workshop (IWAW04), Bath, UK (2004)
[LL03] M. Levene, G. Loizou, Computing the Entropy of User Navigation in the Web, in Intl. Journal of Information Technology and Decision Making, 2: 459-476, (2003)
[MD+00a] B. Mobasher, H. Dai, T. Luo, Y. Sung, J. Zhu, Discovery of Aggregate Usage Profiles for Web Personalization, in Proc. of 2nd WEBKDD Workshop, Boston (2000)

99
[MD+00b] B. Mobasher, H. Dai, T. Luo, Y. Sung, J. Zhu, Integrating web usage and content mining for more effective personalization, in Proc. of the Intl. Conference on Ecommerce and Web Technologies (ECWeb), Greenwich, UK (2000)
[ML+04] R. Meo, P.L. Lanzi, M. Matera, R. Esposito, Integrating Web Conceptual Modeling and Web Usage Mining, in Proc. of the 6th WEBKDD Workshop, Seattle (2004)
[MPG03] E. Manavoglu, D. Pavlov, C.L. Giles, Probabilistic User Behaviour Models, in Proc. of the 3rd Intl. Conference on Data Mining (ICDM 2003)
[MPT99] F. Masseglia, P. Poncelet, M. Teisseire, Using Data Mining Techniques on Web Access Logs to Dynamically Improve Hypertext Structure, in ACM SigWeb Letters, 8(3):13-19, (1999)
[MR95] R. Motwani and P. Raghavan. Randomized Algorithms, Cambridge University Press, United Kingdom (1995)
[MSN] msnbc.com Web Log Data, available from UCI KDD Archive, http://kdd.ics.uci.edu/databases/msnbc/msnbc.html
[MSR04] S. E. Middleton, N. R. Shadbolt, D. C. De Roure, Ontological User Profiling in Recommender Systems, ACM Transactions on Information Systems (TOIS), 22(1):54-88 (2004)
[MTV04] D. Mavroeidis, G. Tsatsaronis, M. Vazirgiannis, Semantic Distances for Sets of Senses and Applications in Word Sense Disambiguation, in Proc. of the 3rd Intl. Workshop on Text Mining and its Applications, Athens, Greece (2004)
[MT+05] D. Mavroeidis, G. Tsatsaronis, M. Vazirgiannis, M. Theobald, G. Weikum, Word Sense Disambiguation for Exploiting Hierarchical Thesauri in Text Classification, in Proc. of the ECML/PKDD 2005 Conference, Porto, Portugal (2005)
[NC+03] O. Nasraoui, C. Cardona, C. Rojas, F. Gonzales, Mining Evolving User Profiles in Noisy Web Clickstream Data with a Scalable Immune System Clustering Algorithm, in Proc. of the 5th WEBKDD Workshop, Washington DC (2003)
[NM02] A. Nanopoulos, Y. Manolopoulos, Efficient Similarity Search for Market Basket Data, in the VLDB Journal, (2002)
[NM03] M. Nakagawa, B. Mobasher, A Hybrid Web Personalization Model Based on Site Connectivity, in Proc. of the 5th WEBKDD Workshop, Washington DC (2003)
[NP03] O. Nasraoui, C. Petenes, Combining Web Usage Mining and Fuzzy Inference for Website Personalization, in Proc. of the 5th WEBKDD Workshop, Washington DC (2003)
[NP04] O. Nasraoui, M. Pavuluri, Complete this Puzzle: A Connectionist Approach to Accurate Web Recommendations based on a Committee of Predictors, in Proc. of the 6th WEBKDD Workshop, Seattle, (2004)
[OB+03] D. Oberle, B. Berendt, A. Hotho, J. Gonzalez, Conceptual User Tracking, in Proc. of the 1st Atlantic Web Intelligence Conf. (AWIC), (2003)
[P80] M. F. Porter, An algorithm for suffix stripping, Program, 14(3):130-137, (1980)

100
[PE00] M. Perkowitz, O. Etzioni, Towards Adaptive Web Sites: Conceptual Framework and Case Study, in Artificiall Intelligence 118(1-2):245-275, (2000)
[PG02] N. Polyzotis, M. Garofalakis, Structure and Value Synopses for XML Data Graphs, in Proc. of the 28th VLDB Conference (2002)
[PGI04] N. Polyzotis, M. Garofalakis, Y. Ioannidis, Approximate XML Query Answers, in Proc. of SIGMOD 2004, Paris, France (2004)
[PL+04] S. Paulakis, C. Lampos, M. Eirinaki, M. Vazirgiannis, SEWeP: A Web Mining System supporting Semantic Personalization, demo paper, in Proc. of the ECML/PKDD 2004 Conference, Pisa, Italy (2004)
[PW00] T. Phelps, R. Wilensky, Robust hyperlinks: Cheap, Everywhere, Now, in Proc. of Digital Documents and Electronic Publishing (DDEP00), Munich, Germany (2000)
[RD02] M. Richardson, P. Domingos, The Intelligent Surfer: Probabilistic Combination of Link and Content Information in PageRank, in Neural Information Processing Systems, 14:1441-1448, (2002)
[S00] R. R. Sarukkai, Link Prediction and Path Analysis Using Markov Chains, in Computer Networks, 33(1-6): 337-386, (2000)
[SA95] R. Srikant, R. Agrawal, Mining Generalized Association Rules, in Proc. of 21st VLDB Conf., Zurich, Switzerland (1995)
[SB98] G. Salton, C. Buckley, Term-weighting approaches in automatic text retrieval, Information Processing and Management, 24:513-523, (1998)
[SC+00] J. Srivastava, R. Cooley, M. Deshpande, P. Tan, Web Usage Mining: Discovery and Applications of Usage Patterns from Web Data, SIGKDD Explorations, 1(2):12-23, (2000)
[SH03] R. Sen, M. Hansen, Predicting a Web user’s next access based on log data, in Journal of Computational Graphics and Statistics, 12(1):143-155, (2003)
[SFW99] M. Spiliopoulou, L. C. Faulstich, K. Wilkler, A data miner analyzing the navigational behaviour of Web users, in Proc. of the Workshop on Machine Learning in User Modelling, Greece (1999)
[SK+00] B. Sarwar, G. Karypis, J. Konstan, J. Riedl, Analysis of Recommendation Algorithms for E-Commerce, in Proc. of ACM EC’00, Minnesota (2000)
[SK+01] B. Sarwar, G. Karypis, J. Konstan, J. Riedl, Item-based Collaborative Filtering Recommendation Algorithms, in Proc. of WWW10, Hong Kong (2001)
[SZ+97] C. Shahabi, A. M. Zarkesh, J. Adibi, V. Shah, Knowledge Discovery for Users Web-Page Navigation, in Workshop on Research Issues in Data Engineering, Birmingham, UK (1997)
[VEA03] J. Vlahakis, M. Eirinaki, S. S. Anand, IKUM: An Integrated Web Personalization Platform Based on Content Structures and Usage Behaviour, in Proc. of the IJCAI-03 Workshop on Intelligent Techniques for Web Personalization (ITWP'03), Acapuclo, Mexico (2003)

101
[VV+04] I. Varlamis, M. Vazirgiannis, M. Halkidi, B. Nguyen, THESUS, A Closer View on Web Content Management Enhanced with Link Semantics, in IEEE Trans. on Knowledge and Data Engineerign Journal (TKDE), 16(6):685-700, (2004)
[Tria] M. Triantafillidis, Triantafillidis On-Line, Modern Greek Language Dictionary, http://kastor.komvos.edu.gr/dictionaries/dictonline/DictOnLineTri.htm
[W3Clog] Extended Log File Format, http://www.w3.org/TR/WD-logfile.html [WCA] Web Characterization Terminology & Definitions, http://www.w3.org/1999/05/WCA-terms/ [WC+02] J. Wang, Z. Chen, L. Tao, W. Ma, L. Wenyin, Ranking User’s Relevance to a
Topic through Link Analysis on Web Logs, in Proc. of WIDM ’02, (2002) [WN] WordNet, A lexical database for the English language, http://www.cogsci.princeton.edu/~wn/ [WP94] Z. Wu, M. Palmer, Verb Semantics and Lexical Selection, 32nd Annual Meetings
of the Associations for Computational Linguistics (1994) [YH03] A. Ypma, T. Heskes, Categorization of web pages and user clustering with
mixtures of Hidden Markov Models, in Proc. of 4th WEBKDD Workshop, Canada (2002)
[YZ+96] T. W. Yan, M. Jacobsen, H. Garcia-Mollina, U. Dayal, From User Access Patterns to Dynamic Hypertext Linking, In 5th Intl. World Wide Web Conference (WWW5), Paris, France (1996)
[ZB04] Q. Zhao, S. S. Bhowmick, Mining History of Changes to Web Access Patterns, in Proc. of the 8th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD 2004), Pisa, Italy (2004)
[ZHH02a] J. Zhu, J. Hong, J. G. Hughes, Using Markov Chains for Link Prediction in Adaptive Web sites, in Proc. of the 1st Intl. Conference on Computing in an Imperfect World (2002)
[ZHH02b] J. Zhu, J. Hong, J. G. Hughes, Using Markov Models for Web Site Link Prediction, in Proc. of ACM HT’02, Maryland (2002)
[ZXH98] O. R. Zaiane, M. Xin, J. Han, Discovering Web Access Patterns and Trends by Applying OLAP and Data Mining Technology on Web Logs, in Proc. of Advances in Digital Libraries Conference (ADL'98), Santa Babara, CA (1998)


103
APPENDIX A
In order to evaluate the usefulness of the SEWeP framework, we presented the users
with three paths, each one having a different “objective”; one (A) containing visits to
contextually irrelevant pages (random surfer), a second (B) including a small path to very
specialized pages (information seeking visitor), and a third one (C) including visits to
top-level, yet research-oriented pages (topic-oriented visitor). This is the 2nd blind test
that was presented to the users, evaluating the usability of original vs. hybrid
recommendations. Note that we presented unlabeled recommendation sets to the users.
Path A http://www.db-net.aueb.gr/people.htm →
http://www.db-net.aueb.gr/links.htm →
http://www.db-net.aueb.gr/courses/courses.htm (→)
Recommendations
A.1 (HYBRID)
http://www.db-net.aueb.gr/pubs.php
http://www.db-net.aueb.gr/research.htm
http://www.db-net.aueb.gr/courses/postgrdb/asilomar.html
A.2 (ORIGINAL)
http://www.db-net.aueb.gr/pubs.php
http://www.db-net.aueb.gr/pubsearch.php
http://www.db-net.aueb.gr/research.htm

104
Path B http://www.db-net.aueb.gr/people/michalis.htm →
http://www.db-net.aueb.gr/mhalk/CV_maria.htm (→)
Recommendations
B.1 (HYBRID)
http://www.db-net.aueb.gr/mhalk/Publ_maria.htm
http://www.db-net.aueb.gr/research.htm
http://www.db-net.aueb.gr/magda/papers/webmining_survey.pdf
B.2 (ORIGINAL)
http://www.db-net.aueb.gr/mhalk/Publ_maria.htm
http://www.db-net.aueb.gr/papers/gr_book/Init_frame.htm
http://www.db-net.aueb.gr/papers/gr_book/Contents.htm
Path C http://www.db-net.aueb.gr/index.php →
http://www.db-net.aueb.gr/research.htm →
http://www.db-net.aueb.gr/people.htm (→)
Recommendations
C.1 (ORIGINAL)
http://www.db-net.aueb.gr/projects.htm
http://www.db-net.aueb.gr/courses/courses.htm
http://www.db-net.aueb.gr/courses/courses.php?ancid=dm
C.2 (HYBRID)
http://www.db-net.aueb.gr/projects.htm
http://www.db-net.aueb.gr/courses/courses.htm
http://www.db-net.aueb.gr/courses/POSTGRDB/ballp.pdf

105
APPENDIX B
We present here the top-10 ranked paths generated using the Start and Total setups
(in Tables 6 and 7 respectively), as well as the 10 most frequent ones (in Table 5),
extracted from the test data set we used in our experiments for the h-PPM framework.
We observe that the rankings of the first two approaches represent the visits of students to
course material. We assume that in that period of time, when the data set was collected,
many students visited the same pages and paths, accessing them directly (probably by a
bookmarked page). Therefore, their visits dominated any other path visited by any other
user. On the other hand, by taking into consideration the “objective” importance of a
page, as denoted by the link structure of the web site, such temporal influence is reduced.
We omit the top-10 ranked paths generated using the PR, SUPR and UPR algorithms,
since they are very similar to the Frequent paths ranking, as shown by the experimental
results (Figure 28).
Table 5. Top-10 Frequent Paths
/news/default.asp /courses/ /authenticate/login.asp?section=mycti&title=mycti&urlahead=studentprofile/studentprofile /cti/studentprofile/studentprofile.asp?section=mycti /news/default.asp /people/ /courses/ finish /news/default.asp /courses/ finish /courses/ /courses/syllabilist.asp /cti/advising/login.asp -> /cti/advising/display.asp?page=intranetnews /news/default.asp /courses/ /courses/syllabilist.asp /news/default.asp /programs/ /people/ /people/search.asp

106
Table 6. Top-10 ranking for Start setup
/news/default.asp /courses/syllabus.asp?course=250-97-802&q=2&y=2002&id=251 /news/default.asp /courses/syllabus.asp?course=250-97-802&q=2&y=2002&id=251 /courses/syllabilist.asp /news/default.asp /courses/syllabus.asp?course=312-99-601&q=3&y=2002&id=263 /news/default.asp /courses/syllabus.asp?course=312-99-601&q=3&y=2002&id=263 finish /news/default.asp /courses/syllabus.asp?course=318-21-601&q=3&y=2002&id=495 /news/default.asp /courses/syllabus.asp?course=318-21-601&q=3&y=2002&id=495 /news/ /news/default.asp /courses/syllabus.asp?course=345-21-901&q=3&y=2002&id=351 /news/default.asp /courses/syllabus.asp?course=345-21-901&q=3&y=2002&id=351 finish /news/default.asp /courses/syllabus.asp?course=364-98-601&q=3&y=2002&id=921 /news/default.asp /courses/syllabus.asp?course=364-98-601&q=3&y=2002&id=921 /courses/syllabus.asp?course=463-98-301&q=3&y=2002&id=323
Table 7. Top-10 ranking for Total setup
/courses/ /courses/syllabus.asp?course=224-21-601&q=3&y=2002&id=561 /courses/ /courses/syllabus.asp?course=224-21-601&q=3&y=2002&id=561 /courses/syllabus.asp?course=224-21-901&q=3&y=2002&id=214 /courses/ /courses/syllabus.asp?course=224-21-601&q=3&y=2002&id=561 /courses/syllabus.asp?course=224-21-901&q=3&y=2002&id=214 /courses/syllabus.asp?course=224-21-902&q=3&y=2002&id=230 /courses/ /courses/syllabus.asp?course=224-21-601&q=3&y=2002&id=561 /courses/syllabus.asp?course=224-21-901&q=3&y=2002&id=214 /courses/syllabus.asp?course=224-21-902&q=3&y=2002&id=230 /courses/syllabus.asp?course=224-21-903&q=3&y=2002&id=250 finish /courses/ /courses/syllabus.asp?course=224-21-903&q=3&y=2002&id=250 /courses/ /courses/syllabus.asp?course=224-21-903&q=3&y=2002&id=250 finish /courses/ /courses/syllabus.asp?course=309-21-903&q=3&y=2002&id=198 /courses/ /courses/syllabus.asp?course=309-21-903&q=3&y=2002&id=198 finish /courses/ /courses/syllabus.asp?course=311-98-601&q=3&y=2002&id=921 /courses/ /courses/syllabus.asp?course=372-98-901&q=3&y=2002&id=326