nist big data public working group · june 1, 2017 volume 1, definitions version 1 overview • big...
TRANSCRIPT

NIST Big Data Public Working Group
Overview of NIST Big Data Interoperability Framework Volumes
NIST CampusGaithersburg, MarylandJune 1, 2017
June 1, 2017
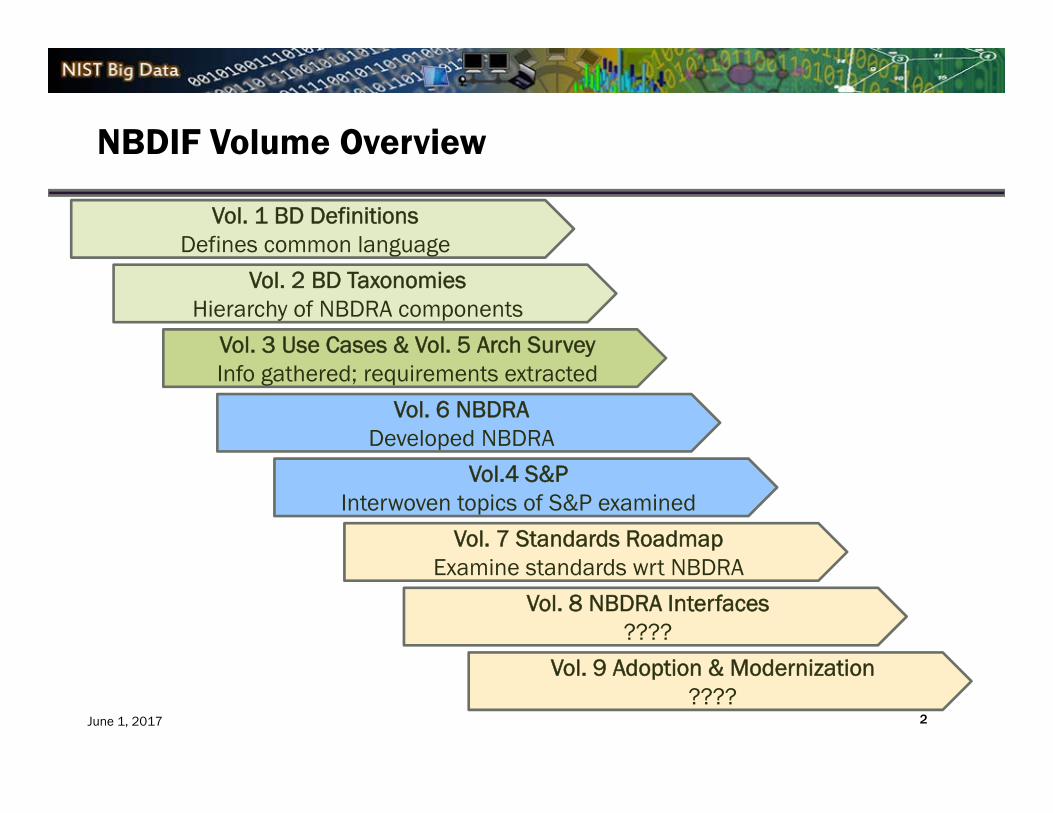
NBDIF Volume Overview
2
Vol. 1 BD DefinitionsDefines common language
Vol. 3 Use Cases & Vol. 5 Arch SurveyInfo gathered; requirements extracted
Vol. 2 BD TaxonomiesHierarchy of NBDRA components
Vol.4 S&PInterwoven topics of S&P examined
Vol. 7 Standards RoadmapExamine standards wrt NBDRA
Vol. 6 NBDRADeveloped NBDRA
Vol. 8 NBDRA Interfaces????
Vol. 9 Adoption & Modernization????

June 1, 2017
Volume Presentation Outline
• For each volume– Scope of the volume
– Brief recap of version 1
– Highlights of version 2 accomplishments
– Summary of version 2 areas needing contributions
– Topics that could be considered for version 3
3

June 1, 2017
Volume 1, Definitions Document Scope
• Define terminology used in community
• Define terminology used in the other volumes of the NBDIF
• Definition of Big Data, Data Science, and related terms
• Narrative description to add conceptual framework around Big Data terminology
• Provides vocabulary to clarify discussions surrounding Big Data
• Audience anyone who is: – New to Big Data to understand concepts
– Want to be compliant with a common vocabulary
– Need to evaluate vendor concepts
4

June 1, 2017
Volume 1, DefinitionsVersion 1 Overview
• Big Data and Data Science Definitions– Big Data consists of extensive datasets, primarily in the characteristics
of volume, variety, velocity, and/or variability, that require a scalable architecture for efficient storage, manipulation, and analysis.
– Data science is the extraction of useful knowledge directly from data through a process of discovery, or of hypothesis formulation and hypothesis testing.
– Comparison to range of Big Data definitions that have been published
5

June 1, 2017
Volume 1, DefinitionsVersion 1 Overview (cont)
• Big Data Features – clarify what is in scope– Data types and metadata (not new)
– Data records (Non-Relational Models not NoSQL)
– Datasets• Distributed storage
• Distributed computing
• Resource Negotiation
• Datasets in Motion (streaming data)
• Data Science Lifecycle Model
– Big Data Analytics (looking at V’s)
6

June 1, 2017
Volume 1, DefinitionsVersion 1 Overview (cont)
• Areas introduced but not covered– Big Data Metrics
– Big Data Security and Privacy
– Data Governance
– Big Data Engineering Patterns
7

June 1, 2017
Volume 1, DefinitionsVersion 2 Accomplishments
• Big Data– Volume, Velocity, Variety, Variability
• Expanded discussion of Big Data Engineering Frameworks– Horizontal infrastructure scaling
– Scalable logical data storage
– Relationship to other technological innovations • HPC, Cloud, IoT, Cyber-Physical Systems, Blockchain
• Reorganized the analysis of big data – i.e. Data Science– Veracity, Validity, Visualization, Value
– Metadata, Data Types, Complexity, Latency
– But not pre-existing cleanliness, completeness, etc
8

June 1, 2017
Volume 1, DefinitionsVersion 2 Accomplishments
• Expand Big Data Science novelty– Machine learning
– Emergent Behavior
– Data Scientists
– Benchmarks
• Big Data security and privacy – still summary of Vol 4
• Management groundwork discussion and definitions– Orchestration
– Governance
– Data Ownership
– Societal Implications
9

June 1, 2017
Volume 1, DefinitionsVersion 2 Opportunities for Contribution
• Concurrency definition and discussion (Section 3.1)
• Enhanced discussion of HPC (S3.3.1), Cloud (S3.3.2), IoT (S3.3.3), CPS (S3.3.4), Blockchain (S3.3.5)
• Latency: describe and relate to Big Data (S4.2.9)
• Emergent Behavior: description and relation to Big Data (S4.4)
• Data cleansing: describe and relate to Big Data (S4.3.1)
• Machine learning: describe and relate to Big Data (S4.3.3)
• Big Data Management (S6.0): discuss wrt Big Data and orchestration (S6.1), data governance (S6.2), and data ownership(S6.3)
• Pointers to external materials not covered here in detail
• References to parallel works by others10

June 1, 2017
Volume 1, DefinitionsPossible Version 3 Topics
• Categorization of Relational/NoSQL/NewSQL/etc attributes– To assist in implementation comparisons
• Metrics guidance
• Discussion of Visualization– Exploratory, Evaluative, Explanatory
– Augmented Reality and Virtual Reality
• Expansion of Machine Learning/Deep Learning/Artificial Intelligence
• Algorithms and Analytics Frameworks
• Dedicated Languages ???
• Emerging topics - ???
11

June 1, 2017
• Review Version 2 slide of remaining items– Do any need so much work they should be deferred to version 3
• What have we missed
• What is not needed or is poorly expressed
• Review of Version 3 slide– Anything that should be put in version 2
– Anything missing
12
Volume 1, DefinitionsBreakout Plan

June 1, 2017
Volume 2, Big Data TaxonomiesDocument Scope
• Provide a taxonomy of the components of the NIST Big Data Reference Architecture (NBDRA)– Organize concepts
• Focus on changes resulting from the shift to the new Big Data paradigm
• Reinforce a common language
• Audience– New to Big Data to understand relationships of items
13
June 1, 2017
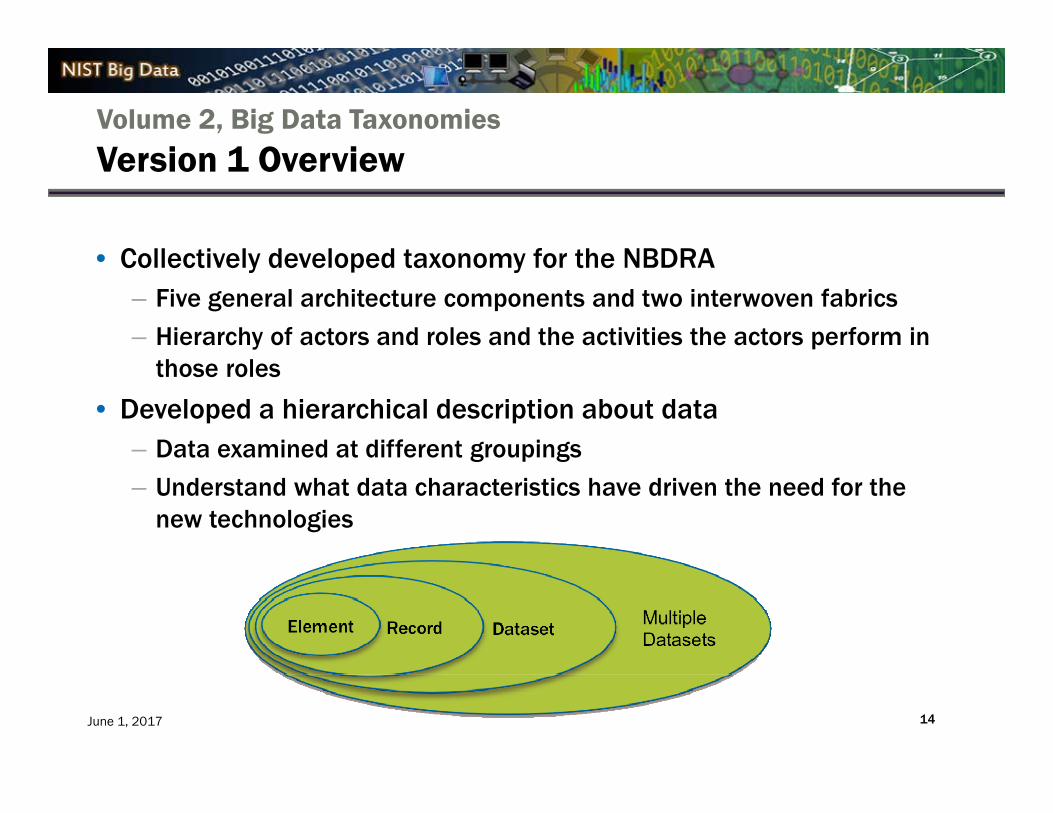
Volume 2, Big Data TaxonomiesVersion 1 Overview
• Collectively developed taxonomy for the NBDRA– Five general architecture components and two interwoven fabrics
– Hierarchy of actors and roles and the activities the actors perform in those roles
• Developed a hierarchical description about data– Data examined at different groupings
– Understand what data characteristics have driven the need for the new technologies
14

June 1, 2017
Volume 2, Big Data TaxonomiesVersion 2 Accomplishments
• Further developed the data characteristic hierarchy
• Investigated the relationship between the NBDRA taxonomy and other taxonomies
15

June 1, 2017
Volume 2, Big Data TaxonomiesVersion 2 Opportunities for Contribution
• Suggest different organization for presentation of characteristics– Create actual taxonomy
• Contribute to comparison of NBDRA taxonomy to the following: – Cloud taxonomy
– High-performance computing (HPC) taxonomy
– Internet of things taxonomy
• Enhance discussion of Management fabric with respect to Big Data systems
• Discuss data virtualization with respect to multiple datasets
• Pointers to other Big Data or related taxonomies
16

June 1, 2017
Volume 2, Big Data TaxonomiesPossible Version 3 Topics
• Comparison with other Big Data Taxonomies
• Features taxonomy of storage techniques
• Comparison with additional related Taxonomies
• Pointers to taxonomies for– Data Types
– Analytics
– Visualization
• Creation of data characteristic Taxonomy
17

June 1, 2017
• Review Version 2 slide of remaining items– Do any need so much work they should be deferred to version 3
• What have we missed
• What is not needed or is poorly expressed
• Review of Version 3 slide– Anything that should be put in version 2
– Anything missing
18
Breakout 1, Definitions and Taxonomies, Breakout Plan

June 1, 2017
Volume 3, Use Cases and General RequirementsDocument Scope
• Version 1 collected 51 big data use cases with a 26 feature template and used this to extract requirements to feed into NIST Big Data Reference Architecture
• The version 2 template merges version 1 General and Security & Privacy use case analysis
• The discussion of this at first NIST Big Data meeting identified need for patterns which were proposed during version 2 work; version 2 template incorporates new questions to help identify patterns.
19

June 1, 2017
Volume 3, Use Cases and General RequirementsVersion 1 Overview
• Gathered and evaluated 51 use cases from nine application domains.
• Gathered input regarding Big Data requirements
• Analyzed and prioritized a list of challenging use case specific requirements that may delay or prevent adoption of Big Data deployment
• Developed a comprehensive list of generalized Big Data requirements
• Developed a set of features that characterized applications– Used to compare different Big Data problems
• Collaborated with the NBD-PWG Reference Architecture Subgroup to provide input for the NBDRA
20

June 1, 2017
51 Detailed Use Cases: Version 1 Contributed July-September 2013
• Government Operation(4): National Archives and Records Administration, Census Bureau
• Commercial(8): Finance in Cloud, Cloud Backup, Mendeley (Citations), Netflix, Web Search, Digital Materials, Cargo shipping (as in UPS)
• Defense(3): Sensors, Image surveillance, Situation Assessment
• Healthcare and Life Sciences(10): Medical records, Graph and Probabilistic analysis, Pathology, Bioimaging, Genomics, Epidemiology, People Activity models, Biodiversity
• Deep Learning and Social Media(6): Driving Car, Geolocate images/cameras, Twitter, Crowd Sourcing, Network Science, NIST benchmark datasets
• The Ecosystem for Research(4): Metadata, Collaboration, Translation, Light source data
• Astronomy and Physics(5): Sky Surveys including comparison to simulation, Large Hadron Collider at CERN, Belle II Accelerator in Japan
• Earth, Environmental and Polar Science(10): Radar Scattering in Atmosphere, Earthquake, Ocean, Earth Observation, Ice sheet Radar scattering, Earth radar mapping, Climate simulation datasets, Atmospheric turbulence identification, Subsurface Biogeochemistry (microbes to watersheds), AmeriFlux and FLUXNET gas sensors
• Energy(1): Smart grid21
http://bigdatawg.nist.gov/usecases.php, 26 Features for each use case

June 1, 2017
Version 1Use Case Template
• Note agreed in this form August 11 2013
• Some clarification on Veracity v. Data Quality added
• Request for picture and summary done by hand for version 1 but included in version 2 template.
• Early version 1 use cases did a detailed breakup of workflow into multiple stages which we want to restore but do not have agreed format yet
22

June 1, 2017
Volume 3, Use Cases and General RequirementsVersion 2 Accomplishments I
• Developed the Use Case Template version 2 to describe additional use cases with more specific information– Extra information developed from looking at 51 version 1 use cases
and seeing where was missing or vague
– Made available as a PDF or Google Form – Version 1 a Word document
• Version 1 use case combined with Security and Privacy (S&P) analysis to generate very detailed information on this– Can also be used to generate only S&P information or only general
information such as analysis environment and data characteristics
• Continued study of characteristics of version 1 use cases– compare Big Data with High Performance Computing workloads
• Will evaluate additional use cases as they are submitted23

June 1, 2017
Volume 3, Use Cases and General RequirementsVersion 2 Accomplishments II
• Socialized Version 1 use cases with the developing ISO Big Data community, which reportedly found them representative and useful
• The new template was developed to:– Better understand processing stages and workflow
– Gather additional use case detail
– Collect use cases with sensitive privacy & other security concerns (sidebar)
– Two versions of the new template were deployed
• Collecting detail-rich use cases is challenging
• Added key use cases from US Census and health care (consent flow and “Break Glass”)
24
- Roles - PII - Covenants, Liability - Ownership, Identity, Distribution - Risk Mitigation - Provenance - Data Life Cycle - Audit and Traceability - Application Provider Security- Framework Provider Security - System Health - Permitted Use Cases

June 1, 2017
Volume 3, Use Cases and General RequirementsVersion 2 Opportunities for Contribution
• More use cases. (Roll up sleeves; budget an hour.)
• Soliciting greater application domain diversity: – Smart cars (Smart X)
– Large scale utility IoT
– Geolocation applications involving people
– Energy from discovery to generation
– Scientific studies involving human subjects at large scale
– Highly distributed use cases bridging multiple enterprises
25
Choose a domain and collect/analyze a set of related use-cases
Develop technology requirements for applications in domainFeed lessons into version 3 of template

June 1, 2017
Volume 3, Use Cases and General RequirementsPossible Version 3 Topics
• Identify gaps in use cases
• Develop plausible, semi-fictionalized use cases from industry reports, white papers, academic project reports
• Identify important parameters for estimating systems
• Microservice use cases
• Use cases mapped to work in Vol 8
• Container-oriented use cases
• Forensic and provenance-centric use cases
• Review fitness of the BDRA to use cases
26

June 1, 2017
Volume 6, Reference ArchitectureDocument Scope
• Develop an open reference architecture for Big Data that achieves the following objectives:– Provides a common language
– Encourages adherence to common standards, specifications, and patterns
– Provides consistent technology implementation methods for similar problem sets
– Illustrates various Big Data components, processes, and systems, in the context of a vendor- and technology-agnostic Big Data conceptual model
– Provides a technical reference to discuss compare BD solutions
– Facilitates analysis of candidate standards for interoperability, portability, reusability, and extendibility.
27

June 1, 2017
Volume 6, Reference ArchitectureVersion 1 Overview
• Collaborated with other subgroups to construct an understanding of Big Data requirements
• Developed a vendor- and technology-agnostic conceptual model with five components and two fabrics:– System Orchestrator
– Data Provider
– Big Data Application Provider
– Big Data Framework Provider
– Data Consumer
– Security and Privacy Fabric
– Management Fabric
28

June 1, 2017
NIST Big Data Reference Architecture
29
Man
agem
ent
Fabr
ic
Secu
rity
and
Pri
vacy
Fab
ric
Secu
rity
and
Pri
vacy
Fab
ricBig Data Framework ProviderBig Data Framework Provider
INFORMATION VALUE CHAIN
K E Y : SWSWService UseBig Data Information Flow
Software Tools and Algorithms Transfer
Big Data Application
Visualization AccessAnalyticsCollection
System Orchestrator
DATADATA
IT VALUE CH
AIN
Data Provider
Data Provider
DATADATA
DAT
ADAT
A
Preparation/ Curation
Infrastructures: Networking, Computing, Storage
Processing: Computing and Analytic
Platforms: Data Organization and Distribution
Virtual ResourcesPhysical Resources
Indexed StorageFile Systems
Batch StreamingInteractive
Resource M
anagem
ent
Messaging
/Com
mun
ications
Data Co
nsum
erData Co
nsum
er
SWSW
DATADATA
SWSW
SWSW

June 1, 2017
Volume 6, Reference ArchitectureVersion 2 Accomplishment
• Primary Goal: Develop a more rigourous set of architecture views
• Decided on two initial views:– Activity – What activities take place within the Roles and Sub-roles of
the BDRA
– Functional Component – What functional components are needed to accomplish the activities within the Roles and Sub-roles
30
Conceptual Logical Physical
Version 1 Version 2

June 1, 2017
Developing Views - Definitions
• Role: A related set of functions performed by one or more actors.
• Fabric: A role which touches upon and supports multiple other roles
• Activity: A class of functions performed to full fill the needs of one or more roles.– Example: Data Collection is a class of activities through which a Big
Data Application obtains data. Instances of such would be web crawling, FTP site, web services, database queries, etc.
• Functional Component: A class of physical items which support one or more activities within a role.– Example: Stream Processing Frameworks are a class of computing
frameworks which implement processing of streaming data. Instances of such frameworks would include SPARK and STORM
31

June 1, 2017
Developing Views - Notation
32
Role
Activity
Sub-role
Functional Components
Control
Data
Software

June 1, 2017
Developing Views – View Template
33
Se
cu
rity
& P
riv
ac
y
Ma
na
ge
me
ntD
ata
Prov
ider
Platforms: Data Organization, Access and Distribution
Big Data Framework Provider
Infrastructures: Networking, Computing, Storage Resources
Processing: Computing and Analytics
System Orchestrator
Big Data Applications
Dat
a C
onsu
mer

June 1, 2017
Activity View (Initial)
34S
ecur
ity
&
Pri
vacy
Man
agem
ent
Data
Con
sum
er
Data
Pro
vider
Big Data Framework Provider
Big Data ApplicationAnalyticsCollection Preparation Visualization Access
System OrchestratorBusiness Ownership Requirements and
MonitoringSystem Architecture
Requirements Definition
Governance Requirements and
Monitoring
Security/Privacy Requirements Definition
and Monitoring
Processing: Computing and Analytic
Batch Processing Interactive Processing
Stream Processing
Platforms: Data Organization and Distribution
Create Read Delete IndexUpdate
Infrastructures: Networking, Computing, Storage
Transmit Receive Store
RetrieveManipulate
Provisioning
Configuration
Package Mgmt
Resource Mgmt
Monitoring
Auditing
Authentication
Authorization
Reso
urce
Mgm
t
Mess
aging
Data Science Requirements and
Monitoring

June 1, 2017
Activities Defined in View
• Reference Architecture: Top Level Activity Classes– Collection: In general, the collection activity of the Big Data Application handles the
interface with the Data Provider. This may be a general service, such as a file server or web server configured by the System Orchestrator to accept or perform specific collections of data, or it may be an application-specific service designed to pull data or receive pushes of data from the Data Provider. Since this activity is receiving data at a minimum, it must store/buffer the received data until it is persisted through the Big Data Framework Provider. This persistence need not be to physical media but may simply be to an in-memory queue or other service provided by the processing frameworks of the Big Data Framework Provider. The collection activity is likely where the extraction portion of the Extract, Transform, Load (ETL)/Extract, Load, Transform (ELT) cycle is performed. At the initial collection stage, sets of data (e.g., data records) of similar structure are collected (and combined), resulting in uniform security, policy, and other considerations. Initial metadata is created (e.g., subjects with keys are identified) to facilitate subsequent aggregation or look-up methods.
• Reference Architecture Implementation: Specific Activities– Log Data Collection: Accept incoming data from log services as files.
Store data on local file system for ingestion processing35

June 1, 2017
Functional Components View (Initial)
36
Sec
urit
y &
P
riva
cy
Man
agem
ent
Data
Con
sum
er
Data
Pro
vider
Big Data Framework Provider
Big Data Application
System Orchestrator
Processing: Computing and Analytic
Platforms: Data Organization and Distribution
Infrastructures: Networking, Computing, Storage
Batch Frameworks
Interactive Frameworks
Streaming Frameworks
Distributed File Systems
Document Platforms
Relational Platforms
Key=ValuePlatforms
Columnar Platforms
Graph Platforms
Hypervisors
Virtual Networks
Virtual Machines
Physical Machines
Physical Networks
Physical PlantStorage
Audit Frameworks
Authenticaion and Authorizaiton Frameworks
MonitoringFrameworks
Provisioning/ Configuration Frameworks
Package Managers
Resource Managers
Algorithms Work Flows Access Services TransformationsVisualizations
Business Processes Policies
Mess
aging
Fra
mewo
rks
Reso
urce
Man
ager
s

June 1, 2017
Functional Components Defined in View
• Reference Architecture: Top Level Component Classes– Graph Platforms : Graph databases typically store two types of objects nodes and
relationships as show in Figure 7 below. Nodes represents objects in the problem domain that are being analyzed be they people, places, organizations, accounts, or other objects. Relationships describe those objects in the domain relate to each other. Relationships can be non-directional/bidirectional but are typically expressed as unidirectional in order to provide more richness and expressiveness to the relationships. Hence, between two people nodes where they are father and son, there would be two relationships. One “is father of” going from the father node to the son node, and the other from the son to the father of “is son of”. In addition, nodes and relationships can have properties or attributes. This is typically descriptive data about the element. For people it might be name, birthdate, or other descriptive quality. For locations it might be an address or geospatial coordinate. ….
• Reference Architecture Implementation: Specific Components– Neo4J configured as a causal cluster of 8 nodes (3 core, 5 read
replicas ) so that client applications enjoy read-your-own-writes semantics.
37

June 1, 2017
BDRA Activity View
Implementation Activity View
BDRA Functional Component View
Implementation Functional
Component View
Applying the BDRA – Developing Implementation Views
38
Architect determines in
collaboration withstake holders what classes of activities
are neededfor each
function(application) of the system
Architect develops activity view for implementation
listing and describing specific activities which the
system must perform to meet the requirements
Architect determines which
classes of functional
components are required to perform
the activities
Architect selects specific functional components and
their configurations necessary to perform the
activities

June 1, 2017
Volume 6, Reference ArchitectureVersion 2 Opportunities for Contribution• Activity View
– Review classes of activities initially defined for completeness
– As required develop zoomed in views
– Develop text descriptions of each activity class
• Functional Component View– Review classes of functional components initially defined for completeness
– As required develop zoomed in views
– Develop text descriptions of each functional component class
• Align Functional Component view to Vol 8 Interfaces
• Define and describe a process for developing implementation activity and functional component views
• Add a discussion of the reference architecture in terms of a system of system (Section 4)
39

June 1, 2017
Volume 6, Reference Architecture Possible Version 3 Topics
• Mapping of Activity and Functional Component classes to specific standards (may be better in Volume 7)
• Develop process for generating functional and system requirements from Activity and Functional Component views
• Refine and expand deployment models to cover containerization
• Link views and deployment models to Dev Ops standards (IEEE P2675)
40

June 1, 2017
Volume 4Document Scope
• Provide a context from which to begin Big Data-specific security and privacy discussions
• Analyze/prioritize a list of challenging security and privacy requirements that may delay or prevent adoption of Big Data deployment
• Develop the Security and Privacy Fabric integrated into the NBDRA
• Develop Big Data security and privacy taxonomies
• Explore mapping between the Big Data security and privacy taxonomies and the NBDRA
• Security and Privacy (SnP) considerations impact all components of the NBDRA
41

June 1, 2017
Volume 4Version 1 Overview
• Provided an overview of SnP with respect to Big Data
• Collected security and privacy specific use cases
• Developed taxonomy of security and privacy topics
• Examined the interwoven nature of the SnP fabric with other NBDRA components
• Mapped collected SnP use cases to the NBDRA
42

June 1, 2017
Volume 4Version 1 Reference Architecture
43

June 1, 2017
Volume 4 Version 2 Accomplishments
• Introduced a safety framework, suitable for use by unaffiliated citizens, big data software architects and IT managers
• Expanded the cryptology discussion
• Expanded discussions of various topics such as the intersection of BD system management and SnP guidelines
• Identified guidelines for integrating Big Data systems dedicated to SnP
• Provided for phase-specific BD systems guidance
• Explored relevance of model-based systems engineering to Big Data SnP
44

June 1, 2017
Volume 4Version 2 Opportunities for Contribution
• Submit completed Use Case Template 2
• Contribute to development of Safety Levels chart
• Build/enhance frameworks for Big Data referencing existing ISO and other standards for big data life cycle, audit, configuration management and privacy preserving practices (Section 2)
• Enhance discussion of emerging technology effects on BD SnP(Section 2.4)
• Contribute risk management text (section 5.9)
• Expand discussion of SnP approaches in analytics
• Increase references to SnP focused standards
• Integrate security fabric concepts into Vol 8
45

June 1, 2017
Domain-Specific SnP Safety Engineering
46

June 1, 2017
Volume 4 Proposed Version 3 Topics
• Big Data SnP Applications for Blockchain
• Features of BD SnP Dependency Models
• Features of security-aware Big Data IDEs
• Traceability Frameworks for “Human Bit”
• Self-Managed, Self-Monitoring Big Data Risk Frameworks
• Impact of AI on Big Data SnP (As User / As Consumer)
• Big Data SnP Microservices and API-First Design Patterns
• DevOps and Container SnP
• Orchestration of SnP Processes
• Big Data Analytics for SnP: Best Practices, Use Cases
• System Communicator Checklists47

June 1, 2017
Volume 8Acknowledgement
• NSF for support of Comet (SDSC, Indiana University)– Members of the NSF comet project
• NBDRA WG members– Tuesday meetings and discussions have considerably contributed to
this effort
– We still need to add your names … please e-mail me at [email protected] …
• Prior effort conducted as part of cloudmesh at Indiana University
48

June 1, 2017
Volume 8Opportunities for Contribution
• Volume 8 is in draft stage.– We look for additional contributors to the volume 8
– We want to keep the initial part of the draft as simple as possible and develop contributions based on ASCII text modifications.
– Contributions can be conducted in multiple ways• A) Make modifications to the PDF document with PDF augmentation tools
such as Adobe or Skim, send via e-mail.
• B) Make modifications in ASCII while specifying the section you like to modify (section header, new paragraph, line numbers), send via e-mail.
• C) Make modifications through git pull requests
49
June 1, 2017
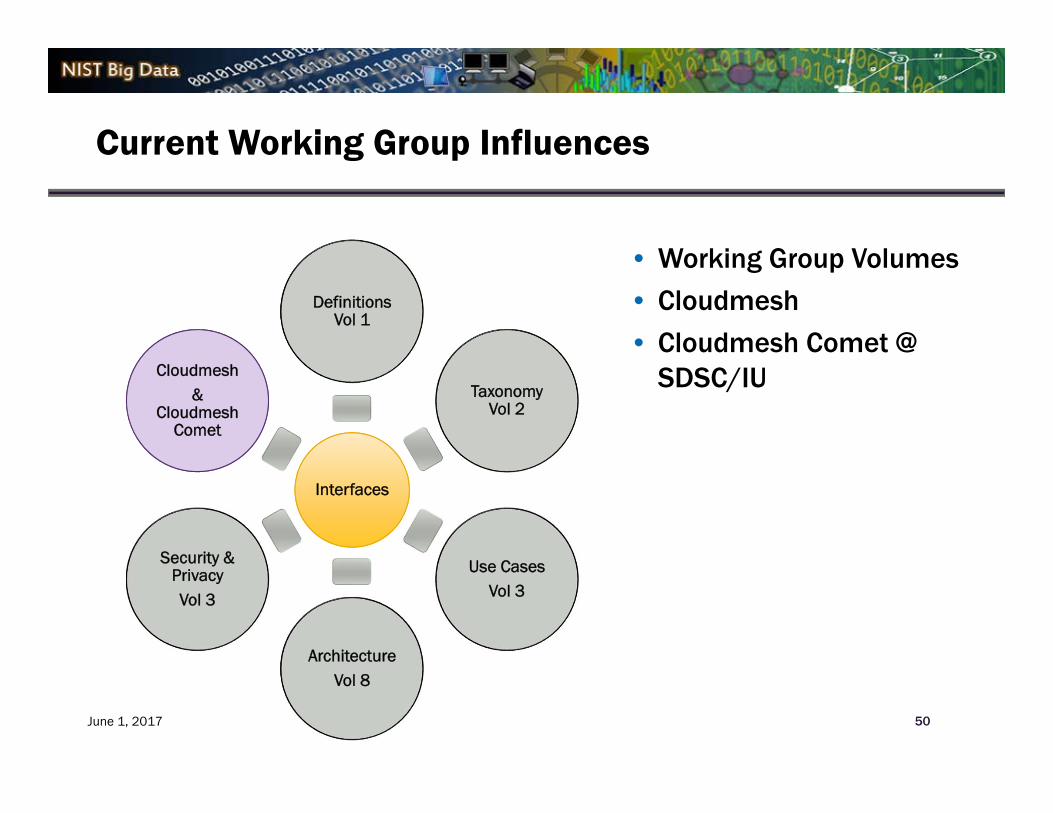
Current Working Group Influences
50
Interfaces
Definitions Vol 1
Taxonomy Vol 2
Use CasesVol 3
ArchitectureVol 8
Security & PrivacyVol 3
Cloudmesh&
Cloudmesh Comet
• Working Group Volumes
• Cloudmesh
• Cloudmesh Comet @ SDSC/IU

June 1, 2017
Volume 6: NIST Big Data Reference Architecture
51
Man
agem
ent
Fabr
ic
Secu
rity
and
Pri
vacy
Fab
ric
Secu
rity
and
Pri
vacy
Fab
ricBig Data Framework ProviderBig Data Framework Provider
INFORMATION VALUE CHAIN
K E Y : SWSWService UseBig Data Information Flow
Software Tools and Algorithms Transfer
Big Data Application
Visualization AccessAnalyticsCollection
System Orchestrator
DATADATA
IT VALUE CH
AIN
Data Provider
Data Provider
DATADATA
DAT
ADAT
A
Preparation/ Curation
Infrastructures: Networking, Computing, Storage
Processing: Computing and Analytic
Platforms: Data Organization and Distribution
Virtual ResourcesPhysical Resources
Indexed StorageFile Systems
Batch StreamingInteractive
Resource M
anagem
ent
Messaging
/Com
mun
ications
Data Co
nsum
erData Co
nsum
er
SWSW
DATADATA
SWSW
SWSW

June 1, 2017
Volume 8 Document Scope
• Established operational interfaces – for management interactions and dataflow with needed resources
between NBDRA components
• Described and defined specific interfaces and the interactions– between NBDRA components
• Developed a set of interfaces defined through examples – that can be used to create schema based definitions of objects that
are manipulated through Big Data design patterns
52

June 1, 2017
Volume 8 Possible Version 3 Topics
• Formalization of the interfaces defined by example
• Validate the interfaces – Verifying select use cases
– Working with domain experts • to identify workflow and interactions among the NBDRA components and
fabrics
– Exploring and modeling interactions • within a small-scale, manageable, and well-defined confined environment
– Aggregating the common data workflow and interactions • between NBDRA components and fabrics and package them into general
interfaces.
53

June 1, 2017
Reference Architecture Software ImplementationEnvironment and Demonstration
54
• Cloudmesh provides a first reference implementation – Features include IaaS,
Hadoop, and software stack deployment.
– It was tested based on Application from Use Case document.
– Code is hosted in github and is available.
• Focus on Cloudmesh command shell and REST service as it is – Scriptable– Interpretable into other
frameworks– Accessible through other
frameworks via REST.
• Disclaimer: we move from our original cm implementation to cms to distinguish the two efforts. The new implementation can use the NIST specification and generates a REST service automatically.

June 1, 2017
Cloudmesh Arcitecture
55
Access
Exp
erim
ent
Cloudmesh Client
HPC Abstraction Container IaaS Abstraction
Cloudmesh Portal
PaaS
Oth
ers
Spa
rk
Had
oop
NIST Applications
Ope
nSta
ck
Doc
ker
AWS
Azur
e
EC2
Oth
ers
Com
et
Oth
ers
SLU
RM
TOR
QU
E
Mau
i
Ope
nPB
S
Oth
ers
• Abstraction essential to Cloudmesh design
• Abstractions at different levels and interaction points– IaaS– Container– HPC– PaaS
• Virtual Cluster
• Integration with Providers– IU OpenStack, NSF
Chameleon cloud, NSF Comet, AWS, Azure, SLURM/XSEDE, …
• Used by hundreds of users

June 1, 2017
Cloudmesh Layered Architecture
56
Cloudmesh Client
ServicesTerminal
Compute
Security Choreography
Batch Queue Abstraction
VM Abstraction
CM Stack
Reservation
CM Group
Workflow
Auth
entic
atio
n
Virtual Cluster Abstraction
Access
API
RESTCommand LinePolicy Management
Aut
horiz
atio
n
Container Abstraction
create, add, modify, delete
Cloudmesh Portal
Data
Database Abstraction
SQLite MongoDB
create, add, modify, delete
Inventory
Command Shell
CM Scripts
Applications
• Easy extensibility
• Developed with command shell in mind
• Developed with REST in mind
• Horizontal Integration– Access – Data – Compute
• Vertical Integration
• `Security - Choreography

June 1, 2017
Deployment Abstractions
57
result data
github
ansiblegalaxy
data
deployment
verification/Result tests
Cloudmesh script
test
calls
verifies
design & modification
executionproduces
chefcookbooks
heatscripts
…
• Possible interaction with different DevOps frameworks
• Leveraging large DevOps community
• Warning we found that there are many DevOps “templates” but not all of them are usable:– lack generality– do not work – too complex– not properly documented

June 1, 2017
Continuous Improvement vs. Continuous Deployment via DevOps
58
design & modification
Cloudmesh script
deployment
data
execution
verification
Continuousimprovement
• DevOps is integrated
• Leads to improvement when not only targeting application but also deployment environment.

June 1, 2017
Simple Interface Usecase: Boot a vm on
59

June 1, 2017
Simple Interface Usecase: Boot & Provision
60

June 1, 2017
Phase 1: Interface Objects
61

June 1, 2017
Specification -> Reference implementation
62
1. Specification 2. Cloudmesh schema 3. Schema 4. Rest Service
1. Vol 8. Specification
2. Cloudmesh schema generates …
3. … a valid schema from the specification
4. The schema is used to automatically generate a REST service

June 1, 2017
Showcase document
• https://laszewski.github.io/papers/NIST.SP.1500-8-draft.pdf
63

Account Management
64

June 1, 2017
Account Management Example: Extension to Architecture
• Accounting across hybrid services• Integrating of accounting records for individuals (in case group account
does not provide this feature)• User Management issues
– Removal of “Dracula Users”: I suck you dry and cinsume all your hours as I will ignore your policies will fully (yes, they do exist)
– Removal of “Uniformed User”: let the know what an experiment costs upfront before you start it.
• Provider Management Issues– Provide feedback to providers: We found that some providers gave us
incomplete information in regards to their accounting practice– Comparison of cost between providers
• Application Benchmarking– If we do make it too easy some will ignore alternatives, Expose
benchmarking results to the community
65

June 1, 2017
Account Management
adminaccount
create
activate
suspend
close
refundadd
service
authorized
user
add
list
invoke
resource
register
unregister
charge
refund
consume
66

June 1, 2017
Account management
67
• Register
• Deposit
• Use
• Deactivation


June 1, 2017
Fingerprint Application
69
• Requires– Application knowledge– Deployment/DevOps
knowledge
• What if application user could do also the deployment?– Use newest software– Use newest hardware– Benchmark different setups

June 1, 2017
Use Case Fingerprint: Deployment is complex
70

June 1, 2017
Cloudmesh Shell – Make Booting Simple
71
$ emacs cloudmesh.yaml
$ cms default cloud=NAME
$ cms default image=NAME
$ cmd default flavor=NAME
$ cms vm boot
$ cms vm login
$ cms vm delete
• cloudmesh.yaml
• Prepare defaults
• Boot
• Login
• Management …

June 1, 2017
Cloudmesh Shell – Manage Hybrid Clouds
72
$ cms aws boot
$ cms vm boot
$ cms default cloud=chameleon
$ cms vm boot
$ cms default cloud=IUCloud
$ cms vm boot
•Boot Cloud A
•Boot Cloud B
•Boot Cloud C

June 1, 2017
Cloudmesh Shell – Create a Hadoop Cluster
73
$ cm default cloud=chameleon
$ cm cluster define - -count=10
- -flavor=m1.large
$ cm hadoop define spark
$ cm hadoop sync # ~30 sec
$ cm hadoop deploy # ~ 7 min
•Set cloud
•Define cluster
•Define hadoop Cluster
•Sync definition to db
•Deploy the cluster

June 1, 2017
Cloudmesh Shell – Create a Hadoop Cluster
74
$ cm default cloud=IUCloud
$ cm cluster define - -count=10
- -flavor=m1.large
$ cm nist fingerprint # ~ 30 min
•Set cloud
•Define cluster
•Run NIST usecase
Additional resources: https://github.com/cloudmesh/classes/blob/master/docs/source/notebooks/fingerprint_matching.ipynb

June 1, 2017
Volume 7, Standards Roadmap
Document Scope
• Provide
– an agnostic resource for organizations to review the current state of big data standards
– a generic outlook on potential impacts of standards development in various areas
• Conduct analysis of where closure of standards gaps may benefit economic and social development
75

June 1, 2017
Volume 7, Standards RoadmapVersion 1 Overview
• Reviewed work from the other six subgroups
• Cataloged a collection of existing Big Data related standards
• Mapped collected standards to NBDRA components
• Identified 16 significant gaps in existing standards, highlighting areas where standards are expected to have significant impact in the future
• Discussed a pathway to address standards gaps
76

June 1, 2017
Volume 7, Standards RoadmapVersion 2 Accomplishments
• Clarified alternative perspectives for viewing standards (functional vs. organizational; product vs. non-product)
• Applied a mapping technique for pairing standards to requirements which were defined in Volume 3
• Applied a mapping technique for pairing standards to selected use cases defined in Volume 3
77

June 1, 2017
Mapping Standards to Specific Requirements from Vol 3
78
June 1, 2017
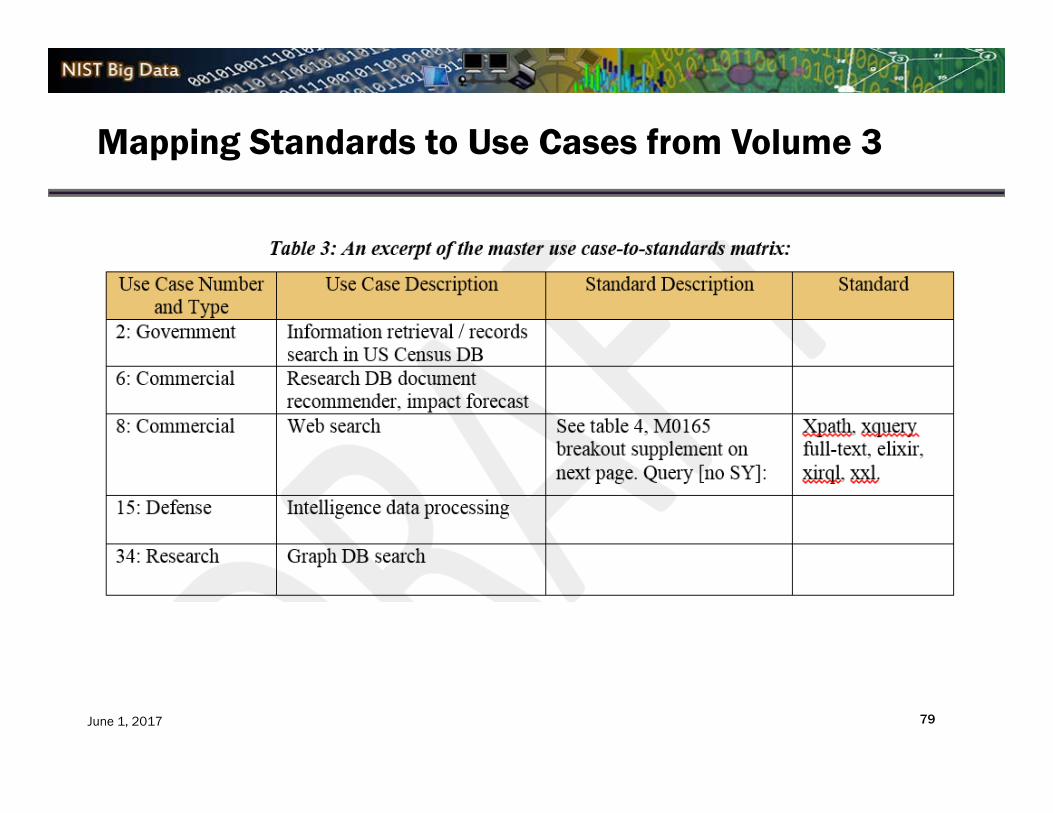
Mapping Standards to Use Cases from Volume 3
79

June 1, 2017
Sections of Use Cases Applied to Mapping Breakouts
80

June 1, 2017
Mapping Existing Standards to Use Case # 8
81

June 1, 2017
Volume 7, Standards RoadmapVersion 2 Opportunities for Contribution
• Expand discussion on standards gaps (from the list of 16) and the impact standards could have on that area (Section 4.4)
• Contribute text for discussion of standards for integration (also Section 4.4)
• Contribute to the catalog of existing data standards (Section 5.2)
• Help complete mapping standards to requirements and standards to use cases (Sections 2.3.1 & 2.3.2)
82

June 1, 2017
Volume 7, Standards RoadmapPossible Version 3 Directions
• Investigate a number of additional areas including: – Internet of Things [IoT] impact
– Network connectivity
– Complex Event [CEP] and real-time processing
– Data Marketplaces
• Create SV-1 / CV-6 frameworks for viewing system and component incompatibilities and interoperability.
• Conform to and integrate with NIST BDPWG User Guide
• Discover guiding principles, practical strategies and suggested sequences of actions for future efforts
83

June 1, 2017
Systems Interface Description SV-1: ID Interconnections and areas of Incompatibility
84

June 1, 2017
CV-6 for Mapping Activities and Capabilities to Reference Architecture
85

June 1, 2017
Volume 9, Adoption and Modernization Document Scope
• Explore current state of adoption of BD systems and barriers to system implementation
• Examine factors affecting the maturity of technologies related to Big Data
• Provide a reusable assessment of the challenges facing modernization projects
• Provide a reusable knowledge base for understanding various roles and technologies involved in modernization projects
86

June 1, 2017
Volume 9, Adoption and ModernizationVersion 2 Accomplishments
• Developed during Phase 2; no version 1 of this document
• Explored adoption of Big Data systems by industry
• Observed barriers to adoption
• Evaluated technology maturity stages
• Discussed organizational maturity and the relationship to successful BD system implementation
87

June 1, 2017
Aggregate Data on Adoption Barriers from a number of Surveys
88

June 1, 2017
Volume 9, Adoption and ModernizationVersion 2 Opportunities for Contribution
• Discuss patterns in BD adoption and factors in successful adoption (Section 3.1.1)
• Contribute to list of types of BD technologies that are being adopted and in which industry (Section 3.1.2)
• Augment discussion of barriers to adoption of BD systems (Section 3.2)
• Enhance discussion of organizational maturity and the relation to successful BD system implementation (Section 4.2)
• Add to discussion of considerations for implementation and modernization (Section 5)
89

June 1, 2017
Volume 9, Adoption and ModernizationPossible Version 3 Directions
• An SV-1 or CV-6 oriented toward mapping business, engineering, and modernization aspects of a big data project, and synchronizing the efforts of all three
• Recommendations on how organizations may initiate big data projects, and meet performance targets
• Conform to / integrate with the NIST BDPWG User Guide
90