no-sql databases
TRANSCRIPT

NoSQL Databases – MongoDB Y CASSANDRA

1 Introducción No-SQL
2 Tipos de bases de datos No-SQL
3 MongoDB - Document Oriented
DataBase
4 Cassandra – Columnar Database

1 - Not Only SQL
2 – Sistemas de almacenaje masivo
3 – Fácilmente escalables (sharding , nodes)
4 – Altamente distribuibles
“
1 Introducción No-SQL

Almacenamiento de un recibo
1 Introducción No-SQL - Ejemplo
RDBMS: Generación de Tablas Cliente, Factura, Albaran Junto con las joins adecuadas
No-SQL: Guardado directo del recibo, formato documento, columnal, grafo, clave-valor …
{
"clientId": "39323657F",
"totalamount": "100€",
"description": {
"ligth": "75€",
"IVA": "25€"
}
}
MongoDB Insert : Db.recibos.insert(JSON) MongoDB Find: Db.recibos.findOne({“clientId” : “39323657F”})

Simple, rápido, eficaz
“
1 Introducción No-SQL - Ejemplo

•Key – Value
•Column Family
•Document Oriented
•Graph
•Others
“
2 Tipos de bases de datos
2 Key – Value DataBases
Store en formato clave – valor { clave1 : valor1, clave2 : valor2 …}
Algunas permiten guardar Listas como Redis y otras no son consistentes como Memcached

2 Column Family DataBases
Store en formato columnar ColumnFamily Recibo Key : 39354999F Store : { version_1 : { key : value, key2: value2 } }
Se basan en tener columnas de datos, Limite en las Column Families de 3 a 100, más de 1B de columnas internas.

2 Document Oriented Databases
Store en Documento : Colection User { FirstName: "Jonathan", Address: "15 Wanamassa Point Road", Children: [ {Name: "Michael", Age: 10}, {Name: "Jennifer", Age: 8}, {Name: "Samantha", Age: 5}, {Name: "Elena", Age: 2} ] }
Capacidad de insertar directamente desde REST API’s, JSON > DB. Lecturas muy rápidas, no schemas.
2 Graph Databases
Inserción basada en nodos, que mantienen relación con los arcos con otros nodos

2 Other No-SQL Databases
Bases de datos MultiModel – Storage K/V , Columnar, Document Oriented…

3 - MongoDB

1 Instalación
2 Starting Query
3 Complex Operations
4 Is your TURN!

3.1 Instalación
http://www.mongodb.org/downloads
Ubuntu Instalation: sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10 echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list Sudo apt-get update sudo apt-get install mongodb-org sudo /etc/init.d/mongod start

3.2 Starting Query
1 – Connect to DataBase Mongo 2 – Show current databases Dbs 3 - Show Current DB Db 4 – Select DB Use DB_NAME
Creating Documents: doc1 = { name : “Cristian” , age :
“25” } doc2 = { x : 3 } db.people.insert(doc1) db.numbers.insert(doc2) 1 – Mostrar las colecciones de la DB show collections 2 – Look for register in DB db.people.find().pretty() db.numbers.find()
Insertando varios documentos con un for i = 0 for (i ; i < 10 ; i++) { db.numbers.insert({ x : i }) }
db.numbers.findOne( { x : 1 } )
Recorriendo con un cursor var cursor = db.numbers.find() while( cursor.hasNext() ) printjson ( cursor.next() ) Acceso como un array : > printjson ( cursor [ 4 ] )

3.3 Complex Operations
1 – Query with Limit db.numbers.find().limit(4) 2 – Query by criteria db.people.find( { age : { $gt : 25 } } ) 3 – Sorting Results db.people.find( { age : { $gt : 25 } } ). sort( { age : 1 } )
Creating more Documents: doc2 = { name : “Juan” , age : 19 } doc3 = { name : “Sonia” , age : 24} doc4 = { name : “Carla” , age : 30 } db.people.remove( { name :
“Cristian” }) db.people.insert({“name” :
“Cristian” , age : 25}) db.people.insert(doc1 to doc5)
Updating Operation db.people.update( { name : “Cristian” } , { $set : { age
: 30 } } )
db.people.findOne( { name : “Cristian” } )
Remove Operations db.people.remove( { name : “Carla” } ) db.people.remove( { age : { $gt : 25 } } ) db.people.find().pretty()

3.4 Is your TURN!
Creación de una base de datos para un blog Colecciones: Users : id_user, name, age, posts => array de posts que tiene el usuario Posts : id_post , post Crear 3 usuarios Crear 6 posts Asignar 2 posts a cada Usuario Listar los usuarios Listar los posts de un usuario
Pistas! Posts es un array! ( posts : [] ) Para añadir un post al usuario teneis que utilizar o el $set modificando el array o un $push con un $each db.collection.update( { QUERY } , { $push : { posts { $each : [ num1 , num2..] } } } ) Para listar los posts de un usuario se pueden/deben usar 2 query.

4 - Cassandra

1 Instalación
2 Primeros Conceptos
3 Starting Query – Cassandra-cli
4 Is your TURN!
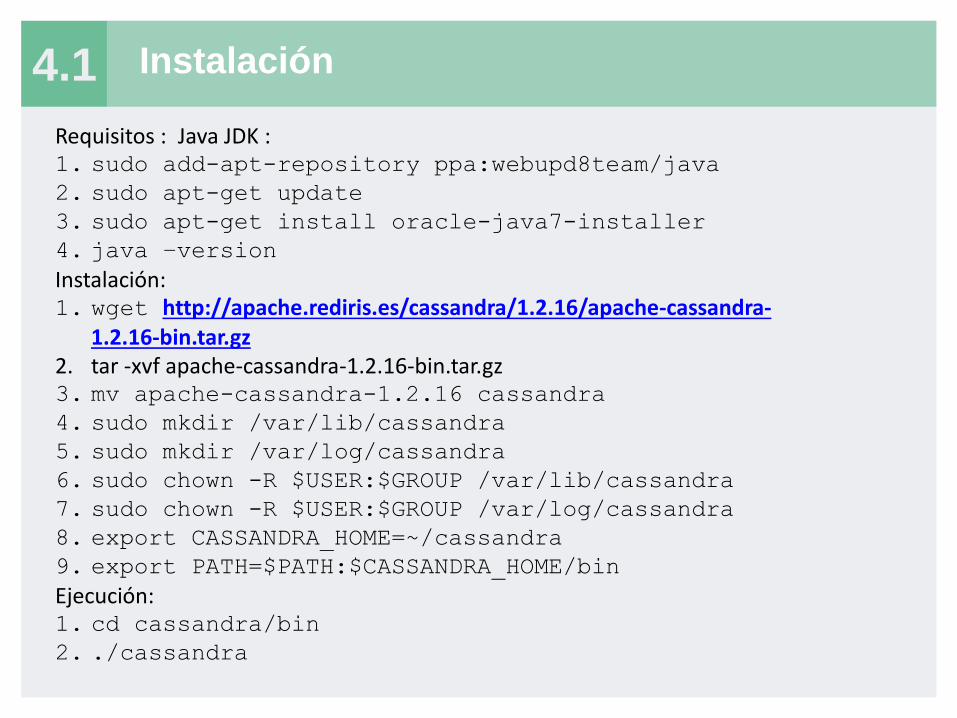
4.1 Instalación
Requisitos : Java JDK : 1. sudo add-apt-repository ppa:webupd8team/java
2. sudo apt-get update
3. sudo apt-get install oracle-java7-installer
4. java –version
Instalación: 1. wget http://apache.rediris.es/cassandra/1.2.16/apache-cassandra-
1.2.16-bin.tar.gz 2. tar -xvf apache-cassandra-1.2.16-bin.tar.gz 3. mv apache-cassandra-1.2.16 cassandra
4. sudo mkdir /var/lib/cassandra
5. sudo mkdir /var/log/cassandra
6. sudo chown -R $USER:$GROUP /var/lib/cassandra
7. sudo chown -R $USER:$GROUP /var/log/cassandra
8. export CASSANDRA_HOME=~/cassandra
9. export PATH=$PATH:$CASSANDRA_HOME/bin
Ejecución: 1. cd cassandra/bin
2. ./cassandra

1 – Base de datos Columnal
2 – Sistema basado en Nodos
3 – Dos sistemas de Query : CLI / CQL
4 – Diferentes Tipos de Column Family
“
4.2 Primeros Conceptos

1 – Column Family
2- Super Column Family
“
4.2 Primeros Conceptos – CF’s

4.2 Primeros Conceptos – CF Ejemplo
Column Family Recibos: Row Key Column1 Column2 Column3
Id_recibo1 Version_1 Version_2 Version_3
Id_recibo2 Version_1 Version_2 Version_3
Version_1 Version_2
Key1 : value1 Key1 : value1
Key2 : value2 Key2 : value2
Key3 : value3 Key3 : value3

4.2 Primeros Conceptos – Super CF Ejemplo
Super Column Family Productos: Row Key Column1 Column2 Column3
Limpieza Producto1 Producto2 Producto3
Abono Producto4 Producto5 Producto6
Version_1 Version_2
Key1 : value1 Key1 : value1
Key2 : value2 Key2 : value2
Key3 : value3 Key3 : value3
Row Key Column1 Column2 Column3
Producto1 Version_1 Version_2 Version_3
Producto4 Version_1 Version_2 Version_3

4.3 Starting Query – Cassandra-cli
1. Starting the cli cd cassandra/bin ./cassandra-cli 2. Creating a keyspace Create keyspace test; 3. Select the keyspace Use test; 4. Creating a CF Create column family User with comparator = UTF8Type; 5. Updating Column Family Schema Update column family User with column_metadata = [ {column_name : first , validation_class : UTF8Type}, {column_name : last , validation_class : UTF8Type}, {column_name : age , validation_class : UTF8Type, index_type : KEYS}, ] 6.Vamos a insertar un registro en la Column Family assume User keys as utf8; set User['cristian']['first'] = ‘Cristian’; set User['cristian']['last'] = ‘Vitales’; set User['cristian']['age'] = '38';

4.3 Starting Query – Cassandra-cli
1. Update the register SET User[‘cristian’][‘first’] = ‘Juan’; 2. Get Data GET User[‘cristian’]; GET User where age = ‘38’; 3.Create SuperColumn Family create column family Super with column_type = 'Super' and comparator = ‘UTF8Type’; Make assumptions for CF Super in ( KEYS / Comparator / Sub_Comparator / Validator ) Set Super[‘Limpieza’][‘version_1’][‘nombre’] = ‘KH7’; Get Super[‘Limpieza’];

4.3 Starting Query – CQL
1. Mostrar los keyspace -> describe keyspaces; 2. Usar un keyspace -> use [Keyspace] -> use test; 3. Crear una Columna/Table: Create Table usuarios ( user_id int primary key , fname text , lname text); Describe tables; INSERT INTO usuarios (user_id, fname, lname) VALUES (1745, 'john', 'smith');
INSERT INTO usuarios (user_id, fname, lname) VALUES (1744, 'john', 'doe');
INSERT INTO usuarios (user_id, fname, lname) VALUES (1746, 'john', 'smith');
Select * from usuarios
Create index on usuarios (lname);
Select * from usuarios where lname = ‘doe’;
DROP table usuarios;

4.3 Is your Turn!
1. Crear un Keyspace llamado “Twitter” 2. Crear una Column Family llamada Tweets (id, tweet, fecha) 3. Crear una Column Family llamada Usuarios(id, nombre,apellido, edad) 4. Insertar Varios Tweets y Varios Usuarios 5. Listar los Usuarios cuya edad sea > 30 6. Listar los tweets cuya fecha sea igual a la de hoy en formato (Y/M/d) 7. Crear un indice sobre el nombre del usuario 8. Crear un indice sobre el tweet 9. Borrar la tabla usuarios.

@gotha229
C/ Jordi Girona 1-3 , Edificio C6 Planta -1
,Campus Nord UPC
http://research.incubio.com/
Cristian Vitales Research Engineer
Gracias por asistir
Preguntas?