october 23, 2015 1 data warehousing and mining. october 23, 2015 2 this session 0. introduction...
TRANSCRIPT

April 20, 2023 1
DATA WAREHOUSING and Mining

April 20, 2023 2
This session 0. Introduction
Evolution of Database What is data warehouse?
Motivation: Why data mining?
What is data mining?
Data Mining: On what kind of data?
Data mining functionality
Are all the patterns interesting?
Classification of data mining systems
Major issues in data mining
I. Data Preprocessing Needs Preprocessing the Data
Data Cleaning
Data Integration and Transformation
Data Reduction
Discretization and Concept Hierarchy Generation

April 20, 2023 3
Evolution of Database Technology 1960s:
Data collection, database creation, IMS and network DBMS
1970s: Relational data model, relational DBMS implementation
1980s: RDBMS, advanced data models (extended-relational,
OO, deductive, etc.) and application-oriented DBMS (spatial, scientific, engineering, etc.)
1990s—2000s: Data mining and data warehousing, multimedia
databases, and Web databases

Short History of Data Mining 1989 - KDD term (Knowledge Discovery in
Databases) appears in (IJCAI Workshop) 1991 - a collection of research papers edited by
Piatetsky-Shapiro and Frawley 1993 – Association Rule Mining Algorithm
APRIORI proposed by Agraval, Imielinski and Swami.
1996 – present: KDD evolves as a conjuction of different knowledge areas (data bases, machine learning, statistics, artificial intelligence) and the term Data Mining becomes popular
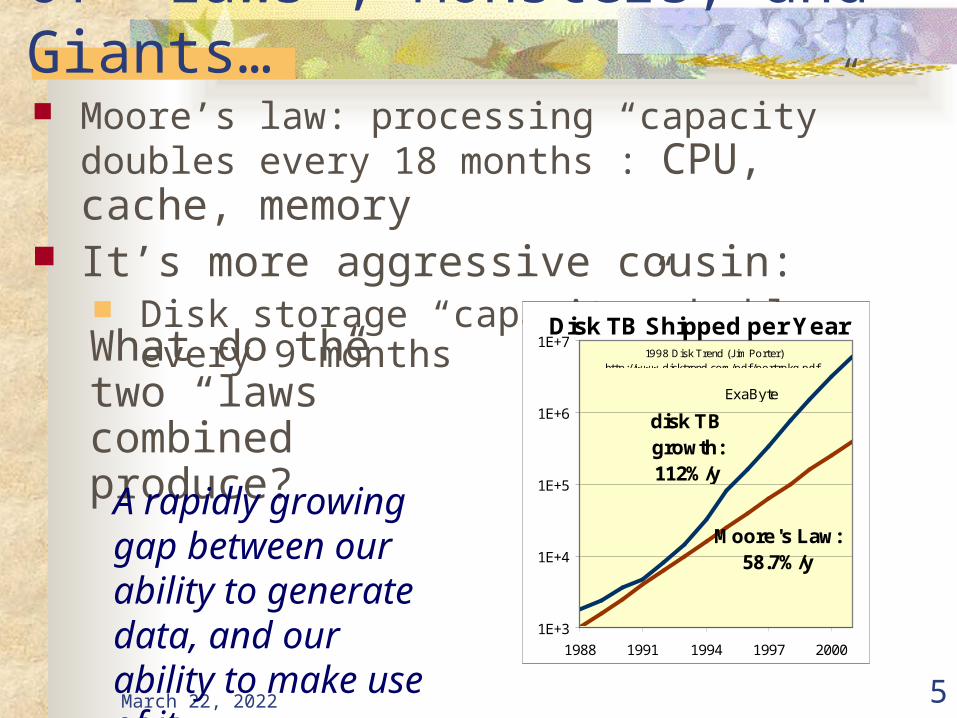
April 20, 2023 5
Of “Laws”, Monsters, and Giants… Moore’s law: processing “capacity” doubles every 18
months : CPU, cache, memory It’s more aggressive cousin:
Disk storage “capacity” doubles every 9 months
1E+3
1E+4
1E+5
1E+6
1E+7
1988 1991 1994 1997 2000
disk TB growth: 112%/y
Moore's Law: 58.7%/y
ExaByte
Disk TB Shipped per Year1998 Disk Trend (J im Porter)
http://www.disktrend.com/pdf/portrpkg.pdf.What do the two “laws” combined produce?
A rapidly growing gap between our ability to generate data, and our ability to make use of it.

April 20, 2023 6
Data, Data everywhere yet ... I can’t find the data I need
data is scattered over the network many versions, subtle differences
I can’t get the data I needneed an expert to get the data
I can’t understand the data I foundavailable data poorly documented
I can’t use the data I foundresults are unexpecteddata needs to be transformed from one form to other
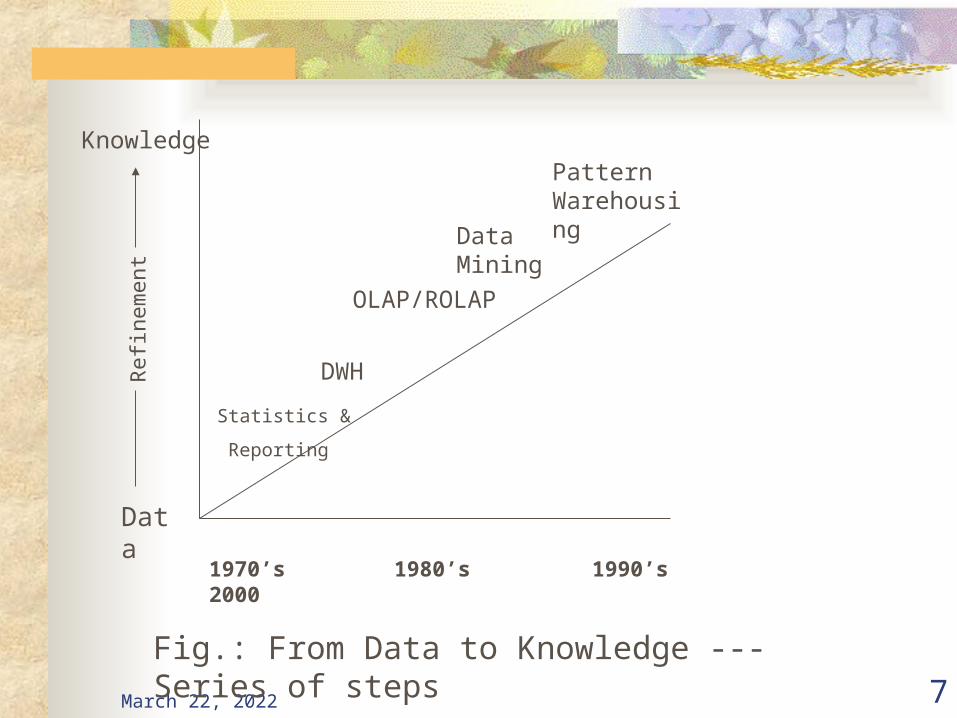
April 20, 2023 7
1970’s 1980’s 1990’s 2000
Statistics &
Reporting
DWH
OLAP/ROLAP
Data Mining
Pattern Warehousing
Data
Knowledge
Fig.: From Data to Knowledge --- Series of steps
Refinement

April 20, 2023 8
What motivated data mining ? Why is it so important ?
• The major reason that data mining has attracted a great deal of attention in the information industry in recent years is due to the wide availability of huge amounts of data and the imminent need for turning such data into useful information and knowledge.
• Data mining can be viewed as a result of the natural evolution of information technology
• It has the following functionalities.
Data Collection and Database Creation, Data management (Including data storage and retrieval and database transaction processing) and Data analysis and understanding (involving database transaction processing)

April 20, 2023 9

April 20, 2023 10
Evolution of Sciences Before 1600, empirical science 1600-1950s, theoretical science
Each discipline has grown a theoretical component. Theoretical models often motivate experiments and generalize our understanding.
1950s-1990s, computational science Over the last 50 years, most disciplines have grown a third, computational branch (e.g.
empirical, theoretical, and computational ecology, or physics, or linguistics.) Computational Science traditionally meant simulation. It grew out of our inability to find
closed-form solutions for complex mathematical models. 1990-now, data science
The flood of data from new scientific instruments and simulations The ability to economically store and manage petabytes of data online The Internet and computing Grid that makes all these archives universally accessible Scientific info. management, acquisition, organization, query, and visualization tasks
scale almost linearly with data volumes. Data mining is a major new challenge! Jim Gray and Alex Szalay, The World Wide Telescope: An Archetype for Online Science,
Comm. ACM, 45(11): 50-54, Nov. 2002

April 20, 2023 11
Evolution of Database Technology 1960s:
Data collection, database creation, IMS and network DBMS 1970s:
Relational data model, relational DBMS implementation 1980s:
RDBMS, advanced data models (extended-relational, OO, deductive, etc.) Application-oriented DBMS (spatial, scientific, engineering, etc.)
1990s: Data mining, data warehousing, multimedia databases, and Web databases
2000s Stream data management and mining Data mining and its applications Web technology (XML, data integration) and global information systems

April 20, 2023 12
What Is Data Mining?
Data mining (knowledge discovery from data) Extraction of interesting (non-trivial, implicit, previously
unknown and potentially useful) patterns or knowledge from huge amount of data
Data mining: a misnomer? Alternative names
Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc.
Watch out: Is everything “data mining”? Simple search and query processing (Deductive) expert systems

April 20, 2023 13
Knowledge Discovery (KDD) Process
Data mining—core of knowledge discovery process
Data Cleaning
Data Integration
Databases
Data Warehouse
Task-relevant Data
Selection
Data Mining
Pattern Evaluation

April 20, 2023 14
Steps in KDD Process1. Data Cleaning : (To remove noise and inconsistent data)
2. Data Integration : (Where multiple data sources may be combined)
3. Data Selection : (Where data relevant to the analysis task are retrieved from the database)
4. Data Transformation : (Where data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations, for instance)
5. Data Mining : (An essential process where intelligent methods are applied in order to extract data patterns )
6. Pattern evaluation : (To identify the truly interesting patterns representing knowledge based on some interestingness measures)
7. Knowledge presentation : (where visualization and knowledge representation techniques are used to present the mined knowledge to the user )

April 20, 2023 15
Architecture of a Typical Data Mining System
Data Warehouse
Data cleaning & data integration Filtering
Databases
Database or data warehouse server
Data mining engine
Pattern evaluation
Graphical user interface
Knowledge-base

April 20, 2023 16
Database, data warehouse, or other information repository : This is one or a set of databases, data warehouses, spreadsheets, or other kinds of informational repositories. Data cleaning and data integration techniques may be performed on the data
Database, or data warehouse server : The database or data warehouse server is responsible for fetching the relevant data, based on the user’s data mining request.
Knowledge base : This is the domain knowledge that is used to guide the search or evaluate the interestingness of resulting patterns
Data mining engine: This is essential to the data mining system and ideally consists of a set of functional modules for tasks such as characterization, association, classification, cluster analysis, and evolution and deviation analysis
Pattern evaluation module : This component typically employs interestingness measures and interacts with data mining modules so as to focus the search towards interesting patterns
Graphical user interface : This module communicates between the users and the data mining system, allowing the user to interact with the system by specifying a query or task.

April 20, 2023 17
Data Mining: On What Kind of Data?
Relational databases Data warehouses Transactional databases Advanced DB and information repositories
Object-oriented and object-relational databases Spatial databases Time-series data and temporal data Text databases and multimedia databases Heterogeneous and legacy databases WWW

April 20, 2023 18
Data Mining Functionalities (1) Concept description: Characterization and discrimination
Generalize, summarize, and contrast data characteristics, e.g., dry vs. wet regions
Association (correlation and causality) Multi-dimensional vs. single-dimensional association age(X, “20..29”) ^ income(X, “20..29K”) à buys (X, “PC”)
[support = 2%, confidence = 60%]
The number of times, this item set appears in the database is called its "support"
Confidence of rule "B given A" is a measure of how much more likely it is that B occurs when A has occurred. It is expressed as a percentage, with 100% meaning B always occurs if A has occurred
contains(T, “computer”) à contains(x, “software”) [1%, 75%]

April 20, 2023 19
Data Mining Functionalities (2) Classification and Prediction
Finding models (functions) that describe and distinguish classes or concepts for future prediction
E.g., classify countries based on climate, or classify cars based on gas mileage
Presentation: decision-tree, classification rule, neural network Prediction: Predict some unknown or missing numerical
values Cluster analysis
Class label is unknown: Group data to form new classes, e.g., cluster houses to find distribution patterns
Clustering based on the principle: maximizing the intra-class similarity and minimizing the interclass similarity

April 20, 2023 20
Data Mining Functionalities (3) Outlier analysis
Outlier: a data object that does not comply with the general behavior of the data
It can be considered as noise or exception but is quite useful in fraud detection, rare events analysis
Trend and evolution analysis Trend and deviation: regression analysis Sequential pattern mining, periodicity analysis Similarity-based analysis
Other pattern-directed or statistical analyses

April 20, 2023 21
Are All the “Discovered” Patterns Interesting? A data mining system/query may generate thousands of patterns,
not all of them are interesting. Suggested approach: Human-centered, query-based, focused
mining Interestingness measures: A pattern is interesting if it is easily
understood by humans, valid on new or test data with some degree of certainty, potentially useful, novel, or validates some hypothesis that a user seeks to confirm
Objective vs. subjective interestingness measures: Objective: based on statistics and structures of patterns, e.g.,
support, confidence, etc. Subjective: based on user’s belief in the data, e.g.,
unexpectedness, novelty, action ability, etc.

April 20, 2023 22
Can We Find All and Only Interesting Patterns? Find all the interesting patterns: Completeness
Can a data mining system find all the interesting patterns? Association vs. classification vs. clustering
Search for only interesting patterns: Optimization Can a data mining system find only the interesting patterns? Approaches
First general all the patterns and then filter out the uninteresting ones.
Generate only the interesting patterns—mining query optimization

April 20, 2023 23
Data Mining: Confluence of Multiple Disciplines
Data Mining
Database Technology
Statistics
OtherDisciplines
InformationScience
MachineLearning Visualization

Classification of Data mining systems Classification according to the kinds of databases mined:
data models(relational ,transactional ,object relational) and type of data
Classification according to the kinds of knowledge mined
association , classification, clustering… Classification according to the kinds of techniques utilized
techniques can be described according to the degree of user interaction involved
Classification according to the applications adapted
finance, telecommunications, DNA, stock
markets, e-mail, and so on.
April 20, 2023 24

April 20, 2023 25
Major Issues in Data Mining Mining methodology
Mining different kinds of knowledge from diverse data types, e.g., bio, stream, Web Performance: efficiency, effectiveness, and scalability Pattern evaluation: the interestingness problem Incorporation of background knowledge Handling noise and incomplete data Parallel, distributed and incremental mining methods Integration of the discovered knowledge with existing one: knowledge fusion
User interaction Data mining query languages and ad-hoc mining Expression and visualization of data mining results Interactive mining of knowledge at multiple levels of abstraction
Applications and social impacts Domain-specific data mining & invisible data mining Protection of data security, integrity, and privacy

April 20, 2023 26
What is Data Warehousing? A process of transforming
data into information and making it available to users in a timely enough manner to make a difference
[Forrester Research, April 1996]
Data
Information

April 20, 2023 27
Very Large Data Bases Terabytes -- 10^12 bytes:
Petabytes -- 10^15 bytes:
Exabytes -- 10^18 bytes:
Zettabytes -- 10^21 bytes:
Zottabytes -- 10^24 bytes:
Walmart -- 24 Terabytes
Geographic Information Systems
National Medical Records
Weather images
Intelligence Agency Videos

April 20, 2023 28
What is a Data Warehouse? A single, complete and
consistent store of data obtained from a variety of different sources made available to end users in a what they can understand and use in a business context.
[Barry Devlin]

April 20, 2023 29
Data Warehousing -- It is a process
Technique for assembling and managing data from various sources for the purpose of answering business questions. Thus making decisions that were not previous possible
A decision support database maintained separately from the organization’s operational database

April 20, 2023 30
What is Data Warehouse? Defined in many different ways, but not rigorously.
A decision support database that is maintained separately from the organization’s operational database
Support information processing by providing a solid platform of consolidated, historical data for analysis.
“A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process.”—W. H. Inmon
Data warehousing: The process of constructing and using data warehouses

April 20, 2023 31
Data Warehouse—Subject-Oriented Organized around major subjects, such as customer,
product, sales.
Focusing on the modeling and analysis of data for decision
makers, not on daily operations or transaction processing.
Provide a simple and concise view around particular
subject issues by excluding data that are not useful in the
decision support process.

April 20, 2023 32
Data Warehouse—Integrated Constructed by integrating multiple, heterogeneous
data sources relational databases, flat files, on-line transaction records
Data cleaning and data integration techniques are applied. Ensure consistency in naming conventions, encoding
structures, attribute measures, etc. among different data sources
E.g., Hotel price: currency, tax, breakfast covered, etc.
When data is moved to the warehouse, it is converted.

April 20, 2023 33
Data Warehouse—Time Variant The time horizon for the data warehouse is
significantly longer than that of operational systems. Operational database: current value data.
Data warehouse data: provide information from a historical
perspective (e.g., past 5-10 years)
Every key structure in the data warehouse Contains an element of time, explicitly or implicitly
But the key of operational data may or may not contain
“time element”.

April 20, 2023 34
Data Warehouse—Non-Volatile A physically separate store of data transformed from
the operational environment.
Operational update of data does not occur in the data
warehouse environment.
Does not require transaction processing, recovery, and
concurrency control mechanisms
Requires only two operations in data accessing:
initial loading of data and access of data.

April 20, 2023 35
Data Warehouse vs. Heterogeneous DBMS
Traditional heterogeneous DB integration: Build wrappers/mediators on top of heterogeneous databases Query driven approach
When a query is posed to a client site, a meta-dictionary is used to translate the query into queries appropriate for individual heterogeneous sites involved, and the results are integrated into a global answer set
Complex information filtering, compete for resources
Data warehouse: update-driven, high performance Information from heterogeneous sources is integrated in advance and
stored in warehouses for direct query and analysis

April 20, 2023 36
Data Warehouse vs. Operational DBMS OLTP (on-line transaction processing)
Major task of traditional relational DBMS Day-to-day operations: purchasing, inventory, banking, manufacturing,
payroll, registration, accounting, etc.
OLAP (on-line analytical processing) Major task of data warehouse system Data analysis and decision making
Distinct features (OLTP vs. OLAP): User and system orientation: customer vs. market Data contents: current, detailed vs. historical, consolidated Database design: ER + application vs. star + subject View: current, local vs. evolutionary, integrated Access patterns: update vs. read-only but complex queries

April 20, 2023 37
OLTP vs. OLAP OLTP OLAP
users clerk, IT professional knowledge worker
function day to day operations decision support
DB design application-oriented subject-oriented
data current, up-to-date detailed, flat relational isolated
historical, summarized, multidimensional integrated, consolidated
usage repetitive ad-hoc
access read/write index/hash on prim. key
lots of scans
unit of work short, simple transaction complex query
# records accessed tens millions
#users thousands hundreds
DB size 100MB-GB 100GB-TB
metric transaction throughput query throughput, response

April 20, 2023 38
Why Separate Data Warehouse? High performance for both systems
DBMS— tuned for OLTP: access methods, indexing, concurrency control, recovery
Warehouse—tuned for OLAP: complex OLAP queries, multidimensional view, consolidation.
Different functions and different data: missing data: Decision support requires historical data
which operational DBs do not typically maintain data consolidation: DS requires consolidation (aggregation,
summarization) of data from heterogeneous sources data quality: different sources typically use inconsistent data
representations, codes and formats which have to be reconciled

April 20, 2023 39
Typical Process Flow Within a Data Warehouse
Archive data
Figure : Process flow within a data warehouse
Data transformation and movement
Source Warehouse Users
Extract And load
Query

April 20, 2023 40
1. Extract and load the data
2. Clean and transform data into a form that can cope with large data volumes and provide good query performance.
3. Back up and archive data
4. Manage queries and direct them to the appropriate data sources.

April 20, 2023 41
Extract and Load Process 1. Controlling the Process
- Determine when to start extracting the data
2. When to initiate the extract
- Data should be in a consistent state
- Start extracting data from data sources when it represents the same snapshot of time as all the other data sources
3. Loading the data
- Do not execute consistency checks until all the data sources have been loaded into the temporary data store
4. Copy Management Tools and Data cleanup

April 20, 2023 42
Clean and Transform Data1. Clean and Transform the dataData needs to be cleaned and checked in the following ways:
- Make sure data is consistent within itself
- Make sure that data is consistent with other data within the same source
- Make sure data is consistent with data in the other source systems.
- Make sure data is consistent with the information already in the warehouse

April 20, 2023 43
2. Transforming into Effective Structure
- Once the data has been cleaned, convert the source data in the temporary data store into a structure that is designed to balance query performance and operational cost

April 20, 2023 44
Backup and Archive Process
The data within the data warehouse is backed up regularly in order to ensure that the data warehouse can always be recovered from data loss, software failure or hardware failure.

April 20, 2023 45
Query Management Process System process that manages the queries an
speeds them up by directing queries to the most effective data source.
Directing Queries to the suitable tables Maximizing System Resources Query Capture
- Query profiles change on a regular basis- In order to accurately monitor and understand what the new query profiles are, it can be very effective to capture the physical queries that are being executed.

April 20, 2023 46
Design of a Data Warehouse: A Business Analysis Framework Four views regarding the design of a data warehouse
Top-down view allows selection of the relevant information necessary for the data
warehouse
Data source view exposes the information being captured, stored, and managed by
operational systems
Data warehouse view consists of fact tables and dimension tables
Business query view sees the perspectives of data in the warehouse from the view of end-
user

April 20, 2023 47
Data Warehouse Design Process Top-down, bottom-up approaches or a combination of both
Top-down: Starts with overall design and planning (mature) Bottom-up: Starts with experiments and prototypes (rapid)
From software engineering point of view Waterfall: structured and systematic analysis at each step before
proceeding to the next Spiral: rapid generation of increasingly functional systems, short turn
around time, quick turn around Typical data warehouse design process
Choose a business process to model, e.g., orders, invoices, etc. Choose the grain (atomic level of data) of the business process Choose the dimensions that will apply to each fact table record Choose the measure that will populate each fact table record
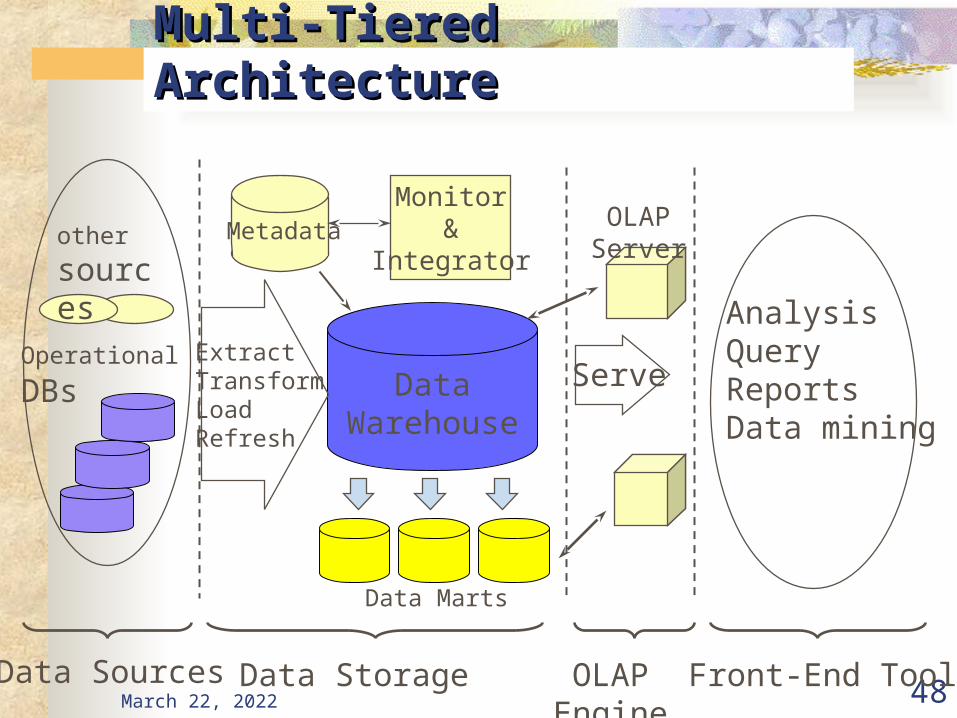
April 20, 2023 48
Multi-Tiered ArchitectureMulti-Tiered Architecture
DataWarehouse
ExtractTransformLoadRefresh
OLAP Engine
AnalysisQueryReportsData mining
Monitor&
IntegratorMetadata
Data Sources Front-End Tools
Serve
Data Marts
Operational DBs
other
sources
Data Storage
OLAP Server

April 20, 2023 49
Three Data Warehouse Models Enterprise warehouse
collects all of the information about subjects spanning the entire organization
Data Mart a subset of corporate-wide data that is of value to a specific
groups of users. Its scope is confined to specific, selected groups, such as marketing data mart
Independent vs. dependent (directly from warehouse) data mart
Virtual warehouse A set of views over operational databases Only some of the possible summary views may be materialized
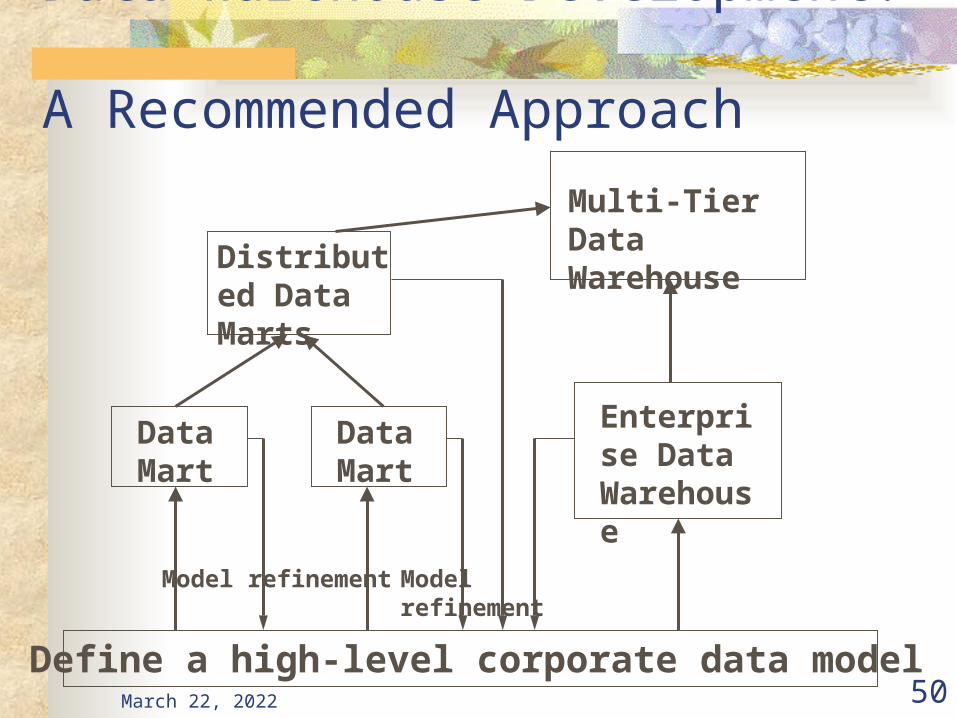
April 20, 2023 50
Data Warehouse Development: A Recommended Approach
Define a high-level corporate data model
Data Mart
Data Mart
Distributed Data Marts
Multi-Tier Data Warehouse
Enterprise Data Warehouse
Model refinementModel refinement

April 20, 2023 51
OLAP Server Architectures Relational OLAP (ROLAP)
Use relational or extended-relational DBMS to store and manage warehouse data and OLAP middle ware to support missing pieces
Include optimization of DBMS backend, implementation of aggregation navigation logic, and additional tools and services
greater scalability
Multidimensional OLAP (MOLAP) Array-based multidimensional storage engine (sparse matrix techniques) fast indexing to pre-computed summarized data
Hybrid OLAP (HOLAP) User flexibility, e.g., low level: relational, high-level: array
Specialized SQL servers specialized support for SQL queries over star/snowflake schemas

April 20, 2023 52

April 20, 2023 53
Data explosion problem
Automated data collection tools and mature database
technology lead to tremendous amounts of data stored in
databases, data warehouses and other information
repositories
We are drowning in data, but starving for knowledge!
Solution: Data warehousing and data mining
Data warehousing and on-line analytical processing
Extraction of interesting knowledge (rules, regularities,
patterns, constraints) from data in large databases
Why Data Mining?

April 20, 2023 54
What Is Data Mining? Data mining (knowledge discovery in databases):
Extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) information or patterns from data in large databases
Alternative names and their “inside stories”: Data mining: a misnomer? Knowledge discovery(mining) in databases (KDD),
knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc.
What is not data mining? (Deductive) query processing. Expert systems or small ML/statistical programs

April 20, 2023 55
Why Data Mining? — Potential Applications
Database analysis and decision support Market analysis and management
target marketing, customer relation management, market basket
analysis, cross selling, market segmentation
Risk analysis and management
Forecasting, customer retention, improved underwriting, quality
control, competitive analysis
Fraud detection and management
Other Applications Text mining (news group, email, documents) and Web analysis.
Intelligent query answering

April 20, 2023 56
Market Analysis and Management (1) Where are the data sources for analysis?
Credit card transactions, loyalty cards, discount coupons, customer complaint calls, plus (public) lifestyle studies
Target marketing Find clusters of “model” customers who share the same
characteristics: interest, income level, spending habits, etc.
Determine customer purchasing patterns over time Conversion of single to a joint bank account: marriage, etc.
Cross-market analysis Associations/co-relations between product sales Prediction based on the association information

April 20, 2023 57
Market Analysis and Management (2) Customer profiling
data mining can tell you what types of customers buy what
products (clustering or classification)
Identifying customer requirements
identifying the best products for different customers
use prediction to find what factors will attract new customers
Provides summary information various multidimensional summary reports
statistical summary information (data central tendency and variation)

April 20, 2023 58
Corporate Analysis and Risk Management Finance planning and asset evaluation
cash flow analysis and prediction contingent claim analysis to evaluate assets cross-sectional and time series analysis (financial-ratio, trend
analysis, etc.) Resource planning:
summarize and compare the resources and spending Competition:
monitor competitors and market directions group customers into classes and a class-based pricing
procedure set pricing strategy in a highly competitive market

April 20, 2023 59
Fraud Detection and Management (1) Applications
widely used in health care, retail, credit card services, telecommunications (phone card fraud), etc.
Approach use historical data to build models of fraudulent behavior
and use data mining to help identify similar instances Examples
auto insurance: detect a group of people who stage accidents to collect on insurance
money laundering: detect suspicious money transactions (US Treasury's Financial Crimes Enforcement Network)
medical insurance: detect professional patients and ring of doctors and ring of references

April 20, 2023 60
Fraud Detection and Management (2) Detecting inappropriate medical treatment
Australian Health Insurance Commission identifies that in many cases blanket screening tests were requested (save Australian $1m/yr).
Detecting telephone fraud Telephone call model: destination of the call, duration,
time of day or week. Analyze patterns that deviate from an expected norm.
British Telecom identified discrete groups of callers with frequent intra-group calls, especially mobile phones, and broke a multimillion dollar fraud.
Retail Analysts estimate that 38% of retail shrink is due to
dishonest employees.

April 20, 2023 61
Other Applications Sports
IBM Advanced Scout analyzed NBA game statistics (shots blocked, assists, and fouls) to gain competitive advantage for New York Knicks and Miami Heat
Astronomy JPL and the Palomar Observatory discovered 22 quasars
with the help of data mining
Internet Web Surf-Aid IBM Surf-Aid applies data mining algorithms to Web
access logs for market-related pages to discover customer preference and behavior pages, analyzing effectiveness of Web marketing, improving Web site organization, etc.

April 20, 2023 62
Data Mining: A KDD Process
Data mining: the core of knowledge discovery process.
Data Cleaning
Data Integration
Databases
Data Warehouse
Task-relevant Data
Selection
Data Mining
Pattern Evaluation

April 20, 2023 63
Steps of a KDD Process Learning the application domain:
relevant prior knowledge and goals of application Creating a target data set: data selection Data cleaning and preprocessing: (may take 60% of effort!) Data reduction and transformation:
Find useful features, dimensionality/variable reduction, invariant representation.
Choosing functions of data mining summarization, classification, regression, association, clustering.
Choosing the mining algorithm(s) Data mining: search for patterns of interest Pattern evaluation and knowledge presentation
visualization, transformation, removing redundant patterns, etc. Use of discovered knowledge
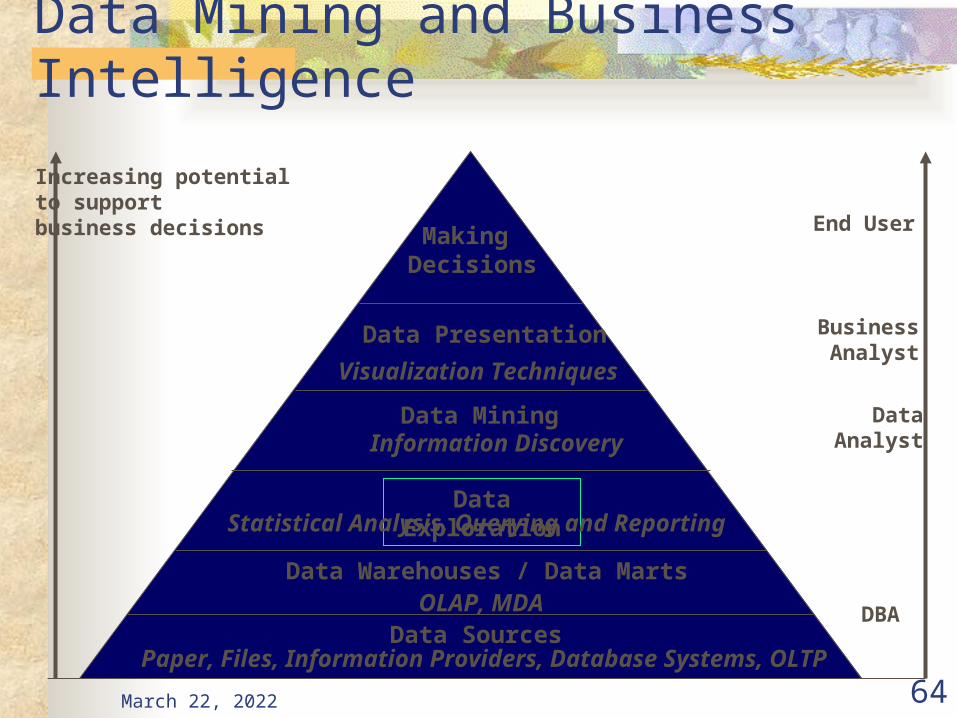
April 20, 2023 64
Data Mining and Business Intelligence
Increasing potentialto supportbusiness decisions End User
Business Analyst
DataAnalyst
DBA
MakingDecisions
Data Presentation
Visualization Techniques
Data MiningInformation Discovery
Data Exploration
OLAP, MDA
Statistical Analysis, Querying and Reporting
Data Warehouses / Data Marts
Data SourcesPaper, Files, Information Providers, Database Systems, OLTP
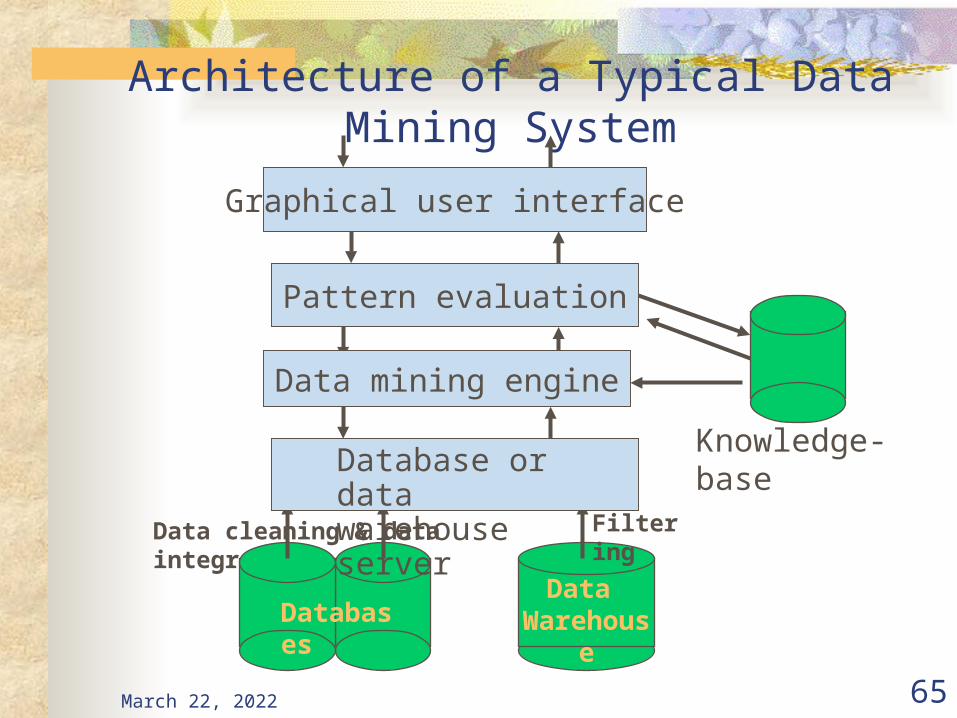
April 20, 2023 65
Architecture of a Typical Data Mining System
Data Warehouse
Data cleaning & data integration Filtering
Databases
Database or data warehouse server
Data mining engine
Pattern evaluation
Graphical user interface
Knowledge-base

April 20, 2023 66
Data Mining: On What Kind of Data? Relational databases Data warehouses Transactional databases Advanced DB and information repositories
Object-oriented and object-relational databases Spatial databases Time-series data and temporal data Text databases and multimedia databases Heterogeneous and legacy databases WWW

April 20, 2023 67
Data Mining Functionalities (1) Concept description: Characterization and
discrimination Generalize, summarize, and contrast data characteristics,
e.g., dry vs. wet regions
Association (correlation and causality) Multi-dimensional vs. single-dimensional association age(X, “20..29”) ^ income(X, “20..29K”) buys(X,
“PC”) [support = 2%, confidence = 60%] contains(T, “computer”) contains(x, “software”) [1%,
75%]

April 20, 2023 68
Data Mining Functionalities (2) Classification and Prediction
Finding models (functions) that describe and distinguish classes or concepts for future prediction
E.g., classify countries based on climate, or classify cars based on gas mileage
Presentation: decision-tree, classification rule, neural network Prediction: Predict some unknown or missing numerical values
Cluster analysis Class label is unknown: Group data to form new classes,
e.g., cluster houses to find distribution patterns Clustering based on the principle: maximizing the intra-
class similarity and minimizing the interclass similarity

April 20, 2023 69
Data Mining Functionalities (3) Outlier analysis
Outlier: a data object that does not comply with the general
behavior of the data
It can be considered as noise or exception but is quite useful in
fraud detection, rare events analysis
Trend and evolution analysis
Trend and deviation: regression analysis
Sequential pattern mining, periodicity analysis
Similarity-based analysis
Other pattern-directed or statistical analyses

April 20, 2023 70
Are All the “Discovered” Patterns Interesting? A data mining system/query may generate thousands of patterns, not all
of them are interesting. Suggested approach: Human-centered, query-based, focused mining
Interestingness measures: A pattern is interesting if it is easily
understood by humans, valid on new or test data with some degree of
certainty, potentially useful, novel, or validates some hypothesis that a
user seeks to confirm
Objective vs. subjective interestingness measures: Objective: based on statistics and structures of patterns, e.g., support,
confidence, etc.
Subjective: based on user’s belief in the data, e.g., unexpectedness, novelty,
actionability, etc.

April 20, 2023 71
Can We Find All and Only Interesting Patterns?
Find all the interesting patterns: Completeness Can a data mining system find all the interesting
patterns?
Association vs. classification vs. clustering
Search for only interesting patterns: Optimization Can a data mining system find only the interesting
patterns?
Approaches First general all the patterns and then filter out the uninteresting
ones.
Generate only the interesting patterns—mining query
optimization

April 20, 2023 72
Data Mining: Confluence of Multiple Disciplines
Data Mining
Database Technology
Statistics
OtherDisciplines
InformationScience
MachineLearning Visualization

April 20, 2023 73
Data Mining: Classification Schemes
General functionality
Descriptive data mining
Predictive data mining
Different views, different classifications
Kinds of databases to be mined
Kinds of knowledge to be discovered
Kinds of techniques utilized
Kinds of applications adapted

April 20, 2023 74
MULTIDIMENSIONAL DATA Analyze data by representing facts and
dimensions within a multidimensional cube.
Purpose of viewing information in a cube is that it lends itself to viewing statistical operations/aggregations, by applying functions against the plane of cube.

April 20, 2023 75
For example: In a retail sales analysis data warehouse, a cubical representation of products by store by day is represented by a three-dimensional cube.
The point of intersection of all axes represents the actual number of sales for a specific product, in a specific store, on a specific day.
Figure: Product by store by day cube
Product
LocationTime

April 20, 2023 76
Some operations in the multidimensional data model Roll-up(drill-up)-Performs aggregation on a data cube,
either by climbing up a concept hierarchy for a dimension or by dimension reduction.
Drill-down- Reverse of roll-up operation. It navigates from less details data to more detailed data.
Slice- Performs a selection on one dimension of the given cube, resulting in a sub-cube.
Dice- Define a sub-cube by performing a selection on two or more dimensions.
Pivot(rotate)- is a visualization operation that rotates the data axes in a view ,in order to provide an alternative presentation of data.

April 20, 2023 77
Dice for(location=”Toronto “ or “vancover”) and (time=”Q1” or “Q2”) and (item=”H.E” or “comp)
Q1
Q2
VancoverToronto
H.E. compItems (types)
605 825 14 400
Home comp phone security entertainment
Q1
Q2
Q3
Q4
Time (quarters)
Items (types)
VancoverToronto
NYChicago
395156
440Location(Cities)
slice fortime “Q1”
605 825 14 400
Home comp phone security entertainment
Vancover
Toronto
Chicago
NY
Pivot
605
825
14
400
VancoverTorontoChicago NY
H.E
Comp
Phone
Security

April 20, 2023 78
605 825 14 400
Home comp phone security entertainment
Q1
Q2
Q3
Q4
VancoverToronto
NY
Chicago
395156
440
Time (quarters)
Location(Cities)
Items (types)
Drill-down on
time(from quarters to months)
JanFeb
MarAppMay
JuneJuly
August
Oct
Nov
Dec
Sep
TorontoNY
Chicago
Vancover
Time (months)
H.E comp phone security
Items (types)
Roll-upOn location(from citiesto country)
H.E comp phone security
Items (types)
Q1 Q2 Q3 Q4
CanadaUSA

April 20, 2023 79
A Multi-Dimensional View of Data Mining Classification
Databases to be mined Relational, transactional, object-oriented, object-relational, active,
spatial, time-series, text, multi-media, heterogeneous, legacy, WWW, etc.
Knowledge to be mined Characterization, discrimination, association, classification,
clustering, trend, deviation and outlier analysis, etc. Multiple/integrated functions and mining at multiple levels
Techniques utilized Database-oriented, data warehouse (OLAP), machine
learning, statistics, visualization, neural network, etc. Applications adapted
Retail, telecommunication, banking, fraud analysis, DNA mining, stock market analysis, Web mining, Weblog analysis, etc.
April 20, 2023 80
OLAP Mining: An Integration of Data Mining and Data Warehousing
Data mining systems, DBMS, Data warehouse
systems coupling No coupling, loose-coupling, semi-tight-coupling, tight-coupling
On-line analytical mining data integration of mining and OLAP technologies
Interactive mining multi-level knowledge Necessity of mining knowledge and patterns at different levels of
abstraction by drilling/rolling, pivoting, slicing/dicing, etc.
Integration of multiple mining functions Characterized classification, first clustering and then association

April 20, 2023 81
Data Warehouse Usage Three kinds of data warehouse applications
Information processing supports querying, basic statistical analysis, and reporting using
crosstabs, tables, charts and graphs Analytical processing
multidimensional analysis of data warehouse data supports basic OLAP operations, slice-dice, drilling, pivoting
Data mining knowledge discovery from hidden patterns supports associations, constructing analytical models, performing
classification and prediction, and presenting the mining results using visualization tools.
Differences among the three tasks

April 20, 2023 82
From On-Line Analytical Processing to On Line Analytical Mining (OLAM)
Why online analytical mining? High quality of data in data warehouses
DW contains integrated, consistent, cleaned data Available information processing structure surrounding data
warehouses ODBC, OLEDB, Web accessing, service facilities, reporting and
OLAP tools OLAP-based exploratory data analysis
mining with drilling, dicing, pivoting, etc. On-line selection of data mining functions
integration and swapping of multiple mining functions, algorithms, and tasks.
Architecture of OLAM

April 20, 2023 83
An OLAM Architecture
Data Warehouse
Meta Data
MDDB
OLAMEngine
OLAPEngine
User GUI API
Data Cube API
Database API
Data cleaning
Data integration
Layer3
OLAP/OLAM
Layer2
MDDB
Layer1
Data Repository
Layer4
User Interface
Filtering&Integration Filtering
Databases
Mining query Mining result

April 20, 2023 84
Major Issues in Data Mining (1)
Mining methodology and user interaction Mining different kinds of knowledge in databases Interactive mining of knowledge at multiple levels of abstraction Incorporation of background knowledge Data mining query languages and ad-hoc data mining Expression and visualization of data mining results Handling noise and incomplete data Pattern evaluation: the interestingness problem
Performance and scalability Efficiency and scalability of data mining algorithms Parallel, distributed and incremental mining methods

April 20, 2023 85
Major Issues in Data Mining (2) Issues relating to the diversity of data types
Handling relational and complex types of data Mining information from heterogeneous databases and
global information systems (WWW) Issues related to applications and social impacts
Application of discovered knowledge Domain-specific data mining tools Intelligent query answering Process control and decision making
Integration of the discovered knowledge with existing knowledge: A knowledge fusion problem
Protection of data security, integrity, and privacy

April 20, 2023 86
Summary Data mining: discovering interesting patterns from large amounts of
data A natural evolution of database technology, in great demand, with
wide applications A KDD process includes data cleaning, data integration, data
selection, transformation, data mining, pattern evaluation, and knowledge presentation
Mining can be performed in a variety of information repositories Data mining functionalities: characterization, discrimination,
association, classification, clustering, outlier and trend analysis, etc. Classification of data mining systems Major issues in data mining

April 20, 2023 87
Why Data Preprocessing? Data in the real world is dirty
incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data
noisy: containing errors or outliers inconsistent: containing discrepancies in codes or names
No quality data, no quality mining results! Quality decisions must be based on quality data Data warehouse needs consistent integration of quality
data

April 20, 2023 88
Multi-Dimensional Measure of Data Quality A well-accepted multidimensional view:
Accuracy Completeness Consistency Timeliness Believability Value added Interpretability Accessibility
Broad categories: intrinsic, contextual, representational, and
accessibility.

April 20, 2023 89
Major Tasks in Data Preprocessing Data cleaning
Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies
Data integration Integration of multiple databases, data cubes, or files
Data transformation Normalization and aggregation
Data reduction Obtains reduced representation in volume but produces the same or
similar analytical results
Data discretization Part of data reduction but with particular importance, especially for
numerical data
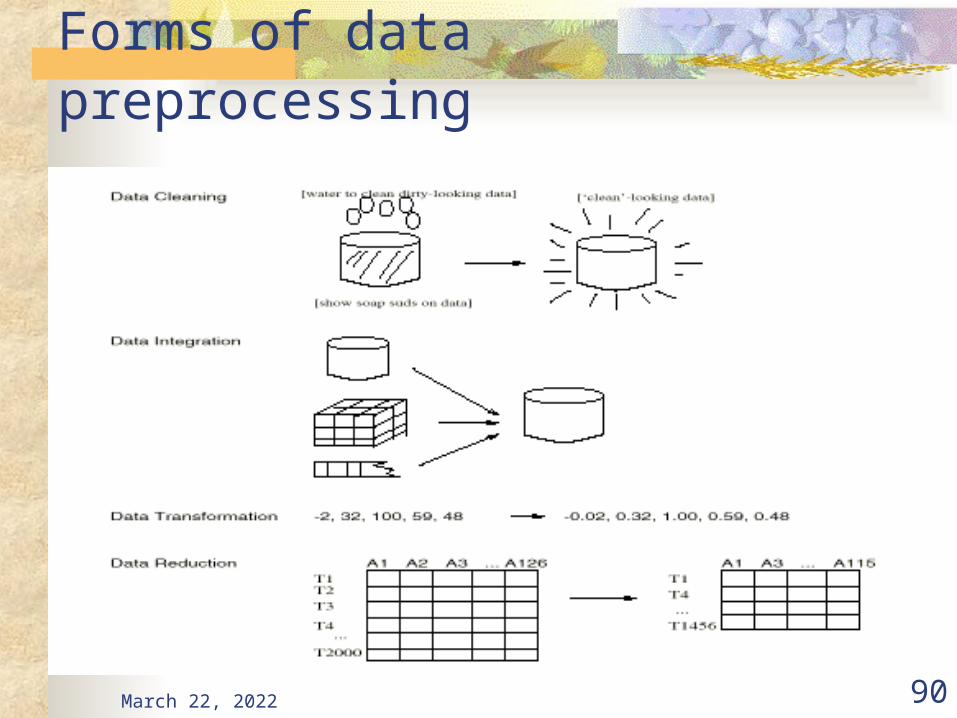
April 20, 2023 90
Forms of data preprocessing

April 20, 2023 91
Data Cleaning Data cleaning tasks
Fill in missing values
Identify outliers and smooth out noisy data
Correct inconsistent data

April 20, 2023 92
Missing Data Data is not always available
E.g., many tuples have no recorded value for several attributes,
such as customer income in sales data
Missing data may be due to equipment malfunction
inconsistent with other recorded data and thus deleted
data not entered due to misunderstanding
certain data may not be considered important at the time of entry
not register history or changes of the data
Missing data may need to be inferred.

April 20, 2023 93
How to Handle Missing Data? Ignore the tuple: usually done when class label is missing
(assuming the tasks in classification—not effective when the
percentage of missing values per attribute varies considerably.
Fill in the missing value manually: tedious + infeasible
Use a global constant to fill in the missing value: e.g.,
“unknown”, a new class?!
Use the attribute mean to fill in the missing value
Use the attribute mean for all samples belonging to the same
class to fill in the missing value: smarter
Use the most probable value to fill in the missing value: inference-based such
as Bayesian formula or decision tree

April 20, 2023 94
Noisy Data Noise: random error or variance in a measured variable Incorrect attribute values may due to
faulty data collection instruments data entry problems data transmission problems technology limitation inconsistency in naming convention
Other data problems which requires data cleaning duplicate records incomplete data inconsistent data

April 20, 2023 95
How to Handle Noisy Data? Binning method:
first sort data and partition into (equi-depth) bins then one can smooth by bin means, smooth by bin
median, smooth by bin boundaries, etc.
Clustering detect and remove outliers
Combined computer and human inspection detect suspicious values and check by human
Regression smooth by fitting the data into regression functions

April 20, 2023 96
Simple Discretization Methods: Binning Equal-width (distance) partitioning:
It divides the range into N intervals of equal size: uniform grid
if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B-A)/N.
The most straightforward But outliers may dominate presentation Skewed data is not handled well.
Equal-depth (frequency) partitioning: It divides the range into N intervals, each containing
approximately same number of samples Good data scaling Managing categorical attributes can be tricky.

April 20, 2023 97
Binning Methods for Data SmoothingSorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26,
28, 29, 34* Partition into (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34* Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29* Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34

April 20, 2023 98
Data Integration Data integration:
combines data from multiple sources into a coherent store Schema integration
integrate metadata from different sources Entity identification problem: identify real world entities
from multiple data sources. Detecting and resolving data value conflicts
for the same real world entity, attribute values from different sources are different
possible reasons: different representations, different scales, e.g., metric vs. British units

April 20, 2023 99
Handling Redundant Data in Data Integration Redundant data occur often when integration of
multiple databases The same attribute may have different names in different
databases One attribute may be a “derived” attribute in another
table, e.g., annual revenue
Redundant data may be able to be detected by correlational analysis
Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality

April 20, 2023 100
Data Transformation Smoothing: remove noise from data Aggregation: summarization, data cube construction Generalization: concept hierarchy climbing Normalization: scaled to fall within a small,
specified range min-max normalization z-score normalization normalization by decimal scaling
Attribute/feature construction New attributes constructed from the given ones

April 20, 2023 101
Data Transformation: Normalization min-max normalization
z-score normalization
normalization by decimal scaling
AAA
AA
A
minnewminnewmaxnewminmax
minvv _)__('
A
A
devstand
meanvv
_'
j
vv
10' Where j is the smallest integer such that Max(| |)<1'v

April 20, 2023 102
Data Reduction Strategies Warehouse may store terabytes of data: Complex data
analysis/mining may take a very long time to run on the complete data set
Data reduction Obtains a reduced representation of the data set that is much
smaller in volume but yet produces the same (or almost the same) analytical results
Data reduction strategies Data cube aggregation Dimensionality reduction Numerosity reduction Discretization and concept hierarchy generation

April 20, 2023 103
Discretization and Concept hierachy
Discretization reduce the number of values for a given continuous
attribute by dividing the range of the attribute into intervals. Interval labels can then be used to replace actual data values.
Concept hierarchies reduce the data by collecting and replacing low level
concepts (such as numeric values for the attribute age) by higher level concepts (such as young, middle-aged, or senior).

April 20, 2023 104
Discretization Three types of attributes:
Nominal — values from an unordered set Ordinal — values from an ordered set Continuous — real numbers
Discretization: divide the range of a continuous attribute into intervals Some classification algorithms only accept categorical
attributes. Reduce data size by discretization Prepare for further analysis

April 20, 2023 105
Discretization and concept hierarchy generation for numeric data
Binning
Histogram analysis
Clustering analysis
Entropy-based discretization
Segmentation by natural partitioning

April 20, 2023 106
Concept hierarchy generation for categorical data Specification of a partial ordering of attributes
explicitly at the schema level by users or experts
Specification of a portion of a hierarchy by
explicit data grouping
Specification of a set of attributes, but not of their
partial ordering
Specification of only a partial set of attributes

April 20, 2023 107
Specification of a set of attributes Concept hierarchy can be automatically generated
based on the number of distinct values per attribute in the given attribute set. The attribute with the most distinct values is placed at the lowest level of the hierarchy.
country
province_or_ state
city
street
15 distinct values
65 distinct values
3567 distinct values
674,339 distinct values

April 20, 2023 108
Summary Data preparation is a big issue for both warehousing
and mining
Data preparation includes
Data cleaning and data integration
Data reduction and feature selection
Discretization
A lot a methods have been developed but still an
active area of research