oozie deck
TRANSCRIPT

RIOT GAMES SOME CATCHY STATEMENT ABOUT WORKFLOWS
AND YORDLES
MATT GOEKE

INTRODUCTION
1
2
3
4
5
6
7

INTRO 1
2
3
4
5
6
7
ABOUT THE SPEAKER

• Previous workflow architecture • What Oozie is • How we incorporated Oozie – Relational Data Pipeline – Non-relational Data Pipeline
• Lessons learned • Where we’re headed
THIS PRESENTATION IS ABOUT…1
2
3
4
5
6
7
INTRO

• Developer and publisher of League of Legends • Founded 2006 by gamers for gamers • Player experience focused – Needless to say, data is pretty important to
understanding the player experience!
WHO is RIOT GAMES? 1
2
3
4
5
6
7
INTRO

1
2
3
4
5
6
7
INTRO LEAGUE OF LEGENDS

ARCHITECTURE
1
2
3
4
5
6
7
ClientMobileWWW
1
2
3
4
5
6
7
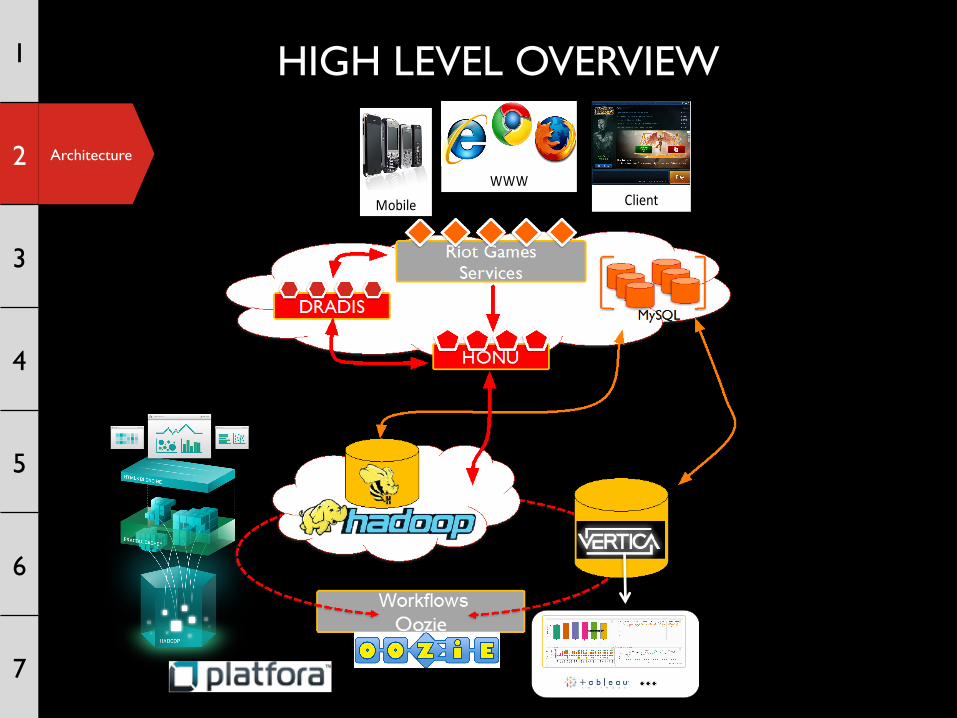
Architecture
HIGH LEVEL OVERVIEW
ClientMobileWWW
1
2
3
4
5
6
7
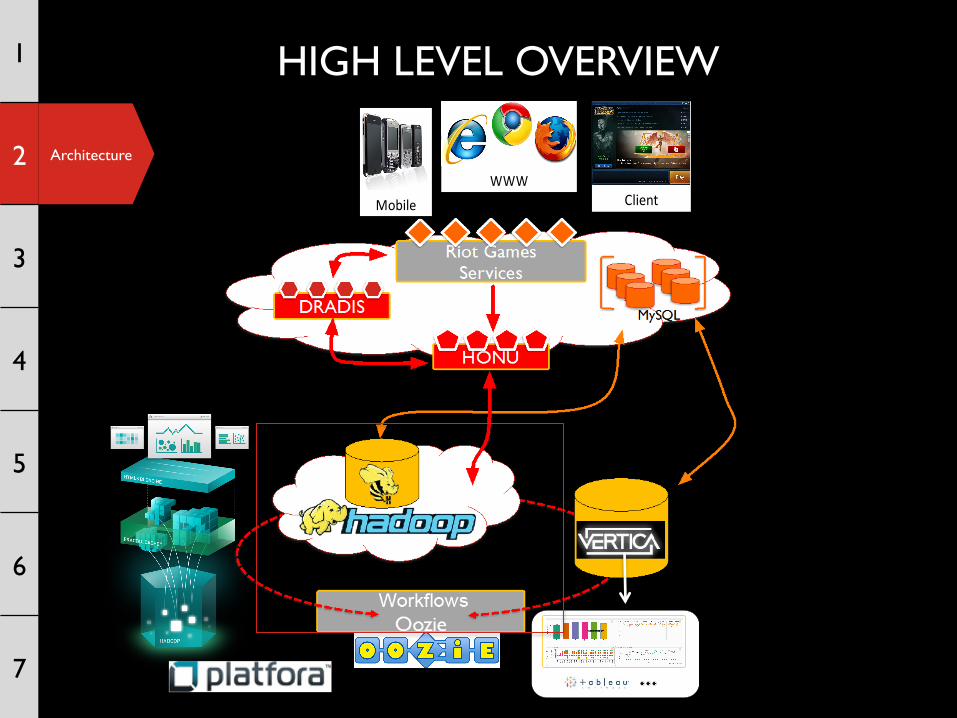
Architecture
HIGH LEVEL OVERVIEW

1
2
3
4
5
6
7
Architecture
WHY WORKFLOWS?
• Retry a series of jobs in the event of failure
• Execute jobs at a specific time or when data is available
• Correctly order job execution based on resolved dependencies
• Provide a common framework for communication and execution of production process
• Use the the workflow to couple resources instead of having a monolithic code base
1
2
3
4
5
6
7
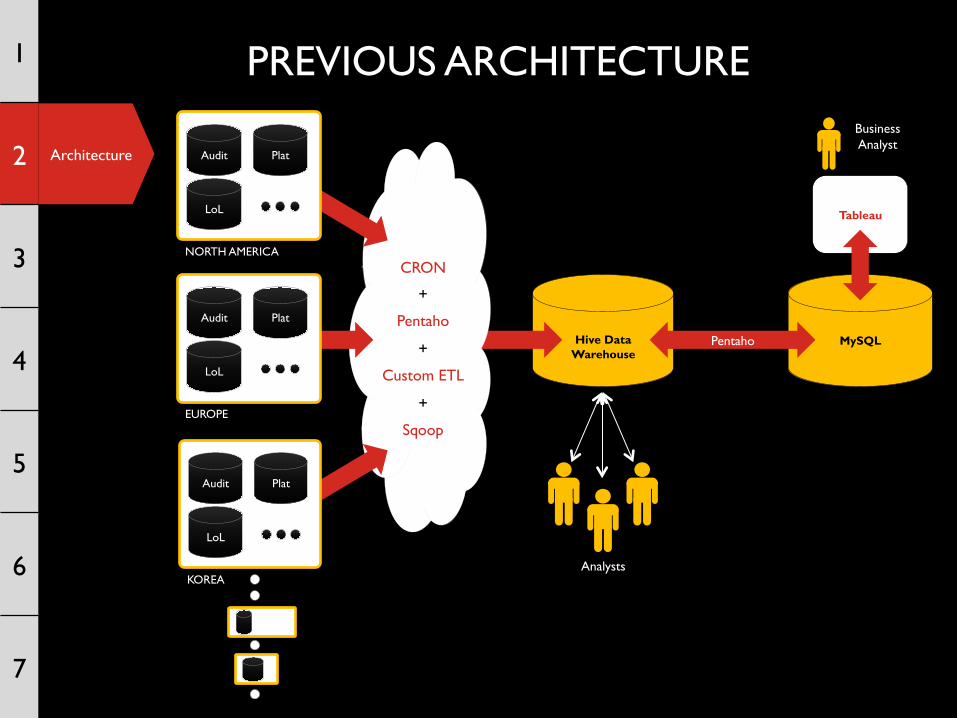
Architecture
PREVIOUS ARCHITECTURE
Tableau
Hive Data
Warehouse
CRON
+
Pentaho
+
Custom ETL
+
Sqoop
MySQL Pentaho
Analysts
EUROPE
Audit Plat
LoL
KOREA
Audit Plat
LoL
NORTH AMERICA
Audit Plat
LoL
Business Analyst

1
2
3
4
5
6
7
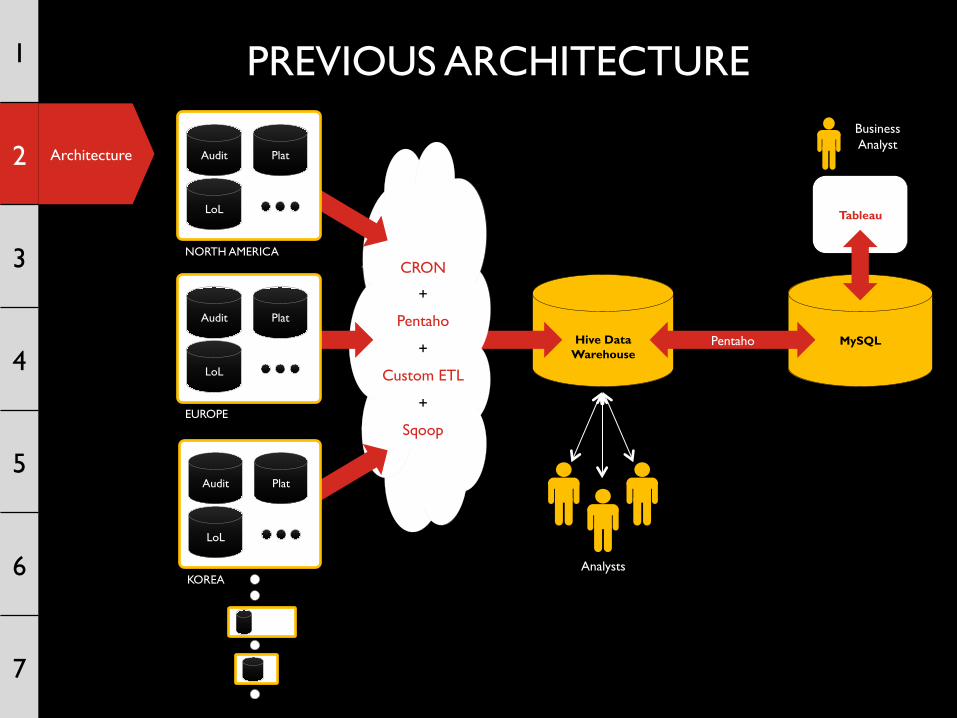
Architecture
ISSUES WITH PREVIOUS PROCESS
• All of the ETL processes were run on one node which limited concurrency
• If our main runner execution died then the whole ETL for that day would need to be restarted
• No reporting of what was run or the configuration of the ETL without log diving on the actual machine
• No retries (outside of native MR tasks) and no good way to rerun a previous config if the underlying code has been changed
1
2
3
4
5
6
7
Architecture
PREVIOUS ARCHITECTURE
Tableau
Hive Data
Warehouse
CRON
+
Pentaho
+
Custom ETL
+
Sqoop
MySQL Pentaho
Analysts
EUROPE
Audit Plat
LoL
KOREA
Audit Plat
LoL
NORTH AMERICA
Audit Plat
LoL
Business Analyst
1
2
3
4
5
6
7
Architecture
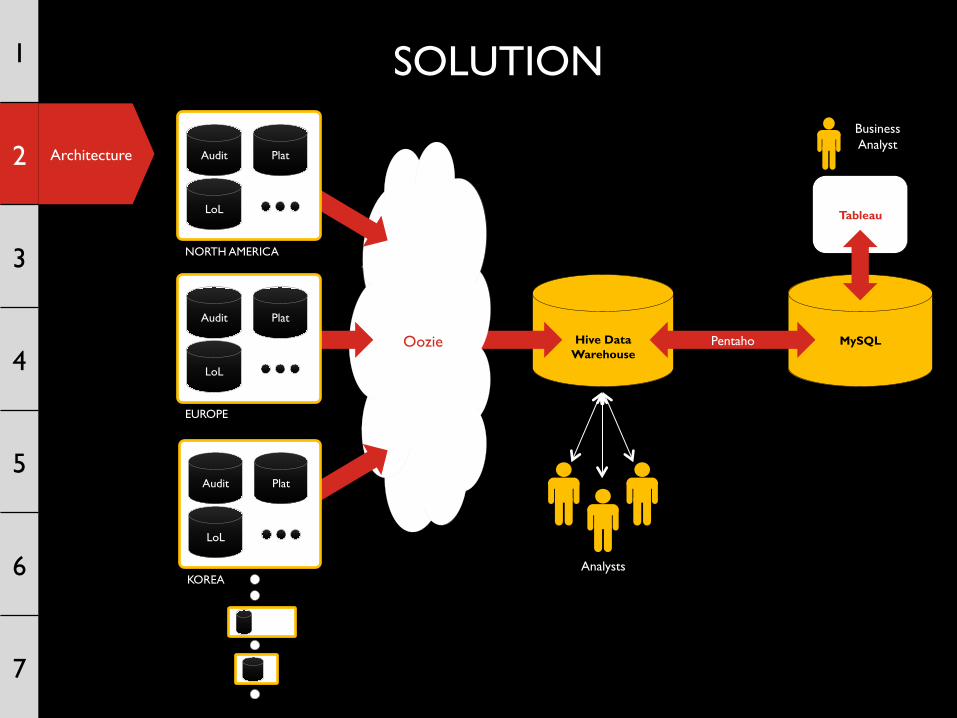
SOLUTION
Tableau
Hive Data
Warehouse Oozie MySQL Pentaho
Analysts
EUROPE
Audit Plat
LoL
KOREA
Audit Plat
LoL
NORTH AMERICA
Audit Plat
LoL
Business Analyst

OOZIE
1
2
3
4
5
6
7

Oozie
1
2
3
4
5
6
7
WHAT IS OOZIE?
• Oozie is a workflow scheduler system to manage Apache Hadoop jobs
• Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box as well as system specific jobs
• Oozie is a scalable, reliable and extensible system

Oozie
1
2
3
4
5
6
7
WHY OOZIE?
No need to create custom hooks for job submission
NATIVE HADOOP INTEGRATION
Jobs are spread against available mappers
HORIZONTALLY SCALABLE
The project has strong community backing and has committers from several companies
OPEN SOURCE
Logging and debugging is extremely quick with the web console and SQL
VERBOSE REPORTING

Oozie
1
2
3
4
5
6
7
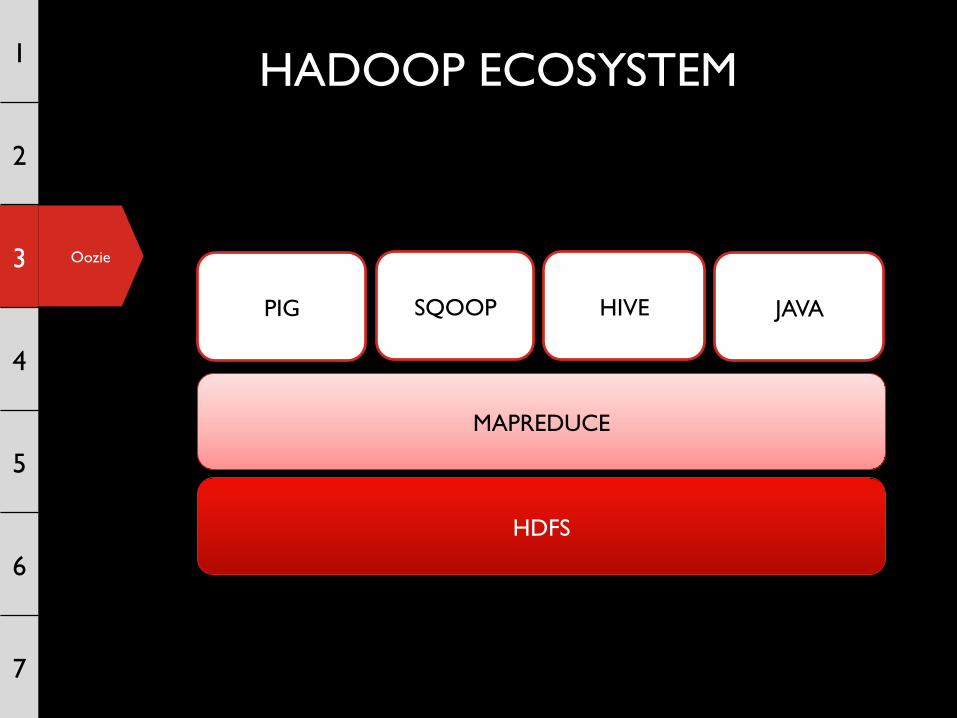
HADOOP ECOSYSTEM

Oozie
1
2
3
4
5
6
7
HADOOP ECOSYSTEM
HDFS

Oozie
1
2
3
4
5
6
7
HADOOP ECOSYSTEM
MAPREDUCE
HDFS
Oozie
1
2
3
4
5
6
7
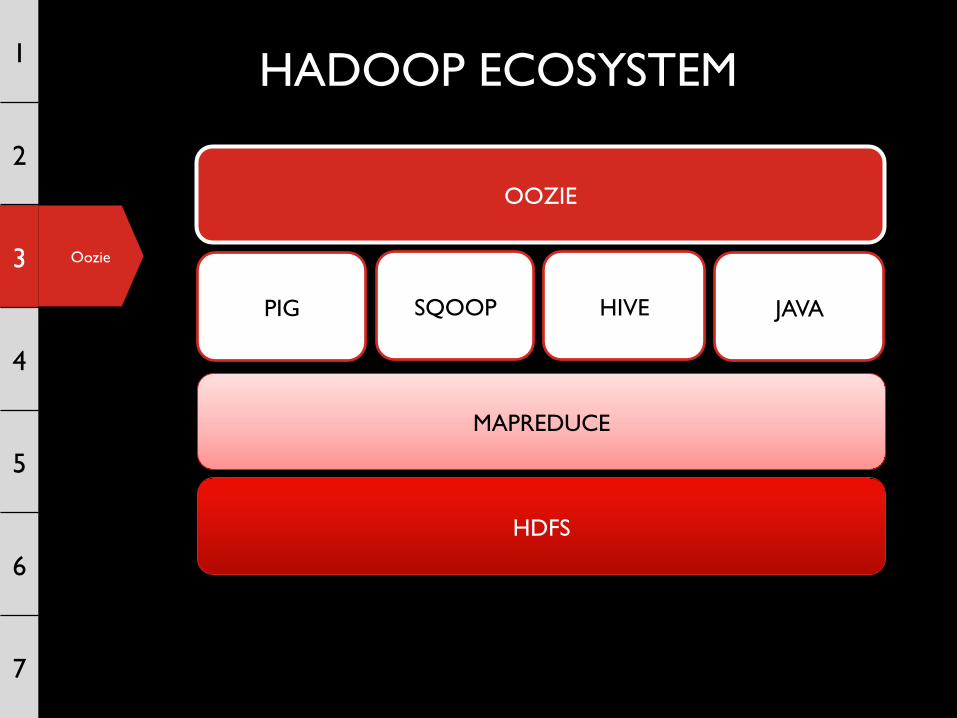
HADOOP ECOSYSTEM
PIG SQOOP HIVE
MAPREDUCE
HDFS
JAVA
Oozie
1
2
3
4
5
6
7
HADOOP ECOSYSTEM
OOZIE
PIG SQOOP HIVE
MAPREDUCE
HDFS
JAVA
1
2
3
4
5
6
7
Oozie
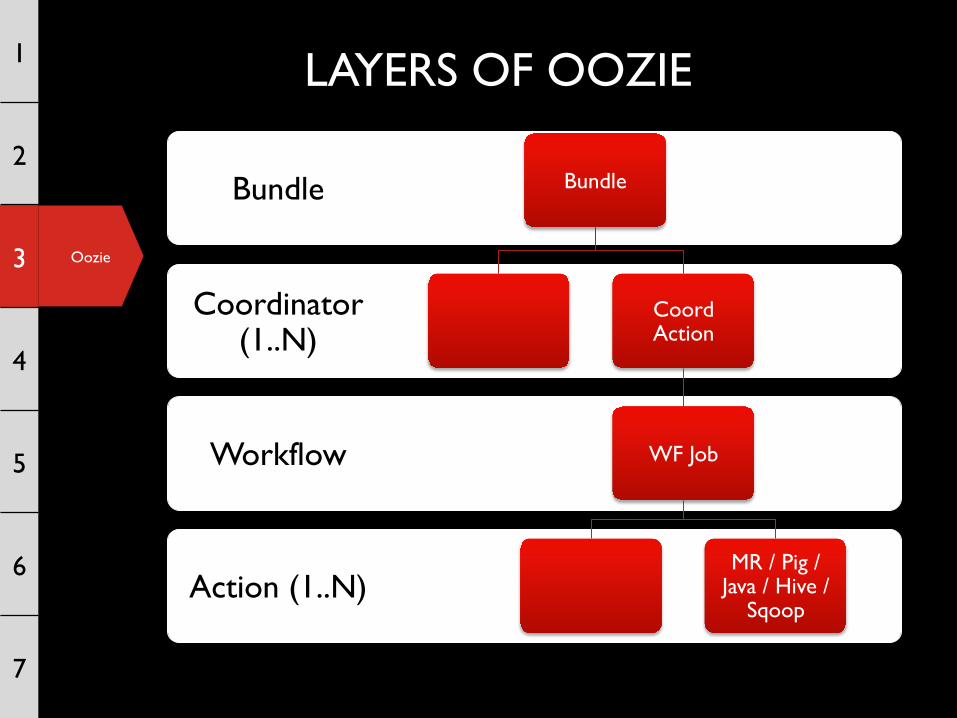
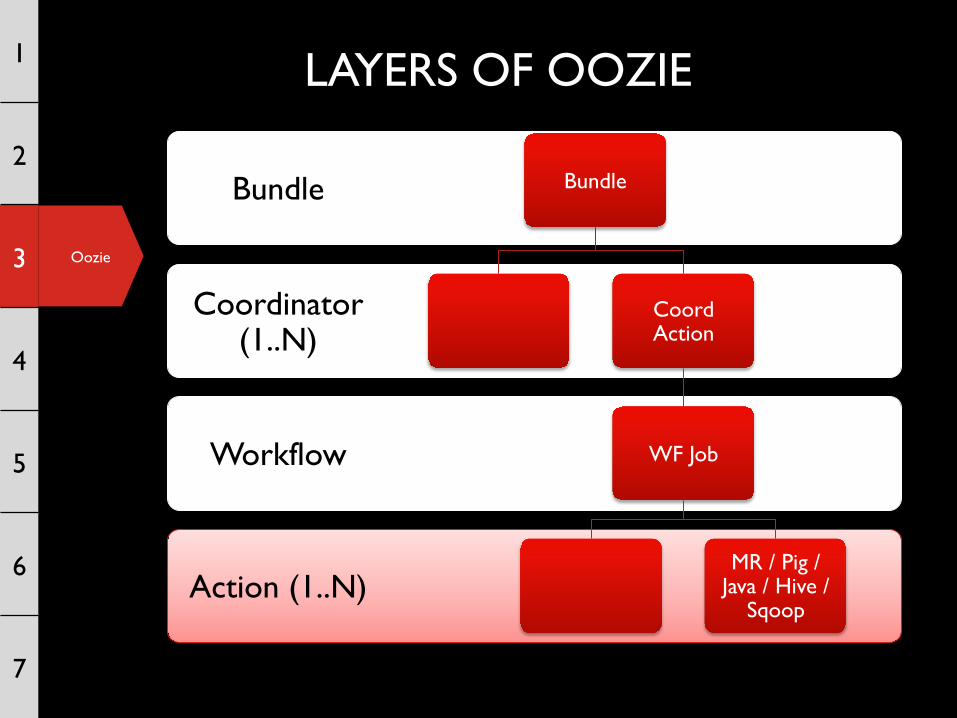
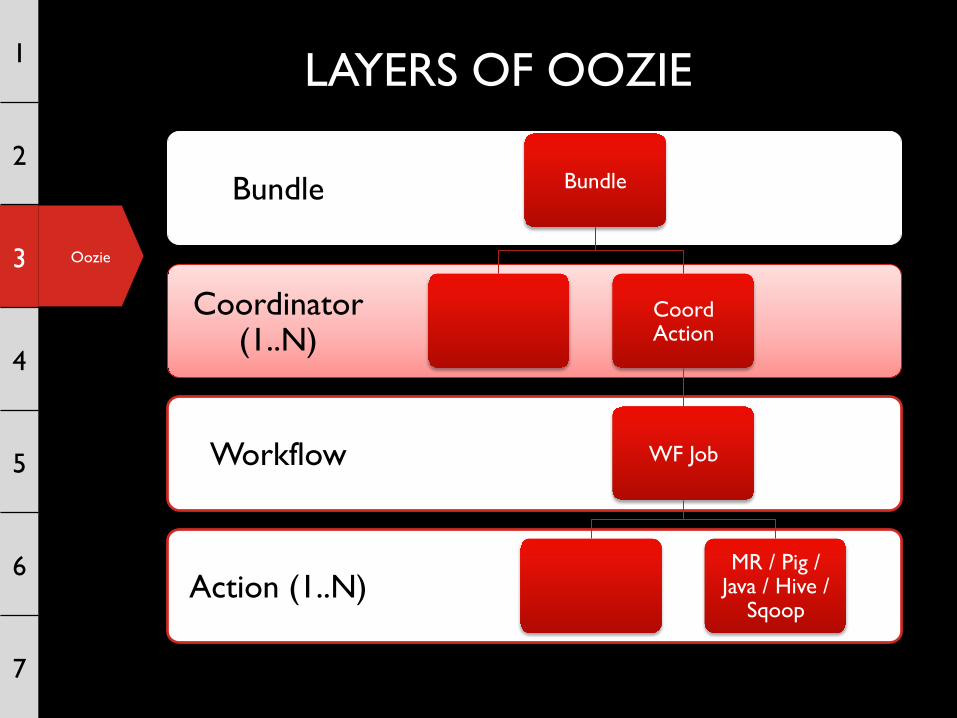
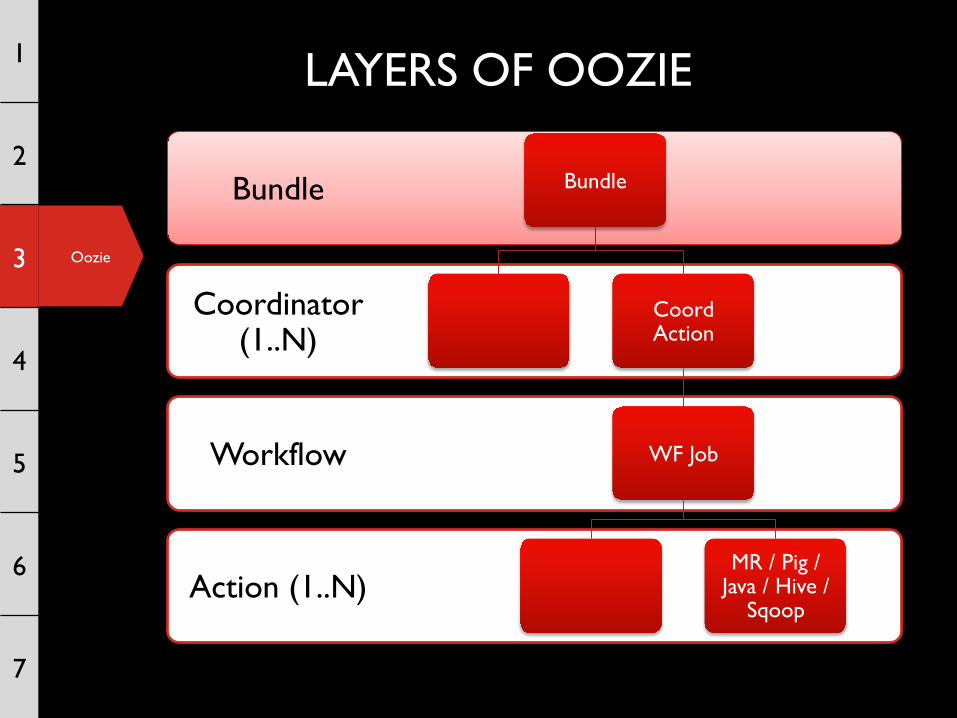
LAYERS OF OOZIE
Action (1..N)
Workflow
Coordinator (1..N)
Bundle Bundle
Coord Action
WF Job
MR / Pig / Java / Hive /
Sqoop
1
2
3
4
5
6
7
Oozie
LAYERS OF OOZIE
Action (1..N)
Workflow
Coordinator (1..N)
Bundle Bundle
Coord Action
WF Job
MR / Pig / Java / Hive /
Sqoop

Oozie
1
2
3
4
5
6
7
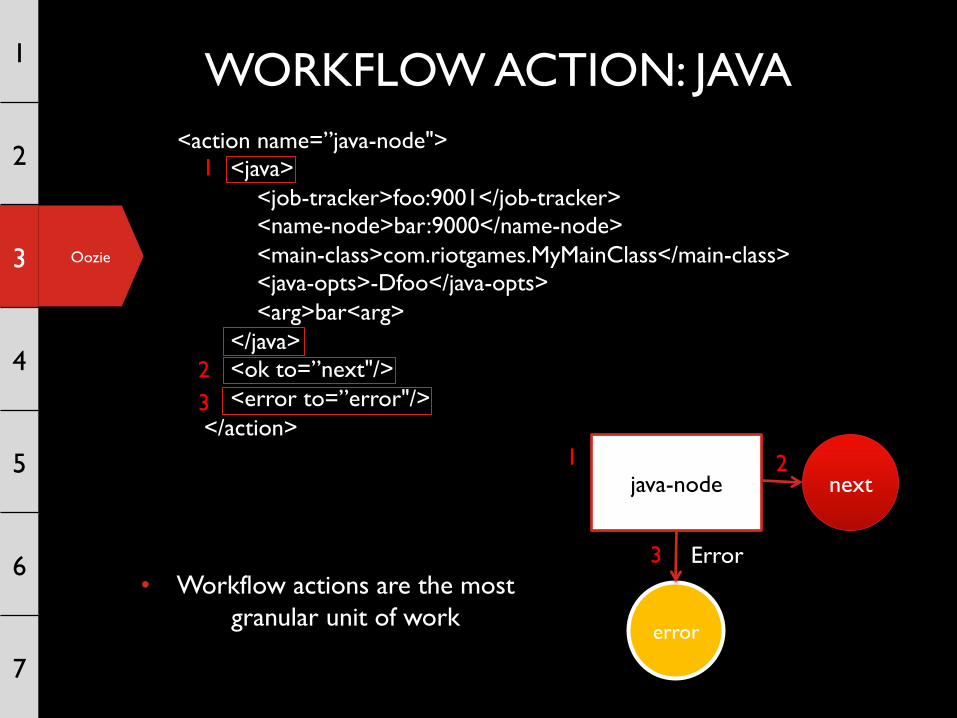
WORKFLOW ACTION: JAVA<action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>com.riotgames.MyMainClass</main-class> <java-opts>-Dfoo</java-opts> <arg>bar<arg> </java> <ok to=”next"/> <error to=”error"/> </action>
• Workflow actions are the most granular unit of work

Oozie
1
2
3
4
5
6
7
WORKFLOW ACTION: JAVA<action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>com.riotgames.MyMainClass</main-class> <java-opts>-Dfoo</java-opts> <arg>bar<arg> </java> <ok to=”next"/> <error to=”error"/> </action>
1
java-node 1
• Workflow actions are the most granular unit of work

Oozie
1
2
3
4
5
6
7
WORKFLOW ACTION: JAVA<action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>com.riotgames.MyMainClass</main-class> <java-opts>-Dfoo</java-opts> <arg>bar<arg> </java> <ok to=”next"/> <error to=”error"/> </action>
1
2
next java-node 1 2
• Workflow actions are the most granular unit of work
Oozie
1
2
3
4
5
6
7
WORKFLOW ACTION: JAVA<action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>com.riotgames.MyMainClass</main-class> <java-opts>-Dfoo</java-opts> <arg>bar<arg> </java> <ok to=”next"/> <error to=”error"/> </action>
1
23
next java-node
error
Error
1 2
3• Workflow actions are the most
granular unit of work

Oozie
1
2
3
4
5
6
7
WORKFLOW ACTION: MAPREDUCE<action name="myfirstHadoopJob"> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <prepare> <delete path="hdfs://foo:9000/usr/foo/output-data"/> </prepare> <job-xml>/myfirstjob.xml</job-xml> <configuration> <property> <name>mapred.input.dir</name> <value>/usr/foo/input-data</value> </property> <property> <name>mapred.output.dir</name> <value>/usr/foo/input-data</value> </property> <property> <name>mapred.reduce.tasks</name> <value>${firstJobReducers}</value> </property> </configuration> </map-reduce> <ok to="myNextAction"/> <error to="errorCleanup"/> </action>

Oozie
1
2
3
4
5
6
7
WORKFLOW ACTION: MAPREDUCE<action name="myfirstHadoopJob"> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <prepare> <delete path="hdfs://foo:9000/usr/foo/output-data"/> </prepare> <job-xml>/myfirstjob.xml</job-xml> <configuration> <property> <name>mapred.input.dir</name> <value>/usr/foo/input-data</value> </property> <property> <name>mapred.output.dir</name> <value>/usr/foo/input-data</value> </property> <property> <name>mapred.reduce.tasks</name> <value>${firstJobReducers}</value> </property> </configuration> </map-reduce> <ok to="myNextAction"/> <error to="errorCleanup"/> </action>
• Each action has a type and each type has defined set of key:values that can be used to configure it

Oozie
1
2
3
4
5
6
7
WORKFLOW ACTION: MAPREDUCE<action name="myfirstHadoopJob"> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <prepare> <delete path="hdfs://foo:9000/usr/foo/output-data"/> </prepare> <job-xml>/myfirstjob.xml</job-xml> <configuration> <property> <name>mapred.input.dir</name> <value>/usr/foo/input-data</value> </property> <property> <name>mapred.output.dir</name> <value>/usr/foo/input-data</value> </property> <property> <name>mapred.reduce.tasks</name> <value>${firstJobReducers}</value> </property> </configuration> </map-reduce> <ok to="myNextAction"/> <error to="errorCleanup"/> </action>
• Each action has a type and each type has defined set of key:values that can be used to configure it
The action must also specify which actions to direct to based on success or failure
1
2
3
4
5
6
7
Oozie
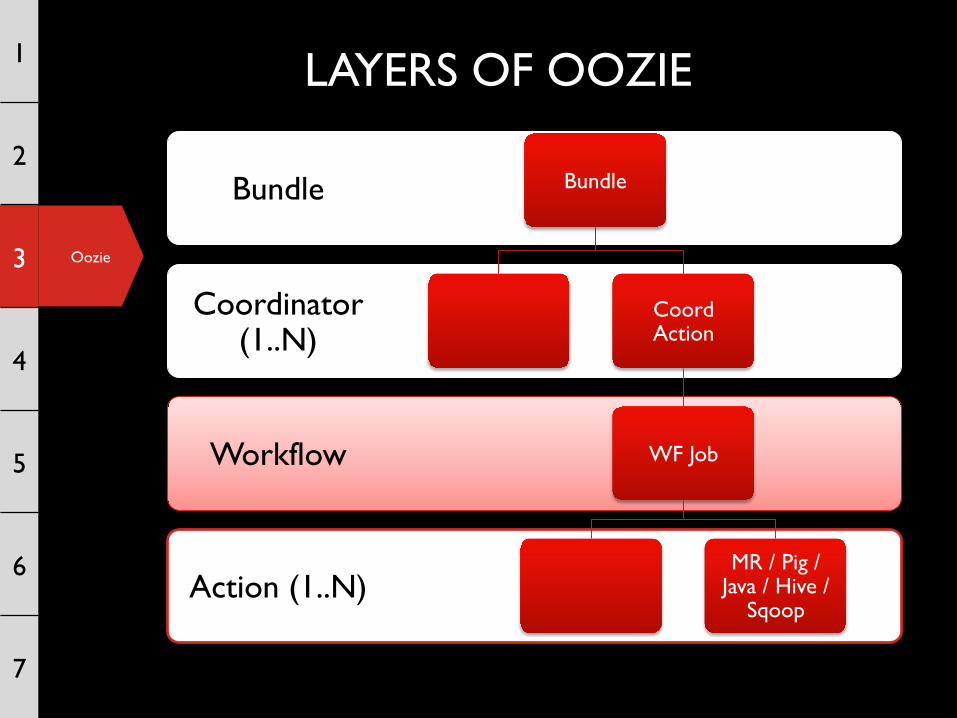
LAYERS OF OOZIE
Action (1..N)
Workflow
Coordinator (1..N)
Bundle Bundle
Coord Action
WF Job
MR / Pig / Java / Hive /
Sqoop
1
2
3
4
5
6
7
Oozie
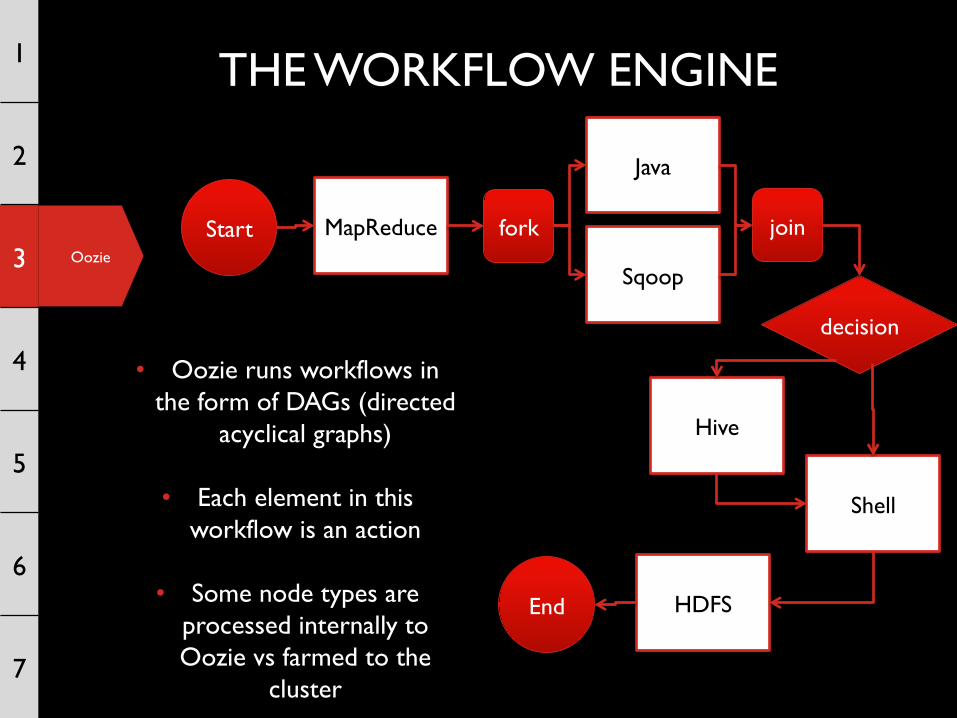
THE WORKFLOW ENGINE
Start
End
fork join MapReduce
Java
Sqoop
Hive
HDFS
Shell
decision
• Oozie runs workflows in the form of DAGs (directed
acyclical graphs)
• Each element in this workflow is an action
• Some node types are processed internally to Oozie vs farmed to the
cluster

1
2
3
4
5
6
7
Oozie
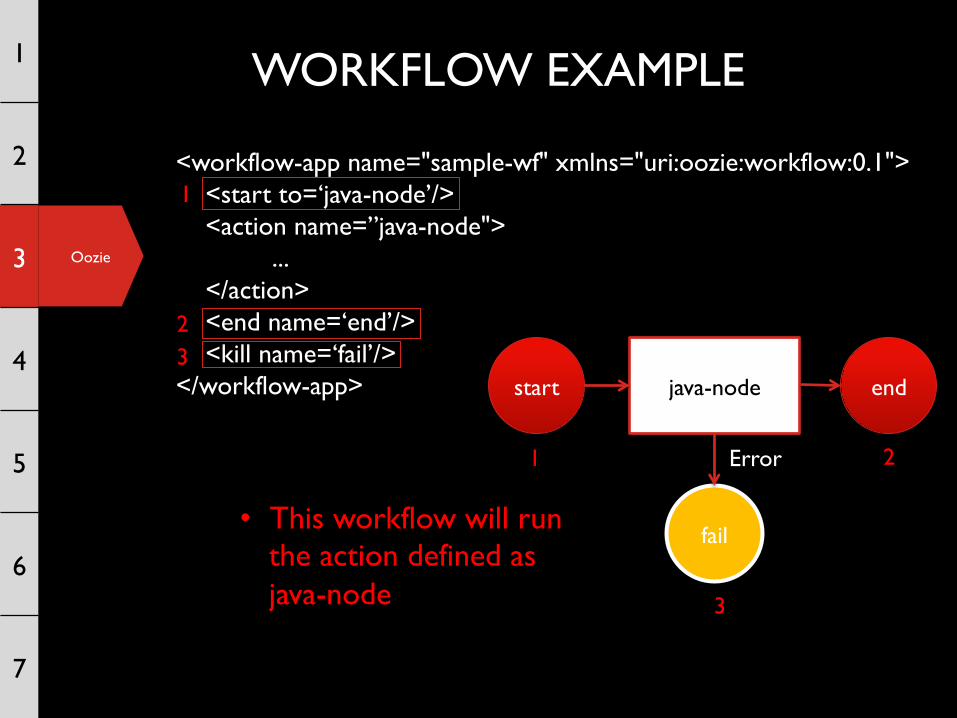
WORKFLOW EXAMPLE
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> ... </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app>
• This workflow will run the action defined as java-node

1
2
3
4
5
6
7
Oozie
WORKFLOW EXAMPLE
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> ... </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app> start java-node
• This workflow will run the action defined as java-node
1
1

1
2
3
4
5
6
7
Oozie
WORKFLOW EXAMPLE
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> ... </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app> start end java-node
• This workflow will run the action defined as java-node
1
2
1 2
1
2
3
4
5
6
7
Oozie
WORKFLOW EXAMPLE
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> ... </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app> start end java-node
fail
Error
• This workflow will run the action defined as java-node
1
23
1 2
3
1
2
3
4
5
6
7
Oozie
LAYERS OF OOZIE
Action (1..N)
Workflow
Coordinator (1..N)
Bundle Bundle
Coord Action
WF Job
MR / Pig / Java / Hive /
Sqoop
1
2
3
4
5
6
7
Oozie
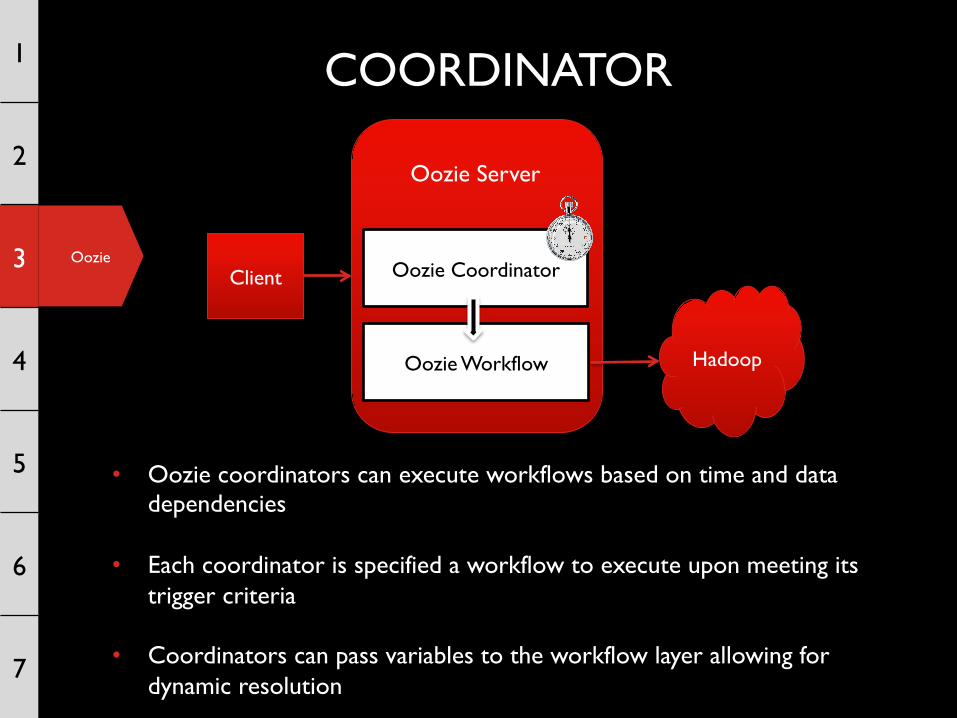
COORDINATOR
• Oozie coordinators can execute workflows based on time and data dependencies
• Each coordinator is specified a workflow to execute upon meeting its trigger criteria
• Coordinators can pass variables to the workflow layer allowing for dynamic resolution
Client Oozie Coordinator
Oozie Workflow
Oozie Server
Hadoop

1
2
3
4
5
6
7
Oozie
EXAMPLE COORDINATOR
<?xml version="1.0" ?><coordinator-app end="${COORD_END}" frequency="${coord:hours(1)}" name="test_job_coord" start="${COORD_START}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1"> <action> <workflow> <app-path>hdfs://bar:9000/user/hadoop/oozie/app/test_job</app-path> </workflow> </action> </coordinator-app> • This coordinator
will run every hour and invoke the workflow found in the /test_job folder

1
2
3
4
5
6
7
Oozie
EXAMPLE COORDINATOR
<?xml version="1.0" ?><coordinator-app end="${COORD_END}" frequency="${coord:hours(1)}" name="test_job_coord" start="${COORD_START}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1"> <action> <workflow> <app-path>hdfs://bar:9000/user/hadoop/oozie/app/test_job</app-path> </workflow> </action> </coordinator-app> • This coordinator
will run every hour and invoke the workflow found in the /test_job folder

1
2
3
4
5
6
7
Oozie
EXAMPLE COORDINATOR
<?xml version="1.0" ?><coordinator-app end="${COORD_END}" frequency="${coord:hours(1)}" name="test_job_coord" start="${COORD_START}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1"> <action> <workflow> <app-path>hdfs://bar:9000/user/hadoop/oozie/app/test_job</app-path> </workflow> </action> </coordinator-app> • This coordinator
will run every hour and invoke the workflow found in the /test_job folder
1
2
3
4
5
6
7
Oozie
LAYERS OF OOZIE
Action (1..N)
Workflow
Coordinator (1..N)
Bundle Bundle
Coord Action
WF Job
MR / Pig / Java / Hive /
Sqoop
Oozie
1
2
3
4
5
6
7
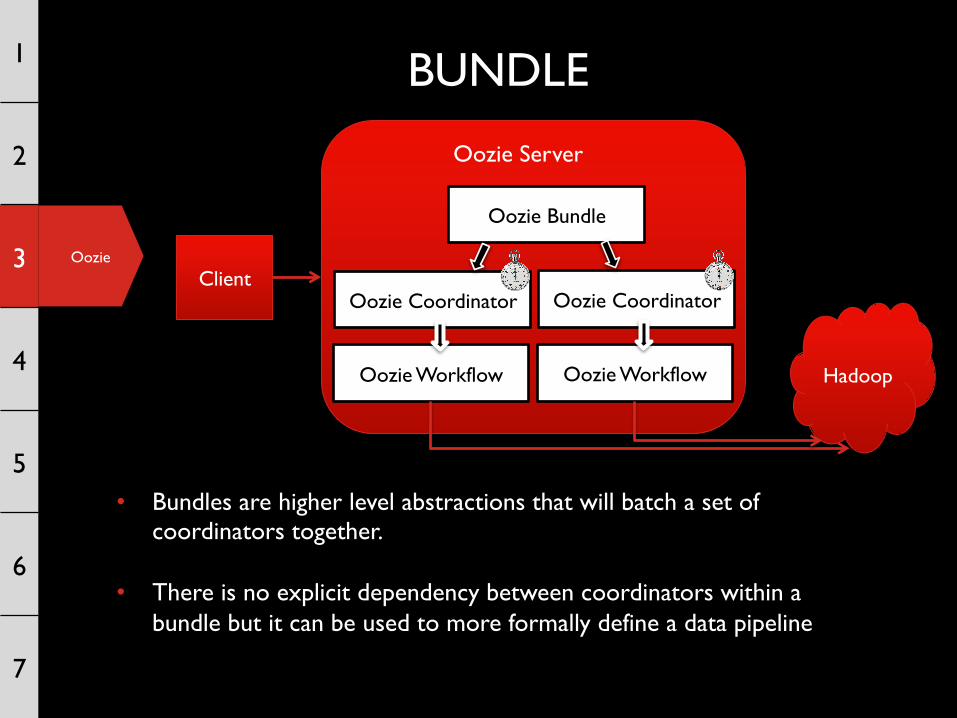
BUNDLE
Client Oozie Coordinator
Oozie Workflow
Oozie Server
Hadoop
Oozie Coordinator
Oozie Workflow
Oozie Bundle
• Bundles are higher level abstractions that will batch a set of coordinators together.
• There is no explicit dependency between coordinators within a bundle but it can be used to more formally define a data pipeline

1
2
3
4
5
6
7
Oozie
THE INTERFACE
Multiple ways to interact with Oozie: • Web Console (read only) • CLI • Java client • Web Service Endpoints • Directly with the DB using SQL
The Java client / CLI are just an abstraction for the web service endpoints and it is easy to extend this functionality in your own apps.

1
2
3
4
5
6
7
Oozie
PIECES OF A DEPLOYABLEThe list of components that are needed for a scheduled workflow: • Coordinator.xml
Contains the scheduler definition and path to workflow.xml
• Workflow.xml
Contains the job definition
• Libraries Optional jar files
• Properties file (also possible through WS call) Initial parameterization and mandatory specification of coordinator path

1
2
3
4
5
6
7
Oozie
JOB.PROPERTIES
NAME_NODE=hdfs://foo:9000 JOB_TRACKER=bar:9001 oozie.libpath=${NAME_NODE}/user/hadoop/oozie/share/lib oozie.coord.application.path=${NAME_NODE}/user/hadoop/oozie/app/test_job
Important note: • Any variable put into the job.properties will be
inherited by the coordinator / workflow • E.g. Given the key:value workflow_name=test_job
you can access it using ${workflow_name}

1
2
3
4
5
6
7
Oozie
COORDINATOR SUBMISSION
• Deploy the workflow and coordinator to HDFS $ hadoop fs –put test_job oozie/app/ • Submit and run the workflow job $ oozie job -run -config job.properties • Check the coordinator status on the web console
1
2
3
4
5
6
7
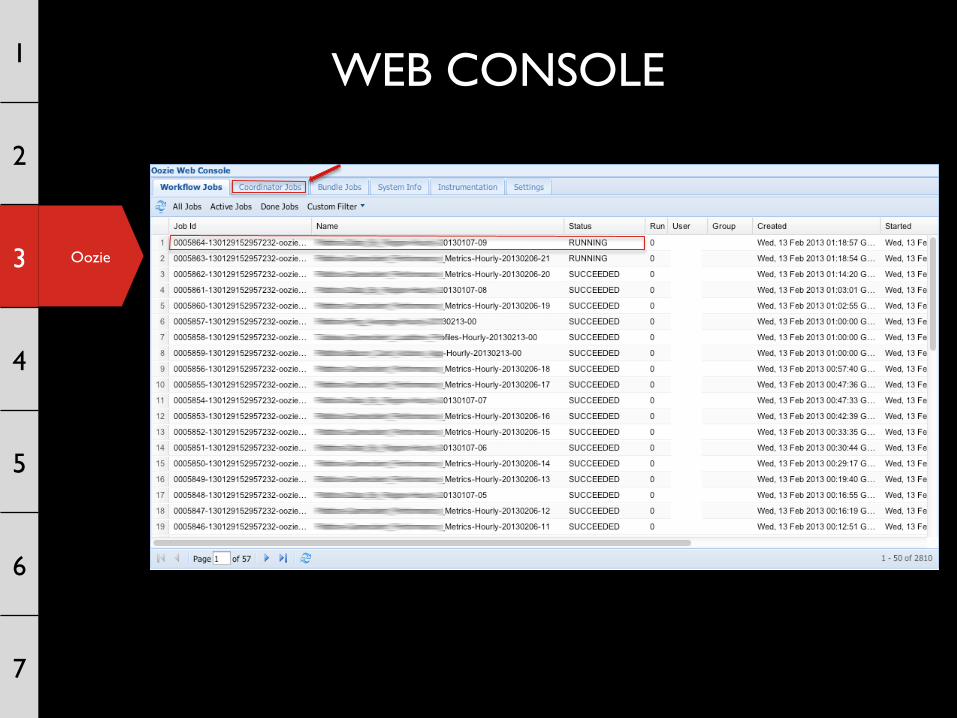
Oozie
WEB CONSOLE
1
2
3
4
5
6
7
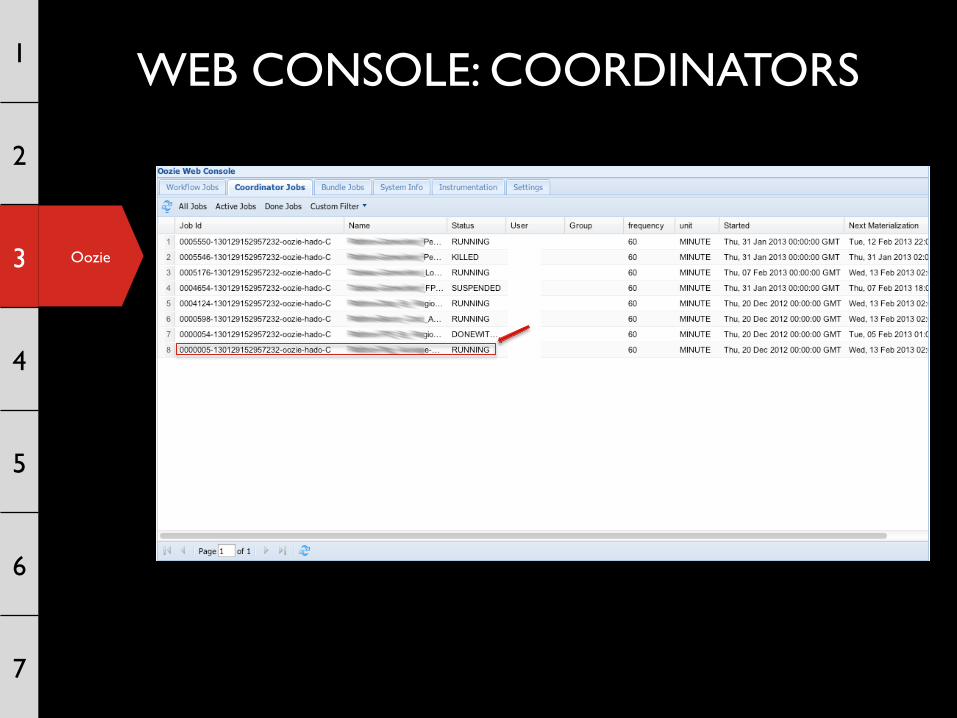
Oozie
WEB CONSOLE: COORDINATORS
1
2
3
4
5
6
7
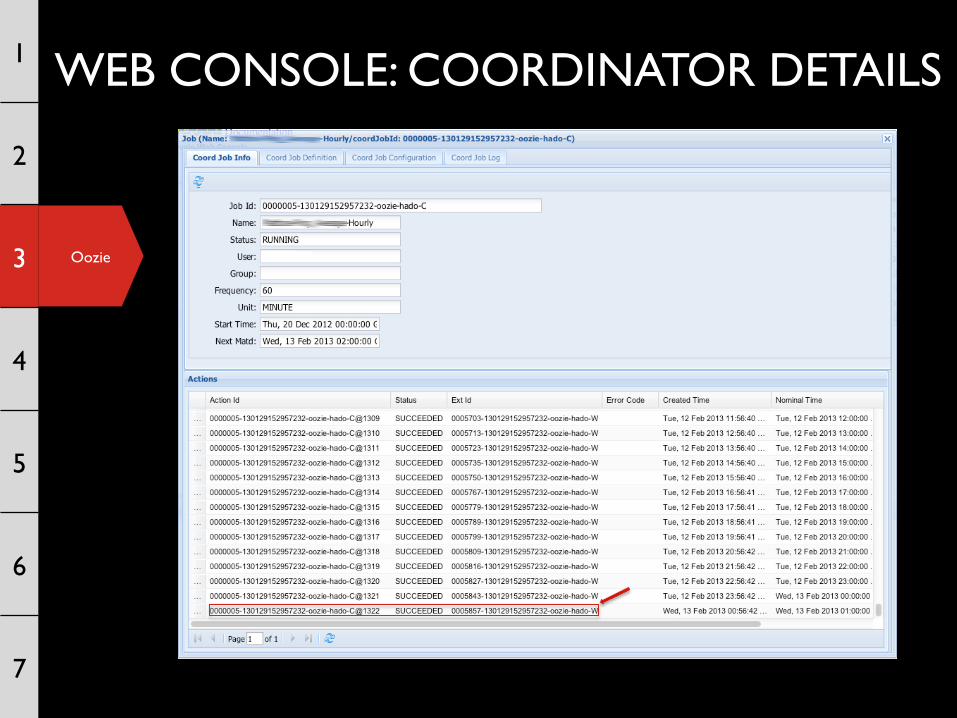
Oozie
WEB CONSOLE: COORDINATOR DETAILS
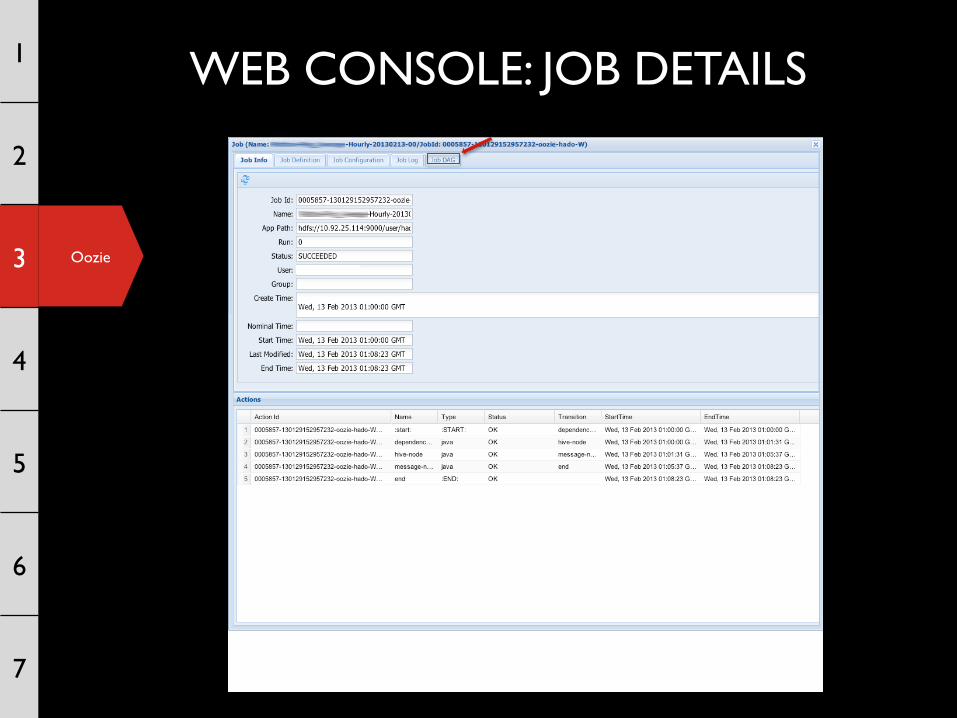
WEB CONSOLE: JOB DETAILS 1
2
3
4
5
6
7
Oozie

WEB CONSOLE: JOB DAG 1
2
3
4
5
6
7
Oozie
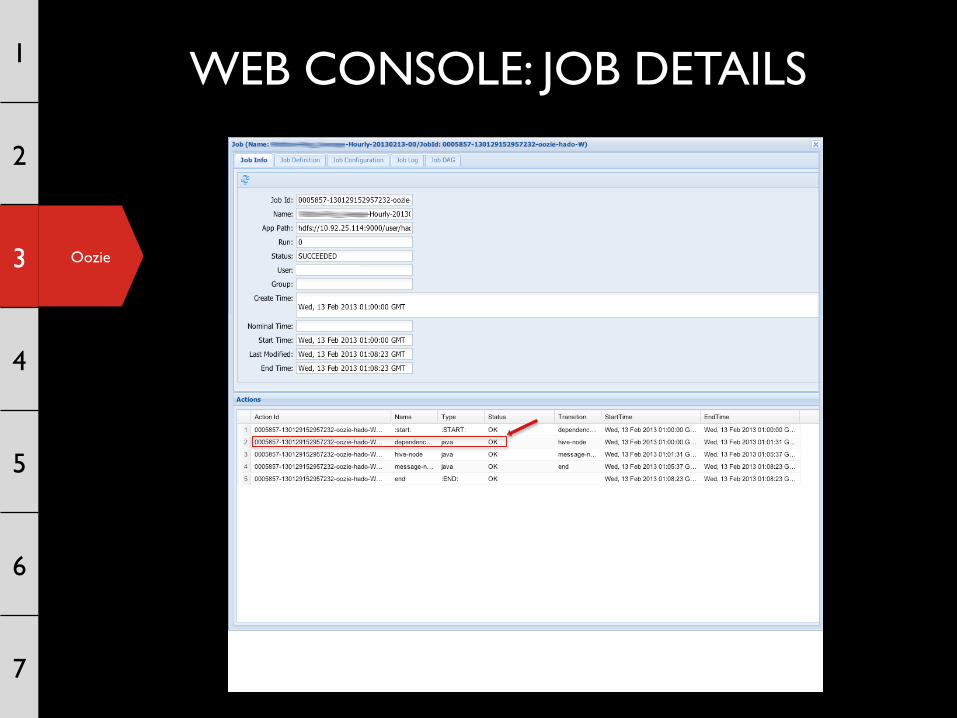
WEB CONSOLE: JOB DETAILS 1
2
3
4
5
6
7
Oozie
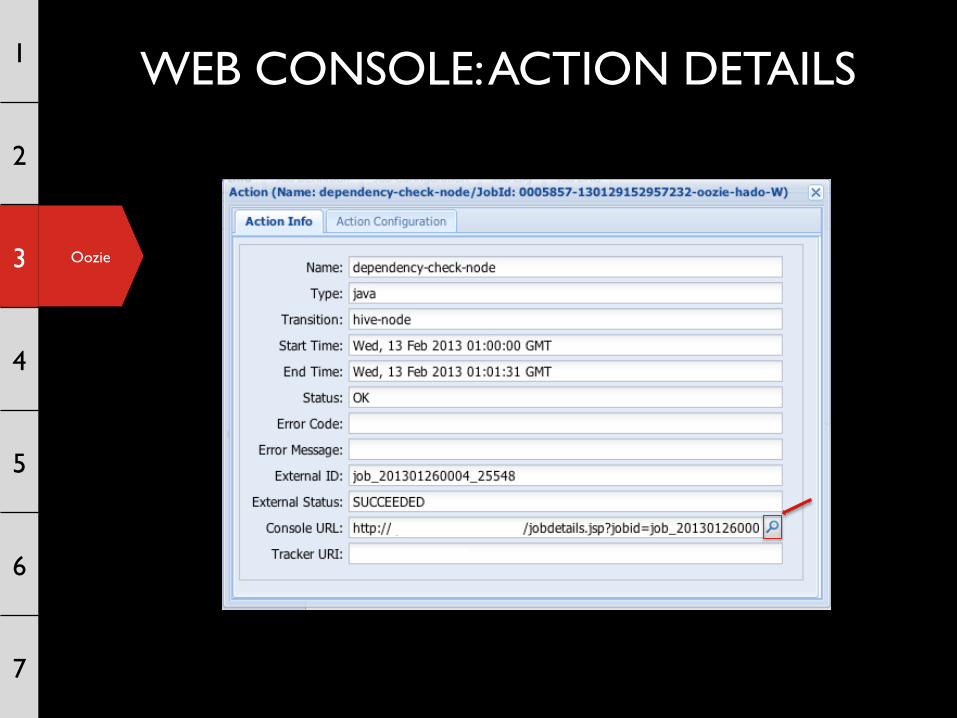
WEB CONSOLE: ACTION DETAILS 1
2
3
4
5
6
7
Oozie
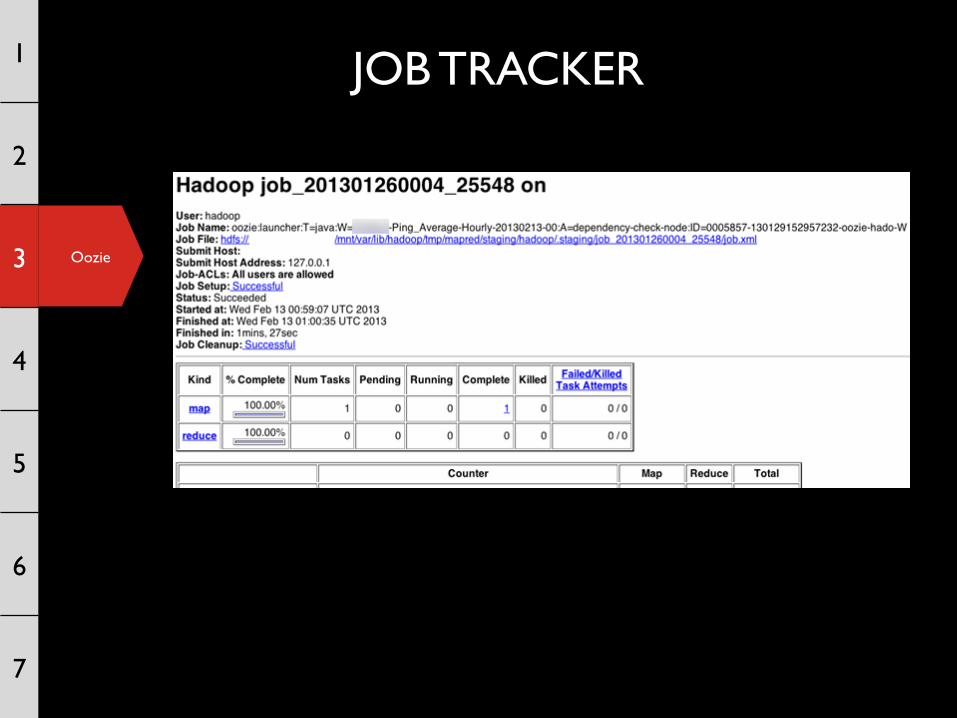
JOB TRACKER 1
2
3
4
5
6
7
Oozie

A USE CASE: HOURLY JOBS 1
2
3
4
5
6
7
Oozie
Replace a current CRON job that runs a bash script once a day (6): • The shell will execute a Java main which pulls data from a
filestream (1), dumps it to HDFS and then runs a MapReduce job on the files (2). It will then email a person when the report is done (3).
• It should start within X amount of time (4) • It should complete within Y amount of time (5) • It should retry Z times on failure (automatic)

WORKFLOW.XML 1
2
3
4
5
6
7
Oozie
<workflow-app name=“filestream_wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>org.foo.bar.PullFileStream</main-class> <arg>argument1</arg> </java> <ok to=”mr-node"/> <error to=”fail"/> </action> <action name=“mr-node”> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <configuration> ... </configuration> </map-reduce> <ok to=”email-node"/> <error to=”fail"/> </action> ...
... <action name=”email-node"> <email xmlns="uri:oozie:email-action:0.1"> <to>[email protected]</to> <cc>[email protected]</cc> <subject>Email notification</subject> <body>The wf completed</body> </email> <ok to="myotherjob"/> <error to="errorcleanup"/> </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app>

WORKFLOW.XML 1
2
3
4
5
6
7
Oozie
<workflow-app name=“filestream_wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>org.foo.bar.PullFileStream</main-class> <arg>argument1</arg> </java> <ok to=”mr-node"/> <error to=”fail"/> </action> <action name=“mr-node”> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <configuration> ... </configuration> </map-reduce> <ok to=”email-node"/> <error to=”fail"/> </action> ...
... <action name=”email-node"> <email xmlns="uri:oozie:email-action:0.1"> <to>[email protected]</to> <cc>[email protected]</cc> <subject>Email notification</subject> <body>The wf completed</body> </email> <ok to="myotherjob"/> <error to="errorcleanup"/> </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app>
1

WORKFLOW.XML 1
2
3
4
5
6
7
Oozie
<workflow-app name=“filestream_wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>org.foo.bar.PullFileStream</main-class> <arg>argument1</arg> </java> <ok to=”mr-node"/> <error to=”fail"/> </action> <action name=“mr-node”> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <configuration> ... </configuration> </map-reduce> <ok to=”email-node"/> <error to=”fail"/> </action> ...
... <action name=”email-node"> <email xmlns="uri:oozie:email-action:0.1"> <to>[email protected]</to> <cc>[email protected]</cc> <subject>Email notification</subject> <body>The wf completed</body> </email> <ok to="myotherjob"/> <error to="errorcleanup"/> </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app>
1
2

WORKFLOW.XML 1
2
3
4
5
6
7
Oozie
<workflow-app name=“filestream_wf" xmlns="uri:oozie:workflow:0.1"> <start to=‘java-node’/> <action name=”java-node"> <java> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <main-class>org.foo.bar.PullFileStream</main-class> <arg>argument1</arg> </java> <ok to=”mr-node"/> <error to=”fail"/> </action> <action name=“mr-node”> <map-reduce> <job-tracker>foo:9001</job-tracker> <name-node>bar:9000</name-node> <configuration> ... </configuration> </map-reduce> <ok to=”email-node"/> <error to=”fail"/> </action> ...
... <action name=”email-node"> <email xmlns="uri:oozie:email-action:0.1"> <to>[email protected]</to> <cc>[email protected]</cc> <subject>Email notification</subject> <body>The wf completed</body> </email> <ok to="myotherjob"/> <error to="errorcleanup"/> </action> <end name=‘end’/> <kill name=‘fail’/> </workflow-app>
1
2
3

COORDINATOR.XML 1
2
3
4
5
6
7
Oozie
<?xml version="1.0" ?><coordinator-app end="${COORD_END}" frequency="${coord:days(1)}" name=”daily_job_coord" start="${COORD_START}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1” xmlns:sla="uri:oozie:sla:0.1"> <action> <workflow> <app-path>hdfs://bar:9000/user/hadoop/oozie/app/test_job</app-path> </workflow> <sla:info> <sla:nominal-time>${coord:nominalTime()}</sla:nominal-time> <sla:should-start>${X * MINUTES}</sla:should-start> <sla:should-end>${Y * MINUTES}</sla:should-end> <sla:alert-contact>[email protected]</sla:alert-contact> </sla:info> </action> </coordinator-app>

COORDINATOR.XML 1
2
3
4
5
6
7
Oozie
<?xml version="1.0" ?><coordinator-app end="${COORD_END}" frequency="${coord:days(1)}" name=”daily_job_coord" start="${COORD_START}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1” xmlns:sla="uri:oozie:sla:0.1"> <action> <workflow> <app-path>hdfs://bar:9000/user/hadoop/oozie/app/test_job</app-path> </workflow> <sla:info> <sla:nominal-time>${coord:nominalTime()}</sla:nominal-time> <sla:should-start>${X * MINUTES}</sla:should-start> <sla:should-end>${Y * MINUTES}</sla:should-end> <sla:alert-contact>[email protected]</sla:alert-contact> </sla:info> </action> </coordinator-app>
4,5

COORDINATOR.XML 1
2
3
4
5
6
7
Oozie
<?xml version="1.0" ?><coordinator-app end="${COORD_END}" frequency="${coord:days(1)}" name=”daily_job_coord" start="${COORD_START}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1” xmlns:sla="uri:oozie:sla:0.1"> <action> <workflow> <app-path>hdfs://bar:9000/user/hadoop/oozie/app/test_job</app-path> </workflow> <sla:info> <sla:nominal-time>${coord:nominalTime()}</sla:nominal-time> <sla:should-start>${X * MINUTES}</sla:should-start> <sla:should-end>${Y * MINUTES}</sla:should-end> <sla:alert-contact>[email protected]</sla:alert-contact> </sla:info> </action> </coordinator-app>
6
4,5

WORKFLOWS @
1
2
3
4
5
6
7

Use Case 1
1
2
3
4
5
6
7
USE CASE 1 – Global Data Means Global Data Problems
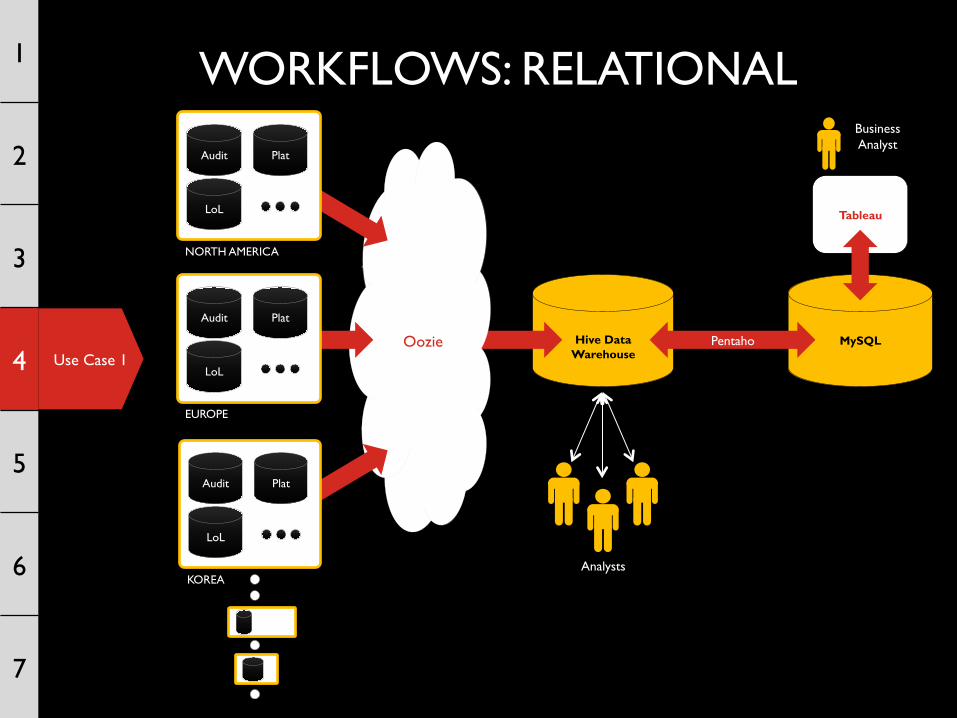
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Tableau
Hive Data
Warehouse Oozie MySQL Pentaho
Analysts
EUROPE
Audit Plat
LoL
KOREA
Audit Plat
LoL
NORTH AMERICA
Audit Plat
LoL
Business Analyst
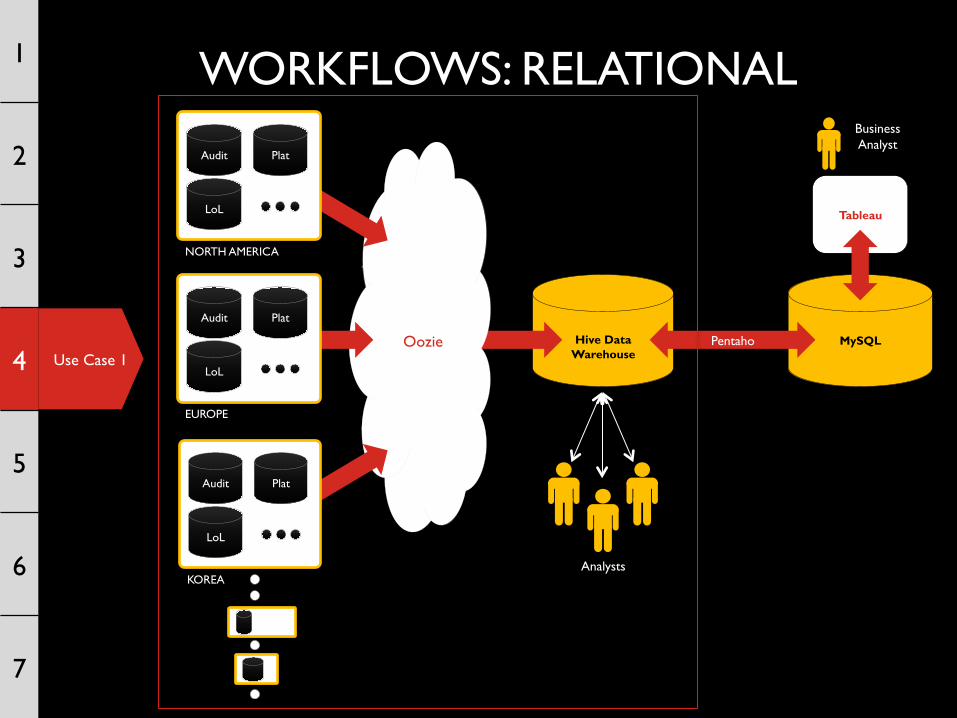
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Tableau
Hive Data
Warehouse Oozie MySQL Pentaho
Analysts
EUROPE
Audit Plat
LoL
KOREA
Audit Plat
LoL
NORTH AMERICA
Audit Plat
LoL
Business Analyst
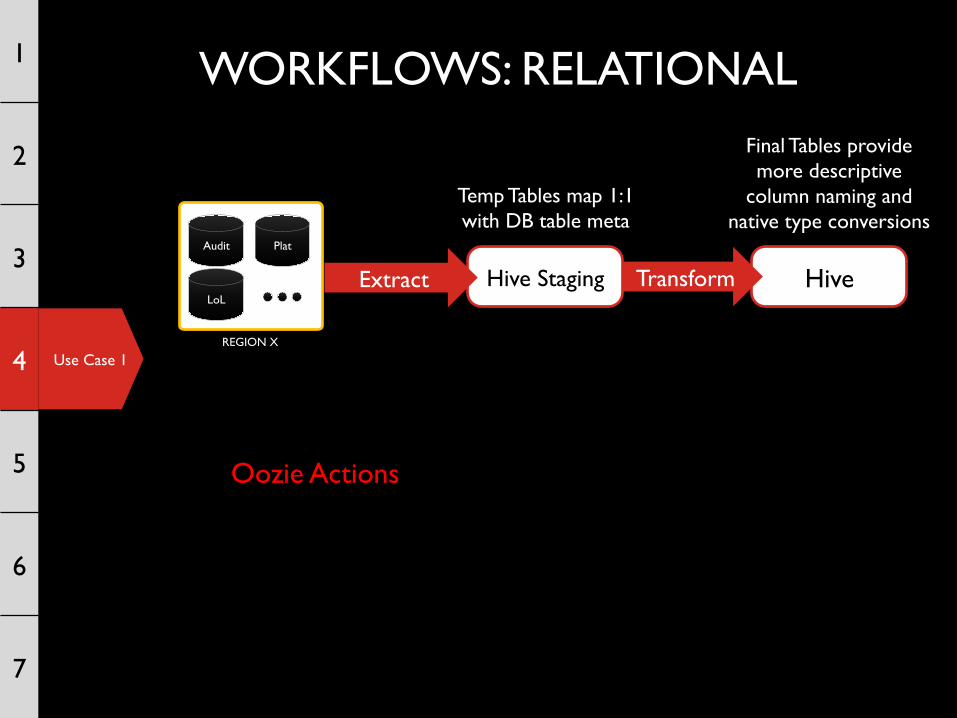
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Hive
Final Tables provide more descriptive
column naming and native type conversions
REGION X
Audit Plat
LoL Hive Staging Transform
Temp Tables map 1:1 with DB table meta
Extract
Oozie Actions
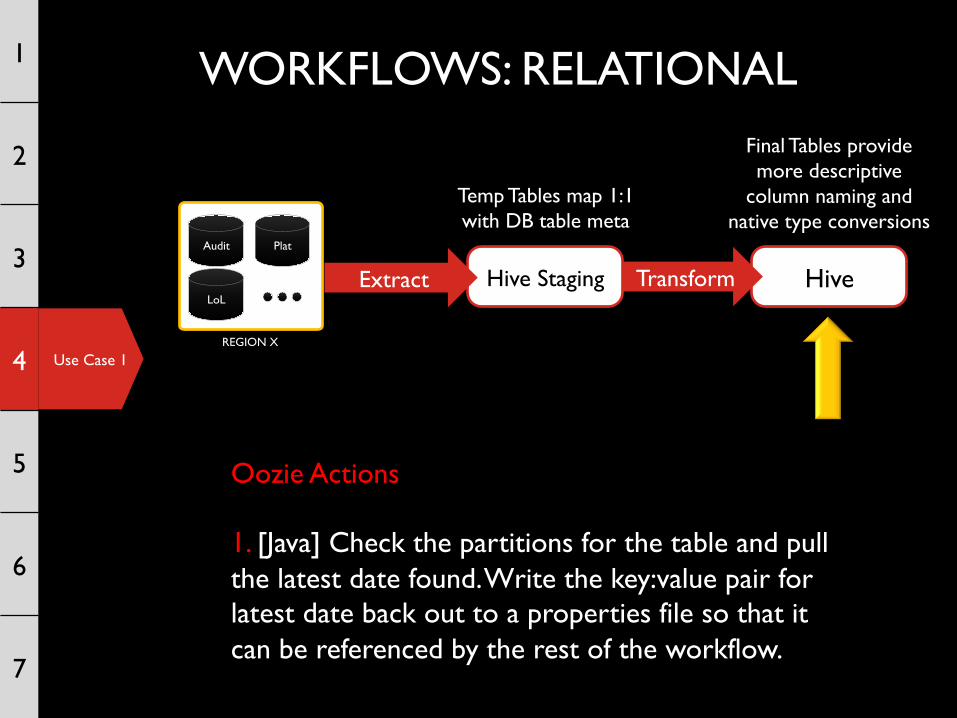
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Hive
Final Tables provide more descriptive
column naming and native type conversions
REGION X
Audit Plat
LoL Hive Staging Transform
Temp Tables map 1:1 with DB table meta
Extract
Oozie Actions 1. [Java] Check the partitions for the table and pull the latest date found. Write the key:value pair for latest date back out to a properties file so that it can be referenced by the rest of the workflow.
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Hive
Final Tables provide more descriptive
column naming and native type conversions
REGION X
Audit Plat
LoL Hive Staging Transform
Temp Tables map 1:1 with DB table meta
Extract
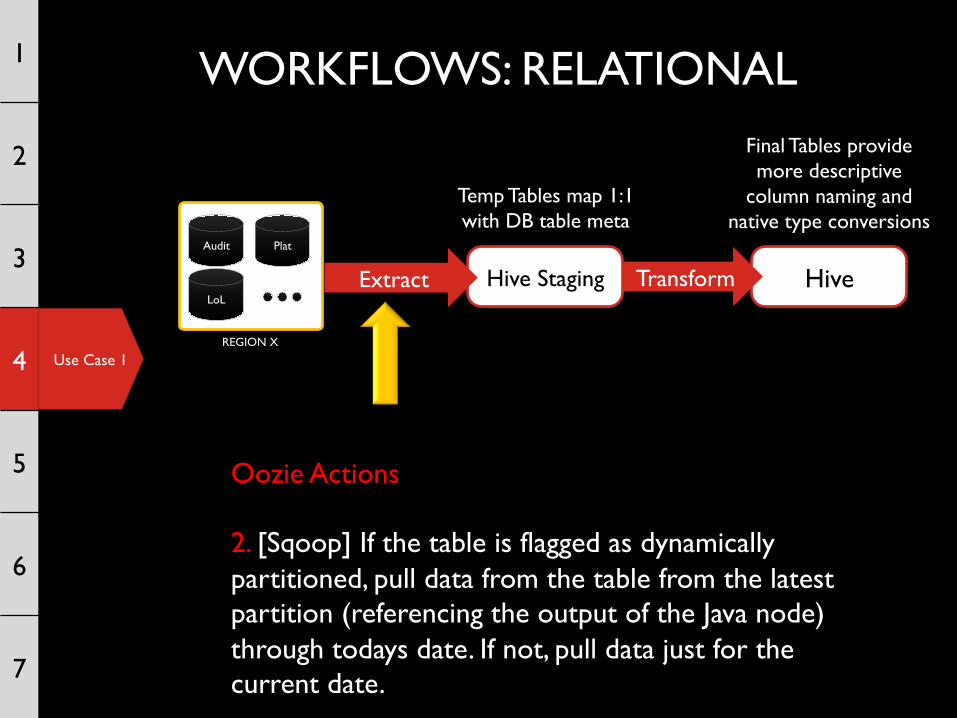
Oozie Actions 2. [Sqoop] If the table is flagged as dynamically partitioned, pull data from the table from the latest partition (referencing the output of the Java node) through todays date. If not, pull data just for the current date.
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Hive
Final Tables provide more descriptive
column naming and native type conversions
REGION X
Audit Plat
LoL Hive Staging Transform
Temp Tables map 1:1 with DB table meta
Extract
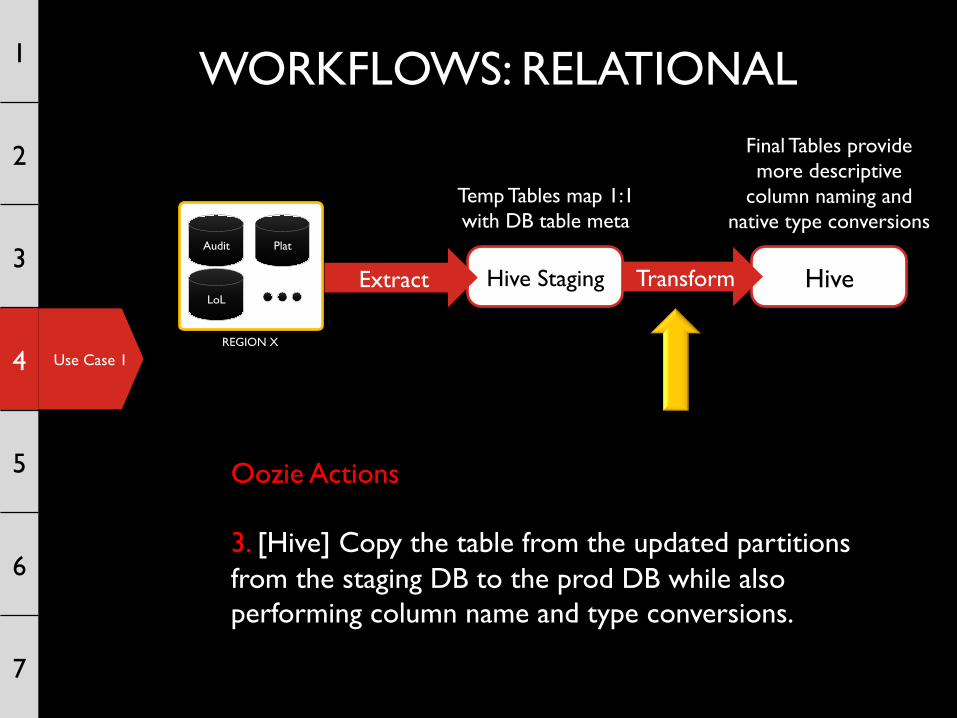
Oozie Actions 3. [Hive] Copy the table from the updated partitions from the staging DB to the prod DB while also performing column name and type conversions.
Use Case 1
WORKFLOWS: RELATIONAL 1
2
3
4
5
6
7
Hive
Final Tables provide more descriptive
column naming and native type conversions
REGION X
Audit Plat
LoL Hive Staging Transform
Temp Tables map 1:1 with DB table meta
Extract
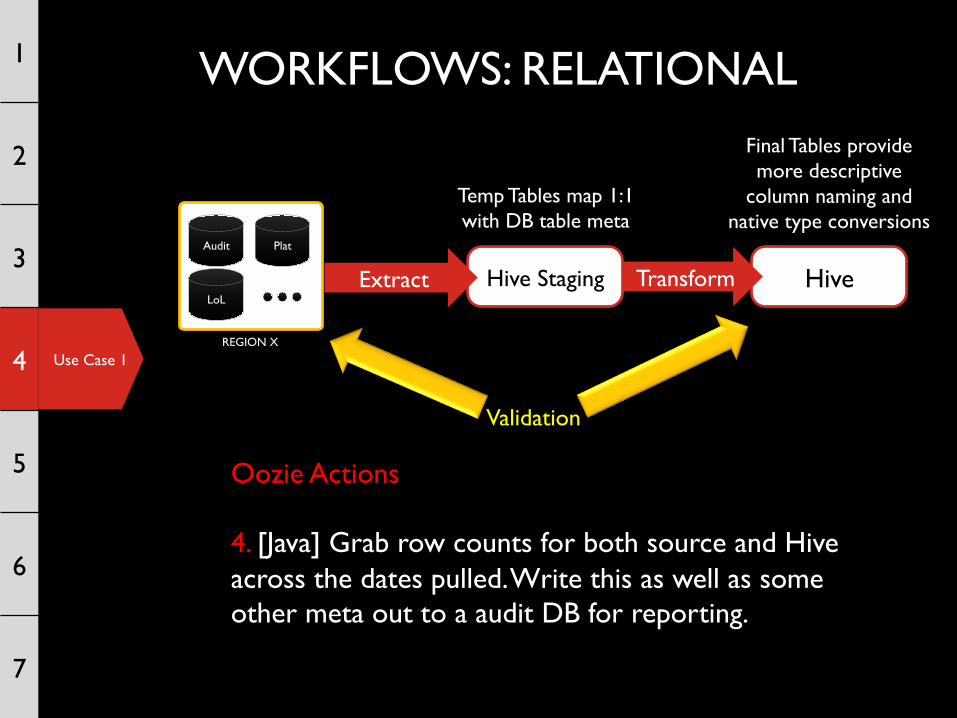
Oozie Actions 4. [Java] Grab row counts for both source and Hive across the dates pulled. Write this as well as some other meta out to a audit DB for reporting.
Validation
Use Case 1
AUDITING 1
2
3
4
5
6
7
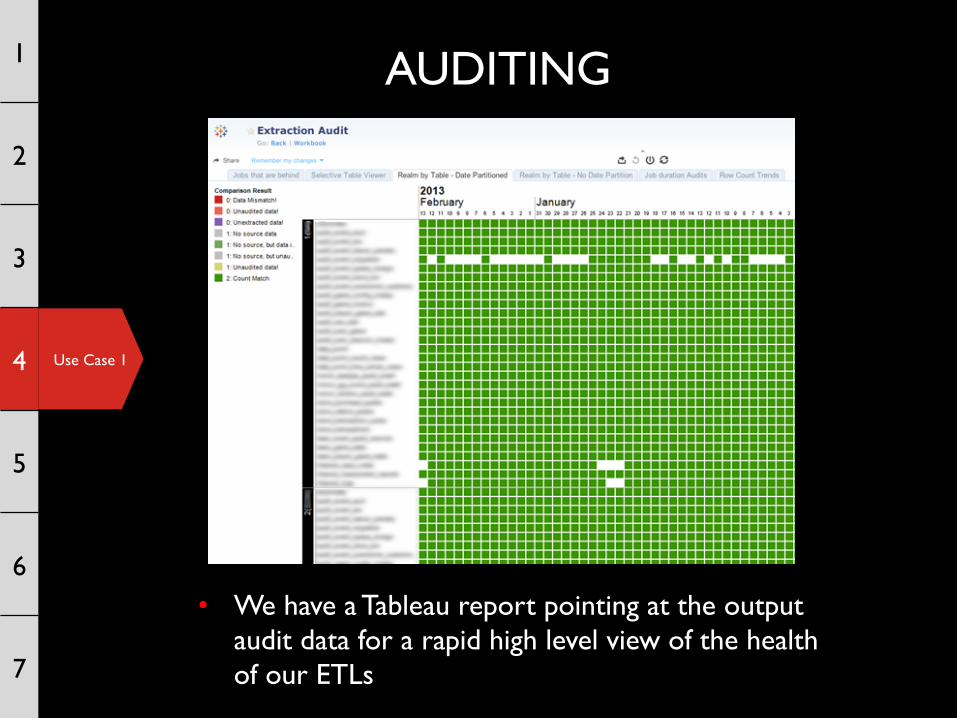
• We have a Tableau report pointing at the output audit data for a rapid high level view of the health of our ETLs
Use Case 1
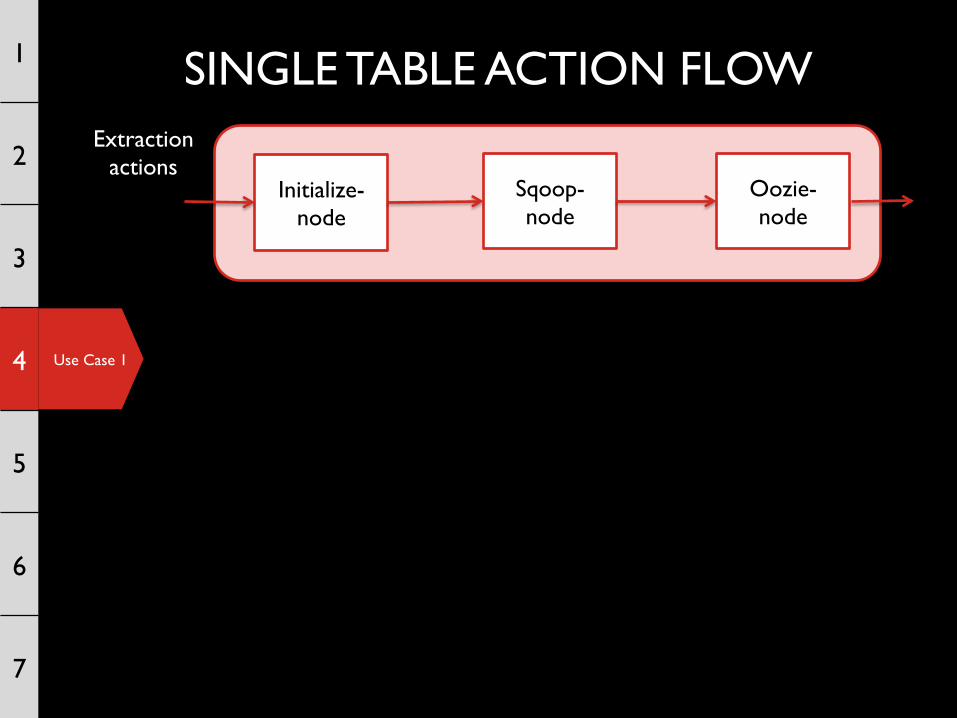
SINGLE TABLE ACTION FLOW 1
2
3
4
5
6
7
Initialize-node
Sqoop-node
Oozie-node
Extraction actions
Use Case 1
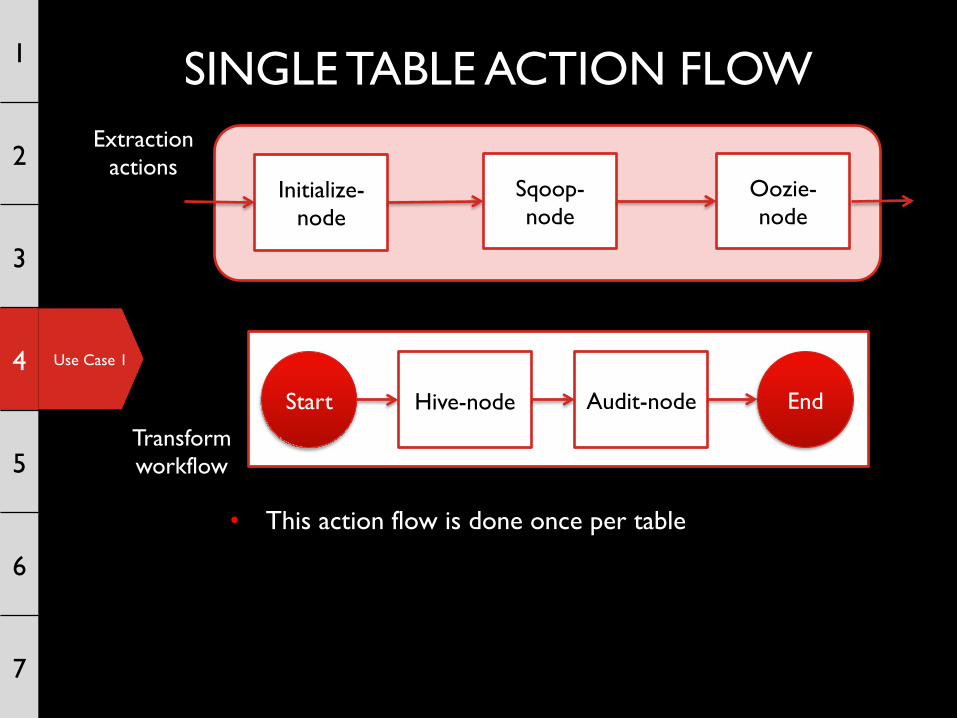
SINGLE TABLE ACTION FLOW 1
2
3
4
5
6
7
End
Initialize-node
Hive-node Audit-node
Sqoop-node
Oozie-node
Start
• This action flow is done once per table
Extraction actions
Transform workflow
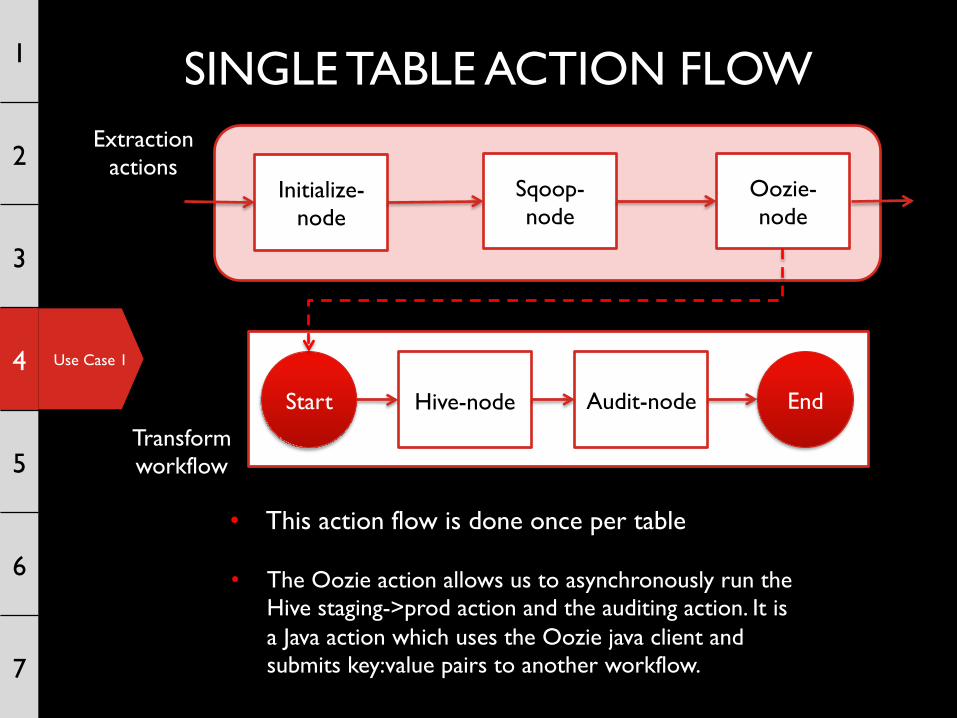
Use Case 1
SINGLE TABLE ACTION FLOW 1
2
3
4
5
6
7
End
Initialize-node
Hive-node Audit-node
Sqoop-node
Oozie-node
Start
• This action flow is done once per table
Extraction actions
Transform workflow
• The Oozie action allows us to asynchronously run the Hive staging->prod action and the auditing action. It is a Java action which uses the Oozie java client and submits key:value pairs to another workflow.
Use Case 1
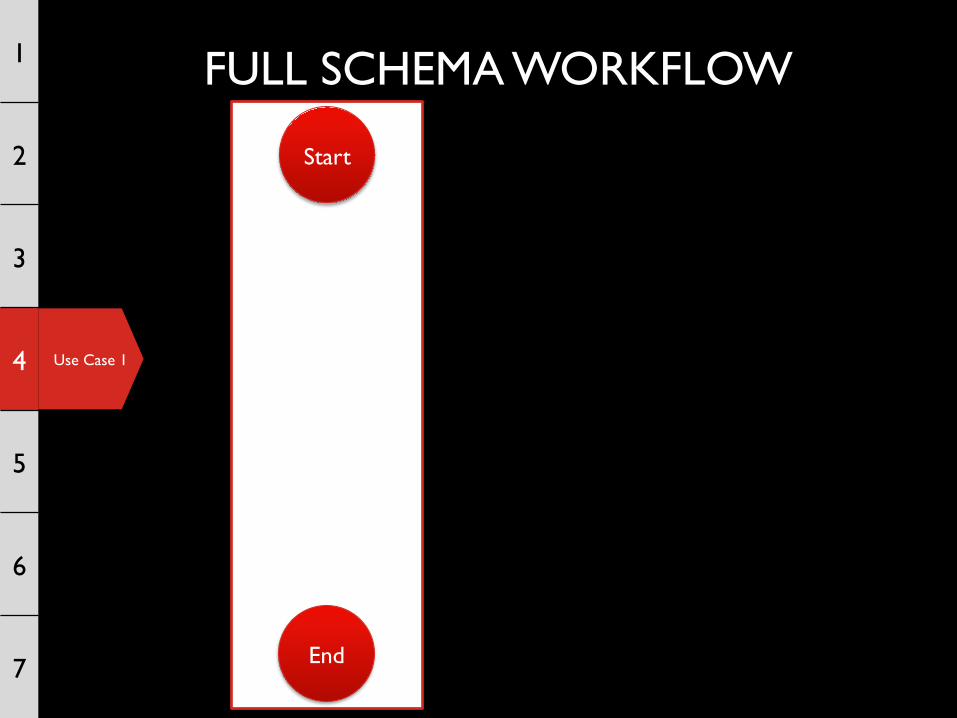
FULL SCHEMA WORKFLOW 1
2
3
4
5
6
7 End
Start
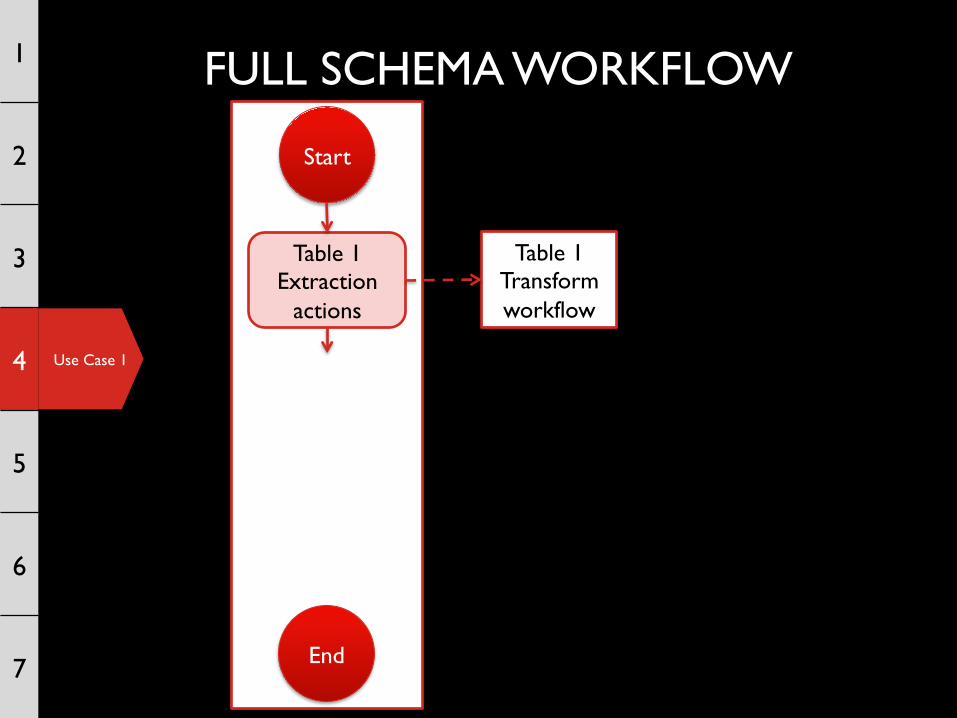
Table 1 Extraction
actions
Use Case 1
FULL SCHEMA WORKFLOW 1
2
3
4
5
6
7 End
Start
Table 1 Transform workflow
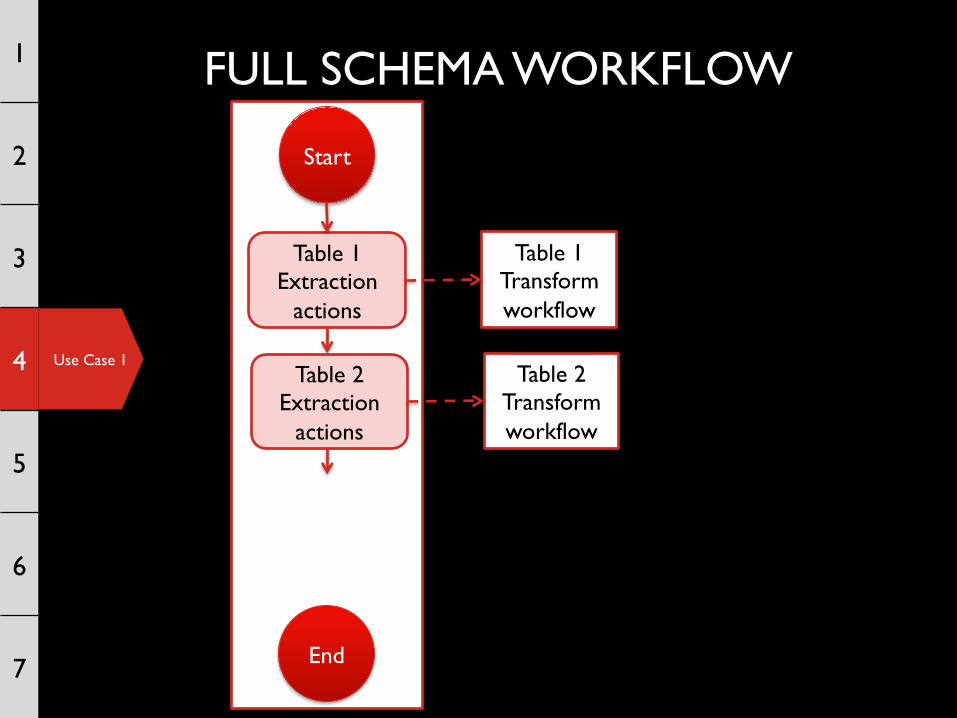
Table 1 Extraction
actions
Use Case 1
FULL SCHEMA WORKFLOW 1
2
3
4
5
6
7 End
Start
Table 1 Transform workflow
Table 2 Extraction
actions
Table 2 Transform workflow
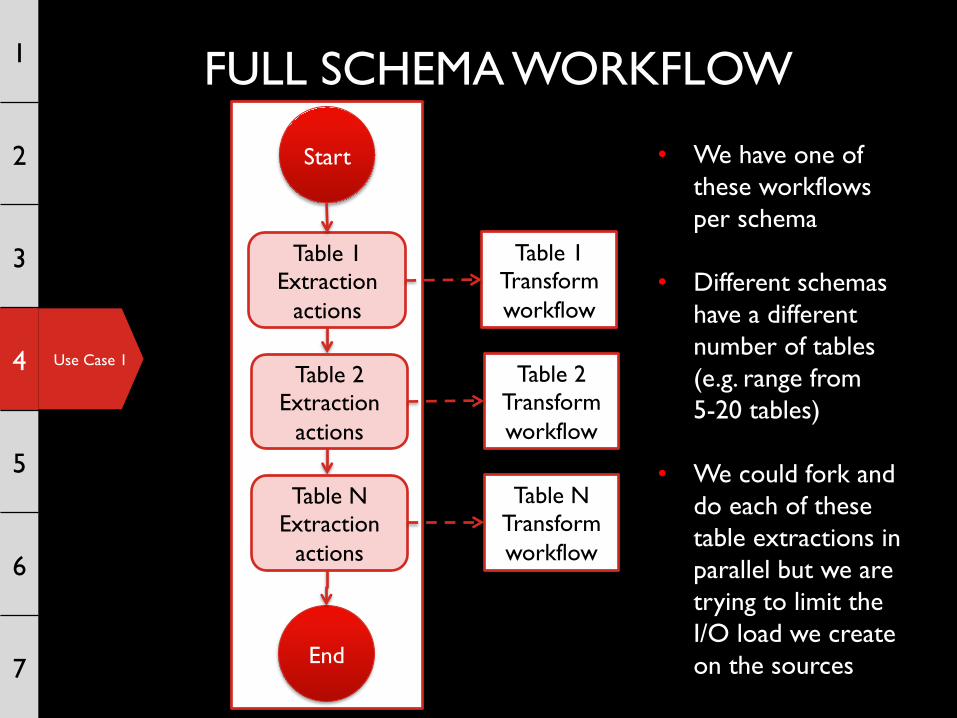
Table 1 Extraction
actions
Use Case 1
FULL SCHEMA WORKFLOW 1
2
3
4
5
6
7 End
Start
Table 1 Transform workflow
Table 2 Extraction
actions
Table 2 Transform workflow
Table N Extraction
actions
Table N Transform workflow
• We have one of these workflows per schema
• Different schemas have a different number of tables (e.g. range from 5-20 tables)
• We could fork and do each of these table extractions in parallel but we are trying to limit the I/O load we create on the sources
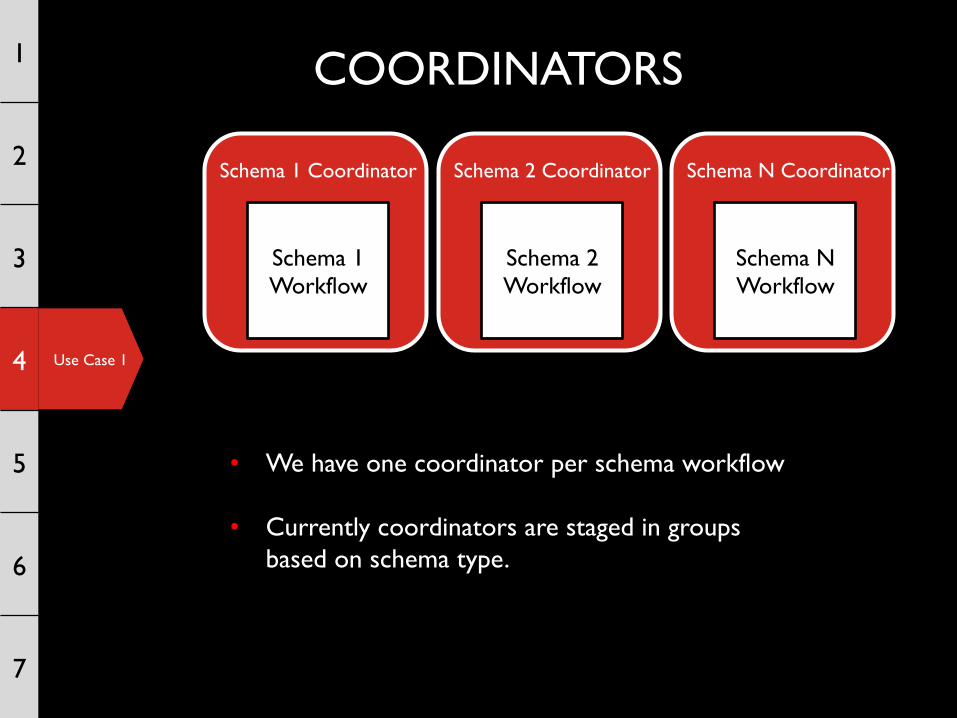
Use Case 1
COORDINATORS 1
2
3
4
5
6
7
Schema 1 Workflow
Schema 1 Coordinator
• We have one coordinator per schema workflow
• Currently coordinators are staged in groups based on schema type.
Schema 2 Workflow
Schema 2 Coordinator
Schema N Workflow
Schema N Coordinator

• 20+ Regions • 5+ DBs per region • 5-20 Tables per DB
20 * 5 * 12(avg) = ~1200 tables!
Use Case 1
IMPORTANT NUMBERS 1
2
3
4
5
6
7

• 20+ Regions • 5+ DBs per region • 5-20 Tables per DB
20 * 5 * 12(avg) = ~1200 tables!
Use Case 1
IMPORTANT NUMBERS 1
2
3
4
5
6
7

• Not if you have a good deployment pipeline!
Use Case 1
TOO UNWIELDY? 1
2
3
4
5
6
7

Use Case 1
DEPLOYMENT STACK 1
2
3
4
5
6
7

Use Case 1
DEPLOYMENT STACK: JAVA 1
2
3
4
5
6
7
• The java project compiles into the library that is used by the workflows
• It also contains some custom functionality for interacting with the Oozie WS endpoints / Oozie DB Tables

Use Case 1
DEPLOYMENT STACK: PYTHON 1
2
3
4
5
6
7
• The python project dynamically generates all of our workflow/coordinator xml files. It has a multiple YML configs which hold the meta associated with tall of the tables. It also interacts with a DB table for the various DB connection meta.

Use Case 1
DEPLOYMENT STACK: GITHUB 1
2
3
4
5
6
7
• GitHub houses all of the Big Data group’s code bases no matter the language.

Use Case 1
DEPLOYMENT STACK: JENKINS 1
2
3
4
5
6
7
• Jenkins polls GitHub and builds either set of artifacts (Java lib / tar containing workflows/coordinators) whenever it detects changes. It deploys the build artifacts to a simple mount point.
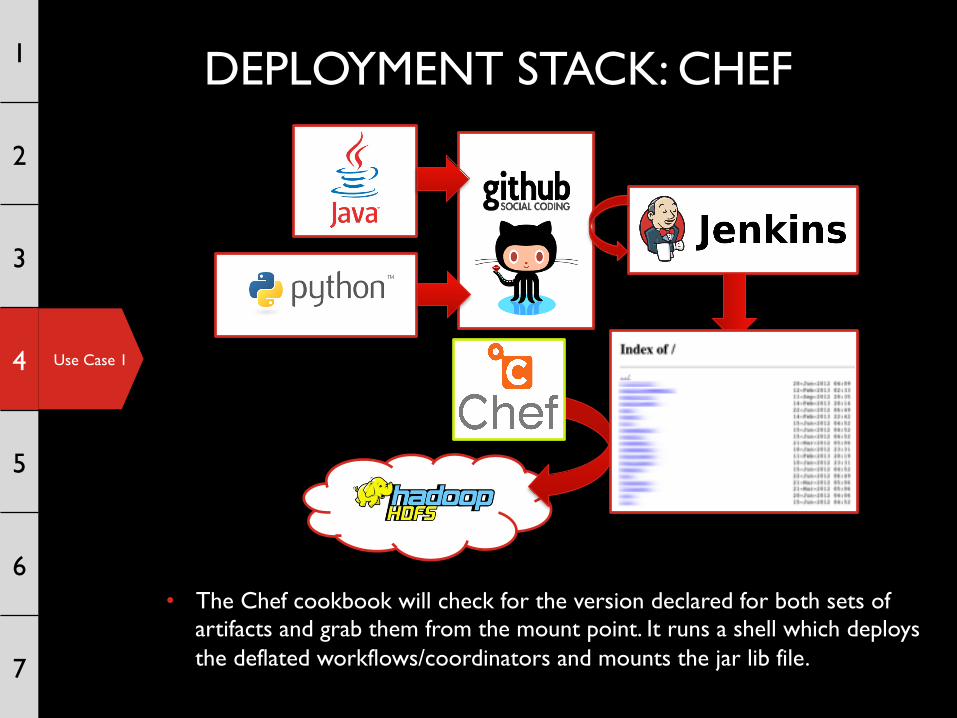
Use Case 1
DEPLOYMENT STACK: CHEF 1
2
3
4
5
6
7
• The Chef cookbook will check for the version declared for both sets of artifacts and grab them from the mount point. It runs a shell which deploys the deflated workflows/coordinators and mounts the jar lib file.

• 20+ Regions • 5+ DBs per region • 5-20 Tables per DB
20 * 5 * 12(avg) = ~1200 tables!
Use Case 1
IMPORTANT NUMBERS 1
2
3
4
5
6
7

• 20+ Regions • 5+ DBs per region • 5-20 Tables per DB
20 * 5 * 12(avg) = ~1200 tables!
Use Case 1
IMPORTANT NUMBERS 1
2
3
4
5
6
7

• 20+ Regions • 5+ DBs per region • 5-20 Tables per DB
20 * 5 * 12(avg) = ~1200 tables!
Use Case 1
IMPORTANT NUMBERS 1
2
3
4
5
6
7

• 20+ Regions • 5+ DBs per region • 5-20 Tables per DB
20 * 5 * 12(avg) = ~1200 tables per day! 1 person < 5 hours a week!
Use Case 1
IMPORTANT NUMBERS 1
2
3
4
5
6
7

Use Case 2
USE CASE 2 – Dashboarding Cloud Data 1
2
3
4
5
6
7
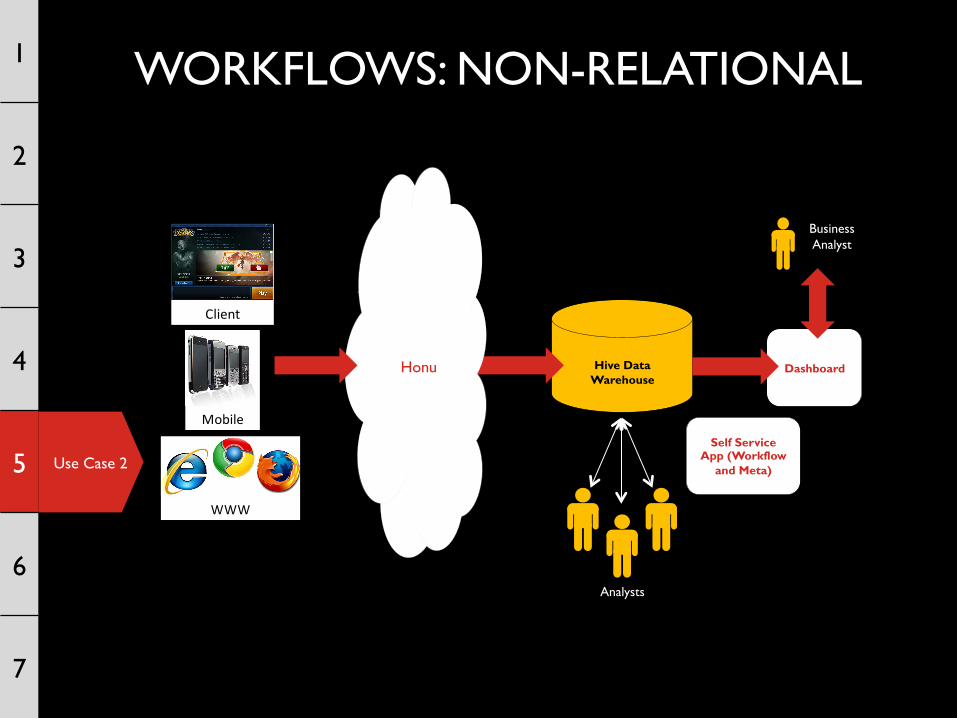
Use Case 2
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
Dashboard
Hive Data Warehouse
Honu
Analysts
Business Analyst
Client
Mobile
WWW
Self Service App (Workflow
and Meta)
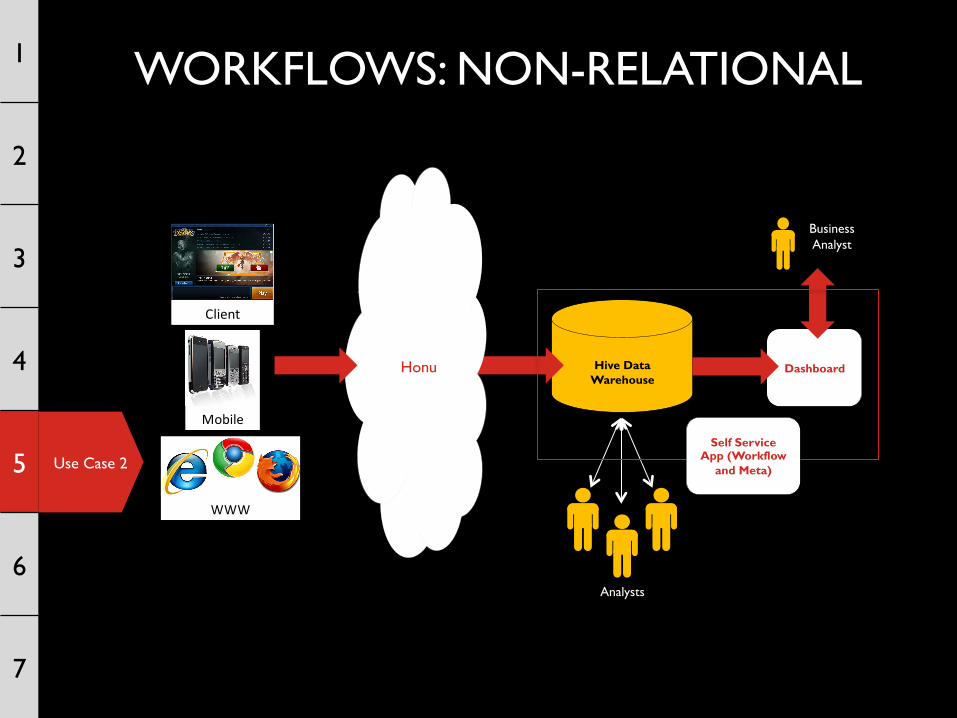
Use Case 2
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
Dashboard
Hive Data Warehouse
Honu
Analysts
Business Analyst
Client
Mobile
WWW
Self Service App (Workflow
and Meta)
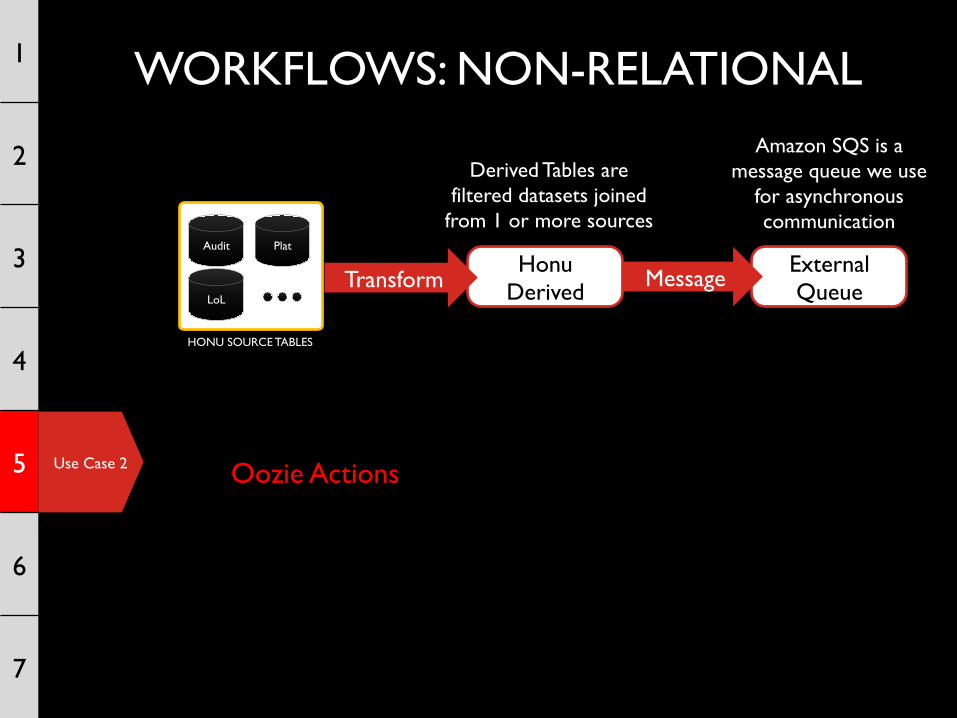
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
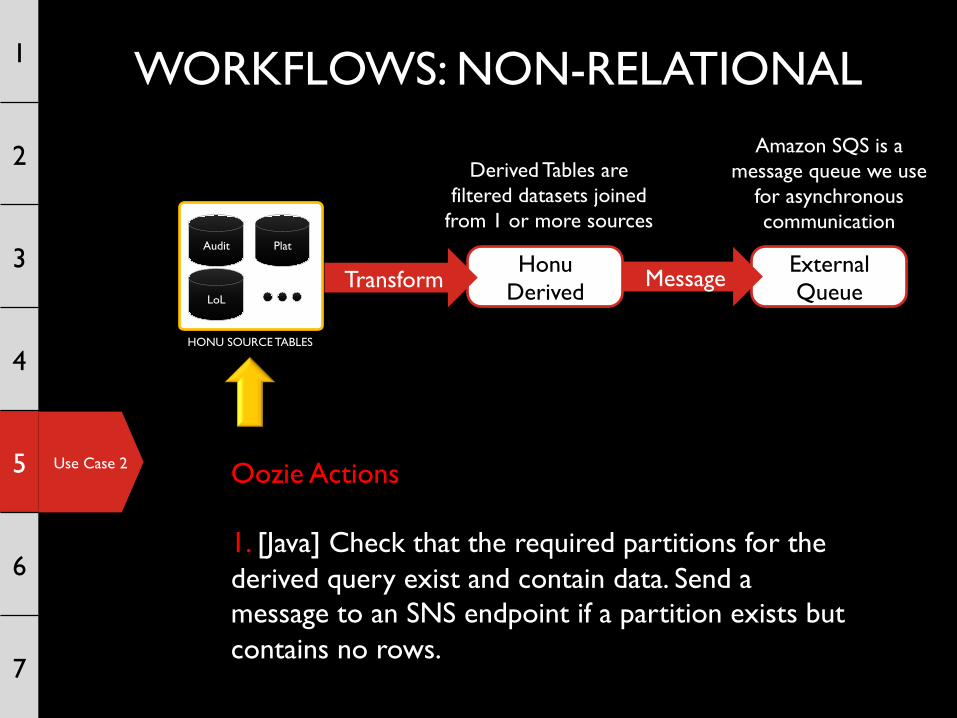
External Queue
Amazon SQS is a message queue we use
for asynchronous communication
HONU SOURCE TABLES
Audit Plat
LoL
Honu Derived Message
Derived Tables are filtered datasets joined
from 1 or more sources
Transform
Oozie Actions
Use Case 2
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
External Queue
Amazon SQS is a message queue we use
for asynchronous communication
HONU SOURCE TABLES
Audit Plat
LoL
Honu Derived Message
Derived Tables are filtered datasets joined
from 1 or more sources
Transform
Oozie Actions 1. [Java] Check that the required partitions for the derived query exist and contain data. Send a message to an SNS endpoint if a partition exists but contains no rows.
Use Case 2
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
External Queue
Amazon SQS is a message queue we use
for asynchronous communication
HONU SOURCE TABLES
Audit Plat
LoL
Honu Derived Message
Derived Tables are filtered datasets joined
from 1 or more sources
Transform
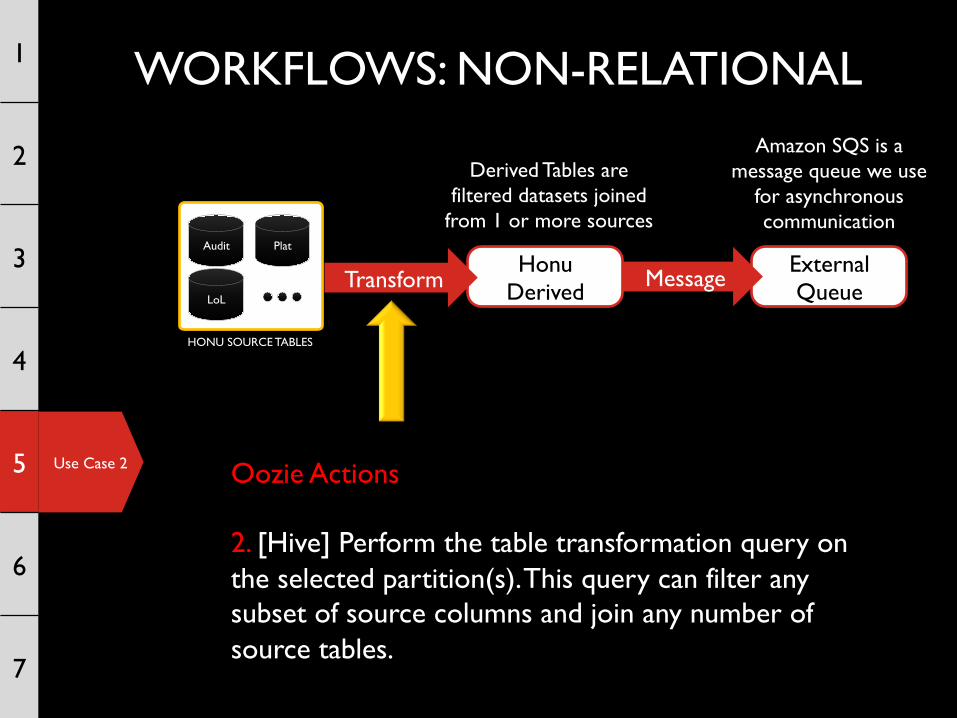
Oozie Actions 2. [Hive] Perform the table transformation query on the selected partition(s). This query can filter any subset of source columns and join any number of source tables.
Use Case 2
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
External Queue
Amazon SQS is a message queue we use
for asynchronous communication
HONU SOURCE TABLES
Audit Plat
LoL
Honu Derived Message
Derived Tables are filtered datasets joined
from 1 or more sources
Transform
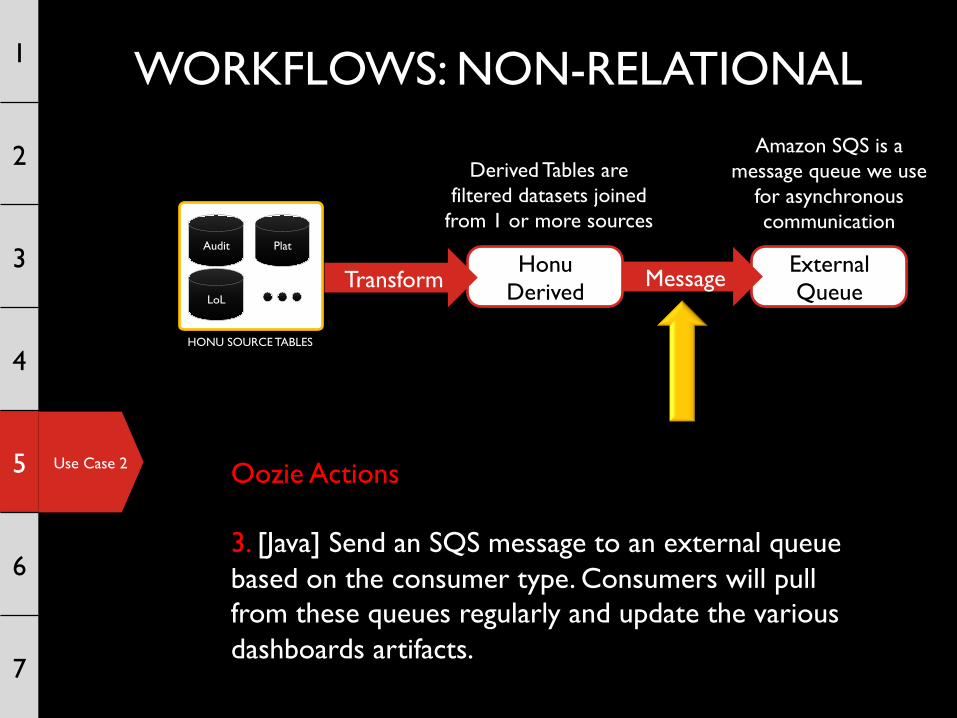
Oozie Actions 3. [Java] Send an SQS message to an external queue based on the consumer type. Consumers will pull from these queues regularly and update the various dashboards artifacts.
Use Case 2
WORKFLOWS: NON-RELATIONAL 1
2
3
4
5
6
7
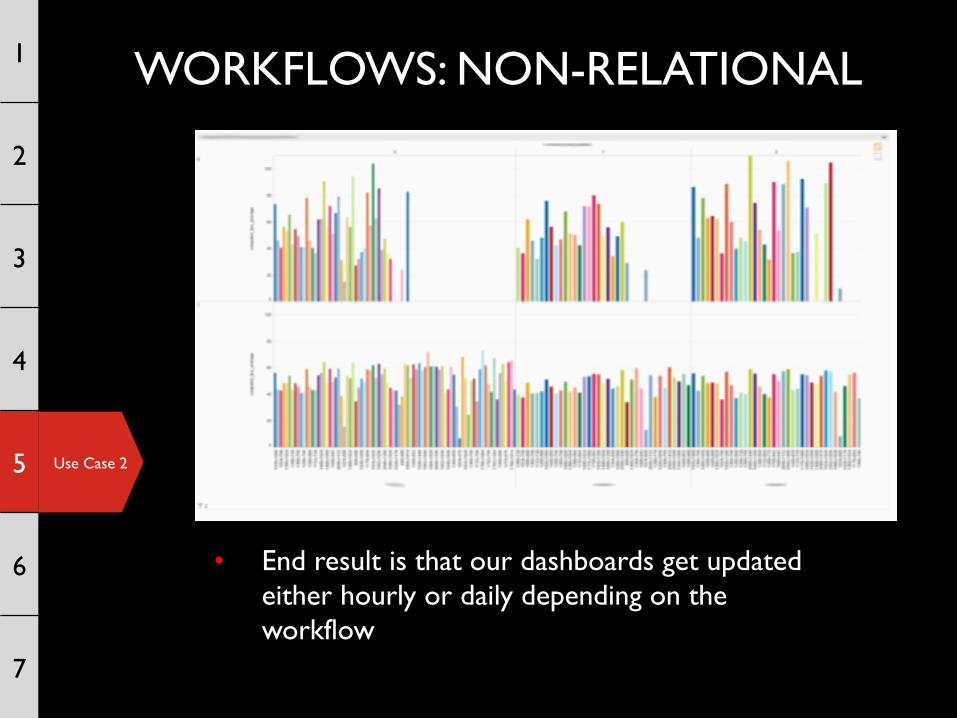
• End result is that our dashboards get updated either hourly or daily depending on the workflow
Use Case 2

LESSONS
1
2
3
4
5
6
7

LESSONS
LESSON #1 Distros and Versioning
• If you choose to go with a distro for
your Hadoop stack, be extremely
vigilant about upgrading to the latest
versions whenever possible. You will
receive a lot more community support
and a lot less headaches if you are not
running into bugs that were patched in
trunk over a year ago!
1
2
3
4
5
6
7

LESSONS
LESSON #2 Solidify Deployment
• The usefulness of Oozie can degrade as
complexity creeps into your pipeline. If
you do not work towards an
automated deployment pipeline at the
early stages of your development, you
will quickly find maintenance costs
rising significantly over time.
1
2
3
4
5
6
7

LESSONS
LESSON #3 Extend Capabilities
• Don’t feel limited to using tools based
on the supplied APIs. Feel free to
implement harnesses that extend
capabilities and submit them back to
the community – we will welcome it
with open arms J
1
2
3
4
5
6
7

LESSONS
LESSON #4 Ask for Help!
• Oozie is an open source project and is
getting new members/organizations
everyday. Don’t spend multiple hours
trying to solve an issue that many of us
have already worked through.
• There is also a large amount of
documentation both in the wikis AND
archived listserv responses – leverage
them both!
1
2
3
4
5
6
7

THE FUTURE
1
2
3
4
5
6
7

1
2
3
4
5
6
7
CONTINUE INCREASING VELOCITY
THE FUTURE
June 2012 July 2013
MySQL tables 180 1200
Pipeline Events/day 0 7+ Billion
Workflows Cronjob + Pentaho Oozie
Environment Datacenter DC + AWS
SLA 1 day 2 hours
Event tracking • 2+ weeks (DB update)
• Dependencies: DBA teams + ETL teams + Tools teams
• Downtime (3h min.)
• 10 minutes
• Self-Service • No downtime

OUR IMMEDIATE GOALS 1
2
3
4
5
6
7 THE FUTURE
• Improve Self-service workflow & tooling • Realtime event aggregation • Global Data Infrastructure • Replace legacy audit/event logging services

CHALLENGE: MAKE IT GLOBAL
• Data centers across the globe since latency has huge effect on gameplay à log data scattered around the world
• Large presence in Asia -- some areas (e.g., PH) have bandwidth challenges or bandwidth is expensive
1
2
3
4
5
6
7 THE FUTURE

CHALLENGE: WE HAVE BIG DATA
+ chat logs + detailed gameplay event tracking + so on….
1
2
3
4
5
6
7
500G DAILY STRUCTURED DATA
> 7PB GAME EVENT DATA
3MM SUBSCRIBERS 448+ MM VIEWS
RIOT YOUTUBE CHANNEL
THE FUTURE

OUR AUDACIOUS GOALS
Have deep, real-time understanding of our systems from player experience and operational standpoints
1
2
3
4
5
6
7
Have ability to identify, understand and react to meaningful trends in real time
Build a world-class data and analytics organization • Deeply understand players across the globe • Apply that understanding to improve games for players • Deeply understand our entire ecosystem, including social media
THE FUTURE

SHAMELESS HIRING PLUG 1
2
3
4
5
6
7 THE FUTURE
Like most everybody else at this conference… we’re hiring!
PLAYER EXPERIENCE FIRST
CHALLENGE CONVENTION
FOCUS ON TALENT AND TEAM
TAKE PLAY SERIOUSLY
STAY HUNGRY, STAY HUMBLE
THE RIOT MANIFESTO

SHAMELESS HIRING PLUG 1
2
3
4
5
6
7 And yes, you can play games at work.
It’s encouraged! THE
FUTURE
