osc2012: big data using open source: netapp project - technical
TRANSCRIPT

Open source Big Data case study: Building a
platform for remote device support at NetApp
(Part II – Technical)

Copyright © 2012 Accenture All rights reserved. 2
Topics
Big Data Perspective
Case Study: NetApp AutoSupport
Technology Primer
Design Overview

Copyright © 2012 Accenture All rights reserved. 3
Big Data
The concept is disruptive. The technology is disruptive. And, markets and
clients are being impacted.
1 Wordle for Credit Suisse, Does Size Matter Only?, September 2011
Copyright © 2012 Accenture All rights reserved. 4
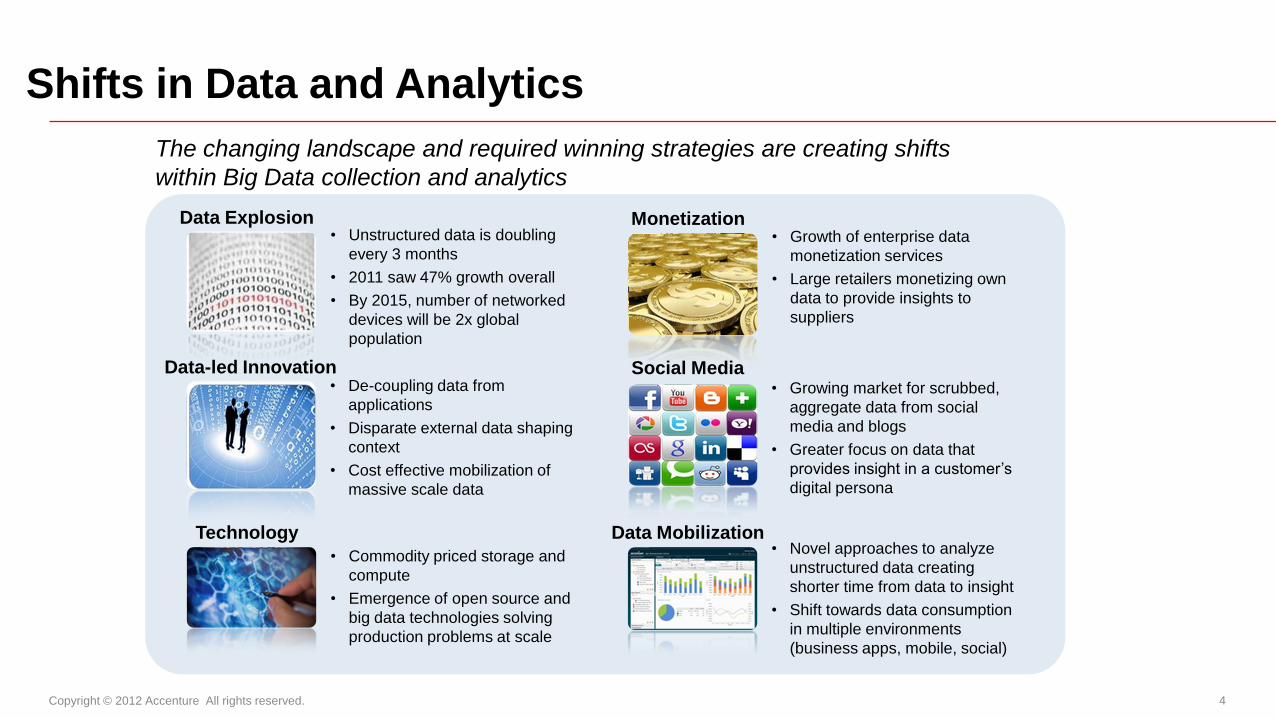
Shifts in Data and Analytics
Data-led Innovation
Data Explosion • Unstructured data is doubling
every 3 months
• 2011 saw 47% growth overall
• By 2015, number of networked
devices will be 2x global
population
• De-coupling data from
applications
• Disparate external data shaping
context
• Cost effective mobilization of
massive scale data
Monetization • Growth of enterprise data
monetization services
• Large retailers monetizing own
data to provide insights to
suppliers
Social Media • Growing market for scrubbed,
aggregate data from social
media and blogs
• Greater focus on data that
provides insight in a customer’s
digital persona
Technology
• Commodity priced storage and
compute
• Emergence of open source and
big data technologies solving
production problems at scale
Data Mobilization • Novel approaches to analyze
unstructured data creating
shorter time from data to insight
• Shift towards data consumption
in multiple environments
(business apps, mobile, social)
The changing landscape and required winning strategies are creating shifts
within Big Data collection and analytics

Copyright © 2012 Accenture All rights reserved. 5
The Big Data Approach
Culture
• Data-driven decision making
• Experimentation and
continuous improvement with
academic rigor
• End-to-end ownership of
services
• Sharing of platform, tools and
code
Treat data as a strategic asset, seek to maximize it’s value to the organization
Invest in common services, data platforms and tools
Rapidly prototype, deliver, and measure value-added data services, evolve over time

Copyright © 2012 Accenture All rights reserved. 6
Topics
Big Data Perspective
Case Study: NetApp AutoSupport
Technology Primer
Design Overview

Copyright © 2012 Accenture All rights reserved. 7
Client Context
NetApp, Inc.
• Industry: Data storage, data management
• 77% Fortune 500 companies are customers
• Creator of Data ONTAP: industry leading storage OS
Copyright © 2012 Accenture All rights reserved. 8
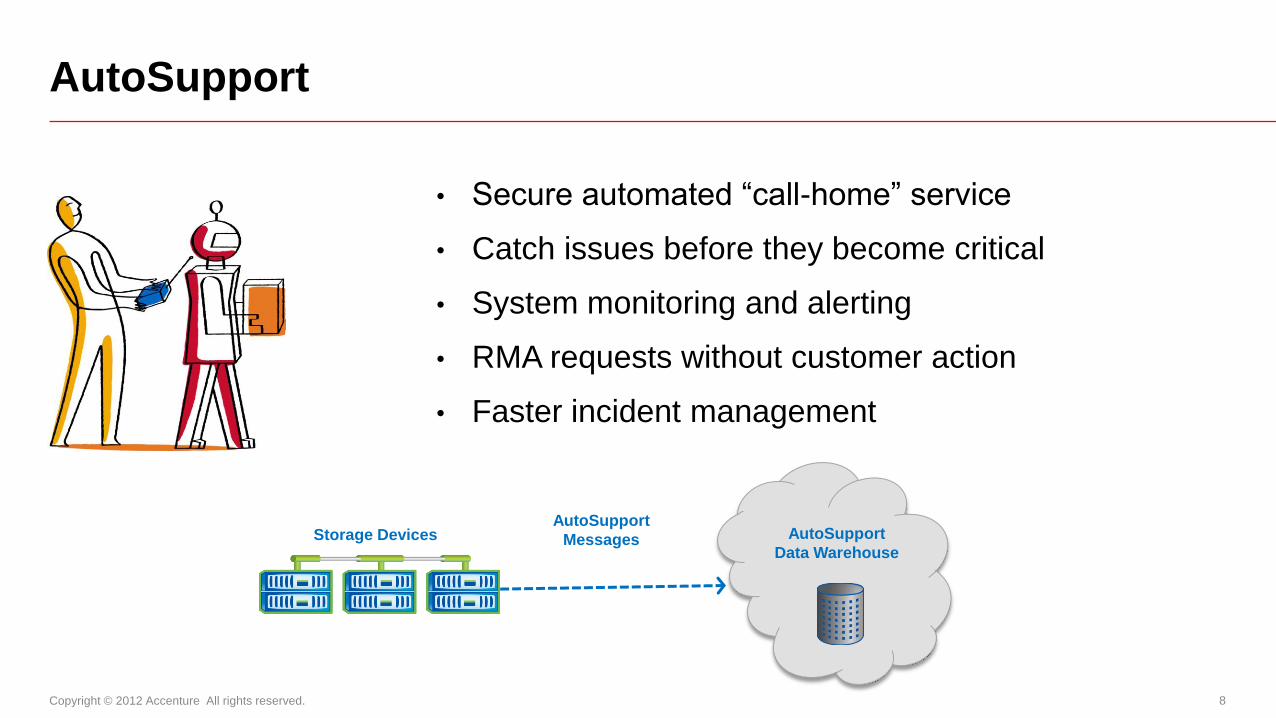
• Secure automated “call-home” service
• Catch issues before they become critical
• System monitoring and alerting
• RMA requests without customer action
• Faster incident management
AutoSupport
AutoSupport
Messages AutoSupport
Data Warehouse Storage Devices

Copyright © 2012 Accenture All rights reserved. 9
Business Challenges
• Increase in response times / lower
availability for services
• Incoming data volume doubling every 16
months
• Proliferation of ad hoc datamarts and
point solutions
• Unable to analyze full AutoSupport
contents efficiently File StorageASUP
Messages
SAP CRM
ODS
DSS
MyASUP STOReBI Analytics & MiningASUP Tools
PWillows
BI
Light
Parser
Core
Parser
Xterra DB
Parser
DW 2 Adhoc DB’s
PMBTA
Adhoc
Parsers
DRM DMHDDSAP CRMSTAGE
PNOW GEO
Transform
Presentation
Interface
Rules
Integrate
RulesRules
Rules
Stage
Extract
Source
Xterra
Parser Parser
Custom ETLCustom ETL Custom ETLCustom ETL
eB
I
DW 3
Java Interface Jasper
Stored Proc
Loader
RulesRules
Rules
Rest InterfaceCRM Module
Rules Module
Xterra File
Various
RulesRules
Rules
0
500
1000
1500
2000
2500
3000
3500
Jan-05 Jan-06 Jan-07 Jan-08 Jan-09 Jan-10 Jan-11 Jan-12 Jan-13 Jan-14 Jan-15 Jan-16
AutoSupport Flat-File Storage Requirement
Total Usage (tb)
Projected Total Usage (tb)
Doubles

Copyright © 2012 Accenture All rights reserved. 10
Solution Design Goals
• Improve system response times
and data availability
• Expose common data services for
consumption across business units
• Standardize key business metrics
into common rules repository
• Lower operational costs as
ecosystem continues to scale
• Provide more granular analytical
capabilities
Improve data access and technology cost effectiveness and performance.

Copyright © 2012 Accenture All rights reserved. 11
Role of Open Source
Platform is composed of open source technologies purpose-built for large-scale
storage, processing and analysis
1 Actual Big Data Solution Blueprint for a hybrid deployment

Copyright © 2012 Accenture All rights reserved. 12
Topics
Big Data Perspective
Case Study: NetApp AutoSupport
Technology Primer
Design Overview

Copyright © 2012 Accenture All rights reserved. 13
Technology Primer – Hadoop
Hadoop Distributed Filesystem
(HDFS) • Divides files into smaller “blocks”,
stored across machines
• Automated replication, fault tolerance
Hadoop MapReduce • Parallel processing for large datasets
across machines
• Breaks job into tasks, using a simple map()
and reduce() paradigm for data flows

Copyright © 2012 Accenture All rights reserved. 14
Technology Primer – MapReduce
MapReduce
(Simple Example – Word Count)
One fish,
two fish,
red fish,
blue fish.
m
m
m
m
r
r
r
<one,1>
<fish,1>
<two,1>
<fish,1>
<red,1>
<fish,1>
<blue,1>
<fish,1>
<one,1>
<two,1>
<red,1>
<blue,1>
<fish,4>
Input
Map Phase Shuffle Phase
Map(key,value)
Reduce(key, List<value> values)

Copyright © 2012 Accenture All rights reserved. 15
Technology Primer – NoSQL
• “Not only” SQL
• Catch-all term for various non-relational database systems
• Typical areas of differentation
• Data model semantics • eg. Database, Document, Key-Value
• CAP trade-offs • Consistency, Availability, Partition-Tolerance
• Scale-out architecture • eg. Sharding, Distributed hash
• Query language
Examples: HBase, Cassandra, mongoDB, Neo4j, etc.

Copyright © 2012 Accenture All rights reserved. 16
Topics
Big Data Perspective
Case Study: NetApp AutoSupport
Technology Primer
Design Overview

Copyright © 2012 Accenture All rights reserved. 17
Data Pipeline Overview
Incoming Messages
Ingestion Core Data
Processing
Data Service
Interface
Ad hoc
analytics
ETL

Copyright © 2012 Accenture All rights reserved. 18
Data Ingestion
Flume
client
Flume
agent
Flume
agent
Flume
agent
Flume
agent
Flume
agent
Flume
agent
Flume
agent
Flume
agent
Flume
agent
Technologies
• Apache Flume, Apache Hadoop, Drools BRMS, JMS
Capabilities
• Handle dynamic data volumes
• Normalization of disparate file formats
• Real-time aggregation of documents
• JMS alerts for critical messages
HDFS
Routing tier
Parsing tier Aggregation & sink tier
Documents from
Front End HTTP/SMTP
Gateway Aggregated files
JMS
Notifications
Rules
Engine

Copyright © 2012 Accenture All rights reserved. 19
HDFS
Core Data Processing
Map
Map
Map
Reduce
Reduce
HBase
Solr Parse text
contents Transform and derive data objects
Technologies
• MapReduce, HBase, Solr, Avro
Capabilities
• Parallel processing for increased throughput
• Efficient storage of complex data objects in Avro
Primary storage
Search indexes
Write derived objects to
data stores
Hive
Documents gathered
from Flume
Data warehouse

Copyright © 2012 Accenture All rights reserved. 20
Data Services
Technologies
• Apache HBase, Solr, Tomcat
Capabilities
• Unified web services API for end
users
• Support for complex queries and
searches across multiple dimensions
with Solr
• Access both raw and derived content
for a given system

Copyright © 2012 Accenture All rights reserved. 21
Analytics / ETL
Technologies
• Apache Hive, Pig, Datameer (Ad hoc analytics)
• Pentaho (ETL / Data Integration)
Capabilities
• Analytical environment for both business analysts and “power
users”
• Hive or Pig as higher level query languages
• Datameer for analytics with a spreadsheet UI
• ETL through Pentaho MapReduce • (runs Pentaho ETL server inside of a MapReduce Job)

Copyright © 2012 Accenture All rights reserved. 22
Successes and Challenges
Successes
• Web service interface contracts simplified integration with
user tools, allowed for flexibility in internal implementation
• Open source core allowed rapid for rapid iteration
• Met or exceeded all SLAs using commodity hardware,
significantly driving down costs
Challenges
• Monitoring a large distributed system requires discipline and
a strong operations team
• Shared storage systems and Big Data technologies don’t
always play well together
• “Schemaless” systems can become a headache to
maintain, especially with complex data models

Copyright © 2012 Accenture All rights reserved. 23
Thank you
Jonathan Bender Consultant, Accenture Technology Labs