overview: graphics processing units · overview: graphics processing units l advent of gpus l gpu...
TRANSCRIPT

Overview: Graphics Processing Units
l advent of GPUs
l GPU architecture
n the NVIDIA Fermi processor
l the CUDA programming model
n simple example, threads organization, memory modeln case study: matrix multiplyn memories, thread synchronization, schedulingn case study: reductionsn performance considerations: bandwidth, scheduling, resource conflicts,
instruction mixu host-device data transfer: multiple GPUs, NVLink, Unified Memory, APUs
l the OpenCL programming model
l directive-based programming modelsl refs: CUDA Toolkit Documentation, An Even Easier Introduction to CUDA (tutorial); NCI NF GPU
page, Programming Massively Parallel Processors, Kirk & Hwu, Morgan-Kaufman, 2010; Cuda ByExample, by Sanders and Kandrot;
OpenCL web page, OpenCL in Action, by Matthew Scarpino
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 1

Advent of General-purpose Graphics Processing Units
l many applications have massive amounts of mostly independent calculations
n e.g. ray tracing, image rendering, matrix computations, molecular simulations,HDTV
n can be largely expressed in terms of SIMD operationsu implementable with minimal control logic & caches, simple instruction sets
l design point: maximize number of ALUs & FPUs and memory bandwidth to takeadvantage of Moore’s’ Law (shown here)
n put this on a co-processor (GPU); have a normal CPU to co-ordinate, run theoperating system, launch applications, etc
l architecture/infrastructure development requires a massive economic base for itsdevelopment (the gaming industry!)
n pre 2006: only specialized graphics operations (integer & float data)n 2006: ‘General Purpose’ (GPGPU): general computations but only through a
graphics library (e.g. OpenGL)n 2009: programmable for general (numeric) calculations (e.g. CUDA, OpenCL)
Some applications have large speedups (10–500×) over a single CPU core.
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 2
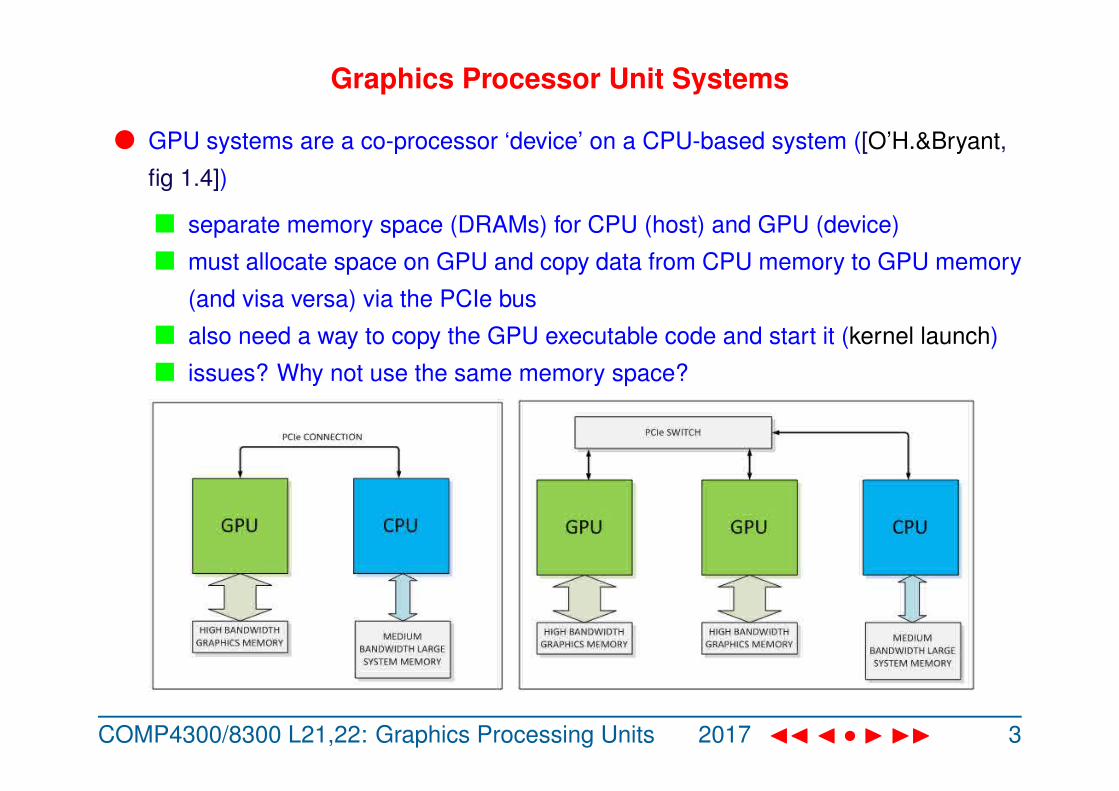
Graphics Processor Unit Systems
l GPU systems are a co-processor ‘device’ on a CPU-based system ([O’H.&Bryant,
fig 1.4])
n separate memory space (DRAMs) for CPU (host) and GPU (device)
n must allocate space on GPU and copy data from CPU memory to GPU memory
(and visa versa) via the PCIe bus
n also need a way to copy the GPU executable code and start it (kernel launch)
n issues? Why not use the same memory space?
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 3

Graphics Processor Unit Architecture
l GPU chip: an array of streaming
multiprocessors (SMs) sharing an L2 cache
n comparison with UltraSPARC T2 (courtesy
Real World Tech)
n each SM has (8–32) streaming
processors (SPs)
u only SPs (= cores) within an SM can
(easily) synchronize, share data
n identical threads are organized into
fixed-size blocks, each allocated to an SM
n blocks in turn are divided into warps
n at any timestep, all SPs execute an
instruction from a warp (‘SIMT’ mode)
n latencies hidden by scheduling from
many warps
TeslaS2050 co-processor
TeslaS2050 architecture(courtesy NVIDIA)
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 4
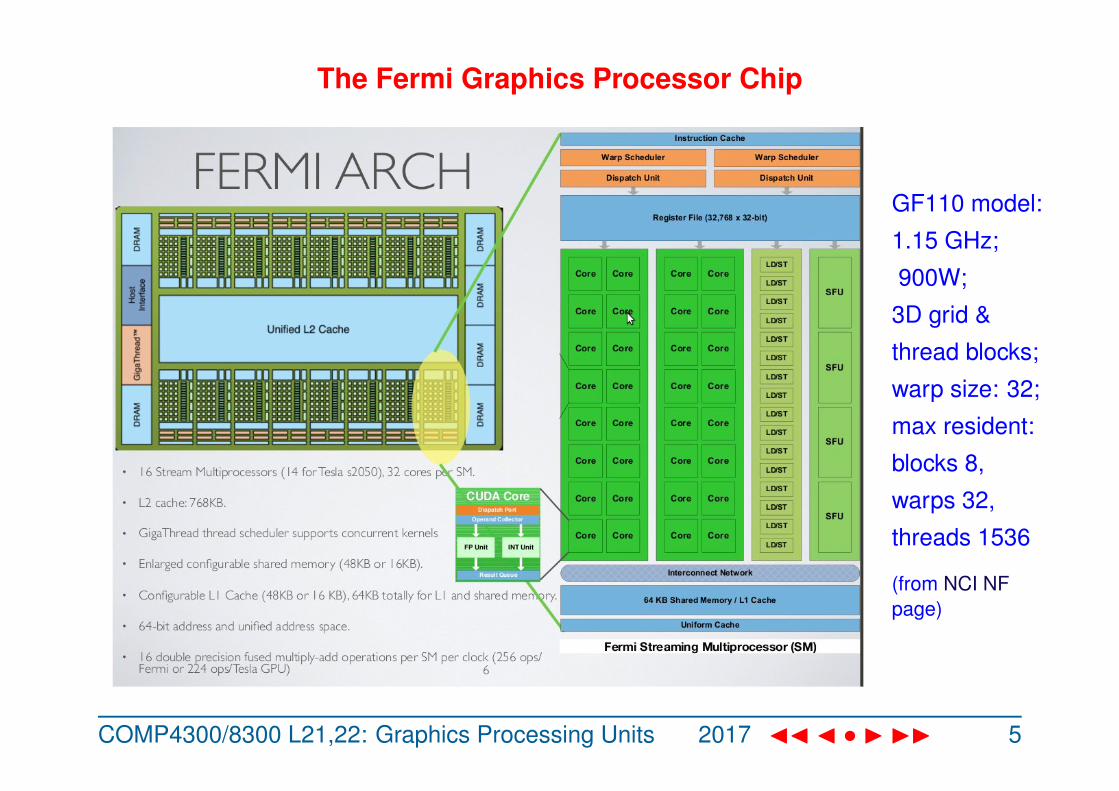
The Fermi Graphics Processor Chip
GF110 model:
1.15 GHz;
900W;
3D grid &
thread blocks;
warp size: 32;
max resident:
blocks 8,
warps 32,
threads 1536
(from NCI NFpage)
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 5
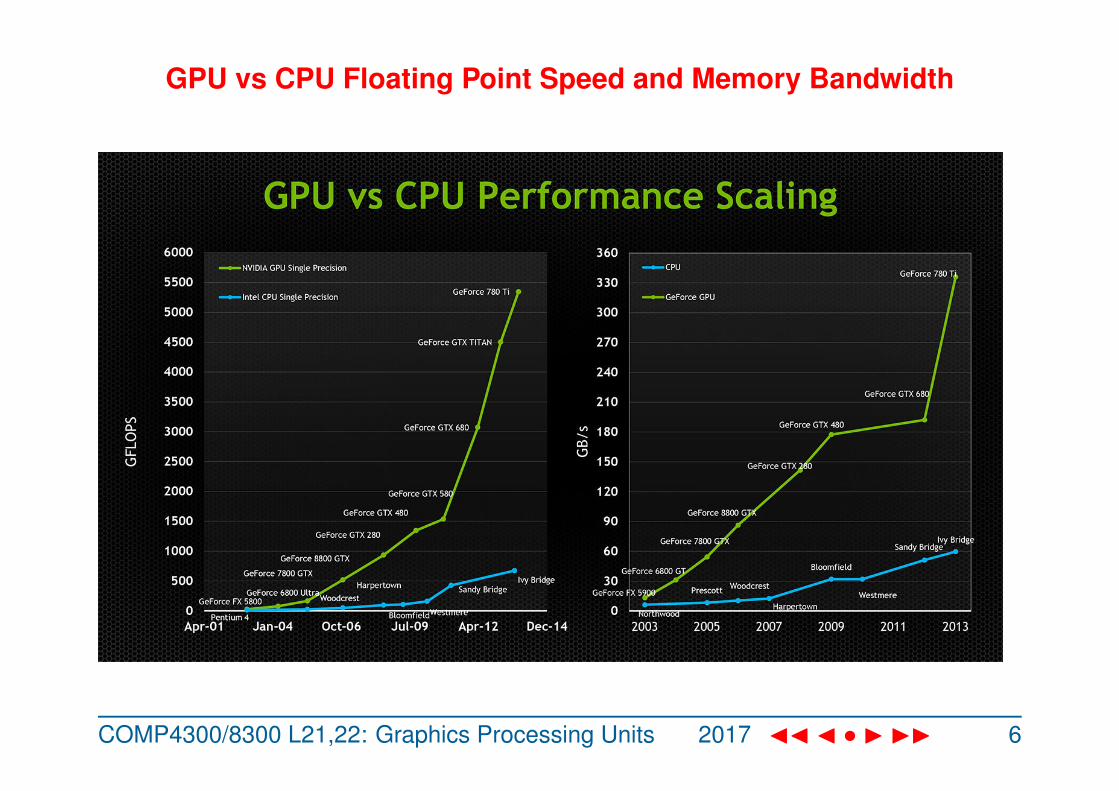
GPU vs CPU Floating Point Speed and Memory Bandwidth
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 6
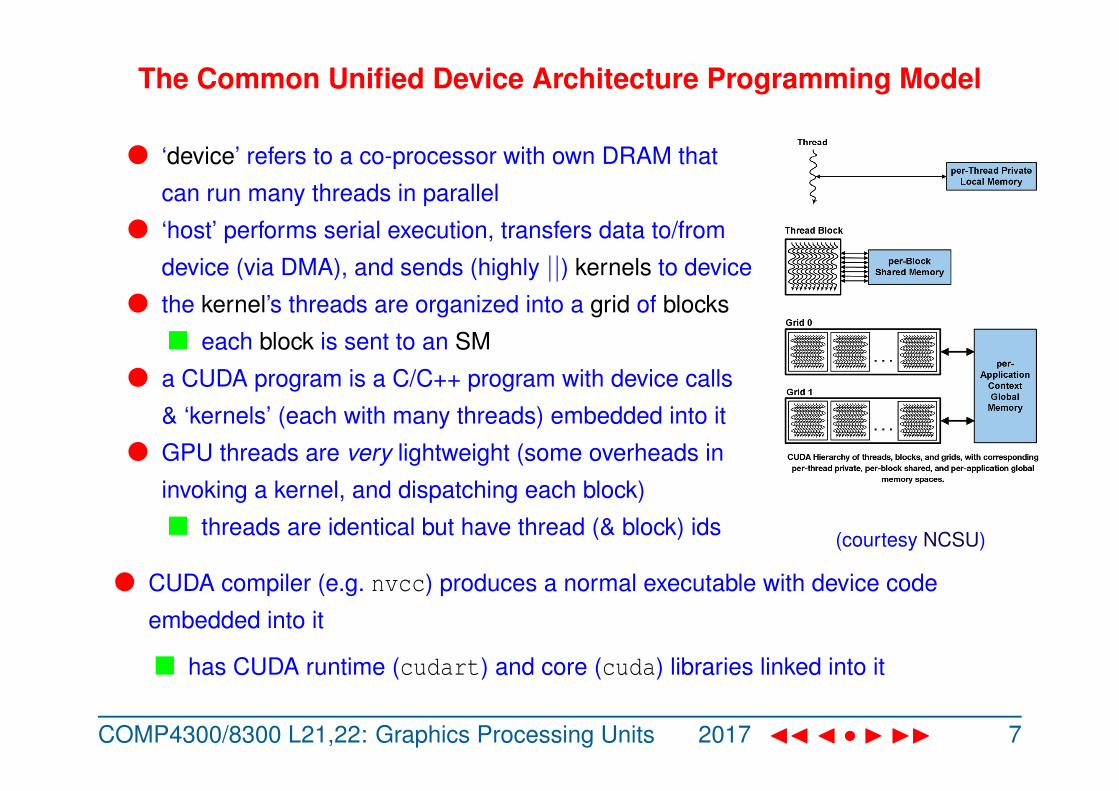
The Common Unified Device Architecture Programming Model
l ‘device’ refers to a co-processor with own DRAM that
can run many threads in parallel
l ‘host’ performs serial execution, transfers data to/from
device (via DMA), and sends (highly ||) kernels to device
l the kernel’s threads are organized into a grid of blocks
n each block is sent to an SM
l a CUDA program is a C/C++ program with device calls
& ‘kernels’ (each with many threads) embedded into it
l GPU threads are very lightweight (some overheads in
invoking a kernel, and dispatching each block)
n threads are identical but have thread (& block) ids (courtesy NCSU)
l CUDA compiler (e.g. nvcc) produces a normal executable with device code
embedded into it
n has CUDA runtime (cudart) and core (cuda) libraries linked into it
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 7

CUDA Program: Simple Examplel reverse an array (reversearray.cu)
global void reverseArray(int ∗ a d , int N) {int idx = threadIdx.x;int v = a[N−idx−1]; a[N−idx−1] = a[idx]; a[idx] = v;
}#define N (1<<16)int main() { //may not dereference a d !
int a[N], ∗ a d , a size = N ∗ sizeof(int);...cudaMalloc ((void ∗∗) &a d , a size );cudaMemcpy(a d , a, a size , cudaMemcpyHostToDevice );reverseArray <<<1, N/2>>> (a d , N);cudaThreadSynchronize (); // wait till threads finishcudaMemcpy(a, a d , a size , cudaMemcpyDeviceToHost );cudaFree( a d ); ...
}
l cf. OpenMP on a normal multicore: style; practicality?#pragma omp parallel num threads (N/2) default(shared){ int idx = omp get threads num ();
int v = a[N−idx−1]; a[N−idx−1] = a[idx]; a[idx] = v;}
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 8
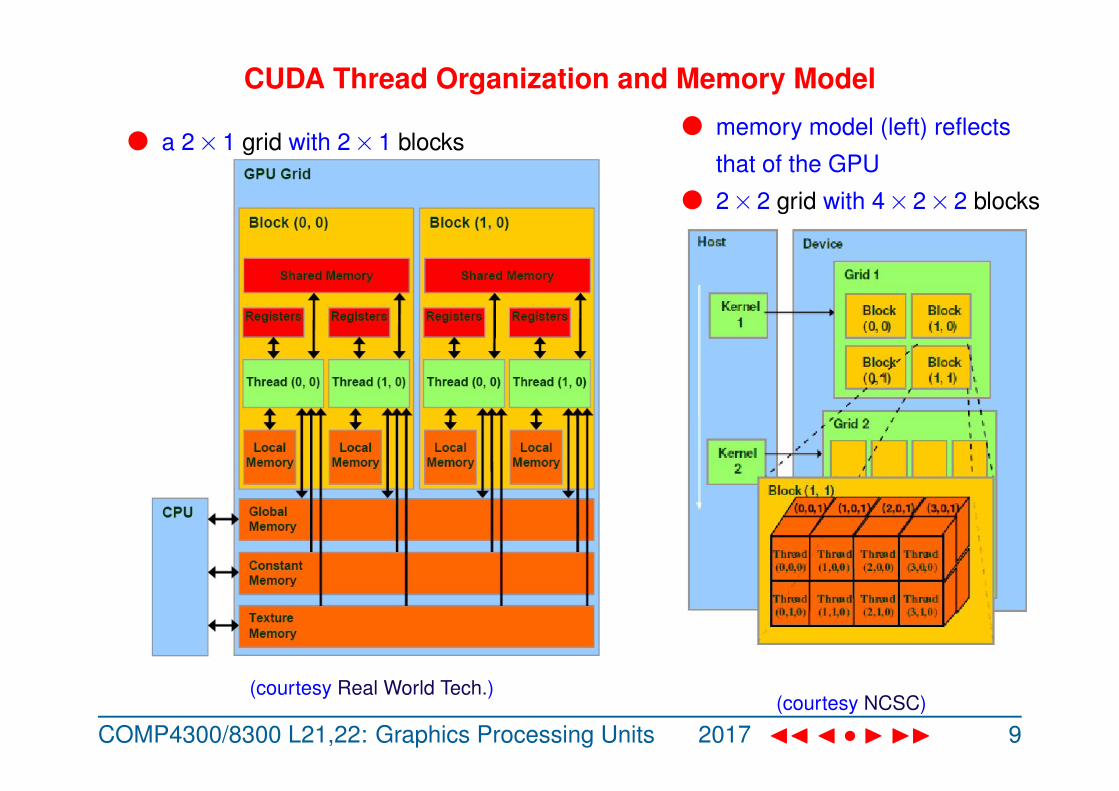
CUDA Thread Organization and Memory Model
l a 2×1 grid with 2×1 blocks
(courtesy Real World Tech.)
l memory model (left) reflects
that of the GPU
l 2×2 grid with 4×2×2 blocks
(courtesy NCSC)
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 9
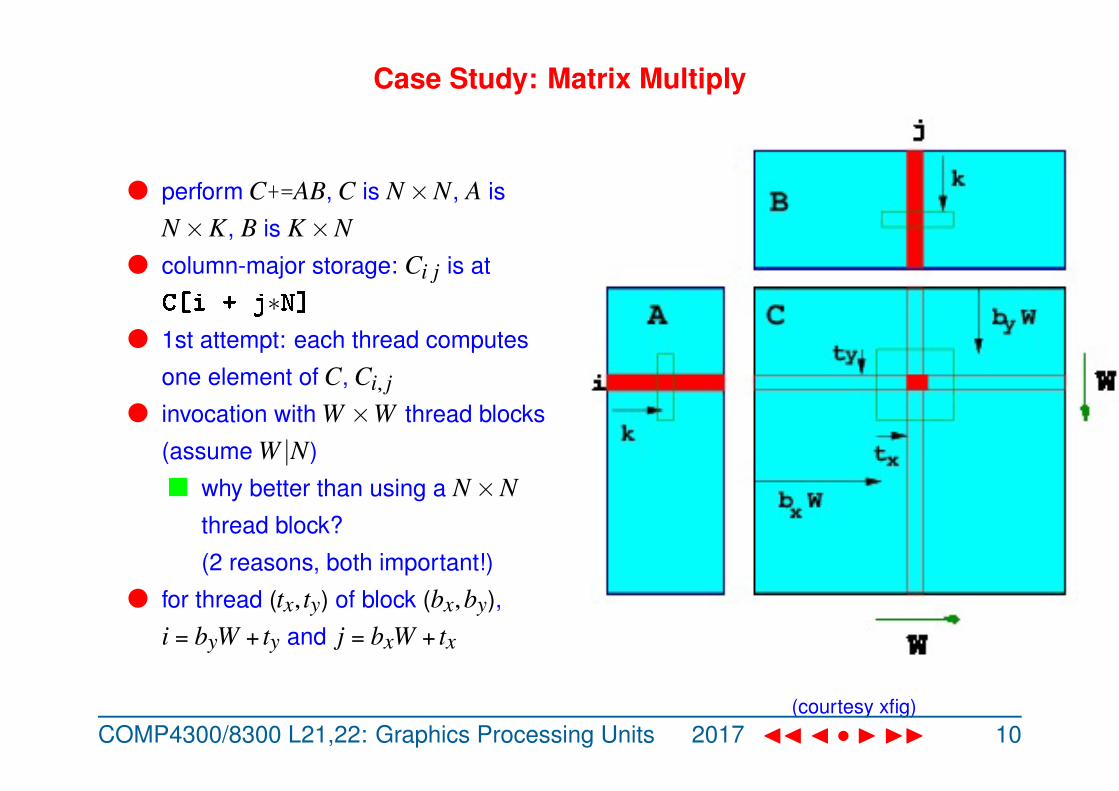
Case Study: Matrix Multiply
l perform C+=AB, C is N×N, A is
N×K, B is K×Nl column-major storage: Ci j is at
C[i + j∗N]l 1st attempt: each thread computes
one element of C, Ci, jl invocation with W ×W thread blocks
(assume W |N)
n why better than using a N×Nthread block?
(2 reasons, both important!)
l for thread (tx, ty) of block (bx,by),
i = byW + ty and j = bxW + tx
(courtesy xfig)COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 10

CUDA Matrix Multiply: Implementationl kernel:
global void matMult(int N, int K, double ∗ A d ,double ∗ B d , double ∗ C d ) {
int i = blockIdx.y ∗ blockDim.y + threadIdx.y;int j = blockIdx.x ∗ blockDim.x + threadIdx.x;double cij = C d [i + j ∗N];for (int k=0; k < K; k++)
cij += A d [i + k ∗N] ∗ B d [k + j ∗K];C d [i + j ∗N] = cij;
}
l main program: needs to allocate device versions of A, B & C (A d, B d, and C d) andcudaMemcpy() host versions into them
l invocation with W ×W thread blocks (assume W |N)dim3 dimG(N/W, N/W);dim3 dimB(W, W); // in kernel blockDim.x == WmatMult <<<dimG , dimB >>> (N, K, A d , B d , C d );
l what if N % W > 0? Add to kernel if (i < N && j < N) and declaredim3 dimG((N+W−1)/W, (N+W−1)/W);
n note: SIMD nature of SPs⇒ cycles for both branches of if are consumed
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 11

CUDA Memories and Thread Synchronization
l GPUs can potentially suffer more still from the memory wall
n DRAM access still may be 100’s of cycles
n bandwidth is limited for load/store intensive kernels
l the shared memory is on-chip (hence very fast)
n the shared type modifier may be used to denote a (fixed) array allocated
to shared memory
l threads within a block can synchronized via the syncthreads() intrinsic
(efficient – why?)
n (SM-level) atomic instructions can enforce data consistency within a block
l note: no way to synchronize between blocks, or safely ensure data consistency
across blocks
n can only be done across separate kernel invocations
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 12

Matrix Multiply Using Shared Memory
l threads (tx,0) . . . (tx,W −1) all access Bk,bxW+tx; ((0, ty) . . . (W −1, ty) access AbyW+ty,k)
n high ratio of load to FP instructionsn harder to hide L1 cache latencies; strains memory bandwidth
l can improve kernel by utilizing SM shared memory:shared double A s [W][W], B s [W][W];global void matMult s (int N, int K, double ∗ A d ,
double ∗ B d , double ∗ C d ) {int ty = threadIdx.y, tx = threadIdx.x;int i = blockIdx.y ∗W + ty, j = blockIdx.x ∗W + tx;double cij = C d [i + j ∗N];for (int k=0; k < K; k+=W) {
A s [ty][tx] = A d [i + (k+tx )∗N];B s [ty][tx] = B d [(k+ty) + j ∗K];syncthreads ();
for (int w=0; w < W; w++)cij += A s [ty][w] ∗ B s [w][tx];syncthreads (); // can this be avoided?
}C d [i + j ∗N] = cij;
}
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 13

GPU Scheduling - Warps
l the GigaThread scheduler assigns the (independently
executable) thread blocks to each SMl each block is divided into
groups (of 32) called
warps
n grouping occurs in
linear order by
tx + bxty + bxbytz(e.g. warp size 4)
l the warp scheduler determines which blocks are ready
to run
n with 32-thread warps, suitable block sizes range
from 4×8 to 16×16
n SIMT: each SP executes next instr’n SIMD-style
(note: requires only a single instruction fetch!)
l thus, a kernel with enough blocks can scale across a
GPU with any number of cores (courtesy NVIDIA - both)
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 14

Reductions and Thread Divergence
l threads within a single 1D blocksumming A[0..N−1]:
global void sumV(int N,double ∗A, double ∗s) {int bx = blockDim.x;
shared double pSum[bx];int tx = threadID.x, x;pSum[tx] = ...for (x=bx/2; x>0; x/=2) {
syncthreads ();if (tx < x)
pSum[tx] += pSum[tx+x];}if (tx==0) ∗s = pSum[tx];
}
l predicated execution: threads in a
warp where the condition is false
execute a ‘no-op’
l if-else statements thus cause thread
divergence (worse when nested)
(courtesy NVIDIA)
l divergence is minimized: occurs only
when x < 32 (on one warp)l cf. alternative algorithm:
for (x=1; x < bx; x ∗=2) {syncthreads ();
if (tx % x == 0)pSum[tx] += pSum[tx+x];
}
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 15

Global Memory Bandwidth Issues
l in reduction example, all threads in warp contiguously access (shared) array pSum
l very important when you have global memory accesses:
n memory subsystem can coalesce these into a single access
n allows DRAM banks to deliver peak bandwidth (burst mode)
u reason: 2D organization of DRAM chips (same row address) (Lect 3, p14)
l matMult example: threads within warp access A contiguously, but not B
n effect of accesses to B in this case is mitigated by use of shared memory in
multiply
n note that this effect is opposite to normal cores, where contiguous access
within a thread is most desirable (maximizes spatial locality)
l worst case scenario: memory strides in (large) powers of 2 – causes memory bank
conflicts
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 16

SM Registers and Warp Scheduling
l the SM maintains block ids of scheduled blocks, and
thread ids (and block sizes) of scheduled threads
l the SM’s (32K word) register file is shared between
all of thesen the block and thread ids are used to index the file
for the registers allocated to a particular thread
l warps whose next instruction has its operands ready
for consumption may be selected
n round-robin used if there are several ready
l thus, registers need to be ‘scoreboarded’n can make use of this to (software) ‘prefetch’ data
and better hide latencies (sh. mem. matMult)l example: if there are 4 instrn’s between a load & its
use, on the G80, with 4 clock cycles needed to
process an instrn., we need 14 active warps to
tolerate a 200-cycle memory latency(courtesy NVIDIA)
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 17
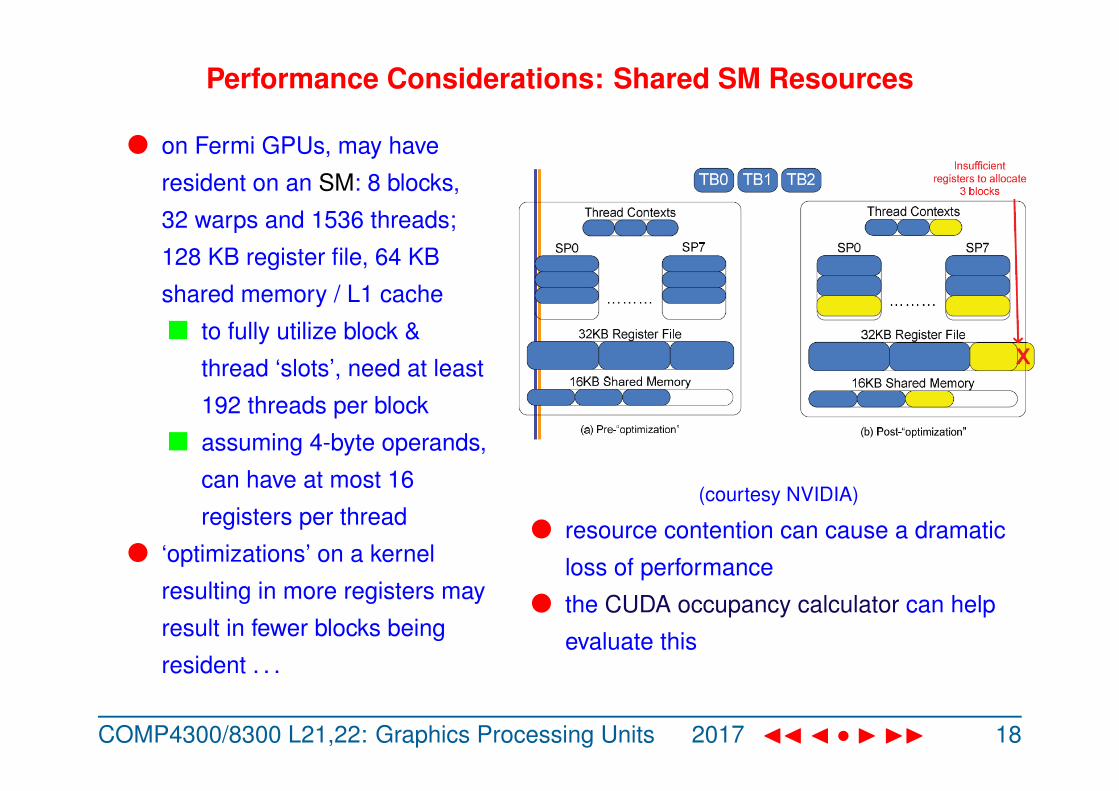
Performance Considerations: Shared SM Resources
l on Fermi GPUs, may have
resident on an SM: 8 blocks,
32 warps and 1536 threads;
128 KB register file, 64 KB
shared memory / L1 cache
n to fully utilize block &
thread ‘slots’, need at least
192 threads per block
n assuming 4-byte operands,
can have at most 16
registers per thread
l ‘optimizations’ on a kernel
resulting in more registers may
result in fewer blocks being
resident . . .
(courtesy NVIDIA)
l resource contention can cause a dramatic
loss of performance
l the CUDA occupancy calculator can help
evaluate this
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 18

Performance Considerations: Instruction Mix
l goal: keep the SP’s FPUs fully occupied doing useful operations
n every other kind of instruction (loads, address calculations, branches) hinders
this!
l matrix multiply revisited:
n strategy 1: ‘unroll’ k loops:for (int k=0; k < K; k+=2)
cij += A d [i+k ∗N]∗ B d [k+j ∗K] +A d [i+(k+1)∗N]∗ B d [k+1+j ∗K];
halves loop index increments & branches
n strategy 2: each thread computes a 2×2 ‘tile’ of C instead of a single element
reduces load instructions; reduces branches by 4 – but may require 4× the
registers!
also increases thread granularity: may help if K is not large
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 19

Host-Device Issues: Multiple GPUs, NVLink, and Unified Memory
l transfer of data to/from host to device is error-prone, potentially a performancebottleneck (what if the array for an advection solver could not fit in GPU memory?)
l the problem is exacerbated when multiple GPUs are connected to one hostn we can select the required device by cudaSetDevice():
cudaSetDevice (0);cudaMalloc(a d , n); cudaMemcpy(a d , a, n, ...);reverseArray<<<1,n/2>>>(a d , n);cudaThreadSynchronize (); cudaMemcpyPeer(a b , 0, b d , 1, n);cudaSetDevice (1);reverseArray<<<1,n/2>>>(b d ,n);
l fast interconnects such as NVLink will reduce the transfer costs (e.g. Sierra system)
l CUDA’s Unified Memory will improve programability issues (and in some cases,performance)
n cudaMallocManaged(a, n); allocates the array on host so that it can migrate,page-by-page, to/from GPU(s) transparently and on demand
l alternatively, have the device and CPU use the same memory, as on AMD’s APUfor Exascale Computing
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 20

The Open Compute Language for Devices and Regular Cores
l open standard – not proprietary like CUDA; based on C (no C++)
l design philosophy: treat GPUs and CPUs as peers,
data- and task- parallel compute model
l similar execution model to CUDA:
n NDRange (CUDA grid): operates on global data, units within cannot synch.
n WorkGroup (CUDA block): units within can use local data (CUDA
shared ), to synch.
n WorkItem (CUDA thread): indpt. unit of execution, also has private data
l example kernel:kernel void reverseArray( global int ∗ a d , int N) {int idx = getGlobalId (0);int v = a[N−idx−1]; a[N−idx−1] = a[idx]; a[idx] = v;
}
l recall that in CUDA, we could launch as reverseArray<<<1,N/2>>>(a d, N),
but in OpenCL. . .
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 21

OpenCL Kernel Launch
l must explicitly create device handle, compute context and work-queue, load andcompile the kernel, and finally enqueue it for executionclGetDeviceIDs (..., CL DEVICE TYPE GPU , 1, &device , ...);context = clCreateContext (0, 1, &device , ...);queue = clCreateCommandQueue(context , device , ...);
program = clCreateProgramWithSource(context , " r e v e r s e A r r a y . cl ", ...)clBuildProgram(program , 1, &device , ...);
reverseArr k = clCreateKernel(program , " r e v e r s e A r r a y ", ...);clSetKernelArg(reverseArray k , 0, sizeof( cl mem ) & a d );clSetKernelArg(reverseArray k , 0, sizeof(int) &N);cnDimension = 1; cnBlockSize = N/2;clEnqueueNDRangeKernel(queue , reverseArray k , 1, 0,
&cnDimension , &cnBlockSize , 0, 0, 0);
l note: CUDA host code is compiled into .cubin intermediate files which follow a similar sequence
l for usage on normal core (CL DEVICE TYPE CPU), a WorkItem corresponds to anitem in a work queue that a number of (kernel-level) threads get work from
n compiler may aggregate these to reduce overheads
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 22

Directive-Based Programming Models
l OpenACC enables us to specify which code is to run on a device, and how totransfer data to/from it#pragma acc parallel loop copyin(a,b) copy(c)
for (i=0; i < N; i++)for (int j=0; j < N; j++) {
double cij = C[i + j ∗N];for (int k=0; k < K; k++)
cij += A[i + k ∗N] ∗ B[k + j ∗K];C[i + j ∗N] = cij;
}
n the data directive may be used to specify data placement across kernels
n the code can be also compiled to run across multiple CPUs
l OpenMP 4.0 operates similarly. For the above example:#pragma omp target map(to:A[0:N ∗K],B[0:N ∗K]) map(tofrom:C[0:N ∗N])#pragma omp parallel for default(shared)
l studies on complex applications where all data must be kept on device indicate a
productivity grain and performance loss of ≈ 2× over CUDA (e.g. Zhe14)
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 23

Graphics Processing Units: Summary
l designed to exploit computations expressible in large numbers of identical,
independent threads
n grouped into blocks: allocated to an SM and hence can have synchronization
within each
l GPU cores are designed for throughput, not single-thread speed
n low clock speed, instructions taking several clock cycles
l SIMT execution to hide long latencies; large amounts of hardware to maintain many
thread contexts
l destructive sharing: appears as resource contention
l may lose performance due to poor utilization, but not from load imbalance
l L2 cache and memory bandwidth an important consideration, but main
consideration in access patterns is within a warp
COMP4300/8300 L21,22: Graphics Processing Units 2017 JJ J • I II × 24