page 1 sendis sectoral operational programme "increase of economic competitiveness"...
TRANSCRIPT

Page 1
SenDiS
Sectoral Operational Programme "Increase of Economic Competitiveness""Investments for your future"
Project co-financed by the European Regional Development Fund
General Word Sense Disambiguation System applied to Romanian and English Languages- SenDiS -
Andrei Mincă - [email protected]
SenDiS – WSD model, components, algorithms, methods & results

Page 2
SenDiS WSD model

Page 3
SenDiS System components

Page 4
SenDiS
Order Lexicon Network (OLN)
Build Meaning Semantic Signatures (BMSS)
Compare Meaning Semantic Signatures (CMSS)
Compute WSD Variants (CwsdV)
WSD phases

Page 5
SenDiS
Input: unordered lexicon network
lexicon network optimizations considering number of edges loops or strong connected components number of roots and leafs number of levels (in the case of leveling the LN)
Output: ordered lexicon network
OLN Algorithms

Page 6
SenDiS
Input a lexicon network (not necessarily ordered) a meaning ( ID )
Builds a semantic interpretation for the specified meaning over the lexicon network spanning trees sets of nodes sequences of edges or combinations of the above
Output : a semantic interpretation (signature) for the meaning
BMSS Algorithms

Page 7
SenDiS
Input: two or more semantic signatures
comparison depends on the nature of the semantic signatures
Output: degrees of similarity
CMSS Algorithms

Page 8
SenDiS
Input : a matrix with degrees of similarity between the context words sense
Output : one or several WSD variants with the highest cost
CwsdV Algorithms
...
11s
12s
13s
14s
21s
22s
1NS
2NS
3NS
NW
1W
2W
1..3 NW

Page 9
SenDiS
Input text list of meanings lexicon network
Computing tokenization of text annotation of text tokens with meaning interpretations selecting a window-text for WSD other context filters or topologies build meaning semantic signatures for each word-sense compare meaning semantic signatures and fill the matrix compute best WSD variants
Output one or more WSD variants with one or more meaning interpretations for each text token
WSD methods

Page 10
SenDiS
tokenization
part-of-speech tagging
lemmatization
sense interpretations
chunking
parsing
general WSD requirements

Page 11
SenDiS
Performance indicators P - precision
P = noCorrectlyDisambiguated_TargetWords / noDisambiguated_TargetWords
R - recall
R = noCorrectlyDisambiguated_TargetWords / noTargetWords F-measure
2 * P * R / (P+R)
state-of-the-art results (F-measure) lexical sample task
coarse-grained : ~ 90%
fine-grained : ~ 73%
All-words task coarse-grained : ~83%
fine-grained : ~ 65%
Testing WSD

Page 12
SenDiS
A test configuration for SenDiS consists of:
a meaning inventory a lexicon network an OLN algorithm a BMSS algorithm a CMSS algorithm a CwsdV algorithm a WSD method a Corpus test
Testing SenDiS
nMIs x nLNsx
nOLNsx
nBMSSs x nCMSSsx
nCwsdVsx
nWSDMsx
nCorpusTests

Page 13
SenDiS ResultsSenseval 2No. Texts LexNet P R F-measure Time (h) Observations
(no POS tagging)
224 WN_ex 0.2891 0.2176 0.24597644 0.4 meaning interpretationsonly for recognized lemmas
225 WN_ex 0.3119 0.2902 0.29973205 0.4 20% coverage for GRAALAN Inflection Form Entries
225 WN_ex 0.3913 0.3913 0.39127589 0.36 20% IFEs + corpus target words lemmas tags
Senseval 3No. Texts LexNet P R F-measure Time (h) Observations
(no POS tagging)
254 WN_ex 0.2313 0.1595 0.18507712 0.1 no IFEs
265 WN_ex 0.2185 0.2088 0.21305191 0.4 20% IFEs
256 WN_ex 0.2845 0.2845 0.28447832 0.33 20% IFEs + corpus target words lemmas tags
SemcorNo. Texts LexNet P R F-measure Time (h) Observations
(no POS tagging)
33,855 WN_ex 0.1961 0.1838 0.18888804 50 20% IFEs
33,866 WN_ex 0.2515 0.2515 0.2514715 46 20% IFEs + corpus target words lemmas tags
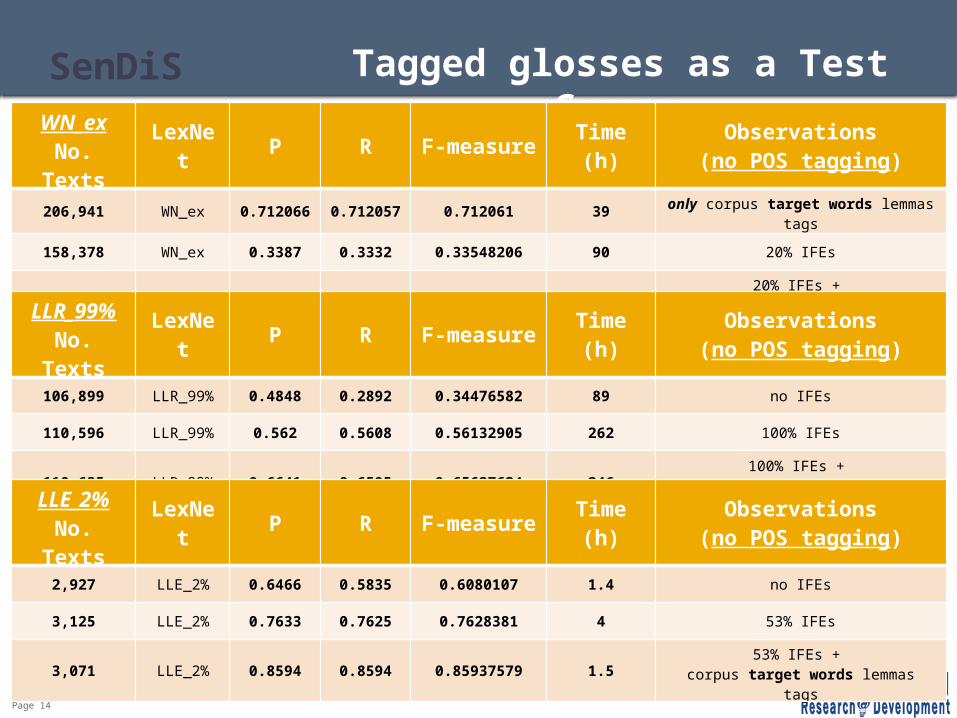
Page 14
SenDiS Tagged glosses as a Test Corpus
WN_exNo. Texts LexNet P R F-measure Time (h) Observations
(no POS tagging)
206,941 WN_ex 0.712066 0.712057 0.712061 39 only corpus target words lemmas tags
158,378 WN_ex 0.3387 0.3332 0.33548206 90 20% IFEs
158,667 WN_ex 0.4577 0.4198 0.43412967 90 20% IFEs + corpus target words lemmas tags
LLR_99%No. Texts LexNet P R F-measure Time (h) Observations
(no POS tagging)
106,899 LLR_99% 0.4848 0.2892 0.34476582 89 no IFEs
110,596 LLR_99% 0.562 0.5608 0.56132905 262 100% IFEs
110,635 LLR_99% 0.6641 0.6505 0.65627624 246 100% IFEs + corpus target words lemmas tags
LLE_2%No. Texts LexNet P R F-measure Time (h) Observations
(no POS tagging)
2,927 LLE_2% 0.6466 0.5835 0.6080107 1.4 no IFEs
3,125 LLE_2% 0.7633 0.7625 0.7628381 4 53% IFEs
3,071 LLE_2% 0.8594 0.8594 0.85937579 1.5 53% IFEs + corpus target words lemmas tags

Page 15
SenDiS