parallel coding approaches in converting sequential code programs to run on parallel machines
Post on 19-Dec-2015
241 views
TRANSCRIPT

Parallel coding
Approaches in converting sequential code programs to run on parallel machines

Goals
Reduce wall-clock timeScalability –
increase resolution expand space without loss of efficiency
It’s all about efficiencyPoor data communicationPoor load balancingInherently sequential algorithm nature

Efficiency
Communication overhead – data transfer is at most 10-3 the processing speedload balancing – uneven load which is statically balanced may cause idle processor time Inherently sequential algorithm nature – if all tasks should be performed serially, no room for parallelization
Lack of efficiency could cause a parallel code to perform worse than a similar sequential code
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
1 2 3 4 5 6 7 8 9
#processors
effi
cien
cy
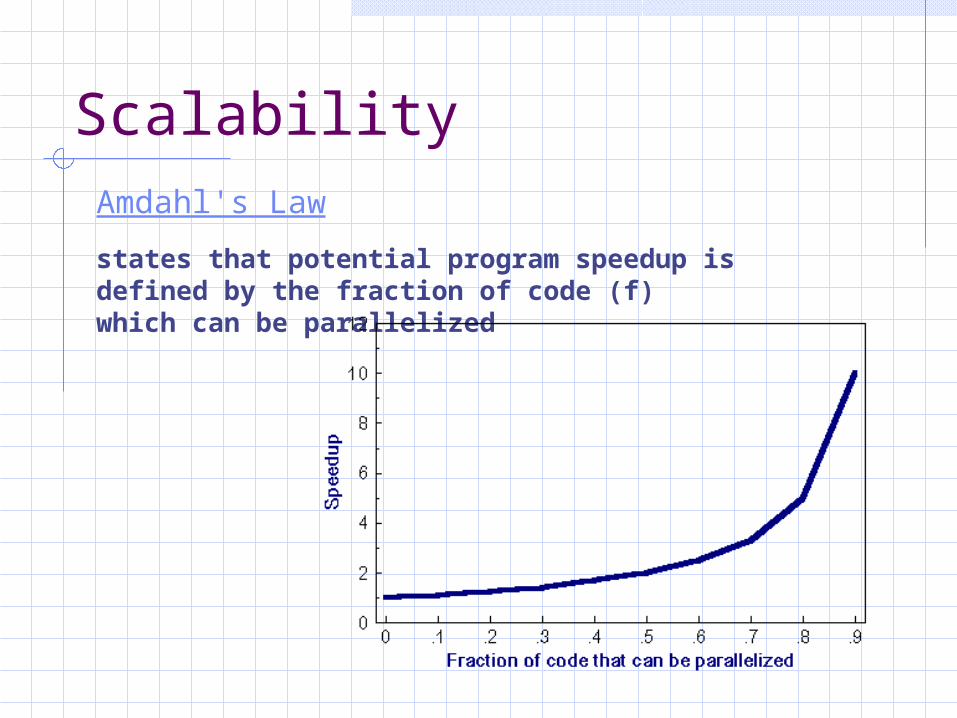
ScalabilityAmdahl's Law
states that potential program speedup is defined by the fraction of code (f) which can be parallelized

speedup
-----------------------
N P = .50 P = .90 P = .99
----- ------- ------- -------
10 1.82 5.26 9.17
100 1.98 9.17 50.25
1000 1.99 9.91 90.99
10000 1.99 9.91 99.02
1 1
speedup = -------- = -----------
1 - f P/N + S
Scalability

Before we start - Framework
• Code may be influenced/determined by machine architecture
The need to understand the architecture• Choose a programming paradigm
Choose the compiler • Determine communication
Choose the network topology• Add code to accomplish task control and communications
Make sure the code is sufficiently optimized (may involve the architecture)
• Debug the code
Eliminate lines that impose unnecessary overhead

Before we start - Program
1. If we are starting with an existing serial program, debug the serial code completely
2. Identify the parts of the program that can be executed concurrently:
• Requires a thorough understanding of the algorithm
• Exploit any inherent parallelism which may exist.
• May require restructuring of the program and/or algorithm. May require an entirely new algorithm.

Before we start - Framework
Architecture – Intel Xeon, 16Gb distributed memory, Rocks ClusterCompiler – Intel FORTRAN/pgfNetwork – star (mesh?)Overhead – make sure the communication channels aren’t clogged (net admin)Optimized Code – write c-code when necessary, use CPU pipelines, use debugged programs…

Sequential Coding Practice

explicitimplicit
HardwareBuy/design dedicated drivers and boards
buy new off-the-shelf products every so often
Instruction sets
Rely on them (MMX/SSE) and do assembly #$%!@ language
Make use of compiler’s optimization
Memorywrite dedicated memory handlers
adjust Do LOOP paging
Cachebranch prediciton / prefetching algorithm
adjust cache fetch by ordering the data streams manually
Improvement methods
Sequential coding practice
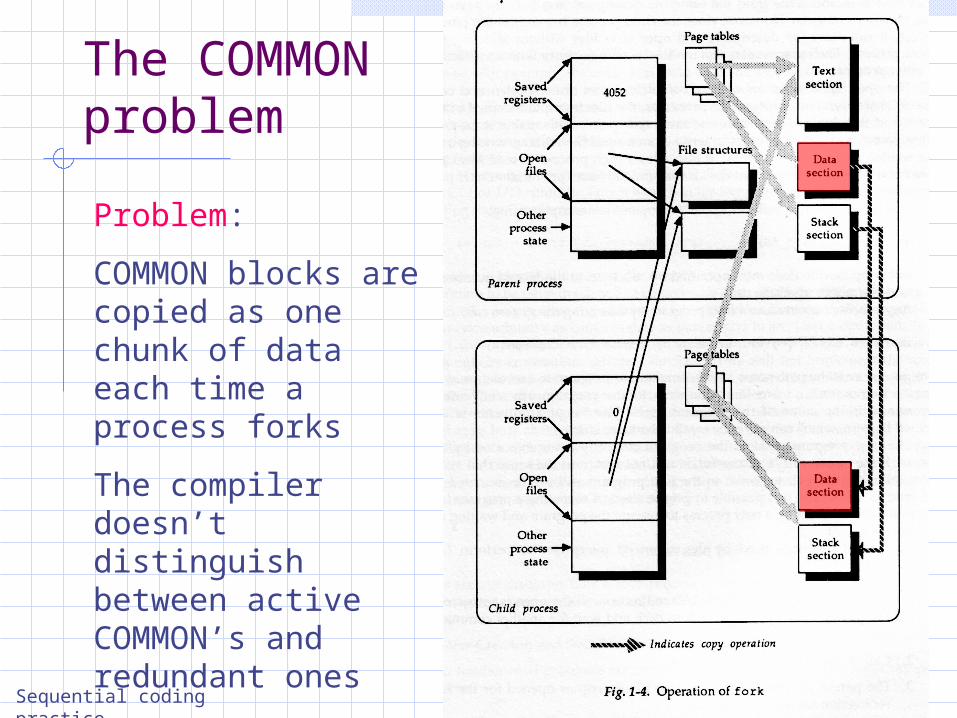
The COMMON problem
Problem:
COMMON blocks are copied as one chunk of data each time a process forks
The compiler doesn’t distinguish between active COMMON’s and redundant ones
Sequential coding practice

The COMMON problem
Problem:
COMMON blocks are copied as one chunk of data each time a process forks
The compiler doesn’t distinguish between declared COMMON’s and redundant ones
Sequential coding practice
On NUMA (Non Uniform Memory Access)MPP/SMP (massively parallel processing/Symmetric Multi Processor)
Vector machinesThis is rarely an issue
On a Distributed Computer (clusters)Crucial (network is congested by this)!!!
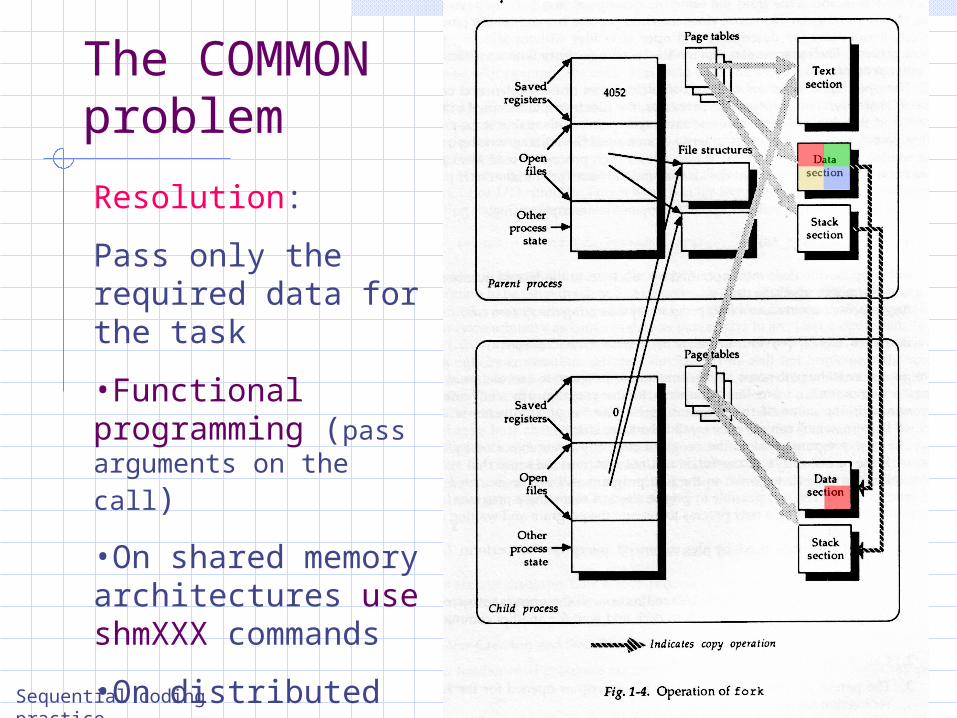
The COMMON problem
Resolution:
Pass only the required data for the task
•Functional programming (pass arguments on the call)
•On shared memory architectures use shmXXX commands
•On distributed memory architectures use message passing
Sequential coding practice

Swapping to secondary storage
Problem: swapping is transparent but uncontrolled – the kernel cannot predict which pages are needed next, only determine which are needed frequently
Sequential coding practice
Swap space is a way to emulate physical ram, right?
No, generally swap space is a repository to hold things from memory when memory is low. Things in swap cannot be addressed directly and need to be paged into physical memory before use, so there's no way swap could be used to emulate memory.
So no, 512M+512M swap is not the same as 1G memory and no swap.
KernelTrap.org

Swapping tosecondary storage - Example
Sequential coding practice
CPU – dual Intel Pentium3Speed - 1000MHzRAM - 512 MBCompiler – IntelFortranOptimization – O2 (default)
381MB X 2
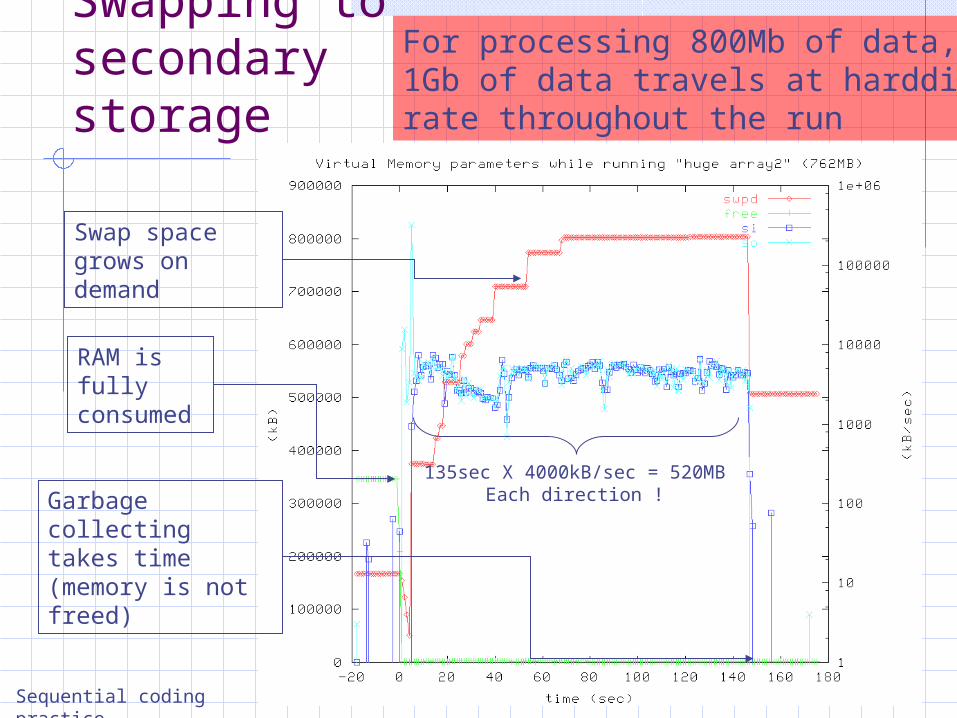
Swapping to secondary storage
Sequential coding practice
Garbage collecting takes time (memory is not freed)
Swap space grows on demand
RAM is fully consumed
135sec X 4000kB/sec = 520MBEach direction !
For processing 800Mb of data,1Gb of data travels at harddiskrate throughout the run

Swapping to secondary storage
Problem: swapping is transparent but uncontrolled – the kernel cannot predict which pages are needed next, only determine which are needed frequently
Resolution: prevent swapping by adjusting the data amount into user process RAM size
(read and write temporary files from/to disk).
Sequential coding practice
Swap space is a way to emulate physical ram, right?
No, generally swap space is a repository to hold things from memory when memory is low. Things in swap cannot be addressed directly and need to be paged into physical memory before use, so there's no way swap could be used to emulate memory.
So no, 512M+512M swap is not the same as 1G memory and no swap.
KernelTrap.org
Swapping to secondary storage
Sequential coding practice
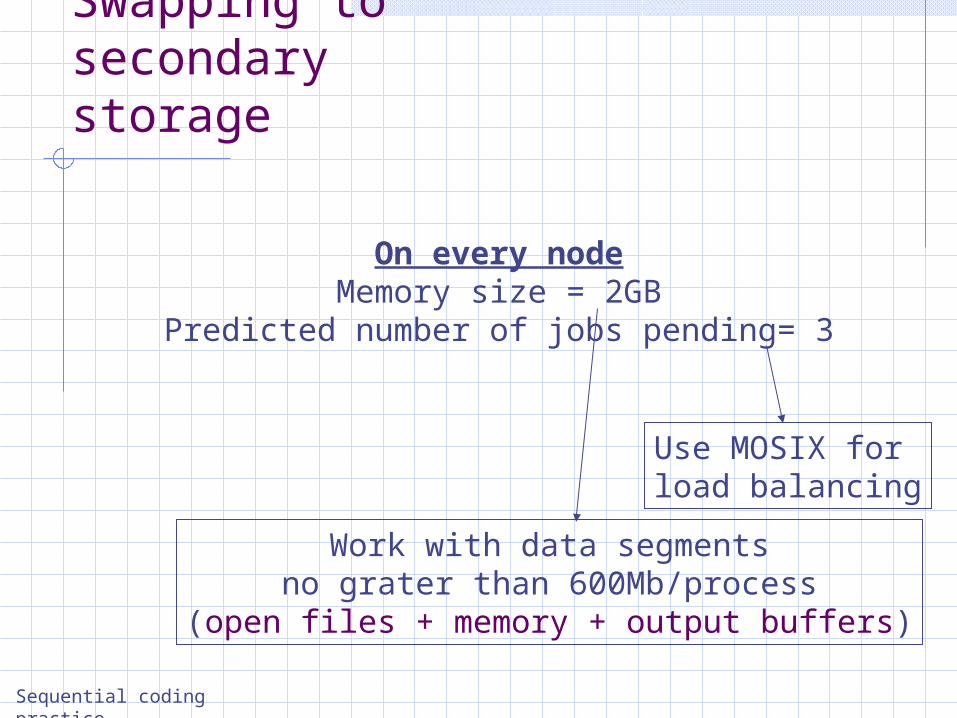
On every nodeMemory size = 2GB
Predicted number of jobs pending= 3
Work with data segmentsno grater than 600Mb/process
(open files + memory + output buffers)
Use MOSIX forload balancing
Paging, cache
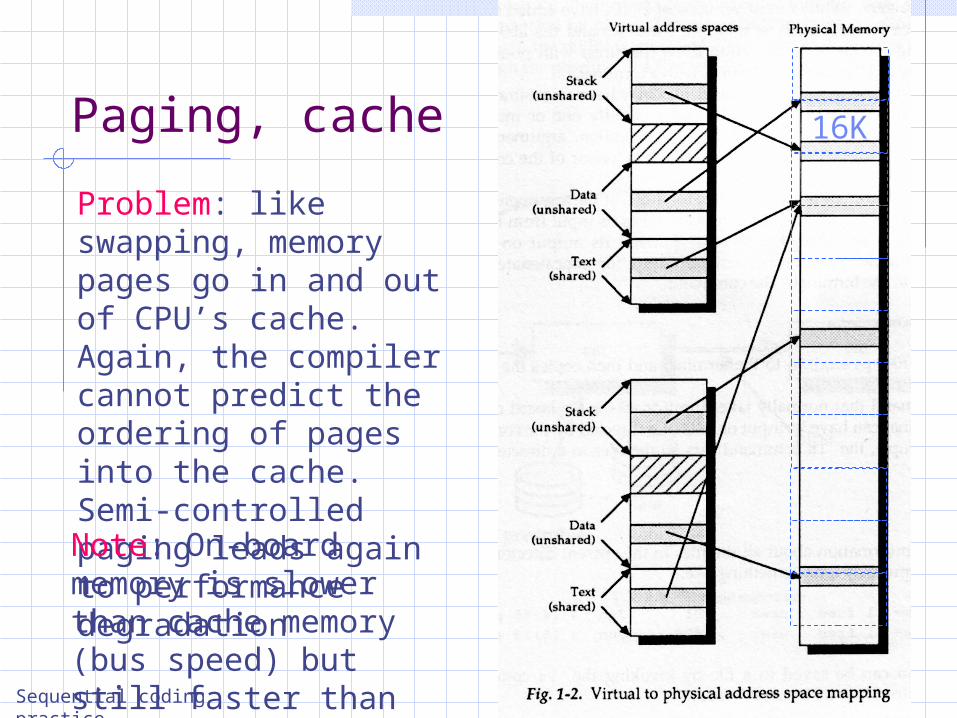
Problem: like swapping, memory pages go in and out of CPU’s cache. Again, the compiler cannot predict the ordering of pages into the cache. Semi-controlled paging leads again to performance degradation
Sequential coding practice
16K
Note: On-board memory is slower than cache memory (bus speed) but still faster than disk access
Paging, cache
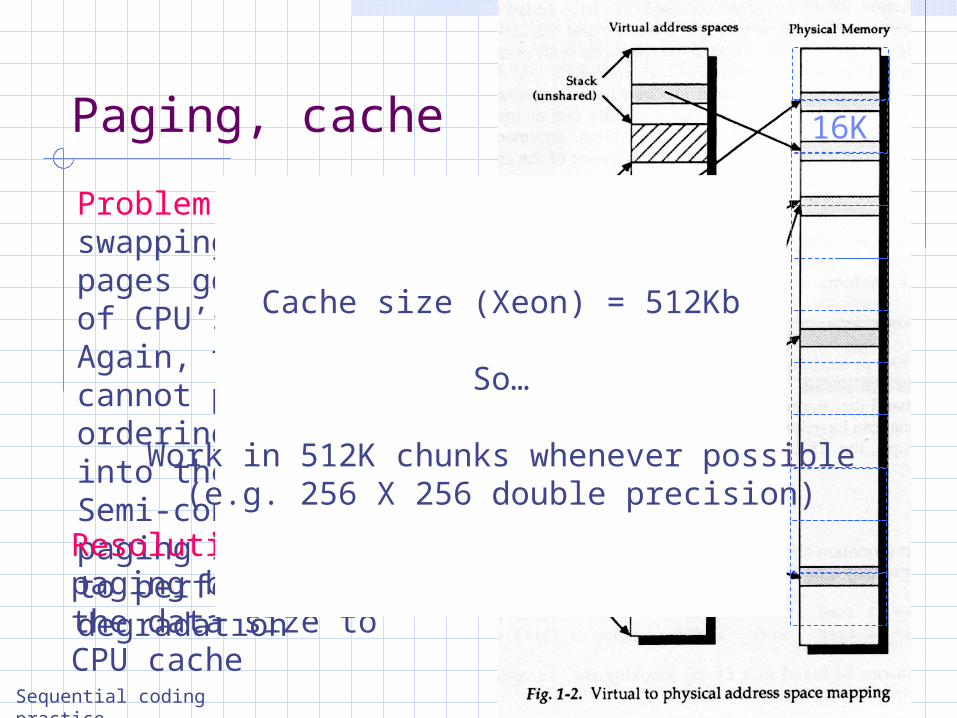
Problem: like swapping, memory pages go in and out of CPU’s cache. Again, the compiler cannot predict the ordering of pages into the cache. Semi-controlled paging leads again to performance degradation
Resolution: prevent paging by adjusting the data size to CPU cache
Sequential coding practice
Cache size (Xeon) = 512Kb
So…
Work in 512K chunks whenever possible(e.g. 256 X 256 double precision)
16K
Example
Sequential coding practice
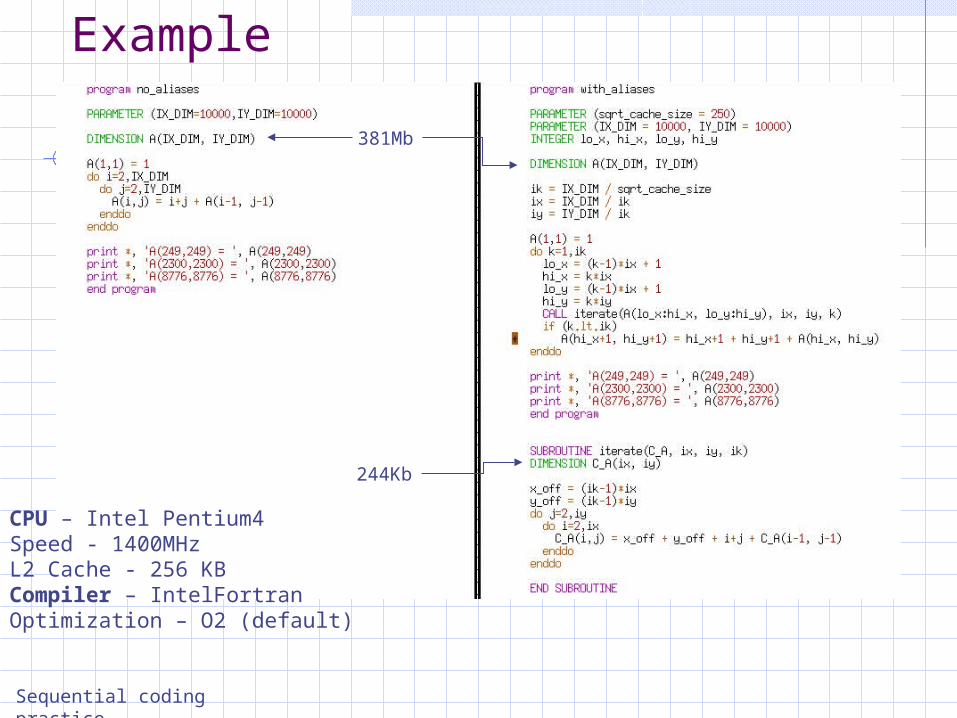
381Mb
CPU – Intel Pentium4Speed - 1400MHzL2 Cache - 256 KBCompiler – IntelFortranOptimization – O2 (default)
244Kb

Exampleresults
Sequential coding practice
2.3 times less code516 times slower
overall361 times slower do-loop execution
36 Cache misses3 Print statements
40 Function calls3 Print statements

Workload summary
Adjust to cache sizeAdjust to cache sizeAdjust to pages in sequence
Adjust to RAM sizeControl disk activity slowest
fastest

Sparse Arrays
Current – Dense (full) arrays All array indices are occupied in memory Matrix manipulations are usually element by
element (no linear algebra manipulations when handling parameters on the grid)
Sequential coding practice
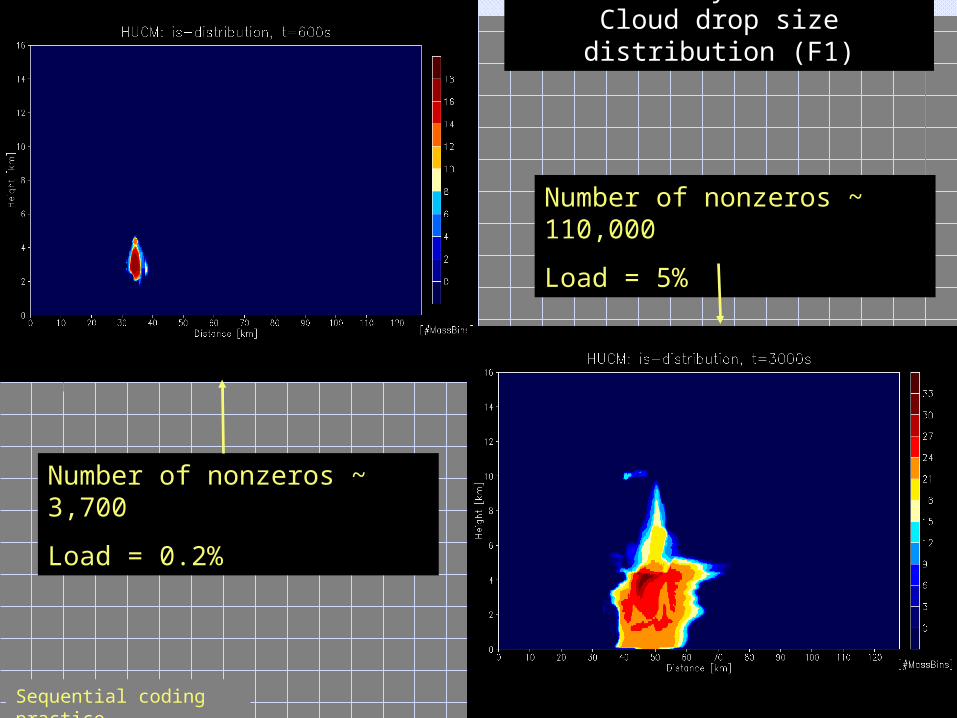
Number of nonzeros ~ 110,000
Load = 5%
Number of nonzeros ~ 3,700
Load = 0.2%
Sequential coding practice
Dense Arrays in HUCM:Cloud drop size distribution
(F1)
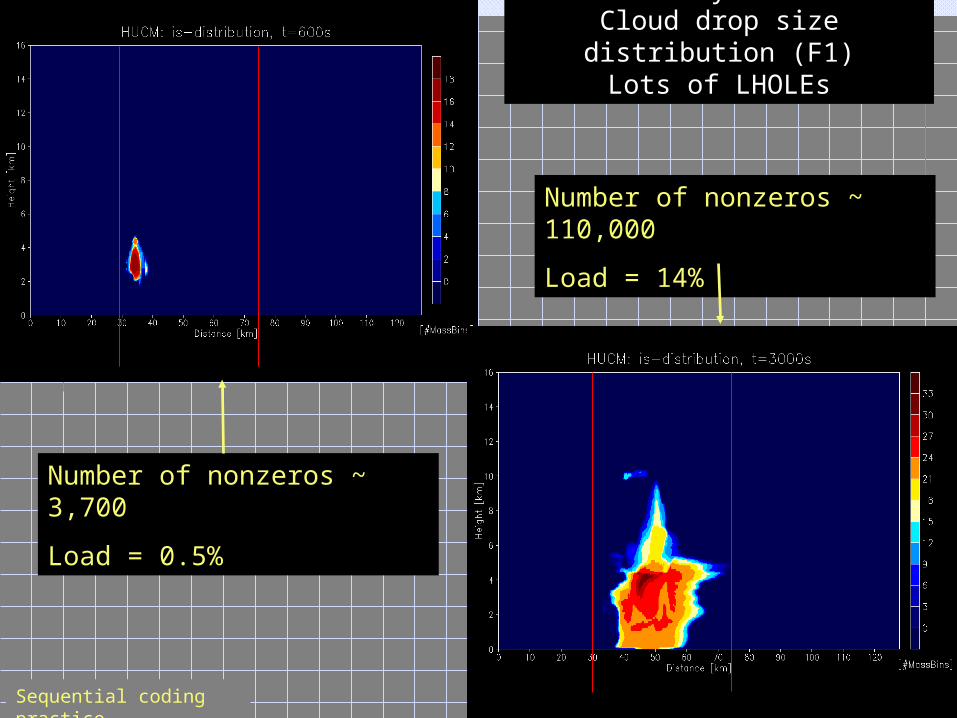
Number of nonzeros ~ 110,000
Load = 14%
Number of nonzeros ~ 3,700
Load = 0.5%
Sequential coding practice
Dense Arrays in HUCM:Cloud drop size distribution
(F1)Lots of LHOLEs

Sparse Arrays
Current – Dense (full) arrays All array subscripts occupy memory Matrix manipulations are usually element by
element (no linear algebra manipulations when handling parameters on the grid)
Improvement – Sparse arrays Only non-zero elements occupy memory cells. Spare
notation When calculating algebraic matrices – run the
profiler to check performance degradation due to sparse data
}0:,|),,{( ijij ajiajiA
Sequential coding practice
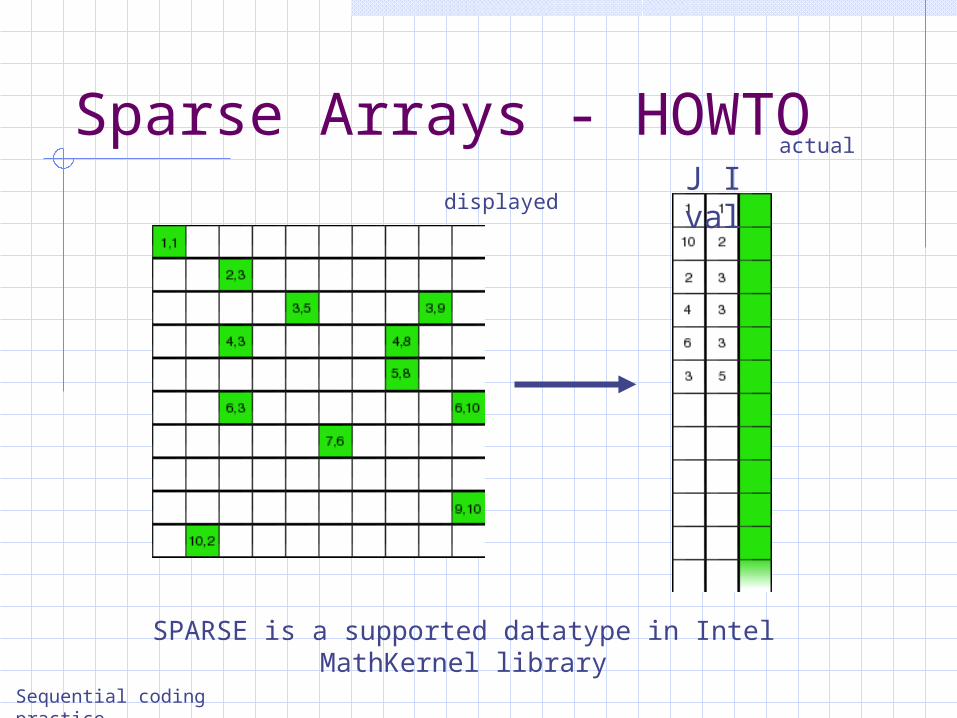
Sparse Arrays - HOWTO
Sequential coding practice
J I val
SPARSE is a supported datatype in Intel MathKernel library
displayed
actual

DO LOOPs
Current – have no respect to memory layout. example – FORTRAN uses column major subscripts
Memory layout
Virtual layout:
a 2D array(Column major)
Sequential coding practice
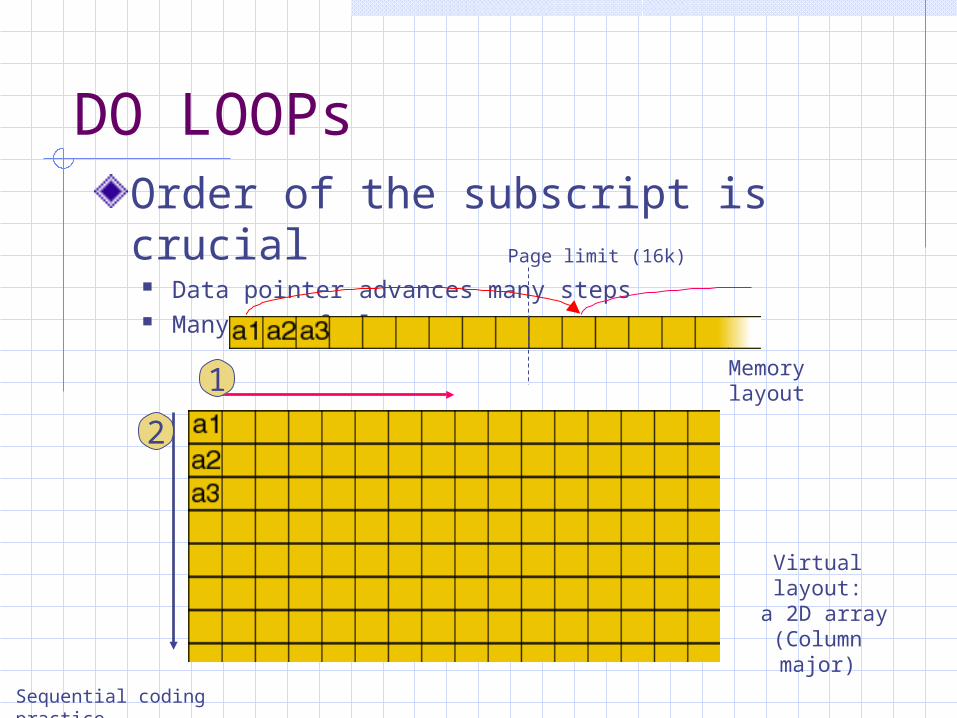
DO LOOPsOrder of the subscript is crucial
Data pointer advances many steps Many page faults
Memory layout
Virtual layout:
a 2D array(Column major)
Sequential coding practice
2
1
Page limit (16k)
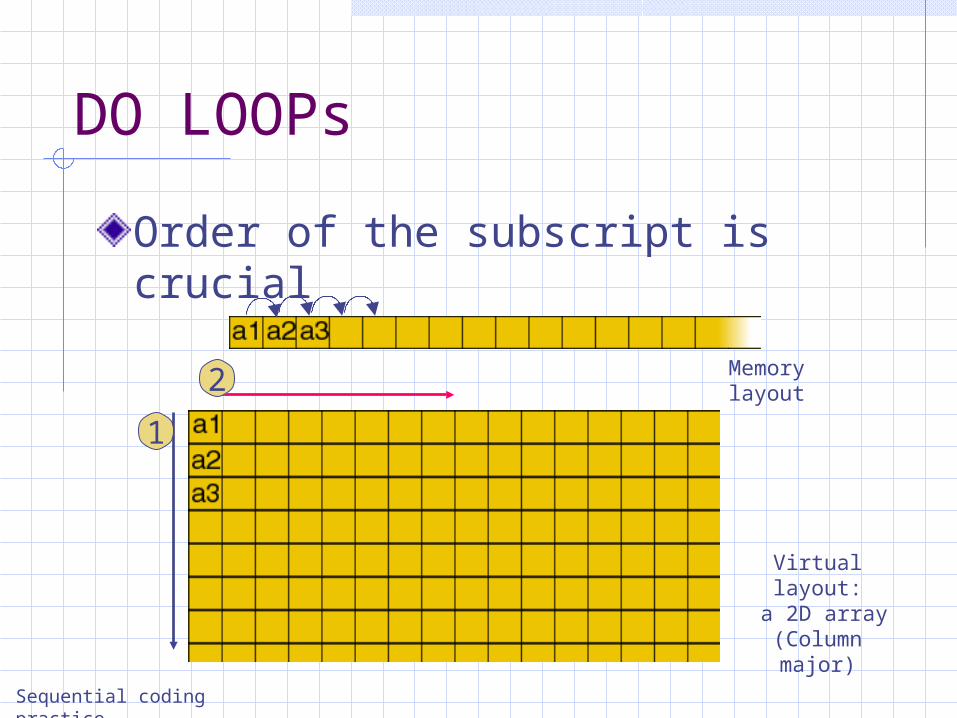
DO LOOPs
Order of the subscript is crucial
Memory layout
Virtual layout:
a 2D array(Column major)
Sequential coding practice
1
2

DO LOOPs - example
Sequential coding practice
125Mb
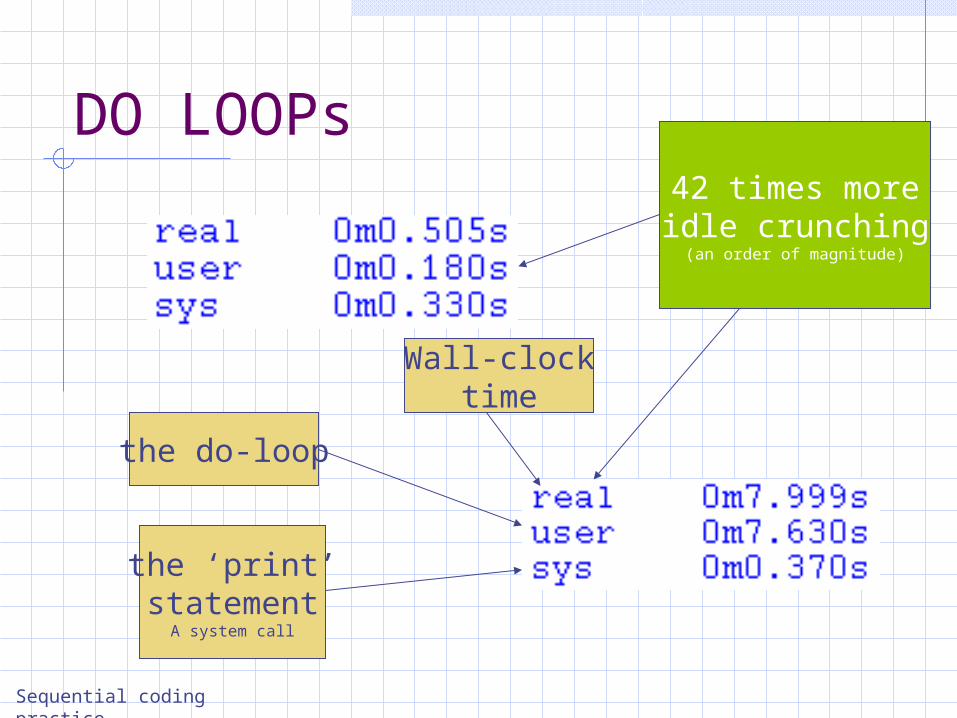
DO LOOPs
Sequential coding practice
the do-loop
the ‘print’statement
A system call
Wall-clocktime
42 times moreidle crunching
)an order of magnitude(

Improvements Reorder the DO LOOPs
or Rearrange the dimensions in an array:
GFF2R(NI, NKR, NK, ICEMAX) ->GFF2R(ICEMAX, NKR, NK,
NI)
DO LOOPs
Innermost (fastest) running subscript
Outermost (slowest) running
subscriptSequential coding practice

Parallel Coding Practice

Job Scheduling
Current Manual batch: hard to track, no monitoring
of the control
Improvements: Batch scheduling / parameter sweep
(e.g. shell scripts, NIMROD) EASY/MAUI backfilling job scheduler
Parallel coding practice

Load balancingCurrent Administrative - manual (and rough) load balancing:
Haim MPI, PVM,… libraries –no load balancing capabilities,
software dependent: RAMS – variable grid point area MM5, MPP - ? WRF - ?
File system – NFS A disaster!!!: client side caching, no segmented file locks, network congestion
Improvements: MOSIX: kernel level governing, better monitoring of jobs, no
stray (defunct) residues MOPI – DFSA (not PVFS, and definitely not NFS)
Parallel coding practice

NFS – client side cache
every node has a non-concurrent mirror of the image Write – 2 writes to the same location
may crash the system Read – old data may be read
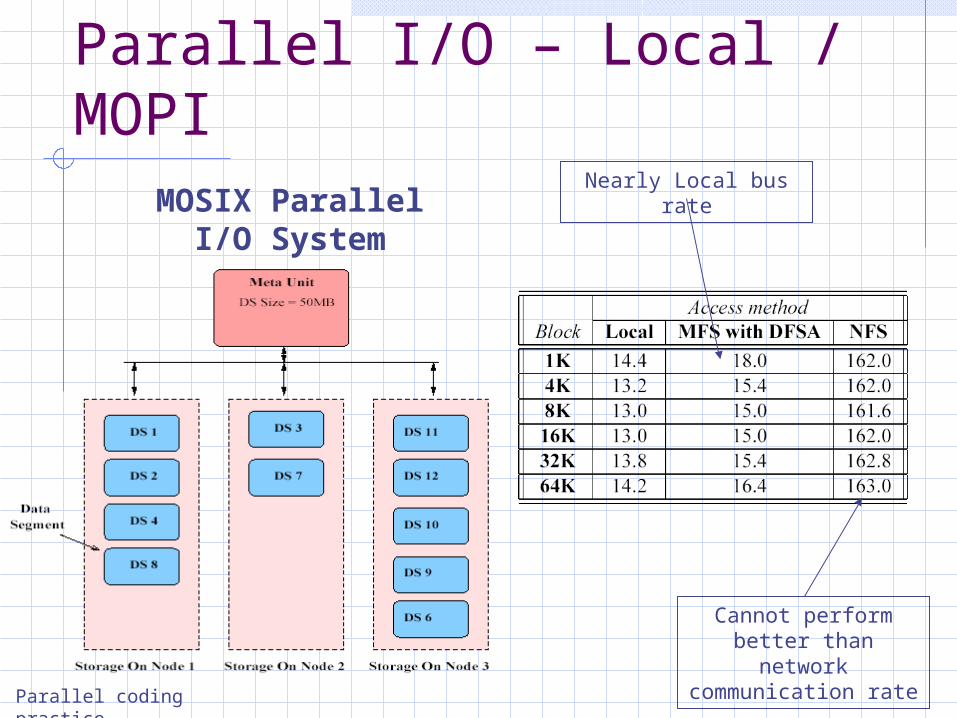
Parallel I/O – Local / MOPI
Parallel coding practice
MOSIX Parallel I/O System
Cannot perform better than network communication rate
Nearly Local bus rate

Parallel I/O – Local / MOPI
Local – can be adapted with minor change in source codeMOPI - Needs installation but requires no changes in source code
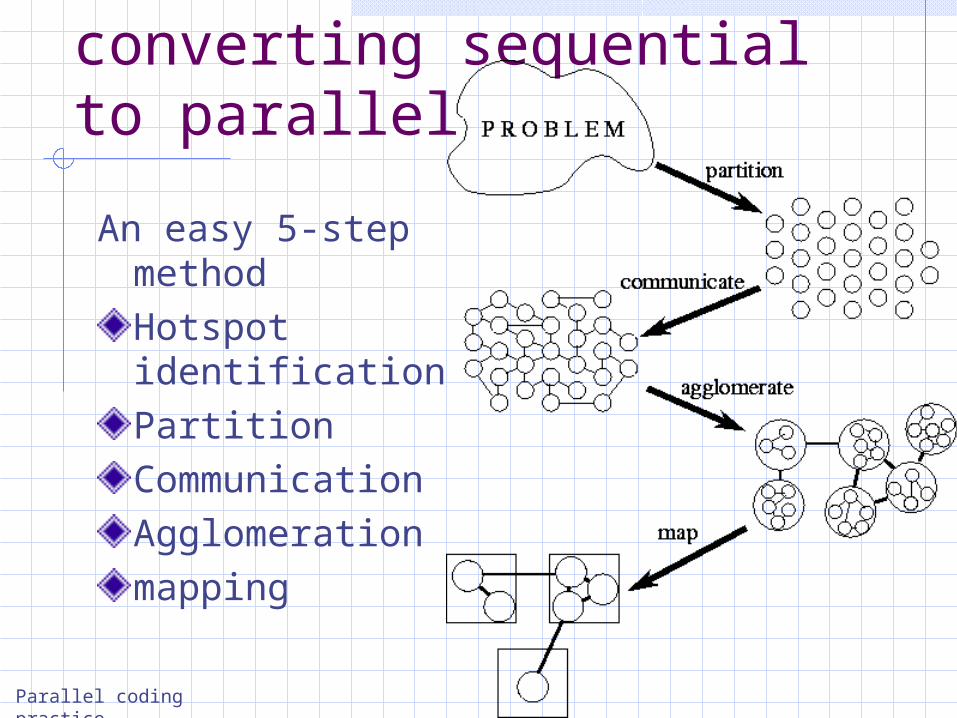
converting sequential to parallel
An easy 5-step method
Hotspot identificationPartitionCommunicationAgglomerationmapping
Parallel coding practice

HotspotsPartitionCommAgglomerateMap
Parallelizing should be done methodically in a clean, accurate and meticulous way.
However intuitive parallel programming is, it does not always allow straightforward automatic mechanical methods.
One of the approaches - the methodical approach (Ian Foster):
This particular method maximizes the potential for parallelizing and provide efficient steps that exploit this potential. Furthermore, it provides explicit checklists on completion of each step (not detailed here).
Parallel coding practice

5-step hotspots HotspotsPartitionCommAgglomerateMap
Identify the hotspots – identify the parts of a program which consume the most run time.
Our goal here is to know which code segments can and should be parallelized.
Why?
For e.g.: Greatly improve code that consumes 10% of the run time may increase performance by 10% whereas optimizing code that consumes 90% of the
runtime may enable an order of magnitude speedup.
How?
Algorithm inspection (in theory)
By looking at the code
By Profiling (tools such as prof or another 3rd party) to identify bottlenecksParallel coding practice

5-step partition1 HotspotsPartitionCommAgglomerateMap
Definition:
The ratio between computation and communication is known as granularity
Parallel coding practice

5-step partition2 HotspotsPartitionCommAgglomerateMap
Goal Partition the tasks into the most fine grain ones.
Why?
We want to discover all the available opportunities for parallel execution, and to provide flexibility when we introduce the following steps (communication, memory and other requirements will enforce the optimal agglomeration and mapping)
How?• Functional Parallelism
• Data Parallelism
Data decomposition – sometimes its easier to start off with partitioning the data into segments which are not mutually dependent
Parallel coding practice
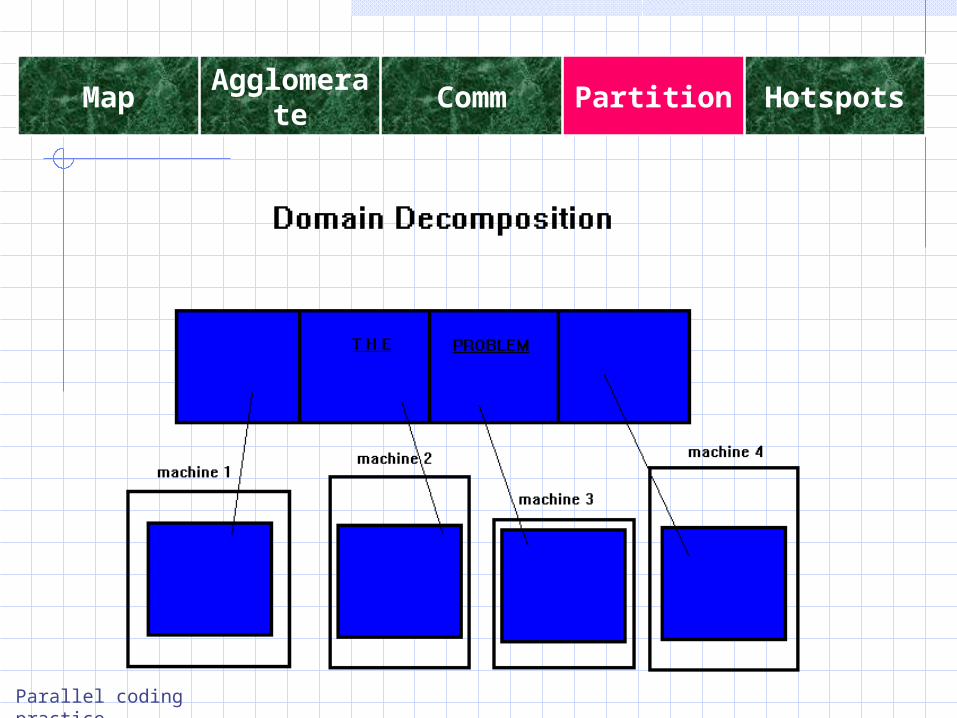
5-step partition3 HotspotsPartitionCommAgglomerateMap
Parallel coding practice

5-step partition4 HotspotsPartitionCommAgglomerateMap
Goal Partition the tasks into the most fine grain ones.
Why?
We want to discover all the available opportunities for parallel execution, and to provide flexibility when we introduce the following steps (communication, memory and other requirements will enforce the optimal agglomeration and mapping)
How?• Functional Parallelism
• Data Parallelism
Functional decomposition –partitioning the calculation into segments which are not mutually dependent (e.g. integration
components are evaluated before the integration step)
Parallel coding practice
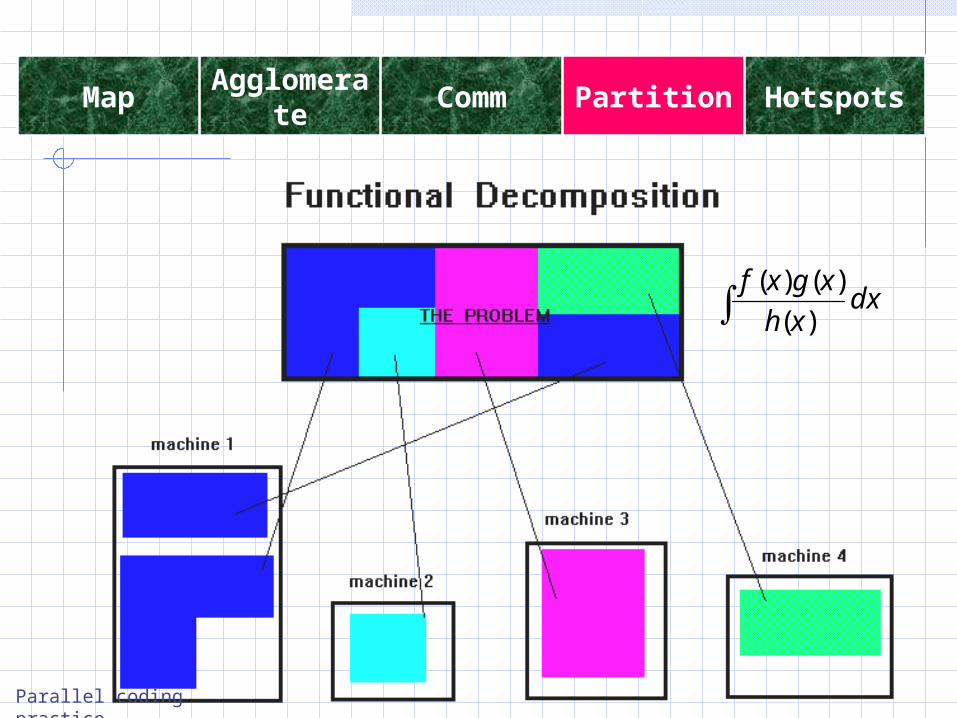
5-step partition5 HotspotsPartitionCommAgglomerateMap
Parallel coding practice
dxxh
xgxf
)(
)()(

5-step communication1 HotspotsPartitionCommAgglomerateMap
Communication occurs during data passing and synchronization. We strive to minimize data communication between tasks or make them more coarse-grained
Sometimes the master process may encounter too much traffic coming in: If large data chunks must be transferred try to form hierarchies in aggregating the data
• The most efficient granularity is dependent upon the algorithm and the hardware environment in which it runs
Decomposing the data has a crucial role here, consider revisiting step 2
Parallel coding practice

5-step communication2 HotspotsPartitionCommAgglomerateMap
Sending data out to sub-tasks:
Point-to-point is best for sending personalized data to each independent task
broadcast is good way to clog the network (all processors update the data, then need to send it back to the master) but we may find good use for it when a large computation can be performed once and lookup tables can be sent across the network
Collection is usually used to perform mathematics like min, max, sum…
Shared memory systems synchronize using the memory locking techniques
Distributed memory systems may use blocking or non-blocking message passing. Blocking MP may be used for synchronization
Parallel coding practice

5-step agglomeration HotspotsPartitionCommAgglomerateMap
Extreme granularity is not a winning scheme
Agglomeration of dependant tasks removes their communication requirements off of the network, and increases the computational and memory usage effectiveness of the processor which handles them
Rule of thumb: Make sure there are an order of magnitude more tasks than processors
Parallel coding practice

5-step map HotspotsPartitionCommAgglomerateMap
Optimization:
• Measure Performance
• Locate Problem Areas
• Improve them
Load balancing (performed by the task scheduler):
• Static load balancing – if the agglomerated tasks run in similar time
• Dynamic load balancing – if the number of tasks is unknown or if there are uneven run-times among the tasks (pool of tasks)
Parallel coding practice

Project management
The physical problem becomes more complex when we consider parallelizing.
Implies large scale project planning:Work in the group should conform to one protocol to allow seamless integration: use the Concurrent Version Systems
Study computer resources to their limits: program to fit calculations in the cache, message packets in the NIC buffers, file decomposition to minimize network traffic
Form a work plan beforehand.

References
Foster I., Designing and Building Parallel Programs (http://www-unix.mcs.anl.gov/dbpp/)Egan, J. I., and Teixeira T. J., (1988), Writing a UNIX device driverSP Parallel Programming Workshop, Maui High Performance Computing Center (http://www.hku.hk/cc/sp2/workshop/html)Amar L., Barak A. and Shiloh A., (2002) The MOSIX Parallel I/O System for Scalable I/O Performance. Proc. 14-th IASTED International Conference on Parallel and Distributed Computing and Systems (PDCS 2002), pp. 495-500, Cambridge, MA.