pedro h. c. avelar thiago l. t. da silveira2
TRANSCRIPT

Superpixel Image Classification with Graph Attention Networks
Pedro H. C. Avelar1,2,* Anderson R. Tavares1 Thiago L. T. da Silveira3
Claudio R. Jung1 Luıs C. Lamb1
1 Federal University of Rio Grande do Sul, Porto Alegre, Brazil2 Data Science Brigade, Porto Alegre, Brazil
3 Federal University of Rio Grande, Rio Grande, Brazil
Abstract
This paper presents a methodology for image clas-sification using Graph Neural Network (GNN) mod-els. We transform the input images into region adja-cency graphs (RAGs), in which regions are superpix-els and edges connect neighboring superpixels. Ourexperiments suggest that Graph Attention Networks(GATs), which combine graph convolutions with self-attention mechanisms, outperforms other GNN mod-els. Although raw image classifiers perform bet-ter than GATs due to information loss during theRAG generation, our methodology opens an inter-esting avenue of research on deep learning beyondrectangular-gridded images, such as 360-degree fieldof view panoramas. Traditional convolutional ker-nels of current state-of-the-art methods cannot han-dle panoramas, whereas the adapted superpixel algo-rithms and the resulting region adjacency graphs cannaturally feed a GNN, without topology issues.
1 Introduction
The generic image classification problem consists ofdetermining what object classes (typically from aset of pre-defined categories) are present in an in-put image. Early approaches followed the traditionalpipeline of extracting image features (e.g., colour,texture, etc.) and feeding them to a classifier. Theseminal work by Krizhevsky and colleagues [12] ex-plored deep neural networks for image classification,winning the ImageNet Large Scale Visual Recogni-tion Challenge (ILSVRC) in 2012 by a large mar-gin and setting a turning point for research on imageclassification. The datasets became more challenging
∗Corresponding author: [email protected]
and the networks grew deeper, with the GoogLeNetarchitecture [27] winning the ILSVRC2014 chal-lenge and “Squeeze-and-Excitation” layers being in-troduced in [7] to win the ILSVRC2017 challenge,with a top-5 error rate of 2.251%.
Despite the recent advances both in terms ofdatasets and network architectures, using traditionalconvolutional kernels limits the applications of thesenetworks in problems that do not present a domainbased on rectangular grids. For example, panora-mas capture a full 360-degree field of view. Althoughthe equirectangular representation does use a rectan-gular domain, sampling is highly non-uniform. Tohandle these issues, some authors proposed networksdesigned to adapt to the spherical domain have beendesigned, such as [4], while others propose to learnhow to adapt convolutional layers to the spherical do-main, as [25]. As another example, we can mentionpoint-cloud classification, in which spatially unstruc-tured data cannot be represented using a rectangulardomain. In this context, some authors either explorea voxelized representation of the scene with 3D net-works [31] or directly use 3D points as input to anetwork.
Graph-based representations can be used to modela variety of problems and domains. Furthermore,they naturally allow several “multiresolution” repre-sentations of the same object. For example, bothpixel-level and superpixel-level representations of thesame image might be modeled using graphs. Infact, superpixel-based representations have the ad-vantage of reducing the input size, and potentiallyallowing different domains (e.g. pinhole and spher-ical images) to be represented as the same (or sim-ilar) graph. Furthermore, there are several recentadvances toward the development of Graph NeuralNetworks (GNNs) [32], which could bridge the gap
1
arX
iv:2
002.
0554
4v2
[cs
.LG
] 1
5 N
ov 2
020

between different domains. In this paper, we exploreGraph Attention Networks (GATs) [29] to classify im-ages based on superpixel representations. GATs area Graph Neural Network model that combine ideas ofgraph convolutions [10], which allows graph nodes toaggregate information from their irregular neighbour-hoods, with self-attention mechanisms [28], which al-lows nodes to learn the relative importance of eachneighbour during the aggregation process.
Our methodology comprises the following steps: (i)generate a superpixel representation of the input im-age; (ii) create a region adjacency graph (RAG) fromthe superpixel representation, by connecting neigh-bouring superpixels; (iii) feed the RAG to the GAT,which will predict the class. Experiments on sev-eral datasets show that the GAT outperforms otherRAG-based GNN classifiers, but the RAG providesmuch less information than the raw image, so thatthe GAT’s performance is inferior compared to theraw-image classifiers.
This paper is organised as follows: in Section 2, wepresent related works and peering approaches. Sec-tion 3 revises existing superpixel segmentation tech-niques and how they are used to represent graphs, ex-posing the differences with the competing approach.Section 4 describes the proposed method, while Sec-tion 5 shows the experimental setup and obtained re-sults. Finally, the conclusions are drawn in Section 6.
2 Related Work
Monti et al. [15] provided, to the best of our knowl-edge, the first application of Graph Neural Networks(GNNs) to image classification, as well as proposingthe MoNET framework for dealing with geometricdata in general. Their framework works by weight-ing the neighbourhood aggregation through a learntscaling factor based on geometric distances.
Velickovic et al. [29] proposed a model using self-attention for weighting the neighbourhood aggrega-tion in GNNs, recognising that this model couldbe seen as a sub-model of the MoNET framework,nonetheless providing extraordinary results on otherdatasets, namely Cora and Citeseer, two famous ci-tation networks [19], and on the FAUST humansdataset [3].
Although graph-based methods can be applied di-rectly to images by considering each pixel a node ofthe graph, as in the seminal paper of Shi and Ma-lik for image segmentation [20], lower-level represen-tations generate smaller graphs. Using each region
produced by a segmentation result might be a natu-ral choice, but generating accurate segmentation re-sults is still an open problem. A compromise solutionbetween using individual pixels and object-related re-gions is superpixels. Superpixels group pixels similarin colour and other low-level properties, like location,into perceptually meaningful representation units (re-gions or segments) [24]. These oversegmented, sim-plified, images can be applied in a number of commontasks in computer vision, including depth estimation,segmentation, and object localization [1]. A compre-hensive survey on superpixels can be found in [24].
The abovementioned work on using GNNs on im-ages, alongside the work on adapting self-attentionfor GNNs and the works for generating superpixelsof images form the pillars on which we based our ex-periments.
Two other models later came to our knowledge,which extended or could be seen as sub-models ofthe MoNET framework, using geometric informationto weight neighbourhood aggregation, and providedresults for the MNIST dataset. One of those is theSplineCNN model [6], which leverages properties ofB-spline bases in their neighbourhood aggregationprocedure. The other is the Geo-GCN model [23],which is a MoNET sub-model with a differently en-gineered learned distance function performing dataaugmentation using rotations and conformations.
Another technique for using GNNs with image datais to use them as a form of semi-supervised augmen-tation for classification, as in [9]. The main differ-ence between their method and ours is that whilethey extract a CNN feature descriptor for each im-age with a (possibly pretrained) convolutional net-work, and then build a graph on which their modelis used (akin to how Graph Convolutional Networksare used for semi-supervised classification in bag-of-words in [10]), we use the GAT as a classifier for agraph representing an image directly. Although theirtechnique is useful for semi-supervised learning, thetechnique of using the network for superpixel classi-fication has some possible advantages of its own, andthey are not directly comparable.
3 Superpixel Graphs
A number of techniques exist to generate superpixelsfrom images, such as SLIC [1], SNIC [2], SEEDS [5],ETPS [34], and the hierarchical approach from [30].For our experiments, we chose to use SLIC [1] sinceit was readily available and had a spatial component
2

Algorithm 1 Region Adjacency Graph (RAG) gen-eration
1: procedure Superpixel2Graph(Image I ofwidth w, height h and k channels, Superpixel seg-mentation technique S, and node feature builderF )
2: s,N ← S(I) . s returns the superpixeln ∈ N of a (x,y) pixel
3: x(n)← F (I, s, n)∀n ∈ N . x(n) is thefeature vector of node n
4: E ← {}5: for 1 ≤ x ≤ w do6: for 1 ≤ y ≤ h do7: if s(x, y) 6= s(x+ 1, y) then8: E ← E ∪ {(s(x, y), s(x+ 1, y))}9: end if
10: if s(x, y) 6= s(x, y + 1) then11: E ← E ∪ {(s(x, y), s(x, y + 1))}12: end if13: end for14: end for15: return G = (N , E), x16: end procedure
in its superpixel segmentation. SLIC is stable andit is still recommended among other state-of-the-artoversegmentation algorithms [24]. Nonetheless, webelieve that other segmentation techniques with sim-ilar characteristics could be used.
After applying a superpixel segmentation tech-nique, we generate a Region Adjacency Graph (RAG)by treating each superpixel as a node and addingedges between all directly adjacent superpixels (1-neighborhood connection). Note that this differsfrom the approach adopted in [15], since their super-pixel graphs have connections that span more thanone neighbour level, with edges formed with the Knearest neighbours. Each graph node can have asso-ciated features, providing an aggregate informationbased on characteristics of the superpixel itself. Al-gorithm 1 describes the adopted procedure, whereasFig. 1 depicts the generation of a RAG from an im-age.
There are many possibilities for building the fea-tures related to each node. For example, statisticsabout the colour and position of a superpixel, suchas the mean, standard deviation, and correlation ma-trices of its pixels are readily available from the super-pixel segmentation. In the case of images defined onrectangular domains, positional information relates
to a 2D point. However, this concept can be easilyadapted to omnidirectional images or point clouds, sothat a single topology based on graphs can be usedin different applications. We do not build features forthe edges, since we use an attention-based technique,and believe that the edge feature will be learned ac-cordingly from the attention mechanism using bothnodes’ features.
In this work in particular, we apply this proce-dure to the well-known MNIST [13], FashionMNIST[33], Street View House Numbers (SVHN) [17] andCIFAR-10 [11] datasets. The first two datasets con-tain grayscale images of 28×28 pixels and 10 classes,and the last two contain RGB images of 32×32 pixels,both also having 10 classes.
Monti and colleagues [15] used the MNIST datasetand converted it into a graph-based format by us-ing a superpixel-based representation. But whereasthey connected nodes through a K-nearest neigh-bour procedure, we do so using RAGs. Hence, ourdataset presents a lower-connectivity graph, whichcould impair information flow and make the classifica-tion problem harder. We also provide results for theRAG representation of the FashionMNIST dataset,since it is a more challenging dataset for which theinformation loss from the superpixel representationcould impact more significantly the model. Sincethese two datasets contain only grayscale images, webuild each superpixel’s feature vector as the concate-nation of the average luminosity of the pixels in asuperpixel and the geometric centroid.
The SVHN and CIFAR datasets, however, bothcontain RGB channels in their images, and a naturalextension for the feature vector is to use the concate-nation of the average value for each colour channeland the geometric centroid. These datasets were usedto see how the model would perform both with simpleand complex colour images.
4 Our Model
We transform the Undirected Graph produced fromthe oversegmented image’s RAG into a DirectedGraph G = (N , E), and feed it to a Neural Networkmodel that operates on Graphs. More specifically, weuse GAT layers stacked on top of each other using thesame adjacency graph on each layer.
Our model is a version of the GAT model by Velick-ovic et al. [29], roughly based on the implementationby Nathani et al. [16]. Attention is implementedby scattering the source and target nodes’ input fea-
3

(a) (b) (c)
Figure 1: From left to right, the image to be converted into a RAG (a), the image with the superpixelsegmentation being shown (b), and the image with the superpixel segmentation and the generated regionadjacency graph overlayed on top of it (c).
Algorithm 2 Implemented GAT Layer
1: procedure GAT-Forward(Directed graph G =(N , E), Node Features x(n)∀n ∈ N , learnabletransition function f and learnable attentionfunction a)
2: Mtgt(te, e)← 1{e = (se, te)}∀e ∈ E3: hsrc(se)← x(se)∀e ∈ E4: htgt(te)← x(te)∀e ∈ E5: h(e)← hsrc(se)‖htgt(te)∀e = (se, te) ∈ E6: y(e)← f(h(e))∀e ∈ E7: α(e)← a(h(e))∀e ∈ E8: αbase(e)← maxe∈E α(e)9: αnorm(e)← α(e)− αbase(e)∀e ∈ E
10: αexp(e)← eαnorm(e)∀e ∈ E11: αsum ← (Mtgt × αexp(e)) + ε12: yα(e)← y(e)αexp(e)∀e ∈ E13: return o = (Mtgt, yα)/αsum14: end procedure
tures into their respective edges, making the transi-tion and activation function on both these inputs andthen summing them up over each target node throughthe edges.
Therefore, for each layer with input dimension diand output dimension do we learn two functions. Thetransition function f : R2di → Rdo , composed of alinear layer followed by a nonlinearity, and the atten-tion function a : R2di → R that tells how much thetarget node of an edge should attend to the sourcenode’s information, also composed of a linear layer.The values produced by the attention function areactivated using softmax for each target node. On theimplementation, we take advantage of the fact thatσ(z + c)j = σ(z)j .
In summary, given a directed graph G = (N , E),
with edges e = (se, te) ∈ E and node featuresx(n)∀n ∈ N , let T (t) be the set of nodes with an edgetowards t, the attention model can be summarised byEquations (1) and (2) below, where ‖ denotes vec-tor/tensor concatenation.
α(s, t) =ea(x(s)‖x(t))∑
s′∈T (t) ea(x(s′)‖x(t)) (1)
o(t) =∑s∈T (t)
α(s, t)f(x(s)‖x(t)) (2)
The detailed algorithm showing the optimisationcan be seen in Algorithm 2. Each of these layerscan be arranged in a multi-head model by concate-nating their outputs after the forward pass of eachlayer. That is, given k heads, the joint output of thek-headed layer, where each head has its own transi-tion and attention functions fi and ai (as well as theintermediary αi), would be as in Equation (3), where
‖ki=1
ak is the concatenation of all vectors/tensors ak:
o(t) =∑s∈T (t)
k
‖i=1
αi(s, t)fi(x(s)‖x(t)) (3)
The output of the final GAT layer can then be sum-pooled, having all the values added, and then passedthrough a MultiLayer Perceptron (MLP) for the finalprediction. The Python/Pytorch implementation inits fullest can be seen in the provided GitHub reposi-tory1 as well. Most operations have been parallelizedas much as the authors could fathom, with some op-erations done in a preprocessing phase to avoid over-load.
1https://github.com/machine-reasoning-ufrgs/
spixel-gat
4

5 Experiments
In this section, we show the potential of our techniqueon four datasets: MNIST [13], FashionMNIST [33],SVHN [17] and CIFAR-10 [11]. The superpixel algo-rithm has a target of 75 regions, so that the analyzedgraphs present approximately 75 nodes each.
All experiments were ran either in a computer witha NVIDIA Quadro P6000 or one with a NVIDIAGTX 1070 Mobile. Both computers have 32GB ofRAM. For development, we adopted the Pytorch li-brary, version 1.X, using CUDA.
For all experiments we set a budget of 100 epochsfor optimisation, with a batch size of 32 images, us-ing a 90/10 split for training and validation in thedataset’s original training data. We use Adam as theoptimiser, with a learning rate of 0.001, β1 = 0.9, andβ2 = 0.999, using the model with the best validationaccuracy on the test dataset. If the model failed toleave a baseline accuracy for the first 10 epochs, werestarted the training procedure from scratch.
5.1 MNIST
We trained two versions of the GAT model: A single-headed GAT with 3 layers, with 32, 64 and 64 neu-rons, and a two-headed GAT, where each head hasthe same amount of neurons as the single-headedmodel. Both models used sum-pooling and a MLPwith two layers of 32 and do neurons for the finalclassification, where do = 10 is the number of classesin MNIST. All neurons use ReLU activations, exceptfor those at the last layer of the classification MLP,which use softmax activations. We did not use anyregularisation technique.
All dataset images are converted to a correspond-ing RAG, using SLICO [22], a zero-parameter vari-ant the SLIC algorithm. We set the target numberof superpixels as 75, but the generated RAGs are notguaranteed to have exactly 75 nodes due to how theSLIC algorithm works.
Table 1 shows that both GAT models performedbetter than the MoNET model [15], showing thata learned representation of the geometric distancecan lead to better performance than the fixed oneof [15]. Note that our model has also to deal withgraphs that are sparser than the ones used in thebaselines [15, 6, 23], since in their graph edges areformed through K-nearest neighbours and ours useonly directly adjacent nodes. Although one could ex-pect worse accuracy, the results suggest that our ap-proach is able to learn relevant geometric information
relating the features from all neighbouring superpix-els. We also report the performance of the graph-based approaches SplineCNN [6] and Geo-GCN [23],as well as recent alternative approaches such as theGenerative Tensor Network Classifier (GTNC) [26]and the best performing method based on SupportVector Classification (SVC) as reported in the datasethomepage2. Although our approach does not reachstate-of-the-art results, it is competitive and the bestamong graph-based methods.
5.2 FashionMNIST
We trained the single-headed and multi-headed GATmodels with the same configuration of Section 5.1.Since the FashionMNIST dataset also has 10 classes,the number of output neurons is do = 10 as well. TheRAGs were also generated as in Section 5.1.
Since none of the found graph-based papers presentresults for both MNIST and FashionMNIST, we pro-vide a performance comparison of our models toGTNC [26] and the two best classifiers from the Fash-ionMNIST benchmark [33] in Table 1. The gap on theperformance between the traditional ML models thatused the full features of the dataset and our models,which use a reduced representation based on the over-segmented image, is higher on FashionMNIST. Thisshows how much harder the FashionMNIST datasetis for oversegmented images, where the informationloss is greater with the aggregation of the features ofthe pixels in the superpixel.
Another interesting fact to note is that the multi-headed model performed worse than the single-headed one. This was further confirmed when wetried learning with a 4-headed model, which per-formed slightly worse than the 2-headed one.
5.3 Street View House Numbers
To check the performance of the model with multi-channel data, we trained and tested the two-headedmodel on the Street View House Numbers (SVHN)dataset [17], using the 32 × 32 cropped version andthe same parameters for oversegmentation as in theprevious sections. We achieved a similar performancewith the two-headed GAT model on the FashionM-NIST dataset, with 80.72% test accuracy. This comesto show that our model works even with full colourdata, as well as the confounders present in the SVHNdataset.
2https://github.com/zalandoresearch/fashion-mnist
5
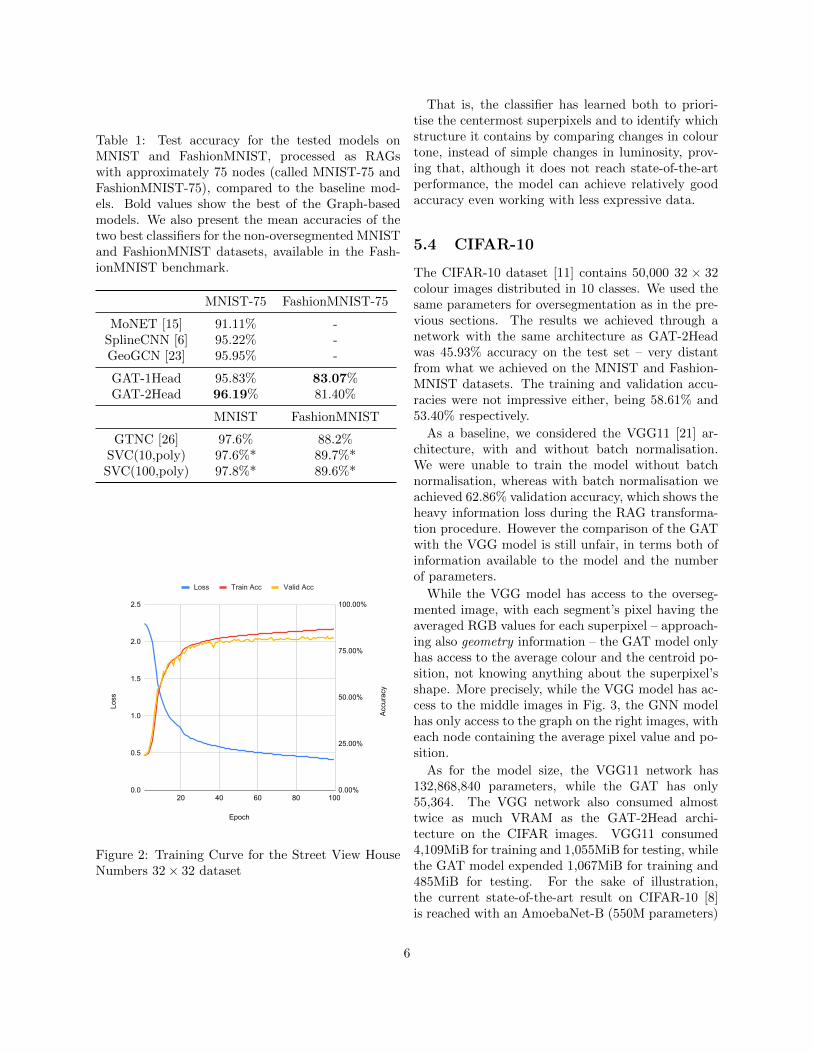
Table 1: Test accuracy for the tested models onMNIST and FashionMNIST, processed as RAGswith approximately 75 nodes (called MNIST-75 andFashionMNIST-75), compared to the baseline mod-els. Bold values show the best of the Graph-basedmodels. We also present the mean accuracies of thetwo best classifiers for the non-oversegmented MNISTand FashionMNIST datasets, available in the Fash-ionMNIST benchmark.
MNIST-75 FashionMNIST-75
MoNET [15] 91.11% -SplineCNN [6] 95.22% -GeoGCN [23] 95.95% -
GAT-1Head 95.83% 83.07%GAT-2Head 96.19% 81.40%
MNIST FashionMNIST
GTNC [26] 97.6% 88.2%SVC(10,poly) 97.6%* 89.7%*SVC(100,poly) 97.8%* 89.6%*
Epoch
Loss
Acc
urac
y
0.0
0.5
1.0
1.5
2.0
2.5
0.00%
25.00%
50.00%
75.00%
100.00%
20 40 60 80 100
Loss Train Acc Valid Acc
Figure 2: Training Curve for the Street View HouseNumbers 32× 32 dataset
That is, the classifier has learned both to priori-tise the centermost superpixels and to identify whichstructure it contains by comparing changes in colourtone, instead of simple changes in luminosity, prov-ing that, although it does not reach state-of-the-artperformance, the model can achieve relatively goodaccuracy even working with less expressive data.
5.4 CIFAR-10
The CIFAR-10 dataset [11] contains 50,000 32 × 32colour images distributed in 10 classes. We used thesame parameters for oversegmentation as in the pre-vious sections. The results we achieved through anetwork with the same architecture as GAT-2Headwas 45.93% accuracy on the test set – very distantfrom what we achieved on the MNIST and Fashion-MNIST datasets. The training and validation accu-racies were not impressive either, being 58.61% and53.40% respectively.
As a baseline, we considered the VGG11 [21] ar-chitecture, with and without batch normalisation.We were unable to train the model without batchnormalisation, whereas with batch normalisation weachieved 62.86% validation accuracy, which shows theheavy information loss during the RAG transforma-tion procedure. However the comparison of the GATwith the VGG model is still unfair, in terms both ofinformation available to the model and the numberof parameters.
While the VGG model has access to the overseg-mented image, with each segment’s pixel having theaveraged RGB values for each superpixel – approach-ing also geometry information – the GAT model onlyhas access to the average colour and the centroid po-sition, not knowing anything about the superpixel’sshape. More precisely, while the VGG model has ac-cess to the middle images in Fig. 3, the GNN modelhas only access to the graph on the right images, witheach node containing the average pixel value and po-sition.
As for the model size, the VGG11 network has132,868,840 parameters, while the GAT has only55,364. The VGG network also consumed almosttwice as much VRAM as the GAT-2Head archi-tecture on the CIFAR images. VGG11 consumed4,109MiB for training and 1,055MiB for testing, whilethe GAT model expended 1,067MiB for training and485MiB for testing. For the sake of illustration,the current state-of-the-art result on CIFAR-10 [8]is reached with an AmoebaNet-B (550M parameters)
6

Figure 3: Examples showing the loss of informationin the RAG procedure when using only the averageof each channel, which negatively affects the perfor-mance of the network.
pre-trained on ImageNet and fine-tuned on CIFAR-10.
6 Conclusion
In this paper, we have investigated the applicationand interplay between Graph Attention Networks(GATs) [29] and image classification problems. In or-der to do so, we have used Region Adjacency Graphs(RAGs) computed from an image segmented using asuperpixel algorithm, SLICO. We showed that usingattention-based graph neural networks on a featurespace that contains the geometric information canbe improved by weighting the edges of a superpixel
graph using a learned function which operates solelyon the geometric information.
However, this approach to image classification hasits shortcomings. The information loss in the pixelaggregation for more complex images can result insignificant performance degradation when comparedto using the full image. Also, graph-based approachesmay come with the same limitations intrinsic to themodels they use, and in our case the GNN-based ar-chitecture imposes some limitations in terms of mem-ory usage for larger graphs due to the batching pro-cedure (and thus finer segmentations), despite thesmaller number of parameters the model itself had.Training in small batches lead to an unreliable train-ing pattern, further aggravating such issues.
These limitations are, however, venues for futurework. It has been shown that architectures based ongraph convolutional networks, such as the GAT, suf-fer from an oversmoothing of node-level information,thus acting like low-pass filters [18]. While GATsmight not be subject to the same limitation, thiscould be investigated to allow deeper GATs with po-tentially better performance in this domain. Anothervenue is helping scaling Graph Neural Networks, ofwhich GAT is a representative, to larger graphs (andthus larger images) or to make them work in an onlinemanner, or with smaller batches.
Also, our models used no regularization what-soever, and investigating regularization techniquesfor these models could incur in better performance.Lastly, investigating different node feature vectorscould provide the network with richer informationand lesser the information loss due to the RAG pro-cedure, possibly with information to recustruct thesuperpixel’s components.
These graph-based approaches to image classifi-cation are also a prime example of application tonon-euclidean images, such as omnidirectional images[14]. The flexibility of a graph-based approach couldbe more invariant to the domain of the image, possi-bly allowing pre-training on planar images and trans-fer to spherical images.
Acknowledgements
We would like to thank NVIDIA Corporation for theQuadro GPU granted to our research group. Thiswork is partly supported by Coordenacao de Aper-feicoamento de Pessoal de Nıvel Superior (CAPES)– Finance Code 001 and by the Brazilian ResearchCouncil CNPq. We would also like to thank the Py-
7

torch developers for their library.
References
[1] Radhakrishna Achanta, Appu Shaji, KevinSmith, Aurelien Lucchi, Pascal Fua, and SabineSusstrunk. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans.Pattern Anal. Mach. Intell., 34(11):2274–2282,2012.
[2] Radhakrishna Achanta and Sabine Susstrunk.Superpixels and polygons using simple non-iterative clustering. In 2017 IEEE Conferenceon Computer Vision and Pattern Recognition,CVPR 2017, Honolulu, HI, USA, July 21-26,2017, pages 4895–4904. IEEE Computer Society,2017.
[3] Federica Bogo, Javier Romero, Matthew Loper,and Michael J. Black. FAUST: dataset andevaluation for 3d mesh registration. In 2014IEEE Conference on Computer Vision and Pat-tern Recognition, CVPR 2014, Columbus, OH,USA, June 23-28, 2014, pages 3794–3801. IEEEComputer Society, 2014.
[4] Taco S Cohen, Mario Geiger, Jonas Kohler, andMax Welling. Spherical cnns. arXiv preprintarXiv:1801.10130, 2018.
[5] Michael Van den Bergh, Xavier Boix, GemmaRoig, Benjamin de Capitani, and Luc Van Gool.SEEDS: superpixels extracted via energy-drivensampling. In Andrew W. Fitzgibbon, Svet-lana Lazebnik, Pietro Perona, Yoichi Sato, andCordelia Schmid, editors, Computer Vision -ECCV 2012 - 12th European Conference onComputer Vision, Florence, Italy, October 7-13,2012, Proceedings, Part VII, volume 7578 of Lec-ture Notes in Computer Science, pages 13–26.Springer, 2012.
[6] Matthias Fey, Jan Eric Lenssen, Frank Weichert,and Heinrich Muller. Splinecnn: Fast geometricdeep learning with continuous b-spline kernels.In 2018 IEEE Conference on Computer Visionand Pattern Recognition, CVPR 2018, Salt LakeCity, UT, USA, June 18-22, 2018, pages 869–877. IEEE Computer Society, 2018.
[7] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE
Conference on Computer Vision and PatternRecognition (CVPR), June 2018.
[8] Yanping Huang, Youlong Cheng, Ankur Bapna,Orhan Firat, Dehao Chen, Mia Chen, Hy-oukJoong Lee, Jiquan Ngiam, Quoc V Le,Yonghui Wu, et al. Gpipe: Efficient trainingof giant neural networks using pipeline paral-lelism. In Advances in neural information pro-cessing systems, pages 103–112, 2019.
[9] Bo Jiang, Doudou Lin, Jin Tang, and Bin Luo.Data representation and learning with graphdiffusion-embedding networks. In Proceedings ofthe IEEE Conference on Computer Vision andPattern Recognition, pages 10414–10423, 2019.
[10] Thomas N Kipf and Max Welling. Semi-supervised classification with graph con-volutional networks. arXiv preprintarXiv:1609.02907, 2016.
[11] Alex Krizhevsky, Geoffrey Hinton, et al. Learn-ing multiple layers of features from tiny images,2009.
[12] Alex Krizhevsky, Ilya Sutskever, and Geoffrey EHinton. Imagenet classification with deep con-volutional neural networks. In Advances in neu-ral information processing systems, pages 1097–1105, 2012.
[13] Yann LeCun, Leon Bottou, Yoshua Bengio, andPatrick Haffner. Gradient-based learning ap-plied to document recognition. Proceedings ofthe IEEE, 86(11):2278–2324, 1998.
[14] Yeon Kun Lee, Jaeseok Jeong, Jong Seob Yun,Wonjune Cho, and Kuk-Jin Yoon. Spherephd:Applying cnns on a spherical polyhedron repre-sentation of 360deg images. In IEEE Confer-ence on Computer Vision and Pattern Recogni-tion, CVPR 2019, Long Beach, CA, USA, June16-20, 2019, pages 9181–9189. Computer VisionFoundation / IEEE, 2019.
[15] Federico Monti, Davide Boscaini, JonathanMasci, Emanuele Rodola, Jan Svoboda, andMichael M. Bronstein. Geometric deep learningon graphs and manifolds using mixture modelcnns. In 2017 IEEE Conference on ComputerVision and Pattern Recognition, CVPR 2017,Honolulu, HI, USA, July 21-26, 2017, pages5425–5434. IEEE Computer Society, 2017.
8

[16] Deepak Nathani, Jatin Chauhan, CharuSharma, and Manohar Kaul. Learningattention-based embeddings for relationprediction in knowledge graphs. In AnnaKorhonen, David R. Traum, and Lluıs Marquez,editors, Proceedings of the 57th Conference ofthe Association for Computational Linguistics,ACL 2019, Florence, Italy, July 28- August 2,2019, Volume 1: Long Papers, pages 4710–4723.Association for Computational Linguistics,2019.
[17] Yuval Netzer, Tao Wang, Adam Coates,Alessandro Bissacco, Bo Wu, and Andrew Y Ng.Reading digits in natural images with unsuper-vised feature learning, 2011.
[18] Hoang NT and Takanori Maehara. Revisitinggraph neural networks: All we have is low-passfilters. CoRR, abs/1905.09550, 2019.
[19] Prithviraj Sen, Galileo Namata, Mustafa Bilgic,Lise Getoor, Brian Gallagher, and Tina Eliassi-Rad. Collective classification in network data.AI Magazine, 29(3):93–106, 2008.
[20] Jianbo Shi and Jitendra Malik. Normalized cutsand image segmentation. IEEE Transactionson pattern analysis and machine intelligence,22(8):888–905, 2000.
[21] Karen Simonyan and Andrew Zisserman. Verydeep convolutional networks for large-scale im-age recognition. In ICLR, 2015.
[22] SLIC superpixels: SLICO. Available athttps://www.epfl.ch/labs/ivrl/research/
slic-superpixels/#SLICO.
[23] Przemyslaw Spurek, Tomasz Danel, Jacek Ta-bor, Marek Smieja, Lukasz Struski, AgnieszkaSlowik, and Lukasz Maziarka. Geometricgraph convolutional neural networks. CoRR,abs/1909.05310, 2019.
[24] David Stutz, Alexander Hermans, and BastianLeibe. Superpixels: An evaluation of the state-of-the-art. Computer Vision and Image Under-standing, 166:1–27, 2018.
[25] Yu-Chuan Su and Kristen Grauman. Kerneltransformer networks for compact spherical con-volution. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition,pages 9442–9451, 2019.
[26] Zheng-Zhi Sun, Cheng Peng, Ding Liu, Shi-Ju Ran, and Gang Su. Generative tensor net-work classification model for supervised machinelearning. Physical Review B, 101(7):075135,2020.
[27] Christian Szegedy, Wei Liu, Yangqing Jia, PierreSermanet, Scott Reed, Dragomir Anguelov, Du-mitru Erhan, Vincent Vanhoucke, and AndrewRabinovich. Going deeper with convolutions. InProceedings of the IEEE conference on computervision and pattern recognition, pages 1–9, 2015.
[28] Ashish Vaswani, Noam Shazeer, Niki Parmar,Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention isall you need. In Advances in Neural InformationProcessing Systems, pages 5998–6008, 2017.
[29] Petar Velickovic, Guillem Cucurull, ArantxaCasanova, Adriana Romero, Pietro Lio, andYoshua Bengio. Graph attention networks.In 6th International Conference on LearningRepresentations, ICLR 2018, Vancouver, BC,Canada, April 30 - May 3, 2018, ConferenceTrack Proceedings. OpenReview.net, 2018.
[30] Xing Wei, Qingxiong Yang, Yihong Gong,Narendra Ahuja, and Ming-Hsuan Yang. Super-pixel hierarchy. IEEE Trans. Image Processing,27(10):4838–4849, 2018.
[31] Zhirong Wu, Shuran Song, Aditya Khosla,Fisher Yu, Linguang Zhang, Xiaoou Tang, andJianxiong Xiao. 3d shapenets: A deep repre-sentation for volumetric shapes. In Proceedingsof the IEEE conference on computer vision andpattern recognition, pages 1912–1920, 2015.
[32] Zonghan Wu, Shirui Pan, Fengwen Chen,Guodong Long, Chengqi Zhang, and S Yu Philip.A comprehensive survey on graph neural net-works. IEEE Transactions on Neural Networksand Learning Systems, 2020.
[33] Han Xiao, Kashif Rasul, and Roland Vollgraf.Fashion-mnist: a novel image dataset for bench-marking machine learning algorithms. CoRR,abs/1708.07747, 2017.
[34] Jian Yao, Marko Boben, Sanja Fidler, andRaquel Urtasun. Real-time coarse-to-fine topo-logically preserving segmentation. In IEEE Con-ference on Computer Vision and Pattern Recog-nition, CVPR 2015, Boston, MA, USA, June
9

7-12, 2015, pages 2947–2955. IEEE ComputerSociety, 2015.
10