pg-strom - gpgpu meets postgresql, pgcon2015
TRANSCRIPT

1
PG-Strom ~GPGPU meets PostgreSQL~
NEC Business Creation Division
The PG-Strom Project
KaiGai Kohei <[email protected]>

2
About me
▌About PG-Strom project
The 1st prototype was unveiled at Jan-2012, based on personal interest
Now, it became NEC internal startup project.
▌Who are you
Name: KaiGai Kohei
Works: NEC
Roles:
• development of software
• development of business
Past contributions:
• SELinux integration (sepgsql) and various security stuff
• Writable FDW & Remote Join Infrastructure
• ...and so on
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL

3
Parallel Database is fun!
▌Growth of data size
▌Analytics makes values hidden in data
▌Price reduction of parallel processors
All the comprehensives requires database be parallel
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
4
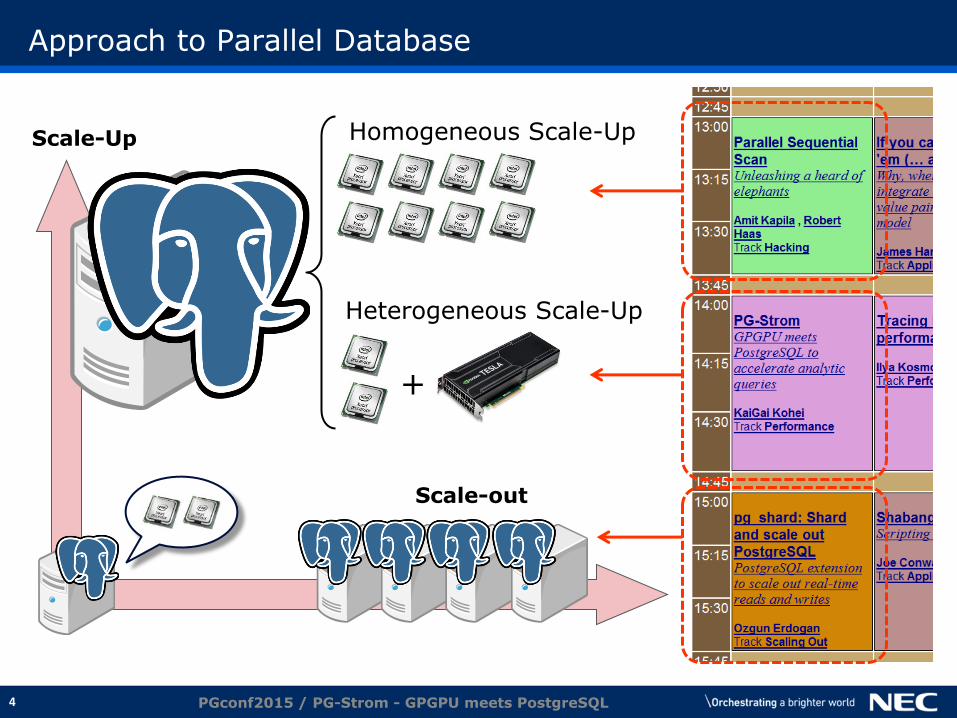
Approach to Parallel Database
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
Scale-out
Scale-Up Homogeneous Scale-Up
Heterogeneous Scale-Up
+

5
Why GPU?
No Free Lunch for Software, by Hardware
▌Power consumption & Dark silicon problem
▌Heterogeneous architecture
▌Software has to be designed to pull out full capability of the modern hardware
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
SOURCE: THE HEART OF AMD INNOVATION, Lisa Su, at AMD Developer Summit 2013
SOURCE: Compute Power with Energy-Efficiency, Jem Davies, at AMD Fusion Developer Summit 2011

6
Features of GPU (Graphic Processor Unit)
▌Massive parallel cores
▌Much higher DRAM bandwidth
▌Better price / performance ratio
▌Advantage
Simple arithmetic operations
Agility in multi-threading
▌Disadvantage
complex control logic
no operating system
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
SOURCE: CUDA C Programming Guide
GPU CPU
Model Nvidia GTX
TITAN X Intel Xeon E5-2690 v3
Architecture Maxwell Haswell
Launch Mar-2015 Sep-2014
# of transistors 8.0billion 3.84billion
# of cores 3072
(simple) 12
(functional)
Core clock 1.0GHz 2.6GHz,
up to 3.5GHz
Peak Flops (single
precision) 6.6TFLOPS
998.4GFLOPS (with AVX2)
DRAM size 12GB, GDDR5 (384bits bus)
768GB/socket, DDR4
Memory band 336.5GB/s 68GB/s
Power consumption
250W 135W
Price $999 $2,094

7
How GPU cores works
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
● item[0]
step.1 step.2 step.4 step.3
Calculation of
𝑖𝑡𝑒𝑚[𝑖]
𝑖=0…𝑁−1
with GPU cores
◆
●
▲ ■ ★
● ◆
●
● ◆ ▲
●
● ◆
●
● ◆ ▲ ■
●
● ◆
●
● ◆ ▲
●
● ◆
●
item[1]
item[2]
item[3]
item[4]
item[5]
item[6]
item[7]
item[8]
item[9]
item[10]
item[11]
item[12]
item[13]
item[14]
item[15]
Sum of items[] by log2N steps
Inter-core synchronization by HW functionality

8
What is PG-Strom (1/2) – Core ideas
▌Core idea
① GPU native code generation on the fly
② Asynchronous execution and pipelining
▌Advantage
Transparent acceleration with 100% query compatibility
Heavy query involving relations join and/or aggregation
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
Parser
Planner
Executor
Custom- Scan/Join Interface
Query: SELECT * FROM l_tbl JOIN r_tbl on l_tbl.lid = r_tbl.rid;
PG-Strom
CUDA driver
nvrtc
DMA Data Transfer
CUDA Source code Massive
Parallel Execution

9
What is PG-Strom (2/2) – Beta functionality at Jun-2015
▌Logics
GpuScan ... Simple loop extraction by GPU multithread
GpuHashJoin ... GPU multithread based N-way hash-join
GpuNestLoop ... GPU multithread based N-way nested-loop
GpuPreAgg ... Row reduction prior to CPU aggregation
GpuSort ... GPU bitonic + CPU merge, hybrid sorting
▌Data Types
Numeric ... int2/4/8, float4/8, numeric
Date and Time ... date, time, timestamp, timestamptz
Text ... Only uncompressed inline varlena
▌Functions
Comparison operator ... <, <=, !=, =, >=, >
Arithmetic operators ... +, -, *, /, %, ...
Mathematical functions ... sqrt, log, exp, ...
Aggregate functions ... min, max, sum, avg, stddev, ...
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL

10
CustomScan Interface (v9.5 new feature)
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
set_rel_pathlist()
set_rel_pathlist_hook
add_paths_to_joinrel()
set_join_pathlist_hook
SeqScan Index Scan
Custom Scan
(GpuScan)
HashJoin NestLoop Custom Scan
(GpuJoin)
PlannedStmt
PlanTree with Custom Logic
11
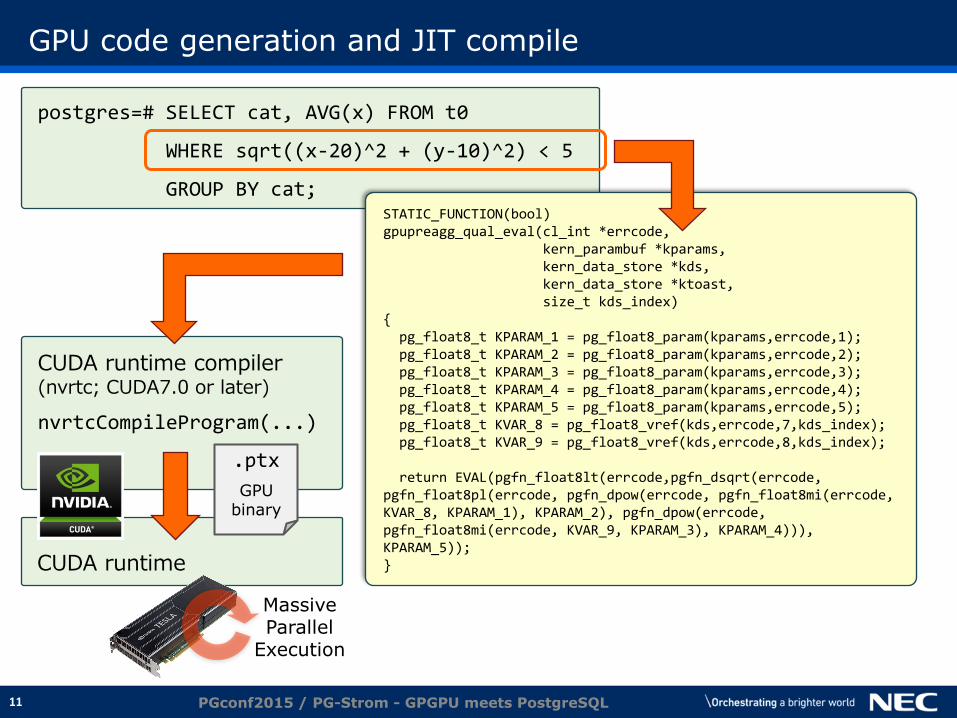
GPU code generation and JIT compile
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
postgres=# SELECT cat, AVG(x) FROM t0
WHERE sqrt((x-20)^2 + (y-10)^2) < 5
GROUP BY cat; STATIC_FUNCTION(bool) gpupreagg_qual_eval(cl_int *errcode, kern_parambuf *kparams, kern_data_store *kds, kern_data_store *ktoast, size_t kds_index) { pg_float8_t KPARAM_1 = pg_float8_param(kparams,errcode,1); pg_float8_t KPARAM_2 = pg_float8_param(kparams,errcode,2); pg_float8_t KPARAM_3 = pg_float8_param(kparams,errcode,3); pg_float8_t KPARAM_4 = pg_float8_param(kparams,errcode,4); pg_float8_t KPARAM_5 = pg_float8_param(kparams,errcode,5); pg_float8_t KVAR_8 = pg_float8_vref(kds,errcode,7,kds_index); pg_float8_t KVAR_9 = pg_float8_vref(kds,errcode,8,kds_index); return EVAL(pgfn_float8lt(errcode,pgfn_dsqrt(errcode, pgfn_float8pl(errcode, pgfn_dpow(errcode, pgfn_float8mi(errcode, KVAR_8, KPARAM_1), KPARAM_2), pgfn_dpow(errcode, pgfn_float8mi(errcode, KVAR_9, KPARAM_3), KPARAM_4))), KPARAM_5)); }
CUDA runtime compiler (nvrtc; CUDA7.0 or later)
nvrtcCompileProgram(...)
CUDA runtime
.ptx
GPU binary
Massive Parallel
Execution

12
(OT) How to combine static and dynamic code
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
STATIC_FUNCTION(cl_uint) gpujoin_hash_value(cl_int *errcode, kern_parambuf *kparams, cl_uint *pg_crc32_table, kern_data_store *kds, kern_multirels *kmrels, cl_int depth, cl_int *outer_index);
GpuScan
GpuJoin
GpuPreAgg
GpuSort
CustomScan Providers
KERNEL_FUNCTION(void) gpujoin_exec_hashjoin(kern_gpujoin *kgjoin, kern_data_store *kds, kern_multirels *kmrels, cl_int depth, cl_int cuda_index, cl_bool *outer_join_map) { : hash_value = gpujoin_hash_value(&errcode, kparams, pg_crc32_table, kds, kmrels, depth, x_buffer); : is_matched = gpujoin_join_quals(&errcode, kparams, kds, kmrels, depth, x_buffer, h_htup);
cuda_ program.c
.ptx
GPU binary
Dynamic Portion
Static Portion

13
How GPU Logic works (1/2) – Case of GpuScan
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
kern_data_store (DMA Buffer)
kern_data_store (On GPU RAM)
● ●
● ●
● ●
● ●
CustomScan (GpuScan)
CUmodule
② Load to DMA buffer (100K~500K Rows/buffer)
③ Kick Asynchronous DMA over PCI-E
RelOptInfo
baserestrictinfo
① GPU code generation & JIT compile
④ Launch GPU kernel function
Each GPU core evaluate each rows
in parallel
⑤ Write back results

14
Asynchronous Execution and Pipelining
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
DMA Send
GPU Kernel Exec
DMA Recv
DMA Send
GPU Kernel Exec
DMA Recv
DMA Send
GPU Kernel Exec
DMA Recv
DMA Send
GPU Kernel Exec
table
scan
Buffer Read
Buffer Read
Buffer Read
Buffer Read
Move to next
Move to next
chunk-(i+1)
chunk-(i+2)
chunk-i
chunk-(i+3)
Current Task
Current Task
Current Task
Current Task
Current Task
Current Task

15
How GPU Logic works (2/2) – Case of GpuNestLoop
Oute
r-Rela
tion
(Nx: u
sually
larg
er)
※ s
plit to
chunk-b
y-c
hunk o
n
dem
and
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
Two dimensional GPU kernel
launch
blockDim.x
blockDim.y
Ny
Nx Thread
(X=2, Y=3)
Inner-Relation (Ny: relatively small)
Only edge thread references DRAM to fetch values.
Nx:32 x Ny:32 = 1024
A matrix can be evaluated with only 64 times DRAM accesses
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL

16
Benchmark Results (1/2) – Microbenchmark
▌SELECT cat, AVG(x) FROM t0 NATURAL JOIN t1 [, ...] GROUP BY cat;
measurement of query response time with increasing of inner relations
▌t0: 100M rows, t1~t10: 100K rows for each, all the data was preloaded.
▌PostgreSQL v9.5devel + PG-Strom (26-Mar), CUDA 7(x86_64)
▌CPU: Xeon E5-2640, RAM: 256GB, GPU: NVIDIA GTX980
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
81.71
122.96
165.05
214.64
261.51
307.18
356.20
406.59
468.59
520.45
8.38 9.02 8.84 10.33 11.47 13.21 14.48 17.15 19.37 21.72
0
100
200
300
400
500
600
1 2 3 4 5 6 7 8 9 10
Qu
ery
Exe
cuti
on
Tim
e [
sec]
number of tables joined
PostgreSQL PG-Strom

17
Benchmark Results (2/2) – DBT-3 with SF=20
▌PostgreSQL v9.5devel + PG-Strom (26-Mar), CUDA 7(x86_64)
▌CPU: Xeon E5-2640, RAM: 256GB, GPU: NVIDIA GTX980
PG-Strom is almost faster than PostgreSQL, up to x10 times(!)
Q21 result is missing because of too large memory allocation by nodeHash.c
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
0
20
40
60
80
100
120
140
160
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20 Q22
Qu
ery
Re
spo
nse
Tim
e [
sec]
Comparison by DBT-3 Benchmark (SF=20)
PostgreSQL PG-Strom

18
(OT) Why columnar-format is ideal for GPU
▌Reduction of I/O workload
▌Higher compression ratio
▌Less amount of DMA transfer
▌Suitable for SIMD operation
▌Maximum performance on GPU kernel, by coalesced memory access
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
SOURCE: Maxwell: The Most Advanced CUDA GPU Ever Made
Core Core Core Core Core Core Core Core Core Core
coalesced memory access
Global Memory (DRAM)
Wide Memory
Bandwidth (256-
384bits)
WARP: Unit of GPU threads that share instruction pointer

19
(OT) Why PG-Strom (at this moment) use row-format
▌Future direction
Integration with native columnar storage
Column Row translation in GPU space
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
storage columnar
cache Tuple
TableSlot
RowColumn
(only once)
ColumnRow
(per execution)
Catastrophic CPU cycle consumption (T_T)
Ideal Performance (^-^)
Not fast, but only once (´へ`)
20
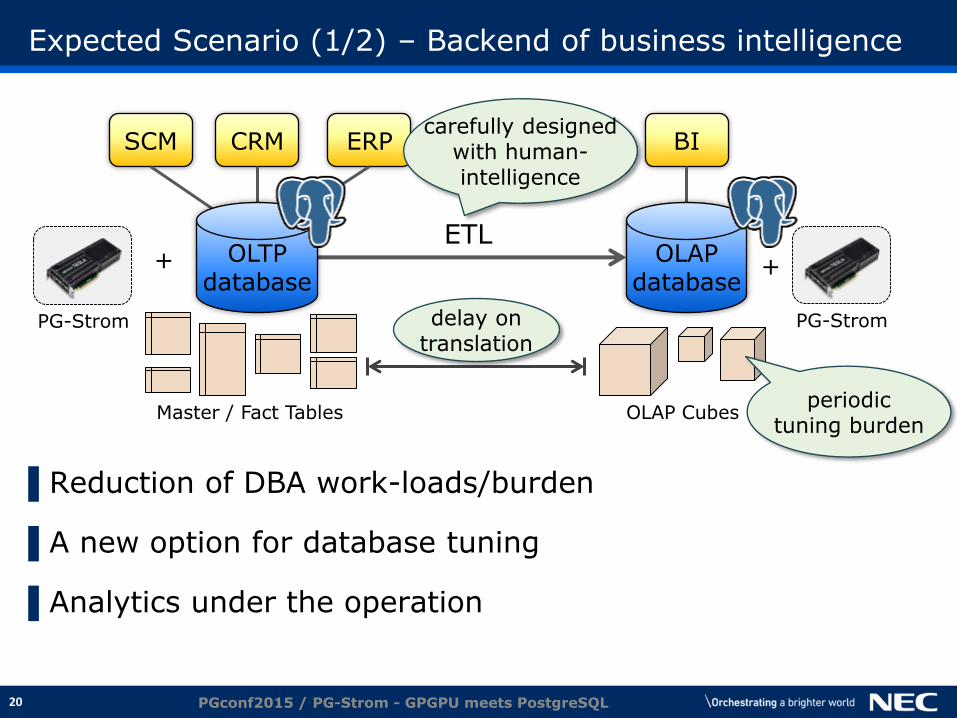
Expected Scenario (1/2) – Backend of business intelligence
▌Reduction of DBA work-loads/burden
▌A new option for database tuning
▌Analytics under the operation
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
ERP CRM SCM BI
OLTP database
OLAP database
ETL
OLAP Cubes Master / Fact Tables
PG-Strom
+
PG-Strom
+
delay on translation
carefully designed with human- intelligence
periodic tuning burden

21
Expected Scenario (2/2) – Computing In-Place
▌Computing In-Place
Why people export data once, to run their algorithm?
RDBMS is not designed as a tool compute stuff
If RDBMS can intermediate the world of data management and computing/calculation?
▌All we need to fetch is data already processed
▌System landscape gets simplified
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
PG-Strom
Extra Tools
pl/CUDA function?
Complicated mathematical logic
on the data exported
future works

22
Welcome your involvement
▌Early adopters are big welcome
SaaS provider or ISV on top of PostgreSQL, notably
Folks who have real-life workloads and dataset
▌Let’s have joint evaluation/development
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL

23
Our sweet spot?
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
SOURCE: Really Big Elephants – Data Warehousing with PostgreSQL, Josh Berkus, MySQL User Conference 2011
• Parallel context and scan
• GPU Acceleration (PG-Strom)
• Funnel Executor
• Aggregate Before Join
• Table partitioning & Sharding
• Native columnar storage

24
Our position
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
WE ARE HERE
SOURCE: The Innovator's Dilemma, Prof. Clayton Christensen , Harvard Business School
25
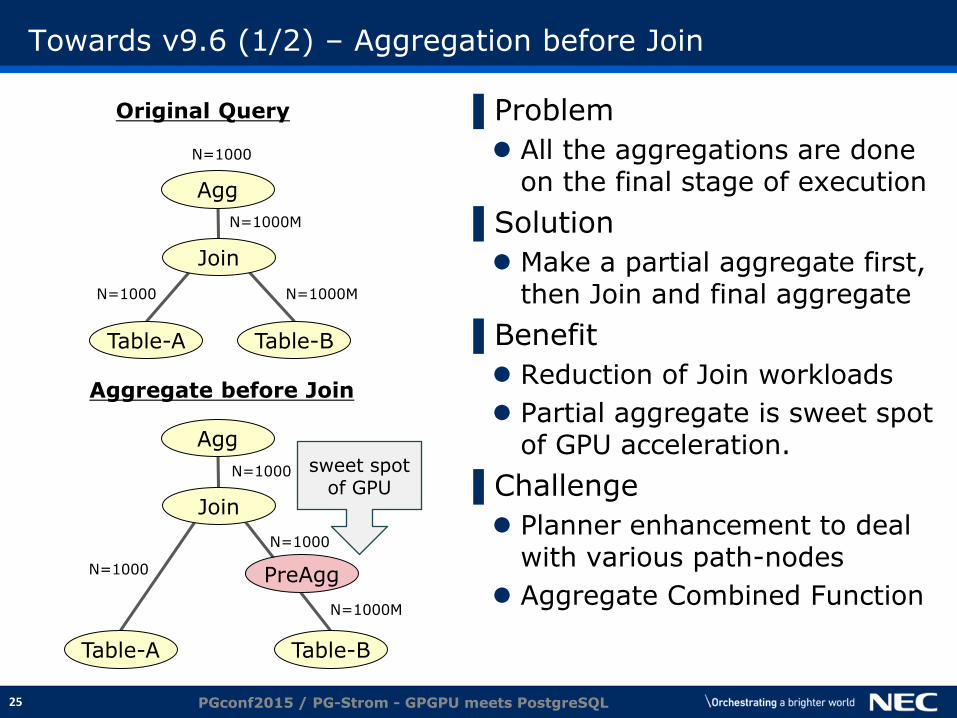
Towards v9.6 (1/2) – Aggregation before Join
▌Problem
All the aggregations are done on the final stage of execution
▌Solution
Make a partial aggregate first, then Join and final aggregate
▌Benefit
Reduction of Join workloads
Partial aggregate is sweet spot of GPU acceleration.
▌Challenge
Planner enhancement to deal with various path-nodes
Aggregate Combined Function
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
Original Query
Aggregate before Join
Agg
Join
Table-A Table-B
Agg
Join
Table-A Table-B
PreAgg
N=1000 N=1000M
N=1000M
N=1000
N=1000
N=1000
N=1000M
N=1000 sweet spot of GPU

26
SSD
Towards v9.6 (2/2) – CustomScan under Funnel Executor
▌Problem
Low I/O density on Scan
Throughput of input stream
▌Solution
Split a large chunk into multiple chunks using BGW
▌Benefit
Higher I/O density
CPU+GPU hybrid parallel
▌Challenge
Planner enhancement to deal with various path-nodes
SSD optimization
CustomScan nodes across multiple processes
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
HashJoin
Outer Scan
(partial)
HashJoin
Outer Scan
(partial)
Inner Scan
Inner Scan
Hash Hash
Funnel Executor
Gpu Join
Gpu Join
Gpu Scan
(partial)
Gpu Scan
(partial)
BgWorker-1 BgWorker-N

27
Resources
▌Source
https://github.com/pg-strom/devel
▌Requirement
PostgreSQL v9.5devel
Hotfix patch (custom_join_children.v2.patch)
CUDA 7.0 provided by NVIDIA
▌On cloud (AWS)
PGconf2015 / PG-Strom - GPGPU meets PostgreSQL
g2.2xlarge
CPU Xeon E5-2670 (8 xCPU)
RAM 15GB
GPU NVIDIA GRID K2 (1536 core)
Storage 60GB of SSD
Price $0.898/hour (*) Tokyo region, at Jun-2015
strom-ami.20150615
AMI-Id: ami-3e29f23e
or, search by “strom”

28
Questions?

29