pgas (uni ed parallel c) model. case study: lattice ... · i a nity !block-size quali er ... case...
TRANSCRIPT

PGAS (Unified Parallel C) Model.Case Study: Lattice-Boltzmann Method
Pedro Valero-Lara
CFD & Computational Technology, Basque Center for Applied Mathematics
March 12, 2015

Motivation
I Introduce the Partitioned Global Address Space (PGAS)paradigm
I Present the main features of UPCI Evaluate the Unified Parallel C (UPC) model
I ImplicitI ExplicitI MPI-OpenMP (LBM-HPC framework)

Partitioned Global Address Space (PGAS)I Shared memory view of distributed memory systems
I Facilitate parallel implementations
I Provide better efficiency and scalability
I Hide important aspects regarding parallel programming
I One-side communication
I No communication calls
I No buffering
I Transparent workload distribution, . . .
I Multiple languages
I Coarray Fortran
I Unified Parallel C (UPC)
I Chapel
I API
I The Global address space Programming Interface (GPI)
I Global Arrays Toolkit

Unified Parallel C (UPC)I Extension of C
I Two thread monitoring:
I THREADS, number of UPC threads
I MYTHREAD, gives the index of the current thread
I Declare array accessible by all UPC threads
I shared
I Affinity → block-size qualifier
I shared type variable
I shared[block-size] type variable[index]
I shared[ ] type variable[index]
I shared[*] type variable[index]
I upc forall(initial;test;increment;affinity)
I affinity:
I pointer
I integer expression (affinity%THREADS)

UPC approaches
Implicit:
#include < upc relaxed.h >int main(int argc, char **argv){int i;
shared [5] int numbers[10];upc forall(i=0; i<10; i++; &numbers[i]){numbers[i] = MYTHREAD;
}}
Explicit:
#include < upc relaxed.h >int main(int argc, char **argv){int i;
shared [*] int numbers[THREADS][5];for(i=0; i<5; i++){numbers[MYTHREAD][i] = MYTHREAD;
}}

Case Study: Lattice-Boltzmann Method (LBM)BGK formulationfi (x + ci∆t, t + ∆t)− fi (x, t) = −∆t
τ
(f (x, t)− f eqi (x, t)
)
Maxwell Equation
f eqi = ρωi
[1 + ci·u
c2s
+ (ci·u)2
2c4s− u2
2c2s
]ω0 = 4/9, ωi = 1/9, i = 1 · · · 4, ω5 = 1/36, i = 5 · · · 8c0 = (0, 0); ci = (±1, 0), c(0,±1), i = 1 · · · 4;ci = (±1,±1), c(±1,±1), i = 5 · · · 8
c2 c1
c8c7
c4
c3
c6 c5
ω0c0
ω2
ω4 ω8ω7
ω6 ω3 ω5
ω1
Given fi (x, t) computeI ρ =
∑fi (x, t)
I ρu =∑
ei fi (x, t)
CollisionI f ∗i (x, t + ∆t) = fi (x, t)− ∆t
τ
(f (x, t)− f eqi (x, t)
)Streaming
I fi (x + ci∆t, t + ∆t) = f ∗i (x, t + ∆t)

LBM Implementation I
LBM pull{For(ind = 1 → Nx · Ny){For(i = 1 → 9){xstream = x − cx [i ]; ystream = y − cy [i ];indstream = ystream · Nx + xstream;f [i ] = f1[i ][indstream];}For(i = 1 → 9){ρ+= f [i ]; ux += cx [i ] · f [i ];uy += cy [i ] · f [i ];}ux = ux/ρ; uy = uy/ρ;For(i = 1 → 9){cu = cx [i ] · ux + cy [i ] · uyfeq = ω[i ] · ρ · (1 + 3 · cu + cu2 − 1.5 · (ux )2 + uy )2))f2[i ][ind ] = f [i ] · (1− 1
τ) + feq · 1
τ}}}

LBM Implementation II - Approaches
Hybrid MPI-OpenMP
I OpenMP pragmas for LBM solver
I MPI send/receive forcommunication
I Ghost cells
UPC Explicit
I Explicit communication
I Ghost cells
I No buffers
I No specific calls
UPC Implicit
I LBM and communication packed
I Transparent
I No ghost cells
MPI_call
MPI_call
OpenMP
Block Block
OpenMP
UPC Block
UPC Block
UPC Block

LBM Implementation III - Explicit UPC
// UPC x( y) UPC threads in x(y)-direction// TH = THREADS// MT = MYTHREADint main(int argc, char **argv){mid x = MT%UPC x;mid y = floor(MT/UPC x);static shared [*] double u[TH][Ly][Lx],v,p;static shared [*] double f1[TH][Ly][Lx][9], f2;t=0;
while(t<It){/*——— Boundary Conditions ———*/
// Top boundaryif(mid y == 0){for(j=0; j<Lx; j++){u[MT][0][j] = uMax;
v[MT][0][j] = v0;
p[MT][0][j] = p0;
for(z=0; z<9; z++){cu=3*(cx[z]*uMax+cy[z]*v0);
f=p0*w[z]*(1.+cu+1./2.* (cu)2)
-(3./2.*((uMax)2+(v0)2));
f1[MT][0][j][z] = f;
}}}...// Other boundary conditions
/*——— Communication ———*/// From bottom to topif(mid y > 0 && UPC y > 1){for(j=0; j<Lx; j++){for(z=0; z<9; z++){f1[MT][0][j][z]=f1[MT-UPC x][Ly-2][j][z];}}}...// Other directions
/*——— LBM ———*/for(i=1; i<Ly-1; i++){for(j=1; j<Lx-1; j++){u local=0.;v local=0.;p local=0.;
for(z=0; z<9; z++){new i=i-cx[z]; new j=j-cy[z];
ftmp[z]= f1[MT][new i][new j][z];
}...
}}t++;
}}

LBM Implementation IV - Implicit UPC
// #DEFINE CHUNK Lx*Ly/THREADSint main(int argc, char **argv){static shared[CHUNK] double u[Ly][Lx],v,p;static shared[CHUNK] double f1[Ly][Lx][9],f2;t=0;
while(t<It){/*——— Boundary Conditions ———*/
upc forall(i=0; i<Ly; i++; &u[i][0]){for(j=0; j<Lx; j++){// Top boundaryif(i==0){u[i][j] = uMax;
v[i][j] = v0;
p[i][j] = p0;
for(z=0; z<9; z++){cu=3*(cx[z]*uMax+cy[z]*v0);
-(3./2.*((uMax)2+(v0)2));
f1[i][j][z] = f;
}}...// Other boundary conditions}}
/*——— LBM and Communication ———*/upc forall(i=1; i<Ly-1; i++; &u[i][0]){for(j=1; j<Lx-1; j++){u local=0.;v local=0.;p local=0.;
for(z=0; z<9; z++){new i=i-cx[z]; new j=j-cy[z];
ftmp[z]= f1[new i][new j][z];}...
}}t++;
}}

Performance Analysis-Platform
High Performance Computing Center Stuttgart (HLRS) of the University of
Stuttgart
Platform Hornet (Cray XC40)Cabinets 21
# Compute nodes 3944# Compute cores 94656 (24 cores per node)
# Processor Intel Xeon CPU E5-2680 v3(30M Cache, 2.50 GHz)
# cores/processor 12Total compute memory 5.4 PB (128 GB per node)Node-node interconnect Cray Aries (Dragonfly topology)
Peak performance (TOP 500) 3786 TeraFLOPS
Performance Analysis-Case Study
I Lid-driven cavityI Performance Analysis
I Boundary ConditionsI CommunicationI LBM solver
I Size problem ≡ 1000million of fluid nodes
I Double precision
I Strong scaling and time
I 240 - 30720 cores

Performance Analysis-Approaches
Hybrid MPI-OpenMP approach
I LBM-HPC framework 1
I module PrgEnv-intel
I mpiCC, -O3, -fopenmp
UPC approaches
I Implicit
I Explicit
I module PrgEnv-cray
I cc -O3 -h upc
1http://www.bcamath.org/en/research/lines/CFDCT/software

Performance Analysis-BC
5 6 7 8 9 10 11log(num_cores)
2
3
4
5
6
7
8
9
10
log(tim
e)
MPI-OpenMPIdeal MPI-OpenMPUPC ExplicitIdeal UPC ExplicitUPC ImplicitIdeal UPC Implicit
0 5000 10000 15000 20000 25000 30000 35000num_cores
0
5000
10000
15000
20000
25000
time(us
)
MPI-OpenMPUPC ExplicitUPC Implicit
I MPI-OpenMP exhibits the best behavior (strong scaling trend and time)
I UPC-Explicit, second best approach.
I UPC-Implicit, the cost does not reduce when using more UPC threads
I Implicit affinity
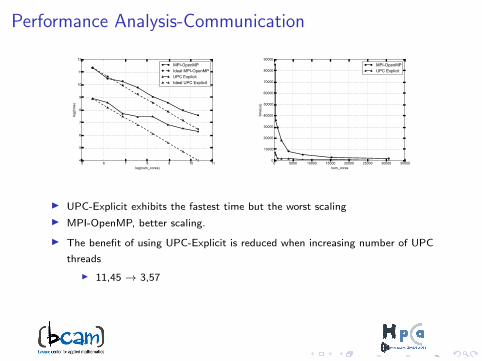
Performance Analysis-Communication
5 6 7 8 9 10 11log(num_cores)
4
5
6
7
8
9
10
11
12
log(
time)
MPI-OpenMPIdeal MPI-OpenMPUPC ExplicitIdeal UPC Explicit
0 5000 10000 15000 20000 25000 30000 35000num_cores
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
time(
us)
MPI-OpenMPUPC Explicit
I UPC-Explicit exhibits the fastest time but the worst scaling
I MPI-OpenMP, better scaling.
I The benefit of using UPC-Explicit is reduced when increasing number of UPC
threads
I 11,45 → 3,57
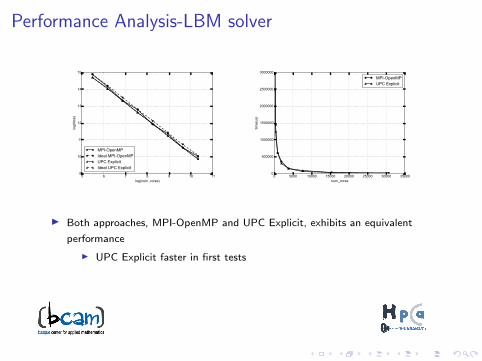
Performance Analysis-LBM solver
5 6 7 8 9 10 11log(num_cores)
9
10
11
12
13
14
15log(tim
e)
MPI-OpenMPIdeal MPI-OpenMPUPC ExplicitIdeal UPC Explicit
0 5000 10000 15000 20000 25000 30000 35000num_cores
0
500000
1000000
1500000
2000000
2500000
3000000
time(us
)
MPI-OpenMPUPC Explicit
I Both approaches, MPI-OpenMP and UPC Explicit, exhibits an equivalent
performance
I UPC Explicit faster in first tests

Performance Analysis-Implicit
5 6 7 8 9 10 11log(num_cores)
9
10
11
12
13
14
15
log(
time)
MPI-OpenMPExplicit-UPCImplicit-UPC
5000 10000 15000 20000 25000 30000num_cores
0.0
0.5
1.0
1.5
2.0
2.5
3.0
time(us
)
MPI-OpenMP/UCP-ImplicitUPC-Explicit/UPC-Implicit
I LBM and communication for MPI-OpenMP and UPC Explicit
I UPC Implicit shows the best trend and highest speedup against MPI-OpenMP
I The higher the number of cores the better performance for UPC Implicit
and Explicit
I Speedup, UPC Explicit (1,12 → 2,19) and UPC Implicit (1,26 → 2,45)

Performance Analysis-Overview
5 6 7 8 9 10 11log(num_cores)
4
6
8
10
12
14
16
log(
time)
MPI-OpenMPIdealCommunicationBC
5 6 7 8 9 10 11log(num_cores)
4
6
8
10
12
14
16
log(
time)
UPC ExplicitIdealCommunicationBC
5 6 7 8 9 10 11log(num_cores)
4
6
8
10
12
14
16
log(tim
e)
UPC ImplicitIdealBC
MPI-OpenMP
I The biggest communication overhead
UPC Explicit
I Low communication overhead
I Equivalent BCs overhead with respect toMPI-OpenMP
UPC Implicit
I Large BCs overhead
I Main bottleneck over high number of cores
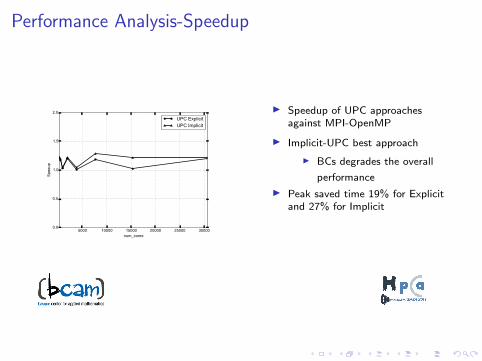
Performance Analysis-Speedup
5000 10000 15000 20000 25000 30000num_cores
0.0
0.5
1.0
1.5
2.0
Spee
up
UPC ExplicitUPC Implicit
I Speedup of UPC approachesagainst MPI-OpenMP
I Implicit-UPC best approach
I BCs degrades the overall
performance
I Peak saved time 19% for Explicitand 27% for Implicit

Conclusions
I UPC is a transparent language for programming overmemory-distributed platforms
I UPC is a more efficient model for communication (one-side)I The benefit is reduced when using higher number of cores
I UPC-ImplicitI The communication is totally transparentI Best performance for LBM and communicationsI Implicit affinity degrades BCs computation (main bottleneck)

THANK YOU FOR YOUR ATTENTION!!!

PGAS (Unified Parallel C) Model.Case Study: Lattice-Boltzmann Method
Pedro Valero-Lara
CFD & Computational Technology, Basque Center for Applied Mathematics
March 12, 2015