probabilistic graphical modelspeople.csail.mit.edu/dsontag/courses/pgm12/slides/lecture14.pdf ·...
TRANSCRIPT

Probabilistic Graphical Models
1
Slides modified from Ankur Parikh at CMU

Today we are going now discuss how linear algebra tools can help us with latent variable models (Spectral Algorithms)
We will discuss the discrete case, although many of the methods can be generalized to the continuous case
The Linear Algebra View of Latent Variable Models
Ankur Parikh, Eric Xing @ CMU, 2012 2
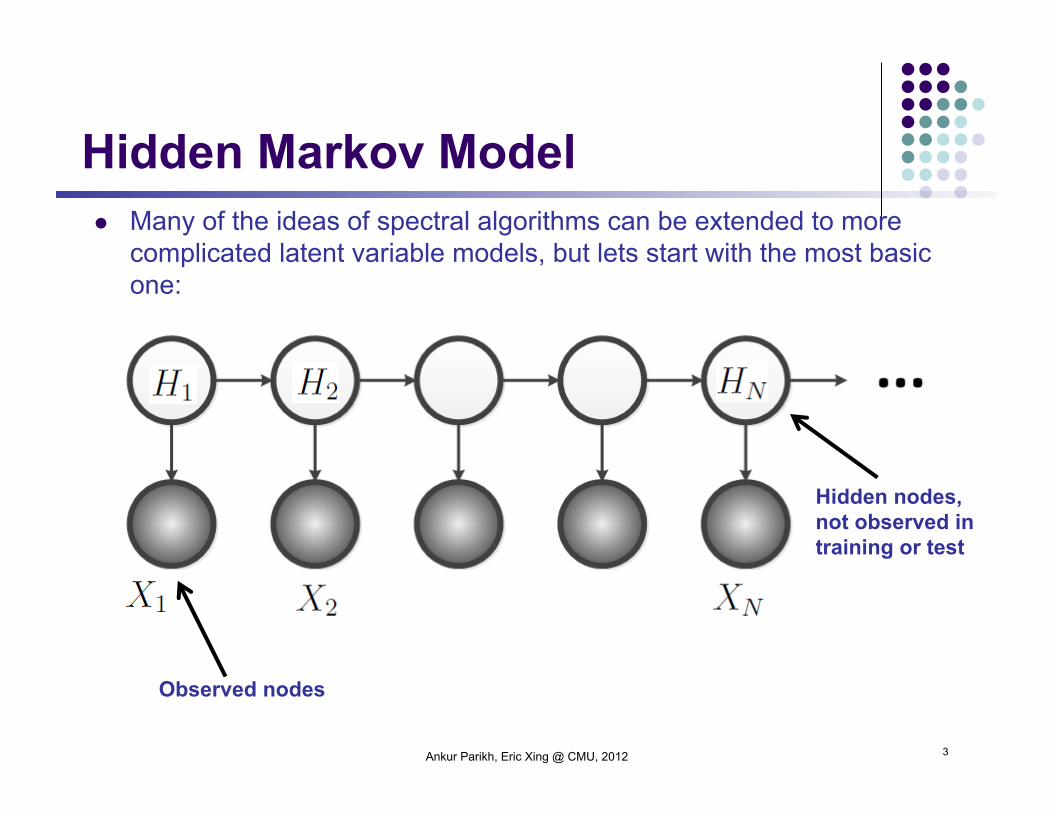
Hidden Markov Model
Ankur Parikh, Eric Xing @ CMU, 2012 3
Many of the ideas of spectral algorithms can be extended to more complicated latent variable models, but lets start with the most basic one:
Observed nodes
Hidden nodes, not observed in training or test
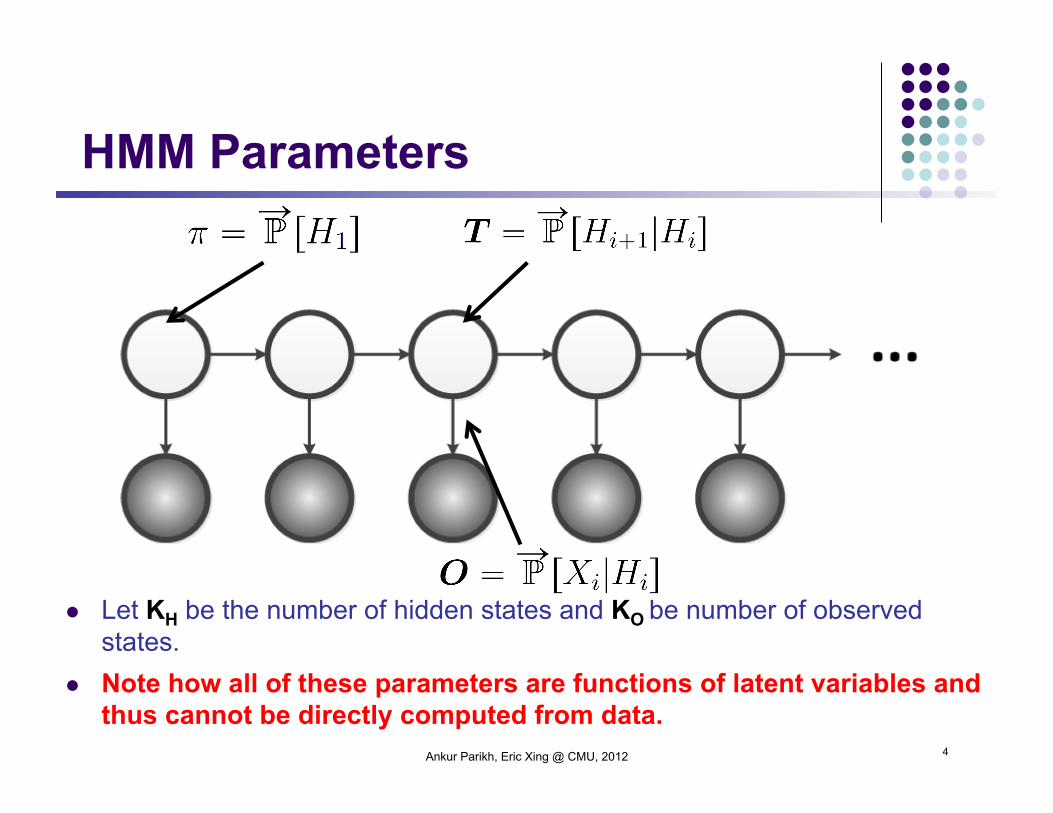
Let KH be the number of hidden states and KO be number of observed states.
Note how all of these parameters are functions of latent variables and thus cannot be directly computed from data.
HMM Parameters
Ankur Parikh, Eric Xing @ CMU, 2012 4
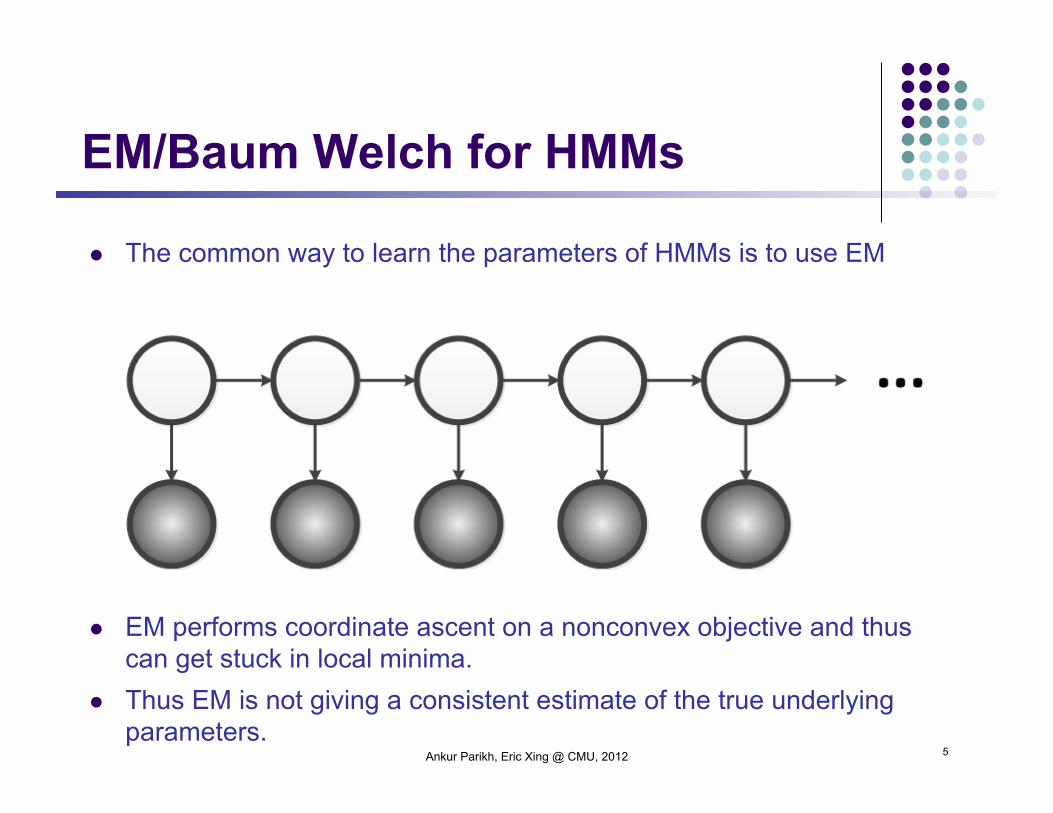
The common way to learn the parameters of HMMs is to use EM
EM performs coordinate ascent on a nonconvex objective and thus can get stuck in local minima.
Thus EM is not giving a consistent estimate of the true underlying parameters.
EM/Baum Welch for HMMs
Ankur Parikh, Eric Xing @ CMU, 2012 5

Optimizing a non-convex objective in general is NP hard, so it is not surprising that the Machine Learning community has resorted to EM / other local search heuristics.
However, the problem doesn’t need to be formulated as an optimization problem.
However, regardless of how it is formulated, is the problem NP hard?
It is NP hard in the general case, but we will see that it is actually not NP hard given certain assumptions [Mossel and Roch
2006]..
Is the problem actually NP hard?
Ankur Parikh, Eric Xing @ CMU, 2012 6
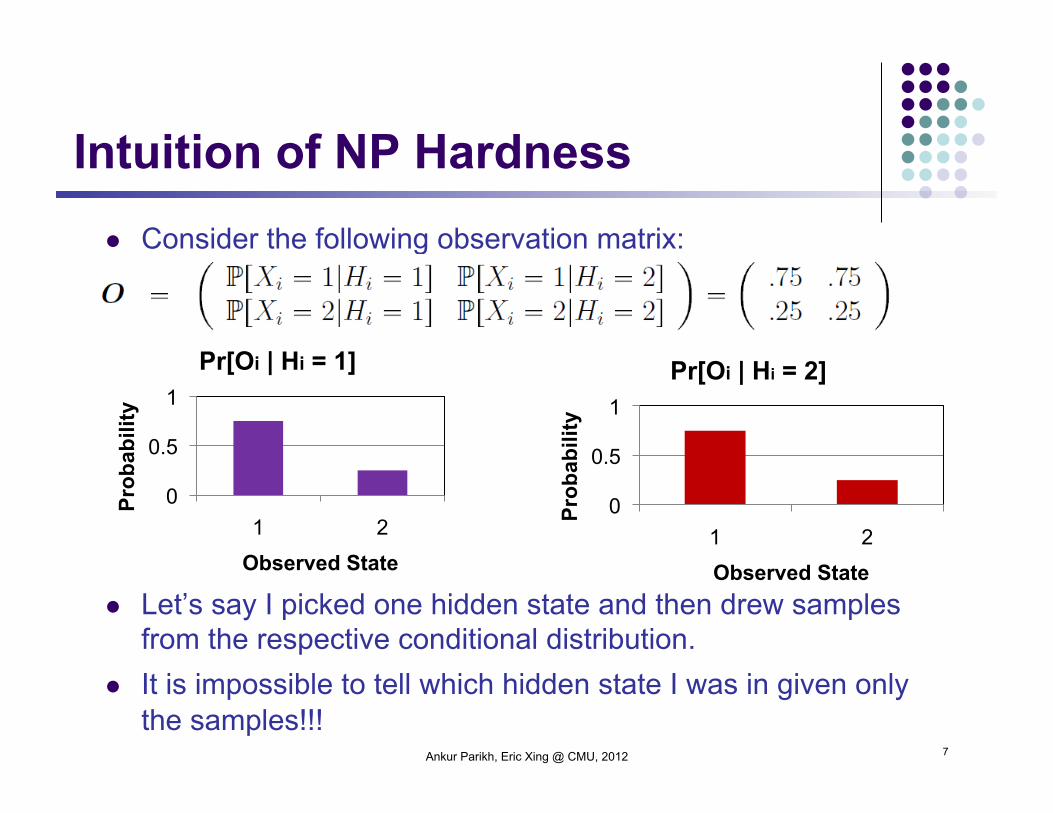
Consider the following observation matrix:
Let’s say I picked one hidden state and then drew samples from the respective conditional distribution.
It is impossible to tell which hidden state I was in given only the samples!!!
Intuition of NP Hardness
Ankur Parikh, Eric Xing @ CMU, 2012 7
0
0.5
1
1 2
Pro
bab
ility
Observed State
Pr[Oi | Hi = 1]
0
0.5
1
1 2
Pro
bab
ility
Observed State
Pr[Oi | Hi = 2]
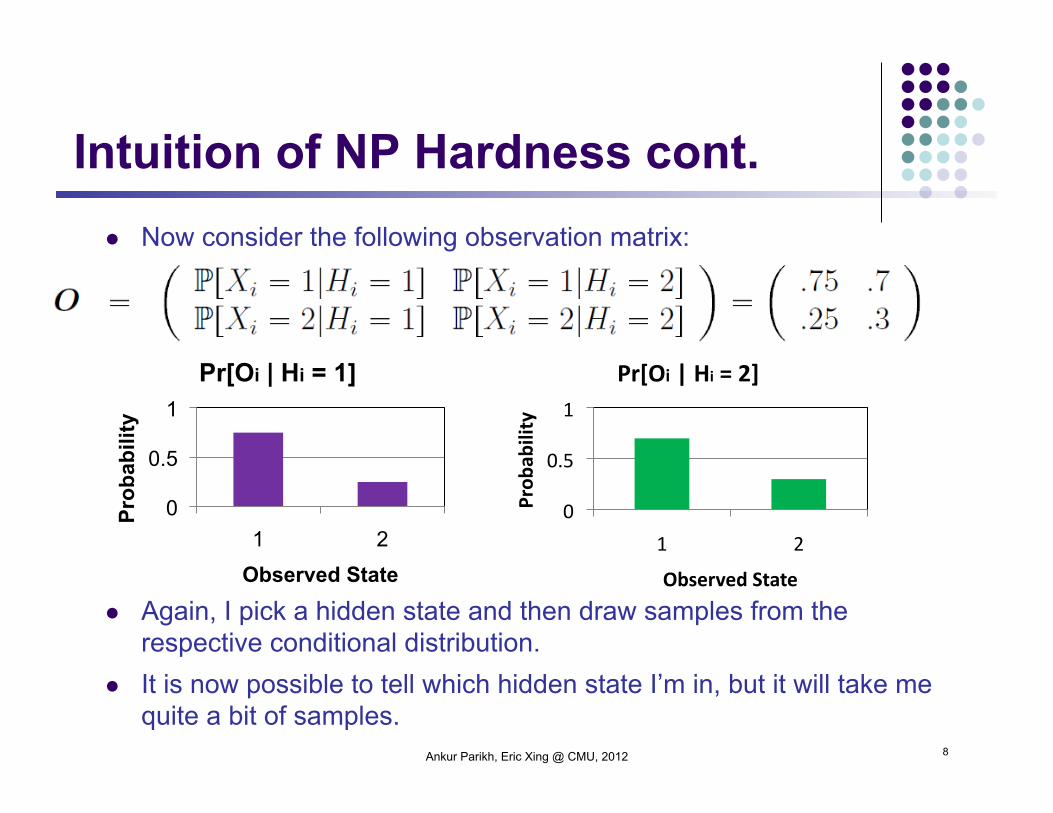
Now consider the following observation matrix:
Again, I pick a hidden state and then draw samples from the respective conditional distribution.
It is now possible to tell which hidden state I’m in, but it will take me quite a bit of samples.
Intuition of NP Hardness cont.
Ankur Parikh, Eric Xing @ CMU, 2012 8
0
0.5
1
1 2
Pro
bab
ility
Observed State
Pr[Oi | Hi = 1]
0
0.5
1
1 2 Prob
ability
Observed State
Pr[Oi | Hi = 2]
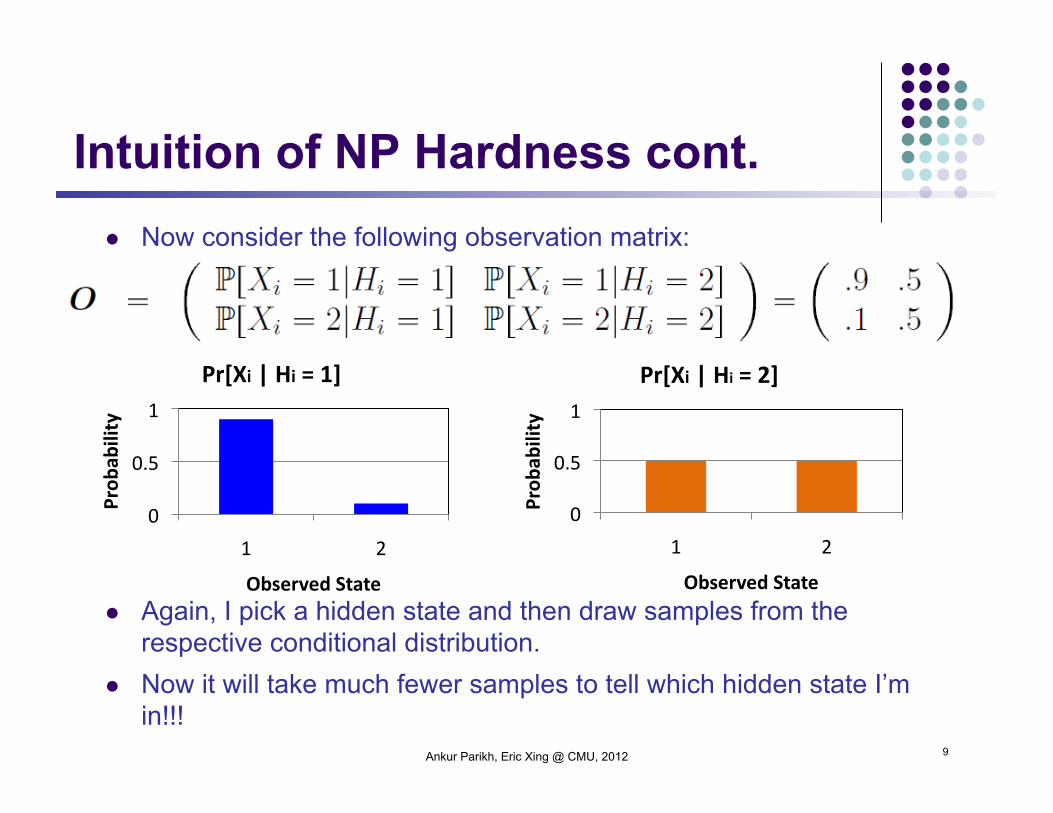
Now consider the following observation matrix:
Again, I pick a hidden state and then draw samples from the respective conditional distribution.
Now it will take much fewer samples to tell which hidden state I’m in!!!
Intuition of NP Hardness cont.
Ankur Parikh, Eric Xing @ CMU, 2012 9
0
0.5
1
1 2 Prob
ability
Observed State
Pr[Xi | Hi = 2]
0
0.5
1
1 2
Prob
ability
Observed State
Pr[Xi | Hi = 1]

From Linear Algebra Perpsective
Ankur Parikh, Eric Xing @ CMU, 2012 10
In linear algebra terms, the problem becomes harder when the observation/transition matrix is rank-deficient: i.e. it has rank smaller than the number of hidden states.
In general, how close a matrix is to being rank-deficient can be measured with its singular values.
Why is this?

Singular Value Decomposition
© Eric Xing @ CMU, 2005-2012 11
Ax̄n OAx̄nO1 P X3, x̄n, X1 P X2, X1
1
1 P X1 P X2, X11
π P X1
M
K
k 1
σkukvk
M̃
K 1
k 1
σkukvk
P1P X 0 0
0 P X 1.55 00 .45
P1.55 00 .45
P1
11.818 00 2.222
P1.48 00 .42
P1
11.724 00 2.083
P2.99 00 .01
4
Ax̄n OAx̄nO1 P X3, x̄n, X1 P X2, X1
1
1 P X1 P X2, X11
π P X1
M
K
k 1
σkukvk
M̃
K 1
k 1
σkukvk
P1P X 0 0
0 P X 1.55 00 .45
P1.55 00 .45
P1
11.818 00 2.222
P1.48 00 .42
P1
11.724 00 2.083
P2.99 00 .01
4

Spectral Algorithms
Spectral Algorithms directly “learn” the parameters of latent variable models without doing optimization.
Unlike EM, one can prove the consistency and characterize the sample complexity of spectral methods.
Providing the observation/transition matrices have rank KH, spectral algorithms are consistent. (Note how this implies that the number of observed states is required to be larger than the number of hidden states).
Ankur Parikh, Eric Xing @ CMU, 2012 12

Spectral Algorithms
How do spectral algorithms learn the parameters of the model?
Two ways:
Directly learn the original parameters using eigenvalue decomposition (unstable in practice, a current area of research) [Mossel and Roch 2006].
Learn a different parameterization of the model (called the observable representation). This approach tends to work better in practice, and is what we will discuss.
Ankur Parikh, Eric Xing @ CMU, 2012 13

The Observable Representation
The observable representation is an alternate parameterization of the model.
Unlike the original parameterization of the model which depended on latent variables, the parameters in the observable representation only depend on observed variables. Ankur Parikh, Eric Xing @ CMU, 2012 14

Caveat of Observable Representation
The observable representation limits us to performing inference among observed variables. Thus we cannot explicitly recover the latent variables (in a stable way).
Ankur Parikh, Eric Xing @ CMU, 2012 15
Examples of things the observable representation can compute:
Examples of things the observable representation can’t compute:

A Trivial Observable Representation
I could just integrate all the latent variables out!!!!!
Now there is one “huge” factor. It technically is an observable parameterization since it is a function of observed variables.
But this would work poorly in practice as well as lead to intractable inference, and therefore defeat the point of a graphical model.
Ankur Parikh, Eric Xing @ CMU, 2012 16

But there is something to be learned here….
We made the representation observable by increasing the number of parameters.
We just got a little carried away and increased the number of parameters by a huge amount.
Can we just get away by increasing the number of parameters by a little bit?
Daniel Hsu, Sham Kakade, and Tong Zhang (COLT 2009) proposed an efficient observable representation for Hidden Markov Models, which is what we will discuss.
Ankur Parikh, Eric Xing @ CMU, 2012 17

A Spectral Algorithm for Learning HMMs [Hsu et al. 2009]
Let us first consider computing the joint probability of all the observed variables.
For simplicity we assume the number of hidden states equals the number of observed states, but the algorithm generalizes to the case when the number of observed states is larger than the number of hidden states.
Ankur Parikh, Eric Xing @ CMU, 2012 18

Prior Vector
Ankur Parikh, Eric Xing @ CMU, 2012 19

Transition Matrix
Ankur Parikh, Eric Xing @ CMU, 2012 20

Observation Probability on Diagonal
Ankur Parikh, Eric Xing @ CMU, 2012 21
XN
P x̄1, ..., x̄N
P xn xn 1, ..., x1
P h1 x1
P h1, h2, ..., hn
T i, j P Hn 1 i Hn j
Ox̄n i, jP Xn x̄n Hn i if i j
0 otherwise
π i P H1 i
P x̄1, ..., x̄N 1 TOx̄N , ...,TOx̄1π
P x̄1, ..., x̄N 1 Ax̄N , ...,Ax̄1π
P x̄1, ..., x̄N 1 Ax̄N , ...,Ax̄1π
Ax̄n TOx̄n
P x̄1, ..., x̄N 1 S1SAx̄NS
1, ...,
SAx̄1S1Sπ
1
2

Express Joint Probability as Matrix Multiplication
Ankur Parikh, Eric Xing @ CMU, 2012 22
Why is this true?

Sum Rule
Equivalent view using Matrix Algebra
Matrix Multiplication Performs Sum Product!
23 Ankur Parikh, Eric Xing @ CMU, 2012

Chain Rule
Equivalent view using Matrix Algebra
Note how diagonal is used to keep Y from being marginalized out.
Using Diagonal Keeps Variable From Getting Summed Out
24 Ankur Parikh, Eric Xing @ CMU, 2012
Means on diagonal

Transform the Representation
Ankur Parikh, Eric Xing @ CMU, 2012 25
Define

Reparameterize the Model
Ankur Parikh, Eric Xing @ CMU, 2012 26

We now have to choose S, such the parameters become functions of observed variables.
Here is a choice that we will show works:
We have assumed number of hidden states equals number of observed states. If the number of observed states is larger then we use a projection matrix U to make S square.
Remember this only works because we have assumed that O is not rank deficient, otherwise S-1 does not exist.
Constructing the Observable Representation
Ankur Parikh, Eric Xing @ CMU, 2012 27

Constructing Observable Representation
Ankur Parikh, Eric Xing @ CMU, 2012 28
Because matrix multiplication performs sum-product.

Constructing Observable Representation
The real question is what to do with the inverse.
Consider the related quantity.
We are going to evaluate the above expression in two ways.
Ankur Parikh, Eric Xing @ CMU, 2012 29
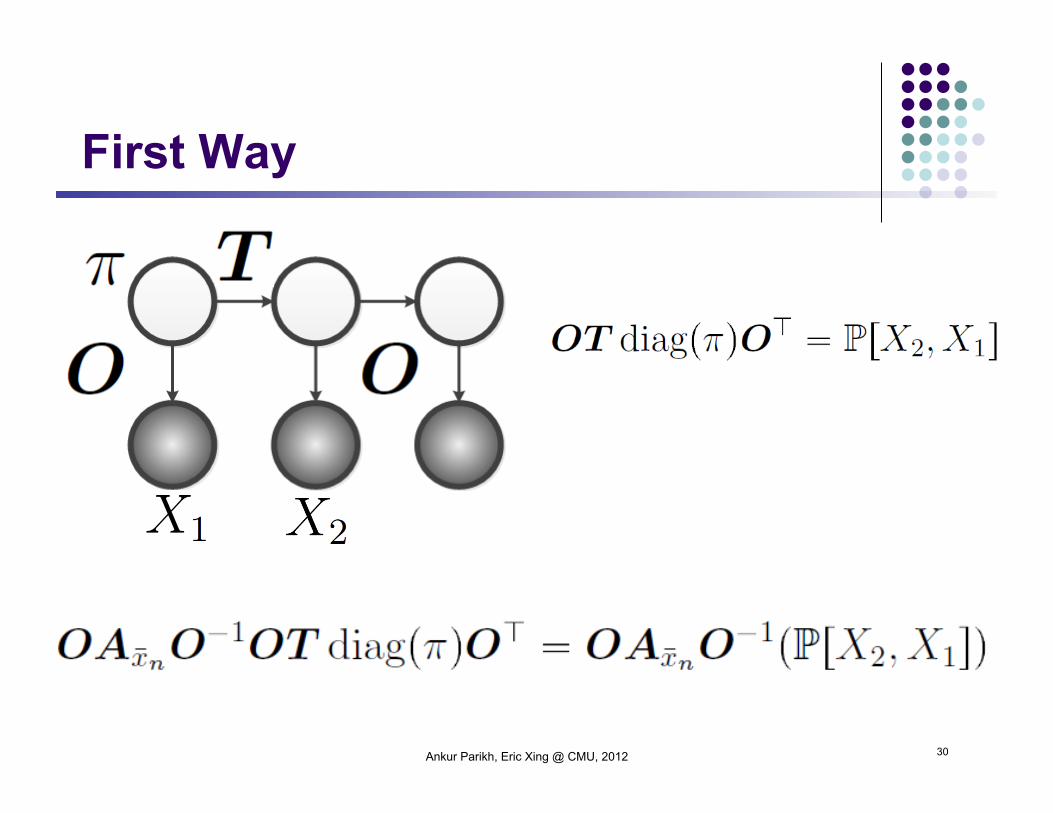
First Way
Ankur Parikh, Eric Xing @ CMU, 2012 30

Second Way
Ankur Parikh, Eric Xing @ CMU, 2012 31

Set the Two Ways Equal to Each Other
Ankur Parikh, Eric Xing @ CMU, 2012 32

The Observable Representation
Ankur Parikh, Eric Xing @ CMU, 2012 33
This is an alternate parameterization of the HMM that depends only on observed variables. Thus it can be computed directly from data!
For simplicity we have constructed the representation with only 3 variables, but in practice it is possible to use all the variables.

What Have We Lost?
There is no free lunch in Machine Learning. Where have we paid the price for the observable representation?
One price we have paid is an increase in number of parameters.
Ankur Parikh, Eric Xing @ CMU, 2012 34
This is actually a cube, since we have to compute the probability matrix for all the choices of the evidence in training.
This is only a matrix, since it was originally diagonal.

What Have We Lost?
We have also lost something else.
What does this mean?
Ankur Parikh, Eric Xing @ CMU, 2012 35
Our observable representation contains inverses of probability matrices.
None of these quantities depend on inverses of probability matrices.

Consider the following probability matrix:
Consider estimating this matrix from a finite number of samples. We may get something like:
Intuition
© Ankur Parikh, Eric Xing @ CMU, 2012 36

Consider the Inverse
37
close!! close!!
© Ankur Parikh, Eric Xing @ CMU, 2012

Now consider this case
© Ankur Parikh, Eric Xing @ CMU, 2005-2012 38
close!! not close!!

What Happened?
Remember that for a diagonal matrix, the eigenvalues are simply the diagonal elements.
By depending on the quality of the inverse estimate, the performance of the spectral algorithm depends on the smallest singular values of certain probability matrices.
© Ankur Parikh, Eric Xing @ CMU, 2012 39
This eigenvalue is high This eigenvalue is low

Generalizations
Can the rank conditions be relaxed. Yes (somewhat): S. Siddiqi, B. Boots, G. Gordon, Reduced Rank Hidden Markov Models.
Can spectral algorithms work for other structures beyond HMMs? Yes (to latent trees): A.P. Parikh, L. Song, E.P. Xing, A Spectral Algorithm for Latent Tree
Graphical Models.
Can even give spectral method to learn mixture models and also admixture models (e.g., Latent Dirichlet Allocation) A. Anandkumar, D. Foster, D. Hsu, S. Kakade, Y. Liu. “Two SVDs
Suffice: Spectral decompositions for probabilistic topic modeling and latent Dirichlet allocation”, arXiv:1204.6703v1, April 30, 2012
Ankur Parikh, Eric Xing @ CMU, 2012 40

References
Mossel, E. and Roch, S. Learning nonsingular phylogenies and hidden markov models. Annals of Applied Probability, 16(2):583–614, 2006.
Hsu, D., Kakade, S., and Zhang, T. A Spectral Algorithm for Learning
Hidden Markov Models. Conference on Learning Theory, 2009.
Siddiqi, S., Boots, B. Gordon, G., Reduced Rank Hidden Markov Models, Artificial Intelligence and Statistics (AISTATS), 2009.
Parikh, A.P. Song, L., and Xing, E.P. A Spectral Algorithm for Latent Tree Graphical Models, International Conference of Machine Learning (ICML), 2010.
Song, L., Boots, B., Siddiqi, S., Gordon, G., and Smola, A. Hilbert space embeddings of Hidden Markov Models. International Conference of Machine Learning (ICML), 2010.
Song, L., Parikh, A.P., and Xing, E.P. Kernel Embeddings of Latent Tree Graphical Models. Neural Information Processing Systems (NIPS) 2011.
Ankur Parikh, Eric Xing @ CMU, 2012 41