proof carrying code (pcc) - cs.unibo.itbabaoglu/courses/security05-06/lucidi/pcc.pdf · il processo...
TRANSCRIPT

Proof Carrying Code (PCC)
Vedi: Necula-Lee www.cs.unibo.it/~laneve/html/metodi1/paper3.ps
visione tradizionale: il software è codice eseguibile
visione più appropriata: il software è codice eseguibile e verificabile
A tal fine:
il software porta con se un certificato (la prova) con il quale è possibile verificare la sua correttezza dinamica
1

i certificati sono già presenti nella tecnologia attuale: con le firme digitali
software
firma digitale
server
verifica della firma digitale
CPU
vantaggio: veloce, semplice, sicuro
svantaggio: non c’ è alcuna garanzia sulla correttezza del codice (ma solo sulla provenienza)
2

la verifica di codice in Java:
Interpreter JIT Compiler
CPU
Java Bytecode Verifier
software
server
vantaggio: general purpose
svantaggio: il JBV è limitato nelle verifiche, l’Interpreter/JIT è costoso e/o grande
3

il desiderata :
CPU
Theorem Prover
software
server
vantaggio: potente
svantaggio: difficile da implementare
4

la visione pcc: Prove Esplicite
vantaggi: server
software
prova di correttezza
verificatore di correttezza
CPU
dimostratore di correttezza
1. le prove hanno una dimensione ragionevole (0-10% del codice)
2. il verificatore di correttezza è semplice e piccolo ( 50KB)
3. non è necessario che il dimostratore di correttezza sia “affidabile”
Questioni a cui bisogna rispondere:
1. come funziona il “dimostratore di correttezza” ?
2. come si verifica la “correttezza” ?
3. cosa dimostra la “prova di correttezza” ? 5

il processo PCC:
1. definizione formale della politica di correttezza. Il produttore di codice definisce in maniera formale e pubblicizza una politica di correttezza (ad esempio, il proprio codice termina, oppure non produce memory leaks, etc.) che desidera venga rispettata dal codice che intende eseguire.
2. certificazione. Il produttore compila il codice e dimostra che il proprio codice è corretto rispetto alla politica pubblicizzata.
3. invio. La dimostrazione viene inviata assieme al codice ad ogni consumatore.
4. validazione. Il consumatore verifica che il codice è corretto secondo la certificazione allegata.
6

esempio: sicurezza della memoria
A è un array (il primo indirizzo) di n elementi di tipo booleano.
correttezza: - A memorizza soltanto booleani - se la funzione termina allora restituisce un booleano - 0 e 1 sono i soli booleani - le letture e le scritture sono ammesse tra A+1 e A + n
politica di correttezza pubblicizzata dal produttore: (assiomi e regole di inferenza)
A : array(T,L) I > 0 I ≤ L A : array(T,L) I > 0 I ≤ L E : T
sel( A + I) : T safewr(A + I, E)
I ≤ E I > 0 0 : bool 1 : bool E ≤ E I - 1 ≤ E
7
(typerd) (wr)
(bool0) (bool1) (leqid) (dec)

codice inviato dal produttore
codice eseguibile + annotazioni + prova
scheletro di prova
bool1 leqid typerd IP0: a0 : array(bool, n0) IP2: i1 ≤ n0 IP3: i1 ≥ 0
. . . .
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ nif i ≤ 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
8

9
osservazione: il codice contiene annotazioni all’inizio ed alla fine e in prossimità dei
cicli (vedremo poi chi inserisce tali annotazioni).
le annotazioni (interessanti) – gli invarianti – sono generati da salti all’indietro (cicli)
lo scheletro di prova è una sequenza di regole (determinismo e assenza di backtracking – cf. programmazione logica)
Generazione delle Condizioni di Verifica (Verification Condition – VC)
il codice viene scandito da una procedura. Quando si incontra una annotazione, la procedura genera un predicato (assunzione) che viene utilizzato dal verificatore per dimostrare la politica di correttezza. Il verificatore consta di due parti:
1. politiche di correttezza
2. assunzioni precedentemente verificate.

graficamente:
Ricostruttore di ProveVerificatore
producer user
software annotazione
prova di correttezza
n CVVCGe
Assiomatizzazione (Politica di Correttezza)
il generatore di condizioni di verifica (VCGen) è una procedura che deriva predicati secondo lo stile di Floyd-Hoare (che è dettagliato in seguito)
il verificatore è un programma logico (scritto in Prolog)
10

comportamento di VCGen e del verificatore
registri simbolici a : a0
n : n0 i : i0 r : r0 t : t0
assunzioni
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ n if i ≤ 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
11

registri simbolici a : a0
n : n0 i : i0 r : r0 t : t0
assunzioni (IP0) a0 : array(bool, n0)
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ n if i ≤ 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
12

registri simbolici a : a0
n : n0 i : n0 r : 1 t : t0
assunzioni (IP0) a0 : array(bool, n0)
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ n if i ≤ 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
osservazione: I valori simbolici di i ed r sono cambiati.
osservazione: ad L0 si incontra una annotazione di tipo INV
occorre invocare il verificatore per dimostrarne la validità
13

il verificatore: Assiomi e Regole di Inferenza
a0 : array(bool, n0)
Verificatore
(Scheletro di) Prova
bool1 leqid typerd IP0
IP2
IP3
. . . .
osservazione: Il verificatore tenta di derivare l’invariante INV attraverso la politica di correttezza e lo scheletro di prova.
INV è istanziato come: 1 : bool && n0 ≤ n0
che segue utilizzando (bool1) e (leqid), come specificato nello scheletro di prova.
14

la verifica continua con il generatore di condizioni di verifica:
registri simbolici a : a0
n : n0 i : i1 r : r1 t : t0
assunzioni (IP0) a0 : array(bool, n0) (IP1) r1 : bool (IP2) i1 ≤ n0
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ n if i ≤ 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
osservazione: i ed r hanno valori simbolici
15

Calcolando gli effetti delle istruzioni if i ≤ 0 goto L1t := a + i
otteniamo:
registri simbolici a : a0
n : n0 i : i1 r : r1 t : a0+i1
assunzioni (IP0) a0 : array(bool, n0) (IP1) r1 : bool (IP2) i1 ≤ n0 (IP3) i1 > 0
(IP4) at(L1) ⇒ (r : bool && i≤0)
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ n if i ≤ 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
osservazione: due assiomi sono stati aggiunti e il valore simbolico di t è stato modificato
16

la prossima istruzione da eseguire, t := *t
è problematica perchè avviene una lettura, quindi bisogna controllare che la lettura riguarda una cella dell’array
registri simbolici a : a0
n : n0 i : i1 r : r1 t : sel(a0+i1)
assunzioni (IP0) a0 : array(bool, n0) (IP1) r1 : bool (IP2) i1 ≤ n0 (IP3) i1 ≥ 0
(IP4) at(L1) ⇒ (r : bool && i<0)
PRE: a: array(bool,n) r := 1 i := n
L0 : INV : r: bool && i ≤ n if i < 0 goto L1t := a + i t := *t r := r && t i := i –1 goto L0
L1 : return r POST : r : bool
17

per verificare sel(a0 + i1) si invoca il verificatore:
Assiomi e Regole di Inferenza
a0 : array(bool, n0) r1 : bool i1 ≤ n0 i1 ≥ 0 at(L1) ⇒ (r : bool && i<0)
(Scheletro di) Prova
bool1 leqid typerd IP0
IP2
IP3
. . . .
Verificatore
osservazione: sel(a0 + i1) segue da (typerd) con ipotesi IP0, IP2 e IP3.
la verifica continua in questo modo alla fine della verifica il codice è pronto per essere eseguito
18

la logica di Floyd-Hoare
è il cuore del generatore di condizioni di verifica (VCGen).
la logica di Floyd-Hoare (1967) è un sistema definito per verificare la correttezza di programmi scritti con diagrammi di flusso.
con questa tecnica si derivano triple:
φ P ψ
dove P è il programma da verificare, mentre φ e ψ sono formule (di solito in logica dei predicati). Il significato di questa tripla è il seguente:
correttezza parziale: se il programma P inizia in una configurazione che soddisfa la proprietà φ e la sua esecuzione termina, allora la configurazione finale verifica la proprietà ψ
osservazione: il programma può non terminare
19

Le regole seguenti sono una istanziazione della tecnica di Floyd-Hoare a bytecode come quello dell’esempio precedente P[i] = x := e φi P[i] φi+1 dom(P)=1..n
φ { e/x } P[i] φ φ1 P φn+1 (φ && e) P[L] ψ P[i] = if e goto L
φ P[i] (φ && e) P[i] = return φ P[L] ψ P[i] = goto L
φ P[i] φ φ P[i] ξ
φ ψ ψ P[i] χ χ ξ
φ P[i] ξ
20

esempio. La somma di due numeri con le operazioni di incremento e decremento.
1 if (x = 0) goto 5 2 y := y+1 3 x := x-1 4 goto 1 5 return
proprietà da dimostrare: (P è il programma di sopra) { x + y = m + n && x ≥ 0 } P { y = m+n && x = 0 }
annotazioni: { x + y = m + n && x ≥ 0 } if (x = 0) goto 5
{ x + y = m + n && x > 0 } y := y+1 { x + y = m + n + 1 && x > 0 } x := x-1 { x + y = m + n && x ≥ 0 } goto 1 { x = 0 && x + y = m + n} return { x = 0 && x + y = m + n}
due problemi: 1. come individuare le formule
2. la regola φ ψ ψ P[i] χ χ ξ φ P ξ
21

1. L’ individuazione delle formule della logica di Floyd-Hoare la tecnica standard è di procedere dalla conclusione (la proprietà che si vuole dimostrare) verso la premessa (cf. Dijkstra weakest preconditions) osservazione: questa tecnica funziona bene se non ci sono salti
in caso di salti: . . .
instr_h . . . instr_k = goto h instr_k+1
. . . ed occorre che φ = ξ ciò può richiedere diverse iterazioni per individuare la formula corretta
Ad esempio, nel caso di sopra, si voleva dimostrare la proprietà:
POST { x = 0 && y = m + n}
Quindi i passi sono i seguenti:
22

if (x = 0) goto 5y := y+1 x := x-1 goto 1 return
{ x = 0 && x + y = m + n }
PASSO 1
if (x = 0) goto 5 y := y+1 x := x-1 goto 1
{ x = 0 && x + y = m + n}
return
{ x = 0 && x + y = m + n}
PASSO 2
φ if (x = 0) goto 5 y := y+1 x := x-1
φ goto 1
{ x = 0 && x + y = m + n}
return
{ x = 0 && x + y = m + n}
PASSO 3 23

φ if (x = 0) goto 5
φ { x-1/x }{ y+1/y }
y := y+1
φ { x-1/x } x := x-1
φ goto 1
{ x = 0 && x + y = m + n }
return
{ x = 0 && x + y = m + n }
PASSO 5
φ if (x = 0) goto 5 y := y+1
φ { x-1/x } x := x-1
φ goto 1
{ x = 0 && x + y = m + n }
return
{ x = 0 && x + y = m + n }
PASSO 4
24

per eseguire il prossimo passo, si osservi che deve esistere una ψ tale che:
ψ if (x = 0) goto 5 { ψ && x ≥ 0 }
osservazione: questa ψ deve soddisfare le seguenti due condizioni:
1. { ψ && x = 0} { x = 0 && x + y = m + n}
2. { ψ && x > 0 } φ { x-1/x }{ y+1/y }
ne segue che
ψ {x + y = m + n && x ≥ 0}
φ {x + y = m + n && x ≥ 0}
dunque otteniamo:
25

{ x + y = m + n && x ≥ 0 }
if (x = 0) goto 5
{ x + y = m + n && x ≥ 0 }{ x-1/x }{ y+1/y }
y := y+1
{ x + y = m + n && x ≥ 0 } { x-1/x } x := x-1
{ x + y = m + n && x ≥ 0 }
goto 1
{ x = 0 && x + y = m + n}
return
{ x = 0 && x + y = m + n}
PASSO 6
in questo semplice caso, il calcolo delle annotazioni termina senza ulteriori iterazioni (perchè φ ψ). In generale occorre iterare.
26

ossevazione: nel contesto PCC, il problema del calcolo delle annotazioni non è rilevante per quanto riguarda il server, visto che esso riceve il codice con le formule (le annotazioni).
verificare una prova è tanto semplice quanto fare type-checking
al contrario, il problema suddetto è rilevante dal punto di vista del produttore, che deve specificare le formule e fornire una prova.
2. La regola φ ψ ψ P[i] χ χ ξ
φ P ξ questa è la regola problematica del sistema di Floyd-Hoare perchè ci sono sistemi logici, ad esempio la logica dei predicati, per cui non esiste alcun algoritmo in grado di decidere “φ ψ”
in generale la verifica non è completamente automatica
27

esempio (performance dei filtri di pacchetti di rete): i filtri di pacchetti di rete sono delle procedure che controllano se un pacchetto in entrata (dalla rete) può essere interessante per l’applicazione utente o meno Questi filtri sono stati implementati utilizzando la tecnica PCC con i seguenti risultati:
lunghezza del codice annotato : 3-4 volte maggiore del bytecode
overhead per la verifica delle prove : 5% (minore delle firme digitali)
tempo per produrre la prova : 1-3 ms (che è ammortizzato presto)
28

Typed Assembly Languages (TAL)
Vedi: Morrisett-Crary-Walker-Grew www.cs.unibo.it/~laneve/html/metodi1/paper4.ps
Il problema di PCC è che tutto il carico del metodo è lasciato al code-producer, il quale deve
1. individuare le annotazioni giuste,
2. dimostrare la correttezza secondo la logica di Floyd-Hoare.
Per ovviare a questa critica è stata definita la seguente tecnica:
1. il programmatore scrive codice ad alto livello, arricchendo il codice con le proprietà attese, utilizzando un opportuno linguaggio di tipi.
2. gli assembly languages sono arricchiti con tipi espliciti che esprimono le proprietà.
29

3. il compilatore traduce le proprietà ad alto livello in tipi dell’assembly language, verificando che il codice è ben tipato.
4. la dimostazione di correttezza si riduce perciò al type-checking (verifica che è nota essere molto efficiente).
Graficamente, la situazione è illustrata dal diagramma seguente.
30
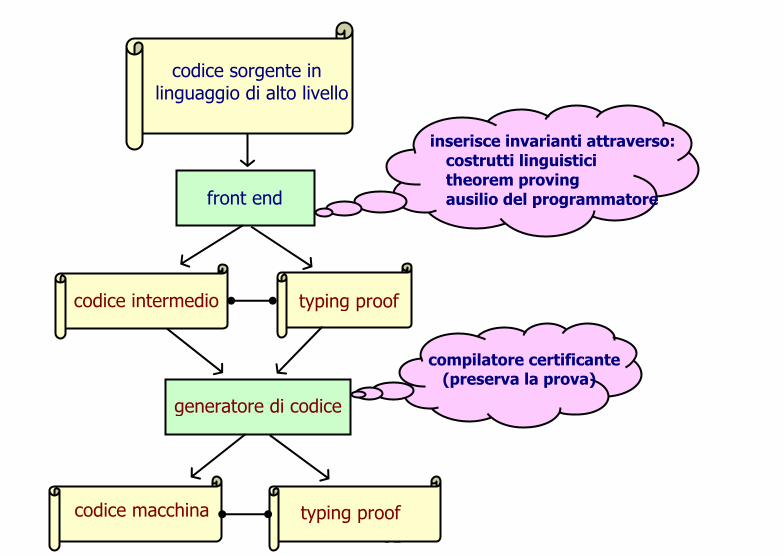
31
codice sorgente in
linguaggio di alto livello
inserisce invarianti attraverso: costrutti linguistici theorem proving ausilio del programmatore
front end
codice intermedio typing proof
generatore di codice
compilatore certificante
(preserva la prova) codice macchina typing proof

osservazione. Il codice intermedio ha annotazioni ( tipi) e il generatore di codice compila anche le annotazioni.
il codice intermedio è
una sequenza di istruzioni assembler I1 ; . . . ; In
ogni istruzione Ik può essere “etichettata”. In questo caso il formato dell’istruzione è:
L : code [ 1 ; . . . ; h ] Γ . { Ik1 ; . . . ; Ik
m }
ed il significato è che, quando si salta all’istruzione L, occorre che i registri e la pila soddisfino la formula:
1 . . . h . Γ
osservazione. La formula 1 . . . h . Γ è “polimorfa”: vale per ogni possibile istanza delle variabili 1 . . . h (di solito con tipi)
32

tecnologia attuale. Bytecode Verification (à la Java)
verifica che le risorse usate sono finite;
politiche di sicurezza (nessun messaggio sulla rete è inviato dopo la lettura dal disco locale);
correttezza.
problemi aperti.
maggiore controllo sulla memoria;
type & proof engeeneering (individuare la giusta sintassi dei tipi e il corretto sistema di inferenza);
. . .
33