readability of bangla news articles for children
TRANSCRIPT

PACLIC 28
!309
Readability of Bangla News Articles for Children
Zahurul Islam and Rashedur RahmanAG Texttechnology
Institut fur InformatikGoethe-Universitat Frankfurt
[email protected], [email protected]
Abstract
Many news papers publish articles for chil-dren. Journalists use their experience and in-tuition to write these. They might not aware ofreadability of articles they write. There is noevaluation tool or method available to deter-mine how appropriate these articles are for thetarget readers. In this paper, we evaluate dif-ficulty of Bangla news articles that are writtenfor children.
1 Introduction
News is the communication of selected informationon current events (Shirky, 2009). This communi-cation is shared by various mediums such as print,online and broadcasting. A newspaper is a printedpublication that contains news and other informativearticles. There are many newspapers that are alsopublished online. Due to the rapid growth of internetuse, it is very common that more people read newsonline nowadays than before. Newspapers try to tar-get certain audience through different topics and sto-ries. Children are also in their target audience. Thistarget group is their future reader.
Nowadays children also read news online. Onethird of children in developed countries such asNetherlands, United Kingdoms and Belgium browseinternet for news (De Cock, 2012; De Cock andHautekiet, 2012). Another study by Livingstone etal. (2010) showed that one fourth of the British chil-dren between age of nine and nineteen look for newson the internet. The ratio could be similar in otherdeveloped countries where most of the citizen haveaccess over the internet.
The number of internet users also increasing indeveloping countries such as Bangladesh and In-dia. According to the English Wikipedia1, morethan thirty three million people in Bangladesh useinternet and many of them read news online. Alsothe Alexa index2 shows that three Bangla news sitesare in the list of ten most visited websites fromBangladesh.
All newspapers contain a variety of sections.These sections are based on different news topics.Some of the them are specific to children. The newsfor children will vary linguistically and cognitivelythan news for adults. This characteristic is similarto the websites dedicated for children. De Cock andHeutekiet (2012) observed difficulties for children tonavigate these websites. Readability of the texts isone of the reasons. There is no specific guideline forwriting texts for this target group. Journalists usetheir experience and intuition while writing. How-ever, a text that is very easy to understand for anadult reader could be very difficult for a child. Thisdifficulty motivate children readers to skip the news-paper in future.
The readability of a text relates to how easilyhuman readers can process and understand a text.There are many text related factors that influence thereadability of a text. These factors include very sim-ple features such as type face, font size, text vocab-ulary as well as complex features like grammaticalconciseness, clarity, underlying semantics and lackof ambiguity. Nielsen (2010) recommended fontsize of 14 for young children and 12 for adults.
1http://en.wikipedia.org/wiki/Internet in Bangladesh2http://en.wikipedia.org/wiki/Alexa Internet
Copyright 2014 by Zahurul Islam and Rashedur Rahman28th Pacific Asia Conference on Language, Information and Computation pages 309–317

PACLIC 28
!310
Readability classification, is a task of mappingtext onto a scale of readability levels. We explore thetask of automatically classifying documents basedon their different readability levels. As an input, thisfunction operates on various statistics relating to dif-ferent text features.
In this paper, we train a readability classificationmodel using a corpus compiled from textbooks andfeatures inherited from our previous works Islamet al. (2012; 2014) and features from Sinha et al.(2012). Later we use the model to classify Banglanews articles for children from different well-knownnews sources from Bangladesh and West Bengal.
The paper is organized as follows: Section 2 dis-cusses related work. Section 3 describes cognitivemodel of children in terms of readability followedby an introduction of the training corpus and newsarticles in Section 4. The features used for classifica-tion are described in Section 5, and our experimentsand results in Section 6 are followed by a discussionin Section 7. Finally, we present our conclusions inSection 8.
2 Related Work
Most of the text readability research works use textsfor adult readers. Only few numbers of related workavailable that only focus on texts for children. DeBelder and Moens (2010) perform a study that trans-fers a complex text into a simpler text so that thetarget text become easier to understand for children.They have focused on two types of simplification:lexical and syntactic. Two traditional readability for-mulas: Flesch-Kincaid (Kincaid et al., 1975) andDale-Chall (Dale and Chall, 1948; Dale and Chall,1995) are used to measure reading difficulty. DeCock and Heutekiet (2012) performed a usabilitystudy to analyze websites for children. The studyuses texts from different websites published in En-glish and Dutch. The usability experiment showsthat previous knowledge of children play an impor-tant role to read and understand texts. They haveused Flesch-Kincaid (Kincaid et al., 1975) to deter-mine the difficulty level of English texts and a vari-ation of the same formula for Dutch texts.
Both of the related work mentioned above use tra-ditional readability formulas to measure text diffi-culty. However these traditional formulas have sig-
nificant drawbacks. These formulas assume thattexts do not contain noise and the sentences are al-ways well-formed. However this is not the case al-ways. Traditional formulas require significant sam-ple sizes of text, they become unreliable for a textthat contains less than 300 words (Kidwell et al.,2011). Si and Callan (2001), Peterson and Osten-dorf (2009) and Feng et al. (2009) show that thesetraditional formulas are not reliable. These formu-las are easy to implement, but have a basic inabil-ity to model the semantic of vocabulary usage in acontext. The most important limitation is that thesemeasures are based only on surface characteristicsof texts and ignore deeper properties. They ignoreimportant factors such as comprehensibility, syntac-tical complexity, discourse coherence, syntactic am-biguity, rhetorical organizations and propositionaldensity of texts. Longer sentences are not alwayssyntactically complex and counting the number ofsyllables of a single word does not show word dif-ficulty. That is why, the validity of these traditionalformulas for text comprehensibility is often suspect.Two recent works on Bangla texts use two of thesetraditional formulas. Das and Roychudhury (2004;2006) show that readability measures proposed byKincaid et al. (1975) and Gunning (1952) work wellfor Bangla. However, the measures were tested onlyfor seven documents, mostly novels.
Since there are not many linguistic tools availablefor Bangla, researchers are exploring language in-dependent and surface features to measure difficultyof Bangla texts. Recently, in our previous works,we proposed a readability classifier for Bangla usinginformation-theoretic features (Islam et al., 2012; Is-lam et al., 2014). We have achieved an F-Scoreof 86.46% by combining these features with somelexical features. Sinha et al. (2012) proposed tworeadability models that are similar to classical read-ability measures for English. They conducted a userexperiment to identify important structural param-eters of Bangla texts. These measures are basedon the average word length (WL), the number ofpoly-syllabic words and the number of consonant–conjuncts. According to their experimental results,consonant–conjuncts plays an important role in textsin terms of readability.
From the beginning of research on text read-ability, researchers proposed different measures for

PACLIC 28
!311
English (Dale and Chall, 1948; Dale and Chall,1995; Gunning, 1952; Kincaid et al., 1975; Senterand Smith, 1967; McLaughlin, 1969). Many com-mercial readability tools use traditional measures.Fitzsimmons et al. (2010) stated that the SMOG(McLaughlin, 1969) readability measure should bepreferred to assess the readability of texts on healthcare.
Due to recent achievements in linguistic dataprocessing, different linguistic features are nowin the focus of readability studies. Islam etal. (2012) summarizes related work regardinglanguage model-based features (Collins-Thompsonand Callan, 2004; Schwarm and Ostendorf, 2005;Aluisio et al., 2010; Kate et al., 2010; Eickhoff etal., 2011), POS-related features (Pitler and Nenkova,2008; Feng et al., 2009; Aluisio et al., 2010; Fenget al., 2010), syntactic features (Pitler and Nenkova,2008; Barzilay and Lapata, 2008; Heilman et al.,2007; Heilman et al., 2008; Islam and Mehler,2013), and semantic features (Feng et al., 2009; Is-lam and Mehler, 2013). Recently, Hancke et al.(2012) found that morphological features influencethe readability of German texts.
Due to unavailability of linguistic resources forBangla, we did not explore any of the linguisticallymotivated features. We have inherited features fromIslam et al. (2012; 2014) and Sinha et al. (2012),these features achieve reasonable classification ac-curacy.
Children’s reading skills is influenced by theircognitive ability. The following section describeschildren’s cognitive model and text readability.
3 Text Readability and Children
Children start building their cognitive skills from anearly age. They use their cognitive skills to per-form different tasks in different environments. Kali(2009) stated that children refine their motor skillsand start to be involved in different social gameswhen they are 5 to 6 years of age. From age of 6 to 8,children start to expand their vision beyond their im-mediate surroundings. Children from 8 to 12 yearsof age acquire the ability to present different entitiesof the world using concepts and abstract represen-tations. Children become more interested in socialinteractions in their teenage years.
Children learn to recognize alphabets prior theydeveloped motor skills. This lead to develop theirreading skills. Reading skills require two processes:word decoding and comprehension. Word decod-ing is a process of identifying a pattern of alpha-bets. Children must have the knowledge about theseand their patterns. For example: it is impossibleto recognise any word from any language withoutknowledge of alphabets of that language. A pat-tern of alphabets carry a semantic in their cognitiveknowledge.
Comprehension is a process of extracting mean-ing from a sequence of words. The sequence ofwords follow an order. It could be impossible forchildren to understand a sentence where the order ofthe words is random. Therefore, word order playsan important role in text comprehension. Readingis different than understanding a picture, it extractsmeaning from words that are separated by whitespaces. The comprehension process is also influ-enced by the memory system.
The cognitive system of humans contains threedifferent memories: sensory memory, working mem-ory and long-term memory (Rayner et al., 2012).The sensory store contains raw, un-analyzed infor-mation very briefly. The ongoing cognitive pro-cess takes place in working memory and the long-term memory is the permanent storehouse of knowl-edge about the world (Kali, 2009). Older childrensometimes are better where they simply retrieve aword from their memory while reading. A youngerchildren might have to sound out of a novel wordspelling. However they are also able to retrieve someof the familiar words. Children derive meaning of asentence by combining words to form propositionsthen combine them get the final meaning. Somechildren might struggle to recognize words whichmake them unable to establish links between words.Children without this problem able to recognizewords and derive meaning from a whole sentence.Generally, older children are better reader due totheir working memory capacity where they can storemore of a sentence in their memory as they are ableto identify propositions in the sentence (De Beni andPalladino, 2000). Older children are able to com-prehend more than younger children because of rec-ognizing ability and more working memory (Kali,2009). They also know more about the world and

PACLIC 28
!312
skilled to use appropriate reading strategies.In summary, children become skilled reader as
their working memories develop over time, extractpropositions and combine them to understand themeaning of a sentence.
4 Data
The goal of this study is to asses difficulty of newsarticles that are aimed for children. The reading abil-ity of children is very different than adult readers.The preceding section describes cognitive develop-ments of children in terms of readability. A childrenwho is 10 years old will have different reading ca-pability than a children who is 15 years of old. Thatis why, a corpus that is categorized by the ages ofchildren would be an ideal resource as training cor-pus. Duarte and Weber (2011) proposed differentcategories of children based on their ages. The cate-gorized list is relevant with our study. However, ourcategorized list is still different than their one. Thecorpus is categorized as following age ranges:
• early elementary: 7� 9 years old
• readers: 10� 11 years old
• old children: 12� 13 years old
• teenagers: 14� 15 years old
• old teenagers: 16� 18 years old
• adults: above 18 years old
In this paper, we train a model using support vec-tor machine (SVM). This technique requires a train-ing corpus. We compile the training corpus fromtextbooks that have been using for teaching in dif-ferent school levels in Bangladesh. The followingsubsections describe the training corpus and chil-dren news articles.
4.1 Training CorpusThe training corpus targets top four age groups de-scribed above. Textbooks from grade two to gradeten are considered as sources for corpus compila-tion. Generally, in Bangladesh children start goingto schools when they are 6 years of old and finish thegrade ten when they are fifteen (Arends-Kuenningand Amin, 2004). In our previous studies, Islam et
Classes Docs Avg. DL Avg. SL Avg. WL
Very easy 234 88.28 7.46 5.27Easy 113 150.46 9.09 5.27Medium 201 197.08 10.35 5.47Difficult 113 251.30 12.19 5.66
Table 1: The Training Corpus.
al. (2012; 2014), we compile the corpus from thesame source. However, the latest version is morecleaned and contains more documents. It containstexts from 54 textbooks. Table 1 shows the statisticsof average document length (DL), average sentencelength (SL) and average word length (WL). Text-books were written using ASCII encoding which re-quired to be converted into Unicode. The classifica-tion distinguishes four readability classes: very easy,easy, medium and difficult. Documents of (school)grade two, three and four are included into the classvery easy. Class easy covers texts of grade five andsix. Texts of grade seven and eight were subsumedunder the class medium. Finally, all texts of gradenine and ten are belong to the class difficult.
4.2 News Articles
The goal of this paper is observing children news ar-ticles in Bangla on the basis of difficulty levels. Asan Indo-Aryan language Banga is spoken in South-east Asia, specifically in present day Bangladesh andthe Indian states of West Bengal, Assam, Tripuraand Andaman and on the Nicobar Islands. Withnearly 250 million speakers (Karim et al., 2013),Bangla is spoken by a large speech community.However, due to lack of linguistic resources Banglais considered as a low-resourced language.
We collected children news articles from fourpopular news sites from Bangladesh and one fromWest Bengal. The sites are: Banglanews243, Bd-news244, Kaler kantho5, Prothom alo6 and Ichch-hamoti7. Banglanews24, Bdnews24 and Ichch-hamoti publish online only. In contrast, Kalerkan-tho and Prothomalo publish as printed newspapersand online. These newspapers publish weekly fea-tured articles for children. We have collected 50 fea-
3www.banglanews24.com4www.bangla.bdnews24.com5www.kalerkantho.com6www.prothomalo.com7http://www.ichchhamoti.in/

PACLIC 28
!313
tured articles from each of the sites and pre-processin similar way as the training corpus. However, thenews articles are already written in Unicode andcover different topics ranges from family, society,science and history to sports. Table 2 shows differ-ent statistics of news articles.
News sites Average DL Average. SL Average WLBanglanews24 50.14 9.48 5.04Bdnews24 62.66 9.82 4.91Kaler kantho 53.08 8.90 4.89Prothom alo 47.92 9.15 4.89Ichchhamoti 105.50 11.86 4.66
Table 2: Statistics of news articles.
5 Feature Selection
A limited number of related works available thatdeal texts from Bangla. All of them are lim-ited into traditional readability formulas, lexical andinformation-theoretic features. Any of features donot require any linguistic pre-processing. The fol-lowing subsections describe feature selection in de-tail.
5.1 Lexical FeaturesWe inherited a list of lexical features from our pre-vious study Islam et al. (2014). Lexical features arevery cheap to compute and shown useful for differ-ent text categorizing tasks. Average SL and aver-age WL are two of most used features for readabil-ity classification. Recently, Learning (2001) showedthat these are the two most reliable measures thataffect readability of texts. The average SL is a quan-titative measure of syntactic complexity. In mostcases, the syntax of a longer sentence is difficult thanthe syntax of a shorter sentence. However, childrenof a lower grade level are not aware of syntax. Along word that contains many syllables is morpho-logically complex and leads to comprehension prob-lems (Harly, 2008). Generally, most of the frequentwords are shorter in length. These frequent wordsare more likely to be processed with a fair degreeof automaticity. This automaticity increases read-ing speed and free-memory for higher level meaningbuilding (Crossley et al., 2008).
Our previous study, Islam et al. (2014) also listeddifferent type token ratio (TTR) formulas. The TTRindicates lexical density of texts, a higher value of
it reflects the diversification of the vocabulary of atext. The diversification causes difficulties for chil-dren. In a diversified text, synonyms may be usedto represent similar concepts. Children face difficul-ties to detect relationship between synonyms (Tem-nikova, 2012).
5.2 Information-Theoretic featuresNowadays, researchers exploring uncertainty basedfeatures from the field of information theory to mea-sure complexity in natural languages (Febres et al.,2014). Information theory studies statistical laws ofhow information can be optimally coded (Cover andThomas, 2006). The entropy rate plays an importantrole in human communication in general (Genzeland Charniak, 2002; Levy and Jaeger, 2007). Therate of information transmission per second in a hu-man speech conversation is roughly constant, that is,transmitting a constant number of bits per second ormaintaining a constant entropy rate. The entropy ofa random variable is related to the difficulty of cor-rectly guessing the value of the corresponding ran-dom variable. In our previous studies, Islam et al.(2012; 2014) and Islam and Mehler (2013) use dif-ferent information-theoretic features for text read-ability classification. Our hypothesis was that thehigher the entropy, the less readable the text alongthe feature represented by the corresponding ran-dom variable. We have inherited seven information-theoretic features from our previous studies.
5.3 Readability Models for BanglaRecently, Sinha et al. (2012) proposed few com-putational models that are similar to the traditionalEnglish readability formulas. A user study was per-formed to evaluate their performance. We also in-herited two of their best performing models:
Model3 = �5.23+1.43⇤AWL+ .01⇤PSW (1)
Model4 = 1.15+ .02⇤JUK� .01⇤PSW30 (2)
In their models, they use structural parame-ters such as average WL, number of jukta-akshars(JUK) or consonant-conjuncts, number of polysyl-labic words (PSW). The PSW30 shows that normal-ized value of PSW over 30 sentences.

PACLIC 28
!314
Features Accuracy F-Score
Model 3 56.61% 49.13%Model 4 56.38% 52.51%Together 66.27% 65.67%
Table 3: Performance of Bangla readability models pro-posed by Sinha et al. (Sinha et al., 2012).
In this paper, we use 20 features to generate fea-ture vectors for the classifier. The following sec-tion describes our experiments and results on train-ing corpus and news articles.
6 Experiments and Results
In order to find the best performing training model,we use 20 features from Islam et al. (2012; 2014)and Sinha et al. (2012). Note that hundred data setswere randomly generated where 80% of the corpuswas used for training and remaining 20% for evalua-tion. The weighted average of Accuracy and F-scoreis computed by considering results of all data sets.We use the SMO (Platt, 1998; Keerthi et al., 2001)classifier model implemented in WEKA (Hall et al.,2009) together with the Pearson VII function-baseduniversal kernel PUK (Ustun et al., 2006).
6.1 Training ModelThe traditional readability formulas that were pro-posed for English texts do not work for Bangla texts(Islam et al., 2012; Islam et al., 2014; Sinha et al.,2012). That is why, we did not explore any of thetraditional formulas.
At first we build a classifier using two readabilitymodels from Sinha et al(2012). The output of thesemodels are used as input for the readability classifier.Table 3 shows the evaluation results. The classifica-tion accuracy is little over than 66%. In our previ-ous study Islam et al. (2014) found better classifi-cation accuracy using these features. However, thecorpus is slightly different. The latest version of thecorpus contains more documents for easy readabil-ity class. The classifier miss-classifies documentsfrom this class mostly. The classifier labeled manyof the documents from this readability class as veryeasy. Miss-classification of documents from otherreadability classes are also observed.
Table 4 shows the performance of features pro-posed in our previous study Islam et al. (2014).
Features Accuracy F-Score
Average SL 61.53% 55.21%TTR (sentence) 47.32% 41.31%TTR (document) 53.84% 52.61%Average DW (sentence) 54.69% 55.28%Number DW (document) 62.56% 60.12%Avg. WL 44.63% 40.82%Corrected TTR 59.38% 54.31%Kohler TTR 54.61% 49.61%Log TTR 47.49% 43.30%Root TTR 60.76% 52.49%Deviation TTR 52.32% 47.83%Word prob. 60.76% 54.49%Character prob. 50.00% 47.13%WL prob. 51.58% 46.40%WF prob. 52.30% 47.80%CF prob. 60.76% 52.18%SL and WL prob. 62.30% 59.74%SL and DW prob. 66.92% 63.09%18 features proposed by Islam et al. (2014) 85.60% 84.46%
Table 4: Performance of features proposed by Islam et al.(2014).
The classification accuracy also drops. The clas-sifier also suffer to classify documents from easyreadability class correctly. However, information-transmission based features (i.e., SL and WL prob.and SL and DW prob.) are the best performing fea-tures. Therefore, a text with higher average SL be-come more difficult when it contains more difficultwords or more longer words.
The classification F-Score rises to 87.87 when wecombine features from Islam et al. (2014) and Sinhaet al. (Sinha et al., 2012).
6.2 News Articles Classification
Total 250 children news articles are collected as can-didate news articles for classification. We considerthe whole training corpus in order to build a train-ing model. The training model is used to classifythe candidate news articles. Among all articles, 160articles are labeled as very easy and 18 articles aseasy. Only 2 articles are labeled as difficult and re-maining 60 articles are labeled as medium. Figure 1shows classification results. More than 60% of newsarticles from newspapers are classified as very easy.However, the amount drops below 20% for the ar-ticles from Icchamoti children magazine. Also arti-cles labeled as difficult belong to this magazine. Theevaluation shows that, among all of the newspapers,news from Banglanews24 are more suitable for chil-dren. Most of articles from that site belong to very
PACLIC 28
!315
Very easy Easy Medium Di�cult
0
20
40
60
80
100
Readability Classes
Percentageofarticlesindi↵erentreadabilityclasses
Banglanews24 Bdnews24 Icchamoti Kaler kantho Prothom alo
Figure 1: Classification of Bangla news articles for chil-dren.
easy and easy readability class.Apart from the classification of children news ar-
ticles we are also interested in behavior of differentfeatures in classified articles. The following sectiondescribes from interesting observation we notice.
7 Observation
Articles from Ichchhamoti has the lowest averageWL. But, have higher values for average DW andaverage SL. Two of the articles from this site are la-beled as difficult. This labeling could be influencedby average DW and average SL. Documents fromtraining corpus have higher average WL.
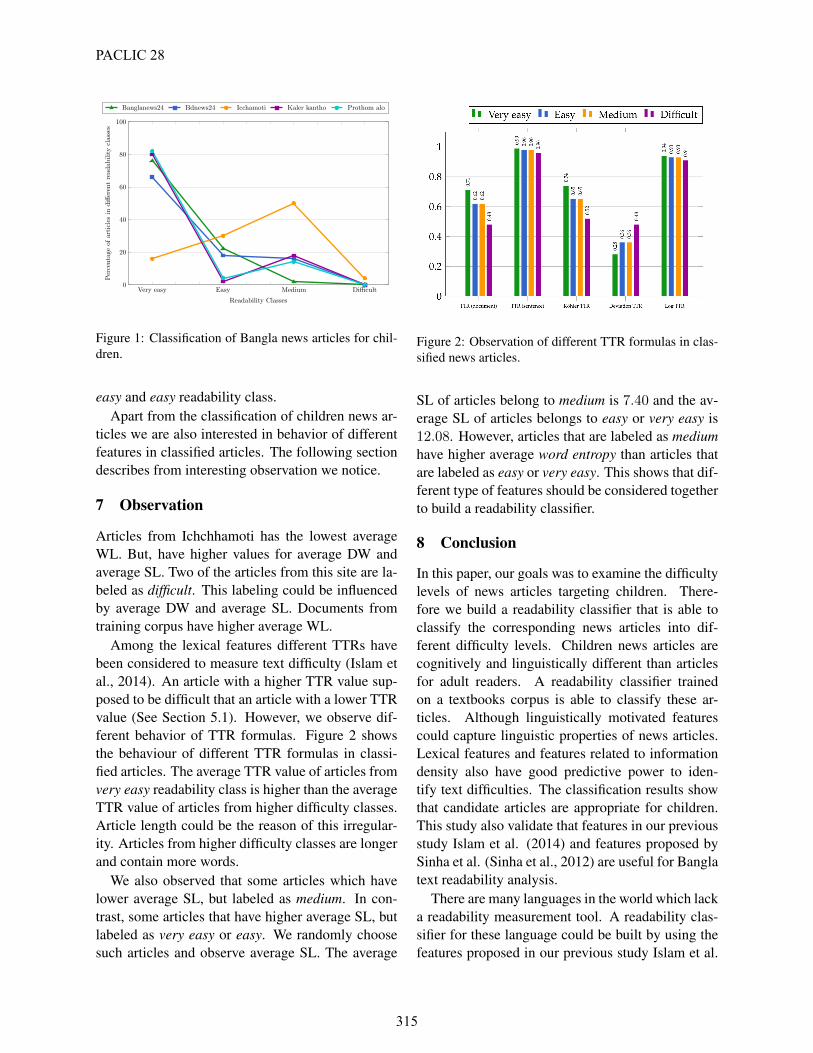
Among the lexical features different TTRs havebeen considered to measure text difficulty (Islam etal., 2014). An article with a higher TTR value sup-posed to be difficult that an article with a lower TTRvalue (See Section 5.1). However, we observe dif-ferent behavior of TTR formulas. Figure 2 showsthe behaviour of different TTR formulas in classi-fied articles. The average TTR value of articles fromvery easy readability class is higher than the averageTTR value of articles from higher difficulty classes.Article length could be the reason of this irregular-ity. Articles from higher difficulty classes are longerand contain more words.
We also observed that some articles which havelower average SL, but labeled as medium. In con-trast, some articles that have higher average SL, butlabeled as very easy or easy. We randomly choosesuch articles and observe average SL. The average
Figure 2: Observation of different TTR formulas in clas-sified news articles.
SL of articles belong to medium is 7.40 and the av-erage SL of articles belongs to easy or very easy is12.08. However, articles that are labeled as mediumhave higher average word entropy than articles thatare labeled as easy or very easy. This shows that dif-ferent type of features should be considered togetherto build a readability classifier.
8 Conclusion
In this paper, our goals was to examine the difficultylevels of news articles targeting children. There-fore we build a readability classifier that is able toclassify the corresponding news articles into dif-ferent difficulty levels. Children news articles arecognitively and linguistically different than articlesfor adult readers. A readability classifier trainedon a textbooks corpus is able to classify these ar-ticles. Although linguistically motivated featurescould capture linguistic properties of news articles.Lexical features and features related to informationdensity also have good predictive power to iden-tify text difficulties. The classification results showthat candidate articles are appropriate for children.This study also validate that features in our previousstudy Islam et al. (2014) and features proposed bySinha et al. (Sinha et al., 2012) are useful for Banglatext readability analysis.
There are many languages in the world which lacka readability measurement tool. A readability clas-sifier for these language could be built by using thefeatures proposed in our previous study Islam et al.

PACLIC 28
!316
(2014).
9 Acknowledgments
We like to thank Prof. Dr. Alexander Mehlerfor arranging money to travel the conference. Wealso like to thank the anonymous reviewers fortheir helpful comments. This work is funded bythe LOEWE Digital-Humanities project at Goethe-University Frankfurt.
ReferencesRa Aluisio, Lucia Specia, Caroline Gasperin, and Car-
olina Scarton. 2010. Readability assessment for textsimplification. In NAACL-HLT 2010: The 5th Work-shop on Innovative Use of NLP for Building Educa-tional Applications.
Mary Arends-Kuenning and Sajeda Amin. 2004. Schoolincentive programs and childrens activities: Thecase of bangladesh. Comparative Education Review,48(3):295–317.
Regina Barzilay and Mirella Lapata. 2008. Modelinglocal coherence: An entity-based approach. Computa-tional Linguistics, 21(3):285–301.
Kevyn Collins-Thompson and James P Callan. 2004. Alanguage modeling approach to predicting reading dif-ficulty. In HLT-NAACL.
Thomas M. Cover and Joy A. Thomas. 2006. Elementsof Information Theory. Wiley-Interscience, Hoboken.
Scott A Crossley, Jerry Greenfield, and Danielle S McNa-mara. 2008. Assessing text readability using cogni-tively based indices. Tesol Quarterly, 42(3):475–493.
Edgar Dale and Jeanne S. Chall. 1948. A formula forpredicting readability. Educational Research Bulletin,27(1):11–20+28.
Edgar Dale and Jeanne S. Chall. 1995. ReadabilityRevisited: The New Dale-Chall Readability formula.Brookline Books.
Sreerupa Das and Rajkumar Roychoudhury. 2004. Test-ing level of readability in bangla novels of bankimchandra chattopodhay w.r.t the density of polysyllabicwords. Indian Journal of Linguistics, 22:41–51.
Sreerupa Das and Rajkumar Roychoudhury. 2006. Read-abilit modeling and comparison of one and two para-metric fit: a case study in bangla. Journal of Quanta-tive Linguistics, 13(1).
Jan De Belder and Marie-Francine Moens. 2010. Textsimplification for children. In Prroceedings of theSIGIR workshop on accessible search systems, pages19–26.
Rossana De Beni and Paola Palladino. 2000. Intrusionerrors in working memory tasks: Are they related to
reading comprehension ability? Learning and Indi-vidual Differences, 12(2):131–143.
Rozane De Cock and Eva Hautekiet. 2012. Chil-drens news online: Website analysis and usabilitystudy results (the united kingdom, belgium, and thenetherlands). Journalism and Mass Communication,2(12):1095–1105.
Rozane De Cock. 2012. Children and online news:a suboptimal relationship. quantitative and qualitativeresearch in flanders. E-youth: Balancing between op-portunities a risks.
Sergio Duarte Torres and Ingmar Weber. 2011. Whatand how children search on the web. In Proceedings ofthe 20th ACM international conference on Informationand knowledge management, pages 393–402. ACM.
Carsten Eickhoff, Pavel Serdyukov, and Arjen P. de Vries.2011. A combined topical/non-topical approach toidentifying web sites for children. In Proceedingsof the fourth ACM international conference on Websearch and data mining.
Gerardo Febres, Klaus Jaffe, and Carlos Gershenson.2014. Complexity measurement of natural and arti-ficial languages. Complexity.
Lijun Feng, Noemie Elhadad, and Matt Huenerfauth.2009. Cognitively motivated features for readabilityassessment. In Proceedings of the 12th Conference ofthe European Chapter of the ACL.
Lijun Feng, Martin Janche, Matt Huenerfauth, andNoemie Elhadad. 2010. A comparison of featuresfor automatic readability assessment. In The 23rd In-ternational Conference on Computational Linguistics(COLING).
PR Fitzsimmons, BD Michael, JL Hulley, and GO Scott.2010. A readability assessment of online parkinsonsdisease information. The Journal of the Royal Collegeof Physicians of Edinburgh, 40:292–296.
Dimitry Genzel and Eugene Charniak. 2002. Entropyrate constancy in text. In Proceedings of the 40stMeeting of the Association for Computational Linguis-tics (ACL 2002).
Robert Gunning. 1952. The Technique of clear writing.McGraw-Hill; Fourh Printing Edition.
Mark Hall, Eibe Frank, Geoffrey Holmes, BernhardPfahringer, Peter Reutemann, and Ian H. Witten.2009. The WEKA data mining software: an update.ACM SIGKDD Explorations, 11(1):10–18.
Julia Hancke, Sowmya Vajjala, and Detmar Meurers.2012. Readability classification for german using lex-ical, syntactic and morphological features. In 24th In-ternational Conference on Computational Linguistics(COLING), Mumbai, India.
Trevor A. Harly. 2008. The Psychology of Language.Psychology Press, Taylor and Francis Group.

PACLIC 28
!317
Michael Heilman, Kevyn Collins-Thompson, and Max-ine Eskenazi. 2007. Combining lexical and grammat-ical features to improve readavility measures for firstand second language text. In Proceedings of the Hu-man Language Technology Conference.
Michael Heilman, Kevyn Collins-Thompson, and Max-ine Eskenazi. 2008. An analysis of statistical modelsand features for reading difficulty prediction. In Pro-ceedings of the Third Workshop on Innovative Use ofNLP for Building Educational Applications (EANL).
Zahurul Islam and Alexander Mehler. 2013. Automaticreadability classification of crowd-sourced data basedon linguistic and information-theoretic features. In14th International Conference on Intelligent Text Pro-cessing and Computational Linguistics.
Zahurul Islam, Alexander Mehler, and Rasherdur Rah-man. 2012. Text readability classification of text-books of a low-resource language. In Proceedings ofthe 26th Pacific Asia Conference on Language, Infor-mation, and Computation.
Zahurul Islam, Md Rashedur Rahman, and AlexanderMehler. 2014. Readability classification of banglatexts. In Computational Linguistics and IntelligentText Processing, pages 507–518. Springer.
Robert V. Kali. 2009. Children and Their Development.Pearson Education.
MA Karim, M Kaykobad, and M Murshed. 2013. Tech-nical Challenges and Design Issues in Bangla Lan-guage Processing. IGI Global.
Rohit J. Kate, Xiaoqiang Luo, Siddharth Patwardhan,Martin Franz, Radu Florian, Raymond J. Mooney,Salim Roukos, and Chris Welty. 2010. Learning topredict readability using diverse linguistic features. In23rd International Conference on Computational Lin-guistics (COLING 2010).
S.S. Keerthi, S. K. Shevade, C. Bhattacharyya, andK. R. K. Murthy. 2001. Improvements to Platt’s SMOalgorithm for SVM classifier design. Neural Compu-tation, 13(3):637–649.
Paul Kidwell, Guy Lebanon, and Kevyn Collins-Thompson. 2011. Statistical estimation of wordacquisition with application to readability predic-tion. Journal of the American Statistical Association,106(493):21–30.
J. Kincaid, R. Fishburne, R. Rodegers, and B. Chissom.1975. Derivation of new readability formulas for Navyenlisted personnel. Technical report, US Navy, BranchReport 8-75, Cheif of Naval Training.
Renaissance Learning. 2001. The ATOS readability for-mula for books and how it compares to other formulas.Madison, WI: School Renaissance Institute.
Roger Levy and T. Florian Jaeger. 2007. Speakers opti-mize information density through syntactic reduction.
Advances in neural information processing systems,pages 849–856.
Sonia Livingstone, Leslie Haddon, Anke Gorzig, andKjartan Olafsson. 2010. Risks and safety for childrenon the internet: the uk report. Politics, 6(2010):1.
G. Harry McLaughlin. 1969. SMOG grading – a newreadability formula. Journal of Reading, 12(8):639–646.
Jakob Nielsen. 2010. Children’s websites: Usability is-sues in designing for kids. Jakob Nielsens Alertbox.
Sarah E. Petersen and Mari Ostendorf. 2009. A machinelearning approach to reading level assesment. Com-puter Speech and Language, 23(1):89–106.
Emily Pitler and Ani Nenkova. 2008. Revisiting read-ability: A unified framework for predicting text qual-ity. In Proceedings of the Conference on EmpiricalMethods in Natural Language Processing (EMNLP).
John C. Platt. 1998. Fast training of support vector ma-chines using sequential minimal optimization. MITPress.
Keith Rayner, Alexander Pollatsek, Jane Ashby, andCharles Clifton Jr. 2012. Psychology of Reading. Psy-chology Press.
Sarah E. Schwarm and Mari Ostendorf. 2005. Read-ing level assessment using support vector machinesand statistical language models. In the Proceedingsof the 43rd Annual Meeting on Association for Com-putational Linguistics(ACL 2005).
R.J. Senter and E. A. Smith. 1967. Automated read-ability index. Technical report, Wright-Patterson AirForce Base.
Clay Shirky. 2009. Here comes everybody: How changehappens when people come together. Penguin UK.
Luo Si and Jamie Callan. 2001. A statistical model forscientific readability. In Tenth International Confer-ence on Information and Knowledge Management.
Manjira Sinha, Sakshi Sharma, Tirthankar Dasgupta, andAnupam Basu. 2012. New readability measures forbangla and hindi texts. In COLING (Posters), pages1141–1150.
Irina Temnikova. 2012. Text Complexity and Text Sim-plification in the Crisis Management Domain. Ph.D.thesis, University of Wolverhampton.
B. Ustun, W.J. Melssen, and L.M.C. Buydens. 2006.Facilitating the application of support vector regres-sion by using a universal Pearson VII function basedkernel. Chemometrics and Intelligent Laboratory Sys-tems, 81(1):29–40.