recognising textual entailment dragos ionut necula ... · chapter 2. background 5 ... (2)bob reads...
TRANSCRIPT

The candidate confirms that the work submitted is their own and the appropriate credit hasbeen given where reference has been made to the work of others.
I understand that failure to attribute material which is obtained from another source may beconsidered as plagiarism.
(Signature of student)
Recognising Textual EntailmentDragos Ionut Necula
Cognitive Science (Industry)2004/2005

SummaryThis project sets out to investigate the task of recognising textual
entailment in automated systems. The first chapter presents a project
summary. In the second chapter the task of textual entailment,and
issues surrounding it are analysed, both from a theoretical standpoint
and regarding existing attempts at implementation in automated
systems. The final section of this chapter outline the implementation
approach proposed, which relies on the division of the task in a
series of subtasks representing various potential sources of
entailment. The third chapter describes in detail the software
implemented, providing an in-depth analysis of the task of entailment
at the same time. Features described are entailment from synonymy,
from hypernymy and from passive sentences. A confidence level estimate
is also proposed and explained. The final chapter gives an account of
the methods used to evaluate the software, corpus design as well as
theoretical considerations. Finally potential future extensions to the
system are reviewed.
i

Acknowledgements
I would like to thank Eric Atwell, my supervisor, for his patience and
useful feedback, Dr. Katja Markert, my assessor, for her comments and
suggestions, as well as the developers behind the tools used in
developing the software and everyone behind the Pascal RTE Challenge.
ii

Contents
Chapter 1. Introduction 1
1.1 Aim 1
1.2 Objectives 1
1.3 Minimum Requirements 2
1.4 Possible Extensions 3
1.5 Project Schedule 3
Chapter 2. Background 5
2.1 The Notion of Entailment 6
2.1.1 Definition 6
2.1.2 Ambiguity of Entailment 7
2.2 Automating Entailment 9
2.2.1 The Pascal RTE Challenge 9
2.2.2 The Probabilistic Approach 10
2.2.3 The Symbolic Approach 12
2.2.4 Proposed Approach 14
Chapter 3. The Software 16
3.1 Overview of Design 16
3.2 Methodology 17
3.3 Software Tools 19
3.3.1 The RASP Toolkit 20
3.3.2 The Wordnet Database 21
iii

3.3.3 The NLTK and Python 22
3.4 The Minimum Requirements of the System 24
3.5 Additional Implemented Features 27
3.5.1 Entailment from Hypernymy 27
3.5.2 Entailment from Passive Sentences 29
3.5.3 Confidence Estimate 30
3.6 Further Refinements 32
Chapter 4. Evaluation 36
4.1 Corpus Development 36
4.2 Testing and Evaluation 38
4.2.1 Analysis of Testing Results 38
4.2.2 Evaluation 41
4.3 Possible Enhancements 43
4.4 Conclusion 45
Bibliography 46
Appendices 49
iv

Chapter 1 Introduction
1.1 Aim
The overall aim of the project is to provide a study of and propose
approaches to the task of automatic textual inferencing in the
context of natural language processing, including a basic Python
program to illustrate and implement some of the methods proposed.
1.2 Objectives
The objectives of the project are to:
● review and critically assess existing literature relevant to
the task of textual entailment
● outline a possible symbolic approach to the task of
implementing the capability of textual inferencing in
computer systems, starting from the idea of dividing the
task of entailment into subtasks reflecting various
entailment sources.
● develop software that would implement methods aimed at
achieving automated textual inferencing along the lines of
the proposed approach. The software is to be developed in
Python and will make use of existing NLP tools (e.g. parsers
or stemmers) included in the Natural Language Toolkit (NLTK
- nltk.sourceforge.net). Given a knowledge base and a novel
sentence the system would return a confidence level of the
truth of the sentence by attempting to infer it from the
knowledge base.
● evaluate the software produced against a specialised corpus,
1

developed around the features of entailment implemented in
the system.
1.3 Minimum Requirements
The minimum requirements are:
● a report on existing literature relevant to the task of
textual entailment
● the successful incorporation of a set of relevant external
tools (e.g. parsers, lexical databases) in the software
produced, with the aim of concentrating the development
process on the task of entailment, as opposed to other
fields of Natural Language Processing (e.g. tokenization,
parsing)
● a working software system that would attempt textual
inferencing with novel simple sentences of the form Subject
-Verb – Direct Object, probably the use of synonymy applied
to a knowledge base consisting of a corpus formed with the
same type of sentences. For instance, given the sentence
'Bob rushed home' and assuming the sentence 'Bob hurried
home' as existing in the knowledge base, the system should
be able to correctly identify that the former is entailed by
its knowledge base.
● the construction of a suitable, relevant corpus of sentences
of the type Subject - Verb – Direct Object that would be
used for the purposes of testing the written software.
● appropriate and correct evaluation of the software, both
through testing with the created corpus and on theoretical
considerations.
Note: The minimum requirements have been modified as a result of the
feedback received after submitting the mid-project report.
2

1.4 Possible Extensions
● the implementation of an entailment confidence estimate that
would approximate, in percentages, the possibility of
entailment of a test sentence from the knowledge base
● the implementation of a feature responsible for detection of
entailment from hypernyms
● the implementation of a feature responsible for detection of
entailment as a result of active – passive sentence
conversions
● the addition of capability for the system to handle sentence
structures more complex than Subject - Verb - Direct Object.
1.5 Project Schedule1
Week 2a – Week 10a - Background reading.
Week 2a – Week 4a - Completing the aims and minimum requirements
form
Week 3a – Week 5a - Familiarization with Python and the NLTK.
Week 3a – Week 7a - Basic outline of the proposed approach to
entailment.
Week 9a – Week 11a - Writing up the mid-project report.
Week 8a – Week 4b - Development of appropriate corpus
Week 8a – Week 11a - Implementation of a prototype consistent with
the basic principles of the proposed approach,
that would satisfy the minimum requirements of
the project.
1 The letters 'a' and 'b' used in the enumeration of the term weeks denote the first and second semestersrespectively (e.g. 'Week 2a' – second week of the first semester, 'Week 5b' – fifth week of the secondsemester).
3

Week 11a – Week 8b - Addition of features to the prototype (as many
as time allows)
Week 5b - Week 8b - Evaluation and testing of the final system.
Week 8b - Week 10b - Completing the final report
Note: The project schedule has been modified as a result of the
feedback received after submitting the mid-project report.
4

Chapter 2 Background
The process of programming linguistic competence into artificial
systems has and is proving to be a highly complex task. There are
many reasons why this is so and most of them have to do with
flexibility. The manner in which humans use language is one that has
resisted formalization so far and this obviously poses a serious
problem as far as implementing the ability to use language into
artificial systems is concerned, since artificial systems tend to
work with formal rules and are as such generally poor at dealing
with ambiguity and flexibility.
In the light of the above it appears that one of the main problems
with natural language processing is language variability. While it
is the case that humans use language to describe or refer to a huge
range of objects (be it environmental factors, internal beliefs or
abstract concepts) and that in itself poses a problem, even in cases
when the problem space is very restricted, the possible choices of
linguistic terms necessary to describe it are wide ranging and
indeed quite varied. A typical example is supplied by the problem
known as many-to many mapping between sense and text. Upon the sight
of a table with a cup on it one would most likely say 'There is a
cup on the table'. However, this is merely the most likely
description of the problem space, but by no means is it the only
one. The sentences 'There exists a cup on the table', 'there is a
porcelain liquid container on the table', 'the table has a cup on
it' and many others also accurately describe the problem space.
5

2.1 The Notion of Entailment
2.1.1 Definition
The concept of entailment accounts for the linguistic situation
described above as well as for other similar ones. Saeed (2003)
gives the following definition for entailment:
“ A sentence p entails a sentence q when the truth of the first (p)
guarantees the truth of the second (q), and the falsity of the
second (q) guarantees the falsity of the first (p).”
To illustrate this definition consider the sentences:
(1)Bob reads a book.
(2)Bob reads a semantics book.
In this instance, according to the definition above (2) entails (1).
Indeed if it is the case that Bob reads a semantics book, it can be
said with certainty that Bob reads a book. Similarly, if it is not
the case that Bob reads a book, it cannon be true that Bob reads a
semantics book.
Given this definition of entailment, Saeed (2003) proceeds to
defining paraphrases as sets of sentences which mutually entail each
other. The sentences produced earlier to describe the problem space
composed of a table with a cup on it would be examples of
paraphrasing.
At first sight, it might be tempting to equate the notion of
entailment as described above to the logical concept of entailment
as it is defined by classical mathematical logic (CML). Cheng (1996)
warns against this by pointing out that entailment in CML is
6

reducible to material implication (A -> B) and as such does not
account for any relation between A and B. In CML the statement
'1+1=2' would legitimately entail from the sentence 'it is raining',
whereas in natural language this is not the case. Starting from this
observation he goes as far as proposing a few alternative relevant
logic systems that solve the paradoxes of CML and other relevant
logics. (Cheng, 1996)
2.1.2 Ambiguity of Entailment
Consider the following sentences:
1) Mary likes animals.
2) Mary likes vicious, savage dogs.
3) Mary took a phone call in her office at noon today.
4) Mary skipped lunch today.
Assuming that sentences (1) – (4) refer to the same person named
Mary and that Mary is a typical individual, most people would quite
likely label (1) True and (2) False. Yet from a logical standpoint
(1) entails (2) since vicious, savage dogs are a type of animals.
According to the definition of entailment given in section 2.1.1,
this makes it quite impossible for (2) to be False while (1) is
True.
This apparent paradox could be resolved by the presence of an
appropriate quantifier (such as 'some') in sentence (1) that would
restrict the domain of the word 'animals' in such a manner as to
exclude the vicious dogs. Indeed, although the quantifier is missing
explicitly, most humans would assume its implied presence and would
understand sentence (1) as meaning 'Mary likes most animals'. This
assumption however, is exclusively the result of the knowledge that
it is highly unlikely that anyone (Mary included) would like all
7

animals. This knowledge is acquired from extensive practical
experience of the kind a computer does not have access to. For this
reason, the use of implicit knowledge of this sort in language poses
a major problem for any system tackling the task of entailment.
A similar principle is at work in the case of sentences (3) and (4).
Though the two utterances appear to be totally unrelated, an
entailment of (4) from (3) is perfectly plausible. Once again, in
order for such a relation to be detected a considerable amount of
experience and background knowledge is required (e.g., lunch breaks
happen at noon, Mary does not have lunch in her office, etc.).
If current limitations of computers systems are taken into account
and consequently the problem space of sentence entailment is
restricted by excluding cases (such as the ones above) involving
experience or implicit knowledge, the task of automating the
detection of entailment between sentences would be similar in nature
to the manual (i.e. performed by a human) task of attempting to
detect entailment between sentences in an unfamiliar language, with
the aid of tools such as various books written in the language,
collections of synonyms of the language or monolingual dictionaries.
Even thus restricted, the problem remains far from straightforward,
mainly because sentence entailment can be generated in a wide range
of manners, all conceptually different from each other. Saeed (2003)
broadly separates the different sources of entailment in two
categories: lexical and syntactical. Examples of the former would be
synonymy and hyponymy, while notions such as active and passive
sentences belong to the latter (e.g. 'I read a book' and 'A book is
read by me'). Depending on the approach to the task, in its initial
stages a program automating the task of entailment could well
account for only a few of the many possible sources of entailment.
8

2.2 Automating Entailment
2.2.1 The Pascal RTE Challenge
Unfortunately few attempts have so far been made to resolve
entailment in natural language systems. This is perhaps surprising
considering the central role it plays in the way humans use language
but it is most likely due to the difficult problem it poses, some of
which have been described above. Acknowledging the importance of the
issue of textual entailment for the field of Natural Language
Processing and many of its applications, as well as being aware of
the little amount of research existent on the topic, Dagan et al
launched in June 2004 the PASCAL Recognizing Textual Entailment
Challenge, with the aims of providing “ a first opportunity for
presenting and comparing possible approaches for modeling textual
entailment” and potentially promoting “ the development of generic
semantic “engines”, which will play an analogous role to that of
generic syntactic analyzers across multiple applications” (Dagan et
al, 2004).
This initiative is important for several reasons. First of all to
this date it provides the only available corpus developed
specifically for the task of entailment. This corpus consists of a
number of sentence pairs, each classified as either True of False
(True in the case the second sentence in the pair entails from the
first, False otherwise) by human annotators, with a roughly equal
balance between True and False pairs, and is divided in seven
subsets, reflecting possible cases of entailment proposed by the
authors (Information Retrieval, Comparative Documents, Reading
Comprehension, Question Answering, Information Extraction, Machine
Translation and Paraphrase Acquisition)2 (for a more detailed
2 Unfortunately due to the fact that the system described in this project was restricted to the handling ofsentences of the type Subject – Verb – Direct Object (see section 3.1), the RTE corpus could not be used fortesting purposes.
9

description, see Dagan et al, 2004).
The existence of the challenge is also important because it
represents a recognition of the importance of the issue of sentence
entailment and as such has attracted considerable amount of interest
from research groups. Indeed, Dagan et al report 13 submissions of
systems in response to the call for participation set out by the
challenge, with overall accuracies ranging between 50 and 60 percent
(Dagan et al, 2005). The relatively low accuracies obtained bear
witness to the difficulty of the task, but provide nonetheless a
useful benchmark against which future systems could be evaluated.
Unfortunately the proximity of the time of publication (10th of April
2005) of a selection of the reports submitted to the deadline for
this report made it impossible for any of them to be reviewed here3.
2.2.2 The probabilistic approach
The interest shown in the Pascal RTE Challenge is particularly
welcome considering that before its launch only a few papers had
been written specifically on the topic of textual entailment as a
Natural Language Processing task.
One of these, written by the two of the initiators of the RTE
challenge, Dagan and Glickman (2003), adopts a probabilistic
approach to entailment. They propose an inference model which does
not represent meanings explicitly, focusing instead directly on the
lexical-syntactic representations of sentences which are usually the
result of automatic parsing of language constructs. The model has at
its core a set of entailment patterns consisting of relations
3 It must be mentioned that the development work on this project and the software it includes proceeded inparallel to the RTE challenge and therefore any similarity between the ideas proposed here and the systemssubmitted for the challenge is purely coincidental.
10

between language expression templates, and associated probabilities.
A template is defined as “ a language expression along with its
syntactic analysis, optionally with variables replacing sub-parts of
the structure” (e.g. X subj buy obj Y). Thus an example of an
entailment pattern could be represented as: (X subj buy obj Y
⇒ X subj own obj Y), P, where P is the probability that a
text that entails the left hand side of the expression also entails
its right hand side. (Dagan and Glickman, 2003)
Given a pairs of sentences and a knowledge base of such entailment
patterns, the inference model identifies templates present in the
sentences and then applies a set of probabilistic inference rules to
combine the relevant pattern probabilities, producing an
approximation of entailment between the given sentences.
This approach has some obvious advantages in that it avoids a number
of problems that would have to be resolved by a logical automated
system dealing with entailment, most notably the existence of an
indefinite number of potential sources of entailment. Its main
disadvantage, however, is its heavy dependence on a large database
of entailment patterns. Dagan and Glickman list a number of possible
methods of pattern acquisition (e.g. extracting paraphrases from a
single corpus, learning patterns from the web) without explicitly
favouring any, but it is difficult to assess the efficiency of any
of them (especially since some of them are not fully developed) with
any degree of certainty (Dagan and Glickman, 2003).
As for the model they propose, without the existence of a database
of entailment patterns, its potential success rate in recognizing
entailment is impossible to predict, which makes the model in itself
difficult to assess.
11

2.2.3 The symbolic approach
Iwanska (1993) favours an approach to the task of entailment that is
radically different from the model proposed by Dagan and Glickman.
Like Cheng (1996) she maintains that first order logic is unsuitable
for representation of natural language constructs. As an alternative
she develops what she refers to as 'a formal, computational,
semantically clean representation of natural language' (Iwanska,
1993). This representation, which she calls UNO, reflects the
semantics of eleven syntactic categories (e.g. nouns, verbs,
adverbs) and accounts for the logical relations of conjunction,
disjunction and negation. This features combined make UNO a powerful
knowledge representation model for natural language. For full
details see Iwanska (1993), but as an example, given the sentences:
(1)John doesn't walk very fast.
(2)Every student works hard.
UNO would produce the following representations:
(R1) john -->{ not walk (speed ⇒ fast (adv ⇒ very)) }
(R2) np (det ⇒ every,
n ⇒ student) -->{[ work (adv ⇒ hard) ]} (Iwanska, 1993)
Starting from the premise that entailment of sentences heavily
depends on the correspondent entailment of their components and
using UNO as a knowledge representation model, Iwanska implements
(in LISP) a system that takes a natural language sentence as input,
converts it into an UNO representation and compares it against a
knowledge base consisting of a set of UNO representations by
comparing its components to components of the UNO representations in
the knowledge base (which she calls rules). According to the results
12

of this process the sentence is classified as True if it entails
from the knowledge base, False if it contradicts it or Unknown if
neither of the previous can be establish with certainty (Iwanska,
1993).
An important aspect of the system is its capability of automatically
expanding its database from the input sentences it receives. If in
the course of the comparison process described above a rule in the
input sentence is identified as having no correspondent in the
knowledge base or as being stronger than or equal to its
correspondent, then this rule is added to the knowledge base. This
implies that the knowledge base only contains “lower boundaries” of
each of the rules it stores, thus avoiding duplicates and allowing
for an infinite number of possible entailing sentences. “ For
example, the UNO representation of a single property walk extremely
fast accounts for the properties walk very fast, walk fast, walk,
walk or dance, etc; at the same time, this single property accounts
for the lack of the properties such as not walk, walk fast but not
very fast, etc.” (Iwanska, 1993)
While perhaps lacking some of the flexibility of the probabilistic
model described above, this symbolic approach to entailment is
designed to cope with relatively sophisticated cases of entailment,
the treatment of which is unclear in the case of the system proposed
by Dagan and Glickman (2003). Another advantage is its ability to
extend its knowledge base from the test sentences, which is an
elegant solution to the problem of an extensive knowledge base.
Unfortunately Iwanska does not provide any accuracy results for her
system, nor does she give any account of testing or evaluation
methods, which makes it impossible, once again, to assess its value.
13

2.2.4 Proposed Approach
The approach to the task of recognizing entailment proposed here,
while essentially symbolic in nature, attempts to combine the
advantages of a systematic representation of natural language, such
as the one described in section 2.2.2, the flexibility given by the
existence of a entailment probability estimate as in section 2.2.1
and the authors' own ideas regarding the issue of entailment and
generally linguistic knowledge representation.
In a similar fashion to both systems already described, this
approach relies on an entailment inference engine and a knowledge
base against which test sentences are to be compared and entailment
judgements made according to the results. However this knowledge
base consists of neither entailment patterns nor symbolic
representations of sentences. Instead the information obtained from
the natural language sentences from which the knowledge base is
generated is stored in the form of lists of the nouns contained in
these sentences, each of the nouns having associated a set of
attributes reflecting additional information provided in the
sentences (e.g. syntactic functions, other parts of speech attached,
syntactic referents, etc.)
This model of knowledge representation was adopted with the view
that nouns are the central building blocks of language constructs. A
detailed defence of this hypothesis does not make the object of this
report. It is enough to point out that this seems to be a matter of
general agreement in the linguistic community. Wordnet (a lexical
database, see section 3.3.2 for further information), for instance,
is focused on representations of lexical relations and categories
between nouns.
The inference engine is similar to the symbolic system proposed by
14

Iwanska, in that it relies on the assumption that entailment between
sentences depends to a large extent on the entailment between their
component parts4. It therefore attempts to establish entailment of
the input sentence from the knowledge base by comparing the
component nouns (and their attributes) of the test sentence to those
present in the knowledge base. Instead of making a definite
judgement, however, it calculates an entailment confidence estimate
(not unlike the probabilities computed in the model proposed by
Dagan and Glickman) based on the proportion of nouns that match the
database and the degree to which they match it.
A system meant to exhibit and develop upon the key aspects of the
approach to the task of automatic recognition of sentence entailment
briefly outlined here has been implemented in Python. The detailed
description of this system and the concepts behind it makes the
object of the next chapter.
4 Though difficult to prove, this claim appeals to human intuitions about language, especially if some of theconsiderations discussed in section 2.1.2 are taken into account.
15

Chapter 3. The Software
3.1 Overview of Design
The planning stage of the development process of the software
intended to test the theoretical principles described above started
from the idea of separating the task of automated sentence
entailment detection into subtasks reflecting possible different
sources of entailment with natural language sentences. Given the
theoretical assumptions, these subtasks would mostly mirror either
issues of sentence structure (e.g. passive sentence entailed by
active sentences, negative sentences entailed by positive sentences)
or semantic relations between component words of the sentences
considered (e.g synonymy, antonymy, hyponymy, meronymy). The next
step was to decide on one such subtask as the main feature of the
program and the first one to be implemented. Several other possible
sources of entailment would then be incorporated into the software
as additional features, taking into account development time
constraints. Finally an entailment confidence estimate feature would
be added, based on which the software would make judgements about
entailment between two sentences.
Thus the end product would behave in the following manner: given a
pair of sentences (a and b) through the means of a standard input
method (e.g. reading from a file) the system would compare them
based on the possible sources of entailment implemented as its
features. It will, in the process, compute an entailment confidence
estimate according to the degree of correspondence encountered
between the two sentences. The outcome would be that sentence b
would be judged as entailing from sentence a if the confidence
estimate would be higher than 0.5, the opposite being true if the
16

confidence estimate would be below 0.5. The system would output the
result and exit.
The sentence structure that the system was designed around and
tested on throughout are of the type Subject – Verb – Direct Object
(e.g. 'Cats drink milk' or 'Books bring wisdom'). This was done with
the intention of significantly reducing the problem space (necessary
given the time constraints of the project and the complexity of the
task at hand), while keeping true to the conceptual implications of
the notion of sentence entailment.
With the same considerations in mind, the system only worked with
lemmatised versions of the words composing the sentences, thus
ignoring issues such as the number for the nouns (e.g. 'students'
was treated as 'student') or the tense and person for the verbs
(e.g. 'liked' and 'likes' were both treated as 'like').
3.2 Methodology
Marks (2002) distinguishes and compares two main currents in the
field of software design methodology – the waterfall approach and
the iterative approach.
He describes waterfall methodologies as “ structuring a project into
distinct phases with defined deliverables from each phase”, where
“ the first phase tries to capture What the system will do (its
requirements), the second determines How it will be designed, in the
middle is the actual programming, the fourth phase is the full
system Testing, and the final phase is focused on Implementation
tasks such as go-live, training, and documentation.” (Marks, 2002)
It is easy to see why a waterfall methodology would be inappropriate
for the software system proposed here. While it is necessary to set
certain system requirements at an early stage, it would be
17

impossible to specify exactly “what the system will do” without a
knowledge of which of the possible sources of entailment will be
implemented. And this knowledge would only become available during
the course of the implementation itself, since it would depend on
the time taken to incorporate each feature.
Another problem is that in order to guarantee a successful final
product, testing would have to be part of each of the subtasks set
to implement various features, rather that being performed at the
end of the development process. Once a feature is implemented,
comprehensive testing is required before the implementation of the
next feature is begun.
Because of these considerations, an alternative iterative
methodology was preferred, since it better suited the modular
character of the system specifications. In a software development
process based on an iterative approach, “ the initial planning will
consist of only a broad outline of the business objectives and
creating a framework for the overall project components. In some
cases, a set of core features for the entire system will be built
initially and subsequent features added as the project progresses.
In other cases, just certain modules will be built entirely during
the early part of the project and other components added over time.”
(Marks, 2002)
The process described in this definition addresses quite effectively
the design specifications of the proposed entailment detection
system, as outlined in section 3.1. The detection of entailment has
been established as the objective of the project, with different
potential sources of entailment (alongside a confidence estimate) as
project components. One of these sources will be decided upon as the
initial feature with others to be added as the project progresses.
18

The main advantage of this approach is flexibility. With an
iterative framework, it is not necessary to decide on all the
features that would be implemented before the code writing begins.
Also, testing can be performed whenever necessary and this is
crucial for the safe delivery of a successful end product.
While on the topic of methodology, it must be mentioned that
throughout the development process whenever possiblecode has been
written in such a manner as to allow room for possible extensions.
3.3 Software Tools
Part of the reason why entailment is a novel topic in the area of
natural language processing is the lack, until recently, of
appropriate tools necessary for any attempt to tackle the task of
entailment to even be possible.
It would be very difficult to make any reasonable judgement
regarding any structural relation between two sentences and between
their components without the existence of competent, appropriate
sentence processing tools such as parsers, taggers or stemmers.
Similarly, one cannot establish semantic relations between different
words without a database documenting such relations on a large
scale.
Thankfully, in recent years, as the interest in the field of natural
language processing rose such tools have been developed and have
become available. Of these, this particular project makes use of the
RASP toolkit, the Wordnet database and some features of the Natural
Language Toolkit. The programming language of choice is Python.
19

3.3.1 The RASP Toolkit
The Robust Accurate Statistical Parsing (in short, RASP) toolkit was
originally developed by Ted Briscoe and John Carroll (for a detailed
description of the system see Briscoe and Carroll, 2002). Briefly
the toolkit comprises of a set of modules, each performing, in this
order, tokenization, part of speech tagging, lemmatisation and
finally parsing. The modules are independent and thus can be run
separately, but for the purposes of this project they were all run
together by executing one of the scripts provided. The script in
question has various display options, with different amounts of
information being displayed.
The initial preferred display, given the sentence 'Students read
books', for example, would produce the following parsing:
[number]
(ncsubj eat cat+s _)
(dobj eat fish _)
where [number] is the order of the sentence from the beginning of
file ('1' for the first sentence, '2' for the second, etc.). The
contents of the brackets depend on the syntactic function of the
word5, but in general the first term would be the syntactic function
of the current word, followed by the referent (i.e. the word on
which the current word depends, the lemmatised version of the
current word and finally the initial syntactic function6.
At a later stage in development, a more complete RASP display was
preferred, which given the same input sentence, would output:
5 For a detailed description of the grammatical notation scheme used see Briscoe and Carroll, 2000.6 In the example provided this is represented by '_', in other words none. Given the sentence 'Books are read
by students', however, the line for the word 'books', for instance, would be (ncsubj read book+s dobj).
20

("students" "read" "books") 1 ; (-5.099)
(|ncsubj| |read_VV0| |student+s_NN2| _)
(|dobj| |read_VV0| |book+s_NN2| _)
The additional information provided by this form of output and of
relevance to the system is the output of the entire sentence rather
than just the sentence order and the inclusion of part-of-speech
tags following every word (VVO, NN2, etc.). The tagset used by the
tagging part of the RASP is the CLAWS2 tagset .
Several features of the RASP toolkit eventually made it the software
of choice for the initial sentence processing step7:
– all in one package including tagging, lemmatising and parsing.
– no need for training
– grammar already included with the parser
– syntactic information included (e.g. subject, direct object)
– similar in approach to the theory behind the system, in the
central role given to nouns (while verbs are mainly regarded as
'referents')
3.3.2 The Wordnet Database
“ WordNet, an electronic lexical database, is considered to be the
most important resource available to researchers in computational
linguistics, text analysis, and many related areas. Its design is
inspired by current psycholinguistic and computational theories of
human lexical memory. English nouns, verbs, adjectives, and adverbs
are organized into synonym sets, each representing one underlying
lexicalized concept. Different relations link the synonym sets.”
7 Initially a combination of NLTK tools were used for tagging, parsing, lemmatising etc. They were droppedearly in the development process as it became increasingly evident that they were incompatible with therequirements of the system (see Chapter 3.3.3).
21

(Fellbaum, 1998)
The choice of Wordnet as an aid in the task of lexically comparing
components of sentences is probably obvious to anyone with an
interest in computational linguistics. A great number of research
projects involving work with lexical relations of various kinds
employ Wordnet as a research tool8.
Comparing components of the sentences considered for entailment is a
key element of the approach to the task on entailment proposed here.
A significant number of the features either implemented or
considered as possible extensions consist of potential sources of
entailment based on lexical relations (such as synonymy or hyponymy)
between components of different sentences. For this reason, Wordnet
was not only an useful aid, but a vital tool in the process of
developing the system detailed here. As an additional advantage, the
organisation of Wordnet resembles in certain aspects some of the
theoretical observations at the base of this project.
3.3.3 The NLTK and Python
Mainly intended as an education tool, the Natural Language Toolkit
(NLTK), written in Python, is an open source collection of
independent modules, each implementing a data structure or task
relevant to the field of natural language processing (Loper and
Bird, 2002). The fact that it is written in Python and that it
includes a comprehensive set of tutorials and generally a detailed
and clear documentation base make it relatively easy to familiarise
with and for the purposes of this project that was considered an
advantage.
8 For an uptodate list of projects using Wordnet,see the Wordnet bibliography, currently maintained byRada Mihalcea, at http://engr.smu.edu/~rada/wnb/
22

Initially the NLTK was intended to play a central role in the
process of development of the entailment software, as the main
source of off-the shelf tools the software would use, including
taggers and parsers. As the development progressed, however, it
became apparent that, because they were designed primarily for
educational rather than research purposes, some of the NLTK tools,
notably the parser, were insufficient for the requirements of this
project. As a consequence eventually the alternative RASP toolkit
was judged as more suitable and thus was preferred for the tasks of
tagging, lemmatising and parsing. Other NLTK modules however, namely
the tokenizer and the Wordnet interface functions, were kept and
successfully used throughout the implementation process.
After some consideration, Python was designated as the programming
language of choice. This was partly because the NLTK is written in
Python, but also because of other important considerations intrinsic
to the language, such as its relatively loose structural
constraints, its ease of use and, perhaps most importantly, the
superior manner in which Python handles data types, compared to
alternatives such as Java or C9. This was a major factor, given the
amount of string and list processing that was necessarily a part of
the entailment software.
The main disadvantage of Python, as well as the NLTK is its lack of
resource efficiency. Russell (2003) reports that, when used with
large sets of data, the NLTK tools prove to be significantly slower
than alternative tools available for the same tasks. This is hardly
surprising given that its developers clearly state that speed was
not one of the design aims of the toolkit (Loper and Bird, 2002) in
addition to the fact that Python is traditionally recognised as
being a slow language compared, for instance, to C.
9 For more information on Python see the Python Tutorials (van Rossum, 2005)
23

Nonetheless, the fact that the entailment system, as well as being a
small scale project as an undergraduate project, was tested with
relatively small amounts of data (see the section on testing) made
the lack of efficiency an acceptable impediment considering the
advantages brought by using Python and the NLTK.
3.4 The Minimum Requirements of the System
(Entailment from Synonymy)
As mentioned previously the software development strategy was
centred around the idea of dividing the task of entailment into
subtasks representing various potential sources of entailment. One
of these subtasks was given priority as the first feature to be
implemented and its successful completion was meant to fulfil the
minimum requirements of a system intended to approach the task of
automated sentence entailment.
After some thought, this initial subtask was set as representing the
case of entailment through synonymy. Take the sentences:
1) Students read books.
2) Pupils read books.
There is little doubt as to the fact that (1) entails (2). Equally
obvious, however, is that, just as well, (2) entails (1). Apart from
being perhaps one of the most common sources of entailment, synonymy
typically produces cases of mutual entailment, a concept known as
paraphrasing (Saeed, 2003). This was one of the reasons why
entailment from synonymy was chosen as the first feature to be
implemented.
Having established that the minimum requirement of the system was
24

detection of entailment from synonymy (i.e. paraphrasing) I shall
now turn to a discussion of the way in which this was implemented.
In virtue of its structure, the corpora provided by the Pascal RTE
Challenge for testing purposes suggests attempting automated textual
entailment by analysing sentence pairs. The system described here
takes a slightly different path in that it treats the data (i.e. the
collection of sentences) by considering two distinct categories: a
set of sentences that are considered as known by the system and
about which no entailment judgements are made (from here on referred
to as 'the knowledge base'); and another set ('the test base') that
the system analyses sentence by sentence, attempting to determine
the potential of entailment of each from the sentences in the
knowledge base.
At the moment this works by the system trying to identify sentences
in the knowledge base that potentially entail the test base sentence
under analysis. As a possible extension, however, the system could
perform more fuzzy searches and attempt entailment from the
knowledge base as a whole. This is one of the reasons why this
approach was preferred over the more popular sentence pairs
alternative. It is an important choice since the knowledge base
approach resembles much closer the manner in which entailment occurs
in human language interaction. Rarely are we presented with pairs of
sentences and asked to make entailment judgements. We usually make
such judgements by comparing utterances we encounter against our
whole spectrum of knowledge, linguistic or otherwise.
Given the requirement that the test data would be split into a
knowledge base and a test base, the system then takes the file
containing the former, parses it10 and stores the contents in a
'knowledge list'. Rather than lists of sentences, or anything to
10 For a description of the parser output, see section 3.3.1
25

that effect, this list contains 'noun tokens'11 (produced with the
aid of the NLTK tokenizer), in conformance with the theoretical
considerations mentioned earlier. At this stage, each of the tokens
stores the following attributes12:
– TEXT: containing the string representation of the token (e.g.
student['TEXT'] = 'student')
– REFERENT: containing the string representation of the word on
which the token depends syntactically (e.g. student['REFERENT'] =
'read', given the sentence 'Students read books'13).
– SYNTAG: containing the syntactic function of the token as given by
the parser (e.g. student['SYNTAG'] = ncsubj, given the same
sentence as above).
– SENTENCE: containing the number of the sentence from which the
token is extracted (e.g. '3' should the relevant sentence be the
third in the processed file).
The next step is the processing of the test base file in a similar
manner to the knowledge base. The subject of the first test sentence
is then identified, and a list of synonyms of the most common sense
is retrieved from the Wordnet database. Each of the synonyms
(including the original word) is then checked against the knowledge
list. If a match is found, a comparison between the syntactic
functions (i.e. the subjects) and then the referents (i.e. the
predicates) of the test word and the synonymous known word is
performed. If the comparison is still positive, in other words if
the two words still match, the knowledge base sentence containing
the synonym is extracted and the same procedure repeats, in that the
next noun token belonging to the test sentence is matched against
11 Tokens are, in simple terms, concrete instantiations of conceptual entities, which can hold a number ofproperties. An extended system built on the one presented here could use types, which are actual conceptualentities as opposed to instantiations of them, instead of tokens. For a more detailed explanation of the notionof 'token', as well as the difference between tokens and types, see the NLTK tutorial on tokenization (Kleinet al, 2004).
12 Later the token attributes were refined to contain more information (see section 3.6).13 Remember the software works with lemmatised versions of the words in sentences.
26

the noun tokens of the corresponding knowledge base sentence.
In the case of a sentence of the type 'subject- verb- direct object'
(S-V-O) (which was the structure of both the test and the known
sentences), this is only a two step process, as S-V-O sentences
necessarily only contain two noun tokens, the subject and the direct
object. There is no reason, however, why the principle would not
work in a similar manner for longer sentences, which could be the
case in an extended system.
If the matching process completes successfully (i.e. all noun tokens
of the test sentence have matches - in terms of TEXT, SYNTAG and
REFERENT – in the selected knowledge base sentence) the test
sentence is established as entailing from the knowledge base, an
output to this effect is produced and the systems proceeds to the
next test sentence.
Thus the set minimum requirements are fulfilled producing a basic
system performing automated recognition of entailment of an S-V-O
test sentence from a known set of S-V-O sentences on the grounds of
synonymy.
3.5 Additional implemented features
3.5.1 Entailment from Hypernymy
Saeed (2003) describes hypernymy as a lexical relation of inclusion.
Given two words x and y, if the meaning of x encompasses and includes
the meaning of y, then a relation of hypernymy exists between the
two words, with the more general term (x) being termed the hypernym
and the more specific term (y) named the hyponym (e.g. 'animal' is a
hypernym of 'cat').
Hypernymy was chosen as one of the features to be implemented mainly
27

in virtue of it being one of the main sources of entailment, but
also because it exhibits nicely the potential complexity of the task
at hand. Given the sentences:
Animals have rights.
Cats have rights.
, the hypernym lies in the sentence that 'does the entailment', the
sentence from which the arrow of implication starts. In a loose
sense, it can be said of this case that 'the hypernym entails the
hyponym'. Whereas with the sentences:
Some animals have rights.
Cats have rights.
the opposite is true. The addition of the 'some' indefinite article
in one of the sentences completely reverses the direction of
entailment, having now the sentence containing the hyponym entailing
the one containing the hypernym.
Because the system described here is designed to handle simple S-V-O
sentences, containing lemmatised nouns with no articles attached, in
all tested cases the sentence containing the hypernym sentence
entailed the hyponym sentence. It is easy to see, however, why an
enhanced system handling with more complex sentence structure would
have to address this issue.
In order to add the entailment from hypernymy feature to the system
the matching process described in section 3.4 had to be modified to
include the recognition of hypernyms, as well as synonyms, in the
knowledge base. Thus, after retrieving the list of synonyms of each
noun token in the test sentence from Wordnet, the system now also
retrieves a list of hypernyms for each of these synonyms (also from
28

Wordnet) and then attempts to find matches in the knowledge base for
each of the synonyms of the test noun tokens as well as for their
corresponding lists of hypernyms.
3.5.2 Entailment from Passive Sentences
Like the previous features implemented, passive sentences are a very
common source of entailment. And, as in the case of synonymy, most
often the active and passive form of a sentence are paraphrases of
each other. Not only does the sentence 'Students read books' entail
the sentence 'Books are read by students', but the reverse (i.e.
'Books are read by students' entails 'Students read books') also
holds true.
The difference between passive sentence derivation and synonymy,
however, is that the former is a syntactic source of entailment
(i.e. entailment is derived through syntactic changes) whereas the
latter is lexical in nature (as is entailment from hypernymy).
The implementation of the entailment derived from passive sentences
is carried out in a different manner from previous features,
reflecting the difference in nature between this and the previous
subtasks. The idea is that the two example sentences used above,
while different in syntactic structure, contain the same linguistic
information. Because of this, there is no reason to assume that the
content of the two sentences ought to be stored in the knowledge
base in different manners14.
Thus instead of altering the matching procedure, like with
14 Indeed, keeping the principle of similarity between the knowledge base idea and human storage of linguisticinformation in mind, this seems justified. Intuitively it seems unlikely that our brains would store basicallythe same information twice, because of structural differences in presentation. Rather some sort of structuraldecoding takes place, as part of the information processing mechanisms. the proposed Implementationstrategy attempts to mimic this behaviour.
29

hypernyms, changes were made to the function responsible for
generating the noun tokens from the parsed output of the sentences.
Passive sentences were identified by the presence of auxiliaries15
and, should a passive sentence be found, the tokenization process
would change to reflect the properties of the component words as
they would be found in the equivalent active sentence. Virtually a
passive-active sentence conversion would be performed, but it would
be done by applying changes to the (parsed) nouns in the sentence
rather that to the sentence as a whole.
3.5.3 Confidence estimate
While perhaps not immediately obvious, the need for a confidence
estimate becomes clear if the matching procedure on which the system
relies is analysed in some details. Briefly matching works by
identifying the subject of a given test sentence and looking for a
match in the knowledge base. should a match be found, the next
identified noun token in the test sentence is identified and the
procedure repeats if a match is found again. Logically this is
correct. Given the hypothesis that entailment between sentences is
linked to the entailment between their components, a test sentence
would entail from a knowledge base only if all its noun tokens
entail from noun tokens in the knowledge base. In practice, however,
while having the advantage of not producing any false positive this
condition is likely to generate some false negatives. The reason for
this is the unavoidable incompleteness of the database used for
retrieval of lexical relations16 (such as synonymy and hypernymy) –
in this case Wordnet. It is perfectly possible that certain words
would have synonyms or hypernyms that are not present in Wordnet.
15 This was a valid criterion since the system was designed to deal with SVO sentences. No auxiliaries wouldbe found in this type of sentence, whereas in the passive conversion of an SVO the presence of anauxiliary (i.e. 'by') is necessary.
16 The parser could potentially be a source of error as well. But given the degree of sophistication of currentparsers, this is less likely, especially when working with simple sentence structures such as SVO
30

If at any stage in the process of iterating through the noun tokens
of the test sentence such a word would occur the loop would break
and the sentence would be categorised as not entailing from the
knowledge base. The use of confidence estimates generally
circumvents this problem. In order to understand why this is the
case, an explanation of the confidence estimate calculation is
necessary.
The overall confidence estimate of an entailment of a test sentence
is represented in percentages. This would be calculated by assigning
a percentage, x, to each of the noun tokens of a test sentence.
During the matching procedure each token is compared against the
knowledge base on three attributes, in this order – its 'TEXT'
(including its synonyms or hypernyms), its 'SYNTAG' and its
'REFERENT' (again, including synonyms and hypernyms). Each attribute
has equal weight, x/3. Therefore each time an attribute has a match
in the corresponding noun token in the knowledge base, x/3 is added
to the overall confidence estimate of the sentence. The order of the
attributes is important because the attempt to match the last two
was made dependent on the successful matching of the first.
Therefore, although the percentage weight is equal between the
three, in fact the first carried more significance. This is a
reasonable constraint since without a lexical relation present,
there is no sense in which a correspondent known token exists in the
first place17.
The process repeats for every token in the test sentence and a final
confidence estimate is computed. If this is greater that 50 percent,
the test sentences is judged as entailing from the knowledge base
and the confidence estimate is displayed. Since the system is
17 Should this condition not exist, tokens could add to the confidence estimate if they depend syntactically onthe same word for instance , or if they have the same syntactic function, which would be illegitimate, since,without a lexical relation present, these attributes are too loose to constitute feasible grounds for anentailment relation
31

designed to handle S-V-O sentences (which only have two noun
tokens), at this stage each noun token was manually assigned a
weight of 50 percent18.
As a final point, it should be mentioned that after some
consideration, the same type of constraint applied to the token
attributes was kept to an extent for the whole sentence, in that the
successful matching of the test sentence subject to a known subject
was a necessary condition for the matching of the other test
sentence tokens. This was done with the purpose of reflecting the
importance of the subject in a sentence (see section 4.2.2) and thus
simulating in some respect, the manner in which humans use language.
Thus given the sentences:
(1) Animals eat lunch.
(2) Cats eat fish.
(3) Students eat lunch.
, the confidence estimate of (2) entailing from (1) would be 50
percent, while the confidence estimate of (3) entailing from (2)
would be 0.
3.6 Further refinements
The software development process concluded with the implementation
of a few final adjustments of the system, aimed primarily at
improving the quality and accuracy of the methods implemented and in
some cases with the purpose of facilitating potential extensions.
18 Later in the development process an automatic method of establishing token weights was introduced (see thesection 3.3).
32

The first of these adjustments was the modification of some of the
properties of the noun tokens19. More precisely, the 'TEXT' and the
'REFERENT' attributes were modified to store a tuple containing both
the string representation of the token and its part of speech tag
(e.g. student['TEXT'] = ('student', 'NN2'), as opposed to student
['TEXT'] = 'student' as it was initially). The reason for this has
to do with the fact that when looking up a word in the Wordnet
database, its part of speech is required in addition to its string
representation. Initially this was provided manually, according to
the 'SYNTAG' of a token ('e.g. if the token is a subject, the part
of speech ought to be a noun). Retrieving this information from the
parser and storing it in the token properties is obviously a better,
more elegant solution. The difference is especially obvious in the
eventuality of an extension designed to cope with pronouns for
instance. In such a case, in would not be possible to determine the
part of speech of a word from its syntactic function (both nouns and
pronouns can be subjects).
Another token property that was modified was the 'SENTENCE'
attribute. When the switch in parser output was decided, the
sentence attribute was changed to store the whole string
representation of the sentence rather than a number denoting its
position in its respective file. Apart from being more accurate,
this simplified the process of identifying passive sentences by the
presence of auxiliaries and improved the quality of the output the
system produced.
The next modification was done to provide further depth and accuracy
to the system. Initially when looking up the synonyms of a noun
token in the Wordnet database only the most common sense was
retrieved. While this is enough to demonstrate the principle of
entailment from synonymy, it is likely to be an important source of
19 A description of the noun tokens and their properties can be found in section 3.4
33

error, since often enough words are used with other senses than the
most common. With this in mind, the system was modified so that the
five most frequent senses were retrieved. The synonyms for different
senses were stored in different lists, making it possible to later
access the sense number for a test noun token synonym should a match
be found in the knowledge base.
The final modification brought to the system was an improvement in
confidence estimate calculation. The obvious disadvantage of the
initial implementation was that the weight assigned to each noun
token (0.5) relied on the presence of exactly two such tokens in
each given sentence. Naturally, in the eventuality of an extension
this might not hold true, and indeed, should the system be able to
cope with sentences containing various numbers of noun tokens, it
becomes problematic. A more general method of calculation was
therefore introduced as an improvement. This method would obtain the
weight of each noun token in a given sentence according to the
number of total noun tokens present in this sentence, while taking
into consideration the sense frequency of the synonym for which a
match is found, as introduced in the improvement described above.
The method can be described by the formula:
x=100n
−s
, where x is the weight assigned to each token (all sentence tokens
have the same weight20), n is the number of tokens in the sentence
and s is the sense number of the match in order of frequency. The
distribution of a token's weight between its attributes remained
unchanged. Thus for a test sentence containing two noun tokens (as
in the case of S-V-O sentences), assuming a match for the third most
common sense of the nouns has been found in the knowledge base, the
20 An alternative system was considered by which the subject token would have a higher weight than theothers. This was dropped eventually, as it was decided that the dependence of the matching of other tokensin two sentences to the successful matching of the subjects accurately and fully reflected the greaterimportance of subjects compared to other syntactic functions.
34

weight of this particular match would be x=1002
−3=47 .
35

Chapter 4. Evaluation
4.1 Corpus Development
As mentioned in section 2.2.1, the only publicly available corpus
designed specifically for the task of entailment is provided by the
organisers of the Pascal RTE Challenge. Unfortunately this corpus
was incompatible with the requirements of the system described here,
firstly because of the fact that the corpus was formed with sentence
pairs while the system was designed to work with a knowledge base
and a set of test sentences and secondly, and perhaps more
importantly because of the system being restricted to S-V-O
sentences (whereas the RTE corpus is formed with much more complex
sentence structures). This restriction also made it impossible for a
corpus to be compiled from other sources since the vast majority of
collections of natural language sentences' available, like the RTE
corpus, contain more complex sentence structures.
The only feasible alternative was the manual construction of a
corpus suitable to the purposes and requirements of the system
presented here. Inevitably this implied that the system was tested
on a relatively small data set.
Since corpus size constituted a major disadvantage, particular care
has been given in the process of constructing the corpus to issues
such as representativeness and corpus bias21. As a result, a mixed
strategy of random selection and selection according to criteria
established based on the features implemented in the system was
adopted to construct a specialised corpus suitable for testing of
21 For a detailed discussion of corpus representativeness as well as general issues surrounding corpusconstruction and corpus use see McEnery and Wilson (1999)
36

the system while relatively free from bias22.
The first stage in the development of the corpus consisted of
generating the sentences that formed the knowledge base. For this
purposes a small Python script was written which made use of NLTK
tools to retrieve the two hundred most frequent common nouns that
occur in the Brown corpus23, sort them alphabetically and output them
to a file (see Appendix 2 for a code listing of the script). A
slightly modified version of the same script was used to produce a
file containing the two hundred most frequent verbs in the Brown
corpus. From these two lists words were selected randomly and
combined in a sensible fashion (i.e. avoiding nonsensical
combinations such as “Experience eats fish”) to twenty sentences of
the type Subject – Verb – Direct Object. This core set of sentences
formed the knowledge base (see Appendix 3 for a list of sentences).
In the next stage a further one hundred sentences were derived from
the initial set. These could be loosely grouped in a number of
categories, each illustrating a method used for derivation (see
Table 1)24
The categories, as well as the number of sentences allocated to each
category, were decided with the purpose of providing a set of
sentences that would thoroughly test the three features implemented
in the system (i.e. entailment from synonymy, hypernymy and passive
sentences) as well as the confidence estimate function. The design
of the categories also allowed a relatively balanced distribution
between the number of test sentences that entailed from the
knowledge base (55 – from categories 1-3, 7, 9) and the number of
those that did not (45 – from categories 4-6, 8, 10).
22 Complete elimination of bias is very difficult, if not impossible, to achieve, especially in the case ofspecialised corpora (McEnery and Wilson, 1999)
23 For further details on the Brown corpus see the Brown Corpus Manual (Francis and Kucera, 1979)24 For a full listing of the sentences forming the test corpus see Appendix 4
37

CategoryNo.
Description No. ofSentences
1sentences derived from the knowledge base set by replacing the subjectwith a synonym or a hyponym. 15
2sentences derived from the knowledge base set by replacing the directobject with a synonym or a hyponym.
10
3sentences derived from the knowledge base set by replacing the predicatewith a synonym.
15
4sentences derived from the knowledge base set by replacing the subjectwith an unrelated word.
10
5sentences derived from the knowledge base set by replacing the directobject with an unrelated word
10
6sentences derived from the knowledge base set by replacing the predicatewith an unrelated word.
10
7sentences derived from the knowledge base set by applying anycombination of the methods described in categories 13.
10
8sentences derived from the knowledge base set by applying anycombination of the methods described in categories 46.
10
9sentences derived from any of the sentences in categories 13, 7 byconversion to passive voice.
5
10sentences derived from any of the sentences in categories 46, 8 byconversion to passive voice.
5
Table 1: Categories of sentences included in the test corpus.
4.2 Testing and Evaluation
4.2.1 Analysis of Testing Results
Running the software with the 20 sentence knowledge base and the 100
sentence test base, generated by the methods described in section
4.1, produced the results summarised in Table 225.
25 See Appendix 5 for a listing of the output of the system run on the test set described.
38
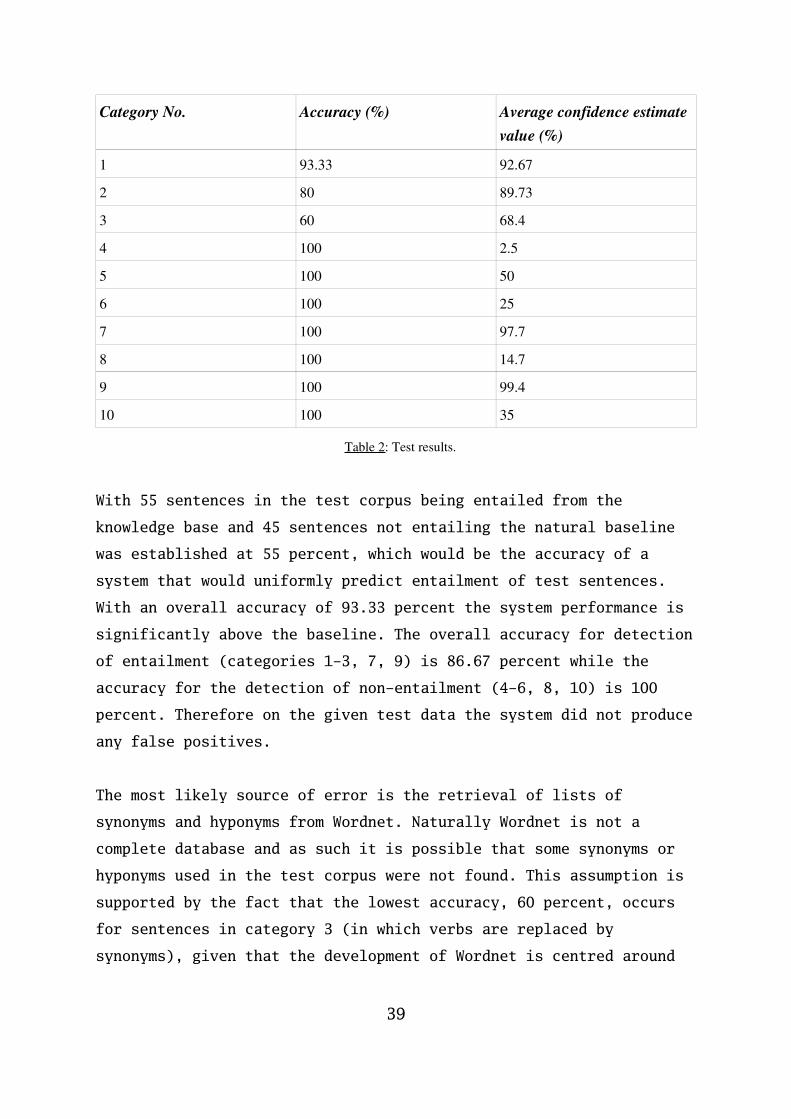
Category No. Accuracy (%) Average confidence estimatevalue (%)
1 93.33 92.67
2 80 89.73
3 60 68.4
4 100 2.5
5 100 50
6 100 25
7 100 97.7
8 100 14.7
9 100 99.4
10 100 35
Table 2: Test results.
With 55 sentences in the test corpus being entailed from the
knowledge base and 45 sentences not entailing the natural baseline
was established at 55 percent, which would be the accuracy of a
system that would uniformly predict entailment of test sentences.
With an overall accuracy of 93.33 percent the system performance is
significantly above the baseline. The overall accuracy for detection
of entailment (categories 1-3, 7, 9) is 86.67 percent while the
accuracy for the detection of non-entailment (4-6, 8, 10) is 100
percent. Therefore on the given test data the system did not produce
any false positives.
The most likely source of error is the retrieval of lists of
synonyms and hyponyms from Wordnet. Naturally Wordnet is not a
complete database and as such it is possible that some synonyms or
hyponyms used in the test corpus were not found. This assumption is
supported by the fact that the lowest accuracy, 60 percent, occurs
for sentences in category 3 (in which verbs are replaced by
synonyms), given that the development of Wordnet is centred around
39

nouns.
The average overall confidence levels are 89.58 percent for entailed
sentences and 23.3 percent for non-entailed sentences26. Factors that
affect the confidence estimate for entailed sentences are primarily
errors of judgement (i.e. sentences being classified as non-
entailing) but also matching of words in the test sentences to less
common synonyms in the knowledge base. The latter is intentional and
is caused by the method used to calculate confidence estimates (see
section 3.6 for further details).
For non-entailed sentences, the high difference in average
confidence estimates between categories 4 and 5 (2.5 percent versus
50 percent) is caused by the design of the matching process at the
core of the system rather than by implementation flaws. The
sentences in category 4 are generated by replacing the subject with
unrelated words whereas in category 5 it is the direct object that
is replaced. Because of the heavy reliance of the system on the
correct matching of subjects, for sentences in category 4 the entire
matching process is interrupted at an early stage, thus having very
low confidence estimates. In contrast the system matches subjects
correctly for sentences in category 5 which eventually produces a
higher confidence level.
Category 6 produces intermediate values (25 percent) because verbs
are matched as referents of the subjects, after matching the
subjects themselves and before attempting to match the remainder of
the sentences.
26 The confidence level measures the probability of entailment of test sentences from the knowledge base,rather than the confidence in the judgement made. Therefore, for a good system, one would expect highconfidence levels for sentences that entail and low confidence level otherwise, rather than uniformly highvalues.
40

4.2.2 Evaluation
Naturally the first step in evaluating a piece of software is a
discussion of the test results. An overall accuracy of 93.33 percent
given a baseline of 55 percent, and the fact that no false positives
were produced proves beyond doubt that the system successfully
implemented the features that it was tested for. Nonetheless, errors
did occur which implies that improvement is possible.
Judging from the test results, it appears as though the main
weakness of the system is its reliance on Wordnet for evidence of
lexical relations such as synonymy and hypernymy. Unfortunately a
solution to this problem is not obvious, given that Wordnet is
currently the largest lexical database available. It is worth
pointing out however, that part of the reason why the use of Wordnet
generated false negatives is the restriction to Subject- Verb
-Direct Object sentence structure. When working with S-V-O sentences
(which necessarily only contain two noun tokens) words carry heavy
confidence level weights. As a result, if just one word in the test
sentence has no match in the knowledge base the confidence level
drops significantly and ultimately leads to the test sentence being
judged as non-entailing. Should the system be capable of handling
more complex sentence structures (which is the primary extension
suggested in section 4.3), unavoidably most often the confidence
level weight for each token would be lower (as there would be more
tokens in a test sentence) and therefore potential errors generated
by Wordnet incompleteness would be less significant in the process
of judging entailment for a test sentence.
Apart from the production of false negatives, the other potential
problem identified from the test results is best illustrated by the
average confidence level for category 5 sentences (50 percent). When
41

constructing the test corpus these were generated by replacing the
direct objects of some of the knowledge base sentences with
unrelated words. Thus the test sentences clearly do not entail, yet,
at 50 percent, the confidence estimate is on the verge on
entailment. There are two reasons for this: the high confidence
weight assigned to each noun token (already discussed in the
paragraph above) and the reliance of the system on the successful
matching of test sentence subjects to knowledge base subjects (as
discussed in section 4.2.1). When the confidence estimate was
introduced, this reliance could have been eliminated (see section
3.5.3). After some thought it has been kept, for theoretical
considerations.
In the process of developing an approach to the task of textual
entailment recognition the assumption has been made that nouns are
the building blocks of utterances (section 2.2.3). In the same
manner, and perhaps more clearly, subjects are considered to play a
central role amongst the nouns a sentence contains. The manner in
which humans use language confirms this. If presented with an
utterance an individual understands its subject, it can be said of
them that they have acquired information, as they are aware of the
fact that something is being said about the subject. If instead they
only recognise the direct object for instance, the information
acquired is less important27. Thus the system places emphasis on
subjects in an attempt to maintain resemblance to human use of
language.
Overall the system successfully fulfils its purpose of highlighting
important aspects of the problem of textual entailment and of
27 It is important to distinguish between grammatical subject and logical subject. For active sentences the twoare identical. However, in passive sentences the logical subject is in fact the direct object. Competent parserswhich include syntactic information recognise this difference. This system also accounts for it byperforming passive active conversion prior to processing the information contained in a sentence (seesection 2.2.2).
42

verifying some of the assumptions behind the proposed approach to
this problem. As the results show, it performs in a satisfactory
manner given the restrictions imposed on it which enforces the
principles at the core of its design. It is intended as a model,
rather than a complete system of automated recognition of textual
entailment. Further development is possible however. The next
section discusses ways in which this may be conducted.
4.3 Possible enhancements
An important aspect of the development of the system described in
Chapter 3 was the consideration given to possible extensions and for
this reason the implementation was done in such a manner as to allow
the addition of such extensions on top of the features already
implemented, without the need for major changes. This is shown by
the fact that a number of possible enhancements has already been
mentioned in the process of describing the manner in which various
features were implemented.
Of these, perhaps the most important would be allowing the system to
deal with more complex sentence structures than S-V-O. Apart from
providing a more complete system this would allow for extensive
testing with existing large corpora and potentially comparison with
other systems dealing with recognition of entailment. For this
purpose, initially the method responsible for the creation of noun
tokens could easily be extended to support the entire set of
grammatical relations the RASP parser can represent (see Annexe 2),
rather than only subject and direct object, as is the case at the
moment. The next step would be the introduction of additional
attributes for the noun tokens that would store other information
potentially contained in the knowledge base sentences (such as
adjectives or determiners).
43

An obvious and important set of extensions would be provided by the
addition of other possible sources of entailment as features. It is
difficult to approximate how many of these would be feasible without
an in-depth study on the topic of sources of entailment. However,
some suggestions would be entailment from determiners (e.g. 'All
animals drink water' entails 'Some animals drink water'), from
holonyms28 (e.g. 'My car was stolen' entails 'My wheel was stolen',
given that the wheel referred to is part of the stolen car), or from
negative sentences (for instance 'I am going [not home]' – e.g. 'to
school' – entails 'I am not going home').
Finally a number of enhancements could be made regarding the
management of the knowledge database of noun tokens. Firstly the
database could be optimised so that any redundant entries would be
removed. This applies to the same nouns appearing in different
sentences but also to synonyms for instance. This is quite a complex
enhancement since the duplicate entries would most likely store
different information in some of their attributes. Methods would
have to be developed to deal with the merging of every one of the
attributed before removal can be done. However, if completed, given
a large knowledge base, an improvement in execution speed would be
an immediate gain. In addition it would open the way for a couple of
other knowledge base enhancements.
One of these is the introduction of the ability to extend the
knowledge base with unknown information identified in the test
sentences, both by the addition of new noun tokens and by the
modification of attributes of noun tokens already known. This would
confer robustness of the knowledge base, enabling, simply put, the
system to 'learn' language.
28 Y is a holonym of X if X is a part of Y (e.g. 'car' is a holonym of 'wheel')
44

The other is the addition of the capability to perform 'fuzzy'
searches during the matching process, allowing entailment judgements
to be made from the knowledge base as a whole rather than by
identifying individual sentences that are potential candidates for
entailment of the test sentence.
4.4 Conclusion
The virtues of having an artificial system that could recognize
entailment and implicitly paraphrasing should be obvious.
Information extraction, information retrieval or question answering
systems would all benefit greatly from having this sort of ability.
More generally, a system that would be able to deal with language in
any sort of fluent manner is impossible to conceive of without a
comprehensive ability to deal with entailment. This fact provides
strong motivation for research directed at attempting to automatise
the recognition of sentence entailment and was a main factor in
choosing entailment as the topic for this project.
By no means providing a complete solution to the problem of
recognition of sentence entailment, nonetheless the approach
described in this project and the software implemented to
demonstrate and test the ideas behind it succeed in their purpose of
identifying some of the key aspects of this task and providing a
starting point for potential development.
45

Bibliography
Briscoe, E. and Carroll, J. Robust Accurate Statistical Annotation
of General Text. Proceedings of the Third International Conference
on Language Resources and Evaluation (LREC 2002), Las Palmas, Canary
Islands, May 2002 pp. 1499-1504.
Briscoe, E. and Carroll, J. Grammatical Relation Annotation.
http://www.informatics.susx.ac.uk/research/nlp/carroll/grdescription
/index.html, 2000 (last visited 27 April 2005)
Cheng J. The Fundamental Role of Entailment in Knowledge
Representation and Reasoning. Journal of Computing and Information
Vol 2, No 1: 853-873, 1996.
Dagan I and Glickman O. Probabilistic Textual Entailment: Generic
Applied Modeling of Language Variability. Learning Methods for Text
Understanding and Mining, 26-29, 2004.
Dagan et al. Recognising Textual Entailment Challenge, 15 June 2004
– 10 April 2005, http://www.pascal-network.org/Challenges/RTE/.
(last visited 27 April 2005)
Dagan et al. The PASCAL Recognising Textual Entailment Challenge,
http://www.cs.biu.ac.il/~glikmao/rte05/dagan_et_al.pdf, (last
visited 27 April 2005)
Fellbaum C. (ed.) WordNet. An Electronic Lexical Database. MIT
Press, Cambridge, 1998.
46

Francis W N and Kucera H. Brown Corpus Manual.
http://khnt.hit.uib.no/icame/manuals/brown/INDEX.HTM, 1979 (last
visited 27 April 2005)
Iwanska L. Logical Reasoning in Natural Language: Is it all about
Language? International Journal of Minds and Machines, Special Issue
on Knowledge Representation for Natural Language, 3: 475-510, 1993.
Klein et al. Elementary Language Processing: Tokenizing Text and
Classifying Words.
http://nltk.sourceforge.net/tutorial/tokenization/index.html, 2004
(last visited 27 April 2005)
Loper E and Bird S. NLTK: The Natural Language Toolkit. Proceedings
of the ACL Workshop on Effective Tools and Methodologies for
Teaching Natural Language Processing and Computational Linguistics,
Philadelphia, 2002.
Marks D. Development Methodologies Compared,
http://www.ncycles.com/e_whi_Methodologies.htm, 2002 (last visited
27 April 2005)
McEnery T and Wilson A. Corpus Linguistics. Edinburgh: Edinburgh
University Press, 1999
Russel K. Natural Language Toolkit (NLTK) 1.2.
http://nltk.sourceforge.net/docs.html, 2003. (last visited 27 April
2005)
Saeed JI. Semantics, Second Edition. Blackwell Publishing Ltd 2003.
47

UCREL CLAWS2 Tagset,
http://www.comp.lancs.ac.uk/ucrel/claws2tags.html, (last visited 27
April 2005)
van Rossum G. Python Tutorial, Release 2.4.
http://docs.python.org/tut/tut.html, 2005. (last visited 27 April
2005)
48

Appendix 1
Given the interdisciplinary character of my degree and a personal interest
in philosophy as well as a taste for innovation, the issue of textual
entailment presented itself as a perfect topic for the final year project.
From the onset I suspected it was going to be difficult but the existence
of the PASCAL RTE challenge (http://www.pascal-
network.org/Challenges/RTE/), of the NLTK (http://nltk.sourceforge.net) and
the fact that I was enrolled for the Natural Language Processing module in
the second semester encouraged me to go ahead with my choice. Only later
did I realise that there was very little relevant research material
available and that few of the topics treated in the NLP module had
connections with entailment. My enthusiasm for the topic remained unchanged
however and drove me to do massive amounts of reading around the topic,
most of which I did not use in the final report. More time still went on
learning Python, NLTK methods, and acquiring general NLP concepts in
advance of their introduction in the relevant module. On the programming
side of things, I spent a few weeks trying to adapt NLTK tools for the
project only to discover eventually that the RASP parser was better suited
to my needs. Because of all these factors I found myself at the end of
Semester 1 only having started the actual work. Obviously this put a lot of
pressure on me and at times I thought I would not finish. The reading did
help, however, indirectly, by giving me an in-depth understanding of the
topic and thus enabling me to develop and implement my ideas in an
efficient manner. The result is a project in which the theoretical
treatment of the topic is the focus and the software is meant as an aid to
understanding and investigating the issues at hand.
The main advice I would have for others interested in the topic is to pay
careful attention to planning. This is crucial, given the complexity of the
topic. Draft a detailed plan in the initial stages, allowing for possible
delays and adhere to it strictly. Entailment is an interesting but
difficult topic, requiring a strong theoretical foundation, even for
someone oriented towards the programming aspect of it. But it is vital to
limit the time spent reading such that you leave yourself enough time to do
49

the work. You will not manage to solve the problem completely, there simply
isn't enough time. Set yourself a number of specific goals early and
advance through them methodically.
Overall I have enjoyed working on this project and managed to keep my
interest for the topic intact throughout.
50

Appendix 2
Script used to retrieve the 200 most frequent nouns
in the Brown corpus.
from nltk.corpus import brown
from nltk.probability import FreqDist
corpus = []
for item in brown.items():
corpus.append(brown.read(item))
fd = FreqDist()
for text in corpus:
for token in text['WORDS']:
if ((token['TAG'] == 'nn') or (token['TAG'] == 'nns')):
fd.inc(token['TEXT'])
f = file('samples', 'a')
counter = 0
for item in fd.sorted_samples():
counter = counter + 1
if counter <= 151:
f.write(item)
f.write('\n')
else: break
f.close()
print 'most frequent word is %s' % fd.max()
print 'Done.'
51

Appendix 3
Knowledge Base Corpus.
felines eat fish.
students make errors.
parents love children.
scientists perform experiments.
countries have governments.
governments pass laws.
education prevents poverty.
boys like girls.
business involves money.
questions require answers.
detectives analyse evidence.
animals want space.
history teaches lessons.
people damage nature.
success builds confidence.
teachers develop minds.
experience brings wisdom.
books provide information.
society needs examples.
companies create jobs.
52

Appendix 4
Test Corpus
cats eat fish.
beasts want space.
tutors develop minds.
textbooks provide information.
cultures need examples.
pupils make errors.
nations have governments.
governance passes laws.
instruction prevents poverty.
doubts require answers.
investigators analyse evidence.
creatures want space.
stories teach lessons.
winners build confidence.
records provide information.
education prevents destitution.
detectives analyse proofs.
questions require feedback.
students make slips.
business involves funds.
students make mistakes.
parents love babies.
society needs lessons.
teachers develop judgements.
success builds trust.
boys like girlfriends.
education prevents impoverishment.
questions require solutions.
companies create business.
history teaches morals.
students create errors.
53

scientists execute experiments.
countries need governments.
governments give laws.
business demands money.
detectives examine evidence.
animals need space.
experience conveys wisdom.
felines consume fish.
success establishes confidence.
sharks eat fish.
justice prevents poverty.
chess develops minds.
explanations need examples.
cities destroy nature.
computers provide information.
investment creates jobs.
age brings wisdom.
banks make errors.
gambling involves money.
countries have citizens.
books provide pleasure.
animals want food.
companies create competition.
questions require interpretation.
people destroy property.
boys like football.
society needs peace.
teachers develop exams.
education prevents ignorance.
parents protect children.
scientists design experiments.
countries elect governments.
business attracts money.
detectives find evidence.
animals enjoy space.
people change nature.
books hold information.
54

society lacks examples.
teachers shape minds.
cats consume fish.
pupils create mistakes.
nations need governments.
instruction prevents destitution.
business demands funds.
doubts require solutions.
detectives examine proofs.
beasts need space.
stories teach morals.
cultures need lessons.
cigarettes destroy health.
parents have duties.
elections involve campaigns.
birds eat seeds.
trains improve transport.
companies sell products.
universities offer diplomas.
people enjoy music.
scientists propose theories.
pictures decorate walls.
information is provided by books.
girls are liked by boys.
evidence is analysed by investigators.
errors are made by pupils.
lessons are needed by society.
jobs are created by investment.
pleasure is provided by books.
exams are developed by teachers.
evidence is found by detectives.
nature is changed by people.
55

Appendix 5
System output after running on the test set in
Appendix 4
Sentence "cats eat fish" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "beasts want space" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "tutors develop minds" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "textbooks provide information" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "cultures need examples" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "pupils make errors" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "nations have governments" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "governance passes laws" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "instruction prevents poverty" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "doubts require answers" entails from the knowledge base.
Confidence level =99.0
56

-----
Sentence "investigators analyse evidence" entails from the knowledge base.
Confidence level =98.0
-----
Sentence "creatures want space" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "stories teach lessons" entails from the knowledge base.
Confidence level =97.0
-----
Sentence "winners build confidence" entails from the knowledge base.
Confidence level =98.0
-----
Sentence "records provide information" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "education prevents destitution" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "detectives analyse proofs" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "questions require feedback" does not entail from any known
sentence.
Confidence level =50
-----
Sentence "students make slips" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "business involves funds" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "students make mistakes" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "parents love babies" entails from the knowledge base.
57

Confidence level =100.0
-----
Sentence "society needs lessons" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "teachers develop judgements" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "success builds trust" does not entail from any known sentence.
Confidence level =50
-----
Sentence "boys like girlfriends" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "education prevents impoverishment" entails from the knowledge
base.
Confidence level =100.0
-----
Sentence "questions require solutions" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "companies create business" does not entail from any known
sentence.
Confidence level =50
-----
Sentence "history teaches morals" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "students create errors" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "scientists execute experiments" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "countries need governments" entails from the knowledge base.
Confidence level =96.0
58

-----
Sentence "governments give laws" does not entail from any known sentence.
Confidence level =25
-----
Sentence "business demands money" entails from the knowledge base.
Confidence level =98.0
-----
Sentence "detectives examine evidence" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "animals need space" entails from the knowledge base.
Confidence level =98.0
-----
Sentence "experience conveys wisdom" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "felines consume fish" entails from the knowledge base.
Confidence level =92.0
-----
Sentence "success establishes confidence" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "sharks eat fish" does not entail from any known sentence.
Confidence level =0
-----
Sentence "justice prevents poverty" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "chess develops minds" does not entail from any known sentence.
Confidence level =0
-----
Sentence "explanations need examples" does not entail from any known
sentence.
Confidence level =0
59

-----
Sentence "cities destroy nature" does not entail from any known sentence.
Confidence level =0
-----
Sentence "computers provide information" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "investment creates jobs" does not entail from any known sentence.
Confidence level =25
-----
Sentence "age brings wisdom" does not entail from any known sentence.
Confidence level =0
-----
Sentence "banks make errors" does not entail from any known sentence.
Confidence level =0
-----
Sentence "gambling involves money" does not entail from any known sentence.
Confidence level =0
-----
Sentence "countries have citizens" does not entail from any known sentence.
Confidence level =50
-----
Sentence "books provide pleasure" does not entail from any known sentence.
Confidence level =50
-----
Sentence "animals want food" does not entail from any known sentence.
Confidence level =50
-----
Sentence "companies create competition" does not entail from any known
sentence.
Confidence level =50
-----
Sentence "questions require interpretation" does not entail from any known
sentence.
Confidence level =50
-----
60

Sentence "people destroy property" does not entail from any known sentence.
Confidence level =50
-----
Sentence "boys like football" does not entail from any known sentence.
Confidence level =50
-----
Sentence "society needs peace" does not entail from any known sentence.
Confidence level =50
-----
Sentence "teachers develop exams" does not entail from any known sentence.
Confidence level =50
-----
Sentence "education prevents ignorance" does not entail from any known
sentence.
Confidence level =50
-----
Sentence "parents protect children" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "scientists design experiments" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "countries elect governments" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "business attracts money" does not entail from any known sentence.
Confidence level =25
-----
Sentence "detectives find evidence" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "animals enjoy space" does not entail from any known sentence.
Confidence level =25
61

-----
Sentence "people change nature" does not entail from any known sentence.
Confidence level =25
-----
Sentence "books hold information" does not entail from any known sentence.
Confidence level =25
-----
Sentence "society lacks examples" does not entail from any known sentence.
Confidence level =25
-----
Sentence "teachers shape minds" does not entail from any known sentence.
Confidence level =25
-----
Sentence "cats consume fish" entails from the knowledge base.
Confidence level =92.0
-----
Sentence "pupils create mistakes" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "nations need governments" entails from the knowledge base.
Confidence level =96.0
-----
Sentence "instruction prevents destitution" entails from the knowledge
base.
Confidence level =99.0
-----
Sentence "business demands funds" entails from the knowledge base.
Confidence level =98.0
-----
Sentence "doubts require solutions" entails from the knowledge base.
Confidence level =98.0
-----
Sentence "detectives examine proofs" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "beasts need space" entails from the knowledge base.
Confidence level =98.0
62

-----
Sentence "stories teach morals" entails from the knowledge base.
Confidence level =97.0
-----
Sentence "cultures need lessons" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "cigarettes destroy health" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "parents have duties" does not entail from any known sentence.
Confidence level =25
-----
Sentence "elections involve campaigns" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "birds eat seeds" does not entail from any known sentence.
Confidence level =25
-----
Sentence "trains improve transport" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "companies sell products" does not entail from any known sentence.
Confidence level =25
-----
Sentence "universities offer diplomas" does not entail from any known
sentence.
Confidence level =0
-----
Sentence "people enjoy music" does not entail from any known sentence.
Confidence level =25
-----
Sentence "scientists propose theories" does not entail from any known
sentence.
63

Confidence level =25
-----
Sentence "pictures decorate walls" does not entail from any known sentence.
Confidence level =22
-----
Sentence "information is provided by books" entails from the knowledge
base.
Confidence level =100.0
-----
Sentence "girls are liked by boys" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "evidence is analysed by investigators" entails from the knowledge
base.
Confidence level =98.0
-----
Sentence "errors are made by pupils" entails from the knowledge base.
Confidence level =100.0
-----
Sentence "lessons are needed by society" entails from the knowledge base.
Confidence level =99.0
-----
Sentence "jobs are created by investment" does not entail from any known
sentence.
Confidence level =25
-----
Sentence "pleasure is provided by books" does not entail from any known
sentence.
Confidence level =50
-----
Sentence "exams are developed by teachers" does not entail from any known
sentence.
Confidence level =50
-----
Sentence "evidence is found by detectives" does not entail from any known
sentence.
Confidence level =25
64

-----
Sentence "nature is changed by people" does not entail from any known
sentence.
Confidence level =25
-----
65

Appendix 6
README instructions for running the software and the
script in Appendix 2.
Both the software and the script make use of the NLTK toolkit which
is not included with standard Python distribution.
Therefore, if running on the University of Leeds, School of
Computing Linux system, prior to running either programs type
'extras nltk' at the command prompt in a console. This sets the NLTK
environment variables.
To run the software type: 'python rte.py' at the command prompt in
the console and follow the instructions on screen.
66