reduction of training noises for text classifiers rey-long liu dept. of medical informatics tzu chi...
TRANSCRIPT

Reduction of Training Noises for Text
Classifiers
Rey-Long Liu
Dept. of Medical Informatics
Tzu Chi University
Taiwan

Outline
• Background
• Problem definition
• The proposed approach: TNR
• Empirical evaluation
• Conclusion
Training Noise Reduction for TC 2

Background
Training Noise Reduction for TC 3

Training of Text Classifiers
• Given– Training documents labeled with category labels
• Return– Text classifiers that can
• Classify in-space documents (those that are relevant to some categories)
• Filter out out-space documents (those that are not relevant to any of the categories of interest)
• Usage: retrieval and dissemination of information
Training Noise Reduction for TC 4

Typical Problem: Noises in the Training
Texts• The training documents are inevitably
unsound and/or incomplete– A lot of noises in the training texts
• Those terms that are irrelevant but happen to appear in the training documents
Training Noise Reduction for TC 5

Problem Definition
Training Noise Reduction for TC 6

Goal & Motivation
• Goal– Develop a technique TNR (Training Noise
Reduction) that removes possible training noises for text classifiers
• Motivation– With the help by TNR, text classifiers can be
trained to have better performance in • Classifying in-space documents
• Filtering out out-space documents
Training Noise Reduction for TC 7

Basic Idea
• Term proximity as the key evidence to identify noises– In a training text d of a category c, a sequence
of consecutive terms (in d) are noises if they have many neighboring terms not related to c
– They are noises because they may simply happen to appear in d and hence are likely to be irrelevant to c
Training Noise Reduction for TC 8

Related Work
• No previous approaches focused on the fusion of relatedness scores of consecutive terms to identify training noises for text classifiers– Term proximity was mainly employed to improve
text ranking or select features to build text classifiers
• TNR can serve as a front-end processor for the techniques of feature selection and classifier development (e.g., SVM)
Training Noise Reduction for TC 9

The Proposed Approach: TNR
Training Noise Reduction for TC 10

Basic Definition
• Positive correlation vs. Negative correlation– A term t is positively correlated to a category c if
occurrence of t in a document d increases the possibility of classifying d into c; otherwise t is negatively correlated to c
• Therefore, TNR should remove those terms that are negatively correlated to c
Training Noise Reduction for TC 11

Training Noise Reduction for TC 12

The Main Hypothesis
• Those terms (in d) that have many neighboring terms with negative or low correlation strengths to c may simply happen to appear in d and hence are likely to be the training noises in d
Training Noise Reduction for TC 13

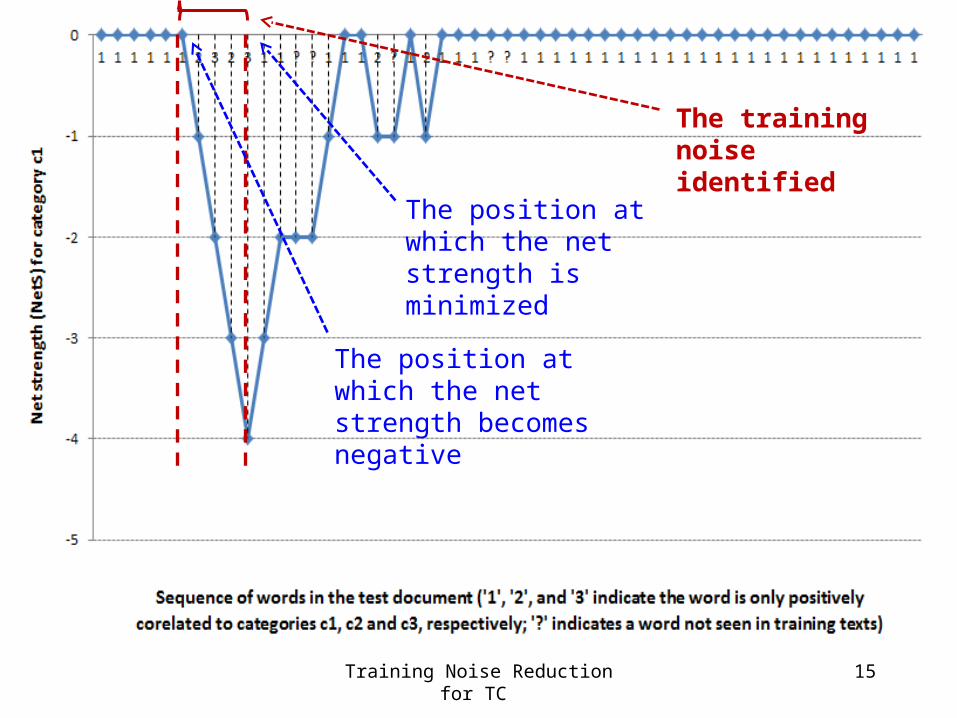
The Algorithm of TNR(1) For a category c, sequentially scan each term t in d
(1.1) Employ the 2 statistics to compute the cumulative correlation strength at t
• Positive correlation if t is more likely to appear in documents of categories c; otherwise negative correlation
• Positive correlation Increase net strength (NetS <= 0)
• Negative correlation Decrease net strength
(2) Identify the term segments (in d) that are likely to be training noises
(2.1) Noise = the text segments that are more likely to contain FP and TN terms
Training Noise Reduction for TC 14
Training Noise Reduction for TC 15
The position at which the net strength is minimized
The position at which the net strength becomes negative
The training noise identified

Empirical Evaluation
Training Noise Reduction for TC 16

Experimental Data• Top-10 fatal diseases and top-20 cancers in
Taiwan– # of diseases: 28– # of documents: 4669 (of 5 aspects: etiology,
diagnosis, treatment, prevention, and symptom)– Source: Web sites of hospitals, healthcare
associations, and department of health in Taiwan– Training documents: 2300 documents– Test documents:
• In-space documents: The remaining 2369 documents• Out-space documents: 446 documents about other diseases
Training Noise Reduction for TC 17

Underlying Classifiers
• Underlying classifier – The Support Vector Machine (SVM)
classifier
Training Noise Reduction for TC 18

Results: Classification of In-Space Documents
• Evaluation criteria– Micro-averaged F1 (MicroF1)
– Macro-averaged F1 (MacroF1)
Training Noise Reduction for TC 19

Training Noise Reduction for TC 20

Training Noise Reduction for TC 21

Results: Filtering of Out-Space Documents
• Evaluation criteria– Filtering ratio (FR) =
# out-space documents successfully rejected by all categories / # out-space documents
– Average number of misclassifications (AM) =
# misclassifications for the out-space documents / # out-space documents
Training Noise Reduction for TC 22

Training Noise Reduction for TC 23

Training Noise Reduction for TC 24

Conclusion
Training Noise Reduction for TC 25

• Text classifiers are essential for archival and dissemination of information
• Many text classifiers are built by a set of training documents– The training documents are inevitably unsound and
incomplete, and so contain many training noises
• Reduction of the training noises can be done by analyzing correlation types of consecutive terms
• We show that the noise reduction is helpful in improving state-of-the-art text classifiers
Training Noise Reduction for TC 26