rounds analytics pipeline
TRANSCRIPT

Rounds Analytics PipelineAviv Laufer CTO, Rounds @avivl

Founded 2008
35 person team (⅔ in R&D)
Tel-Aviv based
Raised over $22 million in funding from industry leading investors such as Sequoia Capital, Samsung Ventures, Rhodium,
Verizon Ventures and many more. Over 25 million users worldwide


Client - Objective-C, Java, C/C++
Server - Python, Go, C++, and bits of Erlang
DB - MySQL (RDS), CouchBase (a few clusters)
Multi Cloud - AWS, GCE, SL, DO
Deployment - Ansible
Monitoring - Sensu, NewRelic, VictorOps
And yes we use Docker…...
Tools of the Trade

We tried to make it work quite a few times, and failed
We kept on trying
We think we got it right this time
ANALYTICS @ROUNDS
DO OR DO NOT. THERE IS NO TRY. - Master Yoda

One monolith app
Data was written to MySql/RDS - row by row
Batch ETL to Vertica
And then came July 2014
GENESIS


Data collection killed our backend app
Slow, failing ETL process
No real time view into events
Preferred users over analytics, we killed the event collection
We were flying blind
CHAOS

Separate ETL process from main app
Clients reports (a request for each event) to a different microservice
First very naive version written in Go - it scales!
Data is written to an Elasticsearch cluster.
ETL from ES to Vertica
EXODUS

Frontends - Receiving user analytics and perform sanity checks
Google Pub/Sub - Store events for future processing
Workers - Pull the events from Pub/Sub and stream to Google BigQuery and ES
...And Then There Were Three...
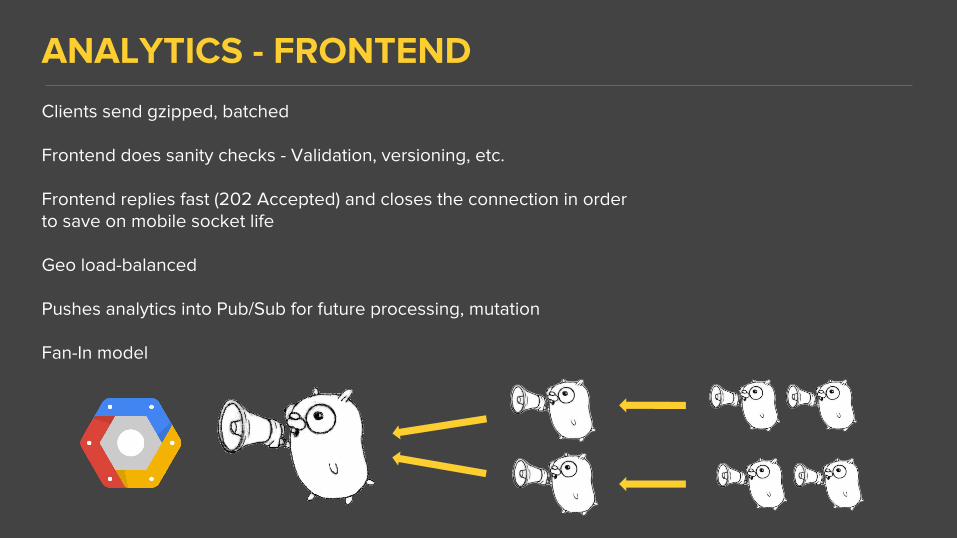
Clients send gzipped, batched
Frontend does sanity checks - Validation, versioning, etc.
Frontend replies fast (202 Accepted) and closes the connection in order to save on mobile socket life
Geo load-balanced
Pushes analytics into Pub/Sub for future processing, mutation
Fan-In model
ANALYTICS - FRONTEND

Pulls analytics from Pub/Sub
Mutate/Enrich data if necessary
Inserts to various DBs, according to usage - Monitoring, BI, Warehousing, etc.
Separation of concerns - Worker cluster per target DB
Fan-out model
Renee Finch, golang.org/doc/gopher/pencil/ANALYTICS - WORKER

Golang, abstraction package
Receives rows, streams to BigQuery (as opposed to load jobs)
Sync (foreground insert) or Async (background insert)
Pros: Instant data availability, no job delay, fast
Cons: Harder handling of bad analytics, Google’s HTTP 500s (requires retry)
Open source, PRs merrily encouraged!
Collecting User Data and Usage - Blog Post - http://bit.ly/CollectingDataRounds
github.com/rounds/go-bqstreamerSTREAMING TO BigQuery

Frontends deployed in several locations in GCE (We Geo load balance them)
Workers are in GCE (Europe West)
ES cluster is in GCE (Europe West)
ACROSS THE UNIVERSE

We started using Elasticsearch for monitoring about a year before elastic.co relaize that
Every new feature received a monitoring dashboard
Debugging
Monitoring (custom sensu checks)
Data is kept for 30 to 90 days
Ad-hoc reporting using Kibana
ELASTICSEARCH


Store data from the beginning till the end of time
Standard(ish) SQL
Very fast
No DBA is needed
Business reports (SiSense) - “Kibana” for BigQuery
BigQuery

NEW ISSUES
Permissive vs hard scheme for events - allow clients ease of use while keeping the scheme strict for ease of BI
Clients make mistakes (Arabic locale dates) - elasticsearch allows while BQ doesn’t
Things we’re integrating as solutions
Every event is a class - compile time validation generated from RAML
Wrote a library for event reporting server side

ANY QUESTIONS
DO YOU HAVE?