self-service bi for big data applications using apache drill (big data amsterdam v2.0, 2015-05-13)
TRANSCRIPT

© 2015 MapR Technologies 1© 2015 MapR Technologies

© 2015 MapR Technologies 2
About me:
• Systems Engineer at MapR Technologies in the Nordic countries
• 20 years experience:
– IBM (Sweden)
• MDM, Data Governance, Information Server, Data Stage
– Teradata (Sweden)
• Developing Warehouses
– Informix / IBM (US)
• Advisory Software Developer at IBM in the IBM Informix datablades group.
• Visionary Ambassador

© 2015 MapR Technologies 3
• Pioneering Data Agility for Hadoop
• Apache open source project
• Scale-out execution engine for low-latency queries
• Unified SQL-based API for analytics & operational applications
APACHE DRILL
40+ contributors150+ years of experience building
databases and distributed systems
© 2015 MapR Technologies 4
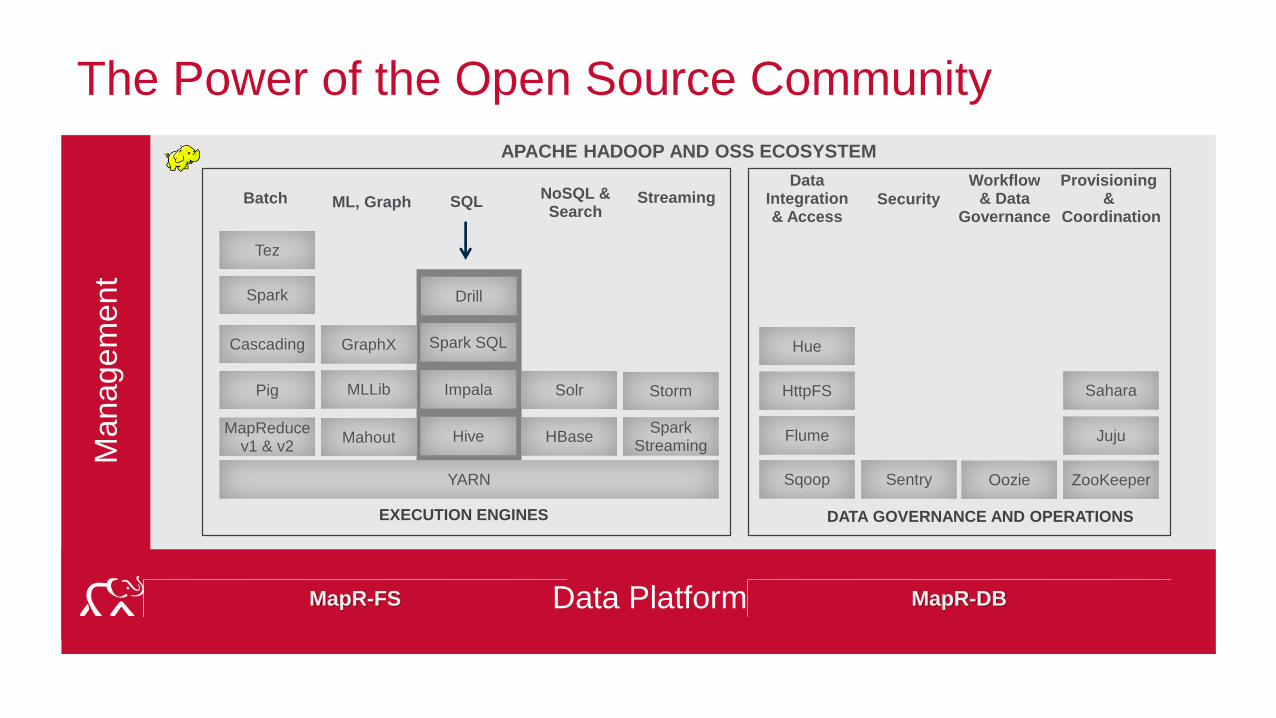
The Power of the Open Source Community
APACHE HADOOP AND OSS ECOSYSTEM
Security
YARN
Spark Streaming
Storm
StreamingNoSQL & Search
Juju
Provisioning &
Coordination
Sahara
ML, Graph
Mahout
MLLib
GraphX
EXECUTION ENGINES DATA GOVERNANCE AND OPERATIONS
Workflow & Data
Governance
Pig
Cascading
Spark
Batch
MapReduce v1 & v2
Tez
HBase
Solr
Hive
Impala
Spark SQL
Drill
SQL
Sentry Oozie ZooKeeperSqoop
Flume
Data Integration& Access
HttpFS
Hue
Data PlatformMapR-FS MapR-DB
Manag
em
ent
© 2015 MapR Technologies 5
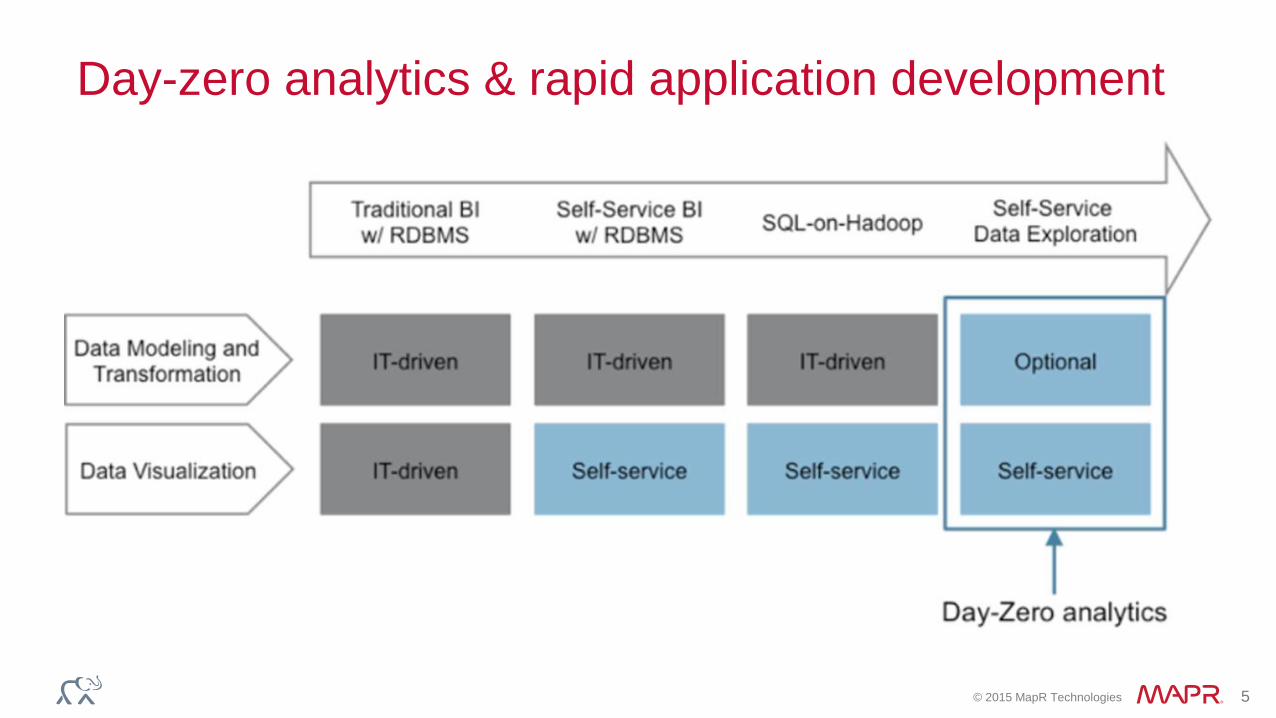
Day-zero analytics & rapid application development

© 2015 MapR Technologies 6
Philosophy question: What is high performance?
• Example 1:
– 2 Month of preparation: 2 seconds of execution
• Example 2:
– 10 minutes preparation, 5 hours execution
• Example 3:
– 2 days of preparation, 20 days of execution
• Apache Drill is about getting to the data quicker, and with less
effort.
• Will it always be quicker?
– It depends how you compare.

© 2015 MapR Technologies 7
Performance is about data management
• How quickly can you incorporate new data
• What types of prep or ETL you need to do
• What you can do without having to read data & calculate statistics
– Remember, many users never read all their data
• Time to first result
• Time to last result
• Managing Scarce Resources
• Concurrency

© 2015 MapR Technologies 8®
© 2014 MapR Technologies 2 © 2014 MapR Technologies ®
“Drill isn’t just about SQL-on-Hadoop. It’s about SQL-on-
pretty-much-anything, immediately, and without formality.”
-Andrew Brust, GigaOM Research, Dec 2014

© 2015 MapR Technologies 9®
© 2014 MapR Technologies 9
Flexibility your tool should
be flexible…
so you don’t have to be

© 2015 MapR Technologies 10
Apache Drill: Self Service SQL for Big data
AGILITYINSTANT INSIGHTS TO BIG DATA
FLEXIBILITYONE INTERFACE
FOR HADOOP & NOSQL
FAMILIARITYEXISTING SKILLS &
TECHNOLOGIES
• Direct queries on self
describing data
• No schemas or ETL
required
• Query HBase and
other NoSQL stores
• Use SQL to natively
operate on complex
data types (such as
JSON)
• Leverage ANSI SQL
skills and BI tools
• Plug-n-play with Hive
schema, file formats,
UDF’s
© 2015 MapR Technologies 11
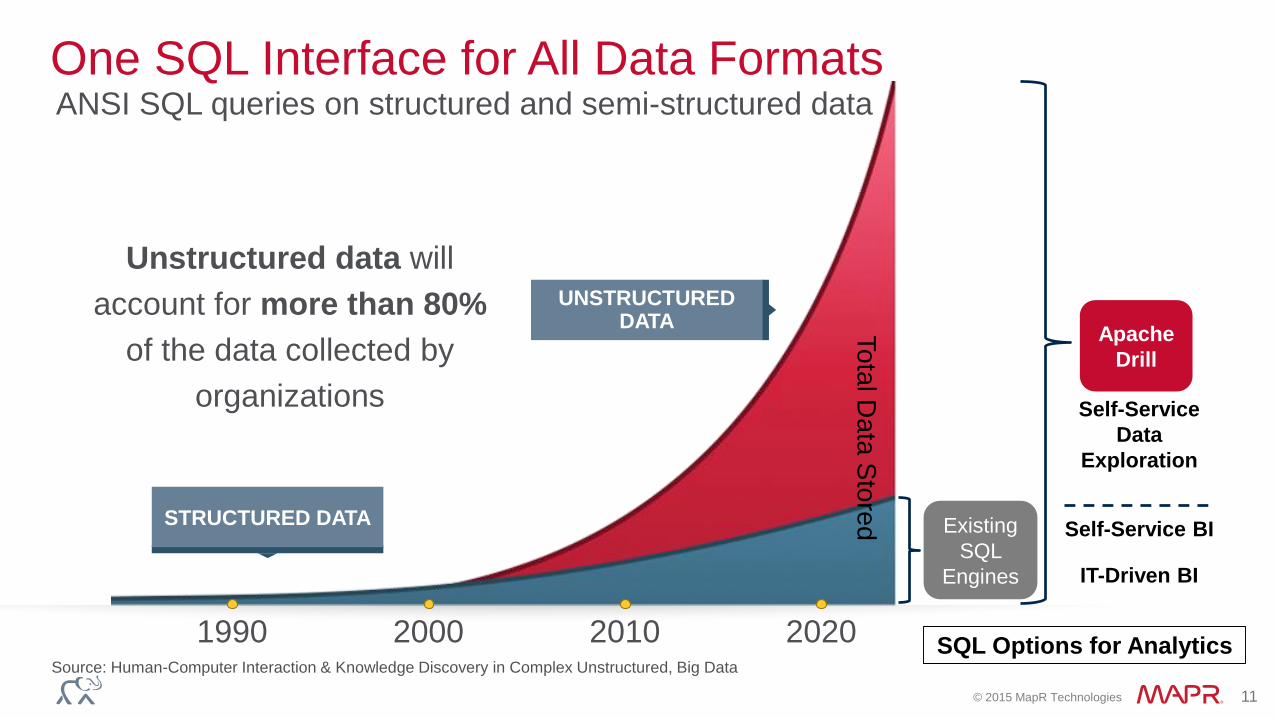
One SQL Interface for All Data FormatsANSI SQL queries on structured and semi-structured data
UNSTRUCTURED DATA
STRUCTURED DATA
2000 20101990 2020
Unstructured data will
account for more than 80%
of the data collected by
organizations
Source: Human-Computer Interaction & Knowledge Discovery in Complex Unstructured, Big Data
To
tal D
ata
Sto
red Existing
SQL
Engines
Apache
Drill
Self-Service
Data
Exploration
IT-Driven BI
Self-Service BI
SQL Options for Analytics
© 2015 MapR Technologies 12
Governed
Approach
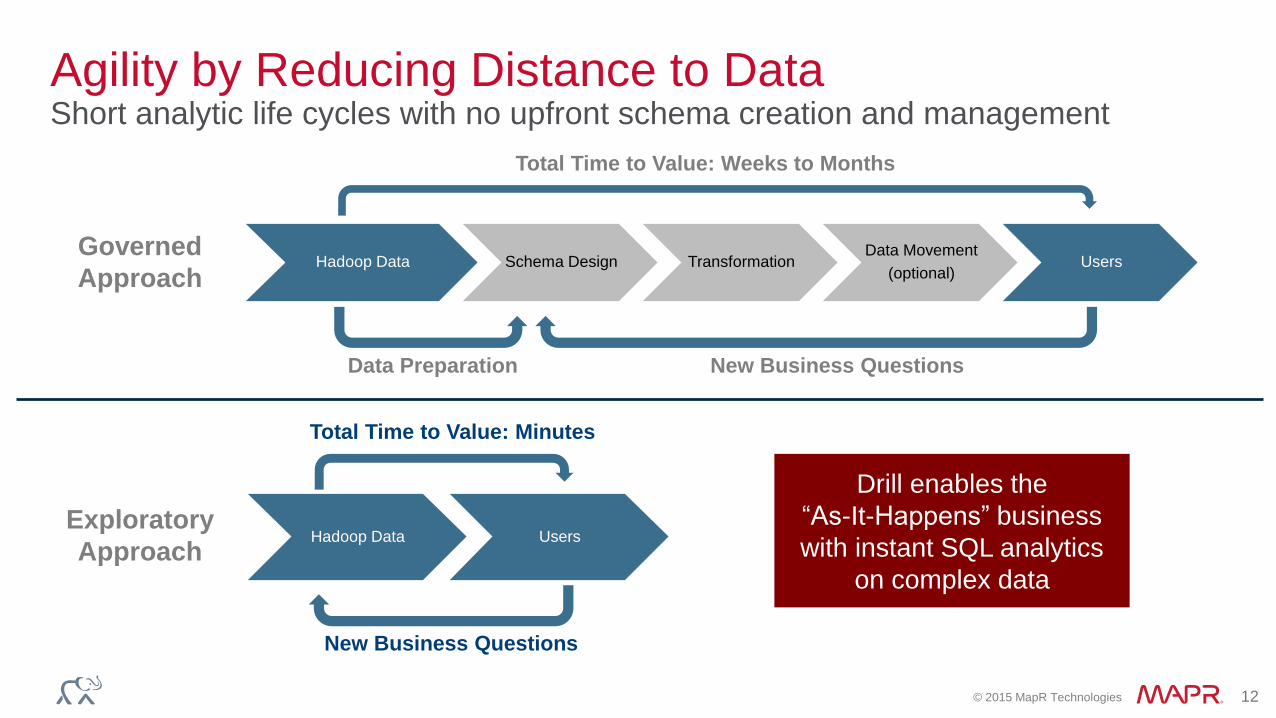
Agility by Reducing Distance to DataShort analytic life cycles with no upfront schema creation and management
Hadoop Data Schema Design TransformationData Movement
(optional)Users
Hadoop Data Users
New Business Questions
Total Time to Value: Weeks to Months
Total Time to Value: Minutes
Exploratory
Approach
Data Preparation
New Business Questions
Drill enables the
“As-It-Happens” business
with instant SQL analytics
on complex data

© 2015 MapR Technologies 13
Apache Drill - Delivering New Capabilities for BIA
gil
ity &
Bu
sin
ess V
alu
e
Technology Enablement for BI
IT-Driven BI
Self-Service BI
Self-Service
Data Exploration
IT-Driven BI IT-Driven BI
Self-Service BI
Analyst-driven with
no IT dependency
Analyst-driven with
IT support for ETL
IT-created
reports, spreadsheets
1980s -1990s 2000s Now
© 2015 MapR Technologies 14
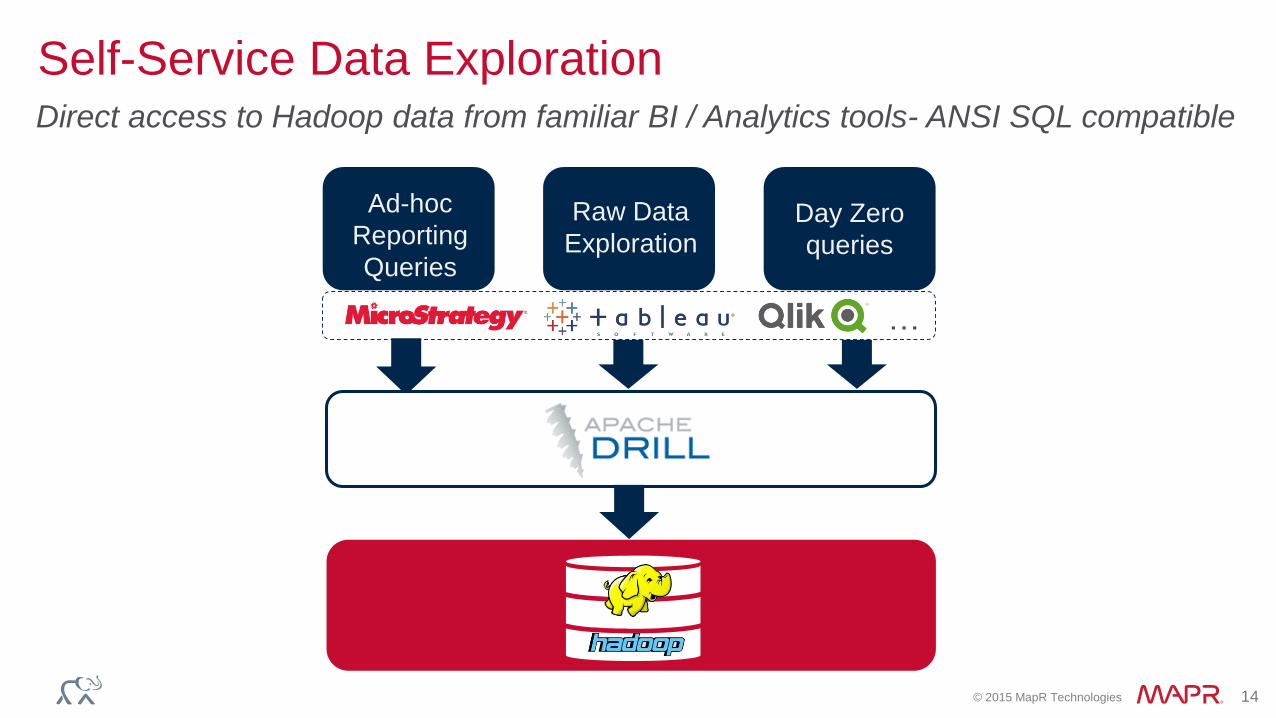
Self-Service Data ExplorationDirect access to Hadoop data from familiar BI / Analytics tools- ANSI SQL compatible
Ad-hoc
Reporting
Queries
Raw Data
ExplorationDay Zero
queries
…

© 2015 MapR Technologies 15
Drill Supports Schema Discovery On-The-Fly
• Fixed schema
• Leverage schema in centralized
repository (Hive Metastore)
• Fixed schema, evolving schema or
schema-less
• Leverage schema in centralized
repository or self-describing data
2Schema Discovered On-The-FlySchema Declared In Advance
SCHEMA ON WRITE
SCHEMA BEFORE READ
SCHEMA ON THE FLY

© 2015 MapR Technologies 16
© 2015 MapR Technologies 17
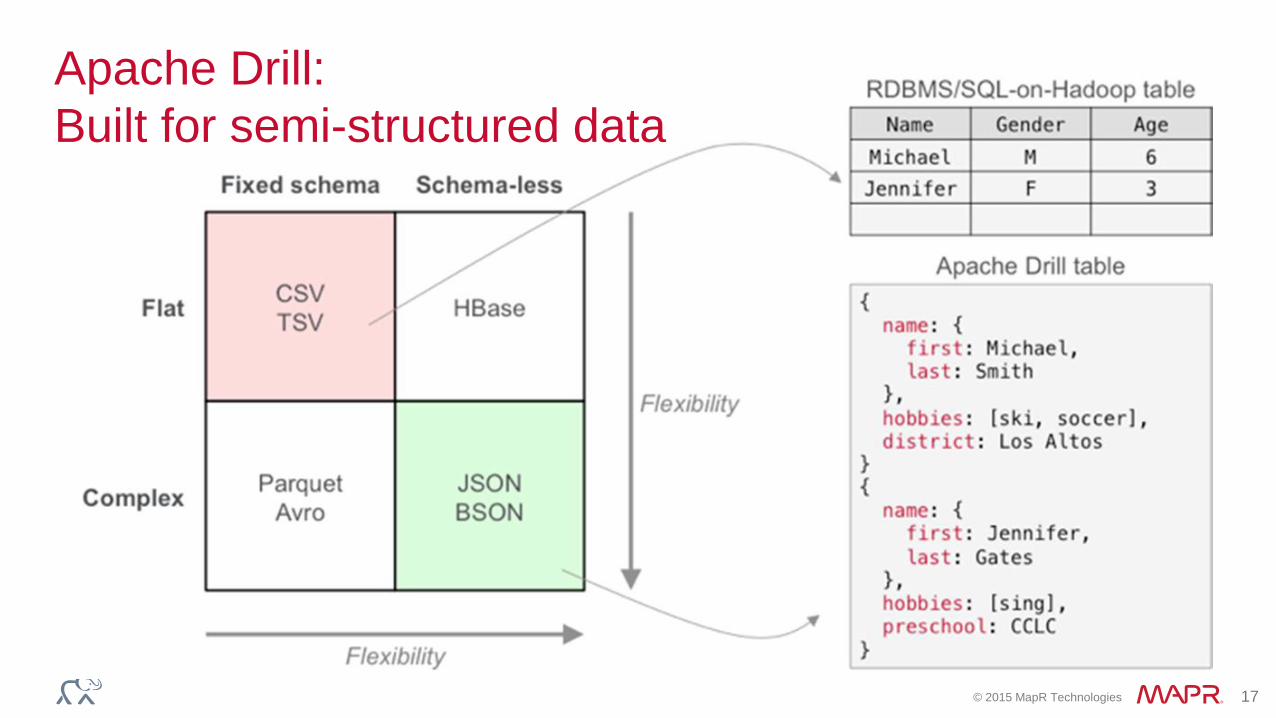
Apache Drill:
Built for semi-structured data

© 2015 MapR Technologies 18
Flexibility in how you describe your data
• Drill doesn’t require schema, detects file types based on
– extensions
– magic bytes (e.g. PAR1) – systems settings
• Query can be planned on any file, anywhere
• Data types are determined as data arrives
• Some formats have known schema
– If they don’t, you can expose them as such through views
– Views are simply JSON files that define view SQL

© 2015 MapR Technologies 19
Familiarity
• Integrates with standard BI
Tools through ANSI SQL
and API’s to provide
access to:
• Files,
• HBase,
• Hive
• <Whatever>
• Hive UDF’s can be used
directly in Drill

© 2015 MapR Technologies 20
Real life examples (terminal recordings)
• Show a simple use case to explore a more complex json (twitter-data collected using Flume– http://showterm.io/4a770a2f02f956a4b7e42
– http://showterm.io/0f203718698ee3f12e532
• A simple use case of accessing a csv file using drill– http://showterm.io/2a807546708217772a115
• Easy extraction of data from Hbase using Drill– http://showterm.io/0666429adb0d673f676bd
• A simple example of using home made integrations (JDBC):– http://showterm.io/f1c8a632bc8dd78e33a7d

© 2015 MapR Technologies 21
Real life examples (terminal recordings) ctd.
• How to access views, and show the explain plan of the view:
– http://showterm.io/b521276d7d829f70e09db
• A simple offloading case where data is taken from a MySQL and
brought into Parquet:
– http://showterm.io/c8046f815c82868a7a64f
• A simple join between CSV, Parquet, or MySQL:
– http://showterm.io/07b83c10a4696849e04f3

© 2015 MapR Technologies 22
• Pioneering Data Agility for Hadoop
• Apache open source project
• Scale-out execution engine for low-latency queries
• Unified SQL-based API for analytics & operational applications
APACHE DRILL
40+ contributors150+ years of experience building
databases and distributed systems

© 2015 MapR Technologies 23
More information and resources
• Apache Foundation project:
– http://drill.apache.org
• MapR Drill sandbox downloads and more:
– http://www.mapr.com/products/drill
• Demo of online retailer use case with Apache Drill:
– https://www.youtube.com/watch?v=FkcegazNuio

© 2015 MapR Technologies 24
Q & A
@mapr maprtech
Engage with us!
MapR
maprtech
mapr-technologies