sequential monte carlo and particle filtering frank wood gatsby, november 2007 texpoint fonts used...
Post on 21-Dec-2015
213 views
TRANSCRIPT

Sequential Monte Carlo and Particle Filtering
Frank Wood
Gatsby, November 2007

Importance Sampling
• Recall:– Let’s say that we want to compute some expectation (integral)
and we remember from Monte Carlo integration theory that with samples from p() we can approximate this integral thusly
Ep [f ] =Z
p(x)f (x)dx
Ep[f ] ¼1L
LX
`=1
f (x`)

What if p() is hard to sample from?
• One solution: use importance sampling– Choose another easier to sample distribution
q() that is similar to p() and do the following:
Ep [f ] =Z
p(x)f (x)dx
=Z
p(x)q(x)
f (x)q(x)dx
¼1L
LX
`=1
p(x`)q(x`)
f (x`) x` » q(¢)

I.S. with distributions known only to a proportionality
• Importance sampling using distributions only known up to a proportionality is easy and common, algebra yields
Ep [f ] ¼Zq
Zp
1L
LX
`=1
~p(x`)~q(x`)
f (x`)
¼LX
`=1
w`f (x`)
~r` = ~p(x` )~q(x` )
w` = ~r `P L
`= 1~r `

A model requiring sampling techniques
• Non-linear non-Gaussian first order Markov model
xt¡ 1 \\xt xt+1
yt¡ 1 yt yt+1
Hidden and of interest
p(x1:i ;y1:i ) =Q N
i=1 p(yi jxi )p(xi jxi ¡ 1)

Filtering distribution hard to obtain
• Often the filtering distribution is of interest
• It may not be possible to compute these integrals analytically, be easy to sample from this directly, nor even to design a good proposal distribution for importance sampling.
p(xi jy1:i ¡ 1) /R
:: :R
p(x1:i ;y1:i )dx1 : : :dxi ¡ 1

A solution: sequential Monte Carlo
• Sample from sequence of distributions that “converge” to the distribution of interest
• This is a very general technique that can be applied to a very large number of models and in a wide variety of settings.
• Today: particle filtering for a first order Markov model

Concrete example: target tracking
• A ballistic projectile has been launched in our direction.
• We have orders to intercept the projectile with a missile and thus need to infer the projectiles current position given noisy measurements.

Problem Schematic
rt
µt
(0,0)
(xt, yt)

Probabilistic approach
• Treat true trajectory as a sequence of latent random variables
• Specify a model and do inference to recover the position of the projectile at time t
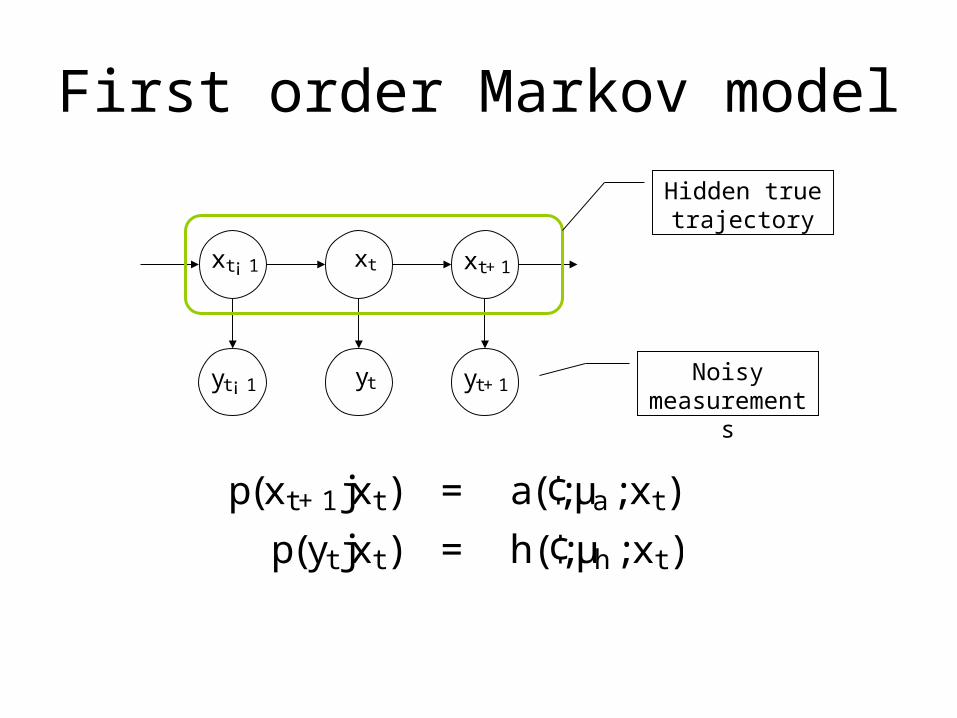
First order Markov model
xt¡ 1 xt xt+1
yt¡ 1 yt yt+1
Hidden true trajectory
Noisy measurements
p(xt+1jxt) = a(¢;µa;xt)
p(ytjxt) = h(¢;µh;xt)

• We want filtering distribution samples
so that we can compute expectations
Posterior expectations
p(xi jy1:i ) / p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Ep[f ] =Z
f (xi )p(xi jy1:i )dxi
Write this down!

Importance sampling
• By identity the posterior predictive distribution can be written as
~p(xi ) / p(yi jxi )p(xi jy1:i ¡ 1) q(xi ) = p(xi jy1:i ¡ 1)
Proposal distribution Distribution from which we want
samples
q(xi ) = p(xi jy1:i ¡ 1) =Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1

Basis of sequential recursion
• If we start with samples from
then we can write the proposal distribution as a finite mixture model
and draw samples accordingly
q(xi ) = p(xi jy1:i ¡ 1) ¼LX
`=1
wi ¡ 1` p(xi jxi ¡ 1
` )
f wim; xi
mgMm=1 » q(¢)
fwi ¡ 1` ;xi ¡ 1
` gL`=1 » p(xi ¡ 1jy1:i ¡ 1)

Samples from the proposal distribution
• We now have samples from the proposal
• And if we recall
f wim; xi
mg» q(xi )
~p(xi ) = p(yi jxi )p(xi jy1:i ¡ 1) q(xi ) = p(xi jy1:i ¡ 1)
Proposal distribution Distribution from which we want
samples

Updating the weights completes importance sampling
• We are left with M weighted samples from the posterior up to observation i
r im = ~p(xi
m )q(xi
m ) = p(yi jxim)wi
m
wim = r i
mP M
m = 1r i
mfwi
m;ximgM
m=1 » p(xi jy1:i )

Intuition
• Particle filter name comes from physical interpretation of samples

Start with samples representing the hidden state
(0,0)
fwi ¡ 1` ;xi ¡ 1
` gL`=1 » p(xi ¡ 1jy1:i ¡ 1)
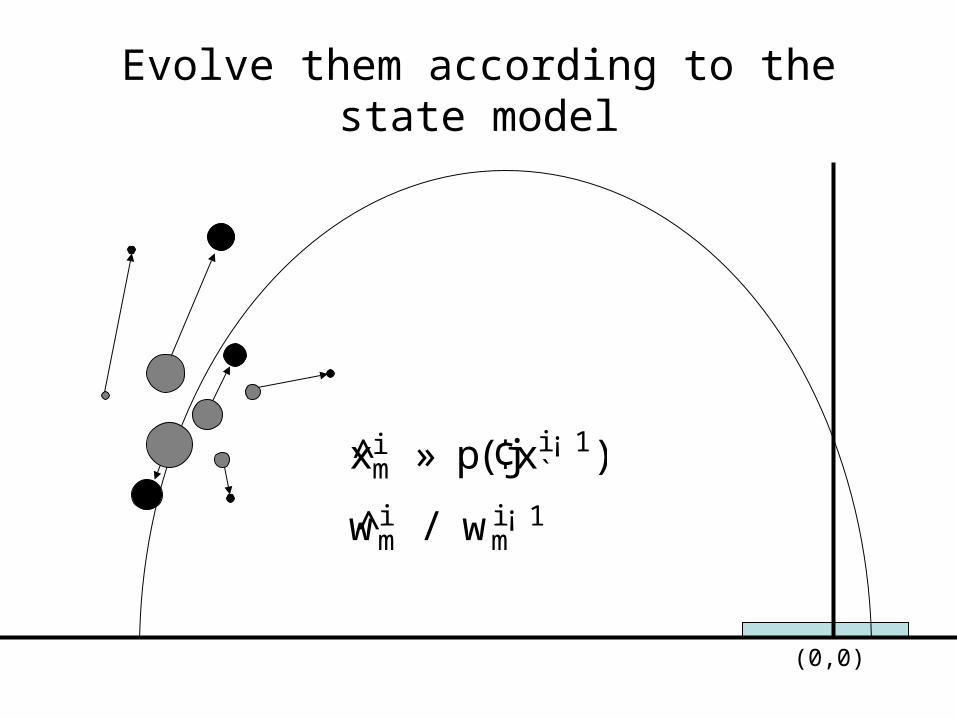
Evolve them according to the state model
(0,0)
wim / wi ¡ 1
m
xim » p(¢jxi ¡ 1
` )

Re-weight them by the likelihood
(0,0)
wim / wi
mp(yi jxim)

Results in samples one step forward
(0,0)
fwi`;x
i`g
L`=1 ¼fwi
m;ximgM
m=1

SIS Particle Filter
• The Sequential Importance Sampler (SIS) particle filter multiplicatively updates weights at every iteration and thus often most weights get very small
• Computationally this makes little sense as eventually low-weighted particles do not contribute to any expectations.
• A measure of particle degeneracy is “effective sample size”
• When this quantity is small, particle degeneracy is severe.
Nef f = 1P L
`= 1(wi
` )2

Solutions
• Sequential Importance Re-sampling (SIR) particle filter avoids many of the problems associated with SIS pf’ing by re-sampling the posterior particle set to increase the effective sample size.
• Choosing the best possible importance density is also important because it minimizes the variance of the weights which maximizes Nef f

Other tricks to improve pf’ing
• Integrate out everything you can
• Replicate each particle some number of times
• In discrete systems, enumerate instead of sample
• Use fancy re-sampling schemes like stratified sampling, etc.

Initial particles
(0,0)
fwi ¡ 1` ;xi ¡ 1
` gL`=1 » p(xi ¡ 1jy1:i ¡ 1)

Particle evolution step
(0,0)
f wim; xi
mgMm=1 » p(xi jy1:i ¡ 1)

Weighting step
(0,0)
fwim;xi
mgMm=1 » p(xi jy1:i )

Resampling step
(0,0)
fwi`;x
i`g
L`=1 » p(xi jy1:i )

Wrap-up: Pros vs. Cons
• Pros:– Sometimes it is easier to build a “good”
particle filter sampler than an MCMC sampler– No need to specify a convergence measure
• Cons:– Really filtering not smoothing
• Issues– Computational trade-off with MCMC

Thank You



Tricks and Variants
• Reduce the dimensionality of the integrand through analytic integration– Rao-Blackwellization
• Reduce the variance of the Monte Carlo estimator through– Maintaining a weighted particle set– Stratified sampling– Over-sampling– Optimal re-sampling

Particle filtering
• Consists of two basic elements:– Monte Carlo integration
– Importance sampling
limL ! 1
LX
`=1
w`f (x`) =Z
f (x)p(x)dx
p(x) ¼LX
`=1
w`±x`

PF’ing: Forming the posterior predictive
The proposal distribution for importance sampling of the posterior up to observation i is this approximate posterior
predictive distribution
p(xi jy1:i ¡ 1) =Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
¼LX
`=1
wi ¡ 1` p(xi jxi ¡ 1
` )
fwi ¡ 1` ;xi ¡ 1
` gL`=1 » p(xi ¡ 1jy1:i ¡ 1)
Posterior up to observation i ¡ 1

Sampling the posterior predictive
• Generating samples from the posterior predictive distribution is the first place where we can introduce variance reduction techniques
• For instance sample from each mixture component several twice such that M, the number of samples drawn, is two times L, the number of densities in the mixture model, and assign weights
f wim; xi
mgMm=1 » p(xi jy1:i ¡ 1); p(xi jy1:i ¡ 1) ¼
LX
`=1
wi ¡ 1` p(xi jxi ¡ 1
` )
wim =
wi ¡ 1`
2

Not the best
• Most efficient Monte Carlo estimator of a function ¡(x)– From survey sampling theory: Neyman
allocation – Number drawn from each mixture density is
proportional to the weight of the mixture density times the std. dev. of the function ¡ over the mixture density
• Take home: smarter sampling possible
[Cochran 1963]

Over-sampling from the posterior predictive distribution
(0,0)
f wim; xi
mgMm=1 » p(xi jy1:i ¡ 1)

• Recall that we want samples from
• and make the following importance sampling identifications
Importance sampling the posterior
p(xi jy1:i ) / p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
~p(xi ) = p(yi jxi )p(xi jy1:i ¡ 1) q(xi ) = p(xi jy1:i ¡ 1)
¼LX
`=1
wi ¡ 1` p(xi jxi ¡ 1
` )
Proposal distribution
Distribution from which we want to sample

Sequential importance sampling
• Weighted posterior samples arise as
• Normalization of the weights takes place as before
• We are left with M weighted samples from the posterior up to observation i
r im = ~p(xi
m )q(xi
m ) = p(yi jxim)wi
m
f wim; xi
mg» q(¢)
wim = r i
`P L
`= 1r i
`
fwim;xi
mgMm=1 » p(xi jy1:i )

An alternative view
f wim; xi
mg »LX
`=1
wi ¡ 1` p(xi jxi ¡ 1
` )
p(xi jy1:i ¡ 1) ¼P M
m=1 wim±xi
m
p(xi jy1:i ) ¼P M
m=1 p(yi jxim)wi
m±x im

Importance sampling from the posterior distribution
(0,0)
fwim;xi
mgMm=1 » p(xi jy1:i )

Sequential importance re-sampling
• Down-sample L particles and weights from the collection of M particles and weights
this can be done via multinomial sampling or in a way that provably minimizes estimator variance
fwi`;x
i`g
L`=1 ¼fwi
m;ximgM
m=1
[Fearnhead 04]

Down-sampling the particle set
(0,0)
fwi`;x
i`g
L`=1 » p(xi jy1:i )

Recap
• Starting with (weighted) samples from the posterior up to observation i-1
• Monte Carlo integration was used to form a mixture model representation of the posterior predictive distribution
• The posterior predictive distribution was used as a proposal distribution for importance sampling of the posterior up to observation i
• M > L samples were drawn and re-weighted according to the likelihood (the importance weight), then the collection of particles was down-sampled to L weighted samples

LSSM Not alone
• Various other models are amenable to sequential inference, Dirichlet process mixture modelling is another example, dynamic Bayes’ nets are another

Rao-Blackwellization
• In models where parameters can be analytically marginalized out, or the particle state space can otherwise be collapsed, the efficiency of the particle filter can be improved by doing so

Stratified Sampling• Sampling from a mixture density using the algorithm on
the right produces a more efficient Monte Carlo estimator
• for n=1:K– choose k according to ¼k
– sample xn from fk
– set wn equal to 1/N
• for n=1:K– choose fn
– sample xn from fn
– set wn equal to ¼n
fwn;xngKn=1 »
X
k
¼kf k(¢)

Intuition: weighted particle set
• What is the difference between these two discrete distributions over the set {a,b,c}?– (a), (a), (b), (b), (c)– (.4, a), (.4, b), (.2, c)
• Weighted particle representations are equally or more efficient for the same number of particles

Optimal particle re-weighting
• Next step: when down-sampling, pass all particles above a threshold c through without modifying their weights where c is the unique solution to
• Resample all particles with weights below c using stratified sampling and give the selected particles weight 1/ c
P Mm=1 minfcwi
m;1g= L
Fearnhead 2004

Result is provably optimal
• In the down-sampling step
• Imagine instead a “sparse” set of weights of which some are zero
• Then this down-sampling algorithm is optimal w.r.t.P M
m=1 Ew[( ~wim ¡ wi
m)2]
fwi`;x
i`g
L`=1 ¼fwi
m;ximgM
m=1
f ~wi`;x
i`g
M`=1 ¼fwi
m;ximgM
m=1
Fearnhead 2004

Problem Details
• Time and position are given in seconds and meters respectively
• Initial launch velocity and position are both unknown• The maximum muzzle velocity of the projectile is
1000m/s• The measurement error in the Cartesian coordinate
system is N(0,10000) and N(0,500) for x and y position respectively
• The measurement error in the polar coordinate system is N(0,.001) for µ and Gamma(1,100) for r
• The kill radius of the projectile is 100m

Data and Support Code
http://www.gatsby.ucl.ac.uk/~fwood/pf_tutorial/

Laws of Motion
• In case you’ve forgotten:
• where v0 is the initial speed and ® is the initial angle
r = (v0cos(®))ti + ((v0sin(®)t ¡ 12gt2)j

Good luck!

Monte Carlo Integration
• Compute integrals for which analytical solutions are unknown
Zf (x)p(x)dx
p(x) ¼LX
`=1
w`±x`

Monte Carlo Integration
• Integral approximated as the weighted sum of function evaluations at L points
Zf (x)p(x)dx ¼
Zf (x)
LX
`=1
w`±x` dx
=LX
`=1
w`f (x`)
Zf (x)p(x)dx
p(x) ¼LX
`=1
w`±x`

Sampling
• To use MC integration one must be able to sample from p(x)
fw`;x`gL`=1 » p(¢)
limL ! 1
LX
`=1
w`±x` ! p(¢)

Theory (Convergence)
• Quality of the approximation independent of the dimensionality of the integrand
• Convergence of integral result to the “truth” is O(1/n1/2) from L.L.N.’s.
• Error is independent of dimensionality of x

Bayesian Modelling
• Formal framework for the expression of modelling assumptions
• Two common definitions: – using Bayes’ rule– marginalizing over models
Prior
EvidenceLikelihood
Posterior
p(µjx) = p(xjµ)p(µ)p(x) = p(xjµ)p(µ)R
p(xjµ)p(µ)dµ
p(µjx) =p(xjµ)p(µ)
p(x)=
p(xjµ)p(µ)Rp(xjµ)p(µ)dµ

Posterior Estimation
• Often the distribution over latent random variables (parameters) is of interest
• Sometimes this is easy (conjugacy)
• Usually it is hard because computing the evidence is intractable

Conjugacy Example
p(µ) =¡ (®+ ¯)¡ (®)¡ (¯)
µ®¡ 1(1¡ µ)¯ ¡ 1
p(xjµ) =µ
Nx
¶µx(1¡ µ)N ¡ x
µ » Beta(®;¯)
xjµ » Binomial(N;µ)
x successes in N trials, µ probability of success

Conjugacy Continued
p(µjx) =p(xjµ)p(µ)Rp(xjµ)p(µ)dµ
=1
Z(x)p(xjµ)p(µ)
=1
Z(x)µ®¡ 1+x(1¡ µ)¯ ¡ 1+N ¡ x
µjx » Beta(®+ x;¯ + N ¡ x)
Z(x) =µ
¡ (®+ ¯ + N )¡ (®+ x)¡ (¯ + N ¡ x)
¶ ¡ 1

Non-Conjugate Models
• Easy to come up with examples
¾2 » N (0;®)
xj¾2 » N (0;¾2)

Posterior Inference
• Posterior averages are frequently important in problem domains– posterior predictive distribution
– evidence (as seen) for model comparison, etc.
p(xi+1jx1:i ) =R
p(xi+1jµ;x1:i )p(µjx1:i )dµ

p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Relating the Posterior to the Posterior Predictive

p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Relating the Posterior to the Posterior Predictive

p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Relating the Posterior to the Posterior Predictive

p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Relating the Posterior to the Posterior Predictive

Importance sampling
Proposal distribution:
easy to sample from
Original distribution:
hard to sample from, easy to
evaluate
Ex [f (x)] =Z
p(x)f (x)dx
=Z
p(x)q(x)
f (x)q(x)dx
¼1L
LX
`=1
p(x`)q(x`)
f (x`)
Importanceweights r` = p(x` )
q(x` )
x` » q(¢)

Importance sampling un-normalized distributions
Un-normalized proposal distribution: still easy to sample from
x` » ~q(¢)
p(x) = ~p(x)Zp
q(x) = ~q(x)Zq
Un-normalized distribution to sample from, still hard to sample from and easy to evaluate
Ex [f (x)] ¼1L
LX
`=1
p(x`)q(x`)
f (x`)
¼Zq
Zp
1L
LX
`=1
~p(x`)~q(x`)
f (x`)New term:
ratio of normalizing constants

Normalizing the importance weights
Ex [f (x)] ¼Zq
Zp
1L
LX
`=1
~p(x`)~q(x`)
f (x`)
¼LX
`=1
w`f (x`)
Zq
Zp¼ LP L
`= 1~r `
Takes a little algebraUn-normalized importance weights
~r` = ~p(x` )~q(x` )
Normalized importance weights
w` = ~r `P L
`= 1~r `

Linear State Space Model (LSSM)
• Discrete time
• First-order Markov chain
xt¡ 1 xt xt+1
yt¡ 1 yt yt+1
xt+1 = axt + ²;² » N (¹ ² ;¾2² )
yt = bxt + ´;´ » N (¹ ´ ;¾2´ )

Inferring the distributions of interest
• Many methods exist to infer these distributions– Markov Chain Monte Carlo (MCMC)– Variational inference– Belief propagation– etc.
• In this setting sequential inference is possible because of characteristics of the model structure and preferable due to the problem requirements

p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Exploiting LSSM model structure…

Particle filtering
p(xi jy1:i ) / p(yi jxi )R
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1

p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Exploiting Markov structure…
xt¡ 1 xt xt+1
yt¡ 1 yt yt+1
Use Bayes’ rule and the conditional independence structure dictated by the first
order Markov hidden variable model

for sequential inference
p(xi jy1:i ) =Z
p(xi ;x1:i ¡ 1jy1:i )dx1:i ¡ 1
/Z
p(yi jxi ;x1:i ¡ 1;y1:i ¡ 1)p(xi ;x1:i ¡ 1;y1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jx1:i ¡ 1;y1:i )p(x1:i ¡ 1jy1:i )dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(x1:i ¡ 1jy1:i ¡ 1)dx1:i ¡ 1
/ p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)

An alternative view
f wim; xi
mg »LX
`=1
wi ¡ 1` p(xi jxi ¡ 1
` )
p(xi jy1:i ¡ 1) ¼P M
m=1 wim±xi
m
p(xi jy1:i ) ¼P M
m=1 p(yi jxim)wi
m±x im

Sequential importance sampling inference
• Start with a discrete representation of the posterior up to observation i-1
• Use Monte Carlo integration to represent the posterior predictive distribution as a finite mixture model
• Use importance sampling with the posterior predictive distribution as the proposal distribution to sample the posterior distribution up to observation i

What?
p(xi jy1:i ) / p(yi jxi )Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
/ p(yi jxi )p(xi jy1:i ¡ 1)
Posterior predictive distribution
State model
Likelihood
Start with a discrete representation of this
distribution

Monte Carlo integration
limL ! 1
LX
`=1
w`f (x`) =Z
f (x)p(x)dxp(x) ¼LX
`=1
w`±x`
General setup
As applied in this stage of the particle filter
p(xi jy1:i ¡ 1) =Z
p(xi jxi ¡ 1)p(xi ¡ 1jy1:i ¡ 1)dxi ¡ 1
¼LX
`=1
wi ¡ 1` p(xi jx
i ¡ 1` )
Finite mixture model
Samples from