serine integrases in genetic circuit design
TRANSCRIPT

Biomolecular Sciences Degree Group
Critical Essay
2015-16
CELLULAR LOGIC AND MEMORY: THE USE OF ɸC31 INTEGRASE AND
RELATED SERINE INTEGRASES IN
GENETIC CIRCUIT DESIGN
Supervised by Dr. Sean Colloms
Dylan MacPhail
Matriculation number: 2022896

2022896 5461 words
Page 1 of 27
ABSTRACT
The serine integrases are a subfamily of phage recombinases which are capable of integrating,
inverting, or excising a segment of DNA between their recognition sites with a high degree of
efficiency. Integration occurs between the phage and bacterial attachment sites (attP/B), and excision
occurs at the resultant attL/R sites to resolve the original state, requiring a recombination
directionality factor (RDF). Inversion of a segment of DNA is also possible by flanking with inverted att
sites. The directionality of inversion can be tightly controlled by expression of an RDF, and thus serine
integrases allow ‘flipping’ of a segment of DNA between two states. Due to the binary nature of
computational logic this control of directionality makes these proteins particularly attractive as a
method of implementing logic and memory into genetic circuit design. This review details aspects of
the origin, structure, and function of the widely utilised serine integrase from bacteriophage ϕC31
and discusses its application in synthetic genetic circuitry.
ABBREVIATIONS
CTD – C terminal domain
LSR – Large Serine Recombinase
NTD – N terminal domain
RAD – Recombinase addressable data
RDF – Recombination Directionality Factor
INTRODUCTION
The field of biology is vast and diverse, and billions of years of trial and error through evolution
have yielded multifaceted designs integrating a near infinite assortment of complex
functionalities. It is therefore not surprising that humans often look to biodiversity to find
inspiration when engineering new materials. One area where this has traditionally not been the
case however is circuitry and computing; an industry which has grown exponentially since its
conception. Despite the vast complexity now achievable by electronics, biology still has much
inspiration to offer to this field in terms of robustness and redundancy in complex networking
(George et al., 2003).

2022896 5461 words
Page 2 of 27
The fact that all biology, on the cellular level, is a product of complex interactions with
and information storage in DNA is too often overlooked. At this level all events can be viewed
as the result of the labyrinthine circuitry of promoters, repressors, activators, and genes which
operate in harmony to produce all components of an entire organism from the same basic DNA
programming. This is achieved through developmental and regulatory switches which are not
dissimilar in function to those found in modern electronics (reviewed by Bonnet and Endy,
2013).
In computing information is stored and processed using binary algorithms in which the
basic unit is one bit. One bit of information represents a switch for which there are two possible
states: 0, or 1. Two bits of information therefore represents the number of switches needed to
record one of four possible combinations (00, 01, 10, or 11), while three bits of information can
record double this amount of patterns (000, 001, 010, 011, 100, 101, 110, or 111). The number
of possible states doubles with each bit of ‘memory’ added to the system (n bits = 2n states) such
that 8 bits represents the capacity to store one of 256 possible patterns of 0 and 1; this is known
as one byte, which can instruct the display of one of 256 characters, numbers, or colours; or
performance of one of 256 possible actions (Horowitz and Hill, 2015). DNA, however, is not a
binary system because each position can be occupied by one of four possible bases, thus
allowing each base to represent one possible combination of a 2-bit system. If the information
storage capacity of DNA were to be fully exploited the region of DNA required to hold the
average bacterial gene (1,100bp) (Parakhia, 2010) could store 2,200 bits of information, or 275
bytes.
The capacity for DNA to securely store information in a stable state is the foundation of
a new field in information technology. Goldman and co-workers (2013) have demonstrated the
in vitro storage and recovery of 739 kilobytes (739x103 bytes) of information in DNA. DNA
2022896 5461 words
Page 3 of 27
cryptography seeks to fully utilise DNA as a stable, low cost storage and encryption tool for
sensitive information which does not require energy input to maintain (Jacob and Murugan,
2013). This information is written into the DNA by chemical synthesis and read by sequencing
however, and as such is not suitable for use in the autonomous regulation of gene networks
within cells through in vivo read and write functions.
With the fields of synthetic biology and genetic engineering expanding rapidly
researchers are searching for methods of increasing control over gene networks such as
metabolism, and as such have begun looking at electronics and computing for the answers they
need. Integration of memory into a circuit (a non-transient switch of state in response to a
certain input) allows programmability as both transient and ongoing inputs can inform the
output of a circuit, while layering of circuits such that the output of one circuit is an input for the
next allows complexity to be achieved (Moon et al., 2012). Circuits which can modulate their
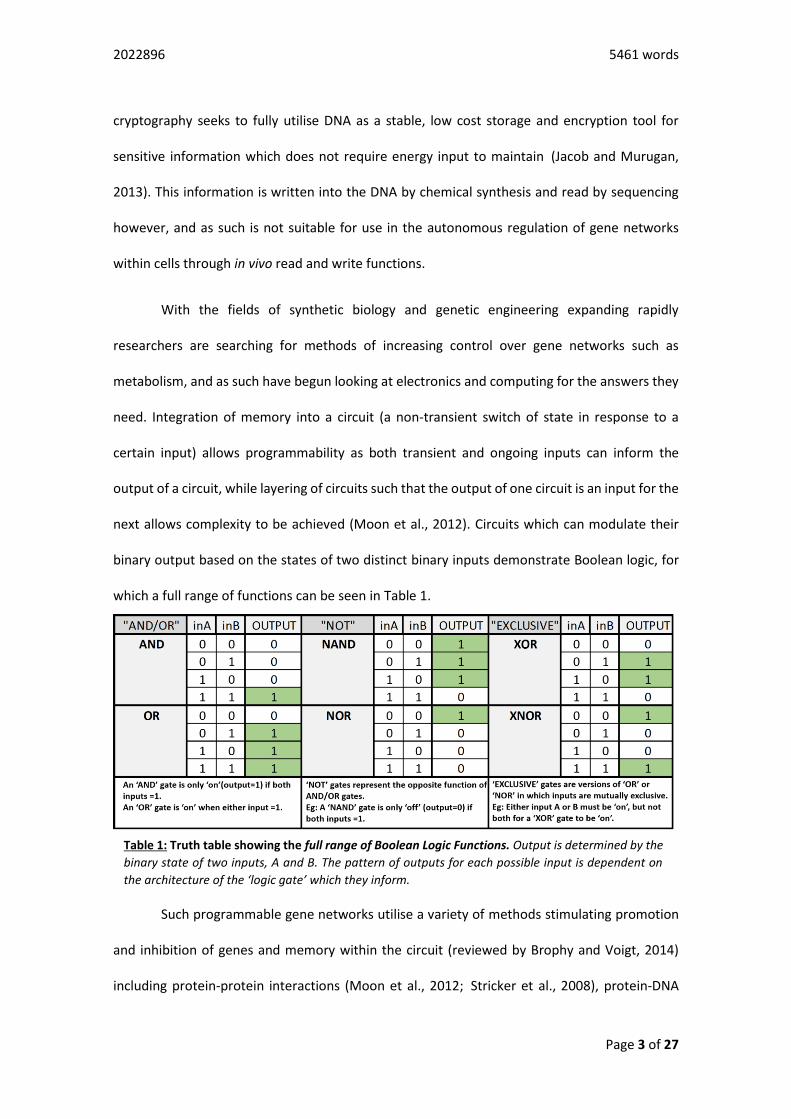
binary output based on the states of two distinct binary inputs demonstrate Boolean logic, for
which a full range of functions can be seen in Table 1.
Such programmable gene networks utilise a variety of methods stimulating promotion
and inhibition of genes and memory within the circuit (reviewed by Brophy and Voigt, 2014)
including protein-protein interactions (Moon et al., 2012; Stricker et al., 2008), protein-DNA
Table 1: Truth table showing the full range of Boolean Logic Functions. Output is determined by the
binary state of two inputs, A and B. The pattern of outputs for each possible input is dependent on
the architecture of the ‘logic gate’ which they inform.

2022896 5461 words
Page 4 of 27
interactions (Lohmueller et al., 2012), RNA – based methods (Liang et al., 2011), and even use
of the recently discovered CRISPR-Cas system (Bikard et al., 2013; Mimee et al., 2015). These
circuits often encounter problems during development not only due to their design, but also
their context within living cells where interaction with other proteins and their high demand for
cellular resources in order to function can impair both the health of the host organism, and the
stability and predictability of the circuit (reviewed by Brophy and Voigt, 2014; Cardinale and
Arkin, 2012). This has led to a drive for the standardisation of components for synthetic biology
applications akin to a ‘parts list’ for electronic circuitry, as well as development of the
computational tools necessary to design and build predictable genetic programming (Rodrigo
and Jaramillo, 2013).
Recombinases in particular have become particularly useful as tools for genome
engineering and synthetic biology in recent years due to their ability to mediate the conservative
inversion, integration, or excision (resolution) of large segments of DNA, allowing efficient
cloning and DNA modification in vivo (reviewed by Fogg et al., 2014). Examples of recombinases
include invertases, resolvases, and integrases; classifications related to their native biological
function. Serine Integrases, a subfamily of the Large Serine Recombinases (LSRs), could be
enormously valuable in genetic circuit design. These are particularly useful due to their
predictability within a vast range of cell types, as well as the low-maintenance cost in terms of
cellular resources, small circuit size, and heritability associated with building circuitry directly
into DNA (reviewed by Fogg et al., 2014). By manipulating their attachment (att) sites phage
integrases can be made to controllably and reversibly invert DNA such that the coding strand is
non coding, or change the directionality of a gene promoter. The binary nature of this
manipulation makes them particularly amenable to the implementation of logic, memory, and
programming in living cells. This review will discuss both structural and functional aspects of the

2022896 5461 words
Page 5 of 27
ϕC31 Serine Integrase and its relatives as well as their current applications and future potential
in integrating logic and memory into synthetic gene networks.
INTEGRASES IN CONTEXT
Temperate bacteriophages encode an archetypal genetic switch which allows them to cycle
between lytic growth and dormant lysogeny within prokaryotic cells in response to changing
environmental cues (reviewed by Fogg et al., 2014; Oppenheim et al., 2005). During lysogeny
lytic genes are suppressed, the phage genome is not transcribed and is replicated within a
specific site of the host genome, and lysogens are immune to superinfection (Oppenheim et al.,
2005). In 1962 Campbell was the first to suggest that the λ prophage is integrated into the host
genome at a specific site by ‘recombination’ during the lysogenic switch (Campbell, 1962). λ
integrase is as such the best understood of the phage integrases, a subset of recombinases
characterised by their ability to mediate both the host integration and excision of prophage DNA
from the host genome under separate conditions (Esposito and Scocca, 1997).
λ integrase is a tyrosine recombinase, one of two large families of recombinase (the
other being the serine recombinases), which are named after the conserved residue within their
active site used to form a covalent phospho-linkage with the DNA backbone during
recombination (reviewed by Fogg et al., 2014). Integrases insert phage DNA into host genomes
by binding the phage DNA attachment site (attP) and the attachment site of the bacterial host
DNA (attB), mediating a recombination reaction in which the end product is integrated phage
DNA flanked by the left and right attachment sites (attL & attR) (Campbell, 1992). These each
consist of one half of attP and one half of attB with a small overlap of complimentary nucleotides
in the middle. This process is unidirectional, and so in order to excise the phage DNA and resolve
the prophage (attL and attR recombination) an excisonase or recombination directionality factor
(RDF) is required (Lewis and Hatfull, 2001). Bacteriophage λ encodes the excisonase Xis, which

2022896 5461 words
Page 6 of 27
it uses to mediate phage resolution, however like all tyrosine integrases a range of host cofactors
are also needed for both integration and excision of the λ prophage (Lewis and Hatfull, 2001).
Naturally att sites are direct repeats when flanking a sequence, however inversion of one att
site such that they are palindromic allows a section of DNA to be ‘flipped’ using a recombinase
(see Figure 1).
The phage encoded serine integrases belong to the LSR family which the retain catalytic
recombinase N terminal domain (NTD), but all exhibit a large, structurally diverse C terminal
extension of around 300-500 amino acids (aa) compared to a typical C terminal domain (CTD) of
40aa in other serine recombinases (Smith and Thorpe, 2002, Smith et al., 2010). While tyrosine
integrases require host co-factors for integration or resolution to occur, serine integrases do
not, and need only their cognate RDF for excision (Smith et al., 2010). In addition to this the
serine integrases also require less genomic space for their att sites, which are both <50bp and
consist of a core TT crossover site flanked by two quasi-symmetrical inverted repeats (Thorpe et
al., 2000). This is compared to >200bp attP, <30bp attB in tyrosine integrases (see Figure 2).
Serine integrases also have no topological restrictions on their att sites, while λ integrase
requires attP to be supercoiled (reviewed by Fogg et al., 2014; Smith et al., 2010).
Properties such as these make Serine integrases like the integrase (Int) from the
Streptomyces phage ϕC31 attractive targets for applications in synthetic biology and genome
Figure 1: att site positioning effects function. Integration causes the attL and attR sites to be arranged
in a directly repeating conformation, allowing excision when Int is expressed with the RDF. If att sites
are arranged to be inverted repeats inversion occurs when Int or Int + RDF are expressed.

2022896 5461 words
Page 7 of 27
engineering due to the smaller sequence requirement to encode all factors needed for in vivo
activity. ɸC31 Int is among the most studied of the serine integrases; first described in 1991
(Kuhstoss and Rao, 1991), it was extensively utilised to mediate recombination within
Streptomyces strains, and also found use as a reliable unidirectional recombinase within other
prokaryotic and eukaryotic cells (reviewed by Smith et al, 2010). While the first RDF for a serine
integrase was discovered for Bxb1 in 2006 (Gosh et al., 2006), the RDF for ϕC31 Int, gp3,
remained elusive until 2011 (Khaleel et al., 2011); a discovery which finally allows full utilisation
of ϕC31 Int as a reversible integrase in synthetic biology applications.
STRUCTURE AND MECHANISM OF THE ΦC31 INTEGRASE
ɸ C31 Int is a 613 amino acid protein which mediates the unidirectional recombination of attP
and attB sites with high specificity (Kuhstoss and Rao, 1991). ɸC31 Int is a dimer in solution, and
binds each att site as such, while studies in the related serine integrase TP901-1 suggest that
both sites are then brought together to form a synaptic tetramer (Yuan et al., 2008). Unlike the
synapsis mechanism of the tyrosine integrases, which relies upon the formation of a Holliday
Junction – like intermediate (reviewed by Fogg et al., 2011), ϕC31 Int and the Serine integrases
cause a staggered double stranded break in the crossover region of each site which leaves a two
Figure 2: att site structure comparison between tyrosine and serine integrases. While Tyrosine
integrases recognise a smaller attB site, their attP site is many times larger than that of the serine
integrases, and contains binding regions for integrase, RDF, and host cofactors. The overlap region of
the tyrosine integrases is also larger.

2022896 5461 words
Page 8 of 27
base pair overhang of Thymine or Adenine bases at each half site (reviewed by Fogg et al., 2011;
Smith and Thorpe, 2002; Smith et al., 2010). Following synapsis, it is thought that a right handed
‘gated rotation’ mechanism rotates each half site 180° relative to the other within the synaptic
tetramer and the overhanging bases are re-ligated and released, forming the attL and attR sites
(Olorunniji et al., 2012). Figure 3 shows the methods of synapsis and strand transfer used by
tyrosine and serine integrases.
Figure 3: Synapsis methods of phage integrases.
(A) Tyrosine integrases bind attP and attB sites forming a synaptic tetramer, and make a single
stranded ‘nick’ in each site (at black arrowheads) by attack with their catalytic residue. The
free 5’OH then attacks the 3’ phospho-tyrosine of the opposing att site nick, knocking off the
integrase monomer bound to it and forming a Holliday junction-like intermediate. This is then
repeated by the remaining integrase subunits (at white arrowheads) to fully integrate the
phage.
(B) Serine integrases also form a synaptic tetramer, however they attack all strands
simultaneously (black arrowheads), causing a double stranded break in each genome with a
two base pair overhang. Bound tightly to the integrase monomers by their 5’ phospho-serine
linkage, strands are rotated as each integrase dimer rotates 180° with respect to one another.
The free 3’OH of each strand then attacks the phosphoserine of the neighbouring half-site,
completing integration.

2022896 5461 words
Page 9 of 27
Mutation of the key active site Serine in the NTD, S12A, abolishes the ability of ϕC31 Int
to induce strand transfer, however synapsis still occurs (Rowley and Smith, 2008), suggesting
regulation is not coupled to catalysis. Sequence alignment has shown the NTD of ϕC31 Int to be
homologous to those of other recombinases (Rowley and Smith, 2008), however only
unpublished data exists for the crystal structure of ϕC31 Int NTD (McMahon et al., 2013). Figure
4 shows the crystal structure of the activated transposon serine recombinase γδ resolvase which
clearly indicates the interface at which gated rotation might occur, and the crystal structure of
Figure 4: Evidence supporting gated rotation of ϕC31 tetramer
(A) Amino acid sequence alignment of ϕC31 Int against γδ resolvase and TP901-1 Int. Conserved
residues are highlighted, showing homology between proteins. Alignment was generated
using CLUSTAL Ω sequence alignment tool.
(B) Adapted from Yuan et al. (2008). Tetramer of activated γδ resolvase NTD bound to DNA.
Interface for rotation can be clearly seen and is indicated by arrowheads.
(C) Adapted from Yuan et al. (2008). Tetramer of TP901-1 Int NTD (unbound) showing structural
similarity to γδ resolvase tetramer. Arrowheads indicate possible rotation interface.
(D) Monomer of TP901-1 Int NTD analogous to subunit II in (C). Structure is coloured in a
spectrum with blue representing the N terminus, and red representing the C terminus.
Monomer was isolated from crystal structure of a tetramer (Yuan et al., 2008). PDB ID: 3BVP.
Image was generated using The PyMOL Molecular Graphics System, Version 1.7.2.2
Schrödinger, LLC.
(E) Monomer of ϕC31 Int NTD showing similarity to TP901-1 Int. Structure is coloured in a
spectrum with blue representing the N terminus, and red representing the C terminus. NTD
was isolated from unpublished crystal structure of N terminal and recombinase domains
(McMahon et al., 2013). PDB ID: 4BQQ. The largest difference between (D) and (E) is the
orientation of the red helix, which may be due to differences in the structures from which the
segment of protein shown was isolated. Image was generated using The PyMOL Molecular
Graphics System, Version 1.7.2.2 Schrödinger, LLC.

2022896 5461 words
Page 10 of 27
a tetramer of the serine integrase TP901-1 Int which is consistent with this being the mechanism
used by serine integrases (Yuan et al., 2008). While it has been suggested that multiple rounds
of rotation are possible within other Serine integrases (Bai et al., 2011) this was demonstrated
to be unlikely during the canonical action of ϕC31 Int as long as the two core att site base pairs
match (Olorunniji et al., 2012).
The default function of ϕC31 Int is therefore recombination of the attP and attB sites,
and band-shift assays by Thorpe, Wilson, and Smith in 2000 showed that attL and attR
recombination (resolution) could not be mediated by ϕC31 Int alone. The mechanism by which
this directionality is controlled is poorly understood, and while it is now known that the RDF gp3
is needed for attL/attR recombination, the CTDs of serine integrases are also known to play a
large role in this regulation (Rowley et al., 2008; McEwan et al., 2009; reviewed by Smith et al.,
2010; Fogg et al., 2011; Rutherford and Van Duyne, 2014). Indeed, it has been shown that a
single amino acid substitution in the CTD of ϕC31 Int, E449K, produces a hyperactive Int which
can not only catalyse attP/attB recombination, but also attL/attR, attL/attL, and attR/attR, and
could still mediate formation of these synapses in the background of an S12A mutation (Rowley
et al., 2008). Several of such hyperactive mutants, including Int E449K, were identified in a coiled
coil domain on the CTD, a motif which commonly mediates protein-protein interactions.
Furthermore, experiments with the purified histidine tagged CTD show that while the CTDs
alone are monomers in solution they interact co-operatively to bind att sites, and that L460P
and Y475H mutations abolished inter-CTD interaction, DNA binding, and synapsis (McEwan,
Rowley and Smith, 2009). The E449K mutant in the isolated CTD could bind DNA, but could not
catalyse synapse formation, suggesting that formation of a CTD synapse is not essential for ϕC31
Int binding, but is intimately involved in the control of directionality.

2022896 5461 words
Page 11 of 27
Although the full role of the RDF in this directionality remains poorly investigated, it is
likely that gp3 plays a structural role in the interaction, conferring a conformational change to
the CTD which allows resolution of the recombination sites. It has been shown in the serine
integrase Bxb1 that RDF binds Int attached to the attP/attB sites tightly and inhibits
recombination, while promoting excision at attL/attR sites (Ghosh, Wasil and Hatfull, 2006).
Without crystal structures for the full ϕC31 Int the mechanism of its RDF will likely
remain difficult to elucidate. Another area which remains cryptic is the mechanism of action of
the DNA binding domain(s) within this protein. Site-directed mutagenesis of conserved residues
within the CTD has indicated a cysteine rich motif and a valine rich motif to be important in DNA
binding (Liu et al., 2010), however the mechanism of this interaction has not been defined. The
cysteine rich motif in the CTD is a putative zinc finger domain (McEwan et al., 2011). Rutherford
and Van Duyne (2014) hypothesise that the specific orientation of the Int on each half site
Figure 5: Proposed roll of coiled coil domains in directionality of serine integrases. Adapted from
Rutherford and Van Duyne (2014). Binding of Int dimers to att sites positions coiled coil domains on
either side of the DNA. These domains then form inter-dimer interactions, and following rotation and
ligation all coiled coil domains are on the same side of the recombined att sites. When a dimer is bound
to a recombined att site in the absence of an RDF following tetramer dissociation the coiled coil
domains form intra-dimer interactions which prevent reformation of the tetramer without the RDF.

2022896 5461 words
Page 12 of 27
conferred by the zinc finger domains allows the CTD coiled coil motifs to interact in an inhibitory
manner upon synapsis such that resolution is not possible without the RDF (see Figure 5).
The mode of DNA interaction is of particular interest in synthetic biology applications as
knowledge of this could allow production of integrases which could specifically bind to
endogenous sites, and also improvement of the existing specificity. It has been shown that ϕC31
Int can be targeted to non-native pseudo-sites which resemble att sequences (Combes et al.,
2002; Malla, 2005; Chalberg et al., 2006), and directed evolution through DNA shuffling has
been reported to have yielded versions of the ϕC31 Int protein which have a high binding
specificity and frequency to a pseudo attP site on human chromosome 8, as well as versions
which integrate more efficiently to pre-inserted sites within the human genome (Sclimenti,
2001; Keravala et al., 2008). High specificity targeting of recombinases has also been
demonstrated using chimeric Zinc finger domains (Akopian and Stark, 2005), however this has
not been demonstrated in ϕC31 Int, and would likely affect the regulation of the integrase.
While integrases can be targeted to ‘landing’ sites introduced into eukaryotic genomes
(reviewed by Fogg et al., 2011), concerns have been raised over the efficiency of ϕC31 Int action
within eukaryotic cells despite its widespread usage for this purpose. Inversion of the DNA
between palindromic att sites introduced using this method was used to re-arrange segments
of the human Y chromosome using ϕC31 Int (Malla, 2005), however it was found that
recombination only occurred in 56% of cells, and in some cases the action of Int had left deleted
regions of DNA, or small insertions attributed to intervention of host double stranded break
repair mechanisms such as non-homologous end joining. This would suggest that the synaptic
complex is around for a much longer time in eukaryotes, and is consistent with findings that
although ϕC31 Int can perform integration with 100% efficiency at pseudo attB sites in E. Coli
and other prokaryotes, integration is only 50% efficient in human cells (Chalberg et al., 2006),

2022896 5461 words
Page 13 of 27
and efficiency in eukaryotic cells varies between organisms. It is possible that bacteriophage
integrases are not well suited to the nuclear environment of eukaryotic cells. In addition to the
lesions observed due to host repair, the efficiency of ϕC31 Int within human cells could be mildly
impaired by interaction with endogenous cell death associated protein DAXX (Chen et al., 2006).
Interestingly, this interaction occurs within the same region of the ϕC31 Int CTD as the putative
coiled coil domain. Despite this hurdle ϕC31 Int continues to be used in eukaryotic cells due to
the ability to predict insertion sites, and reliably preform integration more efficiently than
tyrosine recombinases and other methods of genomic insertion such as homologous
recombination, resulting in long lasting expression of gene products (reviewed by Fogg et al.,
2011).
The reliability of ϕC31 Int in prokaryotic cells and utility in eukaryotic cells, as well as the
reversibility conferred by use of gp3, allows it to be useful in many emerging biotechnologies.
One such advancement is a mechanism for fast and accurate plasmid assembly pioneered by
Colloms and colleagues (Colloms et al., 2013). The SIRA (Serine Integrase Recombination
Assembly) method for plasmid assembly relies on their findings that the two base pairs of the
core att site crossover region do not require conservation so long as both are the same. This
means that one ϕC31 Int enzyme can assemble multiple regions of DNA in an order pre-
determined by careful arrangement of att sites with different crossover regions flanking the
DNA. Through this method a cassette of up to six gene segments can be assembled in one
reaction using different combinations of core nucleotides, abolishing the traditionally arduous
process of using restriction enzymes and ligases in separate reactions for each inserted section
of DNA. In addition to this, any number of the segments can be removed, or replaced entirely
by a previously assembled cassette, or any expanse of DNA flanked by the appropriate
recombination sites. Furthermore, addition of further serine integrases will allow more
fragments to be assembled simultaneously. This technology vastly expands the scope of genetic

2022896 5461 words
Page 14 of 27
circuit design as any number of functional units can be easily integrated or changed in few steps.
Rates of transcription can also be predictably controlled by varying the distance between a gene
and its promoter, or the positioning of an inhibitory genetic signal within the assembled array.
SIRA assembly demonstrates the extensive utility of ϕC31 Int in synthetic biology and adds to a
growing list of advantages for Int use over many of the traditional methods used for genome
engineering
ENGINEERING LOGIC AND MEMORY IN GENETIC CIRCUITRY
In terms of genetic circuit or metabolic design assembly of components by means of the
SIRA method allows greater predictability of gene expression. This could aid the mathematical
design of genetic circuits and metabolic pathways by computational methods, as the functions
of components which utilise binary and Boolean logic can be predicted efficiently (reviewed by
Brophy and Voight, 2014). Additionally, the use of differing base pairs in the crossover region of
the recombination sites could allow control of multiple outputs simultaneously by one input
which drives ϕC31 Int expression with or without its RDF. Although genetic circuitry assembled
in such a fashion could be highly predictable it is however unlikely that such ‘cellular machines’
will ever achieve widespread use as supercomputers due to the existing utility of such electronic
constructs, although it is worth noting that biochemical networks are capable of Turing Machine-
like functions and can compute large and complex calculations in as little time as simple ones
(Hjelmfelt, Weinberger and Ross, 1991).
Although the aforementioned SIRA assembly method technique efficiently utilises
serine integrases for circuit construction, the full potential of these proteins in this application
can be realised by using them as the functional units of the circuit. Recombinase based
approaches to biocomputation and gene control mostly utilise the ability of these proteins to
flip a section of DNA between palindromic attP and attB sites, or attL and attR sites. This ability

2022896 5461 words
Page 15 of 27
therefore changes the sequence of DNA in a non-energy dependant, and importantly heritable
and highly efficient way. This allows the recording of, and response to different stimuli, as well
as binary and Boolean logic functions, to be encoded on a vastly reduced piece of DNA real estate
than use of genetics and biochemical pathways alone permits (reviewed by Brophy and Voight,
2014; Fogg et al, 2011).
One of the most important components which must be implemented into complex
circuitry is memory. Memory allows a sustained or heritable response to transient stimuli within
a circuit, and can permit a response which is informed by multiple sequential inputs (reviewed
by Brophy and Voight, 2014; Horowitz and Hill, 2015). Due to their ability to invert a segment of
DNA between two states, memory is an inherent aspect of the recombinases, and has been
achieved within bacterial cells (Ham et al., 2008; Yang et al., 2014). The ability of serine
integrases such as those from ϕC31 and Bxb1 to controllably invert DNA without the need for
host co-factors or large att sites, however, gives them an edge in this application (Bonnet et al.,
2012; Bonnet et al., 2013; Siuti et al., 2013).
While a single recombinase can be used to achieve digital memory with a 1-bit capacity,
(Bonnet et al., 2013; Siuti et al., 2013), layering of the sites for different recombinases allows
complex memory of order, or number, of inputs in complex ‘state machines’ which fit into a
stretch of DNA smaller than the average gene (Ham et al., 2008; Bonnet et al., 2012; Yang et al.,
2014). Recombination addressable data (RAD) modules were designed by Bonnet and co-
workers (Bonnet et al., 2012) which implemented the serine integrase from Bxb1 as a unit of
reversible memory within cells. Ham and colleagues suggest that 10 recombinases with
overlapping RAD modules could form 1010 possible states of DNA thus recording 1010 different
patterns of input from 10 signals (Ham et al., 2008). Bonnet and co-workers estimated that using
RAD modules construction of an 8bit memory system with 1 byte of memory capable of counting

2022896 5461 words
Page 16 of 27
256 input pulses would require 16 recombinases (Bonnet et al., 2012). Yang and colleagues,
however, have demonstrated recording of 1.375 bytes of information using 11 different RAD
switches designed using serine integrases discovered through data mining for homology to ϕC31
Int (Yang et al., 2014). This is a gargantuan achievement in context as previous studies had only
demonstrated a maximum memory capacity of 2 bits (Bonnet et al., 2013; Siuti et al, 2013).
Although it can be argued that it does not utilise the full 2 bit / base pair capacity of DNA, the
utility of this method of memory is much greater as it can be used in rewritable storage which is
able to record data in living cells, as opposed to the single write functionality of DNA
cryptography (Ham et al., 2008; Goldman et al., 2013). Durational recording has also been shown
to be possible through genetic manipulation, however recording of this information occurred at
the population level in a form of analogue memory based on the increasing number of
responsive cells (Farzadfard and Lu, 2014). This process would be difficult to replicate using
recombinases due to their high efficiency and digital nature, and moreover a population
response would not be amenable to circuit design.
Readouts from large memory modules such as those described above requires
sequencing, digestion, or PCR; however smaller memory modules can also feasibly be
interpreted using fluorescence. The full potential of such memory is only realised however when
it is implemented into genetic circuitry through incorporation of active genetic elements,
permitting logic within the circuit as opposed to single input response (reviewed by Brophy and
Voight, 2014). The ability for logic in recombinases through use of a 2-bit system was exemplified
in 2008 by the ability of bacteria to survive on antibiotic when the associated resistance gene
was not expressed until the constitutively expressed Hin recombinase it encoded (which does
not require an RDF for reversion) was able to solve the Burnt Pancake Problem (Haynes et al.,
2008). The Burnt Pancake Problem is a logic problem whereby a stack of ‘Pancakes’ (DNA flanked
by hix sites in this case in this case) must be sorted into the correct order and each manipulation

2022896 5461 words
Page 17 of 27
reverses the order of one or more ‘pancakes’ within the stack (see Figure 6). While the involved
recombinases were constitutively expressed in this experiment, and did not require an RDF, it
demonstrates the possibility that multiple recombinases with expression under the control of
different inputs could mediate output only in a specific combination. This demonstration is also
potentially useful in durational memory as the duration of a specific input driving Int expression
could be estimated based on the minimum number of random inversions in a stretch of DNA
with specific recognition sites needed to reach the observed configuration form the starting
sequence (Haynes et al., 2008). Since this demonstration a full range of all Boolean logic
functions has been achieved in 2 bit systems using the TP901-1 and Bxb1 integrases, and the
Figure 6: Solving the burnt pancake problem with integrases. In this logic problem a stack of
pancakes is presented which all have one good side facing up (solid colour in figure), and one burnt
side facing down (hashed colour in figure). The stack is the wrong way around, and the aim is to sort
all pancakes in the stack so that they are arranged from smallest (on top) to largest, all with burnt
side facing down. If the red ‘pancake’ represents an antibiotic resistance gene, and the purple
‘pancake’ is a promoter (both flanked by att sites) then the minimum amount of flips required for gene
expression represents the quickest solution (3 flips in this case) to the burnt pancake problem. Using
att sites with different overlap regions (arrowheads) one serine integrase (and its RDF) could solve this
logic problem in cells grown on antibiotic. If three separate integrases were used on their cognate att
sites (arrowheads) each flip could be controlled by a separate input.
2022896 5461 words
Page 18 of 27
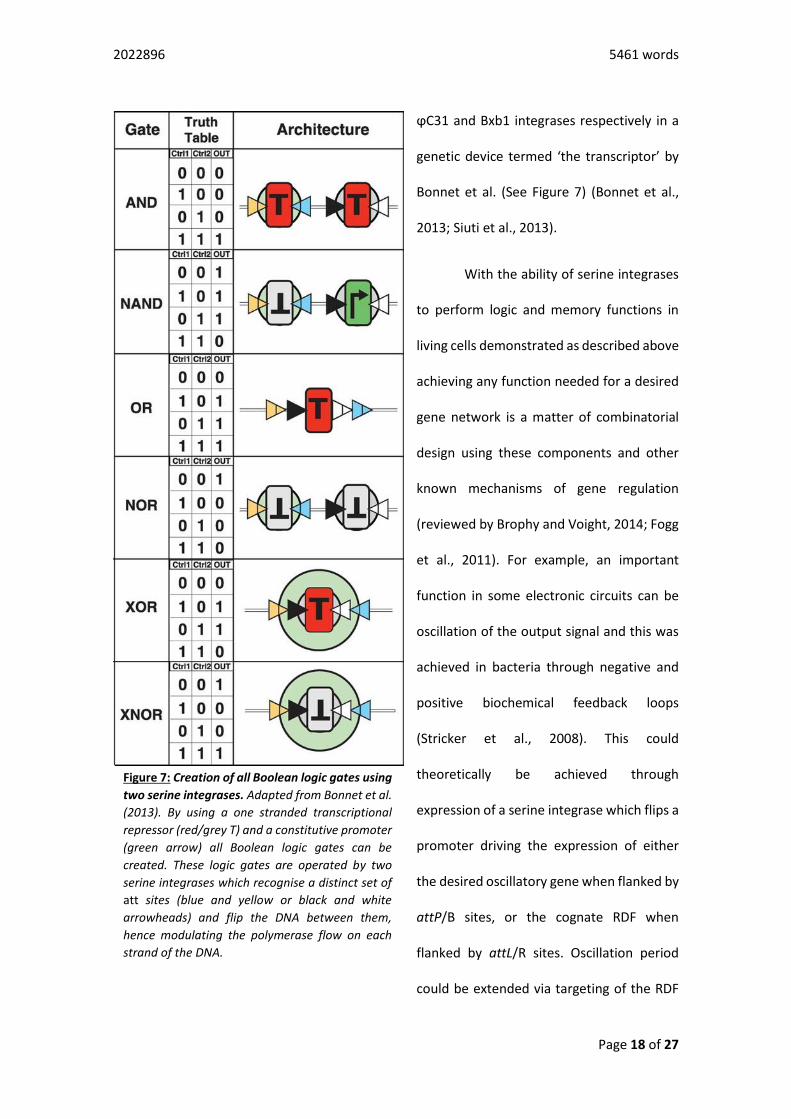
ϕC31 and Bxb1 integrases respectively in a
genetic device termed ‘the transcriptor’ by
Bonnet et al. (See Figure 7) (Bonnet et al.,
2013; Siuti et al., 2013).
With the ability of serine integrases
to perform logic and memory functions in
living cells demonstrated as described above
achieving any function needed for a desired
gene network is a matter of combinatorial
design using these components and other
known mechanisms of gene regulation
(reviewed by Brophy and Voight, 2014; Fogg
et al., 2011). For example, an important
function in some electronic circuits can be
oscillation of the output signal and this was
achieved in bacteria through negative and
positive biochemical feedback loops
(Stricker et al., 2008). This could
theoretically be achieved through
expression of a serine integrase which flips a
promoter driving the expression of either
the desired oscillatory gene when flanked by
attP/B sites, or the cognate RDF when
flanked by attL/R sites. Oscillation period
could be extended via targeting of the RDF
Figure 7: Creation of all Boolean logic gates using
two serine integrases. Adapted from Bonnet et al.
(2013). By using a one stranded transcriptional
repressor (red/grey T) and a constitutive promoter
(green arrow) all Boolean logic gates can be
created. These logic gates are operated by two
serine integrases which recognise a distinct set of
att sites (blue and yellow or black and white
arrowheads) and flip the DNA between them,
hence modulating the polymerase flow on each
strand of the DNA.

2022896 5461 words
Page 19 of 27
mRNA by a complimentary non-coding mRNA, which could be controlled independently (see
Figure 8).
Logic gates operated by serine integrases could be layered in any combination with any
number of downstream effects and feedback loops, integrating any number of other genetically
encoded genomic tools, in order to perform an almost limitless range of specific functions within
cells. These simple genetic components integrate the potentials of computational logic and
memory with synthetic biology, thus allowing programmability for a wide range of highly
predictable functions to an extent which is far beyond the scope of anything achievable in this
field by any other currently known mechanism.
Figure 8: Concept for a synthetic gene oscillator using a serine integrase. Oscillation of a gene of
interest (GOI) is controlled by a promoter within inverted attP/B sites. Expression of the Integrase
(which could be constitutively expressed or under controlled expression) flips the promoter, turning
the GOI expression off. This activates transcription of the RDF, which allows the circuit to be reset.
Oscillatory period, and the state of the circuit, can be modified by controlled expression of a microRNA
which targets the RDF mRNA, or control of integrase expression.

2022896 5461 words
Page 20 of 27
CONCLUSION
This review has discussed aspects of the origin, structure, and function of the serine integrases
with a specific focus on the integrase encoded by bacteriophage ϕC31, establishing them as
powerful tools for synthetic biology and specifically for engineering complex and programmable
behaviours within living cells. The reliability and specificity of these proteins not only allows
efficient site specific integration to occur within cells with higher proficiency than methods
which do not utilise recombinases such as digestion/ligation, but also permits utility beyond
what is capable of traditional recombinases as they do not rely upon host cofactors and
directionality may be controlled. Though larger than their tyrosine relatives, the serine
integrases also allow more efficient use of DNA by requiring recognition sites which can be one
third of the size of those needed by tyrosine recombinases.
ɸC31 integrase mediates recombination in a vast range of organisms, permitting its
prominence in the field of genetic circuit design. It is worth noting however that this integrase
has been reported to be only half as efficient in eukaryotic cells as it is in prokaryotes (Chalberg
et al., 2006), and thus more research is needed in order to improve its eukaryotic stability. Its
modes of recognition and DNA binding are also poorly understood, and thus further study is
needed due to the extensive efficacy which could result from knowledge of how to reliably
target ϕC31 Int to exogenous binding sites. Both of these areas of research would be enormously
aided by complex knowledge of the structure of this protein, however a crystal structure is
elusive.
The ability to predictably programme genetic expression can benefit all fields of
synthetic biology, and will only grow as research continues into this area. Serine Integrases have
been shown to demonstrate all of the components needed for control of a genetic circuit, and

2022896 5461 words
Page 21 of 27
future research which integrates the use of these proteins with existing methods of control (or
focuses on mimicking the results of these other methods) could allow the construction of a
genetic circuit to control any biological application. Now that predictability can be built into such
circuits computationally aided design should make the proposal and implementation of such
devices relatively swift and straightforward.
OUTLOOK
Further research into the ϕC31 Integrase and other serine integrases is likely to revolutionise
the field of genomic engineering. The application of SIRA in rapid pathway assembly has already
demonstrated the utility of a ϕC31 Int in this area, however the continued discovery of more of
such proteins theoretically extends the capacity for memory and logic achievable in synthetic
circuits by 1 bit for every serine integrase incorporated. The construction of such large and
complex circuitry could one day lead to the production of a completely reprogrammable,
entirely integrase-controlled organism, however more realistic applications are likely just
around the corner.
Using serine integrases cells could be made to re-organise chromosomes; delete segments
of their genomes (including all synthetic circuitry); change lineage via expression of master
transcription factors; deliver drugs only in diseased cell states; cycle through production phases
in industry; indicate and record pollution levels; optimise crops to their environment; and so
much more in response to transient or lasting stimuli – be it complex or simple. Serine integrases
could become the standard unit of biological programming such that circuits could be designed
by computers with minimal human input, resulting in the production of a linear DNA segment
to mediate any reaction, and needs only be incorporated into target cells (possibly using
integrases). Predictable genetic manipulation may one day dominate the needs of the industrial,

2022896 5461 words
Page 22 of 27
medicinal, agricultural, and public sectors, and it is likely that ϕC31 Int and other family
members will lead the way into this new era of synthetic biology: predictable genetic circuitry.
REFERENCES
Akopian, A. and Stark, W. (2005). “Site‐Specific DNA Recombinases as Instruments for Genomic Surgery”. Advances in Genetics, pp.1-23.
Bai, H., Sun, M., Ghosh, P., Hatfull, G., Grindley, N. and Marko, J. (2011). “Single-molecule analysis reveals the molecular bearing mechanism of DNA strand exchange by a serine recombinase”. Proceedings of the National Academy of Sciences, 108(18), pp.7419-7424.
Bikard, D., Jiang, W., Samai, P., Hochschild, A., Zhang, F. and Marraffini, L. (2013). “Programmable repression and activation of bacterial gene expression using an engineered CRISPR-Cas system”. Nucleic Acids Research, 41(15), pp.7429-7437.
Bonnet, J. and Endy, D. (2013). “Switches, Switches, Every Where, In Any Drop We Drink.” Molecular Cell, 49(2), pp.232-233.
Bonnet, J., Subsoontorn, P. and Endy, D. (2012). “Rewritable digital data storage in live cells via engineered control of recombination directionality”. Proceedings of the National Academy of Sciences, 109(23), pp.8884-8889.
Bonnet, J., Yin, P., Ortiz, M., Subsoontorn, P. and Endy, D. (2013). “Amplifying Genetic Logic Gates”. Science, 340(6132), pp.599-603.
Brophy, J. and Voigt, C. (2014). “Principles of genetic circuit design”. Nature Methods, 11(5), pp.508-520.
“This review was particularly useful as a starting point to understand the requirements for genetic circuitry and the usefulness of recombinases in this pursuit”
Campbell A. (1962) “Episomes”. Adv. Genet. 11:101–145
Campbell, A. (1992). “Chromosomal insertion sites for phages and plasmids” J. Bacteriol., 174, pp. 7495–7499
Cardinale, S. and Arkin, A. (2012). “Contextualizing context for synthetic biology - identifying causes of failure of synthetic biological systems”. Biotechnology Journal, 7(7), pp.856-866.
Chalberg, T., Portlock, J., Olivares, E., Thyagarajan, B., Kirby, P., Hillman, R., Hoelters, J. and Calos, M. (2006). “Integration Specificity of Phage ϕC31 Integrase in the Human Genome”. Journal of Molecular Biology, 357(1), pp.28-48.
Chen, J., Ji, C., Xu, G., Pang, R., Yao, J., Zhu, H., Xue, J. and Jia, W. (2006). “DAXX interacts with phage ɸC31 integrase and inhibits recombination”. Nucleic Acids Research, 34(21), pp.6298-6304.
Colloms, S., Merrick, C., Olorunniji, F., Stark, W., Smith, M., Osbourn, A., Keasling, J. and Rosser, S. (2013). “Rapid metabolic pathway assembly and modification using serine integrase site-specific recombination”. Nucleic Acids Research, 42(4), pp.e23
“This paper describes the development of the SIRA method for gene assembly; a method which showcases the utility of ϕC31 Int in synthetic biology.”

2022896 5461 words
Page 23 of 27
Combes, P., Till, R., Bee, S. and Smith, M. (2002). “The Streptomyces Genome Contains Multiple Pseudo-attB Sites for the ɸC31-Encoded Site-Specific Recombination System”. Journal of Bacteriology, 184(20), pp.5746-5752.
Esposito, D. and Scocca, J. (1997). “The integrase family of tyrosine recombinases: evolution of a conserved active site domain”. Nucleic Acids Research, 25(18), pp.3605-3614.
Farzadfard, F. and Lu, T. (2014). “Genomically encoded analog memory with precise in vivo DNA writing in living cell populations”. Science, 346(6211), pp.1256272-1256272.
Fogg, P., Colloms, S., Rosser, S., Stark, M. and Smith, M. (2014). “New Applications for Phage Integrases”. Journal of Molecular Biology, 426(15), pp.2703-2716.
“This review was a useful starting point to understand the differences between phage integrases and the utility of the serine integrases in synthetic biology.”
Gaj, T., Mercer, A., Gersbach, C., Gordley, R. and Barbas, C. (2010). “Structure-guided reprogramming of serine recombinase DNA sequence specificity”. Proceedings of the National Academy of Sciences, 108(2), pp.498-503.
George, S., Evans, D. and Marchette, S. (2003). “A biological programming model for self-healing.” Proceedings of the 2003 ACM workshop on Survivable and self-regenerative systems in association with 10th ACM Conference on Computer and Communications Security - SSRS '03.
Ghosh, P., Wasil, L. and Hatfull, G. (2006). “Control of Phage Bxb1 Excision by a Novel Recombination Directionality Factor”. PLoS Biology, 4(6), p.e186.
Goldman, N., Bertone, P., Chen, S., Dessimoz, C., LeProust, E., Sipos, B. and Birney, E. (2013). “Towards practical, high-capacity, low-maintenance information storage in synthesized DNA”. Nature, 494(7435), pp.77-80.
Ham, T., Lee, S., Keasling, J. and Arkin, A. (2008). “Design and Construction of a Double Inversion Recombination Switch for Heritable Sequential Genetic Memory”. PLoS ONE, 3(7), p.e2815.
Haynes, K., Broderick, M., Brown, A., Butner, T., Dickson, J., Harden, W., Heard, L., Jessen, E., Malloy, K., Ogden, B., Rosemond, S., Simpson, S., Zwack, E., Campbell, A., Eckdahl, T., Heyer, L. and Poet, J. (2008). “Engineering bacteria to solve the Burnt Pancake Problem”. J Biol Eng, 2(1), p.8.
Hjelmfelt, A., Weinberger, E. and Ross, J. (1991). “Chemical implementation of neural networks and Turing machines”. Proceedings of the National Academy of Sciences, 88(24), pp.10983-10987.
Horowitz, P. and Hill, W. (2015). “The art of electronics”. New York, NY: CUP.
Jacob, G. and Murugan, A. (2013). “An Encryption Scheme with DNA Technology and JPEG Zigzag Coding for Secure Transmission of Images”. [online] Arxiv.org. Available at: http://arxiv.org/abs/1305.1270v1 [Accessed 13 Feb. 2016].
Keravala, A., Lee, S., Thyagarajan, B., Olivares, E., Gabrovsky, V., Woodard, L. and Calos, M. (2008). “Mutational Derivatives of PhiC31 Integrase with Increased Efficiency and Specificity”. Mol Ther, 17(1), pp.112-120.
Khaleel, T., Younger, E., McEwan, A., Varghese, A. and Smith, M. (2011). “A phage protein that binds φC31 integrase to switch its directionality”. Molecular Microbiology, 80(6), pp.1450-1463.
“This paper represents a key turning point in the research of ϕC31 Int function via the discovery of its RDF gp3. This allows control over the directionality of recombination in genetic circuitry with ϕC31 Int.”
Kuhstoss, S. and Rao, R. (1991). “Analysis of the integration function of the streptomycete bacteriophage φC31”. Journal of Molecular Biology, 222(4), pp.897-908.

2022896 5461 words
Page 24 of 27
Lewis, J., Hatfull, G. (2001). “Control of directionality in integrase-mediated recombination: examination of recombination directionality factors (RDFs) including Xis and Cox proteins”. Nucleic Acids Research, 29(11), pp.2205-2216.
Liang, J., Bloom, R. and Smolke, C. (2011). “Engineering Biological Systems with Synthetic RNA Molecules”. Molecular Cell, 43(6), pp.915-926.
Liu, S., Ma, J., Wang, W., Zhang, M., Xin, Q., Peng, S., Li, R. and Zhu, H. (2010). “Mutational Analysis of Highly Conserved Residues in the Phage PhiC31 Integrase Reveals Key Amino Acids Necessary for the DNA Recombination”. PLoS ONE, 5(1), p.e8863.
Lohmueller, J., Armel, T. and Silver, P. (2012). “A tunable zinc finger-based framework for Boolean logic computation in mammalian cells”. Nucleic Acids Research, 40(11), pp.5180-5187.
Malla, S. (2005). “Rearranging the centromere of the human Y chromosome with ɸC31 integrase”. Nucleic Acids Research, 33(19), pp.6101-6113.
McEwan, A., Raab, A., Kelly, S., Feldmann, J. and Smith, M. (2011). “Zinc is essential for high-affinity DNA binding and recombinase activity of ɸC31 integrase”. Nucleic Acids Research, 39(14), pp.6137-6147.
McEwan, A., Rowley, P. and Smith, M. (2009). “DNA binding and synapsis by the large C-terminal domain of ɸC31 integrase”. Nucleic Acids Research, 37(14), pp.4764-4773.
McMahon, S., McEwan, A., Smith, M. and Naismith, J. (2013). “Protein crystal structure of the N-terminal and recombinase domains of the Streptomyces temperate phage serine recombinase, fC31 integrase”. Unpublished.
Mimee, M., Tucker, A., Voigt, C. and Lu, T. (2015). “Programming a Human Commensal Bacterium, Bacteroides thetaiotaomicron, to Sense and Respond to Stimuli in the Murine Gut Microbiota”. Cell Systems, 1(1), pp.62-71.
Moon, T., Lou, C., Tamsir, A., Stanton, B. and Voigt, C. (2012). “Genetic programs constructed from layered logic gates in single cells”. Nature, 491(7423), pp.249-253.
Olorunniji, F., Buck, D., Colloms, S., McEwan, A., Smith, M., Stark, W. and Rosser, S. (2012). “Gated rotation mechanism of site-specific recombination by ɸC31 integrase”. Proceedings of the National Academy of Sciences, 109(48), pp.19661-19666.
Oppenheim, A., Kobiler, O., Stavans, J., Court, D. and Adhya, S. (2005). “Switches in Bacteriophage Lambda Development”. Annu. Rev. Genet., 39(1), pp.409-429.
Parakhia, M. (2010). “Molecular biology & biotechnology.” New Delhi: New India Publishing, p.112.
Rodrigo, G. and Jaramillo, A. (2013). “AutoBioCAD: Full Biodesign Automation of Genetic Circuits”. ACS Synth. Biol., 2(5), pp.230-236.
Rowley, P. and Smith, M. (2008). “Role of the N-Terminal Domain of ɸC31 Integrase in attB-attP Synapsis”. Journal of Bacteriology, 190(20), pp.6918-6921.
Rowley, P., Smith, M., Younger, E. and Smith, M. (2008). “A motif in the C-terminal domain of ɸC31 integrase controls the directionality of recombination”. Nucleic Acids Research, 36(12), pp.3879-3891.
Rutherford, K. and Van Duyne, G. (2014). “The ins and outs of serine integrase site-specific
recombination”. Current Opinion in Structural Biology, 24, pp.125-131.
Sclimenti, C. (2001). “Directed evolution of a recombinase for improved genomic integration at a native human sequence”. Nucleic Acids Research, 29(24), pp.5044-5051.

2022896 5461 words
Page 25 of 27
Siuti, P., Yazbek, J. and Lu, T. (2013). “Synthetic circuits integrating logic and memory in living cells”. Nat Biotechnol, 31(5), pp.448-452.
“This research fully realises the ability for serine integrases for logic and memory by demonstrating all 16 Boolean logic functions. Released at the same time as competing research (Bonnet, et al., 2013), this paper specifically utilises ϕC31 Int.”
Smith, M. and Thorpe, H. (2002). “Diversity in the serine recombinases”. Molecular Microbiology, 44(2), pp.299-307.
Smith, M., Brown, W., McEwan, A. and Rowley, P. (2010). “Site-specific recombination by φC31 integrase and other large serine recombinases”. Biochm. Soc. Trans., 38(2), pp.388-394.
Stricker, J., Cookson, S., Bennett, M., Mather, W., Tsimring, L. and Hasty, J. (2008). “A fast, robust and tunable synthetic gene oscillator”. Nature, 456(7221), pp.516-519.
Thorpe, H., Wilson, S. and Smith, M. (2000). “Control of directionality in the site-specific recombination system of the Streptomyces phage phiC31”. Molecular Microbiology, 38(2), pp.232-241.
Yang, L., Nielsen, A., Fernandez-Rodriguez, J., McClune, C., Laub, M., Lu, T. and Voigt, C. (2014). “Permanent genetic memory with >1-byte capacity”. Nature Methods, 11(12), pp.1261-1266.
Yuan, P., Gupta, K. and Van Duyne, G. (2008). “Tetrameric Structure of a Serine Integrase Catalytic Domain”. Structure, 16(8), pp.1275-1286.

2022896 5461 words
Page 26 of 27
LOG OF INVESTIGATION
This review began to form when I first decided I wanted to write about something within
the scope of synthetic biology, as I have a keen interest in the idea of modulation in
biological manipulation as a technological asset. I enjoy the possibility that in the future
biological research could focus on ‘plug and play’ manipulation of genomes facilitating
design of complex networks for new applications.
After looking through the list of university staff who worked in this area at
http://www.gla.ac.uk/researchinstitutes/biology/research/syntheticbiology/staff/ and
reading through the research interests of each staff member I sent an email to Dr. Sean
Colloms on 06/10/15 detailing my interest in synthetic biology and particularly biological
circuitry and chassis organisms. In this email I asked if Dr. Colloms would be willing to
supervise me in writing my critical review and suggested we should meet to discuss this
further.
I met with Dr. Colloms on 15/10/15 and we discussed the power of serine integrases in
genetic circuit design and some key concepts in this area. This meeting solidified the
topic of review, and I left with a list of papers to read which Dr. Colloms had provided:
(Bonnet et al., 2012; Bonnet et al., 2013; Bonnet and Endy., 2013)
On 18/10/15 I submitted “Genetic Circuitry: The Use of Serine Integrases in
Synthetic Logic and Memory” as the working title of my critical review.
In the months that followed I gathered resources with which to write a review of my
chosen topic. Some of the research papers used herein were identified through reading
the primary literature, while others were discovered through internet searches using
Google Scholar and various databases such as PubMed. The work of Professor Maggie
Smith of the University of York proved exceptionally useful when researching Integrase
structure and function.
ɸC31 integrase continued to crop up during my research as a well-utilised serine
integrase, however much about the specific mechanism of its directionality remained
unknown and its RDF was late to be discovered. This interested me as a better
understanding of this mechanism would enhance its utility in genetic circuit design,
however most current applications utilised the integrase for unidirectional integration
into host genomes.

2022896 5461 words
Page 27 of 27
The use of this integrase in both the SIRA assembly mechanism (Colloms et al., 2013)
and the implementation of Boolean Logic Gates using serine integrases (Situi et al.,
2013) positioned the protein at the cutting edge of the genetic circuitry and synthetic
biology fields, and cemented the focus of this review.
By early January 2016 I had a solid idea of the shape which this review was going to take
and began planning to write specific sections.
A draft version of the review was sent to Dr. Colloms on 18/02/16 for feedback
I met again with Dr. Colloms on 24/02/16 and we discussed his feedback on my review.
I left with plenty of useful suggestions to improve the review. Notably, Dr. Colloms
suggested areas where figures were necessary, and introduced me to a paper which
suggests the role of the CTD coiled coil motifs in Int directionality (Rutherford and Van
Duyne, 2014).
Having incorporated the feedback of Dr. Colloms into the review and also having proof-
read and edited it in some areas, the review was finally submitted to the school office
on 07/03/16.
While there are many reviews which describe emerging applications for phage
integrases, this review focuses directly on genetic circuits integrating logic and memory,
specifically in the context of a serine integrase which is at the forefront of this
technology. As such, this is a unique piece of work which explores a new field of
biotechnology with specific focus on one small group of proteins which are likely to
revolutionise the possible applications of this research.
ACKNOWLEDGEMENTS
I would like to thank Dr. Colloms for his patience and sound advice when conceiving and
reviewing this document. None of this would have been possible without his input.
I would also like to thank my partner Sarah for her continued support and understanding while
writing this review.
My family has also been incredibly patient and understanding of the time commitment it took
to prepare this piece of work.